







关于SqueezeNet为何能够在达到AlexNet精度的基础之上还能够使模型的参数减小巨多的分析详情,参见SqueezeNet这篇文章,本文章的目的是在实际应用中如何引入SqueezeNet。
设计基本原则
1.使用更小的1*1卷积核来替换3*3卷积核
采取了之后例如GoogleNet,ResNet设计中的3*3卷积来代替ALexNet的7*7卷积,然后用了1*1来部分替代上述的3*3卷积。但是由于为了保证不影响识别的精度,因此不是完全替换,而是进行了部分的替换。
2.减少输入3*3卷积的特征图的数量
如果将conv1-conv2这样直接连接,是没有办法减小feature map的数量的,启发自1*1卷积核的升维降维的作用,使用1*1卷积核来进行过渡,然后将其接3*3卷积核就可以满足上述目标。作者在这里将其封装成了Fire Module。
3.减少pooling
在GooLeNet以及之后的ResNet中,都发现适当地减少pooling能够起到比较好的效果,此处的设计中只进行了3次max pooling和1次global pooling。
Fire Module
Fire Module是本文的核心构件,思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是1x1的卷积kernel,数量记为S11;在expand层里面有1x1和3x3的卷积kernel,数量分别记为E11和E33,要求S11 < input map number即满足上面的设计原则(2)。expand层之后将1x1和3x3的卷积output feature maps在channel维度拼接起来。
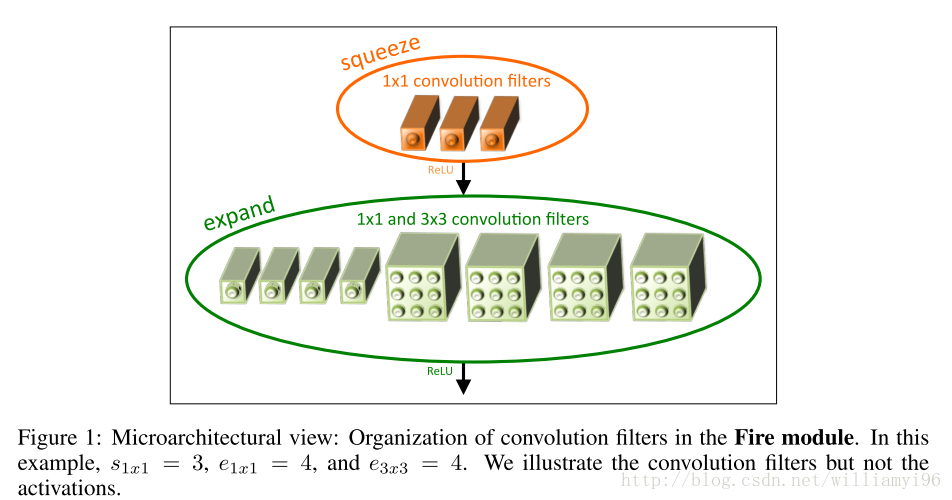
总体网络结构
首先直接上图说明其基本结构:
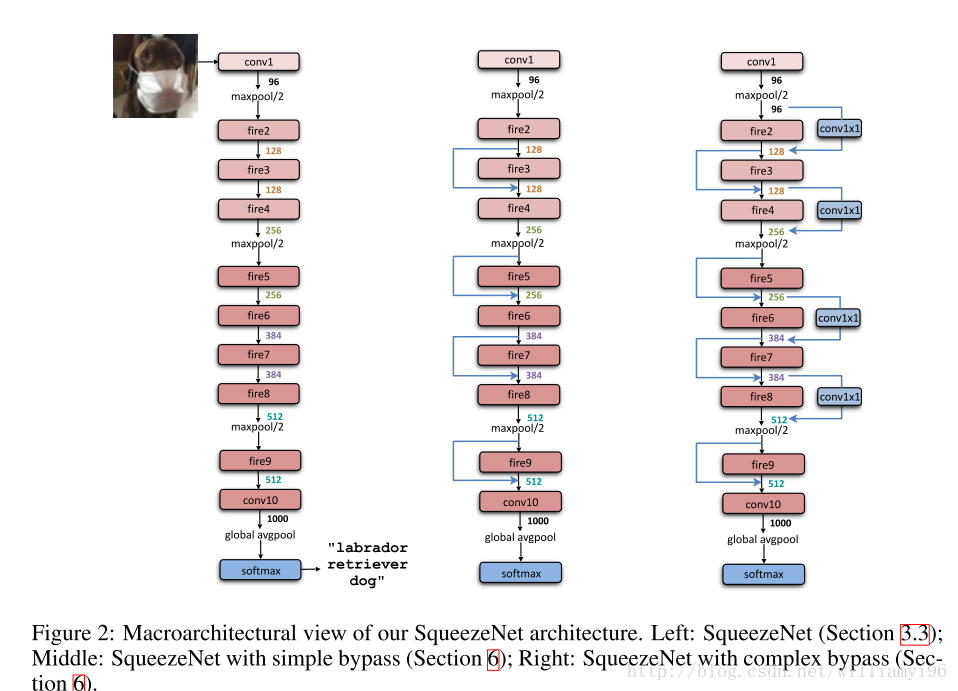
其结构清晰直观,后面的两种结构吸收了ResNet的基本思想进行设计,发现可以一定程度上地提升效果,但是由于并不是其设计思想的功劳,因此后文中没有进行对比。
看一张三种结构的性能对比:

接下来是关于一个各层的详细说明:
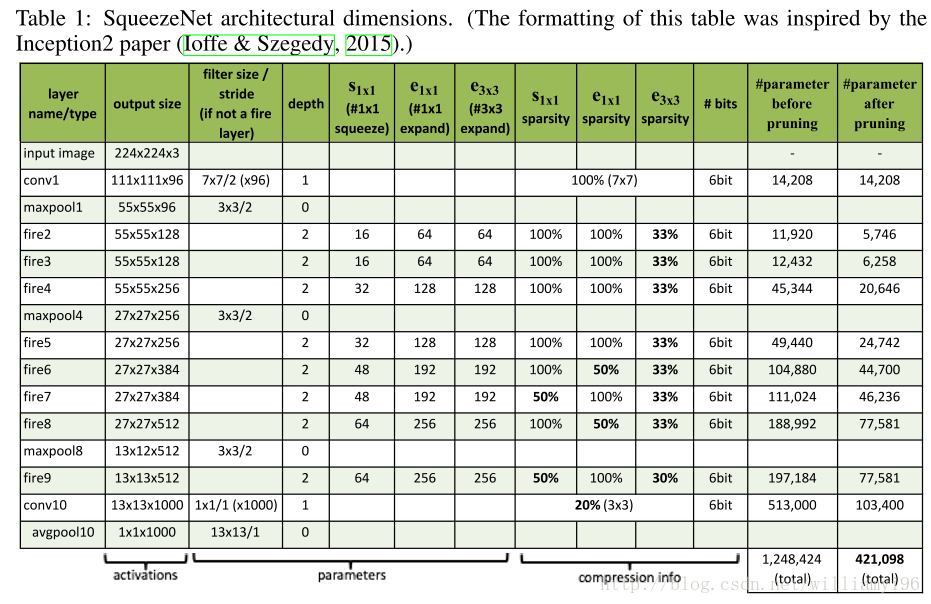
实验结果
主要在imagenet数据上比较了alexnet,可以看到准确率差不多的情况下,squeezeNet模型参数数量显著降低了(下表倒数第三行),参数减少50X;如果再加上deep compression技术,压缩比可以达到461X!还是不错的结果。不过有一点,用deep compression[2]是有解压的代价的,所以计算上会增加一些开销。
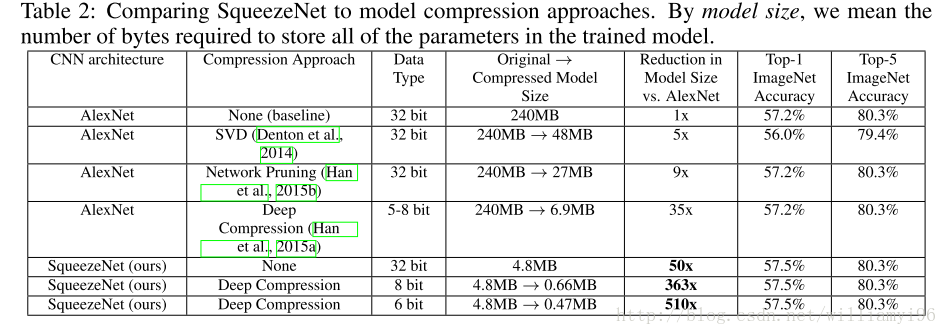















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









