







协议:CC BY-NC-SA 4.0
八、IPv6
在第七章中,我讨论了 Linux 相邻子系统及其实现。在这一章中,我将讨论 IPv6 协议及其在 Linux 中的实现。IPv6 是 TCP/IP 协议栈的下一代网络层协议。它是由互联网工程任务组(IETF)开发的,旨在取代 IPv4,后者仍然承载着绝大多数的互联网流量。
在 90 年代早期,由于预期的互联网增长,IETF 开始努力开发下一代 IP 协议。第一个 IPv6 RFC 来自 1995 年:RFC 1883,“互联网协议,第 6 版(IPv6)规范。”后来在 1998 年,RFC 2460 取代了它。IPv6 解决的主要问题是地址短缺:IPv6 地址的长度是 128 位。IPv6 设置了更大的地址空间。我们在 IPv6 中使用 2¹²⁸ 地址,而不是 IPv4 中的 2³² 地址。这确实大大增加了地址空间,可能远远超过未来几十年的需要。但是扩展地址空间并不是 IPv6 的唯一优势,有些人可能会这么想。基于从 IPv4 中获得的经验,IPv6 做了许多改变来改进 IP 协议。我们将在本章中讨论这些变化。
作为一种改进的网络层协议,IPv6 协议正获得越来越多的支持。互联网在全球的日益普及,以及智能移动设备和平板电脑市场的不断增长,无疑使 IPv4 地址的枯竭成为一个更明显的问题。这就需要过渡到 IPv4 的继任者 IPv6 协议。
IPv6–简短介绍
IPv6 子系统无疑是一个非常广泛的主题,它正在稳步发展。在过去的十年中,令人兴奋的功能被添加进来。这些新功能中有一些是基于 IPv4 的,比如 ICMPv6 套接字、IPv6 组播路由和 IPv6 NAT。IPsec 在 IPv6 中是强制的,在 IPv4 中是可选的,尽管大多数操作系统也在 IPv4 中实现了 IPsec。当我们深入研究 IPv6 内核内部时,我们发现了许多相似之处。有时方法的名字甚至一些变量的名字都是相似的,除了增加了“v6”或“6”然而,在一些地方的实施中有一些变化。
我们选择在本章中讨论 IPv6 的重要新功能,展示它与 IPv4 的一些不同之处,并解释为什么要做出改变。扩展头、多播监听器发现(MLD)协议和自动配置过程是我们讨论的一些新特性,并通过一些用户空间示例进行演示。我们还将讨论接收 IPv6 数据包的工作原理、IPv6 转发的工作原理,以及与 IPv4 的一些不同之处。总的来说,IPv6 的开发者似乎在过去使用 IPv4 的经验的基础上做了很多改进,IPv6 的实现带来了很多 IPv4 没有的好处和很多优于 IPv4 的优点。我们将在下一节讨论 IPv6 地址,包括多播地址和特殊地址。
IPv6 地址
学习 IPv6 的第一步是熟悉 RFC 4291 中定义的 IPv6 寻址架构。IPv6 地址有三种类型:
- 单播: 该地址唯一标识一个接口。发送到单播地址的数据包会被传送到该地址标识的接口。
- 任播: 这个地址可以分配给一组接口(通常在不同的节点上)。IPv4 中不存在这种类型的地址。事实上,它是单播地址和组播地址的混合。发送到任播地址的数据包被传送到该地址所标识的接口之一(根据路由协议,是“最近”的接口)。
- 组播: 这个地址可以分配给一组接口(通常在不同的节点上)。发送到多播地址的数据包会被传送到该地址标识的所有接口。一个接口可以属于任意数量的多播组。
IPv6 中没有广播地址。在 IPv6 中,为了获得与广播相同的结果,可以向所有节点的组组播地址发送数据包(ff02::1))。在 IPv4 中,地址解析协议(ARP)协议的很大一部分功能是基于广播的。IPv6 子系统使用邻居发现而不是 ARP 来将 L3 地址映射到 L2 地址。IPv6 邻居发现协议基于 ICMPv6,它使用组播地址而不是广播地址,正如您在上一章中看到的。在本章的后面,你会看到更多使用多播流量的例子。
IPv6 地址由 8 个 16 位的块组成,总共 128 位。IPv6 地址看起来像这样:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx(其中 x 是十六进制数字。)有时候你会在一个 IPv6 地址里面遇到“::”;这是前导零的快捷方式。
在 IPv6 中,使用地址前缀。事实上,前缀相当于 IPv4 子网掩码。RFC 4291“IP 版本 6 寻址架构”中描述了 IPv6 前缀 IPv6 地址前缀由以下符号表示:ipv6-address/prefix-length。
前缀长度是一个十进制值,指定地址中有多少个最左边的连续位构成前缀。我们使用“/n”来表示前缀 n 位长。例如,对于所有以 32 位2001:0da7开头的 IPv6 地址,使用以下前缀:2001:da7::/32。
现在您已经了解了 IPv6 地址的类型,接下来您将了解一些特殊的 IPv6 地址及其用法。
特殊地址
在本节中,我将描述一些特殊的 IPv6 地址及其用法。建议您熟悉这些特殊地址,因为您将在本章后面的内容中以及浏览代码时遇到其中的一些地址(如 DAD 中使用的全零的未指定地址,或重复地址检测)。以下列表包含特殊的 IPv6 地址及其用法说明:
- 每个接口上应该至少有一个链路本地单播地址。链路本地地址允许与同一物理网络中的其他节点进行通信;邻居发现、自动地址配置等等都需要它。路由器不得转发任何带有本地链路源地址或目的地址的数据包。本地链路地址分配有前缀
fe80::/64。 - 全球单播地址一般格式如下:前 n 位为
global routing prefix,后 m 位为subnet ID,其余 128- n - m 位为interface ID。 global routing prefix:分配给站点的值。它代表网络 ID 或地址前缀。subnet ID:站点内子网的标识符。interface ID:一个id;其值在子网内必须是唯一的。RFC 3513 第 2.5.1 节对此进行了定义。
RFC 3587“IPv6 全球单播地址格式”中描述了全球单播地址 RFC 4291 中定义了可分配的全局单播地址空间。
- IPv6 环回地址是
0:0:0:0:0:0:0:1,简称为::1。 - 全零(
0:0:0:0:0:0:0:0)的地址称为未指定地址。它用于 DAD(重复地址检测),就像你在前一章看到的那样。它不应用作目的地址。您不能通过使用用户空间工具(如ip命令或ifconfig命令)将未指定的地址分配给接口。 - IPv4 映射的 IPv6 地址是以 80 位零开始的地址。接下来的 16 位是 1,剩下的 32 位是 IPv4 地址。例如,
::ffff:192.0.2.128代表 192.0.2.128 的 IPv4 地址。有关这些地址的用法,请参见 RFC 4038,“IPv6 过渡的应用方面” - 不推荐使用与 IPv4 兼容的格式;在这种格式中,IPv4 地址位于 IPv6 地址的低 32 位,所有剩余的位都是 0;前面提到的地址应该是这个格式的
::192.0.2.128。参见 RFC 4291,2.5.5.1 部分。 - 站点本地地址 最初设计用于站点内部寻址,无需全局前缀,但在 2004 年的 RFC 3879“不认可的站点本地地址”中被弃用。
IPv6 地址在 Linux 中由in6_addr结构表示;在in6_addr结构中使用三个数组(8、16 和 32 位元素)的并集有助于位操作操作:
struct in6_addr {
union {
__u8 u6_addr8[16];
__be16 u6_addr16[8];
__be32 u6_addr32[4];
} in6_u;
#define s6_addr in6_u.u6_addr8
#define s6_addr16 in6_u.u6_addr16
#define s6_addr32 in6_u.u6_addr32
};
(include/uapi/linux/in6.h)
多播在 IPv6 中扮演着重要的角色,尤其是对于基于 ICMPv6 的协议,如 NDISC(我在第七章中讨论过,它涉及 Linux 的相邻子系统)和 MLD(将在本章后面讨论)。我将在下一节讨论 IPv6 中的组播地址。
多播地址
多播地址提供了一种定义多播组的方法;一个节点可以属于一个或多个多播组。目的地是多播地址的分组应该被传送到属于该多播组的每个节点。在 IPv6 中,所有组播地址都以 FF 开头(前 8 位)。接下来的 4 位用于标志,4 位用于作用域。最后,最后 112 位是组 ID。标志字段的 4 位含义如下:
- 位 0: 保留供将来使用。
- 位 1: 值 1 表示集合点嵌入在地址中。集合点的讨论更多地与用户空间守护进程相关,不在本书的范围之内。有关更多详细信息,请参见 RFC 3956,“在 IPv6 多播地址中嵌入集合点(RP)地址”这个位有时被称为 R 标志(R 代表集合点。)
- 位 2: 值 1 表示基于网络前缀分配的多播地址。(参见 RFC 3306。)这个位有时被称为 P 标志(P 表示前缀信息。)
- 位 3: 值 0 表示永久分配的(“众所周知的”)多播地址,由互联网号码分配机构(IANA)分配。值 1 表示非永久分配的(“瞬时”)多播地址。该位有时被称为 T 标志(T 代表临时。)
作用域可以是表 8-1 中的一个条目,该表通过 Linux 符号和值显示了各种 IPv6 作用域。
表 8-1 。IPv6 作用域
|十六进制值
|
描述
|
Linux 符号
|
| — | — | — |
| 0x01 | 本地节点 | IPV6 _ ADDR _ 范围 _ 节点本地 |
| 0x02 | 链接本地 | IPV6 _ ADDR _ 范围 _ 链接本地 |
| 0x05 | 本地站点 | IPV6 _ ADDR _ 范围 _ 站点本地 |
| 0x08 | 组织 | IPV6 _ ADDR _ 范围 _ 组织本地 |
| 0x0e | 全球的 | IPV6 _ ADDR _ 范围 _ 全球 |
既然您已经了解了 IPv6 组播地址,您将在下一节了解一些特殊的组播地址。
特殊多播地址
我将在本章中提到一些特殊的多播地址。RFC 4291 的第 2.7.1 节定义了这些特殊的多播地址:
- 所有节点组播地址组:
ff01::1,ff02::1 - 所有路由器组播地址组:
ff01::2、ff02::2、ff05::2
根据 RFC 3810,有这个特殊的地址:所有支持 MLDv2 的路由器组播组,也就是ff02::16。版本 2 多播侦听器报告将被发送到此特殊地址;我将在本章后面的“多播侦听程序发现(MLD)”一节中讨论它。
要求节点计算并加入(在适当的接口上)已经为该节点的接口(手动或自动)配置的所有单播和任播地址的相关请求节点多播地址。请求节点多播地址是基于节点的单播和任播地址计算的。被请求节点多播地址是通过获取地址的低 24 位(单播或任播)并将这些位附加到前缀ff02:0:0:0:0:1:ff00::/104形成的,从而得到范围ff02:0:0:0:0:1:ff00:0000到ff02:0:0:0:0:1:ffff:ffff内的多播地址。参见 RFC 4291。
方法addrconf_addr_solict_mult()计算链路本地的请求节点多播地址(include/net/addrconf.h)。方法addrconf_join_solict()加入请求地址多播组(net/ipv6/addrconf.c)。
在前一章中,您看到了邻居通告消息通过ndisc_send_na()方法发送到本地链路的所有节点地址(ff02::1)。在本章后面的小节中,您将看到更多使用特殊地址的例子,如所有节点多播组地址或所有路由器多播组地址。在本节中,您已经看到了一些组播地址,您将在本章后面以及浏览 IPv6 源代码时遇到这些地址。现在,我将在下一节讨论 IPv6 报头。
IPv6 报头
每个 IPv6 数据包都以 IPv6 报头开始,了解其结构对于全面理解 IPv6 Linux 实现非常重要。IPv6 报头具有 40 字节的固定长度;因此,没有指定 IPv6 报头长度的字段(与 IPv4 相反,IPv4 报头的ihl成员表示报头长度)。请注意,IPv6 报头中也没有校验和字段,这将在本章稍后解释。在 IPv6 中,没有像在 IPv4 中那样的 IP 选项机制。IPv4 中的 IP 选项处理机制具有性能成本。相反,IPV6 具有更有效的扩展头机制,这将在下一节“扩展头”中讨论图 8-1 显示了 IPv6 报头及其字段。

图 8-1 。IPv6 报头
请注意,在最初的 IPv6 标准 RFC 2460 中,优先级(流量类别)是 8 位,流标签是 20 位。在ipv6hdr结构的定义中,priority(业务类别)字段大小是 4 比特。事实上,在 Linux IPv6 实现中,flow_lbl的前 4 位被粘在priority(流量类)字段上,以便形成一个“类”图 8-1 反映了 Linux 对ipv6hdr结构的定义,如下所示:
struct ipv6hdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 priority:4,
version:4;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u8 version:4,
priority:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 flow_lbl[3];
__be16 payload_len;
__u8 nexthdr;
__u8 hop_limit;
struct in6_addr saddr;
struct in6_addr daddr;
};
(include/uapi/linux/ipv6.h)
以下是对ipv6hdr结构成员的描述:
version:4 位字段。应该设置为 6。priority: 表示 IPv6 数据包的流量类别或优先级。RFC 2460 是 IPv6 的基础,它没有定义特定的流量类别或优先级值。flow_lbl: 在编写基础 IPv6 标准(RFC 2460)时,流标签字段被认为是实验性的。它提供了一种标记特定流的数据包序列的方法;上层可以出于各种目的使用这种标记。2011 年的 RFC 6437“IPv6 流标签规范”建议使用流标签来检测地址欺骗。payload_len:16 位字段。不含 IPv6 报头的数据包最大可达 65,535 字节。我将在下一节介绍逐跳选项报头时讨论更大的数据包(“巨型帧”)。nexthdr: 当没有扩展头时,这将是上层协议号,如 UDP 的 IPPROTO_UDP (17)或 TCP 的 IPPROTO_TCP (6)。可用协议列表在include/uapi/linux/in.h中。使用扩展标头时,这将是紧跟在 IPv6 标头之后的下一个标头的类型。我将在下一节讨论扩展头。hop_limit: 一个字节字段。每个转发设备将hop_limit计数器减 1。当它达到零时,一条 ICMPv6 消息被发回,数据包被丢弃。这类似于 IPv4 报头中的 TTL 成员。参见net/ipv6/ip6_output.c中的ip6_forward()方法。saddr: IPv6 源地址(128 位)。daddr: IPv6 目的地址(128 位)。如果使用了路由报头,这可能不是最终的数据包目的地。
请注意,与 IPv4 报头不同,IPv6 报头中没有校验和。假设校验和由第 2 层和第 4 层保证。IPv4 中的 UDP 允许校验和为 0,表示没有校验和;IPV6 中的 UDP 通常需要有自己的校验和。在 IPv6 中有一些特殊情况,IPv6 UDP 隧道允许零 UDP 校验和;请参见 RFC 6935,“隧道数据包的 IPv6 和 UDP 校验和”在处理 IPv4 子系统的第四章中,您会看到在转发数据包时会调用ip_decrease_ttl()方法。此方法重新计算 IPv4 报头的校验和,因为ttl的值已更改。在 IPv6 中,转发数据包时不需要重新计算校验和,因为 IPv6 报头中根本没有校验和。这导致基于软件的路由器的性能提高。
在本节中,您已经看到了 IPv6 报头是如何构建的。您看到了 IPv4 报头和 IPv6 报头之间的一些差异,例如,在 IPv6 报头中没有校验和,也没有报头长度。下一节讨论 IPv6 扩展头,它是 IPv4 选项的对应部分。
扩展标题
IPv4 报头可以包括 IP 选项,其可以将 IPv4 报头的最小大小从 20 字节扩展到 60 字节。在 IPv6 中,我们有可选的扩展头。除了一个例外(逐跳选项报头),在分组到达其最终目的地之前,扩展报头不被分组的传递路径上的任何节点处理;这大大提高了转发过程的性能。基础 IPv6 标准定义了扩展报头。IPv6 数据包可以包括 0 个、1 个或多个扩展标头。这些报头可以放在 IPv6 报头和数据包的上层报头之间。IPv6 报头的nexthdr字段是紧跟在 IPv6 报头之后的下一个报头的编号。这些扩展标头是链接的;每个扩展标头都有一个 Next 标头字段。在最后一个扩展头中,Next 头表示上层协议(如 TCP、UDP 或 ICMPv6)。扩展标头的另一个优点是,将来添加新的扩展标头很容易,并且不需要对 IPv6 标头进行任何更改。
扩展头必须严格按照它们在包中出现的顺序进行处理。每个扩展标头最多应出现一次,但目标选项标头除外,它最多应出现两次。(详见本节下文目的地选项标题的说明。)逐跳选项标头必须紧接在 IPv6 标头之后出现;所有其他选项可以以任何顺序出现。RFC 2460 的第 4.1 节(“扩展报头顺序”)陈述了扩展报头应该出现的推荐顺序,但是这不是强制性的。当处理数据包时遇到未知的下一个报头号时,将通过调用icmpv6_param_prob()方法向发送方发回一条 ICMPv6“参数问题”消息,代码为“未知的下一个报头”(ICMPV6_UNK_NEXTHDR)。本章末尾“快速参考”部分的表 8-4 中描述了可用的 ICMPv6“参数问题代码”。
每个扩展头必须在 8 字节边界上对齐。对于可变大小的扩展头,有一个头扩展长度字段,如果需要,它们使用填充来确保它们在 8 字节边界上对齐。所有 Linux IPv6 扩展头的编号及其 Linux 内核符号表示显示在本章末尾“快速参考”部分的表 8-2“IPv6 扩展头”中。
用inet6_add_protocol()方法为每个扩展报头(除了逐跳选项报头)注册一个协议处理程序。不为逐跳选项报头注册协议处理程序的原因是有一种特殊的方法来解析逐跳选项报头,即ipv6_parse_hopopts()方法。在调用协议处理程序之前调用此方法。(参见ipv6_rcv()方法,net/ipv6/ip6_input.c)。如前所述,逐跳选项报头必须是第一个报头,紧跟在 IPv6 报头之后。以这种方式,例如,用于片段扩展报头的协议处理程序被注册:
static const struct inet6_protocol frag_protocol =
{
.handler = ipv6_frag_rcv,
.flags = INET6_PROTO_NOPOLICY,
};
int __init ipv6_frag_init(void)
{
int ret;
ret = inet6_add_protocol(&frag_protocol, IPPROTO_FRAGMENT);
(net/ipv6/reassembly.c)
以下是对所有 IPv6 扩展标头的描述:
-
**逐跳选项头:**必须在每个节点上处理逐跳选项头。它由
ipv6_parse_hopopts()方法(net/ipv6/exthdrs.c)解析。 -
逐跳选项报头必须紧跟在 IPv6 报头之后。例如,它被多播侦听程序发现协议使用,您将在本章后面的“多播侦听程序发现(MLD)”一节中看到。逐跳选项报头包括可变长度选项字段。它的第一个字节是它的类型,可以是下列之一:
-
路由器警报(Linux 内核符号:IPV6 _ TLV _ 路由器警报,值:5)。请参阅 RFC 6398,“IP 路由器警报注意事项和用法”
-
Jumbo (Linux 内核符号:IPV6_TLV_JUMBO,值:194)。IPv6 数据包有效负载通常最长可达 65,535 字节。使用 jumbo 选项,最高可达 2³² 字节。请参见 RFC 2675,“IPv6 图片”
