









 本文介绍了SIGIR23会议上提出的PrefFedPOI框架,针对时间敏感、异构和数据稀疏的POI推荐问题,通过结合历史近期偏好和周期性偏好,以及强化学习的性能增强聚类机制,实现在不共享数据的情况下提高推荐性能。
本文介绍了SIGIR23会议上提出的PrefFedPOI框架,针对时间敏感、异构和数据稀疏的POI推荐问题,通过结合历史近期偏好和周期性偏好,以及强化学习的性能增强聚类机制,实现在不共享数据的情况下提高推荐性能。
Conference : SIGIR '23: The 46th International ACM SIGIR Conference on Research and Development in Information Retrieval
论文链接:https://dl.acm.org/doi/10.1145/3539618.3591688
代码链接:https://github.com/Leavesy/PrefFedPO
摘要:
出发点:时间敏感、异构、有限的POI记录严重限制了联邦POI推荐的发展
在极其稀疏的历史轨迹下设计了细粒度的偏好感知个性化联邦 POI 推荐框架,即 PrefFedPOI
具体方案:PrefFedPOI通过结合每个本地客户端内的历史近期偏好和周期性偏好来提取当前时段的细粒度偏好。
- 由于某些时段POI数据极度缺乏,针对模型参数上传设计了数据量感知选择性策略。
- 此外,提出了一种带有强化学习的性能增强聚类机制,以捕获所有客户之间的偏好相关性,以鼓励积极的知识共享。
- 此外,还设计了聚类教师网络,通过聚类指导来提高效率。
POI(Point of Interest)数据是指互联网电子地图中的点类数据,通常包括名称、地址、坐标、类别四个属性。它源于基础测绘成果数字线划地图产品中的点类地图要素矢量数据集,并在地理信息系统中指可以抽象成点进行管理、分析和计算的对象。随着互联网电子地图服务与 LBS 应用的普及,POI 数据已经成为信息空间的重要组成部分,涵盖了各种行业和领域,如商家信息、服务介绍、点评信息、排行榜、推荐、状态、社交互动信息、消费金融信息等。POI 数据的跨行业、跨部门整合和空间位置大数据挖掘也使其成为许多企业和机构的重要资源。
1、引言
POI推荐系统必须在令人满意的性能和敏感数据保护之间取得平衡。
引言中列出的参考文章:
FedPOIRec [19] 提出了一个使用同态加密进行参数聚合的联合框架,其中利用社交关系来增强 POI 推荐。PREFER [8] 通过在边缘服务器而不是远程云服务器上聚合参数来加速 POI 推荐的协作训练。文献[26]提出了一种具有联邦学习的跨域 POI 推荐框架,以解决数据稀疏和冷启动问题。黄等人。 [11]提出了一种联合 POI 推荐框架,通过使用地理信息和矩阵分解来增强推荐性能。吴等人[30]通过学习个性化的长期和短期偏好来表征不同用户的品味。孙等人。 [35]利用上下文感知网络和地理扩张 RNN 来建模用户的长期和短期偏好。
面临挑战:
(1)用户的偏好对时间非常敏感。用户倾向于在不同的时间戳访问不同的 POI,这表明了他们对时间敏感的偏好。
图1中不同POI类别的签到频率是不同的。例如,“夜生活点”在晚上打卡最多,而“美食”则通常在用餐时间到访。
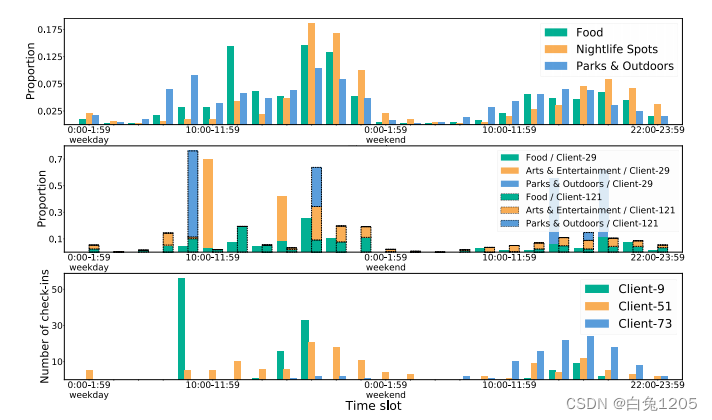
(2)用户偏好差异较大。即使在同一时间段,不同类型的人也可能表现出不同的偏好和不同的移动模式。
例如,第29位客户经常在工作日的10:00-11:59访问“艺术与娱乐”,而第121位客户在同一时间段仅访问“美食”。因此,个性化的POI推荐对于提高性能是必要且重要的。
(3)数据稀疏性。在现实世界中,个人的历史轨迹可能极其稀疏。特别是在提取细粒度的偏好时,某些时段缺乏 POI 数据的情况相当普遍。简而言之,时间敏感、异构且有限的 POI 记录都使得联合 POI 推荐具有挑战性。
提出了 PrefFedPOI,一种细粒度偏好感知的个性化联合 POI 推荐框架来解决上述挑战。
具体方案:
(1)在每个客户端内,考虑稀疏记录,通过结合历史近期偏好和周期性偏好来提取当前时隙中的细粒度偏好。
(2)由于某些时段POI数据极度缺乏,设计了模型参数上传的数据量感知选择性策略。
(3)为了解决异构性挑战,在联邦参数服务器内提出了一种具有强化学习的性能增强聚类机制。基于上传的细粒度偏好,设计的政策网络根据偏好相似性对客户进行分组,以增强积极的知识共享。
(4)为了保证高效的聚类,提出了教师网络,以在聚类指导下加速训练。最后通过局部模型和聚类模型的加权组合实现个性化。
贡献点:
- 在不共享本地数据的情况下,通过解决时间敏感偏好、异构偏好和数据稀疏性挑战,提出了一个通用框架PrefFedPOI,用于联邦学习框架下的偏好感知下一个POI推荐。
- 当前时隙中的细粒度首选项通过组合历史最近首选项和周期性首选项来表示POI推荐。
- 为了减轻异质性的影响,提出了一种基于强化学习的性能增强聚类机制,以鼓励客户之间的积极知识共享。此外,为了提高聚类指导的效率,设计了一个聚类教师网络。通过局部模型和聚类模型的加权组合,可以在每个客户端内部生成个性化推荐模型。
- 在两个真实世界的数据集上进行了大量的实验,PrefFedPOI证明了其优于其他最先进的技术。个性化的PrefFedPOI在数据稀疏客户端中平均可以实现7%的准确率提升。

















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









