







CS224W: Machine Learning with Graphs
Stanford / Winter 2021
02-tradition-ml
Design features for nodes/links/graphs
Use hand-designed features
For simplicity, we focus on undirected graphs
-
Traditional ML Pipeline
- Hand-crafted feature + ML model
Node-level Tasks and Features
Goal: Characterize the structure and position of a node in the network
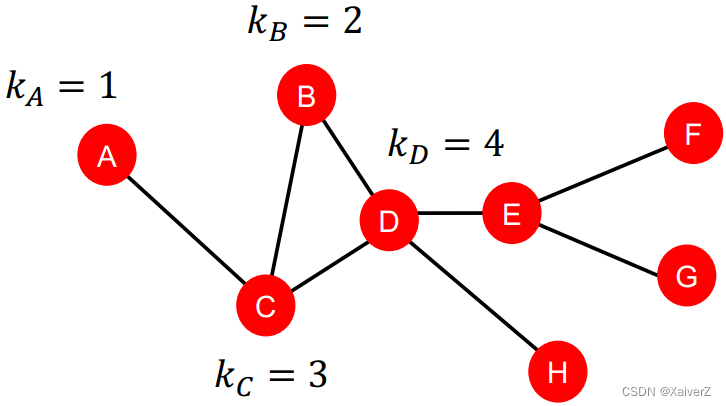
Node Degree
度
Importance-based features
Structure-based features
-
k v k_v kv: the degree of node v v v
-
每个节点的特征为该节点的度
-
Limitation
- Treat all neighboring nodes equally, without capturing their importance
Node Centrality
中心性
Importance-based features
-
c v c_v cv: node centrality of node v v v
-
Node centrality c v c_v cv takes the node importance in a graph into account
Engienvector Centrality
Engienvector Centrality
-
Key Idea: A node v v v is important if surrounded by important neighboring nodes u ∈ N ( v ) u \in N(v) u∈N(v)
-
We model the centrality of node v v v as the sum of the centrality of neighboring nodes
c v = 1 λ ∑ u ∈ N ( v ) c u c_{v}=\frac{1}{\lambda} \sum_{u \in N(v)} c_{u} cv=λ1u∈N(v)∑cu
λ \lambda λ is some positive constant -
上式是以递归形式(Recursive Manner)定义的,将其重写为矩阵形式(Matrix Form)
λ c = A c \lambda \boldsymbol{c}=\boldsymbol{A} \boldsymbol{c} λc=Ac
A \boldsymbol{A} A: (Sub-) Adjacency matrix, A u v = 1 \boldsymbol{A}_{uv} = 1 Auv=1 if u ∈ N ( v ) u \in N(v) u∈N(v); c \boldsymbol{c} c: Centrality vector of node v v v-
从矩阵形式可以看出,节点中心性向量其实就是子邻接矩阵的特征向量
-
The largest eigenvalue λ m a x {\lambda}_{max} λmax is always positive and unique (by Perron-Frobenius Theorem)
-
The leading eigenvector c m a x \boldsymbol{c}_{max} cmax, which corresponds to the largest eigenvalue λ m a x {\lambda}_{max} λmax, is used for centrality
-
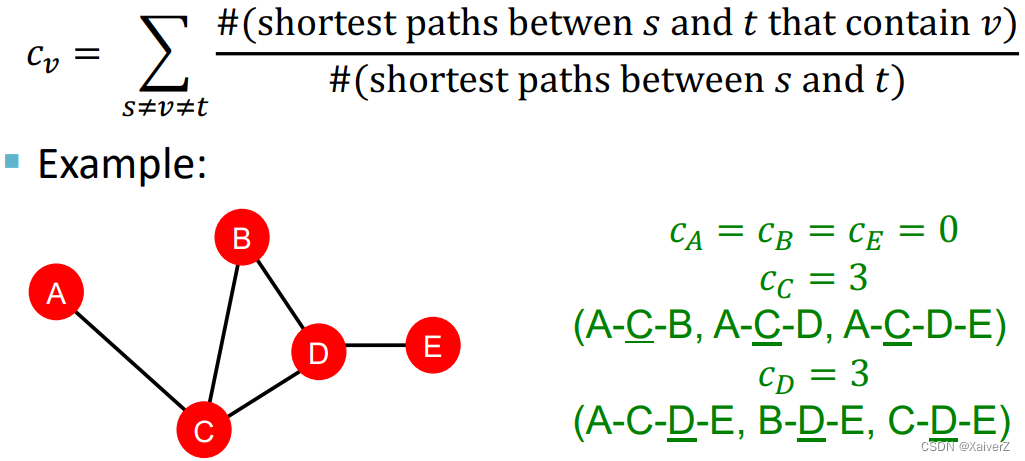
Betweenness Centrality
Betweenness Centrality
