






数据集准备任务
本阶段任务是从Movie101下载数据集并对数据集进行处理,得到能够使mPlug-Owl进行学习训练的数据格式。

Movie101包含101部电影的视频(从西瓜视频爬取),以及带有时间戳的解说文本(由ASR获取并人工修正)和演员台词(由OCR获取)。根据电影片段解说 (MCN) 任务和时序解说定位 (TNG) 任务的要求
数据集下载
训练:Movie101/Movie101v1/dataset/Movie101-G/train.json at main · yuezih/Movie101 · GitHub
验证:Movie101/Movie101v1/dataset/Movie101-G/val.json at main · yuezih/Movie101 · GitHub
测试:Movie101/Movie101v1/dataset/Movie101-G/test.json at main · yuezih/Movie101 · GitHub
原始格式如下:
[
{
"movie_id": "6973286990817002015",
"start_time": 218,
"end_time": 236,
"content": "阿豪站起身,小心地端着一碗粥递给阿花,然后坐下端起另外半碗粥吸溜了两口,勾勾手指,让兄弟三个凑过来,阿平转转眼珠子也好奇地凑上前。"
},
{
"movie_id": "6973286990817002015",
"start_time": 250,
"end_time": 254,
"content": "侧着身子避开包租婆的视线,悄悄塞到阿平手里,"
},...
]下载完成后,使用FileZilla等文件传输软件,将下载后的数据传至服务器
数据集处理
方案一:
我们将同一部电影中的所有解说台词拼接成一个整体,输入mPlug-Owl模型,模型对整个文本进行随机掩盖,并预测掩盖词是什么进行完整化句子。通过这种方式提升模型对电影的理解能力。
处理代码如下:
import json
for mode in ['train', 'test', 'val']:
# 读取json文件
with open(f'{mode}.json', 'r', encoding='utf-8') as file:
data = json.load(file)
# 字典用于存储拼接后的内容
movie_content = {}
# 遍历数据
for entry in data:
movie_id = entry['movie_id']
content = entry['content']
if movie_id in movie_content:
movie_content[movie_id] += content
else:
movie_content[movie_id] = content
# 将结果转换为所需的格式
result = [{'movie_id': movie_id, 'all_content': content} for movie_id, content in movie_content.items()]
# 打印结果
print(result)
with open(f'{mode}_movie_content.json', 'w', encoding='utf-8') as file:
json.dump(result, file, ensure_ascii=False, indent=4)
处理好的数据如下:
[
{
"movie_id": "6973286990817002015",
"all_content": "阿豪站起身,小心地端着一碗粥递给阿花,然后坐下端起另外半碗粥吸溜了两口,勾勾手指,让兄弟三个凑过来,阿平转转眼珠子也好奇地凑上前。侧着身子避开包租婆的视线,悄悄塞到阿平手里,晚上雷洛探长的车停到一间酒楼门口,猪油仔赶忙上前拉开车门。亨特得意地靠着桌子..."
},
{
"movie_id": "6969009002155868709",
"all_content": "天色灰暗,几只健硕的六角怪飞进山谷中,地面上聚集了数以万计的怪物。画面淡出,进入一片幽静的森林当中。老妖后在草丛中4处张望着,矮胖的老妖后和两名随从听到一声低吼,立马停下步子,随从说道:老妖后仓皇逃跑,两名随从相互对视了一眼,冲向后面这两个巨型血妖。一名随从被血妖甩在树干上瞬间昏厥,另一名当场被捏晕。老妖后躲在树后偷..."
},...
]问题
由于每部电影的解说台词拼接特别长,大于有20000个字符,这已经明显超出计算资源的处理能力,而且不利于模型记忆相关信息。因此该方案被否决
方案二
我们将解说台词的形式进行修改,我们输入一句话和下一句话,让mPlug-Owl模型学习训练当前这句话然后预测下一句话,通过这种方式,加深模型对电影的理解能力。即输入一个台词pair。
