






PEFT发展之前
在PEFT之前是通过 in-context learning(上下文学习)
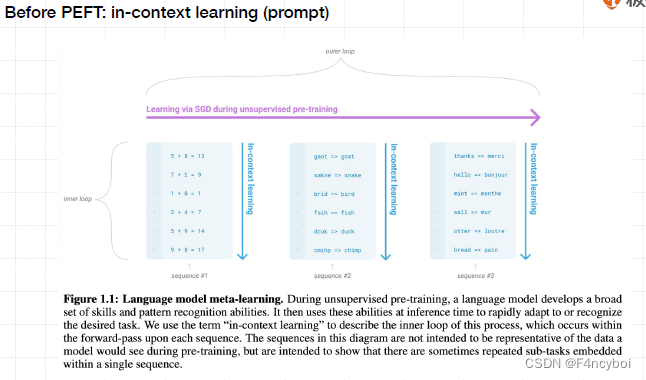
这种学习方法是在无监督预训练期间,通过对大量数据进行学习,使模型获得广泛的技能和模式识别能力。
- Outer Loop(外循环):
- 描述:整个无监督预训练过程,使用 SGD(随机梯度下降)优化模型参数。
- 目的:模型通过大量无标签数据学习,发展出广泛的技能和模式识别能力。
- Inner Loop(内循环):
- 描述:在每个输入序列的前向传播过程中,模型利用已学得的技能和模式进行快速适应或识别所需的任务。
- In-Context Learning(上下文学习):
- 描述:模型通过对输入序列中的上下文进行处理和理解,在推理时快速适应新任务。
- 示例:图中展示了三个序列的例子:
- Sequence #1:数学计算任务(例如,5 + 8 = 13)
- Sequence #2:词汇匹配任务(例如,goat -> goat, snake -> snake)
- Sequence #3:多语言翻译任务(例如,hello -> bonjour)
- Language Model Meta-Learning(语言模型元学习):
- 描述:通过无监督预训练,语言模型发展出一组广泛的技能和模式识别能力。
- 目的:这些能力在推理时用于快速适应新任务。
- In-Context Learning(上下文学习):
- 描述:指模型在每个输入序列的前向传播过程中,通过理解上下文,利用已学得的技能进行任务适应。
- 重要性:这种方法允许模型在不显式微调参数的情况下,仅通过上下文快速适应新任务。
In-Context Learning 是无监督预训练过程中模型发展出的重要能力,使得大模型能够在推理阶段通过上下文快速适应和识别新的任务。这种能力极大地提高了模型的泛化性能和实用性。
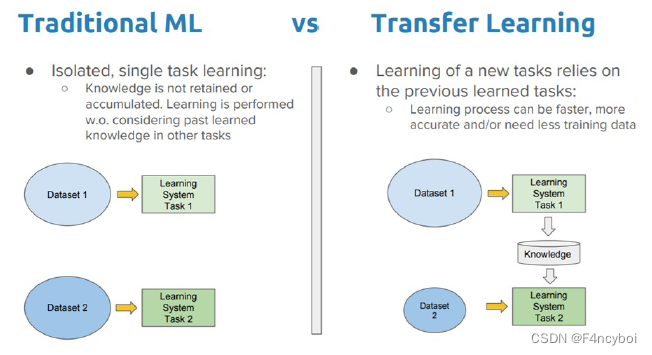
Traditional ML(传统机器学习)
- 单一任务学习:
- 描述:传统机器学习方法通常针对特定任务进行单独训练,每个任务都有独立的数据集和模型。
- 特点:知识不保留或累积,学习过程不考虑其他任务中学到的知识。
- 过程:
- 使用数据集1进行任务1的学习。
- 使用数据集2进行任务2的学习。
- 缺点:每个新任务都需要从头开始训练,耗时且计算资源需求高。
Transfer Learning(迁移学习)
- 依赖于已学任务的新任务学习:
- 描述:迁移学习通过利用之前任务中学到的知识来加速新任务的学习过程。
- 特点:学习过程更快、更准确,且可能需要更少的训练数据。
- 过程:
- 使用数据集1进行任务1的学习,获得知识。
- 将任务1中学到的知识转移到任务2的学习中,使用数据集2进行微调。
- 知识保留与传递:
- 传统机器学习:每个任务独立学习,知识不共享。
- 迁移学习:知识从一个任务转移到另一个任务,促进知识积累和传递。
- 学习效率:
- 传统机器学习:每个任务从头开始,效率低。
- 迁移学习:利用之前任务的知识,加快新任务的学习速度,减少所需训练数据。
- 应用场景:
- 传统机器学习:适用于任务之间完全无关的情况。
- 迁移学习:适用于任务之间有相关性或领域相似的情况,如图像识别、自然语言处理等。
Freeze or Fine-Tune? 如何决定冻结部分层(Freeze)或微调所有层(Fine-Tune)的策略
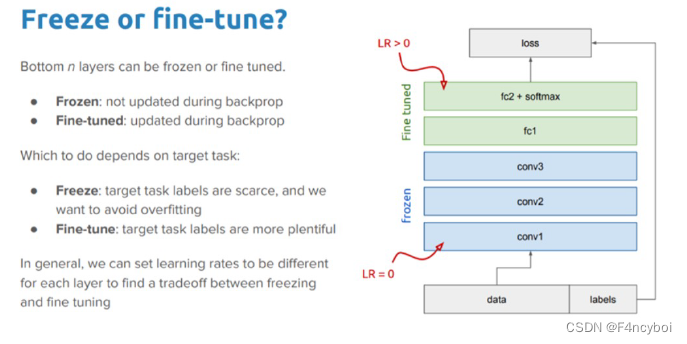
- Frozen Layers(冻结层):
- 定义:在反向传播过程中,这些层的参数不被更新。
- 适用场景:当目标任务的标签数据稀缺时,冻结底层以避免过拟合。
- 学习率(LR):设定为 0,表示这些层不进行参数更新。
- Fine-Tuned Layers(微调层):
- 定义:在反向传播过程中,这些层的参数被更新。
