







1. 背景说明
前段时间,OpenAI发布的O1和O1 mini模型,当时给出了一系列的示例展示,很震撼,模型展示了思维链和模型推理能力的价值。思维链在事实核查和解决复杂问题方面发挥很重要作用。其实思维链,类比到我们自身对于一个复杂问题的思考,更像是你的思考框架,如何将一个复杂问题,通过“分而治之”的方法,拆解为多个子问题,通过解决子问题,来达到最终解决复杂问题的目的,并且能够保证高准确性。
通过提升推理能力和处理长文本的效果,这些模型可以显著减少大模型生成的幻觉问题。同时,它们能够对结果进行复杂总结,提供更深入、精准的答案,降低用户在信息整理和逻辑推理上的时间和成本。
国内的几家主流大模型公司,目前看支持思维链和模型推理能力是趋势,比如kimi、智谱、豆包的产品中,都推出了AI搜索的能力,也就是说能够支持深度阅读大量的网页信息,并通过有效的整理,进行思维链的深度推理。从体验来看,大模型会将用户的问题进行拆解,进行多次搜索和推理,再得到最终的答案。
可以思考下,我们自己在回答一个问题时,如果是脱口而出,大概率这个问题不复杂,而且可能并反复记忆,已经形成了肌肉记忆。但如果是一个类似数学计算问题,很难一下子输出,而是会逐步进行计算,最后拼接多个子步骤的结果,来得到正确答案。大模型也类似,如果一步到位,往往是在训练预料中频繁出现被深刻记忆的结果,但这不代表是正确的,可能这个结果只是和问题中的某一部分关联度较高,但问题的其他条件很可能影响结果的变化,同样需要考虑,通过某种规划的方案将复杂问题拆解,然后逐个解决简单的子问题,再合并,这样的方式会更可靠。其实思维链的方式,是一种有效的提示词技术,关于如何构建有效的提示词,可以看下我们之前的文章《创建有效的大模型提示词Prompt(提示词工程)》。
既然思维链(大模型的思维框架)如此重要,因此本文主要会针对思维链(Chain of Thought, 简称COT)【1】、思维树(Tree of Thought)【2】进行分析。
2. 思维链
