







使用深度回归网络做目标跟踪
原始论文:Learning to Track at 100 FPS with Deep Regression Networks
Computer Science Department, Stanford University
下载链接:http://arxiv.org/abs/1604.01802
算法主页:http://davheld.github.io/GOTURN/GOTURN.html
代码地址:https://github.com/davheld/GOTURN
这篇文章是斯坦福大学2016年4月发的,文中提出了一种通过离线训练带标签的视频来更有效跟踪目标物体的方法。以前的深度学习用来做跟踪的算法都比较慢,这一论文的跟踪器使用了简单的前向传播而无需在线训练,测试时的跟踪帧率达到了100fps.由于在训练网络时既使用了带标签的视频,也使用了大量的图片,可以防止过拟合。跟踪器学习了泛化的运动特征,所以可以去跟踪训练集中没有出现的新物体。
传统通用目标跟踪器(相对于特定目标跟踪器)完全是通过在线抓取来训练,而没有离线训练。如MIL,tracking learning detection等。这种跟踪器性能不好的原因是获取的信息太少,仅仅在线训练不能利用大量视频的优势。而这些视频有可能帮助跟踪器处理旋转,视点改变,光线改变等问题,进而提高跟踪性能。而机器学习已经能够从大量的离线数据中学习。本文提出的算法;Generic Object Tracking Using Regression Networks (GOTURN)就是通过神经网络来跟踪通用的目标。首先通过带标签的视频和图像离线训练,然后在测试/跟踪时只需要在网络上前向传播。GOTURN是第一个完全离线训练的通用目标跟踪器。
方法
输入输出格式
视频一帧画面中有很多物体,跟踪哪个?网络必须获得视频中被跟踪对象的信息。可以通过剪裁和调整前一帧跟踪到的目标来获得跟踪对象,剪裁中心的目标就是跟踪对象。剪裁的crop会在目标周围留有余地,会让网络学习到一些目标背景和环境信息。例如:在t-1帧,目标位置在c = (c x , c y ).宽高为w,h. 在t帧,就可以在c = (c x , c y )剪裁一个k1w,k1h的图像。这个图像将告诉网络跟踪对象是谁。k1决定了环境信息的多少。
在哪找
前一帧的位置信息能够为当前帧目标的定位提高很好的猜想,文中基于前一帧目标位置选择了搜索窗口。剪裁得到搜索窗口送进网络,让网络在搜索窗口内找到目标。文中搜索窗口的中心位置在c = (c x , c y ),搜索区域宽高为2w,2h.当然,目标移动太快的话,搜索窗大小应该再大,网络的复杂度也会加大,为了处理大的运动。该跟踪器可以和其他在线训练的检测器结合。
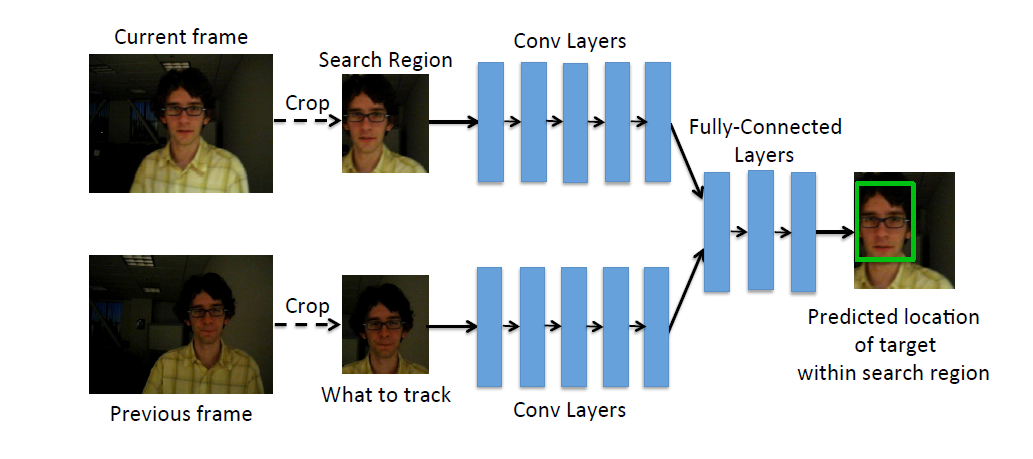
网络结构
本文的网络模型取自CaffeNet的前5个卷积层,3个全连接层。每个全连接层有4096个节点,输出层4个节点,代表输出包围盒。文中网络通过Caffe实现,网络层间参数采用CaffeNet默认值。
