






目录
论文 1:Spikformer: When Spiking Neural Network Meets Transformer (ICLR 2023)[1]
论文 2:Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket [2]
论文 3:Spike-driven Transformer (NeurIPS 2023) [3]
Meta-Transformer模块范式和Meta-Spikeformer模型架构
引言:
在人工智能领域中,模拟生物神经系统的深度学习模型一直是一个充满潜力但也面临巨大挑战的研究方向。最近,脉冲Transformer模型巧妙地将更接近生物神经系统信息处理方式的脉冲神经网络(SNNs)与捕捉复杂特征依赖性的自注意力机制(Self-Attention, SA)结合起来。这项革命性的研究不仅推动了仿生计算模型的发展,而且为构建低能耗、高效能的深度学习模型开启了全新的大门。在神经网络与Transformer相遇的创新旅程中,我们见证了Spikformer模型的蜕变 —— 从初步的小规模模型,到在大规模视觉任务上实现超过80%的准确率[1,2]。Spike-driven Transformer[3]和Meta-SpikeFormer[4]不仅建立了新的性能标准,而且其独创的结构为下一代低功耗、高性能神经形态芯片设计提供了深远的启发。这些突破不仅彰显了SNN在模式识别中的巨大潜能,也为我们追求与人类大脑相匹敌的通用人工智能之路照亮了前行的道路。随着对这一领域研究的不断深化,我们有充分的理由期待,Spikformer及其衍生模型将在人工智能的舞台上开辟新的篇章,取得更多引人注目的成果。
研究背景
近年来,SNNs因其采用了生物启发式的事件驱动脉冲机制,在深度学习领域展现出了显著的节能潜力,与传统人工神经网络(ANNs)相比,实现了大幅度的能耗降低。(仅在输入非零事件时触发的事件驱动计算)尽管如此,SNNs在执行复杂任务时,仍然难以达到ANNs的高准确率。为了弥合这一差距,研究者们提出脉冲驱动范式融入Transformer架构的新方法(Spikeformer [1]、Spikeformer V2 [2]、Spike-driven Transformer [3]和Meta-SpikeFormer [1]),旨在兼具SNNs的能源效率和Transformer的高性能。该方法通过一系列独特的设计原则实现,例如仅在输入非零事件时触发的事件驱动计算,以及将矩阵乘法转换为稀疏加法的二进制脉冲通信。特别引人注目的是,Spike-driven和Meta-Transformer中所提出的脉冲驱动自注意力(SDSA)机制,通过避免乘法运算,仅依赖于掩码和加法操作,实现了线性复杂度,并大幅提高了能量效率。尽管脉冲神经网络(SNNs)与人工神经网络(ANNs)之间存在明显的差距,但这一差距正在逐步缩小。最新的研究成果在ImageNet-1K等关键视觉任务的基准测试中刷新了SNNs的最高记录,并提供了一套为后续开发奠定基础的开源框架,对该领域作出了重大贡献。这些方法不仅凸显了SNNs在保持与ANNs相似的高准确率的同时,大幅降低能耗的潜力,而且为在能源受限的设备和平台上部署高级神经网络模型铺平了道路。
论文 1:Spikformer: When Spiking Neural Network Meets Transformer (ICLR 2023)[1]
