







1.注意力机制
1.1简介


Q:查询向量
K:键向量
V:值向量
常规注意力机制;Q!=K=V;自注意力机制:Q=K=V

- softmax:归一化指数函数

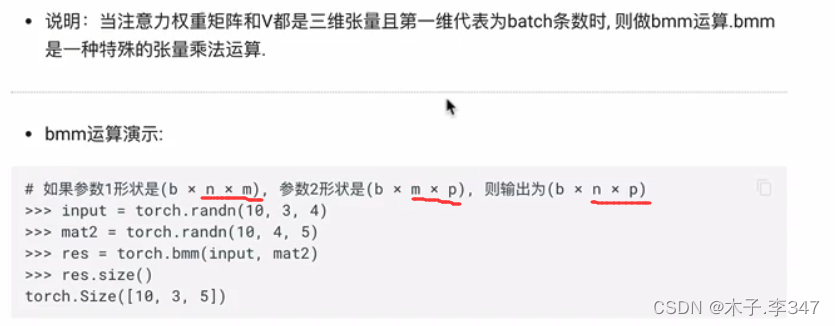
1.2注意力机制

注意力机制Q、K、V的形象解释:
- 假如我们有⼀个问题: 给出⼀段⽂本,使⽤⼀些关键词对它进⾏描述!
为了⽅便统⼀正确答案,这道题可能预先已经给⼤家写出了⼀些关键词作为提示.其中这些给出的提示就可以看作是key, ⽽整个的⽂本信息就相当于是query,value的含义则可以⽐作是你看到这段⽂本信息后,脑⼦⾥浮现的答案信息,这⾥我们⼜假设⼤家最开始都不是很聪明,第⼀次看到这段⽂本后脑⼦⾥基本上浮现的信息就只有提示这些信息,因此key与value基本是相同的,但是随着我们对这个问题的深⼊理解,通过我们的思考脑⼦⾥想起来的东⻄原来越多,并且能够开始对我们query也就是这段⽂本,提取关键信息进⾏表示. 这就是注意⼒作⽤的过程, 通过这个过程,我们最终脑⼦⾥的value发⽣了变化,根据提示key⽣成了query的关键词表示⽅法,也就是另外⼀种特征表示⽅法.- 刚刚我们说到key和value⼀般情况下默认是相同,与query是不同的,这种是我们⼀般的注意⼒输⼊形式,但有⼀种特殊情况,就是我们query与key和value相同,这种情况我们称为⾃注意⼒机制,就如同我
们的刚刚的例⼦, 使⽤⼀般注意⼒机制,是使⽤不同于给定⽂本的关键词表示它. ⽽⾃注意⼒机制,需要⽤给定⽂本⾃身来表达⾃⼰,也就是说你需要从给定⽂本中抽取关键词来表述它, 相当于对⽂本⾃身的⼀次特征提取.(感觉就像自己给自己出题)
bmm运算:可实现与应用网络融为一体

1.3 代码实现

按照上述步骤进行实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self,query_size,key_size,value_size1,value_size2,output_size):
# query_size表示Q的最后一个维度大小,key_size表示K的最后一个维度大小
#value_size1表示V的倒数第二维大小;value_size2表示V的倒数第一维(最后一维)大小
# V的尺寸表示(1,value_size1,value_size2)
# output_size表示输出的最后一个维度的大小
super(Attn, self).__init__()#单继承,即只有一个父类(nn.Module)
# 对继承自(Attn的父类)父类nn.Module的属性进行初始化。而且是用nn.Module的初始化方法来初始化继承的属性。
self.query_size=query_size
self.key_size = key_size
self.value_size1=value_size1
self.value_size2=value_size2
self.output_size=output_size
# 初始化注意力机制实现中第一步的线性层
self.attn=nn.Linear(self.query_size+self.key_size,self.value_size1)
#Linear(x,y)中下x、y分别表示输入和输出的值(包括大小也要一致)
# 初始化注意力机制实现中第三步的线性层
self.attn_combine = nn.Linear(self.query_size + self.value_size2, self.output_size)
def forward(self,Q,K,V):
#注意:假定Q、K、V都是三维张量
#按照第一种注意力计算规则进行计算:Softmax(Linear([Q,K])).V
#第一步,将Q、K进行纵轴的拼接,然后做一次线性变换,最后使用softmax进行处理得到注意力向量
attn_weights=F.softmax(self.attn(torch.cat((Q[0],K[0]),1)),1)
#torch.cat((Q[0],K[0]),1))表示:将两者(Q[0]和K[0])在第一维度上进行拼接
#self.attn(torch.cat((Q[0],K[0]),1))中将torch.cat((Q[0],K[0])作为线性层的输入
#将注意力矩阵和V进行一次bmm运算(即将权重矩阵与V进行乘法运算)
#因为二者都是三维张向量且第一维代表batch条数,故而做bmm运算
attn_applied=torch.bmm(attn_weights.unsqueeze(0),V)
#attn_weights.unsqueeze(0)表示:将attn_weights扩充维度(在第0层);原本为1*32->1*1*32
#第二步,根据第一步采用的计算方法(拼接或转置点积),
# 此处第一步用拼接方法,需要将Q与上一步计算结果拼接
#取Q[0]进行降维,与上面得运算结果进行一次拼接
output=torch.cat((Q[0],attn_applied[0]),1)
#第三步:将上面的输出进行一次线性变换,然后在扩展成三维张量
output=self.attn_combine(output).unsqueeze(0)
return output,attn_weights
#调用实现:
query_size=32
key_size=32
value_size1=32
value_size2=64
output_size=64
attn=Attn(query_size,key_size,value_size1,value_size2,output_size)
Q=torch.randn(1,1,32)
K=torch.randn(1,1,32)
V=torch.randn(1,32,64)
output=attn(Q,K,V)
print(output[0])
print(output[0].size())
print(output[1]) #注意力权重
print(output[1].size())

