






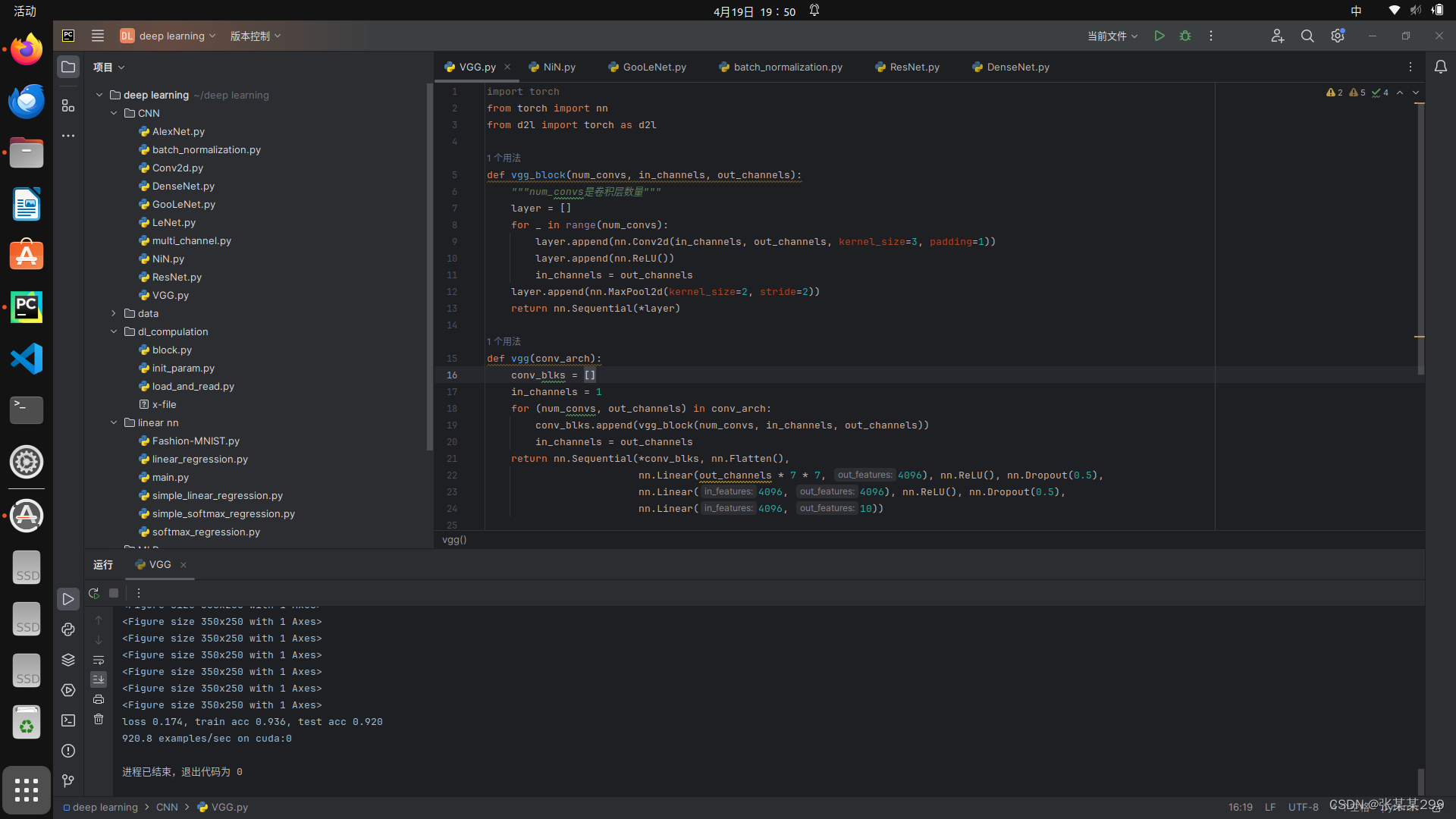
一:VGG
VGG在卷积神经网络中,是第一次采取块结构,将多个神经网络层连接成块直接使用,简易代码如下:
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
"""num_convs是卷积层数量"""
layer = []
for _ in range(num_convs):
layer.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layer.append(nn.ReLU())
in_channels = out_channels
layer.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layer)
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
if __name__ == '__main__':
radio = 4
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
""" pair[0]从名为 pair 的数组或元组中获取第一个元素。
pair[1] // radio从名为 pair 的数组或元组中获取第二个元素,并将其除以变量 radio 的值,然后取整数部分。"""
small_conv_arch = [(pair[0], pair[1] // radio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
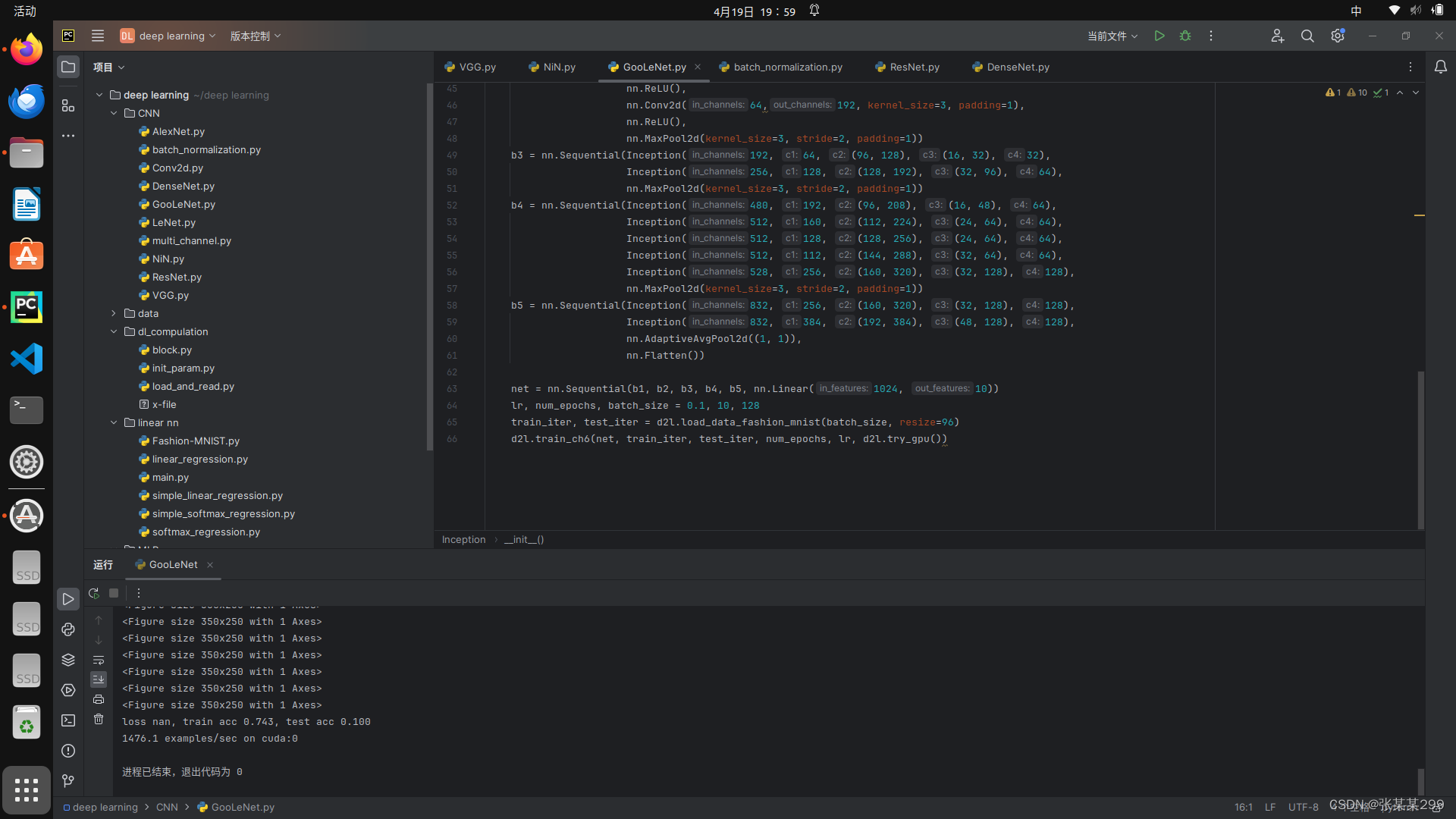
二:GooleNet
GooleNet类似于滤波器,使用多种角度去观察图像的细节,简易代码如下:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
"""goolenet类似于滤波器,使用多种不同角度的通道识别图像细节"""
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
"""*args:用于接收任意数量的位置参数(Positional Arguments)。
当函数被调用时,*args 会将传递给函数的所有位置参数打包成一个元组(Tuple),并将该元组赋值给 args。这样,函数就可以接受任意数量的位置参数。
