







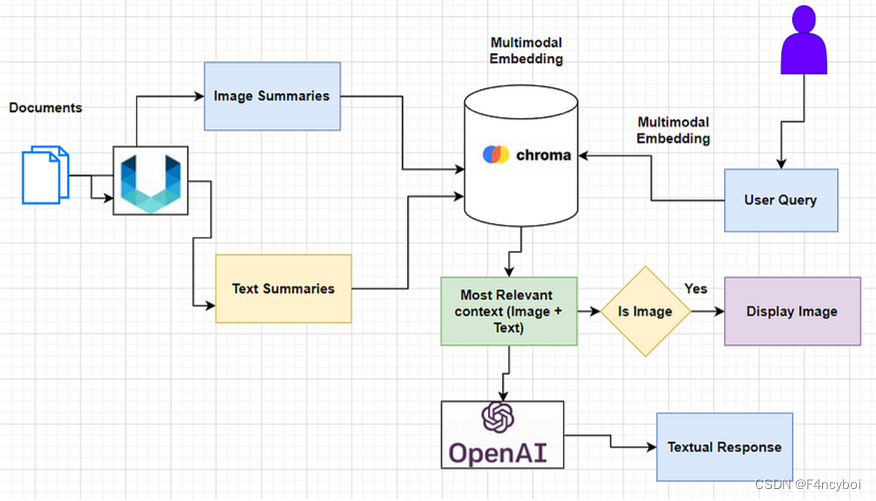
许多文档包含混合内容类型,包括图像和文本。然而,在大多数 RAG 应用程序中,图像中捕获的信息丢失了。随着多模态LLMs(如 GPT4-V、LLaVA 或 FUYU-8b)的出现,值得考虑如何在 RAG 流程中利用图像。
在 RAG 中利用多模态模型的选项很少
Option 1:
- 使用多模态嵌入(如 CLIP)来嵌入图像和文本
- 使用相似性搜索检索两者
- 将原始图像和文本块传递给多模态LLM以进行答案合成
Option 2:
- 使用多模态LLM(如 GPT-4V、LLaVA 或 FUYU-8b)从图像生成文本摘要
- 嵌入和检索文本
- 将文本块传递给LLM以合成答案
Option 3
- 使用多模态LLM(如 GPT-4V、LLaVA 或 FUYU-8b)从图像生成文本摘要
- 嵌入并检索带有原始图像引用的图像摘要
- 将原始图像和文本块传递给多模态LLM以进行答案综合
在这里我们将实现3
涉及的步骤
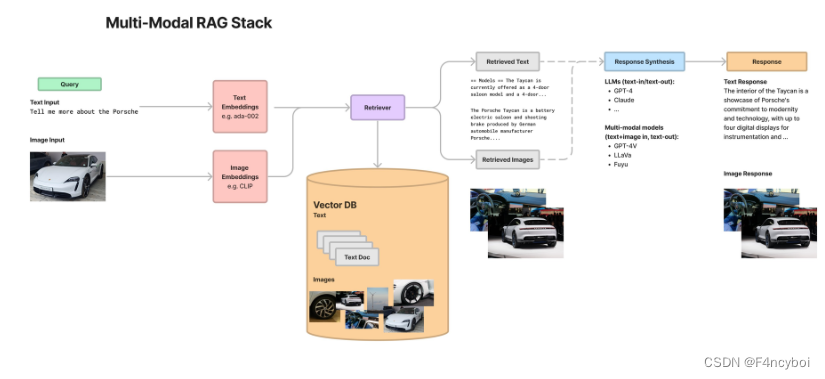
- 使用多模态嵌入(如 CLIP)嵌入图像和文本
- 使用相似性搜索检索两者
- 将原始图像和文本块传递给多模态LLM(GPT4-V)以进行答案合成
使用的技术栈
- 数据加载:Unstructured。它是一个很好的 ETL 工具,适合将文档划分为各种类型(文本、图像、表格)。
- Tesseract:Tesseract 是一个适用于各种操作系统的光学字符识别引擎。它是免费的软件,根据 Apache 许可证发布。
- Langchain:它是一个基于大型语言模型构建应用程序的开源框架 (LLMs)。
- LLM:具备视觉功能的 GPT-4,有时在 API 中被称为 GPT-4V 或 gpt-4-vision-preview,允许模型接收图像并回答有关它们的问题。
代码实现
安装所需的依赖项
对于非结构化数据,您还需要在我们的系统中安装 poppler 和 tesseract。
- https://tesseract-ocr.github.io/tessdoc/Installation.html
- https://pdf2image.readthedocs.io/en/latest/installation.html
非结构化将通过首先删除所有嵌入的图像块来划分 PDF 文件。然后它将使用布局模型(YOLOX)来获取边界框(用于表格)以及 titles ,这些是文档的候选子部分(例如,介绍等)。然后它将进行后处理,以聚合每个 title 下的文本,并根据用户特定的标志(例如,最小块大小等)进一步分块为文本块以进行下游处理。
! pip install pdf2image
! pip install pytesseract
! apt install poppler-utils
! apt install tesseract-ocr
#
! pip install -U langchain openai chromadb langchain-experimental # (newest versions required for multi-modal)
#
# lock to 0.10.19 due to a persistent bug in more recent versions
! pip install "unstructured[all-docs]==0.10.19" pillow pydantic lxml pillow matplotlib tiktoken open_clip_torch torch
数据加载
import os
import shutil
#os.mkdir("Data")
! wget "https://www.getty.edu/publications/resources/virtuallibrary/0892360224.pdf"
shutil.move("0892360224.pdf","Data")
提取图像并将其保存在所需路径中
path = "/content/Data/"
#
file_name = os.listdir(path)
使用下面的 partition_pdf 方法从 Unstructured 中提取文本和图像
# Extract images, tables, and chunk text
from unstructured.partition.pdf import partition_pdf
raw_pdf_elements = partition_pdf(
filename=path + file_name[0],
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path,
按类型对文本元素进行分类
tables = []
texts = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
texts.append(str(element))
#
print(len(tables)
print(len(texts))
#### Response
2
194
