







目录
85. 使用 printf 格式化输出
printf
可以非常灵活、简单地以你期望的格式输出结果。
语法
:
printf “print format”, variable1,variable2,etc.
printf
中的特殊字符
printf
中可以使用下面的特殊字符

使用换行符把 Line1 和 Line2 打印在单独的行里:
$ awk 'BEGIN {printf "Line 1\nLine 2\n"}'
Line 1
Line 2
以制表符分隔字段,Field 1 后面有两个制表符:
$ awk 'BEGIN { printf "Field 1\t\tField 2\tField 3\tField 4\n"}'
Field 1 Field 2 Field 3 Field 4
每个字段后面使用垂直制表符:
$ awk 'BEGIN { printf "Field 1\vField 2\vField 3\vField 4\n" }'
Field 1
Field 2
Field 3
Field 4
下面的例子中,除了第
4
个字段外,每个字段后面使用退格符,这会擦除前三个字段最后的
数字。如
”Field 1”
会被显示为
”Field”,
因为最后一个字符被退格符擦除了。然而
”Field 4”
会照旧
输出,因为它后面没有使用
\b.
$ awk 'BEGIN { printf "Field 1\bField 2\bField 3\bField 4\n" }'
Field Field Field Field 4
下面的例子,打印每个字段后,执行一个“回车”,在当前打印的字段的基础上,打印下一
个字段。这就意味着,最后只能看到
”Field 4”,
因为其他的字段都被覆盖掉了
.
$ awk 'BEGIN { printf "Field 1\rField 2\rField 3\rField 4\n" }'
Field 4
使用
OFS,ORS
当使用
print(
不是
printf)
打印多个以逗号分隔的字段时,
awk
默认会使用内置变量
OFS
和
ORS
处理输出。
下面例子展示
OFS
和
ORS
对单个
print
的影响
:
$ cat print.awk
BEGIN {
FS=",";
OFS=":"; ORS="\n--\n";
}
{
print $2,$3
}
$ awk -f print.awk items.txt
HD Camcorder:Video
--
Refrigerator:Appliance
--
MP3 Player:Audio
--
Tennis Racket:Sports
--
Laser Printer:Office
--
Printf
不受
OFS,ORS
影响
printf
不会使用
OFS
和
ORS
,它只根据
”format”
里面的格式打印数据,如下所示
:
$ cat printf1.awk
BEGIN {
FS=",";
OFS=":";
ORS="\n--\n";
}
{
printf "%s^^%s\n",$2,$3
}
$ awk -f printf1.awk items.txt
HD Camcorder^^Video
Refrigerator^^Appliance
MP3 Player^^Audio
Tennis Racket^^Sports
Laser Printer^^Office
printf
格式化字符
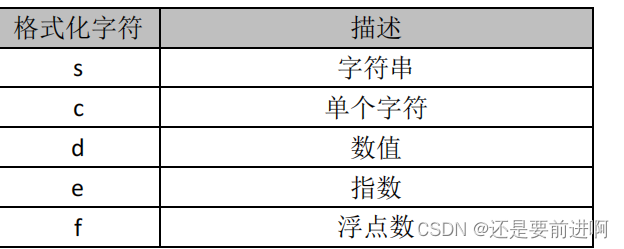

下面展示各个格式化字符的基本用法
:
$ cat printf-format.awk
BEGIN {
printf "s--> %s\n", "String"
printf "c--> %c\n", "String"
printf "s--> %s\n", 101.23
printf "d--> %d\n", 101,23
printf "e--> %e\n", 101,23
printf "f--> %f\n", 101,23
printf "g--> %g\n", 101,23
printf "o--> %o\n", 0x8
printf "x--> %x\n", 16
printf "percentage--> %%\n", 17
}
$ awk -f printf-format.awk
s--> String
c--> S
s--> 101.23
d--> 101
e--> 1.010000e+02
f--> 101.000000
g--> 101
o--> 10
x--> 10
percentage--> %
指定打印列的宽度
要指定打印列的宽度,必须在
%
和格式化字符之间设置一个数字。该数字代表输出列的最小
宽度,如果字符串的宽度比该数字小,会在输出列左侧加上空格以凑足该宽度。
下面例子演示如何指定输出列宽度:
$ cat printf-width.awk
BEGIN {
FS=","
printf "%3s\t%10s\t%10s\t%5s\t%3s\n", "Num","Description","Type","Price","Qty"
printf "------------------------------------------------------------------\n"
}
{
printf "%3d\t%10s\t%10s\t%g\t%d\n", $1,$2,$3,$4,$5
}$ awk -f printf-width.awk items.txt
Num Description Type Price Qty
------------------------------------------------------------------
101 HD Camcorder Video 210 10
102 Refrigerator Appliance 850 2
103 MP3 Player Audio 270 15
104 Tennis Racket Sports 190 20
105 Laser Printer Office 475 5
注意,即是我们指定了输出列的宽度,输出结果仍然没有对齐。因为我们指定的是最小宽度,
而不是绝对宽度;如果字符串长度超过了指定的宽度,整个字符仍然会打印出来。所以,要
在到底打印多少宽度的字符上下点功夫。
如果想在字符串超出指定宽度时,仍然以指定的宽度把字符串打印出来,可以使用
substr
函数
(
或者
)
在指定宽度的数字前面加一个小数点
(
稍后详述
)
。
上面例子中,第二个字段的长度超过了
10
个字符,并不是我们期望的结果。
在左边补空格,把字符串”Good”打印成 6 个字符:
$ awk 'BEGIN { printf "%6s\n","Good" }'
Good
指定宽度为 6,但仍然输出所有字符:
$ awk 'BEGIN { printf "%6s\n", "Good Boy!" }'
Good Boy!
打印指定宽度
(
左对齐
)
当字符串长度小于指定宽度时,如果要让它靠左对齐(右边补空格),那么要在%和格式化字符
之间加上一个减号(-)。
“%6s”是右对齐:
$ awk 'BEGIN { printf "|%6s|\n", "Good" }'
| Good|
“%-6s”
是左对齐
:
$ awk 'BEGIN { printf "|%-6s|\n", "Good" }'
|Good |
打印美元标识
如果要在价钱之前加上美元符号,只需在格式化字符串之前(%之前)加上$即可:
$ cat printf-width2.awk
BEGIN {
FS=","
printf "%3s\t%10s\t%10s\t%5s\t%3s\n", "Num","Description","Type","Price","Qty"
printf "------------------------------------------------------------------\n"}
{
printf "%3d\t%10s\t%10s\t$%-.2f\t%d\n", $1,$2,$3,$4,$5
}
$ awk -f printf-width2.awk items.txt
Num Description Type Price Qty
------------------------------------------------------------------
101 HD Camcorder Video $210.00 10
102 Refrigerator Appliance $850.00 2
103 MP3 Player Audio $270.00 15
104 Tennis Racket Sports $190.00 20
105 Laser Printer Office $475.00 5
字符串长度不足时补
0
默认情况下,右对齐时左边会补空格
$ awk 'BEGIN { printf "|%5s|\n", "100" }'
| 100|
为了在右对齐是,左边补
0 (
而不是空格
),
在指定宽度的数字前面加一个
0
,即使用
”%05s”
代
替
”%5s”
$ awk 'BEGIN { printf "|%05s|\n", "100" }'
|00100|
下面的例子中,在打印的商品数量之前补
0 :
$ vim printf-width3.awk
BEGIN {
FS=","
printf "%-3s\t%-10s\t%-10s\t%-5s\t%-3s\n", "Num","Description","Type","Price","Qty"
printf "---------------------------------------------------------------------\n"
}
{
printf "%-3d\t%-10s\t%-10s\t$%-.2f\t%03d\n", $1,$2,$3,$4,$5
}
$ awk -f printf-width3.awk items.txt
Num Description Type Price Qty
---------------------------------------------------------------------
101 HD Camcorder Video $210.00 010
102 Refrigerator Appliance $850.00 002
103 MP3 Player Audio $270.00 015
104 Tennis Racket Sports $190.00 020
105 Laser Printer Office $475.00 005
以绝对宽度打印字符串
通过之前的例子可以知道,如果字符串长度超过指定的宽度,字符串仍然会整个被打印出来。
$ awk 'BEGIN { printf "%6s\n", "Good Boy!" }'
Good Boy!
