







协议:CC BY-NC-SA 4.0
十二、Linux 中的无线技术
第十一章处理第 4 层协议,它使我们能够与用户空间通信。本章讨论了 Linux 内核中的无线栈。我描述了 Linux 无线协议栈(mac80211 子系统)并讨论了其中一些重要机制的实现细节,如 IEEE 802.11n 中使用的包聚合和块确认,以及省电模式。为了理解无线子系统的实现,熟悉 802.11 MAC 报头是必不可少的。本章深入介绍了 802.11 MAC 报头、其成员及其用法。我还讨论了一些常见的无线拓扑,如基础设施基站、独立基站和网状网络。
Mac80211 子系统
在 20 世纪 90 年代末,在 IEEE 中有关于无线局域网(WLANS)协议的讨论。无线局域网 IEEE 802.11 规范的原始版本于 1997 年发布,并于 1999 年修订。在接下来的几年中,增加了一些扩展,正式称为 802.11 修正案。这些扩展可以分为 PHY(物理)层扩展、MAC(媒体访问控制)层扩展、管理扩展等等。例如,PHY 层扩展是 1999 年的 802.11b、802.11a(也是 1999 年的)和 2003 年的 802.11g。MAC 层扩展例如是用于 QoS 的 802.11e 和用于网状网络的 802.11s。本章的“网状网络”部分涉及 IEEE802.11s 修正案的 Linux 内核实现。IEEE802.11 规范经过修订,2007 年发布了 1232 页的第二版。2012 年,发布了一份 2793 页的规范,从http://standards.ieee.org/findstds/standard/802.11-2012.html开始提供。在本章中,我将该规范称为 IEEE 802.11-2012。以下是 802.11 重要修订的部分列表:
- IEEE 802.11d: 国际(国与国)漫游扩展(2001)。
- IEEE 802.11e: 增强:QoS,包括数据包突发(2005)。
- IEEE 802.11h: 针对欧洲兼容性的频谱管理 802.11 a(2004)。
- IEEE 802.11i: 增强的安全性(2004 年)。
- IEEE 802.11j: 日本的扩展(2004)。
- IEEE 802.11k: 无线电资源测量增强(2008 年)。
- IEEE 802.11n: 使用 MIMO(多输入多输出天线)提高吞吐量(2009)。
- IEEE 802.11p: WAVE:车载环境(如救护车、客车)的无线接入。它有一些特性,如不使用 BSS 概念和较窄的(5/10 MHz)信道。注意,在撰写本文时,Linux 还不支持 IEEE 802.11p。
- IEEE 802.11v: 无线网络管理。
- IEEE 802.11w: 受保护的管理帧。
- *美国 IEEE 802.11y:*3650–3700 MHz 操作(2008 年)
- IEEE 802.11z: 直接链路建立的扩展(DLS)(2007 年 8 月至 2011 年 12 月)。
直到大约 2001 年,大约在 IEEE 802.11 第一个规范被批准四年后,笔记本电脑才变得非常流行;这些笔记本电脑中有许多是带无线网络接口出售的。如今,每台笔记本电脑都将 WiFi 作为标准设备。对于当时的 Linux 社区来说,为这些无线网络接口提供 Linux 驱动程序并提供 Linux 网络无线堆栈是非常重要的,这样才能保持与其他操作系统(如 Windows、Mac OS 等)的竞争力。在架构和设计方面做得较少。正如当时的 Linux 内核无线维护者 Jeff Garzik 所说,“他们只是希望他们的硬件能够工作”。当开发第一个 Linux 无线驱动程序时,还没有通用的无线 API。因此,当开发人员从零开始实现他们的驱动程序时,在驱动程序之间有许多代码重复的情况。一些驱动程序是基于 FullMAC 的,这意味着大多数管理层(MLME) 是在硬件中管理的。在此后的几年中,开发了一种新的 802.11 无线堆栈,称为 mac80211。它在 2007 年 7 月被集成到 Linux 内核中,用于 2.6.22 Linux 内核。mac80211 堆栈基于 d80211 堆栈,d 80211 堆栈是一家名为 Devicescape 的公司开发的开源、GPL 许可的堆栈。
我不能深入研究 PHY 层的细节,因为这个主题非常广泛,值得单独写一本书。但是,我必须指出,802.11 和 802.3 有线以太网有许多不同之处。这里有两个主要区别:
- 以太网适用于 CSMA/CD,而 802.11 适用于 CSMA/CA。CSMA/CA 代表载波侦听多路访问/冲突避免,CSMA/CD 代表载波侦听多路访问/冲突检测。正如您可能猜到的那样,不同之处在于碰撞检测。使用以太网,当介质空闲时,站点开始传输;如果在传输过程中检测到冲突,传输将停止,并开始一个随机退避周期。无线站在传输时无法检测冲突,而有线站可以。使用 CSMA/CA 时,无线站会等待空闲介质,然后才传输帧。在发生冲突的情况下,工作站不会注意到它,但是因为不应该为该数据包发送确认帧,所以如果超时后没有收到确认,它将重新传输。
- 无线流量对干扰很敏感。因此,802.11 规范要求除广播和组播以外的每个帧在收到时都必须得到确认。没有及时得到确认的数据包应该重新传输。请注意,自 IEEE 802.11e 以来,有一种模式不需要确认,即 QoSNoAck 模式,但在实践中很少使用。
802.11 MAC 报头
每个 MAC 帧由 MAC 报头、可变长度的帧体和 32 位 CRC 的 FCS(帧校验序列)组成。图 12-1 显示了 802.11 标题。

图 12-1 。IEEE 802.11 报头。请注意,并不总是使用所有成员,这一节将很快解释
802.11 报头在 mac80211 中由ieee80211_hdr结构表示:
struct ieee80211_hdr {
__le16 frame_control;
__le16 duration_id;
u8 addr1[6];
u8 addr2[6];
u8 addr3[6];
__le16 seq_ctrl;
u8 addr4[6];
} __packed;
(include/linux/ieee80211.h)
与仅包含三个字段(源 MAC 地址、目的 MAC 地址和以太网类型)的以太网报头(struct ethhdr)相比,802.11 报头包含多达六个地址和一些其他字段。但是,对于典型的数据帧,只使用三个地址(例如,接入点或 AP/客户端通信)。对于 ACK 帧,只使用接收方地址。注意图 12-1 只显示了四个地址,但是当使用网状网络时,使用了带有两个额外地址的网状扩展报头。
我现在转向 802.11 报头字段的描述,从 802.11 报头中的第一个字段开始,称为帧控制。这是一个重要的字段,在很多情况下,它的内容决定了 802.11 MAC 报头中其他字段的含义(尤其是地址)。
框架控件
帧控制长度为 16 位。图 12-2 显示了它的字段和每个字段的大小。

图 12-2 。帧控制字段
以下是对框架控制成员的描述:
-
Protocol version:我们用的 MAC 802.11 的版本。目前只有一个 MAC 版本,因此该字段始终为 0。 -
802.11 中有三种类型的数据包——管理、控制和数据:
-
管理数据包 (IEEE80211_FTYPE_MGMT)用于管理操作,如关联、认证、扫描等。
-
控制包 (IEEE80211_FTYPE_CTL)通常与数据包有一定的关联性;例如,PS-Poll 分组用于从 AP 缓冲器中检索分组。再比如:一个要传输的站先发送一个名为 RTS(请求发送)的控制包;如果介质空闲,目的站将发回一个名为 CTS(允许发送)的控制包。
-
数据包 (IEEE80211_FTYPE_DATA)是原始数据包。空包是原始包的特例,不携带数据,主要用于电源管理控制目的。我将在本章后面的“节能模式”一节中讨论空数据包。
-
Subtype:对于所有上述三种类型的数据包(管理、控制和数据),都有一个子类型字段,用于标识所用数据包的特征。例如: -
管理帧中子类型字段的值 0100 表示该分组是探测请求(IEEE80211_STYPE_PROBE_REQ)管理分组,其在扫描操作中使用。
-
控制分组中子类型字段的值 1011 表示这是请求发送(IEEE80211_STYPE_RTS)控制分组。数据包的子类型字段的值 0100 表示这是一个空数据(IEEE80211_STYPE_NULLFUNC)包,用于电源管理控制。
-
数据分组的子类型的值 1000(IEEE 80211 _ STYPE _ QOS _ 数据)意味着这是 QOS 数据分组;这个子类型是由 IEEE802.11e 修正案添加的,它处理 QoS 增强。
-
ToDS:该位被置位时,表示该包是给分布式系统的。 -
FromDS:该位被置位时,表示数据包来自分发系统。 -
More Frag:使用分段时,该位设为 1。 -
Retry:当一个包被重发时,该位被设置为 1。重传的一个典型例子是发送的数据包没有及时收到确认。确认通常由无线驱动程序的固件发送。 -
Pwr Mgmt:当电源管理位被置位时,意味着站点将进入省电模式。我将在本章后面的“节能模式”一节中讨论节能模式。 -
More Data:当 AP 发送它为休眠站缓冲的数据包时,当缓冲区不为空时,它将More Data位设置为 1。因此,该站知道它应该检索更多的分组。当缓冲器清空后,该位被置 0。 -
Protected Frame:该位在帧体加密时置 1;只能加密数据帧和认证帧。 -
对于被称为严格排序的 MAC 服务,帧的顺序很重要。当使用该服务时,顺序位被设置为 1。很少使用。
 注802.11h 修正案引入了行动框架(IEEE80211_STYPE_ACTION),处理频谱和发射功率管理。然而,由于缺乏用于管理分组子类型的空间,动作帧也被用于各种较新的标准修订中,例如,802.11n 中的 HT 动作帧
注802.11h 修正案引入了行动框架(IEEE80211_STYPE_ACTION),处理频谱和发射功率管理。然而,由于缺乏用于管理分组子类型的空间,动作帧也被用于各种较新的标准修订中,例如,802.11n 中的 HT 动作帧
其他 802.11 MAC 报头成员
下面描述帧控制之后的 mac802.11 报头的其他成员:
Duration/ID: 持续时间以微秒为单位保存网络分配向量(NAV) 的值,它由Duration/ID字段的 15 位组成。第十六个字段是 0。当在省电模式下工作时,它是 PS-Poll 帧的站的 AID(关联 ID)(参见 IEEE 802.11-2012 中的 8.2.4.2(a))。网络分配矢量(NAV)是一种虚拟载波侦听机制。我不深入 NAV 内部,因为那超出了本章的范围。Sequence Control: 这是一个 2 字节的字段,用于指定顺序控制。在 802.11 中,数据包可能会被多次接收,最常见的情况是由于某种原因没有收到确认。序列控制字段由一个片段号(4 位)和一个序列号(12 位)组成。序列号由发射站以ieee80211_tx_h_sequence()方式生成。在重传中的重复帧的情况下,它被丢弃,并且被丢弃的重复帧的计数器(dot11FrameDuplicateCount)增加 1;这在ieee80211_rx_h_check()方法中完成。控制数据包中不存在Sequence Control字段。Address1 – Address4: 有四个地址,但你并不总是用全。地址 1 是接收地址(RA),用于所有数据包。地址 2 是发送地址(TA),它存在于除 ACK 和 CTS 包以外的所有包中。地址 3 仅用于管理和数据包。当设置帧控制的 ToDS 和 FromDS 位时,使用地址 4;在无线分布系统中工作时会发生这种情况。QoS Control:QoS 控制字段是由 802.11e 修正案添加的,并且只存在于 QoS 数据包中。因为它不是原始 802.11 规范的一部分,也不是原始 mac80211 实现的一部分,所以它不是 IEEE802.11 头(ieee80211_hdr struct)的成员。事实上,它被添加在 IEEE802.11 报头的末尾,可以通过ieee80211_get_qos_ctl()方法访问。QoS 控制字段包括tid(流量标识)、ACK 策略和称为 A-MSDU 存在的字段,该字段告知 A-MSDU 是否存在。我将在本章后面的“高吞吐量(ieee802.11n)”一节中讨论 A-MSDU。- HT 控制字段:HT (高吞吐量)控制字段由 802.11n 修订版添加(参见 802.11n-2009 规范的 7.1.3.5(a))。
本节介绍了 802.11 MAC 报头及其成员和用途。熟悉 802.11 MAC 报头对于理解 mac802.11 堆栈至关重要。
网络拓扑
802.11 无线网络中有两种流行的网络拓扑。我讨论的第一种拓扑是基础架构 BSS 模式,这是最流行的。您会在家庭无线网络和办公室中遇到基础设施 BSS 无线网络。稍后我将讨论 IBSS(特设)模式。注意,IBSS 是而不是基础设施 BSSIBSS 是独立的 BSS ,这是一个自组织网络,将在本节稍后讨论。
基础设施 BSS
在基础设施 BSS 模式下工作时,有一个中心设备,称为接入点(AP),还有一些客户端站。它们一起形成了一个 BSS(基本服务集)。这些客户站必须首先对 AP 执行关联和认证,以便能够通过 AP 发送分组。在许多情况下,客户站在认证和关联之前执行扫描,以便获得关于 AP 的细节。关联是排他的:在给定时刻,一个客户端只能与一个 AP 关联。当客户端与 AP 成功关联时,它会获得一个 AID(关联 ID),这是一个唯一的编号(对于此 BSS ),范围为 1–2007。AP 实际上是一种无线网络设备,带有一些附加硬件(如以太网端口、led、重置为制造商默认值的按钮等)。管理守护程序在 AP 设备上运行。这种软件的一个例子是hostapd守护进程。该软件处理 MLME 层的一些管理任务,例如认证和关联请求。它通过注册自己经由nl80211接收相关的管理帧来实现这一点。hostapd项目是一个开源项目,它使几个无线网络设备能够作为 AP 运行。
客户端可以通过向 AP 发送分组来与其他客户端(或者与桥接到 AP 的不同网络中的站)通信,这些分组由 AP 中继到它们的最终目的地。为了覆盖一个大的区域,你可以部署多个接入点,并通过有线连接它们。这种类型的部署称为扩展服务集(ESS) 。在 ESS 部署中,有两个或更多 BSS。在一个 BSS 中发送的可能到达附近 BSS 的多播和广播在附近的 BSS 站中被拒绝(802.11 报头中的bssid不匹配)。在这样的部署中,每个 AP 通常使用不同的信道来最小化干扰。
IBSS,或特设模式
IBSS 网络通常是在没有预先规划的情况下形成的,只在需要 WLAN 的时候形成。IBSS 网络也称为自组织网络。创建 IBSS 是一个简单的过程。您可以通过从命令行运行此iw命令来设置 IBSS(注意,2412 参数用于使用通道 1):
iw wlan0 ibss join AdHocNetworkName 2412
或者在使用iwconfig工具时,使用这两个命令:
iwconfig wlan0 mode ad-hoc
iwconfig wlan0 essid AdHocNetworkrName
这通过调用ieee80211_sta_create_ibss()方法(net/mac80211/ibss.c)来触发 IBSS 创建。然后ssid(在本例中为AdHocNetworkName)必须手动(或以其他方式)分发给每个想要连接到自组织网络的人。和 IBSS 一起工作时,你没有 AP。IBSS 的 bssid 是一个随机的 48 位地址(基于调用get_random_bytes()方法)。自组织模式中的电源管理比基础设施 BSS 中的电源管理稍微复杂一些;它使用公告交通指示地图(ATIM)消息。mac802.11 不支持 ATIM,本章不讨论它。
下一节描述省电模式,这是 mac80211 网络堆栈最重要的机制之一。
省电模式
除了转发数据包,AP 还有另一个重要的功能:为进入省电模式的客户站缓冲数据包。客户端通常是电池供电的设备。无线网络接口有时会进入省电模式。
进入省电模式
当客户站进入省电模式时,它通常通过发送空数据包来通知 AP。其实从技术上讲,不一定是空数据包;它是 PM=1 (PM 是帧控制中的电源管理标志)的分组就足够了。获得这种空分组的 AP 开始将去往该站的单播分组保存在称为ps_tx_buf的特殊缓冲器中;每个车站都有这样的缓冲区。该缓冲区实际上是一个数据包链表,每个站最多可容纳 128 个数据包(STA_MAX_TX_BUFFER)。如果缓冲区已满,它将开始丢弃最先收到的数据包(FIFO)。除此之外,还有一个称为bc_buf的缓冲区,用于多播和广播数据包(在 802.11 堆栈中,多播数据包应该由同一 BSS 中的所有站点接收和处理)。bc_buf缓冲区也可以容纳多达 128 个数据包(AP_MAX_BC_BUFFER)。当无线网络接口处于节能模式时,它无法接收或发送数据包。
退出省电模式
不时地,相关的站被它自己唤醒(通过一些定时器);然后它检查 AP 周期性发送的特殊管理包,称为信标 。通常,一个 AP 每秒发送 10 个信标;在大多数 AP 上,这是一个可配置的参数。这些信标包含信息元素中的数据,这些信息元素构成了管理包中的数据。被唤醒的站点通过调用ieee80211_check_tim()方法(include/linux/ieee80211.h)检查一个名为 TIM(交通指示图)的特定信息元素。TIM 是 2008 年条目的数组。因为 TIM 的大小是 251 字节(2008 位),所以允许您发送一个部分虚拟位图,它的大小要小一些。如果该站的 TIM 中的条目被设置,这意味着 AP 保存了该站的单播包,因此该站应该清空 AP 为其保存的包的缓冲区。该站开始发送空分组(或者,更罕见地,称为 PS-Poll 分组的特殊控制分组),以从 AP 检索这些缓冲的分组。通常在缓冲区清空后,站点进入睡眠状态(然而,根据规范,这不是强制性的)。
处理多播/广播缓冲区
每当至少一个站处于睡眠模式时,AP 缓冲多播和广播分组。多播/广播站的 AID 是 0;所以,在这种情况下,你设置 TIM[0]为真。传递组(DTIM)是一种特殊类型的 TIM,它不是在每个信标中发送,而是在预定数量的信标间隔(DTIM 周期)内发送一次。发送 DTIM 后,AP 发送其缓冲的广播和组播数据包。您通过调用ieee80211_get_buffered_bc()方法从多播/广播缓冲区(bc_buf)中检索包。在图 12-3 中,你可以看到一个 AP,它包含一个站(sta_info对象)的链表,每个站都有自己的单播缓存(ps_tx_buf)和一个单独的bc_buf缓存,用于存储组播和广播数据包。
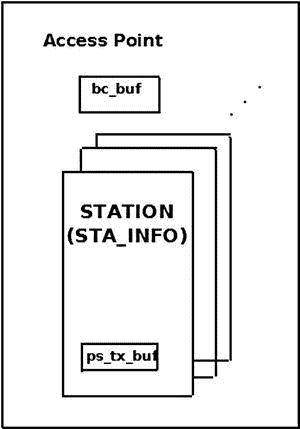
图 12-3 。在 AP 中缓冲数据包
AP 在 mac80211 中被实现为一个ieee80211_if_ap对象。每个这样的ieee80211_if_ap对象都有一个名为ps(ps_data的一个实例)的成员,节电数据存储在其中。ps_data结构的成员之一是广播/组播缓冲器bc_buf。
在图 12-4 中,你可以看到一个客户端发送的 PS-Poll 数据包的流程,目的是从 AP 单播缓冲区ps_tx_buf中检索数据包。请注意,除了最后一个数据包,AP 发送所有带有 IEEE 80211 _ FCTL _ 更多数据标志的数据包。因此,客户端知道它应该继续发送 PS-Poll 分组,直到缓冲区被清空。为了简单起见,此图中不包括 ACK 流量,但这里应该提到的是,数据包应该得到确认。
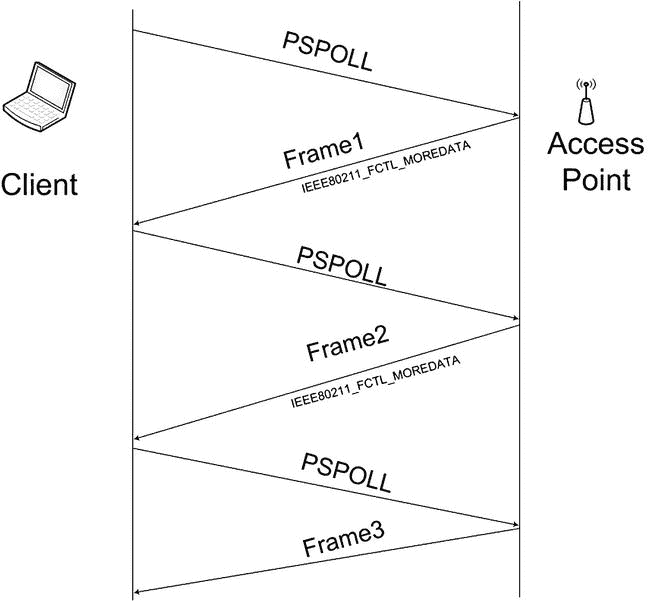
图 12-4 。从客户端发送 PSPOLL 数据包,以从 AP 内的 ps_tx_buf 缓冲区中检索数据包
 注意 电源管理和省电模式是两个不同的话题。电源管理处理执行挂起(无论是挂起到 RAM 还是挂起到磁盘,也称为休眠,或者在某些情况下,挂起到 RAM 和挂起到磁盘,也称为混合挂起)的机器,并在
注意 电源管理和省电模式是两个不同的话题。电源管理处理执行挂起(无论是挂起到 RAM 还是挂起到磁盘,也称为休眠,或者在某些情况下,挂起到 RAM 和挂起到磁盘,也称为混合挂起)的机器,并在net/mac80211/pm.c中处理。在驱动程序中,电源管理由恢复/挂起方法处理。另一方面,省电模式处理进入睡眠模式和唤醒的处理站;它与挂起和休眠无关。
本节描述了省电模式和缓冲机制。下一节讨论管理层及其处理的不同任务。
管理层(MLME)
802.11 管理架构中有三个组件:
- 物理层管理实体(PLME)。
- 系统管理实体(SME)。
- MAC 层管理实体(MLME)。
扫描
扫描有两种:被动扫描和主动扫描。被动扫描意味着被动地监听信标,而不发送任何用于扫描的数据包。当执行被动扫描(扫描通道的标志包含 IEEE80211_CHAN_PASSIVE_SCAN)时,站点从一个通道移动到另一个通道,尝试接收信标。在一些更高的 802.11a 频带中需要被动扫描,因为在听到 AP 信标之前,你根本不允许传输任何东西。对于主动扫描,每个站发送一个探测请求包;这是一个管理数据包,带有子类型探测请求(IEEE80211_STYPE_PROBE_REQ)。同样通过主动扫描,站点从一个通道移动到另一个通道,在每个通道上发送一个探测请求管理包(通过调用ieee80211_send_probe_req()方法)。这是通过调用ieee80211_request_scan()方法来完成的。通过调用ieee80211_hw_config()方法,将 IEEE 80211 _ CONF _ 改变 _ 频道作为参数传递,可以改变频道。注意,在站点操作的信道和它操作的频率之间存在一一对应关系;在给定频道的情况下,ieee80211_channel_to_frequency()方法(net/wireless/util.c)返回电台运行的频率。
证明
通过调用ieee80211_send_auth()方法(net/mac80211/util.c)来完成认证。它发送带有认证子类型(IEEE80211_STYPE_AUTH)的管理帧。有许多认证类型;最初的 IEEE802.11 规范只谈到了两种形式:开放系统认证和共享密钥认证。IEEE802.11 规范要求的唯一强制身份验证方法是开放系统身份验证(WLAN_AUTH_OPEN)。这是一个非常简单的认证算法—事实上,它是一个空认证算法。任何请求使用该算法进行身份验证的客户端都将通过身份验证。认证算法的另一个选项的例子是共享密钥认证(WLAN_AUTH_SHARED_KEY)。在共享密钥身份验证中,工作站应该使用有线等效保密(WEP)密钥进行身份验证。
联合
为了关联,站发送带有关联子类型的管理帧(IEEE80211_STYPE_ASSOC_REQ)。关联是通过调用ieee80211_send_assoc()方法(net/mac80211/mlme.c)完成的。
重新组合
当一个站点在 ESS 内的接入点之间移动时,它被称为漫游。漫游站通过发送具有重新关联子类型的管理帧(IEEE80211 _ STYPE _ REASSOC _ REQ)向新的 AP 发送重新关联请求。重新关联是通过调用ieee80211_send_assoc()方法完成的;关联和重新关联之间有许多相似之处,因此该方法同时处理两者。此外,通过重新关联,如果成功,AP 会向客户端返回一个 AID(关联 ID)。
本节讨论了管理层(MLME)及其支持的一些操作,如扫描、认证、关联等等。在下一节中,我将描述一些 mac80211 实现细节,这些细节对于理解无线协议栈非常重要。
Mac80211 实现
Mac80211 有一个 API,用于与底层设备驱动程序接口。mac80211 的实现很复杂,充满了许多小细节。我无法给出 mac80211 API 和实现的详尽描述;我确实讨论了一些要点,可以为那些想要深入研究代码的人提供一个良好的起点。mac80211 API 的一个基本结构是ieee80211_hw结构(include/net/mac80211.h);它代表硬件信息。ieee80211_hw的priv(指向私有区域的指针)指针属于不透明类型(void *)。大多数无线设备驱动都为这个私有区域定义了一个私有结构,比如lbtf_private (Marvell 无线驱动)或者iwl_priv(英特尔的iwlwifi)。ieee80211_hw struct的内存分配和初始化由ieee80211_alloc_hw()方法完成。下面是一些与ieee80211_hw结构相关的方法:
int ieee80211_register_hw(struct ieee80211_hw *hw):由无线驱动调用,用于注册指定的ieee80211_hw对象。void ieee80211_unregister_hw(struct ieee80211_hw *hw):注销指定的 802.11 硬件设备。struct ieee80211_hw *ieee80211_alloc_hw(size_t priv_data_len, const struct ieee80211_ops *ops):分配一个ieee80211_hw对象并初始化。ieee80211_rx_irqsafe():此方法用于接收数据包。它在net/mac80211/rx.c中实现,并从底层无线驱动程序中调用。
如您之前所见,传递给ieee80211_alloc_hw()方法的ieee80211_ops对象由指向驱动程序回调的指针组成。并非所有这些回调都必须由驱动程序实现。以下是对这些方法的简短描述:
tx(): 发送处理器调用每个发送的数据包。它通常返回 NETDEV_TX_OK(除了在某些有限的条件下)。start(): 激活硬件设备,在第一个硬件设备启用前被调用。它打开帧接收。stop(): 关闭帧接收,通常关闭硬件。add_interface(): 当连接到硬件的网络设备启用时调用。remove_interface(): 通知驱动程序接口正在关闭。config():处理配置请求,如硬件通道配置。configure_filter(): 配置设备的 Rx 滤波器。
图 12-5 显示了 Linux 无线子系统架构的框图。你可以看到无线设备驱动层和 mac80211 层之间的接口是ieee80211_ops对象及其回调。
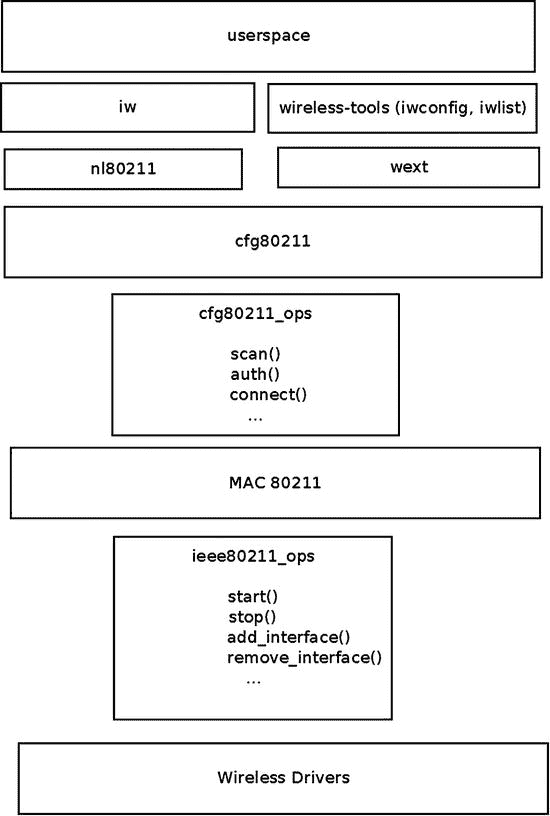
图 12-5 。Linux 无线架构
另一个重要的结构是sta_info struct ( net/mac80211/sta_info.h),代表一个车站。这个结构的成员包括各种统计计数器、各种标志、debugfs条目、用于缓冲单播包的ps_tx_buf数组等等。电台被组织在散列表(sta_hash)和列表(sta_list)中。与sta_info相关的重要方法如下:
int sta_info_insert(struct sta_info *sta):增加一个电台。int sta_info_destroy_addr(struct ieee80211_sub_if_data *sdata, const u8 *addr):删除一个电台(通过调用__sta_info_destroy()方法)。struct sta_info *sta_info_get(struct ieee80211_sub_if_data *sdata, const u8 *addr):取站;车站的地址(它是bssid)作为参数传递。
Rx 路径
ieee80211_rx()函数 ( net/mac80211/rx.c)是主接收处理程序。接收到的数据包的状态(ieee80211_rx_status)由无线驱动程序传递给嵌入在 SKB 控制缓冲器(cb)中的 mac80211。IEEE80211_SKB_RXCB()宏用于获取该状态。例如,Rx 状态的flag字段指定数据包的 FCS 检查是否失败(RX_FLAG_FAILED_FCS_CRC)。本章“快速参考”部分的表 12-1 中给出了flag字段的各种可能值。在ieee80211_rx()方法中,调用ieee80211_rx_monitor()删除 FCS(校验和)并删除无线接口处于监控模式时可能添加的无线报头(struct ieee80211_radiotap_header)。(例如,在嗅探的情况下,您可以在监控模式下使用网络接口。并非所有无线网络接口都支持监控模式,请参阅本章后面的“无线模式”一节。)
如果您使用 HT (802.11n),如果需要,您可以通过调用ieee80211_rx_reorder_ampdu()方法来执行 AMPDU 重新排序。然后调用__ieee80211_rx_handle_packet()方法,最终调用ieee80211_invoke_rx_handlers()方法。然后一个接一个地调用不同的接收处理程序(使用一个名为 CALL_RXH 的宏)。调用这些处理程序的顺序很重要。每个处理器检查它是否应该处理分组。如果它决定不处理这个包,那么你返回 RX_CONTINUE 并继续下一个处理程序。如果它决定它应该处理这个包,那么你返回 RX_QUEUED。
在某些情况下,处理程序会决定丢弃数据包;在这些情况下,它返回 RX_DROP_MONITOR 或 RX_DROP_UNUSABLE。例如,如果您收到一个 PS-Poll 数据包,而接收方的类型显示它不是 AP,则返回 RX_DROP_UNUSABLE。另一个例子:对于一个管理帧,如果 SKB 的长度小于最小值(24),则丢弃该数据包并返回 RX_DROP_MONITOR。或者如果该分组不是管理分组,则该分组也被丢弃并且 RX_DROP_MONITOR 被返回。下面是实现这一点的ieee80211_rx_h_mgmt_check()方法的代码片段:
ieee80211_rx_h_mgmt_check(struct ieee80211_rx_data *rx)
{
struct ieee80211_mgmt *mgmt = (struct ieee80211_mgmt *) rx->skb->data;
struct ieee80211_rx_status *status = IEEE80211_SKB_RXCB(rx->skb);
. . .
if (rx->skb->len < 24)
return RX_DROP_MONITOR;
if (!ieee80211_is_mgmt(mgmt->frame_control))
return RX_DROP_MONITOR;
. . .
}
(net/mac80211/rx.c)
Tx 路径
ieee80211_tx()方法是传输(net/mac80211/tx.c)的主要处理程序。首先,它调用__ieee80211_tx_prepare()方法,该方法执行一些检查并设置某些标志。然后它调用invoke_tx_handlers()方法,该方法一个接一个地调用各种传输处理程序(使用一个名为 CALL_TXH 的宏)。如果一个发送处理程序发现它不应该对数据包做任何事情,它返回 TX_CONTINUE,你继续下一个处理程序。如果它决定应该处理某个数据包,它返回 TX_QUEUED,如果它决定应该丢弃该数据包,它返回 TX_DROP。invoke_tx_handlers()方法在成功时返回 0。让我们简短地看一下ieee80211_tx()方法的实现:
static bool ieee80211_tx(struct ieee80211_sub_if_data *sdata,
struct sk_buff *skb, bool txpending,
enum ieee80211_band band)
{
struct ieee80211_local *local = sdata->local;
struct ieee80211_tx_data tx;
ieee80211_tx_result res_prepare;
struct ieee80211_tx_info *info = IEEE80211_SKB_CB(skb);
bool result = true;
int led_len;
执行健全性检查,如果 SKB 长度小于 10:
if (unlikely(skb->len < 10)) {
dev_kfree_skb(skb);
return true;
}
/* initialises tx */
led_len = skb->len;
res_prepare = ieee80211_tx_prepare(sdata, &tx, skb);
if (unlikely(res_prepare == TX_DROP)) {
ieee80211_free_txskb(&local->hw, skb);
return true;
} else if (unlikely(res_prepare == TX_QUEUED)) {
return true;
}
调用 Tx 处理程序;如果一切正常,继续调用__ieee80211_tx()方法:
. . .