- 图像存储在文件路径中
from PIL import Image
Image.open("/content/data/figure-26-1.jpg")

多模态嵌入文档
在这里我们使用了 OpenClip 多模态嵌入。
- 我们使用了更大的模型以获得更好的性能(设置在 langchain_experimental.open_clip.py 中)。
- model_name = “ViT-g-14” checkpoint = “laion2b_s34b_b88k”
import os
import uuid
import chromadb
import numpy as np
from langchain.vectorstores import Chroma
from langchain_experimental.open_clip import OpenCLIPEmbeddings
from PIL import Image as _PILImage
# Create chroma
vectorstore = Chroma(
collection_name="mm_rag_clip_photos", embedding_function=OpenCLIPEmbeddings()
)
# Get image URIs with .jpg extension only
image_uris = sorted(
[
os.path.join(path, image_name)
for image_name in os.listdir(path)
if image_name.endswith(".jpg")
]
)
# Add images
vectorstore.add_images(uris=image_uris)
# Add documents
vectorstore.add_texts(texts=texts)
# Make retriever
retriever = vectorstore.as_retriever()
检索增强生成
- vectorstore.add_images 将以 base64 编码字符串的形式存储/检索图像。
- 然后这些信息可以传递给 GPT-4V。
import base64
import io
from io import BytesIO
import numpy as np
from PIL import Image
def resize_base64_image(base64_string, size=(128, 128)):
"""
Resize an image encoded as a Base64 string.
Args:
base64_string (str): Base64 string of the original image.
size (tuple): Desired size of the image as (width, height).
Returns:
str: Base64 string of the resized image.
"""
# Decode the Base64 string
img_data = base64.b64decode(base64_string)
img = Image.open(io.BytesIO(img_data))
# Resize the image
resized_img = img.resize(size, Image.LANCZOS)
# Save the resized image to a bytes buffer
buffered = io.BytesIO()
resized_img.save(buffered, format=img.format)
# Encode the resized image to Base64
return base64.b64encode(buffered.getvalue()).decode("utf-8")
def is_base64(s):
"""Check if a string is Base64 encoded"""
try:
return base64.b64encode(base64.b64decode(s)) == s.encode()
except Exception:
return False
def split_image_text_types(docs):
"""Split numpy array images and texts"""
images = []
text = []
for doc in docs:
doc = doc.page_content # Extract Document contents
if is_base64(doc):
# Resize image to avoid OAI server error
images.append(
resize_base64_image(doc, size=(250, 250))
) # base64 encoded str
else:
text.append(doc)
return {"images": images, "texts": text}
为什么选择 Lanchain 表达语言?
