







目录
本文基于在标准数据集上训练自定义模型,展示利用MMDetection工具包,通过替换Faster R-CNN模型中的neck组件,完成在自定义数据集上的权重训练,以及记录自己选用合适的组件来提升模型精度的学习过程,如果你是在使用MMDetection的计算机视觉目标检测er,并且想了解关于如何学习模型的自定义,那么我希望通过本帖能够给你一丝启发!

一、官方示例
请注意,若你的实际项目并不是官方示例中基于cityscapes数据集,在Cascade Mask R-CNN R50中新增AugFPN模块的操作,以下步骤仅供参考,并非普适所有自定义模型训练。
1. 定义新的 neck (例如 AugFPN)
首先创建新文件mmdet/models/necks/augfpn.py.
import torch.nn as nn
from mmdet.registry import MODELS
@MODELS.register_module()
class AugFPN(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_outs,
start_level=0,
end_level=-1,
add_extra_convs=False):
pass
def forward(self, inputs):
# implementation is ignored
pass
__init__方法是类的初始化方法,通常用于定义和初始化类的属性,包括网络层、超参数等forward方法是神经网络模型中定义前向传播计算逻辑的核心方法。
我们在初学阶段,一个深度学习模型的__init__和forward方法都仅仅是pass,尚未实现具体内容,这样做是可以的,但最终你仍需要填充这两个方法来定义模型结构和前向传播逻辑,以便让模型能正确地处理输入并产生有意义的输出。不然这个模型将无法进行有效的训练和推断。
2. 导入模块
你可以采用两种方式导入模块,第一种是在mmdet/models/necks/__init__.py中添加如下内容
from .augfpn import AugFPN
也可以顺便在__all__列表中添加‘AugFPN’,该操作确保用户在使用例如from .neck import *的导入时能正确获得所需的类。如果不打算通过 * 导入,则此__all__的设置并不是必需的,但如果提供了__all__,则应当保持两者的一致性。
__all__ = [
'FPN', 'BFP', 'ChannelMapper', 'HRFPN', 'NASFPN', 'FPN_CARAFE', 'PAFPN',
'NASFCOS_FPN', 'RFP', 'YOLOV3Neck', 'FPG', 'DilatedEncoder',
'CTResNetNeck', 'SSDNeck', 'YOLOXPAFPN', 'DyHead', 'CSPNeXtPAFPN', 'SSH',
'FPN_DropBlock', 'AugFPN'
]
第二种是增加如下代码到对应配置中,这种方式的好处是不需要改动代码
custom_imports = dict(
imports=['mmdet.models.necks.augfpn'],
allow_failed_imports=False)
3. 修改配置
neck=dict(
type='AugFPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
二、模型内组件替换实际应用展示
我们可以使用MMDetection工具包内集成的neck组件进行替换,但是替换模型组件也需要遵循相应的原则,例如将 Faster R-CNN 中的FPN替换成FPG,需要注意FPG是否支持与Faster R-CNN相同的操作,例如特征融合和多尺度检测,同时需要确保参数传递正确,以便FPG能正确构建和初始化。如果FPG具有额外的参数要求,则需要在模型配置中补充相应的参数,否则就会报错。当然最终也需要考虑到GPU的内存占用,和是否改进有效等问题。