if (!invoke_tx_handlers(&tx))
result = __ieee80211_tx(local, &tx.skbs, led_len,
tx.sta, txpending);
return result;
}
(net/mac80211/tx.c)
分裂
802.11 中的分片只针对单播包。每个站被分配一个碎片阈值大小(以字节为单位)。大于此阈值的数据包应该被分段。您可以通过减小碎片阈值大小,使数据包更小来减少冲突的数量。您可以通过运行iwconfig或检查相应的debugfs条目来检查站点的碎片阈值(参见本章后面的“Mac80211 debugfs一节)。您可以使用iwconfig命令设置碎片阈值;因此,例如,您可以通过以下方式将碎片阈值设置为 512 字节:
iwconfig wlan0 frag 512
每个片段都被确认。如果存在更多片段,片段头中的更多片段字段被设置为 1。每个片段都有一个片段号(帧控制的序列控制字段中的一个子字段)。接收器上的片段重组是根据片段编号完成的。发射器端的分段通过ieee80211_tx_h_fragment()方法(net/mac80211/tx.c)完成。接收器端的重组通过ieee80211_rx_h_defragment()方法(net/mac80211/rx.c)完成。分段与聚合(用于更高的吞吐量)是不兼容的,并且考虑到高速率和短(时间)分组,现在很少使用它。
Mac80211 调试程序
debugfs 是一种能够将调试信息导出到用户空间的技术。它在sysfs文件系统下创建条目。debugfs是一个专门用于调试信息的虚拟文件系统。对于 mac80211,处理 mac80211 debugfs大多在net/mac80211/debugfs.c。安装debugfs后,可以查看各种 mac802.11 统计和信息条目。安装debugfs是这样进行的:
mount -t debugfs none_debugs /sys/kernel/debug
 注意在构建内核时必须设置 CONFIG_DEBUG_FS,以便能够挂载和使用
注意在构建内核时必须设置 CONFIG_DEBUG_FS,以便能够挂载和使用debugfs。
比如说你的phy是phy0;以下是对/sys/kernel/debug/ieee80211/phy0下部分词条的讨论:
-
total_ps_buffered:这是 AP 为电台缓冲的数据包总数(单播和多播/广播)。对于单播,total_ps_buffered计数器增加ieee80211_tx_h_unicast_ps_buf(),对于多播或广播,ieee80211_tx_h_multicast_ps_buf()计数器增加。 -
在
/sys/kernel/debug/ieee80211/phy0/statistics下,有各种统计信息,例如: -
frame_duplicate_count表示重复帧的数量。这个debugfs条目表示重复帧计数器dot11FrameDuplicateCount,其由ieee80211_rx_h_check()方法递增。 -
transmitted_frame_count表示发送的数据包数量。这个debugfs条目代表dot11TransmittedFrameCount;它通过ieee80211_tx_status()方法递增。 -
retry_count表示重发次数。这个debugfs条目代表dot11RetryCount;它也通过ieee80211_tx_status()方法递增。 -
fragmentation_threshold:碎片阈值的大小,以字节为单位。参见前面的“碎片化”部分。 -
在
/sys/kernel/debug/ieee80211/phy0/netdev:wlan0下,你有一些给出接口信息的条目;例如,如果接口处于站模式,则aid表示站的关联 id,assoc_tries表示站尝试执行关联的次数,bssid表示站的 bssid,依此类推。 -
每个站都使用速率控制算法。它的名字由下面的
debugfs条目导出:/sys/kernel/debug/ieee80211/phy1/rc/name。
无线模式
您可以将无线网络接口设置为在多种模式下运行,具体取决于其预期用途和部署它的网络拓扑。在某些情况下,你可以用iwconfig命令设置模式,而在某些情况下,你必须使用像hostapd这样的工具。请注意,并非所有设备都支持所有模式。参见www.linuxwireless.org/en/users/Drivers获得支持不同模式的 Linux 驱动列表。或者,您也可以检查驱动程序代码中的wiphy成员的interface_modes字段(在ieee80211_hw对象中)被初始化为哪些值。interface_modes被初始化为nl80211_iftype enum的一个或多个模式,如 NL80211_IFTYPE_STATION 或 NL80211_IFTYPE_ADHOC(参见:include/uapi/linux/nl80211.h)。以下是这些无线模式的详细描述:
- AP 模式: 在此模式下,设备充当 AP (NL80211_IFTYPE_AP)。AP 维护和管理相关站的列表。网络(BSS)名称是 AP 的 MAC 地址(
bssid)。BSS 还有一个人可读的名称,称为 SSID。 - 站基础架构模式: 基础架构模式下的管理站(NL80211_IFTYPE_STATION)。
- 监控模式: 在监控模式(NL80211_IFTYPE_MONITOR)下,所有传入的数据包都是未经过滤的。这对嗅探很有用。通常可以在监控模式下传输数据包。这被称为包注入;这些数据包标有特殊标志(IEEE80211_TX_CTL_INJECTED)。
- *Ad Hoc (IBSS)模式:*Ad Hoc(IBSS)网络中的一个站点(NL80211_IFTYPE_ADHOC)。在 Ad Hoc 模式下,网络中没有 AP 设备。
- *无线分布系统(WDS)模式:*WDS 网络中的一个站(NL80211_IFTYPE_WDS)。
- 网状模式: 网状网络(NL80211_IFTYPE_MESH_POINT)中的一个站点,将在本章后面的“网状网络(802.11s)”一节中讨论。
下一节将讨论提供更高性能的 ieee802.11n 技术,以及它如何在 Linux 无线协议栈中实现。您还将了解 802.11n 中的块确认和数据包聚合,以及如何使用这些技术来提高性能。
高吞吐量(ieee802.11n)
802.11g 被批准后不久,在 IEEE 中创建了一个新的任务组,称为高吞吐量任务组(TGn) 。IEEE 802.11n 在 2009 年底成为最终规范。IEEE 802.11n 协议允许与传统设备共存。有一些厂商在官方批准之前已经销售了基于 802.11n 草案的 802.11n 预标准设备。Broadcom 开创了基于草案发布无线接口的先例。2003 年,它发布了基于 802.11g 草案的无线设备芯片组。遵循这一先例,早在 2005 年,一些供应商就发布了基于 802.11n 草案的产品。例如,英特尔 Santa Rose 处理器具有英特尔下一代 Wireless-N(英特尔 WiFI Link 5000 系列),支持 802.11n。其他英特尔无线网络接口,如 4965AGN,也支持 802.11n。其他供应商,包括 Atheros 和 Ralink,也发布了基于 802.11n 草案的无线设备。WiFi 联盟于 2007 年 6 月开始认证 802.11n 草案设备。一长串供应商发布了符合 Wi-Fi 认证的 802.11n 草案 2.0 的产品。
802.11n 可以在 2.4 GHz 和/或 5 GHz 频带上工作,而 802.11g 和 802.11b 仅在 2.4 GHz 射频频带上工作,802.11a 仅在 5 GHz 射频频带上工作。802.11n MIMO(多输入多输出)技术增加了无线覆盖区域内流量的范围和可靠性。MIMO 技术在接入点和客户端使用多个发射机和接收机天线,以支持同步数据流。结果是增加了范围和吞吐量。使用 802.11n,您可以实现高达 600 Mbps 的理论 PHY 速率(由于介质访问规则等原因,实际吞吐量会低得多)。
802.11n 为 802.11 MAC 层增加了许多改进。最广为人知的是分组聚合,它将多个应用数据分组连接成单个传输帧。添加了块确认(BA)机制(将在下一节讨论)。BA 允许单个数据包确认多个数据包,而不是为每个收到的数据包发送 ACK。两个连续分组之间的等待时间被缩短。这使得能够以单个分组的固定开销成本发送多个数据分组。BA 协议是在 2005 年的 802.11e 修正案中引入的。
分组聚合
有两种类型的数据包聚合:
- AMSDU: 聚合 Mac 业务数据单元
- AMPDU: 聚合 Mac 协议数据单元
注意,AMSDU 仅在 Rx 上受支持,在 Tx 上不受支持,并且完全独立于本节描述的块 Ack 机制;因此,本节中的讨论仅适用于 AMPDU。
块确认会话有两方:发起方和接收方。每个块会话都有一个不同的流量标识符(TID)。发起者通过调用ieee80211_start_tx_ba_session()方法启动块确认会话。这通常是通过驱动器中的速率控制算法来完成的。例如,对于 ath9k 无线驱动程序,速率控制回调函数ath_tx_status()调用ieee80211_start_tx_ba_session()方法。ieee80211_start_tx_ba_session()方法将状态设置为 HT_ADDBA_REQUESTED_MSK,并通过调用ieee80211_send_addba_request()方法发送 ADDBA 请求包。对ieee80211_send_addba_request()的调用传递会话的参数,比如想要的重排序缓冲区大小和会话的 TID。
重排序缓冲区大小限制在 64K(参见include/linux/ieee80211.h中ieee80211_max_ampdu_length_exp的定义)。这些参数是结构addba_req中功能成员capab的一部分。对 ADDBA 请求的响应应该在 1 Hz 内被接收,这在 x86_64 机器中是一秒(ADDBA _ RESP _ 间隔)。如果您没有及时得到响应,sta_addba_resp_timer_expired()方法将通过调用___ieee80211_stop_tx_ba_session()方法来停止 BA 会话。当另一端(接收方)收到 ADDBA 请求时,它首先发送一个 ACK(IEEE 802.11 中的每个数据包都应该得到确认,如前所述)。然后它通过调用ieee80211_process_addba_request()方法处理 ADDBA 请求;如果一切正常,它将这台机器的聚合状态设置为 OPERATIONAL(HT _ AGG _ STATE _ OPERATIONAL)并通过调用ieee80211_send_addba_resp()方法发送 ADDBA 响应。它还通过调用该定时器上的del_timer_sync() 来停止响应定时器(将sta_addba_resp_timer_expired()方法作为其回调的定时器)。会话开始后,发送包含多个 MPDU 数据包的数据块。因此,发起者通过调用ieee80211_send_bar()方法发送一个块确认请求(BAR)包。
阻塞确认请求(BAR)
BAR 是具有块确认请求子类型(IEEE80211_STYPE_BACK_REQ)的控制包。BAR 包包括 SSN(起始序列号),它是块中应该被确认的最早的 MSDU 的序列号。如果需要,接收方接收 BAR 并相应地重新排序ampdu缓冲区。图 12-6 显示了一个条形请求。

图 12-6 。酒吧请求
发送 BAR 时,帧控制中的type子字段是 control (IEEE80211_FTYPE_CTL),而subtype子字段是 Block Ack 请求(IEEE80211_STYPE_BACK_REQ)。该栏由ieee80211_bar结构表示:
struct ieee80211_bar {
__le16 frame_control;
__le16 duration;
__u8 ra[6];
__u8 ta[6];
__le16 control;
__le16 start_seq_num;
} __packed;
(include/linux/ieee80211.h)
RA 是接收方地址,TA 是发送方(发起方)地址。BAR 请求的控制字段包括 TID。
块确认
有两种类型的块确认:立即块确认和延迟块确认。图 12-7 显示了立即块确认。

图 12-7 。立即块确认
立即块确认和延迟块确认之间的区别在于,对于延迟块确认,BAR 请求本身首先用确认来应答,然后经过一段延迟后,用 BA(块确认)来应答。当使用延迟块确认时,有更多的时间来处理 BAR,当使用基于软件的处理时,这有时是需要的。使用立即块确认在性能方面更好。广管局本身也承认。当发起者没有更多的数据要发送时,它可以通过调用ieee80211_send_delba()方法来终止 Block Ack 会话;此函数向另一端发送 DELBA 请求包。DELBA 请求由ieee80211_process_delba()方法处理。导致块确认会话拆除的 DELBA 消息可以从块确认会话的发起者或接收者发送。AMPDU 的最大长度是 65535 个八位字节。请注意,数据包聚合仅适用于接入点和受管站点;规范不支持 IBSS 的数据包聚合。
网状网络(802.11s)
IEEE 802.11s 协议于 2003 年 9 月作为 IEEE 的一个研究组开始,并于 2004 年成为一个名为 TGs 的任务组。2006 年,15 个提案中的 2 个提案(“SEEMesh”和“Wi-Mesh”提案)合并为一个提案,形成了 D0.01. 802.11s 草案,于 2011 年 7 月获得批准,现已成为 IEEE 802.11-2012 的一部分。网状网络允许在完全和部分连接的网状拓扑上创建 802.11 基本服务集。这可以看作是对 802.11 特设网络的改进,后者需要全连接的网状拓扑。图 12-8 和 12-9 说明了这两种网状拓扑之间的区别。
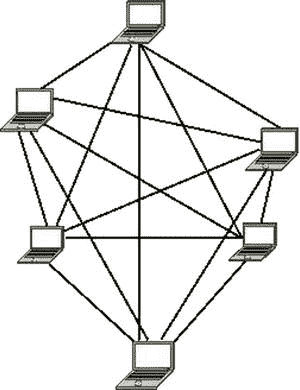
图 12-8 。全目
在部分连接的网格中,节点只连接到其他一些节点,而不是所有节点。这种拓扑在无线网状网络中更为常见。图 12-9 显示了一个局部网格的例子。
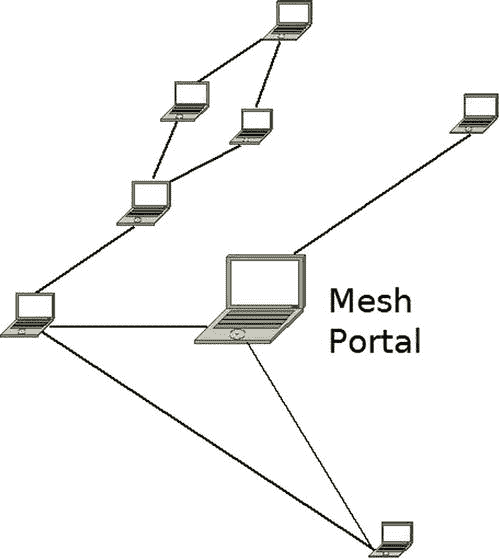
图 12-9 。偏目
无线网状网络在多个无线跳上转发数据分组。每个网格节点充当其他网格节点的中继点/路由器。在内核 2.6.26 (2008)中,由于 open80211s 项目,对无线网状网络(802.11s)草案的支持被添加到网络无线堆栈中。open80211s 项目的目标是创建 802.11s 的第一个开放实现。该项目得到了 OLPC 项目和一些商业公司的赞助。Luis Carlos Cobo 和 Javier Cardona 以及来自 Cozybit 的其他开发人员开发了 Linux mac80211 Mesh 代码。
现在,您已经了解了一些关于网状网络和网状网络拓扑的知识,可以开始下一节了,这一节将介绍网状网络的 HWMP 路由协议。
HWMP 议定书
802.11s 协议定义了名为 HWMP(混合无线网状协议)的默认路由协议。HWMP 协议在第 2 层工作,处理 MAC 地址,而 IPV4 路由协议在第 3 层工作,处理 IP 地址。HWMP 路由基于两种类型的路由(因此被称为混合)。第一种是按需路由,第二种是主动路由。这两种机制的主要区别在于启动路径建立的时间(路径是用于第 2 层路由的名称)。在按需路由中,只有在协议栈接收到目的地的帧后,协议才会建立到目的地的路径。这最小化了维护网状网络所需的管理流量,代价是在数据流量中引入了额外的等待时间。如果已知网格节点是大量网格流量的接收者,则可以使用主动路由。在这种情况下,节点将周期性地在网状网络上宣布它自己,并触发从网络中的所有网状节点到它自己的路径建立。按需路由和主动路由都在 Linux 内核中实现。有四种类型的路由消息:
- *PREQ(路径请求):*这种类型的消息是在您寻找某个您仍然没有路线到达的目的地时作为广播发送的。该 PREQ 消息在网状网络中传播,直到它到达其目的地。在每个站点上执行查找,直到到达最终目的地(通过调用
mesh_path_lookup()方法)。如果查找失败,PREQ 将被转发(作为广播)到其它站。PREQ 消息在管理分组中发送;它的子类型是 action (IEEE80211_STYPE_ACTION)。它由hwmp_preq_frame_process()方法处理。 - *PREP(路径回复):*这种类型是作为对 PREQ 消息的回复而发送的单播数据包。此数据包在反向路径上发送。准备消息也在管理包中发送,其
subtype也是动作子类型(IEEE80211_STYPE_ACTION)。它由hwmp_prep_frame_process()方法处理。PREQ 和准备消息都是通过mesh_path_sel_frame_tx()方法发送的。 - *PERR(路径错误):*如果途中出现故障,将发送 PERR。PERR 消息由
mesh_path_error_tx()方法处理。 - RANN(根通告) : 根网格点周期性地广播该帧。接收它的网状点经由它从其接收 RANN 的 MP 向根发送单播 RREQ。作为响应,根网状网将向每个 PREQ 发送 PREP 响应。
 注意该路由考虑了无线电感知度量(广播时间度量)。广播时间度量通过
注意该路由考虑了无线电感知度量(广播时间度量)。广播时间度量通过airtime_link_metric_get()方法计算(基于速率和其他硬件参数)。网状点持续监控其链路,并与邻居更新度量值。
发送 PREQ 的站点可能会尝试将数据包发送到最终目的地,但仍然不知道到达该目的地的路由;这些数据包保存在 skb 的一个名为frame_queue的缓冲区中,它是mesh_path对象(net/mac80211/mesh.h)的一个成员。在这种情况下,当 PREP 最终到达时,该缓冲区的未决数据包被发送到最终目的地(通过调用mesh_path_tx_pending()方法)。对于未解析的目的地,每个目的地缓冲的最大帧数为 10 (MESH_FRAME_QUEUE_LEN)。网状组网的优势如下:
- 快速部署
- 最低配置,价格低廉
- 易于在难以布线的环境中部署
- 节点移动时的连接
- 更高的可靠性:无单点故障和自我修复能力
缺点如下:
- 许多广播会限制网络性能。
- 目前并非所有的无线驱动程序都支持网格模式。
设置网状网络
在 Linux 中有两套用于管理无线设备和网络的用户空间工具:一套是较老的用于 Linux 的无线工具,这是一个基于 IOCTLs 的开源项目。无线工具的命令行实用程序的例子有iwconfig、iwlist、ifrename等等。较新的工具是基于通用 netlink 套接字的iw(在第二章的中描述)。但是,有些任务只有更新的工具iw才能执行。您可以仅使用iw命令将无线设备设置为在网状模式下工作。
示例:设置无线网络接口(wlan0)在网状模式下工作的方法如下:
iw wlan0 set type mesh
注意设置无线网络接口(wlan0)在网状模式下工作也可以这样做:iw wlan0 set type mp
mp代表网格点。参见http://wireless.kernel.org/en/users/Documentation/iw中的“添加带 iw 的接口”
通过iw wlan0 mesh join "my-mesh-ID"连接网格
您可以通过以下方式显示电台的统计信息:
iw wlan0 station dumpiw wlan0 mpath dump
这里我还应该提到authsae和wpa_supplicant工具,它们可以用来创建安全的网状网络,并且不依赖于iw。
Linux 无线开发过程
大多数开发都是使用git分布式版本控制系统完成的,就像许多其他 Linux 子系统一样。git树主要有三种;最危险的是无线测试树。还有常规无线树和无线下一个树。以下是开发树的git库的链接:
-
无线测试开发树:
git://git.kernel.org/pub/scm/linux/kernel/git/linville/wireless-testing.git -
无线开发树:
git://git.kernel.org/pub/scm/linux/kernel/git/linville/wireless-2.6.git -
无线-下一个发展树:
git://git.kernel.org/pub/scm/linux/kernel/git/linville/wireless-next-2.6.git
补丁在无线邮件列表中发送和讨论:linux-wireless@vger.kernel.org。不时地,一个拉请求被发送到内核网络邮件列表netdev,在第一章中提到。
正如在涉及 Mac80211 子系统的“mac80211 子系统”一节中提到的,一些无线网络接口供应商在他们自己的站点上为他们的 Linux 驱动程序维护他们自己的开发树。在某些情况下,他们使用的代码不使用 mac80211 API 比如一些雷凌和 Realtek 的无线设备驱动。自 2006 年 1 月以来,Linux 无线子系统的维护者是 John W. Linville,他取代了 Jeff Garzik。mac80211 的维护者是 Johannes Berg,2007 年 10 月。有一些年度 Linux 无线峰会;第一次发生在 2006 年的比弗顿。这里有一个非常详细的 wiki 页面:http://wireless.kernel.org/。这个网站包括许多重要的文档。例如,一个表格指定了每个无线网络接口支持的模式。这个 wiki 页面中有许多关于许多无线设备驱动程序、硬件和各种工具的信息(例如 CRDA、中央管理域代理、hostapd、iw等等)。
摘要
近年来,在 Linux 无线堆栈方面已经做了很多开发。最显著的变化是 mac80211 堆栈的集成和移植无线驱动程序以使用 mac80211 API,使代码更有组织性。情况比以前好多了;Linux 支持更多的无线设备。由于 open802.11s 项目,网状网络最近得到了推动。它被集成在 Linux 2.6.26 内核中。未来可能会看到更多支持新标准 IEEE802.11ac 的驱动程序,IEEE 802.11 AC 是一种只有 5 GHz 的技术,最大吞吐量可以达到每秒 1 千兆比特以上,以及更多支持 P2P 的驱动程序。
第十三章讨论了 Linux 内核中的 InfiniBand 和 RDMA。“快速参考”部分涵盖了与本章中讨论的主题相关的主要方法,按其上下文排序。
快速参考
我用一个 Linux 无线子系统的重要方法的简短列表来结束这一章,其中一些在这一章中被提到。表 12-1 显示了ieee80211_rx_status对象的flag成员的各种可能值。
方法
本节讨论这些方法。
见 ieee80211_send_bar(结构 ieee80211_vif *vif,u8 *ra,u16 tid,u16 SSN);
此方法发送块确认请求。
int IEEE 80211 _ start _ tx _ ba _ session(struct IEEE 80211 _ sta * pubsta,u16 tid,u16 time out);
该方法通过调用无线驱动程序ampdu_action()回调,传递 IEEE80211_AMPDU_TX_START 来启动块确认会话。因此,驱动程序稍后将调用ieee80211_start_tx_ba_cb()回调或ieee80211_start_tx_ba_cb_irqsafe()回调,这将启动聚合会话。
int IEEE 80211 _ stop _ tx _ ba _ session(struct IEEE 80211 _ sta * publica,u16 tid);
该方法通过调用无线驱动程序ampdu_action()函数,传递 IEEE80211_AMPDU_TX_STOP 来停止块确认会话。驱动程序稍后必须调用ieee80211_stop_tx_ba_cb()回调或ieee80211_stop_tx_ba_cb_irqsafe()回调。
静态 void IEEE 80211 _ send _ addba _ request(struct IEEE 80211 _ sub _ if _ data * sdata,const u8 *da,u16 tid,u8 dialog_token,u16 start_seq_num,u16 agg_size,u16 time out);
此方法发送 ADDBA 消息。ADDBA 消息是管理动作消息。
void IEEE 80211 _ process _ addba _ request(struct IEEE 80211 _ local * local,struct sta_info *sta,struct ieee80211_mgmt *mgmt,size _ t len);
该方法处理 ADDBA 消息。
静态 void IEEE 80211 _ send _ addba _ resp(struct IEEE 80211 _ sub _ if _ data * sdata,u8 *da,u16 tid,u8 dialog_token,u16 status,u16 policy,u16 buf_size,u16 time out);
此方法发送 ADDBA 响应。ADDBA 响应是一个管理包,带有动作的subtype(IEEE 80211 _ STYPE _ ACTION)。
静态 IEEE 80211 _ rx _ result debug _ no inline IEEE 80211 _ rx _ h _ amsdu(struct IEEE 80211 _ rx _ data * rx);
该方法处理 AMSDU 聚合(Rx 路径)。
void IEEE 80211 _ process _ delba(struct IEEE 80211 _ sub _ if _ data * sdata,struct sta_info *sta,struct ieee80211_mgmt *mgmt,size _ t len);
这个方法处理 DELBA 消息。
void IEEE 80211 _ send _ delba(struct IEEE 80211 _ sub _ if _ data * sdata,const u8 *da,u16 tid,u16 initiator,u16 reason _ code);
该方法发送 DELBA 消息。
void IEEE 80211 _ rx _ IRQ safe(struct IEEE 80211 _ HW * HW,struct sk _ buff * skb);
此方法接收数据包。可以在硬件中断上下文中调用ieee80211_rx_irqsafe()方法。
静态 void IEEE 80211 _ rx _ reorder _ ampdu(struct IEEE 80211 _ rx _ data * rx,struct sk _ buff _ head * frames);
这个方法处理 MPDU 重排序缓冲区。
静态 bool IEEE 80211 _ sta _ manage _ reorder _ buf(struct IEEE 80211 _ sub _ if _ data * sdata,struct tid_ampdu_rx *tid_agg_rx,struct sk _ buff _ head * frames);
这个方法处理 MPDU 重排序缓冲区。
静态 IEEE 80211 _ rx _ result debug _ no inline IEEE 80211 _ rx _ h _ check(struct IEEE 80211 _ rx _ data * rx);
该方法丢弃重传的重复帧,并增加dot11FrameDuplicateCount和站num_duplicates计数器。
void IEEE 80211 _ send _ null func(struct IEEE 80211 _ local * local,struct IEEE 80211 _ sub _ if _ data * sdata,int power save);
这个方法发送一个特殊的空数据帧。
void IEEE 80211 _ send _ pspoll(struct IEEE 80211 _ local * local,struct IEEE 80211 _ sub _ if _ data * sdata);
该方法向 AP 发送 PS-Poll 控制分组。
静态 void IEEE 80211 _ send _ assoc(struct IEEE 80211 _ sub _ if _ data * sdata);
此方法通过发送关联子类型分别为 IEEE80211_STYPE_ASSOC_REQ 或 IEEE80211 _ STYPE _ REASSOC _ REQ 的管理数据包来执行关联或重新关联。从ieee80211_do_assoc()方法调用ieee80211_send_assoc()方法。
void IEEE 80211 _ send _ auth(struct IEEE 80211 _ sub _ if _ data * sdata,u16 transaction,u16 auth_alg,u16 status,const u8 *extra,size_t extra_len,const u8 *bssid,const u8 *key,u8 key_len,u8 key_idx,u32 tx _ flags);
该方法通过发送具有认证子类型(IEEE80211_STYPE_AUTH)的管理包来执行认证。
静态内联 bool IEEE 80211 _ check _ Tim(const struct IEEE 80211 _ Tim _ ie * Tim,u8 tim_len,u16 aid);
该方法检查是否设置了tim[aid];aid 作为一个参数传递,它表示站点的关联 id。
int IEEE 80211 _ request _ scan(struct IEEE 80211 _ sub _ if _ data * sdata,struct CFG 80211 _ scan _ request * req);
此方法启动主动扫描。
void mesh _ path _ tx _ pending(struct mesh _ path * mpath);
这个方法从frame_queue发送数据包。
struct mesh _ path * mesh _ path _ lookup(struct IEEE 80211 _ sub _ if _ data * sdata,const u8 * dst);
该方法在网格点的网格路径表(路由表)中执行查找。mesh_path_lookup()方法的第二个参数是目标的硬件地址。如果表中没有条目,则返回 NULL,否则返回一个指向找到的网格路径结构的指针。
静态 void IEEE 80211 _ sta _ create _ ibss(struct IEEE 80211 _ sub _ if _ data * sdata);
此方法创建一个 IBSS。
int IEEE 80211 _ HW _ config(struct IEEE 80211 _ local * local,u32 已更改);
驱动程序为各种配置调用此方法;在大多数情况下,它将调用委托给driver config()方法,如果实现的话。第二个参数指定要采取的操作(例如,IEEE 80211 _ CONF _ 改变 _ 频道以改变频道,或 IEEE 80211 _ CONF _ 改变 _PS 以改变驱动程序的节能模式)。
struct IEEE 80211 _ HW * IEEE 80211 _ alloc _ HW(size _ t priv _ data _ len,const struct IEEE 80211 _ ops * ops);
此方法分配新的 802.11 硬件设备。
int ieee80211 _ 寄存器 _ 硬件(struct ieee80211 _ 硬件*硬件);
此方法注册 802.11 硬件设备。
void IEEE 80211 _ unregister _ HW(struct IEEE 80211 _ HW * HW);
此方法注销 802.11 硬件设备并释放其分配的资源。
int sta _ info _ insert(struct sta _ info * sta):
此方法将电台添加到电台哈希表和电台列表中。
int sta _ info _ destroy _ addr(struct IEEE 80211 _ sub _ if _ data * sdata,const u8 * addr);
此方法删除一个工作站并释放其资源。
struct sta _ info * sta _ info _ get(struct IEEE 80211 _ sub _ if _ data * sdata,const u8 * addr);
此方法通过在站点的哈希表中执行查找来返回指向站点的指针。
void IEEE 80211 _ send _ probe _ req(struct IEEE 80211 _ sub _ if _ data * sdata,u8 *dst,const u8 *ssid,size_t ssid_len,const u8 *ie,size_t ie_len,u32 ratemask,bool directed,u32 tx_flags,struct IEEE 80211 _ channel * channel,bool scan);
该方法发送探测请求管理包。
静态内联 void IEEE 80211 _ tx _ skb(struct IEEE 80211 _ sub _ if _ data * sdata,struct sk _ buff * skb);
此方法传输一个 SKB。
int IEEE 80211 _ channel _ to _ frequency(int chan,enum ieee80211_band 频带);
这个方法返回一个站点工作的频率,给定它的信道。信道和频率之间是一一对应的。
static int mesh _ path _ sel _ frame _ tx(enum mpath _ frame _ type action,u8 flags,const u8 *orig_addr,_le32 orig_sn,u8 *target,const u8 *da, _ le32 hop _ count,u8 ttl,__le32 lifetime,__le32 metric,__le32 preq_id,struct ieee80211 _ sub _ if _ data *
此方法发送 PREQ 或 PREP 管理数据包。
静态 void hwmp _ preq _ frame _ process(struct IEEE 80211 _ sub _ if _ data * sdata,struct ieee80211_mgmt *mgmt,const u8 *preq_elem,u32 metric);
此方法处理 PREQ 消息。
struct IEEE 80211 _ rx _ status * IEEE 80211 _ SKB _ RXCB(struct sk _ buff * skb);
该方法返回与控制缓冲区(cb)关联的ieee80211_rx_status对象,该控制缓冲区与指定的 SKB 关联。
静态 bool IEEE 80211 _ tx(struct IEEE 80211 _ sub _ if _ data * sdata,struct sk_buff *skb,bool txpending,enum IEEE 80211 _ band band);
这个方法是传输的主要处理程序。
桌子
表 12-1 显示了ieee80211_rx_status结构的标志成员(一个 32 位字段)的位和相应的 Linux 符号。
表 12-1。Rx Flags:IEEE 80211 _ Rx _ status 对象的标志字段的各种可能值
|
Linux 符号
|
少量
|
描述
|
| — | — | — |
| 接收标志 MMIC 错误 | Zero | 在此帧中报告了 Michael MIC 错误。 |
| RX _ FLAG _ 解密 | one | 这个帧是用硬件解密的。 |
| RX _ FLAG _ MMIC _ 剥离 | three | 迈克尔麦克风从这个框架中剥离,硬件已经完成验证。 |
| RX_FLAG_IV_STRIPPED | four | IV/ICV 从该帧中被剥离。 |
| RX_FLAG_FAILED_FCS_CRC | five | 帧上的 FCS 检查失败。 |
| RX_FLAG_FAILED_PLCP_CRC | six | 对框架的 PCLP 检查失败。 |
| rx _ flag _MACTIME_START-rx _ 旗标 _ MAC time _ start | seven | 在 RX 状态中传递的时间戳是有效的,并且包含接收到 MPDU 的第一个符号的时间。 |
| RX_FLAG_SHORTPRE 函数 | eight | 该帧使用了短前导码。 |
| RX_FLAG_HT | nine | 使用 HT MCS,rate_idx是 MCS 索引 |
| RX_FLAG_40MHZ | Ten | 使用 HT40 (40 MHz)。 |
| RX_FLAG_SHORT_GI | Eleven | 使用了短保护间隔。 |
| rx _ flag _ no _ signal _ val-rx _ flag _ no _ signal _ val-rx _ flag _ no _ signal _ val-rx _ flag _ no _ signal _ val | Twelve | 信号强度值不存在。 |
| RX_FLAG_HT_GF | Thirteen | 该帧是在 HT-greenfield 传输中接收的 |
| rx _ flag _ ampdu _ 详细信息 | Fourteen | A-MPDU 的详细资料是已知的,特别是参考编号必须填写,并且是每个 A-MPDU 的唯一编号。 |
| RX_FLAG_AMPDU_REPORT_ZEROLEN | Fifteen | 驱动程序报告长度为 0 的子帧。 |
| RX_FLAG_AMPDU_IS_ZEROLEN | Sixteen | 这是一个零长度子帧,仅用于监控目的。 |
| RX_FLAG_AMPDU_LAST_KNOWN | Seventeen | 最后一个子帧是已知的,应该在单个 A-MPDU 的所有子帧上设置。 |
| RX_FLAG_AMPDU_IS_LAST | Eighteen | 这个子帧是 A-MPDU 的最后一个子帧。 |
| RX_FLAG_AMPDU_DELIM_CRC_ERROR | Nineteen | 在此子帧上检测到分隔符 CRC 错误。 |
| RX_FLAG_AMPDU_DELIM_CRC_KNOWN | Twenty | 定界符 CRC 字段是已知的(CRC 存储在ieee80211_rx_status的ampdu_delimiter_crc字段中) |
| rx _ flag _MACTIME_END-rx _ 旗标 _ MAC time _ end | Twenty-one | 在接收状态中传递的时间戳是有效的,并且包含接收到 MPDU(包括 FCS)的最后一个符号的时间。 |
| S7-1200 可编程控制器 | Twenty-two | 使用 VHT MCS,rate_index是 MCS 指标 |
| RX_FLAG_80MHZ | Twenty-three | 使用了 80 MHz |
| RX_FLAG_80P80MHZ | Twenty-four | 使用了 80+80 MHz |
| RX_FLAG_160MHZ | Twenty-five | 使用了 160 MHz |
十三、InfiniBand
本章由 InfiniBand 专家 Dotan Barak 撰写。Dotan 是 Mellanox Technologies 的高级软件经理,在 RDMA 技术公司工作。Dotan 已经在 Mellanox 工作了 10 多年,担任过各种角色,包括开发人员和经理。此外,Dotan 还维护着一个关于 RDMA 技术的博客: http://www.rdmamojo.com。
第十二章讲述了无线子系统及其在 Linux 中的实现。在这一章中,我将讨论 InfiniBand 子系统及其在 Linux 中的实现。尽管对于不熟悉 InfiniBand 技术的人来说,InfiniBand 技术可能被认为是一种非常复杂的技术,但是它背后的概念却非常简单,这一点您将在本章中看到。我将从远程直接内存访问(RDMA)开始我们的讨论,并讨论它的主要数据结构和它的 API。我将给出一些例子来说明如何使用 RDMA,并以一个关于从内核级和用户空间使用 RDMA API 的简短讨论来结束本章。
RDMA 和 InfiniBand—概述
远程直接内存访问(RDMA) 是一台机器访问——即读取或写入——远程机器上内存的能力。有几个主要的网络协议支持 RDMA: InfiniBand、融合以太网 RDMA(RoCE)和互联网广域 RDMA 协议(iWARP),它们都共享相同的 API。InfiniBand 是一种全新的网络协议,其规范可以在“InfiniBand 架构规范”文档中找到,该文档由 InfiniBand 贸易协会(IBTA)维护。 RoCE 允许您通过以太网实现 RDMA,其规范可以在 InfiniBand 规范的附件中找到。iWARP 是一种允许在 TCP/IP 上使用 RDMA 的协议,其规范可以在由 RDMA 联盟维护的文档“RDMA 协议规范”中找到。动词是从客户端代码使用 RDMA 的 API 的描述。在版本 2.6.11 中,RDMA API 实现被引入到 Linux 内核中。最初,它只支持 InfiniBand,在几个内核版本之后,它也加入了 iWARP 和 RoCE 支持。在描述 API 时,我只提到其中的一种,但下面的文字是指所有的。这个 API 的所有定义都可以在include/rdma/ib_verbs.h中找到。以下是关于 API 和 RDMA 堆栈实现的一些说明:
-
有些函数是内联函数,有些不是。未来的实现可能会改变这种行为。
-
大多数 API 都有前缀“IB”;但是,这个 API 支持 InfiniBand、iWARP 和 RoCE。
-
标题
ib_verbs.h包含以下人员使用的功能和结构: -
RDMA 堆栈本身
-
RDMA 设备的低级驱动程序
-
使用堆栈作为消费者的内核模块
我将集中讨论只与使用堆栈作为消费者的内核模块相关的函数和结构(第三种情况)。下一节讨论内核树中的 RDMA 堆栈组织。
RDMA 堆栈组织
几乎所有的内核 RDMA 堆栈代码都在内核树的drivers/infiniband下。以下是它的一些重要模块(这不是一个详尽的列表,因为我在本章中没有涵盖整个 RDMA 堆栈):
- CM: 沟通经理(
drivers/infiniband/core/cm.c) - **IPoIB:**IP over InfiniBand(
drivers/infiniband/ulp/ipoib/) - 伊瑟: iSCSI 扩展为 RDMA (
drivers/infiniband/ulp/iser/) - RDS: 可靠数据报套接字(
net/rds/) - SRP: SCSI RDMA 协议(
drivers/infiniband/ulp/srp/) - 不同厂商的硬件底层驱动(
drivers/infiniband/hw) - **动词:**核心动词(
drivers/infiniband/core/verbs.c) - uverbs: 用户动词(
drivers/infiniband/core/uverbs_*.c) - MAD: 管理数据报(
drivers/infiniband/core/mad.c)
图 13-1 显示了 Linux InfiniBand 栈架构。
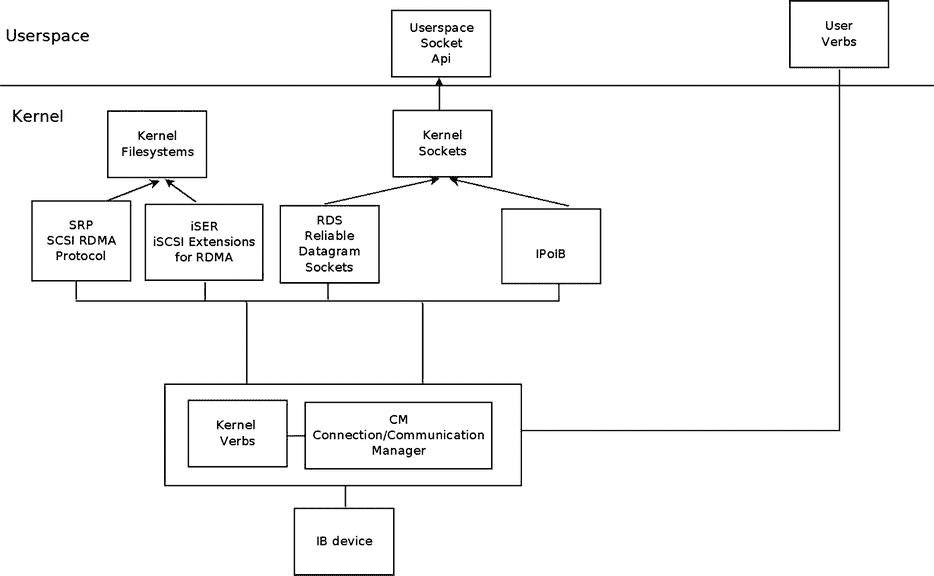
图 13-1 。Linux Infiniband 堆栈架构
在这一节中,我介绍了 RDMA 堆栈结构以及 Linux 内核中的内核模块。
RDMA 的技术优势
在这里,我将介绍 RDMA 技术的优势,并解释使其在许多市场广受欢迎的特性:
- 零拷贝: 直接向远程存储器写入数据和从远程存储器读取数据的能力允许您直接访问远程缓冲区,而无需在不同的软件层之间进行拷贝。
- 内核旁路: 从代码的同一个上下文(即用户空间或内核级)发送和接收数据节省了上下文切换时间。
- CPU 卸载: 使用专用硬件发送或接收数据而无需任何 CPU 干预的能力允许减少远程端 CPU 的使用,因为它不执行任何活动操作。
- 低延迟: RDMA 技术让你的短消息达到非常低的延迟。(在当前的硬件和服务器上,发送几十个字节的延迟可能会达到几百纳秒。)
- 高带宽: 在一个以太网设备中,最大带宽受技术限制(即 10 或 40 Gbits/sec)。在 InfiniBand 中,相同的协议和设备可以在 2.5 千兆位/秒到 120 千兆位/秒的范围内使用。(在当前的硬件和服务器上,带宽最高可达 56 千兆位/秒。)
InfiniBand 硬件组件
与任何其他互连技术一样,在 InfiniBand 中,规范中描述了几个硬件组件,其中一些是数据包的端点(生成数据包和数据包的目标),一些在同一子网或不同子网之间转发数据包。这里我将介绍最常见的几种:
- 主机通道适配器(HCA ): 可以放置在主机或任何其他系统(如存储设备)上的网络适配器。该组件发起数据包或者是数据包的目标。
- 交换机 : 知道如何从一个端口接收数据包并将其发送到另一个端口的组件。如果需要,它可以复制多播消息。(InfiniBand 不支持广播。)与其他技术不同,每个交换机都是一个非常简单的设备,带有由子网管理器(SM)配置的转发表,SM 是一个配置和管理子网的实体(在本节的后面,我将更详细地讨论它的作用)。交换机不会自己学习任何东西,也不会解析和分析数据包;它只在同一子网内转发数据包。
- 路由器 : 连接多个不同 InfiniBand 子网的组件。
子网是一组连接在一起的 HCA、交换机和路由器端口。在本节中,我描述了 InfiniBand 中的各种硬件组件,现在我将讨论 InfiniBand 中的设备、系统和端口的寻址。
在 InfiniBand 中寻址
以下是关于 InfiniBand 寻址的一些规则和一个示例:
- 在 InfiniBand 中,组件的唯一标识符是全球唯一标识符(GUID),它是一个 64 位的值,在世界上是唯一的。
- 子网中的每个节点都有一个节点 GUID。这是节点的标识符,也是节点的常量属性。
- 子网中的每个端口,包括 HCA 和交换机中的端口,都有一个端口 GUID。这是端口的标识符,也是端口的常量属性。
- 在由几个组件组成的系统中,可以有一个系统 GUID。该系统中的所有组件都具有相同的系统 GUID。
这里有一个例子演示了前面提到的所有 GUIDs:一个由几个交换芯片组合而成的大型交换系统。每个交换芯片都有一个唯一的节点 GUID。每个交换机中的每个端口都有一个唯一的端口 GUID。该系统中的所有芯片都具有相同的系统 GUID。
- 全球标识符(GID) 用于标识结束端口或多播组。在索引 0 的 GID 表中,每个端口至少有一个有效的 GID。它基于端口 GUID 加上该端口所属的子网标识符。
- 本地标识符(LID) 是由子网管理器分配给每个子网端口的 16 位值。交换机是一个例外,交换机管理端口具有 LID 分配,而不是其所有端口。每个端口只能分配一个 LID 或一系列连续的 LID,以便有多条路径到达该端口。在同一子网中的特定时间点,每个 LID 都是唯一的,交换机在转发数据包时使用 LID 来确定使用哪个出口端口。单播 LID 的范围是 0x001 至 0xbfff。多播 LIDs 范围是 0xc000 到 0xfffe。
InfiniBand 功能
这里我们将介绍 InfiniBand 协议的一些特性:
-
InfiniBand 允许您配置 HCA、交换机和路由器的端口分区,并允许您在同一物理子网内提供虚拟隔离。每个分区键(P_Key)都是一个 16 位的值,由以下各项组合而成:15 个 LSB 是键值,msb 是成员级别;0 是受限成员;1 是正式会员。每个端口都有一个由 SM 配置的 P_Key 表,每个队列对(QP,InfiniBand 中发送和接收数据的实际对象)都与该表中的一个 P_Key 索引相关联。一个 QP 只有在与其相关联的 P_Keys 中满足以下条件时,才能发送或接收来自远程 QP 的数据包:
-
键值相等。
-
其中至少有一个是正式会员。
-
队列密钥(Q_Key): 一个不可靠的数据报(UD) QP 只有当报文的 Q_Key 等于这个 UD QP 的 Q_Key 值时,才会从一个远程 UD QP 得到单播或组播报文。
-
虚拟通道(VL): 这是一种在单个物理链路上创建多个虚拟链路的机制。每个虚拟通道代表一组用于在每个端口发送和接收数据包的自主缓冲器。支持的 VLs 数量是端口的一个属性。
-
服务级别(SL): InfiniBand 最多支持 16 个服务级别。该协议没有指定每个级别的策略。在 InfiniBand 中,使用 SL 到 VL 的映射和每个 VL 的资源来实现 QoS。
-
故障转移: 连接的 QP 是只能向一个远程 QP 发送数据包或从其接收数据包的 qp。InfiniBand 允许为连接的 qp 定义主路径和备用路径。如果主路径出现问题,将自动使用备用路径,而不是报告错误。
在下一节中,我们将看看 InfiniBand 中的数据包是什么样子的。这在您调试 InfiniBand 中的问题时非常有用。
InfiniBand 数据包
InfiniBand 中的每个数据包都是几个报头的组合,在许多情况下,还有一个有效载荷,即客户端想要发送的消息数据。仅包含 ACK 或零字节消息的消息(例如,如果仅发送即时数据)将不包含有效载荷。这些报头描述了数据包发送的位置、数据包的目标、使用的操作、将数据包分成消息所需的信息以及检测数据包丢失错误所需的足够信息。
图 13-2 展示了 InfiniBand 数据包报头。

图 13-2 。InfiniBand 数据包报头
以下是 InfiniBand 中的标头:
- 本地路由头(LRH): 8 字节。永远存在。它标识数据包的本地源端口和目的端口。它还指定消息的请求 QoS 属性(SL 和 VL)。
- 全局路由头(GRH): 40 字节。可选。存在于多播数据包或在多个子网中传输的数据包。它使用 GID 描述源端口和目的端口。其格式与 IPv6 报头相同。
- 基础传输头(BTH): 12 字节。永远存在。它指定了源和目的 QPs、操作、包序列号和分区。
- 扩展传输头(ETH): 从 4 到 28 个字节。可选。可能存在的额外标头系列,具体取决于服务的类别和所使用的操作。
- 有效载荷: 可选。客户端想要发送的数据。
- 即时数据: 4 字节。可选。可添加到发送和 RDMA 写操作的带外 32 位值。
- 不变 CRC (ICRC): 4 字节。永远存在。它涵盖了数据包在子网中传输时不应更改的所有字段。
- 变体 CRC (VCRC): 2 字节。永远存在。它覆盖了数据包的所有字段。
管理实体
SM 是子网中负责分析和配置子网的实体。以下是它的一些使命:
- 发现子网的物理拓扑。
- 为子网中的每个端口分配 lid 和其他属性,如活动 MTU、活动速度等。
- 在子网交换机中配置转发表。
- 检测拓扑中的任何变化(例如,是否在子网中添加或删除了新节点)。
- 处理子网中的各种错误。
子网管理器通常是一个软件实体,可以运行在交换机(称为管理交换机)或子网中的任何节点上。
几个 SMs 可以在一个子网中运行,但其中只有一个是活动的,其余的将处于待机模式。有一个内部协议来执行主机选择并决定哪个 SM 将是活动的。如果活动 SM 关闭,备用 SM 之一将成为活动 SM。子网中的每个端口都有一个子网管理代理(SMA),,它是一个知道如何接收 SM 发送的管理消息、处理它们并返回响应的代理。子网管理员(SA)是 SM 的一部分。以下是它的一些使命:
- 提供有关子网的信息,例如,有关如何从一个端口到达另一个端口的信息(即路径查询)。
- 允许您注册以获得事件通知。
- 提供子网管理服务,如加入或离开多播。这些服务可能导致 SM(重新)配置子网。
通信管理器(CM) 是一个能够在每个端口上运行的实体,如果该端口支持的话,以建立、维护和拆除 QP 连接。
RDMA 资源公司
在 RDMA API 中,在发送或接收任何数据之前,需要创建和处理大量资源。所有资源都在特定 RDMA 设备的范围内,这些资源不能在多个本地设备之间共享或使用,即使同一台机器上有多个设备也是如此。图 13-3 展示了 RDMA 资源创建层次结构。
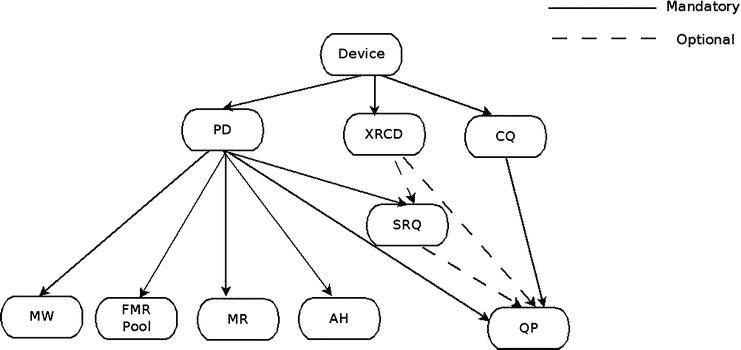
图 13-3 。RDMA 资源创造层级
RDMA 装置
客户端需要向 RDMA 堆栈注册,以便在系统中添加或删除任何 RDMA 设备时得到通知。初始注册后,所有现有的 RDMA 设备都会通知客户端。每个 RDMA 设备都将被调用一个回调,客户端可以通过以下方式开始使用这些设备:
- 查询设备的各种属性
- 修改设备属性
- 创建、使用和销毁资源
ib_register_client()方法注册一个想要使用 RDMA 堆栈的内核客户端。将为当前存在于系统中的每个新的 InfiniBand 设备调用指定的回调,这些新的 InfiniBand 设备将被添加到系统中或从系统中移除(使用热插拔功能)。ib_unregister_client()方法注销想要停止使用 RDMA 堆栈的内核客户端。通常,在卸载驱动程序时调用它。下面是一个示例代码,展示了如何在内核客户端中注册 RDMA 堆栈:
static void my_add_one(struct ib_device *device)
{
...
