







 本文介绍了在处理图片数据集时的分析方法,包括无标注图片的尺寸信息、亮度、横纵比和对比度/锐度分析,以及标注数据如何影响数据增强、模型选择和损失函数。通过这些分析,可以更好地理解数据集特性并优化机器学习任务。
本文介绍了在处理图片数据集时的分析方法,包括无标注图片的尺寸信息、亮度、横纵比和对比度/锐度分析,以及标注数据如何影响数据增强、模型选择和损失函数。通过这些分析,可以更好地理解数据集特性并优化机器学习任务。
当拿到一批图片数据集的时候,我应该做哪些分析?这里是我自己从业过程中的一些分析手段,从哪里学习的已经不可考,如果有其他的大家觉得有用的分析,可以和我分享一下,避免我自己闭门造车。
这里根据已知的信息量分类两种情况
1. 只有图片数据,没有标注数据,这种情况下,是针对纯图像进行一种无标注的分析,这种分析帮助我们熟悉这些图片,对一些异常的情况进行一个初步筛选。
2. 既有图片数据又有标注数据,这种情况的图片分析会影响我们选择什么样的数据增强策略,模型选择以及损失函数的选择。
一、纯图片无标注情况中的数据分析
1.1 图像size信息
这里指的是图像的像素点行列数量信息。统计数据集中每个图片的size信息:遍历得到每张图片的长*宽,就是图像的分辨率数值,然后绘制成直方图观察图像数据的尺寸;一般我喜欢绘制成10bin的直方图,考虑到有些数据集因为来源不同导致采集的数据大小不一,可以考虑绘制的时候x轴以log_10为底进行绘制。
简单的效果图如下
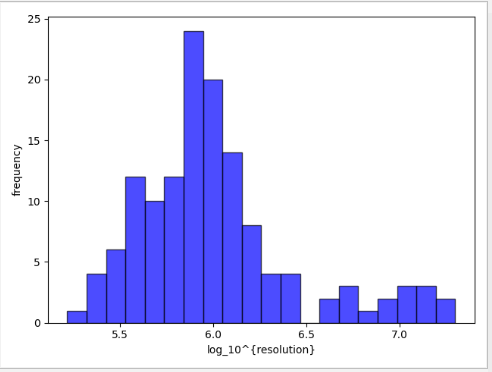
一般来说如果数据集的尺寸信息差别较大,那么研究者需要心中有数,这些数据往往是不同的设备采集得到的,因此数据集的分布往往不会呈比较统一的分布情况,如果需要划分训练集和测试集,需要有意识的将各种尺寸的数据进行较为平均的分配;不然很可能训练集的准确率指标和测试集相差较大。另外我们在进行目标检测等任务时,往往会把图片resize到统一的尺寸,如果图片尺寸比较奇怪的,可以在训练前删除或者分割。
1.2 图像亮度信息
亮度信息反应了像素点的明亮程度,一般图片是RGB通道表示的,每个通道上的像素点值范围在[0-255]之间,那么值越大,则越接近白色;值越小越接近黑色;如下面的两张图,左图的亮度为58,右图为154。

关于亮度的计算,因为图像可以表示为颜色三通道的RGB,也可以表示为HSV(色域、饱和度、亮度)。
我一般直接用RGB信道的方式对图片计算平均亮度,然后绘图统计一下图片的亮度分布,一般在做日夜景的目标检测时,会有意识看一下这个指标。
from PIL import Image,ImageStat
def brightness_method( im_file ):
#返回像素平均亮度
im = Image.open(im_file).convert('L')
stat = ImageStat.Stat(im)
return stat.mean[0]1.3图像的横纵比
横纵比是以宽度/高度这种比率的形式表示的图像形状信息。大于0,无上界,但是一般不超过5,大部分集中在0.6~1.8之间。我们在进行目标检测等任务训练时,往往会把图片resize到统一的尺寸,如果图片尺寸比较奇怪的,可以在训练前删除或者分割。
1.4 图像的对比度/锐度
对比度或者锐度一般反应图像细节边缘变化的敏锐程度,一般来说高对比度的图像看起来更加清晰。
如图所示,左边的图片明显比右边的图片模糊一点,就是在物体边缘的处理上,右边图片像素值变换更大。

