










论文地址
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0306457322000139?via%3Dihub
论文首页

笔记框架
 基于语义知识和辅助信息增强讽刺检测方法
基于语义知识和辅助信息增强讽刺检测方法
📅出版年份:2022
📖出版期刊:Information Processing & Management
📈影响因子:8.6
🧑文章作者:Wen Zhiyuan,Gui Lin,Wang Qianlong,Guo Mingyue,Yu Xiaoqi,Du Jiachen,Xu Ruifeng
📍 期刊分区:JCR分区: Q1 中科院分区升级版: 管理学1区 中科院分区基础版: 工程技术2区 影响因子: 8.6 5年影响因子: 8.2 EI: 是 CCF: B 南农高质量: A
🔎摘要:
讽刺表达是一种普遍存在的文学手法,人们有意表达与暗示相反的意思。准确检测文本中的讽刺可以帮助理解说话者的真实意图,并促进其他自然语言处理任务,尤其是情感分析任务。由于讽刺是一种隐含的情感表达,而且说话者会故意混淆听众的视听,因此仅通过文本检测讽刺具有很大的挑战性。现有的基于机器学习和深度学习的方法在处理表达复杂或需要特定背景知识才能理解的讽刺文本时,效果并不理想。特别是,由于中文自身的特点,中文中的讽刺语言检测更加困难。为了缓解中文讽刺检测的这一困境,我们提出了一种语义和辅助增强注意力神经模型--SAAG。在词的层面,我们引入语义知识来增强中文词的表征学习。词素是词义的最小单位,是对词的精细刻画。在句子层面,我们利用一些辅助信息(如新闻标题)来学习讽刺表达的语境和背景表示。然后,我们逐步、动态地构建文本表达的表征。在由新闻文本评论组成的讽刺数据集上进行的评估表明,我们提出的方法是有效的,并且优于最先进的模型。
🌐研究目的:
以前的基于单词的模型经常遇到由于误解文本中多义词所暗示的潜在语义而引起的潜在问题。为了缓解这一困境,我们尝试引入词义知识,以增强模型在讽刺检测中对句子语义的理解。
📰研究背景:
由于讽刺是一种隐含的情感表达,而且说话者会故意混淆听众的视听,因此仅通过文本检测讽刺具有很大的挑战性。
由于中文自身的特点,中文中的讽刺语言检测更加困难。
尽管现有的基于深度学习的方法取得了有希望的进展,但它们通常无法处理文本中复杂的讽刺表达,特别是当表达与背景知识高度相关时。
🔬研究方法:
🔩SAAG模型架构:
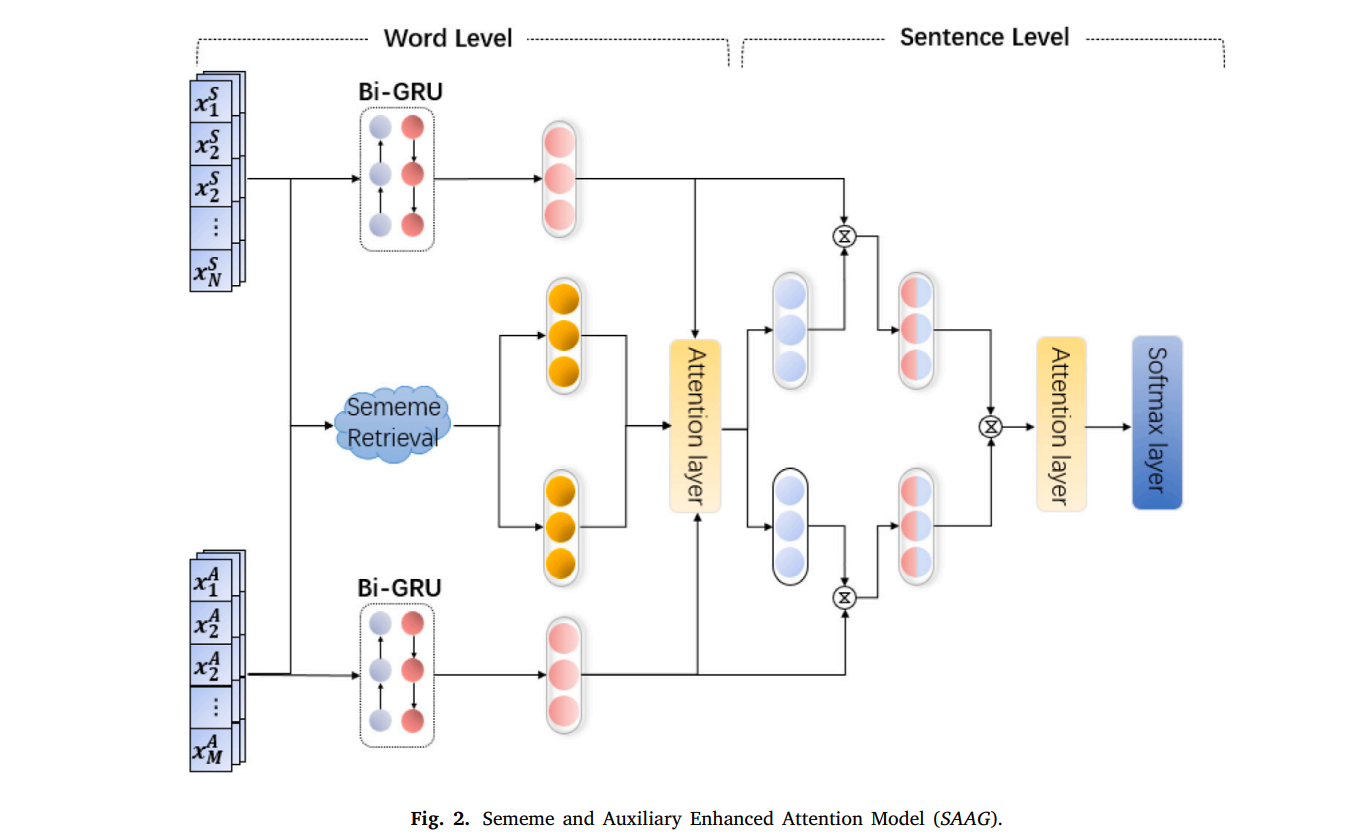
具体来说,我们提出的模型主要由两个部分组成:
-
在单词级别,该模型结合语义知识来增强单词的表示学习;
-
在句子层面,模型利用辅助信息来获取讽刺表达的上下文和背景。
我们使用两个基于双向 GRU(Bahdanau、Cho 和 Bengio,2015)的编码器和多头注意力机制作为骨干,逐步动态地构建文本表达的表示。
语义检索组件
在单词级别,我们首先使用 OpenHownet API (Qi et al., 2019) 分别获取讽刺输入和辅助输入中每个单词的语义知识。
通过HowNet我们可以得到语义信息表示的树状结构。
基于 GRU 的文本编码器
一个词的含义不仅取决于它前面的词,还取决于它后面的词。然而,GRU 只能捕获一个方向的信息。为了解决这个难题,我们使用双向 GRU 对单词及其上下文信息进行编码。
语义匹配注意力机制
为了解决这种多语义现象,我们利用注意力匹配机制来动态匹配合适的语义到单词。
在我们的模型中,我们使用缩放点积注意力机制(Vaswani 等人,2017)。
我们使用多头注意力,因为能够共同关注来自不同位置的不同表示子空间的信息。
为了合并上下文信息,我们不直接使用单词表示作为查询 Q 的源。我们使用文本编码器生成的隐藏状态 H 作为查询 Q 的源。
词融合。为了将词义表示 Sem 合并到主干中,我们将隐藏状态 H 与以词为单位的词义表示 Sem 连接起来。
自注意力组件
在句子级别,为了更好地整合讽刺输入和辅助输入,同时强调显着部分,我们连接语义知识增强的隐藏表示矩阵,并利用自注意力机制来计算最终表示。
讽刺检测
最后,我们利用softmax来计算讽刺的概率分布。
交叉熵用作模型优化中的损失函数。
🧪实验:
📇 数据集:
在我们的实验中,要预测的文本是从中国新闻网站“观察者”上发布的用户评论中收集的。该语料由五位获得多数票的注释者手动注释。
讽刺收集了2019年4月至5月观察者上发布的2197条新闻。
新闻涵盖国际、军事、金融、经济、科技、汽车等主题。
总共还收集了 178,237 条相关用户的评论。注释了 720 篇新闻文章的 4972 条评论。
为了更好地研究讽刺,该语料库还收集了新闻标题、新闻文章和新闻类别等辅助信息。

📏评估指标:
我们使用准确率、精确率、召回率和F1分数来评估整体性能。
📉 优化器&超参数:
