







6.逻辑斯蒂回归
首先记下课程中的几个关键点:
- 和线性回归不同,逻辑斯蒂回归是分类任务,所以标签label不同,损失函数也不一样
- 标签都为0,1值注意导入交叉熵计算时这个里的0,1应该变成浮点数0.0,1.0才可以计算
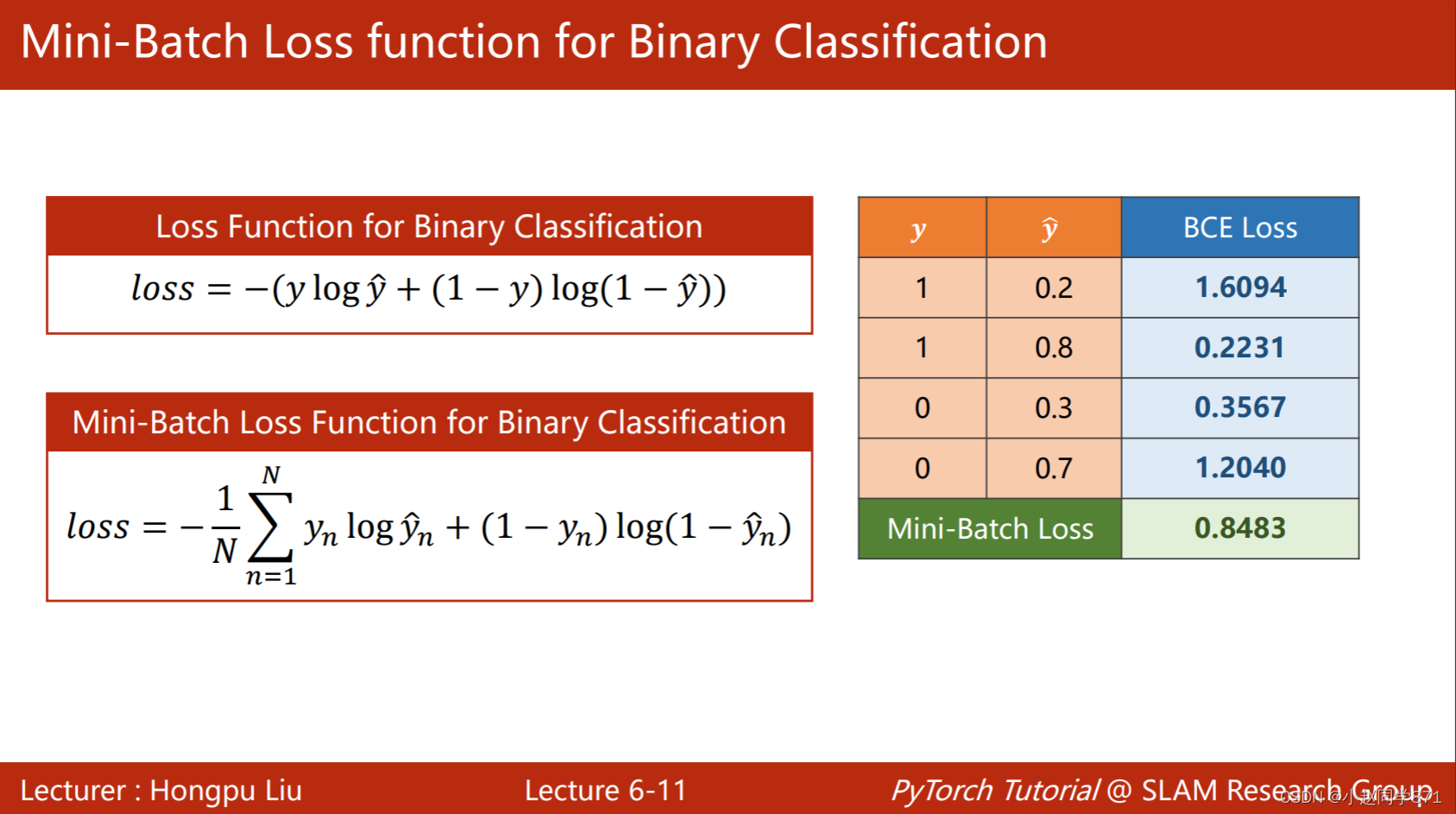
- 这里不可以用MSEloss,因为label不再是联系值,无法用欧氏距离衡量这种损失。这里是一种概率分布,常用的计算两个分布之间的差异性的有KL散度、交叉熵,这里采样交叉熵BCELoss,如下图,可以看出与真实label月接近,BCELoss值越小。BCELoss 是CrossEntropyLoss的一个特例,只用于二分类问题,而CrossEntropyLoss可以用于二分类,也可以用于多分类
- 这里通过添加一个非线性激活函数sgmoid函数来将这个最后的输出值映射到[0,1]区间内
关于代码这块,主要流程和线性回归还是一样,不同就在于因为label变了,损失函数要变,同时也多加了个非线性变化sgmoid来将输出映射到[0,1]区间内,具体来看代码:
import torch
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[0.0],[0.0],[1.0]]) #二元交叉熵这里要是浮点数
class Lr(torch.nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = torch.nn.Linear(1,1)
self.activation = torch.nn.Sigmoid()
def forward(self,x):
y_pred = self.activation(self.linear(x))
return y_pred
loss_list = []
epoch_list = []
model = Lr()
criterion = torch.nn.BCELoss(size_average=False) #这里是分类任务要用交叉熵做损失函数
optimizer = torch.optim.Adam(model.parameters() , lr = 0.5)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_list.append(loss)
epoch_list.append(epoch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_test=',y_test.item())
plt.plot(epoch_list,loss_list)
plt.show()
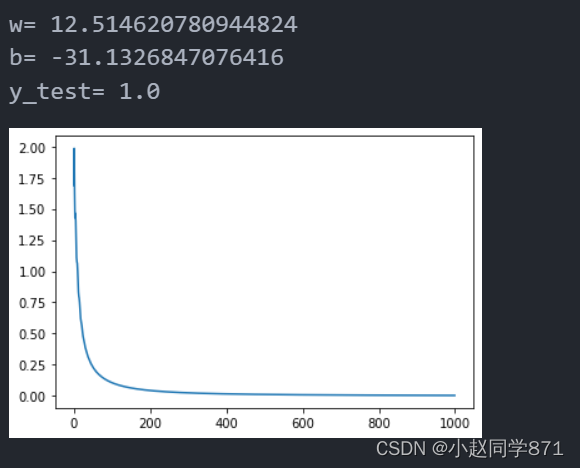
这里采用了Adam优化器,同时概率学习率为0.5,效果还不错
再简单总结下sigmoid函数,如下图这类函数是饱合函数,导函数类似于正态分布
sigmoid函数实际叫做Logistic Functions,用于分类任务,输出一个概率值
常见的激活函数可视化网站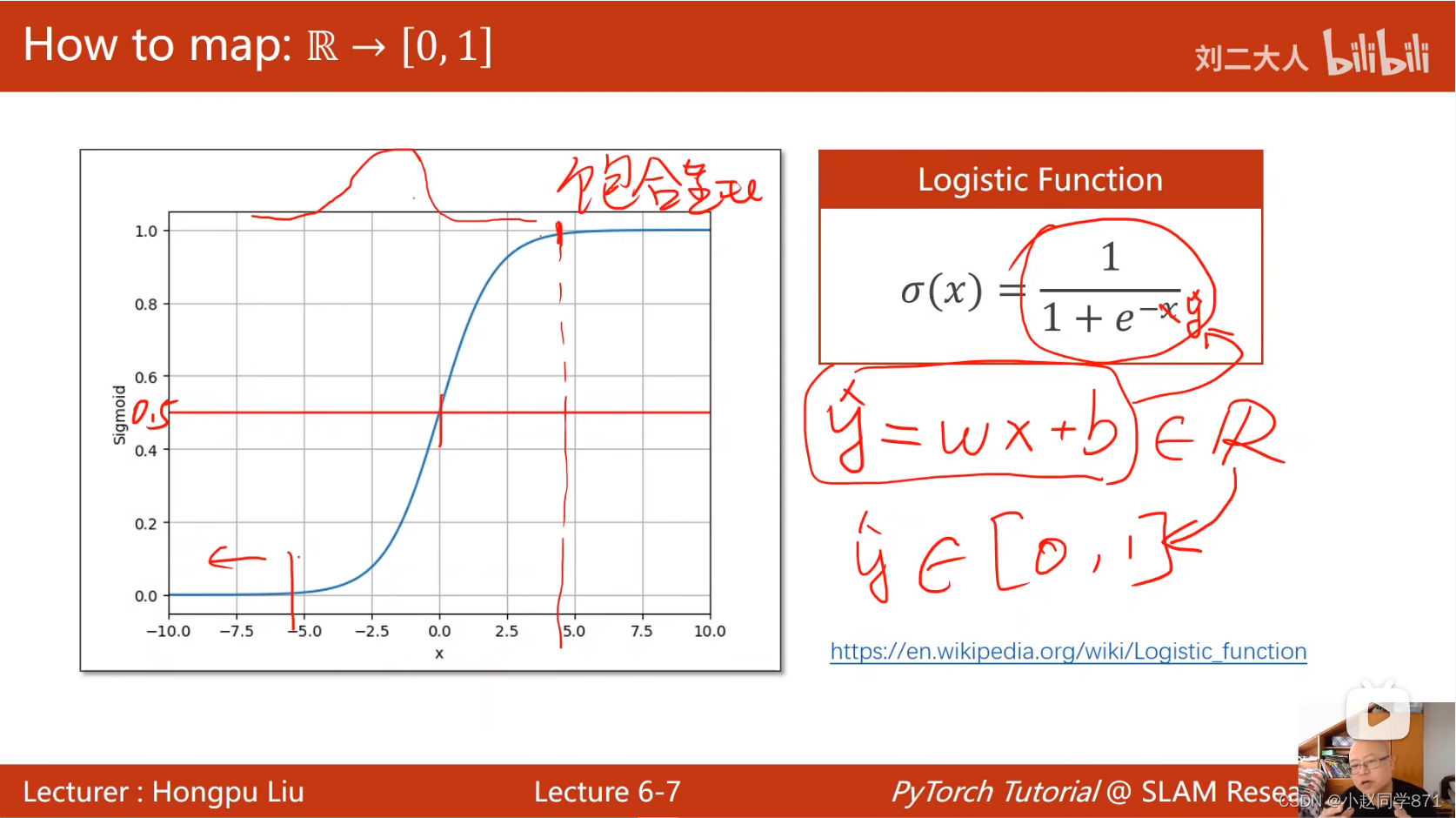
7.处理多维特征的输入