- 适用场景:当目标任务的标签数据充足时,微调所有层以充分利用数据进行学习。
- 学习率(LR):设定为大于 0 的值,表示这些层进行参数更新。
- 数据流动(Data Flow):
- 输入数据和标签(data and labels):模型的输入数据和对应的标签。
- 冻结层(conv1, conv2, conv3):底层卷积层设置为冻结状态(LR = 0)。
- 微调层(fc1, fc2 + softmax):全连接层和 softmax 层设置为微调状态(LR > 0)。
- 损失(loss):通过计算损失函数指导反向传播和参数更新。
- Freeze(冻结):
- 适用场景:当目标任务的标签数据稀缺时,通过冻结底层参数来避免过拟合。
- 好处:减少训练参数数量,降低计算资源需求,避免过拟合。
- Fine-Tune(微调):
- 适用场景:当目标任务的标签数据充足时,通过微调所有层充分利用数据进行学习。
- 好处:提高模型的适应性和性能,充分利用丰富的标签数据。
在实际应用中,可以通过设置不同层的学习率来找到冻结和微调之间的平衡。例如,可以为较低层设置较小的学习率,逐渐增大较高层的学习率,从而实现部分微调。
BERT 预训练和微调
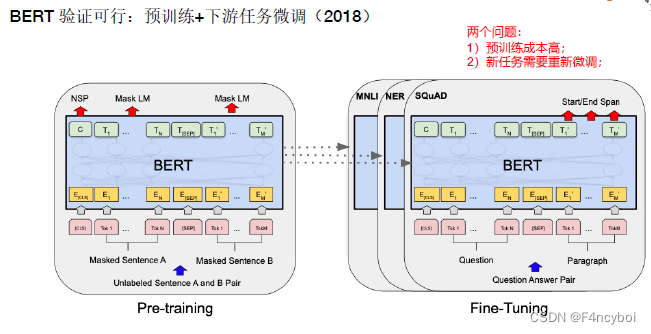
预训练(Pre-training)
- 输入:
- Unlabeled Sentence A and B Pair(未标记的句子对):输入为两个未标记的句子。
- Masked Sentence A and B(掩码句子):在句子中随机掩盖一些词语(Token),并要求模型预测这些掩码词。
- 预训练任务:
- Mask LM(Masked Language Model):语言模型任务,通过掩盖部分词语,要求模型预测被掩盖的词语。
- NSP(Next Sentence Prediction):下一个句子预测任务,要求模型判断两个句子是否为连续句子。
- 过程:
- 模型通过大量未标记的数据进行预训练,学习语言的基础知识和上下文关系。
微调(Fine-Tuning)
- 输入:
- 下游任务数据:如 MNLI(Multi-Genre Natural Language Inference)、NER(Named Entity Recognition)、SQuAD(Question Answering)等任务的数据。
- 微调过程:
- 模型在特定的下游任务数据上进行微调,参数在训练过程中被更新,以适应特定任务的需求。
- 微调任务:
- MNLI/NER:多类文本分类或命名实体识别任务。
- SQuAD:问答任务,需要模型从段落中找到问题的答案。
- 预训练成本高:
- 预训练需要大量的计算资源和时间,因为模型需要在大规模未标记数据上进行训练。
- 解决方法:可以使用预训练好的模型,如 BERT-base 或 BERT-large,直接进行下游任务的微调。
- 新任务需要重新微调:
- 每当有新的下游任务时,模型需要重新微调,以适应新的任务需求。
- 解决方法:通过参数高效微调(PEFT)技术,如 Adapter Tuning、P-Tuning 等,可以减少微调成本和时间。
Adapter Tuning (2019 Google) 开启大模型PEFT

文章Link:
[该类型的内容暂不支持下载]
- 问题背景:
- 微调(Fine-tuning)预训练模型是一种有效的迁移学习方法,但这种方法在处理多个下游任务时参数效率低。
- 传统的微调方法需要为每个新任务训练一个新的模型,这样会导致大量的参数冗余。
- 解决方案:
- 论文提出了使用适配器模块(Adapter Modules)来解决这个问题。
- 适配器模块是紧凑且可扩展的模型,允许每个任务仅添加少量的新参数,同时保留原始模型的参数不变。
- 这种方法支持参数共享,提高了模型的参数效率。
- 实验结果:
- 将这种方法应用于BERT模型,在26个不同的文本分类任务上进行测试。
- 在GLUE基准测试中,适配器模块达到了接近全模型微调的性能,仅增加了0.4%的参数。
