







微调对所有人来说都很有趣!
DeepLearning 课程:
https://www.deeplearning.ai/short-courses/finetuning-large-language-models/

在微调过程中,我们首先使用大规模数据集和强大的计算资源预训练一个深度学习模型(例如大语言模型)。预训练的模型已经学习到了大量的通用特征和模式,因此它可以作为许多具体任务的基础。然后,我们在预训练模型的基础上,使用特定任务的数据集进行进一步训练,以便模型能更好地处理该特定任务。
- 允许你在模型中放入比提示更多的数据:通过微调,你可以让模型吸收更多的信息,而不仅仅是提示中的内容。
- 让模型学习数据,而不仅仅是访问数据:微调使模型真正理解和内化数据,而不仅仅是简单地读取或访问这些数据。

- 基础模型 (Base Model):基础模型在没有微调的情况下,只能根据有限的提示信息做出判断。例如,在皮肤刺激、红肿和瘙痒等症状的提示下,基础模型可能会简单地输出“可能是痤疮(Probably acne)”。
- 微调后的模型 (Finetuned Model):通过微调后,模型不仅能接收到提示信息,还能学习和内化大量与皮肤病学相关的数据。这使得微调后的模型在处理相同提示时,可以给出更详细和专业的诊断。例如,输出“你有混合型的非炎症性粉刺和炎症性丘疹性痤疮(You have a mix of non-inflammatory comedonal acne and inflammatory papulopustular acne)”。
- 左侧:基础模型接收到一些症状描述(如皮肤刺激、红肿和瘙痒),但由于没有进行微调,它只能给出一个简单的、可能不够准确的诊断。
- 右侧:微调后的模型在接收到相同的症状描述后,由于之前已经通过皮肤病学数据进行过微调训练,它能够给出更加细致和准确的诊断。

- 学习新知识
- 更一致可靠的输出和行为
- 减少幻觉
- 定制为特定的用途
Prompt Engineering VS Finetuning
| 类别 | 提示工程 (Prompting) | 微调 (Finetuning) |
| 优点 (Pros) | - 无需数据即可开始 (No data to get started) - 前期成本较低 (Smaller upfront cost) - 不需要技术知识 (No technical knowledge needed) - 通过检索连接数据 (Connect data through retrieval (RAG)) | - 几乎无限的数据适配 (Nearly unlimited data fits) - 学习新信息 (Learn new information) - 纠正错误信息 (Correct incorrect information) - 如果模型较小,后期成本较低 (Less cost afterwards if smaller model) - 也可以使用检索增强生成 (Use RAG too) |
| 缺点 (Cons) | - 适配的数据量较少 (Much less data fits) - 忘记数据 (Forgets data) - 产生幻觉 (Hallucinations) - 检索增强生成失败或获取错误数据 (RAG misses, or gets incorrect data) | - 更多高质量数据 (More high-quality data) - 前期计算成本 (Upfront compute cost) - 需要一些技术知识,特别是数据方面 (Needs some technical knowledge, esp. data) |
| 适用场景 (Use Cases) | 泛用的、边项目、原型 (Generic, side projects, prototypes) | 特定领域、企业级、生产使用、隐私 (Domain-specific, enterprise, production usage, ...privacy!) |
性能 (Performance)
- 停止幻觉 (stop hallucinations)
- 增加一致性 (increase consistency)
- 减少不需要的信息 (reduce unwanted info)
隐私 (Privacy)
- 本地或虚拟私有云部署 (on-prem or VPC)
- 防止泄漏 (prevent leakage)
- 无数据泄露 (no breaches)
成本 (Cost)
- 每次请求成本更低 (lower cost per request)
- 提高透明度 (increased transparency)
- 更大的控制权 (greater control)
可靠性 (Reliability)
- 控制运行时间 (control uptime)
- 更低延迟 (lower latency)
- 适度管理 (moderation)
Code部分对比详见:
https://s172-30-104-126p8888.lab-aws-production.deeplearning.ai/tree
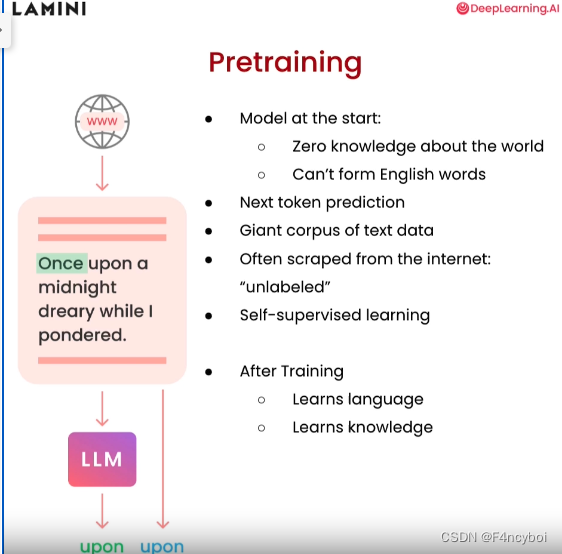
预训练(Pretraining)
- 模型起始时:
- 对世界没有任何知识(Zero knowledge about the world)
- 无法形成英语单词(Can't form English words)
- 下一个词预测(Next token prediction):模型通过预测下一个词来学习语言模式和结构。
- 大规模文本数据(Giant corpus of text data):预训练模型使用了大量的文本数据进行训练。
- 通常从互联网抓取(Often scraped from the internet: "unlabeled"):这些数据通常是从互联网抓取的非标签化数据。
- 自监督学习(Self-supervised learning):模型通过自监督的方式进行学习,不需要人工标注数据。
- 经过训练后:
- 学习语言(Learns language):模型能够理解和生成语言。
- 学习知识(Learns knowledge):模型积累了大量的知识,可以回答问题和提供信息。
- 步骤1:从互联网上获取大量的非标签化文本数据。
- 步骤2:模型通过预测文本中的下一个词进行训练。例如,给定“Once upon a midnight dreary while I pondered...”,模型会学习预测接下来的词。
- 步骤3:通过不断地预测和调整,模型逐渐学会语言结构和知识。
什么是“从互联网上抓取的数据”?