处理代码如下:
import json
for mode in ['train', 'val', 'test']:
# 假设文件名为train.json
with open(f'{mode}.json', 'r', encoding='utf-8') as file:
data = json.load(file)
output = []
for i in range(len(data) - 1):
current_entry = data[i]
next_entry = data[i + 1]
# 检查是否有相同的 movie_id
if current_entry['movie_id'] == next_entry['movie_id']:
combined_content = {
"movie_id": current_entry['movie_id'],
"text": f"The following is a conversation between a curious human and AI assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. This Task type is 'content Prediction'.\nHuman: {current_entry['content']}\nAI: {next_entry['content']}",
"task_type": "llava_sft"
}
output.append(combined_content)
print(len(output))
# 将结果保存到一个新的文件中
with open(f'combined_{mode}.json', 'w', encoding='utf-8') as file:
json.dump(output, file, ensure_ascii=False, indent=4)
处理好的格式如下:
[
{
"movie_id": "6973286990817002015",
"text": "The following is a conversation between a curious human and AI assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. This Task type is 'content Prediction'.\nHuman: 阿豪站起身,小心地端着一碗粥递给阿花,然后坐下端起另外半碗粥吸溜了两口,勾勾手指,让兄弟三个凑过来,阿平转转眼珠子也好奇地凑上前。\nAI: 侧着身子避开包租婆的视线,悄悄塞到阿平手里,",
"task_type": "llava_sft"
},
{
"movie_id": "6973286990817002015",
"text": "The following is a conversation between a curious human and AI assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. This Task type is 'content Prediction'.\nHuman: 侧着身子避开包租婆的视线,悄悄塞到阿平手里,\nAI: 晚上雷洛探长的车停到一间酒楼门口,猪油仔赶忙上前拉开车门。",
"task_type": "llava_sft"
},...
]使用这种方案可以解决方案一的问题,同时能够加深模型对电影理解能力
处理好的数据集情况
训练集共有81部电影,其中处理好的训练样本数为24427个,每个电影的解说台词约为20000字
验证集共有10部电影,其中处理好的训练样本数为2758个,每个电影的解说台词约为20000字
测试集共有10部电影,其中处理好的训练样本数为2888个,每个电影的解说台词约为20000字
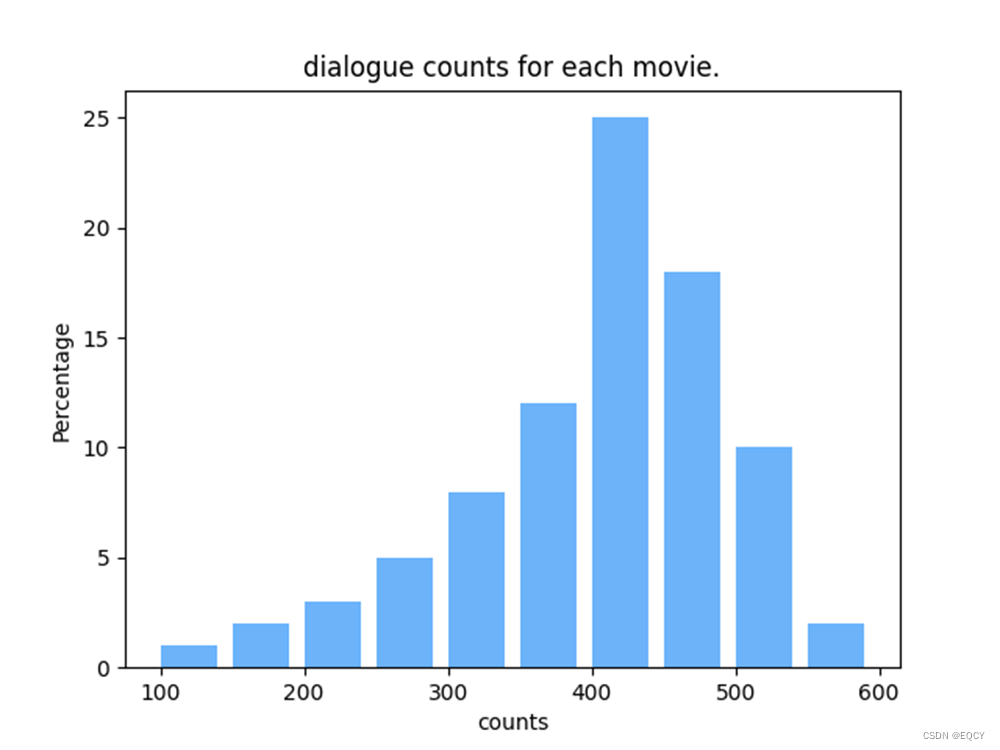
与其他数据集对比
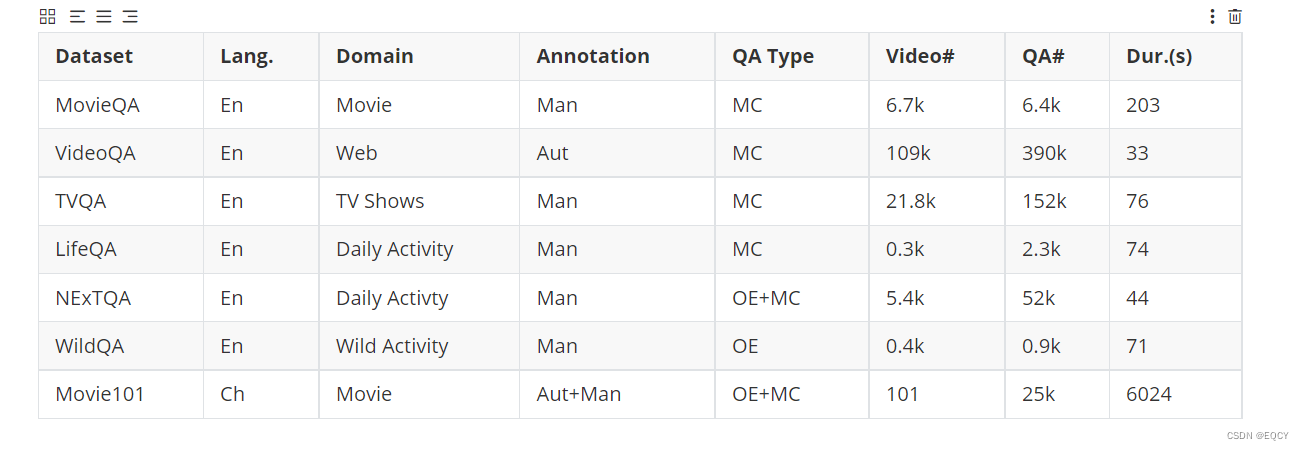
我们数据集与代表性现有视频问答数据集的比较。“Lang.”表示数据的语言,“En”代表英语,“Ch”代表中文。“Annotation”表示数据是否由人工或自动标注。“Aut”代表自动标注,“Man”代表人工标注。“QAType”表示答案是多项选择(MC)还是开放式回答(OE)。“Dur. (s)”是视频的平均时长(秒)。
















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