- 对比:全模型微调需要更新100%的参数,而适配器模块仅增加3.6%的参数。
- 图1:
- 描述:展示了模型性能和训练参数数量之间的权衡。
- 内容:在不增加大量参数的情况下,适配器模块(蓝色区域)达到了与全模型微调(橙色区域)相似的性能。
- 参数效率:
- 适配器模块通过添加少量参数,实现了接近全模型微调的性能,大大提高了参数效率。
- 适配器模块的优势:
- 紧凑和可扩展:每个新任务只需添加少量参数,无需修改原始模型。
- 参数共享:多个任务可以共享预训练模型的参数,提高了模型的总体效率。
- 实验验证:
- 适配器模块在多个文本分类任务上表现优异,在GLUE基准测试中接近全模型微调的性能,但只增加了很少的参数。
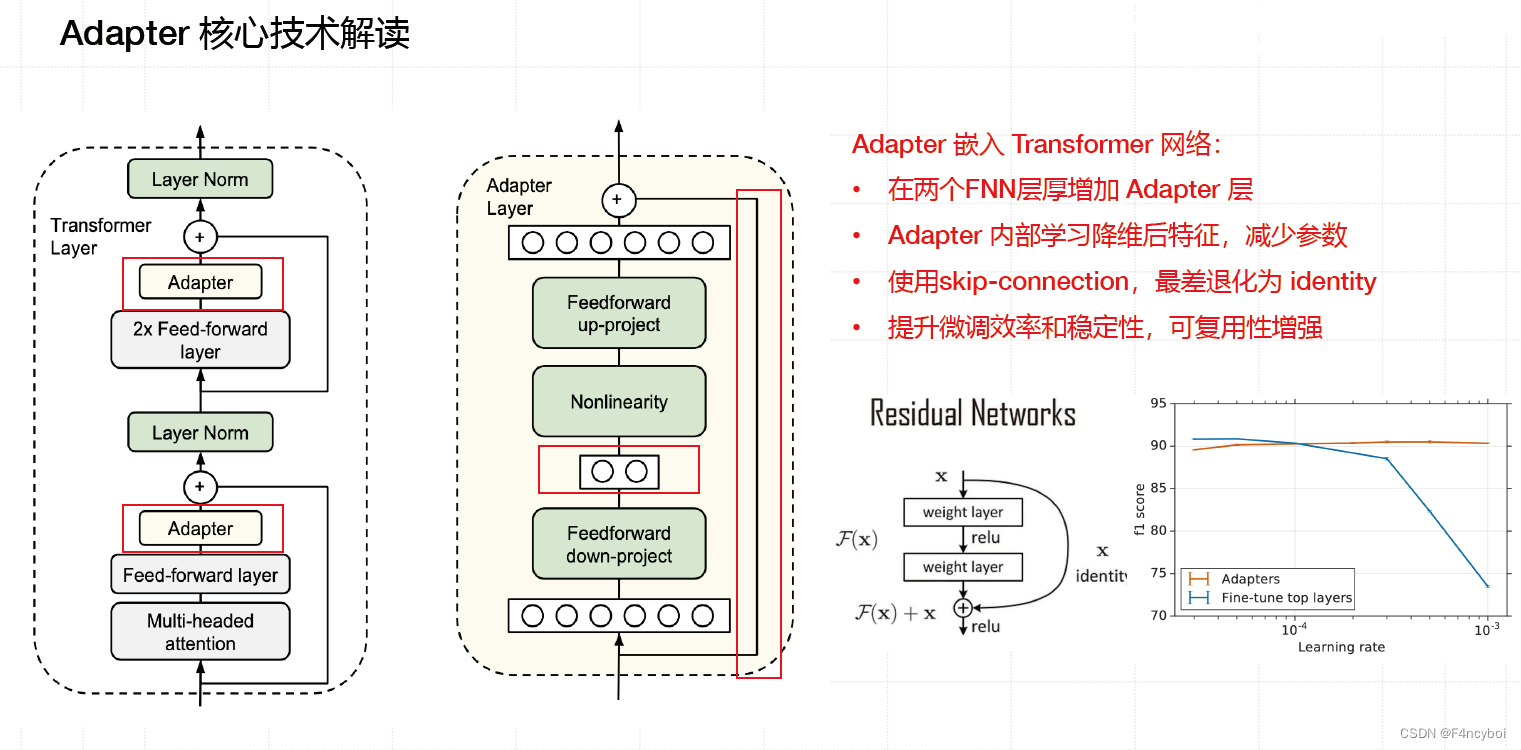
Adapter 的嵌入方式
- Transformer Layer(Transformer 层):
- 结构:包含 Layer Norm、Multi-headed Attention 和 Feed-forward Layer。
- 嵌入位置:在两个 Feed-forward 层之间嵌入 Adapter 层。
- Adapter Layer(适配器层):
- 结构:包括 Feedforward up-project、Nonlinearity 和 Feedforward down-project 三部分。
- 作用:通过增加少量参数,实现特定任务的微调,而不改变原始模型的主要参数。
Adapter 的核心技术点
- 参数降维:
- 方法:适配器内部学习降维和升维操作,减少参数量。
- 过程:
- Feedforward up-project:将输入数据升维。
- Nonlinearity:应用非线性激活函数。
- Feedforward down-project:将数据降维回原始维度。
- Skip-Connection(跳跃连接):
- 作用:通过跳跃连接,最小化信息丢失,提升激活效率和稳定性。
- 残差网络:使用类似残差网络的结构,使得模型在增加适配器层后依然可以高效传递信息。
- 可复用增强:
- 优点:适配器可以在不同任务之间复用,提升模型的扩展性和适应性。
- 图表解释:图表显示了在不同学习率下,Adapter 和全模型微调的性能比较。
- 结果:在学习率较小的情况下,Adapter 的性能接近全模型微调,但参数量大大减少。
- 左侧图示:展示了适配器层在 Transformer 层中的嵌入位置。可以看到适配器层被嵌入到每两个 Feed-forward 层之间,替代了部分传统的 Transformer 结构。
- 中间图示:详细展示了适配器层的内部结构,包括了一个升维操作、非线性激活函数以及降维操作。这个设计使得适配器能够在不显著增加参数量的情况下,实现对特定任务的高效适应。
- 右侧图示:展示了在不同学习率下,适配器技术(Adapters)和全模型微调(Fine-tune top layers)的性能对比。图中可以看到,在学习率较小时,适配器技术的 F1 分数几乎与全模型微调相当,但所需的训练参数量大大减少,体现了其高效性。

[该类型的内容暂不支持下载]
- 背景:
- 微调(Fine-tuning)是利用大规模预训练语言模型执行下游任务的标准方法。然而,微调修改了模型的所有参数,因此需要为每个任务存储一个完整的模型副本。
- 提出的解决方案:
- 论文提出了一种轻量级的替代方法:Prefix Tuning。
- Prefix Tuning 保持语言模型的参数冻结,仅优化一个小的连续任务特定向量(前缀)。
- 这种方法灵感来源于提示词(prompting),允许后续的 tokens 关注该前缀,就像它们是“虚拟 tokens”一样。
- 应用和结果:
- Prefix Tuning 应用于 GPT-2 和 BART 的生成任务,包括表格到文本生成和摘要生成。
- 结果显示,Prefix Tuning 仅需要全量参数的 0.1% 即可在完整数据设置中获得可比的性能。
