







yolobody的网络结构如下图所示(该图来自别的博客【目标检测】yolov5模型详解-CSDN博客),是下图最中间Neck和右边Head的网络结构,该结构输出的是1X45X20X20,1X45X40X40和1X45X80X80三个数据(其中45=3*(num_classes+5))。
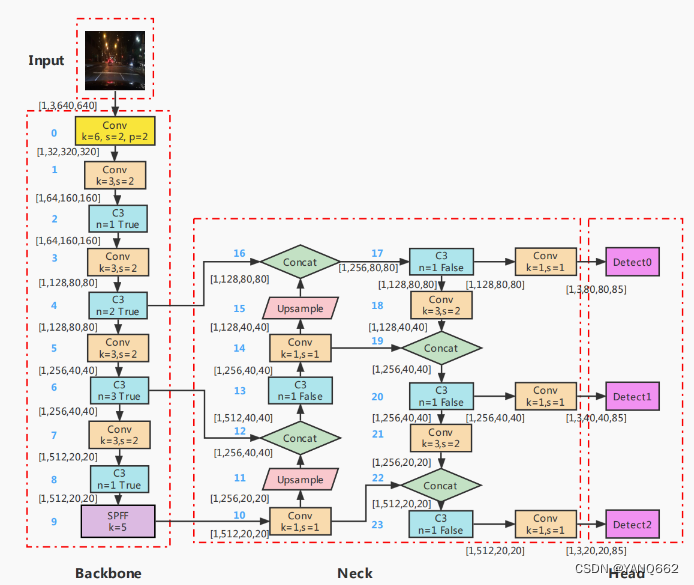
代码如下:
import torch
import torch.nn as nn
import cv2
#from nets.ConvNext import ConvNeXt_Small, ConvNeXt_Tiny
from nets.CSPdarknet import C3, Conv, CSPDarknet
#from nets.Swin_transformer import Swin_transformer_Tiny
#---------------------------------------------------#
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, backbone='cspdarknet', pretrained=False, input_shape=[640, 640]):
super(YoloBody, self).__init__()
depth_dict = {'s' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,}
width_dict = {'s' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,}
dep_mul, wid_mul = depth_dict[phi], width_dict[phi]
base_channels = int(wid_mul * 64) # 64 "s"==>32
base_depth = max(round(dep_mul * 3), 1) # 3 "s"==>1
# -----------------------------------------------#
# 输入图片是640, 640, 3
# 初始的基本通道是64
# -----------------------------------------------#
self.backbone_name = backbone
if backbone == "cspdarknet":
# ---------------------------------------------------#
# 生成CSPdarknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 80,80,256
# 40,40,512
# 20,20,1024
# ---------------------------------------------------#
self.backbone = CSPDarknet(base_channels, base_depth, phi, pretrained)
# else:
# #---------------------------------------------------#
# # 如果输入不为cspdarknet,则调整通道数
# # 使其符合YoloV5的格式
# #---------------------------------------------------#
# self.backbone = {
# 'convnext_tiny' : ConvNeXt_Tiny,
# 'convnext_small' : ConvNeXt_Small,
# 'swin_transfomer_tiny' : Swin_transformer_Tiny,
# }[backbone](pretrained=pretrained, input_shape=input_shape)
# in_channels = {
# 'convnext_tiny' : [192, 384, 768],
# 'convnext_small' : [192, 384, 768],
# 'swin_transfomer_tiny' : [192, 384, 768],
# }[backbone]
# feat1_c, feat2_c, feat3_c = in_channels
# self.conv_1x1_feat1 = Conv(feat1_c, base_channels * 4, 1, 1)
# self.conv_1x1_feat2 = Conv(feat2_c, base_channels * 8, 1, 1)
# self.conv_1x1_feat3 = Conv(feat3_c, base_channels * 16, 1, 1)
#两次上采样和两次下采样
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.conv_for_feat3 = Conv(base_channels * 16, base_channels * 8, 1, 1)#20,20,1024===>20,20,512
self.conv3_for_upsample1 = C3(base_channels * 16, base_channels * 8, base_depth, shortcut=False)#20,20,1024===>40,40,512
self.conv_for_feat2 = Conv(base_channels * 8, base_channels * 4, 1, 1)#40,40,512===>40,40,256
self.conv3_for_upsample2 = C3(base_channels * 8, base_channels * 4, base_depth, shortcut=False)#40,40,512===>80,80,256
self.down_sample1 = Conv(base_channels * 4, base_channels * 4, 3, 2)#80,80,256===>80,80,256
self.conv3_for_downsample1 = C3(base_channels * 8, base_channels * 8, base_depth, shortcut=False)#80,80,512===>40,40,512
self.down_sample2 = Conv(base_channels * 8, base_channels * 8, 3, 2)#80,80,512===>80,80,512
self.conv3_for_downsample2 = C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False)#80,80,1024===>20,20,1024