-
Key Idea: A node is important if it lies on many shortest paths between other nodes (something like transit hub)
Closeness Centrality
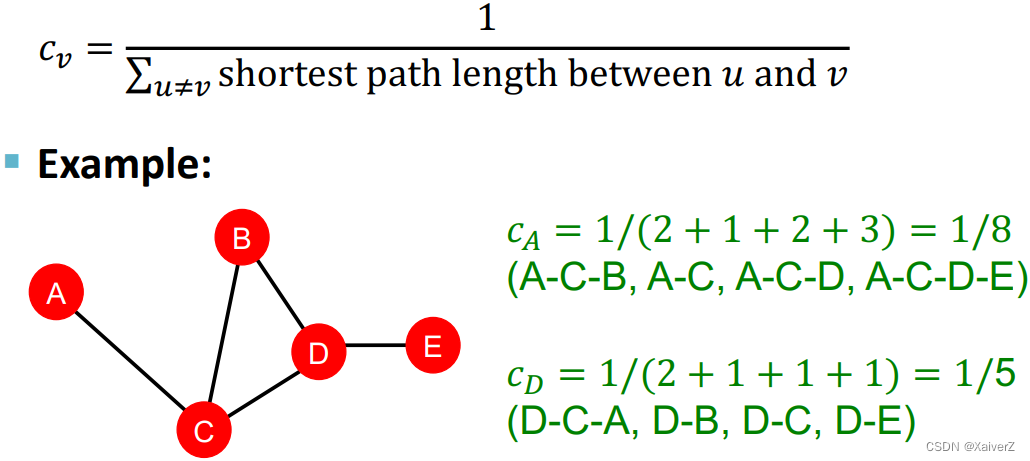
Closeness Centrality
-
Key Idea: A node is important if it has small shortest path lengths to all other nodes (其余节点到该节点的最短路径长度之和越小,该节点越重要,因为这样的节点一般处于中心位置,到其余节点的距离最短)
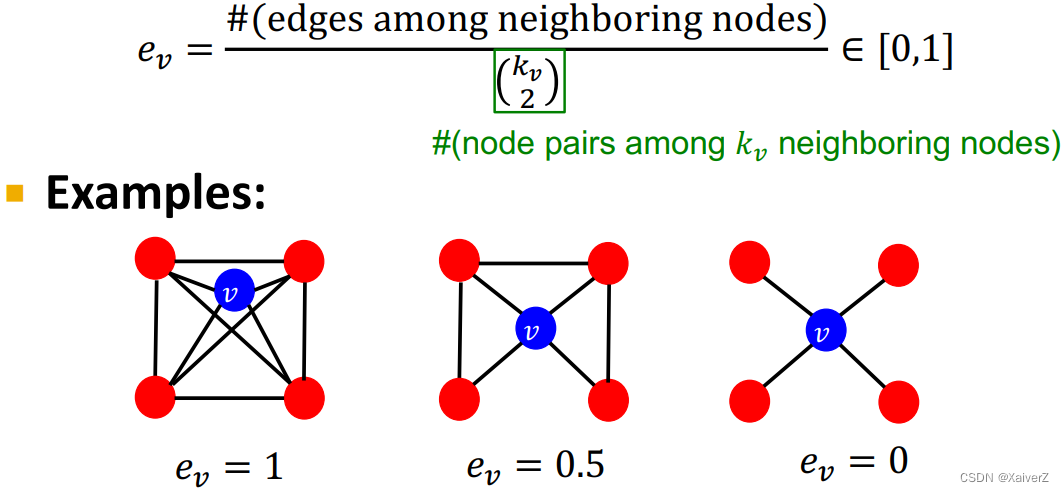
Clustering Coefficient
聚类系数
Structure-based features
-
Key Idea: Measures how connected v v v’s neighboring nodes are (衡量节点 v v v的邻居节点的连接程度)
-
除了与节点 v v v的邻居关系,聚类系数计算过程与节点 v v v本身没有直接的关系
- 以图1为例, e v e_v ev的分子为邻居节点之间的实际连边数,即为6(抹去 v v v以及与其相连的边,剩下的即为邻居节点的边); e v e_v ev的分母为组合数,从 v v v的 k v k_v kv个邻居节点中任选两点进行连边,计算最大连边总数
-
Graphlets
有根、连接的、非同构子图(Rooted connected non-isomorphic subgraphs)
-
以2-node graphlet为例,只有一种连接方式,且根节点的位置无论在哪个节点都是同构的,所以只有一种形式的有根连接非同构子图
-
以3-node graphlet为例,有两种连接方式,在第一种连接方式 G 1 G_1 G1中,根节点在两端以及在中心这两种情况是非同构的,所以 G 1 G_1 G1其实有两种有根连接非同构子图;在第二种连接方式 G 2 G_2 G2中,根节点无论在哪个点都是同构的,所以 G 2 G_2 G2只有一种有根连接非同构子图。总的来说,3-node graphlet共有三种有根连接非同构子图
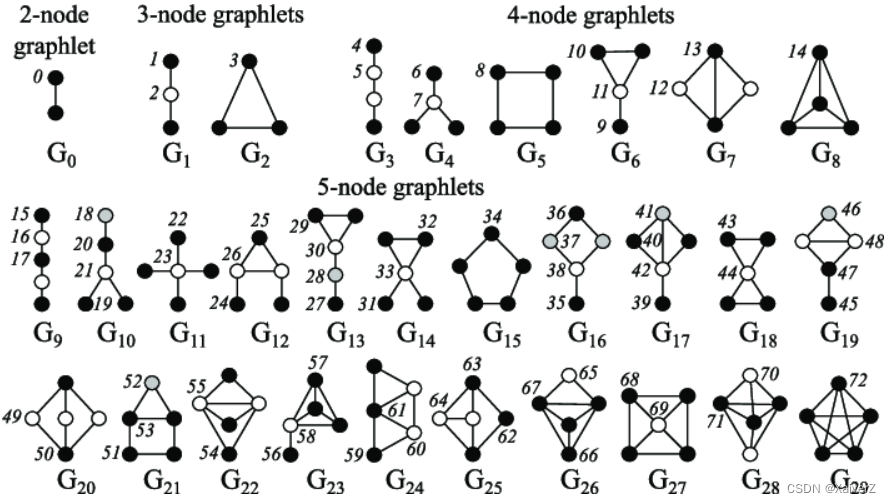
Graphlet Degree Vector (GDV)
Graphlet-base features for nodes, which counts #(graphlets) that a node touches
Structure-based features
-
Key Idea: A count vector of graphlets rooted at a given node
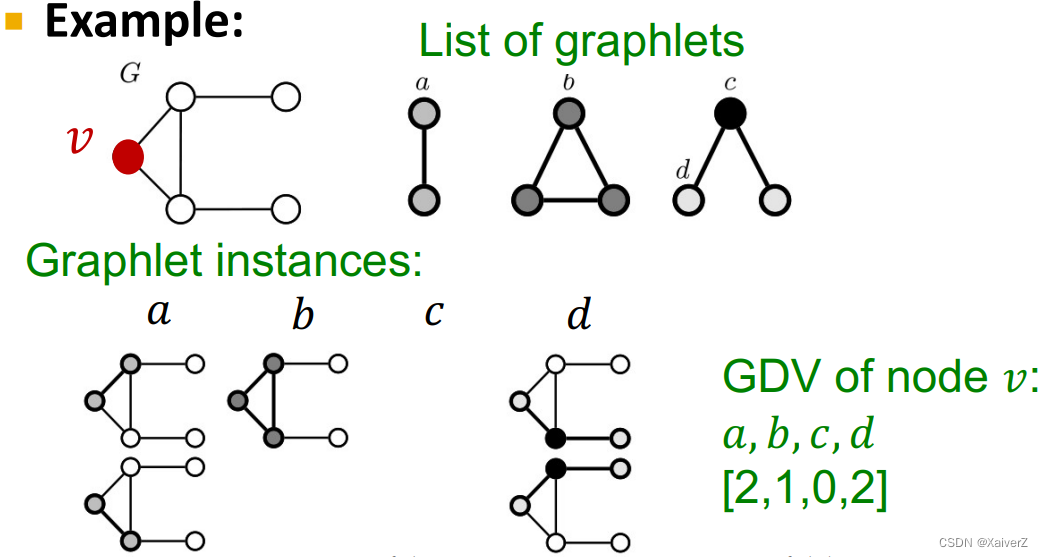
-
如上图所示,只考虑2-3 nodes graphlets,共有四种有根连接非同构子图的形式,根节点分别为 a a a、 b b b、 c c c、 d d d
-
在计算节点 v v v的GDV时,以 v v v为根节点分别去匹配四种graphlets的形式,并计数
-
Tips:根节点 c c c的graphlet匹配数为0,因为原图以 v v v为根节点的“三角形”有三条连边,而以 c c c为根节点的graphlet只有两条连边(Graphlets的定义:有根、连接、非同构,缺一不可)
-
-
如果考虑2-5 nodes graphlets,那么
-
会得到73种有根连接非同构子图,描述了节点周围邻居的拓扑结构
-
捕捉到4跳以内距离(distance of 4 hops)的节点互连关系
-
-
Graphlet degree vector (GDV) provides a measure of a node’s local network topology
Link-level Tasks and Features
Goal: To predict new links based on existing links
