






前言
由于近期需要改DeepSeekMoE的结构,因此没办法,还是要手搓源码,顺便记录一下笔记,会对一些结构的形状推导、函数用法以及论文公式推导(包括这些公式对应哪些代码)进行详细解释
待讲完DeepSeekMoE核心代码之后,如果有机会的话会讲一下怎么修改结构并进行训练的(不过这部分出教程概率不高,因为对模型架构底层源码的理解要求太高了。。)
由于本文对每一行代码剖析的特别细致,难免篇幅过长,且本文结合了很多大佬的精华,即便没有任何基础的AI初学者也能够看懂!
本文仅讲解MoEGate内容,后续内容按照篇幅大小进行划分,至少一篇都会讲一个重要的部分
其实原本想把所有内容都囊括进来的,但可能是讲的太细,导致光是讲Gate就花了快5k字,无奈只能分章节。
DeepSeekMoE核心代码地址
来自于huggingface/modules/transformers_modules/deepseek-moe-16b-base/modeling_deepseek.py,可以使用下面的代码进行学习:modeling_deepseek.py · deepseek-ai/deepseek-moe-16b-base at main
由于该代码还有很多关于分布式的内容,鉴于篇幅所限,且本文会讲的特别细致(可能涉及演算步骤),而源代码长达1600行,如果都进行解读可能会导致篇幅超过5w字(尤其是注意力那部分超级麻烦),因此本文仅对DeepSeekMoE的核心架构代码进行解读,但即便如此,也已经超过5k字了,其中删减了很多冗余的内容,尽可能让文章更加简洁易懂。
代码结构
configuration_deepseek.py
configuration_deepseek.py 是 DeepSeek 模型的配置类文件,定义了模型的所有超参数和配置选项。它基于 Hugging Face 的 PretrainedConfig 类,通过 DeepseekConfig 类为模型提供了灵活的配置能力。主要作用包括:
- 参数定义:包括词汇表大小 (vocab_size)、隐藏层大小 (hidden_size)、注意力头数 (num_attention_heads)、MoE 层相关参数(如 n_routed_experts 和 num_experts_per_tok)等。
- 模型实例化支持:通过配置对象实例化 DeepSeek 模型,确保模型结构和行为符合预期。
- 灵活性:允许用户根据任务需求调整模型架构,例如是否使用 MoE 层、RoPE 缩放策略等。
modeling_deepseek.py
modeling_deepseek.py 是 DeepSeek 模型的核心实现文件,包含模型的具体架构和前向传播逻辑。它基于 PyTorch 和 Hugging Face 的 Transformers 库,实现了从嵌入层到输出层的完整 Transformer 模型。主要作用包括:
- 模型组件实现:包括归一化层、注意力机制、MLP、MoE 层等核心模块。
- 模型构建:根据 DeepseekConfig 中的参数构建完整的模型结构,支持因果语言建模和序列分类任务。
- 功能支持:支持多种注意力实现(如 Flash Attention、SDPA)、缓存机制和梯度检查点等特性。
两者关系
- configuration_deepseek.py 提供蓝图:它定义了模型的超参数和架构细节,作为输入传递给 modeling_deepseek.py。
- modeling_deepseek.py 实现具体逻辑:根据配置类中的参数,实例化和运行模型,确保配置与实现一致。
- 依赖性:modeling_deepseek.py 中的类(如 DeepseekModel、DeepseekMoE 等)直接引用 DeepseekConfig 对象来初始化参数和行为。
导入模型及检查配置
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "/mnt/public/weights/deepseek-moe-16b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
# 打印模型配置
print("Number of experts per token:", model.config.num_experts_per_tok)
print("n_routed_experts:", model.config.n_routed_experts)
print("scoring_func:", model.config.scoring_func)
print("aux_loss_alpha:", model.config.aux_loss_alpha)
print("seq_aux:", model.config.seq_aux)
print("norm_topk_prob:", model.config.norm_topk_prob)
print("hidden_size:", model.config.hidden_size)
text = "who are you"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)

可以看到这里的Number of experts per token为6,与configuration_deepseek.py中的默认值是不一致的,如果需要进行配置查看可以修改上述代码。
Preliminaries :Mixture-of-Experts for Transformers
本节会讲一下MoE最基本的假设和公式,该部分是后续公式推导的基础,是MoE的基础,DeepSeekMoE是在该公式的基础上进行的。
——同时为了本文论证的有效性,会附上论文对应公式截图进行讲解
arxiv.org/pdf/2401.06066:DeepSeekMoE v1主要提出在MoE基础上添加专家细粒度切分和共享专家、专家级和设备级负载均衡优化,本文的MoEGate暂时还没涉及该论文的创新点,但用到了其基础假设即Preliminaries
Transformers