}
static void my_remove_one(struct ib_device *device)
{
...
}
static struct ib_client my_client = {
.name = "my RDMA module",
.add = my_add_one,
.remove = my_remove_one
};
static int __init my_init_module(void)
{
int ret;
ret = ib_register_client(&my_client);
if (ret) {
printk(KERN_ERR "Failed to register IB client\n");
return ret;
}
return 0;
}
static void __exit my_cleanup_module(void)
{
ib_unregister_client(&my_client);
}
module_init(my_init_module);
module_exit(my_cleanup_module);
以下是对处理 InfiniBand 设备的其他几种方法的描述。
ib_set_client_data()方法将客户端上下文设置为与 InfiniBand 设备相关联。ib_get_client_data()方法使用ib_set_client_data()方法返回与 InfiniBand 设备相关联的客户端上下文。ib_register_event_handler()方法为 InfiniBand 设备将要发生的每个异步事件注册一个要调用的回调。回调结构必须用 INIT_IB_EVENT_HANDLER 宏初始化。ib_unregister_event_handler()方法注销事件处理程序。ib_query_device()方法查询 InfiniBand 设备的属性。这些属性是不变的,不会在这个方法的后续调用中改变。ib_query_port()方法查询 InfiniBand 设备端口的属性。其中一些属性是不变的,一些属性可能会在随后调用该方法时发生变化,例如,端口 LID、state 和其他一些属性。rdma_port_get_link_layer()方法返回设备端口的链路层。ib_query_gid()方法在特定索引中查询 InfiniBand 设备端口的 GID 表。ib_find_gid()方法返回端口的 GID 表中特定 GID 值的索引。ib_query_pkey()方法在特定索引中查询 InfiniBand 设备端口的 P_Key 表。ib_find_pkey()方法返回端口的 P_Key 表中特定 P_Key 值的索引。
保护域(PD)
一个 PD 允许与其他几个 RDMA 资源相关联,例如 SRQ、QP、AH 或 MR,以便在它们之间提供一种保护手段。与 PDx 相关联的 RDMA 资源不能使用与 PDy 相关联的 RDMA 资源。试图混合这些资源将导致错误。通常,每个模块都有一个 PD。然而,如果一个特定的模块想要增加它的安全性,它将为它使用的每个远程 QP 或服务使用一个 PD。PD 的分配和取消分配是这样完成的:
- 方法分配一个 PD。它将注册后调用驱动程序回调时返回的设备对象的指针作为参数。
ib_dealloc_pd()方法释放一个 PD。它通常在卸载驱动程序或销毁与 PD 相关的资源时调用。
地址句柄(AH)
在 UD QP 的发送请求中使用 AH 来描述消息从本地端口到远程端口的路径。如果所有 qp 使用相同的属性向相同的远程端口发送消息,则相同的 AH 可以用于多个 qp。以下是对与 AH 相关的四种方法的描述:
- 方法创建了一个 AH。它将 PD 和 AH 的属性作为参数。AH 的 AH 属性可以直接填充,也可以通过调用
ib_init_ah_from_wc()方法来填充,该方法将接收到的工作完成(ib_wc对象)作为一个参数,该参数包括成功完成的传入消息的属性,以及接收该消息的端口。我们可以调用ib_create_ah_from_wc()方法,而不是先调用ib_init_ah_from_wc()方法,然后再调用ib_create_ah()方法。 ib_modify_ah()方法修改现有 AH 的属性。ib_query_ah()方法查询现有 AH 的属性。- 方法销毁一个 AH。当不需要向 AH 描述路径的节点发送任何进一步的消息时,就调用它。
存储区
RDMA 设备访问的每个内存缓冲区都需要注册。在注册过程中,在存储缓冲器上执行以下任务:
- 将连续的内存缓冲区分隔成内存页面。
- 将完成虚拟到物理转换的映射。
- 检查存储器页面权限以确保它们支持 MR 的请求权限。
- 内存页面被固定,以防止它们被换出。这保持了虚拟到物理的映射不变。
成功完成内存注册后,它有两个密钥:
- 本地键(lkey): 本地工作请求访问该内存的键。
- 远程键(rkey): 远程机器使用 RDMA 操作访问该存储器的键。
当引用这些内存缓冲区时,这些键将在工作请求中使用。即使使用不同的权限,相同的内存缓冲区也可以注册多次。以下是与 MR 相关的一些方法的描述:
ib_get_dma_mr()方法返回一个可用于 DMA 的系统内存区域。它将 PD 和 MR 请求的访问权限作为参数。ib_dma_map_single()方法将由kmalloc()方法族分配的内核虚拟地址映射到 DMA 地址。这个 DMA 地址将用于访问本地和远程存储器。应该使用ib_dma_mapping_error()方法来检查映射是否成功。ib_dma_unmap_single()方法取消了使用ib_dma_map_single()完成的 DMA 映射。当不再需要这个内存时,应该调用它。
 注意有更多种类的
注意有更多种类的ib_dma_map_single()允许页面映射,根据 DMA 属性映射,使用分散/聚集列表映射,或使用具有 DMA 属性的分散/聚集列表映射:ib_dma_map_page()、ib_dma_map_single_attrs()、ib_dma_map_sg()和ib_dma_map_sg_attrs()。都有对应的 unmap 函数。
在访问 DMA 映射存储器之前,应调用以下方法:
ib_dma_sync_single_for_cpu()如果 DMA 区域将被 CPU 访问,或者ib_dma_sync_single_for_device()如果 DMA 区域将被 InfiniBand 设备访问。ib_dma_alloc_coherent()方法分配一个可以被 CPU 访问的内存块,并将其映射到 DMA。ib_dma_free_coherent()方法释放使用ib_dma_alloc_coherent()分配的内存块。ib_reg_phys_mr()方法获取一组物理页面,注册它们,并准备一个可以被 RDMA 设备访问的虚拟地址。如果你想在创建后改变它,你应该调用ib_rereg_phys_mr()方法。ib_query_mr()方法检索特定 MR 的属性,注意大多数低级驱动程序不实现这个方法。ib_dereg_mr()方法注销 MR。
快速内存区域(FMR)池
内存区域的注册是一个“繁重的”过程,可能需要一些时间来完成,如果调用它时所需的资源不可用,执行它的上下文甚至可能会休眠。这种行为在某些情况下可能会有问题,例如在中断处理程序中。使用 FMR 池,您可以使用注册为“轻量级”的 fmr,并且可以在任何上下文中注册。FMR 泳池的 API 可以在include/rdma/ib_fmr_pool.h中找到。
存储窗口(MW)
可以通过两种方式实现对存储器的远程访问:
- 注册启用了远程权限的内存缓冲区。
- 注册一个内存区域,然后将一个内存窗口绑定到它。
这两种方式都将创建一个远程密钥(rkey),该密钥可用于以指定的权限访问该存储器。然而,如果您希望使rkey无效以防止对该内存的远程访问,执行内存区域注销可能是一个繁重的过程。在此内存区域上使用内存窗口,并在需要时绑定或解除绑定,可以为启用和禁用对内存的远程访问提供一个“轻量级”过程。以下是与医疗废物相关的三种方法的说明:
ib_alloc_mw()方法分配一个内存窗口。它接受 PD 和 MW 类型作为参数。ib_bind_mw()方法通过向 QP 发送特殊的工作请求,将内存窗口绑定到具有特定地址、大小和远程权限的指定内存区域。当您希望允许临时远程访问它的内存时,就会调用它。将在 QP 的发送队列中生成一个工作完成来描述该操作的状态。如果ib_bind_mw()被一个已经绑定的内存窗口调用到同一个内存区域或者不同的区域,那么之前的绑定将会失效。- 方法释放指定的 MW 对象。
完成队列(CQ)
发送或接收队列的每个已发布的工作请求都被视为未完成,直到它或在它之后发布的任何工作请求都有相应的工作完成。当工作请求未完成时,它所指向的内存缓冲区的内容是不确定的:
- 如果 RDMA 设备读取这个内存并通过网络发送它的内容,客户端就不知道这个缓冲区是否可以被重用或释放。如果这是一个可靠的 QP,成功的工作完成意味着消息被远程端接收到。如果这是一个不可靠的 QP,一个成功的工作完成意味着消息被发送。
- 如果 RDMA 设备将消息写入该内存,客户端无法知道该缓冲区是否包含传入的消息。
工作完成指定相应的工作请求已经完成,并提供一些相关信息:状态、使用的操作码、大小等等。CQ 是包含工作完成的对象。客户端需要轮询 CQ,以读取它所拥有的工作完成。CQ 基于先进先出(FIFO) 原则工作:客户端将从其中出队的工作完成顺序将根据 RDMA 设备将它们排入 CQ 的顺序。客户端可以在轮询模式下读取工作完成,或者请求在新的工作完成被添加到 CQ 时获得通知。CQ 不能容纳比其大小更多的工作完成。如果添加的工作完成多于其容量,将添加一个出错的工作完成,将生成一个 CQ 错误异步事件,并且所有与之关联的工作队列都将出错。以下是一些与 CQ 相关的方法:
ib_create_cq()方法 创造了一个 CQ。它将以下内容作为其参数:注册后调用驱动程序回调时返回的设备对象的指针,以及 CQ 的属性,包括其大小和当此 CQ 上有异步事件或向其添加工作完成时将调用的回调。ib_resize_cq()方法改变 CQ 的大小。新的条目数不能少于当前填写 CQ 的工作完成数。ib_modify_cq()方法改变 CQ 的调节参数。如果至少有特定数量的工作完成进入 CQ,或者超时将过期,将生成完成事件。使用它可能有助于减少 RDMA 设备中发生的中断数量。ib_peek_cq()方法返回 CQ 中可用工作完成的数量。ib_req_notify_cq()方法 请求在下一个工作完成或包括请求事件指示的工作完成被添加到 CQ 时生成完成事件通知。如果在调用了ib_req_notify_cq()方法之后,没有工作完成被添加到 CQ,则不会发生完成事件通知。ib_req_ncomp_notif()方法要求当 CQ 中存在特定数量的工作完成时,创建完成事件通知。与ib_req_notify_cq()方法不同,当调用ib_req_ncomp_notif()方法时,即使 CQ 当前持有这个数量的工作完成,也会生成一个完成事件通知。ib_poll_cq()方法从 CQ 轮询工作完成。它按照工作完成被添加到 CQ 的顺序从其中读取工作完成,并从其中删除它们。
下面是一个清空 CQ 的代码示例,即从 CQ 中读取所有工作完成,并检查它们的状态:
struct ib_wc wc;
int num_comp = 0;
while (ib_poll_cq(cq, 1, &wc) > 0) {
if (wc.status != IB_WC_SUCCESS) {
printk(KERN_ERR "The Work Completion[%d] has a bad status %d\n",
num_comp, wc.status);
return -EINVAL;
}
num_comp ++;
}
扩展可靠连接(XRC)域
XRC 域是用于限制传入消息可以作为目标的 XRC srq 的对象。该 XRC 域可以与和 XRC 一起工作的其他几个 RDMA 资源相关联,例如 SRQ 和 QP 。
共享接收队列(SRQ)
SRQ 是 RDMA 架构在接收端更具可伸缩性的一种方式。不是每个队列对都有一个单独的接收队列,而是有一个所有 qp 都连接到的共享接收队列。当他们需要使用接收请求时,他们从 SRQ 获取请求。图 13-4 展示了与 SRQ 相关的 qp。
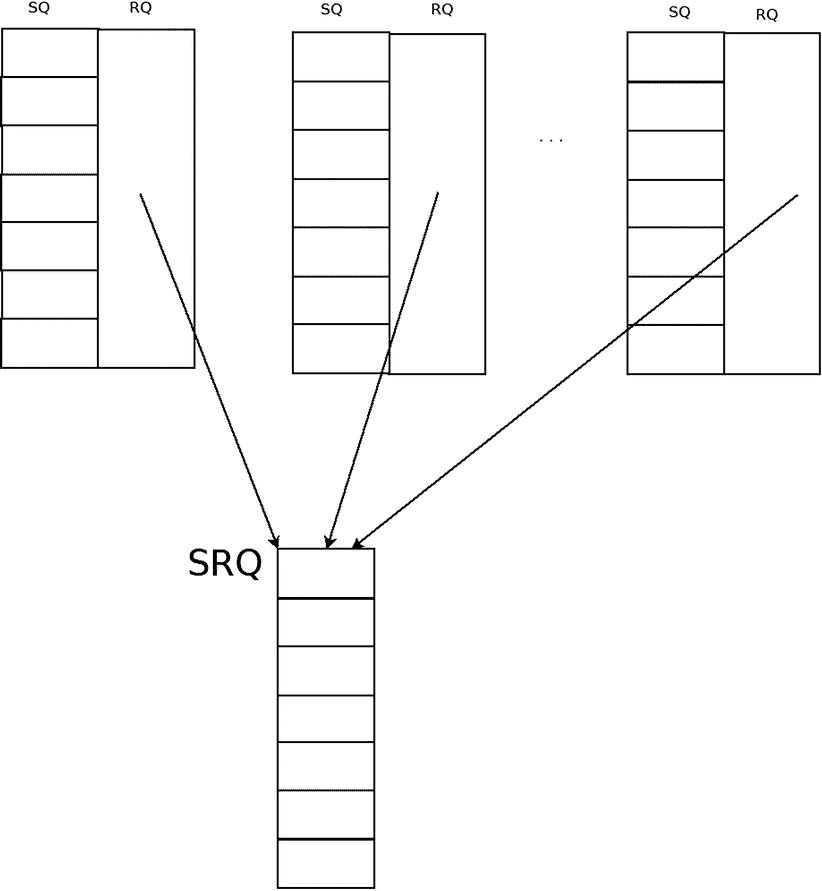
图 13-4 。与 SRQ 相关联的 qp
如果你有 N 个 qp,每个 qp 都可能在随机时间收到一串 M 的消息,你可以这么做:
- 如果不使用 SRQ,您会发送 N*M 个接收请求。
- 使用 SRQs,您发布 K*M(其中 K << N)个接收请求。
与 QP 不同,它没有任何机制来确定其中未完成的工作请求的数量,而使用 SRQ,您可以设置一个水印限制。当接收请求的数量低于此限制时,将为此 SRQ 创建一个 SRQ 限制异步事件。使用 SRQ 的缺点是,您无法预测哪个 QP 将使用来自 SRQ 的每个已发布的接收请求,因此每个已发布的接收请求能够容纳的消息大小必须是任何 qp 可能获得的最大传入消息大小。这个限制可以通过创建几个 srq 来处理,每个 srq 对应一个不同的最大消息大小,并根据它们的预期消息大小将它们与相关 qp 相关联。
以下是与 SRQ 相关的一些方法的描述和一个示例:
ib_create_srq()方法创建一个 SRQ。SRQ 需要一个 PD 和属性。ib_modify_srq()方法修改 SRQ 的属性。它用于为 SRQ 极限事件设置新的水印值,或者为支持它的设备调整 SRQ 的大小。
下面是一个设置水印值的示例,当 SRQ 中的 RRs 数量降至 5 以下时,该值将获得一个异步事件:
struct ib_srq_attr srq_attr;
int ret;
memset(&srq_attr, 0, sizeof(srq_attr));
srq_attr.srq_limit = 5;
ret = ib_modify_srq(srq, &srq_attr, IB_SRQ_LIMIT);
if (ret) {
printk(KERN_ERR "Failed to set the SRQ's limit value\n");
return ret;
}
以下是对处理 SRQ 的几种其他方法的描述。
ib_query_srq()方法查询当前的 SRQ 属性。这种方法通常用于检查 SRQ 的内容极限值。在ib_srq_attr对象的srq_limit成员中的值 0 意味着没有任何 SRQ 限制水印集。- 方法销毁一个 SRQ。
ib_post_srq_recv()方法将接收请求的链表作为参数,并将它们添加到指定的共享接收队列中,以供将来处理。
下面是一个向 SRQ 提交单个接收请求的示例。它使用其在单个集合条目中注册的 DMA 地址,将传入消息保存在内存缓冲区中:
struct ib_recv_wr wr, *bad_wr;
struct ib_sge sg;
int ret;
memset(&sg, 0, sizeof(sg));
sg.addr = dma_addr;
sg.length = len;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.next = NULL;
wr.wr_id = (uintptr_t)dma_addr;
wr.sg_list = &sg;
wr.num_sge = 1;
ret = ib_post_srq_recv(srq, &wr, &bad_wr);
if (ret) {
printk(KERN_ERR "Failed to post Receive Request to an SRQ\n");
return ret;
}
队列对(QP)
队列对是用于在 InfiniBand 中发送和接收数据的实际对象。它有两个独立的工作队列:发送和接收队列。每个工作队列都有一个特定数量的工作请求(WR ),每个 WR 都支持多个分散/聚集元素,以及一个 CQ,其处理已经结束的工作请求将向其添加工作完成。这些工作队列可以使用相似或不同的属性来创建,例如,可以发送到每个工作队列的 wr 的数量。每个工作队列中的顺序是有保证的,也就是说,发送队列中工作请求的处理将根据发送请求提交的顺序开始。同样的行为也适用于接收队列。但是,它们之间没有任何关系—也就是说,未完成的发送请求可以被处理,即使它是在向接收队列提交接收请求之后提交的。图 13-5 显示了一个 QP。
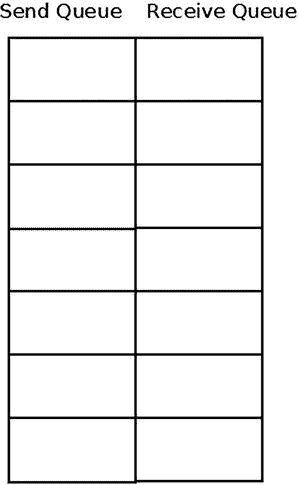
图 13-5 。QP(队列对)
创建后,每个 QP 在特定时间点在 RDMA 设备上都有一个唯一的编号。
QP 运输类型
InfiniBand 支持多种 QP 传输类型:
- 可靠连接(RC): 一个 RC QP 连接到单个远程 RC QP,并且可靠性是有保证的——也就是说,具有与发送它们相同的内容的所有分组根据它们的顺序到达是有保证的。在发送方,每个消息都被分割成大小为路径 MTU 的数据包,并在接收方进行碎片整理。这个 QP 支持发送、RDMA 写、RDMA 读和原子操作。
- 不可靠连接(UC): 一个 UC QP 连接到一个远程 UC QP,可靠性没有保证。此外,如果消息中的一个数据包丢失,则整个消息都会丢失。在发送方,每个消息都被分割成大小为路径 MTU 的数据包,并在接收方进行碎片整理。该 QP 支持发送和 RDMA 写操作。
- 不可靠数据报(UD): 一个 UD QP 可以向子网中的任何 UD QP 发送单播消息。支持多播消息。可靠性不能保证。每个消息限于一个分组消息,其大小限于路径 MTU 大小。此 QP 仅支持发送操作。
- 扩展可靠连接(XRC): 来自同一个节点的几个 qp 可以向特定节点中的远程 SRQ 发送消息。这有助于将两个节点之间的 QP 数量从 CPU 内核数量的数量级(即每个内核一个进程的 QP)减少到一个 QP。该 QP 支持 QP 钢筋混凝土公司支持的所有操作。这种类型只与用户空间应用相关。
- **原始数据包:**允许客户端构建一个完整的数据包,包括 L2 报头,并按原样发送。在接收端,RDMA 设备不会剥离任何报头。
- **原始 IPv6/原始以太网类型:**允许发送未经 IB 设备解释的原始数据包的 qp。目前,任何 RDMA 设备都不支持这两种类型。
有一些特殊的 QP 传输类型用于子网管理和特殊服务:
- SMI/QP0: 用于子网管理数据包的 QP。
- GSI/QP1: QP 用于一般服务数据包。
ib_create_qp()方法创建一个 QP。它采用一个 PD 和请求的属性作为参数来创建这个 QP。下面是一个使用已创建的 PD 创建 RC QP 的示例,它有两个不同的 CQ:一个用于发送队列,一个用于接收队列。
struct ib_qp_init_attr init_attr;
struct ib_qp *qp;
memset(&init_attr, 0, sizeof(init_attr));
init_attr.event_handler = my_qp_event;
init_attr.cap.max_send_wr = 2;
init_attr.cap.max_recv_wr = 2;
init_attr.cap.max_recv_sge = 1;
init_attr.cap.max_send_sge = 1;
init_attr.sq_sig_type = IB_SIGNAL_ALL_WR;
init_attr.qp_type = IB_QPT_RC;
init_attr.send_cq = send_cq;
init_attr.recv_cq = recv_cq;
qp = ib_create_qp(pd, &init_attr);
if (IS_ERR(qp)) {
printk(KERN_ERR "Failed to create a QP\n");
return PTR_ERR(qp);
}
QP 国家机器
QP 有一个状态机,它定义了 QP 在每个状态下能够做什么:
-
复位状态: 每个 QP 都是在这个状态下产生的。在这种状态下,不能向它发送任何发送请求或接收请求。所有传入的消息都会被无声地丢弃。
-
初始化状态: 在此状态下,不能向其发送任何请求。然而,接收请求可以被发布,但不会被处理。所有传入的消息都会被无声地丢弃。在将接收请求转移到 RTR(准备接收)之前,在这种状态下向 QP 发布接收请求是一个很好的做法。这样做可以防止远程 QP 发送需要使用接收请求的消息,但是这些消息还没有发布。
-
准备接收(RTR)状态: 在此状态下,不能向其发送任何发送请求,但可以发送和处理接收请求。所有传入的消息都将被处理。在这种状态下收到的第一个传入消息将生成通信建立异步事件。只接收消息的 QP 可以保持这种状态。
-
准备发送(RTS)状态 : 在这种状态下,发送请求和接收请求都可以被发送和处理。所有传入的消息都将被处理。这是 QPs 的常见状态。
-
发送队列排空(SQD)状态: 在这种状态下,QP 完成其处理已经开始的所有发送请求的处理。只有当没有任何消息可以发送时,您才可以更改一些 QP 属性。这种状态分为两种内部状态:
-
**排出:**消息仍在发送中。
-
**耗尽:**消息发送完毕。
-
发送队列错误(SQE)状态: 当不可靠传输类型的发送队列中出现错误时,RDMA 设备会自动将 QP 移至此状态。导致错误的发送请求将会以错误原因完成,并且所有连续的发送请求都将被刷新。接收队列仍将工作,也就是说,可以发送接收请求,并处理传入的消息。客户端可以从此状态中恢复,并将 QP 状态修改回 RTS。
-
错误状态: 在此状态下,所有未完成的工作请求将被刷新。如果这是一种可靠的传输类型,并且发送请求有错误,或者无论使用哪种传输类型,接收队列中都有错误,则 RDMA 设备可以将 QP 移到此状态。所有传入的消息都会被无声地丢弃。
QP 可以通过ib_modify_qp()从任何状态转换到复位状态和错误状态。将 QP 移至错误状态将刷新所有未完成的工作请求。将 QP 移至重置状态将清除所有以前配置的属性,并删除 QP 正在处理的完成队列中在此 QP 上结束的所有未完成的工作请求和工作完成。图 13-6 展示了一个 QP 状态机图。
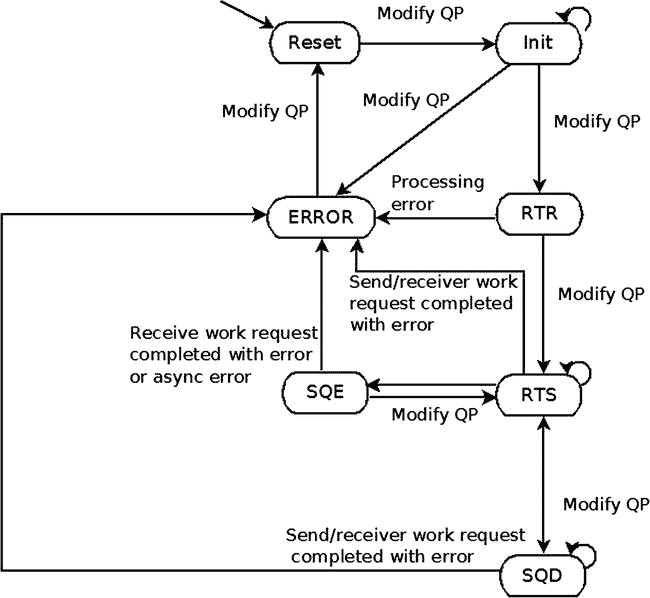
图 13-6 。QP 国家机器
ib_modify_qp()方法修改 QP 的属性。它将需要修改的 QP 和将要修改的 QP 的属性作为参数。QP 的状态机可以根据图 13-6 所示的示意图进行改变。每种 QP 传输类型都需要在每个 QP 状态转换中设置不同的属性。
下面是一个将新创建的 RC QP 修改为 RTS 状态的示例,在该状态下,它可以发送和接收数据包。本地属性是发送队列的输出端口、使用的 SL 和起始数据包序列号。所需的远程属性是接收 PSN、QP 号码和它使用的端口的 LID。
struct ib_qp_attr attr = {
.qp_state = IB_QPS_INIT,
.pkey_index = 0,
.port_num = port,
.qp_access_flags = 0
};
ret = ib_modify_qp(qp, &attr,
IB_QP_STATE |
IB_QP_PKEY_INDEX |
IB_QP_PORT |
IB_QP_ACCESS_FLAGS);
if (ret) {
printk(KERN_ERR "Failed to modify QP to INIT state\n");
return ret;
}
attr.qp_state = IB_QPS_RTR;
attr.path_mtu = mtu;
attr.dest_qp_num = remote->qpn;
attr.rq_psn = remote->psn;
attr.max_dest_rd_atomic = 1;
attr.min_rnr_timer = 12;
attr.ah_attr.is_global = 0;
attr.ah_attr.dlid = remote->lid;
attr.ah_attr.sl = sl;
attr.ah_attr.src_path_bits = 0,
attr.ah_attr.port_num = port
ret = ib_modify_qp(ctx->qp, &attr,
IB_QP_STATE |
IB_QP_AV |
IB_QP_PATH_MTU |
IB_QP_DEST_QPN |
IB_QP_RQ_PSN |
IB_QP_MAX_DEST_RD_ATOMIC |
IB_QP_MIN_RNR_TIMER);
if (ret) {
printk(KERN_ERR "Failed to modify QP to RTR state\n");
return ret;
}
attr.qp_state = IB_QPS_RTS;
attr.timeout = 14;
attr.retry_cnt = 7;
attr.rnr_retry = 6;
attr.sq_psn = my_psn;
attr.max_rd_atomic = 1;
ret = ib_modify_qp(ctx->qp, &attr,
IB_QP_STATE |
IB_QP_TIMEOUT |
IB_QP_RETRY_CNT |
IB_QP_RNR_RETRY |
IB_QP_SQ_PSN |
IB_QP_MAX_QP_RD_ATOMIC);
if (ret) {
printk(KERN_ERR "Failed to modify QP to RTS state\n");
return ret;
}
以下是对处理 QP 的几种其他方法的描述:
ib_query_qp()方法查询当前的 QP 属性。有些属性是不变的(客户端指定的值),有些属性是可以改变的(例如,状态)。- 方法销毁了一个 QP。当不再需要 QP 时,就叫它。
工作请求处理
每个发送到发送或接收队列的工作请求都被认为是未完成的,直到有一个工作完成,该工作完成是从与该工作请求的该工作队列或在该工作请求之后发送的同一工作队列中的工作请求相关联的 CQ 轮询的。接收队列中每个未完成的工作请求都会以工作完成结束。工作队列中的工作请求处理流程如图图 13-7 所示。
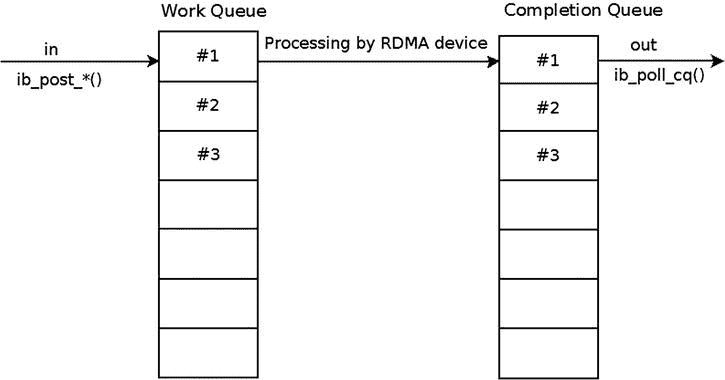
图 13-7 。工作请求处理流程
在发送队列中,您可以选择(在创建 QP 时)是希望每个发送请求都以工作完成结束,还是希望选择以工作完成结束的发送请求—即选择性信号。对于无信号发送请求,您可能会遇到错误;但是,将为其生成状态为“不良”的工作完成。
当工作请求未完成时,用户不能(重新)使用或释放在发布此工作请求时在其中指定的资源。例如:
- 当发布 UD QP 的发送请求时,AH 不能被释放。
- 当提交接收请求时,无法读取分散/收集(s/g)列表中引用的内存缓冲区,因为不知道 RDMA 设备是否已经在其中写入了数据。
“防护”是指在之前的 RDMA 读取和原子操作处理结束之前,阻止处理特定发送请求的能力。例如,当使用从远程地址读取的 RDMA 并在同一个发送队列中发送数据或数据的一部分时,将栅栏指示添加到发送请求可能是有用的。如果没有防护,发送操作可能会在数据被检索并在本地内存中可用之前开始。当向 UC 或 RC QP 发送发送请求时,到目标的路径是已知的,因为它是在将 QP 转移到 RTR 状态时提供的。但是,当向 UD·QP 提交发送请求时,您需要添加一个 AH 来描述该消息的目标路径。如果存在与发送队列相关的错误,并且这是一种不可靠的传输类型,则发送队列将进入错误状态(即 SQE 状态),但接收队列仍将完全正常工作。客户端可以从此状态中恢复,并将 QP 状态改回 RTS。如果存在与接收队列相关的错误,QP 将被移至错误状态,因为这是一个不可恢复的错误。当工作队列被移至错误状态时,导致错误的工作请求以指示错误性质的状态结束,并且该队列中的其余工作请求因错误而被刷新。
RDMA 架构中支持的操作
InfiniBand 支持多种操作类型:
- **发送:**通过网络发送信息。远程端需要有一个可用的接收请求,消息将被写入其缓冲区。
- **立即发送:**使用额外的 32 位带外数据通过网络发送消息。远程端需要有一个可用的接收请求,消息将被写入其缓冲区。该即时数据将在接收器的工作完成时可用。
- RDMA 写道:通过电线向远程地址发送信息。
- **RDMA 立即写信:**通过电线发送消息,并将其写到远程地址。远程端需要有一个可用的接收请求。该即时数据将在接收器的工作完成时可用。这个操作可以看作是带有零字节消息的 RDMA 写+立即发送。
- **RDMA 读取:**读取一个远程地址,并用其内容填充本地缓冲区。
- **比较和交换:**将一个远程地址的内容与 valueX 进行比较;如果它们相等,用 valueY 替换它的内容。所有这些都是以原子的方式执行的。原始远程存储器内容被发送并保存在本地。
- **取加:**以原子的方式给远程地址的内容加一个值。原始远程存储器内容被发送并保存在本地。
- **屏蔽比较和交换:**使用远程地址的 maskX 与 valueX 比较内容部分;如果相等,用 valueY 替换 maskY 中的部分内容。所有这些都是以原子的方式执行的。原始远程存储器内容被发送并保存在本地。
- **屏蔽取加:**以原子的方式给远程地址的内容加一个值,只改变屏蔽中指定的位。原始远程存储器内容被发送并保存在本地。
- **绑定内存窗口:**将一个内存窗口绑定到一个特定的内存区域。
- **快速注册:**使用工作请求注册快速存储区。
- **局部无效:**使用工作请求使快速内存区域无效。如果有人用它的旧
lkey/rkey,会被认为是错误。它可以与发送/RDMA 读取相结合;在这种情况下,首先将执行发送/读取,然后该快速存储区域将被无效。
接收请求指定为使用接收请求的操作保存传入消息的位置。分散列表中指定的内存缓冲区的总大小必须等于或大于传入消息的大小。
对于 UD QP,由于事先不知道消息的来源(同一个子网或另一个子网,单播或组播消息),因此必须在接收请求缓冲区中添加额外的 40 字节,这是 GRH 报头的大小。前 40 个字节将用消息的 GRH 填充(如果有的话)。该 GRH 信息描述了如何将消息发送回发送者。消息本身将从分散列表中描述的内存缓冲区中的偏移量 40 开始。
ib_post_recv()方法获取接收请求的链表,并将它们添加到特定 QP 的接收队列中,以供将来处理。下面是一个为 QP 提交单个接收请求的示例。它使用其在单个收集条目中注册的 DMA 地址将传入消息保存在内存缓冲区中。qp是使用ib_create_qp()创建的 QP 的指针。内存缓冲区是一个使用kmalloc()分配并使用ib_dma_map_single()映射到 DMA 的块。使用的lkey来自使用ib_get_dma_mr()注册的 MR。
struct ib_recv_wr wr, *bad_wr;
struct ib_sge sg;
int ret;
memset(&sg, 0, sizeof(sg));
sg.addr = dma_addr;
sg.length = len;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.next = NULL;
wr.wr_id = (uintptr_t)dma_addr;
wr.sg_list = &sg;
wr.num_sge = 1;
ret = ib_post_recv(qp, &wr, &bad_wr);
if (ret) {
printk(KERN_ERR "Failed to post Receive Request to a QP\n");
return ret;
}
ib_post_send()方法将发送请求的链表作为参数,并将它们添加到特定 QP 的发送队列中,以供将来处理。下面是一个提交 QP 发送操作的单个发送请求的示例。它在单个集合条目中使用其注册的 DMA 地址发送内存缓冲区的内容。
struct ib_sge sg;
struct ib_send_wr wr, *bad_wr;
int ret;
memset(&sg, 0, sizeof(sg));
sg.addr = dma_addr;
sg.length = len;
sg.lkey = mr->lkey;
memset(&wr, 0, sizeof(wr));
wr.next = NULL;
wr.wr_id = (uintptr_t)dma_addr;
wr.sg_list = &sg;
wr.num_sge = 1;
wr.opcode = IB_WR_SEND;
wr.send_flags = IB_SEND_SIGNALED;
ret = ib_post_send(qp, &wr, &bad_wr);
if (ret) {
printk(KERN_ERR "Failed to post Send Request to a QP\n");
return ret;
}
工作完成状态
每个工作完成可以成功结束,也可以出错结束。如果成功结束,则操作完成,并且根据传输类型可靠性级别发送数据。如果这个工作完成包含一个错误,内存缓冲区的内容是未知的。工作请求状态指示存在错误的原因有很多:违反保护、地址错误等等。违规错误不会执行任何重新传输。但是,有两个特殊的重试流程值得一提。这两种情况都是由 RDMA 设备自动完成的,它会重新传输数据包,直到问题得到解决或超过重新传输的次数。如果问题解决了,除了暂时的性能问题之外,客户端代码甚至不会意识到发生了这种情况。这仅与可靠的传输类型相关。
重试流程
如果接收方在预期的超时时间内没有向发送方返回任何 ACK 或 NACK,发送方可能会根据 QP 属性中配置的超时和重试计数属性再次发送消息。出现这样的问题可能有几种原因:
- 远程 QP 的属性或路径不正确。
- 远程 QP 状态(至少)没有到达 RTR 状态。
- 远程 QP 状态移至错误状态。
- 消息本身在从发送方到接收方的途中被丢弃(例如,CRC 错误)。
- 消息的 ACK 或 NACK 在从接收方到发送方的途中被丢弃(例如,CRC 错误)。
图 13-8 显示了由于数据包丢失克服了数据包丢失的重试流程。
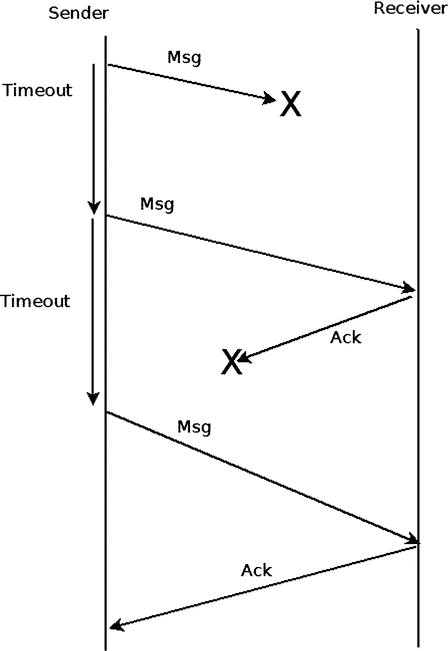
图 13-8 。重试流(在可靠传输类型上)
如果发送方 QP 最终成功接收到 ACK/NACK,它将继续发送其余的消息。如果将来有任何邮件也有这个问题,也会对该邮件再次执行重试流程,而不会记录以前执行的任何操作。如果在重试几次之后,接收方仍然没有响应,那么在发送方将会有一个带有重试错误的工作完成。
接收器未就绪(RNR)流程
如果接收方从接收方队列中得到一个需要使用接收请求的消息,但是没有任何未完成的接收请求,接收方将向发送方发回一个 RNR NACK。过一会儿,根据 RNR NACK 中指定的时间,发送者将再次尝试发送消息。
如果最终接收方及时发送了一个接收方请求,并且传入的消息使用了它,那么将向发送方发送一个 ACK 来表明消息被成功保存。如果将来的任何邮件也有此问题,RNR 重试流程也会针对此邮件再次执行,而不会记录以前执行此操作的历史。如果即使在重试几次之后,接收方仍然没有发布接收方请求,并且为每个发送的消息向发送方发送了 RNR NACK,则在发送方将生成带有 RNR 重试错误的工作完成。图 13-9 显示了 RNR 重试流程,该流程在接收器端克服了一个丢失的接收请求。