At test time, all node pairs (no existing links) are ranked, and top K K K node pairs are predicted
Key: To design features for a pair of nodes
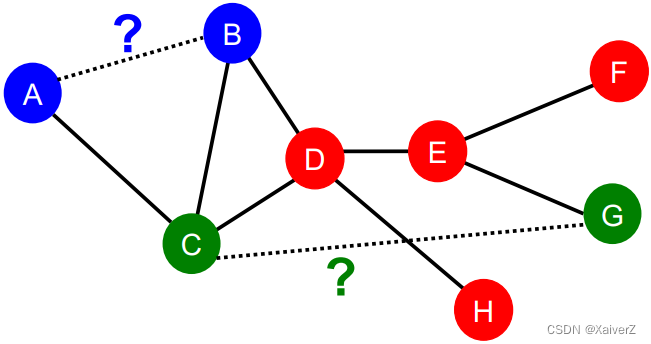
-
Two formulations of the link prediction task
-
Links missing at random
Remove a random set of links and then aim to predict them
-
Links over time
Assume that our network evolves over time (e.g. social network) and new links will be added in the future. Give G [ t 0 , t 0 ′ ] G[t_0, t_0'] G[t0,t0′] a graph on edges up to time t 0 ′ t_0' t0′, output a ranked list L L L of links (not in G [ t 0 , t 0 ′ ] G[t_0, t_0'] G[t0,t0′]) that are predicted to appear in G [ t 1 , t 1 ′ ] G[t_1, t_1'] G[t1,t1′]
- Evaluation: Take top n elements of L L L and count correct edges that actually appear in test period [ t 1 , t 1 ′ ] [t_1, t_1'] [t1,t1′]
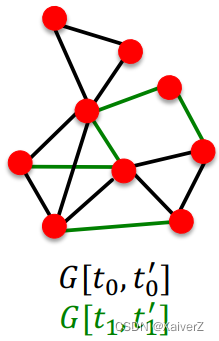
-
-
Link Prediction via Proximity
-
For each pair of nodes ( x , y ) (x, y) (x,y) compute score c ( x , y ) c(x,y) c(x,y)
- As an example, c ( x , y ) c(x,y) c(x,y) could be the number of common neighbors of x x x and y y y
-
Sort pairs ( x , y ) (x,y) (x,y) by the decreasing score c ( x , y ) c(x,y) c(x,y)
-
Predict top n n n pairs as new links
-
Eval: See which of these links actually appear in G G G
-
Distance-Based Features
Distance-Based Features
-
Key Idea: Shortest-path distance between two nodes (两个节点间最短路径的距离)
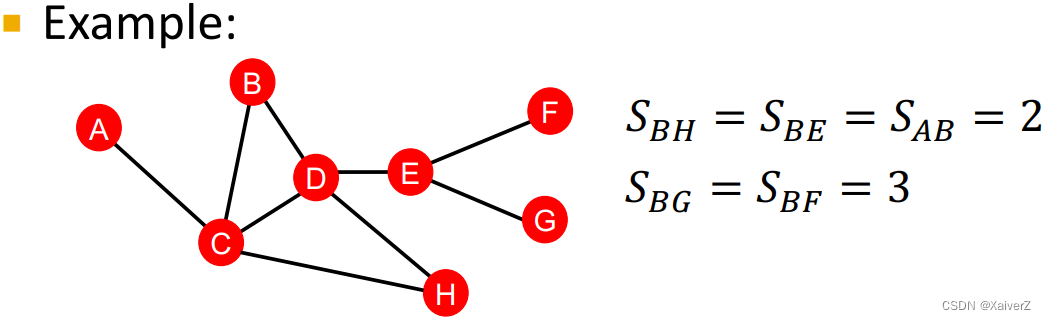
-
However, this does not capture the degree of neighborhood overlap (这种方法并没有考虑到两个节点的共同邻居数量)
- ( B , H ) (B, H) (B,H) has 2 shared neighboring nodes, while ( B , E ) (B, E) (B,E) only have 1 such node
Local Neighborhood Overlap
Local Neighborhood Overlap
- Key Idea: Captures the number of neighboring nodes shared between two nodes v 1 v_1 v1 and v 2 v_2 v2 (两节点共同邻居的数量)