-
Pad1 (Linux 内核符号:IPV6_TLV_PAD1,值:0)。Pad1 选项用于插入一个字节的填充。当需要多个填充字节时,应使用 PadN 选项(见下一步)(而不是多个 Pad1 选项)。参见 RFC 2460 的第 4.2 节。
-
PadN (Linux 内核符号:IPV6_TLV_PADN,值:1)。PadN 选项用于在报头的选项区域插入两个或多个八位字节的填充。
-
路由选项头: 这与 IPv4 松散源记录路由(IPOPT_LSRR)平行,在第四章的“IP 选项”一节中讨论。它提供了指定一个或多个路由器的能力,这些路由器应该沿着数据包到其最终目的地的遍历路由被访问。
-
分片选项头: 与 IPv4 相反,IPv6 中的分片只能发生在发送数据包的主机上,而不能发生在任何中间节点上。碎片由从
ip6_finish_output()方法调用的ip6_fragment()方法实现。在ip6_fragment()方法中,有一条慢速路径和一条快速路径,这与 IPv4 分段非常相似。IPv6 分片的实现在net/ipv6/ip6_output.c,IPv6 碎片整理的实现在net/ipv6/reassembly.c。 -
认证头: 认证头(AH)提供数据认证、数据完整性和防重放保护。它在 RFC 4302“IP 认证头”中有描述,这使得 RFC 2402 过时了。
-
**封装安全有效载荷选项头:**RFC 4303“IP 封装安全有效载荷(ESP)”中有描述,使得 RFC 2406 过时。注意:封装安全有效载荷(ESP)协议在第十章的中讨论,其中讨论了 IPsec 子系统。
-
目的地选项头: 目的地选项头在一个数据包中可以出现两次;在路由选项报头之前和之后。当它在路由选项报头之前时,它包括应该由路由器选项报头指定的路由器处理的信息。当它在路由器选项报头之后时,它包括应该由最终目的地处理的信息。
在下一节中,您将看到 IPv6 协议处理程序,即ipv6_rcv()方法,是如何与 IPv6 数据包相关联的。
IPv6 初始化
inet6_init()方法执行各种 IPv6 初始化(如procfs初始化、TCPv6、UDPv6 和其他协议的协议处理程序注册)、IPv6 子系统初始化(如 IPv6 邻居发现、IPv6 多播路由和 IPv6 路由子系统)等。更多细节,请看net/ipv6/af_inet6.c。通过为 IPv6 定义一个packet_type对象并用dev_add_pack()方法注册它,将ipv6_rcv()方法注册为 IPv6 数据包的协议处理程序,这与 IPv4 中的做法非常相似:
static struct packet_type ipv6_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IPV6),
.func = ipv6_rcv,
};
static int __init ipv6_packet_init(void)
{
dev_add_pack(&ipv6_packet_type);
return 0;
}
(net/ipv6/af_inet6.c)
作为刚才显示的注册的结果,以太网类型为 ETH_P_IPV6 (0x86DD)的每个以太网数据包将由ipv6_rcv()方法处理。接下来,我将讨论用于设置 IPv6 地址的 IPv6 自动配置机制。
自动配置
自动配置是一种允许主机为其每个接口获取或创建唯一地址的机制。IPv6 自动配置过程在系统启动时启动;节点(主机和路由器)为其接口生成一个链路本地地址。该地址被视为“暂定”(设置接口标志 IFA _ F _ 暂定);这意味着它只能与邻居发现消息通信。应该验证该地址没有被链路上的另一个节点使用。这是通过 DAD(重复地址检测)机制来完成的,在前一章讨论 Linux 相邻子系统时已经描述过了。如果节点不是唯一的,自动配置过程将停止,需要手动配置。如果地址是唯一的,自动配置过程将继续。主机自动配置的下一阶段包括向所有路由器多播组地址发送一个或多个路由器请求(ff02::2)。这是通过从addrconf_dad_completed()方法中调用ndisc_send_rs()方法来完成的。路由器回复路由器通告消息,该消息被发送到所有主机地址ff02::1。路由器请求和路由器广告都通过 ICMPv6 消息使用邻居发现协议。路由器请求 ICMPv6 类型是 NDISC_ROUTER_SOLICITATION (133),路由器通告 ICMPv6 类型是 NDISC_ROUTER_ADVERTISEMENT (134)。
radvd守护进程是一个开源路由器广告守护进程的例子,用于无状态自动配置(http://www.litech.org/radvd/)。您可以在radvd配置文件中设置一个前缀,它将在路由器广告消息中发送。radvd守护进程定期发送路由器广告。除此之外,它还监听路由器请求(RS)请求,并用路由器广告(RA) 回复消息进行应答。这些路由器广告(RA)消息包括一个前缀字段,它在自动配置过程中起着重要的作用,您马上就会看到这一点。前缀长度必须为 64 位。当主机收到路由器广告(RA)消息时,它会根据该前缀和自己的 MAC 地址来配置其 IP 地址。如果设置了隐私扩展功能(CONFIG_IPV6_PRIVACY ),那么在 IPV6 地址创建中还会增加一些随机性。隐私扩展机制通过添加前面提到的随机性,避免了从 IPv6 地址获取关于机器身份的细节,IPv6 地址通常是使用其 MAC 地址和前缀生成的。有关隐私扩展的更多详细信息,请参见 RFC 4941,“IPv6 中无状态地址自动配置的隐私扩展”
当主机收到路由器通告消息时,它可以自动配置自己的地址和其它一些参数。它还可以根据这些广告选择默认路由器。也可以为主机上自动配置的地址设置优选寿命和有效寿命。preferred lifetime 值指定通过无状态地址自动配置从前缀生成的地址保持在首选状态的时间长度(秒)。当优选时间结束时,该地址将停止通信(不会应答ping6等)。).valid lifetime 值以秒为单位指定地址有效的时间长度(即,已经使用它的应用可以继续使用它);当这个时间结束时,地址被删除。首选生存期和有效生存期在内核中分别由inet6_ifaddr对象的prefered_lft和valid_lft字段表示(include/net/if_inet6.h)。
重新编号是用新前缀替换旧前缀,并根据新前缀更改主机 IPv6 地址的过程。使用radvd也可以很容易地完成重新编号,方法是在它的配置设置中添加一个新的前缀,设置一个首选生存期和一个有效生存期,然后重新启动radvd守护进程。另请参见 RFC 4192,“无标志日的 IPv6 网络重新编号程序”,以及 RFCs 5887、6866 和 6879。
动态主机配置协议版本 6 (DHCPv6) 是有状态地址配置的一个例子;在有状态自动配置模型中,主机从服务器获取接口地址和/或配置信息和参数。服务器维护一个数据库,该数据库记录哪些地址分配给了哪些主机。在这本书里我不会深究 DHCPv6 协议的细节。DHCPv6 协议由 RFC 3315“IPv6 的动态主机配置协议(DHCPv6)”指定 RFC 4862“IPv6 无状态地址自动配置”中描述了 IPv6 无状态自动配置标准
在本节中,您已经了解了自动配置过程,并且看到了通过配置和重启radvd用新前缀替换旧前缀是多么容易。下一节将讨论作为 IPv6 协议处理程序的ipv6_rcv()方法如何处理 IPv6 数据包的接收,其方式与您在 IPv4 中看到的方式有些相似。
接收 IPv6 数据包
主要的 IPv6 接收方法是ipv6_rcv()方法,它是所有 IPv6 数据包(包括多播;如前所述,IPv6 中没有广播)。IPv4 和 IPv6 中的 Rx 路径有许多相似之处。与在 IPv4 中一样,我们首先进行一些完整性检查,比如检查 IPv6 报头的版本是否为 6,以及源地址是否为多播地址。(根据 RFC 4291 的第 2.7 节,这是禁止的。)如果有逐跳选项头,一定是第一个。如果 IPV6 报头的nexthdr的值为 0,这表示逐跳选项报头,并且通过调用ipv6_parse_hopopts()方法对其进行解析。真正的工作由ip6_rcv_finish()方法完成,该方法通过调用 NF_HOOK()宏来调用。如果此时注册了一个 netfilter 回调函数(NF_INET_PRE_ROUTING),它将被调用。我将在下一章讨论 netfilter 钩子。让我们来看看ipv6_rcv()的方法:
int ipv6_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
const struct ipv6hdr *hdr;
u32 pkt_len;
struct inet6_dev *idev;
从与套接字缓冲区(SKB)相关联的网络设备获取网络名称空间 :
struct net *net = dev_net(skb->dev);
. . .
从 SKB 获取 IPv6 报头:
hdr = ipv6_hdr(skb);
执行一些健全性检查,并在必要时丢弃 SKB:
if (hdr->version != 6)
goto err;
/*
* RFC4291 2.5.3
* A packet received on an interface with a destination address
* of loopback must be dropped.
*/
if (!(dev->flags & IFF_LOOPBACK) &&
ipv6_addr_loopback(&hdr->daddr))
goto err;
. . .
/*
* RFC4291 2.7
* Multicast addresses must not be used as source addresses in IPv6
* packets or appear in any Routing header.