SAAG 模型
使用由 GloVe 初始化的 300 维词嵌入(Pennington、Socher 和 Manning,2014)。
采用具有 128 个隐藏单元的两层双向 GRU。
使用4头多头注意力机制
使用学习率为 5e-5 的 Adam 优化器
小批量大小为 8
每次折叠时训练模型 70 个 epoch
BERT 模型
在每次折叠时训练模型 5 个时期
使用10倍交叉验证来评估性能
💻 实验设备:
单个 2080Ti GPU
📊 消融实验:
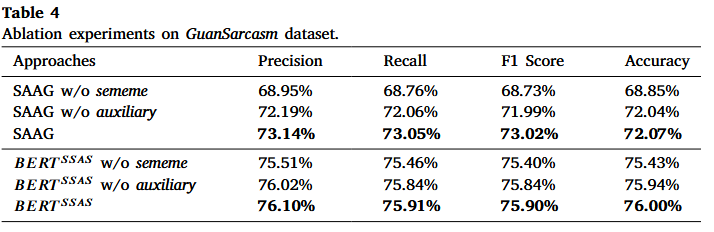
证明我们的模型可以利用语义知识和辅助信息来提高性能,并且语义知识对模型有更大的贡献。
BERT SSAS 上的消融实验结果与 SAAG 类似。
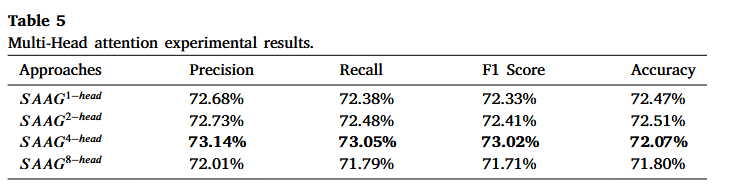
证明了该模型可以通过使用多头注意力机制而受益。
最好的结果是通过使用 4 头注意力的模式获得的。
📋 实验结果:
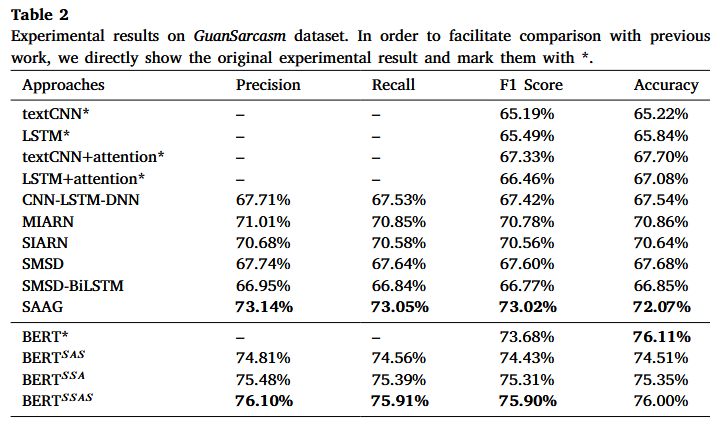
与没有预训练模型的方法相比,我们提出的模型 SAAG 取得了最佳性能,并且 F1 分数明显优于之前最好的方法,提高了 2.24%。
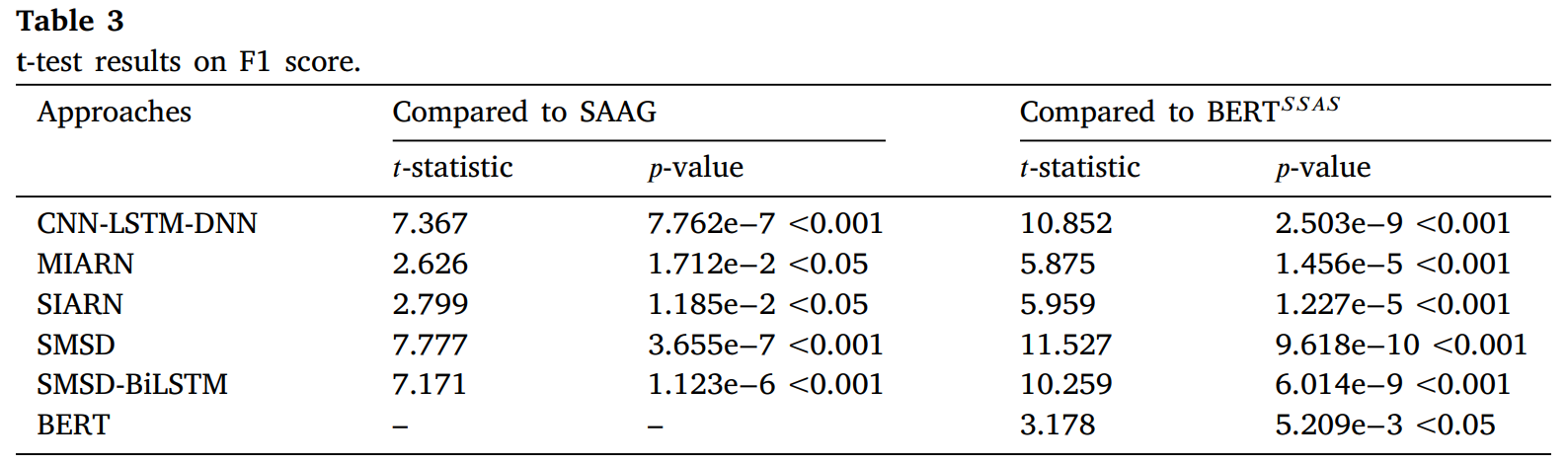
对于预训练模型部分,我们的模型 BERT SAS 、 BERT SSA 和 BERT SSAS 均优于之前的模型。
使用语义知识更接近相应的单词可以在检测讽刺方面获得更好的性能,并且模型可以通过添加特定的分隔符标记而受益。
🚩研究结论:
在这项工作中,我们提出了一种语义和辅助增强注意神经模型 SAAG,用于讽刺检测。
我们提出的模型主要可以分为两个方面:在单词级别,我们结合语义知识来增强单词的表示学习;在句子层面,我们利用一些辅助信息来获取讽刺表达的上下文和背景。
我们使用两个基于 GRU 的双向编码器和多头注意力机制作为骨干,逐步动态地构建文本表达的表示。
为了进一步验证语义知识和辅助信息在讽刺检测上的有效性,我们还在BERT上进行了一些尝试,通过设计一些输入格式将语义知识和辅助信息纳入预训练模型中。
实验结果表明,语义知识和辅助信息可以增强模型检测讽刺的能力。
📝总结
💡创新点:
提出了一种词素和辅助增强注意力神经模型--SAAG。在词的层面,我们引入词义知识来增强中文词的表征学习。