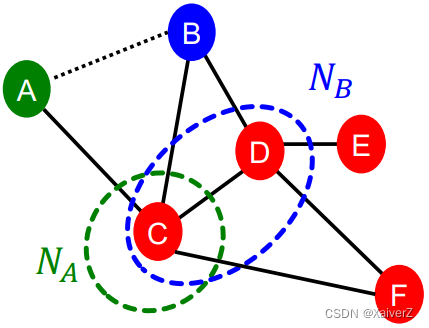
Common Neighbors
Common Neighbors
-
Mathematical Form
∣ N ( v 1 ) ∩ N ( v 2 ) ∣ \left|N\left(v_{1}\right) \cap N\left(v_{2}\right)\right| ∣N(v1)∩N(v2)∣
-
Example: ∣ N ( A ) ∩ N ( B ) ∣ = ∣ { C } ∣ = 1 |N(A) \cap N(B)|=|\{C\}|=1 ∣N(A)∩N(B)∣=∣{C}∣=1
Jaccard’s Coefficient
Jaccard’s Coefficient
-
Mathematical Form
∣ N ( v 1 ) ∩ N ( v 2 ) ∣ ∣ N ( v 1 ) ∪ N ( v 2 ) ∣ \frac{\left|N\left(v_{1}\right) \cap N\left(v_{2}\right)\right|}{\left|N\left(v_{1}\right) \cup N\left(v_{2}\right)\right|} ∣N(v1)∪N(v2)∣∣N(v1)∩N(v2)∣
-
Example: ∣ N ( A ) ∩ N ( B ) ∣ ∣ N ( A ) ∪ N ( B ) ∣ = ∣ { C } ∣ ∣ { C , D } ∣ = 1 2 \frac{|N(A) \cap N(B)|}{|N(A) \cup N(B)|}=\frac{|\{C\}|}{|\{C, D\}|}=\frac{1}{2} ∣N(A)∪N(B)∣∣N(A)∩N(B)∣=∣{C,D}∣∣{C}∣=21
Adamic-Adar Index
Adamic-Adar Index
-
Mathematical Form
∑ u ∈ N ( v 1 ) ∩ N ( v 2 ) 1 log ( k u ) \sum_{u \in N\left(v_{1}\right) \cap N\left(v_{2}\right)} \frac{1}{\log \left(k_{u}\right)} u∈N(v1)∩N(v2)∑log(ku)1
-
Example: 1 log ( k C ) = 1 log 4 \frac{1}{\log \left(k_{C}\right)}=\frac{1}{\log 4} log(kC)1=log41
Global Neighborhood Overlap
Global Neighborhood Overlap
-
Limitation of local neighborhood features
- Metric is always zero if the two nodes do not have any neighbors in common

- However, the two nodes may still potentially be connected in the future
Katz Index
Katz Index
-
Key Idea: Count the number of paths of all lengths between a given pair of nodes (计算一对节点间所有不同长度路径的数量)
-
Tricks: Use adjacency matrix powers to compute Katz Index
-
A u v A_{uv} Auv specifies #paths of length 1 (direct neighborhood) between u u u and v v v
-
A u v 2 A^2_{uv} Auv2 specifies #paths of length 2 (neighbor of neighbor) between u u u and v v v
-
Inductively, A u v l A^l_{uv} Auvl specifies #paths of length l l l between u u u and v v v
-
-
Katz index between v 1 v_1 v1 and v 2 v_2 v2 is calculated as
