







优化改进
backtrader 版本 1.8.12.99 包括了 数据源 和 结果 在多进程中的管理改进。
注意
对两者的行为进行了调整
这些选项的行为可以通过两个新的 Cerebro 参数进行控制:
-
optdatas(默认:True)如果为
True并且正在优化(并且系统可以preload并使用runonce,数据预加载将仅在主进程中执行一次,以节省时间和资源。 -
optreturn(默认:True)如果为
True,则优化结果将不是完整的Strategy对象(以及所有 数据,指标,观察器等),而是具有以下属性的对象(与Strategy中相同):-
params(或p)执行策略时的参数 -
analyzers执行的策略
在大多数情况下,只需要 analyzers 和使用哪些 params 来评估策略的表现。如果需要对生成的值(例如 指标)进行详细分析,请关闭此选项。
-
数据源管理
在 优化 场景中,这是 Cerebro 参数的可能组合:
-
preload=True(默认)在运行任何回测代码之前,数据源将被预加载
-
runonce=True(默认)指标 将以批处理模式计算在一个紧密的 for 循环中,而不是逐步进行。
如果两个条件都为 True 并且 optdatas=True,则:
- 在生成新子进程(负责执行 回测 的子进程)之前,数据源 将在主进程中预加载
结果管理
在 优化 场景中,评估每个 策略 运行时使用的不同参数时,两件事应该起到最重要的作用:
-
strategy.params(或strategy.p)回测中使用的实际值集
-
strategy.analyzers负责提供 策略 实际表现评估的对象。示例:
SharpeRatio_A(年化 SharpeRatio)
当 optreturn=True 时,将创建占位符对象,而不是返回完整的 策略 实例,这些对象携带上述两个属性,以便进行评估。
这样可以避免传递大量生成的数据,例如 回测 期间指标生成的值
如果希望使用 完整的策略对象,只需在 cerebro 实例化 期间或进行 cerebro.run 时将 optreturn=False。
一些测试运行
backtrader 源代码中的 优化 示例已经扩展,以添加对 optdatas 和 optreturn 的控制(实际上是禁用它们)
单核运行
作为参考,当 CPU 数量限制为 1 且未使用 multiprocessing 模块时发生了什么:
$ ./optimization.py --maxcpus 1
==================================================
**************************************************
--------------------------------------------------
OrderedDict([(u'smaperiod', 10), (u'macdperiod1', 12), (u'macdperiod2', 26), (u'macdperiod3', 9)])
**************************************************
--------------------------------------------------
OrderedDict([(u'smaperiod', 10), (u'macdperiod1', 13), (u'macdperiod2', 26), (u'macdperiod3', 9)])
...
...
OrderedDict([(u'smaperiod', 29), (u'macdperiod1', 19), (u'macdperiod2', 29), (u'macdperiod3', 14)])
==================================================
Time used: 184.922727833
多核运行
不限制 CPU 数量时,Python 的 multiprocessing 模块将尝试使用所有 CPU。optdatas 和 optreturn 将被禁用。
optdata和optreturn均处于激活状态
默认行为:
$ ./optimization.py
...
...
...
==================================================
Time used: 56.5889185394
多核和数据提供以及结果改进带来的总改进意味着从184.92秒降至56.58秒。
请注意,示例使用252根柱和指标仅生成长度为252点的值。这只是一个例子。
真正的问题是这有多少归因于新行为。
optreturn已停用
让我们将完整的策略对象传递给调用者:
$ ./optimization.py --no-optreturn
...
...
...
==================================================
Time used: 67.056914007
执行时间增加了18.50%(或加速比为15.62%)。
optdatas已停用
每个子进程被强制加载其自己的数据提供值集:
$ ./optimization.py --no-optdatas
...
...
...
==================================================
Time used: 72.7238112637
执行时间增加了28.52%(或加速比为22.19%)。
两者均已停用
仍然使用多核但保持旧的非改进行为:
$ ./optimization.py --no-optdatas --no-optreturn
...
...
...
==================================================
Time used: 83.6246643786
执行时间增加了47.79%(或加速比为32.34%)。
这表明使用多核是时间改进的主要贡献者。
注意
执行是在装有i7-4710HQ(4 核/8 逻辑)和 16 GBytes RAM 的 Windows 10 64 位笔记本电脑上进行的。在其他条件下情况可能会有所不同
结论
-
优化期间减少时间的最大因素是使用多核
-
使用
optdatas和optreturn的示例运行显示每个的加速比约为22.19%和15.62%(在测试中两者一起为32.34%)
示例用法
$ ./optimization.py --help
usage: optimization.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--maxcpus MAXCPUS] [--no-runonce]
[--exactbars EXACTBARS] [--no-optdatas]
[--no-optreturn] [--ma_low MA_LOW] [--ma_high MA_HIGH]
[--m1_low M1_LOW] [--m1_high M1_HIGH] [--m2_low M2_LOW]
[--m2_high M2_HIGH] [--m3_low M3_LOW]
[--m3_high M3_HIGH]
Optimization
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--maxcpus MAXCPUS, -m MAXCPUS
Number of CPUs to use in the optimization
- 0 (default): use all available CPUs
- 1 -> n: use as many as specified
--no-runonce Run in next mode
--exactbars EXACTBARS
Use the specified exactbars still compatible with preload
0 No memory savings
-1 Moderate memory savings
-2 Less moderate memory savings
--no-optdatas Do not optimize data preloading in optimization
--no-optreturn Do not optimize the returned values to save time
--ma_low MA_LOW SMA range low to optimize
--ma_high MA_HIGH SMA range high to optimize
--m1_low M1_LOW MACD Fast MA range low to optimize
--m1_high M1_HIGH MACD Fast MA range high to optimize
--m2_low M2_LOW MACD Slow MA range low to optimize
--m2_high M2_HIGH MACD Slow MA range high to optimize
--m3_low M3_LOW MACD Signal range low to optimize
--m3_high M3_HIGH MACD Signal range high to optimize
异常
设计目标之一是尽早退出,并让用户完全透明地了解错误的发生情况。目标是迫使自己拥有会在异常情况下中断并强制重新访问受影响部分的代码。
但时机已经成熟,一些异常可能会慢慢添加到平台中。
层次结构
所有异常的基类是BacktraderError(它是Exception的直接子类)
位置
-
在模块
errors内,例如可以通过以下方式访问:import backtrader as bt class Strategy(bt.Strategy): def __init__(self): if something_goes_wrong(): raise bt.errors.StrategySkipError` -
直接来自
backtrader,如下所示:import backtrader as bt class Strategy(bt.Strategy): def __init__(self): if something_goes_wrong(): raise bt.StrategySkipError`
异常
StrategySkipError
请求平台跳过此策略进行回测。在实例化(__init__)阶段引发
写入器
将以下内容写入流:
-
包含数据源、策略、指标和观察器的 csv 流
可以通过每个对象的
csv属性控制哪些对象实际进入 csv 流(对于数据源和观察器默认为 True / 对于指标默认为 False) -
属性摘要
-
数据源
-
策略(行数和参数)
-
指标/观察器:(行数和参数)
-
分析器:(参数和分析结果)
-
只定义了一个称为 WriterFile 的写入器,可以添加到系统中:
-
通过将 cerebro 的
writer参数设置为 True将实例化标准的
WriterFile -
通过调用
Cerebro.addwriter(writerclass, **kwargs)writerclass将在回测执行期间使用给定的kwargs实例化鉴于标准的
WriterFile不会默认输出csv,以下addwriter调用将负责处理:cerebro.addwriter(bt.WriterFile, csv=True)`
参考文献
backtrader.WriterFile 类
系统范围的写入器类。
可以用以下方式进行参数化:
-
out(默认:sys.stdout):要写入的输出流如果传递了字符串,则将使用参数内容的文件名
-
close_out(默认:False)如果
out是一个流,则是否需要写入器显式关闭它 -
csv(默认:False)如果在执行期间需要将数据源、策略、观察器和指标的 csv 流写入流
可以通过每个对象的
csv属性控制哪些对象实际进入 csv 流(对于数据源和观察器默认为 True / 对于指标默认为 False) -
csv_filternan(默认:True)是否需要将nan值从 csv 流中清除(替换为空字段) -
csv_counter(默认:True)如果写入器应该保留并打印实际输出的行数计数器 -
indent(默认:2)每个级别的缩进空格数 -
separators(默认:['=', '-', '+', '*', '.', '~', '"', '^', '#'])用于各个部分/子(子)部分的行分隔符使用的字符
-
seplen(默认:79)包括缩进在内的一行分隔符的总长度
-
rounding(默认:None)要将浮点数舍入到的小数位数。使用
None时不执行舍入
数据提要
数据源
backtrader配备了一组数据源解析器(在撰写本文时全部基于 CSV),让您可以从不同来源加载数据。
-
Yahoo(在线或已保存到文件中)
-
VisualChart(请参阅www.visualchart.com
-
Backtrader CSV(用于测试的自有格式)
-
通用 CSV 支持
从快速入门指南中应清楚地了解到,您可以将数据源添加到Cerebro实例中。稍后,不同策略将可以在以下位置访问数据源:
-
一个数组 self.datas(插入顺序)
-
数组对象的别名:
-
self.data 和 self.data0 指向第一个元素
-
self.dataX 指向数组中索引为 X 的元素
-
有关插入方式的快速提醒:
import backtrader as bt
import backtrader.feeds as btfeeds
data = btfeeds.YahooFinanceCSVData(dataname='wheremydatacsvis.csv')
cerebro = bt.Cerebro()
cerebro.adddata(data) # a 'name' parameter can be passed for plotting purposes
数据源常见参数
此数据源可以直接从 Yahoo 下载数据并馈送到系统中。
参数:
-
dataname(默认值:None)必须提供其含义随数据源类型而异(文件位置、股票代码等)
-
name(默认值:‘’)用于绘图的装饰目的。如果未指定,可能会从
dataname派生(例如:文件路径的最后部分) -
fromdate(默认值:mindate)Python 日期时间对象,指示应忽略任何早于此日期时间的日期时间
-
todate(默认值:maxdate)Python 日期时间对象,指示应忽略任何晚于此日期时间的日期时间
-
timeframe(默认值:TimeFrame.Days)潜在值:
Ticks,Seconds,Minutes,Days,Weeks,Months和Years -
compression(默认值:1)每根柱子的实际条数。信息性的。仅在数据重采样/重播中有效。
-
sessionstart(默认值:None)数据的会话开始时间指示。可能被类用于重新采样等目的
-
sessionend(默认值:None)数据的会话结束时间指示。可能被类用于重新采样等目的
CSV 数据源常见参数
参数(除了常见的之外):
-
headers(默认值:True)表示传递的数据是否具有初始标题行
-
separator(默认值:“,”)考虑到每个 CSV 行的标记分隔符
GenericCSVData
该类提供了一个通用接口,允许解析几乎每种 CSV 文件格式。
根据参数定义的顺序和字段存在性解析 CSV 文件
特定参数(或特定含义):
-
dataname要解析的文件名或类似文件的对象
-
datetime(默认值:0)包含日期(或日期时间)字段的列 -
time(默认值:-1)包含时间字段的列,如果与日期时间字段分开(-1 表示不存在) -
open(默认值:1),high(默认值:2),low(默认值:3),close(默认值:4),volume(默认值:5),openinterest(默认值:6)包含相应字段的列的索引
如果传递了负值(例如:-1),表示 CSV 数据中不存在该字段
-
nullvalue(默认值:float(‘NaN’))如果应该有一个值缺失(CSV 字段为空),则使用的值
-
dtformat(默认:%Y-%m-%d %H:%M:%S)用于解析 datetime CSV 字段的格式
-
tmformat(默认:%H:%M:%S)如果“存在”,则用于解析时间 CSV 字段的格式(“时间” CSV 字段的默认设置是不存在)
一个覆盖以下要求的示例用法:
-
限制输入至 2000 年
-
HLOC 顺序而不是 OHLC
-
缺失值将被替换为零(0.0)
-
提供日线数据,日期时间仅为格式为 YYYY-MM-DD 的日期
-
没有
openinterest列
代码:
import datetime
import backtrader as bt
import backtrader.feeds as btfeeds
...
...
data = btfeeds.GenericCSVData(
dataname='mydata.csv',
fromdate=datetime.datetime(2000, 1, 1),
todate=datetime.datetime(2000, 12, 31),
nullvalue=0.0,
dtformat=('%Y-%m-%d'),
datetime=0,
high=1,
low=2,
open=3,
close=4,
volume=5,
openinterest=-1
)
...
稍作修改的要求:
-
限制输入至 2000 年
-
HLOC 顺序而不是 OHLC
-
缺失值将被替换为零(0.0)
-
提供分钟线数据,带有单独的日期和时间列
-
日期的格式为 YYYY-MM-DD
-
时间的格式为 HH.MM.SS(而不是通常的 HH:MM:SS)
-
-
没有
openinterest列
代码:
import datetime
import backtrader as bt
import backtrader.feeds as btfeed
...