这一节呢主要是理解下Linear线性层可以用来进行降维操作,本来的特征输入大多数都是不止一维的,对于多维的特征输入,可以利用Linear里的参数来进行输入输出特征维度的转化,如下图经过线性变换和sigmoid激活函数变换后,这里的输出变为(N,1)维的这样就可以用来进行分类
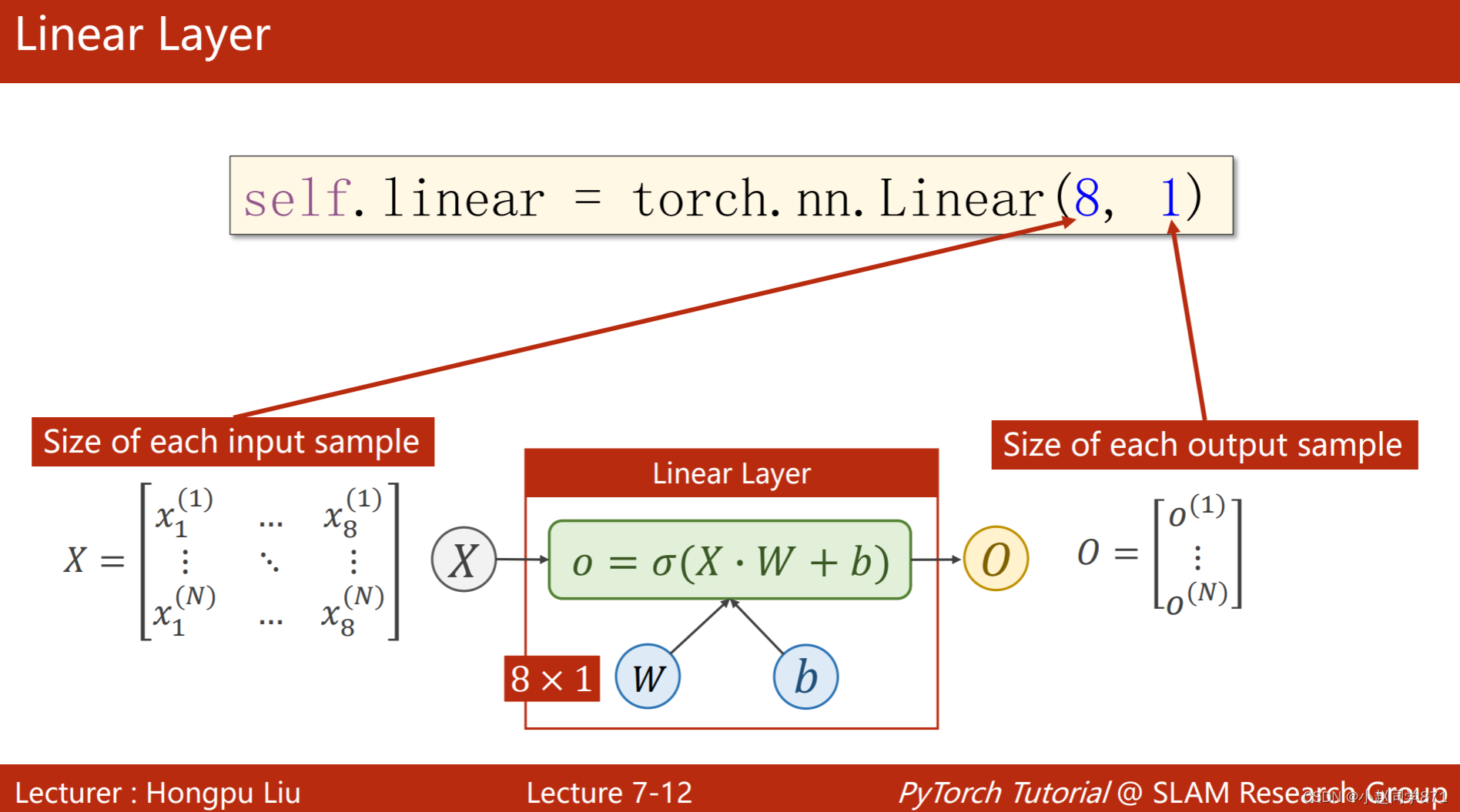
具体看代码如下:
import numpy as np
import torch
import matplotlib.pyplot as plt
#导入数据
data = np.loadtxt('datasets/diabetes.csv.gz',delimiter = ',',dtype=np.float32)
print('输入数据维度:',data.shape)
#分割为样本feature和label
x_data = torch.tensor(data[:,:-1])
y_data = torch.tensor(data[:,[-1]]) #注意这里要加上[],来讲y的维度变为(N,1)的矩阵,如果不加(N)为向量
print('x维度:',x_data.shape)
print('y维度:',y_data.shape)
#定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
self.relu = torch.nn.ReLU()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
#实例化模型
model = Model()
#定义损失函数
criterion = torch.nn.BCELoss(reduction='mean') #取了平均以后这里的loss就更小一些
#定义优化器
optimizer = torch.optim.Adam(model.parameters(),lr=0.5)
epoch_list = []
loss_list = []
#迭代不同次数
for epoch in range(100000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss)
epoch_list.append(epoch)
if epoch%100000 == 99999:
#计算acc值
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0])) #找到预测大于等于0.5的赋值为张量1.0,否则赋值为张量0.0
acc = torch.eq(y_pred_label,y_data).sum().item()/y_data.size(0) #计算预测和真实值相等的个数总和再除以所有数据个数
print('loss=',loss.item(),'acc=',acc)
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
8.加载数据集
上一节我们采用的方法是大批量一次性的梯度下降算法,这种算法的优点在于速度快利用矩阵的并行化处理,但是缺点也较为明显,在优化过程中很容易遇到鞍点,这样就很难找到极小值。但是采用一个个样本进行处理,会解决鞍点这个问题,但是运行速度又会变慢,由此采用折中的办法,采用小批量进行处理数据,即可以并行化处理还可以缓解鞍点问题,这就是这节需要用到的方法创建自己的Dataset类和利用DataLoader
