






本次学习的重心是YOLOV3
首先搞清楚目标检测要做什么。目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图
片的任何地方,并且物体还可以是多个类别。
目标检测核心思想:
(1)滑动窗口

滑动窗口在图像上进行滑动遍历,滑动次数太多,计算太慢;目标大小不同,每一个滑动位置需要用很多框。从这两个问题引出了Two-Stage, One-Stage。
下面进行One-Stage的简单阐述,其基本思想是简化的二分类问题,在本例-葫芦娃检测中,其只检测一类(葫芦娃脸),此时有不少新学者,例如本人也也有一个疑问:如何确定其大小,位置,概率?分类问题进一步扩展为:分类+回归。
(2)YOLO基本思想

在深度学习目标检测中经典框架Faster R-CNN(twp-stage),YOLO系列。这两种方式各有其特点。YOLO的优势在于速度非常快,适合做实时检测任务,速度的代价就是检测效果打折扣。相反Faster R CNN 等检测速度虽然没那么快,但是其检测效果较好。
YOLO中常见的一些评价指标:
1:精确度(Precision):指检测出的目标中真正为目标的比例,即检测结果中正确预测为目标的数量与所有预测为目标的数量的比值。
2:召回率(Recall):指所有真正为目标的样本中被正确检测出的比例,即检测结果中正确预测为目标的数量与所有真实目标的数量的比值。
3:F1 值:精确度和召回率的调和平均值,是一个综合评价指标。F1 值越高,表示模型的性能越好。
4:平均精确度(Average Precision,AP):用于评估目标检测算法在不同类别上的表现。对于每个类别,计算其精确度和召回率的曲线下的面积,然后取平均值作为平均精确度。