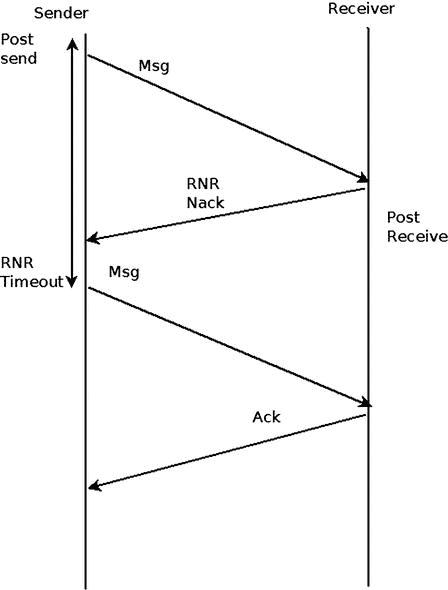
图 13-9 。RNR 重试流(在可靠传输类型上)
在这一节中,我介绍了工作请求状态和一些可能发生在消息上的错误流程。在下一节中,我将讨论多播组。
多播组
多播组是一种从一个 UD QP 向许多 UD qp 发送消息的方式。想要得到这个消息的每个 UD QP 需要被附加到多播组。当一个设备得到一个多播数据包时,它会将它复制到附属于该组的所有 qp。以下是与多播组相关的两种方法的描述:
ib_attach_mcast()方法将 UD QP 连接到 InfiniBand 设备内的多播组。它接受要附加的 QP 和多播组属性。ib_detach_mcast()方法将 UD QP 从多播组中分离。
用户空间和内核级 RDMA API 的区别
RDMA 堆栈 API 的用户空间和内核级非常相似,因为它们覆盖相同的技术,并且需要能够提供相同的功能。当用户空间从 RDMA API 调用控制路径的方法时,它执行到内核级的上下文切换,以保护特权资源并同步需要同步的对象(例如,同一个 QP 号码不能同时分配给多个 QP)。
然而,用户空间和内核级 RDMA API 和功能之间存在一些差异:
- 内核级中所有 API 的前缀都是“ib_”,而在用户空间中前缀是“ibv_”。
- 有一些枚举和宏只存在于内核级的 RDMA API 中。
- 有些 QP 类型只在内核中可用(例如,SMI 和 GSI qp)。
- 有些特权操作只能在内核级执行,例如,注册物理内存、使用 WR 注册 MR 和 FMRs。
- 有些功能在用户空间的 RDMA API 中是不可用的——例如,N 通知请求。
- 内核 API 是异步的。存在异步事件或完成事件时调用的回调。在用户空间中,一切都是同步的,用户需要明确检查其运行上下文(即线程)中是否有异步事件或完成事件。
- XRC 与内核级客户端无关。
- 内核级引入了一些新特性,但是它们在用户空间还不可用。
用户空间 API 由用户空间库“libibverbs”提供尽管用户级的一些 RDMA 功能比内核级的少,但它足以享受 InfiniBand 技术的好处。
摘要
在本章中,您已经了解了 InfiniBand 技术的优势。我回顾了 RDMA 堆栈组织。我讨论了资源创建层次结构和所有重要的对象及其 API,这是编写使用 InfiniBand 的客户端代码所需要的。您还看到了一些使用这个 API 的例子。下一章将讨论像网络名称空间和蓝牙子系统这样的高级主题。
快速参考
我将用 RDMA API 的重要方法的简短列表来结束这一章。本章提到了其中一些。
方法
下面是方法。
int IB _ register _ client(struct IB _ client * client);
注册一个想要使用 RDMA 堆栈的内核客户端。
void IB _ unregister _ client(struct IB _ client * client);
注销想要停止使用 RDMA 堆栈的内核客户端。
void IB _ set _ client _ data(struct IB _ device * device,struct ib_client *client,void * data);
将客户端上下文设置为与 InfiniBand 设备相关联。
void *ib_get_client_data(结构 ib_device *device,结构 IB _ client * client);
读取与 InfiniBand 设备关联的客户端上下文。
int ib_register_event_handler(结构 ib _ event _ handler *事件处理程序);
为 InfiniBand 设备发生的每个异步事件注册一个要调用的回调。
int ib_unregister_event_handler(结构 ib _ event _ handler *事件处理程序);
取消注册 InfiniBand 设备发生的每个异步事件要调用的回调。
int ib_query_device(结构 ib _ device *设备,结构 ib _ device _ attr *设备属性);
查询 InfiniBand 设备的属性。
int ib_query_port(结构 ib_device *device,u8 port_num,结构 IB _ port _ attr * port _ attr);
查询 InfiniBand 设备端口的属性。
枚举 rdma _ link _ layer rdma _ port _ get _ link _ layer(struct IB _ device * device,u8 port _ num);
查询 InfiniBand 设备端口的链路层。
int IB _ query _ GID(struct IB _ device * device,u8 port_num,int index,union IB _ GID * GID);
在 InfiniBand 设备的端口 GID 表的特定索引中查询 GID。
int IB _ query _ pkey(struct IB _ device * device,u8 port_num,u16 index,u16 * pkey);
在 InfiniBand 设备的端口 P_Key 表中查询特定于 P_Key 的索引。
int IB _ find _ GID(struct IB _ device * device,union ib_gid *gid,u8 *port_num,u16 * index);
在 InfiniBand 设备的端口 GID 表中找到特定 GID 值的索引。
int ib_find_pkey(结构 IB _ 设备*设备,u8 端口号,u16 pkey,u16 *索引);
在 InfiniBand 设备的端口 P_Key 表中查找特定 P_Key 值的索引。
结构 ib_pd *ib_alloc_pd(结构 IB _ device * device);
分配一个 PD 供以后创建其他 InfiniBand 资源时使用。
int IB _ deal loc _ PD(struct IB _ PD * PD);
取消分配 PD。
struct IB _ ah * IB _ create _ ah(struct IB _ PD * PD,struct IB _ ah _ attr * ah _ attr);
创建将在 UD QP 中发布发送请求时使用的 AH。
int ib_init_ah_from_wc(结构 ib_device *device,u8 port_num,结构 ib_wc *wc,结构 ib_grh *grh,结构 IB _ ah _ attr * ah _ attr);
从接收消息的工作完成和 GRH 缓冲区初始化 AH 属性。那些 AH 属性可以在调用ib_create_ah()方法时使用。
struct IB _ ah * IB _ create _ ah _ from _ WC(struct IB _ PD * PD,struct ib_wc *wc,struct ib_grh *grh,u8 port _ num);
从接收消息的工作完成和 GRH 缓冲区创建 AH。
int ib_modify_ah(struct ib_ah *ah,struct IB _ ah _ attr * ah _ attr);
修改现有 AH 的属性。
int ib_query_ah(struct ib_ah *ah,struct IB _ ah _ attr * ah _ attr);
查询现有 AH 的属性。
int IB _ destroy _ ah(struct IB _ ah * ah);
消灭一个啊。
struct IB _ Mr * IB _ get _ DMA _ Mr(struct IB _ PD * PD,int Mr _ access _ flags);
返回可用于 DMA 的 MR 系统内存。
静态内联 int IB _ DMA _ mapping _ error(struct IB _ device * dev,u64 DMA _ addr);
检查 DMA 内存是否指向无效地址,即检查 DMA 映射操作是否失败。
静态内联 u64 IB _ DMA _ map _ single(struct IB _ device * dev,void *cpu_addr,size_t size,enum DMA _ data _ direction direction);
将内核虚拟地址映射到 DMA 地址。
静态内联 void IB _ DMA _ unmap _ single(struct IB _ device * dev,u64 addr,size_t size,enum DMA _ data _ direction direction);
取消虚拟地址的 DMA 映射。
静态内联 u64 IB _ DMA _ map _ single _ attrs(struct IB _ device * dev,void *cpu_addr,size_t size,enum DMA _ data _ direction direction,struct dma_attrs *attrs)
根据 DMA 属性将内核虚拟内存映射到 DMA 地址。
静态内联 void IB _ DMA _ unmap _ single _ attrs(struct IB _ device * dev,u64 addr,size_t size,enum DMA _ data _ direction direction,struct DMA _ attrs * attrs);
取消根据 DMA 属性映射的虚拟地址的 DMA 映射。
静态内联 u64 IB _ DMA _ map _ page(struct IB _ device * dev,struct page *page,无符号长偏移量,size_t size,enum dma_data_direction 方向);
将物理页面映射到 DMA 地址。
静态内联 void IB _ DMA _ unmap _ page(struct IB _ device * dev,u64 addr,size_t size,enum DMA _ data _ direction direction);
取消物理页面的 DMA 映射。
static inline int IB _ DMA _ map _ SG(struct IB _ device * dev,struct scatterlist *sg,int nents,enum DMA _ data _ direction direction);
将分散/收集列表映射到 DMA 地址。
静态内联 void IB _ DMA _ unmap _ SG(struct IB _ device * dev,struct scatterlist *sg,int nents,enum DMA _ data _ direction direction);
取消分散/收集列表的 DMA 映射。
静态内联 int IB _ DMA _ map _ SG _ attrs(struct IB _ device * dev,struct scatterlist *sg,int nents,enum DMA _ data _ direction direction,struct DMA _ attrs * attrs);
根据 DMA 属性将分散/收集列表映射到 DMA 地址。
静态内联 void IB _ DMA _ unmap _ SG _ attrs(struct IB _ device * dev,struct scatterlist *sg,int nents,enum DMA _ data _ direction direction,struct DMA _ attrs * attrs);
根据 DMA 属性取消分散/收集列表的 DMA 映射。
静态内联 u64 IB _ SG _ DMA _ address(struct IB _ device * dev,struct scatter list * SG);
返回分散/聚集条目的地址属性。
静态内联无符号 int IB _ SG _ DMA _ len(struct IB _ device * dev,struct scatter list * SG);
返回分散/聚集条目的长度属性。
静态内联 void IB _ DMA _ sync _ single _ for _ CPU(struct IB _ device * dev,u64 addr,size_t size,enum DMA _ data _ direction dir);
将 DMA 区域所有权转移给 CPU。它应该在 CPU 访问 DMA 映射区之前调用,该映射区的所有权先前已转移给设备。
静态内联 void IB _ DMA _ sync _ single _ for _ device(struct IB _ device * dev,u64 addr,size_t size,enum DMA _ data _ direction dir);
将 DMA 区域所有权转移给设备。应该在设备访问 DMA 映射区域之前调用该函数,该区域的所有权之前已经转移给了 CPU。
静态内联 void * IB _ DMA _ alloc _ coherent(struct IB _ device * dev,size_t size,u64 *dma_handle,GFP _ t flag);
分配一个 CPU 可以访问的内存块,映射到 DMA。
静态内联 void IB _ DMA _ free _ coherent(struct IB _ device * dev,size_t size,void *cpu_addr,u64 DMA _ handle);
释放使用ib_dma_alloc_coherent()分配的内存块。
struct IB _ Mr * IB _ reg _ phys _ Mr(struct IB _ PD * PD,struct IB _ phys _ buf * phys _ buf _ array,int num_phys_buf,int mr_access_flags,u64 * iova _ start);
获取一个物理页列表,并准备好供 InfiniBand 设备访问。
int IB _ rereg _ phys _ Mr(struct IB _ Mr * Mr,int mr_rereg_mask,struct ib_pd *pd,struct IB _ phys _ buf * phys _ buf _ array,int num_phys_buf,int mr_access_flags,u64 * iova _ start);
更改 MR 的属性。
int ib_query_mr(struct ib_mr *mr,struct IB _ Mr _ attr * Mr _ attr);
查询 MR 的属性。
int IB _ dereg _ Mr(struct IB _ Mr * Mr);
取消 MR 的注册
struct IB _ MW * IB _ alloc _ MW(struct IB _ PD * PD,enum ib_mw_type 类型);
分配一个 MW。此 MW 将用于允许远程访问 MR。
静态内联 int ib_bind_mw(struct ib_qp *qp,struct ib_mw *mw,struct IB _ MW _ bind * MW _ bind);
将一个 MW 绑定到一个 MR,以允许使用特定权限远程访问本地内存。
int IB _ dealloc _ MW(struct IB _ MW * MW);
解除分配一个 MW。
struct IB _ CQ * IB _ create _ CQ(struct IB _ device * device,ib_comp_handler comp_handler,void(* event _ handler)(struct IB _ event *,void *),void *cq_context,int cqe,int comp _ vector);
创建 CQ。此 CQ 将用于指示发送或接收队列的已结束工作请求的状态。
int ib_resize_cq(struct ib_cq *cq,int cqe);
更改 CQ 中的条目数。
int ib_modify_cq(structib_cq *cq,u16 cq_count,u16 CQ _ period);
修改 CQ 的审核属性。这种方法用于减少 InfiniBand 设备的中断次数。
int ib_peek_cq(structib_cq *cq,intwc _ CNT);
返回 CQ 中可用的工作完成数。
静态内联 int IB _ req _ notify _ CQ(struct IB _ CQ * CQ,enum ib_cq_notify_flags 标志);
请求在将下一个工作完成添加至 CQ 时生成完成通知事件。
静态内嵌 int IB _ req _ ncmp _ notf(struct IB _ CQ * CQ,int WC _ CNT);
当 CQ 中有特定数量的工作完成时,请求生成完成通知事件。
静态内联 int ib_poll_cq(struct ib_cq *cq,int num_entries,struct IB _ WC * WC);
从 CQ 中读取并删除一个或多个工作完成。它们是按照加入 CQ 的顺序来读的。
struct IB _ srq * IB _ create _ srq(struct IB _ PD * PD,struct IB _ srq _ init _ attr * srq _ init _ attr);
创建一个 SRQ,用作几个 qp 的共享接收队列。
int IB _ modify _ srq(struct IB _ srq * srq,struct ib_srq_attr *srq_attr,enum IB _ srq _ attr _ mask srq _ attr _ mask);
修改 SRQ 的属性。
int IB _ query _ srq(struct IB _ srq * srq,struct IB _ srq _ attr * srq _ attr);
查询 SRQ 的属性。在随后对此方法的调用中,SRQ 限制值可能会更改。
int ib_destroy_srq(结构 IB _ srq * srq);
摧毁一个 SRQ。
struct IB _ qp * IB _ create _ qp(struct IB _ PD * PD,struct IB _ qp _ init _ attr * qp _ init _ attr);
创建 QP。每个新的 QP 都分配有一个 QP 号码,其他 qp 不会同时使用这个号码。
int ib_modify_qp(struct ib_qp *qp,struct ib_qp_attr *qp_attr,int qp _ attr _ mask);
修改 QP 的属性,包括发送和接收队列属性以及 QP 状态。
int ib_query_qp(struct ib_qp *qp,struct ib_qp_attr *qp_attr,int qp_attr_mask,struct IB _ qp _ init _ attr * qp _ init _ attr);
查询 QP 的属性。在后续调用此方法时,可能会更改某些属性。
int IB _ destroy _ qp(struct IB _ qp * qp);
摧毁一个 QP。
静态内联 ib_post_srq_recv(结构 ib_srq *srq,结构 ib_recv_wr *recv_wr,结构 IB _ recv _ wr * * bad _ recv _ wr);
向 SRQ 添加接收请求的链接列表。
静态内联 ib_post_recv(结构 ib_qp *qp,结构 ib_recv_wr *recv_wr,结构 IB _ recv _ wr * * bad _ recv _ wr);
向 QP 的接收队列添加接收请求的链接列表。
静态内联 int ib_post_send(struct ib_qp *qp,struct ib_send_wr *send_wr,struct IB _ send _ wr * * bad _ send _ wr);
向 QP 的发送队列添加发送请求的链接列表。
int IB _ attach _ mcast(struct IB _ qp * qp,union ib_gid *gid,u16 lid);
将 UD QP 附加到多播组。
int IB _ detach _ mcast(struct IB _ qp * qp,union ib_gid *gid,u16 lid);
从多播组中分离一个 UD QP。
十四、高级主题
第十三章讲述了 InfiniBand 子系统及其在 Linux 中的实现。本章讨论了几个高级主题和一些逻辑上不适合其他章节的主题。本章首先讨论网络名称空间,这是一种轻量级的进程虚拟化机制,近年来被添加到 Linux 中。我将讨论一般的名称空间实现,特别是网络名称空间。您将了解到,为了实现名称空间,只需要两个新的系统调用。您还将看到几个例子,说明使用iproute2的ip命令创建和管理网络名称空间是多么简单,以及将一个网络设备从一个网络名称空间移动到另一个网络名称空间以及将指定的进程附加到指定的网络名称空间是多么简单。cgroups 子系统还提供资源管理解决方案,这与名称空间不同。我将描述 cgroups 子系统及其两个网络模块net_prio和cls_cgroup,并给出两个使用这些 cgroup 网络模块的例子。
在本章的后面,您将了解繁忙的轮询套接字以及如何调优它们。繁忙轮询套接字特性为需要低延迟并愿意为更高的 CPU 利用率付出代价的套接字提供了一种有趣的性能优化技术。内核 3.11 提供了繁忙轮询套接字特性。我还将介绍蓝牙子系统、IEEE 802.15.4 子系统和近场通信(NFC)子系统;这三个子系统通常在短程网络中工作,并且针对这些子系统的新特征的开发正在快速进行。我还将讨论通知链,这是您在开发或调试内核网络代码和 PCI 子系统时可能会遇到的一种重要机制,因为许多网络设备都是 PCI 设备。我不会深入研究 PCI 子系统的细节,因为这本书不是关于设备驱动程序的。我将用三个简短的部分来结束这一章,一个是关于组队网络驱动程序(这是新的内核链路聚合解决方案),一个是关于以太网点对点(PPPoE)协议,最后一个是关于 Android。
网络名称空间
本节介绍 Linux 名称空间、它们的用途以及它们是如何实现的。它包括对网络名称空间的深入讨论,并给出一些示例来演示它们的用法。Linux 名称空间本质上是一个虚拟化解决方案。在 Xen 或 KVM 等解决方案进入市场之前,操作系统虚拟化已经在大型机中实现了很多年。对于 Linux 名称空间,这是一种进程虚拟化的形式,这个想法一点也不新鲜。在 Plan 9 操作系统中尝试过(参见 1992 年的这篇文章:《Plan 9 中名称空间的使用》,www.cs.bell-labs.com/sys/doc/names.html)。
名称空间是轻量级进程虚拟化的一种形式,它提供了资源隔离。与 KVM 或 Xen 等虚拟化解决方案不同,使用名称空间,您不需要在同一台主机上创建额外的操作系统实例,而是只使用一个操作系统实例。在这种情况下,我应该提到 Solaris 操作系统有一个名为 Solaris Zones 的虚拟化解决方案,它也使用单个操作系统实例,但是资源分区的方案与 Linux 名称空间的方案有些不同(例如,在 Solaris Zones 中有一个全局区域,它是主区域,具有更多功能)。在 FreeBSD 操作系统中,有一种称为jails,的机制,它也提供资源分区,而无需运行多于一个内核实例。
Linux 名称空间的主要思想是在进程组之间划分资源,以使一个进程(或几个进程)拥有与其他进程组中的进程不同的系统视图。例如,这个特性用于在 Linux 容器项目(http://lxc.sourceforge.net/)中提供资源隔离。Linux 容器项目还使用了 cgroups 子系统提供的另一种资源管理机制,这将在本章后面介绍。有了容器,您可以使用操作系统的一个实例在同一台主机上运行不同的 Linux 发行版。高性能计算(HPC)中使用的检查点/恢复功能也需要名称空间。比如用在 CRIU ( http://criu.org/Main_Page )),OpenVZ ( http://openvz.org/Main_Page)的一个软件工具,主要在用户空间为 Linux 进程实现检查点/恢复功能,虽然 CRIU 内核补丁合并的地方很少。我应该提到有一些项目在内核中实现检查点/恢复,但是这些项目在主线中没有被接受,因为它们太复杂了。以 CKPT 项目为例:https://ckpt.wiki.kernel.org/index.php/Main_Page。检查点/恢复功能(有时也称为检查点/重启)支持在文件系统上停止和保存多个进程,并在以后从文件系统中恢复这些进程(可能在不同的主机上),并从停止的地方继续执行。如果没有名称空间,检查点/恢复的使用案例非常有限,特别是只有使用它们才能进行实时迁移。网络名称空间的另一个用例是当您需要建立一个环境,该环境需要模拟不同的网络堆栈来进行测试、调试等。对于想了解更多关于检查点/重启的读者,我建议阅读 Sukadev Bhattiprolu、Eric W. Biederman、Serge Hallyn 和 Daniel Lezcano 撰写的文章“主流 Linux 中的虚拟服务器和检查点/重启”。
对于内核 2.4.19,挂载名称空间是 2002 年合并的第一种 Linux 名称空间。在内核 3.8 中,对于几乎所有的文件系统类型,用户名称空间是最后实现的。正如本节后面所讨论的,可能会开发额外的名称空间。要创建一个名称空间,除了用户名称空间之外,您应该对所有名称空间都具有 CAP_SYS_ADMIN 功能。尝试为除用户名称空间之外的所有名称空间创建没有 CAP_SYS_ADMIN 功能的名称空间,将导致–EPRM 错误(“不允许操作”)。许多开发人员参与了名称空间的开发,其中包括 Eric W. Biederman、Pavel Emelyanov、Al Viro、Cyrill Gorcunov、Andrew Vagin 等等。
在了解了关于进程虚拟化和 Linux 名称空间的一些背景知识,以及它们是如何使用的之后,现在就可以开始深入研究血淋淋的实现细节了。
名称空间实现
在撰写本文时,Linux 内核中已经实现了六个名称空间。下面是为了在 Linux 内核中实现名称空间并支持用户空间包中的名称空间而需要的主要添加和更改的描述:
-
添加了一个名为
nsproxy(名称空间代理)的结构。该结构包含指向实现的六个名称空间中的五个名称空间的指针。在nsproxy结构中没有指向用户命名空间的指针;然而,所有其他五个名称空间对象都包含一个指向拥有它们的用户名称空间对象的指针,并且在这五个名称空间的每一个中,用户名称空间指针都被称为user_ns。用户名称空间是一个特例;它是凭证结构(cred)的成员,称为user_ns。cred结构表示进程的安全上下文。每个流程描述符(task_struct)包含两个cred对象,用于有效和客观的流程描述符凭证。我不会深入研究用户名称空间实现的所有细节和细微差别,因为这不在本书的范围之内。一个nsproxy对象由create_nsproxy()方法创建,并由free_nsproxy()方法释放。一个指向nsproxy对象的指针,也称为nsproxy,被添加到流程描述符中(流程描述符由task_struct结构、include/linux/sched.h表示)。)让我们来看看nsproxy结构,因为它很短,应该是不言自明的:struct nsproxy { atomic_t count; struct uts_namespace *uts_ns; struct ipc_namespace *ipc_ns; struct mnt_namespace *mnt_ns; struct pid_namespace *pid_ns; struct net *net_ns; }; (include/linux/nsproxy.h) -
你可以在
nsproxy结构中看到五个名称空间指针(没有用户名称空间指针)。在流程描述符(task_struct对象)中使用nsproxy对象代替五个名称空间对象是一种优化。当执行fork()时,一个新的子元素很可能和它的父元素存在于同一个名称空间集合中。因此,不是五次引用计数器递增(每个名称空间一次),而是一次引用计数器递增(对于nsproxy对象)。nsproxy count成员是一个引用计数器,当nsproxy对象由create_nsproxy()方法创建时,它被初始化为 1,由put_nsproxy()方法递减,由get_nsproxy()方法递增。请注意,nsproxy对象的pid_ns成员在内核 3.11 中被重命名为pid_ns_for_children。 -
添加了一个新的系统调用
unshare()。该系统调用获得一个参数,该参数是 CLONE标志的位掩码。当 flags 参数由一个或多个名称空间 CLONE_NEW标志组成时,unshare()系统调用执行以下步骤: -
首先,它根据指定的标志创建一个新的名称空间(或几个名称空间)。这是通过调用
unshare_nsproxy_namespaces()方法完成的,该方法又通过调用create_new_namespaces()方法创建了一个新的nsproxy对象和一个或多个名称空间。根据指定的 CLONE_NEW*标志确定新名称空间的类型。create_new_namespaces()方法返回一个新的nsproxy对象,它包含新创建的名称空间。 -
然后,它通过调用
switch_task_namespaces()方法将调用流程附加到新创建的nsproxy对象。
当 CLONE_NEWPID 是系统调用unshare()的标志时,的工作方式与其他标志不同;这是对fork()的隐含论证;只有子任务会发生在新的 PID 名称空间中,而不是调用unshare()系统调用的那个。其他 CLONE_NEW*标志会立即将调用进程放入一个新的名称空间。
为支持名称空间的创建而添加的六个 CLONE_NEW*标志将在本节稍后描述。unshare()系统调用的实现在kernel/fork.c中。
-
添加了一个新的系统调用
setns()。它将调用线程附加到现有的命名空间。它的原型是int setns(int fd, int nstype);这些参数是: -
fd:表示名称空间的文件描述符。这些是通过打开/proc/<pid>/ns/目录的链接获得的。 -
nstype:可选参数。当它是新的 CLONE_NEW名称空间标志之一时,指定的文件描述符必须引用与指定的 CLONE_NEW标志的类型相匹配的名称空间。当没有设置nstype(其值为 0)时,fd参数可以引用任何类型的名称空间。如果nstype不对应于与指定的fd相关联的名称空间类型,则返回值–EINVAL。
你可以在kernel/nsproxy.c中找到setns()系统调用的实现。
-
为了支持命名空间,添加了以下六个新的克隆标志:
-
CLONE_NEWNS(用于挂载名称空间)
-
CLONE_NEWUTS(用于 UTS 名称空间)
-
CLONE_NEWIPC(用于 IPC 名称空间)
-
CLONE_NEWPID(用于 PID 名称空间)
-
CLONE_NEWNET(用于网络名称空间)
-
CLONE_NEWUSER(用于用户名称空间)
传统上使用系统调用来创建一个新的进程。对它进行了调整,以支持这些新标志,这样它将创建一个附加到新名称空间(或多个名称空间)的新进程。请注意,在本章后面的一些示例中,您将会遇到使用 CLONE_NEWNET 标志来创建新的网络名称空间。
-
有名称空间支持的六个子系统中的每个子系统都实现了自己独特的名称空间。例如,mount 名称空间由一个名为
mnt_namespace的结构表示,network 名称空间由一个名为net的结构表示,这将在本节的后面讨论。我将在本章后面提到其他名称空间。 -
对于名称空间的创建,添加了一个名为
create_new_namespaces()的方法(kernel/nsproxy.c)。此方法获取一个 CLONE_NEW标志或 CLONE_NEW标志的位图作为第一个参数。它首先通过调用create_nsproxy()方法创建一个nsproxy对象,然后根据指定的标志关联一个名称空间;由于标志可以是标志的位掩码,create_new_namespaces()方法可以关联多个名称空间。我们来看看create_new_namespaces()的方法:static struct nsproxy *create_new_namespaces(unsigned long flags, struct task_struct *tsk, struct user_namespace *user_ns, struct fs_struct *new_fs) { struct nsproxy *new_nsp; int err;
分配一个nsproxy对象,并将其引用计数器初始化为 1:
new_nsp = create_nsproxy();
if (!new_nsp)
return ERR_PTR(-ENOMEM);
. . .
在成功创建了一个nsproxy对象之后,我们应该根据指定的标志创建名称空间,或者将一个现有的名称空间关联到我们创建的新的nsproxy对象。我们首先为挂载名称空间调用copy_mnt_ns(),然后为 UTS 名称空间调用copy_utsname()、。我将在这里简单描述一下copy_utsname()方法,因为 UTS 名称空间将在本章后面的“UTS 名称空间实现”一节中讨论。如果在copy_utsname()方法的指定标志中没有设置 CLONE_NEWUTS,则copy_utsname()方法不会创建新的 UTS 名称空间;它返回由tsk->nsproxy->uts_ns作为最后一个参数传递给copy_utsname()方法的 UTS 名称空间。如果设置了 CLONE_NEWUTS,copy_utsname()方法通过调用clone_uts_ns()方法克隆指定的 UTS 名称空间。clone_uts_ns()方法依次分配一个新的 UTS 命名空间对象,将指定的 UTS 命名空间(tsk->nsproxy->uts_ns)的new_utsname对象复制到新创建的 UTS 命名空间对象的new_utsname对象中,并返回新创建的 UTS 命名空间。在本章后面的“UTS 名称空间实现”一节中,您将了解到更多关于new_utsname结构的内容:
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
if (IS_ERR(new_nsp->uts_ns)) {
err = PTR_ERR(new_nsp->uts_ns);
goto out_uts;
}
. . .