先来理解三个概念:
1.Epoch:次数迭代次数,一次完整训练所有样本一次
2.Batch-size:每个批次的数据量
3.Iteration:按照Batch-size去分所有样本,总共分了多少组

可以通过下面这个图直观理解下DataLoader,所做的事情,这个类可以给样本随机打乱,并且按照batch-size进行分组,方便进行批量化处理
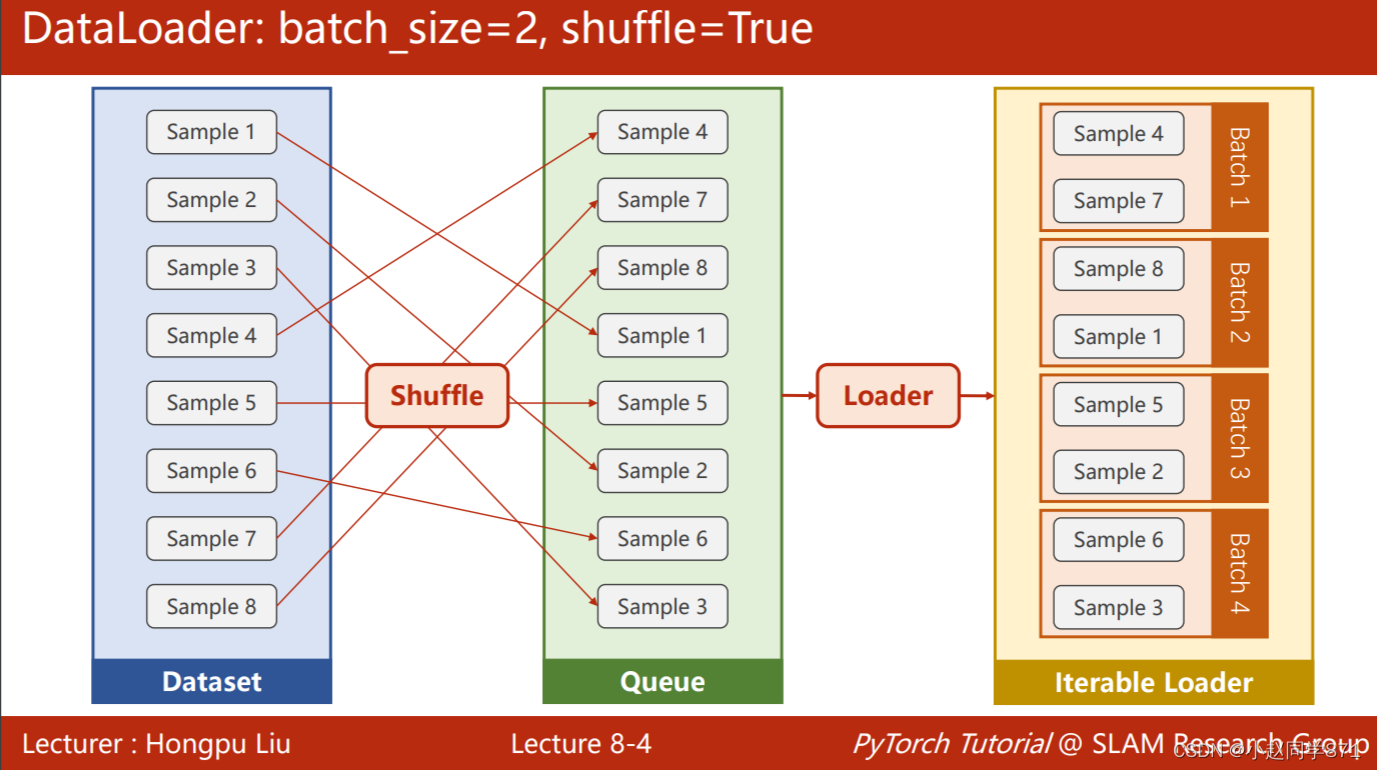
这里需要注意几点
1.Dataset是抽象类,这个类只能继承其他类,不能实例化
2.DataLoader是一个类帮助加载数据到pytorch
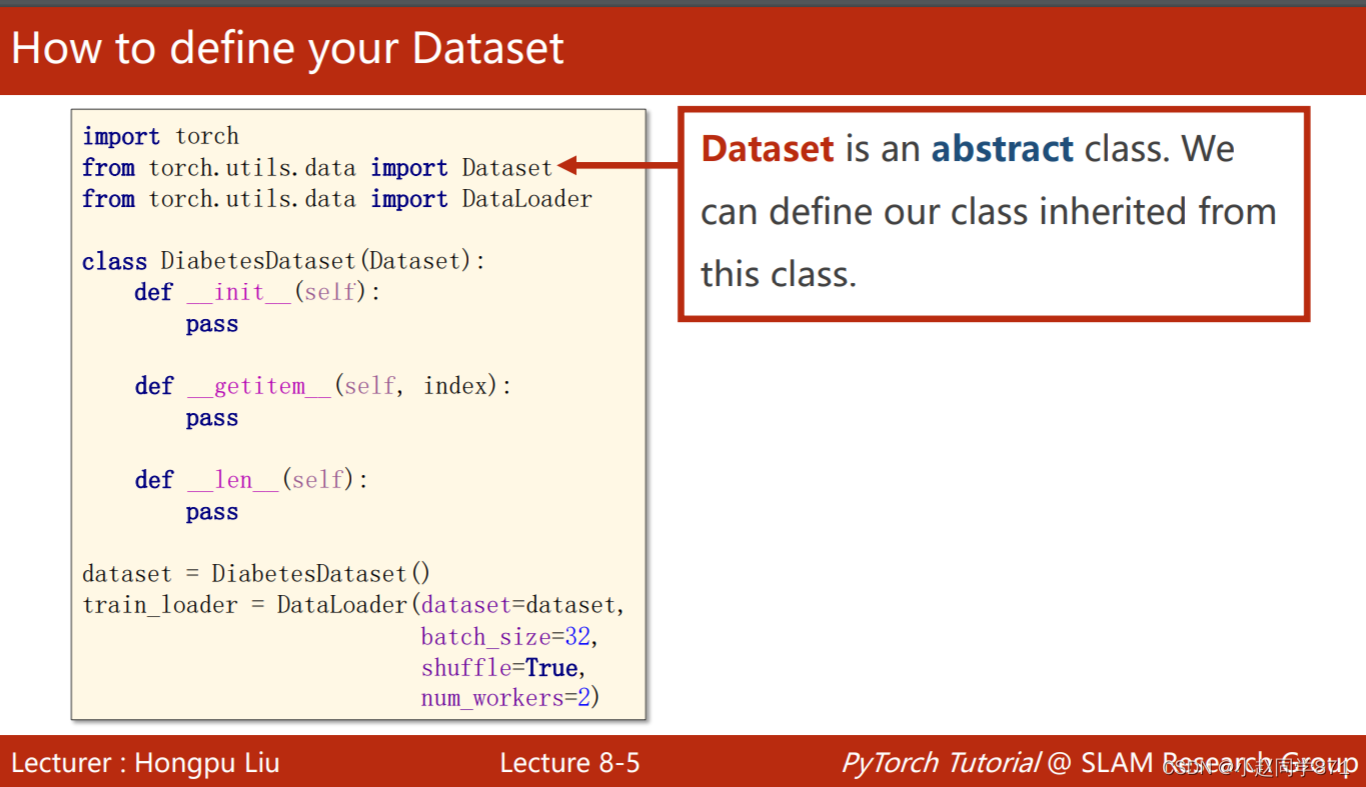
如下图所要注意的是:
1.定义自己的数据集类,这个类用来初步导入数据,索引数据,计算数据量,后面两个都是私有属性,魔法功能
2.导入数据后,再用DataLoader进行随机化、分组数据
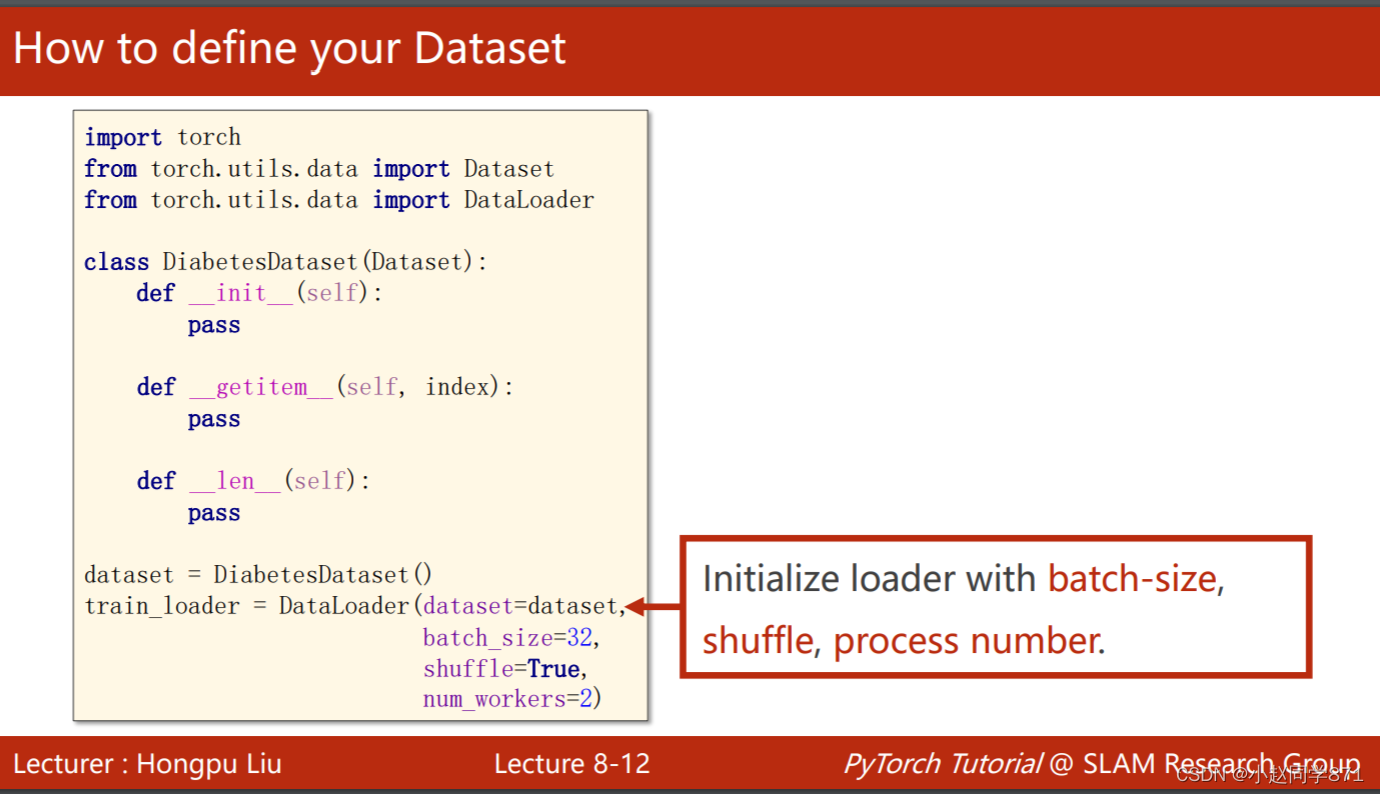
下面这里需要注意的是:
1.num_workers表示并行化处理个数这里为2
2.Windows系统会出现bug,需要加上这个语句if _name_ == '_main_':

torchvision.datasets里面还有这些常用的数据集,可以通过以下语句进行加载
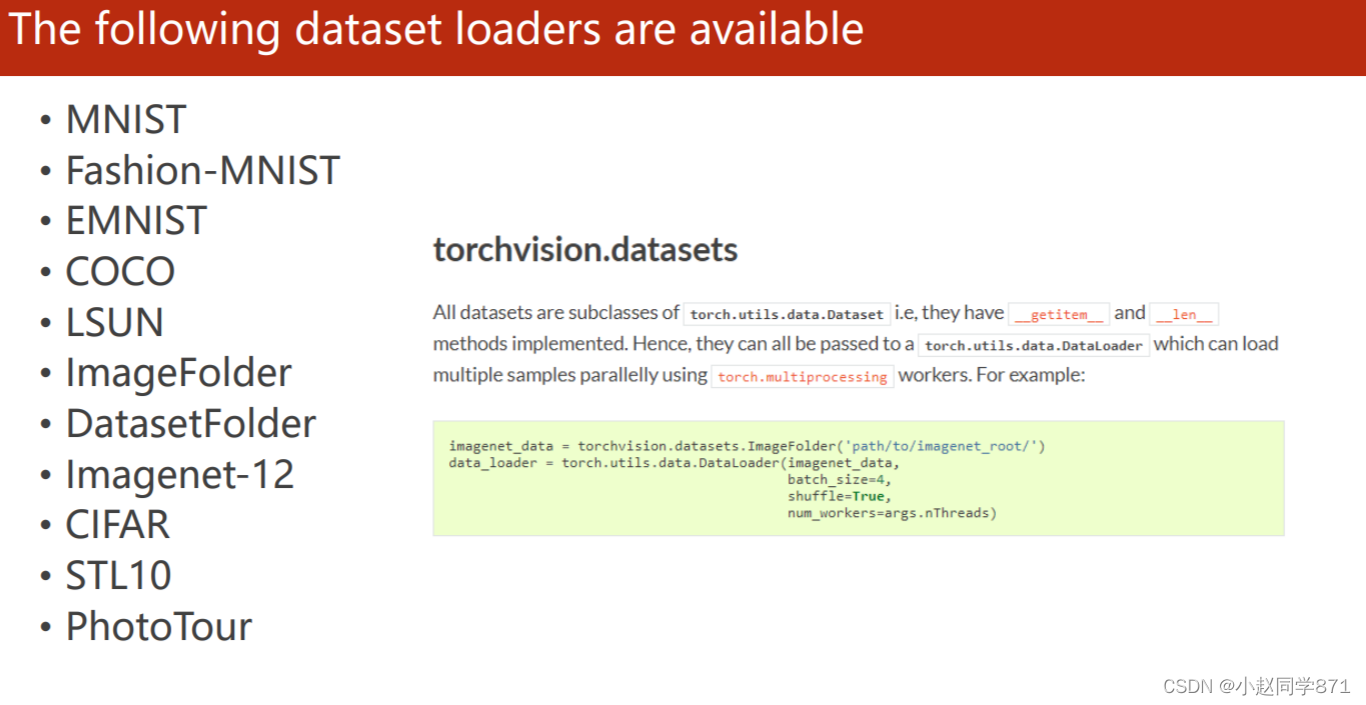
首先加载数据,然后利用DataLoader()分组数据
贴下整个流程的代码:
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split
#导入数据集
data = np.loadtxt('datasets/diabetes.csv.gz',delimiter = ',',dtype=np.float32)
X = torch.tensor(data[:,:-1])
y = torch.tensor(data[:,[-1]])
#划分为训练测试集
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
#定义批量化数据处理类
class DDataset(Dataset):
def __init__(self,data,label):
super(DDataset,self).__init__()
self.x_data = data
self.y_data = label
self.len = data.shape[0]
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#数据集实例化
trian_dataset = DDataset(x_train,y_train)
#批量后加载数据集
train_loader = DataLoader(trian_dataset,batch_size=32,shuffle=True,num_workers=0)
#定义模型类
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
self.relu = torch.nn.ReLU()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