对forward函数进行考察:
print('catshape==',torch.cat((Q[0],K[0]),1).shape)
print('attnshape==',self.attn(torch.cat((Q[0],K[0]),1)).shape)
print('attn_weights==',attn_weights.shape)#权重矩阵
print('attn_applied==',attn_applied.shape)
print('outputshape==',output.shape)
print(output[0].size())
print(output[1].size())

分析:
Q、K的第0层(都是1* 32)进行纵轴拼接,输出1* 64;
拼接后的结果经线性层后(此处线性层输入要求32+32=64,正好符合)输出1* 32;
再经softmax后还是1* 32;
权重矩阵经扩维后变为1* 1* 32,与V(1* 32* 64)进行bmm计算,输出1* 1* 64;
之后其第0层(1* 64)与Q0进行纵轴拼接,输出1* 96;
再经线性层输出out_size尺寸,即1* 64,再扩维成1* 1* 64
2.多头注意力机制
多头注意力机制(Multi-Head Attention)是 Transformer 模型的核心组件之一,它通过同时计算多个不同的注意力机制,使模型能够关注输入的不同子空间特征。多头注意力机制的设计目的是让模型从不同的“角度”或“头”去理解输入数据,从而更好地捕捉复杂的依赖关系。

2.1. 基础概念
在单头注意力机制中,给定查询(Query)、键(Key)、值(Value)向量,注意力机制通过缩放点积注意力计算出一组注意力权重,并将这些权重应用于值向量上,产生输出。
然而,单头注意力只能从一个角度处理这些向量,可能不足以捕捉到输入序列中不同部分的各种依赖关系。多头注意力通过引入多个“头”,在不同的子空间中并行执行注意力计算,从而获得更丰富的表达能力。
2.2 多头注意力的工作原理
- 线性变换与分割:
- 输入的查询(Query)、键(Key)、值(Value)向量首先通过线性变换被映射到 d_k 维度(其中 d_k是每个头的维度)。(这些变换不会改变原有张量的尺⼨,因此每个变换矩阵都是⽅阵,得到输出结果后)
- 然后,将这些向量分别分割为多个头。例如,如果我们有 8 个头,输入的维度是 d_model,每个头的维度 d_k 通常是 d_model /num_heads。
- 独立计算注意力:
每个头分别计算自己的注意力得分矩阵,并应用于相应的值向量。这意味着每个头都在不同的子空间上执行独立的注意力计算。
- 连接头并线性变换:
将所有头的输出连接起来,形成一个新的向量。
最后,经过一次线性变换(通常是全连接层),将连接后的向量映射回 d_model 维度。


2.3多头注意力的优势
-
捕捉多样化的关系:每个头可以专注于输入序列的不同部分或不同特征,使模型能够捕捉到多样化的上下文关系。
-
提升表达能力:通过并行计算多个注意力,模型可以在不同的子空间中学习特征,从而增强整体的表达能力。
-
增强模型的稳健性:多个头的独立注意力机制减少了模型依赖单一视角的风险,从而提升模型的泛化能力。
2.4 代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.linear_q = nn.Linear(d_model, d_model)
self.linear_k = nn.Linear(d_model, d_model)
self.linear_v = nn.Linear(d_model, d_model)
self.linear_out = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1. 线性变换并分头
query = self.linear_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
key = self.linear_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
value = self.linear_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. 缩放点积注意力
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
# 3. 将注意力权重应用到值上
x = torch.matmul(p_attn, value)
# 4. 连接所有头并进行线性变换
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.linear_out(x), p_attn















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