# 80, 80, 256 => 80, 80, 3 * (5 + num_classes) => 80, 80, 3 * (4 + 1 + num_classes)
self.yolo_head_P3 = nn.Conv2d(base_channels * 4, len(anchors_mask[2]) * (5 + num_classes), 1)
# 40, 40, 512 => 40, 40, 3 * (5 + num_classes) => 40, 40, 3 * (4 + 1 + num_classes)
self.yolo_head_P4 = nn.Conv2d(base_channels * 8, len(anchors_mask[1]) * (5 + num_classes), 1)
# 20, 20, 1024 => 20, 20, 3 * (5 + num_classes) => 20, 20, 3 * (4 + 1 + num_classes)
self.yolo_head_P5 = nn.Conv2d(base_channels * 16, len(anchors_mask[0]) * (5 + num_classes), 1)
def forward(self, x):
# backbone
feat1, feat2, feat3 = self.backbone(x) # torch.Size([1, 128, 80, 80]) torch.Size([1, 256, 40, 40]) torch.Size([1, 512, 20, 20])
# if self.backbone_name != "cspdarknet":
# feat1 = self.conv_1x1_feat1(feat1)
# feat2 = self.conv_1x1_feat2(feat2)
# feat3 = self.conv_1x1_feat3(feat3)
# 20, 20, 1024 -> 20, 20, 512
P5 = self.conv_for_feat3(feat3)
# 20, 20, 512 -> 40, 40, 512
P5_upsample = self.upsample(P5)
# 40, 40, 512 -> 40, 40, 1024
P4 = torch.cat([P5_upsample, feat2], 1)
# 40, 40, 1024 -> 40, 40, 512
P4 = self.conv3_for_upsample1(P4)
# 40, 40, 512 -> 40, 40, 256
P4 = self.conv_for_feat2(P4)
# 40, 40, 256 -> 80, 80, 256
P4_upsample = self.upsample(P4)
# 80, 80, 256 cat 80, 80, 256 -> 80, 80, 512
P3 = torch.cat([P4_upsample, feat1], 1)
# 80, 80, 512 -> 80, 80, 256
P3 = self.conv3_for_upsample2(P3)
# 80, 80, 256 -> 40, 40, 256
P3_downsample = self.down_sample1(P3)
# 40, 40, 256 cat 40, 40, 256 -> 40, 40, 512
P4 = torch.cat([P3_downsample, P4], 1)
# 40, 40, 512 -> 40, 40, 512
P4 = self.conv3_for_downsample1(P4)
# 40, 40, 512 -> 20, 20, 512
P4_downsample = self.down_sample2(P4)
# 20, 20, 512 cat 20, 20, 512 -> 20, 20, 1024
P5 = torch.cat([P4_downsample, P5], 1)
# 20, 20, 1024 -> 20, 20, 1024
P5 = self.conv3_for_downsample2(P5)
# ---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,75,80,80)
# ---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
# ---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,75,40,40)
# ---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
# ---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,75,20,20)
# ---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
return out0, out1, out2
if __name__ == "__main__":
print("...............开始.................")
img_path="D:\AI\yq\mubiao_detect\\6_yolov5\\nets\\000.jpg"
img=cv2.imread(img_path)
img=cv2.resize(img,(640,640))
size=img.shape
np_data=img.reshape((1,size[2],size[0],size[1]))
#>>>>>>>>>>>>>>>>>>>>array---->tensor,该数据用于神经网络
datas=torch.tensor(np_data).float()
yoloBody=YoloBody(anchors_mask=[[6, 7, 8], [3, 4, 5], [0, 1, 2]], num_classes=10, phi="s")
output=yoloBody(datas)
print(output[0].shape)
print(output[1].shape)
print(output[2].shape)
以上代码输入num_classes=10时,得到结果如下:
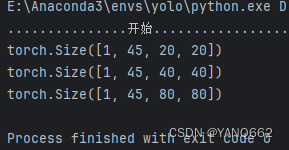
比如[1, 45, 20, 20]:
1表示batchsize;
45=3*(num_classes+5);
20,20表示数组的大小为20X20。















 2204
2204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