- 在低数据设置中,Prefix Tuning 的表现优于全量参数微调,并且能更好地推广到训练中未见的示例。
- Fine-Tuning vs Prefix-Tuning:
- Fine-Tuning:顶部图示展示了传统微调方法,需要更新所有 Transformer 参数(红色框),并为每个任务存储一个完整的模型副本。
- Prefix-Tuning:底部图示展示了 Prefix Tuning 方法,只需优化前缀(红色前缀块),冻结 Transformer 参数。这样只需为每个任务存储前缀,使 Prefix Tuning 模块化且节省空间。
- 小的连续任务特定向量(前缀):
- 前缀作为任务特定的可训练参数,插入到模型的输入中,指导生成任务。
- 参数高效性:
- Prefix Tuning 通过优化少量参数实现任务特定的微调,避免了全量参数微调的高计算成本和存储需求。
- 性能和泛化能力:
- Prefix Tuning 在低数据环境下表现优异,并能推广到训练时未见的示例。
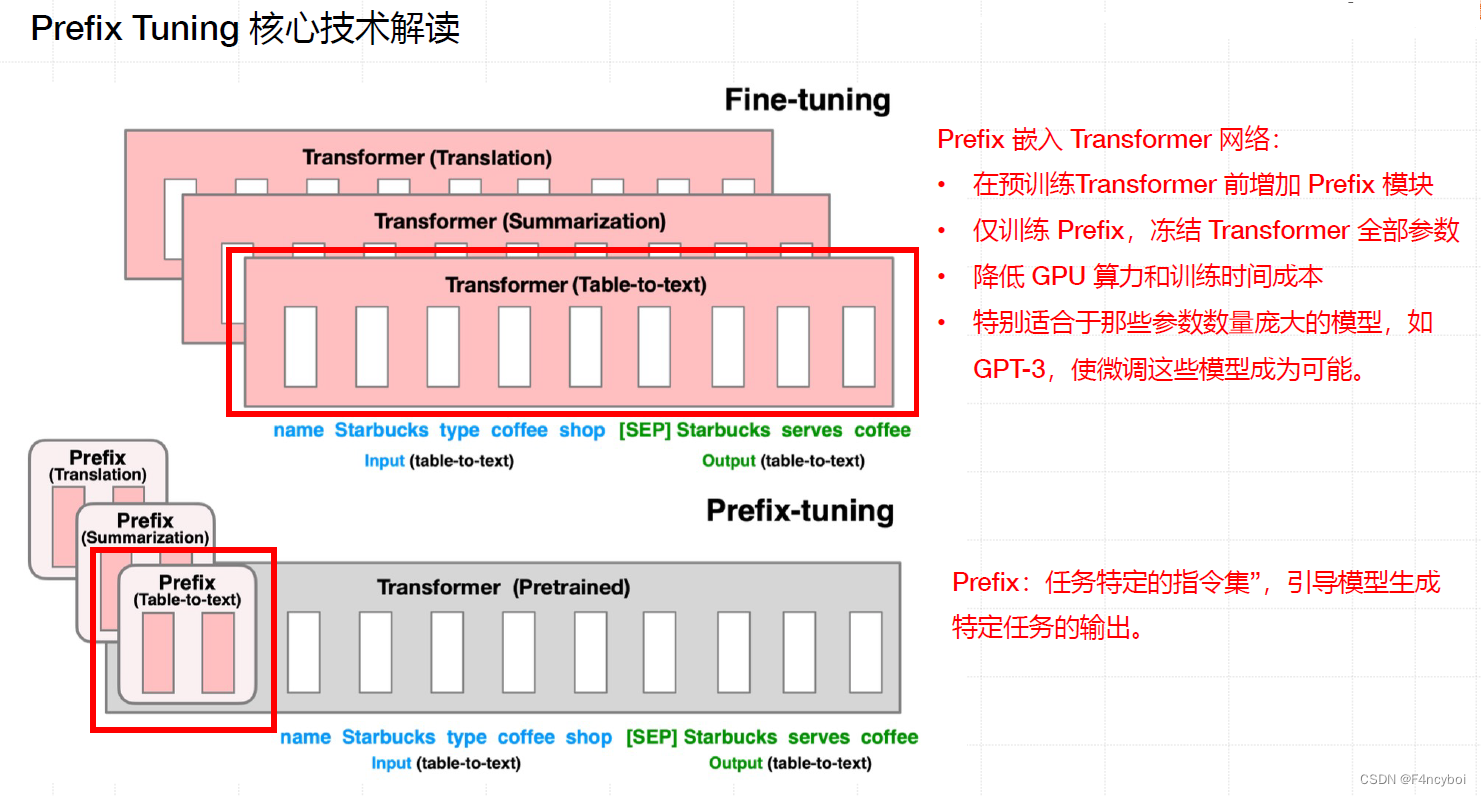
- Fine-Tuning(全量微调):
- 图示顶部展示了传统的微调方法,需对所有 Transformer 参数进行更新(红色框)。
- 每个任务(如翻译、摘要生成、表格到文本生成)都需要微调整个模型,导致大量计算和存储开销。
- Prefix Tuning(前缀调优):
- 图示底部展示了 Prefix Tuning 方法,仅需优化前缀部分(红色前缀块),而保持 Transformer 参数冻结。
- 每个任务只需存储特定的前缀参数,节省了大量存储空间和计算资源。
- Prefix Tuning 的嵌入方式:
- 在预训练的 Transformer 前添加 Prefix 模块。
- 仅微调前缀参数,冻结 Transformer 全部参数。
- 降低成本:
- 降低 GPU 算力和训练时间成本。
- 特别适合于那些参数数量巨大的模型,如 GPT-3,使微调这些模型成为可能。
- 前缀的作用:
- 前缀作为任务特定的指令集,引导模型生成特定任务的输出。
- 在不同任务(如翻译、摘要生成、表格到文本生成)中使用不同的前缀,实现高效的任务适应。
- 图表解释:图表展示了在学习率较小时,Prefix Tuning 的性能与全量微调相近,但其参数量和计算需求大大减少。
- 结果:Prefix Tuning 通过优化少量参数,实现了任务特定的高效微调,避免了全量微调的高成本。

- Autoregressive Model(自回归模型):
- 模型:例如 GPT-2。
- 结构:包括前缀(Prefix)、源内容(source table)和目标内容(target utterance)。
- 激活和索引:
- Activation:激活函数。
- Indexing:索引表明哪些位置是前缀(虚拟 token)和哪些位置是源内容和目标内容。
- 公式:
| CSS |
- Encoder-Decoder Model(编码器-解码器模型):
- 模型:例如 BART。
- 结构:包括前缀(Prefix’)、源内容(source table)和目标内容(target utterance)。
- 激活和索引:
- 与自回归模型类似,但在编码器-解码器结构中,前缀作用在编码器部分,目标内容作用在解码器部分。
- Summarization Example(摘要生成示例):
- 文章:关于伦敦大学学院的研究发现。
- 摘要:生成的摘要自然扭曲了身体图像,可能解释饮食失调。
- Table-to-text Example(表格到文本生成示例):
- 表格:包含名称、评分、食品类型等信息。
- 文本描述:生成的文本描述了某咖啡店的详细信息。
- 公式解释:
- 激活向量 h_i 的计算:
- 如果索引 i 属于前缀部分 P_idx,则激活向量从可训练矩阵 P_θ 提取。
- 否则,由语言模型 LM_φ 根据源内容 z_i 和之前的激活向量 h_<i 计算。