1. 判断需要替换的新组件内的初始化参数是否必须传入
- 如果某个参数在
__init__方法签名中有明确的默认值(如default=None或其他非None值),则该参数不是必须传入的。当然,即使有默认值,也可能存在某些情况下需要用户自行设定的情况,取决于默认值是否适用。 - 文档注释或官方API文档:许多开源项目都有详细的API文档或类的docstring注释,其中会清楚地标注哪些参数是可选的,哪些是必填的。
FPG(Feature Pyramid Grids)
可以看到在mmdetection/mmdet/models/necks/fpg.py中,初始化参数如下
class FPG(BaseModule):
def __init__(self,
in_channels,
out_channels,
num_outs,
stack_times,
paths,
inter_channels=None,
same_down_trans=None,
same_up_trans=dict(
type='conv', kernel_size=3, stride=2, padding=1),
across_lateral_trans=dict(type='conv', kernel_size=1),
across_down_trans=dict(type='conv', kernel_size=3),
across_up_trans=None,
across_skip_trans=dict(type='identity'),
output_trans=dict(type='last_conv', kernel_size=3),
start_level=0,
end_level=-1,
add_extra_convs=False,
norm_cfg=None,
skip_inds=None,
init_cfg=[
dict(type='Caffe2Xavier', layer='Conv2d'),
dict(
type='Constant',
layer=[
'_BatchNorm', '_InstanceNorm', 'GroupNorm',
'LayerNorm'
],
val=1.0)
]):
stack_times:金字塔结构堆叠的次数。paths:每层栈的路径顺序,可以是 ‘bu’(自底向上)或 ‘td’(自顶向下)。same_down_trans、same_up_trans、across_lateral_trans、across_down_trans、across_up_trans、output_trans和across_skip_trans等参数,分别代表不同类型转换层的具体配置字典。
在mmdetection/configs/_base_/models/faster-rcnn_r50_fpn.py中,模型组件neck的代码如下所示
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
因此根据有无给定默认值的原则,stack_times 和paths必须给定初始化参数,需要做如下的字典序内参数替换
neck=dict(
type='FPG',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5,
stack_times=..., # 必须提供
paths=..., # 必须提供
same_down_trans=...,
same_up_trans=...,
# ... 其他必要参数
)
不过实际上FPG中的必须提供的参数和其他必要参数其实是息息相关的,我们可以查看MMDetection已经集成的使用FPG的模型来模仿修改如何将自己的模型的neck组件改为FPG,例如查看mmdetection/configs/fpg/faster-rcnn_r50_fpg_crop640-50e_coco.py
_base_ = 'faster-rcnn_r50_fpn_crop640-50e_coco.py'
