






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于深度强化学习DQN的无人机导航研究
一、深度强化学习DQN的核心原理
-
Q值函数与神经网络结合
DQN通过深度神经网络(如CNN)替代传统Q-Learning中的Q表,解决了高维状态空间下的维度灾难问题。神经网络从输入状态中提取特征,输出各动作的Q值,实现端到端的学习与决策。 -
关键技术创新
- 经验回放:通过存储历史经验(状态、动作、奖励、下一状态)并随机抽样训练,打破数据相关性,提升训练稳定性。
- 目标网络:独立的目标网络用于计算目标Q值,减少训练过程中的波动,参数定期更新以保持稳定性。
- Double Q-Learning:利用目标网络选择最优动作,避免Q值过估计问题。
-
探索策略
采用ε-贪婪策略,以概率ε随机选择动作(探索),否则选择Q值最大的动作(利用),平衡探索与利用。
二、无人机导航的网格环境建模方法
- 网格划分与动态建模
- 基础网格法:将空间划分为X×Y的单元格,障碍物标记为不可达区域。传统方法存在存储和计算效率问题,尤其是三维场景下网格数量指数级增长。
- 动态环境建模:
- EHG结构:适应动态障碍物和天气变化,优化路径搜索效率。
- GeoSOT-3D网格:结合5G通信需求,实现空域的多尺度划分与轨迹规划。
- 降维方法:通过平面投影忽略低风险区域,减少三维网格数量,提升实时性。
- 路径规划算法选择
- 基于图搜索的方法(如A*、Dijkstra):保证解的存在性,适用于高精度网格。
- 改进算法:如Matrix Alignment Dijkstra(MAD)结合动态网格结构,兼顾效率与安全性。
三、基于DQN的避障与导航策略
-
状态与动作空间设计
- 状态表示:无人机位置、速度、障碍物相对距离/航向角(通过Faster R-CNN检测结果转换)。
- 动作空间:离散动作(前进、转向等)或连续动作(需结合DDPG等算法)。
-
避障算法改进
- D3QN:双重网络减少Q值高估,提升避障鲁棒性。
- T-DQN:引入LSTM存储历史信息,通过阈值筛选经验池加速收敛。
- FRDDM-DQN:结合目标检测模型(Faster R-CNN)与环境准入机制,降低数据复杂度。
-
多目标协同避障
在多无人机场景中,采用多智能体DQN(如DQN-SS、MADQN),优化数据收集效率并避免碰撞。
四、路径优化的目标函数设计
-
多目标权衡
目标函数需综合以下因素:- 路径长度:最小化飞行时间与能耗。
- 避碰惩罚:通过障碍物距离函数(如排斥势场)设计负奖励。
- 飞行稳定性:限制高度波动与转向角度,提升平滑度。
-
数学表达式示例
-
路径长度函数:
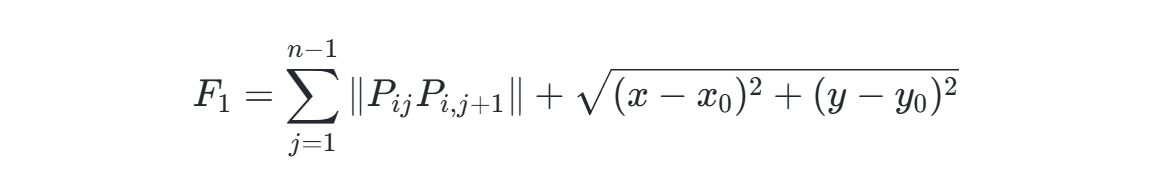
-
能量消耗函数:
结合无人机阻力模型与推进效率,通过数值积分优化能量消耗。
-
五、奖励机制设计与优化
-
奖励函数类型
- 终端奖励:成功到达目标(正奖励)、碰撞障碍物(负奖励)。
- 非终端奖励:基于距离目标的欧氏距离、航向角偏差、危险区域接近度等。
-
改进方法
- 人工势场理论:引力(目标导向)与斥力(避障)结合,设计方向奖励函数。
- 动态探索因子:训练后期减少随机探索,侧重策略利用,提升收敛速度。
- 经验准入机制:筛选高质量经验(如避障成功样本)存入回放池,加速学习。
六、现有研究案例与性能评估
-
典型应用场景
- 动态障碍物环境:课程学习策略逐步增加障碍物密度,DQN在动态环境中成功率可达61%。
- 军事任务:西北工业大学团队利用FRDDM-DQN实现雷达失效下的避障,成功率提升20%以上。
- 无线供电数据收集:DQN优化无人机轨迹,数据流量提升30%,能量效率提高25%。
-
算法对比
算法 改进点 性能提升(对比DQN) T-DQN LSTM+阈值筛选经验池 收敛步数减少41.1% MP-DQN 多经验池+方向奖惩函数 路径长度缩短15% MS-DDQN 多步更新+细分奖励 成功率97%(动态环境)
七、挑战与未来研究方向
-
现存问题
- 动态障碍物适应性:现有方法假设障碍物静态或简单运动,复杂动态场景(如人群避让)效果有限。
- 计算资源限制:高分辨率网格与复杂网络结构需边缘计算或模型压缩技术。
- 多目标冲突:路径长度、能耗、安全性的权衡需更优帕累托前沿。