**kwargs:用于接收任意数量的关键字参数(Keyword Arguments)。
当函数被调用时,**kwargs 会将传递给函数的所有关键字参数打包成一个字典(Dictionary),并将该字典赋值给 kwargs。这样,函数就可以接受任意数量的关键字参数。"""
"""def example_function(*args, **kwargs):
print("Positional arguments (args):", args)
print("Keyword arguments (kwargs):", kwargs)
# 调用函数
example_function(1, 2, 3, name='John', age=30)"""
super(Inception, self).__init__(**kwargs)
#c1--c4是每条路径的输出通道
#路径1 单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
#路径2 1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
#路径3 1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
#路径4 3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(F.relu(self.p4_1(x))))
return torch.cat((p1, p2, p3, p4), dim=1)
if __name__ == '__main__':
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
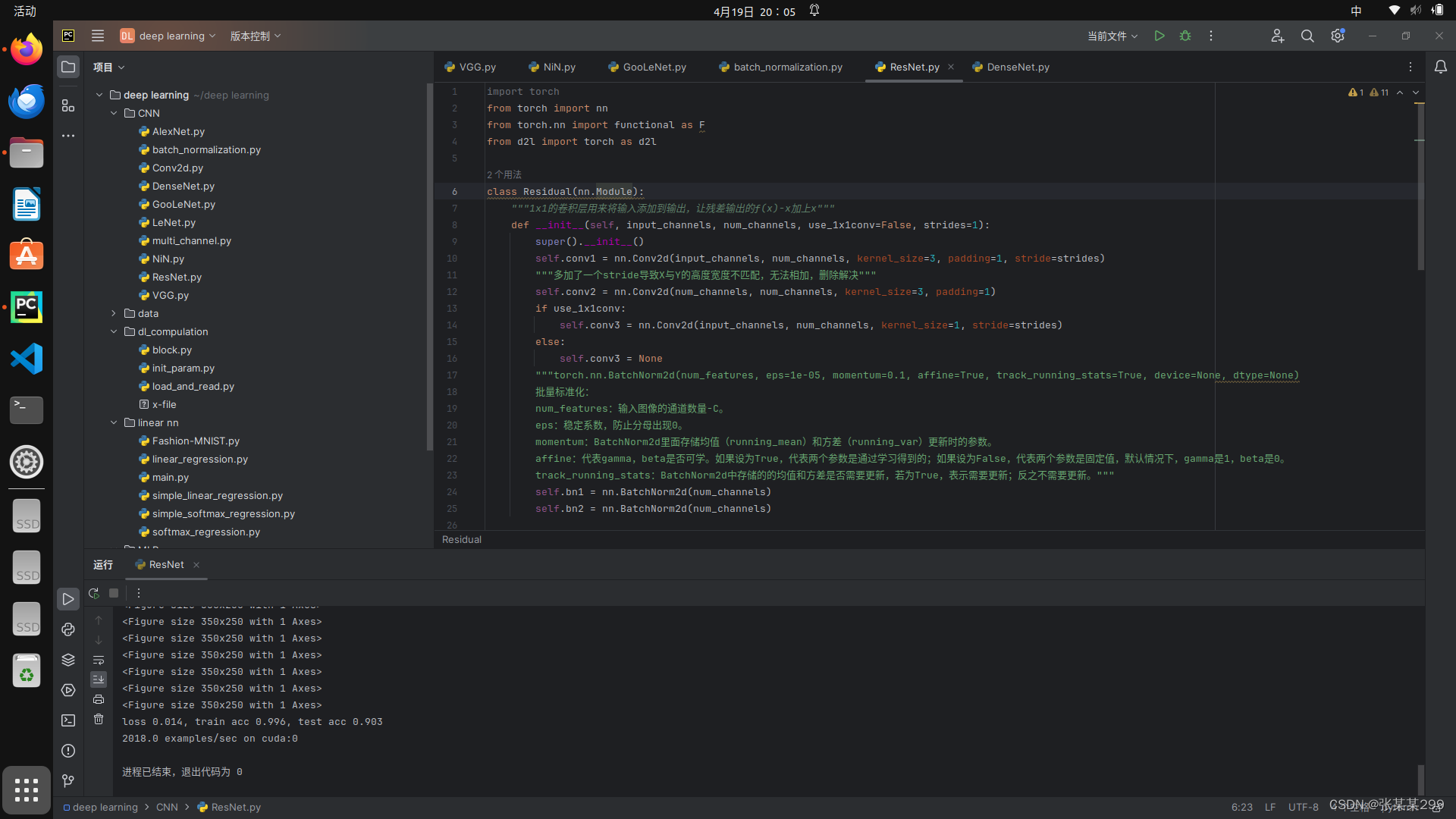
三:ResNet
残差神经网络的特点是,输出从f(x)变成f(x)-x,在最后结果上再加入x,特点是实际问题中更好优化,简易代码如下:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
"""1x1的卷积层用来将输入添加到输出,让残差输出的f(x)-x加上x"""
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