*/
if (ipv6_addr_is_multicast(&hdr->saddr))
goto err;
. . .
if (hdr->nexthdr == NEXTHDR_HOP) {
if (ipv6_parse_hopopts(skb) < 0) {
IP6_INC_STATS_BH(net, idev, IPSTATS_MIB_INHDRERRORS);
rcu_read_unlock();
return NET_RX_DROP;
}
}
. . .
return NF_HOOK(NFPROTO_IPV6, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip6_rcv_finish);
err:
IP6_INC_STATS_BH(net, idev, IPSTATS_MIB_INHDRERRORS);
drop:
rcu_read_unlock();
kfree_skb(skb);
return NET_RX_DROP;
}
(net/ipv6/ip6_input.c)
ip6_rcv_finish()方法首先通过调用ip6_route_input()方法在路由子系统中执行查找,以防没有dst连接到 SKB。ip6_route_input()方法最终会调用fib6_rule_lookup()。
int ip6_rcv_finish(struct sk_buff *skb)
{
. . .
if (!skb_dst(skb))
ip6_route_input(skb);
调用附属于 SKB 的dst的input回调;
return dst_input(skb);
}
(net/ipv6/ip6_input.c)
 注意
注意fib6_rule_lookup()方法有两种不同的实现:一种是在net/ipv6/fib6_rules.c中设置策略路由(CONFIG_IPV6_MULTIPLE_TABLES)时,一种是在net/ipv6/ip6_fib.c中未设置策略路由时。
正如您在第五章中看到的,该章讨论了 IPv4 路由子系统的高级主题,路由子系统中的查找构建了一个dst对象,并设置了它的input和output回调;在 IPv6 中,执行类似的任务。在ip6_rcv_finish()方法在路由子系统中执行查找之后,它调用dst_input()方法,该方法实际上调用了与数据包相关联的dst对象的input回调。
图 8-2 显示了网络驱动程序接收到的数据包的接收路径(Rx) 。此数据包可以被传送到本地机器,也可以被转发到另一台主机。路由表中的查找结果决定了这两个选项中的哪一个会发生。
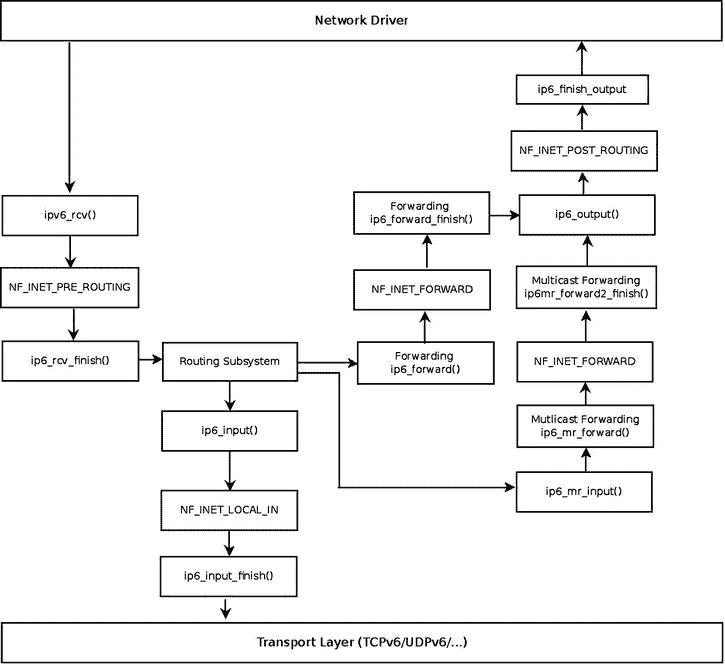
图 8-2 。接收 IPv6 数据包
 注为简单起见,该图不包括扩展头/IPsec 方法的分段/碎片整理/解析。
注为简单起见,该图不包括扩展头/IPsec 方法的分段/碎片整理/解析。
IPv6 路由子系统中的查找将目的缓存(dst)的input回调设置为:
ip6_input()当数据包的目的地是本地机器时。ip6_forward()何时转发数据包。ip6_mc_input()当数据包的目的地是组播地址时。ip6_pkt_discard()数据包将被丢弃的时间。ip6_pkt_discard()方法丢弃数据包,并用目的地不可达(icmp V6 _ DEST _ 未到达)消息回复发送方。
传入的 IPv6 数据包可以在本地传递或转发;在下一节中,您将了解 IPv6 数据包的本地传送。
本地交付
让我们首先看看本地交付案例:ip6_input()方法是一个非常短的方法:
int ip6_input(struct sk_buff *skb)
{
return NF_HOOK(NFPROTO_IPV6, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip6_input_finish);
}
(net/ipv6/ip6_input.c)
如果在这个点(NF_INET_LOCAL_IN)注册了一个 netfilter 钩子,它将被调用。否则,我们将继续使用ip6_input_finish()方法:
static int ip6_input_finish(struct sk_buff *skb)
{
struct net *net = dev_net(skb_dst(skb)->dev);
const struct inet6_protocol *ipprot;
inet6_dev结构(include/net/if_inet6.h)是 IPv4 in_device结构的 IPv6 并行。它包含与 IPv6 相关的配置,例如网络接口单播地址列表(addr_list)和网络接口组播地址列表(mc_list)。该 IPv6 相关配置可由用户使用ip命令或ifconfig命令进行设置。
struct inet6_dev *idev;
unsigned int nhoff;
int nexthdr;
bool raw;
/*
* Parse extension headers
*/
rcu_read_lock();
resubmit:
idev = ip6_dst_idev(skb_dst(skb));
if (!pskb_pull(skb, skb_transport_offset(skb)))
goto discard;
nhoff = IP6CB(skb)->nhoff;
从 SKB 获取下一个标题号:
nexthdr = skb_network_header(skb)[nhoff];
首先,在原始套接字包的情况下,我们尝试将其传递到原始套接字:
raw = raw6_local_deliver(skb, nexthdr);
每个扩展头(除了逐跳扩展头)都有一个协议处理程序,该程序由inet6_add_protocol()方法注册;这个方法实际上在全局inet6_protos数组中添加了一个条目(参见net/ipv6/protocol.c)。
if ((ipprot = rcu_dereference(inet6_protos[nexthdr])) != NULL) {
int ret;
if (ipprot->flags & INET6_PROTO_FINAL) {
const struct ipv6hdr *hdr;
/* Free reference early: we don't need it any more,
and it may hold ip_conntrack module loaded
indefinitely. */
nf_reset(skb);
skb_postpull_rcsum(skb, skb_network_header(skb),
skb_network_header_len(skb));
hdr = ipv6_hdr(skb);
RFC 3810 是 MLDv2 规范,它说:“请注意,MLDv2 消息不受源过滤的限制,必须始终由主机和路由器进行处理。”我们不希望由于源过滤而丢弃 MLD 多播分组,因为这些 MLD 分组应该总是根据 RFC 来处理。因此,在丢弃该分组之前,我们确保如果该分组的目的地地址是多播地址,则该分组不是 MLD 分组。这是通过在丢弃之前调用ipv6_is_mld()方法来完成的。如果该方法指示该分组是 MLD 分组,则它不会被丢弃。您还可以在本章后面的“多播侦听器发现(MLD)”一节中了解更多信息。
if (ipv6_addr_is_multicast(&hdr->daddr) &&
!ipv6_chk_mcast_addr(skb->dev, &hdr->daddr,
&hdr->saddr) &&
!ipv6_is_mld(skb, nexthdr, skb_network_header_len(skb)))
goto discard;
}
当 INET6_PROTO_NOPOLICY 标志被设置时,这表示不需要对该协议执行 IPsec 策略检查:
if (!(ipprot->flags & INET6_PROTO_NOPOLICY) &&
!xfrm6_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard;
ret = ipprot->handler(skb);
if (ret > 0)
goto resubmit;
else if (ret == 0)
IP6_INC_STATS_BH(net, idev, IPSTATS_MIB_INDELIVERS);
} else {
if (!raw) {
if (xfrm6_policy_check(NULL, XFRM_POLICY_IN, skb)) {
IP6_INC_STATS_BH(net, idev,
IPSTATS_MIB_INUNKNOWNPROTOS);
icmpv6_send(skb, ICMPV6_PARAMPROB,
ICMPV6_UNK_NEXTHDR, nhoff);
}
kfree_skb(skb);
} else {
一切都很顺利,所以增加 INDELIVERS SNMP MIB 计数器(/proc/net/snmp6/Ip6InDelivers)并使用consume_skb()方法释放数据包:
IP6_INC_STATS_BH(net, idev, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
rcu_read_unlock();
return 0;
discard:
IP6_INC_STATS_BH(net, idev, IPSTATS_MIB_INDISCARDS);
rcu_read_unlock();
kfree_skb(skb);
return 0;
}
(net/ipv6/ip6_input.c)
您已经看到了本地交付的实现细节,这是由ip6_input()和ip6_input_finish()方法执行的。现在是时候转向 IPv6 中转发的实现细节了。同样在这里,IPv4 中的转发和 IPv6 中的转发有许多相似之处。
促进
IPv6 中的转发与 IPv4 中的转发非常相似。不过,还是有一些细微的变化。例如,在 IPv6 中,转发数据包时不计算校验和。(如前所述,IPv6 报头中根本没有校验和字段。)我们来看看ip6_forward()法:
int ip6_forward(struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct ipv6hdr *hdr = ipv6_hdr(skb);
struct inet6_skb_parm *opt = IP6CB(skb);
struct net *net = dev_net(dst->dev);
u32 mtu;
应该设置 IPv6 procfs转发条目(/proc/sys/net/ipv6/conf/all/forwarding):
if (net->ipv6.devconf_all->forwarding == 0)
goto error;
使用大型接收卸载(LRO)时,数据包长度将超过最大传输单位(MTU)。与在 IPv4 中一样,当启用 LRO 时,SKB 被释放,并返回错误–EINVAL:
if (skb_warn_if_lro(skb))
goto drop;
if (!xfrm6_policy_check(NULL, XFRM_POLICY_FWD, skb)) {
IP6_INC_STATS(net, ip6_dst_idev(dst), IPSTATS_MIB_INDISCARDS);
goto drop;
}
丢弃不是发往本地主机的数据包。与 SKB 相关联的pkt_type是根据传入分组的以太网报头中的目的地 MAC 地址来确定的。这是通过eth_type_trans()方法完成的,该方法通常在网络设备驱动程序中处理传入的数据包时调用。见eth_type_trans()法,net/ethernet/eth.c。
if (skb->pkt_type != PACKET_HOST)
goto drop;
skb_forward_csum(skb);
/*
* We DO NOT make any processing on
* RA packets, pushing them to user level AS IS
* without any WARRANTY that application will be able
* to interpret them. The reason is that we
* cannot make anything clever here.
*
* We are not end-node, so that if packet contains
* AH/ESP, we cannot make anything.