在处理了 UTS 名称空间之后,我们继续调用copy_ipcs()方法来处理 IPC 名称空间,copy_pid_ns()来处理 PID 名称空间, copy_net_ns()来处理网络名称空间。注意,没有调用copy_user_ns()方法,因为nsproxy不包含指向用户名称空间的指针,如前所述。我将在这里简单描述一下copy_net_ns()方法。如果 CLONE_NEWNET 没有在create_new_namespaces()方法的指定标志中设置,那么copy_net_ns()方法将返回作为第三个参数传递给copy_net_ns()方法tsk->nsproxy->net_ns的网络名称空间,就像copy_utsname()所做的那样,正如您在本节前面所看到的。如果设置了 CLONE_NEWNET,copy_net_ns()方法通过调用net_alloc()方法分配一个新的网络名称空间,i通过调用setup_net()方法将其初始化,并将其添加到所有网络名称空间的全局列表中,net_namespace_list:
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
if (IS_ERR(new_nsp->net_ns)) {
err = PTR_ERR(new_nsp->net_ns);
goto out_net;
}
return new_nsp;
}
注意,setns()系统调用,不创建新的名称空间,只是将调用线程附加到指定的名称空间,也调用create_new_namespaces(),但它将 0 作为第一个参数传递;这意味着通过调用create_nsproxy()方法只创建了一个nsproxy,但没有创建新的名称空间,而是调用线程与一个现有的网络名称空间相关联,该名称空间由setns()系统调用的指定fd参数标识。稍后在setns()系统调用实现中,switch_task_namespaces()方法被调用,它将刚刚创建的新nsproxy分配给调用线程(参见kernel/nsproxy.c)。
-
在
kernel/nsproxy.c中增加了一个名为exit_task_namespaces()的方法。当进程终止时,通过do_exit()方法(kernel/exit.c)调用它。exit_task_namespaces()方法获取流程描述符(task_struct对象)作为单个参数。事实上,它唯一做的事情就是调用switch_task_namespaces()方法,传递指定的流程描述符和一个空的nsproxy对象作为参数。switch_task_namespaces()方法反过来使正在被终止的进程的进程描述符的nsproxy对象无效。如果没有其他进程使用这个nsproxy,它就会被释放。 -
添加了一个名为
get_net_ns_by_fd()的方法。这个方法获取一个文件描述符作为它的单个参数,并返回与指定文件描述符对应的 inode 相关联的网络名称空间。对于不熟悉文件系统和 inode 语义的读者来说,我建议阅读由 Daniel P. Bovet 和 Marco Cesati (O’Reilly,2005)在理解 Linux 内核中的第十二章“虚拟文件系统”的“Inode 对象”一节。 -
增加了一个名为
get_net_ns_by_pid()的方法。该方法获取一个 PID 号作为单个参数,并返回该进程附加到的网络命名空间对象。 -
在
/proc/<pid>/ns下添加了六个条目,每个名称空间一个。这些文件在打开时应该被输入到setns()系统调用中。您可以使用ls –al或readlink来显示与名称空间相关联的惟一 proc inode 号。这个惟一的 proc inode 在创建名称空间时由proc_alloc_inum()方法创建,在释放名称空间时由proc_free_inum()方法释放。例如,参见kernel/pid_namespace.c中的create_pid_namespace()方法。在下面的例子中,右边方括号中的数字是每个名称空间的惟一 proc inode 号:ls -al /proc/1/ns/ total 0 dr-x--x--x 2 root root 0 Nov 3 13:32 . dr-xr-xr-x 8 root root 0 Nov 3 12:17 .. lrwxrwxrwx 1 root root 0 Nov 3 13:32 ipc -> ipc:[4026531839] lrwxrwxrwx 1 root root 0 Nov 3 13:32 mnt -> mnt:[4026531840] lrwxrwxrwx 1 root root 0 Nov 3 13:32 net -> net:[4026531956] lrwxrwxrwx 1 root root 0 Nov 3 13:32 pid -> pid:[4026531836] lrwxrwxrwx 1 root root 0 Nov 3 13:32 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 Nov 3 13:32 uts -> uts:[4026531838] -
如果满足以下任一条件,命名空间可以保持活动状态:
-
/proc/<pid>/ns/描述符下的命名空间文件被保存。 -
将命名空间 proc 文件绑定挂载到其他地方,例如,对于 PID 命名空间,通过:
mount --bind /proc/self/ns/pid /some/filesystem/path -
对于六个名称空间中的每一个,定义了一个 proc 名称空间操作对象(
proc_ns_operations结构的一个实例)。这个对象由回调组成,例如inum,以返回与名称空间或install相关联的唯一 proc inode 号,用于名称空间安装(在install回调中,执行名称空间特定的动作,例如将特定名称空间对象附加到nsproxy对象,等等;install回调由setns系统调用调用)。proc_ns_operations结构在include/linux/proc_fs.h中定义。以下是六个proc_ns_operations对象的列表: -
utsns_operations为 UTS 命名空间(kernel/utsname.c) -
ipcns_operations对于 IPC 名称空间(ipc/namespace.c) -
mntns_operations对于挂载命名空间(fs/namespace.c) -
pidns_operations对于 PID 名称空间(kernel/pid_namespace.c) -
userns_operations用于用户命名空间(kernel/user_namespace.c) -
netns_operations用于网络命名空间(net/core/net_namespace.c) -
对于每个名称空间,除了挂载名称空间之外,都有一个初始名称空间:
-
init_uts_ns:用于 UTS 命名空间(init/version.c)。 -
init_ipc_ns:对于 IPC 命名空间(ipc/msgutil.c)。 -
init_pid_ns:用于 PID 命名空间(kernel/pid.c)。 -
init_net:用于网络命名空间(net/core/net_namespace.c)。 -
init_user_ns:用于用户命名空间(kernel/user.c)。 -
定义了一个初始的、默认的
nsproxy对象:它被称为init_nsproxy,包含指向五个初始名称空间的指针;除了 mount 命名空间被初始化为空之外,都被初始化为对应的特定初始命名空间:struct nsproxy init_nsproxy = { .count = ATOMIC_INIT(1), .uts_ns = &init_uts_ns, #if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC) .ipc_ns = &init_ipc_ns, #endif .mnt_ns = NULL, .pid_ns = &init_pid_ns, #ifdef CONFIG_NET .net_ns = &init_net, #endif }; (kernel/nsproxy.c) -
添加了一个名为
task_nsproxy()的方法;它以单个参数的形式获取一个流程描述符(task_struct对象),并返回与指定的task_struct对象相关联的nsproxy。参见include/linux/nsproxy.h。
在撰写本文时,Linux 内核中有六个可用的名称空间:
-
**挂载名称空间:**挂载名称空间允许进程查看自己的文件系统视图及其挂载点。在一个挂载命名空间中挂载文件系统不会传播到其他挂载命名空间。挂载名称空间是通过在调用
clone()或unshare()系统调用时设置 CLONE_NEWNS 标志来创建的。为了实现挂载名称空间,添加了一个名为mnt_namespace的结构(fs/mount.h),nsproxy持有一个指向名为mnt_ns的mnt_namespace对象的指针。内核 2.4.19 提供了挂载名称空间。挂载名称空间主要在fs/namespace.c中实现。创建新的装载命名空间时,以下规则适用: -
所有以前的装载将在新的装载命名空间中可见。
-
新挂载名称空间中的挂载/卸载对于系统的其余部分是不可见的。
-
全局装载命名空间中的装载/卸载在新的装载命名空间中可见。
挂载名称空间使用一种 VFS 增强,称为共享子树,它是在 Linux 2.6.15 内核中引入的;特性引入了新的标志:MS_PRIVATE、MS_SHARED、MS_SLAVE 和 MS_UNBINDABLE。(参见http://lwn.net/Articles/159077/和Documentation/filesystems/sharedsubtree.txt。)我不会讨论挂载名称空间实现的内部。对于想了解更多关于挂载名称空间用法的读者,我建议阅读以下文章:“应用挂载名称空间”,作者 Serge E. Hallyn 和 Ram Pai ( http://www.ibm.com/developerworks/linux/library/l-mount-namespaces/index.html )。
* **PID 名称空间:**PID 名称空间为不同 PID 名称空间中的不同进程提供了拥有相同 PID 的能力。这个特性是 Linux 容器的构建块。这对于进程的检查点/恢复非常重要,因为在一台主机上设置了检查点的进程可以在另一台主机上恢复,即使该主机上存在具有相同 PID 的进程。当在新的 PID 名称空间中创建第一个进程时,它的 PID 是 1。这个流程的行为有点像init流程的行为。这意味着当一个进程死亡时,它的所有孤立子进程现在将拥有 PID 1 作为其父进程的进程(child reaping)。向 PID 为 1 的进程发送 SIGKILL 信号不会终止该进程,无论 SIGKILL 信号是在哪个命名空间发送的,是在初始 PID 命名空间还是在任何其他 PID 命名空间。但是从另一个 PID 名称空间(父名称空间)中删除一个 PID 名称空间的init将会起作用。在这种情况下,所有存在于以前命名空间中的任务都将被终止,PID 命名空间将被停止。PID 名称空间是通过在调用clone()或unshare()系统调用时设置 CLONE_NEWPID 标志来创建的。为了实现 PID 名称空间,添加了一个名为pid_namespace的结构(include/linux/pid_namespace.h),nsproxy保存了一个指向名为pid_ns的pid_namespace对象的指针。为了支持 PID 名称空间,应该设置 CONFIG_PID_NS。PID 名称空间在内核 2.6.24 中可用。PID 名称空间主要在kernel/pid_namespace.c`中实现。
- **网络名称空间:**网络名称空间允许创建看似内核网络堆栈的多个实例。当调用
clone()或unshare()系统调用时,通过设置 CLONE_NEWNET 标志来创建网络名称空间。为了实现网络名称空间,添加了一个名为net的结构(include/net/net_namespace.h),nsproxy持有一个指向名为net_ns的net对象的指针。为了支持网络命名空间,应该设置 CONFIG_NET_NS。我将在本节的后面讨论网络名称空间。内核 2.6.29 提供了网络名称空间。网络名称空间主要在net/core/net_namespace.c中实现。 - **IPC 名称空间:**IPC 名称空间允许进程拥有自己的 System V IPC 资源和 POSIX 消息队列资源。IPC 名称空间是通过在调用
clone()或unshare()系统调用时设置 CLONE_NEWIPC 标志来创建的。为了实现 IPC 名称空间,添加了一个名为ipc_namespace的结构(include/linux/ipc_namespace.h),nsproxy持有一个指向名为ipc_ns的ipc_namespace对象的指针。为了支持 IPC 名称空间,应该设置 CONFIG_IPC_NS。内核 2.6.19 中的 IPC 名称空间提供了对 System V IPC 资源的支持。对 IPC 名称空间中 POSIX 消息队列资源的支持是后来在内核 2.6.30 中添加的。IPC 名称空间主要在ipc/namespace.c中实现。 - **UTS 名称空间:**UTS 名称空间为不同的 UTS 名称空间提供了拥有不同的主机名或域名(或者由
uname()系统调用返回的其他信息)的能力。UTS 名称空间是通过在调用clone()或unshare()系统调用时设置 CLONE_NEWUTS 标志来创建的。在实现的六个名称空间中,UTS 名称空间实现是最简单的。为了实现 UTS 名称空间,添加了一个名为uts_namespace的结构(include/linux/utsname.h),nsproxy保存了一个指向名为uts_ns的uts_namespace对象的指针。为了支持 UTS 命名空间,应该设置 CONFIG_UTS_NS。内核 2.6.19 提供了 UTS 名称空间。UTS 名称空间主要在kernel/utsname.c中实现。 - **用户名称空间:**用户名称空间允许映射用户和组 id。这种映射是通过写入两个为支持用户名称空间而添加的
procfs条目来完成的:/proc/sys/kernel/overflowuid和/proc/sys/kernel/overflowgid。附加到用户名称空间的进程可以具有与宿主不同的一组功能。当调用clone()或unshare()系统调用时,通过设置 CLONE_NEWUSER 标志来创建用户名称空间。为了实现用户名称空间,添加了一个名为user_namespace的结构(include/linux/user_namespace.h)。user_namespace对象包含一个指向创建它的用户名称空间对象的指针(parent)。与其他五个名称空间不同,nsproxy不持有指向user_namespace对象的指针。我不会深入研究用户名称空间的更多实现细节,因为它可能是最复杂的名称空间,并且超出了本书的范围。为了支持用户名称空间,应该设置 CONFIG_USER_NS。从内核 3.8 开始,几乎所有文件系统类型都可以使用用户名称空间。用户名称空间主要在kernel/user_namespace.c中实现。
在四个用户空间包中增加了对名称空间的支持:
-
在
util-linux中: -
从版本 2.17 开始,
unshare实用程序可以创建六个名称空间中的任何一个。 -
从版本 2.23 开始提供的
nsenter实用程序(实际上是围绕setns系统调用的一个轻量级包装器)。 -
在
iproute2中,网络名称空间的管理是通过ip netns命令完成的,在本章的后面你会看到几个这样的例子。此外,您可以使用ip link命令将网络接口移动到不同的网络名称空间,您将在本章后面的“将网络接口移动到不同的网络名称空间”一节中看到。 -
在
ethtool中,增加了对 enable 的支持,可以发现是否为指定的网络接口设置了 NETIF_F_NETNS_LOCAL 特性。如果设置了 NETIF_F_NETNS_LOCAL 功能,这表示网络接口位于该网络命名空间的本地,您不能将其移动到不同的网络命名空间。NETIF_F_NETNS_LOCAL 特性将在本节稍后讨论。 -
在 wireless
iw包中,添加了一个选项,允许将无线接口移动到不同的名称空间。
 注在 2006 年渥太华 Linux 研讨会(OLS)的一次演讲《全球 Linux 名称空间的多个实例》中,Eric w . Biederman(Linux 名称空间的主要开发者之一)提到了十个名称空间;他在本演示中提到的其他四个尚未实现的名称空间是:设备名称空间、安全名称空间、安全密钥名称空间和时间名称空间。(见
注在 2006 年渥太华 Linux 研讨会(OLS)的一次演讲《全球 Linux 名称空间的多个实例》中,Eric w . Biederman(Linux 名称空间的主要开发者之一)提到了十个名称空间;他在本演示中提到的其他四个尚未实现的名称空间是:设备名称空间、安全名称空间、安全密钥名称空间和时间名称空间。(见https://www.kernel.org/doc/ols/2006/ols2006v1-pages-101-112.pdf .) For more information about namespaces, I suggest reading a series of six articles about it by Michael Kerrisk (https://lwn.net/Articles/531114/ ))。移动操作系统虚拟化项目引发了支持设备名称空间的开发工作;关于设备名称空间的更多信息,它还不是内核的一部分,参见 Jake Edge 的“设备名称空间”(http://lwn.net/Articles/564854/ ) and also (http://lwn.net/Articles/564977/ ). There was also some work for implementing a new syslog namespace (see the article “Stepping Closer to Practical Containers: “syslog” namespaces”, http://lwn.net/Articles/527342/ )。```sh`
* `clone():`创建一个附加到新名称空间的新进程。名称空间的类型由作为参数传递的 CLONE_NEW*标志指定。请注意,您也可以使用这些 CLONE_NEW*标志的位掩码。`clone()`系统调用的实现在`kernel/fork.c`中。
* `unshare()`:本节前面讨论过。
* `setns()`:本节前面讨论过。
 **注意**名称空间在内核中没有用户空间进程可以用来与之对话的名称。如果名称空间有名字,这就需要在另一个特殊的名称空间中全局保存它们。这将使实施变得复杂,并可能在检查点/恢复等方面引发问题。相反,用户空间进程应该打开`/proc/<pid>/ns/`下的名称空间文件,它们的文件描述符可以用来与特定的名称空间对话,以保持该名称空间的活力。名称空间由创建时生成的唯一 proc inode 号标识,释放时释放。六个名称空间结构中的每一个都包含一个名为`proc_inum`的整数成员,它是名称空间惟一的 proc inode 号,通过调用`proc_alloc_inum()`方法来分配。六个名称空间中的每一个都有一个`proc_ns_operations`对象,它包括特定于名称空间的回调;其中一个回调函数叫做`inum`,返回相关名称空间的`proc_inum`(关于`proc_ns_operations`结构的定义,请参考`include/linux/proc_fs.h`)。
在讨论网络名称空间之前,让我们描述一下最简单的名称空间,即 UTS 名称空间是如何实现的。这是理解其他更复杂的名称空间的良好起点。
UTS 命名空间实现
为了实现 UTS 命名空间,添加了一个名为`uts_namespace`的结构:
```sh
struct uts_namespace {
struct kref kref;
struct new_utsname name;
struct user_namespace *user_ns;
unsigned int proc_inum;
};
(include/linux/utsname.h)
下面是对uts_namespace结构成员的简短描述:
kref:参考计数器。它是一个通用的内核引用计数器,由kref_get()方法递增,由kref_put()方法递减。除了 UTS 命名空间,PID 命名空间也有一个kref对象作为引用计数器;所有其他四个名称空间都使用原子计数器进行引用计数。关于krefAPI 的更多信息请看Documentation/kref.txt。name:一个new_utsname对象,包含类似domainname和nodename的字段(稍后将讨论)。user_ns:与 UTS 命名空间相关联的用户命名空间。proc_inum:UTS 名称空间的唯一进程索引节点号。
nsproxy结构包含一个指向uts_namespace的指针:
struct nsproxy {
. . .
struct uts_namespace *uts_ns;
. . .
};
(include/linux/nsproxy.h)
正如您之前看到的,uts_namespace对象包含了一个new_utsname结构的实例。让我们看一下new_utsname结构,这是 UTS 名称空间的本质:
struct new_utsname {
char sysname[__NEW_UTS_LEN + 1];
char nodename[__NEW_UTS_LEN + 1];
char release[__NEW_UTS_LEN + 1];
char version[__NEW_UTS_LEN + 1];
char machine[__NEW_UTS_LEN + 1];
char domainname[__NEW_UTS_LEN + 1];
};
(include/uapi/linux/utsname.h)
new_utsname的nodename成员是主机名,domainname是域名。添加了一个名为utsname()的方法;这个方法只是返回与当前运行的进程相关联的new_utsname对象(current):
static inline struct new_utsname *utsname(void)
{
return ¤t->nsproxy->uts_ns->name;
}
(include/linux/utsname.h)
现在,新的gethostname()系统调用实现如下:
SYSCALL_DEFINE2(gethostname, char __user *, name, int, len)
{
int i, errno;
struct new_utsname *u;
if (len < 0)
return -EINVAL;
down_read(&uts_sem);
调用utsname()方法,该方法访问与当前进程关联的 UTS 命名空间的new_utsname对象:
u = utsname();
i = 1 + strlen(u->nodename);
if (i > len)
i = len;
errno = 0;
将utsname()方法返回的new_utsname对象的nodename复制到用户空间:
if (copy_to_user(name, u->nodename, i))
errno = -EFAULT;
up_read(&uts_sem);
return errno;
}
(kernel/sys.c)
你可以在uname()系统调用的sethostbyname()和中找到类似的方法,它们也在kernel/sys.c中定义。我应该注意,UTS 名称空间实现也处理 UTS procfs条目。只有两个 UTS procfs条目,/proc/sys/kernel/domainname和/proc/sys/kernel/hostname,它们是可写的(这意味着您可以从用户空间更改它们)。还有其他不可写的 UTS procfs条目,如/proc/sys/kernel/ostype和/proc/sys/kernel/osrelease。如果您查看 UTS procfs条目uts_kern_table (kernel/utsname_sysctl.c)的表格,您会看到一些条目,如ostype和osrelease,具有“0444”模式,这意味着它们不可写,只有其中的两个条目hostname和domainname具有“0644”模式,这意味着它们是可写的。UTS procfs条目的读写由proc_do_uts_string()方法处理。想要了解更多关于如何处理 UTS procfs条目的读者应该查看proc_do_uts_string()方法和get_uts()方法;两人都在kernel/utsname_sysctl.c。
既然您已经了解了最简单的名称空间——UTS 名称空间是如何实现的,那么是时候了解网络名称空间及其实现了。
网络名称空间实现
网络名称空间在逻辑上是网络堆栈的另一个副本,具有自己的网络设备、路由表、邻居表、网络过滤表、网络套接字、网络procfs条目、网络sysfs条目和其他网络资源。网络名称空间的一个实用特性是,在给定名称空间(比如说ns1)中运行的网络应用将首先在/etc/netns/ns1下寻找配置文件,然后才在/etc下寻找。因此,举例来说,如果您创建了一个名为ns1的名称空间,并且您已经创建了/etc/netns/ns1/hosts,那么每个试图访问hosts文件的用户空间应用将首先访问/etc/netns/ns1/hosts,并且只有到那时(如果所寻找的条目不存在)它才会读取/etc/hosts。这个特性是使用绑定挂载实现的,并且只适用于使用ip netns add命令创建的网络名称空间。
网络命名空间对象(struct net)
现在让我们来看一下net结构的定义,它是代表网络名称空间的基本数据结构:
struct net {
. . .
struct user_namespace *user_ns; /* Owning user namespace */
unsigned int proc_inum;
struct proc_dir_entry *proc_net;
struct proc_dir_entry *proc_net_stat;
. . .
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
. . .
int ifindex;
. . .
struct net_device *loopback_dev; /* The loopback */
. . .
atomic_t count; /* To decided when the network
* namespace should be shut down.
*/
struct netns_ipv4 ipv4;
#if IS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
#if defined(CONFIG_IP_SCTP) || defined(CONFIG_IP_SCTP_MODULE)
struct netns_sctp sctp;
#endif
. . .
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct netns_ct ct;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
struct netns_nf_frag nf_frag;
#endif
. . .
struct net_generic __rcu *gen;
#ifdef CONFIG_XFRM
struct netns_xfrm xfrm;
#endif
. . .
};
(include/net/net_namespace.h)
下面是对net结构中几个成员的简短描述:
user_ns表示创建网络命名空间的用户命名空间;它拥有网络名称空间及其所有资源。它在setup_net()方法中被赋值。对于初始网络名称空间对象(init_net),创建它的用户名称空间是初始用户名称空间,init_user_ns。proc_inum是与网络名称空间相关联的唯一 proc inode 号。这个惟一的进程索引节点是由proc_alloc_inum()方法创建的,该方法还将proc_inum指定为进程索引节点号。proc_alloc_inum()方法由网络名称空间初始化方法net_ns_net_init()调用,通过调用网络名称空间清理方法net_ns_net_exit()中的proc_free_inum()方法释放。proc_net代表网络名称空间procfs条目(/proc/net),因为每个网络名称空间维护其自己的procfs条目。proc_net_stat代表网络名称空间procfs统计条目(/proc/net/stat),因为每个网络名称空间维护其自己的procfs统计条目。dev_base_head指向所有网络设备的链表。dev_name_head指向一个网络设备的哈希表,其中的键是网络设备名。dev_index_head指向一个网络设备的哈希表,其中的键是网络设备索引。ifindex是网络名称空间内分配的最后一个设备索引。索引在网络命名空间中被虚拟化;这意味着回送设备在所有网络名称空间中的索引总是为 1,而其他网络设备在不同的网络名称空间中可能具有相同的索引。loopback_dev是环回设备。每个新的网络命名空间都是用一个网络设备创建的,即环回设备。在loopback_net_init()方法drivers/net/loopback.c中分配网络名称空间的loopback_dev对象。您不能将环回设备从一个网络名称空间移动到另一个网络名称空间。count是网络名称空间引用计数器。当通过setup_net()方法创建网络名称空间时,它被初始化为 1。它通过get_net()方法递增,通过put_net()方法递减。如果在put_net()方法中count参考计数器达到 0,则调用__put_net()方法。然后,__put_net()方法将网络名称空间添加到要删除的网络名称空间的全局列表中,cleanup_list,然后删除它。- IPv4 子系统的
ipv4(netns_ipv4结构的一个实例)。netns_ipv4结构包含 IPv4 特定字段,这些字段对于不同的名称空间是不同的。例如,在第六章的中,您看到了名为net的指定网络名称空间的组播路由表存储在net->ipv4.mrt中。我将在本节稍后讨论netns_ipv4。 - IPv6 子系统的
ipv6(netns_ipv6结构的一个实例)。 - 用于 SCTP 套接字的
sctp(netns_sctp结构的一个实例)。 ct(netns_ct结构的一个实例,在第九章)中讨论了 netfilter 连接跟踪子系统。gen(net_generic结构的一个实例,在include/net/netns/generic.h中定义)是描述可选子系统的网络名称空间上下文的结构上的一组通用指针。例如,sit模块(简单互联网过渡,IPv6 隧道,在net/ipv6/sit.c实现)使用这个引擎将其私有数据放在struct net上。引入这一点是为了不使struct net淹没每个网络子系统的指针,每个网络子系统都愿意拥有每个网络名称空间上下文。xfrm(netns_xfrm结构的一个实例,在 IPsec 子系统的第十章)中多次提到。
让我们来看看 IPv4 特定的名称空间,netns_ipv4结构:
struct netns_ipv4 {
. . .
#ifdef CONFIG_IP_MULTIPLE_TABLES
struct fib_rules_ops *rules_ops;
bool fib_has_custom_rules;
struct fib_table *fib_local;
struct fib_table *fib_main;
struct fib_table *fib_default;
#endif
. . .
struct hlist_head *fib_table_hash;
struct sock *fibnl;
struct sock **icmp_sk;
. . .
#ifdef CONFIG_NETFILTER
struct xt_table *iptable_filter;
struct xt_table *iptable_mangle;
struct xt_table *iptable_raw;
struct xt_table *arptable_filter;
#ifdef CONFIG_SECURITY
struct xt_table *iptable_security;
#endif
struct xt_table *nat_table;
#endif
int sysctl_icmp_echo_ignore_all;
int sysctl_icmp_echo_ignore_broadcasts;
int sysctl_icmp_ignore_bogus_error_responses;
int sysctl_icmp_ratelimit;
int sysctl_icmp_ratemask;
int sysctl_icmp_errors_use_inbound_ifaddr;
int sysctl_tcp_ecn;
kgid_t sysctl_ping_group_range[2];
long sysctl_tcp_mem[3];
atomic_t dev_addr_genid;
#ifdef CONFIG_IP_MROUTE
#ifndef CONFIG_IP_MROUTE_MULTIPLE_TABLES
struct mr_table *mrt;
#else
struct list_head mr_tables;
struct fib_rules_ops *mr_rules_ops;
#endif
#endif
};
(net/netns/ipv4.h)
您可以在netns_ipv4结构中看到许多特定于 IPv4 的表和变量,比如路由表、netfilter 表、多播路由表等等。
网络名称空间实现:其他数据结构
为了支持网络名称空间,在网络设备对象(struct net_device)中添加了一个名为nd_net的成员,它是一个指向网络名称空间的指针。通过调用dev_net_set()方法来设置网络设备的网络名称空间,通过调用dev_net()方法来获取与网络设备相关联的网络名称空间。请注意,在给定时刻,一个网络设备只能属于一个网络命名空间。nd_net通常在网络设备注册或网络设备移动到不同的网络名称空间时设置。例如,在注册 VLAN 设备时,会使用上述两种方法:
static int register_vlan_device(struct net_device *real_dev, u16 vlan_id)
{
struct net_device *new_dev;
要分配给新 VLAN 设备的网络名称空间是与真实设备相关联的网络名称空间,它作为参数传递给register_vlan_device()方法;我们通过调用dev_net(real_dev)获得这个名称空间:
struct net *net = dev_net(real_dev);
. . .
new_dev = alloc_netdev(sizeof(struct vlan_dev_priv), name, vlan_setup);
if (new_dev == NULL)
return -ENOBUFS;
通过调用dev_net_set()方法切换网络名称空间:
dev_net_set(new_dev, net);
. . .
}
一个名为sk_net的成员,一个指向网络名称空间的指针,被添加到代表套接字的struct sock中。为一个sock对象设置网络名称空间是通过调用sock_net_set()方法来完成的,获取与一个sock对象相关联的网络名称空间是通过调用sock_net()方法来完成的。像在nd_net对象的情况下一样,sock对象在给定时刻也只能属于一个网络名称空间。
当系统引导时,会创建一个默认的网络名称空间init_net,。引导后,所有物理网络设备和所有套接字都属于该初始命名空间,网络环回设备也是如此。
一些网络设备和一些网络子系统应该具有网络命名空间特定的数据。为了实现这一点,添加了一个名为pernet_operations的结构;这个结构包括一个init和exit回调:
struct pernet_operations {
. . .
int (*init)(struct net *net);
void (*exit)(struct net *net);
. . .
int *id;
size_t size;
};
(include/net/net_namespace.h)
需要网络名称空间特定数据的网络设备应该定义一个pernet_operations对象,并分别为设备特定的初始化和清理定义其init()和exit()回调,并在模块初始化时调用register_pernet_device()方法,在模块被移除时调用unregister_pernet_device()方法,在这两种情况下将pernet_operations对象作为单个参数传递。例如,PPPoE 模块通过procfs条目/proc/net/pppoe导出关于 PPPoE 会话的信息。此procfs条目导出的信息取决于此 PPPoE 设备所属的网络名称空间(因为不同的 PPPoE 设备可能属于不同的网络名称空间)。所以 PPPoE 模块定义了一个名为pppoe_net_ops的pernet_operations对象:
static struct pernet_operations pppoe_net_ops = {
.init = pppoe_init_net,
.exit = pppoe_exit_net,
.id = &pppoe_net_id,
.size = sizeof(struct pppoe_net),
}
(net/ppp/pppoe.c)
在init回调pppoe_init_net()中,它只通过调用proc_create()方法创建 PPPoE procfs条目/proc/net/pppoe:
static __net_init int pppoe_init_net(struct net *net)
{
struct pppoe_net *pn = pppoe_pernet(net);
struct proc_dir_entry *pde;
rwlock_init(&pn->hash_lock);
pde = proc_create("pppoe", S_IRUGO, net->proc_net, &pppoe_seq_fops);
#ifdef CONFIG_PROC_FS
if (!pde)
return -ENOMEM;
#endif
return 0;
}
(net/ppp/pppoe.c)
在exit回调pppoe_exit_net()中,它只通过调用remove_proc_entry()方法移除 PPPoE procfs条目/proc/net/pppoe:
static __net_exit void pppoe_exit_net(struct net *net)
{
remove_proc_entry("pppoe", net->proc_net);
}
(net/ppp/pppoe.c)
需要网络命名空间特定数据的网络子系统应该在初始化子系统时调用register_pernet_subsys(),在移除子系统时调用unregister_pernet_subsys()。你可以在net/ipv4/route.c里找例子,还有很多其他复习这些方法的例子。网络名称空间模块本身也定义了一个net_ns_ops对象,并在引导阶段注册它:
static struct pernet_operations __net_initdata net_ns_ops = {
.init = net_ns_net_init,
.exit = net_ns_net_exit,
};
static int __init net_ns_init(void)
{
. . .
register_pernet_subsys(&net_ns_ops);
. . .
}
(net/core/net_namespace.c)
每次创建新的网络名称空间时,调用init回调(net_ns_net_init),每次删除网络名称空间时,调用exit回调(net_ns_net_exit)。net_ns_net_init()唯一做的事情是通过调用proc_alloc_inum()方法为新创建的名称空间分配一个惟一的 proc inode 新创建的唯一 proc inode 编号被分配给net->proc_inum:
static __net_init int net_ns_net_init(struct net *net)
{
return proc_alloc_inum(&net->proc_inum);
}
net_ns_net_exit()方法做的唯一一件事就是通过调用proc_free_inum()方法删除这个惟一的 proc inode:
static __net_exit void net_ns_net_exit(struct net *net)
{
proc_free_inum(net->proc_inum);
}
当您创建新的网络命名空间时,它只有网络环回设备。创建网络命名空间最常见的方法是:
- 由一个用户空间应用创建一个网络名称空间,该应用使用
clone()系统调用或unshare()系统调用,在两种情况下都设置 CLONE_NEWNET 标志。 - 使用
iproute2的ip netns命令(您将很快看到一个例子)。 - 使用
util-linux的unshare实用程序,带有--net标志。
网络名称空间管理
接下来,您将看到一些使用iproute2包的ip netns命令来执行诸如创建网络名称空间、删除网络名称空间、显示所有网络名称空间等操作的例子。
-
Creating a network namespace named
ns1is done by:ip netns add ns1运行这个命令首先触发一个名为
/var/run/netns/ns1的文件的创建,然后通过系统调用unshare()创建网络名称空间,并向其传递一个 CLONE_NEWNET 标志。然后通过一个bind挂载将/var/run/netns/ns1附加到网络名称空间(/proc/self/ns/net)(用 MS_BIND 调用mount()系统调用)。请注意,网络名称空间可以嵌套,这意味着从ns1中您还可以创建一个新的网络名称空间,等等。 -
Deleting a network namespace named
ns1is done by:ip netns del ns1请注意,如果有一个或多个进程附加到网络命名空间,这将不会删除该命名空间。如果没有这样的过程,则删除
/var/run/netns/ns1文件。还要注意,当删除一个命名空间时,它的所有网络设备都被移动到初始的默认网络命名空间init_net,但网络命名空间本地设备除外,它们是设置了 NETIF_F_NETNS_LOCAL 特性的网络设备。此类网络设备将被删除。详见本章后面的“将网络接口移动到网络名称空间”部分和附录 A 。 -
Showing all the network namespaces in the system that were added by
ip netns addis done by:ip netns list实际上,运行
ip netns list只是显示/var/run/netns下的文件名。注意,ip netns add没有添加的网络名称空间ip netns list不会显示,因为创建这样的网络名称空间不会触发/var/run/netns下任何文件的创建。所以,比如运行ip netns list时,由unshare --net bash创建的网络名称空间不会出现。 -
Monitoring creation and removal of a network namespace is done by:
ip netns monitor运行
ip netns monitor后,当您通过ip netns add ns2添加新的命名空间时,您将在屏幕上看到以下消息:“添加 ns2”,通过ip netns delete ns2删除该命名空间后,您将在屏幕上看到以下消息:“删除 ns2”。注意,添加和删除网络名称空间不是通过分别运行ip netns add和ip netns delete``, does not trigger displaying any messages on screen byip netns monitor。通过在/var/run/netns上设置一个inotify手表来执行ip netns monitor命令。请注意,如果您在使用ip netns add添加至少一个网络名称空间之前运行ip netns monitor,您将得到以下错误:inotify_add_watch failed: No such file or directory。原因是试图在/var/run/netns上设置一个尚不存在的手表失败。参见man inotify_init() and man inotify_add_watch()。
* Start a shell in a specified namespace (ns1` in this example) is done by:
`ip netns exec ns1 bash`
注意,使用`ip netns exec`可以在指定的网络名称空间中运行**任何**命令。例如,以下命令将显示名为`ns1`的网络名称空间中的所有网络接口:
`ip netns exec ns1 ifconfig -a``
在最近版本的iproute2`(从版本 3.8 开始)中,您有了这两个额外的有用命令:
-
Show the network namespace associated with the specified
pid:ip netns identify #pid这是通过读取
/proc/<pid>/ns/net并迭代/var/run/netns下的文件来找到匹配(使用stat()系统调用)来实现的。 -
Show the PID of a process (or list of processes) attached to a network namespace called
ns1by:ip netns pids ns1这是通过读取
/var/run/netns/ns1,然后迭代/proc/<pid>条目来找到匹配的/proc/pid/ns/net条目(使用stat()系统调用)来实现的。
 注关于各种 ip netns 命令选项的更多信息,参见
注关于各种 ip netns 命令选项的更多信息,参见man ip netns。
将网络接口移动到不同的网络名称空间
使用ip命令可以将网络接口移动到名为ns1的网络名称空间。例如,出自:ip link set eth0 netns ns1。作为实现网络名称空间的一部分,一个名为 NETIF_F_NETNS_LOCAL 的新特性被添加到了net_device对象的特性中(net_device结构代表一个网络接口)。有关net_device结构及其特性的更多信息,参见附录 A 。您可以通过查看ethtool -k eth0输出或ethtool --show-features eth0输出中的netns-local标志来确定是否为指定的网络设备设置了 NETIF_F_NETNS_LOCAL 功能(这两个命令是等效的。)注意不能用ethtool设置 NETIF_F_NETNS_LOCAL 特性。该特征在被设置时表示网络设备是网络命名空间本地设备。例如,回环、网桥、VXLAN 和 PPP 设备都是网络命名空间本地设备。尝试移动 NETIF_F_NETNS_LOCAL 功能设置为不同名称空间的网络设备将会失败,并出现–EINVAL 错误,您将很快在下面的代码片段中看到这一点。当试图将网络接口移动到不同的网络名称空间时,调用dev_change_net_namespace()方法,例如通过:ip link set eth0 netns ns1。让我们来看看dev_change_net_namespace()的方法:
int dev_change_net_namespace(struct net_device *dev, struct net *net, const char *pat)
{
int err;
ASSERT_RTNL();
/* Don't allow namespace local devices to be moved. */
err = -EINVAL;
如果设备是本地设备,则返回–EINVAL(设置了net_device对象特性中的 NETIF_F_NETNS_LOCAL 标志)
if (dev->features & NETIF_F_NETNS_LOCAL)
goto out;
. . .