- 通常不会公开如何预训练(Often not publicized how to pretrain):
- 预训练模型的具体数据来源和方法通常不会公开,这些数据通常来自互联网的各种来源。
- EleutherAI 的开源预训练数据:“The Pile”(Open-source pretraining data: "The Pile"):
- The Pile 是一个著名的开源数据集,专门用于语言模型的预训练,包含了大量多样化的文本数据。
- 训练成本高且耗时(Expensive & time-consuming to train):
- 预训练过程需要大量的计算资源和时间,这使得整个过程昂贵且耗时。
图中显示了几种类型的文本数据,这些数据都是从互联网上抓取的:
- 历史演讲文本(例如:林肯的葛底斯堡演讲):
- "Four score and seven years ago, our fathers brought forth upon this..."
- 食谱(例如:胡萝卜蛋糕食谱):
- "Carrot Cake: 2 cups flour, 2 dozen carrots..."
- 医学文献(例如:儿童急性下呼吸道感染的低氧血症流行病学):
- "Epidemiology of hypoxemia in children with acute lower respiratory infection..."
这些不同类型的文本数据被用来训练大语言模型,使其能够理解和生成各种类型的文本内容。
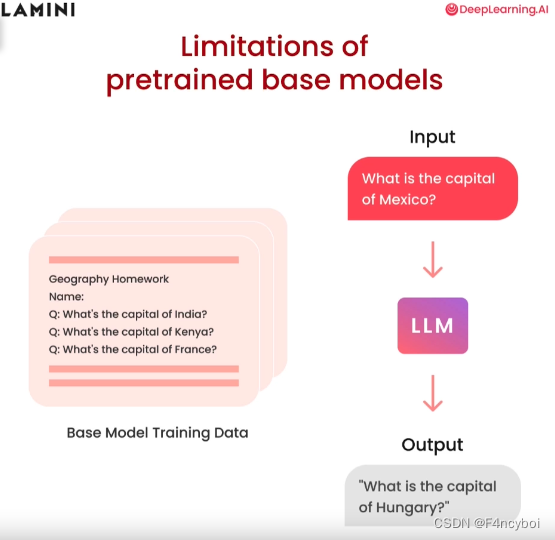
- 输入(Input): "What is the capital of Mexico?"(墨西哥的首都是哪里?)
- 输出(Output): "What is the capital of Hungary?"(匈牙利的首都是哪里?)
- 预训练基础模型在处理某些问题时,可能会给出错误或不相关的答案。这是因为模型在训练过程中没有见过特定的问题或没有学习到相关的知识。
- 基础模型训练数据(Base Model Training Data):
- 图中展示了一个地理作业示例,其中包含了一些地理问题,如印度、肯尼亚和法国的首都。
- 模型在训练过程中接触了这些数据,但在遇到新的问题时(如墨西哥的首都),由于缺乏相关训练数据或上下文,可能会输出错误的答案(如匈牙利的首都)。
- 数据覆盖不全:预训练模型可能没有见过所有可能的问题,特别是当训练数据中缺乏某些特定领域或问题的信息时。
- 缺乏上下文理解:模型在某些情况下无法理解问题的上下文,从而给出不相关或错误的答案。
- 通用性问题:预训练模型在广泛领域上有良好的表现,但在特定领域或具体问题上可能表现不佳,需要进一步微调。
- 微调(Finetuning):通过使用特定领域的数据对模型进行微调,可以弥补预训练模型的局限性,提高其在特定任务上的表现。
- 检索增强生成(RAG):结合检索机制,动态获取相关信息以支持回答,提高模型的准确性和相关性。
预训练后的微调(Finetuning after pretraining)

- 预训练 (Pre-training) -> 基础模型 (Base Model):
- 预训练阶段生成一个基础模型。
- 预训练 (Pre-training) -> 基础模型 (Base Model) -> 微调 (Finetuning) -> 微调模型 (Finetuned Model):
- 在基础模型的基础上进行微调,生成一个微调后的模型。
- 微调通常指进一步训练模型:
- 可以是自监督的无标签数据(self-supervised unlabeled data)。
- 可以是你精心策划的有标签数据(“labeled” data you curated)。
- 需要的数据量相对较少(Much less data needed)。
- 是你工具箱中的一个工具(Tool in your toolbox)。
- 生成任务的微调尚未明确定义:
- 更新整个模型,而不仅仅是其中的一部分(Updates entire model, not just part of it)。
- 使用相同的训练目标:下一个词的预测(Same training objective: next token prediction)。
- 更高级的方法减少需要更新的内容(More advanced ways reduce how much to update (more later!))。
- 微调过程:
- 预训练:在大规模数据集上进行预训练,生成一个基础模型。基础模型已经学习了通用的语言模式和知识。
- 微调:使用特定任务的数据对基础模型进行进一步训练。微调的数据可以是自监督学习的数据,也可以是经过精心标注的数据。通过微调,模型能够适应特定任务,提供更准确的结果。
- 微调的优势:
- 数据需求少:相比预训练,微调所需的数据量较少,因为基础模型已经具备了通用的语言知识。
- 灵活性:微调可以针对不同的任务进行定制,使模型在特定任务上的表现更佳。
- 效率高:微调的计算成本较低,且时间消耗相对较少,是提高模型性能的有效手段。
- 生成任务的微调:
- 生成任务(如文本生成、对话生成等)的微调过程尚未完全明确,但通常会更新整个模型,而不仅仅是某个特定部分。
- 使用与预训练相同的目标(如下一个词的预测),但会有更高级的方法来减少需要更新的部分,从而提高微调的效率和效果。
微调能为你做什么?(What is finetuning doing for you?)