思维链这个想法说实话其实挺直观的,使用过大模型的同学,其实很容易能想到这种思路,看cot的论文,更像是一篇实验类型的文章。所以论文是通过大量的实验验证了这一策略在复杂任务中的有效性。论文的核心贡献并不是提出一个完全新颖的概念,而是系统性地展示了如何通过思维链让大模型在处理复杂问题时取得更好的效果。从实验结果出发,证明了这一方法对提升模型推理能力的显著作用。
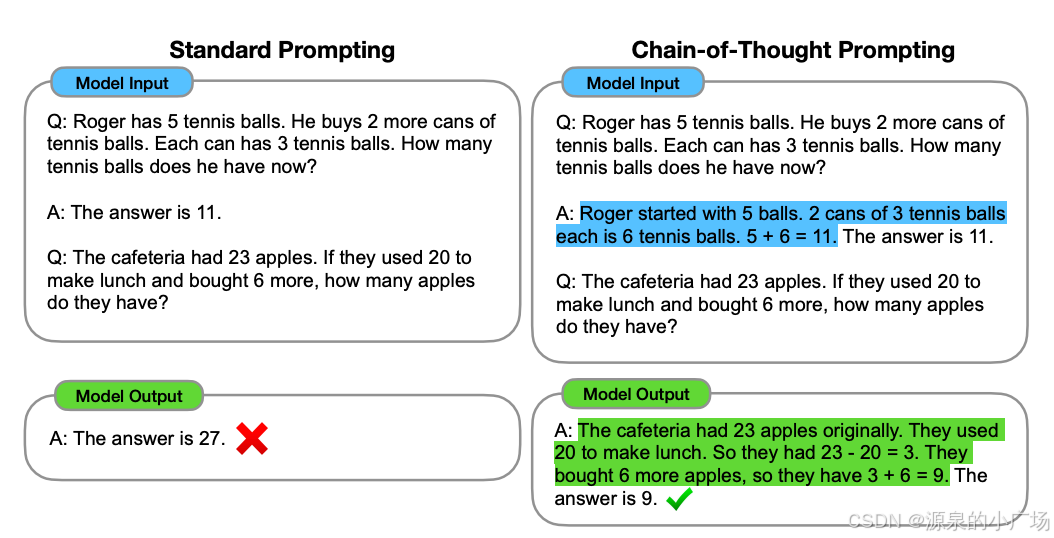
首先我们看一下论文【1】的第一个例子来直观感受一下,通过给予提示子步骤,来教大模型学会思考,这个例子也可以作为few-shot的提示词类型。右子图通过给出一个具体的问题和它的详细解答过程(即chain-of-thought),模型被引导去理解如何解决问题。few-shot提示词会通过展示一个或几个例子来指导模型如何进行思考和推理,而不是简单地给出一个直接的答案。在“Chain-of-Thought Prompting”部分,问题和解答过程被详细地展示出来,这有助于模型理解如何将问题分解成更小的步骤,并逐步解决。这种逐步的推理过程是few-shot提示词的一个关键特征,因为它提供了解决问题的示例,而不需要大量的训练数据。
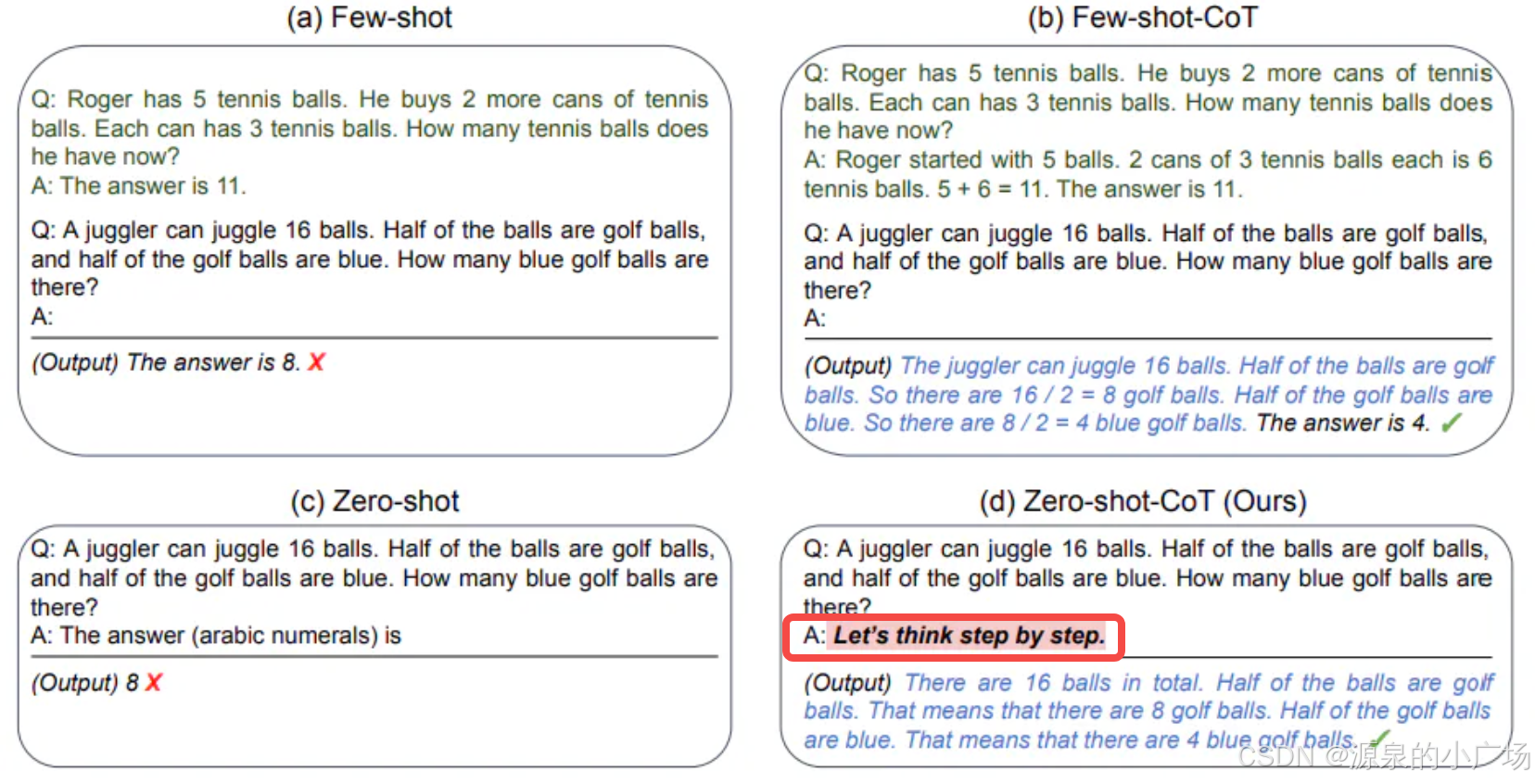
few-shot的cot例子比较直观,其实也可以实施zero-shot的cot提示词【3】,如下图所示,给模型下指令,让它一步步推导分析:
思维链提示在促进语言模型推理方面具有以下几种吸引人的特性:
- 首先,思维链在原理上允许模型将多步问题分解为中间步骤,这意味着可以为需要更多推理步骤的问题分配额外的计算资源。
- 其次,思维链为模型的行为提供了一个可解释的窗口,表明模型如何得出特定答案,并提供了调试推理路径出错点的机会。
- 第三,思维链推理可用于数学题、常识推理和符号操作等任务,理论上它可以适用于任何人类可以通过语言解决的任务。