如果要最多打印
6
个字符,要在指定宽度的数字前面加一个小数点,即使用
”%.6s”
代替
”%6s”,
这样即使字符串比指定宽度长,也只打印字符串中的前
6
个字符。
$ awk 'BEGIN { printf "%.6s\n", "Good Boy!" }'
Good B
这个例子并非适用于所有版本的
awk
,在
GAWK 3.1.5
上可以,但在
GAWK 3.1.7
上则不行。
当然,以绝对宽度打印字符串,最可取的方法是使用
substr
函数
$ awk 'BEGIN { printf "%6s\n", substr("Good Boy!",1,6) }'
Good B
控制精度
数字前面的点,用来指定其数值精度。
下面的例子说明如何控制精度,展示了使用
.1
和
.4
时数值
”101.23”
的精度
(
使用的格式化
字符有
d,e,f
和
g)
$ cat dot.awk
BEGIN {
print "---------- Using .1 -----------"
printf ".1d--> %.1d\n", 101.23
printf ".1e--> %.1e\n", 101.23
printf ".1f--> %.1f\n", 101.23
printf ".1g--> %.1g\n", 101.23
print "---------- Using .4 -----------"
printf ".4d--> %.4d\n", 101.23
printf ".4e--> %.4e\n", 101.23
printf ".4f--> %.4f\n", 101.23
printf ".4g--> %.4g\n", 101.23
}
$ awk -f dot.awk
---------- Using .1 -----------
.1d--> 101
.1e--> 1.0e+02
.1f--> 101.2
.1g--> 1e+02
---------- Using .4 -----------
.4d--> 0101
.4e--> 1.0123e+02
.4f--> 101.2300
.4g--> 101.2
把结果重定向到文件
Awk
中可以吧
print
语句打印的内容重定向到指定的文件中。下面的例子中,第一个
print
语句使用
”>report.txt”
创建
report.txt
文件并把内容保存到该文件中。随后的所有
print
语句
都使用
”>>report.txt”,
把内容追加到已存在的
report.txt
文件中。
$ cat printf-width4.awk
BEGIN {
FS=","
printf "%-3s\t%-10s\t%-10s\t%-5s\t%-3s\n", "Num","Description","Type","Price","Qty" >
"report.txt"
printf "---------------------------------------------------------------------\n" >> "report.txt"
}
{
if($5 > 10)
printf "%-3d\t%-10s\t%-10s\t$%-.2f\t%03d\n", $1,$2,$3,$4,$5 >> "report.txt"
}
~
$ awk -f printf-width4.awk items.txt
$ cat report.txt
Num Description Type Price Qty
---------------------------------------------------------------------
103 MP3 Player Audio $270.00 015
104 Tennis Racket Sports $190.00 020
另一中方法是不在
print
语句中使用
”>”
或
”>>”
,而是在执行
awk
脚本时使用重定向
$ vim printf-width5.awk
BEGIN {
FS=","
printf "%-3s\t%-10s\t%-10s\t%-5s\t%-3s\n", "Num","Description","Type","Price","Qty"
printf "---------------------------------------------------------------------\n"
}
{
if($5 > 10)
printf "%-3d\t%-10s\t%-10s\t$%-.2f\t%03d\n", $1,$2,$3,$4,$5
}
$ awk -f printf-width5.awk items.txt >report.txt
$ cat report.txt
Num Description Type Price Qty
---------------------------------------------------------------------
103 MP3 Player Audio $270.00 015
104 Tennis Racket Sports $190.00 020
86. awk 内置数值函数
Awk
有很多内置的数值、字符串、输入输出函数,下面介绍其中的一部分。
int(n)
函数
int()
函数返回给定参数的整数部分值。
n
可以是整数或浮点数,如果使用整数做参数,返回
值即是它本身,如果指定浮点数,小数部分会被截断。
int
函数示例
:
$ awk 'BEGIN {
> print int(3.534);
> print int(4);
> print int(-5.223);
> print int(-5);
> }'
输出结果为
:
3
4
-5
-5
log(n)
函数
:
log(n)
函数返回给定参数的自然对数,参数
n
必须是正数,否则会抛出错误
log 函数示例:
$ awk 'BEGIN {
print log(12);
print log(0);
print log(1);
print log(-1);
> }'
2.48491
-inf
0
awk: cmd. line:4: warning: log: received negative argument -1
nan
可以看到,该例子中
log(0)
的值是无穷大,显示为
-inf, log(-1)
抛出了错误
(
非数字
)
注意:你可以同时会看到
log(-1)
抛出如下错误信息
awk: cmd. line:4: warning: log: received
negative argument -1
sqrt(n)
函数
sqrt
函数返回指定整数的正平方根,该函数参数也必须是整数,如果传递负数将会报错。
sqrt
函数示例:
$ awk 'BEGIN { print sqrt(3.5) }'
1.87083
$ awk 'BEGIN {
> print sqrt(16);
> print sqrt(0);
> print sqrt(-12);
> } '
4
0
awk: cmd. line:4: warning: sqrt: called with negative argument -12
nan
exp(n)
函数
exp
函数返回
e
的
n
次幂
exp
函数示例
:
$ awk 'BEGIN {
> print exp(123434346);
> print exp(0);
> print exp(-12);
> }'
awk: cmd. line:1: warning: exp: argument 1.23434e+08 is out of range
inf
1
6.14421e-06
这个例子中,
exp(1234346)
返回的值是
inf,
因为这个值已经超出范围
(
溢出
)
了。
sin(n)
函数
sin(n)
返回
n
的正弦值
,n
是弧度值
sin
函数示例
:
$ awk 'BEGIN {
> print sin(90);
> print sin(45);
> }'
0.893997
0.850904
cos(n)
函数
cos(n)
返回
n
的余弦值,
n
是弧度值
cos 函数示例:
$ awk 'BEGIN {> print cos(90);
> print cos(45);
> }'
-0.448074
0.525322
atan2(m,n)
函数
该函数返回
m/n
的反正切值
,m
和
n
是弧度值。
atan2
函数示例
:
$ awk 'BEGIN { print atan2(30,45) }'
0.588003
87. 随机数生成器
rand()
函数用于产生
0~1
之间的随机数,它只返回
0~1
之间的数,绝不会返回
0
或
1
。这些
数在
awk
运行时是随机的,但是在多次运行中,又是可预知的。
awk
使用一套算法产生随机数,因为这个算法是固定的,所以产生的数也有重复的。
下面的例子产生
1000
个
0
到
100
之间的随机数,并且演示了每个数是怎么产生的
产生
1000
个随机数
(0
到
100
之间
):
$ cat rand.awk
BEGIN {
while(i<1000)
{
n = int(rand()*100);
rnd[n]++;
i++;
}
for(i=0;i<=100;i++)
{
print i,"Occured",rnd[i],"times";
}
}
$ awk -f rand.awk
0 Occured 11 times
1 Occured 8 times
2 Occured 9 times
3 Occured 15 times
4 Occured 16 times
5 Occured 5 times
6 Occured 8 times
7 Occured 9 times
8 Occured 7 times
9 Occured 7 times
10 Occured 11 times
11 Occured 7 times
12 Occured 10 times
13 Occured 9 times
14 Occured 6 times
15 Occured 18 times
16 Occured 10 times
17 Occured 10 times
18 Occured 9 times
19 Occured 8 times
20 Occured 11 times
21 Occured 13 times
22 Occured 10 times
23 Occured 9 times
24 Occured 15 times
25 Occured 8 times
26 Occured 3 times
27 Occured 17 times
28 Occured 9 times
29 Occured 13 times
30 Occured 11 times
31 Occured 9 times
32 Occured 12 times
33 Occured 12 times
34 Occured 9 times
35 Occured 6 times
36 Occured 13 times
37 Occured 15 times
38 Occured 6 times
39 Occured 9 times
40 Occured 7 times
41 Occured 8 times