S v 1 v 2 = ∑ l = 1 ∞ β l A v 1 v 2 l S_{v_{1} v_{2}}=\sum_{l=1}^{\infty} \beta^{l} \boldsymbol{A}_{v_{1} v_{2}}^{l} Sv1v2=l=1∑∞βlAv1v2l
A v 1 v 2 l \boldsymbol{A}_{v_{1} v_{2}}^{l} Av1v2l is #paths of length l l l between v 1 v_1 v1 and v 2 v_2 v2; 0 < β < 1 0 < \beta < 1 0<β<1 is a discount factor -
Katz index matrix is computed in closed-form (by geometric series of matrices)
S = ∑ i = 1 ∞ β i A i = ( I − β A ) − 1 ⏟ = ∑ i = 0 ∞ β i A i − I \boldsymbol{S}=\sum_{i=1}^{\infty} \beta^{i} \boldsymbol{A}^{i}=\underbrace{(\boldsymbol{I}-\beta \boldsymbol{A})^{-1}}_{=\sum_{i=0}^{\infty} \beta^{i} \boldsymbol{A}^{i}}-\boldsymbol{I} S=i=1∑∞βiAi==∑i=0∞βiAi (I−βA)−1−I
Graph-level Features and Graph kernels
Goal: We want features that characterize the structure of an entire graph
Key Idea: Design kernels instead of feature vectors
-
Quick Intro to Kernels
-
Kernel K ( G , G ′ ) ∈ R K(G, G') \in R K(G,G′)∈R measures similarity between data
-
Kernel matrix K = ( K ( G , G ′ ) ) G , G ′ K = (K(G, G'))_{G, G'} K=(K(G,G′))G,G′ must always be positive semidefinite (i.e. has positive eigenvals)
-
There exists a feature representation ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) such that K ( G , G ′ ) = ϕ ( G ) T ϕ ( G ′ ) K\left(G, G^{\prime}\right)=\phi(G)^{\mathrm{T}} \phi\left(G^{\prime}\right) K(G,G′)=ϕ(G)Tϕ(G′)
-
-
Graph Kernel
Graph Kernels: Measure similarity between two graphs
-
Goal: Design graph feature vector ϕ ( G ) \phi{(G)} ϕ(G)
-
Key Idea: Bag-of-Words (BoW) for a graph, which simply used the word counts as features for documents (no ordering considered)
-
Naive extension to a graph: Regard nodes as words
-
Since both graphs have 4 red nodes, we get the same feature vector for two different graphs…
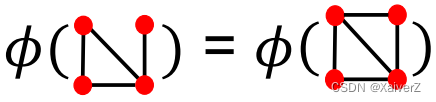
-
And what if we use Bag of node degrees ?