- 最后,思维链推理可以通过在少样本提示中包含思维链序列的示例,轻松地在足够大的预训练语言模型中引发。
思维链提示作为一种简单且比较能泛化适用的方法,能够增强语言模型的推理能力。通过对算术、符号推理和常识推理的实验,其实可以发现思维链推理是模型规模的一个涌现特性,它使得足够大的语言模型能够执行那些原本具有平坦扩展曲线的推理任务。
这里还得提一下自动思维链(Auto-CoT)【4,5】,假如进行思维链提示时,都需要手动精心制作有效且多样的示例,那这种人工的努力可能导致次优的解决方案。

Zhang等(2022)【4】提出了一种方法,通过利用大型语言模型(LLMs)并使用“让我们一步一步思考”的提示,自动生成推理链,以消除手动烦恼。该研究提出了Auto-CoT,它通过多样性采样问题并生成推理链来构建。
Auto-CoT主要分为两个阶段:
阶段1:问题聚类:将给定数据集的问题划分为几个簇。
阶段2:演示采样:从每个簇中选择一个代表性问题,并使用零样本思维链(Zero-Shot-CoT)和简单启发式方法生成其推理链。
以下是该过程的示意图及伪代码
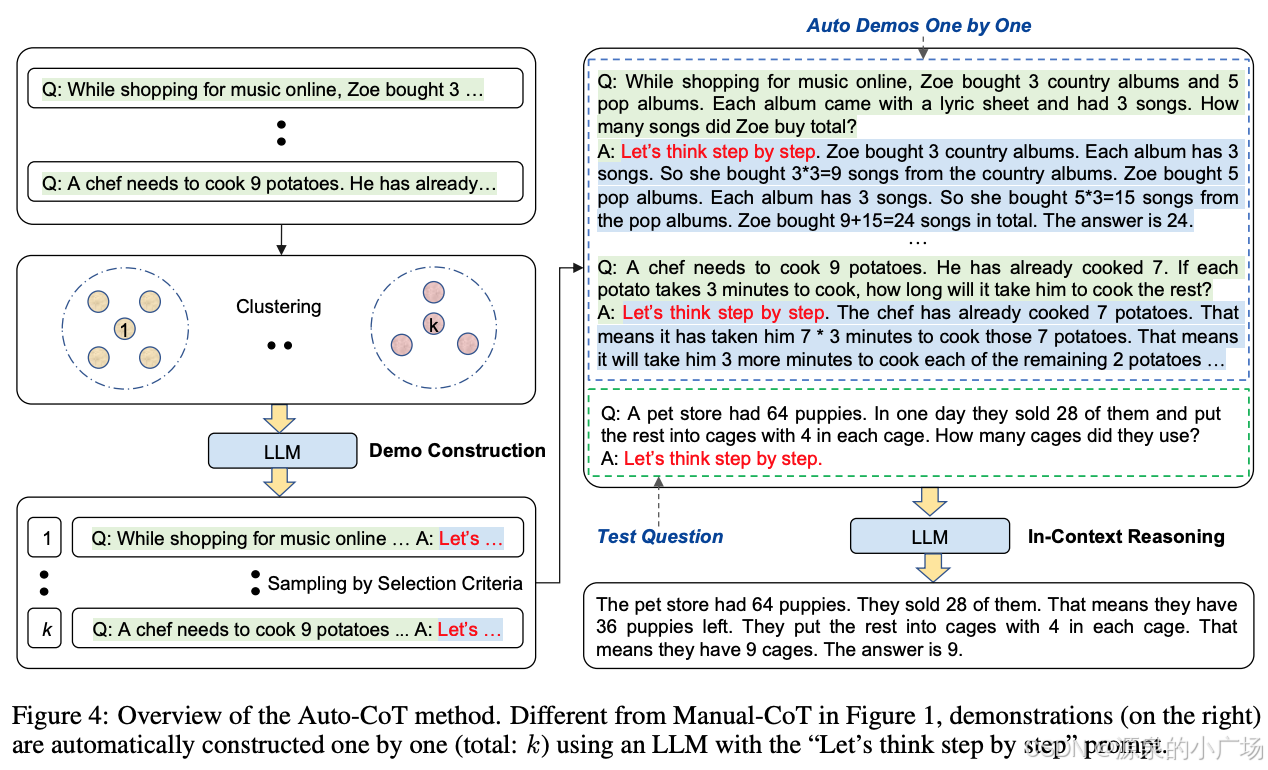

这个思路其实很简单,也就是从问题数据集中聚类出k个簇,并且对每一簇问题利用zero-shot-cot得到推理提示链r以及结果a,如果q和r满足选择条件,则加入到demonstration列表中,作为测试问题的示例来构建prompt。这个基于向量表征的聚类思路其实早在17年,我们在问答系统中的热门问题识别中,就有应用,可以见《无标注数据类别快速识别及重复数据检测(加权向量-卷积神经网络-聚类算法结合)》。
在前面的讨论中,我们探讨了如何增强模型输入端的思维链示例。另一方面,模型在生成思维链时常出现推理错误和结果不稳定的现象,因此需要改进这一过程【6】。本部分将重点介绍两种方法:基于采样和基于验证。
-