42 Occured 6 times
43 Occured 8 times
44 Occured 10 times
45 Occured 7 times
46 Occured 10 times
47 Occured 8 times
48 Occured 16 times
49 Occured 12 times
50 Occured 6 times
51 Occured 15 times
52 Occured 6 times
53 Occured 12 times
54 Occured 8 times
55 Occured 13 times
56 Occured 6 times
57 Occured 16 times
58 Occured 5 times
59 Occured 7 times
60 Occured 11 times
61 Occured 12 times
62 Occured 14 times
63 Occured 11 times
64 Occured 9 times
65 Occured 6 times
66 Occured 7 times
67 Occured 10 times
68 Occured 8 times
69 Occured 12 times
70 Occured 13 times
71 Occured 9 times
72 Occured 10 times
73 Occured 11 times
74 Occured 7 times
75 Occured 13 times
76 Occured 13 times
77 Occured 10 times
78 Occured 5 times
79 Occured 12 times
80 Occured 17 times
81 Occured 8 times
82 Occured 7 times
83 Occured 10 times
84 Occured 12 times
85 Occured 12 times
86 Occured 11 times
87 Occured 14 times
88 Occured 4 times
89 Occured 8 times
90 Occured 15 times
91 Occured 10 times
92 Occured 15 times
93 Occured 8 times
94 Occured 11 times
95 Occured 5 times
96 Occured 12 times
97 Occured 11 times
98 Occured 7 times
99 Occured 11 times
100 Occured times
通过这个例子可以看出,
rand()
函数产生的随机数有很高的重复率。
srand(n)函数
srand(n)函数使用给定的参数 n 作为种子来初始化随机数的产生过程。不论何时启动,awk
只会从 n 开始产生随机数,如果不指定参数 n,awk 默认使用当天的时间作为产生随机数的
种子。
产生
5
个从
5
到
50
的随机数
:
$ cat srand.awk
BEGIN {
#Initialize the sedd with 5.
srand(5);
#Totally I want to generate 5 numbers
total = 5;
#maximun number is 50
max = 50;
count = 0;
while(count < total)
{
rnd = int(rand()*max);
if( array[rnd] == 0 )
{
count++;
array[rnd]++;
}
}
for ( i=5;i<=max;i++)
{
if (array[i])
print i; }
}
$ awk -f srand.awk
14
16
23
33
35
该例中
:
首先使用
rand()
函数产生随机数,然后乘以期望的最大值,获得一个小于
50
的数
检测产生的数是否存在于数组中,如果不存在,增加数组的索引和循环数。本例中
产生
5
个数
最后在
for
循环中,从最小到最大一次打印每个索引对应的元素值。
88. 常用字符串函数
下面是一些可以在所有风格的
awk
上运行的常用字符串函数。
index
函数
index
函数用来获取给定字符串在输入字符串中的索引
(
位置
)
。
下面的例子中,字符串
”Cali”
在字符串
”CA is California”
中的位置是
7.
也可以用
index
来检测指定的字符串
(
或者字符
)
是否存在于输入字符串中。如果指定的字符
串没有出现,返回
0
,就说明指定的字符串不存在,如下所示。
$ cat index.awk
BEGIN {
state="CA is California"
print "String CA starts at location",index(state,"CA");
print "String Cali starts at location",index(state,"Cali");
if(index(state,"NY")==0)
print "String NY is not found in:",state
}
$ awk -f index.awk
String CA starts at location 1
String Cali starts at location 7
String NY is not found in: CA is California
length
函数
length 函数返回字符串的长度,下面例子将打印 items.txt 文件中每行字符串的总数。
$ awk '{print length($0)}' items.txt
30
33
28
32
30
split
函数
语法
:
split(input-string,output-array,separator)
split
函数把字符串分割成单个数组元素,其接受如下参数:
input-string:
这个是需要被分割的字符串
output-array:
这个是分割后的字符串存放的数组
separator:
分割字符串的字段分隔符
为了演示这个例子,要对原先的
items-sold.txt
文件做小小的改动,使其包含不同的字段分
隔符,即使用冒号分隔商品编号和销售量,在销售量列表中,每个数字之间以逗号分隔。
为了统计某件特定商品的销售量,我们需要取出第
2
个字段
(
以逗号分隔的销售量数字列表
),
然后使用逗号作为分隔符,将其分隔并保存在一个数组中,然后使用循环遍历数组统计总和。
$ cat items-sold1.txt
101:2,10,5,8,10,12
102:0,1,4,3,0,2
103:10,6,11,20,5,13
104:2,3,4,0,6,5
105:10,2,5,7,12,6
$ cat split.awk
BEGIN {
FS=":"
}
{
split($2,quantity,",");
total=0;
for(x in quantity)
total=total+quantity[x];
print "Item",$1,":",total,"quantities sold";
}
$ awk -f split.awk items-sold1.txt
Item 101 : 47 quantities sold
Item 102 : 10 quantities sold
Item 103 : 65 quantities sold
Item 104 : 20 quantities sold
Item 105 : 42 quantities sold
substr
函数
语法:
substr(input-string,location,length)
substr
函数从字符串中ᨀ取指定的部分
(
子串
)
,上面语法中:
input-string:
包含子穿的字符串
location:
子串的开始位置
length:
从
location
开始起,出去的字符串的总长度。这个选项是可选的,如果不指
定长度,那么从
location
开始一直取到字符串的结尾
下面的例子从字符串的第
5
个字符开始,取到字符串结尾并打印出来。开始的
3
个字符是商
品编号,第
4
个字符时逗号。所以下面的例子会跳过商品编号,打印剩余的内容。
$ awk '{ print substr($0,5) }' items.txt
HD Camcorder,Video,210,10
Refrigerator,Appliance,850,2
MP3 Player,Audio,270,15
Tennis Racket,Sports,190,20
Laser Printer,Office,475,5
从第
2
个字段的第
1
个字符起,打印
5
个字符
:
$ awk -F"," '{ print substr($2,1,5) }' items.txt
HD Ca
Refri
MP3 P
Tenni
Laser
89. GAWK/NAWK 的字符串函数
下面这些函数只能在
GAWK
和
NAWK
中使用。
sub
函数:
语法:
sub(original-string,replacement-string,string-variable)
sub
代表
substitution(
替换
)
的意思
original-string:
将被替换掉的字符串。也可以是一个正则表达式。
replacement-string:
用来替换的字符串
string-variable:
既是输入字符串,也是输出字符串。必须小心,一旦替换操作成功
执行,你将丢失该字符串原来的值。
下面的例子中:
original-string:
这里是一个正则表达式
C[Aa],
匹配
CA
或者
Ca
replacement-string:
如果匹配到
original-string
,则用
”KA”
替换之
string-variable:
执行替换操作之前,该变量保存的是输入字符串
(
替换前的字符串
)
,
一旦执行替换操作,该变量保存的是输出字符串
(
替换后的字符串
)
需要注意的是,
sub
函数只替换第一次出现的
original-string
。
$ cat sub.awk
BEGIN {
state="CA is California"
sub("C[Aa]","KA",state);
print state;
}
$ awk -f sub.awk
KA is California
第
3
个参数
string-variable
是可选的,如果没有指定,
awk
会使用
$0(
当前记录
)
做为第
3
个参
数,如下所示。这个例子把头两个字符从
”10”
替换为
”20”,
所有,商品编号
101
变成了
201,102
变成了
202
,依此类推。
$ awk '{ sub("10","20"); print $0 }' items.txt
201,HD Camcorder,Video,210,10
202,Refrigerator,Appliance,850,2
203,MP3 Player,Audio,270,15
204,Tennis Racket,Sports,190,20
205,Laser Printer,Office,475,5
如果替换操作执行成功,
sub
函数返回
1
,否则返回
0.