通过将net_device对象的nd_net设置为新的指定名称空间来实际切换网络名称空间:
dev_net_set(dev, net)
. . .
out:
return err;
}
(net/core/dev.c)
注意您可以将网络接口移动到名为ns1的网络名称空间,方法是指定附加到该名称空间的进程的 PID,而无需显式指定名称空间名称。例如,如果你知道一个 PID 为的进程附加到了 ns1,运行ip link set eth1 netns <pidNumber>会将eth1移动到ns1名称空间。实现细节:在指定其附属进程的 PID 之一时获取网络名称空间对象由get_net_ns_by_pid()方法实现,而在指定网络名称空间名称时获取网络名称空间对象由get_net_ns_by_fd()方法实现;两种方法都在net/core/net_namespace.c。为了将无线网络接口移动到不同的网络名称空间,您应该使用iw命令。例如,如果您想要将wlan0移动到一个网络名称空间,并且您知道一个 PID 为的进程被附加到那个名称空间,那么您可以运行 iw phy phy0 set netns <pidNumber>来将其移动到那个网络名称空间。实现细节参见net/wireless/nl80211.c中的nl80211_wiphy_netns()方法。
两个网络名称空间之间的通信
我将用一个两个网络名称空间如何相互通信的简短例子来结束网络名称空间一节。可以通过使用 Unix 套接字或者使用虚拟以太网(VETH)网络驱动程序创建一对虚拟网络设备并将其中一个移动到另一个网络命名空间来实现。例如,下面是前两个名称空间,ns1和ns2:
ip netns add ns1
ip netns add ns2
在ns1中启动 Shell:
ip netns exec ns1 bash
创建一个虚拟以太网设备(类型为veth):
ip link add name if_one type veth peer name if_one_peer
将if_one_peer移动到ns2:
ip link set dev if_one_peer netns ns2
现在,您可以像往常一样使用ifconfig命令或ip命令在if_one和if_one_peer上设置地址,并从一个网络名称空间向另一个发送数据包。
 注意网络名称空间对于内核映像不是强制性的。默认情况下,在大多数发行版中,网络名称空间是启用的(CONFIG_NET_NS 已设置)。但是,您可以在禁用网络名称空间的情况下构建和引导内核。
注意网络名称空间对于内核映像不是强制性的。默认情况下,在大多数发行版中,网络名称空间是启用的(CONFIG_NET_NS 已设置)。但是,您可以在禁用网络名称空间的情况下构建和引导内核。
我在本节中讨论了什么是名称空间,特别是什么是网络名称空间。我提到了实现名称空间所需的一些主要变化,比如添加了 6 个新的 CLONE_NEW*标志,添加了两个新的系统调用,向流程描述符添加了一个nsproxy对象,等等。我还描述了所有名称空间中最简单的 UTS 名称空间的实现,以及网络名称空间的实现。给出了几个例子,展示了用iproute2包的ip netns命令操纵网络名称空间是多么简单。接下来我将描述 cgroups 子系统,它提供了另一种资源管理解决方案,以及属于它的两个网络模块。
群组
cgroups 子系统是由 Paul Menage、Rohit Seth 和其他 Google 开发人员在 2006 年启动的项目。它最初被称为“过程容器”,但后来被重命名为“控制组”它为进程组提供资源管理和资源核算。从内核 2.6.24 开始,它就已经是主线内核的一部分,并在几个项目中使用:例如由systemd(一个取代 SysV init 脚本的服务管理器;例如,Fedora 和 openSUSE)、本章前面提到的 Linux Containers 项目、Google containers ( https://github.com/google/lmctfy/)、libvirt ( http://libvirt.org/cgroups.html)等等。就性能而言,Cgroups 内核实现大多是非关键路径。cgroups 子系统实现了一个名为“cgroups”的新的虚拟文件系统(VFS)类型。所有的 cgroups 动作都是由文件系统动作完成的,比如在 cgroup 文件系统中创建 cgroups 目录,在这些目录中写入或读取条目,挂载 cgroup 文件系统等等。有一个名为libcgroup(又名libcg))的库,它提供了一组用于 cgroups 管理的用户空间实用程序:例如,cgcreate用于创建一个新的 cgroup,cgdelete用于删除一个 cgroup,, cgexec用于在指定的控制组中运行一个任务,等等。事实上,这是通过从libcg库中调用 cgroup 文件系统操作来完成的。libcg库在未来很可能会减少使用,因为它不在试图使用 cgroup 控制器的多方之间提供任何协调。将来可能所有的 cgroup 文件操作都将由一个库或一个守护进程来执行,而不是直接执行。目前实现的 cgroups 子系统需要某种形式的协调,因为每种资源类型只有一个控制器。当多个参与者修改它时,这必然会导致冲突。cgroups 控制器可以被许多项目同时使用,如libvirt、systemd、lxc等等。当只通过 cgroups 文件系统操作工作时,当所有的项目都试图在太低的级别上通过 cgroups 强加它们自己的策略时,在彼此不了解的情况下,它们可能会意外地相互忽略。例如,当每一个都将与一个守护进程对话时,这样的冲突将被避免。有关libcg的更多信息,请参见http://libcg.sourceforge.net/。
与名称空间相反,没有添加新的系统调用来实现 cgroup 子系统。与名称空间一样,可以嵌套几个 cgroups。在引导阶段添加了代码,主要是为了初始化 cgroups 子系统,以及各种子系统,比如内存子系统或安全子系统。以下是您可以使用 cgroups 执行的部分简短任务列表:
- 用 cpusets cgroup 控制器将一组 CPU 分配给一组进程。您还可以使用 cpusets cgroup 控制器来控制 NUMA 节点内存的分配。
- 操作内存不足(
oom)杀手操作,或使用内存组控制器(memcg)创建内存量有限的进程。在本章的后面你会看到一个例子。 - 使用设备组将权限分配给
/dev下的设备。稍后,您将在“设备组-简单示例”一节中看到使用设备组的示例。 - 为流量分配优先级(请参阅本章后面的“net_prio 模块”一节)。
- 用冷冻器组冷冻过程。
- 使用 cpuacct cgroup 报告 cgroup 任务的 CPU 资源使用情况。请注意,还有 cpu 控制器,它可以按优先级或绝对带宽提供 CPU 周期,并提供相同的统计信息或统计信息的超集。
- 用类别标识符(
classid)标记网络流量;请参阅本章后面的“cls_cgroup 分类器”一节。
接下来,我将非常简要地描述为支持 cgroups 所做的一些更改。
Cgroups 实现
cgroup 子系统非常复杂。这里有几个关于 cgroup 子系统的实现细节,应该可以为您提供一个深入研究其内部的良好起点:
-
增加了一个名为
cgroup_subsys的新结构 (include/linux/cgroup.h)。它代表一个 cgroup 子系统(也称为 cgroup 控制器)。实现了以下 cgroup 子系统: -
mem_cgroup_subsys:mm/memcontrol.c -
blkio_subsys:block/blk-cgroup.c -
cpuset_subsys:kernel/cpuset.c -
devices_subsys:security/device_cgroup.c -
freezer_subsys:kernel/cgroup_freezer.c -
net_cls_subsys:net/sched/cls_cgroup.c -
net_prio_subsys:net/core/netprio_cgroup.c -
perf_subsys:kernel/events/core.c -
cpu_cgroup_subsys:kernel/sched/core.c -
cpuacct_subsys:kernel/sched/core.c -
hugetlb_subsys:mm/hugetlb_cgroup.c -
添加了一个名为
cgroup的新结构;它代表一个对照组(linux/cgroup.h) -
A new virtual file system was added; this was done by defining the
cgroup_fs_typeobject and acgroup_opsobject (instance ofsuper_operations):static struct file_system_type cgroup_fs_type = { .name = "cgroup", .mount = cgroup_mount, .kill_sb = cgroup_kill_sb, }; static const struct super_operations cgroup_ops = { .statfs = simple_statfs, .drop_inode = generic_delete_inode, .show_options = cgroup_show_options, .remount_fs = cgroup_remount, }; (kernel/cgroup.c)像其他文件系统一样,用
cgroup_init()方法中的register_filesystem()方法注册它;参见kernel/cgroup.c。 -
当初始化 cgroup 子系统时,默认创建下面的
sysfs条目/sys/fs/cgroup;这是通过在cgroup_init()方法中调用kobject_create_and_add("cgroup", fs_kobj)来完成的。请注意,cgroup 控制器也可以安装在其他目录中。 -
有一个名为
subsys的cgroup_subsys对象的全局数组,在kernel/cgroup.c中定义(注意从内核 3.11 开始,数组名从subsys改为cgroup_subsys)。此数组中有 CGROUP_SUBSYS_COUNT 个元素。名为/proc/cgroups的procfs条目由 cgroup 子系统导出。可以用两种方式显示全局subsys数组的元素: -
通过运行
cat /proc/cgroups。 -
通过
libcgroup-tools的lssubsys效用。 -
创建新的 cgroup 需要始终在该 cgroup VFS 下生成以下四个控制文件:
-
它的初始值是从它的父代继承的。它代表一个布尔变量,它的用法与
release_agent相关,只在最顶层的控制文件,稍后解释。 -
cgroup.event_control:这个文件允许使用eventfd()系统调用从 cgroup 获取通知。参见man 2 eventfd,和fs/eventfd.c。 -
tasks:附属于该组的 PID 列表。将一个进程附加到一个 cgroup 是通过将其 PID 的值写入到tasks控制文件中来完成的,并且由cgroup_attach_task()方法kernel/cgroup.c来处理。显示一个进程附加到的 cgroups 是由cat /proc/<processPid>/cgroup完成的。这在内核中由kernel/cgroup.c中的proc_cgroup_show()方法处理。 -
cgroup.procs:附属于该 cgroup 的线程组 id 的列表。tasks条目允许将同一个进程的线程连接到不同的 cgroup 控制器,而cgroup.procs有一个进程级的粒度(单个进程的所有线程被一起移动并属于同一个 cgroup)。 -
除了这四个控制文件之外,还为最顶层的 cgroup 根对象创建了一个名为
release_agent的控制文件。这个文件的值是一个可执行文件的路径,当一个 cgroup 的最后一个进程终止时,这个可执行文件将被执行;应设置前面提到的notify_on_release,以便启用release_agent功能。release_agent可以被指定为一个 cgroup 挂载选项;例如,《??》中的 Fedora 就是这种情况。release_agent机制基于用户模式助手:每次激活release_agent时,都会调用call_usermodehelper()方法并创建一个新的用户空间进程,这在性能方面代价很高。参见:《对照组的过去、现在、未来》,lwn.net/Articles/574317/。关于release_agent的实现细节,请参见kernel/cgroup.c中的cgroup_release_agent()方法。 -
除了这四个默认控制文件和
release_agent最顶层的控制文件,每个子系统都可以创建自己的特定控制文件。这是通过定义一个cftype(控制文件类型)对象的数组并将该数组分配给cgroup_subsys对象的base_cftypes成员来实现的。例如,对于内存组控制器,我们对usage_in_bytes控制文件有这样的定义:static struct cftype mem_cgroup_files[] = { { .name = "usage_in_bytes", .private = MEMFILE_PRIVATE(_MEM, RES_USAGE), .read = mem_cgroup_read, .register_event = mem_cgroup_usage_register_event, .unregister_event = mem_cgroup_usage_unregister_event, }, . . . struct cgroup_subsys mem_cgroup_subsys = { .name = "memory", . . . .base_cftypes = mem_cgroup_files, }; (mm/memcontrol.c) -
一个名为
cgroups的成员被添加到流程描述符task_struct中,它是一个指向css_set对象的指针。css_set对象包含一个指向cgroup_subsys_state对象的指针数组(每个 cgroup 子系统一个这样的指针)。流程描述符本身(task_struct)不包含指向与其相关联的 cgroup 子系统的直接指针,但是这可以从这个cgroup_subsys_state指针.的数组中确定
添加了两个 cgroups 网络模块。我们将在本节稍后讨论它们:
net_prio(net/core/netprio_cgroup.c)。cls_cgroup(net/sched/cls_cgroup.c)。
 注意cgroup 子系统仍处于早期阶段,其功能和界面可能会有相当大的发展。
注意cgroup 子系统仍处于早期阶段,其功能和界面可能会有相当大的发展。
接下来,您将看到一个简短的示例,说明如何使用设备组控制器来更改设备文件的写权限。
群组设备控制器:一个简单的例子
让我们看一个使用设备组的简单示例。运行以下命令将创建一个设备组:
mkdir /sys/fs/cgroup/devices/0
将在/sys/fs/cgroup/devices/0下创建三个控制文件:
devices.deny:访问被拒绝的设备。devices.allow:允许访问的设备。devices.list:可用设备。
每个这样的控制文件包含四个字段:
type:可能的值为:“a”表示全部,“c”表示字符设备,“b”表示块设备。- 设备主号码。
- 设备次要编号。
- 访问权限:’ r ‘是读取权限,’ w ‘是写入权限,’ m '是执行
mknod的权限。
默认情况下,创建新的设备组时,它拥有所有权限:
cat /sys/fs/cgroup/devices/0/devices.list
a *:* rwm
以下命令将当前 shell 添加到您之前创建的设备组中:
echo $$ > /sys/fs/cgroup/devices/0/tasks
以下命令将拒绝所有设备的访问:
echo a > /sys/fs/cgroup/devices/0/devices.deny
echo "test" > /dev/null
-bash: /dev/null: Operation not permitted
以下命令将返回所有设备的访问权限:
echo a > /sys/fs/cgroup/devices/0/devices.allow
运行之前失败的以下命令现在将成功:
echo "test" > /dev/null
群组内存控制器:一个简单的例子
例如,您可以禁用内存不足(OOM)杀手:
mkdir /sys/fs/cgroup/memory/0
echo $$ > /sys/fs/cgroup/memory/0/tasks
echo 1 > /sys/fs/cgroup/memory/0/memory.oom_control
现在,如果你运行一些占用内存的用户空间程序,OOM 杀手将不会被调用。可以通过以下方式启用 OOM 杀手:
echo 0 > /sys/fs/cgroup/memory/0/memory.oom_control
您可以使用eventfd()系统调用,在用户空间应用中获取关于 cgroup 状态变化的通知。参见man 2 eventfd。
 注意您可以限制一个 cgroup 中的一个进程最多可拥有 20M 的内存,例如:
注意您可以限制一个 cgroup 中的一个进程最多可拥有 20M 的内存,例如:
echo 20M >/sys/fs/cgroup/memory/0/memory . limit _ in _ bytes
net_prio 模块
网络优先级控制组(net_prio)提供了一个接口,用于设置各种用户空间应用生成的网络流量的优先级。通常这可以通过设置 SO_PRIORITY 套接字选项来完成,该选项设置 SKB 的优先级,但是并不总是希望使用该套接字选项。为了支持net_prio模块,一个名为priomap的对象,一个netprio_map结构的实例,被添加到了net_device对象中。让我们来看看netprio_map的结构:
struct netprio_map {
struct rcu_head rcu;
u32 priomap_len;
u32 priomap[];
};
(include/net/netprio_cgroup.h)
priomap数组正在使用net_prio sysfs条目,您很快就会看到这一点。net_prio模块向 cgroup sysfs导出两个条目:net_prio.ifpriomap和net_prio.prioidx。net_prio.ifpriomap用于设置指定网络设备的priomap对象,您将在接下来的例子中看到。在 Tx 路径中,dev_queue_xmit()方法调用skb_update_prio()方法,根据priomap设置skb->priority,该priomap与出局网络设备(skb->dev)相关联。net_prio.prioidx是一个只读条目,显示 cgroup 的 id。net_prio模块是一个很好的例子,说明用不到 400 行代码开发一个 cgroup 内核模块是多么简单。net_prio模块由 Neil Horman 开发,可从内核 3.3 获得。更多信息见Documentation/cgroups/net_prio.txt。以下是如何使用网络优先级 cgroup 模块的示例(注意,如果 CONFIG_NETPRIO_CGROUP 设置为模块而非内置模块,则必须加载netprio_cgroup.ko内核模块):
mkdir /sys/fs/cgroup/net_prio
mount -t cgroup -onet_prio none /sys/fs/cgroup/net_prio
mkdir /sys/fs/cgroup/net_prio/0
echo "eth1 4" > /sys/fs/cgroup/net_prio/0/net_prio.ifpriomap
这个命令序列会将源自属于 net prio“0”组的进程并在接口eth1上传出的任何流量设置为优先级 4。最后一个命令触发向名为priomap的net_device对象中的字段写入一个条目。
注意为了使用 net_prio,需要设置 CONFIG_NETPRIO_CGROUP。
cls_cgroup 分类器
cls_cgroup分类器提供了用类标识符(classid)标记网络数据包的接口。您可以将它与tc工具结合使用,为来自不同 cgroups 的数据包分配不同的优先级,您很快就会看到这个例子。cls_cgroup模块将一个条目导出到 cgroup sysfs,net_cls.classid。对照组分类器(cls_cgroup)被合并到 kernel 2.6.29 中,由 Thomas Graf 开发。与上一节讨论的net_prio模块一样,这个 cgroup 内核模块也不到 400 行代码,这再次证明了通过内核模块添加 cgroup 控制器并不是一项繁重的任务。下面是一个使用控制组分类器的例子(注意,如果 CONFIG_NETPRIO_CGROUP 被设置为模块而不是内置的,您必须加载cls_cgroup.ko内核模块):
mkdir /sys/fs/cgroup/net_cls
mount -t cgroup -onet_cls none /sys/fs/cgroup/net_cls
mkdir /sys/fs/cgroup/net_cls/0
echo 0x100001 > /sys/fs/cgroup/net_cls/0/net_cls.classid
最后一个命令将 classid 10:1 分配给组 0。iproute2包包含一个名为tc的实用程序,用于管理流量控制设置。你可以使用这个类 id 的tc工具,例如:
tc qdisc add dev eth0 root handle 10: htb
tc class add dev eth0 parent 10: classid 10:1 htb rate 40mbit
tc filter add dev eth0 parent 10: protocol ip prio 10 handle 1: cgroup
更多信息见Documentation/cgroups/net_cls.txt(仅来自内核 3.10。)
 注为了配合
注为了配合cls_cgroup工作,需要设置 CONFIG_NET_CLS_CGROUP。
我将用一小段关于挂载 cgroup 的内容来结束关于 cgroup 子系统的讨论。
安装 c 组子系统
除了默认创建的/sys/fs/cgroup之外,还可以在其他挂载点挂载 cgroup 子系统。例如,您可以按以下顺序将内存控制器安装在/mycgroup/mymemtest上:
mkdir –p /mycgroup/mymemtest
mount -t cgroup -o memory mymemtest /mycgroup/mymemtest
以下是装载 cgroup 子系统时的一些装载选项:
-
all:挂载所有 cgroup 控制器。 -
none:不要安装任何控制器。 -
release_agent:一个可执行文件的路径,当一个 cgroup 的最后一个进程终止时,该可执行文件将被执行。Systemd使用release_agent组装载选项。 -
noprefix:避免在控制文件中使用前缀。每个 cgroup 控制器都有自己的控制文件前缀;例如,cpuset 控制器条目mem_exclusive显示为cpuset.mem_exclusive。noprefix 挂载选项避免了添加控制器前缀。例如,mkdir /cgroup mount -t tmpfs xxx /cgroup/ mount -t cgroup -o noprefix,cpuset xxx /cgroup/ ls /cgroup/ cgroup.clone_children mem_hardwall mems cgroup.event_control memory_migrate notify_on_release cgroup.procs memory_pressure release_agent cpu_exclusive memory_pressure_enabled sched_load_balance cpus memory_spread_page sched_relax_domain_level mem_exclusive memory_spread_slab tasks
注意想要深入研究如何解析 cgroups 挂载选项的读者应该研究一下parse_cgroupfs_options()方法,kernel/cgroup.c.
有关 cgroups 的更多信息,请参见以下资源:
Documentation/cgroups- cgroups 邮件列表:
cgroups@vger.kernel.org - cgroups 邮件列表存档:
http://news.gmane.org/gmane.linux.kernel.cgroups git仓库:git://git.kernel.org/pub/scm/linux/kernel/git/tj/cgroup.git
 注意 Linux 名称空间和 cgroups 是正交的,技术上不相关。您可以构建支持名称空间和不支持 cgroups 的内核,反之亦然。过去有一个名为“ns”的 cgroups 命名空间子系统的实验,但是代码最终被删除了。
注意 Linux 名称空间和 cgroups 是正交的,技术上不相关。您可以构建支持名称空间和不支持 cgroups 的内核,反之亦然。过去有一个名为“ns”的 cgroups 命名空间子系统的实验,但是代码最终被删除了。
您已经看到了什么是 cgroups,并且了解了它的两个网络模块,net_prio和cls_cgroup。您还看到了演示如何使用设备、内存和网络组控制器的简短示例。内核 3.11 及更高版本中添加的繁忙轮询套接字特性为套接字提供了更低的延迟。让我们看看它是如何实现的,以及它是如何配置和使用的。
忙轮询套接字
当套接字队列耗尽时,网络堆栈的传统操作方式是休眠,等待驱动程序将更多数据放入套接字队列,或者如果是非阻塞操作,则返回。由于中断和上下文切换,这会导致额外的延迟。对于需要尽可能低的延迟并愿意为更高的 CPU 利用率付出代价的套接字应用,Linux 增加了对内核 3.11 及更高版本的套接字进行忙轮询的功能(最初,这种技术被称为低延迟套接字轮询,但根据 Linus 的建议,它被更改为忙轮询套接字)。繁忙轮询采用更积极的方法将数据转移到应用。当应用请求更多数据而套接字队列中没有数据时,网络堆栈会主动调用设备驱动程序。驱动程序检查新到达的数据,并通过网络层(L3)将其推送到套接字。驱动程序可能会找到其他套接字的数据,并且也会推送这些数据。当轮询调用返回到网络堆栈时,套接字代码检查套接字接收队列上是否有新数据挂起。
为了让网络驱动程序支持忙轮询,它应该提供自己的忙轮询方法,并将其添加为net_device_ops对象的ndo_busy_poll回调。这个驱动程序ndo_busy_poll回调应该将数据包移动到网络堆栈中;例如,参见ixgbe_low_latency_recv()方法、drivers/net/ethernet/intel/ixgbe/ixgbe_main.c。这个ndo_busy_poll回调应该返回移动到堆栈中的包的数量,如果没有这样的包,则返回 0,如果有问题,则返回 LL_FLUSH_FAILED 或 LL_FLUSH_BUSY。未填充 ndo_busy_poll回调的未修改驱动程序将继续照常工作,并且不会忙于轮询。
提供低延迟的一个重要因素是忙轮询。有时,当驱动程序轮询例程返回时没有数据,更多的数据正在到达,只是错过了返回到网络堆栈。这就是繁忙轮询发挥作用的地方。网络堆栈在一段可配置的时间内轮询驱动程序,以便新数据包一到达就可以被拾取。
设备驱动程序的主动和繁忙轮询可以提供与硬件非常接近的减少的延迟。繁忙轮询可以同时用于大量套接字,但不会产生最佳结果,因为当使用相同的 CPU 内核时,一些套接字上的繁忙轮询会降低其他套接字的速度。图 14-1 对比了传统的接收流程和已启用忙轮询的套接字流程。

图 14-1 。传统接收流与繁忙轮询套接字接收流
1\. Application checks for receive. 1\. Application checks for receive
2\. No immediate receive – thus block. 2\. Check device driver for pending packet (poll starts).
3\. Packet Received. 3\. Meanwhile, packet received to NIC.
4\. Driver passes packet to the protocol layer. 4\. Driver processes pending packet
5\. Protocol/socket wakes application. 5\. Driver passes to the protocol layer
- Bypass context switch and interrupt.
6\. Application receives data through sockets. 6\. Application receives data through sockets.
Repeat. Repeat.
全球启用
可以通过procfs参数为所有套接字全局打开套接字上的忙轮询,也可以通过设置 SO_BUSY_POLL 套接字选项为单个套接字打开忙轮询。全局使能有两个参数:net.core.busy_poll和net.core.busy_read,分别由/proc/sys/net/core/busy_poll和/proc/sys/net/core/busy_read输出到procfs。默认情况下,这两个值都为零,这意味着繁忙轮询处于关闭状态。设置这些值将启用全局忙轮询。值为 50 通常会产生良好的结果,但是一些实验可能有助于为某些应用找到更好的值。
busy_read控制忙轮询时阻塞读操作的时间限制。对于非阻塞读取,如果套接字启用了繁忙轮询,则堆栈代码在将控制权返回给用户之前只轮询一次。busy_poll控制 select 和 poll 将在多长时间内忙轮询,等待任何已启用忙轮询的套接字上的新事件。只有启用了忙读套接字操作的套接字才会被忙轮询。
更多信息,请参见:Documentation/sysctl/net.txt。
每套接字启用
启用忙轮询的一个更好的方法是修改应用以使用 SO_BUSY_POLL 套接字选项,该选项设置套接字对象的sk_ll_usec(sock结构的一个实例)。通过使用这个套接字选项,应用可以指定哪些套接字在忙着轮询,以便只增加这些套接字的 CPU 利用率。来自其他应用和服务的套接字将继续使用传统的接收路径。SO_BUSY_POLL 的建议起始值是 50。sysctl.net.busy_read值必须设置为 0,并且sysctl.net.busy_poll值应按照Documentation/sysctl/net.txt中所述进行设置。
调谐和配置
这里有几种方法可以调整和配置忙轮询套接字:
- 网络设备上
rx-usecs的中断合并(ethtool -C设置应该在 100 左右,以降低中断率。这限制了由中断引起的上下文切换的数量。 - 通过在网络设备上使用
ethtool -K禁用 GRO 和 LRO 可以避免接收队列上的无序数据包。只有当混合的批量和低延迟流量到达同一队列时,这才应该是一个问题。一般来说,启用 GRO 和 LRO 通常能获得最佳效果。 - 应用线程和网络设备 IRQ 应该绑定到不同的 CPU 内核。两组内核应该与网络设备位于同一个 CPU NUMA 节点上。当应用和 IRQ 在同一个内核上运行时,会有一点点损失。如果中断合并设置为较低的值,这种损失可能会非常大。
- 为了获得最低延迟,关闭 I/O 内存管理单元(IOMMU)支持可能会有所帮助。在某些系统上,这可能已经被默认禁用。
性能
许多使用繁忙轮询套接字的应用应该显示出减少的延迟和抖动以及改进的每秒事务数。然而,随着 CPU 争用的增加,用太多忙于轮询的套接字使系统过载会损害性能。参数net.core.busy_poll、net.core.busy_read和 SO_BUSY_POLL 套接字选项都是可调的。试验这些值可能会为各种应用提供更好的结果。
我现在将开始讨论三个无线子系统,它们通常服务于短距离和低功耗设备:蓝牙子系统、IEEE 802.15.4 和 NFC。随着新的激动人心的功能稳步增加,人们对这三个子系统的兴趣越来越大。我将从蓝牙子系统开始讨论。
Linux 蓝牙子系统
蓝牙协议是主要用于小型和嵌入式设备的主要传输协议之一。如今,几乎每一台新的笔记本电脑或平板电脑、每一部手机以及许多电子产品中都包含了蓝牙网络接口。蓝牙协议是由移动供应商爱立信在 1994 年创建的。起初,它是用来替代点对点连接的电缆。后来,它发展到支持无线个人区域网络(pan)。蓝牙工作在 2.4 GHz 工业、科学和医疗(ISM)无线电频段,低功率传输无需许可证。蓝牙规范由成立于 1998 年的蓝牙特别兴趣小组(SIG)正式制定;参见https://www.bluetooth.org。SIG 负责蓝牙规范的开发和认证过程,这有助于确保不同厂商的蓝牙设备之间的互操作性。蓝牙核心规范是免费的。多年来,蓝牙有多种规范,我将提到最近的一种:
- 蓝牙 2.0 +增强数据速率(EDR) 从 2004 年开始。
- 蓝牙 v 2.1+EDR 2007;包括通过安全简单配对(SSP)来改进配对过程。
- 2009 年起的蓝牙 v3.0 + HS(高速);主要的新功能是 AMP(备用 MAC/PHY),增加了 802.11 作为高速传输。
- 蓝牙 4.0 + BLE(蓝牙低能耗,以前称为 WiBree)从 2010 年开始。
蓝牙协议有多种用途,如文件传输、音频流、医疗保健设备、网络等等。蓝牙是为短距离数据交换而设计的,通常在 10 米的范围内。蓝牙设备分为三类,范围如下:
- 1 级–大约 100 米
- 2 级–大约 10 米
- 3 级–大约 1 米
Linux 蓝牙协议栈被称为 BlueZ。最初它是由高通发起的一个项目。它被正式集成到内核 2.4.6 (2001)中。图 14-2 显示了蓝牙堆栈。
图 14-2 。蓝牙栈。注意:在 L2CAP 以上的层中,可能有本章未讨论的其他蓝牙协议,如 AVDTP(音频/视频分发传输协议)、HFP(免提模式)、音频/视频控制传输协议(AVCTP)等等
-
较低的三层(无线电层、链路控制器和链路管理协议)在硬件或固件中实现。
-
主机控制器接口(HCI) 指定主机如何与本地蓝牙设备(控制器)交互和通信。我将在本章后面的“HCI 层”部分讨论它。
-
L2CAP(逻辑链路控制和适配协议)提供从其他蓝牙设备发送和接收数据包的能力。应用可以使用 L2CAP 协议作为基于消息的、不可靠的数据传输协议,类似于 UDP 协议。从用户空间访问 L2CAP 协议是通过 BSD sockets API 完成的,这在第十一章中讨论过。请注意,在 L2CAP 中,数据包总是按照发送的顺序传送,这与 UDP 相反。在图 14-2 中,我展示了位于 L2CAP 之上的三个协议(如前所述,在 L2CAP 之上还有其他协议没有在本章中讨论)。
-
BNEP:蓝牙网络封装协议。在本章的后面,我将给出一个使用 BNEP 协议的例子。
-
RFCOMM:射频通信(RFCOMM)协议是一个可靠的基于流的协议。RFCOMM 只允许在 30 个端口上运行。RFCOMM 用于模拟串行端口上的通信和发送无帧数据。
-
SDP:服务发现协议。支持应用在其运行的 SDP 服务器中注册描述和端口号。客户端可以在提供描述的 SDP 服务器中执行查找。
-
SCO(面向同步连接)层:用于发送音频;我在这一章不深入研究它的细节,因为它超出了本书的范围。
-
蓝牙规范定义了可能的应用,并规定了支持蓝牙的设备用来与其他蓝牙设备通信的一般行为。蓝牙 profiles 有很多,我就提几个最常用的:
-
文件传输配置文件(FTP):操作和传输另一个系统的对象存储(文件系统)中的对象(文件和文件夹)。
-
医疗设备配置文件(HDP):处理医疗数据。
-
人机界面设备配置文件(HID):USB HID(人机界面设备)的包装,为鼠标和键盘等设备提供支持。
-
对象推送配置文件(OPP)-推送对象配置文件。
-
个人区域网络配置文件(PAN):通过蓝牙链接提供网络;在本章后面的 BNEP 部分你会看到一个例子。
-
耳机模式(HSP):支持与手机配合使用的蓝牙耳机。
此图中的七层大致与操作系统模型的七层平行。无线电(RF)层平行于物理层,链路控制器平行于数据链路层,链路管理协议平行于网络协议,等等。Linux 蓝牙子系统由几个部分组成:
-
蓝牙核心
-
HCI 设备和连接管理器、调度器;文件:
net/bluetooth/hci*.c,net/bluetooth/mgmt.c。 -
蓝牙地址家族套接字;文件:
net/bluetooth/af_bluetooth.c。 -
SCO 音频链接;文件:
net/bluetooth/sco.c。 -
L2CAP(逻辑链路控制和适配协议);文件:
net/bluetooth/l2cap*.c。 -
LE(低能量)链路上的 SMP(安全管理协议);文件:
net/bluetooth/smp.c -
AMP 经理-替代 MAC/PHY 管理;文件:
net/bluetooth/a2mp.c。 -
HCI 设备驱动程序(硬件接口);文件:
drivers/bluetooth/*。包括供应商特定的驱动程序和通用驱动程序,如蓝牙 USB 通用驱动程序btusb。 -
RFCOMM 模块(RFCOMM 协议);文件:
net/bluetooth/rfcomm/*。 -
BNEP 模块(蓝牙网络封装协议);文件:
net/bluetooth/bnep/*。 -
ISDN 协议使用的 CMTP 模块(CAPI 报文传输协议)。CMTP 实际上已经过时了;文件:
net/bluetooth/cmtp/*。 -
HIDP 模块(人机接口设备协议);文件:
net/bluetooth/hidp/*。
我简要地讨论了蓝牙协议、蓝牙协议栈的架构、Linux 蓝牙子系统树以及蓝牙规范。在下一节中,我将描述 HCI 层,它是 LMP 上面的第一层(见本节前面的图 14-2 )。
HCI 层
我将从描述 HCI 设备开始 HCI 层的讨论,它代表一个蓝牙控制器。在这一部分的后面,我将描述 HCI 层和它下面的层,链路控制器层之间的接口,以及 HCI 和它上面的层,L2CAP 和 SCO 之间的接口。
人机界面设备
蓝牙设备由struct hci_dev表示。这个结构相当大(超过 100 个成员),这里将部分显示:
struct hci_dev {
char name[8];
unsigned long flags;
__u8 bus;
bdaddr_t bdaddr;
__u8 dev_type;
. . .
struct work_struct rx_work;
struct work_struct cmd_work;
. . .
struct sk_buff_head rx_q;
struct sk_buff_head raw_q;
struct sk_buff_head cmd_q;
. . .
int (*open)(struct hci_dev *hdev);
int (*close)(struct hci_dev *hdev);
int (*flush)(struct hci_dev *hdev);
int (*send)(struct sk_buff *skb);
void (*notify)(struct hci_dev *hdev, unsigned int evt);
int (*ioctl)(struct hci_dev *hdev, unsigned int cmd, unsigned long arg);
}
(include/net/bluetooth/hci_core.h)
以下是对hci_dev结构中一些重要成员的描述:
-
flags:表示设备的状态,如 HCI_UP 或 HCI_INIT。 -
bus:与设备相关的总线,如 USB (HCI_USB)、UART (HCI_UART)、PCI (HCI_PCI)等。(参见include/net/bluetooth/hci.h)。 -
每个 HCI 设备都有一个唯一的 48 位地址。由
/sys/class/bluetooth/<hciDeviceName>/address出口到sysfs -
dev_type:蓝牙设备有两种类型: -
基本速率器件(HCI_BREDR)。
-
备用 MAC 和 PHY 设备(HCI_AMP)。
-
rx_work:通过hci_rx_work()回调处理接收保存在 HCI 设备的rx_q队列中的数据包。 -
cmd_work:通过hci_cmd_work()回调处理发送保存在 HCI 设备的cmd_q队列中的命令包。 -
rx_q:skb 的接收队列。在hci_recv_frame()方法中,当接收到 SKB 时,通过调用skb_queue_tail()方法将 skb 添加到rx_q中。 -
raw_q:通过调用hci_sock_sendmsg()方法中的skb_queue_tail()方法将 skb 添加到raw_q中。 -
cmd_q:命令队列。通过调用hci_sock_sendmsg()方法中的skb_queue_tail()方法,skb 被添加到cmd_q中。
hci_dev回调(如open()、close()、send()等)通常在蓝牙设备驱动程序的probe()方法中分配(例如参考通用 USB 蓝牙驱动程序drivers/bluetooth/btusb.c)。
HCI 层导出注册/注销 HCI 设备的方法(分别通过hci_register_dev()和hci_unregister_dev()方法)。这两种方法都将一个hci_dev对象作为单个参数。如果没有定义指定的hci_dev对象的open()或close()回调,注册将会失败。
有五种类型的 HCI 数据包:
- HCI_COMMAND_PKT:从主机发送到蓝牙设备的命令。
- HCI_ACLDATA_PKT:从蓝牙设备发送或接收的异步数据。ACL 代表异步面向连接的链路(ACL)协议。
- HCI_SCODATA_PKT:从蓝牙设备发送或接收的同步数据(通常是音频)。SCO 代表面向同步连接(SCO)。
- HCI_EVENT_PKT:事件(如连接建立)发生时发送。
- HCI_VENDOR_PKT:用于某些蓝牙设备驱动程序中,以满足供应商的特定需求。
HCI 及其下层(链路控制器)
HCI 通过以下方式与其下一层(链路控制器)通信:
- 通过调用
hci_send_frame()方法发送数据包(HCI_ACLDATA_PKT 或 HCI_SCODATA_PKT ),该方法将调用委托给hci_dev对象的send()回调。hci_send_frame()方法获取一个 SKB 作为单个参数。 - 通过调用
hci_send_cmd()方法发送命令包(HCI_COMMAND_PKT)。例如,发送扫描命令。 - 通过调用
hci_acldata_packet()方法或调用hci_scodata_packet()方法接收数据包。 - 通过调用
hci_event_packet()方法接收事件包。处理 HCI 命令是异步的;因此,在发送命令包(HCI_COMMAND_PKT)一段时间后,HCIrx_work work_queue(hci_rx_work()方法)会收到一个或几个事件作为响应。有超过 45 个不同的事件(参见include/net/bluetooth/hci.h中的 HCI_EV_*)。例如,当使用命令行hcitool扫描附近的蓝牙设备时,到hcitool scan,会发送一个命令包(HCI_OP_INQUIRY)。因此,异步返回三个事件包,由hci_event_packet()方法处理:HCI_EV_CMD_STATUS、HCI_EV_EXTENDED_INQUIRY_RESULT 和 HCI_EV_INQUIRY_COMPLETE。
HCI 及其上面的层(L2CAP/SCO)
让我们来看看 HCI 层与其上层(L2CAP 层和 SCO 层)通信的方法:
- HCI 在接收数据包时通过调用
hci_acldata_packet()方法与其上面的 L2CAP 层通信,该方法调用 L2CAP 协议的l2cap_recv_acldata()方法。 - HCI 通过调用 SCO 协议的
sco_recv_scodata()方法调用hci_scodata_packet()方法,在接收 SCO 包时与其上面的 SCO 层进行通信。
人机界面连接
HCI 连接由hci_conn结构表示:
struct hci_conn {
struct list_head list;
atomic_t refcnt;
bdaddr_t dst;
. . .