...
data = btfeeds.GenericCSVData(
dataname='mydata.csv',
fromdate=datetime.datetime(2000, 1, 1),
todate=datetime.datetime(2000, 12, 31),
nullvalue=0.0,
dtformat=('%Y-%m-%d'),
tmformat=('%H.%M.%S'),
datetime=0,
time=1,
high=2,
low=3,
open=4,
close=5,
volume=6,
openinterest=-1
)
这也可以通过子类化来永久实现:
import datetime
import backtrader.feeds as btfeed
class MyHLOC(btfreeds.GenericCSVData):
params = (
('fromdate', datetime.datetime(2000, 1, 1)),
('todate', datetime.datetime(2000, 12, 31)),
('nullvalue', 0.0),
('dtformat', ('%Y-%m-%d')),
('tmformat', ('%H.%M.%S')),
('datetime', 0),
('time', 1),
('high', 2),
('low', 3),
('open', 4),
('close', 5),
('volume', 6),
('openinterest', -1)
)
现在只需提供 dataname,就可以重用这个新类:
data = btfeeds.MyHLOC(dataname='mydata.csv')
扩展数据源
GitHub 上的问题实际上推动了完成文档部分或帮助我理解 backtrader 是否具有我最初设想的易用性和灵活性,以及沿途做出的决策。
在这种情况下是 问题 #9。
最终问题似乎归结为:
- 最终用户是否能轻松地扩展现有机制,以添加额外信息,比如像
open、high等的其他现有价格信息点呢?
据我所知,问题的答案是:是的
发帖人似乎有以下需求(来自问题 #6):
-
正在解析为 CSV 格式的数据源
-
使用
GenericCSVData加载信息这种通用 csv 支持是针对这个 问题 #6 开发的。
-
这是一个额外的字段,显然包含需要传递的 P/E 信息,这些信息将传递给解析后的 CSV 数据。
让我们继续 CSV 数据源开发和 GenericCSVData 示例帖子。
步骤:
-
假设 P/E 信息被设置在解析后的 CSV 数据中。
-
使用
GenericCSVData作为基类 -
将现有线(open/high/low/close/volumen/openinterest)扩展为
pe -
给调用者添加一个参数,让其确定 P/E 信息的列位置。
结果:
from backtrader.feeds import GenericCSVData
class GenericCSV_PE(GenericCSVData):
# Add a 'pe' line to the inherited ones from the base class
lines = ('pe',)
# openinterest in GenericCSVData has index 7 ... add 1
# add the parameter to the parameters inherited from the base class
params = (('pe', 8),)
工作完成了…
稍后,在策略中使用这个数据源时:
import backtrader as bt
....
class MyStrategy(bt.Strategy):
...
def next(self):
if self.data.close > 2000 and self.data.pe < 12:
# TORA TORA TORA --- Get off this market
self.sell(stake=1000000, price=0.01, exectype=Order.Limit)
...
绘制那条额外的 P/E 线
显然,数据源中的这行额外信息没有自动化的绘图支持。
最好的替代方法是对该行进行简单移动平均,并在单独的轴上绘制它:
import backtrader as bt
import backtrader.indicators as btind
....
class MyStrategy(bt.Strategy):
def __init__(self):
# The indicator autoregisters and will plot even if no obvious
# reference is kept to it in the class
btind.SMA(self.data.pe, period=1, subplot=False)
...
def next(self):
if self.data.close > 2000 and self.data.pe < 12:
# TORA TORA TORA --- Get off this market
self.sell(stake=1000000, price=0.01, exectype=Order.Limit)
...
CSV 数据源开发
backtrader已经提供了通用 CSV 数据源和一些特定的 CSV 数据源。总结:
-
通用 CSV 数据
-
VisualChartCSV 数据
-
YahooFinanceData(用于在线下载)
-
YahooFinanceCSVData(用于已下载的数据)
-
BacktraderCSVData(内部…用于测试目的,但可用)
但即使如此,最终用户可能希望为特定的 CSV 数据源开发支持。
通常的座右铭可能是:“说起来容易做起来难”。实际上,结构的目的是使其易于操作。
步骤:
-
继承自
backtrader.CSVDataBase -
如有必要,定义任何
params -
在
start方法中进行任何初始化 -
在
stop方法中进行任何清理 -
定义一个
_loadline方法,在其中进行实际工作此方法接收一个参数:linetokens。
如其名,此数据包含根据
separator参数(继承自基类)拆分当前行后的标记。如果完成工作后有新数据……填充相应行并返回
True如果没有可用内容,因此解析已经结束:返回
False如果在幕后代码中读取文件行时发现没有更多行可解析,则可能甚至不需要返回
False。
已经考虑到的事项:
-
打开文件(或接收文件样式对象)
-
如果指示存在,则跳过标题行
-
读取行
-
对行进行标记
-
预加载支持(一次性在内存中加载整个数据源)
通常,一个例子胜过千言万语的需求描述。让我们使用BacktraderCSVData中定义的内部 CSV 解析代码的简化版本。这个版本不需要初始化或清理(例如,可以是打开套接字,然后稍后关闭)。
注意
backtrader数据源包含通常的行业标准数据源,需要填充。即:
-
日期时间
-
打开
-
高
-
低
-
关闭
-
成交量
-
持仓量
如果您的策略/算法或简单的数据查看仅需要例如收盘价,则可以将其他值保持不变(每次迭代结束之前,它们会自动填充为 float(‘NaN’)值,以使最终用户代码有机会执行任何操作。
在此示例中,仅支持每日格式:
import itertools
...
import backtrader as bt
class MyCSVData(bt.CSVDataBase):
def start(self):
# Nothing to do for this data feed type
pass
def stop(self):
# Nothing to do for this data feed type
pass
def _loadline(self, linetokens):
i = itertools.count(0)
dttxt = linetokens[next(i)]
# Format is YYYY-MM-DD
y = int(dttxt[0:4])
m = int(dttxt[5:7])
d = int(dttxt[8:10])
dt = datetime.datetime(y, m, d)
dtnum = date2num(dt)
self.lines.datetime[0] = dtnum
self.lines.open[0] = float(linetokens[next(i)])
self.lines.high[0] = float(linetokens[next(i)])
self.lines.low[0] = float(linetokens[next(i)])
self.lines.close[0] = float(linetokens[next(i)])
self.lines.volume[0] = float(linetokens[next(i)])
self.lines.openinterest[0] = float(linetokens[next(i)])
return True
代码期望所有字段已就位并可转换为浮点数,除日期时间外,日期时间具有固定的 YYYY-MM-DD 格式,并且可在不使用datetime.datetime.strptime的情况下解析。
只需添加几行代码,即可满足更复杂的需求,以处理空值,日期格式解析。GenericCSVData执行此操作。
购买者注意
使用GenericCSVData现有数据源和继承,可以完成很多工作以支持各种格式。
让我们为Sierra Chart每日格式添加支持(始终以 CSV 格式存储)。
定义(通过查看一个**‘.dly’**数据文件:
-
字段:日期、开盘价、最高价、最低价、收盘价、成交量、持仓量
行业标准和已经由
GenericCSVData支持的标准顺序(也是行业标准) -
分隔符:,
-
日期格式:YYYY/MM/DD
针对这些文件的解析器:
class SierraChartCSVData(backtrader.feeds.GenericCSVData):
params = (('dtformat', '%Y/%m/%d'),)
params的定义只是重新定义基类中的一个现有参数。在这种情况下,只需更改日期的格式化字符串。
Et voilá … Sierra Chart 的解析器完成了。
下面是GenericCSVData的参数定义,以便提醒:
class GenericCSVData(feed.CSVDataBase):
params = (
('nullvalue', float('NaN')),
('dtformat', '%Y-%m-%d %H:%M:%S'),
('tmformat', '%H:%M:%S'),
('datetime', 0),