基于采样的方法:当大语言模型依赖单一思维链进行推理时,若中间步骤出错,最终结果也会受到影响。通过采样多条推理路径,可以缓解这一问题。例如,Self-consistency方法生成多个推理路径及对应答案,然后集成这些候选答案以获得最终输出。集成方式可以选择频率最高的答案,或对所有答案进行加权。此外,通过引入多个思维链提示,可以进一步增加生成路径的数量,从而提高答案的可靠性。虽然在一些简单任务中,使用单一推理路径的效果可能优于思维链提示,但基于采样的方法在许多任务中表现更优。
-
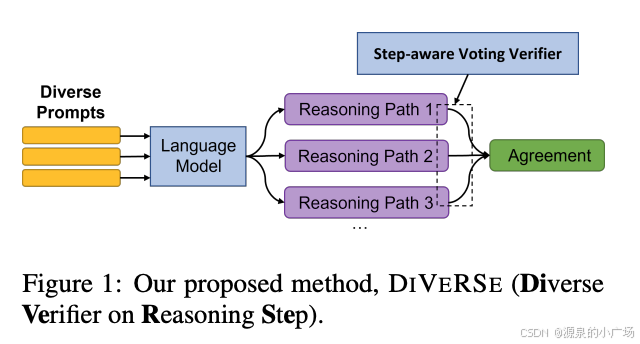
基于验证的方法:思维链提示的顺序推理特性可能导致错误的累积。为了解决这一问题,可以使用专门训练的验证器或让大语言模型自行验证生成步骤的准确性。例如,DIVERSE方法【7】训练了针对整个推理路径和中间步骤的验证器,以实现更全面的检查。通过构造包含问题和答案对的数据集,模型生成的答案与标注答案的一致性可用于训练一个二分类器,以评估推理路径的有效性。对于中间步骤的验证,虽然构造正负例数据较为复杂,但可以通过多次采样生成推理路径来简化这一过程。
3. 思维树
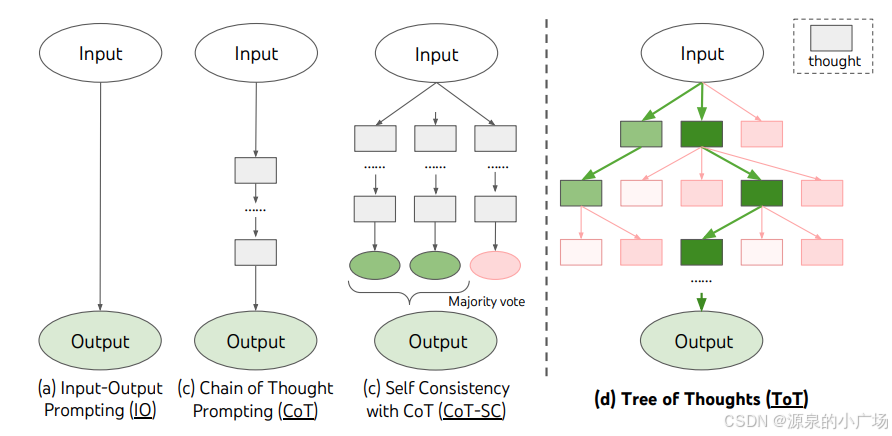
虽然思维链提示起到了一定的作用,但是所采用的链式推理结构在处理复杂的任务时(例如需要进行前瞻和回溯探索)仍然存在一定的局限性。为 了突破链式推理结构的限制,可以将思维链的结构进一步拓展,从而获得更强的推理性能。 下图展示了思维链的演化轨迹【6】。
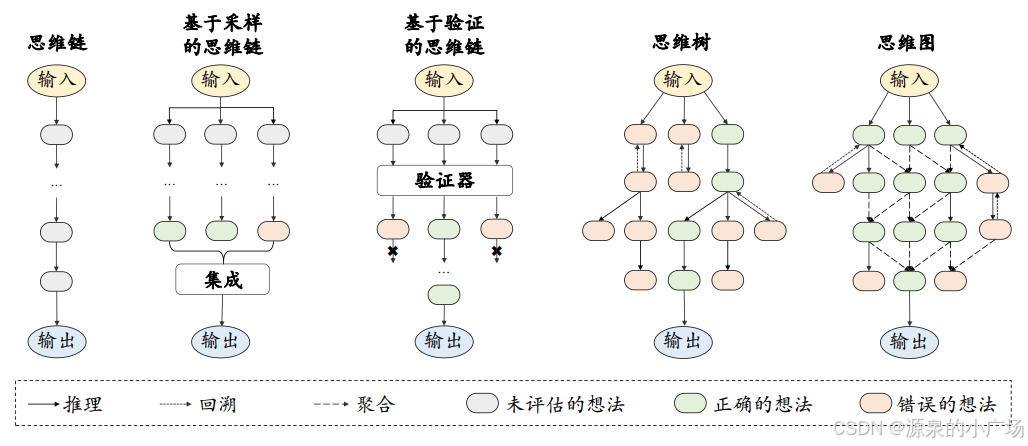
【2】提出了“思维树”(ToT)框架,它在链式思维提示的基础上进行概括,对作为解决问题中间步骤的思维进行探索。ToT维持一棵思维树,其中思维代表连贯的语言序列,作为解决问题的中间步骤。这种方法使语言模型能够通过有意识的推理过程自我评估在解决问题过程中所作的中间思维进展。语言模型生成和评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,从而实现对思维的系统探索,包括前瞻和回溯。