为了探索将生物合理的SNN与能够捕捉特征依赖性的自注意力机制结合的可能性,以实现低能耗、事件驱动的深度学习模型。该研究团队提出Spikformer模型,一种利用脉冲形式的Query(Q),Key(K)和Value(V),无需传统Transformer架构中的Softmax操作,从而大幅降低了计算能耗。
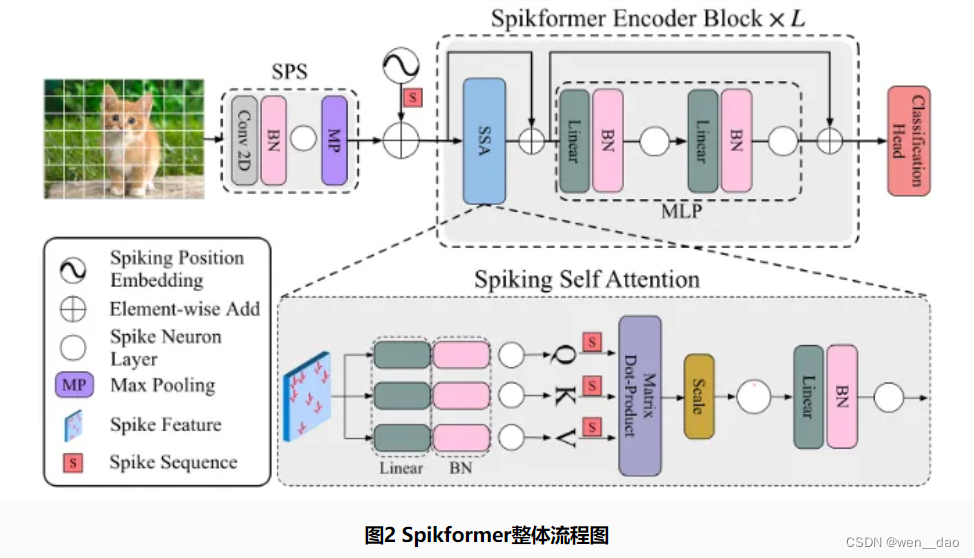
Spikformer模型架构
Spikformer模型同样继承了ViT主体架构。具体地,在脉冲块分离模块(SPS)(patch embedding 将图片转化为脉冲序列)中,利用适合图像任务的卷积操作来引入归纳偏置。(归纳偏置实际上就是利用对问题、任务或者数据的理解对模型进行一定的先验假设。)
接着,由于浮点形式的position embedding在SNN中无法使用,将其替换成条件position embedding生成器生成脉冲形式的相对position embedding(RPE),并将RPE添加到patches序列X 中得到X_0
其余处理流程和传统Transformer大致相同。唯一区别的不同是,传统连续激活函数均替换为泄漏整合的脉冲神经元(LIF)(LIF的工作过程可被简化描述为:“当膜电位达到阈值Vth 时神经元将激发脉冲,同时膜电位回落至静息值Vreset”。)。
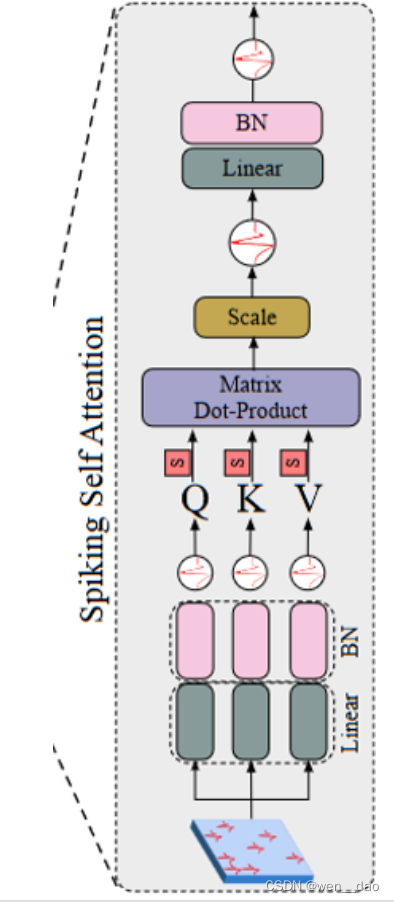
Spiking Self Attention算法架构
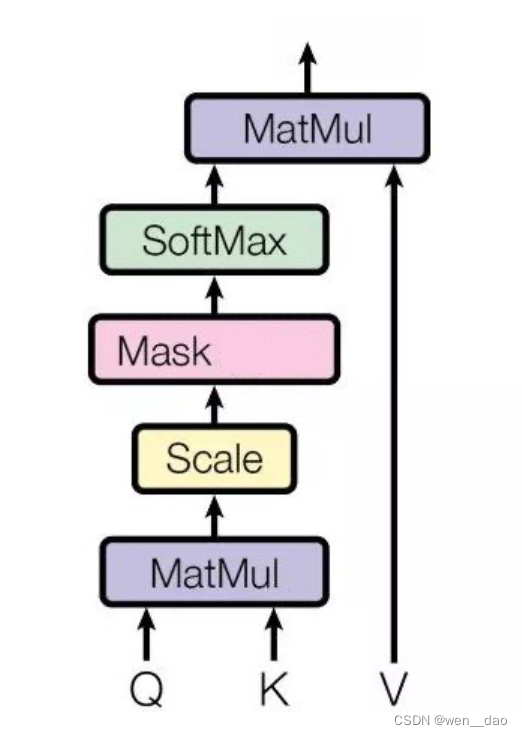
对比发现:
去掉了softmax层
However, the calculation of VSA is not applicable in SNNs for two reasons. 1) The float-point matrix multiplication of , and softmax function which contains exponent calculation and division operation, do not comply with the calculation rules of SNNs. 2) The quadratic space and time complexity of the sequence length of VSA do not meet the efficient computational requirements of SNNs.
但是,由于两个原因,VSA的计算并不适用于snn。
1)浮点矩阵乘法和包含指数计算和除法运算的softmax函数不符合snn的计算规则。
2)VSA序列长度的二次空间复杂度和时间复杂度不能满足snn的高效计算需求。
在传统Transformer的SA架构中需要Softmax激活函数来限制注意力分数的区间范围。然而,Softmax激活函数所带来的指数运算和归一化操作限制了并行处理效率。相比之下,脉冲序列中天然的01离散特性能够很好地规避这一问题。
此外,b图的1.2是等价的:(下面的解释or矩阵乘法的结合性)
1 and 2 are indeed not equivalent mathematically, but they are equivalent functionally.