('time', -1),
('open', 1),
('high', 2),
('low', 3),
('close', 4),
('volume', 5),
('openinterest', 6),
)
二进制数据源开发
原文:
www.backtrader.com/docu/datafeed-develop-general/datafeed-develop-general/
注意
示例中使用的二进制文件goog.fd属于 VisualChart,不能与backtrader一起分发。
VisualChart可以免费下载,供有兴趣直接使用二进制文件的人使用。
CSV 数据源开发展示了如何添加新的基于 CSV 的数据源。现有的基类 CSVDataBase 提供了框架,大多数情况下子类可以简单地执行以下操作:
def _loadline(self, linetokens):
# parse the linetokens here and put them in self.lines.close,
# self.lines.high, etc
return True # if data was parsed, else ... return False
基类负责参数、初始化、文件打开、读取行、拆分行为标记和其他额外的事情,比如跳过不符合用户可能已定义的日期范围(fromdate、todate)的行。
开发非 CSV 数据源遵循相同的模式,而不是下降到已分割的行标记。
要做的事情:
-
派生自
backtrader.feed.DataBase。 -
添加任何你可能需要的参数
-
如果需要初始化,请覆盖
__init__(self)和/或start(self)。 -
如果需要任何清理代码,覆盖
stop(self)。 -
工作发生在必须始终被覆盖的方法内:
_load(self)
让我们使用backtrader.feed.DataBase已提供的参数:
from backtrader.utils.py3 import with_metaclass
...
...
class DataBase(with_metaclass(MetaDataBase, dataseries.OHLCDateTime)):
params = (('dataname', None),
('fromdate', datetime.datetime.min),
('todate', datetime.datetime.max),
('name', ''),
('compression', 1),
('timeframe', TimeFrame.Days),
('sessionend', None))
具有以下含义:
-
dataname是数据源识别如何获取数据的参数。在CSVDataBase的情况下,此参数应为文件路径或已经是类似文件的对象。 -
fromdate和todate定义将传递给策略的日期范围。提供的任何值超出此范围的数据将被忽略。 -
name是为了绘图目的而设计的。 -
timeframe指示时间工作参考可能的值:
Ticks、Seconds、Minutes、Days、Weeks、Months和Years。 -
compression(默认值:1)每个柱子的实际条数。提供信息。仅在数据重采样/重播中有效。
-
compression -
如果传递了
sessionend(一个 datetime.time 对象),将会添加到数据源datetime行中,以便识别会话结束。
样本二进制数据源
backtrader已经为VisualChart的导出定义了一个 CSV 数据源(VChartCSVData),但也可以直接读取二进制数据文件。
让我们做吧(完整的数据源代码可以在底部找到)
初始化
二进制的 VisualChart 数据文件可以包含每日数据(.fd 扩展名)或分钟数据(.min 扩展名)。在这里,参数timeframe将用于区分正在读取的文件类型。
在__init__中,为每种类型设置不同的常量。
def __init__(self):
super(VChartData, self).__init__()
# Use the informative "timeframe" parameter to understand if the
# code passed as "dataname" refers to an intraday or daily feed
if self.p.timeframe >= TimeFrame.Days:
self.barsize = 28
self.dtsize = 1
self.barfmt = 'IffffII'
else:
self.dtsize = 2
self.barsize = 32
self.barfmt = 'IIffffII'
开始
当回测开始时(在优化过程中实际上可以多次启动),数据源将会启动。
在start方法中,打开二进制文件,除非已传递了类似文件的对象。
def start(self):
# the feed must start ... get the file open (or see if it was open)
self.f = None
if hasattr(self.p.dataname, 'read'):
# A file has been passed in (ex: from a GUI)
self.f = self.p.dataname
else:
# Let an exception propagate
self.f = open(self.p.dataname, 'rb')
停止
在回测完成时调用。
如果文件已打开,则将其关闭
def stop(self):
# Close the file if any
if self.f is not None:
self.f.close()
self.f = None
实际加载
实际工作是在_load中完成的。调用以加载下一组数据,这种情况下的下一个数据是:datetime、open、high、low、close、volume、openinterest。在backtrader中,“实际”时刻对应于索引 0。
从打开的文件中读取一定数量的字节(由__init__期间设置的常量确定),使用struct模块解析,如果需要进一步处理(例如使用 divmod 操作处理日期和时间),然后存储在数据源的lines中:datetime、open、high、low、close、volume、openinterest。
如果无法从文件中读取数据,则假定已到达文件结束(EOF)。
- 返回
False表示没有更多数据可用
或者如果数据已加载并解析:
- 返回
True表示数据集加载成功
def _load(self):
if self.f is None:
# if no file ... no parsing
return False
# Read the needed amount of binary data
bardata = self.f.read(self.barsize)
if not bardata:
# if no data was read ... game over say "False"
return False
# use struct to unpack the data
bdata = struct.unpack(self.barfmt, bardata)
# Years are stored as if they had 500 days
y, md = divmod(bdata[0], 500)
# Months are stored as if they had 32 days
m, d = divmod(md, 32)
# put y, m, d in a datetime
dt = datetime.datetime(y, m, d)
if self.dtsize > 1: # Minute Bars
# Daily Time is stored in seconds
hhmm, ss = divmod(bdata[1], 60)
hh, mm = divmod(hhmm, 60)
# add the time to the existing atetime
dt = dt.replace(hour=hh, minute=mm, second=ss)
self.lines.datetime[0] = date2num(dt)
# Get the rest of the unpacked data
o, h, l, c, v, oi = bdata[self.dtsize:]
self.lines.open[0] = o
self.lines.high[0] = h
self.lines.low[0] = l
self.lines.close[0] = c
self.lines.volume[0] = v
self.lines.openinterest[0] = oi
# Say success
return True
其他二进制格式
可以将相同的模型应用于任何其他二进制源:
-
数据库
-
分层数据存储
-
在线来源
再次执行以下步骤:
-
__init__-> 实例的任何初始化代码,仅一次 -
start-> 开始回测(如果将进行优化,则一次或多次)例如,这将打开到数据库的连接或到在线服务的套接字
-
stop-> 清理工作,如关闭数据库连接或打开的套接字 -
_load-> 查询数据库或在线源以获取下一组数据,并将其加载到对象的lines中。标准字段包括:datetime、open、high、low、close、volume、openinterest
VChartData 测试
VCharData 从本地“.fd”文件加载谷歌 2006 年的数据。
这只涉及加载数据,因此甚至不需要Strategy的子类。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import backtrader as bt
from vchart import VChartData
if __name__ == '__main__':
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
###########################################################################
# Note:
# The goog.fd file belongs to VisualChart and cannot be distributed with
# backtrader
#
# VisualChart can be downloaded from www.visualchart.com
###########################################################################