行为改变(Behavior change)
- 学会更一致地回应(Learning to respond more consistently): 微调可以帮助模型在不同情境下提供更一致的回答。
- 学会聚焦,例如内容监管(Learning to focus, e.g., moderation): 微调可以提高模型在特定任务或领域中的专注能力,例如内容适度管理。
- 发展出特定能力,例如更好地进行对话(Teasing out capability, e.g., better at conversation): 微调可以增强模型在特定能力上的表现,例如提高对话质量。
增长知识(Gain knowledge)
- 增加新概念的知识(Increasing knowledge of new specific concepts): 微调可以使模型学习并掌握新的概念和知识。
- 纠正旧的错误信息(Correcting old incorrect information): 微调可以更新模型的知识库,纠正之前的错误信息。
两者兼具(Both)
- 行为改变与增长知识的综合效果(Combined effect of behavior change and knowledge gain): 微调不仅能够改变模型的行为,还能增长模型的知识,提升整体性能。

文本输入-文本输出任务(Just text-in, text-out)
- 提取任务(Extraction):
- 文本输入,文本输出减少(text in, less text out):
- "阅读"("Reading"):
- 关键词(Keywords)
- 主题(Topics)
- 路由(Routing)
- 代理(Agents): 规划(planning)、推理(reasoning)、自我批评(self-critic)、工具使用(tool use)等
- 扩展任务(Expansion):
- 文本输入,文本输出增加(text in, more text out):
- "写作"("Writing"):
- 聊天、写电子邮件、写代码:
- 聊天(Chat)
- 写电子邮件(Write emails)
- 写代码(Write code)
成功的关键指标(Key indicator of success)
- 任务清晰度(Task clarity)是成功的关键指标
- 清晰度(Clarity)意味着知道什么是差的、好的和更好的
- 知道差的 vs. 好的 vs. 更好的区别
- 提取任务(Extraction):文本输入后,通过关键词、主题等提取少量的相关信息。
- 扩展任务(Expansion):文本输入后,生成更多的相关文本内容,如写作、聊天等。
第一次微调(First time finetuning)
- 识别任务(Identify task(s) by prompt-engineering a large LLM):
- 通过提示工程在一个大型语言模型(LLM)中识别任务。
- 找到LLM表现还不错的任务(Find tasks that you see an LLM doing ~OK at):
- 找到一个大型语言模型在某些任务上表现还不错的任务。
- 选择一个任务(Pick one task):
- 从中选择一个具体的任务进行微调。
- 为任务获取大约1000个输入和输出(Get ~1000 inputs and outputs for the task):
- 收集大约1000个该任务的输入和输出,确保这些数据优于LLM目前的表现。
- 在这些数据上微调一个小型LLM(Finetune a small LLM on this data):
- 在收集的数据上微调一个小型语言模型。
Code部分见:
https://s172-30-104-126p8888.lab-aws-production.deeplearning.ai/tree

- 指令微调(Instruction Finetuning) 是微调的一种形式,专门针对使模型能够更好地遵循指令和行为,更像一个对话机器人(chatbot)。
- 也被称为 "instruction-tuned" 或 "instruction-following" 大语言模型(LLMs)。
- 教模型更像对话机器人(Teaches model to behave more like a chatbot):通过指令微调,模型可以更好地理解和执行用户的指令,提供更自然和流畅的对话体验。
- 改进模型交互的用户界面(Better user interface for model interaction):
- 将 GPT-3 转变为 ChatGPT(Turned GPT-3 into ChatGPT):通过指令微调,GPT-3 变得更适合作为对话机器人使用。
- 增加 AI 的采用率,从成千上万的研究人员到数百万人(Increase AI adoption, from thousands of researchers to millions of people):更好的用户体验和交互界面,使更多的人能够使用和受益于 AI 技术。
指令跟随数据集(Instruction-following datasets)