训练
使用图像和视频序列训练,通过网络预测的包围盒和ground-truth包围盒的L1-Loss训练网络。
学习连续运动
真实世界中的目标都是连续运动的,如果一个图形是模糊的,目标位置不能确定,跟踪器应当预测目标在前一帧观测位置附近,为了具体化运动连续的思想,我们根据前一帧包围盒中心对当前帧的包围盒的中心位置(cx’, cy’) 建模:
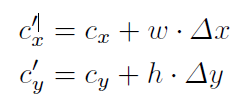
∆x,∆y 衡量包围盒位置相对于其大小的改变的随机变量。在我们的训练集中,我们发现,∆x,∆y 可以通过均值为0的Laplace分布建模,这一分布让小的运动有了更大的概率。
模型大小的改变通过下式调整:
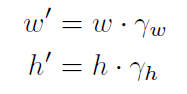
γ w 和γ h代表了包围盒尺寸的改变,并且它们可以通过均值为1的Laplace分布建模。这一分布让包围盒更有可能与前一帧包围盒大小相同。
为了让网络学习到小运动而不是大运动。训练集加了许多随机的crops。这些随机的crops就是从前述的拉普拉斯分布中取的。这一分布不会给跟踪器带来限制,仅仅是让网络能够预测小运动而不是大运动。相比标准正态分布,拉普拉斯分布让跟踪器有了更好的性能。
拉普拉斯参数通过交叉验证来选择,bx=1/5(包围盒中心的运动), bs=1/15(包围盒大小的改变)。得到的crop在每个维度上至少应当包含目标物体的一半。
实验
训练集:ALOV++ 从314个视频序列中去除7个。实际用307个
训练集:252个目标物体,共计13082张图,平均每个物体52帧。
验证集 :56个物体 2795张图。
训练集和验证集无重复
训练集中也用了图片来训练。图片来源自ImageNet 2014
测试集: VOT2014 上的25个序列,不用VOT2015的原因是VOT2015的数据集中有大量视频与测试集重复。
评价参数:精确度(A),鲁棒性(R),精确度误差(1-A),鲁棒性误差(1-R),总误差(1-(A+R)/2)
实验结果:
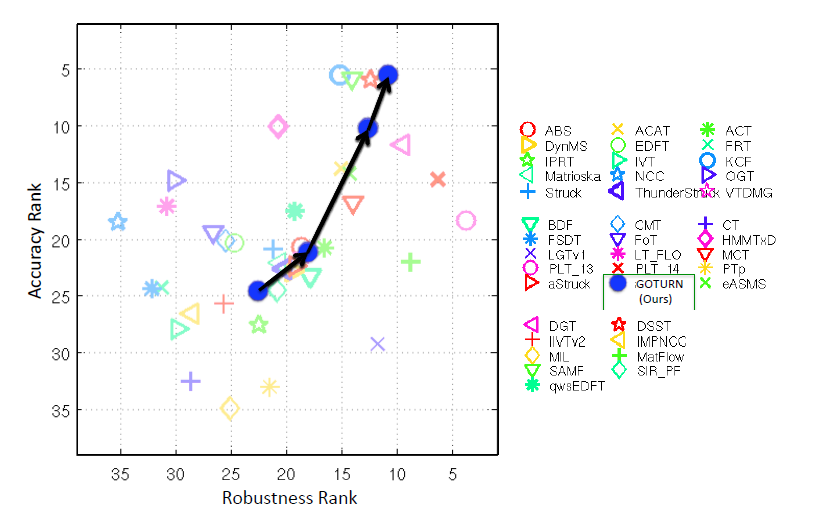
小结:
本文主要在训练网络时的方法比较有特点:
1.当前帧的跟踪预测参考前一帧的跟踪结果。
2.采用视频和图片训练的方式有较强的泛化能力。可以跟踪训练集中没有出现的物体
3.crop的方式采用了拉普拉斯分布而不是高斯分布。让跟踪器能够更适应微小运动,进而实现跟踪的连续性。
4.文中对比的算法都是经典算法,没有与目前基于深度学习的跟踪算法的比较。虽然文章是2016年的。
5.不需要在线微调网络参数,只需要一次前向传播得到目标位置,所以很快,如题跟踪可达100FPS.
写这篇文章时算法主页和代码都没有给出,所以暂时没有结合代码的分析。















 8024
8024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