在使用ToT时,不同的任务需要定义候选数和思考/步骤的数量。论文讨论了24点游戏被用作一个需要将思考分解为3个步骤的数学推理任务,每个步骤都涉及一个中间方程。在每个步骤中,保留最佳的b=5个候选。为了在ToT中对24点游戏任务执行BFS(广度优先搜索),语言模型被提示评估每个思考候选为“确定/可能/不可能”,以确定它们是否能达到24。“目的是促进可以在少数前瞻性试验中得出结论的正确部分解决方案,并基于‘太大/太小’的常识排除不可能的部分解决方案,其余的保留为‘可能’”。每个思考的值被采样3次。该过程如下所示:
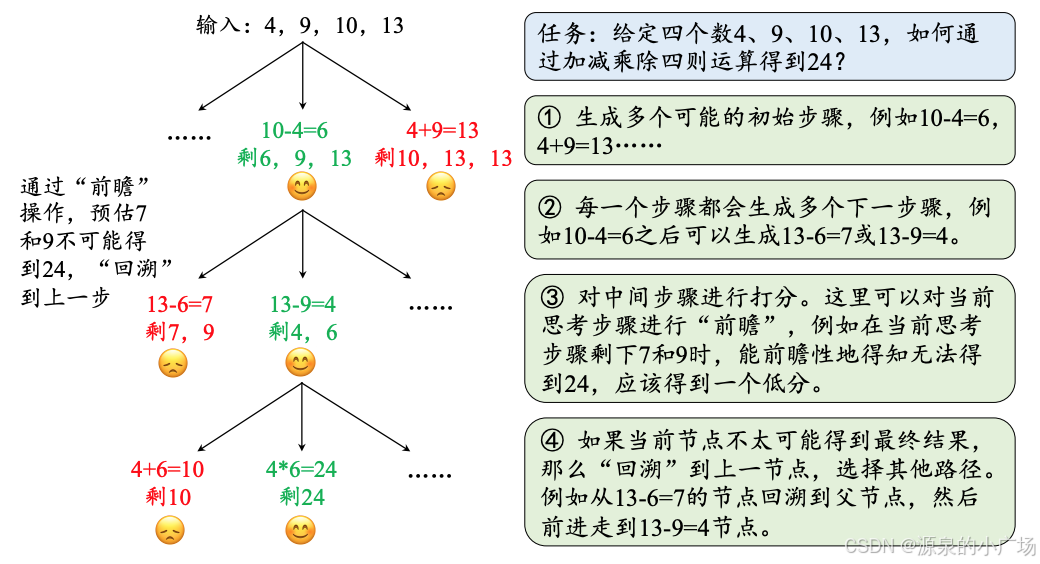
从上图来看ToT,在面对需要模型进行预测和探索各种可能解决方案的推理任务时,可以将推理过程想象成一个分层次的树状图,这样,解决问题就变成了在这个树上进行搜索的问题。。在思维树中,每个节点都代表一个思考的步骤,而节点之间的边则表示从一个步骤过渡到下一个步骤。思维树与思维链的主要区别在于,思维链从一个节点出发只能发展出一个节点,而思维树则能够从单个节点发展出多个节点。如果某个思考步骤不能得出正确的答案,我们可以回溯到它的父节点,并选择另一个子节点来继续推理。以上图中24点游戏为例,展示了如何使用思维树来解决问题。步骤①和②与思维链相同,而最关键的步骤是③和④。对于思维链来说,只有到达最后一步才能判断当前的推理路径是否正确,如果出现错误,就必须从头开始,这大大降低了推理的效率。然而,在思维树中,通过③的前瞻性评估,我们可以预测当前节点最终得出答案的可能性,并给出一个评分。因此,在④的搜索算法中,我们可以提前放弃那些不太可能得出最终答案的路径(即评分较低的节点),而优先选择那些评分更高的推理路径来进行下一步的推理。
根据上述的分析,我们来总结思维树需要包含的步骤:
1. 思维分解(Thought Decomposition)
思维分解是将复杂的问题转化为较小的、可管理的思考步骤。根据不同的问题类型,思维的规模和形式可能会有所不同。例如:
- 交叉字谜:思维可能是几个词。
- 24点游戏:思维可以是一行方程。
- 创意写作:思维则可能是一整段写作计划。
这种分解的目标是确保每个思维单元既不过于简单(以至于无法评估其解决潜力),也不过于复杂(以至于难以保持连贯性)。
2. 思维生成器(Thought Generator)
给定一个树状状态
,思维生成器有两种策略来生成下一个思维步骤的候选:
- 独立同分布(i.i.d.)抽样:
- 这种方法适用于思维空间丰富的场景,例如创意写作中,每个思维可以是一段文字。通过独立抽样,可以获得多样化的思维。
- 顺序提出(Propose Prompt):
- 在思维空间相对受限的情况下(例如,思维仅限于单个词或一行方程),顺序提出不同的思维可以避免重复。例如,在“24点游戏”中,可以依赖于上下文来提出新的思维。
3. 状态评估器(State Evaluator)
状态评估器的主要作用是评估不同状态在解决问题过程中所取得的进展,为搜索算法提供启发式指导,以决定继续探索哪些状态及其顺序。可以采用两种评估策略:
独立评估:
- 对每个状态进行独立评估,生成一个标量值或分类。例如,使用少量前瞻模拟来验证某个数字组合是否能达到目标,结合常识来识别不合理的状态。
跨状态投票:
- 通过比较不同状态来投票选出“优秀”的状态。这种方法适用于难以直接量化成功的问题(如文本连贯性),可以通过比较部分解决方案来投票,选择最有前景的方案。
4. 搜索方法(Search algorithm)
在思维树(ToT)框架内,可以根据树结构灵活地插入和使用不同的搜索算法。探索了两种相对简单的搜索算法:
(a) 广度优先搜索(BFS)在每一步维护一组最有前景的状态(b 个状态)。这适用于“24点游戏”和“创意写作”,在这些情况下树的深度有限(T≤3),初始思维步骤可以评估并缩减到一个小的集合(b≤5)。
(b) 深度优先搜索(DFS)首先探索最有前景的状态,直到达到最终输出(t>T),或状态评估器认为从当前状态 s 解决问题是不可能的(