- FAQ(常见问题解答):
- 这些数据集通常包含常见问题及其对应的答案,是训练模型理解和回答常见问题的良好资源。
- 客户支持对话(Customer support conversations):
- 包含客户和支持人员之间的对话记录,适合训练模型处理客户查询、提供解决方案和支持。
- Slack 消息(Slack messages):
- 来自 Slack 的对话消息,包含大量实时交流内容,适合训练模型处理日常对话和团队协作。
这些数据集通常已经在线可用,可以直接用于训练模型。这些数据集帮助模型学习如何跟随指令,提供准确和相关的回复。
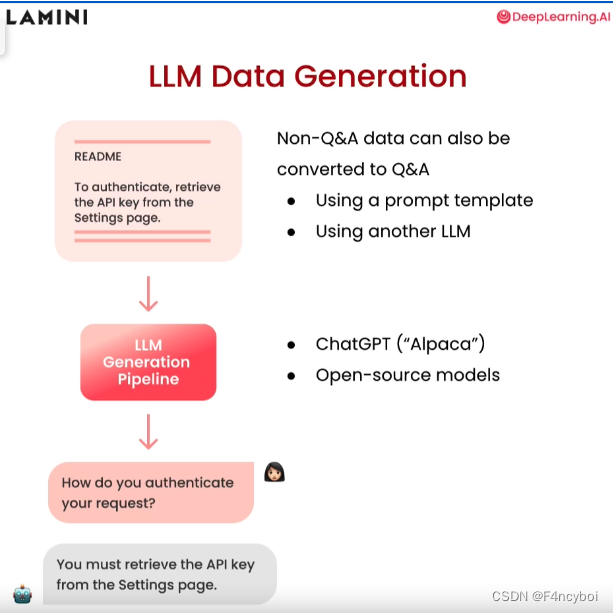
非问答数据可以通过以下两种方法转换为问答数据:
- 使用提示模板(Using a prompt template):通过预定义的模板,将非问答格式的数据转换为问答格式。
- 使用另一个 LLM(Using another LLM):利用另一个大语言模型生成问答对。
- 读取非问答数据:
- 示例数据:README 文档中包含的指示信息,如 “To authenticate, retrieve the API key from the Settings page.”
- LLM 生成管道(LLM Generation Pipeline):
- 使用 LLM 生成管道处理数据,生成问答对。
- 生成问答对:
- 示例问题:How do you authenticate your request?
- 示例回答:You must retrieve the API key from the Settings page.
- ChatGPT ("Alpaca"):【"Alpaca" 是斯坦福大学发布的一个开源项目,旨在通过微调 GPT-3 模型,使其在指令跟随任务中表现更好。这个项目展示了如何使用有限的计算资源和数据,对大型语言模型进行高效的微调】使用 ChatGPT 或类似的 LLM 模型生成问答数据。
- 开源模型(Open-source models):利用开源的 LLM 模型生成问答数据。
- 非问答数据(README 文档):
- 包含指示信息或其他说明性内容。
- 通过 LLM 生成管道处理数据:
- 将非问答数据输入到 LLM 管道中。
- 生成问答对:
- 生成相应的问题和回答对,便于训练和优化问答系统。
指令微调泛化能力(Instruction Finetuning Generalization)
可以访问模型的预先存在的知识(Can access model's pre-existing knowledge):
- 指令微调后的模型不仅可以利用微调数据中的信息,还可以访问其预先存在的知识库。
将指令泛化到微调数据集以外的数据(Generalize following instructions to other data, not in finetuning dataset):
- 微调后的模型能够将学到的指令执行能力泛化到未在微调数据集中出现的数据上。
示例1:基于微调数据的问题回答
- 问题:What's the capital of France?(法国的首都是哪里?)
- 回答:Paris(巴黎)
- 这是一个在微调数据集中可能包含的问题和答案。
示例2:基于模型预先存在知识的问题回答
- 问题:Can you write a function that computes the Fibonacci sequence in Python?(你能写一个计算斐波那契数列的 Python 函数吗?)
- 回答:
| Python |
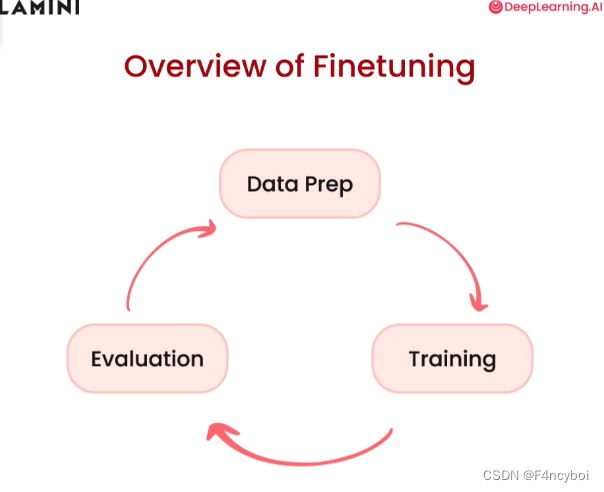
- 数据准备(Data Prep)
- 数据收集:收集用于微调的相关数据。这些数据可以是特定领域的文本、问答对、对话记录等。
- 数据清洗:清洗和预处理数据,去除噪声和不相关信息,确保数据质量。
- 数据标注:如果需要,对数据进行标注,使其适合用于模型训练。
- 训练(Training)
- 模型选择:选择适合任务的预训练模型,通常是一个已经在大规模数据上预训练的模型。
- 参数设置:设置训练参数,包括学习率、批次大小、训练轮数等。
- 训练过程:使用准备好的数据对模型进行微调训练,使其在特定任务上表现更好。
- 评估(Evaluation)
- 性能评估:使用验证集或测试集评估模型的性能,衡量其在特定任务上的准确性、召回率、F1值等指标。
- 错误分析:分析模型在评估中的错误,找出模型表现不佳的原因,指导后续的改进。
- 模型调优:根据评估结果,调整模型和训练参数,进一步优化模型性能。
Code部分见:
https://s172-30-136-94p8888.lab-aws-production.deeplearning.ai/tree/L3

