






目录
1.《Measurement and prediction of systemic risk in China’s banking industry》2023
2.《Improving financial distress prediction using textual sentiment of annual reports》2023
3.《Predicting distresses using deep learning of text segments in annual reports》2019
4.《Speech emotion recognition and text sentiment analysis for financial distress prediction》2023
1.《Measurement and prediction of systemic risk in China’s banking industry》2023
https://www.sciencedirect.com/science/article/pii/S0275531922002604
这篇文章主要采用了传统的金融风险分析方法,做的是中国的银行业的系统性风险预测,如KMV模型、EWMA模型 和 Monte Carlo模拟,并没有使用机器学习或深度学习方法。
亮点:
- 使用混合系统性风险指标(rSYR)测度2009-2019年中国银行业系统性金融风险。
- 将rSYR与sSYR(新标准化rSYR)相结合,除去银行规模的影响,可以更准确地判断系统重要性银行。
- 我们对未来一段时间的系统性风险进行了预测,发现大型银行的系统重要性较高。
- 关注一些规模较小的银行(如华夏银行、光大银行)可能带来的系统性风险。
以下是文章中使用的传统方法的回顾:
- KMV模型:用于计算银行资产的市场价值和违约概率,基于期权定价模型。
- EWMA模型:用于计算银行之间资产回报的协方差矩阵,帮助分析银行间的关联性和风险传递。
- Monte Carlo模拟:用于预测未来一段时间银行的资产变化,评估未来的系统性风险。
这些方法属于经典的金融风险预测模型,侧重于金融数据的统计分析和模型推断,而非大模型的搭建。
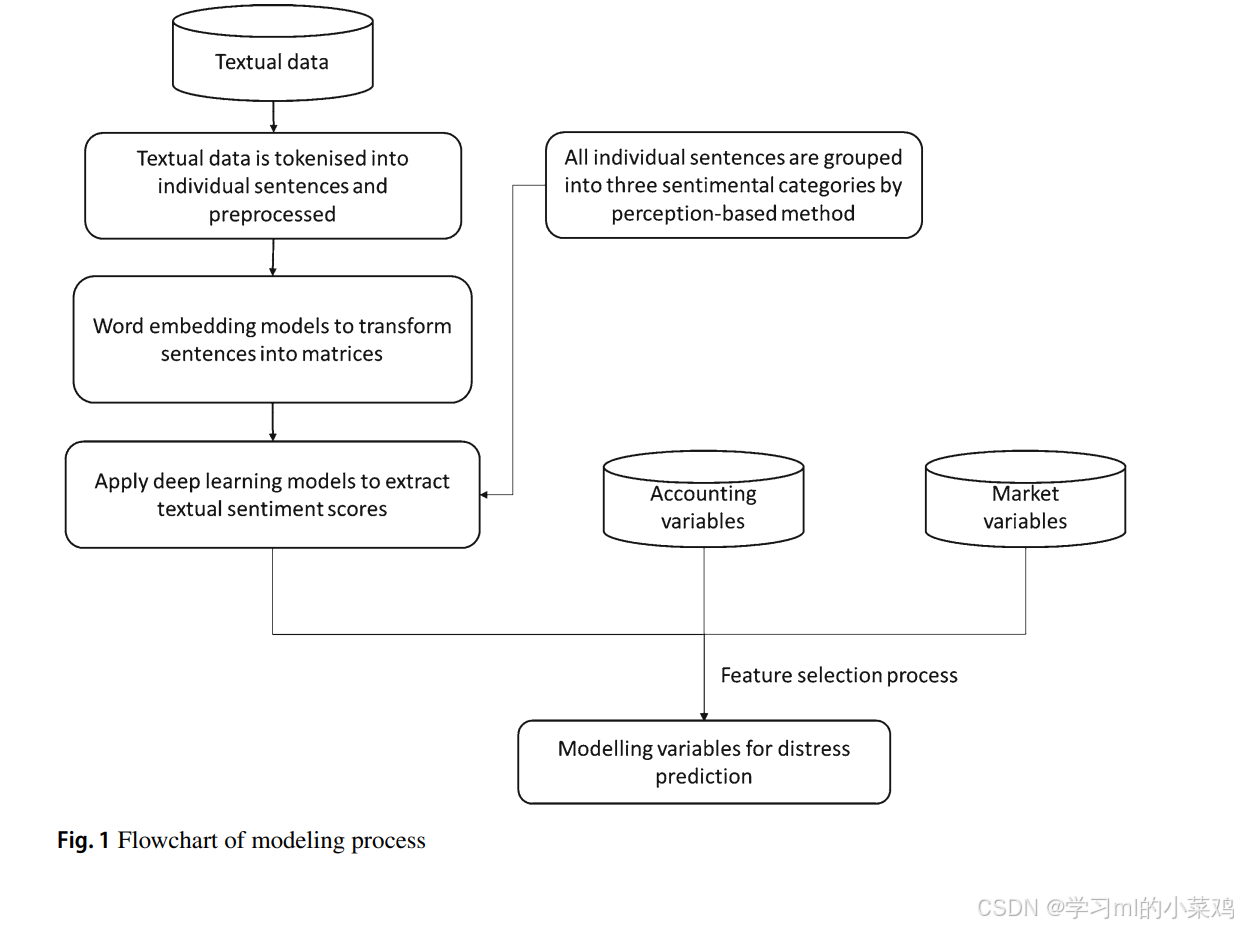
2.《Improving financial distress prediction using textual sentiment of annual reports》2023
文章以中国上市公司为样本,证明运用年报文本情绪可以显著提高财务困境预测的准确性。使用深度学习技术分别提取了MD&A(管理层讨论与分析)部分和审计报告中的文本情感,并和会计数据、市场营销数据融合起来(特征选择)最后进行建模预测金融困境。最终得出结论:通过增加审计报告的情绪而实现的增量改进比通过增加管理报表的情绪所实现的增量改进更显著。并且,两种情绪得分的纳入并没有导致仅包括审计报告情绪的模型的进一步显著改进。
另外的结论:在文本情感提取部分,采用BERT+CNN的方法是对于MD&A部分的最优搭配,而Word2Vec+CNN是对于审计部分的最优搭配,在两部分中CNN的表现都优于LSTM,但是BERT在后一部分的表现低于Word2Vec,可能的原因是审计部分的报告复杂度较低。
3.《Predicting distresses using deep learning of text segments in annual reports》2019