Since Q,K,V are generated by the same type of function (a linear transformation) from the same input and there is no softmax in 1, are no longer Query, Key, Value with clear meaning. Therefore, we can let be the Query matrix and be the Key matrix.
如图1(b)所示,QKV的运算顺序可以根据输入训练数据中的采样步长和隐藏层维度进行选择,以此来降低模型的时间复杂度。
(其中,图中红色的FLOPs和SOPs分别表示包含8个编码块和512维隐藏维度的模型在ImageNet-1K测试集上(脉冲步长为1)计算QKV理论上所需的浮点运算数和突触操作数,uJ代表理论模型所需能耗)。
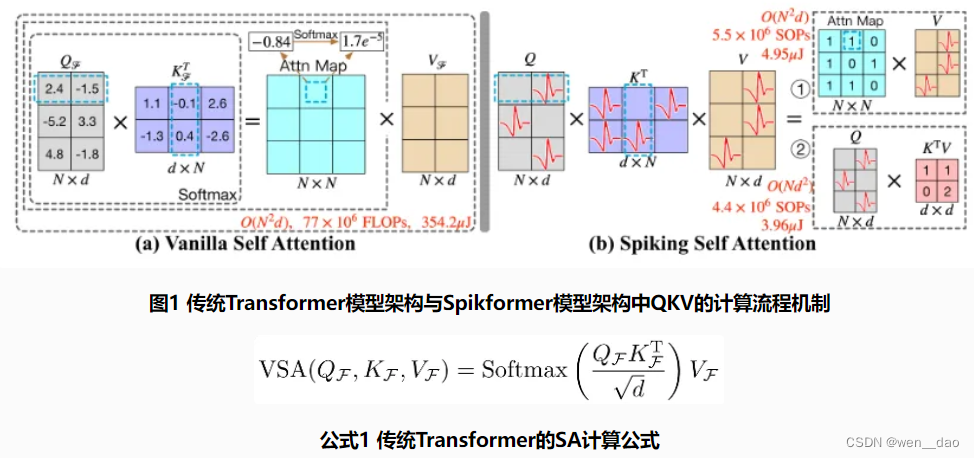
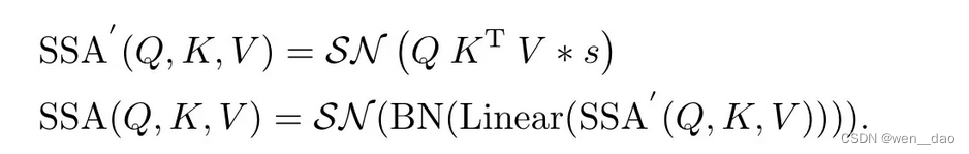
受VSA的启发,作者增加了一个比例因子s来控制矩阵乘法结果的大值,s 不影响SSA的性质。
![]()
论文 2:Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket [2]
论文 3:Spike-driven Transformer (NeurIPS 2023) [3]
为了更近一步降低Spikformer的时间复杂度,研究团队将脉冲驱动的范式与Transformer进行结合来构建一种新的模型架构,Spike-driven Transformer。该模型架构有四个主要特性:
-
脉冲驱动自注意力(Spike-driven Self-Attention,SDSA):Spike-driven Transformer提出了一种尖峰驱动自注意力机制,它利用二进制尖峰信号进行计算,将所有与尖峰矩阵相关的矩阵乘法转换为稀疏加法,从而显著降低了计算能耗;
-
事件驱动计算:当Transformer的输入为零时,不触发任何计算,实现了真正的事件驱动计算模式,进一步提升了能效;