仅打印替换成功的记录 :
$ awk '{ if(sub("HD","High-Def")) print $0; }' items.txt
101,High-Def Camcorder,Video,210,10
gsub
函数
gsub 代表全局替换。和
sub
基本相同,只不过它把所有出现的
original-string
都替换为
replacement-string
。
下面例子中,
”CA”
和
”Ca”
都将被替换成
”KA”:
$ cat gsub.awk
BEGIN {
state="CA is California"
gsub("C[Aa]","KA",state);
print state;
}
$ awk -f gsub.awk
KA is KAlifornia
和
sub
函数相同,第
3
个参数也是可选的,如果没有指定,则使用
$0
作为第
3
个参数。
下面的例子把所有出现的
”10”
都替换为
”20”
,它不仅会替换商品编号,如果其他字段包含了
10
,也会进行替换。
$ awk '{ gsub("10","20"); print $0 }' items.txt
201,HD Camcorder,Video,220,20
202,Refrigerator,Appliance,850,2
203,MP3 Player,Audio,270,15
204,Tennis Racket,Sports,190,20
205,Laser Printer,Office,475,5
match
函数和
RSTART,RLENGTH
变量
match
函数从输入字符串中检索给定的字符串
(
或正则表达式
)
,当检索到字符串时,返回一
个正数值。
语法:
match(input-string,search-string)
input-string:
这是需要被检索的字符串
search-string:
要检索的字符串,需要包含在
input-string
中,它可以是一个正则表达
式
下面例子在
state
字符串中检索
”Cali”,
如果
Cali
出现,则打印一条检索成功的消息。
$ cat match.awk
BEGIN {
state="CA is California"
f(match(state,"Cali"))
{
print substr(state,RSTART,RLENGTH),"is present in:",state;
}
}
$ awk -f match.awk
Cali is present in: CA is California
match
函数设置了两个特殊变量,这个例子在调用
substr
函数时使用了它们用来打印检索成
功的消息。
RSTART – search-string
的开始位置
RLENGTH – search-string
的长度
90. GAWK 字符串函数
tolower
和
toupper
函数仅在
GAWK
中可以使用。正如函数名一样,这两个函数把给定的字
符串转换成小写或大写形式,如下所示:
$ awk '{ print tolower($0) }' items.txt
101,hd camcorder,video,210,10
102,refrigerator,appliance,850,2
103,mp3 player,audio,270,15
104,tennis racket,sports,190,20
105,laser printer,office,475,5
$ awk '{ print toupper($0) }' items.txt
101,HD CAMCORDER,VIDEO,210,10
102,REFRIGERATOR,APPLIANCE,850,2
103,MP3 PLAYER,AUDIO,270,15
104,TENNIS RACKET,SPORTS,190,20
105,LASER PRINTER,OFFICE,475,5
91.处理参数(ARGC,ARGV,ARGIND)
之前我们已经讨论过
awk
内置变量,
FS,NFS,RS,NR,FILENAME,OFS
和
ORS
,这些变量在所有的
awk
版本
(
包括
nawk
和
gawk)
上都可以使用。
本节中ᨀ到的环境变量仅仅适用于
nawk
和
gawk
可以使用
ARGC
和
ARGV
从命令行传递一些参数给
awk
脚本
ARGC
保存着传递给
awk
脚本的所有参数的个数
ARGV
是一个数组,保存着传递给
awk
脚本的所有参数,其索引范围从
0
到
ARGC
当传递
5
个参数是,
ARGC
的值为
6
ARGV[0]
的值永远是
awk
下面的例子
arguments.awk
演示
ARGC
和
ARGV
的作用
:
$ cat arguments.awk
BEGIN {
print "ARGC=",ARGC
for(i=0;i<ARGC;i++)
print ARGV[i]
}
$ awk -f arguments.awk
arg1 arg2 arg3 arg4 arg5
ARGC= 6
awk
arg1
arg2
arg3
arg4
arg5
在下面的例子中
:
我们以
”—
参数名 参数值
”
的格式给
awk
脚本传递一些参数
awk
脚本获取传递元素的内容和数量作为参数
如果把
”—item 104 –qty 25”
作为参数传递给
awk
脚本,
awk
会把商品
104
的数量设
置为
25
如果把
”—item 105 –qty 3”
作为参数传递给
awk
脚本,
awk
会把商品
105
的数量设
置为
3
$ cat argc-argv.awk
BEGIN {
FS=","; OFS=",";
for(i=0;i<ARGC;i++)
{
if(ARGV[i] == "--item")
{
itemnumber=ARGV[i+1];
delete ARGV[i]
i++;
delete ARGV[i]
}
else if (ARGV[i]=="--qty")
{
quantity=ARGV[i+1]
delete ARGV[i]
i++;
delete ARGV[i]
}
}
}
{
if ($1==itemnumber)
print $1,$2,$3,$4,quantity
else
print $0
}
$ awk -f argc-argv.awk --item 104 --qty 25 items.txt
101,HD Camcorder,Video,210,10
102,Refrigerator,Appliance,850,2
103,MP3 Player,Audio,270,15
104,Tennis Racket,Sports,190,25
105,Laser Printer,Office,475,5
在
gawk
中,当前处理的文件被存放在数组
ARGV
中,该数组在
body
区域被访问。
ARGIND
是
ARGV
的一个索引,其对应的值是当前正在处理的文件名。
当
awk
脚本仅处理一个文件时,
ARGIND
的值是
1
,
ARGV[ARGIND]
会返回当前正在处理的文
件名。
下面的例子只有
body
区域,打印
ARGIND
的值以及
ARGV[ARGIND]
$ cat argind.awk
{
print "ARGIND:",ARGIND print "Current file:",ARGV[ARGIND]
}
调用这个脚本时,可以传递两个文件给它,没处理一行记录就会打印两条数据。这个例子意
在让你搞清楚
ARGIND
和
ARGV[ARGIND]
的值是怎么存储的。
$ awk -f argind.awk items.txt items-sold1.txt
ARGIND: 1
Current file: items.txt
ARGIND: 1
Current file: items.txt
ARGIND: 1
Current file: items.txt
ARGIND: 1
Current file: items.txt
ARGIND: 1
Current file: items.txt
ARGIND: 2
Current file: items-sold1.txt
ARGIND: 2
Current file: items-sold1.txt
ARGIND: 2
Current file: items-sold1.txt
ARGIND: 2
Current file: items-sold1.txt
ARGIND: 2
Current file: items-sold1.txt
92. OFMT
内置变量
OFMT
仅适用于
NAWK
和
GAWK
。
当一个数值被转换成字符串并打印时,
awk
适用
OFMT
格式来决定如何打印这些值。
OFMT
默认值是
”%.6g”,
包括小数点两边的数字,它打印一共
6
个长度的字符。
在使用
g
时,必须数清楚小数点两边的数字位数,如
”%.4g”
表示包括小数点两侧,一共打印
4
个字符。
在使用
f
时,只需要数清楚小数点后面的数字位数,如
”%.4f”
表示小数点后面会打印
4
个字
符。在此不必关系小数点左边有多少个字符。
下面的脚本