#损失函数、优化器、模型实例化
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(),lr = 0.4) #这里只是梯度下降不是随机批量梯度下降
loss_list = []
acc_list = []
epoch_loss_list = []
acc_epoch_list = []
#定义训练函数
def train(epoch):
loss_batch = 0
iteration = 0
for i, data in enumerate(train_loader):
features,labels = data
y_pred = model(features)
loss = criterion(y_pred,labels)
loss_batch += loss
iteration += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch%2000 ==1999: #每2000个epoch打印
print('epoch=',epoch,'train_loss=',loss_batch.item()/iteration)
return loss_batch/iteration #输出这一epoch下的的损失均值
def test():
with torch.no_grad(): #梯度清零
y_pred = model(x_test)
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label,y_test).sum().item()/y_test.shape[0]
print('test_acc=',acc)
return acc
epoch_acc = 0 #一般这种都要放在迭代的前面
for epoch in range (10000):
loss = train(epoch)
loss_list.append(loss)
epoch_loss_list.append(epoch)
if epoch%2000 == 1999:
acc = test()
acc_list.append(acc)
epoch_acc += 1
acc_epoch_list.append(epoch_acc)
print(epoch_acc)
简单画两个图一个损失图,一个acc图
plt.plot(epoch_loss_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('L')
plt.show()
plt.plot(acc_epoch_list,acc_list)
plt.xlabel('epoch')
plt.ylabel('acc')
plt.title('ACC')
plt.show()
作业Tianic训练
这里用的是kaggle里的Tianic数据集,以下是具体代码:
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from sklearn.preprocessing import StandardScaler
#数据预处理函数:填充空值转化为数值型,数据标准化
def Dataset_pre(trian_filepath,test_filepath):
#导入训练测试数据