-
线性复杂度的自注意力:在令牌和通道维度上都实现了线性复杂度,大幅降低了自注意力机制的计算成本;
-
二进制尖峰通信:通过二进制尖峰进行通信,简化了网络的计算过程,使得Spike-driven Transformer能够在神经形态芯片上友好运行,进一步降低能耗。
尽管混合计算有助于减少transformer中添加spiking神经元带来的准确性损失,但要从SNN的低能源成本中获益可能是一项挑战,特别是考虑到spikformer在神经形态芯片上几乎不可用。为了解决这个问题,我们提出了一种新的spike-driven transformer,它在整个网络中实现了SNN的spike-driven,同时具有良好的任务性能。Transformer的两个核心模块VSA和多层感知器(MLP),被重新设计为具有spike-driven的范式。
VSA的三个输入矩阵是Query(Q)、Key(K)和Value(V)(图第1(a)段)。Q和K首先进行相似度计算以获得注意力图,注意力图包括矩阵乘法、缩放和softmax三个步骤。然后使用注意力映射来对V进行加权(另一个矩阵乘法)。spikformer[20,19]中典型的spike自注意将Q、K、V转换为spike形式,然后执行两次类似于VSA中的矩阵乘法。区别在于尖峰矩阵乘法可以转换为加法,而softmax不是必需的[20]。但这些方法不仅在输出中产生大整数(因此需要额外的尺度乘法进行归一化以避免梯度消失),而且未能充分利用spike-driven范式与自我注意相结合的能量效率潜力。
我们提出了尖峰驱动的自注意(SDSA)来解决这些问题,包括两个方面(参见图1中的SDSA版本1(b)):
i)阿达玛乘积取代矩阵乘法;
ii)矩阵逐列求和和尖峰神经元层起softmax和scale的作用。
前者可以被视为不消耗能量,因为尖峰之间的Hadamard乘积等效于逐元素masked。
后者也几乎不消耗能量,因为要逐列求和的矩阵非常稀疏(通常,非零元素的比率小于0.02)。
我们还观察到SDSA是一种特殊的线性注意[23,24],即图1(b)的版本2。在这种观点中,将Q、K和V转换为尖峰形式的尖峰神经元层是一个核函数。