LCEL 通过提供以下内容,使从基本组件构建复杂链条变得容易:
- 统一接口:每个 LCEL 对象都实现了
Runnable接口,该接口定义了一组通用的调用方法(invoke、batch、stream、ainvoke、……)。这使得 LCEL 对象链也可以自动支持这些调用。也就是说,每个 LCEL 对象链本身就是一个 LCEL 对象。 - 组成原语:LCEL 提供了许多原语,使得组合链、并行化组件、添加后备、动态配置链内部等变得容易。
在这里,我们使用 RunnableParallel 格式化输入,同时我们为 ChatPromptTemplates 添加图像支持。
步骤:
- 我们首先计算上下文(在这种情况下是“文本”和“图像”)和问题(这里只是一个 RunnablePassthrough)
- 然后我们将其传递到我们的提示模板中,这是一个为 gpt-4-vision-preview 模型格式化消息的自定义函数。
- 最后,我们将输出解析为字符串。
- 我们传递响应以及源上下文
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough,RunnableParallel
def prompt_func(data_dict):
# Joining the context texts into a single string
formatted_texts = "\n".join(data_dict["context"]["texts"])
messages = []
# Adding image(s) to the messages if present
if data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{data_dict['context']['images'][0]}"
},
}
messages.append(image_message)
# Adding the text message for analysis
text_message = {
"type": "text",
"text": (
"As an expert art critic and historian, your task is to analyze and interpret images, "
"considering their historical and cultural significance. Alongside the images, you will be "
"provided with related text to offer context. Both will be retrieved from a vectorstore based "
"on user-input keywords. Please use your extensive knowledge and analytical skills to provide a "
"comprehensive summary that includes:\n"
"- A detailed description of the visual elements in the image.\n"
"- The historical and cultural context of the image.\n"
"- An interpretation of the image's symbolism and meaning.\n"
"- Connections between the image and the related text.\n\n"
f"User-provided keywords: {data_dict['question']}\n\n"
"Text and / or tables:\n"
f"{formatted_texts}"
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]
代码返回来源文档
from google.colab import userdata
openai_api_key = userdata.get('OPENAI_API_KEY')
model = ChatOpenAI(temperature=0,
openai_api_key=openai_api_key,
model="gpt-4-vision-preview",
max_tokens=1024)
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(split_image_text_types),
"question": RunnablePassthrough(),
}
| RunnableParallel({"response":prompt_func| model| StrOutputParser(),
"context": itemgetter("context"),})
)
调用 RAG 问答链
response = chain.invoke("hunting on the lagoon")
#
print(response['response'])
print(response['context'])
############# RESPONSE ###############
The image depicts a serene scene of a lagoon with several groups of people engaged in bird hunting. The visual elements include calm waters, boats with hunters wearing red and white clothing, and birds both in flight and used as decoys. The hunters appear to be using long poles, possibly to navigate through the shallow waters or to assist in the hunting process. In the background, there are simple straw huts, suggesting temporary shelters for the hunters. The sky is painted with soft clouds, and the overall color palette is muted, with the reds of the hunters' clothing standing out against the blues and greens of the landscape.
The historical and cultural context of this image is rooted in the Italian Renaissance, specifically in Venice during the late 15th to early 16th century. Vittore Carpaccio, the artist, was known for his genre paintings, which depicted scenes from everyday life with great detail and realism. This painting, "Hunting on the Lagoon," is a testament to Carpaccio's keen observation of his environment and the activities of his contemporaries. The inclusion of diverse figures, such as some black individuals, reflects the cosmopolitan nature of Venetian society at the time.