# Create a Data Feed
datapath = '../../datas/goog.fd'
data = VChartData(
dataname=datapath,
fromdate=datetime.datetime(2006, 1, 1),
todate=datetime.datetime(2006, 12, 31),
timeframe=bt.TimeFrame.Days
)
# Add the Data Feed to Cerebro
cerebro.adddata(data)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
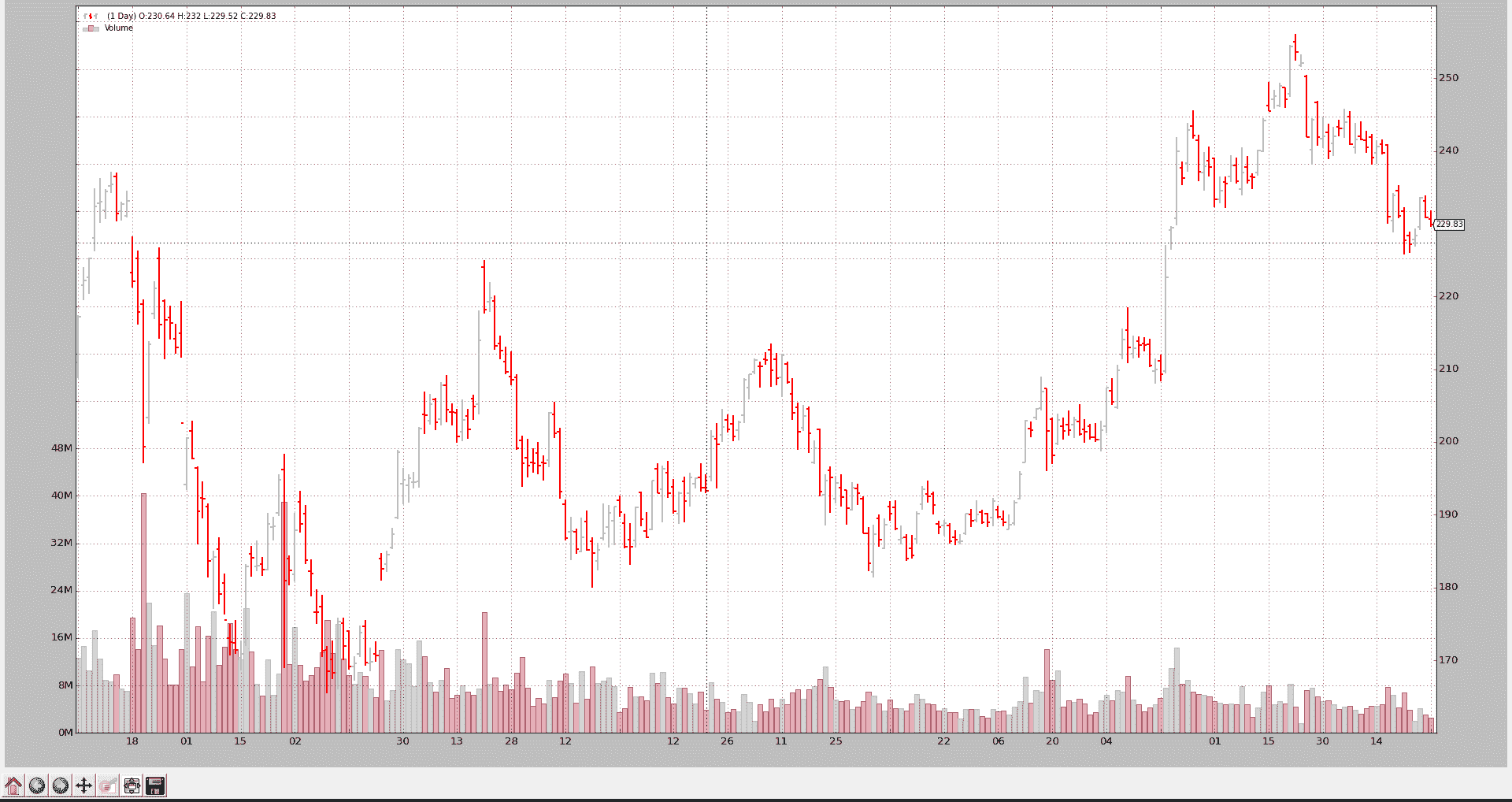
VChartData 完整代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import struct
from backtrader.feed import DataBase
from backtrader import date2num
from backtrader import TimeFrame
class VChartData(DataBase):
def __init__(self):
super(VChartData, self).__init__()
# Use the informative "timeframe" parameter to understand if the
# code passed as "dataname" refers to an intraday or daily feed
if self.p.timeframe >= TimeFrame.Days:
self.barsize = 28
self.dtsize = 1
self.barfmt = 'IffffII'
else:
self.dtsize = 2
self.barsize = 32
self.barfmt = 'IIffffII'
def start(self):
# the feed must start ... get the file open (or see if it was open)
self.f = None
if hasattr(self.p.dataname, 'read'):
# A file has been passed in (ex: from a GUI)
self.f = self.p.dataname
else:
# Let an exception propagate
self.f = open(self.p.dataname, 'rb')
def stop(self):
# Close the file if any
if self.f is not None:
self.f.close()
self.f = None
def _load(self):
if self.f is None:
# if no file ... no parsing
return False
# Read the needed amount of binary data
bardata = self.f.read(self.barsize)
if not bardata:
# if no data was read ... game over say "False"
return False
# use struct to unpack the data
bdata = struct.unpack(self.barfmt, bardata)
# Years are stored as if they had 500 days
y, md = divmod(bdata[0], 500)
# Months are stored as if they had 32 days
m, d = divmod(md, 32)
# put y, m, d in a datetime
dt = datetime.datetime(y, m, d)
if self.dtsize > 1: # Minute Bars
# Daily Time is stored in seconds
hhmm, ss = divmod(bdata[1], 60)
hh, mm = divmod(hhmm, 60)
# add the time to the existing atetime
dt = dt.replace(hour=hh, minute=mm, second=ss)
self.lines.datetime[0] = date2num(dt)
# Get the rest of the unpacked data
o, h, l, c, v, oi = bdata[self.dtsize:]
self.lines.open[0] = o
self.lines.high[0] = h
self.lines.low[0] = l
self.lines.close[0] = c
self.lines.volume[0] = v
self.lines.openinterest[0] = oi
# Say success
return True
数据 - 多时间框架
原文:
www.backtrader.com/docu/data-multitimeframe/data-multitimeframe/
有时,投资决策是根据不同的时间框架进行的:
-
每周评估趋势
-
每日执行入场
或者 5 分钟对比 60 分钟。
这意味着需要在backtrader中组合多个时间框架的数据以支持这种组合。
平台已经内置了对此的本地支持。最终用户只需遵循这些规则:
-
具有最小时间框架(因此具有更多柱状图)的数据必须是添加到 Cerebro 实例的第一个数据
-
数据必须正确地对齐日期时间,以便平台能够理解它们的含义
此外,最终用户可以自由地在较短/较大的时间框架上应用指标。当然:
- 应用于较大时间框架的指标将产生较少的柱状图
平台还将考虑以下内容
- 较大时间框架的最小周期
可能会有最小周期的副作用,这可能导致在策略添加到 Cerebro 后需要消耗几个数量级的较小时间框架柱状图才能开始执行。
内置的cerebro.resample将用于创建较大的时间框架。
以下是一些示例,但首先是测试脚本的来源。
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
cerebro.adddata(data) # First add the original data - smaller timeframe
tframes = dict(daily=bt.TimeFrame.Days, weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
if args.noresample:
datapath = args.dataname2 or '../../datas/2006-week-001.txt'
data2 = btfeeds.BacktraderCSVData(dataname=datapath)
# And then the large timeframe
cerebro.adddata(data2)
else:
cerebro.resampledata(data, timeframe=tframes[args.timeframe],
compression=args.compression)
# Run over everything
cerebro.run()
步骤:
-
加载数据
-
根据用户指定的参数重新采样
该脚本还允许加载第二个数据
-
将数据添加到 cerebro
-
将重新采样的数据(更大的时间框架)添加到 cerebro
-
运行
示例 1 - 每日和每周
脚本的调用:
$ ./multitimeframe-example.py --timeframe weekly --compression 1
输出图表:
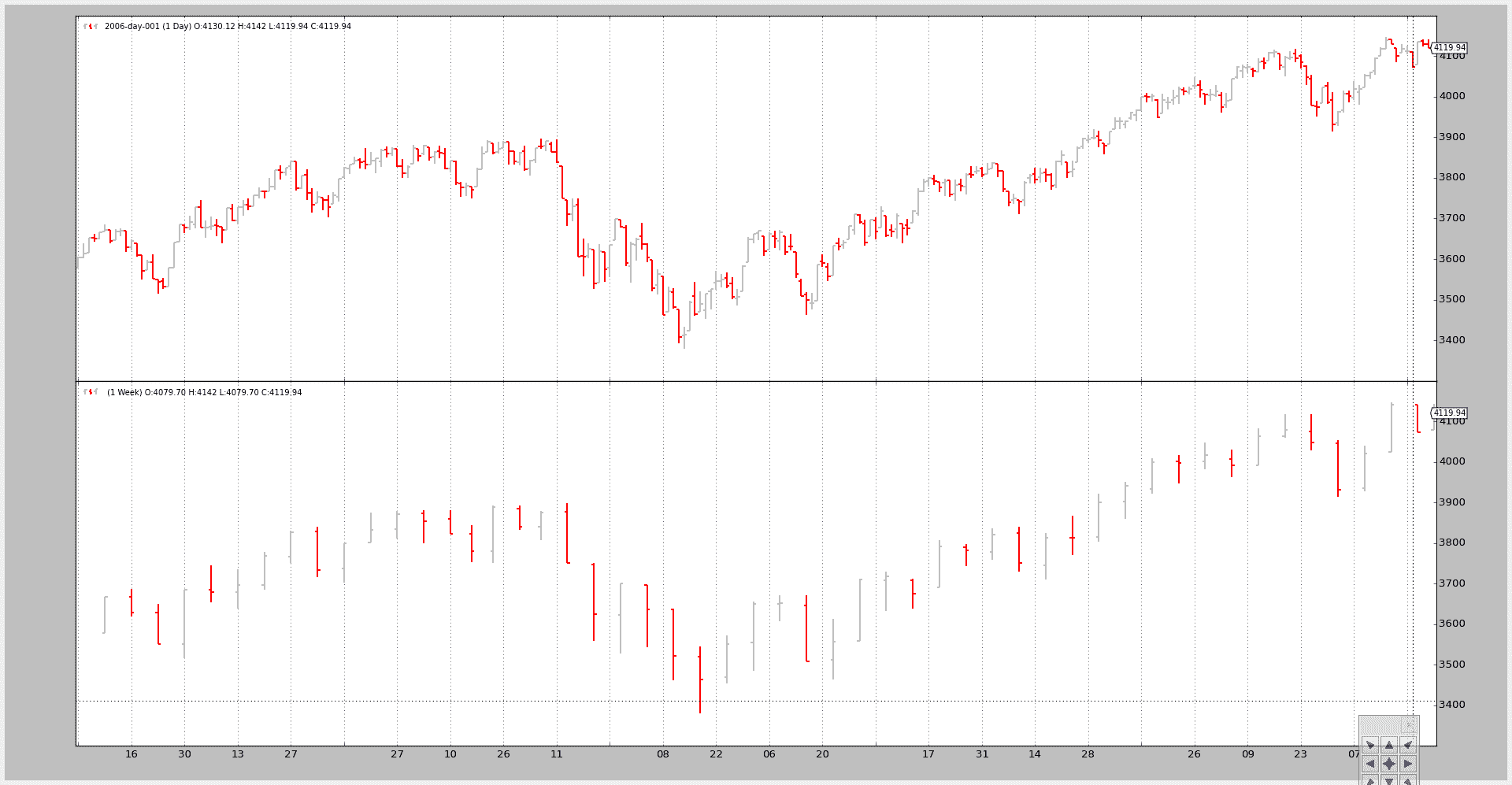
示例 2 - 每日和每日压缩(2 根柱状图合并为 1 根)
脚本的调用:
$ ./multitimeframe-example.py --timeframe daily --compression 2
输出图表:
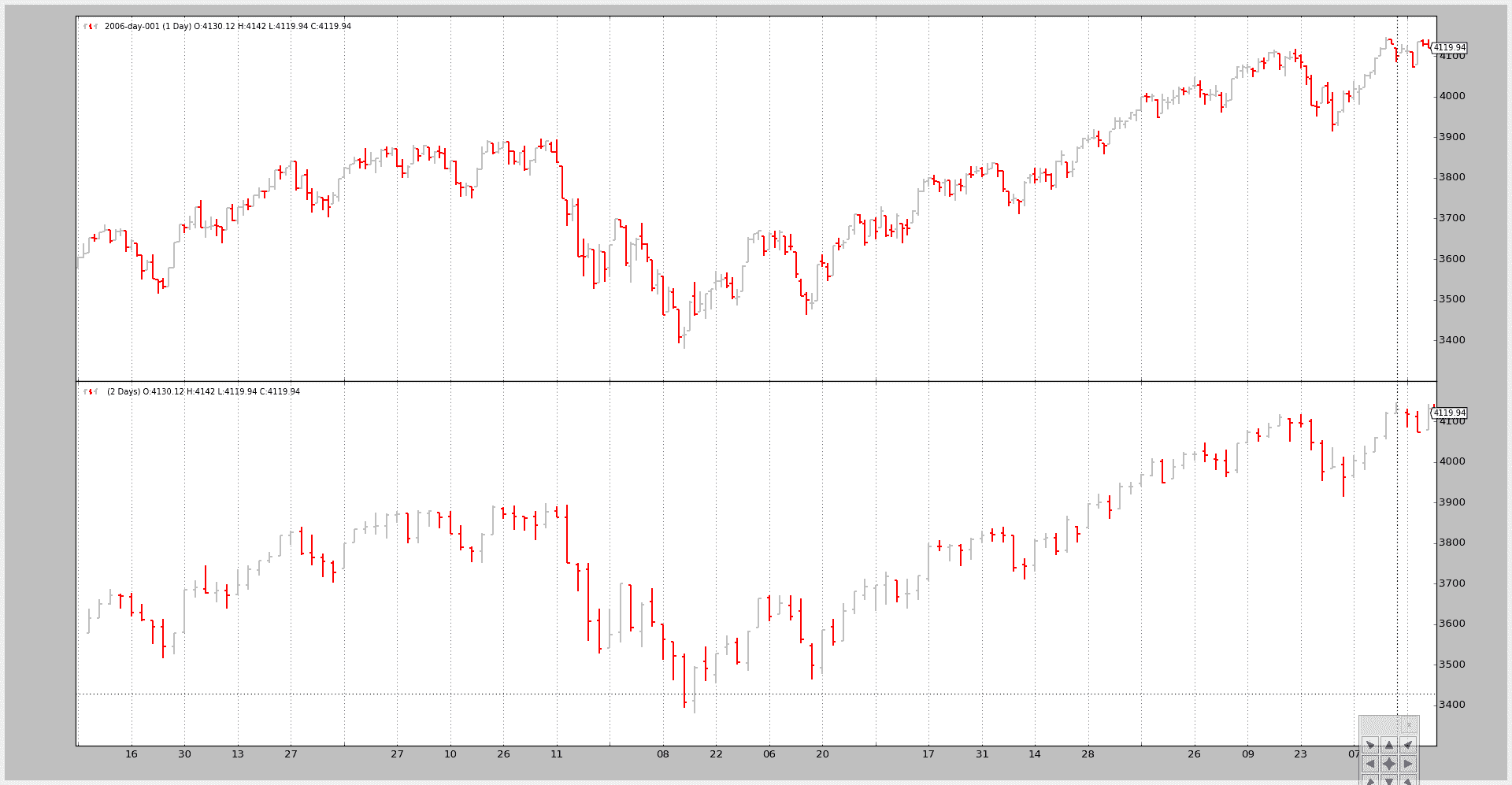
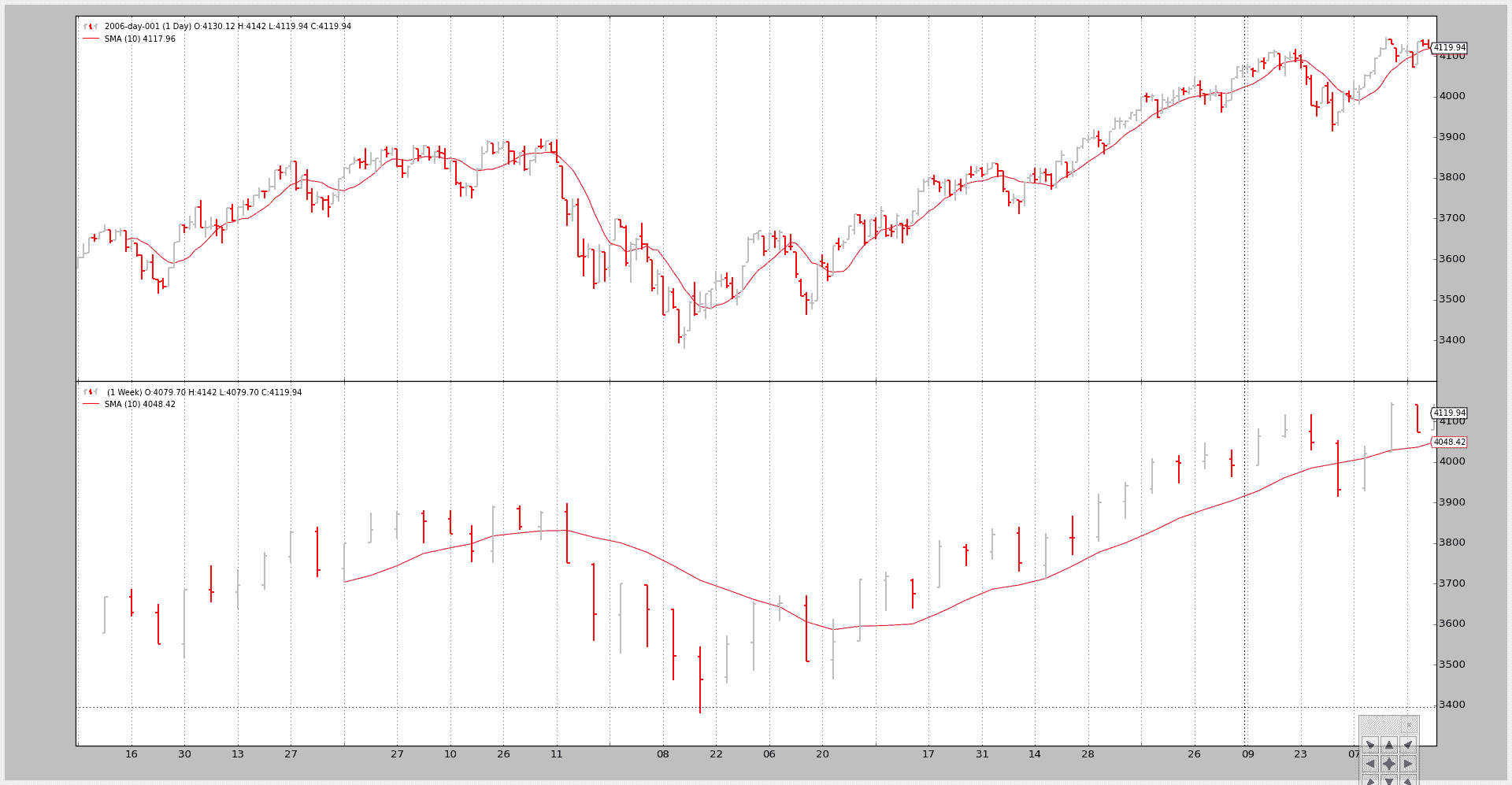
示例 3 - 带有 SMA 的策略
尽管绘图很好,但这里的关键问题是展示较大的时间框架如何影响系统,特别是当涉及到起始点时
该脚本可以使用--indicators来添加一个策略,该策略在较小和较大时间框架数据上创建周期为 10的简单移动平均线。
如果只考虑较小的时间框架:
-
next将在第 10 根柱状图之后首先被调用,这是简单移动平均线需要产生数值的时间注意:请记住,策略监视创建的指标,并且只有当所有指标都产生数值时才调用
next。其理念是,最终用户已经添加了指标以在逻辑中使用它们,因此如果指标没有产生数值,则不应进行任何逻辑操作。
但在这种情况下,较大的时间框架(每周)会延迟调用next,直到每周数据上的简单移动平均线产生数值,这需要… 10 周。
该脚本覆盖了nextstart,它只被调用一次,默认调用next以显示第一次调用的时间。
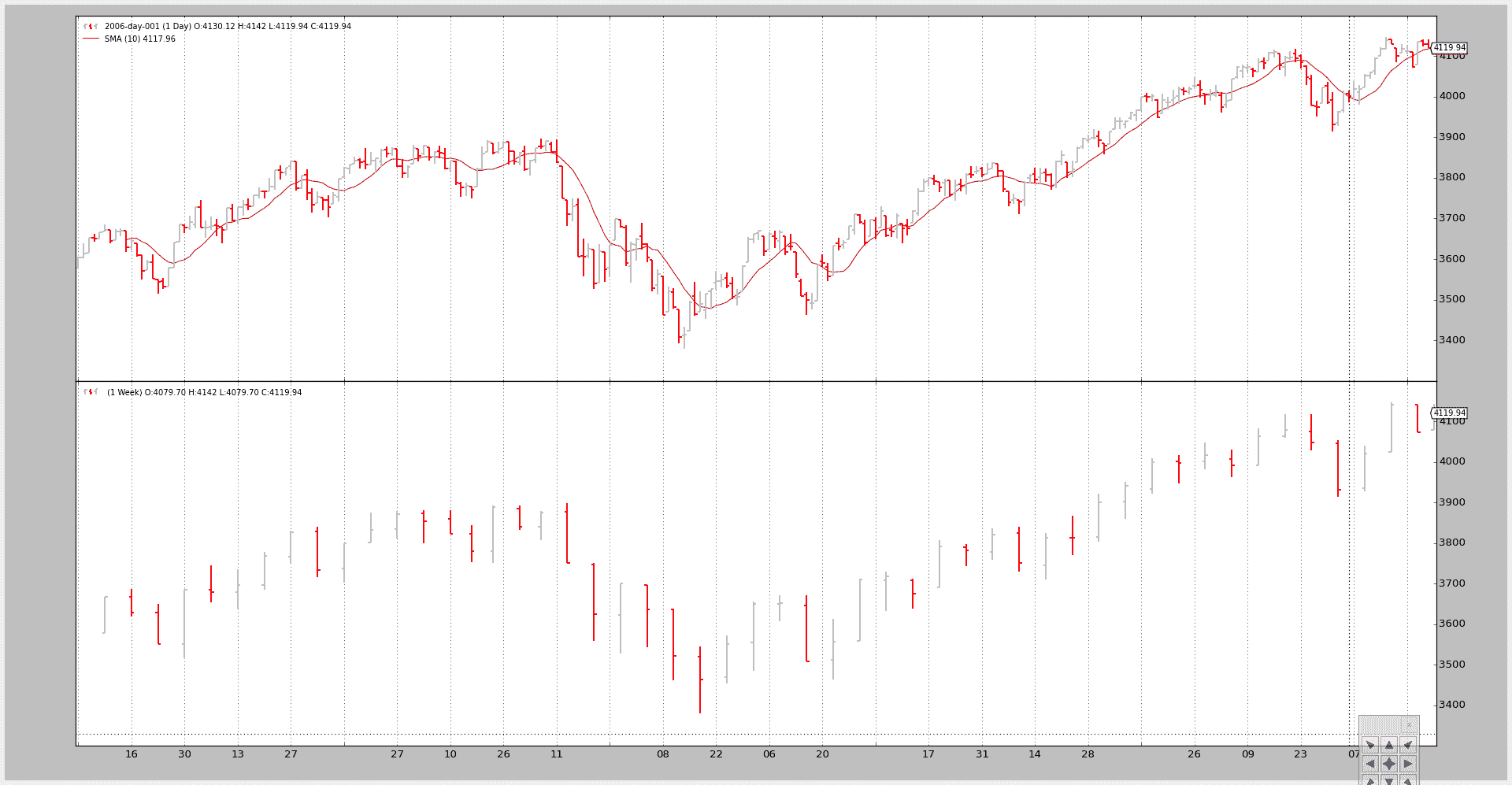
调用 1:
只有较小的时间框架,每日,获得一个简单移动平均线
命令行和输出
$ ./multitimeframe-example.py --timeframe weekly --compression 1 --indicators --onlydaily
--------------------------------------------------
nextstart called with len 10
--------------------------------------------------
以及图表。
调用 2:
两个时间框架都有一个简单移动平均线
命令行:
$ ./multitimeframe-example.py --timeframe weekly --compression 1 --indicators
--------------------------------------------------
nextstart called with len 50
--------------------------------------------------
--------------------------------------------------