这个公式是在没有使用MoE架构的时候,即使用Transformers中自注意力机制,里面使用稠密FFN时的数学表达式。
变量说明在截图中英文部分已经说的很清楚了,此处为了讲解就不再赘述了
注意这个公式缺少了层归一化的操作,实际上是会有层归一化的,此处只是为了简便书写
在arxiv.org/pdf/2101.03961 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 中告诉了层归一化的公式说明:
其实公式1跟下一小节中的公式5是差不多的,只是符号不一样,然后公式2跟下面的公式3一样,即 T 个专家的加权输出。只是下面讲的更加细
注意:公式 2 中的门值 pi(x)pi(x) 允许路由器的可微性。不过该文居然没有讲解怎么证明可微性的,有点可惜,感觉这个证明十分重要


基础MoE架构公式-代码对应关系

注意这个公式缺少了层归一化的操作,实际上是会有层归一化的,此处只是为了简便书写
可以看到Transformers和MoE在htlhtl 方面是不一样的,而MoE多了gi,tgi,t ,使计算htlhtl时更加稀疏了。
这三个公式共同构成了MoE (Mixture of Experts) 的核心机制:
- 计算每个token与专家的相似度(公式5)
- 基于相似度选择top-k个专家(公式4)
- 将选中的专家输出加权组合(公式3)
这样可以让每个token动态地选择最相关的专家进行处理,提高模型的效率和性能。
由于本文对MoEGate的代码进行了详细的解释,而这一部分则是MoE公式的基石部分
代码在本文的MoEGate章节中,本文会用该代码所在行数和内容来指代,不懂的话可以翻阅下文的代码找到对应位置
注意到,对应的数学变量如下:
-
这里的htlhtl 其实是第ll层中第tt 个token经过MoE架构的输出,而utlutl 则是该token。
-
gi,tgi,t是该 utlutl token 前K个专家亲和度分数最高的值
-
si,tsi,t 是第i个专家与该token的亲和度分数
公式5
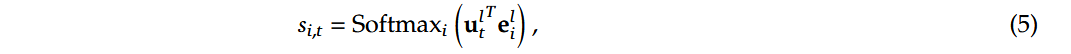
logits = F.linear(hidden_states, self.weight, None)
if self.scoring_func == 'softmax':
scores = logits.softmax(dim=-1)
解释:这段代码实现了公式5中的相似度计算。通过线性变换计算某个token utlutl (即hidden_states)与专家权重 eileil 的内积,然后通过softmax函数得到最终的相似度分数si,tsi,t。这里的 self.weight 对应公式中的 eileil。
公式4
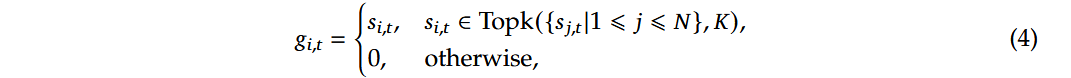
对应下文MoEGate代码中的第27-33行
logits = F.linear(hidden_states, self.weight, None)
if self.scoring_func == 'softmax':
scores = logits.softmax(dim=-1)
topk_weight, topk_idx = torch.topk(scores, k=self.top_k, dim=-1, sorted=False)
解释:这段代码实现了公式4中的门控机制。首先计算每个token与每个专家的相似度得分,然后通过softmax归一化得到 sj,tsj,t。接着使用 topk 操作选择最高的K个专家,对应公式中的 Topk({sj,t∣1≤j≤N},K)Topk({sj,t∣1≤j≤N},K),即上面第4行就是si,tsi,t 。