ofmt.awk
演示在使用不同的
OFMT
值
(g
和
f)
时,如何打印字符串
$ cat ofmt.awk
BEGIN {
total=143.123456789; print "--- using g ---"
print "Default OFMT:",total;
OFMT="%.3g"
print "%.3g OFMT:",total;
OFMT="%.4g"
print "%.4g OFMT:",total;
OFMT="%.5g"
print "%.5g OFMT:",total;
OFMT="%.6g"
print "%.6g OFMT:",total;
print "--- using f ---"
OFMT="%.0f";
print "%.0f OFMT:",total;
OFMT="%.1f";
print "%.1f OFMT:",total;
OFMT="%.2f";
print "%.2f OFMT:",total;
OFMT="%.3f";
print "%.3f OFMT:",total;
}
$ awk -f ofmt.awk
--- using g ---
Default OFMT: 143.123
%.3g OFMT: 143
%.4g OFMT: 143.1
%.5g OFMT: 143.12
%.6g OFMT: 143.123
--- using f ---
%.0f OFMT: 143
%.1f OFMT: 143.1
%.2f OFMT: 143.12
%.3f OFMT: 143.123
93. GAWK 内置的环境变量
本节讨论的内置变量仅适用于
GAWK
。
ENVIRON
如果能在
awk
脚本中访问
shell
环境变量会十分有用。
ENVIRON
是一个包含所有
shell
环境变
量的数组,其索引就是环境变量的名称。
如元素
ENVIRON[“PATH”]
的值是环境变量
PATH
的值。
下面的例子打印所有环境变量名称和值。
$ cat environ.awk
BEGIN {
OFS="="
for(x in ENVIRON)
print x,ENVIRON[x]
}
$ awk -f environ.awk
MAIL=/var/mail/root
CPU=x86_64
XDG_CONFIG_DIRS=/etc/xdg
LC_CTYPE=en_US.UTF-8
INPUTRC=/etc/inputrc
HOST=mkey
PWD=/root
FROM_HEADER=
………..
IGNORECASE
默认情况下,
IGNORECASE
的值是
0
,所有
awk
区分大小写。
当把
IGNORECASE
的值设置为
1
时,
awk
则不区分大小写,这在使用正则表达式和比较字符
串时很有效率。
下面的例子不会打印任何内容,因为它想用匹配小写的”video”,但 items.txt 中包含的却是
大写的”Video”.
awk '/video/ {print}' items.txt
然而,当把 IGNORECASE 设置为 1 时,就能匹配并打印包含”Video”的行,因为现在 awk 不
区分大小写。
$ awk 'BEGIN{IGNORECASE=1} /video/{print}' items.txt
101,HD Camcorder,Video,210,10
下面的例子同时支持字符串比较和正则表达式。
$ cat ignorecase.awk
BEGIN {
FS=",";
IGNORECASE=1;
}
{
if ($3 == "video") print $0;
if ($2 ~ "TENNIS") print $0;
}
$ awk -f ignorecase.awk items.txt
101,HD Camcorder,Video,210,10
104,Tennis Racket,Sports,190,20
ERRNO
当执行
I/O
操作
(
比如
getline)
出错时,变量
ERRNO
会保存错误信息。
下面的例子试图用
getline
读取一个不存在的文件,此时
ERRNO
的内容将会是
”No such file or
directory”
。
$ cat errno.awk
{
print $0;
x = getline < "dummy-file.txt"
if ( x == -1 )
print ERRNO
else
print $0
}
$ awk -f errno.awk items.txt
101,HD Camcorder,Video,210,10
No such file or directory
102,Refrigerator,Appliance,850,2
No such file or directory
103,MP3 Player,Audio,270,15
No such file or directory
104,Tennis Racket,Sports,190,20
No such file or directory
105,Laser Printer,Office,475,5
No such file or directory
94. pgawk – awk 运行分析器
pgawk
程序用来生成
awk
执行的结果报告。用
pgawk
可以看到
akw
每次执行了多少条语句
(
以
及用户自定义的函数
)
。
首先建立下面的
awk
脚本作为样本,以供
pgawk
执行,然后分析其结果。
$ cat profiler.awk
BEGIN {
FS=",";
print "Report Generate On:",strftime("%a %b %d %H:%M:%S %Z %Y",systime());
}
{
if ( $5 <= 5 )
print "Buy More: Order",$2,"immediately!"
else print "Sell More: Give discount on",$2,"immediately!"
}
END {
print "----------"
}
接下来使用 pgawk(不是直接调用 awk)来执行该样本脚本。
$ pgawk -f profier.awk items.txt
Report Generate On: Tue Apr 09 15:56:26 CST 2013
Sell More: Give discount on HD Camcorder immediately!
Buy More: Order Refrigerator immediately!
Sell More: Give discount on MP3 Player immediately!
Sell More: Give discount on Tennis Racket immediately!
Buy More: Order Laser Printer immediately!
----------
pgawk
默认会创建输出文件
profier.out(
或者
awkprof.out)
,使用
—profier
选项可以指定输出
文件,如下所示。
$ pgawk --profile=myprofiler.out -f profier.awk items.txt
查看默认的输出文件
awkprof.out
来弄清楚每条单独的
awk
语句的执行次数。
$ cat awkprof.out
# gawk profile, created Tue Apr 9 15:56:26 2013
# BEGIN block(s)
BEGIN {
1 FS = ","
1 print "Report Generate On:", strftime("%a %b %d %H:%M:%S %Z %Y", systime())
}
# Rule(s)
5 {
5 if ($5 <= 5) { # 2
2 print "Buy More: Order", $2, "immediately!"
3 } else {
3 print "Sell More: Give discount on", $2, "immediately!"
}
}
# END block(s)
END {
1 print "----------"
}
查看
awkprof.out
文件时,务必牢记
:
左侧一列有一个数字,标识着该
awk
语句执行的次数。如
BEGIN
区域里的
print
语
句仅执行了一次
(duh!)
。而
while
循环执行了
5
次。
对于任意一个条件判断语句,左边有一个数字,括号右边也有一个数字。左边数字
代表该判断语句执行了多少次,右边数字代表判断语句为
true
的次数。上面的例
子中,由
(# 2)
可以判定,
if
语句执行了
5
次,但只有
2
次为
true
。
95. 位操作
和
C
语言类似,
awk
也可以进行位操作。在日常工作中用不到,但可以说明你可以利用位操
作来做什么。
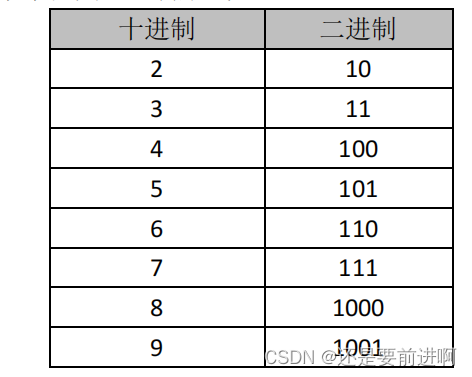
下面表格列出了十进制数字及其二进制形式
AND (
按位与
)
要使
AND
结果为
1
,两个操作数都必须为
1.
