







 本文深入探讨了使用K-means算法进行特征提取的过程,包括K-means的目标、优化条件以及与其他特征学习算法的联系。通过实例介绍了K-means在图像特征学习中的应用,包括数据预处理、K-means聚类和特征提取步骤,特别是软编码的非线性映射方法。文章还展示了如何在CIFAR-10数据集上提取特征,并进行了数据的归一化和白化处理,以提高特征学习的效果。
本文深入探讨了使用K-means算法进行特征提取的过程,包括K-means的目标、优化条件以及与其他特征学习算法的联系。通过实例介绍了K-means在图像特征学习中的应用,包括数据预处理、K-means聚类和特征提取步骤,特别是软编码的非线性映射方法。文章还展示了如何在CIFAR-10数据集上提取特征,并进行了数据的归一化和白化处理,以提高特征学习的效果。
原理部分主要来自大牛zouxy09和trnadomeet两个人的博客;后面的代码详细讲解为自己精心编写
一、概述
非监督学习的一般流程是:先从一组无标签数据中学习特征,然后用学习到的特征提取函数去提取有标签数据特征,然后再进行分类器的训练和分类。之前说到,一般的非监督学习算法都存在很多hyper-parameters需要调整。而,最近我们发现对于上面同样的非监督学习流程中,用K-means聚类算法来实现特征学习,也可以达到非常好的效果,有时候还能达到state-of-the-art的效果。亮瞎了凡人之俗眼。
托“bag of features ”的福,K-means其实在特征学习领域也已经略有名气。今天我们就不要花时间迷失在其往日的光芒中了。在这里,我们只关注,如果要K-means算法在一个特征学习系统中发挥良好的性能需要考虑哪些因素。这里的特征学习系统和其他的Deep Learning算法一样:直接从原始的输入(像素灰度值)中学习并构建多层的分级的特征。另外,我们还分析了K-means算法与江湖中其他知名的特征学习算法的千丝万缕的联系(天下武功出少林,哈哈)。
经典的K-means聚类算法通过最小化数据点和最近邻中心的距离来寻找各个类中心。江湖中还有个别名,叫“矢量量化vector quantization”(这个在我的博客上也有提到)。我们可以把K-means当成是在构建一个字典D∊Rnxk,通过最小化重构误差,一个数据样本x(i)∊Rn可以通过这个字典映射为一个k维的码矢量。所以K-means实际上就是寻找D的一个过程:
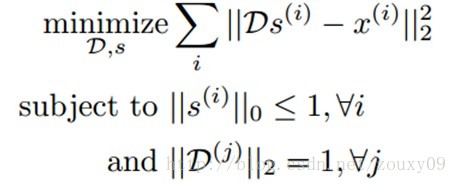
这里,s(i)就是一个与输入x(i)对应的码矢量。D(j)是字典D的第j列。K-means毕生的目标就是寻找满足上面这些条件的一个字典D和每个样本x(i)对应的码矢量s(i)。我们一起来分析下这些条件。首先,给定字典D和码矢量s(i),我们需要能很好的重构原始的输入x(i)。数学的表达是最小化x(i)和它的重构D s(i)。这个目标函数的优化需要满足两个约束。首先,|| s(i)||0<=1,意味着每个码矢量s(i)被约束为最多只有一个非零元素。所以我们寻找一个x(i)对应的新的表达,这个新的表达不仅需要更好的保留x(i)的信息,还需要尽可能的简单。第二个约束要求字典的每列都是单位长度,防止字典中的元素或者特征变得任意大或者任意小。否则,我们就可以随意的放缩D(j)和对应的码矢量,这样一点用都木有。
这个算法从精神层面与其他学习有效编码的算法很相似,例如sparse coding:
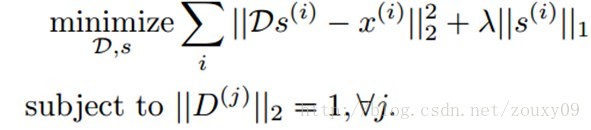
Sparse coding也是优化同样类型的重构。但对于编码复杂度的约束是通过在代价函数中增加一个惩罚项λ|| s(i)||1,以限制s(i)是稀疏的。这个约束和K-means的差不多,但它允许多于一个非零值。在保证s(i)简单的基础上,可以更准确的描述x(i)。
虽然Sparse coding比K-means性能要好,但是Sparse coding需要对每个s(i)重复的求解一个凸优化问题,当拓展到大规模数据的时候,这个优化问题是非常昂贵的。但对于K-means来说,对s(i)的优化求解就简单很多了:
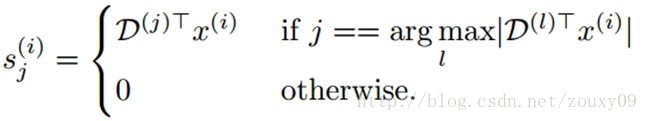
这个求解是很快的,而且给定s求解D也很容易,所以我们可以通过交互的优化D和s(可以了解下我博客上的EM算法的博文)来快速的训练一个非常大的字典。另外,K-means还有一个让人青睐的地方是,它只有一个参数需要调整,也就是要聚类的中心的个数k。
二、数据、数据预处理
2.1数据:
下载的CIFAR-10数据库;其中的每个data_batch都是10000x3072大小的,即有1w个样本图片,每个图片都是32*32且rgb三通道的,这里的每一行表示一个样本。
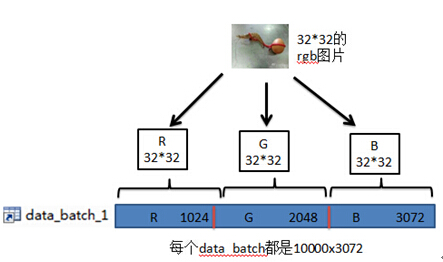
提取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