更好的数据(Better)
- 更高质量(Higher Quality):
- 高质量的数据具有准确性、完整性和一致性,减少噪声和错误的信息。
- 多样性(Diversity):
- 数据集应包含多种不同类型的数据,以确保模型能够泛化到不同的场景和应用中。
- 真实数据(Real):
- 真实世界的数据能够更好地反映实际应用场景,而不是人为生成的数据。
- 更多数据(More):
- 更多的数据能够提供更丰富的信息,有助于提高模型的学习效果和泛化能力。
更差的数据(Worse)
- 较低质量(Lower Quality):
- 低质量的数据包含错误、噪声和不一致的信息,会导致模型学习错误的模式。
- 同质性(Homogeneity):
- 同质性的数据缺乏多样性,模型可能只能在有限的场景下表现良好,缺乏泛化能力。
- 生成数据(Generated):
- 虽然生成数据在某些情况下有用,但它们可能缺乏真实世界的数据特点和多样性。
- 较少数据(Less):
- 数据量不足会限制模型的学习能力,导致模型难以在不同的场景中表现良好。
- 高质量和多样性:
- 一个包含不同背景、年龄、性别和语言的对话数据集。
- 真实数据:
- 从实际客户服务对话记录中提取的数据。
- 更多数据:
- 包含上百万条对话记录的数据集。
- 低质量和同质性:
- 一个包含大量拼写错误、语法错误和重复信息的对话数据集。
- 生成数据:
- 由简单规则生成的对话数据,缺乏真实对话的复杂性和多样性。
- 较少数据:
- 仅包含几千条对话记录的数据集。
- 数据清洗:
- 确保数据质量,通过去除噪声、错误和重复信息来提高数据集的准确性。
- 数据扩充:
- 增加数据量,通过收集更多的真实数据或从多个数据源获取数据。
- 数据多样性:
- 确保数据的多样性,通过包含不同类型、背景和情境的数据来增强模型的泛化能力。
- 收集指令-响应对(Collect instruction-response pairs)
- 目标:收集用于训练模型的指令和对应的响应对。
- 示例:
- 指令:"What is the capital of France?"
- 响应: "Paris"
- 来源:这些对话数据可以来源于现有的问答数据集、客户支持对话记录、FAQ 数据等。
- 连接对(Concatenate pairs)
- 目标:将指令和响应对连接起来,必要时可以添加提示模板。
- 示例:将指令和响应连接成一个完整的字符串,或者使用预定义的模板来构造输入。
- 添加提示模板(如果适用):例如,可以使用 "Instruction: {instruction} Response: {response}" 的格式。
- 分词:填充和截断(Tokenize: Pad, Truncate)
- 目标:将文本数据转换为模型可以处理的格式,即将文本分割成词或子词。
- 填充(Pad):为了使所有输入序列具有相同的长度,使用特殊的填充标记(如 [PAD])来补齐短序列。
- 截断(Truncate):为了控制输入序列的最大长度,截断超过指定长度的序列。
| Python |
- 划分训练/测试集(Split into train/test)
- 目标:将数据集划分为训练集和测试集,以便评估模型性能。
- 常见划分比例:通常使用 80-20 或 90-10 的比例,将大部分数据用于训练,少部分数据用于测试。
| Python |

数据分词(Tokenizing your data)
- 分词:将文本数据转换为模型可以处理的数值表示形式,即“令牌”(tokens)。
- 示例文本:"Fine Tuning is fun for all!"
- 分词结果:文本被分割成独立的词或子词,如 "Fine", "Tuning", "is", "fun", "for", "all!"
编码和解码(Encoding and Decoding)
- 编码(Encoding):将分词后的文本转换为数值表示,即将每个词或子词映射到一个唯一的数字。
- 示例编码:["Fine", "Tuning", "is", "fun", "for", "all!"] -> [34389, 13932, 278, 318, 1257, 329, 477, 0]
- 解码(Decoding):将数值表示转换回原始文本,即从唯一的数字映射回对应的词或子词。
- 示例解码:[34389, 13932, 278, 318, 1257, 329, 477, 0] -> "Fine Tuning is fun for all!"
- 多种流行的分词器(Multiple popular tokenizers):
- 市面上有许多流行的分词器,如 BERT 的分词器、GPT-3 的分词器等。
- 选择合适的分词器:应使用与模型关联的分词器,以确保分词和编码过程与模型训练时使用的方式一致。
Code部分见:
- https://s172-30-128-119p8888.lab-aws-production.deeplearning.ai/tree/L4
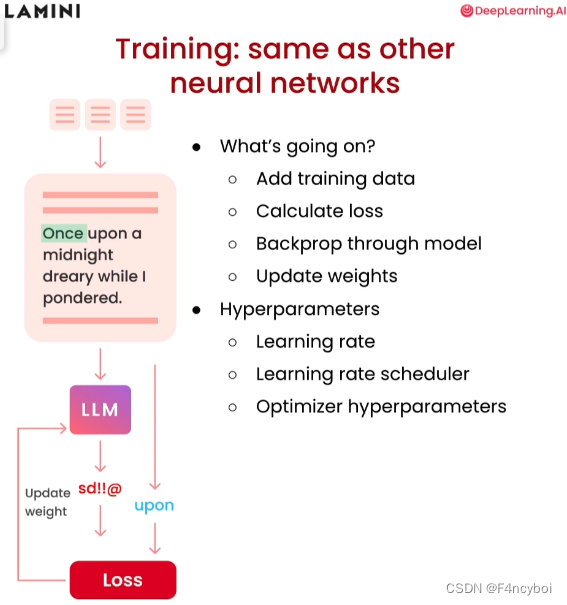
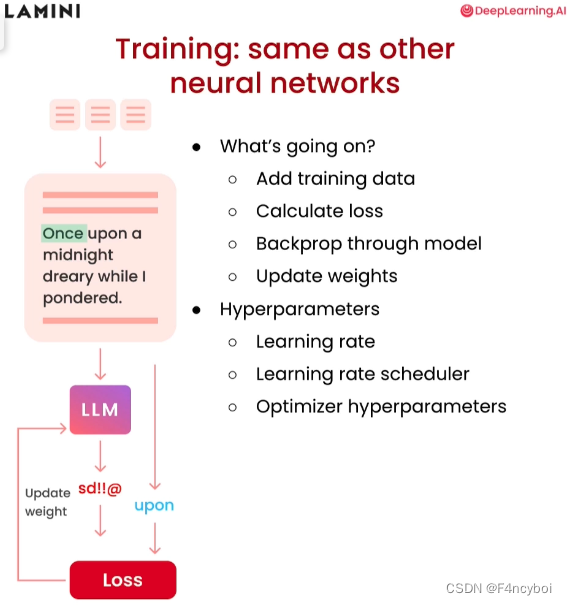
- 添加训练数据(Add training data):
- 将准备好的训练数据输入模型,数据通常包括文本和相应的标签(例如,输入文本和目标输出)。
- 计算损失(Calculate loss):
- 使用损失函数(如交叉熵损失)计算模型输出与目标输出之间的误差。损失值用于衡量模型预测的准确性。
- 通过模型反向传播(Backprop through model):
- 反向传播算法用于计算损失相对于模型参数的梯度。这些梯度用于更新模型权重,使模型更准确地预测目标输出。
- 更新权重(Update weights):
- 使用优化算法(如梯度下降、Adam)根据计算出的梯度更新模型的权重。这一步是训练过程的核心,通过不断调整权重,模型逐渐提高预测准确性。
超参数(Hyperparameters)
- 学习率(Learning rate):
- 学习率决定了每次权重更新的步长大小。较高的学习率可能使训练过程更快,但容易导致不稳定;较低的学习率则训练更稳定,但速度较慢。
- 学习率调度器(Learning rate scheduler):
- 学习率调度器用于动态调整学习率,通常在训练过程中逐步降低学习率,以确保训练的稳定性和收敛性。
- 优化器超参数(Optimizer hyperparameters):
- 优化器的其他超参数,如 Adam 优化器的 beta1 和 beta2,影响优化过程的细节。调整这些超参数可以进一步优化训练过程。
- 输入文本:
- 文本数据输入模型,例如 "Once upon a midnight dreary while I pondered."
- 计算损失:
- 模型生成预测结果,与目标输出对比计算损失。
- 反向传播和权重更新:
- 根据损失计算梯度,通过反向传播更新模型权重,使模型的预测结果逐渐逼近目标输出。
Code部分见:
https://s172-30-128-119p8888.lab-aws-production.deeplearning.ai/tree/L5