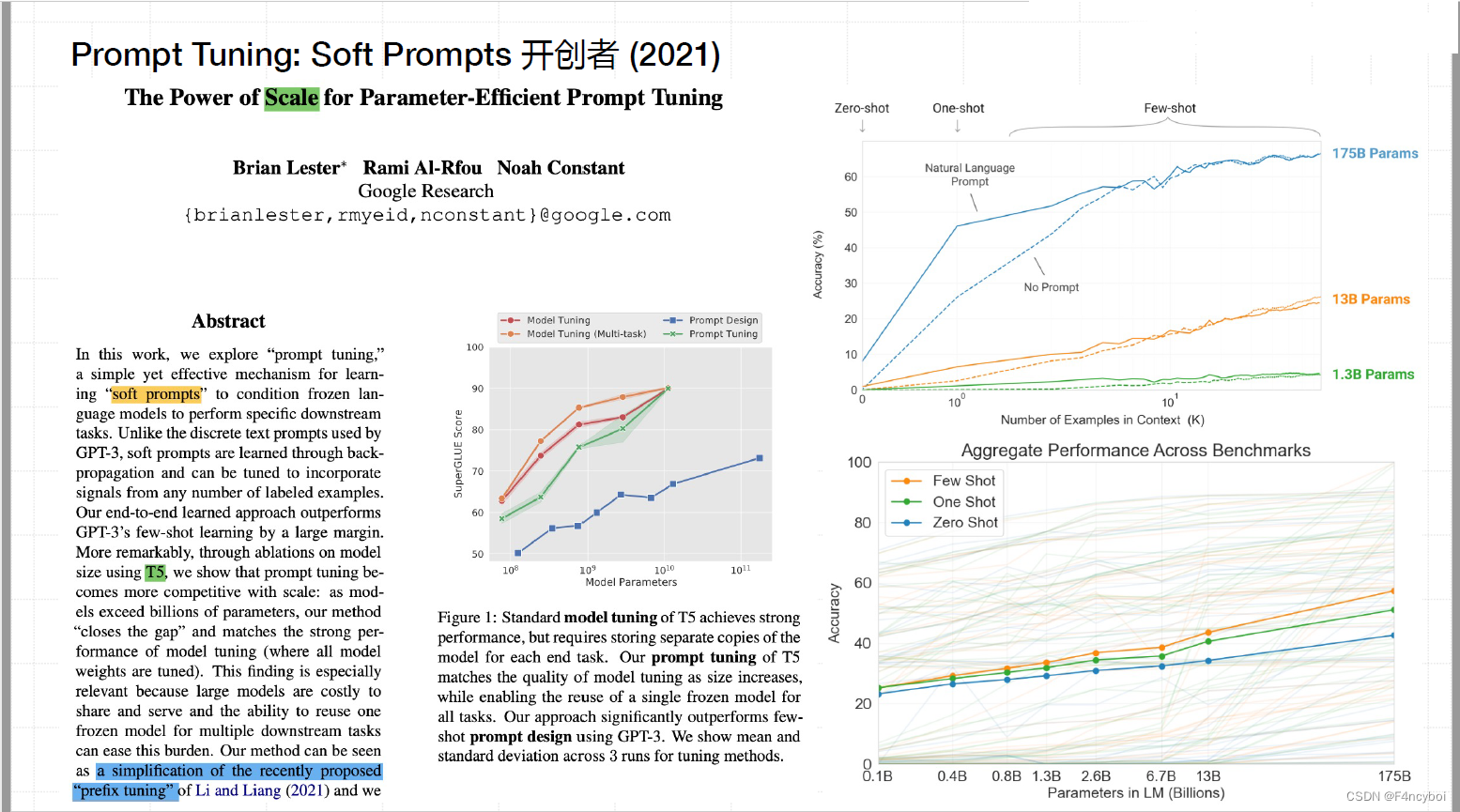
目标:该研究探索了 "Prompt Tuning" 这一简单而有效的方法,通过对 GPT-3 等大型预训练模型进行软提示调整(Soft Prompt Tuning),从而学习特定任务的提示。这种方法的核心思想是,通过引入任务特定的软提示向量,来指导预训练模型在下游任务中的表现。
方法:
- 提出了一种将软提示融入预训练模型的前向传递中的方法。
- 这种软提示是通过反向传播来优化的。
- 与传统的微调方法不同,这种方法无需对模型的所有参数进行更新,而是仅仅调整少量的软提示参数,从而实现参数高效的调整。
- 性能提升:
- 研究发现,通过软提示调整,模型在多个任务上的表现显著提升。
- 在某些任务中,软提示调整的表现甚至超过了全量微调。
- 参数高效:
- 软提示调整只需调整少量参数,相较于全量微调,所需的计算资源和存储空间显著减少。
- 扩展性:
- 软提示调整方法具有良好的扩展性,可以方便地应用于不同的任务,而无需针对每个任务进行大规模的参数调整。
- 性能图(左上角):
- 显示了在不同规模的模型上,使用软提示调整(Prompt Tuning)、全量微调(Model Tuning)和不使用提示(No Prompt)的性能对比。
- 可以看到,随着模型规模的增加,软提示调整的效果越来越显著。
- 参数量与性能(右上角):
- 展示了在不同任务中的零样本学习(Zero-Shot)、单样本学习(One-Shot)和少样本学习(Few-Shot)的性能表现。
- 图中显示了在不同参数规模(1.38B, 138B, 175B)下,软提示调整的表现。
- 跨基准的总体性能(右下角):
- 展示了在多个基准测试中的总体性能表现,软提示调整在多个任务中的表现优于标准调整方法。
[该类型的内容暂不支持下载]
Prompt Tuning 的主要贡献
- 直观性:
- Prompt tuning 使用直观的语言提示来引导模型,使其更易于理解和操作。这种方法通过向模型输入提示,使得模型能够根据提示生成相应的输出。
- 适用性:
- 这种方法特别适用于那些预训练模型已经掌握了大量通用知识的情况,通过简单的提示就能激发特定的响应。这意味着只需少量调整即可将预训练模型应用到各种特定任务中。
- 微调成本低:
- Prompt tuning 可以在微调时减少所需的计算资源,同时保持良好的性能。相较于传统的全量参数微调,这种方法只需调整少量提示参数,显著降低了微调的计算成本和时间。
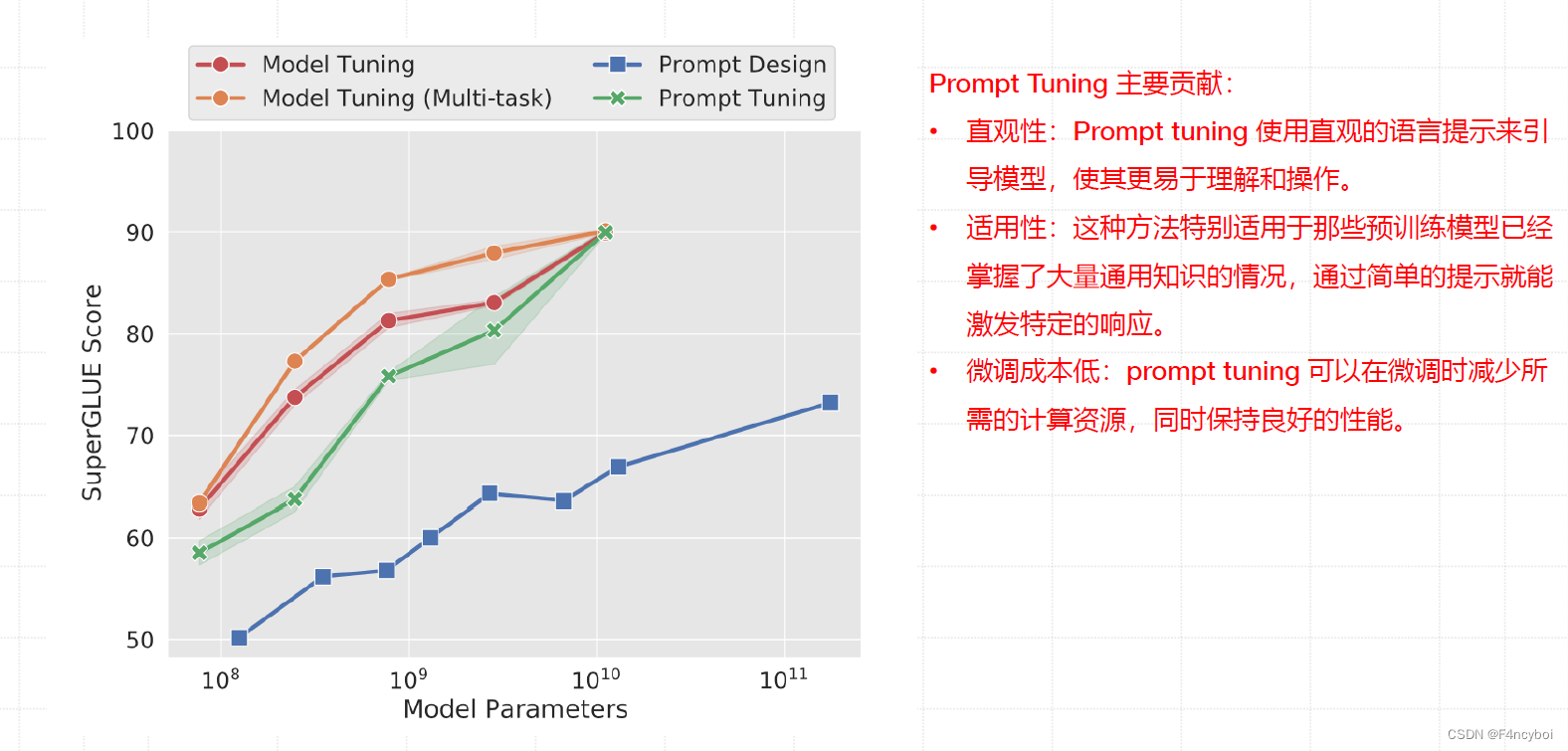
- 性能对比图(左上角):
- 图中展示了在不同模型参数规模(横轴)下,使用 Model Tuning(模型微调)、Model Tuning (Multi-task)(多任务模型微调)、Prompt Design(提示设计)和 Prompt Tuning(提示调优)的方法在 SuperGLUE 基准测试中的得分(纵轴)。
- 随着模型参数规模的增加,Prompt Tuning 的表现显著提升,并在某些情况下超过了传统的全量参数微调方法。
- SuperGLUE 得分:
- SuperGLUE 是一个用于评估自然语言理解任务的基准测试,得分越高表示模型在各种任务中的综合表现越好。
- 从图中可以看出,Prompt Tuning 在较大模型参数下(如 10^11 参数规模)表现尤为出色,接近甚至超过全量参数微调的方法。
Prompt Tuning 通过引入任务特定的软提示,实现了高效的参数调整。与传统的全量参数微调相比,这种方法具有以下优点:
- 简化操作:使用直观的提示进行模型调整,操作简单直观。
- 广泛适用:适用于各种任务,只需调整提示即可应用不同领域。
- 成本效益:显著减少计算资源和时间,适合大规模模型的高效微调。
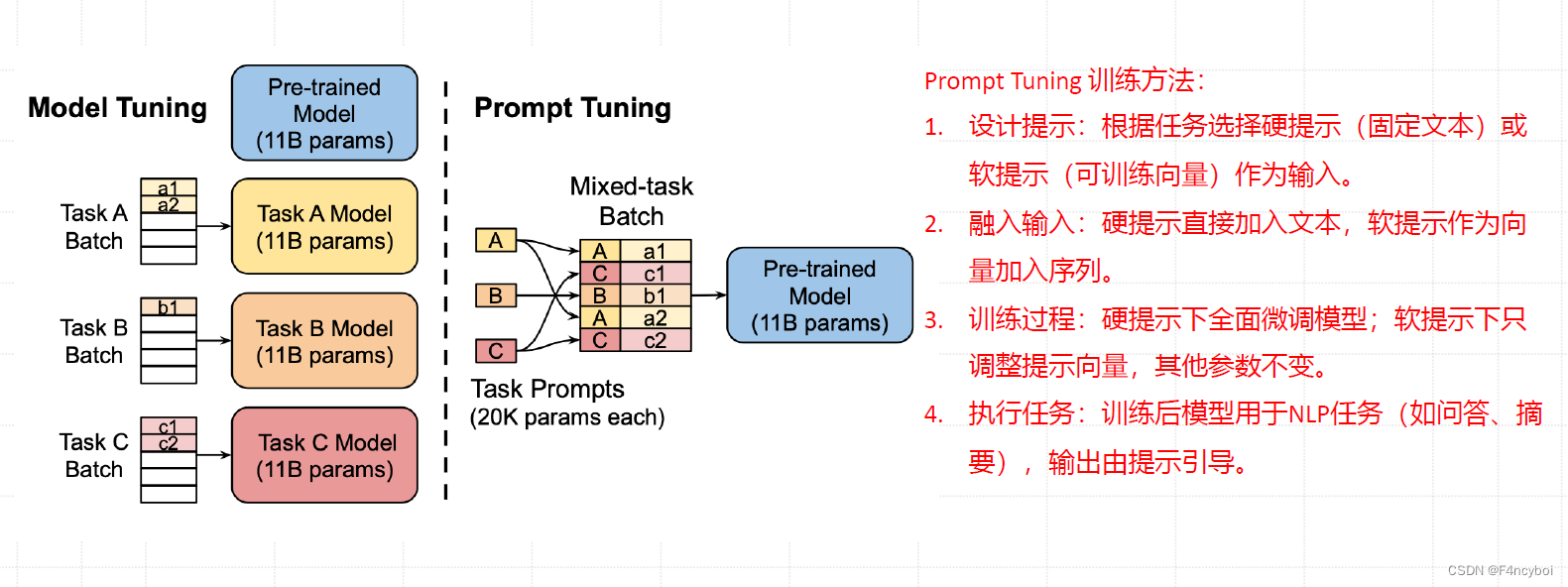
prompt Tuning 的训练方法
- 设计提示:
- 根据任务选择硬提示(固定文本)或软提示(可训练向量)作为输入。
- 硬提示通常是预定义的文本,如问题或命令。
- 软提示是可训练的向量,用于优化特定任务的性能。
- 融入输入:
- 硬提示直接加入文本。
- 软提示作为向量加到输入序列中,指导模型生成任务特定的输出。
- 训练过程:
- 硬提示下进行全面微调模型参数。
- 软提示下只调整提示向量,保持其他参数不变。
- 这种方法显著降低了微调成本,特别适用于大规模模型。
- 执行任务:
- 训练后模型用于各种 NLP 任务(如问答、摘要生成),输出由提示引导。
- Model Tuning(模型微调):
- 对每个任务(Task A、Task B、Task C),分别进行模型微调,生成多个特定任务模型。
- 每个任务都有一个独立的模型,需要调整所有参数,计算成本高。
- Prompt Tuning(提示调优):
- 使用预训练模型(如 11B 参数的模型)处理混合任务批次(Mixed-task Batch)。
- 每个任务使用独立的提示(Task Prompts,20K 参数每个)。
- 只需调整提示向量,预训练模型参数保持不变,节省计算资源。
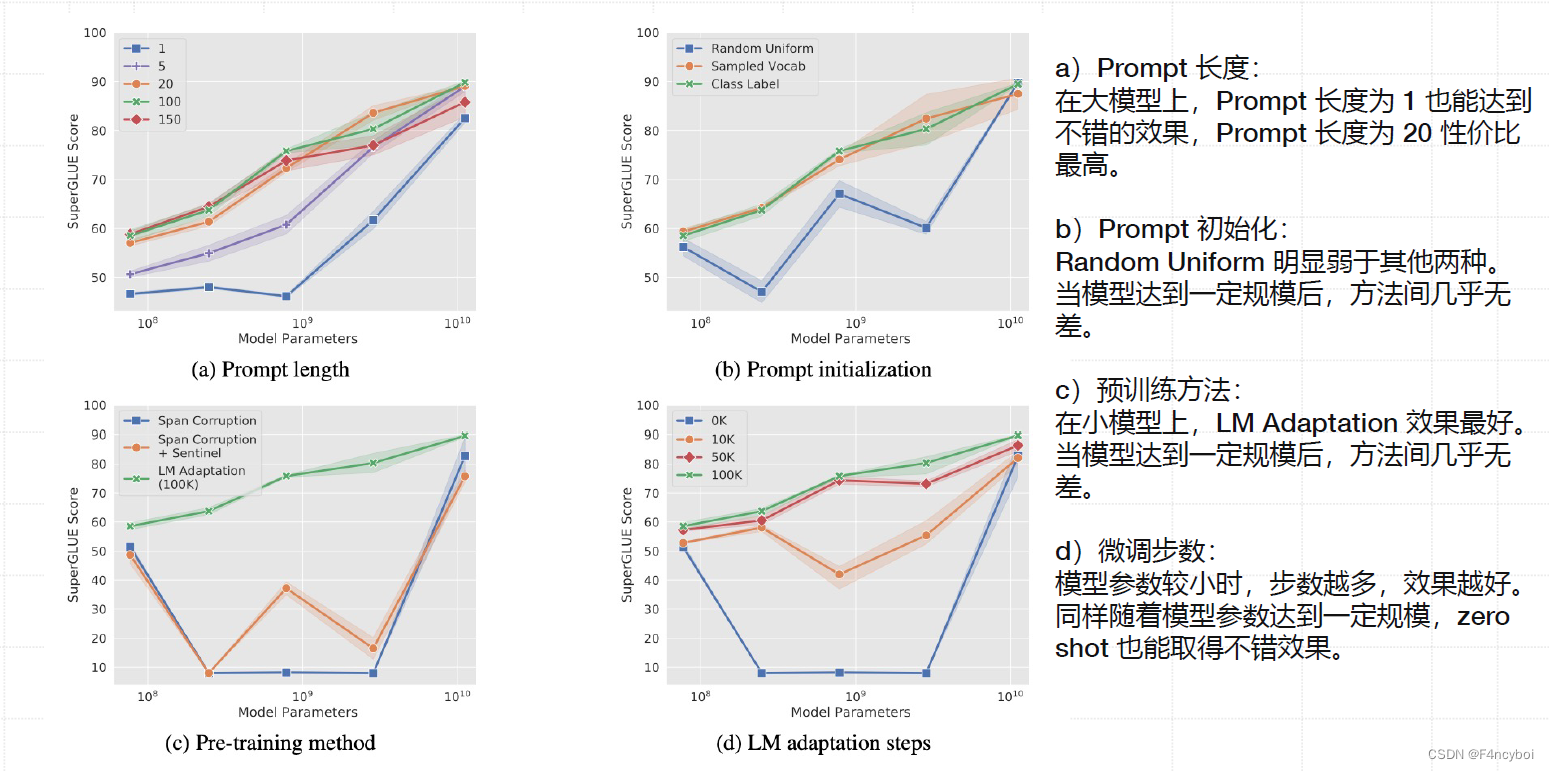
a) Prompt 长度
图表 (a) 显示了在不同模型参数规模下,Prompt 长度对 SuperGLUE 得分的影响。
- 结果:
- 在大模型上,即使 Prompt 长度为 1 也能达到不错的效果。
- Prompt 长度为 20 性能最高,随着 Prompt 长度增加,性能逐渐提高,但在长度超过 20 后提升效果不明显。
- 解读:
- 短的 Prompt 已经可以提供足够的信息来引导模型完成任务。
- 适中的 Prompt 长度(如 20)可以提供更丰富的信息,从而提升模型性能。
b) Prompt 初始化
图表 (b) 比较了三种不同的 Prompt 初始化方法:Random Uniform、Sampled Vocab 和 Class Label。
- 结果:
- Random Uniform 明显弱于其他两种方法。
- Sampled Vocab 和 Class Label 在模型达到一定规模后,性能几乎无差别。
- 解读:
- 初始 Prompt 的选择对小模型影响较大,而对大模型影响较小。
- 随着模型参数的增加,Prompt 初始化的重要性降低。
c) 预训练方法
图表 (c) 显示了不同预训练方法对 Prompt Tuning 的影响,包括 Span Corruption、Span Corruption + Sentinel 和 LM Adaptation。
- 结果:
- 在小模型上,LM Adaptation 效果最好。
- 当模型达到一定规模后,各方法间的性能差异几乎消失。
- 解读:
- 预训练方法在小模型中起到重要作用。
- 随着模型规模增加,预训练方法对性能的影响减小。
d) 微调步数
图表 (d) 显示了不同微调步数对模型性能的影响。
- 结果:
- 模型参数较小时,微调步数越多,效果越好。
- 随着模型参数增加,性能提升效果减弱,Zero-shot 也能取得不错的效果。
- 解读:
- 在小模型中,更多的微调步数有助于提升模型性能。
- 大模型中,即使是 Zero-shot 也能取得较好的结果,说明大模型本身已经具备强大的泛化能力。
P-Tuning v1 (2021 Tsinghua, MiT)将提示转化为可学习的连续嵌入

P-Tuning 的创新点:将离散的自然语言提示(Prompt)转化为可训练的连续嵌入层(Embedding Layer),并通过直接对嵌入层参数进行优化来提升模型性能。
Abstract 解析
- 问题:手动设计的离散提示往往会导致不稳定的性能,即更改提示中的一个单词可能会显著影响模型的表现。
- 方法:提出了一种新的方法 P-Tuning,通过使用可训练的连续提示嵌入与离散提示连接,来稳定训练并提升性能。