* Defragmentation also would be mistake, RA packets
* cannot be fragmented, because there is no warranty
* that different fragments will go along one path. --ANK
*/
if (opt->ra) {
u8 *ptr = skb_network_header(skb) + opt->ra;
我们应该尝试将数据包传送到由setsockopt()设置了 IPV6_ROUTER_ALERT 套接字选项的套接字。这是通过调用ip6_call_ra_chain()方法来完成的;如果ip6_call_ra_chain()中的传递成功,ip6_forward()方法返回 0,数据包不被转发。参见net/ipv6/ip6_output.c中ip6_call_ra_chain()方法的实现。
if (ip6_call_ra_chain(skb, (ptr[2]<<8) + ptr[3]))
return 0;
}
/*
* check and decrement ttl
*/
if (hdr->hop_limit <= 1) {
/* Force OUTPUT device used as source address */
skb->dev = dst->dev;
当跳数限制为 1(或更少)时,发送回 ICMP 错误消息,这与我们在 IPv4 中转发数据包且 TTL 达到 0 时的情况非常相似。在这种情况下,数据包将被丢弃:
icmpv6_send(skb, ICMPV6_TIME_EXCEED, ICMPV6_EXC_HOPLIMIT, 0);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_INHDRERRORS);
kfree_skb(skb);
return -ETIMEDOUT;
}
/* XXX: idev->cnf.proxy_ndp? */
if (net->ipv6.devconf_all->proxy_ndp &&
pneigh_lookup(&nd_tbl, net, &hdr->daddr, skb->dev, 0)) {
int proxied = ip6_forward_proxy_check(skb);
if (proxied > 0)
return ip6_input(skb);
else if (proxied < 0) {
IP6_INC_STATS(net, ip6_dst_idev(dst),
IPSTATS_MIB_INDISCARDS);
goto drop;
}
}
if (!xfrm6_route_forward(skb)) {
IP6_INC_STATS(net, ip6_dst_idev(dst), IPSTATS_MIB_INDISCARDS);
goto drop;
}
dst = skb_dst(skb);
/* IPv6 specs say nothing about it, but it is clear that we cannot
send redirects to source routed frames.
We don't send redirects to frames decapsulated from IPsec.
*/
if (skb->dev == dst->dev && opt->srcrt == 0 && !skb_sec_path(skb)) {
struct in6_addr *target = NULL;
struct inet_peer *peer;
struct rt6_info *rt;
/*
* incoming and outgoing devices are the same
* send a redirect.
*/
rt = (struct rt6_info *) dst;
if (rt->rt6i_flags & RTF_GATEWAY)
target = &rt->rt6i_gateway;
else
target = &hdr->daddr;
peer = inet_getpeer_v6(net->ipv6.peers, &rt->rt6i_dst.addr, 1);
/* Limit redirects both by destination (here)
and by source (inside ndisc_send_redirect)
*/
if (inet_peer_xrlim_allow(peer, 1*HZ))
ndisc_send_redirect(skb, target);
if (peer)
inet_putpeer(peer);
} else {
int addrtype = ipv6_addr_type(&hdr->saddr);
/* This check is security critical. */
if (addrtype == IPV6_ADDR_ANY ||
addrtype & (IPV6_ADDR_MULTICAST | IPV6_ADDR_LOOPBACK))
goto error;
if (addrtype & IPV6_ADDR_LINKLOCAL) {
icmpv6_send(skb, ICMPV6_DEST_UNREACH,
ICMPV6_NOT_NEIGHBOUR, 0);
goto error;
}
}
请注意,根据基础 IPV6 标准 RFC 2460 的第五部分“数据包大小问题”,IPv6 的 IPV6_MIN_MTU 为 1280 字节。
mtu = dst_mtu(dst);
if (mtu < IPV6_MIN_MTU)
mtu = IPV6_MIN_MTU;
if ((!skb->local_df && skb->len > mtu && !skb_is_gso(skb)) ||
(IP6CB(skb)->frag_max_size && IP6CB(skb)->frag_max_size > mtu)) {
/* Again, force OUTPUT device used as source address */
skb->dev = dst->dev;
用“数据包太大”的 ICMPv6 消息回复发送者,并释放 SKB;在这种情况下,ip6_forward()方法返回–EMSGSIZ:
icmpv6_send(skb, ICMPV6_PKT_TOOBIG, 0, mtu);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_INTOOBIGERRORS);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_FRAGFAILS);
kfree_skb(skb);
return -EMSGSIZE;
}
if (skb_cow(skb, dst->dev->hard_header_len)) {
IP6_INC_STATS(net, ip6_dst_idev(dst), IPSTATS_MIB_OUTDISCARDS);
goto drop;
}
hdr = ipv6_hdr(skb);
数据包将被转发,因此减少 IPv6 报头的hop_limit。
/* Mangling hops number delayed to point after skb COW */
hdr->hop_limit--;
IP6_INC_STATS_BH(net, ip6_dst_idev(dst), IPSTATS_MIB_OUTFORWDATAGRAMS);
IP6_ADD_STATS_BH(net, ip6_dst_idev(dst), IPSTATS_MIB_OUTOCTETS, skb->len);
return NF_HOOK(NFPROTO_IPV6, NF_INET_FORWARD, skb, skb->dev, dst->dev,
ip6_forward_finish);
error:
IP6_INC_STATS_BH(net, ip6_dst_idev(dst), IPSTATS_MIB_INADDRERRORS);
drop:
kfree_skb(skb);
return -EINVAL;
}
(net/ipv6/ip6_output.c)
ip6_forward_finish()方法是一个单行方法,它简单地调用目的缓存(dst ) output回调:
static inline int ip6_forward_finish(struct sk_buff *skb)
{
return dst_output(skb);
}
(net/ipv6/ip6_output.c)
在本节中,您已经看到了 IPv6 数据包的接收是如何处理的,是通过本地传送还是通过转发。您还看到了接收 IPv6 数据包和接收 IPv4 数据包之间的一些差异。在下一节中,我将讨论多播流量的 Rx 路径。
接收 IPv6 组播数据包
ipv6_rcv()方法是单播包和组播包的 IPv6 处理程序。如上所述,在一些完整性检查之后,它调用ip6_rcv_finish()方法,该方法通过调用ip6_route_input()方法在路由子系统中执行查找。在ip6_route_input()方法中,在接收多播包的情况下,input回调被设置为ip6_mc_input方法。我们来看看ip6_mc_input()的方法:
int ip6_mc_input(struct sk_buff *skb)
{
const struct ipv6hdr *hdr;
bool deliver;
IP6_UPD_PO_STATS_BH(dev_net(skb_dst(skb)->dev),
ip6_dst_idev(skb_dst(skb)), IPSTATS_MIB_INMCAST,
skb->len);
hdr = ipv6_hdr(skb);
ipv6_chk_mcast_addr()方法 ( net/ipv6/mcast.c)检查指定网络设备的组播地址列表(mc_list)中是否包含指定的组播地址(本例中为 IPv6 头中的目的地址,hdr->daddr)。注意,因为第三个参数为空,所以我们在这个调用中不检查是否有任何源地址的源过滤器;本章稍后将讨论如何处理源过滤。
deliver = ipv6_chk_mcast_addr(skb->dev, &hdr->daddr, NULL);
如果本地机器是一个多播路由器(也就是说,CONFIG_IPV6_MROUTE 被设置),我们在对ip6_mr_input()方法进行一些检查之后继续。IPv6 组播路由实现与 IPv4 组播路由实现非常相似,在第六章中已经讨论过,所以在本书中不再讨论。IPv6 组播路由实现在net/ipv6/ip6mr.c中。基于 Mickael Hoerdt 的补丁,在内核 2.6.26 (2008)中增加了对 IPv6 多播路由的支持。
#ifdef CONFIG_IPV6_MROUTE
. . .
if (dev_net(skb->dev)->ipv6.devconf_all->mc_forwarding &&
!(ipv6_addr_type(&hdr->daddr) &
(IPV6_ADDR_LOOPBACK|IPV6_ADDR_LINKLOCAL)) &&
likely(!(IP6CB(skb)->flags & IP6SKB_FORWARDED))) {
/*
* Okay, we try to forward - split and duplicate
* packets.