Spike-driven Transformer模型架构
Spike-driven Transformer是遵循了Spikformer和Spikformer V2网络架构模式。主要由脉冲块分离模块(SPS)和基于SDSA的脉冲驱动Transformer模块组成。具体地,为了保证SDSA范式能够正常工作(即保证稀疏加法中脉冲信息的01二值特性),整个模型框架中均使用膜电压进行残差连接操作(Membrane Shortcut,MS),同时残差连接后均搭配脉冲神经元来保证脉冲序列的二值性。值得注意的是,目前基于脉冲的模型中并没有规范的残差连接策略,基于相关研究、生物可塑性以及动态等距性的相关理论,该研究团队最终选择MS来实现残差连接。
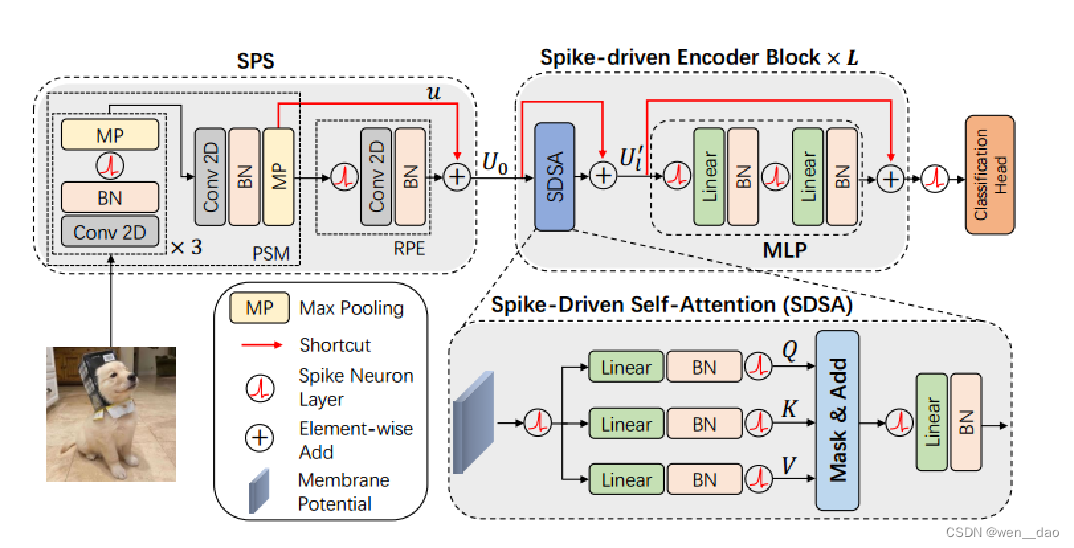
其中具体的运算:
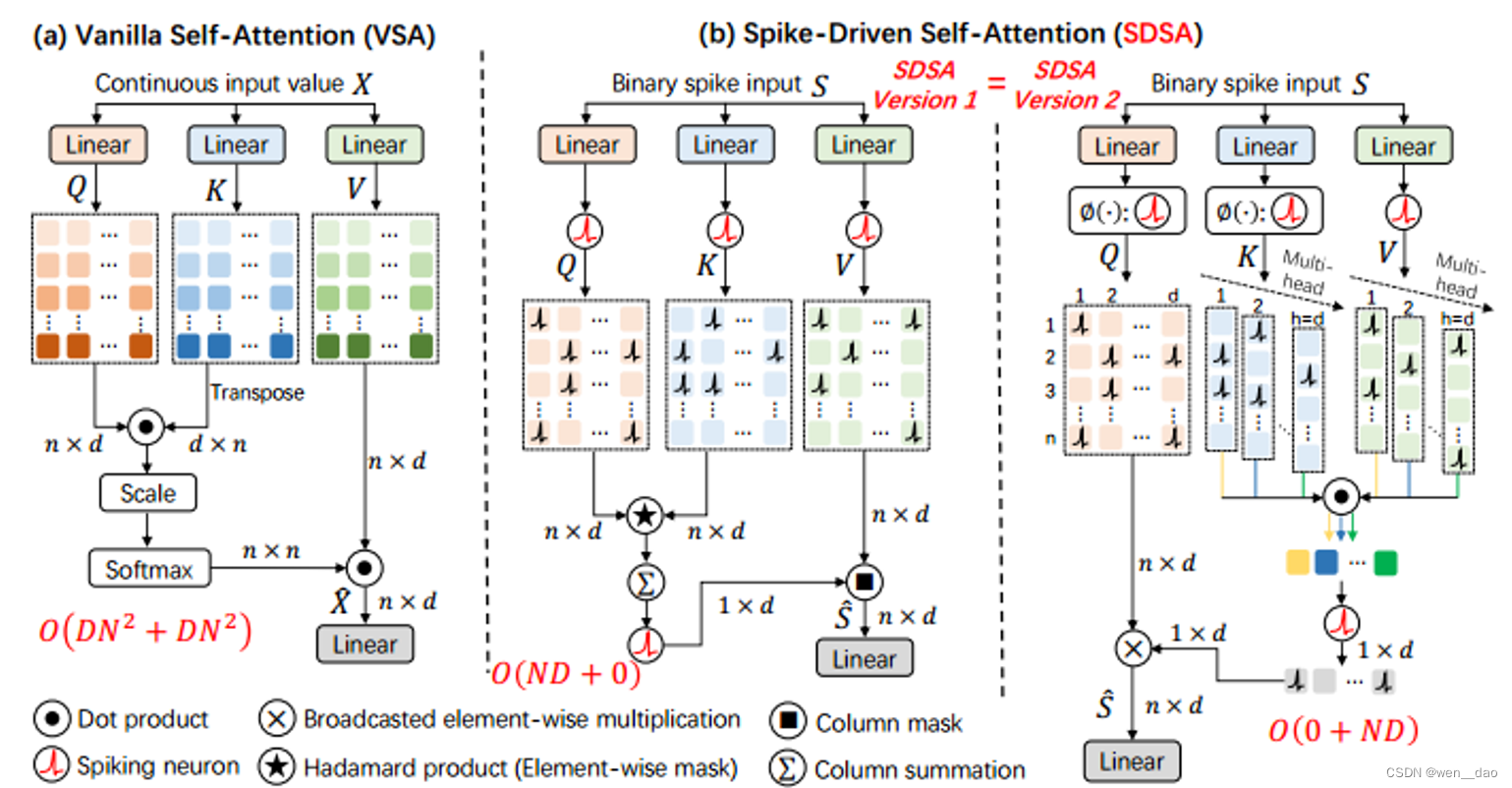

对比spikingformer:
残差连接:
目前 SNN 领域中一共有三种残差连接。一种是直接参考 ResNet 的 Vanilla Shortcut [6],在不同层的膜电势和脉冲之间建立捷径;一种是 SEW [3],在不同层的脉冲之间建立捷径;一种是 MS [4],在不同层的膜电势之间建立捷径。MS 连接之后会跟随一个脉冲神经元,这可以将膜电势之和转化为 0/1,从而保证网络中所有脉冲张量与权重矩阵之间的乘法可以被转换为加法。因此,本文使用 MS 残差来保证 spike-driven。
论文 4:Spike-driven Transformer V2, Meta Spiking Neural Network Architecture Inspiring The Design of Next-Generation Neuromorphic Chips (ICLR 2024) [4]
为了解决目前神经计算领域的基于卷积的SNN神经芯片的主导地位以及提升基于Transformer的SNN模型性能。Spike-driven Transformer原研究团队提出“Meta-SpikeFormer”,一种新脉冲驱动的Transformer范式结构,以促进下一代神经芯片的设计。具体来说,Meta-SpikeFormer具备以下三种特点:
-
低功耗:在模型中只有系数加法计算;
-
广泛支持下游图像任务:在图像分类、检测和分割的下游任务上Meta-Transformer能超越目前SNN的SOTA模型;
-
高性能:Meta-Transformer相比于基于卷积的SNN网络模型在各项任务中均有较大提升;
-
元架构:为下一代神经计算芯片提供灵感启发。
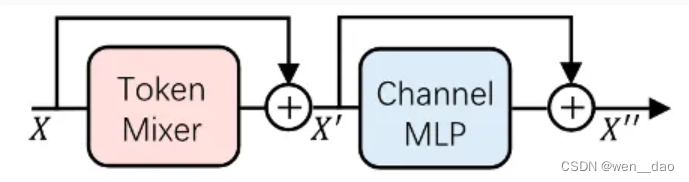
Meta-Transformer模块范式和Meta-Spikeformer模型架构
如图所示,受到Meta-Transformer模块(主体由Token Mixer模块和Channel MLP架构组成)启发,研究团队在Spike-driven Transformer的工作基础之上又进一步规范了网络架构。具体地,在基于卷积的模块SNN网络中在使用分离的卷积操作来进一步降低网络的模型参数。同时,基于Spike-driven Transformer中的相关经验,使用卷积层来替代全连接操作。同样地,为了减少模型参数,研究人员在基于Transformer的脉冲驱动的自注意力模块中,使用重置化参数矩阵(两个连续的3*3矩阵来替换原先的线形层)。然而,在基于Transformer的脉冲驱动自注意力模块中Channel MLP部分,则仍保留线形层结构。
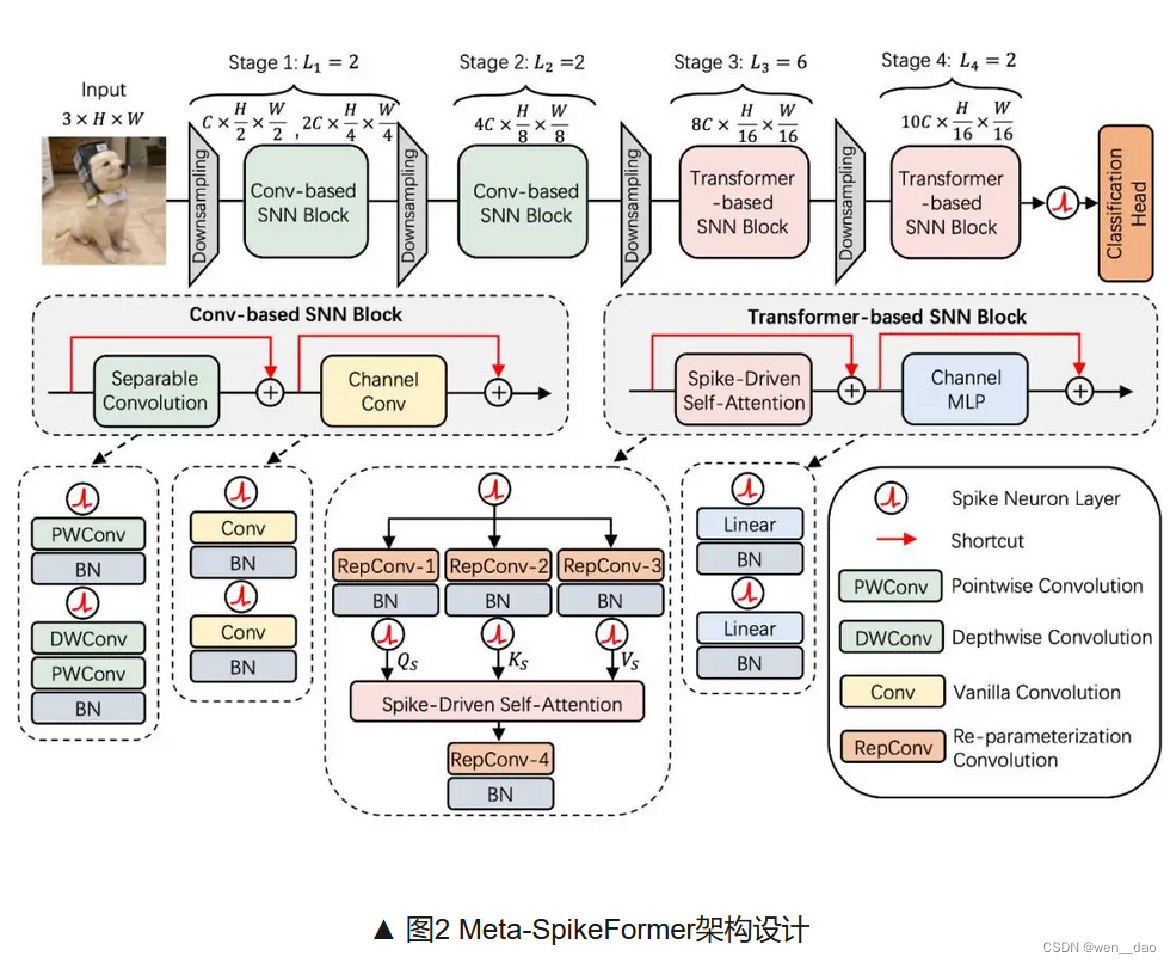
具体地,本文将spike-driven Transformer中的脉冲编码层扩充为4个Conv-based SNN块,并对Transformer-based SNN块进行了重新设计,如图2所示。
预备知识:
作者在文中给出ViT模型如下架构图,其中主要有三个部分组成:
1)Linear Projection of Flattened Patches(Embedding层,将子图映射为向量);
2)Transformer Encoder(编码层,对输入的信息进行计算学习);
3)MLP Head(用于分类的层结构);