5:mAP(mean Average Precision)所有类别的平均精确度的平均值。是衡量目标检测法整体性能的重要指标之一。
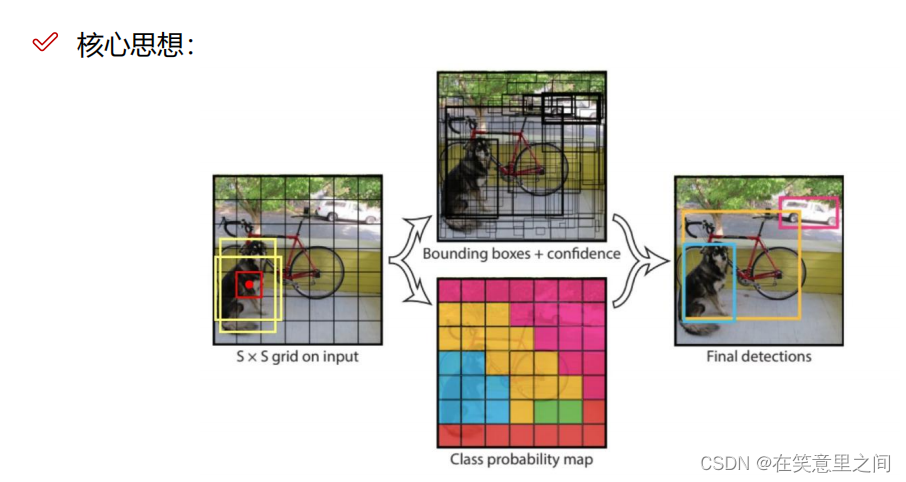
输入图片分为S*S区域,然后进一步生成候选框+置信度,同时生成分类概率图,之后输出检测结果。
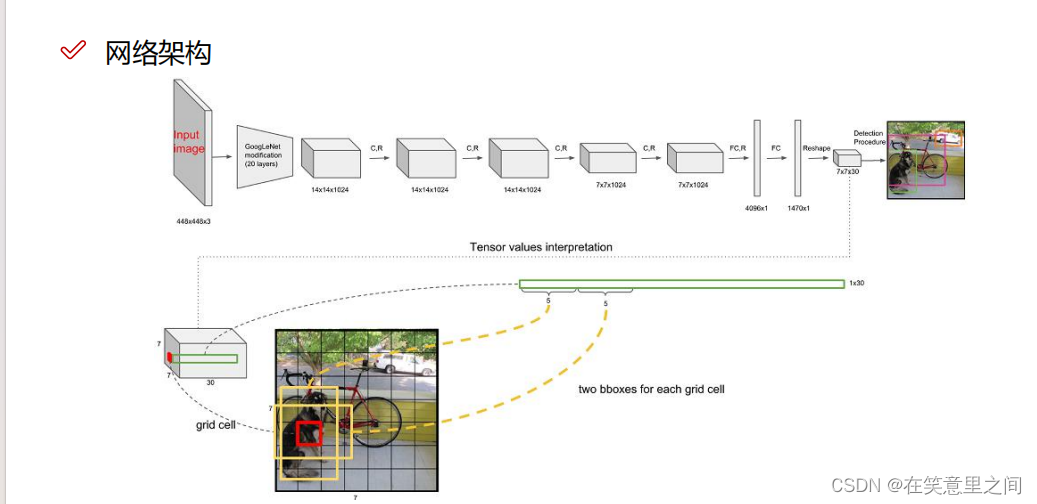
网络结构包含24个卷积层和2个全连接层;其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层,和2个全连接层。
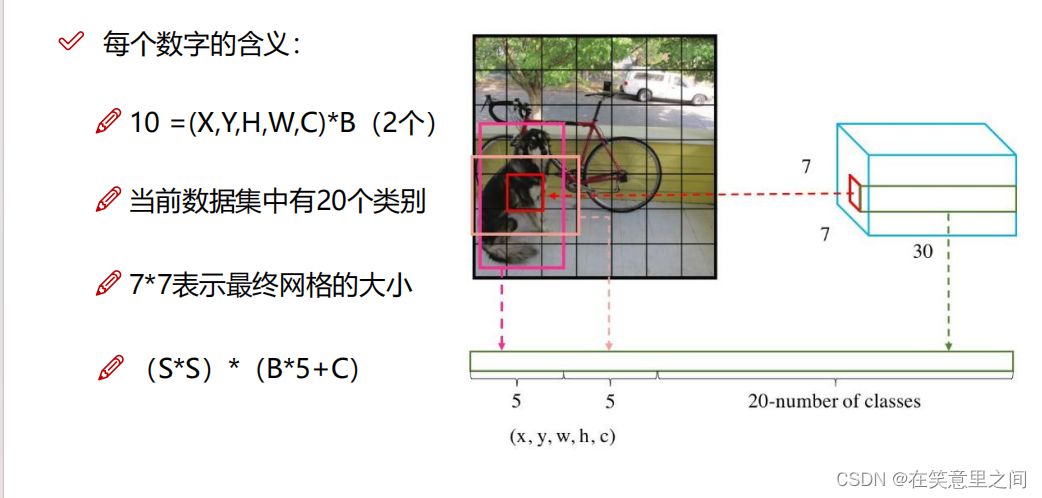
至此,我们对YOLO有一个简单的了解,其网络框架代码的实现此处暂不介绍。
(3)Lossfunc设计
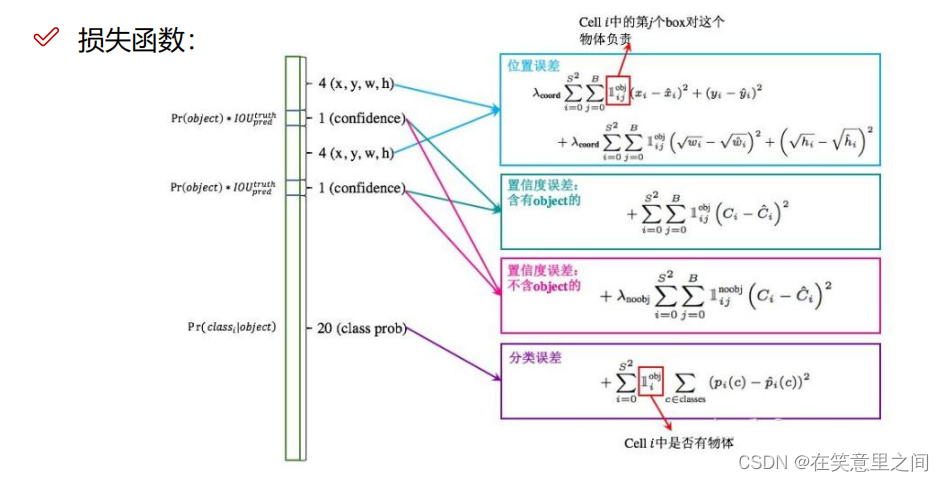
YOLOv1 使用逻辑回归来预测目标的存在与否,并使用均方误差来测量预测边界框和真实边界框之间的差异。该损失包括两部分:分类损失和置信度损失。
(1)分类损失(Class Loss):使用逻辑回归计算类别预测的交叉熵损失。
(2)置信度损失(Confidence Loss):使用均方误差来衡量预测边界框与真实边界框之间的差异。
边界框回归损失(Bounding Box Regression Loss):
YOLOv1 使用均方误差来衡量预测边界框和真实边界框之间的差异。
总的损失函数如下:















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