train_data = pd.read_csv(trian_filepath,header=0)
test_data = pd.read_csv(test_filepath,header=0)
#拼接一起方便处理
df= pd.concat([train_data, test_data], ignore_index=True)
df['Age'] = df['Age'].fillna(df['Age'].median()) #将空缺的年龄数据填充为中位数
df['Embarked'] = df['Embarked'].fillna(df['Embarked'].mode()[0]) #登船口众数填充
df = df.drop(['Cabin'],axis=1) #Cabin数据缺失太多直接删除
df['Sex'] = df['Sex'].map({'male':0,'female':1}) #性别进行编码0,1
df['Embarked'] = df['Embarked'].map({'S':0,'C':1,'Q':2}) #转化为数字编码
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1 #将SibSp和Parch合并为一列
df['IsAlone'] = 0 #创建单独旅行列
df.loc[df['FamilySize']==1, 'IsAlone'] = 1
features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'FamilySize', 'IsAlone']
#分为输入特征和标签
X_data = df[features]
y_data = df['Survived']
#分为训练和测试集
X_train = X_data.iloc[:len(train_data),:]
y_train = y_data.iloc[:len(train_data)]
X_test = X_data.iloc[len(train_data):,:]
y_test = y_data.iloc[len(train_data):]
#数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #防止数据泄露,用训练集的方差均值进行标准化
return X_train,X_test,y_train,y_test
X_train,X_test,y_train,y_test = Dataset_pre('datasets/titanic/train.csv','datasets/titanic/test.csv')
#定义训练数据预处理类
class Train_Dataset(Dataset):
def __init__(self,X_train,y_train):
super(Train_Dataset,self).__init__()
self.X_train = torch.tensor(X_train,dtype=torch.float32)
self.y_train = torch.tensor(y_train,dtype=torch.float32)
self.len = self.X_train.shape[0]
def __getitem__(self, index):