nextstart called with len 51
--------------------------------------------------
--------------------------------------------------
nextstart called with len 52
--------------------------------------------------
--------------------------------------------------
nextstart called with len 53
--------------------------------------------------
--------------------------------------------------
nextstart called with len 54
--------------------------------------------------
这里有两件事需要注意:
-
策略在 50 个周期后而不是 10 个周期后首次调用。
这是因为应用于较大(每周)时间框架的简单移动平均线在 10 周后产生一个值……那就是
10 周 * 5 天 / 周 …… 50 天 -
nextstart被调用了 5 次,而不是只有 1 次。这是混合时间框架并且(在这种情况下仅有一个)指标应用于较大时间框架的自然副作用。
较大时间框架的简单移动平均产生了 5 次相同的值,而同时消耗了 5 个每日的条形图。
并且因为周期的开始由较大的时间框架控制,
nextstart被调用了 5 次。
以及图表。
结论
在 backtrader 中,可以使用多个时间框架的数据,无需特殊对象或调整:只需先添加较小的时间框架。
测试脚本。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class SMAStrategy(bt.Strategy):
params = (
('period', 10),
('onlydaily', False),
)
def __init__(self):
self.sma_small_tf = btind.SMA(self.data, period=self.p.period)
if not self.p.onlydaily:
self.sma_large_tf = btind.SMA(self.data1, period=self.p.period)
def nextstart(self):
print('--------------------------------------------------')
print('nextstart called with len', len(self))
print('--------------------------------------------------')
super(SMAStrategy, self).nextstart()
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
if not args.indicators:
cerebro.addstrategy(bt.Strategy)
else:
cerebro.addstrategy(
SMAStrategy,
# args for the strategy
period=args.period,
onlydaily=args.onlydaily,
)
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
cerebro.adddata(data) # First add the original data - smaller timeframe
tframes = dict(daily=bt.TimeFrame.Days, weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
if args.noresample:
datapath = args.dataname2 or '../../datas/2006-week-001.txt'
data2 = btfeeds.BacktraderCSVData(dataname=datapath)
# And then the large timeframe
cerebro.adddata(data2)
else:
cerebro.resampledata(data, timeframe=tframes[args.timeframe],
compression=args.compression)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Multitimeframe test')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--dataname2', default='', required=False,
help='Larger timeframe file to load')
parser.add_argument('--noresample', action='store_true',
help='Do not resample, rather load larger timeframe')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
parser.add_argument('--indicators', action='store_true',
help='Wether to apply Strategy with indicators')
parser.add_argument('--onlydaily', action='store_true',
help='Indicator only to be applied to daily timeframe')
parser.add_argument('--period', default=10, required=False, type=int,
help='Period to apply to indicator')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
数据重新采样
当数据仅在单个时间框架中可用并且必须为不同时间框架进行分析时,是进行一些重新采样的时候了。
“重新取样”实际上应该称为“上取样”,因为从一个源时间框架到一个更大的时间框架(例如:从天到周)
通过将原始数据通过过滤器对象传递给 backtrader 来支持重新采样。虽然有几种实现方法,但存在一种简单的接口来实现:
-
使用
cerebro.adddata(data)将data放入系统中,而不是cerebro.resampledata(data, **kwargs)
有两个主要选项可以控制
-
调整时间范围
-
压缩条
要这样做,请在调用resampledata时使用以下参数:
-
timeframe(默认:bt.TimeFrame.Days)目标时间范围,必须等于或大于源时间
-
compression(默认:1)将选定值“n”压缩为 1 条
让我们看一个从每日到每周的手工脚本示例:
$ ./resampling-example.py --timeframe weekly --compression 1
输出:
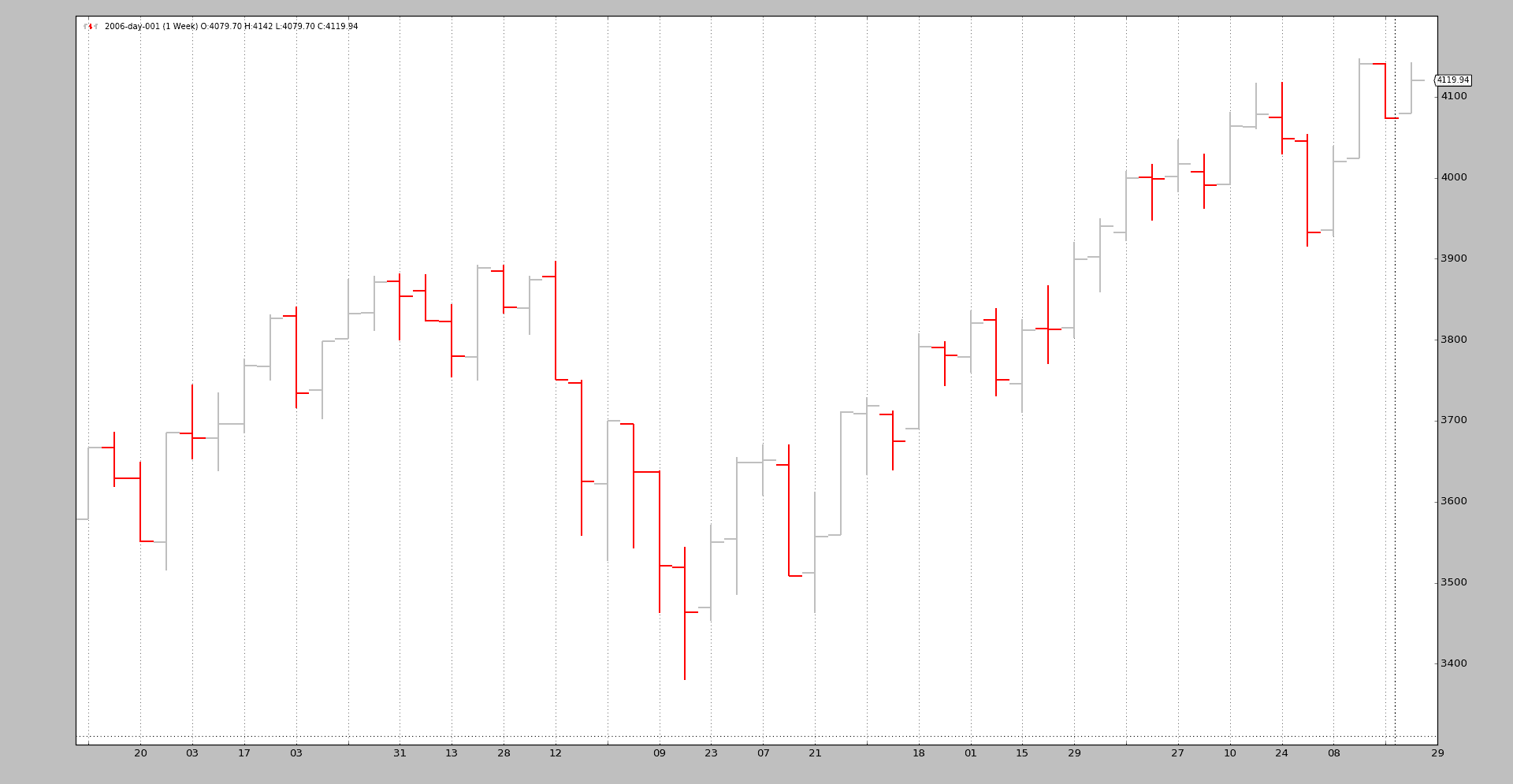
我们可以将其与原始的每日数据进行比较:
$ ./resampling-example.py --timeframe daily --compression 1
输出:
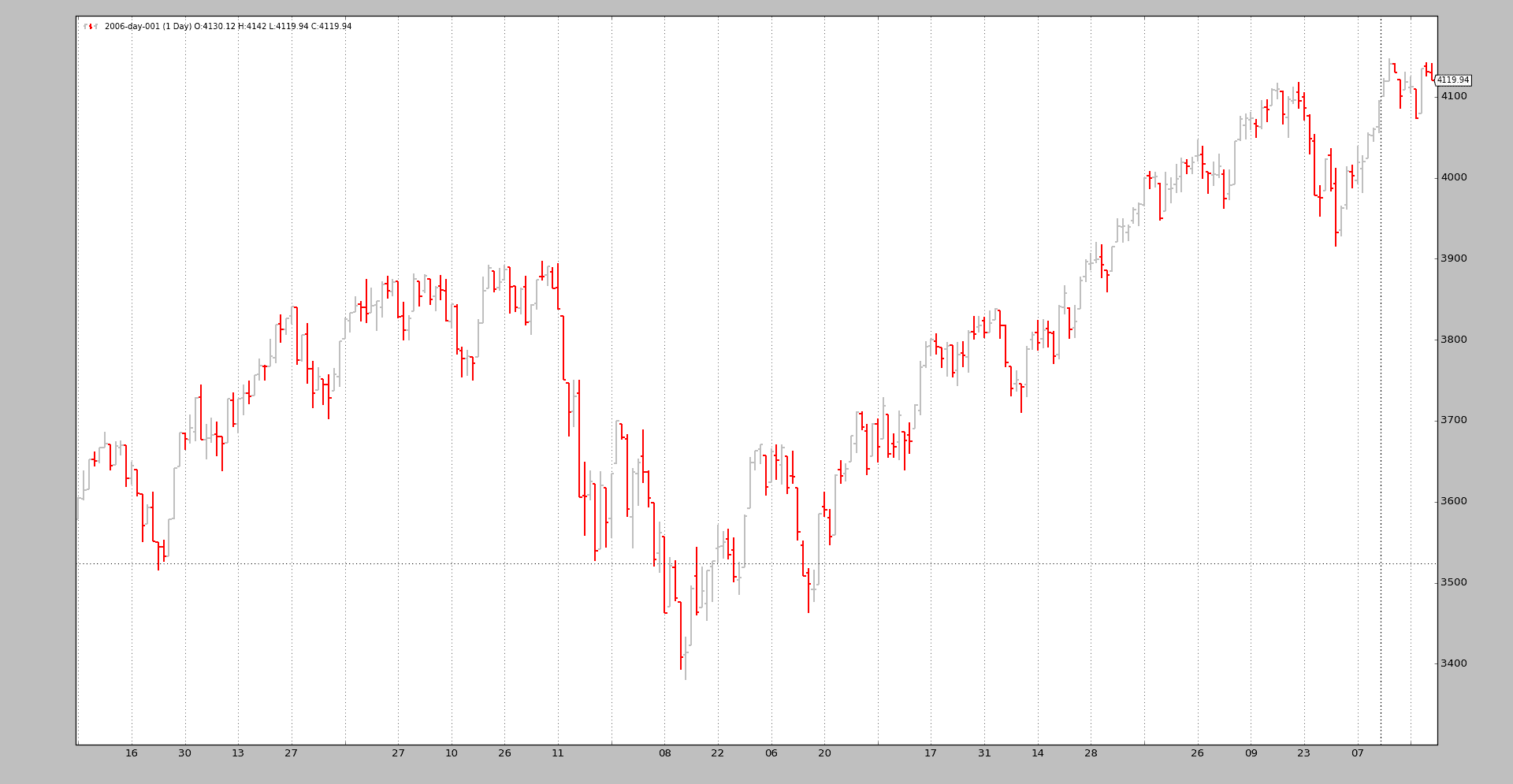
通过执行以下步骤完成魔术:
-
像往常一样加载数据
-
将数据使用
resampledata与所需参数输入到 cerebro 中:-
timeframe -
compression
-
样本中的代码(整个脚本在底部)。
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Add the resample data instead of the original
cerebro.resampledata(data,
timeframe=tframes[args.timeframe],
compression=args.compression)
最后一个示例,我们首先将时间框架从每日更改为每周,然后应用 3 比 1 的压缩:
$ ./resampling-example.py --timeframe weekly --compression 3
输出:
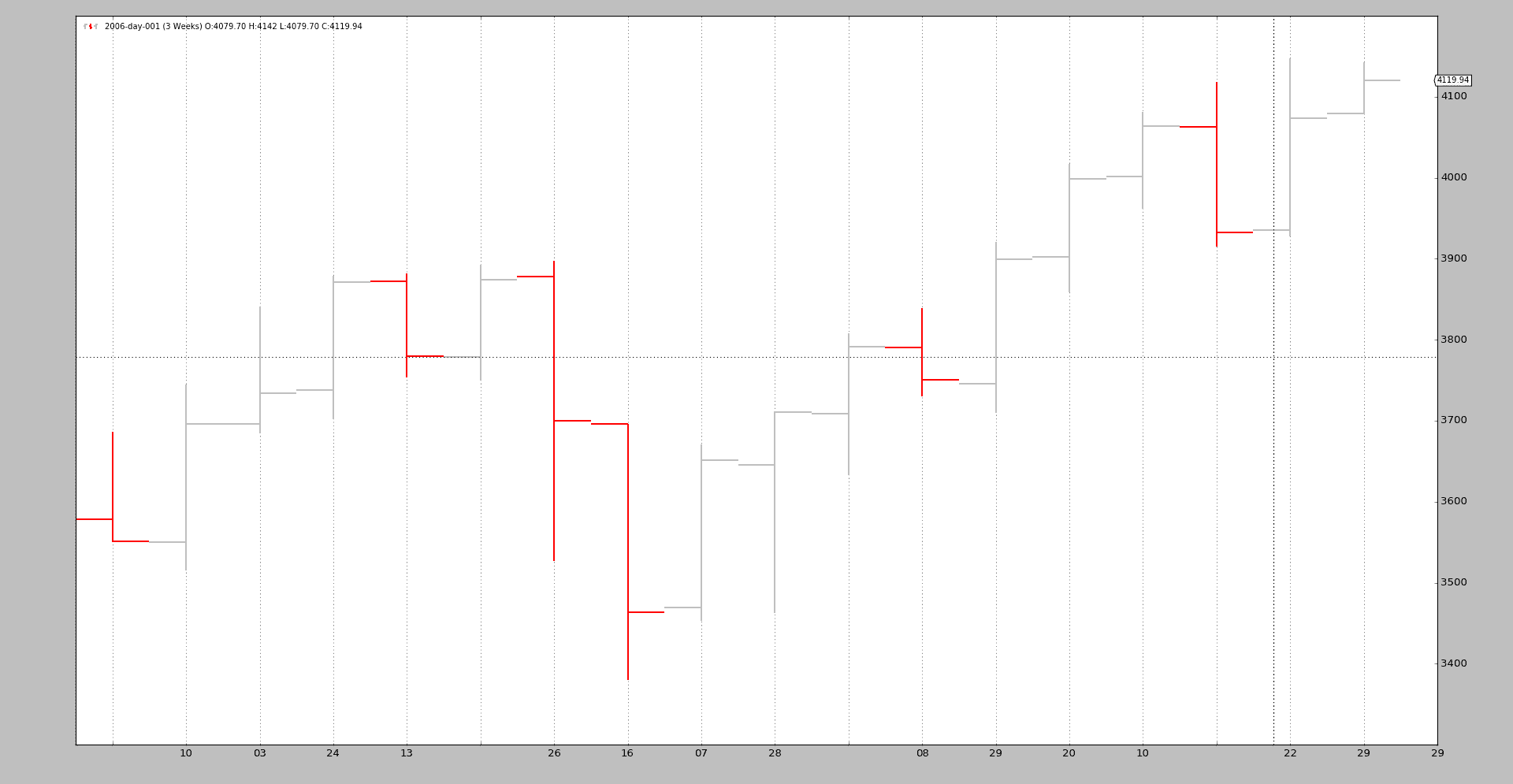
从原始的 256 个每日条到 18 个 3 周条。拆分:
-
52 周
-
52 / 3 = 17.33,因此 18 个条
也不需要更多。当然,分时数据也可以重新采样。
重新采样过滤器支持附加参数,在大多数情况下不应该触及:
-
bar2edge(默认:True)使用时间边界作为目标的重新采样。例如,使用“ticks -> 5 秒”,结果为 5 秒的条将与 xx:00、xx:05、xx:10 对齐…
-
adjbartime(默认:True)使用边界时间来调整传递的重新采样条的时间,而不是最后一次看到的时间戳。例如,如果重新采样到“5 秒”,则条的时间将被调整为 hh
 05,即使最后一次看到的时间戳是 hh
05,即使最后一次看到的时间戳是 hh 04.33。
04.33。注意
如果“bar2edge”为 True,只会调整时间。如果条未对齐到边界,调整时间是没有意义的
-
rightedge(默认:True)使用时间边界的右边来设置时间。
如果为 False 并且将重采样的间隔压缩到 5 秒,则在 hh
 00 和 hh
00 和 hh 04 之间的秒钟的情况下,重采样条的时间将为 hh
04 之间的秒钟的情况下,重采样条的时间将为 hh 00(起始边界
00(起始边界如果为 True,则时间的使用边界将为 hh
 05(结束边界)
05(结束边界) -
boundoff(默认值:0)将重采样/重播的边界推进单位数量。
例如,如果重采样的时间从 1 分钟 到 15 分钟,则默认行为是从 00:01:00 到 00:15:00 取 1 分钟的条来生成一个 15 分钟的重播/重采样条。
如果
boundoff设置为1,则边界向前推进1 个单位。 在这种情况下,原始的 单位 是一个 1 分钟 的条。 因此,现在重采样/重播将会:- 使用从 00:00:00 到 00:14:00 的条来生成 15 分钟的条