norm_cfg = dict(type='BN', requires_grad=True)
model = dict(
neck=dict(
type='FPG',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
inter_channels=256,
num_outs=5,
stack_times=9,
paths=['bu'] * 9,
same_down_trans=None,
same_up_trans=dict(
type='conv',
kernel_size=3,
stride=2,
padding=1,
norm_cfg=norm_cfg,
inplace=False,
order=('act', 'conv', 'norm')),
across_lateral_trans=dict(
type='conv',
kernel_size=1,
norm_cfg=norm_cfg,
inplace=False,
order=('act', 'conv', 'norm')),
across_down_trans=dict(
type='interpolation_conv',
mode='nearest',
kernel_size=3,
norm_cfg=norm_cfg,
order=('act', 'conv', 'norm'),
inplace=False),
across_up_trans=None,
across_skip_trans=dict(
type='conv',
kernel_size=1,
norm_cfg=norm_cfg,
inplace=False,
order=('act', 'conv', 'norm')),
output_trans=dict(
type='last_conv',
kernel_size=3,
order=('act', 'conv', 'norm'),
inplace=False),
norm_cfg=norm_cfg,
skip_inds=[(0, 1, 2, 3), (0, 1, 2), (0, 1), (0, ), ()]))
将其中的neck直接替换到你需要自定义的Faster R-CNN模型中。此操作可以确保模型权重训练不会出现问题,后续进阶学习到FPG模块各个初始化参数的具体含义之后,我们可以进行自定义修改,从而使得组件的替换更好地适配特定的数据集训练任务,以此提升模型的训练精度。
可以看到训练命令执行后,终端显示训练权重即将保存的位置,这表明配置文件各项信息均正确,不过我们课题组实在太卷了,服务器GPU都爆满,所以这里就不展示具体的训练结果啦~可以参考以下NAS-FPN的替换,相信大家会有所收获!
NAS-FPN(Neural Architecture Search based Feature Pyramid Network)
该组件位于mmdetection/mmdet/models/necks/nas_fpn.py,NAS-FPN是一种基于神经架构搜索(Neural Architecture Search, NAS)技术优化的特征金字塔网络(FPN)。尽管NASFPN受到了FPN的启发,但它并不是标准FPN的一个简单变体,而是通过自动化的方法寻找最优的特征金字塔结构。在该组件代码中的初始化参数如下:
class NASFPN(BaseModule):
def __init__(
self,
in_channels: List[int],
out_channels: int,
num_outs: int,
stack_times: int,
start_level: int = 0,
end_level: int = -1,
norm_cfg: OptConfigType = None,
init_cfg: MultiConfig = dict(type='Caffe2Xavier', layer='Conv2d')
) -> None:
对比模型配置文件中原有的neck,只有一个需要额外添加的必选初始化参数
stack_times: int:此处的stack_times可能代表了在构建特征金字塔过程中,某种特定操作或模块被重复使用的次数。
因此模型的neck组件可以改写成:
neck=dict(
type='NASFPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5,
stack_times=2)
此次修改可以正常训练,训练日志如下:
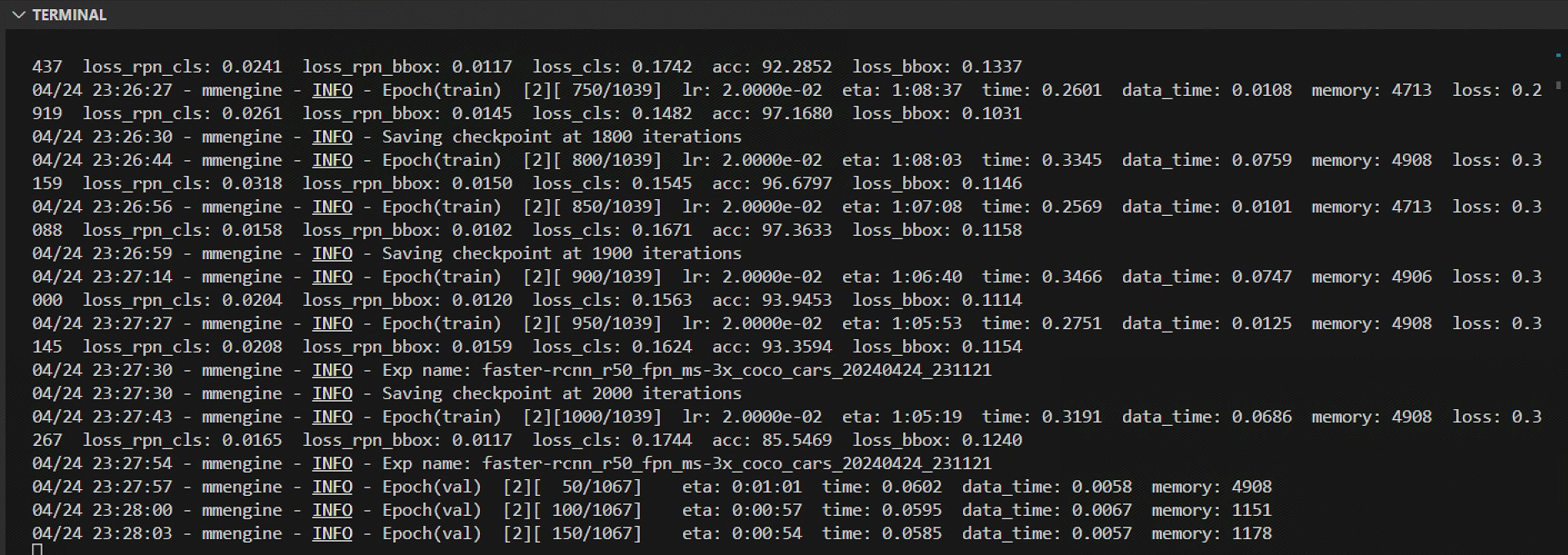
训练结果如下
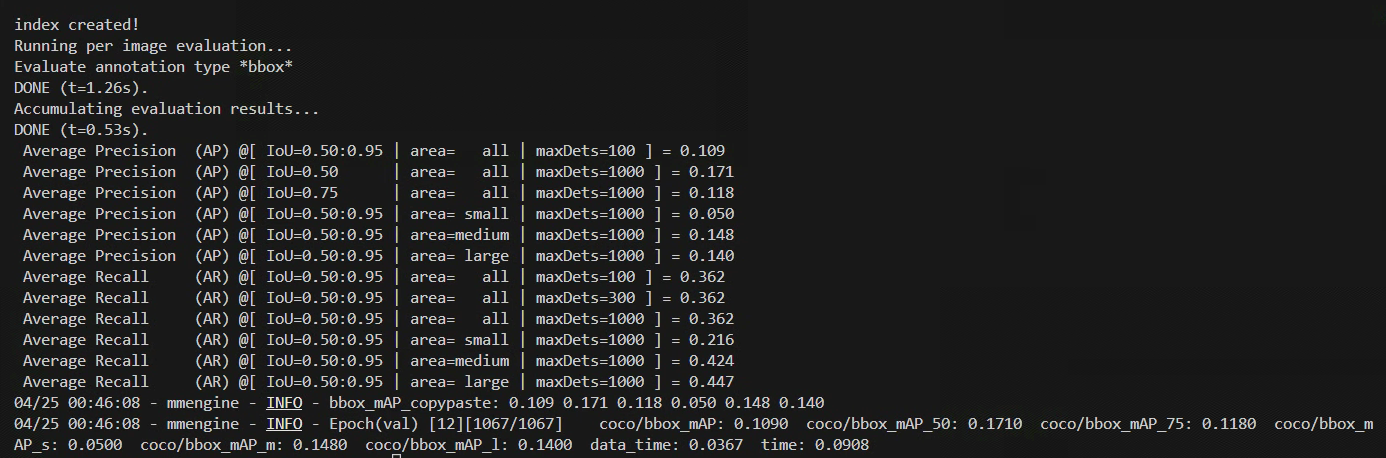
从输出的结果来看,将Faster RCNN的neck组件从FPN换成NAS-FPN的训练结果并不理想,甚至大部分精度评估有了显著下降,这说明该组件不适用于给定的数据集训练模型。
2. 直接选择需要替换的组件的改进版本
FPN-DropBlock
选择直接选择替换neck组件为FPN的改进版本FPN_DropBlock,就不用担心参数传入问题了!该组件位于 mmdetection/mmdet/models/necks/fpn_dropblock.py。FPN 是一种特征提取结构,而FPN_DropBlock则是在FPN基础上添加了DropBlock正则化手段,即在卷积神经网络中引入了一种空间dropout形式,旨在打破过拟合问题,并强制模型学习更鲁棒的特征表示作为一种增强原有FPN网络性能和泛化能力的技术。
neck=dict(
type='FPN_DropBlock',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
三、多GPU训练
补充PORT端口占用情况的解决方案
如果你想在一台机器上启动多个任务的话,比如在一个有 8 块 GPU 的机器上启动 2 个需要 4 块GPU的任务,你需要给不同的训练任务指定不同的端口(默认为 29500)来避免冲突

报错
Runtimerror: The server socket has failed to listen on any local network address. the server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use).表明端口被占用。
若想查看29500有无被占用,可以在终端键入此命令
netstat -tlnp | grep 29500
当你通过netstat或类似的命令查看网络端口状态时,如果结果显示为LISTEN,这通常意味着这个端口当前正被某个服务或进程占用并处于监听状态,等待来自其他主机的连接请求。在端口处于LISTEN状态下,其他服务如果尝试在同一主机上也使用相同的端口启动服务,将会因端口已被占用而无法成功绑定

指定未被占用的端口PORT=29501后即可正常进行多GPU训练
CUDA_VISIBLE_DEVICES=2,3,5\
PORT=29051\
./tools/dist_train.sh\
configs/cars/faster-rcnn_r50_fpn_ms-3x_coco_cars.py\
3
替换模型的neck组件为FPN_DropBlock的训练的结果如下:
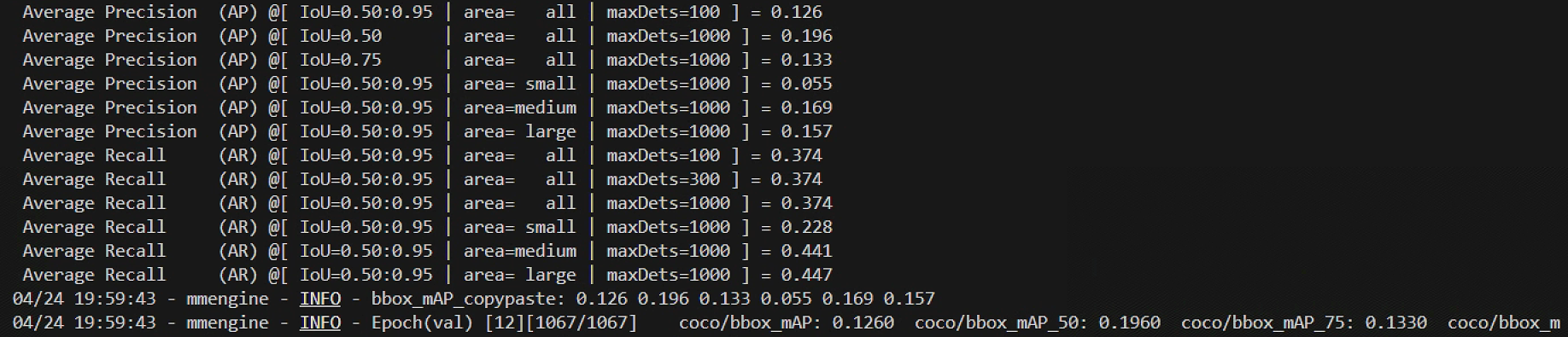
结果来看,在neck组件中使用带有dropout的FPN (FPN_DropBlock)相比于普通的FPN并没有显著提高模型的表现,精度评估参数不相上下,但比NAS-FPN的效果要好一些,所以如果还需要尝试重新替换新的组件。不过本次学习,相信大家已经掌握了自定义模型中组件的替换基本流程,下一步可以进阶研究不同组件对于模型之于数据集的精度改进效果了。














 2884
2884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









