






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
由于灰狼优化算法(GWO)的新颖性,文献中还没有设计该算法的多目标 版本的研究。针对多目标优化问题,本文首次提出了一种多目标灰狼优化 (MOGWO)算法。一个规模不变的外部存档被集成到 GWO 中,用于保存和检索帕累托最优解。然后,该存档被用来定义社会等级,并模拟灰狼在多目标搜索空间中的狩猎行为。该方法在 10 个多目标基准问题上进行了测试,并与两个著名的元启发式算法——基于分解的多目标进化算法(MOEA/D)和多目标粒子群优化(MOPSO)算法进行了比较。定性和定量的结果表明,所提出的算法能够给出非常有竞争力的结果,并优于其他算法。
关键字:多目标优化;进化算法;多准则优化;启发式算法;元启发式算法;
工程优化;灰狼优化算法

详细讲解见第4部分。
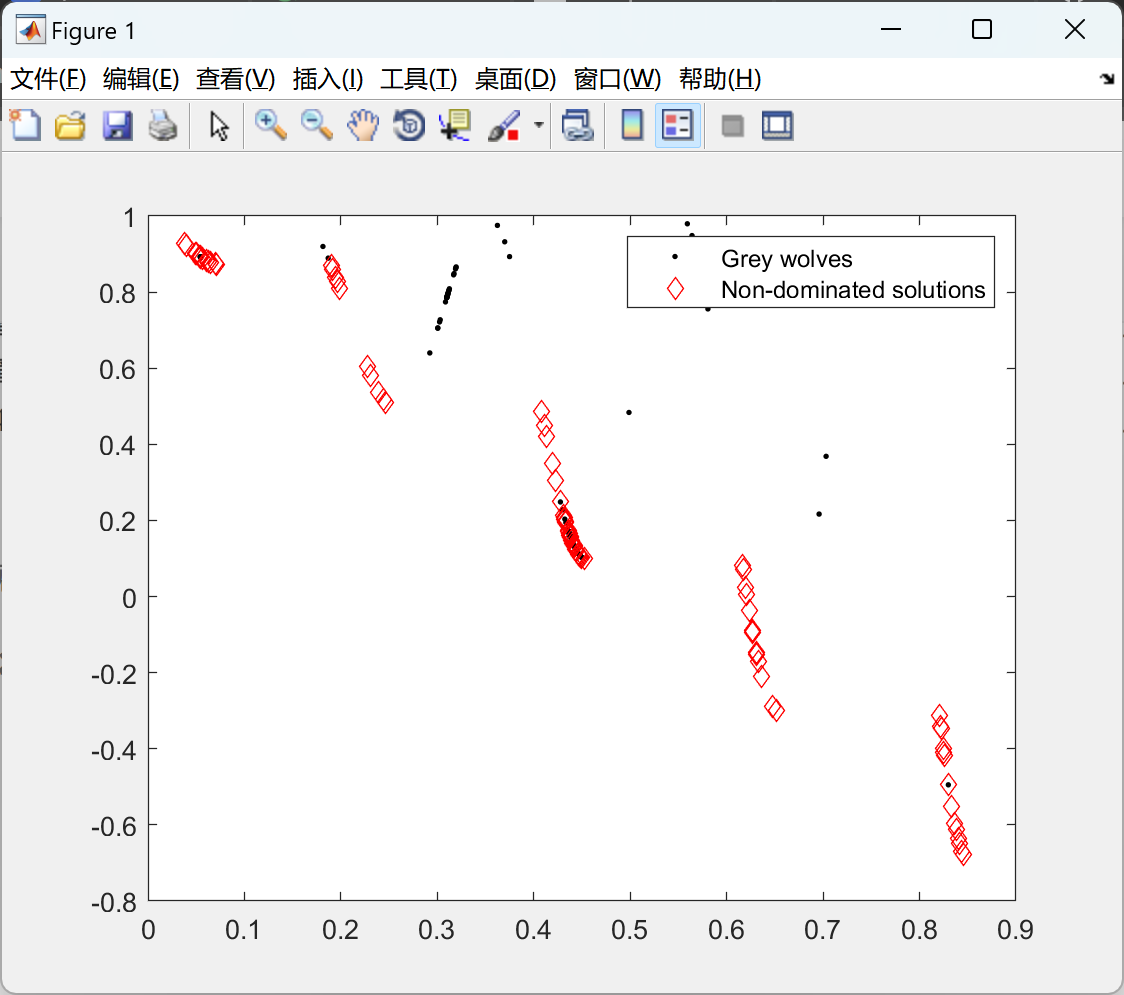
📚2 运行结果
部分代码:
clear all
clc
drawing_flag = 1;
nVar=5;
fobj=@(x) ZDT3(x);
% Lower bound and upper bound
lb=zeros(1,5);
ub=ones(1,5);
VarSize=[1 nVar];
GreyWolves_num=100;
MaxIt=50; % Maximum Number of Iterations
Archive_size=100; % Repository Size
alpha=0.1; % Grid Inflation Parameter
nGrid=10; % Number of Grids per each Dimension
beta=4; %=4; % Leader Selection Pressure Parameter
gamma=2; % Extra (to be deleted) Repository Member Selection Pressure
% Initialization
GreyWolves=CreateEmptyParticle(GreyWolves_num);
for i=1:GreyWolves_num
GreyWolves(i).Velocity=0;
GreyWolves(i).Position=zeros(1,nVar);
for j=1:nVar
GreyWolves(i).Position(1,j)=unifrnd(lb(j),ub(j),1);
end
GreyWolves(i).Cost=fobj(GreyWolves(i).Position')';
GreyWolves(i).Best.Position=GreyWolves(i).Position;
GreyWolves(i).Best.Cost=GreyWolves(i).Cost;
end
GreyWolves=DetermineDomination(GreyWolves);
Archive=GetNonDominatedParticles(GreyWolves);
Archive_costs=GetCosts(Archive);
G=CreateHypercubes(Archive_costs,nGrid,alpha);
for i=1:numel(Archive)
[Archive(i).GridIndex Archive(i).GridSubIndex]=GetGridIndex(Archive(i),G);
end
% MOGWO main loop
for it=1:MaxIt
a=2-it*((2)/MaxIt);
for i=1:GreyWolves_num
clear rep2
clear rep3
% Choose the alpha, beta, and delta grey wolves
Delta=SelectLeader(Archive,beta);
Beta=SelectLeader(Archive,beta);
Alpha=SelectLeader(Archive,beta);
% If there are less than three solutions in the least crowded
% hypercube, the second least crowded hypercube is also found
% to choose other leaders from.
if size(Archive,1)>1
counter=0;
for newi=1:size(Archive,1)
if sum(Delta.Position~=Archive(newi).Position)~=0
counter=counter+1;
rep2(counter,1)=Archive(newi);
end
end
Beta=SelectLeader(rep2,beta);
end
% This scenario is the same if the second least crowded hypercube