-
未来方向
- 异构网络融合:结合5G通信、边缘计算与DQN,实现实时环境感知与决策。
- 迁移学习:预训练模型适应新环境,减少在线学习时间。
- 多模态输入:融合视觉、LiDAR等多传感器数据,提升状态表征能力。
八、结论
基于DQN的无人机导航技术通过神经网络与强化学习的结合,在复杂网格环境中展现出强大的自适应能力。通过环境建模、避障策略、目标函数与奖励机制的优化,无人机能够高效规划路径并动态避障。未来研究需进一步解决动态环境适应性与多目标优化难题,推动技术向物流、救援、军事等实际场景落地。
📚2 运行结果

部分代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from collections import deque
.....
# ✅ Train DQN Agent Until a Good Reward is Achieved
def train_agent(env, agent, max_episodes=5000, reward_threshold=80):
rewards = []
for episode in range(max_episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action_idx = agent.choose_action(state)
action = env.actions[action_idx]
next_state, reward, done = env.step(action)
agent.store_experience(state, action_idx, reward, next_state, done)
agent.train(batch_size=32)
state = next_state
total_reward += reward
rewards.append(total_reward)
if episode % 100 == 0:
print(f"Episode {episode}: Total Reward = {total_reward}")
# ✅ Stop training early if reward threshold is met
if np.mean(rewards[-50:]) >= reward_threshold:
print(f"✅ Training stopped at episode {episode} (Average reward: {np.mean(rewards[-50:])})")
break
return rewards
# ✅ Run Training
target_position = (9, 9)
env = UAVEnvironment(grid_size, target_position, obstacle_positions)
agent = DQNAgent(env)
training_rewards = train_agent(env, agent)
# ✅ Plot Training Performance
plt.plot(training_rewards)
plt.xlabel("Episodes")
plt.ylabel("Total Reward")
plt.title("Training Performance - UAV DQN with Dataset-Based Rewards")
plt.show()
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]汪亮,王文,王禹又,等.强化学习方法在通信拒止战场仿真环境中多无人机目标搜寻问题上的适用性研究[J].中国科学:信息科学, 2020, 50(3):21.
[2]曹英杰.基于深度强化学习的应急无人机基站部署策略研究[D].电子科技大学,2024.
[3]张帅.基于深度强化学习的无人机集群网络资源优化技术研究[D].北京工业大学,2022.
[4]谢文勋.城市环境下基于深度强化学习的无人机多维路径规划[D].中国民用航空飞行学院,2023.
🌈4 Python代码、数据下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