- 效果:P-Tuning 不仅稳定了训练过程,还显著提高了在多种自然语言理解任务中的表现,如 LAMA 和 SuperGLUE。
- 离散性(Discreteness):
- 已经通过预训练优化过的语言模型直接对输入提示嵌入进行随机初始化训练,可能会导致局部最优解。
- 关联性(Association):
- 这种方法难以有效捕捉提示与提示之间的相互关系。
- 图表(左上角):
- 显示了在 7 个 SuperGLUE 开发数据集上的平均得分对比,比较了 BERT 和 GPT 模型在微调(Fine-tuning)和 P-Tuning 方法下的表现。
- 可以看到,P-Tuning 在大规模模型(340M 参数)上相较于微调有显著提升(+3.1)。
- 表格(右下角):
- 显示了在 LAMA-TREX 数据集上的精确度(P@1)对比,比较了不同提示形式在有无 P-Tuning 下的表现。
- 结果表明,离散提示在没有 P-Tuning 时表现不稳定,P-Tuning 稳定了性能并提高了准确性。

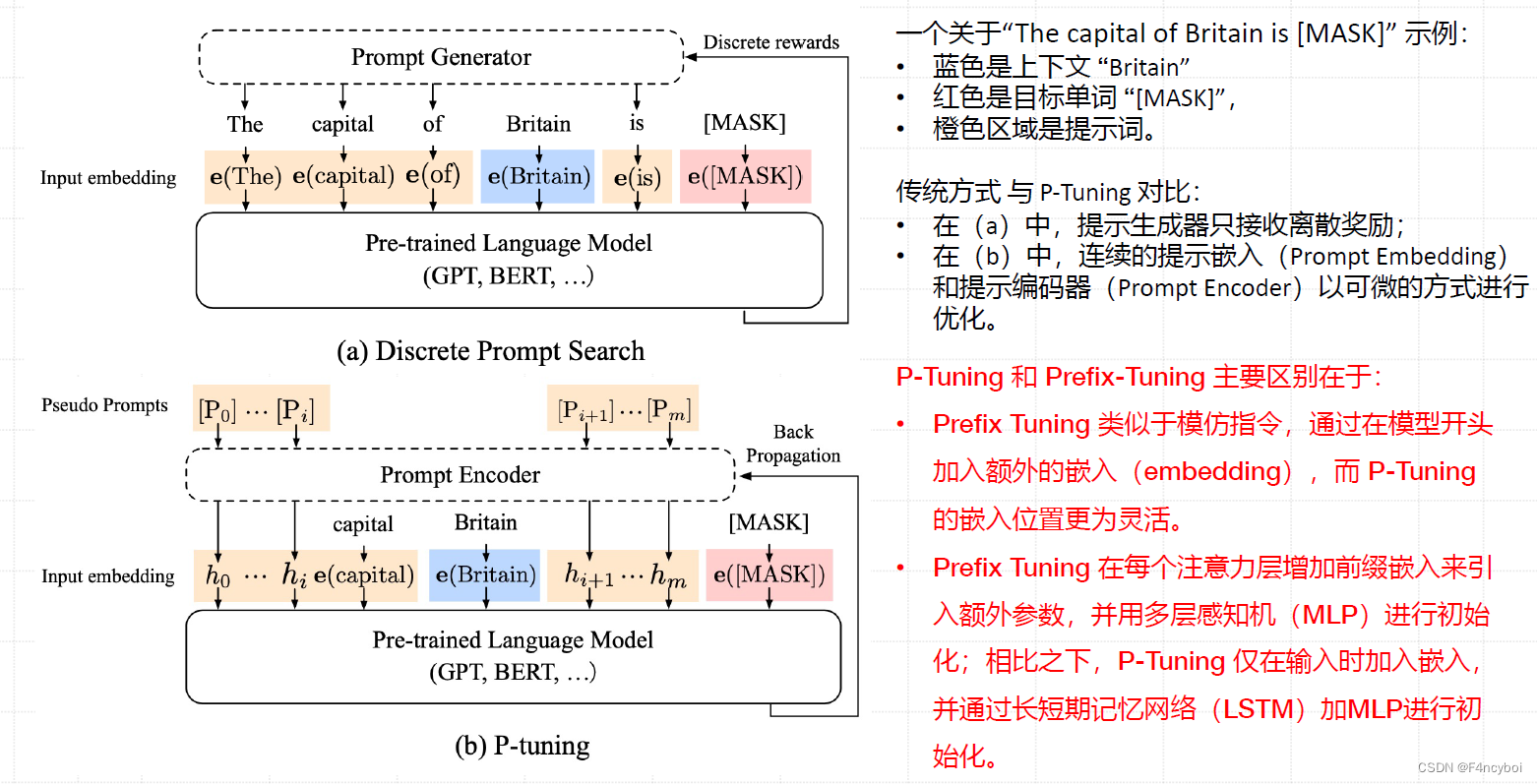
- 概述
P-Tuning 和 Prefix-Tuning 都是针对大语言模型(如 GPT、BERT)进行参数高效微调的方法。它们通过引入额外的提示来引导模型执行特定任务,但在实现细节和方法上有所不同。
- 传统提示与 P-Tuning
- 传统提示(如图 a 所示):
- 使用离散提示(Discrete Prompts),即手动设计的自然语言提示。
- 提示生成器根据离散奖励调整提示词。
- 缺点:提示的设计往往依赖于试错过程,且小的修改可能导致显著的性能波动。
- P-Tuning(如图 b 所示):
- 引入伪提示(Pseudo Prompts),即可训练的连续嵌入(Prompt Embedding)。
- 提示编码器(Prompt Encoder)将伪提示与输入序列结合,优化提示嵌入以提升模型性能。
- 优势:通过连续优化,使提示设计更灵活、稳定。
- 实例解析
示例句子:"The capital of Britain is [MASK]"示例句子:“The capital of Britain is [MASK]”
- 蓝色表示“Britain”
- 红色表示目标单词“[MASK]”
- 橙色表示输入的提示词
- P-Tuning 与 Prefix-Tuning 的主要区别
- 位置灵活性:
- P-Tuning:位置更灵活,提示嵌入可以在输入序列的任意位置。
- Prefix-Tuning:提示嵌入在每个注意力层之前增加前缀,并通过多层感知机(MLP)进行初始化。
- 嵌入方式:
- P-Tuning:仅在输入序列中加入嵌入,并通过长短期记忆网络(LSTM)和 MLP 进行初始化。
- Prefix-Tuning:在每个注意力层增加前缀嵌入,并通过 MLP 进行初始化。
P-Tuning 与 Prefix-Tuning 对比分析
- 概述
P-Tuning 和 Prefix-Tuning 都是针对大语言模型(如 GPT、BERT)进行参数高效微调的方法。它们通过引入额外的提示来引导模型执行特定任务,但在实现细节和方法上有所不同。
- 传统提示与 P-Tuning
- 传统提示(如图 a 所示):
- 使用离散提示(Discrete Prompts),即手动设计的自然语言提示。
- 提示生成器根据离散奖励调整提示词。
- 缺点:提示的设计往往依赖于试错过程,且小的修改可能导致显著的性能波动。
- P-Tuning(如图 b 所示):
- 引入伪提示(Pseudo Prompts),即可训练的连续嵌入(Prompt Embedding)。
- 提示编码器(Prompt Encoder)将伪提示与输入序列结合,优化提示嵌入以提升模型性能。
- 优势:通过连续优化,使提示设计更灵活、稳定。
- 实例解析
示例句子:"The capital of Britain is [MASK]"示例句子:“The capital of Britain is [MASK]”