0 and 0 = 0
0 and 1 = 0
1 and 0 = 0
1 and 1 =1
例如,在十进制数
15
和
25
上执行
AND
操作,结果是二进制的
01001
,也就是十进制的
9.
15 = 01111
25 = 11001
15 and 25 = 01001
OR(
按位或
)
要使
OR
结果为
1
,任意一个操作数为
1
即可
0 or 0 = 0
0 or 1 = 1
1 or 0 = 1
1 or 1 = 1
例如,在十进制数
15
和
25
上执行
OR
操作,结果是二进制的
11111
,也就是十进制的
31.
15 = 01111
25 = 11001
15 and 25 = 11111
XOR(
按位异或
)
要使
XOR
结果为
1
,必须只有一个操作数为
1
0 xor 0 = 0
0 xor 1 = 1
1 xor 0 = 1
1 xor 1 = 0
例如,在十进制数
15
和
25
上执行
XOR
操作,结果是二进制的
10110
,也就是十进制的
22.
15 = 01111
25 = 11001
15 and 25 = 10110
complement(
取反码
)
反码把
0
变成
1
,把
1
变成
0
如,给
15
取反码。
15 = 01111
15 compl= 10000
Left Shift(
左移
)
该函数把操作数向左位移,可以指定位移多少次
,
位移后右边补
0
。
例如把十进制数
15
向左位移
(
移两次
),
结果将是二进制的
111100
,即十进制的
60.
15 = 1111
lshift twice = 111100
Right Shift(
右移
)
该函数把操作数向右位移,可以指定位移多少次
,
位移后左边补
0
。
例如把十进制数
15
向右位移
(
移两次
),
结果将是二进制的
0011
,即十进制的
3.
15 = 1111
lshift twice = 0011
awk
位移函数示例
$ cat bits.awk
BEGIN {
number1=15
number2=25
print "AND: " and(number1,number2);
print "OR: " or(number1,number2);
print "XOR: " xor(number1,number2);
print "LSHIFT: " lshift(number1,2); print "RSHIFT: " rshift(number1,2);
}
$ awk -f bits.awk
AND: 9
OR: 31
XOR: 22
LSHIFT: 60
RSHIFT: 3
96.用户自定义函数
awk
运行用户自定义函数,这在编写大量代码同时又要多次重复执行其中某些片段时特别有
用,这些片段就适合定义成函数。
语法:
function fn-name(parameters)
{
function-body
}
其中
:
fn-name:
函数名,和
awk
变量名一样,用户定义的函数名应该以字母开头,后续
字符可以数字、字母或下划线,关键字不能用做函数名
parameters:
多个参数要使用逗号分开,也可以定义一个没有参数的函数
function-body:
一条或多条
awk
语句
如果你在
awk
中已经使用了某个名字作为变量名,那么它就不能再用来作函数名。
下面的例子创建了一个简单的用户自定义函数——
discount,
它返回商品打折后的价钱,如
discount(10)
返回打九折后的价钱。
对于任意一种商品,如果数量不大于
10
,则打九折,否则打
5
折。
$ cat function.awk
BEGIN {
FS=","
OFS=","
}
{
if ($5 <= 10)
print $1,$2,$3,discount(10),$5
else
print $1,$2,$3,discount(50),$5
}function discount(percentage)
{
return $4 - ($4*percentage/100);
}
$ awk -f function.awk items.txt
101,HD Camcorder,Video,189,10
102,Refrigerator,Appliance,765,2
103,MP3 Player,Audio,135,15
104,Tennis Racket,Sports,95,20
105,Laser Printer,Office,427.5,5
自定义函数另外一个作用是打印
debug
信息。
下面是一个简单的
mydebug
函数
:
$cat function-debug.awk
{
i=2; total=0;
while (i <= NF ) {
mydebug("quantity is "$i);
total = total + $i;
i++;
}
print "Item",$1,":",total,"quantities sold";
}
function mydebug( message )
{
printf("DEBUG[%d]>%s\n",NR,message);
}
$ awk -f function-debug.awk items-sold.txt
DEBUG[1]>quantity is 2
DEBUG[1]>quantity is 10
DEBUG[1]>quantity is 5
DEBUG[1]>quantity is 8
DEBUG[1]>quantity is 10
DEBUG[1]>quantity is 12
Item 101 : 47 quantities sold
DEBUG[2]>quantity is 0
DEBUG[2]>quantity is 1
DEBUG[2]>quantity is 4
DEBUG[2]>quantity is 3
DEBUG[2]>quantity is 0
DEBUG[2]>quantity is 2
Item 102 : 10 quantities sold
DEBUG[3]>quantity is 10
DEBUG[3]>quantity is 6
DEBUG[3]>quantity is 11
DEBUG[3]>quantity is 20
DEBUG[3]>quantity is 5
DEBUG[3]>quantity is 13
Item 103 : 65 quantities sold
DEBUG[4]>quantity is 2
DEBUG[4]>quantity is 3
DEBUG[4]>quantity is 4
DEBUG[4]>quantity is 0
DEBUG[4]>quantity is 6
DEBUG[4]>quantity is 5
Item 104 : 20 quantities sold
DEBUG[5]>quantity is 10
DEBUG[5]>quantity is 2
DEBUG[5]>quantity is 5
DEBUG[5]>quantity is 7
DEBUG[5]>quantity is 12
DEBUG[5]>quantity is 6
Item 105 : 42 quantities sold
97. 使输出摆脱语言依赖(国际化)
在使用
awk
脚本打时,可能需要用
print
打印指定的
header
和
footer
信息。你或许会用英文
把
header
和
footer
写成固定的内容。但在其他语言中,你希望它会打印什么信息?最终你
可能会把脚本复制过去,然后修改要打印的固定信息,来适应当前的语言环境。
有个更容易的方法来实现这个目的——国际化,这样使用同一个脚本,仅需要在运行脚本时
修改那些固定的输出信息即可。
在运行大型程序,而出于某些原因你要频繁地修改那些固定的输出信息时;或者希望用户能
自行修改要输出的内容时,这个方法也很有用。
下面的例子演示了在
awk
中实现国际化的关键
4
步。
步骤
1 –
建立文本域
创建一个文本域文件,并把它和
awk
要搜寻的目录绑定。下面以当前目录为例。
$ cat iteminfo.awk
BEGIN {
FS=","
TEXTDOMAIN = "item" bindtextdomain(".")
