






之前分析处理数据总是在SPSS里做方差分析,之后在Origin里作图,之后手动添加显著性字母,因此我就想到在R语言中同时实现这两者。
本文涉及的是单因素单组方差分析,单因素多组方差分析在下篇。
显著性检验方法选取
首先我们要了解一下应该如何选取显著性分析方法,不然之后做出来的都没有意义。
当我们对一组数据进行检验前,首先需要对其正态性和方差齐性进行检验,如果该组数据符合正态分布同时方差齐,那么我们将采取参数检验;反之,数据满足正态分布但方差齐、数据不满足正态分布但方差齐和数据不满足正态分布同时方差不齐都将采取非参数检验。
请参考该博客,讲得超级清晰。
统计方法的选择(1)--正态性和方差齐性 - 简书 (jianshu.com)
知道了该用什么,接下来就是查这些方法在R语言中如何表示。
#1.数据的正态检验,p>0.05数据正态分布,适合数据量3-5000,大于5000则可以不用进行正态性检验
shapiro.test(data$values)
#2.方差齐性检验
#2.1符合正态分布才能进行Bartlett检验,p>0.05表示方差齐
#bartlett.test(data$values ~ data$group, data=data)
#2.2该方法对数据正态性不敏感,因此正态性与非正态性数据均适用,p>0.05表示方差齐
leveneTest(data$values ~ as.factor(data$group), data=data)在这我是分别采用了shapiro-wilk test和Levene's test对其正态性和方差齐性进行检验
参数检验并转换成字母
#3.符合正态分布且方差齐-参数检验
variance<-aov(values ~ group, data=data)
summary(variance) #极显著的情况下才能进行后续多重比较,不然无意义
#3.1比较次数<=3
MC <- LSD.test(variance,"group", p.adj="bonferroni")#结果显示:标记字母法out$group
MC
#3.2比较次数多于3
#library(multcomp)
#MC <- duncan.test(variance,"group")
error=as.data.frame(MC$groups)
error$group=row.names(error)
error2=merge(error,df,by="group")
colnames(error2)=c("group","values","label","mean","sd")
#3.3
#MC <- TukeyHSD(variance,"group")
#MC
#library(multcompView)
#tukey_letters1 <- multcompLetters4(variance, MC) #显示abc
#error <- as.data.frame.list(tukey_letters1$group)
#error$group=row.names(error)
#把df和error2合并
#error2=merge(error,df,by="group")
#colnames(error2)=c("group","label","a","values","sd")参数检验是采取了anova方法,因为我是3组,所以我用多重检验中的LSD方法进行了显著性检验,当然,其他多重检验方法我也放在这里了,具体的选取可以进一步细化选取。(别嫌我啰嗦哇,这是为了后续代码修改做铺垫~)
非参数检验并转换成字母
#当数据不符合正态分布或者方差不齐时,不适用ANOVA检验,用Kruskal-Wallis非参数检验
#不符合正态性分布或方差不齐-非参数检验
data$group=as.factor(data$group)
#方差检验,相当于参数检验中的aov()
result <- kruskal.test(values ~ group, data = data)
result #Kruskal-Wallis p=0.29
#多重检验
library(reshape2) # 需要此包来进行两两比较
pairwise_pvalues <- pairwise.wilcox.test(data$values, data$group, p.adjust.method = "bonferroni")
pairwise_pvalues #这个数据格式对着,就看后续如何处理
p_matrix <- pairwise_pvalues$p.value
library(multcompView)
# 提取p值的辅助函数
extraxt_P <- function(x) {
rn <- row.names(x)
cn <- colnames(x)
an <- unique(c(cn, rn))
myval <- x[!is.na(x)]
mymat <- matrix(1, nrow = length(an), ncol = length(an), dimnames = list(an, an))
for(ext in 1:length(cn)) {
for(int in 1:length(rn)) {
if(is.na(x[row.names(x) == rn[int], colnames(x) == cn[ext]])) next
mymat[row.names(mymat) == rn[int], colnames(mymat) == cn[ext]] <- x[row.names(x) == rn[int], colnames(x) == cn[ext]]
mymat[row.names(mymat) == cn[ext], colnames(mymat) == rn[int]] <- x[row.names(x) == rn[int], colnames(x) == cn[ext]]
}
}
return(mymat)
}
# 提取p值矩阵
p_matrix <- extraxt_P(p_matrix)
# 获取每个组别的均值
group_means <- tapply(data$values, data$group, mean)
# 根据均值对组别进行排序,使得均值最大的组别在前
sorted_groups <- names(sort(group_means, decreasing = TRUE))
# 重新排列p值矩阵的行和列,以匹配排序后的组别顺序
sorted_p_matrix <- p_matrix[sorted_groups, sorted_groups]
# 使用multcompLetters函数
letters_result <- multcompLetters(sorted_p_matrix)
error=as.data.frame(letters_result$Letters)
error$group=row.names(error)
#把df和error2合并
error2=merge(error,df,by="group")
