






我们有一部分正常人和脊柱侧弯患者的生理活动的时序数据,下面是对该数据概率分布的一些测试以及想法。
第一步,将文件夹中的所有文件读入到文件名列表和文件路径列表里:
path = '本地上文件所在的根目录'
import os
list_data_filenames = []
list_data_paths = []
for filepath,dirnames,filenames in os.walk(path):
for filename in filenames:
data_path = os.path.join(filepath,filename)
list_data_paths.append(data_path)
list_data_filenames.append(filename)
print(len(list_data_paths))第二步,对于数据分布,由于是有几十个文件,每个文件里有6个channel(column),而每一个channel里面又有几百个数据,所以我的第一个想法是对每个文件里的每一个channel利用numpy.mean()求一个平均值,再观察平均值的分布。以下是对第一个channel所执行的代码
import pandas as pd
import seaborn as sns
import numpy as np
channel_One = []
channel_Two = []
channel_Three = []
channel_Four = []
channel_Five = []
channel_Six = []
for i,list_data_path in enumerate(list_data_paths):
df = pd.read_excel(list_data_path,names=['time','channel1','channel2','channel3','channel4','channel5','channel6'],header=0)
if np.sum(np.sum(df=='--')) != 0:
print(i)
continue
for channel in ['channel1','channel2','channel3','channel4','channel5','channel6']:
if channel == 'channel1':
mean = np.mean(df[channel])
channel_One.append(mean)
if channel == 'channel2':
mean = np.mean(df[channel])
channel_Two.append(mean)
if channel == 'channel3':
mean = np.mean(df[channel])
channel_Three.append(mean)
if channel == 'channel4':
mean = np.mean(df[channel])
channel_Four.append(mean)
if channel == 'channel5':
mean = np.mean(df[channel])
channel_Five.append(mean)
if channel == 'channel6':
mean = np.mean(df[channel])
channel_Six.append(mean)
print(channel_One)
sns.displot(channel_One, kde=True, bins=58)上述代码中,利用python的seaborn库中的displot函数画出数据的概率分布直方图,并画出其核密度函数,如图:
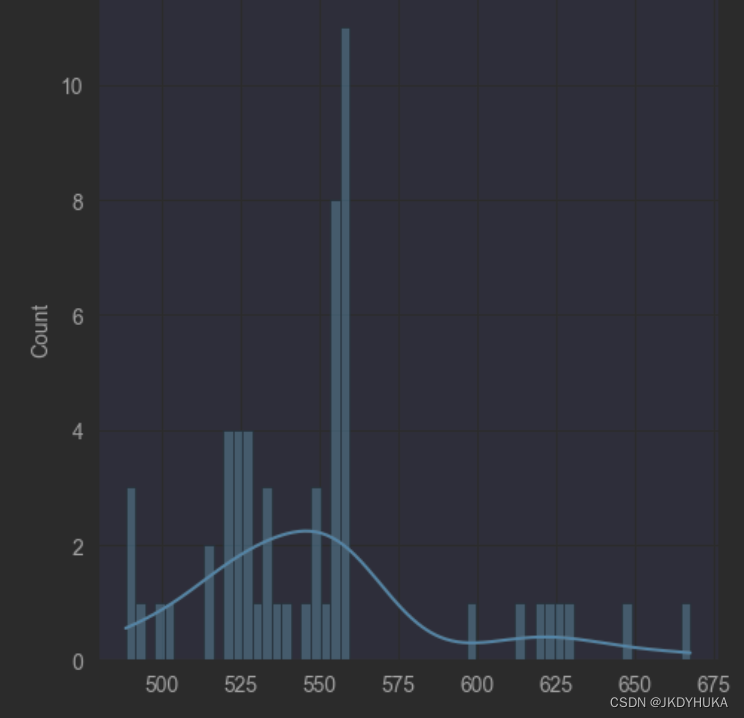
我们可以通过直方图看出,大部分数据均值集中分布再550到560左右,剩下的一部分数据的均值分布在625和525左右。而这些数据的均值的核密度函数并不能直接看出来符合什么分布,所以通过判断数据的均值,我们并没有得到多少有效信息。
并且根据均值画出的图,有部分直方是无法可视化在图像中的,所以我们尝试把所有channel1的数据全部输入,然后求所有数据的概率直方图。以下是需要修改的代码部分:
if channel == 'channel1':
for element in df[channel]:
channel_One.append(element)经过以上改变之后,channel_One列表中储存了每个文件的第一个channel的所有数据,而利用这些数据得出的结果具有一定明显的特征。我们不难从下图看出,这些数据的分布类似于正态分布。
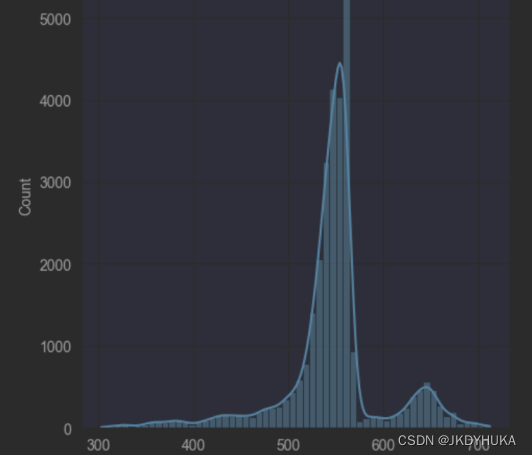
但是该直方图右侧有第二个峰值,通过其核密度曲线可以很明显的看出来。因此,我们利用卡方检验去验证一下这些数据是否符合二项分布。如下为卡方检验的代码和结果:
from scipy import stats
ks_test = stats.kstest(channel_One, 'norm')
print(ks_test)
在输出的结果中,pvalue为nan,原因是p值太小无法表达。而在该卡方检验中,p值大于0.05才能说明该数据符合正态分布。
我们想到由于这个图片中的数据是由患者和正常人组成的,所以这时有个想法是:如果把患者与正常人分开,那么他们的数据分布会不会不同?通过测试证实,仅包含患者的数据的话,其channel1数据的概率直方图与之前并无明显区别(如下第一张图),但是如果只包含正常人的话,其概率直方图会有一定不同(如下第二张图)
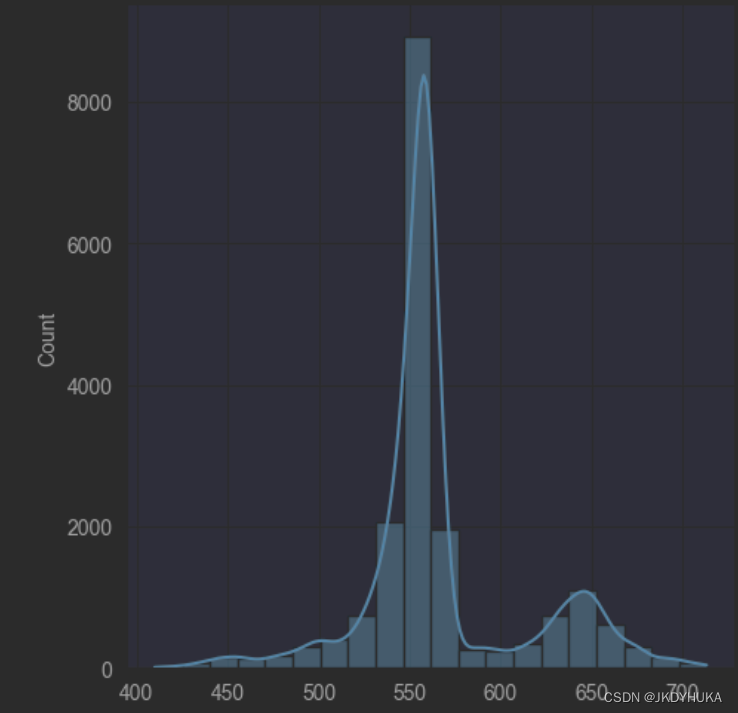
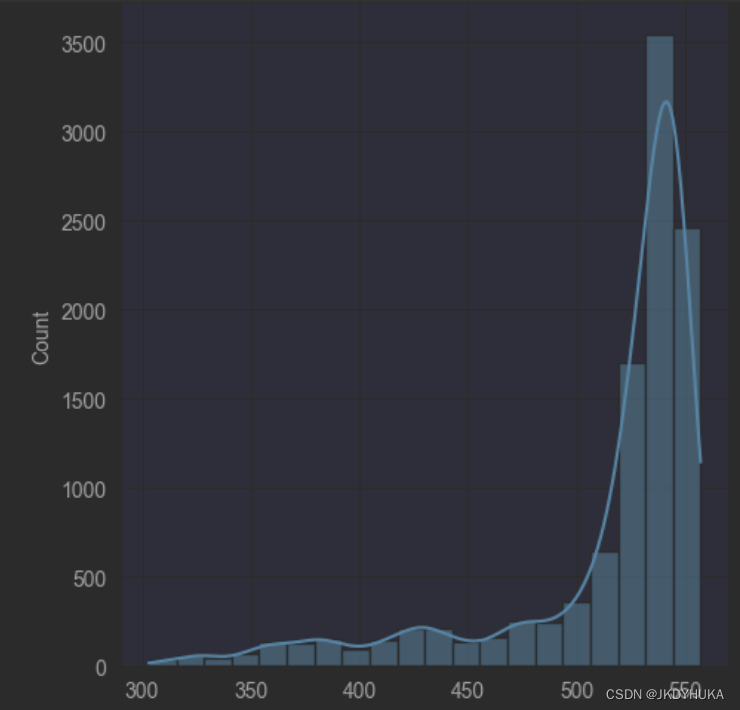
可以看出,在患者组,会有一小部分数据值落在650左右,而在正常人组中没有数据会落在650,但是目前依然无法根据这个特征判断,是否有数据落在650就一定是患者,没有数据落在650就一定是正常人,因为这是一组时序数据。
时序数据是一组时间序列数据,其数据包含一定的时间信息,我们到目前为止并没有用到这些数据包含的时序信息。
因为这些数据之间都隔了一段时间,所以如果我们关注他时序数据的变化值,即用当前数据减去前一个数据的差构成整个列表,该列表的长度应为n-1,如下是代码表示单人的数据变化:
channel_One = []
list_data_normal = list_data_paths[:1]
for i,list_data_path in enumerate(list_data_normal):