return self.X_train[index],self.y_train[index]
def __len__(self):
return self.len
#数据实例化
trian_data = Train_Dataset(X_train,y_train)
#批量化数据
train_loader = DataLoader(dataset=trian_data,batch_size=16,shuffle=True)
#定义模型
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = nn.Linear(7,64)
self.linear2 = nn.Linear(64,32)
self.linear3 = nn.Linear(32,1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
#实例化模型
model = Model()
#损失函数、优化器
criterion = nn.BCELoss(reduction='mean')
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
#损失列表
epoch_list = []
loss_list = []
#训练迭代循环
for epoch in range(10000):
loss_batch = 0
iteration = 0
for i ,data in enumerate(train_loader):
features,labels = data
y_pred = model(features)
loss = criterion(y_pred.squeeze(1),labels)
loss_batch += loss.item()
iteration += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch=',epoch,'loss=',loss_batch/iteration)
loss_list.append(loss_batch/iteration)
epoch_list.append(epoch)
import matplotlib.pyplot as plt
plt.plot(epoch_list,loss_list)
plt.show()
#测试集预测
with torch.no_grad():
X_test = torch.tensor(X_test,dtype=torch.float32)
y_pred = model(X_test)
y_pred_labels = torch.round(y_pred).squeeze().numpy().astype(int)
print(y_pred_labels.shape)
#保存预测结果
test_df = pd.read_csv('datasets/titanic/test.csv',header=0)
submission = pd.DataFrame({'PassengerId': test_df['PassengerId'], 'Survived': y_pred_labels})
submission.to_csv('submission.csv', index=False)
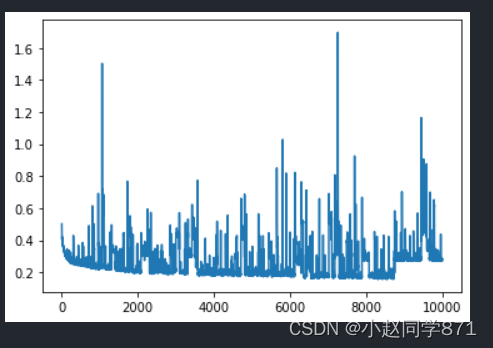