- 蓝色表示“Britain”
- 红色表示目标单词“[MASK]”
- 橙色表示输入的提示词
- P-Tuning 与 Prefix-Tuning 的主要区别
- 位置灵活性:
- P-Tuning:位置更灵活,提示嵌入可以在输入序列的任意位置。
- Prefix-Tuning:提示嵌入在每个注意力层之前增加前缀,并通过多层感知机(MLP)进行初始化。
- 嵌入方式:
- P-Tuning:仅在输入序列中加入嵌入,并通过长短期记忆网络(LSTM)和 MLP 进行初始化。
- Prefix-Tuning:在每个注意力层增加前缀嵌入,并通过 MLP 进行初始化。
p-Tuning v2 (2022 Tsinghua, BAAl, Shanghai Qi Zhi Institute)

P-Tuning v2: 提升小模型和多任务微调质量 (2022)
P-Tuning v2 是在 P-Tuning 基础上优化和改进的一种方法,旨在使提示调整(Prompt Tuning)在不同规模的预训练模型上,针对各种下游任务都能达到类似全面微调(Fine-tuning)的效果。
Abstract 解析
- 目标:通过连续提示的调整(Prompt Tuning)显著减少每个任务的存储和内存使用。
- 挑战:发现现有的提示调整方法在正常规模的预训练模型上表现不佳,特别是在硬序列标记任务中。
- 创新点:提出了一种经验性发现,通过适当优化的提示调整可以在不同规模的模型和自然语言理解任务中普遍有效。
- 效果:P-Tuning v2 在拥有仅 0.1%-3% 任务特定参数的情况下,实现了与全面微调相当的性能。
- 模型规模差异:在大型预训练模型中,Prompt Tuning 和 P-Tuning 能取得与全面微调相似的效果,但在参数较少的小模型中表现不佳。
- 任务类型差异:无论是 Prompt Tuning 还是 P-Tuning,在序列标注任务上的表现都较差。
图示显示了在 RTE、BoolQ 和 CB 数据集上的平均得分,比较了 Fine-tuning、Lester et al. & P-tuning 和 P-tuning v2 的表现:
- 330M 参数模型:P-tuning v2 略优于 Fine-tuning。
- 2B 参数模型:P-tuning v2 与 Fine-tuning 相当。
- 10B 参数模型:P-tuning v2 略优于 Fine-tuning。
P-Tuning v2 通过多方面的优化,实现了在不同模型规模和任务中的高效提示调优。以下是其核心技术的详细解读:
- 重参数化(Reparameterization)
- 目的:在 Prefix Tuning 和 P-Tuning 中,多层感知机(MLP)被用于构造可训练的嵌入(embedding)。
- 实现:P-Tuning v2 的研究发现,针对不同的任务和数据集,这种方法可能产生相同的效果,特别是在自然语言理解领域。
- 提示长度(Prompt Length)
- 发现:不同任务对应的最佳提示长度是不同的。例如,在简单的分类任务中,长度为20的提示可能是最佳选择;而对于更复杂的任务,则需要更长的提示长度。
- 多任务学习(Multi-task Learning)
- 可选性:对于 P-Tuning v2 而言,多任务学习是可选的,但它可以提供更好的参数初始化,从而进一步提升模型性能。
- 分类头(Classification Head)
- 发现:在 Prompt Tuning 中,使用语言模型(LM)头来预测动词是核心思路。
- 调整:然而,P-Tuning v2 的研究发现,在完整数据集上这种做法并非必要,且与序列标记任务不兼容。因此,P-Tuning v2 采用类似 BERT 的方式,在第一个 token 处应用随机初始化的分类头。















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