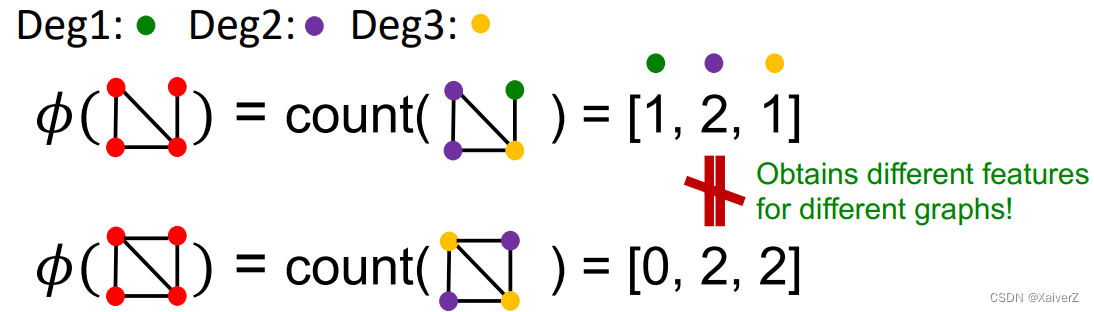
-
-
Both Graphlet Kernel and Weisfeiler-Lehman (WL) Kernel use Bag-of-* representation of graph, where * is more sophisticated than node degrees
Graphlet Kernel
Paper : Efficient graphlet kernels for large graph comparison
Graphlet Kernel
-
Key Idea: Count the number of different graphlets in a graph
-
The defination of graphlets here is slightly different from node-level features
-
Nodes in graphlets here do not need to be connected (allows for isolated nodes)
-
The graphlets here are not rooted
-
-
-
Let G k = ( g 1 , g 2 , … , g n k ) \mathcal{G}_{k}=\left(g_{1}, g_{2}, \ldots, g_{n_{k}}\right) Gk=(g1,g2,…,gnk) be a list of graphlets of size k k k
-
For k = 3 k=3 k=3, there are 4 graphlets
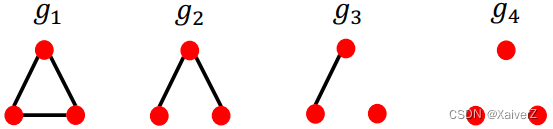
-
For k = 4 k=4 k=4, there are 11 graphlets
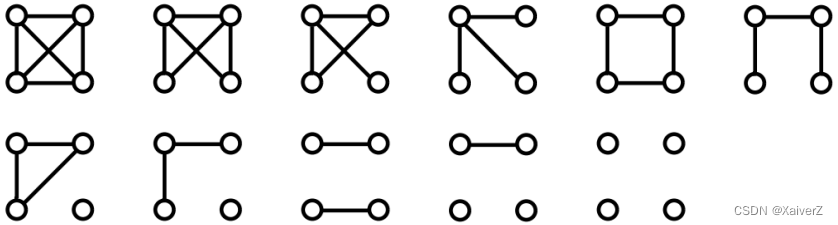
-
-
Given graph G G G, and a graphlet list G k = ( g 1 , g 2 , … , g n k ) \mathcal{G}_{k}=\left(g_{1}, g_{2}, \ldots, g_{n_{k}}\right) Gk=(g1,g2,…,gnk), define the graphlet count vector f G ∈ R n k f_{G} \in \mathbb{R}^{n_{k}} fG∈Rnk as
( f G ) i = # ( g i ⊆ G ) for i = 1 , 2 , … , n k \left(\boldsymbol{f}_{G}\right)_{i}=\#\left(g_{i} \subseteq G\right) \text { for } i=1,2, \ldots, n_{k} (fG)i=#(gi⊆G) for i=1,2,…,nk
-
Example for k = 3 k=3 k=3
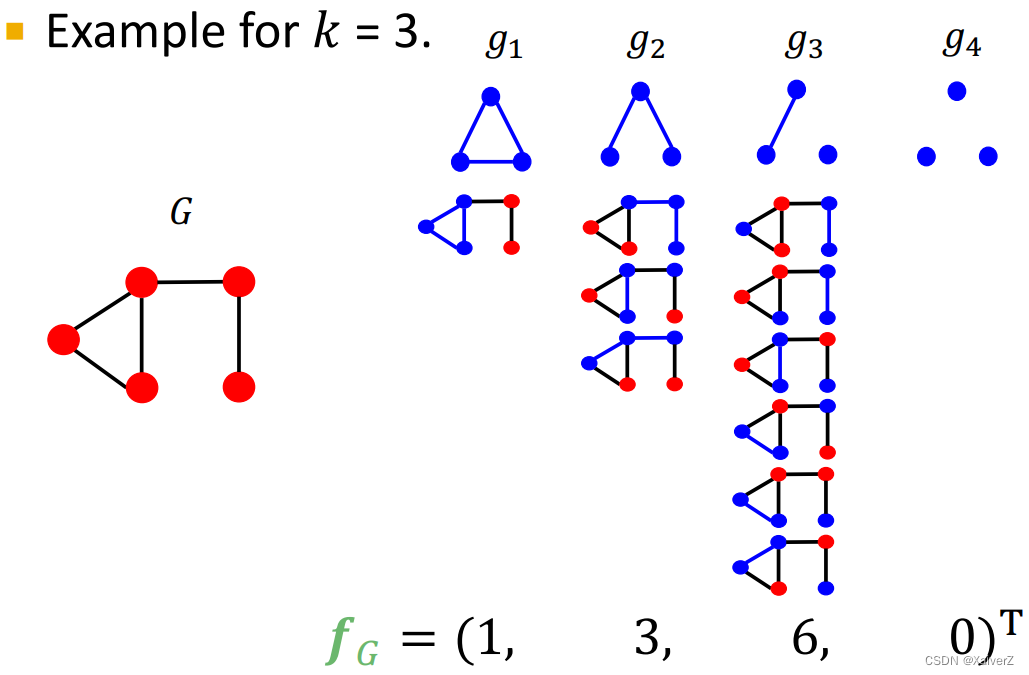
-
Given two graphs, G G G and G ′ G' G′, graphlet kernel is computed as