这里调了半天的学习率发现0.01左右比较好,epoch次数迭代的比较多,这里主要是想按照老师上课所说的四大流程走一遍,效果好坏另说,最后将结果上传到kaggle上得分为0.72248。
9.多分类问题
之前所学习的是简单的二分类问题,那么在现实生活中我们还会经常遇到更为复杂一些的多分类问题,这节主要是学习利用minist数据集进行多分类任务。首先我们希望通过神经网络训练的数据输出满足一定的分布,这里需要满足两个条件,都大于0且和为1
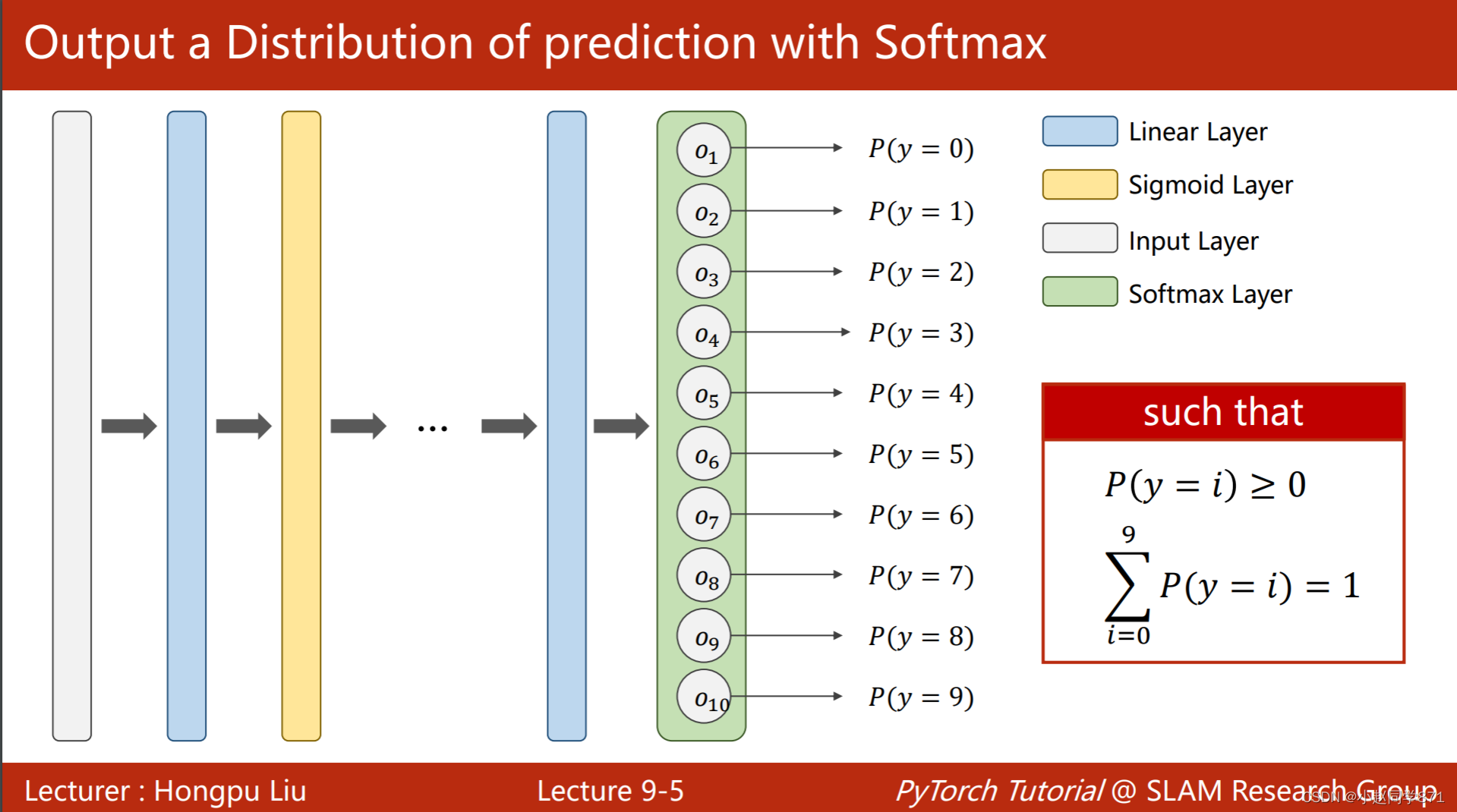
所以这里引入了softmax函数,用来将数据转化为所需的数据
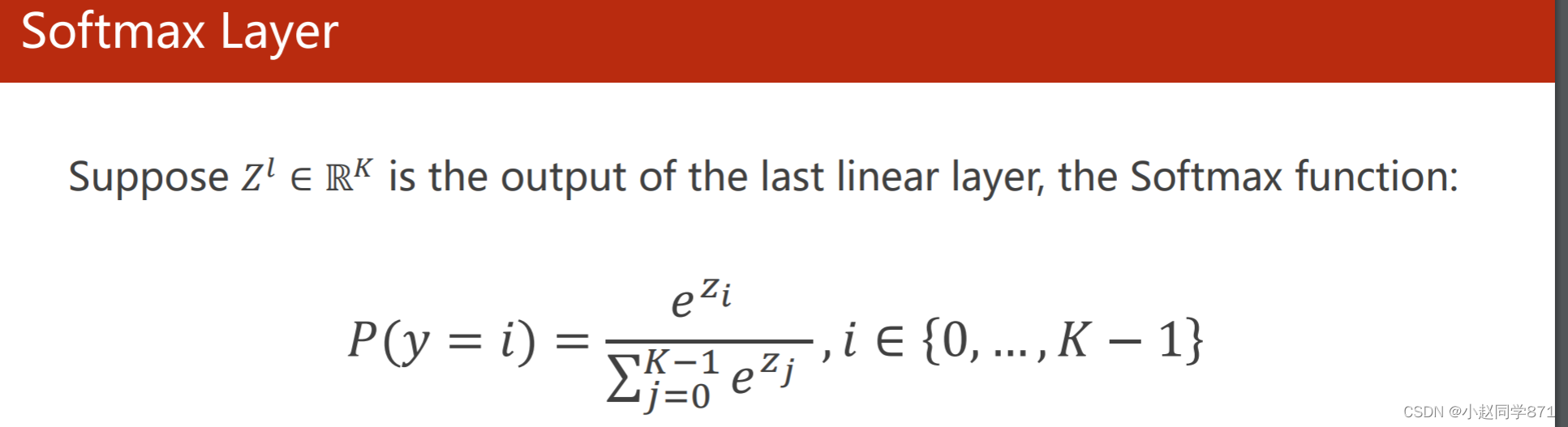
这里用的损失函数不同于二分类里的交叉熵,用的如下的损失函数NLLLoss,这里将多分类转化为二分类,正确的标签设置为1,其余为0,利用这个损失计算后,可以看到其他不是这个概率的都和0相乘,我们只要正确概率的最大即可,加个负号即损失最小
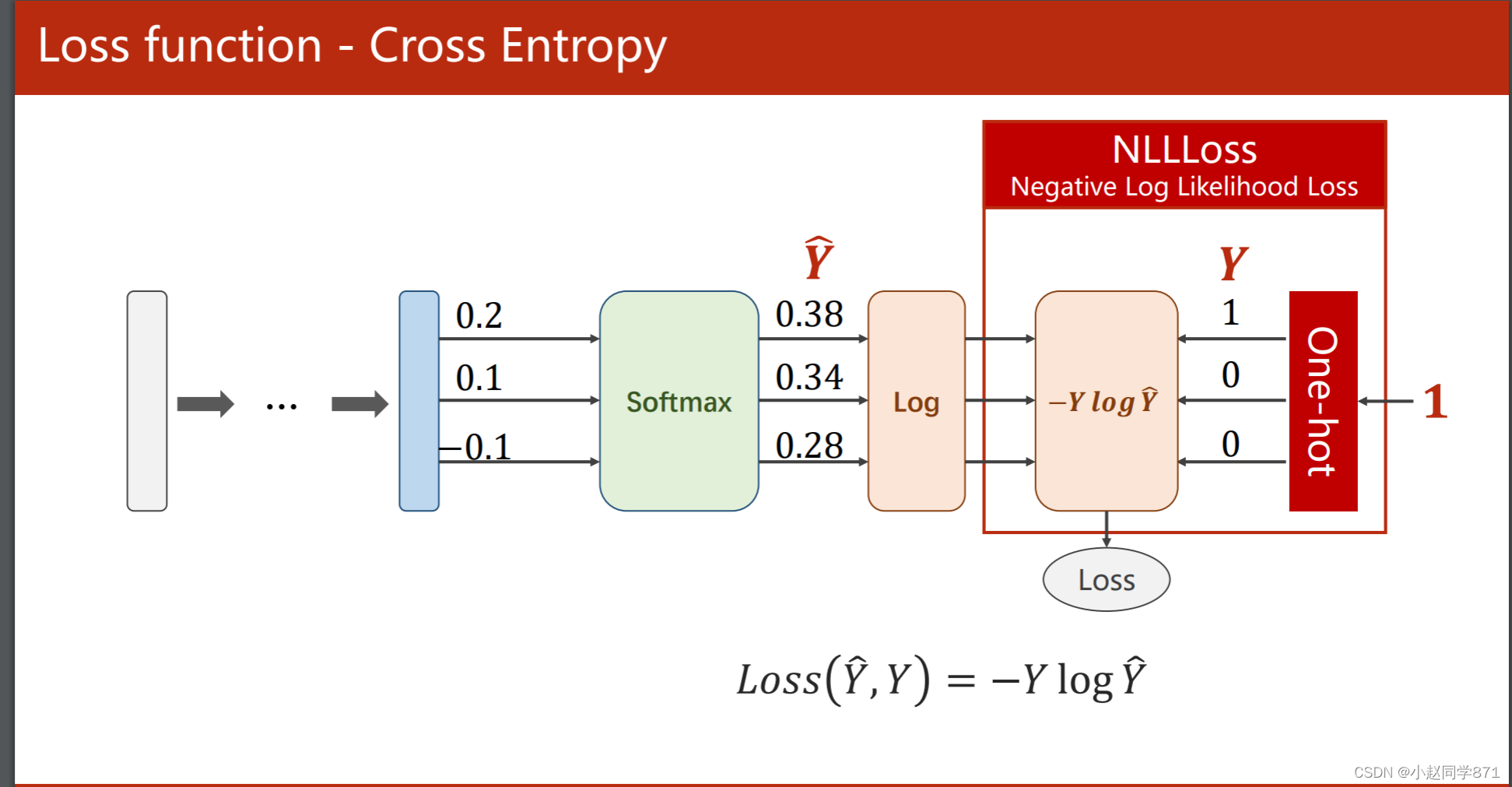
当然这个损失越小越好,代码如下:
import numpy as np
y = np.array([1,0,0])
z = np.array([0.2,0.1,-0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (-y*np.log(y_pred)).sum()
print(loss)
用pytorch里的算:
#利用pytorch里的Cross Entropy去求
import torch
y = torch.Tensor([[0,1,0]]) #用torch.LongTensor()也可以[0]表示张量第一个为0,
z = torch.Tensor([[0.2,0.1,-0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z,y)
print(loss)
对比一下,可以看出损失越小,预测越好
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.tensor([2,0,1])
Y_pred1 = torch.tensor([[0.1,0.2,0.9],
[1.1,0.1,0.2],
[0.2,2.1,0.1]])
Y_pred2 = torch.tensor([[0.8,0.2,0.3],
[0.2,0.3,0.5],
[0.2,0.2,0.5]])
loss1 = criterion(Y_pred1,Y) #这里输入Y的维度要是([3])是个一维张量
loss2 = criterion(Y_pred2,Y)
print('l1=',loss1.item(),'\nl2=',loss2.item())
这里要首先理解CrossEntropyLoss和NLLLoss的区别,区别就在于前者是一条龙服务里面包含了softmax函数,后者不包含softmax处理需要自己加softmax

返回我们本节的主要任务:设计一个多分类任务,预测mnist手写字符串数据集,首先简单了解下这个数据集每张图片大小都为28x28每个像素值为[0,256]
接下来进行实操,这里的流程和之前一样,只不过最后多了一个测试集
上代码!