% has one solution, so the delta leader should be chosen from the
% third least crowded hypercube.
if size(Archive,1)>2
counter=0;
for newi=1:size(rep2,1)
if sum(Beta.Position~=rep2(newi).Position)~=0
counter=counter+1;
rep3(counter,1)=rep2(newi);
end
end
Alpha=SelectLeader(rep3,beta);
end
% Eq.(3.4) in the paper
c=2.*rand(1, nVar);
% Eq.(3.1) in the paper
D=abs(c.*Delta.Position-GreyWolves(i).Position);
% Eq.(3.3) in the paper
A=2.*a.*rand(1, nVar)-a;
% Eq.(3.8) in the paper
X1=Delta.Position-A.*abs(D);
% Eq.(3.4) in the paper
c=2.*rand(1, nVar);
% Eq.(3.1) in the paper
D=abs(c.*Beta.Position-GreyWolves(i).Position);
% Eq.(3.3) in the paper
A=2.*a.*rand()-a;
% Eq.(3.9) in the paper
X2=Beta.Position-A.*abs(D);
% Eq.(3.4) in the paper
c=2.*rand(1, nVar);
% Eq.(3.1) in the paper
D=abs(c.*Alpha.Position-GreyWolves(i).Position);
% Eq.(3.3) in the paper
A=2.*a.*rand()-a;
% Eq.(3.10) in the paper
X3=Alpha.Position-A.*abs(D);
% Eq.(3.11) in the paper
GreyWolves(i).Position=(X1+X2+X3)./3;
% Boundary checking
GreyWolves(i).Position=min(max(GreyWolves(i).Position,lb),ub);
GreyWolves(i).Cost=fobj(GreyWolves(i).Position')';
end
GreyWolves=DetermineDomination(GreyWolves);
non_dominated_wolves=GetNonDominatedParticles(GreyWolves);
Archive=[Archive
non_dominated_wolves];
Archive=DetermineDomination(Archive);
Archive=GetNonDominatedParticles(Archive);
for i=1:numel(Archive)
[Archive(i).GridIndex Archive(i).GridSubIndex]=GetGridIndex(Archive(i),G);
end
if numel(Archive)>Archive_size
EXTRA=numel(Archive)-Archive_size;
Archive=DeleteFromRep(Archive,EXTRA,gamma);
Archive_costs=GetCosts(Archive);
G=CreateHypercubes(Archive_costs,nGrid,alpha);
end
disp(['In iteration ' num2str(it) ': Number of solutions in the archive = ' num2str(numel(Archive))]);
save results
% Results
costs=GetCosts(GreyWolves);
Archive_costs=GetCosts(Archive);
if drawing_flag==1
hold off
plot(costs(1,:),costs(2,:),'k.');
hold on
plot(Archive_costs(1,:),Archive_costs(2,:),'rd');
legend('Grey wolves','Non-dominated solutions');
drawnow
end
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
🌈4 Matlab代码、文档
回复:多目标灰狼
免费领取














 2394
2394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