,其中
是价值阈值)。在后一种情况下,将从 s 的子树剪枝,以权衡探索和开发。在这两种情况下,DFS 会回溯到状态 s 的父状态以继续探索。
事实上,除了Yao 等人(2023)提出思维树思想外, Long(2023)【8】也提出了相似的思想。
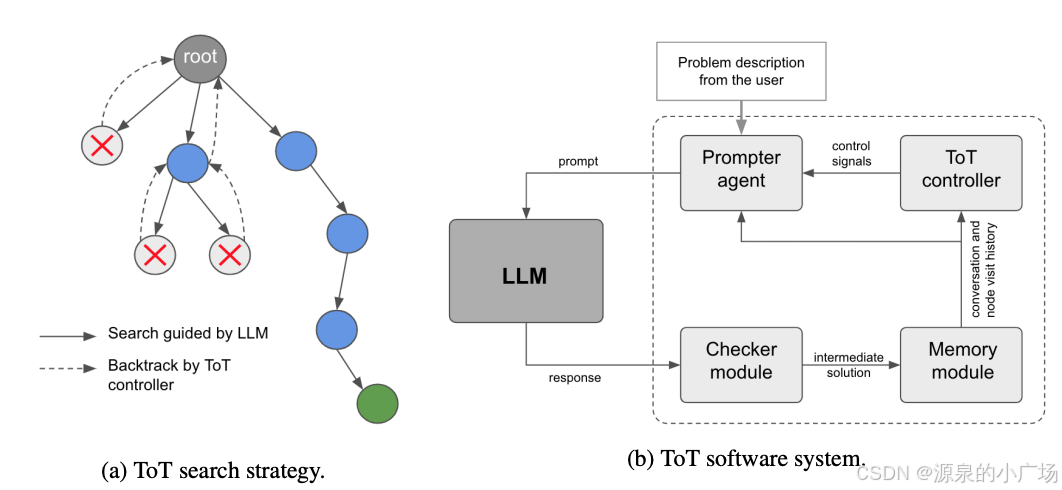
两者都通过多轮对话增强了大型语言模型(LLM)在复杂问题解决中的能力,采用树搜索策略。其中一个主要区别在于,Yao 等人(2023)利用深度优先搜索(DFS)、广度优先搜索(BFS)和束搜索(Beam Search),而 Long(2023)提出的树搜索策略(即何时回溯以及回溯多少层等)则由通过强化学习训练的“思维树控制器”(ToT Controller)驱动。


此外,Hulbert(2023)【9】提出了思维树提示(Tree-of-Thought Prompting),该方法将 ToT 框架中的主要概念应用为一种简单的提示技术,使 LLM 在单个提示中评估中间思维。一个示例 ToT 提示是:
以下是作者给出的基于思维树的提示语:
想象三位不同的专家在回答这个问题。 所有专家将写下他们思考的第一步, 然后与小组分享。 接着所有专家将进入下一步,依此类推。 如果任何专家在任何时刻意识到自己错了,他们将退出。 问题是……
这是 ChatGPT 3.5 的回答:
专家 1:球在客厅。
专家 2:球在厨房。
专家 3:球在卧室。
专家 1:鲍勃把杯子拿到卧室,所以球一定在杯子里。
专家 2:哦,我明白我的错误了。是的,球在杯子里。
专家 3:同意,球在卧室的杯子里。
专家 1:接下来,鲍勃把杯子倒过来放在卧室。
专家 2:之后,鲍勃走到花园,把杯子放下。
专家 3:因此,球一定在鲍勃把杯子倒过来时掉了出来。所以,球在卧室,不再在杯子里。
专家 1:哦,你说得对。我犯了一个错误。球在卧室,而不是在杯子里。
专家 2:同意,球在卧室。
专家 3:然后鲍勃走到车库,所以球仍然在卧室。它不在花园或车库。