重采样测试脚本的示例代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Add the resample data instead of the original
cerebro.resampledata(data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
数据 - 回放
时间已经过去,针对完全形成和关闭的每日柱进行策略测试是好的,但可以更好。
这就是数据回放发挥作用的地方。如果:
- 该策略在时间框架 X 的数据上运行(示例:每日)
且
- 较小时间框架 Y 的数据(示例:1 分钟)可用
数据回放正是其名称所示的:
- 使用 1 分钟数据重放每日柱
当然,这并不完全是市场的发展方式,但比孤立地查看每日完全形成和关闭的柱要好得多:
如果策略在形成日柱时实时运行,则柱的形成近似会给予机会复制策略在实际条件下的实际行为
实施数据回放遵循backtrader的常规使用模式
-
加载数据源
-
将数据传递给 cerebro,使用
replaydata -
添加一个策略
注意
当数据被重新播放时,不支持预加载,因为每个柱实际上是实时构建的。它将自动在任何Cerebro实例中禁用。
可以传递给replaydata的参数:
-
timeframe(默认值:bt.TimeFrame.Days)目标时间框架必须与源时间框架相等或更大才能发挥作用
-
compression(默认值:1)将所选值“n”压缩为 1 根柱
扩展参数(如果不是真正需要,请勿修改):
-
bar2edge(默认值:True)使用时间边界作为封闭柱的目标进行回放。例如,“ticks -> 5 seconds”,生成的 5 秒柱将对齐到 xx:00、xx:05、xx:10 等。
-
adjbartime(默认值:False)使用边界处的时间来调整交付的重新采样柱的时间,而不是上次看到的时间戳。例如,如果重新采样为“5 秒”,则柱的时间将被调整为 hh
 05,即使上次看到的时间戳是 hh
05,即使上次看到的时间戳是 hh 04.33。
04.33。注意:仅当“bar2edge”为 True 时才会调整时间。如果柱未对齐到边界,调整时间是没有意义的
-
rightedge(默认值:True)使用时间边界的右边缘来设置时间。
如果为 False,并且压缩到 5 秒,则对于 hh
 00 和 hh
00 和 hh 04 之间的秒数,重新采样柱的时间将是 hh
04 之间的秒数,重新采样柱的时间将是 hh 00(起始边界
00(起始边界如果为 True,则用于时间的边界将是 hh
 05(结束边界)
05(结束边界)
为了与示例一起工作,将标准的 2006 年日常数据按周重放。这意味着:
-
最终将有 52 个柱,每周一个
-
Cerebro 将总共调用
prenext和next255 次,这是每日 K 线的原始计数
技巧:
-
当周 K 线形成时,策略的长度(
len(self))将保持不变。 -
每到新的一周,长度将增加一次
下面是一些示例,但首先是测试脚本的源码,其中数据被加载并通过replaydata传递给 cerebro,然后运行。
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# First add the original data - smaller timeframe
cerebro.replaydata(data,
timeframe=tframes[args.timeframe],
compression=args.compression)
示例 - 每日重放到周线
脚本的调用:
$ ./replay-example.py --timeframe weekly --compression 1
不幸的是,图表无法向我们展示背景中真实发生的事情,所以让我们看看控制台输出:
prenext len 1 - counter 1
prenext len 1 - counter 2
prenext len 1 - counter 3
prenext len 1 - counter 4
prenext len 1 - counter 5
prenext len 2 - counter 6
...
...
prenext len 9 - counter 44
prenext len 9 - counter 45
---next len 10 - counter 46
---next len 10 - counter 47
---next len 10 - counter 48
---next len 10 - counter 49
---next len 10 - counter 50
---next len 11 - counter 51
---next len 11 - counter 52
---next len 11 - counter 53
...
...
---next len 51 - counter 248
---next len 51 - counter 249
---next len 51 - counter 250
---next len 51 - counter 251
---next len 51 - counter 252
---next len 52 - counter 253
---next len 52 - counter 254
---next len 52 - counter 255
正如我们所看到的,内部的self.counter变量正在跟踪每次调用prenext或next。前者在应用简单移动平均产生值之前调用。后者在简单移动平均产生值时调用。
关键:
- 策略的长度(len(self))每 5 根 K 线(一周 5 个交易日)变化一次
策略有效地看到:
-
每周 K 线如何在 5 次迭代中发展。
再次强调,这并不复制市场的实际逐笔(甚至不是分钟、小时)发展,但比看到一根 K 线要好。
可视化输出是周线图表,这是系统正在进行测试的最终结果。
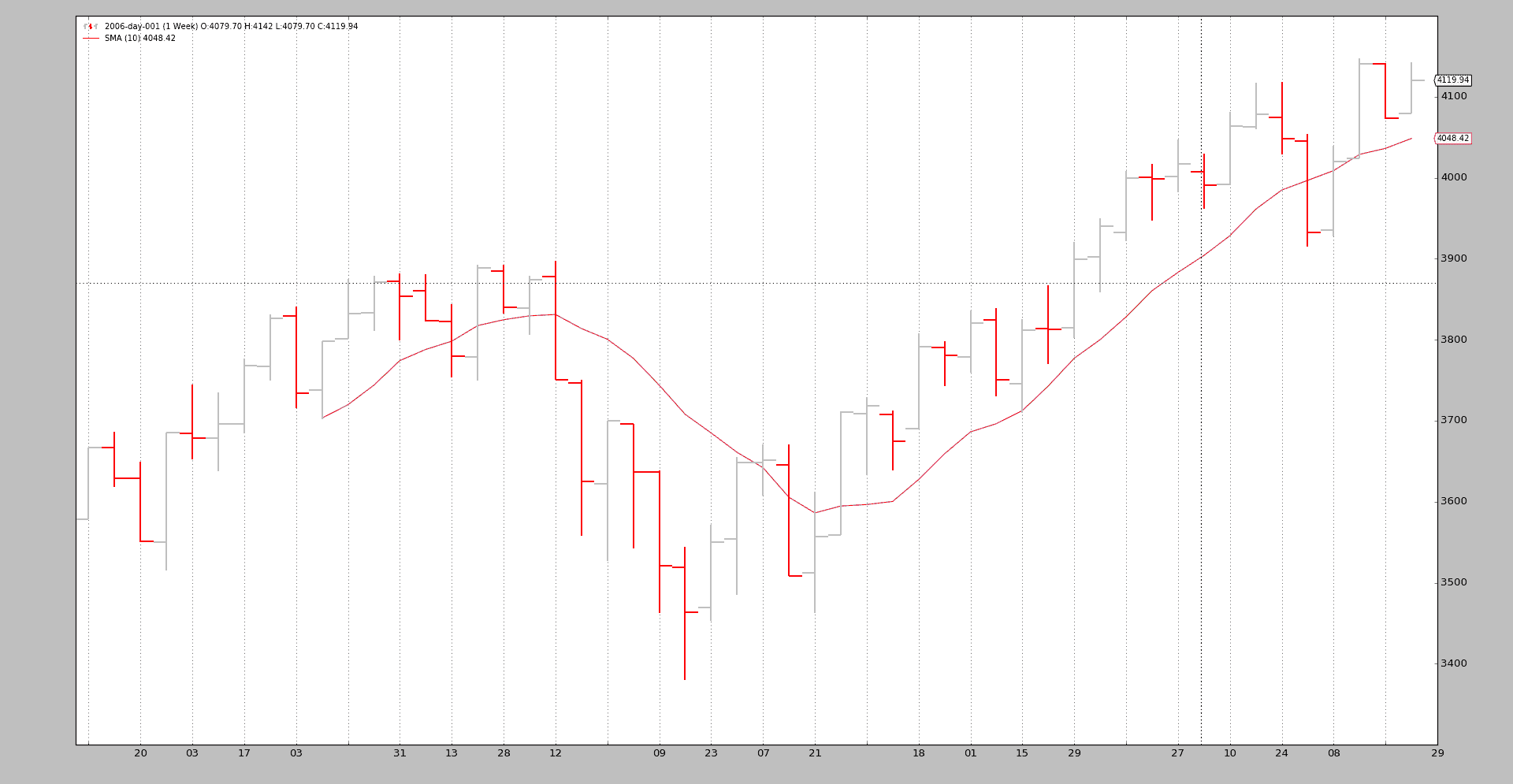
示例 2 - 每日到每日的压缩
当然,“重放”也可以应用于相同的时间框架,但进行压缩。
控制台:
$ ./replay-example.py --timeframe daily --compression 2
prenext len 1 - counter 1
prenext len 1 - counter 2
prenext len 2 - counter 3
prenext len 2 - counter 4
prenext len 3 - counter 5
prenext len 3 - counter 6
prenext len 4 - counter 7
...
...
---next len 125 - counter 250
---next len 126 - counter 251
---next len 126 - counter 252
---next len 127 - counter 253
---next len 127 - counter 254
---next len 128 - counter 255
这次我们得到了预期的一半 K 线,因为请求的压缩因子是 2。
图表:
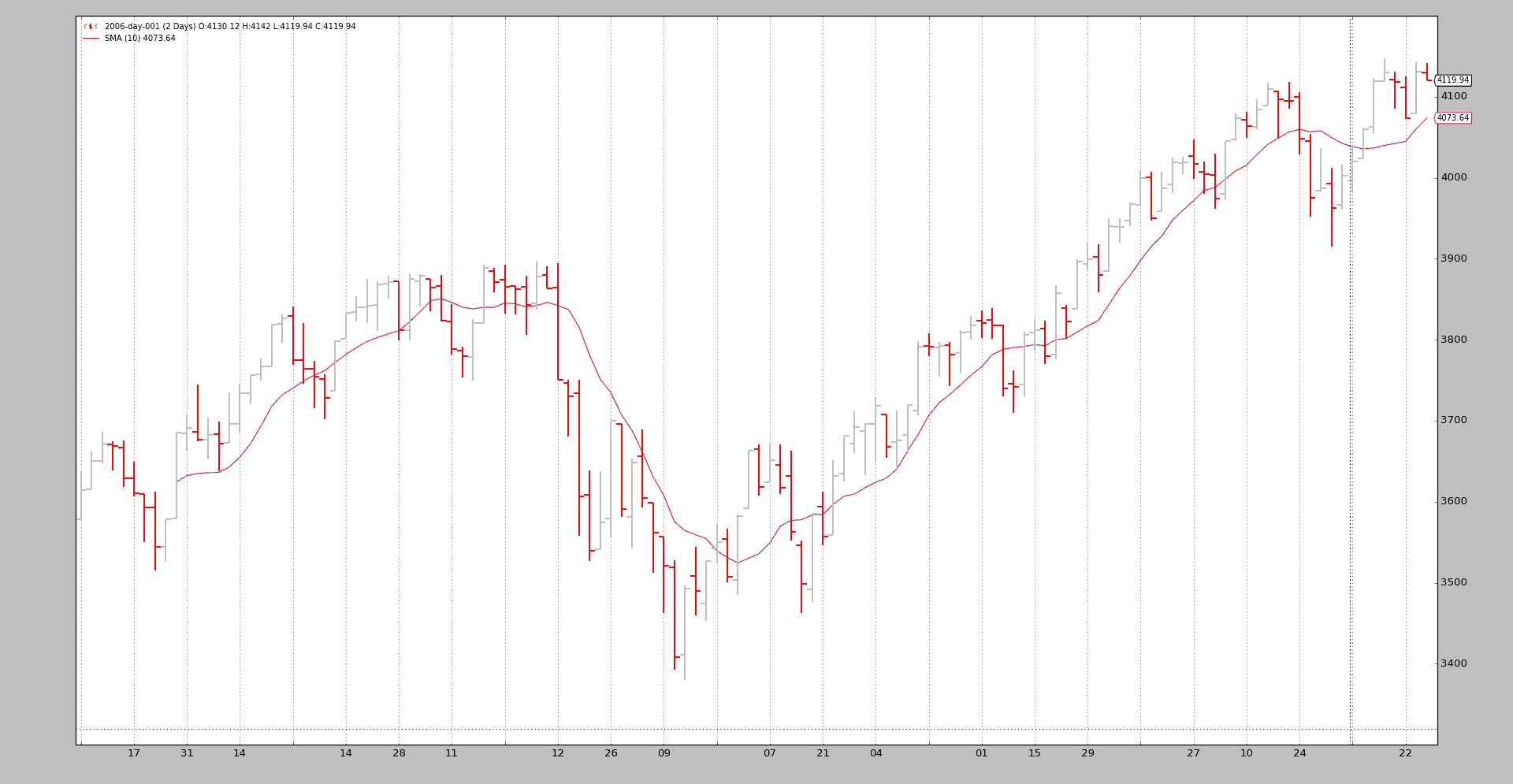
结论
可以重建市场发展的过程。通常会有一组较小时间框架的数据可用,并且可以用来离散地重放系统运行的时间框架。
测试脚本。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class SMAStrategy(bt.Strategy):
params = (
('period', 10),
('onlydaily', False),
)
def __init__(self):
self.sma = btind.SMA(self.data, period=self.p.period)
def start(self):
self.counter = 0
def prenext(self):
self.counter += 1
print('prenext len %d - counter %d' % (len(self), self.counter))
def next(self):
self.counter += 1
print('---next len %d - counter %d' % (len(self), self.counter))
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
cerebro.addstrategy(
SMAStrategy,
# args for the strategy
period=args.period,
)
# Load the Data
datapath = args.dataname or '../../datas/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# First add the original data - smaller timeframe
cerebro.replaydata(data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
parser.add_argument('--period', default=10, required=False, type=int,
help='Period to apply to indicator')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
期货滚动
原文:
www.backtrader.com/docu/data-rollover/rolling-futures-over/
并非每个提供商都为可以交易的工具提供连续期货。有时提供的数据是仍然有效的到期日的数据,即:仍在交易的数据
当涉及到回测时,这并不是很有帮助,因为数据分散在几种不同的工具上,而且…在时间上重叠。
能够正确地将过去的这些工具的数据合并为连续流可以减轻痛苦。问题在于:
- 没有规定如何最好地将不同到期日的数据合并为连续期货
一些文献,由SierraChart提供:
滚动数据源
backtrader 已经在 1.8.10.99 版本中添加了将不同到期日期货数据合并为连续期货的可能性:
import backtrader as bt
cerebro = bt.Cerebro()
data0 = bt.feeds.MyFeed(dataname='Expiry0')
data1 = bt.feeds.MyFeed(dataname='Expiry1')
...