用的是公司年报中的纯文本数据,没有加情感,得出了和上面那篇文章重合度极高的结论:使用审计报告部分比使用MD&A部分的效果更好,且两者同时使用不会增强模型的效果,最后把向量化的文本数据与财务指标拼接起来对公司财务困境做了预测。
4.《Speech emotion recognition and text sentiment analysis for financial distress prediction》2023
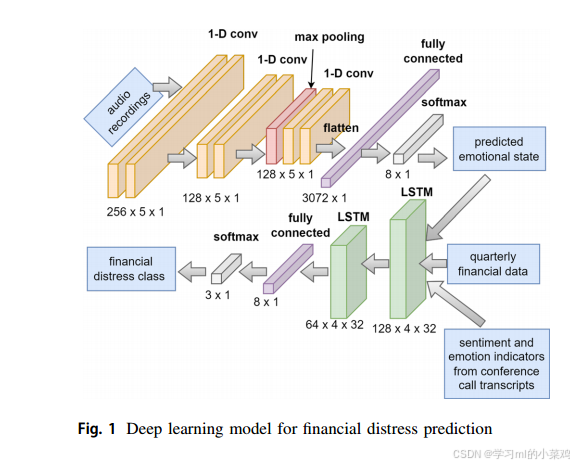
这篇文章融合多模态数据,将电话会议中的管理者的语音情绪数据(使用CNN提取)、电话会议转录地文本情绪数据和财报指标数据进行融合后输入给LSTM进行财政困境预测,采用美国40家最大公司的1278次收益电话会议验证了所提出的模型性能表现优于SOTA。


















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