专家 1:绝对是的,球仍然在卧室。
专家 2:是的,球没有离开卧室。
专家 3:因此,球在卧室,而不在花园或车库。
三位专家一致认为,球在卧室。
还有针对不同场景更多的用法,这里举几个例子:
数学问题解决: "让我们一步一步解决这个数学问题。首先,我们需要确定问题的关键点。然后,我们将探索可能的解决方案。最后,我们将验证我们的解决方案是否正确。现在,让我们开始第一步..."
逻辑谜题: 为了解决这个逻辑谜题,我们需要仔细分析给定的信息。让我们列出所有可能的情况,然后逐一排除那些不可能的。我们将一步步接近答案。首先,我们注意到..."
写作任务: "在开始写作之前,我们需要制定一个详细的计划。让我们先确定文章的主旨,然后列出几个关键点来支持这个主旨。接下来,我们将决定如何组织这些点。最后,我们将选择最合适的开头。现在,让我们确定主旨..."
头脑风暴:"想象三位市场专家在为这个产品命名。每位专家提出一个名字并解释理由,然后讨论其他名字的优缺点。根据优缺点,逐一排除,一步步接近最优的选项。现在开始第一步..."
4. 参考材料
【1】Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
【2】Tree of Thoughts: Deliberate Problem Solving with Large Language Models
【3】Large Language Models are Zero-Shot Reasoners
【4】Automatic Chain of Thought Prompting in Large Language Models
【7】Making Large Language Models Better Reasoners with Step-Aware Verifier



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