对比度计算的算法很多,比如传统CV中采用Laplace算子、sobel算子,SMD算子等等,总之他们的计算逻辑就是计算每个像素点的一阶导数或者二阶导数,这反映了像素点值变换的剧烈程度。一般按照不同的计算方式,数值范围都不同,但是数值越大往往表示像素的变化越大,也即是对比度越高。
比如下面两张图采用laplace得到的数值分别为左图22,右图140。

提供两种常用的对比度计算方式
import numpy as np
import cv2
def laplacian_method(im_path):
'''
部分图片无效
'''
image = cv2.imread(im_path)
gray_image =cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
lap = cv2.Laplacian(gray_image,cv2.CV_64F).var()
score = np.mean(lap)
return score
def SMD2(img_path):
'''
:param img:narray 二维灰度图像
:return: int 图像约清晰越大
有效,但是时间开销长
'''
color_img = cv2.imread(img_path)
img = cv2.cvtColor(color_img,cv2.COLOR_BGR2GRAY)
img = cv2.resize(img,(0,0),fx=0.5,fy=0.5,interpolation=cv2.INTER_NEAREST)
shape = np.shape(img)
output = 0
for x in range(0, shape[0]-1):
for y in range(0, shape[1]-1):
output+=math.fabs(int(img[x,y])-int(img[x+1,y]))*math.fabs(int(img[x,y]-int(img[x,y+1])))
return output/(shape[0]*shape[1])关于这个对比度指标,怎么说呢,你说他有意义吧,确实能够筛出一些明显清晰度不高的图片,但是不同数值的图片之间的清晰度并没有那么明确的关系,如果一张图片的清晰度数值高于另一张图片,并不能说就一定比另一张图片清晰,因为这些方法都和图像的梯度变换有关,不同图像的拍摄内容导致本身像素的梯度就各有不同。很难利用这个指标客观评估不同图像之间的清晰度区别。这个指标适合用于在做图片处理的锐化处理前和锐化处理后的图片之间的比较。
1.5 图像有损无法打开的情况
有时候部分图片可能会因为传输或者其他原因,根本无法打开。可以采用下面的代码进行图片的筛选,不需要自己逐一尝试。
import fleep
def judge_correct_image_type(image_path):
anno_type = image_path.split('.')[-1].lower()
if anno_type=='jpg':
anno_type='jpeg'
image_data = open(image_path,'rb').read()[:128]
info = fleep.get(image_data)
if info is not None and len(info.mime)==1:
essential_type = info.mime[0].split('/')[-1]
if len(essential_type)==0:
essential_type = 'broken'
else:
essential_type='broken'
return anno_type,essential_type需要注意,上面的代码只能判断无法打开的图片,不能判断如下这种图片缺损的情况:下面这种图片问题,暂时没有找到可行的修复策略,如果有哪位高手有办法,非常期待获得新的知识~

1.6 图像格式分布以及标注图片格式错误的情况
图片的格式jpg/png/gif/pdf/bmp,样本的标注格式可能和实际的格式不一致。因此需要对图片进行格式分析,给与正确的后缀名称,未来训练过程中,处理输入的坑也可以少一点。
代码还是上面的代码。
1.7 颜色域直方图
有时候我们非常希望获得图片关于颜色分布的特征,但是很遗憾,CV中常用的RGB颜色直方图比较不直观,比如它会分别绘制出红绿蓝三个颜色的分布情况,但是大家知道红色和绿色混合构成黄色,黄色是蓝色的补色,两者混合构成白色。然后当绘制的颜色直方图任何一个分布都不能说明这种颜色占主导。有趣的是当我们把图像从RGB转为HSV格式之后,就可以进行视觉的量化了。