*/
struct sk_buff *skb2;
if (deliver)
skb2 = skb_clone(skb, GFP_ATOMIC);
else {
skb2 = skb;
skb = NULL;
}
if (skb2) {
通过ip6_mr_input()方法(net/ipv6/ip6mr.c)继续 IPv6 组播路由代码:
ip6_mr_input(skb2);
}
}
#endif
if (likely(deliver))
ip6_input(skb);
else {
/* discard */
kfree_skb(skb);
}
return 0;
}
(net/ipv6/ip6_input.c)
当多播数据包不打算通过多播路由转发时(例如,当 CONFIG_IPV6_MROUTE 未设置时),我们将继续使用ip6_input()方法,正如您已经看到的,它实际上是ip6_input_finish()方法的包装器。在ip6_input_finish()方法中,我们再次调用ipv6_chk_mcast_addr()方法,但是这次第三个参数不为空,它是来自 IPv6 报头的源地址。这一次,我们在ipv6_chk_mcast_addr()方法中检查是否设置了源过滤,并相应地处理数据包。源筛选将在本章后面的“多播源筛选(MSF)”一节中讨论。接下来,我将描述多播监听器发现协议,它与 IPv4 IGMPv3 协议并行。
多播监听器发现(MLD)
MLD 协议用于在多播主机和路由器之间交换组信息。MLD 协议是非对称协议;它为多播路由器和多播侦听器指定了不同的行为。在 IPv4 中,组播组管理由互联网组管理协议(IGMP)处理,正如你在第六章中看到的。在 IPv6 中,多播组管理由 MLDv2 协议处理,该协议在 2004 年的 RFC 3810 中指定。MLDv2 协议源自 IPv4 使用的 IGMPv3 协议。然而,与 IGMPv3 协议相反,MLDv2 是 ICMPv6 协议的一部分,而 IGMPv3 是不使用任何 ICMPv4 服务的独立协议;这是 IPv6 中不使用 IGMPv3 协议的主要原因。请注意,您可能会遇到术语 GMP (群组管理协议),它用于指代 IGMP 和 MLD。
多播监听器发现协议的先前版本是 MLDv1,并且它在 RFC 2710 中被指定;它源自 IGMPv2。MLDv1 基于任意源多播(ASM)模型;这意味着您不需要指定从单个源地址或一组地址接收多播流量。MLDv2 通过添加对源特定多播(SSM)的支持来扩展 MLDv1 这意味着节点能够指定是否有兴趣监听来自特定单播源地址的数据包。这个特性被称为源过滤。在本节的后面,我将展示一个简短、详细的用户空间示例,说明如何使用源代码过滤。请参阅 RFC 4604“使用 Internet 组管理协议版本 3 (IGMPv3)和多播侦听程序发现协议版本 2 (MLDv2)进行特定于源的多播”
MLDv2 协议基于多播监听器报告和多播监听器查询。MLDv2 路由器(有时也称为“查询者”)周期性地发送多播监听器查询,以便了解节点的多播组的状态。如果在同一链路上有几个 MLDv2 路由器,则只选择其中一个作为查询者,所有其他路由器都设置为非查询者状态。如 RFC 3810 的 7.6.2 节所述,这是通过查询者选举机制来完成的。节点用多播监听器报告来响应这些查询,在报告中,它们提供关于它们所属的多播组的信息。当侦听器想要停止侦听某个多播组时,它会通知查询者,查询者必须查询该多播组地址的其他侦听器,然后才能将其从其多播地址侦听器状态中删除。MLDv2 路由器可以向多播路由协议提供关于监听器的状态信息。
现在您已经大致了解了什么是 MLD 协议,在下一节中,我将把您的注意力转向如何处理加入和离开多播组。
加入和离开多播组
在 IPv6 中有两种加入或离开多播组的方法。第一个是在内核中,通过调用ipv6_dev_mc_inc()方法,该方法获得一个网络设备对象和一个组播组地址作为参数。比如注册网络设备时,调用ipv6_add_dev()方法;每个设备应该加入接口本地所有节点多播组(ff01::1)和链路本地所有节点多播组(ff02::1)。
static struct inet6_dev *ipv6_add_dev(struct net_device *dev) {
. . .
/* Join interface-local all-node multicast group */
ipv6_dev_mc_inc(dev,&in6addr_interfacelocal_allnodes);
/* Join all-node multicast group */
ipv6_dev_mc_inc(dev,&in6addr_linklocal_allnodes);
. . .
}
(net/ipv6/addrconf.c)
路由器是设置了其procfs转发条目/proc/sys/net/ipv6/conf/all/forwarding的设备。除了前面提到的每台主机加入的两个多播组之外,路由器还加入了三个多播地址组。它们是链路本地所有路由器多播组(ff02::2)、接口本地所有路由器多播组(ff01::2)和站点本地所有路由器多播组(ff05::2)。
注意,设置 IPv6 procfs转发条目值是由addrconf_fixup_forwarding()方法处理的,该方法最终调用dev_forward_change()方法,该方法根据procfs条目的值(由idev->cnf.forwarding表示,如下面的代码片段所示)使指定的网络接口加入或离开这三个组播地址组:
static void dev_forward_change(struct inet6_dev *idev)
{
struct net_device *dev;
struct inet6_ifaddr *ifa;
. . .
dev = idev->dev;
. . .
if (dev->flags & IFF_MULTICAST) {
if (idev->cnf.forwarding) {
ipv6_dev_mc_inc(dev, &in6addr_linklocal_allrouters);
ipv6_dev_mc_inc(dev, &in6addr_interfacelocal_allrouters);
ipv6_dev_mc_inc(dev, &in6addr_sitelocal_allrouters);
} else {
ipv6_dev_mc_dec(dev, &in6addr_linklocal_allrouters);
ipv6_dev_mc_dec(dev, &in6addr_interfacelocal_allrouters);
ipv6_dev_mc_dec(dev, &in6addr_sitelocal_allrouters);
}
}
. . .
}
(net/ipv6/addrconf.c)
要从内核中离开一个多播组,应该调用ipv6_dev_mc_dec()方法。加入多播组的第二种方式是通过在用户空间中打开 IPv6 套接字,创建多播请求(ipv6_mreq对象)并将请求的ipv6mr_multiaddr设置为该主机想要加入的多播组地址,并将ipv6mr_interface设置为它想要设置的网络接口的ifindex。然后,它应该使用 IPV6_JOIN_GROUP 套接字选项:调用setsockopt()
int sockd;
struct ipv6_mreq mcgroup;
struct addrinfo *results;
. . .
/* read an IPv6 multicast group address to which we want to join */
/* into the address info object (results) */
. . .
设置我们想要使用的网络接口(通过其ifindex值):
mcgroup.ipv6mr_interface=3;
在请求中为我们想要加入的组设置多播组地址(ipv6mr_multiaddr):
memcpy( &(mcgroup.ipv6mr_multiaddr),
&(((struct sockaddr_in6 *) results->ai_addr)->sin6_addr),
sizeof(struct in6_addr));
sockd = socket(AF_INET6, SOCK_DGRAM,0);
用 IPV6_JOIN_GROUP 调用setsockopt()加入组播组;这个调用在内核中由ipv6_sock_mc_join()方法(net/ipv6/mcast.c)处理。
status = setsockopt(sockd, IPPROTO_IPV6, IPV6_JOIN_GROUP,
&mcgroup, sizeof(mcgroup));
. . .
可以使用 IPV6_ADD_MEMBERSHIP socket 选项来代替 IPV6_JOIN_GROUP。(它们是等价的。)注意,通过将网络接口的不同值设置为mcgroup.ipv6mr_interface,我们可以在多个网络设备上设置相同的多播组地址。mcgroup.ipv6mr_interface的值作为ifindex参数传递给ipv6_sock_mc_join()方法。在这种情况下,内核构建并发送一个 MLDv2 多播监听器报告包(ICMPV6_MLD2_REPORT),其中目的地址是ff02::16(所有支持 MLDv2 的路由器多播组地址)。根据 RFC 3810 中的第 5.2.14 节,所有支持 MLDv2 的多播路由器都应该侦听该多播地址。MLDv2 报头中的组播地址记录数(如图 8-3 中的所示)将为 1,因为只使用了一个组播地址记录,其中包含了我们想要加入的组播组的地址。主机想要加入的多播组地址是 ICMPv6 报头的一部分。带有路由器警报的逐跳选项报头在此数据包中设置。MLD 数据包包含一个逐跳选项报头,该报头又包含一个路由器警告选项报头;逐跳扩展报头的下一个报头是 IPPROTO_ICMPV6 (58),因为在逐跳报头之后是 ICMPV6 分组,它包含 MLDv2 消息。
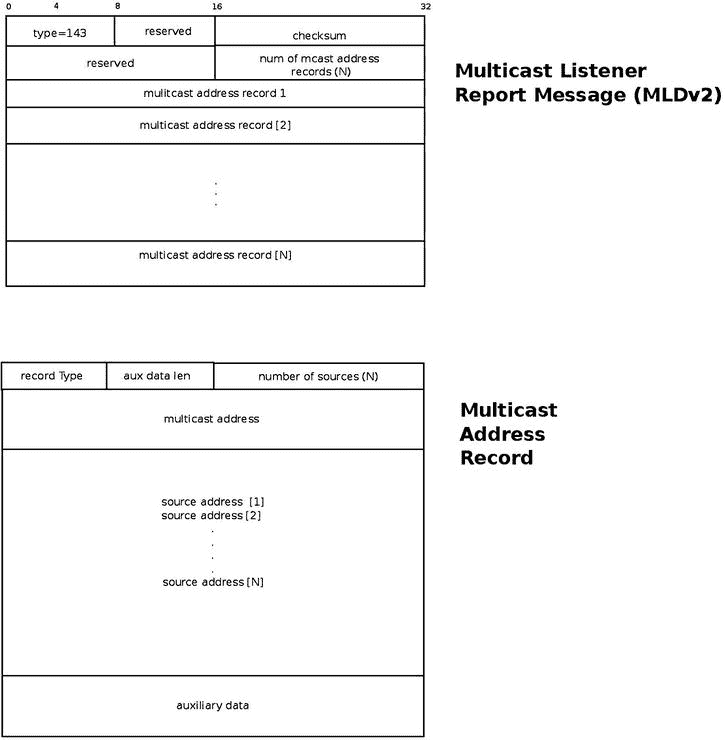
图 8-3 。MLDv2 多播侦听器报告
主机可以通过使用 IPV6_DROP_MEMBERSHIP 套接字选项调用setsockopt() 来离开多播组,这在内核中通过调用ipv6_sock_mc_drop()方法或关闭套接字来处理。请注意,IPV6_LEAVE_GROUP 等同于 IPV6_DROP_MEMBERSHIP。
在讨论了如何处理加入和离开多播组之后,是时候看看什么是 MLDv2 多播侦听器报告了。
MLDv2 多播侦听器报告
MLDv2 多播监听器报告在内核中由mld2_report结构表示:
struct mld2_report {
struct icmp6hdr mld2r_hdr;
struct mld2_grec mld2r_grec[0];
};
(include/net/mld.h)
mld2_report结构的第一个成员是mld2r_hdr,它是一个 ICMPv6 头;它的icmp6_type应该设置为 ICMPV6_MLD2_REPORT (143)。mld2_report结构的第二个成员是mld2r_grec[0],它是mld2_grec结构的一个实例,代表 MLDv2 组记录。(这是图 8-3 中的组播地址记录。)下面是mld2_grec结构的定义:
struct mld2_grec {
__u8 grec_type;
__u8 grec_auxwords;
__be16 grec_nsrcs;
struct in6_addr grec_mca;
struct in6_addr grec_src[0];
};
(include/net/mld.h)
以下是对mld2_grec结构成员的描述:
grec_type:指定组播地址记录的类型。参见本章末尾“快速参考”部分的表 8-3 “组播地址记录(记录类型)”。grec_auxwords:辅助数据的长度(图 8-3 中的辅助数据长度)。辅助数据字段(如果存在的话)包含与该多播地址记录相关的附加信息。通常是 0。另请参见 RFC 3810 中的第 5.2.10 节。grec_nsrcs:源地址的数量。grec_mca:该组播地址记录所属的组播地址。grec_src[0]:单播源地址(或单播源地址的数组)。这些是我们想要过滤(阻止或允许)的地址。
