







-
岭回归
Ridge Regression
min w ∑ i = 1 m ( y i − w T x i ) 2 + λ ∥ w ∥ 2 2 \min _{\boldsymbol{w}} \sum_{i=1}^{m}\left(y_{i}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}\right)^{2}+\lambda\|\boldsymbol{w}\|_{2}^{2} wmini=1∑m(yi−wTxi)2+λ∥w∥22
-
LASSO
Least Absolute Shrinkage and Selection Operator
min w ∑ i = 1 m ( y i − w T x i ) 2 + λ ∥ w ∥ 1 \min _{\boldsymbol{w}} \sum_{i=1}^{m}\left(y_{i}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}\right)^{2}+\lambda\|\boldsymbol{w}\|_{1} wmini=1∑m(yi−wTxi)2+λ∥w∥1
-
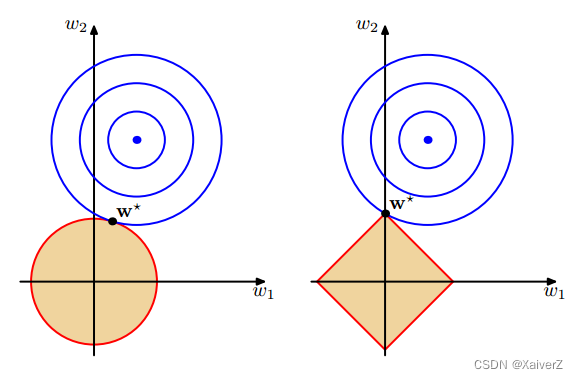
L 1 L_1 L1和 L 2 L_2 L2范数正则化都有助于降低过拟合风险,但 L 1 L_1 L1比 L 2 L_2 L2更容易获得稀疏解(Sparse),即它求得的 w w w会有更少的非零分量
关于正则化与 L 1 L_1 L1、 L 2 L_2 L2范数的理解
- w w w取得稀疏解意味着初始的 d d d个特征中仅有对应着 w w w的非零分量的特征才会出现在最终模型中,所以,求解 L 1 L_1 L1范数正则化的结果就是得到了仅采用一部分初始特征的模型;换言之,基于 L 1 L_1 L1正则化的学习方法就是一种嵌入式特征选择方法,特征选择过程与学习器训练过程融为一体,同时完成
-
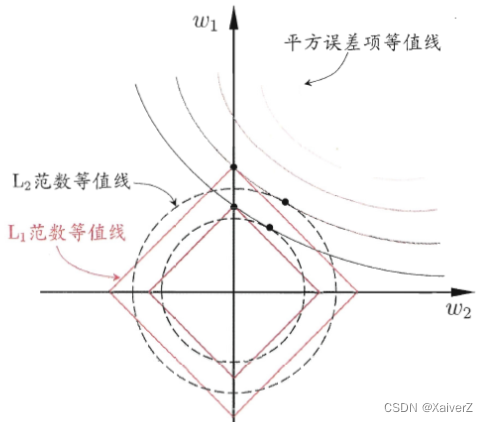
为什么L1范数比L2范数更容易获得稀疏解?
图源PRML
-
原优化问题为
min w E D ( w ) \min _{w} E_{D}(w) wminED(w)
-
加入正则化项后,目标函数(优化问题)变为
min w E D ( w ) + λ E R ( w ) \min _{w} E_{D}(w)+\lambda E_{R}(w) wminED(w)+λER(w)
其中, λ \lambda λ为正则化项系数,为超参数 -
实际上,上述优化问题与下述优化问题是完全等价的,即对一个特定的 λ \lambda λ总存在一个 η \eta η使这两个问题等价(其实加入正则化项,惩罚模型参数,相当于在优化原目标函数的基础上,对正则化项表达的含模型参数的多项式加上限制,使参数限制在某个范围,与上述式子其实是一样的效果)
min w E D ( w ) s.t. E R ( w ) ⩽ η \begin{aligned} &\min _{w} E_{D}(w) \\ &\text { s.t. } E_{R}(w) \leqslant \eta \end{aligned} wminED(w) s.t. ER(w)⩽η
-
基于以上优化问题的转化,根据 L 1 L_1 L1、 L 2 L_2 L2范数的定义,可将限制优化条件以图中橙色区域表示出来
∥ w ∥ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ ≤ η \|w\|_1 = |w_1| + |w_2| \leq \eta ∥w∥1=∣w1∣+∣w2∣≤η
∥ w ∥ 2 = w 1 2 + w 2 2 ≤ η \|w\|_2 = \sqrt{w_1^2 + w_2^2} \leq \eta ∥w∥2=w12+w22≤η -
限制优化区域固定,改变经验损失等值线, L 1 L_1 L1范数更易与其“首次”相交于坐标轴上的点(离经验损失中心点越远损失越大,故在满足解集落在限制区域的前提下,离经验损失中心点越近),所以 L 1 L_1 L1范数更易获得稀疏解
-














07-05
 1380
1380
1380
05-20
430
430
05-14
699
699
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