print _"START_TIME:" strftime("%a %b %d %H:%M:%S %Z %Y",systime());
printf "%-3s\t",_"Num";
printf "%-10s\t",_"Description"
printf "%-10s\t",_"Type"
printf "%-5s\t",_"Price"
printf "%-3s\n",_"Qty"
printf _"---------------------------------------------------\n"
}
{
printf "%-3d\t%-10s\t%-10s\t%-.2f\t%03d\n",$1,$2,$3,$4,$5
}
注意:这个例子中,前面带
”_”
的字符串均可以自行定义。字符串前面的
_(
下划线
)
不会影响
字符串内容的打印,即它和下面的输出完全相同。
$ awk -f iteminfo.awk items.txt
START_TIME:Thu Apr 11 11:37:40 CST 2013
Num Description Type Price Qty
---------------------------------------------------
101 HD Camcorder Video 210.00 010
102 Refrigerator Appliance 850.00 002
103 MP3 Player Audio 270.00 015
104 Tennis Racket Sports 190.00 020
105 Laser Printer Office 475.00 005
步骤
2
:生成
.po
文件
建立如下可移植对象文件
(
扩展名
.po)
,注意,除了使用
—gen-po
之外,也可以使用
”-W gen-po”
$ gawk --gen-po -f iteminfo.awk > iteminfo.po
$ cat iteminfo.po
#: iteminfo.awk:5
msgid "START_TIME:"
msgstr ""
#: iteminfo.awk:6
msgid "Num"
msgstr ""
#: iteminfo.awk:7
msgid "Description"
msgstr ""
#: iteminfo.awk:8
msgid "Type"
msgstr ""
#: iteminfo.awk:9
msgid "Price"
msgstr ""
#: iteminfo.awk:10
msgid "Qty"
msgstr ""
#: iteminfo.awk:11
msgid "---------------------------------------------------\n"
""
msgstr ""
现在修改该文件中相应的内容。例如要显示
”Report Generated on:”(
替换原来
的
”START_TIME”)
,那么修改
iteminfo.po
文件,把
START_TIME
右下方的
msgstr
修改为“
Reprot
Genterated On:”
$ cat iteminfo.po
#: iteminfo.awk:5
msgid "START_TIME:"
msgstr "Report Generated On:"
ᨀ示:这个例子中,其余的
msgstr
字符串均被置空。
步骤
3
:生成消息对象
使用
msgfmt
命令
(
从可移植对象文件生成
)
生成消息对象文件。
如果
iteminfo.po
文件中所有的
msgstr
都是空,那么将不会生成任何消息对象文件,如:
$ msgfmt –v iteminfo.po
0 translated messages, 7 untranslated messages.
我们已经创建了一条消息,所以会生成
messages.mo
文件。
$ msgfmt -v iteminfo.po
1 translated message, 6 untranslated messages.
$ ls -l messages.mo
-rw-r--r-- 1 root root 89 Apr 11 12:11 messages.mo
把
message.mo
文件复制到消息目录下,消息目录应该在当前目录下创建
$ mkdir -p en_US/LC_MESSAGES
$ mv messages.mo en_US/LC_MESSAGES/item.mo
注意:目标文件的名字要和初始
awk
文件中的
TEXTDOAMIN
后面的值相同。之前的
awk
文
件中
TEXTDOMAIN=”item”
。
步骤
4
:核证消息
现在可以看到,
awk
将不再显示
”START_TIME”,
而是转换为
”Report Generated On:”
然后打印出
来:
$ gawk -f iteminfo.awk items.txt
Reprot Generated On:Thu Apr 11 12:16:19 CST 2013
Num Description Type Price Qty
---------------------------------------------------
101 HD Camcorder Video 210.00 010
102 Refrigerator Appliance 850.00 002
103 MP3 Player Audio 270.00 015
104 Tennis Racket Sports 190.00 020
105 Laser Printer Office 475.00 005
98. 双向管道
awk
可以使用
”|&”
和外部进程通信,这个过程是双向的。
下面的例子把关键字
”Awk”
替换为
”Sed and Awk”
。
$ echo "Awk is great" | sed 's/Awk/Sed and Awk/'
Sed and Awk is great
下面的例子使用
”|&”
了模拟实现上面的例子,以说明
awk
是如何双向管道的。
$ cat two-way.awk
BEGIN {
command = "sed 's/Awk/Sed and Awk/'"
print "Awk is Great!" |& command
close(command,"to");
command |& getline tmp
print tmp;
close(command);
}
$ awk -f two-way.awk
Sed and Awk is Great!
这个例子中:
command = “sed ‘s/Awk/Sed and Awk/’” –
这是要和
awk
双向管道对接的命令。它是
一个简单的
sed
替换命令,把
”Awk”
替换为
”Sed and Awk”
。
print “Awk is Great!” |& command – command
的输入,即
sed
替换命令的输入是
”Awk
is Great!”
。
”|&”
表示这里是双向管道。
”|&”
右边命令的输入来自左边命令的输出。
close(command,”to”) –
一旦命令执行完成,应该关闭
”to”
进程。
command |& getline tmp –
既然命令已经执行完成,就要用
getline
获取其输出。前
面命令的输出会被存在变量
”tmp”
中。
print tmp –
打印输出
close(command) –
最后,关闭命令。
双向管道迟早会派上用场,尤其是当
awk
对外部程序的输出依赖比较大时。
99. 系统函数
可以使用操作系统内置的函数来执行操作系统命令,但请注意,调用系统命令和使用双向管
道是不同的。
使用
”|&”
时,可以把任意
awk
命令的输出作为外部命令的输入;也可以接收外部命令的输
出作为
awk
的输入
(
要不怎么叫双向管道呢
)
。
执行系统命令时,可以传递任意的字符串作为命令的参数,它会被当做操作系统命令准确第
执行,并返回结果
(
这和双向管道有所不同
)
。
下面的例子在
awk
中调用
pwd
和
date
命令:
$ awk 'BEGIN { system("pwd") }'
/root
$ awk 'BEGIN { system("date") }'
Wed Apr 10 17:07:08 CST 2013
在执行比较大的
awk
脚本时,你或许想在脚本开始和结束时发送一封电子邮件。下面的例
子展示如何在
BEGIN
和
END
区域中调用系统命令,在脚本开始和结束时发送邮件。
$ cat system.awk
BEGIN {
system("echo 'Started' | mail -s 'Program system.awk started ..' ramesh@thegeekstuff.com");
}
{
split($2,quantity,",");
total=0;
for (x in quantity)
total=total+quantity[x];
print "Item",$1,":",total,"quantities sold";
}
END {
system("echo
'Completed'
|
mail
-s 'Program system.awk completed..'