colnames(error2)=c("group","label","values","sd")别着急!简化版在下面
既然要么参数检验,要么非参数检验,那么理所当然会想到if语句
所以代码思路就是:if 符合正态分布&方差齐,用参数检验;else用非参数检验。
所以单因素单组显著性检验代码如下:
首先是导入的数据格式(各分组下包含重复)
#单组用这个
library(agricolae)
library(car)
library(multcompView)
library(reshape2)
data=read.table("data.txt", header = 1, check.names = F, sep = "")
#求mean和sd
df2=aggregate(x=data$values, by=list(data$group),FUN=function(x) c(mean=mean(x), sd=sd(x)))
df2$mean=df2$x[,1]
df2$sd=df2$x[,2]
df2=df2[,-2]
colnames(df2)=c("group","mean","sd")
#1.数据的正态检验,p>0.05数据正态分布,适合数据量3-5000,大于5000则可以不用进行正态性检验
a=shapiro.test(data$values)
ZT=a$p.value
ZT
#2.方差齐性检验
#2.1符合正态分布才能进行Bartlett检验,p>0.05表示方差齐
#bartlett.test(data$values ~ data$group, data=data)
#2.2该方法对数据正态性不敏感,因此正态性与非正态性数据均适用,p>0.05表示方差齐
b=leveneTest(data$values ~ as.factor(data$group), data=data)
c=as.data.frame(b$`Pr(>F)`)
FC=c[1,]
FC
if(ZT > 0.05 & FC>0.05) {
variance<-aov(values ~ group, data=data)
MC <- LSD.test(variance,"group", p.adj="bonferroni")#结果显示:标记字母法out$group
error=as.data.frame(MC$groups)
error$group=row.names(error)
error2=merge(error,df2,by="group")
error2=error2[,-2]
colnames(error2)=c("group","label","values","sd")
} else {
data$group=as.factor(data$group)
#方差检验,相当于参数检验中的aov()
result <- kruskal.test(values ~ group, data = data)
pairwise_pvalues <- pairwise.wilcox.test(data$values, data$group, p.adjust.method = "bonferroni",exact=FALSE)
p_matrix <- pairwise_pvalues$p.value
extraxt_P <- function(x) {
rn <- row.names(x)
cn <- colnames(x)
an <- unique(c(cn, rn))
myval <- x[!is.na(x)]
mymat <- matrix(1, nrow = length(an), ncol = length(an), dimnames = list(an, an))
for(ext in 1:length(cn)) {
for(int in 1:length(rn)) {
if(is.na(x[row.names(x) == rn[int], colnames(x) == cn[ext]])) next
mymat[row.names(mymat) == rn[int], colnames(mymat) == cn[ext]] <- x[row.names(x) == rn[int], colnames(x) == cn[ext]]
mymat[row.names(mymat) == cn[ext], colnames(mymat) == rn[int]] <- x[row.names(x) == rn[int], colnames(x) == cn[ext]]
}
}
return(mymat)
}
p_matrix <- extraxt_P(p_matrix)
group_means <- tapply(data$values, data$group, mean)
sorted_groups <- names(sort(group_means, decreasing = TRUE))
sorted_p_matrix <- p_matrix[sorted_groups, sorted_groups]
letters_result <- multcompLetters(sorted_p_matrix)
error=as.data.frame(letters_result$Letters)
error$group=row.names(error)
error2=merge(error,df2,by="group")
colnames(error2)=c("group","label","values","sd")
}
最终要的就是error2数据表,长这样:
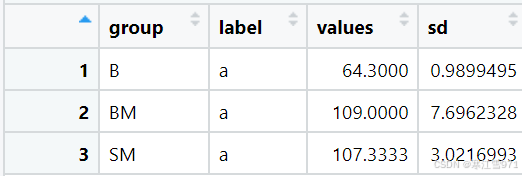
再把error2数据表各列添加到绘图过程中的geom_text()函数中就行了,具体操作如下:
#做一个柱状图
p1 <- ggplot(df, aes(x=group, y=mean))+ #aes里面设置你想要的x轴和y轴
geom_bar(aes(fill=group),stat = "identity", position = position_dodge())+
geom_errorbar(aes(ymin=mean-sd,ymax=mean+sd,group=group), #加误差线
position=position_dodge(width=0.8),linewidth = 0.8, width = 0.2)+
#想加显著性请先求出显著性字母,并运行下一句添加显著性字母
geom_text(data=error2,aes(x=group,y=values+sd,label=label),size=8,color="red",vjust=-0.5)
多组放下篇啦!
做学习小记,欢迎交流指正!

















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