K ( G , G ′ ) = f G T f G ′ K\left(G, G^{\prime}\right)=\boldsymbol{f}_{G}^{\mathrm{T}} \boldsymbol{f}_{G^{\prime}} K(G,G′)=fGTfG′
- 若 G G G和 G ′ G' G′的节点数不同,那么Graphlet Kernel计算出来的相似度可能存在值偏移(Skew the value),所以这里对特征向量 f G \boldsymbol{f}_{G} fG进行normalize,并使用normalize后的特征向量进行相似度计算
h G = f G Sum ( f G ) K ( G , G ′ ) = h G T h G ′ \boldsymbol{h}_{G}=\frac{\boldsymbol{f}_{G}}{\operatorname{Sum}\left(\boldsymbol{f}_{G}\right)} \quad K\left(G, G^{\prime}\right)=\boldsymbol{h}_{G}{ }^{\mathrm{T}} \boldsymbol{h}_{G^{\prime}} hG=Sum(fG)fGK(G,G′)=hGThG′
这样一来, f G \boldsymbol{f}_{G} fG中的每个分量都代表graphlet出现的概率,避免了因图节点数量不同而造成的数据偏移 -
Limitation: Counting graphlets is expensive
-
Counting size-k graphlets for a graph with size n n n by enumeration takes n k n^k nk
-
This is unavoidable in the worst-case since subgraph isomorphism test (judging whether a graph is a subgraph of another graph) is NP-hard
-
If a graph’s node degree is bounded by d d d, an O ( n d k − 1 ) O(nd^{k-1}) O(ndk−1) algorithm exists to count all the graphlets of size k k k
-
Weisfeiler-Lehman Kernel
Paper : Weisfeiler-Lehman Graph Kernels
Weisfeiler-Lehman Kernel (WL Kernel)
-
Goal: Design an efficient graph feature descriptor ϕ ( G ) \phi{(G)} ϕ(G)
-
Idea: Use neighborhood structure to iteratively enrich node vocabulary —— Color Refinement
Color Refinement
Color Refinement
-
Given: A graph G G G with a set of nodes V V V
-
Assign an initial color c ( 0 ) ( v ) c^{(0)}(v) c(0)(v) to each node v v v
-
Iteratively refine node colors by