ramesh@thegeekstuff.com");
}
$ awk -f system.awk items-sold.txt
Item 101 : 2 quantities sold
Item 102 : 0 quantities sold
Item 103 : 10 quantities sold
Item 104 : 2 quantities sold
Item 105 : 10 quantities sold
100. 时间函数
这些命令仅适用于
GAWK
。
看下面的例子,
systime()
函数返回系统的
POSIX
时间,即自
1970
年
1
月
1
日起至今经过的
秒数。
$ awk 'BEGIN { print systime() }'
1365585325
如果使用
strftime
函数把
POSIX
时间转换为可读的格式,
systime
函数就变动很有用了。
下面例子使用
systime
和
strftime
以可读的格式打印当前时间。
$ awk 'BEGIN { print strftime("%c",systime()) }'
Wed Apr 10 17:17:35 2013
下面的例子展示了多种可用的时间格式。
$ cat strftime.awk
BEGIN {
print "--- basic formats ---"
print strftime("Format 1: %m/%d/%Y %H:%M:%S",systime())
print strftime("Format 2: %m/%d/%y %I:%M:%S %p",systime())
print strftime("Format 3: %m-%b-%Y %H:%M:%S",systime())
print strftime("Format 4: %m-%b-%Y %H:%M:%S %Z",systime())
print strftime("Format 5: %a %b %d %H:%M:%S %Z %Y",systime())
print strftime("Format 6: %A %B %d %H:%M:%S %Z %Y",systime())
print "--- quick formats ---"
print strftime("Format 7: %c",systime())
print strftime("Foramt 8: %D",systime())
print strftime("Format 9: %F",systime())
print strftime("Format 10: %x",systime())
print strftime("Format 11: %X",systime())
print "--- single line format with %t ---"
print strftime("%Y %t%B %t%d",systime())
print "--- multi line format with %n ---"
print strftime("%Y%n%B%n%d",systime())
}
$ awk -f strftime.awk
--- basic formats ---
Format 1: 04/10/2013 18:04:06
Format 2: 04/10/13 06:04:06 PM
Format 3: 04-Apr-2013 18:04:06
Format 4: 04-Apr-2013 18:04:06 CST
Format 5: Wed Apr 10 18:04:06 CST 2013
Format 6: Wednesday April 10 18:04:06 CST 2013
--- quick formats ---
Format 7: Wed Apr 10 18:04:06 2013
Foramt 8: 04/10/13
Format 9: 2013-04-10
Format 10: 04/10/13
Format 11: 18:04:06
--- single line format with %t ---
2013 April 10
--- multi line format with %n ---
2013
April
10
下面是
strftime
函数可用的时间格式标识符,需要注意的是,下面所有的标识符依赖于本地
系统的设置,下面的示例是打印英文时间。


101. getline 命令
如你所知,没从输入文件读取一行,
body
区域的代码就会执行一次。你无法干预,
awk
自
动执行这个过程。
然而使用
geline
命令可以控制
awk
从输入文件
(
或其他文件
)
读取数据。注意,一旦
getline
执行完成,
awk
脚本会重置
NF,NR,FNR
和
$0
等内置变量。
getline
示例
$ awk -F"," '{getline;print $0;}' items.txt
102,Refrigerator,Appliance,850,2
104,Tennis Racket,Sports,190,20
105,Laser Printer,Office,475,5
当在
body
区域使用了
getline
时,会直接读取下一行数据。这个例子中,第一条语句便是
getline
,所以即使
awk
已经读取了第一行数据,
getline
也会继续读取下一行,因为我们强制
它读取下一行,因此,
getline
后面的
print $0
会打印输入文件的第二行。
这个例子中:
开始执行
body
区域时,执行任何命令之前,
awk
从
items.txt
文件中读取第一行数
据,保存在变量
$0
中
getline –
我们用
getline
命令强制
awk
读取下一行数据,保存在变量
$0
中
(
之前的内
容被覆盖掉了
)
print $0 –
既然现在
$0
中保存的是第二行数据,
print $0
会打印文件第二行
(
而不是第
一行
)
z
body
区域继续执行,只打印偶数行的数据。
(
注意到最后一行
105
也打印了么?
)
把
getline
的内容保存的变量中
除了把
getline
的内容放到
$0
中,还可以把它保存在变量中。
只打印奇数行内容
$ awk -F"," '{getline tmp; print $0;}' items.txt
101,HD Camcorder,Video,210,10
103,MP3 Player,Audio,270,15
105,Laser Printer,Office,475,5
这个例子如何工作:
开始执行
body
区域时,执行任何命令之前,
awk
从
items.txt
文件中读取第一行数
据,保存在变量
$0
中
getline tmp –
强制
awk
读取下一行,并保存在变量
tmp
中
print $0 –
此时
$0
仍然是第一行数据,因为
getline tmp
没有覆盖
$0,
因此会打印第
一行数据
(
而不是第二行
)
body
区域继续执行,只打印奇数行的数据。
下面的例子同时打印
$0
和
tmp
,可以看到,
$0
是奇数行,而
tmp
是偶数行
$ awk -F"," '{getline tmp; print "$0->",$0;print "tmp->",tmp;}' items.txt
$0-> 101,HD Camcorder,Video,210,10
tmp-> 102,Refrigerator,Appliance,850,2
$0-> 103,MP3 Player,Audio,270,15
tmp-> 104,Tennis Racket,Sports,190,20
$0-> 105,Laser Printer,Office,475,5
tmp-> 104,Tennis Racket,Sports,190,20
从其他的文件
getline
内容
上面两个例子,
getline
都是从当前输入文件获取内容,其实也可以从其他文件
(
非当前输入
文件
)
读取内容,如下所示。
在两个文件中循环切换,打印所有内容。
$ awk -F"," '{print $0;getline <"items-sold.txt"; print $0;}' items.txt
101,HD Camcorder,Video,210,10
101 2 10 5 8 10 12
102,Refrigerator,Appliance,850,2
102 0 1 4 3 0 2
103,MP3 Player,Audio,270,15
103 10 6 11 20 5 13
104,Tennis Racket,Sports,190,20
104 2 3 4 0 6 5
105,Laser Printer,Office,475,5
105 10 2 5 7 12 6
这个例子中:
开始执行
body
区域时,执行任何命令之前,
awk
从
items.txt
文件中读取第一行数
据,保存在变量
$0
中
z
print $0 –
打印
items.txt
文件的第一行
z
getline <”items-sold.txt” –
读取
items-sold.txt
中第一行并保存在
$0
中
z
print $0 –
打印
items-sold.txt
文件中的第一行
z
body
区域继续执行,轮番打印
items.txt
和
items-sold.txt
的剩余内容
从其他的文件
getline
内容到变量中
除了把两个文件的内容都读到
$0
中之外,也可以使用
”getline var”
把读取的内容保存到变量
中。
继续使用上面那两个文件,打印所有内容
(
使用
tmp
变量
)
$ awk -F"," '{print $0; getline tmp < "items-sold.txt";print tmp;}' items.txt
101,HD Camcorder,Video,210,10
101 2 10 5 8 10 12
102,Refrigerator,Appliance,850,2
102 0 1 4 3 0 2
103,MP3 Player,Audio,270,15
103 10 6 11 20 5 13
104,Tennis Racket,Sports,190,20
104 2 3 4 0 6 5
105,Laser Printer,Office,475,5
105 10 2 5 7 12 6
除了把第二个文件的内容保存到变量之外,这个例子和之前的例子是相同的。
getline
执行外部命令
getline
也可以执行
UNIX
命令并获取其输出。
下面的例子使用
getline
获取
date
命令的输出并打印出来。请注意这里也要使用
close
刚执
行的命令,
date
命令的输出保存在变量
$0
中,如下所示。
使用这个方法可以在输出报文的
header
和
footer
中显示时间戳。
$ cat getline1.awk
BEGIN {
FS=",";
"date" | getline
close("date")
print "Timestamp:" $0
}
{
if ( $5 <= 5)
print "Buy More:Order",$2,"immediately!"
else
print "Sell More:Give discount on",$2,"immediatelty!"
}
$ awk -f getline1.awk items.txt
Timestamp:Thu Apr 11 11:07:47 CST 2013
Sell More:Give discount on HD Camcorder immediatelty!
Buy More:Order Refrigerator immediately!
Sell More:Give discount on MP3 Player immediatelty!
Sell More:Give discount on Tennis Racket immediatelty!
Buy More:Order Laser Printer immediately!
除了把命令输出保存在
$0
中之外,也可以把它保存在任意的
awk
变量中
(
如
timestamp),
如下
所示。
$ cat getline2.awk
BEGIN { FS=",";
"date" | getline timestamp
close("date")
print "Timestamp:" timestamp
}
{
if ( $5 <= 5)
print "Buy More: Order",$2,"immediately!"
else
print "Sell More: Give discount on",$2,"immediately!"
}
$ awk -f getline2.awk items.txt
Timestamp:Thu Apr 11 11:20:05 CST 2013
Sell More: Give discount on HD Camcorder immediately!
Buy More: Order Refrigerator immediately!
Sell More: Give discount on MP3 Player immediately!
Sell More: Give discount on Tennis Racket immediately!
Buy More: Order Laser Printer immediately!
资料来源于《SedandAwk101Hacks》,大家有兴趣可以买一本,也可以关注我,我更新完它。
曾经,我花费大半月将它们跑完,现在啥都忘了,还是要常用。
只为学习交流,不为获利,侵权联系立删。















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









