







大家可能看到网上有很多教大家微调大模型的教程,但是大多数作者往往都没有告诉我们微调适用于哪些场景,而哪些场景不需要微调。
对大模型还不甚了解的客户可能会问:我的企业需要花时间精力微调或者训练一个自己的大模型吗?
今天我就用实际案例给大家来分享一下我们对这个问题的看法,如有不对之处,欢迎大家纠正,共同交流学习。
先说结论:大多数情况下都不需要自己训练,直接使用开源的大模型即可
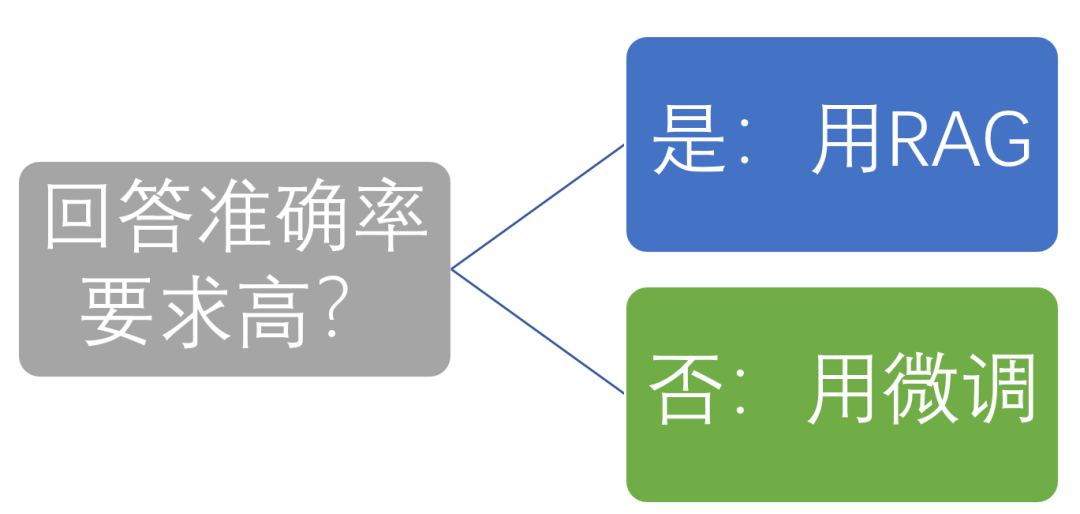
为什么这么说呢?
因为微调后AI大模型并不会严格按照你的数据进行回答,所以如果您是政务,医疗,法律等对回答准确度要求很高的客户,不能答错一个字,则您需要的是AI语义匹配算法,而不是训练大模型。
下面我就用一个实际例子来跟大家展示实际微调后的效果,这是一个医疗问诊开源大模型微调的项目
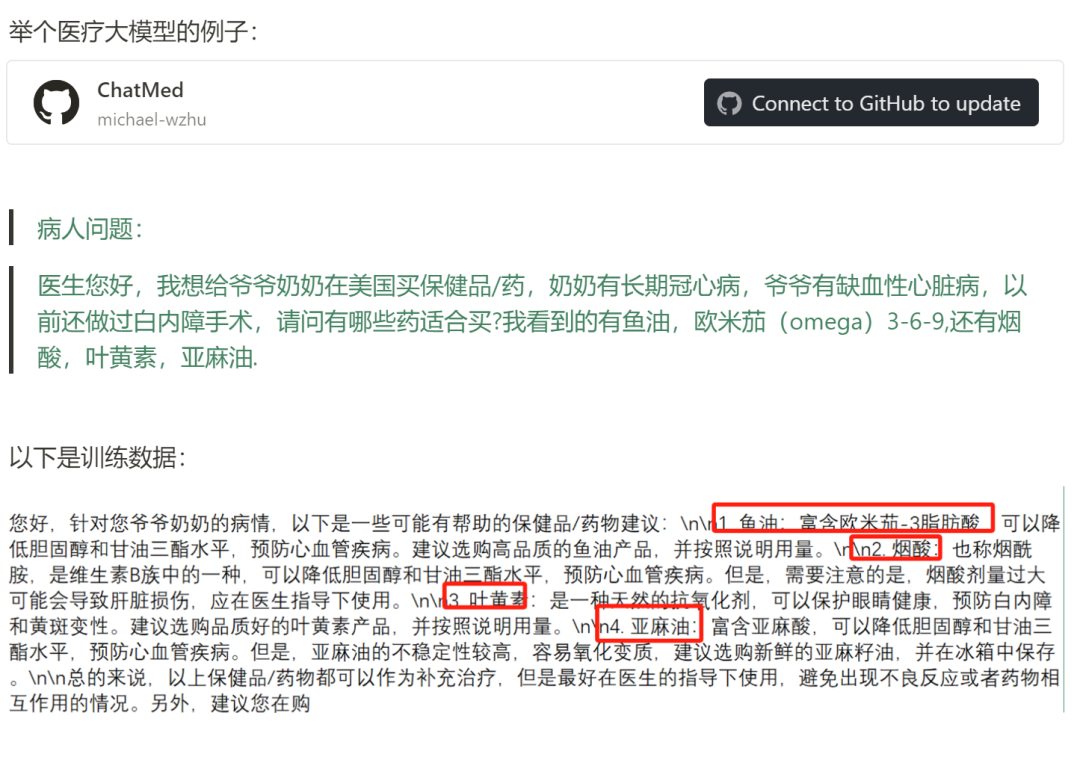
上面用户的问题是:想咨询哪些保健品适合爷爷奶奶
训练数据首先提到可以尝试:鱼油 ;二 烟酸 三 叶黄素
作者用50多万条实际医疗问诊数据来微调拉玛模型,这是其中一条问题,同时也是训练数据,我们现在看看训练后同样的问题是否会产生同样的答案
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