dataN = bt.feeds.MyFeed(dataname='ExpiryN')
drollover = cerebro.rolloverdata(data0, data1, ..., dataN, name='MyRoll', **kwargs)
cerebro.run()
注意
可能的 **kwargs 如下所述
也可以通过直接访问RollOver数据源来完成(如果进行子类化,则很有帮助):
import backtrader as bt
cerebro = bt.Cerebro()
data0 = bt.feeds.MyFeed(dataname='Expiry0')
data1 = bt.feeds.MyFeed(dataname='Expiry1')
...
dataN = bt.feeds.MyFeed(dataname='ExpiryN')
drollover = bt.feeds.RollOver(data0, data1, ..., dataN, dataname='MyRoll', **kwargs)
cerebro.adddata(drollover)
cerebro.run()
注意
可能的 **kwargs 如下所述
注意
使用RollOver时,名称使用dataname分配。这是用于传递名称/标记的所有数据源的标准参数。在这种情况下,它被重用以为所有滚动期货分配一个公共名称。
在cerebro.rolloverdata的情况下,使用name将名称分配给数据源,这已经是该方法的一个命名参数
底线:
-
数据源像往常一样创建,但不会添加到
cerebro -
这些数据源作为输入提供给
bt.feeds.RollOver还提供了一个
dataname,主要用于识别目的。 -
然后将此滚动数据源添加到
cerebro
滚动选项
提供了两个参数来控制滚动过程
-
checkdate(默认值:None)这必须是一个可调用对象,具有以下签名:
checkdate(dt, d):`其中:
-
dt是一个datetime.datetime对象 -
d是当前活跃期货的数据源
预期返回值:
-
True:只要可调用函数返回此值,就可以切换到下一个期货如果商品在三月的第三个星期五到期,
checkdate可能会在到期周的整个周返回True。 -
False:到期无法发生
-
-
checkcondition(默认值:None)注意
仅当
checkdate返回True时才会调用此函数如果
None,这将在内部评估为True(执行滚动)否则,这必须是一个具有此签名的可调用对象:
checkcondition(d0, d1)`其中:
-
d0是当前活跃期货的数据源 -
d1是下一个到期的数据源
预期返回值:
-
True:滚动到下一个期货接下来是
checkdate示例,这可以说明只有当d0的volume已经小于d1的 volume 时,才能进行滚动 -
False:到期无法发生
-
子类化RollOver
如果仅指定可调用对象不够,总是有机会对RollOver进行子类化。要子类化的方法:
-
def _checkdate(self, dt, d):与上面相同名称的参数的signature相匹配。预期的返回值也是相同的。
-
def _checkcondition(self, d0, d1)与上面相同名称的参数的signature相匹配。预期的返回值也是相同的。
让我们开始
注意
样本中的默认行为是使用cerebro.rolloverdata。可以通过传递-no-cerebro标志来更改此行为。在这种情况下,样本使用RollOver和cerebro.adddata
实现包括在backtrader源代码中提供的示例。
期货连接
让我们从运行无参数的示例开始查看纯连接。
$ ./rollover.py
Len, Name, RollName, Datetime, WeekDay, Open, High, Low, Close, Volume, OpenInterest
0001, FESX, 199FESXM4, 2013-09-26, Thu, 2829.0, 2843.0, 2829.0, 2843.0, 3.0, 1000.0
0002, FESX, 199FESXM4, 2013-09-27, Fri, 2842.0, 2842.0, 2832.0, 2841.0, 16.0, 1101.0
...
0176, FESX, 199FESXM4, 2014-06-20, Fri, 3315.0, 3324.0, 3307.0, 3322.0, 134777.0, 520978.0
0177, FESX, 199FESXU4, 2014-06-23, Mon, 3301.0, 3305.0, 3265.0, 3285.0, 730211.0, 3003692.0
...
0241, FESX, 199FESXU4, 2014-09-19, Fri, 3287.0, 3308.0, 3286.0, 3294.0, 144692.0, 566249.0
0242, FESX, 199FESXZ4, 2014-09-22, Mon, 3248.0, 3263.0, 3231.0, 3240.0, 582077.0, 2976624.0
...
0306, FESX, 199FESXZ4, 2014-12-19, Fri, 3196.0, 3202.0, 3131.0, 3132.0, 226415.0, 677924.0
0307, FESX, 199FESXH5, 2014-12-22, Mon, 3151.0, 3177.0, 3139.0, 3168.0, 547095.0, 2952769.0
...
0366, FESX, 199FESXH5, 2015-03-20, Fri, 3680.0, 3698.0, 3672.0, 3695.0, 147632.0, 887205.0
0367, FESX, 199FESXM5, 2015-03-23, Mon, 3654.0, 3655.0, 3608.0, 3618.0, 802344.0, 3521988.0
...
0426, FESX, 199FESXM5, 2015-06-18, Thu, 3398.0, 3540.0, 3373.0, 3465.0, 1173246.0, 811805.0
0427, FESX, 199FESXM5, 2015-06-19, Fri, 3443.0, 3499.0, 3440.0, 3488.0, 104096.0, 516792.0
这使用cerebro.chaindata,结果应该是清楚的:
-
一旦一个data feed结束,下一个就接管
-
这总是发生在星期五和星期一之间:样本中的期货总是在星期五到期
期货滚动无需检查
让我们执行--rollover
$ ./rollover.py --rollover --plot
Len, Name, RollName, Datetime, WeekDay, Open, High, Low, Close, Volume, OpenInterest
0001, FESX, 199FESXM4, 2013-09-26, Thu, 2829.0, 2843.0, 2829.0, 2843.0, 3.0, 1000.0
0002, FESX, 199FESXM4, 2013-09-27, Fri, 2842.0, 2842.0, 2832.0, 2841.0, 16.0, 1101.0
...
0176, FESX, 199FESXM4, 2014-06-20, Fri, 3315.0, 3324.0, 3307.0, 3322.0, 134777.0, 520978.0
0177, FESX, 199FESXU4, 2014-06-23, Mon, 3301.0, 3305.0, 3265.0, 3285.0, 730211.0, 3003692.0
...
0241, FESX, 199FESXU4, 2014-09-19, Fri, 3287.0, 3308.0, 3286.0, 3294.0, 144692.0, 566249.0
0242, FESX, 199FESXZ4, 2014-09-22, Mon, 3248.0, 3263.0, 3231.0, 3240.0, 582077.0, 2976624.0
...
0306, FESX, 199FESXZ4, 2014-12-19, Fri, 3196.0, 3202.0, 3131.0, 3132.0, 226415.0, 677924.0
0307, FESX, 199FESXH5, 2014-12-22, Mon, 3151.0, 3177.0, 3139.0, 3168.0, 547095.0, 2952769.0
...
0366, FESX, 199FESXH5, 2015-03-20, Fri, 3680.0, 3698.0, 3672.0, 3695.0, 147632.0, 887205.0
0367, FESX, 199FESXM5, 2015-03-23, Mon, 3654.0, 3655.0, 3608.0, 3618.0, 802344.0, 3521988.0
...
0426, FESX, 199FESXM5, 2015-06-18, Thu, 3398.0, 3540.0, 3373.0, 3465.0, 1173246.0, 811805.0
0427, FESX, 199FESXM5, 2015-06-19, Fri, 3443.0, 3499.0, 3440.0, 3488.0, 104096.0, 516792.0
相同的行为。可以清楚地看到合同变更是在 Mar、Jun、Sep、Dec 的第三个星期五进行的。
但这基本上是错误的。backtrader不可能知道,但作者知道EuroStoxx 50期货交易停止时间是12:00 CET。因此,即使到期月份的第三个星期五有每日条,更改也发生得太晚了。

在一周内进行更改
在示例中实现了一个checkdate可调用对象,用于计算当前活动合同的到期日期。
checkdate将允许在月份的第三个星期五到来时进行滚动(例如,如果星期一是银行假日,则可能是星期二)
$ ./rollover.py --rollover --checkdate --plot
Len, Name, RollName, Datetime, WeekDay, Open, High, Low, Close, Volume, OpenInterest
0001, FESX, 199FESXM4, 2013-09-26, Thu, 2829.0, 2843.0, 2829.0, 2843.0, 3.0, 1000.0
0002, FESX, 199FESXM4, 2013-09-27, Fri, 2842.0, 2842.0, 2832.0, 2841.0, 16.0, 1101.0
...
0171, FESX, 199FESXM4, 2014-06-13, Fri, 3283.0, 3292.0, 3253.0, 3276.0, 734907.0, 2715357.0
0172, FESX, 199FESXU4, 2014-06-16, Mon, 3261.0, 3275.0, 3252.0, 3262.0, 180608.0, 844486.0
...
0236, FESX, 199FESXU4, 2014-09-12, Fri, 3245.0, 3247.0, 3220.0, 3232.0, 650314.0, 2726874.0
0237, FESX, 199FESXZ4, 2014-09-15, Mon, 3209.0, 3224.0, 3203.0, 3221.0, 153448.0, 983793.0
...
0301, FESX, 199FESXZ4, 2014-12-12, Fri, 3127.0, 3143.0, 3038.0, 3042.0, 1409834.0, 2934179.0
0302, FESX, 199FESXH5, 2014-12-15, Mon, 3041.0, 3089.0, 2963.0, 2980.0, 329896.0, 904053.0
...
0361, FESX, 199FESXH5, 2015-03-13, Fri, 3657.0, 3680.0, 3627.0, 3670.0, 867678.0, 3499116.0
0362, FESX, 199FESXM5, 2015-03-16, Mon, 3594.0, 3641.0, 3588.0, 3629.0, 250445.0, 1056099.0
...
