







作者:老余捞鱼
原创不易,转载请标明出处及原作者。
写在前面的话:
本文转自一篇论文,主要讨论了在不同行业中时间序列预测的重要性,以及如何利用机器学习、生成式人工智能(Generative AI)和深度学习来提高预测的准确性。时间序列数据是按特定时间间隔收集或记录的数据点序列,例如股票价格、天气数据、销售数字和传感器读数。预测未来值的能力可以显著改进决策过程和运营效率。
本文介绍了包括ARIMA、SARIMA、Prophet、XGBoost、GANs、WaveNet、LSTM、GRU、Transformer、Seq2Seq、TCN和DeepAR在内的多种时间序列预测模型,介绍了各自模型的特点以及具体代码。如我们首先从机器学习方法开始。
一、机器学习方法
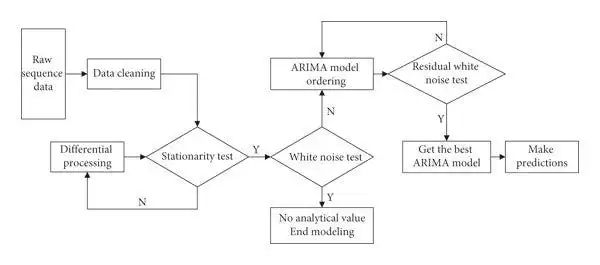
1.1 ARIMA(自回归积分滑动平均模型)
ARIMA(自回归积分滑动平均模型)一种经典的统计方法,结合了自回归(AR)、差分(使数据平稳)和滑动平均(MA)模型。
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# Load your time series data
time_series_data = pd.read_csv('time_series_data.csv')
time_series_data['Date'] = pd.to_datetime(time_series_data['Date'])
time_series_data.set_index('Date', inplace=True)
# Fit ARIMA model
model = ARIMA(time_series_data['Value'], order=(5, 1, 0)) # (p,d,q)
model_fit = model.fit()
# Make predictions
predictions = model_fit.forecast(steps=10)
print(predictions)1.2 SARIMA(季节性ARIMA)
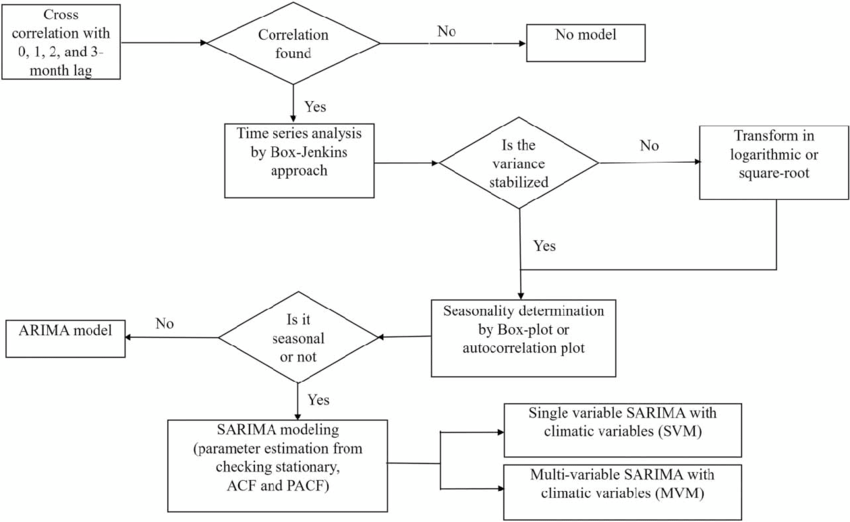
SARIMA(季节性ARIMA)是在ARIMA的基础上增加了季节性效应的考虑。
import pandas as pd
import numpy as np
from statsmodels.tsa.statespace.sarimax import SARIMAX
# Load your time series data
time_series_data = pd.read_csv('time_series_data.csv')
time_series_data['Date'] = pd.to_datetime(time_series_data['Date'])
time_series_data.set_index('Date', inplace=True)
# Fit SARIMA model
model = SARIMAX(time_series_data['Value'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12)) # (p,d,q) (P,D,Q,s)
model_fit = model.fit(disp=False)
# Make predictions
predictions = model_fit.forecast(steps=10)
print(predictions)1.3 Prophet
Prophet由Facebook开发,适用于处理缺失数据和异常值,并提供可靠的不确定性区间。

from fbprophet import Prophetimport pandas as pd
# Load your time series datatime_series_data = pd.read_csv('time_series_data.csv')time_series_data['Date'] = pd.to_datetime(time_series_data['Date'])time_series_data.rename(columns={'Date': 'ds', 'Value': 'y'}, inplace=True)
# Fit Prophet modelmodel = Prophet()model.fit(time_series_data)
# Make future dataframe and predictionsfuture = model.make_future_dataframe(periods=10)forecast = model.predict(future)print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])1.4 XGBoost
XGBoost是一种梯度增强框架,通过将问题转化为监督学习任务来进行时间序列预测。
import pandas as pdimport numpy as npfrom xgboost import XGBRegressorfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_error
# Load your time series datatime_series_data = pd.read_csv('time_series_data.csv')time_series_data['Date'] = pd.to_datetime(time_series_data['Date'])time_series_data.set_index('Date', inplace=True)
# Prepare data for supervised learningdef create_lag_features(data, lag=1): df = data.copy() for i in range(1, lag + 1): df[f'lag_{i}'] = df['Value'].shift(i) return df.dropna()
lag = 5data_with_lags = create_lag_features(time_series_data, lag=lag)X = data_with_lags.drop('Value', axis=1)y = data_with_lags['Value']
# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# Fit XGBoost modelmodel = XGBRegressor(objective='reg:squarederror', n_estimators=1000)model.fit(X_train, y_train 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