c ( k + 1 ) ( v ) = HASH ( { c ( k ) ( v ) , { c ( k ) ( u ) } u ∈ N ( v ) } ) c^{(k+1)}(v)=\operatorname{HASH}\left(\left\{c^{(k)}(v),\left\{c^{(k)}(u)\right\}_{u \in N(v)}\right\}\right) c(k+1)(v)=HASH({c(k)(v),{c(k)(u)}u∈N(v)})
where HASH \operatorname{HASH} HASH maps different inputs to different colors -
After K K K steps of color refinement, c ( k ) ( v ) c^{(k)}(v) c(k)(v) summarizes the structure of K-hop neighborhood
-
-
Example: Use digits for colors
-
Assign initial colors

-
Aggregate neighboring colors
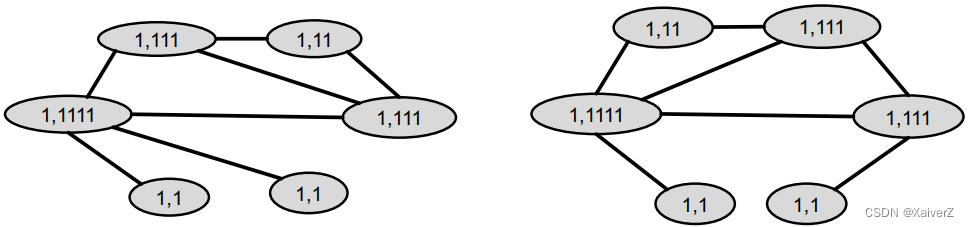
-
Hash aggregated colors
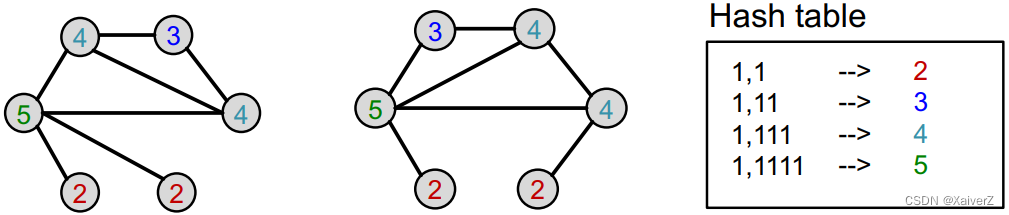
-
Aggregate neighboring colors
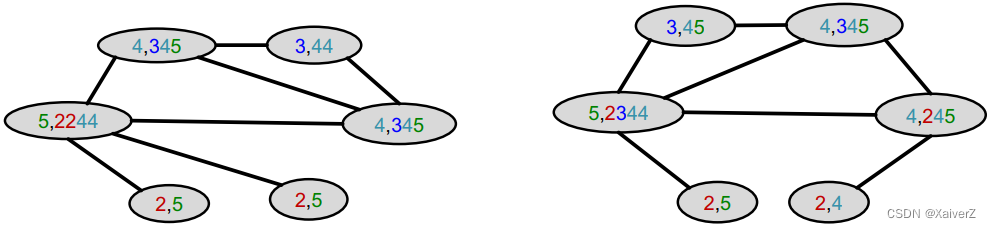
-
Hash aggregated colors
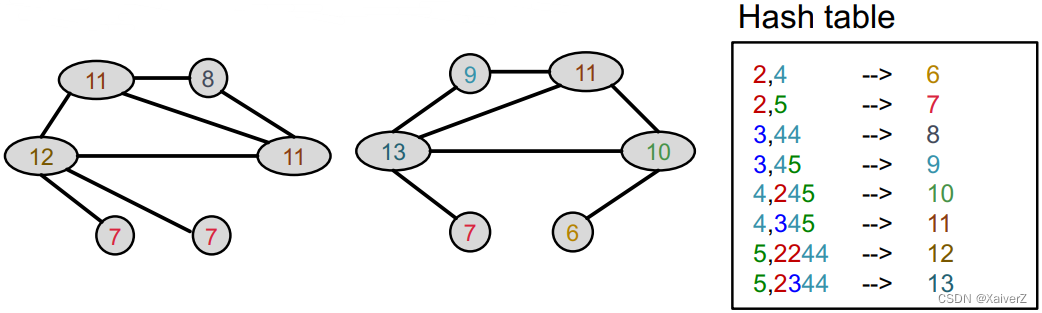
-
After color refinement, WL kernel counts number of nodes with a given color
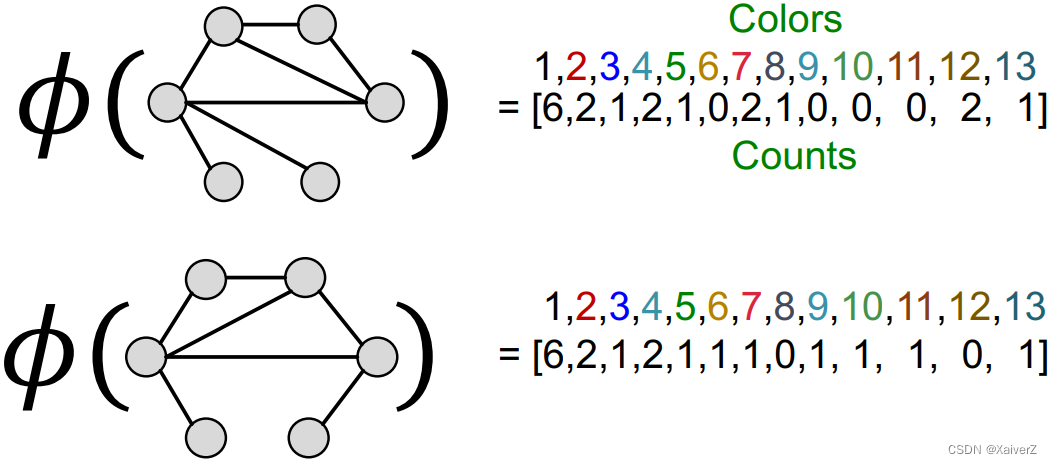
-
The WL kernel value is computed by the inner product of the color count vectors

-
-
WL kernel is computationally efficient
-
The time complexity for color refinement at each step is linear in #(edges), since it involves aggregating neighboring colors
-
When computing a kernel value, only colors appeared in the two graphs need to be tracked. Thus, #(colors) is at most the total number of nodes
-
Counting colors takes linear-time w.r.t. #(nodes)
-
In total, time complexity is linear in #(edges)
-
-
The computation manner of WL kernel closely related to Graph Neural Network














 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