在句子层面,我们利用一些辅助信息(如新闻标题)来学习讽刺表达的语境和背景表示。
为了构建有效的单词表示,我们明确地将存储在 HowNet 中的语义知识纳入讽刺检测中。这些语义知识可以帮助模型利用单词之外的细粒度信息,从而提高讽刺检测的性能和可解释性。
利用一些辅助信息来补充模型训练中句子的重要背景知识,从而可以更好地理解上下文。
为了更好地理解句子的讽刺信息,我们利用一些辅助信息来恢复讽刺的上下文和背景。在此基础上,我们使用两个双向门循环单元(GRU)分别对文本信息和辅助信息进行编码。为了更好地整合这两种信息并强调显着部分,我们将两个表示连接起来并使用自注意力机制来获得最终表示。
为了验证语义知识和辅助信息是否可以帮助预训练模型,我们还设计了三种输入格式,将语义知识和辅助信息合并到大规模预训练模型中(本文以 BERT 为例)。
⚠局限性:
提高了模型的复杂度,增加了计算的开销
🔧改进方法:
🖍️知识补充:
我们分析了讽刺文本的特征,尤其是社交媒体上发布的讽刺文本。研究发现,讽刺句子,特别是复杂的讽刺句子,经常伴随着多义或未记录的单词出现。
讽刺文本中的词语通常具有多种含义。
语义(Sememe)被定义为人类语言中最小的语义单位(Bloomfield,1926 年)。
GRU(门控循环单元)(Bahdanau et al., 2015)是 RNN 的变体(Mikolov, Karafiát, Burget, Černock`y, & Khudanpur, 2010)。与 LSTM (Hochreiter & Schmidhuber, 1997) 相比,GRU 使用门控机制来控制序列的状态,而无需单独的存储单元。它包括两种类型的门:重置门和更新门。通过使用这两个门共同控制信息流。
BERT 是一种预训练的 Transformer(Vaswani 等人,2017)模型,在各种 NLP 任务上取得了显着的性能。
语义和辅助增强型 BERT
我们设计了三种输入格式来联合讽刺输入、辅助信息和语义知识。
首先,我们连接讽刺输入和辅助输入作为输入句子 A,然后我们连接讽刺和辅助输入作为输入句子 B。最后,我们连接由特殊标记([SEP])分隔的句子 A 和句子 B,并添加第一个位置的特殊标记([CLS])。


















 4958
4958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