- 人类评估(Human Evaluation):
- 由人类专家对生成模型的输出进行评估和打分。
- 优点:最可靠,因为人类可以根据上下文和语境理解生成的内容。
- 缺点:耗时且成本高,不适用于大规模评估。
- 测试套件(Test Suites):
- 使用预定义的测试数据和测试用例来评估模型的性能。
- 优点:可以自动化,适用于大规模评估。
- 缺点:测试套件的质量和覆盖范围直接影响评估结果的可靠性。
- Elo 排名(Elo Rankings):
- 使用 Elo 排名系统来比较不同模型的性能。
- 优点:能够动态更新模型的相对排名,适用于对抗性评估。
- 缺点:需要大量的比较数据来保证排名的准确性。
- 人类专家评估是最可靠的(Human expert evaluation is most reliable):
- 尽管耗时且成本高,人类专家评估能够提供最准确和可靠的反馈。
- 高质量的测试数据至关重要(Good test data is crucial):
- 高质量(High-quality):测试数据应当准确无误,能够反映真实世界的情况。
- 准确(Accurate):测试数据应当是精确的,能够正确衡量模型的性能。
- 泛化(Generalized):测试数据应当能够覆盖多种情况,确保模型的泛化能力。
- 未在训练数据中出现(Not seen in training data):测试数据应当与训练数据分离,以确保评估结果的公正性和可靠性。
- Elo 排名比较也很流行(Elo comparisons also popular):
- 使用 Elo 排名系统对不同模型进行比较也是一种常见的方法,可以帮助了解模型的相对性能。
LLM 基准测试:评估方法套件(LLM Benchmarks: Suite of Evaluation Methods)
常见的 LLM 基准测试(Common LLM benchmarks)
- ARC:
- 描述:ARC 是一组小学问题,测试模型对基础知识和推理能力的掌握。
- 评价:通过回答与小学教育水平相当的问题来评估模型的表现。
- HellaSwag:
- 描述:HellaSwag 是一个常识测试,评估模型的常识推理能力。
- 评价:通过回答与日常常识相关的问题来评估模型的常识性理解。
- MMLU:
- 描述:MMLU 是一个多任务度量标准,涵盖基础数学、美国历史、计算机科学、法律等多个领域。
- 评价:通过涉及多个学科的任务来评估模型的综合知识和推理能力。
- TruthfulQA:
- 描述:TruthfulQA 测量模型重复在线常见错误信息的倾向。
- 评价:通过评估模型对虚假信息的再现程度来衡量其真实性和准确性。
表格展示了几种模型在这些基准测试中的表现:
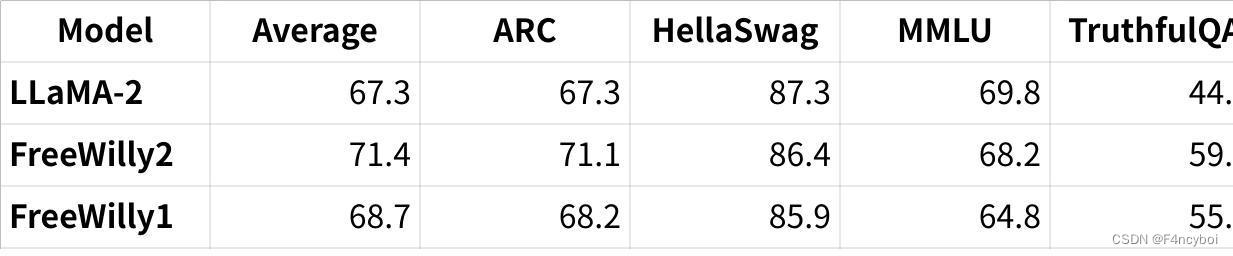
点击图片可查看完整电子表格
- Average:表示在所有基准测试中的平均得分。
- ARC:每个模型在 ARC 测试中的得分。
- HellaSwag:每个模型在 HellaSwag 测试中的得分。
- MMLU:每个模型在 MMLU 测试中的得分。
- TruthfulQA:每个模型在 TruthfulQA 测试中的得分。
从表中可以看出:
- FreeWilly2 模型在平均得分和 ARC、TruthfulQA 基准测试中表现最佳。
- LLaMA-2 模型在 HellaSwag 和 MMLU 基准测试中表现优异。
- FreeWilly1 模型在各个基准测试中的表现相对较为均衡。
错误分析(Error Analysis)