Interpreting the symbolism and meaning of the image, one might consider the lagoon as a symbol of Venice itself—a city intertwined with water, where the boundary between land and sea is often blurred. The act of hunting could represent the human endeavor to harness and interact with nature, a common theme during the Renaissance as people sought to understand and depict the natural world with increasing accuracy. The presence of decoys suggests themes of illusion and reality, which were also explored in Renaissance art.
The connection between the image and the related text is clear. The text provides valuable insights into the painting's background, such as its use as a window cover, which adds a layer of functionality and interactivity to the artwork. The trompe l'oeil on the back with the illusionistic cornice and the real hinge further emphasizes the artist's interest in creating a sense of depth and reality. The mention of the lily blossom at the bottom indicates that the painting may have been altered from its original form, which could have included more symbolic elements or been part of a larger composition.
The text also notes that Carpaccio was famous as a landscape painter, which aligns with the detailed and atmospheric depiction of the lagoon setting. The discovery of the painting only a few years ago suggests that there is still much to learn about Carpaccio's work and the nuances of this particular piece. The lack of complete understanding of the subject matter invites further research and interpretation, allowing viewers to ponder the daily life and environment of Renaissance Venice.
{'images': [''],
'texts': ["VITTORE CARPACCIO Venetian, 1455/56-1525/26 Hunting on the Lagoon oil on panel, 75.9x63.7cm 6 Carpaccio is considered to be the first great genre painter of the Italian Renaissance, and it is ob- vious that he was a careful observer of his surroundings. The subject of this unusual painting is not yet completely understood, but it apparently depicts groups of Venetians, including some blacks, hunting for birds on the Venetian lagoon. Some birds standing upright in the boats must be decoys. In the background are huts built of straw, which the hunters must have used as temporary lodging. The back of the painting shows an illusionistic cornice with some letters and memoranda—still legible—fastened to the wall. The presence of a real hinge on the back indicates the painting was used as a door to a cupboard or more probably a window cover. It is therefore possible that one had the illusion of looking into the lagoon when the window was shuttered. The presence of a lily blossom at the bottom implies that the painting has been cut down; originally it may have shown the lily in a vase or it may have been cut from a still larger painting in which our fragment was only the background. Reperse: Trompe l'Oeil ",
'3\n\nThis painting was discovered only a few years ago. Unfortunately very little is known about its',
'18\n\npersonality and artistic interests, but he was most famous as a landscape painter.']}
print(response['context']['images'])
辅助函数用于显示作为生成响应的源上下文的一部分检索到的任何图像
from IPython.display import HTML, display
def plt_img_base64(img_base64):
# Create an HTML img tag with the base64 string as the source
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# Display the image by rendering the HTML
display(HTML(image_html))
- 显示与检索文本相关的图像
plt_img_base64(response['context']['images'][0])

- 问题 2
response = chain.invoke("Woman with children")
print(response['response'])
print(response['context'])
########### RESPONSE ######################
The image in question appears to be a portrait of a woman with children, painted in oil on canvas and measuring 94.4x114.2 cm. The woman is likely the central figure in the painting, and the children are probably depicted around her, possibly playing with various instruments as suggested by the text. The woman's age is given as 21, and the painting is dated 1632, which places it in the early 17th century.
The historical and cultural context of this image is significant. The early 17th century was a time of great change and upheaval in Europe, with the Thirty Years' War raging and the rise of absolutist monarchies. In the art world, this was the era of the Baroque, characterized by dramatic, emotional, and often theatrical compositions. The fact that the woman is identified by her age suggests that this is a portrait of a specific individual, possibly a member of the nobility or upper class, as such portraits were often commissioned to commemorate important life events or to display wealth and status.
The symbolism and meaning of the image could be interpreted in several ways. The presence of children suggests themes of motherhood, family, and domesticity. The fact that they are playing instruments could symbolize harmony, creativity, and the importance of music and the arts in the family's life. The woman's age, 21, could also be significant, as it is often considered the age of adulthood and independence.
The related text mentions that the painting was discovered only a few years ago and that very little is known about it. This adds an element of mystery to the image and suggests that there may be more to uncover about its history and significance. The text also mentions a French artist, born in 1702 and died in 1766, which could indicate that the painting is French in origin, although the date of the painting does not align with the artist's lifetime. The mention of Marc de Villiers, born in 1671 and the subject of a painting dated 1747, suggests that the image may be part of a larger collection of portraits of notable individuals from this period.