0426, FESX, 199FESXM5, 2015-06-18, Thu, 3398.0, 3540.0, 3373.0, 3465.0, 1173246.0, 811805.0
0427, FESX, 199FESXM5, 2015-06-19, Fri, 3443.0, 3499.0, 3440.0, 3488.0, 104096.0, 516792.0
好多了。现在滚动发生在5 天之前。快速检查Len索引即可看到。例如:
199FESXM4到199FESXU4发生在len171-172。没有checkdate时发生在176-177
滚动将在到期月份的第三个星期五之前的星期一发生。
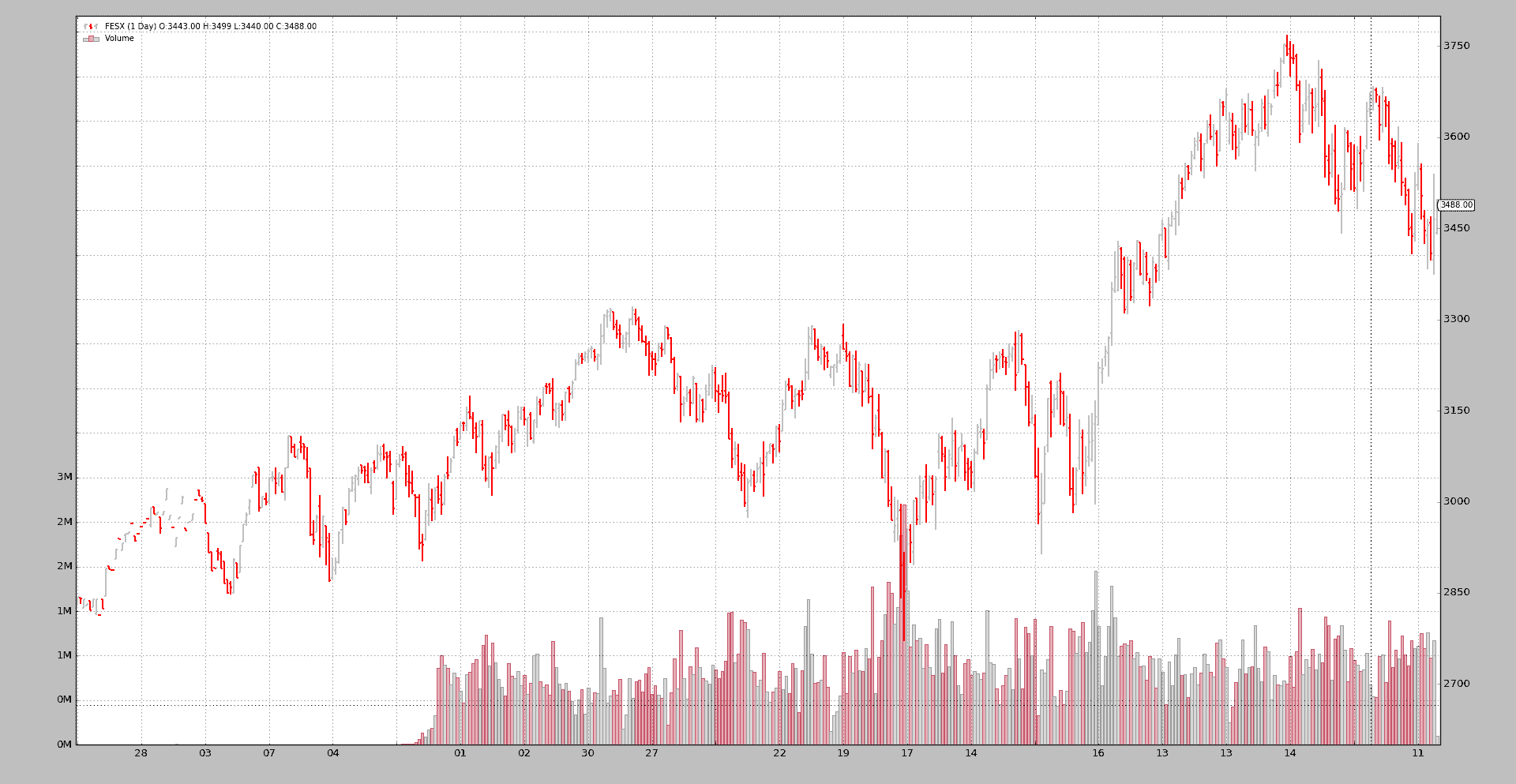
添加体积条件
即使有所改进,情况仍然可以进一步改善,不仅考虑日期,还将考虑协商的volume。如果新合同的交易量超过当前活动合同,则进行切换。
让我们将checkcondition添加到混合物中并运行。
$ ./rollover.py --rollover --checkdate --checkcondition --plot
Len, Name, RollName, Datetime, WeekDay, Open, High, Low, Close, Volume, OpenInterest
0001, FESX, 199FESXM4, 2013-09-26, Thu, 2829.0, 2843.0, 2829.0, 2843.0, 3.0, 1000.0
0002, FESX, 199FESXM4, 2013-09-27, Fri, 2842.0, 2842.0, 2832.0, 2841.0, 16.0, 1101.0
...
0175, FESX, 199FESXM4, 2014-06-19, Thu, 3307.0, 3330.0, 3300.0, 3321.0, 717979.0, 759122.0
0176, FESX, 199FESXU4, 2014-06-20, Fri, 3309.0, 3318.0, 3290.0, 3298.0, 711627.0, 2957641.0
...
0240, FESX, 199FESXU4, 2014-09-18, Thu, 3249.0, 3275.0, 3243.0, 3270.0, 846600.0, 803202.0
0241, FESX, 199FESXZ4, 2014-09-19, Fri, 3273.0, 3293.0, 3250.0, 3252.0, 1042294.0, 3021305.0
...
0305, FESX, 199FESXZ4, 2014-12-18, Thu, 3095.0, 3175.0, 3085.0, 3172.0, 1309574.0, 889112.0
0306, FESX, 199FESXH5, 2014-12-19, Fri, 3195.0, 3200.0, 3106.0, 3147.0, 1329040.0, 2964538.0
...
0365, FESX, 199FESXH5, 2015-03-19, Thu, 3661.0, 3691.0, 3646.0, 3668.0, 1271122.0, 1054639.0
0366, FESX, 199FESXM5, 2015-03-20, Fri, 3607.0, 3664.0, 3595.0, 3646.0, 1182235.0, 3407004.0
...
0426, FESX, 199FESXM5, 2015-06-18, Thu, 3398.0, 3540.0, 3373.0, 3465.0, 1173246.0, 811805.0
0427, FESX, 199FESXM5, 2015-06-19, Fri, 3443.0, 3499.0, 3440.0, 3488.0, 104096.0, 516792.0
更好。我们已经将切换日期移至众所周知的到期月份第三个星期五之前的星期四
这应该不会让人感到意外,因为期货到期的星期五交易时间较短,成交量必然很小。
注意
roll over 日期也可以通过 checkdate 可调用函数设置为星期四。但这并不是示例的重点。
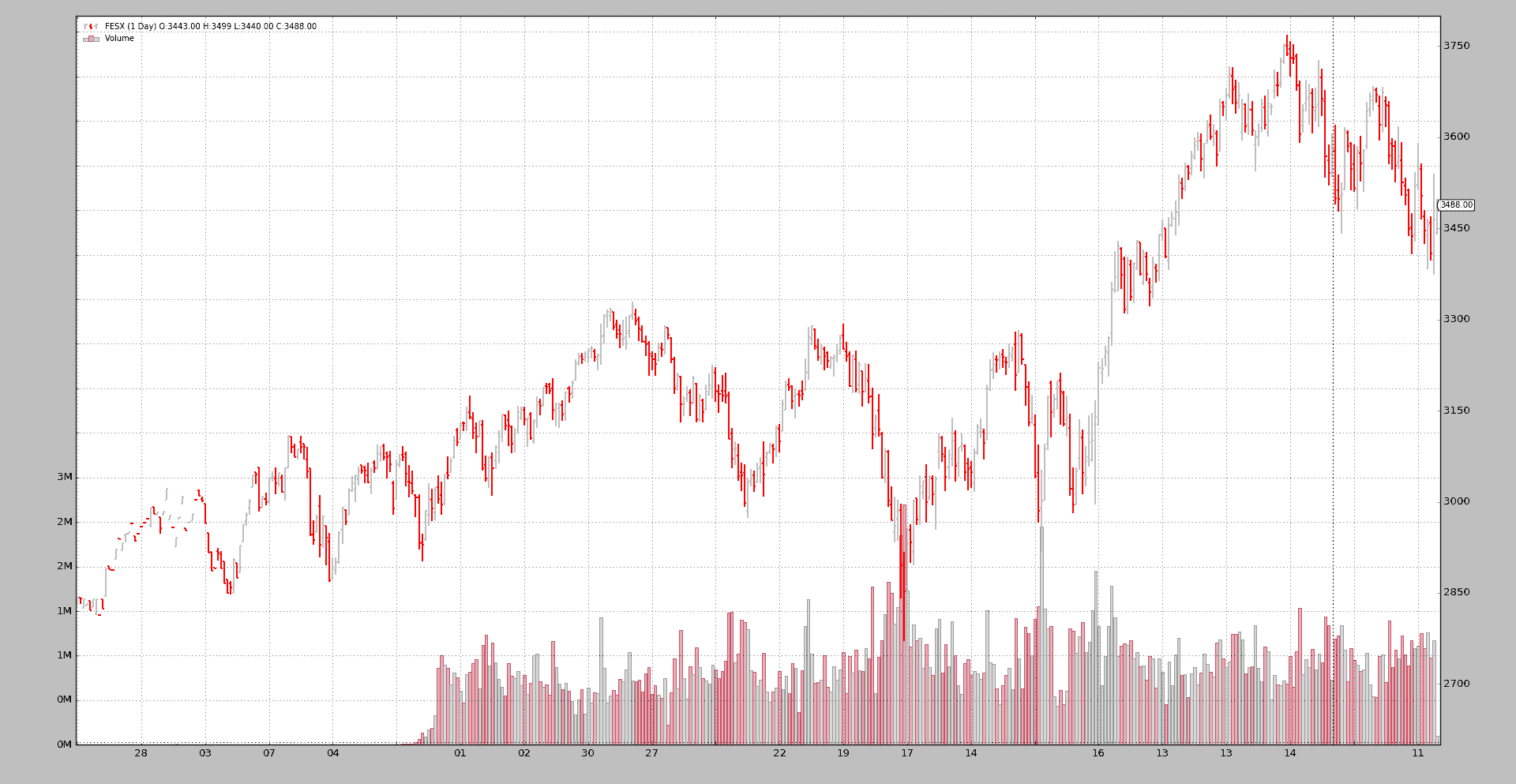
结论
backtrader 现在包含了一个灵活的机制,允许滚动期货以创建连续的流。
示例用法
$ ./rollover.py --help
usage: rollover.py [-h] [--no-cerebro] [--rollover] [--checkdate]
[--checkcondition] [--plot [kwargs]]
Sample for Roll Over of Futures
optional arguments:
-h, --help show this help message and exit
--no-cerebro Use RollOver Directly (default: False)
--rollover
--checkdate Change during expiration week (default: False)
--checkcondition Change when a given condition is met (default: False)
--plot [kwargs], -p [kwargs]
Plot the read data applying any kwargs passed For
example: --plot style="candle" (to plot candles)
(default: None)
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import bisect
import calendar
import datetime
import backtrader as bt
class TheStrategy(bt.Strategy):
def start(self):
header = ['Len', 'Name', 'RollName', 'Datetime', 'WeekDay', 'Open',
'High', 'Low', 'Close', 'Volume', 'OpenInterest']
print(', '.join(header))
def next(self):
txt = list()
txt.append('%04d' % len(self.data0))
txt.append('{}'.format(self.data0._dataname))
# Internal knowledge ... current expiration in use is in _d
txt.append('{}'.format(self.data0._d._dataname))
txt.append('{}'.format(self.data.datetime.date()))
txt.append('{}'.format(self.data.datetime.date().strftime('%a')))
txt.append('{}'.format(self.data.open[0]))
txt.append('{}'.format(self.data.high[0]))
txt.append('{}'.format(self.data.low[0]))
txt.append('{}'.format(self.data.close[0]))
txt.append('{}'.format(self.data.volume[0]))
txt.append('{}'.format(self.data.openinterest[0]))
print(', '.join(txt))
def checkdate(dt, d):
# Check if the date is in the week where the 3rd friday of Mar/Jun/Sep/Dec
# EuroStoxx50 expiry codes: MY
# M -> H, M, U, Z (Mar, Jun, Sep, Dec)
# Y -> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 -> year code. 5 -> 2015
MONTHS = dict(H=3, M=6, U=9, Z=12)
M = MONTHS[d._dataname[-2]]
centuria, year = divmod(dt.year, 10)
decade = centuria * 10
YCode = int(d._dataname[-1])
Y = decade + YCode
if Y < dt.year: # Example: year 2019 ... YCode is 0 for 2020
Y += 10
exp_day = 21 - (calendar.weekday(Y, M, 1) + 2) % 7
exp_dt = datetime.datetime(Y, M, exp_day)
# Get the year, week numbers
exp_year, exp_week, _ = exp_dt.isocalendar()
dt_year, dt_week, _ = dt.isocalendar()
# print('dt {} vs {} exp_dt'.format(dt, exp_dt))
# print('dt_week {} vs {} exp_week'.format(dt_week, exp_week))
# can switch if in same week
return (dt_year, dt_week) == (exp_year, exp_week)
def checkvolume(d0, d1):
return d0.volume[0] < d1.volume[0] # Switch if volume from d0 < d1
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
fcodes = ['199FESXM4', '199FESXU4', '199FESXZ4', '199FESXH5', '199FESXM5']
store = bt.stores.VChartFile()
ffeeds = [store.getdata(dataname=x) for x in fcodes]
rollkwargs = dict()
if args.checkdate:
rollkwargs['checkdate'] = checkdate
if args.checkcondition:
rollkwargs['checkcondition'] = checkvolume
if not args.no_cerebro:
if args.rollover:
cerebro.rolloverdata(name='FESX', *ffeeds, **rollkwargs)
else:
cerebro.chaindata(name='FESX', *ffeeds)
else:
drollover = bt.feeds.RollOver(*ffeeds, dataname='FESX', **rollkwargs)
cerebro.adddata(drollover)
cerebro.addstrategy(TheStrategy)
cerebro.run(stdstats=False)
if args.plot:
pkwargs = dict(style='bar')
if args.plot is not True: # evals to True but is not True
npkwargs = eval('dict(' + args.plot + ')') # args were passed
pkwargs.update(npkwargs)
cerebro.plot(**pkwargs)
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Sample for Roll Over of Futures')
parser.add_argument('--no-cerebro', required=False, action='store_true',
help='Use RollOver Directly')
parser.add_argument('--rollover', required=False, action='store_true')
parser.add_argument('--checkdate', required=False, action='store_true',
help='Change during expiration week')
parser.add_argument('--checkcondition', required=False,
action='store_true',
help='Change when a given condition is met')
# Plot options
parser.add_argument('--plot', '-p', nargs='?', required=False,
metavar='kwargs', const=True,
help=('Plot the read data applying any kwargs passed\n'
'\n'
'For example:\n'
'\n'
' --plot style="candle" (to plot candles)\n'))
if pargs is not None:
return parser.parse_args(pargs)
return parser.parse_args()
if __name__ == '__main__':
runstrat()

















 4436
4436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