__u8 type;
}
(include/net/bluetooth/hci_core.h)
下面是对hci_conn结构的一些成员的描述:
-
refcnt:参考计数器。 -
dst:蓝牙目的地址。 -
type:表示连接的类型: -
SCO_LINK 用于 SCO 连接。
-
ACL 连接的 ACL_LINK。
-
用于扩展同步连接的 ESCO_LINK。
-
LE _ LINK–代表 LE(低能量)连接;是在内核 v2.6.39 中添加的,支持蓝牙 V4.0,增加了 LE 特性。
-
AMP _ LINK–在 3.6 版中添加,支持蓝牙放大器控制器。
HCI 连接是通过调用hci_connect()方法创建的。有三种类型的连接:SCO、ACL 和 LE 连接。
L2CAP
为了提供几个数据流,L2CAP 使用通道,这些通道由l2cap_chan结构(include/net/bluetooth/l2cap.h)表示。有一个全球频道链表,名为chan_list。对这个列表的访问由一个全局读写锁chan_list_lock序列化。
我在本章前面的“HCI 和它上面的层(L2CAP/SCO)”一节中描述的l2cap_recv_acldata()方法在 HCI 将数据包传递到 L2CAP 层时被调用。l2cap_recv_acldata()方法首先执行一些完整性检查,如果有问题就丢弃数据包,然后在收到完整数据包的情况下调用l2cap_recv_frame()方法。每个收到的数据包都以 L2CAP 报头开始:
struct l2cap_hdr {
__le16 len;
__le16 cid;
} __attribute__ ((packed));
(include/net/bluetooth/l2cap.h)
l2cap_recv_frame()方法通过检查l2cap_hdr对象的cid来检查接收包的通道 id。如果是 L2CAP 命令(?? 为 0x0001),则调用l2cap_sig_channel()方法来处理它。例如,当另一个蓝牙设备想要连接到我们的设备时,在 L2CAP 信号通道上接收到一个 L2CAP _ 连接 _ 请求,这个请求将由l2cap_connect_req()方法net/bluetooth/l2cap_core.c处理。在l2cap_connect_req()方法中,通过pchan->ops->new_connection()调用l2cap_chan_create()方法来创建 L2CAP 通道。L2CAP 通道状态设置为 BT_OPEN,配置状态设置为 CONF _ 非 _ 完整。这意味着应该配置通道以便使用它。
BNP
BNEP 协议支持蓝牙上的 IP,这实际上意味着在 L2CAP 蓝牙信道上运行 TCP/IP 应用。您也可以通过蓝牙 RFCOMM 上的 PPP 运行 TCP/IP 应用,但是通过串行 PPP 链接联网效率较低。BNEP 协议使用 PAN 协议。我将展示一个使用 BNEP 协议建立基于 IP 的蓝牙的简短例子,随后我将描述实现这种通信的内核方法。探究 BNEP 的细节超出了本书的范围。如果你想了解更多,请参阅 BNEP 规范,它可以在:http://grouper.ieee.org/groups/802/15/Bluetooth/BNEP.pdf中找到。创建 PAN 的一个非常简单的方法是运行:
-
在服务器端:
-
pand --listen --role=NAP -
注:NAP 代表:网络接入点(NAP)
-
在客户端
-
pand --connect btAddressOfTheServer
在两个端点上,创建一个虚拟接口(bnep0)。之后,您可以使用ifconfig命令(或使用ip命令)在bnep0上为两个端点分配 IP 地址,就像以太网设备一样,您将在这些端点之间通过蓝牙建立网络连接。详见http://bluez.sourceforge.net/contrib/HOWTO-PAN。
pand --listen命令创建一个 L2CAP 服务器套接字,并调用accept()系统调用,而pand --connect btAddressOfTheServer创建一个 L2CAP 客户端套接字并调用connect()系统调用。当服务器端收到连接请求时,它发送一个 BNEPCONNADD 的 IOCTL,这个 IOCTL 在内核中由bnep_add_connection()方法(net/bluetooth/bnep/core.c)处理,它执行以下任务:
- 创建一个 BNEP 会话(
bnep_session对象)。 - 通过调用
__bnep_link_session()方法将 BNEP 会话对象添加到 BNEP 会话列表(bnep_session_list)。 - 创建一个名为
bnepX的网络设备(对于第一个 BNEP 设备,X 为 0,对于第二个设备,X 为 1,依此类推)。 - 通过调用
register_netdev()方法注册网络设备。 - 创建一个名为“
kbnepd btDeviceName”的内核线程。这个内核线程运行包含无限循环的bnep_session()方法来接收或发送数据包。只有当用户空间应用发送一个 BNEPCONNDEL 的 IOCTL,调用方法bnep_del_connection()来设置 BNEP 会话的终止标志时,或者当套接字的状态改变并且不再连接时,这个无限循环才会终止。 bnep_session()方法调用bnep_rx_frame()方法接收传入的数据包并将其传递给网络堆栈,它调用bnep_tx_frame()方法发送传出的数据包。
接收蓝牙数据包:示意图
图 14-3 显示了接收到的蓝牙 ACL 数据包的路径(与 SCO 相反,SCO 用于处理音频,处理方式不同)。通过hci_acldata_packet()方法,处理数据包的第一层是 HCI 层。然后它通过调用l2cap_recv_acldata()方法前进到更高的 L2CAP 层。
图 14-3 。接收 ACL 数据包
l2cap_recv_acldata()方法调用l2cap_recv_frame()方法,后者从 SKB 获取 L2CAP 头(l2cap_hdr对象在前面已经描述过了)。
根据 L2CAP 报头的信道 ID 采取行动。
L2CAP 扩展功能
内核 2.6.36 中增加了对 L2CAP 扩展特性(也称为 eL2CAP)的支持。这些扩展功能包括:
- 增强型重传模式(ERTM),一种具有错误和流量控制的可靠协议。
- 流模式(SM),一种不可靠的流协议。
- 帧校验序列(FCS),即每个接收到的数据包的校验和。
- L2CAP 数据包的分段和重组(SAR)使重新传输更加容易。
其中一些扩展是新配置文件所必需的,如蓝牙健康设备配置文件(HDP)。请注意,这些功能以前也是可用的,但它们被认为是实验性的,默认情况下是禁用的,您应该设置 CONFIG_BT_L2CAP_EXT_FEATURES 来启用它们。
蓝牙工具
从用户空间访问内核是用套接字完成的,只做了很小的改动:我们使用 AF_BLUTOOTH 套接字,而不是 AF_INET 套接字。以下是一些重要且有用的蓝牙工具的简短描述:
hciconfig:配置蓝牙设备的工具。显示诸如接口类型(BR/EDR 或 AMP)、蓝牙地址、标志等信息。hciconfig工具的工作原理是打开一个原始 HCI 套接字(BTPROTO_HCI)并发送 IOCTLs 例如,为了启动或关闭 HCI 设备,分别发送 HCIDEVUP 或 HCIDEVDOWN。这些 IOCTLs 在内核中由hci_sock_ioctl()方法net/bluetooth/hci_sock.c处理。- 用于配置蓝牙连接和向蓝牙设备发送一些特殊命令的工具。例如
hcitool scan会扫描附近的蓝牙设备。 hcidump:转储来自和去往蓝牙设备的原始 HCI 数据。- 发送一个 L2CAP 回应请求并接收回答。
- 更友好的版本。
- 更友好的版本。
您可以在以下网址找到有关 Linux 蓝牙子系统的更多信息:
-
Linux BlueZ,官方 Linux 蓝牙网站
:http://www.bluez.org。 -
Linux 蓝牙邮件列表:
linux-bluetooth@vger.kernel.org。 -
Linux 蓝牙邮件列表档案:
http://www.spinics.net/lists/linux-bluetooth/。 -
注意,这个邮件列表是针对蓝牙内核补丁和蓝牙用户空间补丁的。
-
freenode.net上的 IRC 频道: -
bluez(发展相关话题) -
bluez-users(与发展无关的话题)
在这一节中,我描述了 Linux 蓝牙子系统,重点是这个子系统的网络方面。您了解了蓝牙协议栈的各个层,以及它们是如何在 Linux 内核中实现的。您还了解了重要的蓝牙内核结构,如 HCI 设备和 HCI 连接。接下来,我将描述第二个无线子系统,IEEE 802 . 15 . 4 子系统及其实现。
IEEE 802.15.4 和 6LoWPAN
IEEE 802.15.4 标准(IEEE Std 802.15.4-2011)为低速率无线个人区域网(LR-WPAN)指定了媒体接入控制(MAC) 层和物理层(PHY)。适用于短程网络中的低成本和低功耗设备。支持多种频段,其中最常见的是 2.4 GHz ISM 频段、915 MHz 和 868 MHz。IEEE 802.15.4 设备可用于无线传感器网络(WSNs) 、安全系统、工业自动化系统等。它被设计用来组织传感器、开关、自动化设备等的网络。最大允许比特率为 250 kb/s。该标准还支持 2.4 GHz 频段的 1000 kb/s 比特率,但不太常见。典型的个人操作空间约为 10 米。IEEE 802.15.4 标准由 IEEE 802.15 工作组(http://www.ieee802.org/15/)维护。IEEE 802.15.4 之上有几个协议;最著名的是 ZigBee 和 6LoWPAN。
ZigBee 联盟(ZA)已经发布了 IEEE802.15.4 的非 GPL 规范,以及 ZigBee IP (Z-IP)开放标准(http://www.zigbee.org/Specifications/ZigBeeIP/Overview.aspx)。它基于 IPv6、TCP、UDP、6LoWPAN 等互联网协议。对 IEEE 802.15.4 使用 IPv6 协议是一个很好的选择,因为 IPv6 地址有巨大的地址空间,这使得为每个 IPv6 节点分配唯一的可路由地址成为可能。IPv6 标头比 IPv4 标头简单,处理其扩展标头比处理 IPv4 标头选项简单。使用 IPv6 和 LR-WPAN 被称为低功率无线个人区域网(6LoWPAN)上的 IPv6。IPv6 不适合在 LR-WPAN 上使用,因此需要适配层,这将在本节稍后解释。有五个 RFC 与 6LoWPAN 相关:
- RFC 4944:“通过 IEEE 802.15.4 网络传输 IPv6 数据包。”
- RFC 4919:“IPv6 在低功耗无线个人区域网(6LoWPANs)上的应用:概述、假设、问题陈述和目标。”
- RFC 6282:“基于 IEEE 802.15.4 的网络上 IPv6 数据报的压缩格式。”该 RFC 引入了一种新的编码格式,即 LOWPAN_IPHC 编码格式,而不是 LOWPAN_HC1 和 LOWPAN_HC2。
- RFC 6775:“低功耗无线个人区域网(6LoWPANs)上 IPv6 的邻居发现优化。”
- RFC 6550:“RPL:用于低功耗和有损耗网络的 IPv6 路由协议。”
实施 6LoWPAN 的主要挑战是:
- 不同的数据包大小:IPv6 的 MTU 为 1280,而 IEEE802.15.4 的 MTU 为 127 (IEEE802154_MTU)。为了支持大于 127 字节的分组,应该定义 IPv6 和 IEEE 802.15.4 之间的适配层。该适配层负责 IPv6 分组的透明分段/碎片整理。
- 不同地址:IPv6 地址是 128 位的,而 IEEE802.15.4 是 IEEE 64 位扩展的(IEEE 802154 _ ADDR _ 长),或者在关联之后和分配 PAN id 之后,是在 PAN 中唯一的 16 位短地址(IEEE 802154 _ ADDR _ 短)。主要的挑战是,我们需要压缩机制来减小 6LoWPAN 数据包的大小,该数据包主要由 IPv6 地址组成。6 例如,LoWPAN 可以利用 IEEE802.15.4 支持 16 位短地址的事实来避免对 64 位 IID 的需求。
- IEEE 802.15.4 本身不支持多播,而 IPv6 对 ICMPv6 和依赖 ICMPv6 的协议(如邻居发现协议)使用多播。
IEEE 802.15.4 定义了四种类型的帧:
- 信标帧(IEEE802154_FC_TYPE_BEACON)
- MAC 命令帧(IEEE802154_FC_TYPE_MAC_CMD)
- 确认帧(IEEE802154_FC_TYPE_ACK)
- 数据帧(IEEE802154_FC_TYPE_DATA)
IPv6 数据包必须在第四种类型的数据帧上传输。虽然建议对数据包进行确认,但这不是强制性的。与 802.11 一样,有些设备驱动程序自己实现协议的大部分(HardMAC 设备驱动程序),有些设备驱动程序在软件中处理大部分协议(SoftMAC 设备驱动程序)。6LoWPAN 中有三种类型的节点:
- 6LoWPAN 节点(6LN):主机或路由器。
- 6LoWPAN 路由器(6LR):可以发送和接收路由器广告(RA)和路由器请求(RS)消息,以及转发和路由 IPv6 数据包。这些节点比简单的 6LoWPAN 节点更复杂,可能需要更多的内存和处理能力。
- 6LoWPAN 边界路由器(6LBR):位于独立的 6LoWPAN 网络连接处或 6LoWPAN 网络和另一个 IP 网络之间的边界路由器。6LBR 负责 IP 网络和 6LoWPAN 网络之间的转发,以及 6LoWPAN 节点的 IPv6 配置。6LBR 比 6LN 需要更多的内存和处理能力。它们共享 LoWPAN 中节点的上下文,使用 6LoWPAN-ND 和 RPL 跟踪注册的节点。一般来说,6LBR 总是开着的,而 6LN 大部分时间都在睡觉。图 14-4 显示了一个使用 6LBR 的简单设置,它连接 IP 网络和基于 6LoWPAN 的无线传感器网络。
图 14-4 。6LBR 将 IP 网络连接到 WSN,该网络在 6LoWPAN 上运行
邻居发现优化
我们应该对 IPv6 邻居协议进行优化和扩展有两个原因:
- IEEE 802.15.4 链路层不支持多播,尽管它支持广播(它使用 0xFFFF 短地址进行消息广播)。
- 邻居发现协议是为供电充足的设备设计的,IEEE 802.15.4 设备可以休眠以保存能量;此外,正如 RFC 所说,它们在有损耗的网络环境中运行。
处理邻居发现优化的 RFC 6775 增加了新的优化,例如:
-
主机发起的路由器通告信息刷新。在 IPv6 中,路由器通常会定期发送路由器广告。此功能消除了从路由器向主机发送定期或主动路由器广告的需要。
-
基于 EUI-64 的 IPv6 地址被认为是全球唯一的。当使用这样的地址时,不需要 DAD(重复地址检测)。
-
增加了三个选项:
-
地址注册选项(ARO):ARO 选项(33)可以是单播 NS 消息的一部分,主机将该消息作为 NUD(邻居不可到达性检测)的一部分发送,以确定它仍然可以到达默认路由器。当主机拥有非本地链路地址时,它会定期向默认路由器发送带有 ARO 选项的 NS 消息,以注册其地址。注销是通过发送一个包含生存期为 0 的 ARO 的 NS 来完成的。
-
6 低 PAN 上下文选项(6CO):6CO 选项(34)携带用于低 PAN 报头压缩的前缀信息,并且类似于 RFC 4861 中规定的前缀信息选项(PIO)。
-
权威边界路由器选项(ABRO):ABRO 选项(35)允许在路由拓扑上传播前缀和上下文信息。
-
新增两条爸爸消息:
-
重复地址请求(DAR)。157 的新型 ICMPv6。
-
重复地址确认(DAC)。158 的新型 ICMPv6。
Linux 内核 6LoWPAN
6LoWPAN 基本实现被集成到 3.2 版 Linux 中。它是由西门子公司技术部门的嵌入式系统开放平台小组提供的。它有三层:
-
网络层-
net/ieee802154(包括 6lowpan 模块、原始 IEEE 802.15.4 套接字、netlink 接口等)。 -
MAC 层-
net/mac802154。为 SoftMAC 设备驱动程序实现部分 MAC 层。 -
PHY 层-
drivers/net/ieee802154–IEEE 802154 设备驱动程序。 -
目前支持两种 802.15.4 设备:
-
AT86RF230/231 收发器驱动器
-
微芯片 MRF24J40
-
有 Fakelb 驱动(IEEE 802.15.4 环回接口)。
-
这两款器件以及许多其它 802.15.4 收发器通过 SPI 连接。还有一个串行驱动程序,虽然它没有包含在主线内核中,仍然是实验性的。还有像
atusb这样的设备,它们基于 AT86RF231 BN,但在撰写本文时还不在主流中。
6LoWPAN 初始化
在lowpan_init_module()方法中,通过调用lowpan_netlink_init()方法完成 6LoWPAN netlink sockets 的初始化,通过调用dev_add_pack()方法为 6LoWPAN 数据包注册一个协议处理程序:
. . .
static struct packet_type lowpan_packet_type = {
.type = __constant_htons(ETH_P_IEEE802154),
.func = lowpan_rcv,
};
. . .
static int __init lowpan_init_module(void)
{
. . .
dev_add_pack(&lowpan_packet_type);
. . .
}
(net/ieee802154/6lowpan.c)
lowpan_rcv()方法是 6LoWPAN 数据包的主要接收处理程序,其以太类型为 0x00F6 (ETH_P_IEEE802154)。它处理两种情况:
- 接收未压缩的数据包(调度类型为 IPv6。)
- 接收压缩包。
您使用虚拟链路来确保 6LoWPAN 和 IPv6 数据包之间的转换。此虚拟链路的一个端点使用 IPv6,MTU 为 1280,这是 6LoWPAN 接口。另一个说 6LoWPAN,MTU 为 127,这是 WPAN 接口。压缩的 6LoWPAN 数据包由lowpan_process_data()方法处理,该方法调用lowpan_uncompress_addr()解压缩地址,并调用lowpan_uncompress_udp_header()根据 IPHC 报头解压缩 UDP 报头。然后未压缩的 IPv6 数据包通过lowpan_skb_deliver()方式(net/ieee802154/6lowpan.c)传递到 6LoWPAN 接口。
图 14-5 显示了 6LoWPAN 适配层。

图 14-5 。6LoWPAN 适配层
图 14-6 显示了一个数据包从 PHY 层 (驱动程序)经过 MAC 层到 6LoWPAN 适配层的路径。
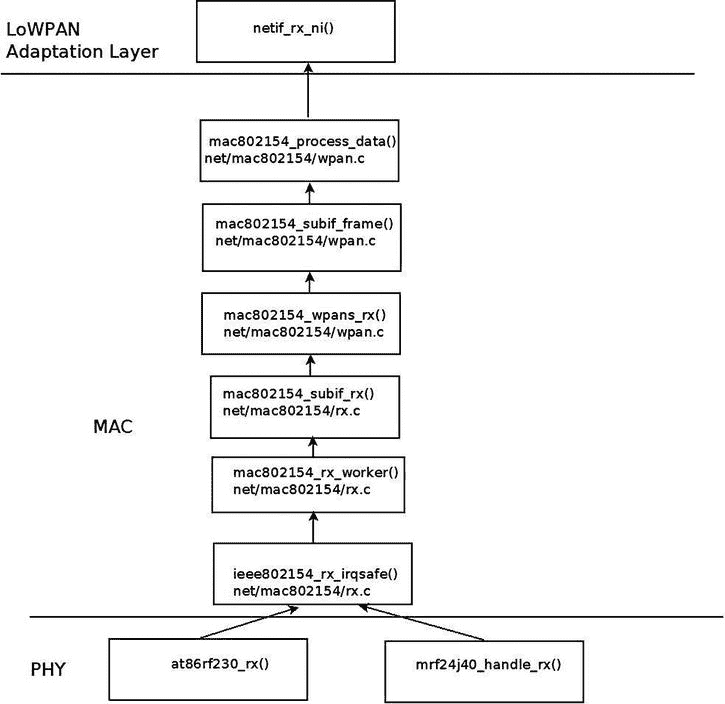
图 14-6 。接收数据包
我将不深究设备驱动程序实现的细节,因为这超出了我们的范围。我将提到每个设备驱动程序应该通过调用ieee802154_alloc_device()方法创建一个ieee802154_dev对象,作为参数传递一个ieee802154_ops对象。每个驱动都应该定义一些ieee802154_ops对象回调,像xmit、start、stop等等。这仅适用于 SoftMAC 驱动程序。
我将在这里提到一个互联网草案,该草案旨在将 6LoWPAN 技术应用于蓝牙低能耗设备(这些设备是蓝牙 4.0 规范的一部分,如前一章所述)。参见“通过蓝牙低能耗传输 IPv6 数据包”。
 注
注 Contiki是实现物联网(IoT)概念的开源操作系统;Linux IEEE802.15.4 6LoWPAN 的一些补丁就是从它派生出来的,比如 UDP 头压缩和解压缩。它实现了 6LoWPAN 和 RPL。它是由亚当·邓克尔斯开发的。参见http://www.contiki-os.org/
有关 6LoWPAN 和 802.15.4 的其他资源:
-
书籍:
-
“6LoWPAN:无线嵌入式互联网”,作者 Zach Shelby 和 Carsten Bormann,Wiley,2009 年。
-
让-菲利普·瓦瑟尔和亚当·邓克尔斯(Contiki 开发者),摩根·考夫曼于 2010 年出版的《智能物体与 IP 互联:下一个互联网》。
-
一篇关于 IPv6 邻居发现优化的文章:
http://www.internetsociety.org/articles/ipv6-neighbor-discovery-optimization。
lowpan-tools是一组管理 Linux LoWPAN 堆栈的实用程序。参见:http://sourceforge.net/projects/linux-zigbee/files/linux-zigbee-sources/0.3/
 注意IEEE 802 . 15 . 4 并没有维护自己的
注意IEEE 802 . 15 . 4 并没有维护自己的git库(尽管过去有一个)。补丁被发送到netdev邮件列表;一些开发者首先将补丁发送到 linux zigbee 开发者邮件列表,以获得一些反馈:https://lists.sourceforge.net/lists/listinfo/linux-zigbee-devel
在这一节中,我描述了 IEEE 802.15.4 和 6LoWPAN 协议,以及它给 Linux 内核集成带来的挑战,比如添加邻居发现消息。在下一节中,我将介绍第三个无线子系统,这是本章介绍的三个无线子系统中距离最短的一个:近场通信(NFC)子系统。
近场通信
近场通信是一种非常短距离的无线技术(小于两英寸),旨在通过非常低的延迟链路以高达 424 kb/s 的速度传输少量数据。NFC 有效载荷的范围从非常简单的 URL 或原始文本到更复杂的带外数据,以触发连接切换。通过其非常短的范围和延迟,NFC 通过将接近度与 NFC 数据有效载荷触发的即时动作联系起来,实现了“点击和共享”的概念。用支持 NFC 的手机触摸 NFC 标签,例如,这将立即启动网络浏览器。
NFC 工作在 13.65MHz 频段,基于射频识别(RFID) ISO14443 和 FeliCa 标准。NFC 论坛(http://www.nfc-forum.org/)是一个负责通过一系列规范实现技术标准化的联盟,范围从 NFC 数字层到高级服务定义,如 NFC 连接切换或个人健康设备通信(PHDC)定义。所有采用的 NFC 论坛规范都是免费提供的。参见http://www.nfc-forum.org/specs/。
NFC 论坛规范的核心是 NFC 数据交换格式(NDEF)定义。它定义了用于从 NFC 标签或在 NFC 对等体之间交换 NFC 有效载荷的 NFC 数据结构。所有 NDEF 都包含一个或多个嵌入实际有效载荷的 NDEF 记录。NDEF 记录头包含元数据,允许应用在 NFC 有效载荷和阅读器端触发的动作之间建立语义链接。
NFC 标签
NFC 标签很便宜,大多是静态和无电池的数据容器。它们通常由连接到非常少量闪存的感应天线组成,以许多不同的形式封装(标签、钥匙圈、贴纸等)。).根据 NFC 论坛的定义,NFC 标签是无源设备,即它们不能产生任何无线电场。相反,它们由 NFC 有源设备启动的射频场供电。NFC 论坛定义了四种不同的标签类型,每一种都带有强大的 RFID 和智能卡传统:
- 类型 1 规格源自 Innovision/Broadcom Topaz 和 Jewel card 规格。它们可以以 106 kb/s 的速度暴露 96kb 到 2kb 的数据。
- 类型 2 标签基于恩智浦 Mifare 超轻规格。它们非常类似于类型 1 标签。
- 类型 3 标签建立在 Sony FeliCa 标签的非安全部分之上。它们比类型 1 和类型 2 标签更贵,但可以以 212 或 424 kb/s 的速度携带高达 1 兆字节的数据。
- Type 4 规格基于恩智浦 DESFire 卡,支持高达 424 kb 和三种传输速度:106、212 或 424 kb/s。
NFC 设备
与 NFC 标签相反,NFC 设备可以产生自己的磁场来启动 NFC 通信。支持 NFC 的手机和 NFC 阅读器是最常见的 NFC 设备。它们支持比 NFC 标签更大的功能集。它们可以读取或写入 NFC 标签,但它们也可以伪装成一张卡,并被任何读取器视为简单的 NFC 标签。但是,NFC 技术相对于 RFID 的一个关键优势是,两个 NFC 设备可以以特定于 NFC 的对等模式相互通信。只要两个 NFC 设备在磁性范围内,这两个设备之间的链路就保持活动。在实践中,这意味着两个 NFC 设备可以在彼此物理接触的同时保持对等链路。这引入了一系列全新的移动使用案例,用户可以通过触摸他人的 NFC 设备来交换数据、上下文或凭证。
通信和操作模式
NFC 论坛定义了两种通信和三种操作模式。当两个 NFC 设备可以通过交替产生磁场来相互通话时,就建立了主动 NFC 通信。这意味着两个设备都有自己的电源,因为它们不依赖于任何感应产生的电力。主动通信只能在 NFC 点对点模式下建立。另一方面,在被动 NFC 通信中,只有一个 NFC 设备生成无线电场,另一个设备使用该场进行回复。
有三种 NFC 操作模式:
- 读取器/写入器:NFC 设备(例如,支持 NFC 的移动电话)读取或写入 NFC 标签。
- 对等:两个 NFC 设备建立逻辑链路控制协议(LLCP ),在该协议上可以复用若干 NFC 服务:用于交换 NDEF 格式数据的简单 NDEF 交换协议(SNEP ),用于发起运营商(蓝牙或 WiFi)切换的连接切换,或任何专有协议。
- 卡仿真:NFC 设备通过伪装成 NFC 标签来回复阅读器轮询。支付和交易发行商依靠这种模式在 NFC 基础上实现非接触式支付。在卡仿真模式下,在可信执行环境(也称为“安全元件”)上运行的支付小程序控制 NFC 无线电,并将自己暴露为可从支持 NFC 的销售点终端读取的传统支付卡。
主机控制器接口
硬件控制器和主机堆栈之间的通信必须遵循精确定义的接口:主机控制器接口(HCI)。在这方面,NFC 硬件生态系统相当分散,因为大多数初始 NFC 控制器都实现了 ETSI 指定的 HCI,该 HCI 最初是为 SIM 卡和非接触式前端之间的通信而设计的。(参见http://www.etsi.org/deliver/etsi_ts/102600_102699/102622/07.00.00_60/ts_102622v070000p.pdf)。这种 HCI 不是为 NFC 特定用例定制的,因此每个制造商都定义了大量专有扩展来支持他们的功能。NFC 论坛试图通过定义自己的接口来解决这种情况,该接口更加面向 NFC,即 NFC 控制器接口(NCI)。行业趋势清楚地表明,制造商放弃 ETSI HCI,转而支持 NCI,建立一个更加标准化的硬件生态系统。
Linux NFC 支持
与 Android 操作系统 NFC 堆栈不同,标准的 Linux 操作系统 NFC 堆栈部分是由内核本身实现的。自 3.1 Linux 内核发布以来,基于 Linux 的应用将找到一个 NFC 专用套接字域,以及一个通用的 netlink 系列。(参见http://git.kernel.org/?p=linux/kernel/git/sameo/nfc-next.git;a=shortlog;h=refs/heads/master。)NFC 通用 netlink 系列旨在成为用于控制和监控 NFC 适配器的 NFC 带外通道。NFC 套接字域支持两个系列:
- 用于发送 NFC 帧的原始套接字,这些帧未经修改就到达驱动程序
- 用于实现 NFC 点对点服务的 LLCP 套接字
硬件抽象在 NFC 内核驱动程序中实现,这些驱动程序针对堆栈的各个部分进行注册,主要取决于它们支持的控制器所使用的主机-控制器接口。因此,Linux 应用可以在与硬件无关且完全兼容 POSIX 的 NFC 内核 API 上工作。Linux NFC 堆栈被分为内核和用户空间。内核 NFC 套接字允许用户空间应用通过原始协议发送特定于标签类型的命令来实现 NFC 标签支持。NFC 点对点协议(SNEP、连接切换、PHDC 等。)也可以通过 NFC 套接字传输它们的特定有效载荷来实现。最后,卡仿真模式建立在内核 NFC netlink API 的安全元素部分之上。Linux NFC 守护进程neard,位于内核之上,实现所有三种 NFC 模式,而不管 NFC 控制器物理连接到主机平台。(参见https://01.org/linux-nfc/。)
图 14-7 显示了 NFC 系统的概况。
图 14-7 。NFC 概述
NFC 套接字
NFC 套接字有两种:原始和 LLCP。原始 NFC 套接字在设计时考虑了阅读器模式支持,因为它们提供了一种传输标签特定命令和接收标签回复的方式。在读取器和写入器模式下,neard守护进程使用 NFC 原始套接字来实现所有四种标签类型支持。LLCP 套接字实现 NFC 对等逻辑链路控制协议,在该协议之上neard实现所有 NFC 论坛指定的对等服务(SNEP、连接切换和 PHDC)。
根据所选的协议,NFC 套接字语义会有所不同。
原始套接字
connect:选择并启用检测到的 NFC 标签bind:不支持send/recv:发送和接收原始 NFC 有效载荷。NFC 核心实现不会修改这些有效载荷。
LLCP 套接字
connect:连接到检测到的对等设备上的特定 LLCP 服务,如 SNEP 或连接切换服务。bind:将设备链接到特定的 LLCP 服务。该服务将通过 LLCP 服务名称查找(SNL)协议导出,以便任何 NFC 对等设备尝试与之连接。send/recv:将 LLCP 服务有效载荷传输到 NFC 对等设备或从 NFC 对等设备传输。内核将处理 LLCP 特定的链路层封装和分段。- LLCP 传输可以是连接的,也可以是无连接的,这是通过 UNIX 标准 SOCK_STREAM 和 SOCK_DGRAM 套接字类型来处理的。NFC LLCP 套接字也支持 SOCK_RAW 类型,用于监视和嗅探目的。
NFC net link API
NFC 通用 netlink API 旨在实现带外 NFC 特定操作。它还处理来自 NFC 控制器的任何可发现的安全元件。通过 NFC netlink 命令,您可以:
- 列出所有可用的 NFC 控制器。
- 开启和关闭 NFC 控制器。
- 启动(和停止)NFC 轮询以发现 NFC 标签和设备。
- 在本地控制器和远程 NFC 对等设备之间启用 NFC 点对点(也称为 LLCP)链接。
- 发送 LLCP 服务名称查找请求,以便发现远程对等端上可用的 LLCP 服务。
- 启用和禁用 NFC 可发现安全元件(通常是基于 SIM 卡或嵌入式安全元件)。
- 向启用的安全元素发送 ISO7816 帧。
- 触发 NFC 控制器固件下载。
netlink API 不仅可以从 NFC 应用发送同步命令,还可以接收异步 NFC 相关事件。在 NFC netlink 套接字上侦听广播 NFC 事件的应用将收到以下通知:
- 检测到 NFC 标签和设备
- 发现的安全元素
- 安全元素交易状态
- LLCP 服务名称查找回复
整个 netlink API(包括命令和事件)以及 socket API 通过内核头文件导出,并在标准 Linux 发行版上的/usr/include/linux/nfc.h处安装。
NFC 初始化
NFC 初始化通过nfc_init()方法完成:
static int __init nfc_init(void)
{
int rc;
. . .
注册通用 netlink NFC 系列和 NFC 通知程序回调,nfc_genl_rcv_nl_event()方法:
rc = nfc_genl_init();
if (rc)
goto err_genl;
/* the first generation must not be 0 */
nfc_devlist_generation = 1;
初始化 NFC 原始套接字:
rc = rawsock_init();
if (rc)
goto err_rawsock;
初始化 NFC LLCP 套接字:
rc = nfc_llcp_init();
if (rc)
goto err_llcp_sock;
初始化 AF_NFC 协议:
rc = af_nfc_init();
if (rc)
goto err_af_nfc;
return 0;
. . .
}
(net/nfc/core.c)
驱动程序 API
如前所述,如今大多数 NFC 控制器使用 HCI 或 NCI 作为其主机控制器接口。其他人通过 USB 定义他们的专有接口,例如,像大多数 PC 兼容的 NFC 阅读器。还有一些“软”NFC 控制器期望主机平台实现 NFC 论坛数字层,并与仅支持模拟的固件对话。为了支持各种硬件控制器,NFC 内核实现了 NFC NCI、HCI 和数字层。根据他们打算支持的 NFC 硬件,设备驱动程序开发人员将需要在模块探测时针对这些堆栈之一进行注册,或者直接针对纯专有协议的 NFC 核心实现进行注册。注册时,它们通常提供堆栈操作数实现,这是 NFC 内核驱动程序和 NFC 堆栈核心部分之间的实际硬件抽象层。NFC 驱动程序注册 API 和操作数原型在内核include/net/nfc/目录中定义。
图 14-8 显示了 NFC Linux 架构的框图。
图 14-8 。NFC Linux 内核架构。(注意 NFC 数字层不在内核 3.9 中。它将被集成到内核 3.13 中。)
通过查看将 NFC 设备驱动程序直接注册到 NFC 核心并针对 HCI 和 NCI 层的实现细节,可以更好地理解该图中所示的层级:
-
直接针对 NFC 核心的注册通常在驱动程序
probe()回调中完成。注册通过以下步骤完成: -
通过调用
nfc_allocate_device()方法创建一个nfc_dev对象。 -
调用
nfc_register_device()方法,将在上一步中创建的nfc_dev对象作为单个参数传递。 -
参见:
drivers/nfc/pn533.c。 -
针对 HCI 层的注册通常也在驱动程序的
probe()回调中完成;在内核 3.9 中仅有的 HCI 驱动程序pn544和microreadNFC 设备驱动程序的情况下,这个probe()方法由 I2C 子系统调用。注册通过以下步骤完成: -
通过调用
nfc_hci_allocate_device()方法创建一个nfc_hci_dev对象。 -
nfc_hci_dev结构在include/net/nfc/hci.h中定义。 -
调用
nfc_hci_register_device()方法,将在上一步中创建的nfc_hci_dev对象作为单个参数传递。通过调用nfc_register_device()方法,nfc_hci_register_device()方法反过来执行对 NFC 核心的注册。 -
参见
drivers/nfc/pn544/pn544.c和drivers/nfc/microread/microread.c。 -
针对 NCI 层的注册通常也在驱动程序的
probe()回调中完成,例如在nfcwilink驱动程序中。注册通过以下步骤完成: -
通过调用
nci_allocate_device()方法创建一个nci_dev对象。 -
nci_dev结构在include/net/nfc/nci_core.h.中定义 -
调用
nci_register_device()方法,将在上一步中创建的nci_dev对象作为单个参数传递。通过调用nfc_register_device()方法,nci_register_device()方法反过来执行针对 NFC 核心的注册,类似于您在本节前面看到的针对 HCI 层的注册。 -
参见
drivers/nfc/nfcwilink.c。
当直接针对 NFC 内核工作时,驱动程序必须在nfs_ops对象中定义五个回调(该对象作为nfc_allocate_device()方法):的第一个参数传递)
start_poll:设置驱动程序在轮询模式下工作。stop_poll:停止轮询。- 激活选定的目标。
- 取消激活一个选定的目标。
im_transceive:收发操作。
当使用 HCI 时,hci_nfc_ops对象(它是nfs_ops,的一个实例)定义了这五个回调,当用nfc_hci_allocate_device()方法分配一个 HCI 对象时,nfc_allocate_device()方法被调用,这个hci_nfc_ops对象作为第一个参数。
与 NCI,有一些非常相似的东西,与nci_nfc_ops对象;参见:net/nfc/nci/core.c。
用户空间架构
neard ( http://git.kernel.org/?p=network/nfc/neard.git;a=summary)是运行在内核 NFC APIs 之上的 Linux NFC 守护进程。它是一个单线程、基于 GLib 的进程,实现了 NFC 点对点堆栈的更高层,以及用于读取和写入 NFC 标签的四种标签类型特定命令。NDEF 推协议(NPP)、SNEP、PHDC 和连接切换规范都是通过neard插件实现的。neard 的主要设计目标之一是为愿意提供高级 NFC 服务的基于 Linux 的应用提供一个小型、简单和统一的 NFC API。这是通过一个小型的 D-Bus API 实现的,它抽象了标签和设备接口和方法,对应用开发人员隐藏了 NFC 的复杂性。此 API 与 freedesktop D-Bus ObjectManager 兼容,并提供以下接口:
org.neard.Adapter:用于检测新的 NFC 控制器、开启和关闭控制器以及启动 NFC 轮询。org.neard.Device, org.neard.Tag:用于表示检测到的 NFC 标签和设备。呼叫设备。Push 方法将在标记时向对等设备发送 NDEFs。Write 会将它们写入选定的标签。org.neard.Record:表示人类可读和可理解的 NDEF 记录有效载荷和属性。根据org.neard.NDEF代理接口注册代理将使应用能够访问 NDEF 原始负载。
您可以在这里找到关于neard用户空间守护进程的更多信息:http://git.kernel.org/cgit/network/nfc/neard.git/tree/doc。
Android 上的 NFC
最初的 NFC 支持是在 2010 年 12 月随着 2.3(姜饼)正式发布而添加到 Android 操作系统中的。Android 2.3 仅支持阅读器/写入器模式,但自那以后情况有了显著改善,最新的 Android 版本(Jelly Bean 4.3)提供了全功能的 NFC 支持。更多信息请参见 Android NFC 页面:http://developer.android.com/guide/topics/connectivity/nfc/index.html。遵循经典的 Android 架构,Java 特定的 NFC API 可用于应用来提供 NFC 服务和操作。通过本地硬件抽象层(HAL)实现这些 API 的任务留给了集成商。谷歌推出了 Broadcom NFC HAL,目前仅支持 Broadcom NFC 硬件。同样,Android OEMs 和集成商要么让 Broadcom NFC HAL 适应他们选择的 NFC 芯片组,要么实现他们自己的 HAL。值得注意的是,由于 Broadcom 堆栈实现了 NFC 控制器接口(NCI)规范,因此对其进行调整以支持任何 NCI 兼容的 NFC 控制器相对容易。Android NFC 架构可以称为用户空间 NFC 堆栈。事实上,整个 NFC 实现是通过 HAL 在用户空间中完成的。然后,NFC 帧通过内核驱动程序存根被下推到 NFC 控制器。驱动程序只是将这些帧封装到缓冲区中,准备发送到主机平台和 NFC 控制器之间的物理链路(例如,I2C、SPI、UART)。
 注
注nfc-next git树的 Pull 请求发送到wireless-next树(除了 NFC 子系统,还有蓝牙子系统和 mac802.11 子系统 pull 请求由无线维护人员处理)。从wireless-next树,拉请求被发送到net-next树,并从那里发送到 Linus linux-next树。nfc-next树可用于:git://git.kernel.org/pub/scm/linux/kernel/git/sameo/nfc-next.git
还有一个nfc-fixes git存储库,其中包含当前版本的紧急和关键修复(-rc*)。nfc-fixes的git树出现在:git://git.kernel.org/pub/scm/linux/kernel/git/sameo/nfc-fixes.git/
NFC 邮件列表:linux-nfc@lists.01.org 。
NFC 邮件列表档案:https://lists.01.org/pipermail/linux-nfc/`。
在本节中,您了解了什么是 NFC,以及 Linux NFC 子系统实现和 Android NFC 子系统实现。在下一节中,我将讨论通知链机制,这是一种向网络设备通知各种事件的重要机制。
通知链
网络设备状态可以动态改变;有时,用户/管理员可以注册/取消注册网络设备、更改其 MAC 地址、更改其 MTU 等。网络堆栈和其他子系统和模块应该能够被通知这些事件并正确处理它们。网络通知链提供了一种处理这类事件的机制,我将在这一节描述它的 API 和它处理的可能的网络事件。关于事件的完整列表,见本章后面的表 14-1 。每个子系统和每个模块都可以向通知链注册自己。这通过定义一个notifier_block并注册它来完成。通知链注册和注销的核心方法分别是notifier_chain_register()和notifier_chain_unregister()方法。通知事件的生成是通过调用notifier_call_chain()方法完成的。这三个方法不是直接用的(不导出;见kernel/notifier.c),而且他们没有使用任何锁定机制。以下方法是围绕notifier_chain_register()、的包装器,它们都在kernel/notifier.c中实现:
atomic_notifier_chain_register()blocking_notifier_chain_register()raw_notifier_chain_register()srcu_notifier_chain_register()register_die_notifier()
表 14-1。网络设备事件:
|
事件
|
意义
|
| — | — |
| NETDEV_UP | 设备启动事件 |
| 网络开发 _ 关闭 | 设备停机事件 |
| 网络开发 _ 重启 | 检测到硬件崩溃并重新启动设备 |
| 网络开发 _ 变更 | 设备状态变化 |
| NETDEV _ 寄存器 | 设备注册事件 |
| NETDEV_UNREGISTER | 设备注销事件 |
| NETDEV_CHANGEMTU(网络配置文件) | 设备 MTU 已更改 |
| NETDEV_CHANGEADDR | 设备 MAC 地址已更改 |
| NETDEV_GOING_DOWN | 设备正在关闭 |
| NETDEV_CHANGENAME | 设备已更改其名称 |
| 网络发展 _ 专长 _ 改变 | 设备功能已更改 |
| NETDEV_BONDING_FAILOVER | 绑定故障转移事件 |
| NETDEV_PRE_UP | 此事件允许否决将设备状态更改为启动;例如,在 cfg80211 中,如果已知设备已被射频识别,则拒绝设置接口。参见cfg80211_netdev_notifier_call() |
| 网络开发 _ 前期 _ 类型 _ 变更 | 该设备即将改变其类型。这是 NETDEV_BONDING_OLDTYPE 标志的推广,它被 NETDEV_PRE_TYPE_CHANGE 所取代 |
| 网络开发 _ 发布 _ 类型 _ 更改 | 设备改变了类型。这是 NETDEV_BONDING_NEWTYPE 标志的推广,它被 NETDEV_POST_TYPE_CHANGE 所取代 |
| 网络开发 _ 发布 _ 初始化 | 该事件在设备注册(register_netdevice())中生成,在netdev_register_kobject()创建网络设备对象之前;用于 cfg80211 (net/wireless/core.c) |
| NETDEV_UNREGISTER_FINAL | 为完成设备注销而生成的事件。 |
| 网络开发 _ 发布 | 释放绑定的最后一个从机(当通过绑定使用 netconsole 时)(在br_if.c中,该标志也曾用于网桥)。 |
| 网络开发 _ 通知 _ 对等方 | 通知网络对等体事件(即,设备想要通知网络的其余部分某种重新配置,例如故障转移事件或虚拟机迁移) |
| 网络开发 _ 加入 | 设备添加了一个从属设备。例如在绑定驱动程序中使用,在bond_enslave()方法中,我们添加了一个从机;参见drivers/net/bonding/bond_main.c |
还有相应的包装器方法,用于注销通知链和为每个包装器生成通知事件。例如,对于用atomic_notifier_chain_register()方法注册的通知链,atomic_notifier_chain_unregister()用于取消注册通知链,__atomic_notifier_call_chain()方法用于生成通知事件。这些包装器中的每一个都有相应的宏来定义通知链;对于atomic_notifier_chain_register()包装器,它是ATOMIC_NOTIFIER_HEAD宏(include/linux/notifier.h)。
注册一个notifier_block对象后,当表 14-1 中显示的每一个事件发生时,调用一个notifier_block中指定的回调。通知链的基本数据结构是notifier_block结构;让我们来看看:
struct notifier_block {
int (*notifier_call)(struct notifier_block *, unsigned long, void *);
struct notifier_block __rcu *next;
int priority;
};
(include/linux/notifier.h)
notifier_call:要调用的回调。- 首先执行具有较高优先级的
notifier_block对象的priority:回调。
在网络子系统和其他子系统中有许多链。我们来提几个重要的:
netdev_chain:通过register_netdevice_notifier()方式注册,通过unregister_netdevice_notifier()方式取消注册(net/core/dev.c)。inet6addr_chain:通过register_inet6addr_notifier()方式注册,通过unregister_inet6addr_notifier ()方式取消注册。通知由inet6addr_notifier_call_chain ()方法生成(net/ipv6/addrconf_core.c)。netevent_notif_chain:通过register_netevent_notifier()方式注册,通过unregister_netevent_notifier()方式取消注册。通知由call_netevent_notifiers()方法生成(net/core/netevent.c)。inetaddr_chain:通过register_inetaddr_notifier()方式注册,通过unregister_inetaddr_notifier()方式取消注册。通知是通过调用blocking_notifier_call_chain()方法生成的。
让我们来看一个使用netdev_chain的例子;您之前已经看到,使用netdev_chain,注册是通过register_netdevice_notifier()方法完成的,它是raw_notifier_chain_register()方法的包装器。下面是一个注册名为br_device_event的回调的例子;首先定义一个notifier_block对象,然后通过调用register_netdevice_notifier()方法注册它:
struct notifier_block br_device_notifier = {
.notifier_call = br_device_event
};
(net/bridge/br_notify.c)
static int __init br_init(void)
{
...