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
#准备数据集
batch_size = 64
#实例化一个转化组合进行两次转化先转化为张量,再进行标准化
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
'''
transforms.Compose()是PyTorch中一个用于图像数据预处理的函数,它可以将多个数据预处理操作组合在一起,形成一个完整的数据预处理流程
图片数据通常是以PIL(Python Imaging Library)格式加载进来的,可以使用transforms.ToTensor()将其转换为张量形式
transforms.Normalize()对通道进行标准化,里面传入参数均值和方差,这里只有一个通道所以只传入了一个均值和方差
'''
#导入训练集
train_dataset = datasets.MNIST(root = 'D:\zhuomian\python\PyTorch\datasets\Mnist',
train = True,
transform = transform,
download = True)
#批量化
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size)
#导入测试集
test_dataset = datasets.MNIST(root = 'D:\zhuomian\python\PyTorch\datasets\Mnist',
train = False,
transform = transform,
download = True)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size)
#来看下训练集有多少数据量60032个,以及输入的数据维度信息,方便下面定义模型
N = 0
for i ,(inputs,labels) in enumerate(train_loader):
N += 1
print('\tN=',N*64,'\tX_size=',inputs.shape,'\ty_size',labels.shape)
#定义模型
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.linear1 = nn.Linear(784,512)
self.linear2 = nn.Linear(512,256)
self.linear3 = nn.Linear(256,128)
self.linear4 = nn.Linear(128,64)
self.linear5 = nn.Linear(64,32)
self.linear6 = nn.Linear(32,10)
self.relu = nn.ReLU()
def forward(self,x):
x = x.view(-1,28*28) #将数据展平为向量形式,改变张量形状,方便进行Linear线性操作,维度为[64,28*28],-1表示自动计算
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.relu(self.linear4(x))
x = self.relu(self.linear5(x))
x = self.linear6(x) #最后一层不进行这样操作,因为损失函数Cross里包含softmax函数
return x #输出维度为[64,10]
#实例化模型、定义损失函数、优化器
model = Net()
criterion = nn.CrossEntropyLoss(reduction='mean')
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
loss_list = []
#封装训练函数
def train(epoch):
running_loss = 0.0
for i , (inputs,labels) in enumerate(train_loader):
y_pred = model(inputs)
loss = criterion(y_pred,labels) #这里要理解输入的维度,y_pred为[64,10]张量,labels为[64]向量,具体可以再理解下前面的CRoss损失函数
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if i%300 ==299: #每300个batch打印出一些东西
print('[%d,%5d] loss:%.3f' % (epoch+1,i+1,running_loss/300))
loss_list.append(running_loss/300) #把300次的均值loss添加到列表记录一下
#封装测试集
Acc_list = []
def test():
correct = 0
total = 0
with torch.no_grad():
for (inputs,labels) in test_loader:
y_pred = model(inputs)
_ , predicted = torch.max(y_pred,dim=1) #找到预测的最大的概率索引,不要这个值只要索引,维度为[64]的向量
total += labels.size(0)
correct += (predicted == labels).sum().item() #计算相等的个数
print('Accuracy on test set:%d%%' %(100*correct/total))
Acc_list.append(100*correct/total)
#开始训练
for epoch in range(10):
train(epoch)
test()
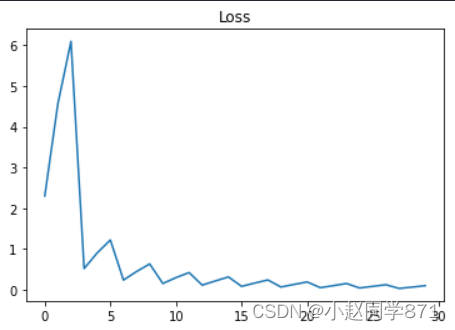
画两个图看看:
import matplotlib.pyplot as plt
epoch_list = list(np.arange(0,30,1))
plt.plot(epoch_list,loss_list)
plt.title('Loss')
plt.show()
import matplotlib.pyplot as plt
epoch_acc_list = list(np.arange(0,len(Acc_list),1))
plt.plot(epoch_acc_list,Acc_list)
plt.title('Acc')
plt.show()
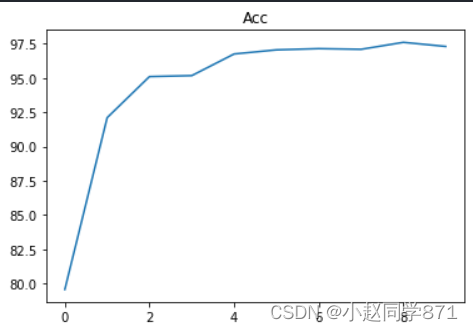
目前看来效果还行,对于这种图片数据还是要用CNN去训练,效果会好点,这样提取到的特征很抽象有问题
作业Otto
直接上代码,我把我这个代码最后预测的上传到kaggle,得分为2点多,效果不是很好,可能因为没有进行特征处理,只是简单的进行了数据标准化,然后就用神经网络去训练了,简单看下代码吧:
import pandas as pd
import torch
import numpy as np
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from sklearn.preprocessing import StandardScaler
import torch.optim as optim
labels_dict = {'Class_1':0,'Class_2':1,'Class_3':2,'Class_4':3,'Class_5':4,
'Class_6':5,'Class_7':6,'Class_8':7,'Class_9':8}
#定义导入数据数据预处理函数
def pre_dataset(filepath_train,filepath_test):
df_train = pd.read_csv(filepath_train,header=0)
df_test = pd.read_csv(filepath_test,header=0)
#size = int(df_train.shape[0]*0.8) #拿80%的训练集做训练剩下做验证
#处理标签
df_train['target'] = df_train['target'].map(labels_dict)
X_train = df_train.iloc[:,1:94]
y_train = df_train.iloc[:,-1]
#X_dev = df_train.iloc[size:,1:94]
#y_dev = df_train.iloc[size:,-1]
X_test = df_test.iloc[:,1:94]
#标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
return X_train,X_test,y_train
#导入数据
X_train,X_test,y_train = pre_dataset('D:\\zhuomian\\python\\PyTorch\\datasets\\Otto\\train.csv','D:\\zhuomian\\python\\PyTorch\\datasets\\Otto\\test.csv')
#定义datasets类给训练数据变为张量,加索引和记录长度
class datasets(Dataset):
def __init__(self,X_train,y_train):
super(datasets,self).__init__()
self.X_train = torch.tensor(X_train,dtype=torch.float32)
self.y_train = torch.tensor(y_train)
self.len = X_train.shape[0]
def __getitem__(self, index):
return self.X_train[index],self.y_train[index]
def __len__(self):
return self.len
#实例化
train_datasets = datasets(X_train,y_train)
#dev_datasets = datasets(np.array(X_dev),np.array(y_dev))
#批量化训练数据集batch
train_loader = DataLoader(dataset=train_datasets,batch_size=64,shuffle=True)
#dev_loader = DataLoader(dataset=train_datasets,batch_size=64,shuffle=True) #测试集还是可以打乱的
#定义模型
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = nn.Linear(93,64)
self.linear2 = nn.Linear(64,32)
self.linear3 = nn.Linear(32,16)
self.linear4 = nn.Linear(16,9)
self.relu = nn.ReLU()
def forward(self,x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.linear4(x)
return x #输出维度为[64,9]二维张量
#实例化模型、损失函数、优化器
model = Model()
criterion = nn.CrossEntropyLoss(reduction='mean')
optimizer = optim.Adam(model.parameters(),lr=0.01)
loss_list = []
#封装训练函数
def train(epoch):
running_loss = 0
for i , (inputs,labels) in enumerate(train_loader):
y_pred = model(inputs)
loss = criterion(y_pred,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if i%500 ==499:
print('[%d,%5d]loss:%.3f'%(epoch+1,i+1,running_loss/300))
running_loss = 0
loss_list.append(running_loss/300)
Acc_list = []
'''
#封装验证函数
def dev():
correct = 0
total = 0
with torch.no_grad():
for (inputs,labels) in (dev_loader):
y_pred = model(inputs)
total += inputs.shape[0]
_ , predicted = torch.max(y_pred,dim=1)
correct += (predicted == labels).sum().item()
print('ACC on dev sets:%d%%'%(100*correct/total))
Acc_list.append(100*correct/total)
'''
#开始训练
for epoch in range(100):
train(epoch)
#dev()
以上是训练过程下面是预测代码:
#输出为(0,1)的概率值
import torch.nn.functional as F
with torch.no_grad():
y_test_pred = model(torch.tensor(X_test,dtype=torch.float32))
y_test_pred = F.softmax(y_test_pred).data
y_test_pred = np.around(y_test_pred.numpy(),decimals=1) #四舍五入保留一位小数
y_test_pred
sampleSubmission = pd.read_csv('D:\zhuomian\python\PyTorch\datasets\Otto\sampleSubmission.csv',header=0)
sampleSubmission['Class_1'] = 0
y_test_pred = pd.DataFrame(y_test_pred,columns= ['Class_1','Class_2','Class_3','Class_4','Class_5','Class_6','Class_7','Class_8','Class_9'])
sampleSubmission.iloc[:,1:] = y_test_pred.copy()
sampleSubmission
#保存
sampleSubmission.to_csv('submission_Otto_1.csv', index=False)
至此前9节完结,下来开始更为复杂的CNN和RNN学习















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