df = pd.read_excel(list_data_path,names=['time','channel1','channel2','channel3','channel4','channel5','channel6'],header=0)
if np.sum(np.sum(df=='--')) != 0:
print(i)
continue
for channel in ['channel1','channel2','channel3','channel4','channel5','channel6']:
# df[channel] = savgol_filter(df[channel], 5, 3, mode='nearest')
if channel == 'channel1':
print(df[channel][0])
i = 1
for element in df[channel]:
if element == df[channel][0]:
continue
var = element - df[channel][i-1]
print(var)
channel_One.append(var)
i = i + 1
print(channel_One)
pic = sns.displot(channel_One, kde=True, bins=20)通过这段代码得出的结果如下图:
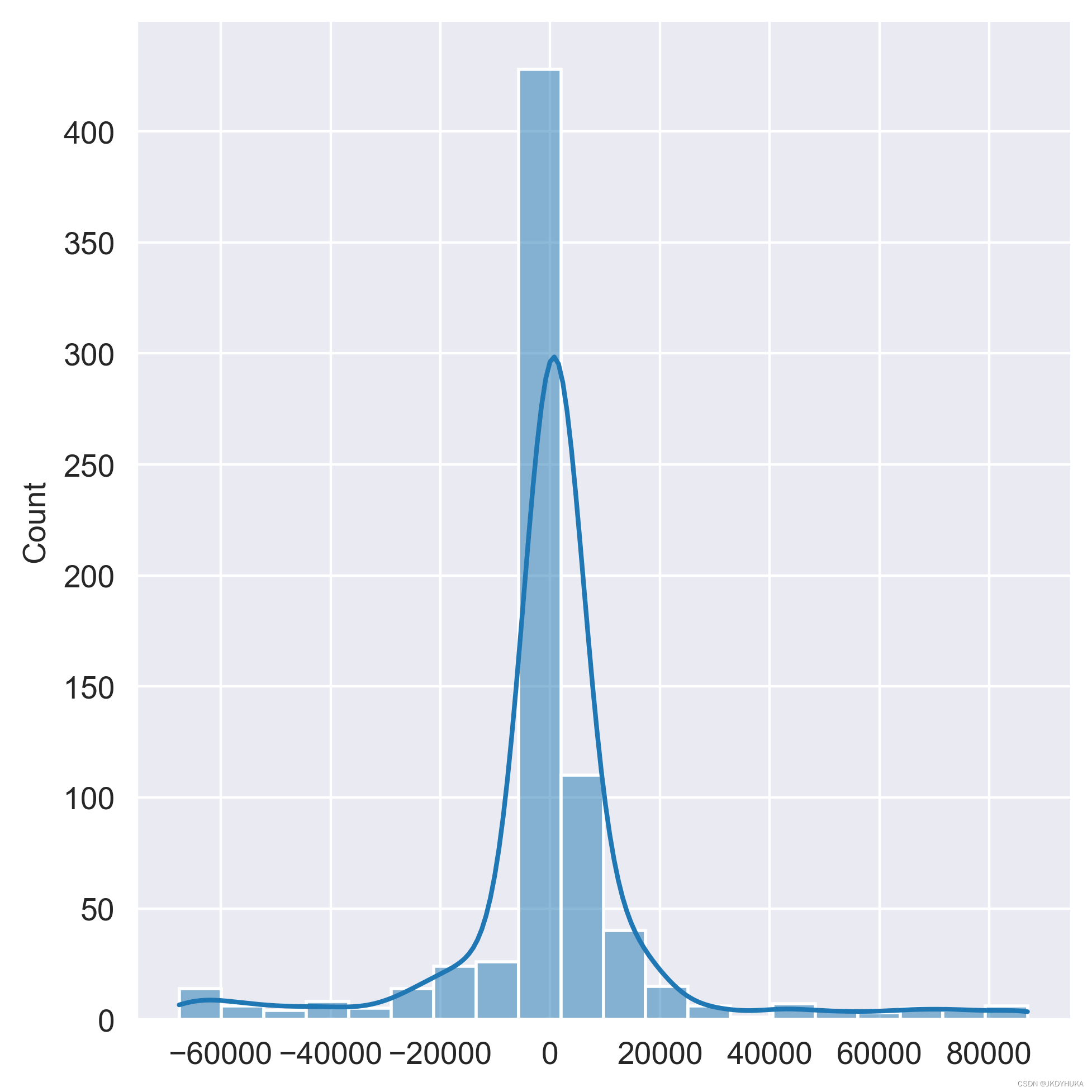
通过画出的核密度函数,不难发现,其差值的分布与正态分布非常相似。下面是通过卡方检验来检测这组差值是否真正符合正态分布:
channel_One = preprocessing.scale(channel_One)
ks_test = stats.kstest(channel_One, 'norm')
print(ks_test.pvalue)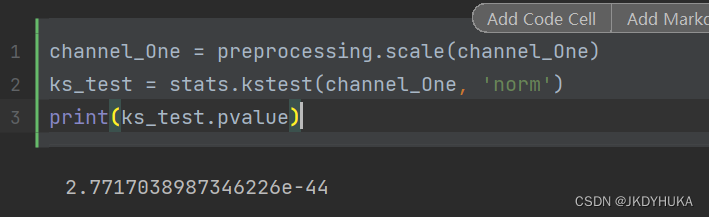
但是由卡方检验所得出来的p值仍远小于0.01,所以我们并不能认为这组差值符合正态分布。
通过概率分布来进行判断的方法告一段落,后面继续做特征分析















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









