







目录
在人工智能深度学习领域,高质量的数据集是推动深度学习模型训练研究与应用的关键。Kaggle作为一个广受欢迎的数据科学竞赛平台,提供了丰富的公开数据集供研究者和开发者使用。本帖将指导大家如何在Kaggle上找到并下载所需数据集,并将其迁移至Linux服务器,以便于利用服务器的强大计算资源进行多GPU训练。下面将为大家介绍详细步骤:
1. 准备工作:下载安装谷歌浏览器Google Chrome
首先,确保你的计算机上安装了谷歌浏览器Google Chrome。Chrome以其出色的兼容性和速度成为许多开发者的首选浏览器。访问Google Chrome官网下载并安装。
2. 注册Kaggle账号
访问Kaggle网站,打开浏览器,输入Kaggle的官方网站地址:https://www.kaggle.com/。在页面右上角,点击“Sign Up”或者“Register”按钮。如果您使用的是中文界面,按钮可能显示为“注册”,推荐大家使用邮箱注册登录。
3. 寻找数据集:浏览Kaggle数据集
打开Chrome浏览器,访问Kaggle数据集页面。此页面汇集了成千上万的公开数据集,覆盖各种领域。
4. 精确搜索数据集
在Kaggle页面顶部的搜索框中输入英文关键词,如“object detection COCO”,以寻找包含目标检测任务且遵循COCO数据集格式的数据集。COCO(Common Objects in Context)是一种广泛使用的标准,特别适合物体识别和检测任务。或者加上“animal”检索,以寻找动物相关的COCO数据集。
5. 预览与评估数据集
点击进入感兴趣的项目页面,仔细阅读About Dataset部分,了解数据集概述、来源及使用许可等信息。

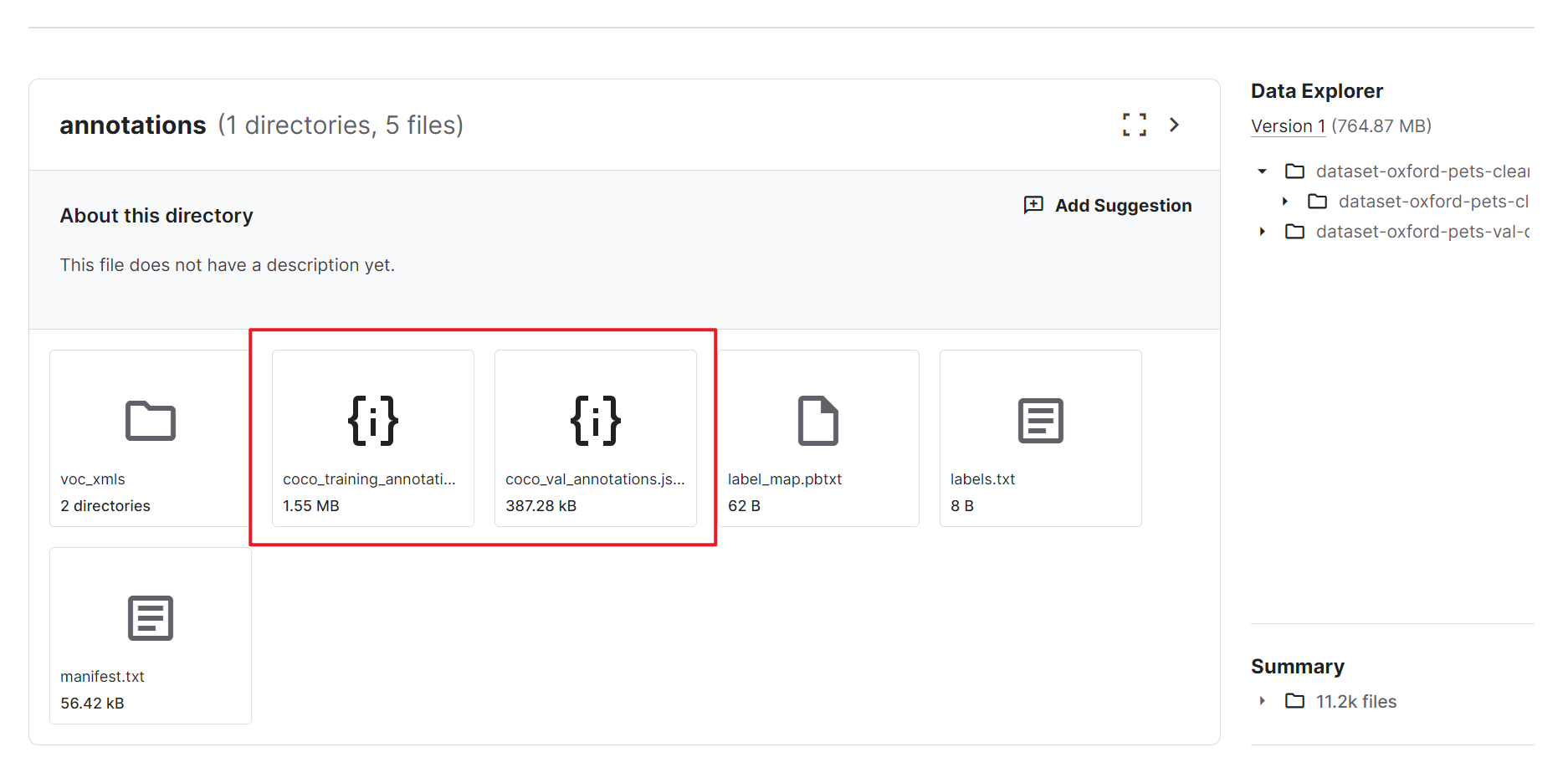
随后,利用About this directory & Data Explorer功能预览数据样本,确保数据集符合你的需求。特别是检查文件列表,确认存在如annotations文件夹中的.json文件,这对于COCO格式的数据集至关重要。
6. 下载数据集
找到Download按钮,点击下载整个数据集的压缩包(通常是.zip格式)。对于大型数据集,Kaggle可能需要您加入竞赛或请求数据访问权限。