在下一节中,我将讨论多播源过滤(MSF) 特性。您将在其中找到如何在源过滤中使用多播地址记录的详细示例。
组播源过滤(MSF)
通过多播源过滤,内核将丢弃来自非预期源的多播流量。该功能也称为特定源多播(SSM ),不是 MLDv1 的一部分。它是在 MLDv2 中引入的;参见 RFC 3810。它与任意源多播(ASM)相反,在 ASM 中,接收者对目的地多播地址表示兴趣。为了更好地理解多播源过滤是什么,我将在这里展示一个用户空间应用的例子,演示如何使用源过滤加入和离开多播组。
使用源过滤加入和离开多播组
主机可以通过在用户空间中打开 IPv6 套接字,创建多播组源请求(group_source_req对象),并在请求中设置三个参数: 来加入具有源过滤的多播组
gsr_group:该主机想要加入的组播组地址gsr_source:希望允许的组播组源地址ipv6mr_interface:要设置的网络接口的 ifindex
然后它应该使用 MCAST_JOIN_SOURCE_GROUP 套接字选项调用setsockopt()。下面是演示这一点的用户空间应用的代码片段(为了简洁起见,删除了检查系统调用是否成功):
int sockd;
struct group_source_req mreq;
struct addrinfo *results1;
struct addrinfo *results2;
/* read an IPv6 multicast group address that we want to join into results1 */
/* read an IPv6 multicast group address which we want to allow into results2 */
memcpy(&(mreq.gsr_group), results1->ai_addr, sizeof(struct sockaddr_in6));
memcpy(&(mreq.gsr_source), results2->ai_addr, sizeof(struct sockaddr_in6));
mreq.gsr_interface = 3;
sockd = socket(AF_INET6, SOCK_DGRAM, 0);
setsockopt(sockd, IPPROTO_IPV6, MCAST_JOIN_SOURCE_GROUP, &mreq, sizeof(mreq));
这个请求首先在内核中由ipv6_sock_mc_join()方法处理,然后由ip6_mc_source()方法处理。要离开群组,您应该使用 MCAST_LEAVE_SOURCE_GROUP 套接字选项调用setsockopt(),或者关闭您打开的套接字。
您可以设置您想要允许的另一个地址,并使用此套接字通过 MCAST_UNBLOCK_SOURCE 套接字选项再次调用setsockopt() 。这将向源过滤器列表添加额外的地址。对setsockopt()的每个这样的调用将触发发送具有一个多播地址记录的 MLDv2 多播监听器报告消息;记录类型将是 5(“允许新源”),源的数量将是 1(您想要解除阻止的单播地址)。我现在将展示一个使用 MCAST_MSFILTER 套接字选项进行源过滤的示例。
示例:使用 MCAST_MSFILTER 进行源过滤
您还可以使用 MCAST_MSFILTER 和一个group_filter对象在一个setsockopt()调用中阻止或允许来自多个多播地址的多播流量。首先,我们来看看用户空间中group_filter结构定义的定义,这个定义相当自明:
struct group_filter
{
/* Interface index. */
uint32_t gf_interface;
/* Group address. */
struct sockaddr_storage gf_group;
/* Filter mode. */
uint32_t gf_fmode;
/* Number of source addresses. */
uint32_t gf_numsrc;
/* Source addresses. */
struct sockaddr_storage gf_slist[1];
};
(include/netinet/in.h)
过滤模式(gf_fmode)可以是 MCAST_INCLUDE(当您希望允许来自某些单播地址的多播流量时)或 MCAST_EXCLUDE(当您希望禁止来自某些单播地址的多播流量时)。以下是这方面的两个例子:第一个将允许来自三个资源的多播流量,第二个将不允许来自两个资源的多播流量:
struct ipv6_mreq mcgroup;
struct group_filter filter;
struct sockaddr_in6 *psin6;
int sockd[2];
设置我们想要加入的组播组地址,ffff::9。
inet_pton(AF_INET6,"ffff::9", &mcgroup.ipv6mr_multiaddr);
通过它的ifindex设置我们想要使用的网络接口(这里我们使用eth0,它的ifindex值为 2):
mcgroup.ipv6mr_interface=2;
设置过滤器参数:使用相同的ifindex (2),使用 MCAST_INCLUDE 来设置过滤器,以允许来自过滤器指定的源的流量,并将gf_numsrc设置为 3,因为我们想要准备 3 个单播地址的过滤器:
filter.gf_interface = 2;
我们要准备两个过滤器: 第一个过滤器允许来自一组三个多播地址的流量,第二个过滤器允许来自一组两个多播地址的流量。首先将过滤器模式设置为 MCAST_INCLUDE,这意味着允许来自此过滤器的流量:
filter.gf_fmode = MCAST_INCLUDE;
将过滤器的源地址数量(gf_numsrc)设置为 3:
filter.gf_numsrc = 3;
将过滤器(gf_group)的组地址设置为我们之前用于mcgrouop、ffff::9的地址:
psin6 = (struct sockaddr_in6 *)&filter.gf_group;
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "ffff::9", &psin6->sin6_addr);
我们想要允许的三个单播地址是2000::1、2000::2和2000::3。
相应地设置filter.gf_slist[0]、filter.gf_slist[1]和filter.gf_slist[2]:
psin6 = (struct sockaddr_in6 *)&filter.gf_slist[0];
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "2000::1", &psin6->sin6_addr);
psin6 = (struct sockaddr_in6 *)&filter.gf_slist[1];
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "2000::2", &psin6->sin6_addr);
psin6 = (struct sockaddr_in6 *)&filter.gf_slist[2];
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "2000::3",&psin6->sin6_addr);
创建一个套接字,并加入一个多播组:
sockd[0] = socket(AF_INET6, SOCK_DGRAM,0);
status = setsockopt(sockd[0], IPPROTO_IPV6, IPV6_JOIN_GROUP,
&mcgroup, sizeof(mcgroup));
激活我们创建的过滤器:
status=setsockopt(sockd[0], IPPROTO_IPV6, MCAST_MSFILTER, &filter,
GROUP_FILTER_SIZE(filter.gf_numsrc));
这将触发向所有嵌入了多播地址记录对象(mld2_grec)的 MLDv2 路由器(ff02::16)发送 MLDv2 多播监听器报告(ICMPV6_MLD2_REPORT)。(参见前面对mld2_report结构和图 8-3 的描述。)字段mld2_grec的值如下:
grec_type将是 MLD2_CHANGE_TO_INCLUDE (3)。grec_auxwords将为 0。(我们不使用辅助数据。)grec_nsrcs是 3(因为我们想要使用具有 3 个源地址的过滤器,我们将gf_numsrc设置为 3)。grec_mca将是ffff::9;这是多播地址记录所属的多播组地址。
以下三个单播源地址:
grec_src[0]是2000::1grec_src[1]是2000::2grec_src[2]是2000::3
现在,我们想要创建一个过滤器,过滤掉我们想要排除的 2 个单播源地址。所以首先创建一个新的用户空间套接字:
sockd[1] = socket(AF_INET6, SOCK_DGRAM,0);
将过滤器模式设置为排除,并将过滤器的来源数量设置为 2:
filter.gf_fmode = MCAST_EXCLUDE;
filter.gf_numsrc = 2;
设置我们想要排除的两个地址,2001::1 和 2001::2:
psin6 = (struct sockaddr_in6 *)&filter.gf_slist[0];
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "2001::1", &psin6->sin6_addr);
psin6 = (struct sockaddr_in6 *)&filter.gf_slist[1];
psin6->sin6_family = AF_INET6;
inet_pton(PF_INET6, "2001::2", &psin6->sin6_addr);
创建一个套接字,并加入一个多播组:
status = setsockopt(sockd[1], IPPROTO_IPV6, IPV6_JOIN_GROUP,
&mcgroup, sizeof(mcgroup));
激活过滤器:
status=setsockopt(sockd[1], IPPROTO_IPV6, MCAST_MSFILTER, &filter,
GROUP_FILTER_SIZE(filter.gf_numsrc));
这将再次触发向所有 MLDv2 路由器发送 MLDv2 多播监听报告(icmp V6 _ ml D2 _ Report)(ff02::16)。这一次多播地址记录对象(mld2_grec)的内容将有所不同:
-
grec_type将 MLD2_CHANGE_TO_EXCLUDE (4)。 -
grec_auxwords将为 0。(我们不使用辅助数据。) -
grec_nsrcs是 2(因为我们想要使用 2 个源地址,我们将gf_numsrc设置为 2)。 -
grec_mca会是ffff::9,和以前一样;这是多播地址记录所属的多播组地址。 -
以下两个单播源地址:
-
grec_src[0]是2001::1 -
grec_src[1]是2002::2
 注意我们可以显示我们通过
注意我们可以显示我们通过cat/proc/net/mcfilter6创建的源过滤映射;这在内核中由igmp6_mcf_seq_show()方法处理。
例如,该映射中的前三个条目将显示对于ffff::9多播地址,我们允许(包括)来自2000::1、2000::2和2000::3的多播流量。请注意,对于前三个条目,INC (Include)列中的值是 1。对于第四和第五个条目,我们不允许来自2001::1和2001::2的流量。请注意,对于第四个和第五个条目,EX (Exclude)列中的值为 1。