"""多加了一个stride导致X与Y的高度宽度不匹配,无法相加,删除解决"""
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
"""torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
批量标准化:
num_features:输入图像的通道数量-C。
eps:稳定系数,防止分母出现0。
momentum:BatchNorm2d里面存储均值(running_mean)和方差(running_var)更新时的参数。
affine:代表gamma,beta是否可学。如果设为True,代表两个参数是通过学习得到的;如果设为False,代表两个参数是固定值,默认情况下,gamma是1,beta是0。
track_running_stats:BatchNorm2d中存储的的均值和方差是否需要更新,若为True,表示需要更新;反之不需要更新。"""
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
def resnet_block(input_channels, num_channels, num_residual, first_block=False):
blk = []
for i in range(num_residual):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
if __name__ == '__main__':
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
"""n.AdaptiveAvgPool2d((1,1)) 中的参数 (1,1) 表示希望输出的特征图的大小为 1x1。
这意味着无论输入特征图的大小是多少,经过这个池化层处理后,输出的特征图的大小将始终为 1x1。
如果输入的特征图的大小是 (batch_size, channels, height, width),那么经过 nn.AdaptiveAvgPool2d((1,1)) 操作后,
输出的特征图的大小将为 (batch_size, channels, 1, 1),其中每个通道的特征值是该通道在输入特征图中所有像素的平均值。"""
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