register_netdevice_notifier(&br_device_notifier);
...
}
(net/bridge/br.c)
通过调用call_netdevice_notifiers()方法来生成netdev_chain的通知。此方法的第一个参数是事件。call_netdevice_notifiers()方法:实际上是raw_notifier_call_chain()的包装器。
因此,当生成网络通知时,所有已注册的回调都被调用;在这个例子中,无论发生了哪个网络事件,都将调用br_device_event()回调;回调将决定如何处理通知,或者可能忽略它。我们来看看回调方法,br_device_event():
static int br_device_event(struct notifier_block *unused, unsigned long event, void *ptr)
{
struct net_device *dev = ptr;
struct net_bridge_port *p;
struct net_bridge *br;
bool changed_addr;
int err;
. . .
br_device_event()方法的第二个参数是事件(所有事件都在include/linux/netdevice.h中定义):
switch (event) {
case NETDEV_CHANGEMTU:
dev_set_mtu(br->dev, br_min_mtu(br));
break;
. . .
}
 注意通知链的注册不仅限于网络子系统。因此,例如,
注意通知链的注册不仅限于网络子系统。因此,例如,clockevents子系统定义了一个名为clockevents_chain的链并通过调用raw_notifier_chain_register()方法注册它,hung_task模块定义了一个名为panic_notifier_list的链并通过调用atomic_notifier_chain_register()方法注册它。
除了本节讨论的通知之外,还有另一种类型的通知,称为 RTNetlink 通知;这些通知通过rtmsg_ifinfo()方法发送。:这种类型的通知在第二章中讨论过,它处理 Netlink 套接字。
以下是联网支持的事件类型(注意:下表中提到的事件类型在include/linux/netdevice.h中定义):
我们现在已经介绍了通知事件,这是一种机制,它使网络设备能够获得关于 MTU 更改、MAC 地址更改等事件的通知。下一节将简要讨论 PCI 子系统,描述它的一些主要数据结构。
PCI 子系统
许多网络接口卡是外围组件互连(PCI)设备,应该与 Linux PCI 子系统协同工作。不是所有的网络接口都是 PCI 设备;有许多嵌入式设备的网络接口不在 PCI 总线上;这些设备的初始化和处理是以不同的方式完成的,下面的讨论与这些非 PCI 设备无关。新的 PCI 设备是 PCI Express (PCIe 或 PCIe)设备;该标准创建于 2004 年。它们有一个串行接口而不是并行接口,因此它们有更高的最大系统总线吞吐量。每个 PCI 设备都有一个只读配置空间;它至少有 256 个字节。PCI-X 2.0 和 PCI Express 总线中提供的扩展配置空间为 4096 字节。您可以通过lspci读取 PCI 配置空间和扩展 PCI 配置空间(该lspci工具属于pciutils包):
lspci -xxx:显示 PCI 配置空间的十六进制转储。lspci –xxxx:显示扩展 PCI 配置空间的十六进制转储。
Linux PCI API 提供了三种读取配置空间的方法,用于处理 8 位、16 位和 32 位粒度:
static inline int pci_read_config_byte(const struct pci_dev *dev, int where, u8 *val)static inline int pci_read_config_word(const struct pci_dev *dev, int where, u16 *val)static inline int pci_read_config_dword(const struct pci_dev *dev, int where, u32 *val)
写配置空间也有三种方法;同样,也可以处理 8 位、16 位和 32 位粒度:
static inline int pci_write_config_byte(const struct pci_dev *dev, int where, u8 val)static inline int pci_write_config_word(const struct pci_dev *dev, int where, u16 val)static inline int pci_write_config_dword(const struct pci_dev *dev, int where, u32 val)
每个 PCI 制造商至少给 PCI 设备的配置空间中的供应商、设备和类别字段赋值。Linux PCI 子系统通过一个pci_device_id对象来识别 PCI 设备。pci_device_id struct在include/linux/mod_devicetable.h中定义:
struct pci_device_id {
__u32 vendor, device; /* Vendor and device ID or PCI_ANY_ID*/
__u32 subvendor, subdevice; /* Subsystem ID's or PCI_ANY_ID */
__u32 class, class_mask; /* (class,subclass,prog-if) triplet */
kernel_ulong_t driver_data; /* Data private to the driver */
};
(include/linux/mod_devicetable.h)
pci_device_id中的厂商、设备和类别字段标识一个 PCI 设备;大多数驱动程序不需要指定类别,因为供应商/设备通常就足够了。
每个 PCI 设备驱动程序声明一个pci_driver对象。我们来看看pci_driver的结构:
struct pci_driver {
. . .
const char *name;
const struct pci_device_id *id_table; /* must be non-NULL for probe to be called */
int (*probe) (struct pci_dev *dev, const struct pci_device_id *id); /* New device inserted */
void (*remove) (struct pci_dev *dev); /* Device removed (NULL if not a hot-plug capable driver) */
int (*suspend) (struct pci_dev *dev, pm_message_t state); /* Device suspended */
. . .
int (*resume) (struct pci_dev *dev); /* Device woken up */
. . .
};
(include/linux/pci.h)
下面是对pci_driver结构成员的简短描述:
name:PCI 设备的名称。id_table:它支持的pci_device_id对象的数组。初始化id_table通常用 DEFINE_PCI_DEVICE_TABLE 宏来完成。probe:设备初始化的一种方法。remove:释放设备的方法。remove()方法通常会释放在probe()方法中分配的所有资源。- 对于支持电源管理的设备,将设备置于低功耗状态的电源管理回调。
- 对于支持电源管理的设备,从低功耗状态唤醒设备的电源管理回调。
PCI 设备由struct pci_dev表示。它是一个大的结构;让我们来看看它的一些成员(他们不言自明):
struct pci_dev {
. . .
unsigned short vendor;
unsigned short device;
unsigned short subsystem_vendor;
unsigned short subsystem_device;
. . .
struct pci_driver *driver; /* which driver has allocated this device */
. . .
pci_power_t current_state; /* Current operating state. In ACPI-speak,
this is D0-D3, D0 being fully functional,
and D3 being off. */
struct device dev; /* Generic device interface */
int cfg_size; /* Size of configuration space */
unsigned int irq;
};
(include/linux/pci.h)
向 PCI 子系统注册 PCI 网络设备是通过定义一个pci_driver对象并调用pci_register_driver()宏来完成的,这个宏得到一个pci_driver对象作为它的单个参数。为了在使用前初始化 PCI 设备,驱动程序应该调用pci_enable_device()方法。如果设备挂起,此方法会唤醒设备,并分配所需的 I/O 资源和内存资源。注销 PCI 驱动程序是通过pci_unregister_driver()方法.完成的。通常在驱动程序module_init()方法中调用pci_register_driver()宏,在驱动程序module_exit()方法中调用pci_unregister_driver()方法。每个驱动程序应该在设备启动时调用指定 IRQ 处理程序的request_irq()方法,在设备关闭时调用free_irq()。
当使用未缓存的内存缓冲区时,DMA(直接内存访问)内存的分配和释放通常通过dma_alloc_coherent()/dma_free_coherent()完成。使用dma_alloc_coherent(),我们不需要担心缓存一致性,因为这个方法的映射是缓存一致的。参见e1000_alloc_ring_dma(), drivers/net/ethernet/intel/e1000e/netdev.c中的例子。Linux DMA API 在文档/DMA-API.txt 中有描述。
注意单根 I/O 虚拟化(SR-IOV)是一种 PCI 特性,它使一个物理设备表现为几个虚拟设备。SR-IOV 规范是由 PCI SIG 创建的。参见http://www.pcisig.com/specifications/iov/single_root/。更多信息见Documentation/PCI/pci-iov-howto.txt。
关于 PCI 的更多信息可以在 Jonathan Corbet、Alessandro Rubini 和 Greg Kroah-Hartman 所著的第三版“Linux 设备驱动程序”中找到,可以通过以下网址获得(在知识共享许可下): http://lwn.net/Kernel/LDD3/ 。
局域网唤醒(WOL)
LAN 唤醒是一种标准,它允许已被软断电的设备被网络数据包通电或唤醒。默认情况下,局域网唤醒是禁用的。有一些网络设备驱动程序允许系统管理员启用局域网唤醒功能,通常是通过从用户空间运行ethtool命令。为了支持这一点,网络设备驱动程序应该在ethtool_ops对象中定义一个set_wol()回调。例如,RealTek ( net/ethernet/realtek/8139cp.c)的8139cp驱动程序。运行ethtool <networkDeviceName>显示网络设备是否支持局域网唤醒。ethtool还让系统管理员定义哪些包应该唤醒设备;例如,ethtool -s eth1 wol g将启用 MagicPacket 帧的 LAN 唤醒(MagicPacket 是 AMD 的一个标准)。您可以使用net-tools包的ether-wake实用程序来发送 LAN 唤醒 MagicPacket 帧。
分组网络设备
虚拟分组网络设备驱动程序旨在替代绑定网络设备(drivers/net/bonding)。绑定网络设备提供链路聚合解决方案(也称为:“链路捆绑”或“中继”)。参见Documentation/networking/bonding.txt。绑定驱动程序完全在内核中实现,众所周知,它非常大,容易出问题。与绑定网络驱动程序相反,成组网络驱动程序由用户空间控制。用户空间守护进程被称为teamd,它通过库名libteam与内核团队驱动程序通信。libteam 库基于通用的 netlink 套接字(参见第二章)。
分组驱动程序有四种模式:
-
loadbalance: Used in Link Aggregation Control Protocol (LACP), which is part of the 802.3ad standard.
net/team/team_mode_loadbalance.c -
activebackup: Only one port is active at a given time. This port can transmit and receive SKBs. The other ports are backup ports. A userspace application can specify which port to use as the active port.
net/team/team_mode_activebackup.c -
broadcast: All packets are sent by all ports.
net/team/team_mode_broadcast.c -
roundrobin: Selection of ports is done by a round robin algorithm. No need for interaction with userspace for this mode.
net/team/team_mode_roundrobin.c
注意组队网络驱动程序位于drivers/net/team下,由 Jiri Pirko 开发。
更多信息见http://libteam.org/ 。
``libteam地点:https://github.com/jpirko/libteam 。`
`我们对团队驱动因素的简要概述到此结束。许多读者在网上冲浪时使用 PPPoE 服务。以下简短部分介绍了 PPPoE 协议。
PPPoE 协议
PPPoE 是一种将多个客户端连接到远程站点的规范。DSL 提供商通常使用 PPPoE 来处理 IP 地址和鉴定用户。PPPoE 协议提供了对以太网数据包使用 PPP 封装的能力。PPPoE 协议在 1999 年的 RFC 2516 中指定,PPP 协议在 1994 年的 RFC 1661 中指定。PPPoE 分为两个阶段:
-
PPPoE 发现阶段。发现是在客户端-服务器会话中完成的。该服务器被称为接入集中器,并且可以有多个。这些接入集中器通常由互联网服务提供商(ISP) 部署。这是发现阶段的四个步骤:
-
PPPoE 主动发现发起(PADI) 。从主机发送广播数据包。PPPoE 报头中的
code为 0x 09(PADI _ 码),PPPoE 报头中的会话 id (sid)必须为 0。 -
PPPoE 主动发现要约(PADO) 。接入集线器用 PADO 回复来回复 PADI 请求。目的地址是发送 PADI 的主机的地址。PPPoE 报头中的
code是 0x07 (PADO 代码)。PPPoE 报头中的会话 id (sid)必须再次为 0。 -
PPPoE 主动发现请求(PADR) 。主机收到 PADO 回复后,会向接入集线器发送 PADR 数据包。PPPoE 报头中的
code是 0x19 (PADR 代码)。PPPoE 报头中的会话 id (sid)必须再次为 0。 -
PPPoE 主动发现会话-确认(PADS)。当接入集中器收到 PADR 请求时,它会生成一个唯一的会话 id,并发送一个 PADS 数据包作为回复。PPPoE 报头中的
code是 0x65 (PADS_CODE)。PPPoE 报头中的会话 id (sid)是它生成的会话 id。数据包的目的地是发送 PADR 请求的主机的 IP 地址。 -
通过发送 PPPoE 主动发现终止(PADT) 数据包来终止会话。PPPoE 报头中的
code是 0xa7 (PADT 代码)。PADT 可以由接入集线器或主机发送,并且可以在会话建立后的任何时间发送。目的地址是单播地址。所有五个发现数据包(PADI、PADO、PADR、PADS 和 PADT)的以太网报头的以太网类型是 0x8863 (ETH_P_PPP_DISC)。 -
PPPoE 会话阶段。一旦 PPPoE 发现阶段成功完成,就使用 PPP 封装发送数据包,这意味着添加两个字节的 PPP 报头。使用 PPP 可以使用 PPP 子协议进行注册和认证,如密码认证协议 (PAP)或挑战握手认证协议(CHAP),以及称为链路控制协议(LCP) 的 PPP 子协议,它负责建立和测试数据链路连接。以太网报头的以太类型是 0x8864 (ETH_P_PPP_SES)。
每个 PPPoE 数据包都以 6 字节的 PPPoE 报头开始,为了更好地理解 PPPoE 协议,您必须了解 PPPoE 报头。
PPPoE 报头
我将首先展示 Linux 内核中的 PPPoE 头定义:
struct pppoe_hdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ver : 4;
__u8 type : 4;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u8 type : 4;
__u8 ver : 4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 code;
__be16 sid;
__be16 length;
struct pppoe_tag tag[0];
} __packed;
(include/uapi/linux/if_pppox.h)
以下是对pppoe_hdr结构成员的描述:
-
ver:ver字段是一个 4 位字段,根据 RFC 2516 的第四部分,它必须设置为 0x1。 -
type:type字段是一个 4 位字段,根据 RFC 2516 的第四部分,它也必须设置为 0x1。 -
code:代码字段为 8 位字段,可以是前面提到的常量之一:PADI 代码、PADO 代码、PADR 代码、PADS 代码、PADT 代码。 -
sid:会话 ID (16 位)。 -
length:length为 16 位字段,表示 PPPoE 净荷的长度,不含 PPPoE 头的长度,也不含以太网头的长度。 -
tag[0]:PPPoE 有效载荷可以包含零个或多个标签,采用类型-长度-值(TLV)格式。标签由 3 个字段组成: -
TAG_TYPE: 16 位(例如 AC-Name、Service-Name、Generic-Error 等)。
-
TAG_LENGTH: 16 位。
-
TAG_VALUE:长度可变。
-
RFC 2516 的附录 A 列出了各种标签类型和标签值。
图 14-9 显示了一个 PPPoE 头:
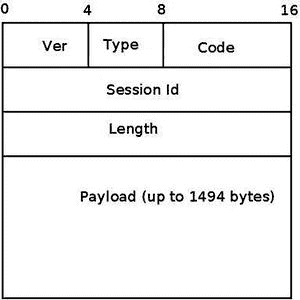
图 14-9 。PPPoE 报头
PPPoE 初始化
PPPoE 初始化由pppoe_init()方法drivers/net/ppp/pppoe.c完成。注册了两个 PPPoE 协议处理程序,一个用于 PPPoE 发现数据包,一个用于 PPPoE 会话数据包。让我们来看看 PPPoE 协议处理程序的注册:
static struct packet_type pppoes_ptype __read_mostly = {
.type = cpu_to_be16(ETH_P_PPP_SES),
.func = pppoe_rcv,
};
static struct packet_type pppoed_ptype __read_mostly = {
.type = cpu_to_be16(ETH_P_PPP_DISC),
.func = pppoe_disc_rcv,
};
static int __init pppoe_init(void)
{
int err;
dev_add_pack(&pppoes_ptype);
dev_add_pack(&pppoed_ptype);
. . .
return 0;
}
dev_add_pack()方法是注册协议处理程序的通用方法,您在前面的章节中会遇到。通过pppoe_init()方法注册的协议处理程序有:
pppoe_disc_rcv()方法是 PPPoE 发现包的处理程序。pppoe_rcv()方法是 PPPoE 会话数据包的处理程序。
PPPoE 模块将条目导出到procfs、/proc/net/pppoe。该条目由会话 id、MAC 地址和当前 PPPoE 会话的设备组成。运行cat /proc/net/pppoe由pppoe_seq_show()方法处理。通过调用register_netdevice_notifier(&pppoe_notifier),由pppoe_init()方法注册一个通知链。
PPPoX 套接字
PPPoX 套接字由pppox_sock结构(include/linux/if_pppox.h)表示,并在net/ppp/pppox.c中实现。这些套接字实现了一个通用的 PPP 封装套接字系列。除了 PPPoE,PPP 上的第 2 层隧道协议(L2TP)也使用它们。通过调用pppoe_init()方法中的register_pppox_proto(PX_PROTO_OE, &pppoe_proto)来注册 PPPoX 套接字。让我们来看看pppox_sock结构的定义:
struct pppox_sock {
/* struct sock must be the first member of pppox_sock */
struct sock sk;
struct ppp_channel chan;
struct pppox_sock *next; /* for hash table */
union {
struct pppoe_opt pppoe;
struct pptp_opt pptp;
} proto;
__be16 num;
};
(include/linux/if_pppox.h)
当 PPPoE 使用 PPPoX 套接字时,使用pppox_sock对象的proto联合的pppoe_opt。pppoe_opt结构包含一个名为pa的成员,它是pppoe_addr结构的一个实例。pppoe_addr结构表示 PPPoE 会话的参数:会话 id、对等体的远程 MAC 地址以及所使用的网络设备的名称:
struct pppoe_addr {
sid_t sid; /* Session identifier */
unsigned char remote[ETH_ALEN]; /* Remote address */
char dev[IFNAMSIZ]; /* Local device to use */
};
(include/uapi/linux/if_pppox.h)
注意对嵌入在proto联合中的pppoe_opt结构的pa成员的访问在大多数情况下是在 PPPoE 模块中使用pppoe_pa宏完成的:
#define pppoe_pa proto.pppoe.pa
(include/linux/if_pppox.h)
使用 PPPoE 发送和接收数据包
如前所述,一旦发现阶段完成,就必须使用 PPP 协议来支持两个对等体之间的流量。当通过运行pppd eth0启动 PPP 连接时(参见本节后面的例子),用户空间pppd守护进程通过调用socket(AF_PPPOX, SOCK_STREAM, PX_PROTO_OE)创建一个 PPPoE 套接字;这是在pppd守护进程的rp-pppoe插件中,在pppd/plugins/rp-pppoe/plugin.c的PPPOEConnectDevice()方法中完成的。这个socket()系统调用通过 PPPoE 内核模块的pppoe_create()方法创建一个 PPPoE 套接字。PPPoE 会话完成后释放套接字是由 PPPoE 内核模块的pppoe_release()方法完成的。我们来看看pppoe_create()方法:
static const struct proto_ops pppoe_ops = {
.family = AF_PPPOX,
.owner = THIS_MODULE,
.release = pppoe_release,
.bind = sock_no_bind,
.connect = pppoe_connect,
. . .
.sendmsg = pppoe_sendmsg,
.recvmsg = pppoe_recvmsg,
. . .
.ioctl = pppox_ioctl,
};
static int pppoe_create(struct net *net, struct socket *sock)
{
struct sock *sk;
sk = sk_alloc(net, PF_PPPOX, GFP_KERNEL, &pppoe_sk_proto);
if (!sk)
return -ENOMEM;
sock_init_data(sock, sk);
sock->state = SS_UNCONNECTED;
sock->ops = &pppoe_ops;
sk->sk_backlog_rcv = pppoe_rcv_core;
sk->sk_state = PPPOX_NONE;
sk->sk_type = SOCK_STREAM;
sk->sk_family = PF_PPPOX;
sk->sk_protocol = PX_PROTO_OE;
return 0;
}
(drivers/net/ppp/pppoe.c)
通过定义pppoe_ops,我们为这个套接字设置了回调。所以从用户空间调用 AF_PPPOX 套接字上的connect()系统调用将由内核中 PPPoE 模块的pppoe_connect()方法处理。创建 PPPoE 套接字后,PPPOEConnectDevice()方法调用connect()。让我们来看看pppoe_connect()方法:
static int pppoe_connect(struct socket *sock, struct sockaddr *uservaddr,
int sockaddr_len, int flags)
{
struct sock *sk = sock->sk;
struct sockaddr_pppox *sp = (struct sockaddr_pppox *)uservaddr;
struct pppox_sock *po = pppox_sk(sk);
struct net_device *dev = NULL;
struct pppoe_net *pn;
struct net *net = NULL;
int error;
lock_sock(sk);
error = -EINVAL;
if (sp->sa_protocol != PX_PROTO_OE)
goto end;
/* Check for already bound sockets */
error = -EBUSY;
当会话 id 不为 0 时,stage_session()方法返回true(如前所述,会话 id 仅在发现阶段为 0)。如果套接字已连接并且处于会话阶段,则套接字已经被绑定,因此我们退出:
if ((sk->sk_state & PPPOX_CONNECTED) &&
stage_session(sp->sa_addr.pppoe.sid))
goto end;
到达这里意味着套接字没有连接(它的sk_state不是 PPPOX_CONNECTED)我们需要注册一个 PPP 通道:
. . .
/* Re-bind in session stage only */
if (stage_session(sp->sa_addr.pppoe.sid)) {
error = -ENODEV;
net = sock_net(sk);
dev = dev_get_by_name(net, sp->sa_addr.pppoe.dev);
if (!dev)
goto err_put;
po->pppoe_dev = dev;
po->pppoe_ifindex = dev->ifindex;
pn = pppoe_pernet(net);
网络设备必须启动:
if (!(dev->flags & IFF_UP)) {
goto err_put;
}
memcpy(&po->pppoe_pa,
&sp->sa_addr.pppoe,
sizeof(struct pppoe_addr));
write_lock_bh(&pn->hash_lock);
__set_item()方法将pppox_sock对象po插入到 PPPoE 套接字哈希表中;哈希密钥是根据会话 id 和远程对等 MAC 地址通过hash_item()方法生成的。远程对等 MAC 地址是po->pppoe_pa.remote。如果哈希表中有一个条目具有相同的会话 id、相同的远程 MAC 地址和相同的网络设备的ifindex,__set_item()方法将返回错误–eal ready:
error = __set_item(pn, po);
write_unlock_bh(&pn->hash_lock);
if (error < 0)
goto err_put;
po->chan是一个ppp_channel对象,参见前面的pppox_sock结构定义。在用ppp_register_net_channel()方法注册它之前,它的一些成员应该被初始化:
po->chan.hdrlen = (sizeof(struct pppoe_hdr) +
dev->hard_header_len);
po->chan.mtu = dev->mtu - sizeof(struct pppoe_hdr);
po->chan.private = sk;
po->chan.ops = &pppoe_chan_ops;
error = ppp_register_net_channel(dev_net(dev), &po->chan);
if (error) {
delete_item()方法从 PPPoE 套接字哈希表中删除一个pppox_sock对象。
delete_item(pn, po->pppoe_pa.sid,
po->pppoe_pa.remote, po->pppoe_ifindex);
goto err_put;
}
设置要连接的套接字状态:
sk->sk_state = PPPOX_CONNECTED;
}
po->num = sp->sa_addr.pppoe.sid;
end:
release_sock(sk);
return error;
err_put:
if (po->pppoe_dev) {
dev_put(po->pppoe_dev);
po->pppoe_dev = NULL;
}
goto end;
}
通过注册 PPP 频道,我们可以使用 PPP 服务。我们能够通过从pppoe_rcv_core()方法调用通用 PPP 方法ppp_input()来处理 PPPoE 会话数据包。PPPoE 会话数据包的传输采用通用的ppp_start_xmit()方法。
RP-PPPoE 是一个开源项目,它为 Linux: http://www.roaringpenguin.com/products/pppoe提供了 PPPoE 客户端和 PPPoE 服务器。运行 PPPoE 服务器的一个简单示例是:
pppoe-server -I p3p1 -R 192.168.3.101 -L 192.168.3.210 -N 200
本例中使用的选项有:
- -I:接口名称(
p3p1) - -L:设置本地 IP 地址(192.168.3.210)
- -R:设置起始远程 IP 地址(192.168.3.101)
- -N:并发 PPPoE 会话的最大数量(本例中为 200)
有关其他选项,请参见man 8 pppoe-server。
同一个局域网上的客户端可以使用rp-pppoe插件,通过pppd守护进程创建到该服务器的 PPPoE 连接。
作为智能手机和平板电脑的移动操作系统,Android 的受欢迎程度正在稳步增长。我将用一小段关于 Android 的内容来结束这本书,简要讨论 Android 开发模型,并展示四个关于 Android 网络的例子。
安卓
近年来,Android 操作系统被证明是一个非常可靠和成功的移动操作系统。Android 操作系统基于 Linux 内核,谷歌开发人员对其进行了修改。Android 运行在数百种移动设备上,这些设备大多基于 ARM 处理器。(我要提一下,有一个把 Android 移植到 Intel x86 处理器的项目,http://www.android-x86.org/ ). The first generation of Google TV devices is based on x86 processors by Intel, but the second generation of Google TV devices are based on ARM. Originally Android was developed by “Android Inc.”, a company that was founded in California in 2003 by Andy Rubin and others. Google bought this company in 2005\. The Open Handset Alliance (OHA), a consortium of over 80 companies, announced Android in 2007\. Android is an open source operating system, and its source code is released under the Apache License. Unlike Linux, most of the development is done by Google employees behind closed doors. As opposed to Linux, there is no public mailing list where developers are sending and discussing patches. One can, however, send patches to public Gerrit (see http://source.android.com/source/submit-patches.html )。但是他们是否会被包含在 Android 系统中只能由谷歌来决定。``
``谷歌开发者对 Linux 内核贡献良多。在本章的前面,您已经了解到 cgroup 子系统是由 Google 开发人员启动的。我还将提到两个 Linux 内核网络补丁,Google 的 Tom Herbert 开发的接收包控制(RPS)补丁和接收流控制(RFS)补丁(参见http://lwn.net/Articles/362339/和http://lwn.net/Articles/382428/,它们被集成到内核 2.6.35 中。当使用多核平台时,RPS 和 RFS 允许您根据有效负载的散列将数据包导向特定的 CPU。还有很多其他 Google 对 Linux 内核做出贡献的例子,看起来将来你也会遇到 Google 对 Linux 内核做出的许多重要贡献。在 Linux 内核的 staging tree 中可以找到很多来自 Android 内核的代码。不过,Android 内核是否会完全合并到 Linux 内核中还不好说;很可能它的很大一部分会进入 Linux 内核。更多关于 Android 主流化的信息,请看这个维基:http://elinux.org/Android_Mainlining_Project。过去有许多障碍,因为谷歌实施了独特的机制,如唤醒锁、替代电源管理、自己的 IPC(称为 Binder),它基于轻量级远程过程调用(RPC)、Android 共享内存驱动程序(Ashmem)、低内存黑仔等等。事实上,内核社区在 2010 年就拒绝了谷歌电源管理 wakelocks 补丁。但从那时起,这些功能中的一些被合并,情况发生了变化。(参见“Autosleep and Wake Locks”,https://lwn.net/Articles/479841/,以及“LPC Android microconference”,https://lwn.net/Articles/570406/ ). Linaro (www.linaro.org/)是一家非营利性组织,由 ARM、飞思卡尔、IBM、三星、意法爱立信和德州仪器(TI)等领先的大公司于 2010 年成立。它的工程团队开发 Linux ARM 内核,并为 GCC 工具链进行优化。Linaro 团队在协调和推动/调整上游变化方面做得非常出色。深入研究 Android 内核实现和主线的细节超出了本书的范围。
`安卓联网
然而,Android 的主要网络问题不是由于 Linux 内核,而是由于 Android 用户空间。Android 严重依赖 HAL,即使是联网,以及系统框架。最初(例如,直到 4.2),在框架级别根本没有以太网支持。如果驱动程序在内核中编译,TCP/IP 堆栈仍然允许基本的以太网连接用于 Android 调试桥(ADB)调试,但仅此而已。从 4.0 开始,Android-x86 project fork 在框架层增加了一个以太网的早期实现(设计很差,但还能工作)。从 4.2 开始,官方上游源支持以太网,但没有办法实际配置它(它检测以太网插入/拔出,如果有 DHCP 服务器,它向接口提供 IP 地址)。应用实际上可以通过框架使用这个接口,但大多数情况下没有人这样做。如果您需要真正的以太网支持(例如,能够配置您的接口,静态/DHCP 配置它,设置代理,确保所有应用都使用该接口),那么仍然需要大量的黑客攻击(参见www.slideshare.net/gxben/abs-2013-dive-into-android-networking-adding-ethernet-connectivity ))。在所有情况下,一次只支持一个接口(仅支持eth0,即使您有eth0和eth1,所以不要期望充当任何类型的路由器)。我将在这里展示四个简短的例子来说明 Android 网络与 Linux 内核网络的不同之处:
- 安全特权和联网:Android 在 Linux 内核中增加了一个安全特性(名为“偏执网络”),根据调用进程的组来限制对一些联网特性的访问。在标准的 Linux 内核中,任何应用都可以打开一个套接字并使用它进行传输/接收,而在 Android 中,对网络资源的访问是由 Gid(组 ID)过滤的。网络安全的部分可能很难合并到主线内核中,因为它包括许多 Android 独有的功能。有关 Android 网络安全的更多信息,请参见
http://elinux.org/Android_Security#Paranoid_network-ing。 - 蓝牙:Bluedroid 是由 Broadcom 开发的基于代码的蓝牙协议栈。它取代了 Android 4.2 中基于 BlueZ 的堆栈。2013 年 7 月,Android 4.3 (API 级别 18)引入了对蓝牙低能耗(BLE 或蓝牙 LE)设备(也称为蓝牙智能和智能就绪设备)的支持。在此之前,Android 开源项目(AOSP)不支持 BLE 设备,但有一些供应商向 BLE 提供了 API。
- Netfilter:谷歌有一个有趣的项目,在 Android 上提供了更好的网络统计。这是由一个 netfilter 模块
xt_qtaguid实现的,它使用户空间应用能够标记它们的套接字。这个项目需要对 Linux 内核 netfilter 子系统进行一些修改。这些变化的补丁也被发送到 Linux 内核邮件列表(LKML);参见http://lwn.net/Articles/517358/。详情请见http://www.linuxplumbersconf.org/2013/ocw/sessions/1491.的“Android netfilter 变化” - NFC:正如本章前面的近场通信(NFC)部分所述,Android NFC 架构是一个用户空间 NFC 堆栈:通过 Broadcom 或 Android OEMs 提供的 HAL 在用户空间中实现。
Android 内部:资源
虽然有很多关于为 Android 开发应用的资源(无论是书籍、邮件列表、论坛、课程等。),关于 Android 内部的资源很少。对于那些有兴趣了解更多信息的读者,我推荐这些资源:
- 卡里姆·亚格穆尔的《嵌入式 Android:移植、扩展和定制》一书
- 幻灯片:Maxime Ripard,Alexandre Belloni 的 Android 系统开发(超过 400 张幻灯片);
http://free-electrons.com/doc/training/android/。 - 幻灯片:Benjamin Zores 的 Android 平台剖析(59 张幻灯片);
http://www.slideshare.net/gxben/droidcon-2013-france-android-platform-anatomy。 - 幻灯片:Benjamin Zores 的 Jelly Bean 设备移植(127 张幻灯片);
http://www.slideshare.net/gxben/as-2013-jelly-bean-device-porting-walkthrough。 - 网址:
http://developer.android.com/index.html。 - Android 平台内部论坛-档案:
http://news.gmane.org/gmane.comp.handhelds.android.platform - 一年一度的 Android 构建者峰会(ABS)正在举行。首届 ABS 于 2011 年在旧金山举行。建议看幻灯片,看视频,或者参加。
- XDA 开发者大会:
http://xda-devcon.com/;http://xda-devcon.com/presentations/中的幻灯片和视频 - 幻灯片:Android 内部,Marko Gargenta:
http://www.scandevconf.se/db/Marakana-Android-Internals.pdf
 注意 Android git 库在
注意 Android git 库在https://android.googlesource.com/中可用
注意,Android 使用一个基于python的特殊工具repo来管理数百个git库,这使得使用git更加容易。```sh````````


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









