






在选取pearson和spearman方法检验数据时,比较严谨的做法是对数据提前进行正态性检验,本文就借用for循环实现了对数据的批量检验
初始data数据格式这样,就是要检验A,B,C,D.....的正态性

setwd("D:/数据集")
#整理下数据
data <- read.csv("data.txt",sep = "",header= T,row.names=1,check.names = T)
data=t(data)
#小于50的样本采取S-W检验方法
name1<-c()
result<-c()
#批量处理
for (i in 1:nrow(data)){
g1=row.names(data)[i]
a=shapiro.test(as.numeric(data[i,]))[[2]]
name1=c(name1,g1)
result=c(result,a)
}
SW<-data.frame(name1,result)
#加个显著性星号
SW$sig=NA #添加新列
SW$sig <- ifelse(SW$result>0.05, "正态性分布","非正态性分布")
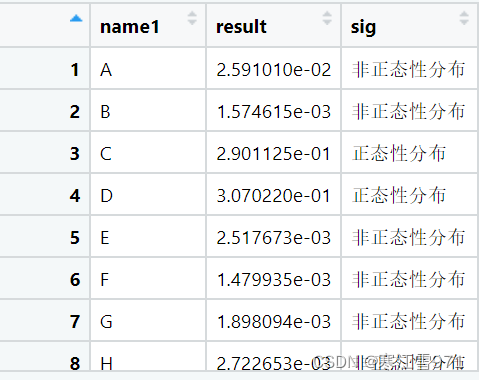
最后展示出来就是这样啦
学习小记,欢迎交流

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