如果不在top-k中,则权重为0:该代码在DeepSeekMoE类中,首先会经MoEGate的forward函数传递topk_idx, topk_weight (对应下面MoEGate类第62行代码)给DeepSeekMoE类:
return topk_idx, topk_weight, aux_loss # 返回专家索引、权重和辅助损失
然后在DeepseekMoE类中进行接收:
topk_idx, topk_weight, aux_loss = self.gate(hidden_states) # 通过门控获取专家索引、权重和辅助损失 topk_idx, topk_weight的形状为 [bsz * seq_len, topk] ,aux_loss为一个标量
topk_idx和topk_weight被用作索引专家,并进行专家加权融合
aux_loss则被用于添加到AddAuxiliaryLoss中,使辅助负载均衡损失能够通过后向传播进行更新,使其成为可优化的参数
y = AddAuxiliaryLoss.apply(y, aux_loss) # 添加辅助损失到计算图
公式3
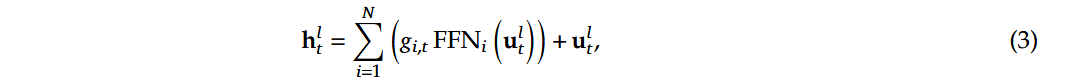
该代码在DeepSeekMoE类中,因为该公式是整合所有MoE层的结果,所以在MoEGate中没有体现,DeepSeekMoE类会在下一节详细讲解
训练模式
下面代码计算了FFNi(utl)FFNi(utl) 这一项:
y = torch.empty_like(hidden_states)
for i, expert in enumerate(self.experts):
y[flat_topk_idx == i] = expert(hidden_states[flat_topk_idx == i])
下面代码计算了∑i=1N(gi,tFFNi(utl))∑i=1N(gi,tFFNi(utl)) 这一项:
y = (y.view(*topk_weight.shape, -1) * topk_weight.unsqueeze(-1)).sum(dim=1)
推理模式
下面代码计算了∑i=1N(gi,tFFNi(utl))∑i=1N(gi,tFFNi(utl)) 这一项。
y = self.moe_infer(hidden_states, flat_topk_idx, topk_weight.view(-1, 1)).view(*orig_shape)
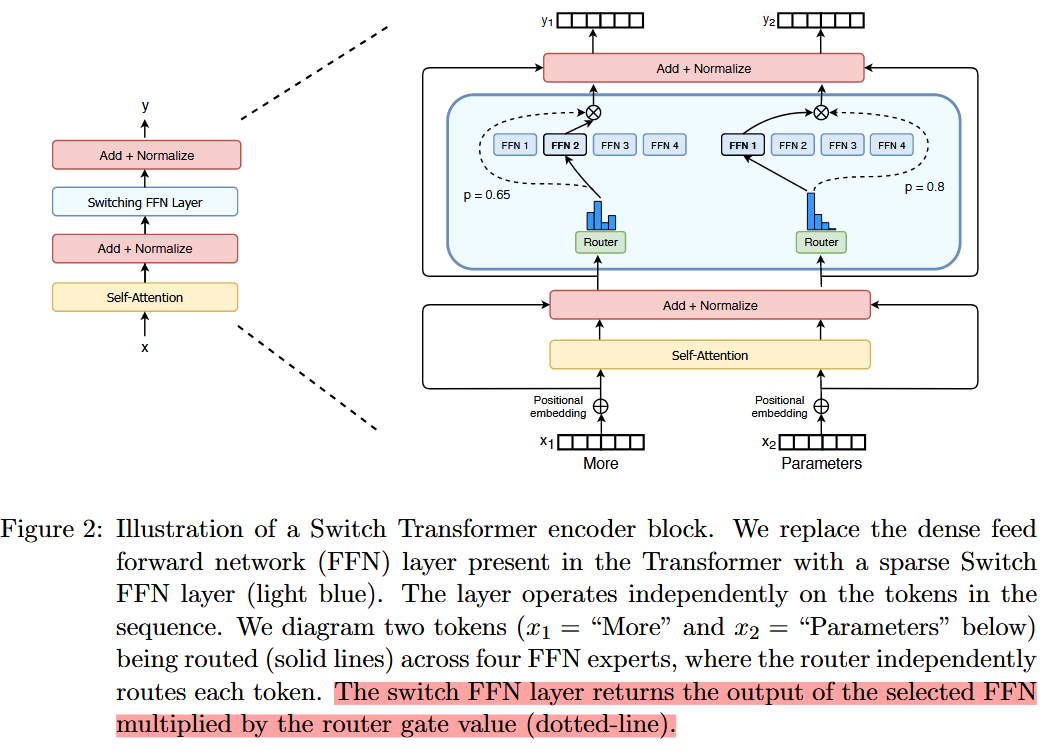
解释:这段代码实现了公式3中的混合专家计算。其中 htlhtl 是通过对每个选中的专家 FFNiFFNi 进行计算,然后与对应的门控权重 gi,tgi,t 相乘并求和得到。最后加上输入 uiluil 完成残差连接。 下图也说明了将htlhtl 和gi,tgi,t 相乘的存在:
来自:arxiv.org/pdf/2101.03961 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
辅助负载均衡损失损失公式-代码对应
arxiv.org/pdf/2101.03961:DeepSeekMoE仍然保留了Switch Transformers中的辅助损失部分,本文同样会讲解该部分的代码和公式
动态buffer/专家容量

可以看到,动态专家容量计算公式如下:

















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