- 理解基础模型行为:在微调之前,首先需要理解基础模型的行为,找出其在生成文本时常犯的错误。
- 分类错误:对错误进行分类,通过在数据空间上迭代修复这些问题来改进模型性能。
- 拼写错误(Misspelling)
- 问题示例:"Your kidney is healthy, but your lever is sick. Go get your lever checked."
- 这里的“lever”应为“liver”。
- 修正示例:"Your kidney is healthy, but your liver is sick."
- 修正拼写错误,使句子正确无误。
- 过长(Too long)
- 问题示例:"Diabetes is less likely when you eat a healthy diet, because eating a healthy diet makes diabetes less likely, making..."
- 句子过长且冗余,难以理解。
- 修正示例:"Diabetes is less likely when you eat a healthy diet."
- 简化句子,去除冗余部分,使其更加简洁明了。
- 重复(Repetitive)
- 问题示例:"Medical LLMs can save healthcare workers time and money and time and money and time and money."
- 句子中存在重复的部分。
- 修正示例:"Medical LLMs can save healthcare workers time and money."
- 去除重复部分,使句子更加简洁。
Code部分见:
https://s172-30-128-119p8888.lab-aws-production.deeplearning.ai/tree/L6
确定你的任务(Figure out your task)
- 首先要明确你要完成的具体任务是什么。这可以是文本生成、分类、问答等。
收集与任务相关的输入/输出数据(Collect data related to the task’s inputs/outputs)
- 收集与任务相关的训练数据,这些数据应该包含输入和期望的输出。
如果数据不够,生成数据(Generate data if you don’t have enough data)
- 如果现有数据不足,可以使用生成数据的方法来扩充数据集。例如,使用数据增强技术或合成数据生成。
微调一个小模型(e.g. 400M-1B)(Finetune a small model)
- 从微调一个较小的模型开始(例如,400M到1B参数的模型),这可以帮助快速迭代和实验。
改变提供给模型的数据量(Vary the amount of data you give the model)
- 尝试提供不同数量的数据给模型,观察其性能变化。这可以帮助确定模型对数据量的敏感性。
评估你的 LLM,了解哪些方面表现良好,哪些不良(Evaluate your LLM to know what’s going well vs. not)
- 对微调后的模型进行评估,找出表现好的方面和不足之处。这可以通过使用验证集、测试集和特定的评估指标来完成。
收集更多数据以改进(Collect more data to improve)
- 根据评估结果,收集更多的数据来改进模型的性能。数据的多样性和质量都是关键因素。
增加任务复杂性(Increase task complexity)
- 随着模型性能的提升,可以逐步增加任务的复杂性,以进一步挑战和提升模型能力。
增加模型大小以提高性能(Increase model size for performance)
- 如果任务复杂性增加后,现有模型无法满足需求,可以考虑增加模型的规模(参数数量)以提升性能。
任务复杂性(Complexity)