7. 数据集迁移至Linux服务器
使用XFTP上传数据:首先,在本地计算机上安装XFTP或其他SFTP客户端。配置连接至Linux服务器,登录后,将下载好的数据集压缩包拖拽至服务器部署项目中指定的data目录下。
8. 解压缩数据集
通过vscode连接至Linux服务器,在Terminal终端使用命令行工具执行以下命令解压数据集:
unzip /path/to/your/dataset.zip -d /path/to/extract/to
请替换上述路径为实际的文件路径。
9. 修改数据集配置文件
根据实际项目需求,可能需要调整数据集的配置文件,比如在MMDetection中修改配置文件中的路径指向(data_root)、类别数量(num_classes)等。具体操作移步利用MMDetection在自定义数据集上进行训练。
10. 多GPU模型训练
- 安装依赖与环境:确保服务器已根据官方README文件安装必要的深度学习框架(如PyTorch),并配置好CUDA和cuDNN以支持GPU加速。
- 配置多GPU训练:在训练脚本中,利用框架提供的多GPU支持特性。在终端键入相应命令分配任务到多个GPU。具体操作移步利用MMDetection在标准数据集上训练预定义的模型。
CUDA_VISIBLE_DEVICES=2,7\
./tools/dist_train.sh\
configs/oxford/faster-rcnn_r50_fpn_ms-3x_coco_oxford.py\
2
一切准备就绪后,即可产生如下训练日志,表明模型训练成功进行!
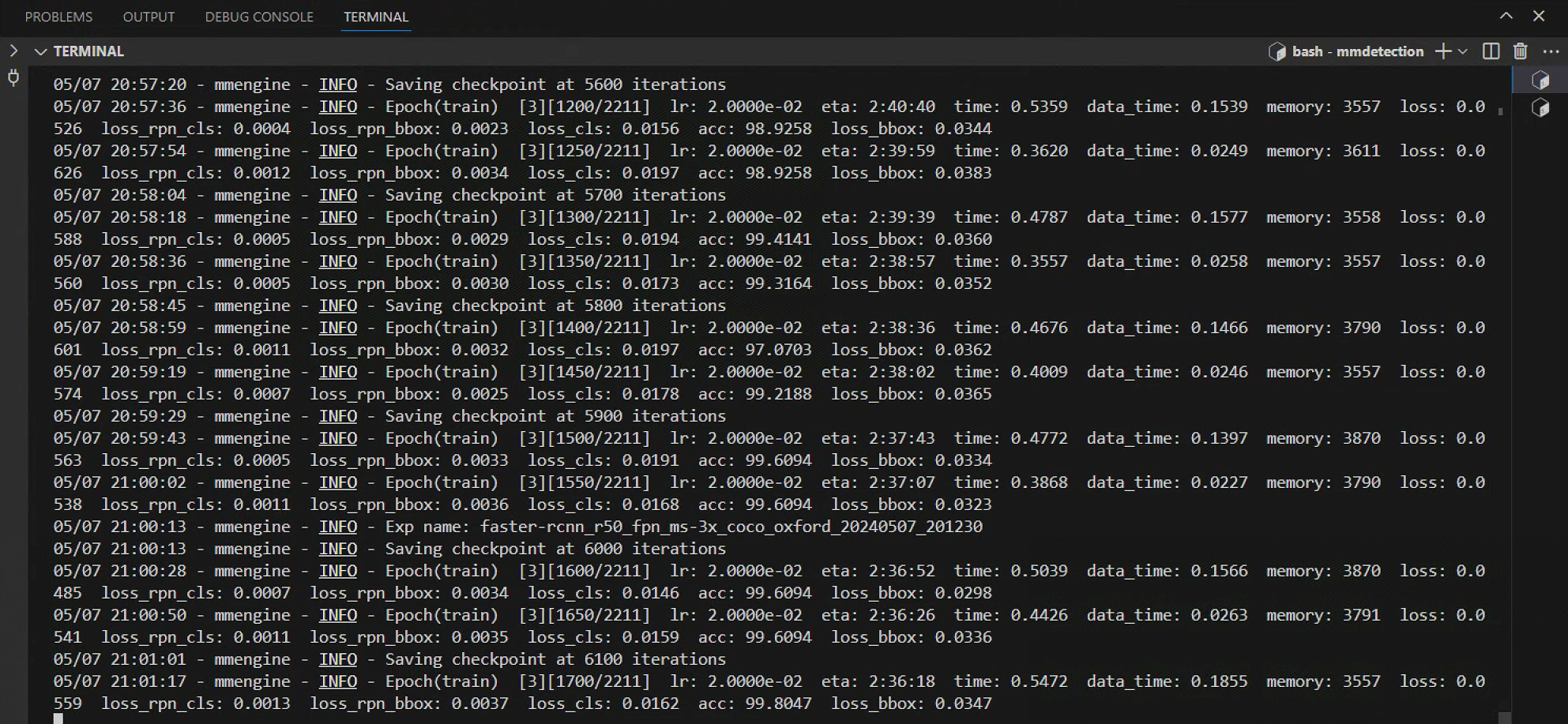
训练完成后,模型训练精度结果展示:

11. 单张图片模型预测

















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