定义:将颜色空间按照人眼视觉特征量化为72个维度,统计图片中每个颜色的直方图。
范围:直方图值域范围[0-1]
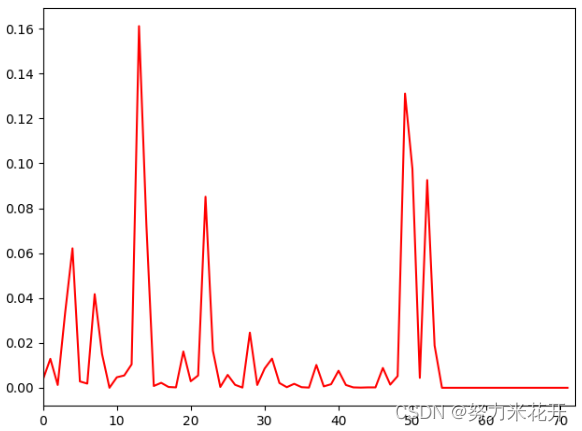
单张图片的展示并没有什么特别的作用,顶多看看颜色分布情况,从左到右,颜色分布大致依次为红-->黄-->绿-->青-->蓝-->紫。
这个分析真正有用在于可以搜寻颜色空间相似的图片!比如每张图片缩减到72维度之后,利用向量之间的相似性计算公式(可以是余弦相似度或者是L1距离),可以得到每张图片颜色分布相似图片,巧妙利用阈值筛选,就可以得到某张图片的相似颜色图片集:



核心代码1: 抽取图像颜色直方图,返回每个图片的vector,维度为72。入口函数colors
def quantilize(value):
'''hsv直方图量化
value : [21, 144, 23] h, s, v
opencv中,h-[0,180], s-[0,255], v-[0,255]
'''
#
value[0] = value[0] * 2
hlist = [20, 40, 75, 155, 190, 270, 290, 316, 360]
svlist = [21, 178, 255]
for i in range(len(hlist)):
if value[0] <= hlist[i]:
h = i % 8
break
for i in range(len(svlist)):
if value[1] <= svlist[i]:
s = i
break
for i in range(len(svlist)):
if value[2] <= svlist[i]:
v = i
break
return 9 * h + 3 * s + v
def colors(imagepath):
img = cv2.imread(imagepath)
img = cv2.resize(img,(0,0),fx=0.1,fy=0.1)
hsv = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
nhsv = np.zeros(hsv.shape[:2], dtype=np.uint8)
t2 = datetime.now()
for i in range(hsv.shape[0]):
for j in range(hsv.shape[1]):
nhsv[i][j] = quantilize(hsv[i][j])
# nhsv[i][j] = color_quantilize(hsv[i][j])
print(imagepath, datetime.now() - t2)
hist = cv2.calcHist([nhsv], [0], None, [72], [0, 71]) # 40x faster than np.histogramfaster than np.histogram
hist = hist / (hsv.shape[0] * hsv.shape[1])
plt.plot(hist, color='r')
plt.xlim([0, 72])
plt.show()
return hist.reshape(-1)
1.8 暂不考虑的图像分析
其余暂时不考虑的图像分析维度:
1. 颜色矩,比如一阶颜色矩即均值。反映图像的整体明暗程度。值越大,图像越亮。
原因:和亮度重合,更加适用于单张图片的分析
2. 颜色直方图描述的是图像不同颜色在整幅图中像中所占的比例,反映了图像颜色分布的统计特性,
原因:一般用于图片的PS,单张图片的分析,色域调整,还可以用于图像的检测
3. 信噪比:理论上说,信噪比是对每个像素亮度变化的统计分析。直观的说就是那些图像中的“颗粒”,或者是颜色因为噪声产生波动变化的情况。这是由于成像原理或者设备干扰导致的。这是一个成像质量的判断依据。一般信噪比的计算需要在同一个画面拍摄多张图片,利用多张图片相同位置的均值方差来作为去噪效果,其他图片作为噪声图片,来计算针对这个场景的信噪比。如果是只有一张图片,需要选择一张图片上的ROI区域来计算信号的噪声情况。对于真实的样本图片来说,这个指标是否有意义?
参考文献
[利用ENVIIDL实现图像清晰度评价——点锐度算法](https://www.cnblogs.com/enviidl/p/16315698.html)
[Python图像处理之图像清晰度评价](Python图像处理之图像清晰度评价_python_脚本之家)
[python下对hsv颜色空间进行量化操作](python下对hsv颜色空间进行量化操作_python_脚本之家)
[关于HSV了解这些就够了,python-opencv获取图片精确hsv的值](关于HSV了解这些就够了,python-opencv获取图片精确hsv的值_hsv值_骑摩托的蜗牛的博客-CSDN博客)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