- 输出更多的令牌更难(More tokens out is harder):
- 当任务需要生成更多的令牌时,任务的复杂性会增加。
- 提取任务更容易(Extract "reading" is easier):
- 关键词、主题、路由、代理(Keywords, topics, routing, agents):这些任务通常涉及从输入文本中提取关键信息,相对来说难度较小。
- 例子:阅读理解任务,提取特定信息。
- 扩展任务更难(Expand "writing" is harder):
- 聊天、写邮件、写代码(Chat, write emails, write code):这些任务需要生成长文本,涉及复杂的语言生成。
- 例子:对话生成、邮件撰写、代码生成。
- 组合任务比单一任务更难(Combination of tasks is harder than 1 task):
- 当模型需要同时处理多种任务时,复杂性显著增加。
- 更难或更通用的任务需要更大的模型(Harder or more general = larger model):
- 难度更大或需要更高泛化能力的任务通常需要更大的模型来处理。
- 例子:你可能希望一个代理能够灵活地一次性完成多种任务或一步完成复杂任务。
- 提取任务(Extraction, Smaller Model):
- 示意图:少量输出令牌 -> 小模型
- 描述:这些任务相对简单,只需要从输入中提取关键信息。
- 扩展任务(Expansion, Larger Model):
- 示意图:大量输出令牌 -> 大模型
- 描述:这些任务更复杂,需要生成长文本或处理复杂的语言生成任务。
参数高效微调方法(PEFT: Parameter-Efficient Finetuning)
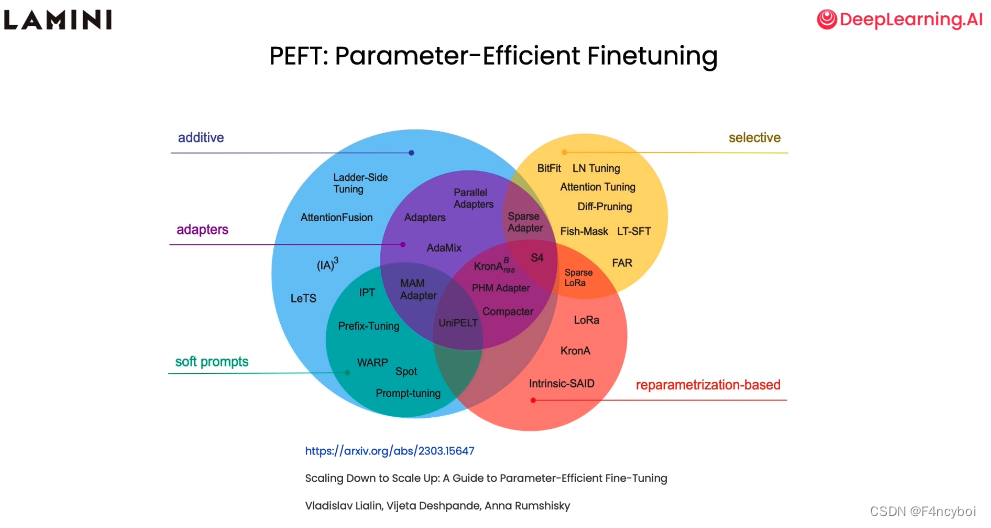
- Additive(加法式微调):
- 方法:这些方法通过添加额外的参数或模块来实现微调,而不是修改原有模型的参数。
- 示例:Ladder-Side Tuning, AttentionFusion
- Adapters(适配器):
- 方法:这些方法使用适配器模块来捕获特定任务的信息,可以在不大幅修改原模型参数的情况下进行微调。
- 示例:Parallel Adapters, AdaMix, (IA)^3, LeTS, Prefix-Tuning, MAM Adapter, PHM Adapter, UniPELT, Compacter
- Soft Prompts(软提示):
- 方法:这些方法通过引入软提示(soft prompts)来引导模型进行特定任务的微调,而不需要大幅修改模型参数。
- 示例:WARP, Spot, Prompt-tuning, IPT
- Selective(选择性微调):
- 方法:这些方法选择性地微调模型的一部分参数,而不是微调整个模型。
- 示例:BitFit, LN Tuning, Attention Tuning, Diff-Pruning, Fish-Mask, LT-SFT, FAR
- Reparametrization-Based(基于重新参数化的微调):
- 方法:这些方法通过重新参数化模型的某些部分来实现微调,可以更高效地调整模型以适应特定任务。
- 示例:LoRa, KronA, Intrinsic-SAID, Sparse LoRa, KronA^B, KronA^Res
- Ladder-Side Tuning:
- 描述:一种加法式微调方法,通过添加侧边模块来捕获特定任务的信息。
- Parallel Adapters:
- 描述:一种适配器方法,使用并行适配器模块来进行微调。
- Prompt-Tuning:
- 描述:一种软提示方法,通过引入任务相关的提示词来引导模型进行微调。
- BitFit:
- 描述:一种选择性微调方法,通过选择性地微调特定参数(如偏置项)来进行微调。
- LoRa:
- 描述:一种基于重新参数化的微调方法,通过重新参数化低秩近似来实现高效微调。
- 图中引用了论文《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》,作者为 Vladislav Lialin, Vijeta Deshpande, Anna Rumshisky。你可以在 arXiv 上找到这篇论文,以获得更多详细信息。
为什么不需要微调所有参数(Why finetune all the parameters?)

LoRA:低秩适应方法(LoRA: Low-Rank Adaptation of LLMs)
- 更少的可训练参数(Fewer trainable parameters):
- 对于 GPT-3,使用 LoRA 方法时,可训练参数数量比完整微调少 10000 倍。
- 这种大幅减少可训练参数的方式,使得模型微调更加高效。
- 更少的 GPU 内存(Less GPU memory):
- 对于 GPT-3,使用 LoRA 方法时,所需的 GPU 内存减少了 3 倍。
- 这使得在相同硬件资源下,可以处理更大的模型或更多的任务。
- 稍低于完整微调的准确性(Slightly below accuracy to finetuning):
- 使用 LoRA 方法进行微调时,模型的准确性略低于完全微调,但差距不大。
- 在大多数应用场景中,这样的准确性差异是可以接受的。
- 相同的推理延迟(Same inference latency):
- 使用 LoRA 方法不会增加模型的推理时间,保持与完全微调相同的推理延迟。
训练新权重和冻结主权重(Train new weights in some layers, freeze main weights)
- 新权重:原始权重变化的秩分解矩阵(New weights: rank decomposition matrices of original weights' change):
- 在某些层中训练新的权重,这些新权重是原始权重变化的低秩分解矩阵。
- 这种方法有效地减少了需要调整的参数数量。
- 推理时,与主权重合并(At inference, merge with main weights):
- 在推理过程中,新权重与主权重合并,确保模型的输出与完全微调后的输出一致。
使用 LoRA 适应新的不同任务(Use LoRA for adapting to new, different tasks)
- LoRA 方法可以用于适应新的和不同的任务,而不需要微调整个模型的所有参数。
- 这使得模型在处理多任务时更加高效和灵活。
- 预训练权重(Pretrained Weights):模型的原始预训练权重。
- LoRA:通过低秩适应方法训练的新权重。
- 在推理过程中,LoRA 权重与预训练权重合并,确保模型的输出质量。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