Overall, this image of a woman with children is a rich and complex work that offers insights into the cultural and historical context of the early 17th century. Its symbolism and meaning are open to interpretation, and the connections between the image and the related text suggest that there is still much to learn about this painting and its place in art history.
{'images': [],
'texts': ['31\n\nThis portrait is dated 1632 and gives the age of the sitter, 21. To our eyes she would appear to be',
'3\n\nThis painting was discovered only a few years ago. Unfortunately very little is known about its',
'oil on canvas, 94.4x114.2 cm\n\n4l\n\nat which they want to play their various instruments.',
'French, 1702-1766\n\n46\n\nThe sitter, Marc de Villiers, was born in 1671, and since this painting is signed and dated in 1747,']}
- 注意:此查询没有相关的图像,因此图像检索结果为空列表
- 问题 3
response = chain.invoke("Moses and the Messengers from Canaan")
print(response['response'])
print(response['context'])
########### RESPONSE #############
The image you've provided appears to be a classical painting depicting a group of figures in a pastoral landscape. Unfortunately, the image does not directly correspond to the provided keywords "Moses and the Messengers from Canaan," nor does it seem to relate to the text snippets you've included. However, I will do my best to analyze the image based on its visual elements and provide a general interpretation that might align with the themes of historical and cultural significance.
Visual Elements:
- The painting shows a group of people gathered in a natural setting, which seems to be a forest clearing or the edge of a wooded area.
- The figures are dressed in what appears to be classical or ancient attire, suggesting a historical or mythological scene.
- The color palette is composed of earthy tones, with a contrast between the light and shadow that gives depth to the scene.
- The composition is balanced, with trees framing the scene on the left and the background opening up to a brighter, possibly sunlit area.
Historical and Cultural Context:
- The painting style and attire of the figures suggest it could be from the Renaissance or Baroque period, which were times of great interest in classical antiquity and biblical themes.
- The reference to "Arcadian shepherds discovering a tomb" and "Poussin" in the text indicates a connection to Nicolas Poussin, a French painter of the Baroque era known for his classical landscapes and historical scenes.
Interpretation and Symbolism:
- Without a direct connection to the story of Moses and the messengers from Canaan, it's challenging to provide a precise interpretation. However, the painting could be depicting a scene of discovery or revelation, common themes in Poussin's work.
- The pastoral setting might symbolize an idyllic, peaceful world, often associated with the concept of Arcadia in classical literature and art.
- The gathering of figures could represent a moment of communal storytelling or the sharing of important news, which could loosely tie into the idea of messengers or a significant event.
Connections to Related Text:
- The text mentions the theme of "Arcadian shepherds discovering a tomb," which is a motif Poussin famously depicted in his painting "Et in Arcadia ego." While the image does not show a tomb, the pastoral setting and classical attire could suggest a similar thematic exploration.
- The reference to Flemish art and the interaction with Italian Renaissance artists might imply a fusion of Northern European and Italian artistic styles, which could be reflected in the painting's technique and composition.
In conclusion, while the image does not directly depict the story of Moses and the messengers from Canaan, it does evoke the classical and pastoral themes prevalent in the work of artists like Poussin during the Baroque period. The painting may represent a general scene of classical antiquity or a mythological event, characterized by a serene landscape and a gathering of figures engaged in a significant moment. The historical and cultural significance of such a painting would lie in its representation of the values and aesthetics of the time, as well as its potential to blend different artistic traditions.
{'images': [''],
'texts': ['16\n\nThe theme of Arcadian shepherds discovering a tomb originated in painting with Poussin in the',
'Flemish, 1488-1541\n\n20\n\nWhen Italian artists of the Renaissance came into contact with paintings from the north, they']}
- 显示检索到的图像
for images in response['context']['images']:
plt_img_base64(images)

结论
我们已经成功地使用多模态LLM、Langchain 和非结构化包从非结构化数据中实现了 RAG。通过使用这些,我们不仅利用了嵌入在文档中的图像信息,还利用了文本信息。















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