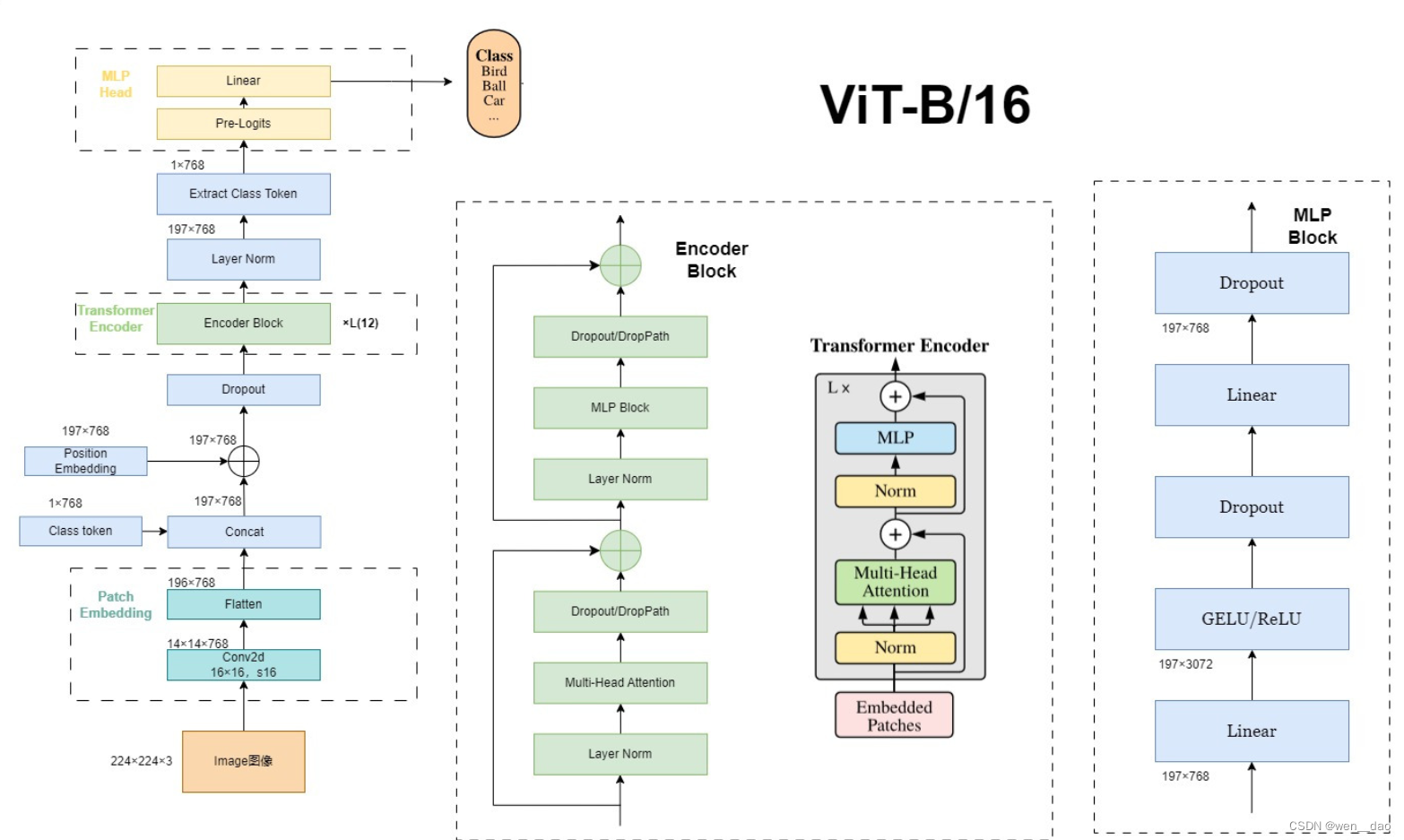
Linear Projection:使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现线性映射,这个卷积操作产生shape变化为[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平(Flattened Patches)即可,shape变化为([14, 14, 768] -> [196, 768]),此时正好变成了一个二维矩阵,符合Transformer输入的需求。其中,196表征的是patches的数量,将每个Patche数据shape为[16, 16, 3]通过卷积映射得到一个长度为768的向量(后面都直接称为token)。
flatten层:
Flatten层的作用就是将卷积层与池化层输出的特征展平、做维度的转换,如此一来才能放入全连接层做分类
全连接层
全连接层:全连接层是一个列向量,用于深度神经网络的后面几层,是将每一个节点都与上一层的所有节点相连,把前面提取到的特征综合起来。全连接层就是相当于一个超平面,将各个类别在特征空间将它们分开。
全连接层的作用:对数据进行分类。
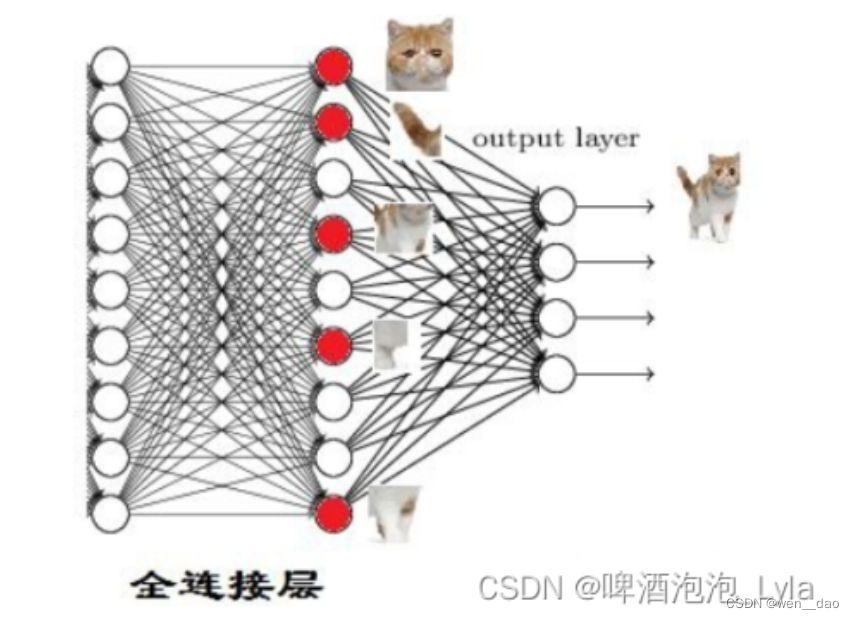
dropout层:
Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作,以减少网络对特定神经元的依赖
BN层:
BN层就是用在激活函数前,用来使上一层的输出,分布在均值为0,方差为1的情况下,也就是对下一层的输入做归一化的操作,这样就能够使它经过激活函数时能够有一定的梯度,从而避免值太大而进入饱和区,梯度就非常小了,不利于梯度下降。
MP层:
最大池化的目的在于保留原特征的同时减少神经网络训练的参数,使得训练时间减少。
softmax公式
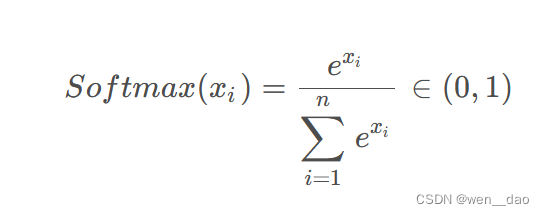
CAFormer:
CAFormer是一种结合了通道注意力机制的Transformer变体,其中包含两个CNN阶段和两个Transformer阶段。
这种架构首先利用CNN阶段来提取特征并进行通道间的关系建模,然后通过Transformer阶段来进一步处理这些特征以获得更好的表示。
这种前卷积/后自注意力的架构是计算机视觉中的经典架构,被认为有助加速网络收敛和提升任务性能
CAFormer的设计使其能够更好地处理图像等数据,提高模型对通道维度信息的处理效率和准确性,是在计算机视觉任务中具有良好表现的经典架构。
参考文章:
可信及通用人工智能实验室 微信公众号 : 论文分享:「Spike add X 系列」 之 「当Spike遇上Transformer」
-
Zhou Z, Zhu Y, He C, et al. Spikformer: When Spiking Neural Network Meets Transformer[C]//The Eleventh International Conference on Learning Representations. 2022.
-
Zhou Z, Che K, Fang W, et al. Spikformer v2: Join the high accuracy club on imagenet with an snn ticket[J]. arXiv preprint arXiv:2401.02020, 2024.
-
Yao M, Hu J, Zhou Z, et al. Spike-driven transformer[J]. Advances in Neural Information Processing Systems, 2023, 36.
-
Yao M, Hu J K, Hu T, et al. Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips[C]//The Twelfth International Conference on Learning Representations. 2024.

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