cat /proc/net/mcfilter6
Idx Device Multicast Address Source Address INC EXC
2 eth0 ffff0000000000000000000000000009 20000000000000000000000000000001 1 0
2 eth0 ffff0000000000000000000000000009 20000000000000000000000000000002 1 0
2 eth0 ffff0000000000000000000000000009 20000000000000000000000000000003 1 0
2 eth0 ffff0000000000000000000000000009 20010000000000000000000000000001 0 1
2 eth0 ffff0000000000000000000000000009 20010000000000000000000000000002 0 1
 注意通过用 MCAST_MSFILTER 调用
注意通过用 MCAST_MSFILTER 调用setsockopt()方法创建过滤器是由ip6_mc_msfilter()方法在内核中处理的,在net/ipv6/mcast.c中。
MLD 路由器(有时也称为“查询者”)在启动时加入所有支持 MLDv2 的路由器多播组(ff02::16)。它周期性地发送多播监听器查询分组,以便知道哪些主机属于多播组,以及它们属于哪个多播组。这些是类型为 ICMPV6_MGM_QUERY 的 ICMPv6 数据包。这些查询包的目的地址是所有主机多播组(ff02::1)。当主机接收到 ICMPv6 多播监听器查询数据包时,ICMPv6 Rx 处理程序(icmpv6_rcv()方法)调用igmp6_event_query()方法来处理该查询。注意,igmp6_event_query()方法 处理 MLDv2 查询和 MLDv1 查询(因为两者都使用 ICMPV6_MGM_QUERY 作为 ICMPV6 类型)。igmp6_event_query()方法通过检查消息的长度来确定消息是 MLDv1 还是 MLDv2 在 MLDv1 中,长度为 24 字节,在 MLDv2 中,长度至少为 28 字节。处理 MLDv1 和 MLDv2 消息是不同的;对于 MLDv2,我们应该支持源滤波,如本节之前所述,而 MLDv1 不支持此功能。主机通过调用igmp6_send()方法发回一个多播监听器报告。多播侦听器报告数据包是一个 ICMPv6 数据包。
IPv6 MLD 路由器的一个例子是开源 XORP 项目的mld6igmp守护进程:http://www.xorp.org。MLD 路由器保存关于网络节点(MLD 监听器)的多播地址组的信息,并动态更新该信息。该信息可以提供给多播路由守护程序。深入研究 MLDv2 路由守护进程(如mld6igmp守护进程)的实现,或者其他多播路由守护进程的实现,超出了本书的范围,因为它是在用户空间中实现的。
根据 RFC 3810,MLDv2 应该与实现 MLDv1 的节点互操作;MLDv2 的实现必须支持以下两种 MLDv1 消息类型:
- MLDv1 多播侦听器报告(ICMPV6_MGM_REPORT,十进制 131)
- MLDv1 多播侦听器完成(ICMPV6_MGM_REDUCTION,十进制 132)
我们可以使用 MLDv1 协议代替 MLDv2 协议来处理多播监听消息;这可以通过使用以下方法来实现:
echo 1 > /proc/sys/net/ipv6/conf/all/force_mld_version
在这种情况下,当主机加入多播组时,将通过igmp6_send()方法发送多播监听器报告消息。此消息将使用 MLDv1 的 ICMPV6_MGM_REPORT (131)作为 ICMPV6 类型,而不是 MLDv2 中的 ICMPV6_MLD2_REPORT(143)。请注意,在这种情况下,您不能对此邮件使用源过滤请求,因为 MLDv1 不支持它。我们将通过调用igmp6_join_group()方法加入多播组。当您离开多播组时,将会发送一条多播监听器完成消息。在此消息中,ICMPv6 类型为 ICMPV6_MGM_REDUCTION (132)。
在下一节中,我将非常简要地谈谈 IPv6 Tx 路径,它与 IPv4 Tx 路径非常相似,在本章中我不会深入讨论。
发送 IPv6 数据包
IPv6 Tx 路径非常类似于 IPv4 Tx 路径;甚至方法的名字也非常相似。同样在 IPv6 中,从第 4 层(传输层)发送 IPv6 数据包有两种主要方法:第一种是由 TCP、流控制传输协议(SCTP)和数据报拥塞控制协议(DCCP)使用的ip6_xmit()方法和方法。第二种方法是ip6_append_data()方法,,它被 UDP 和原始套接字使用。在本地主机上创建的数据包通过ip6_local_out()方法发送出去。ip6_output()方法被设置为与协议无关的dst_entry的输出回调;它首先调用 NF_INET_POST_ROUTING 钩子的 NF_HOOK()宏,然后调用ip6_finish_output()方法。如果需要分片,ip6_finish_output()方法调用ip6_fragment()方法处理;否则,它调用ip6_finish_output2()方法,最终发送数据包。有关实现细节,请查看 IPv6 Tx 路径代码;多半是在net/ipv6/ip6_output.c里。
在下一节中,我将简单介绍一下 IPv6 路由,它与 IPv4 路由非常相似,我在本章中不会深入讨论。
IPv6 路由
IPv6 路由的实现与第五章中讨论的 IPv4 路由实现非常相似,第五章讨论了 IPv4 路由子系统。与 IPv4 路由子系统一样,IPv6 也支持策略路由(当设置了 CONFIG_IPV6_MULTIPLE_TABLES 时)。在 IPv6 中,路由条目由rt6_info结构(include/net/ip6_fib.h)表示。rt6_info对象平行于 IPv4 rtable结构,flowi6结构(include/net/flow.h)平行于 IPv4 flowi4结构。(事实上,它们都有相同的flowi_common对象作为第一个成员。)有关实现细节,请查看 IPv6 路由模块:net/ipv6/route.c、net/ipv6/ip6_fib.c和策略路由模块net/ipv6/fib6_rules.c。
摘要
在本章中,我讨论了 IPv6 子系统及其实现。我讨论了各种 IPv6 主题,如 IPv6 地址(包括特殊地址和组播地址)、IPv6 报头是如何构建的、IPv6 扩展报头是什么、自动配置过程、IPv6 中的 Rx 路径以及 MLD 协议。在下一章,我们将继续我们的内核网络内部的旅程,并讨论 netfilter 子系统及其实现。在接下来的“快速参考”一节中,我们将按照上下文的顺序,介绍与我们在本章中讨论的主题相关的顶级方法。
快速参考
我用 IPv6 子系统的重要方法的简短列表来结束这一章。本章提到了其中一些。随后,有三个表格和两个小节介绍了 IPv6 特殊地址和 IPv6 中路由表的管理。
方法
先说方法。
bool IPv6 _ addr _ any(const struct in 6 _ addr * a);
如果指定的地址是全零地址(“未指定的地址”),该方法返回true。
bool IPv6 _ addr _ equal(const struct in 6 _ addr * a1,const struct in 6 _ addr * a2);
如果两个指定的 IPv6 地址相等,此方法返回true。
静态内联 void IPv6 _ addr _ set(struct in 6 _ addr * addr,__be32 w1,__be32 w2,_be32 w3, _ be32 w4);
此方法根据四个 32 位输入参数设置 IPv6 地址。
bool IPv6 _ addr _ is _ multicast(const struct in 6 _ addr * addr);
如果指定的地址是组播地址,这个方法返回true。
bool IPv6 _ ext _ HDR(u8 nexthdr);
如果指定的nexthdr是一个众所周知的扩展头,这个方法返回true。
ipv6hdr *ipv6_hdr 结构(const struct sk _ buf * skb);
该方法返回指定skb的 IPv6 头(ipv6hdr)。
struct inet 6 _ dev * in 6 _ dev _ get(const struct net _ device * dev);
该方法返回与指定设备相关联的inet6_dev对象。
bool IPv6 _ is _ mld(struct sk _ buff * skb,int nexthdr,int offset);
如果指定的nexthdr是 ICMPv6 (IPPROTO_ICMPV6 ),并且位于指定偏移量处的 ICMPv6 头的类型是 MLD 类型,则该方法返回true。它应该是下列之一:
- ICMPV6_MGM_QUERY
- ICMPV6_MGM_REPORT
- ICMPV6_MGM_REDUCTION
- ICMPV6_MLD2_REPORT
bool raw 6 _ local _ deliver(struct sk _ buff *,int);
该方法尝试将数据包传递给原始套接字。如果成功,它将返回true。
int ipv6_rcv(struct sk_buff *skb,struct net_device *dev,struct packet_type *pt,struct net _ device * orig _ dev);
该方法是 IPv6 数据包的主要接收处理程序。
bool IPv6 _ accept _ ra(struct inet 6 _ dev * idev);
如果主机被配置为接受路由器广告,此方法返回true,在以下情况下:
- 如果启用转发,则应设置特殊混合模式,这意味着
/proc/sys/net/ipv6/conf/<deviceName>/accept_ra为 2。 - 如果没有启用转发,
/proc/sys/net/ipv6/conf/<deviceName>/accept_ra应该为 1。
void ip6 _ route _ input(struct sk _ buff * skb);
该方法是 Rx 路径中主要的 IPv6 路由子系统查找方法。它根据路由子系统中的查找结果设置指定的skb的dst entry。
int ip6 _ forward(struct sk _ buff * skb);
这种方式是主要的转发方式。
struct dst _ entry * ip6 _ route _ output(struct net * net,const struct sock *sk,struct flow i6 * fl6);
该方法是 Tx 路径中主要的 IPv6 路由子系统查找方法。返回值是目的缓存条目(dst)。
 注意
注意ip6_route_input()方法和ip6_route_output()方法最终都通过调用fib6_lookup()方法来执行查找。
void in 6 _ dev _ hold(struct inet 6 _ dev * idev);和 void _ _ in6 _ dev _ put(struct inet 6 _ dev * idev);
该方法分别递增和递减指定idev对象的引用计数器。
int ip6 _ MC _ ms filter(struct sock * sk,struct group _ filter * gsf);
这个方法用 MCAST_MSFILTER 处理一个setsockopt()调用。
int ip6 _ MC _ input(struct sk _ buff * skb);
这个方法是多播数据包的主要接收处理程序。
int ip6 _ Mr _ input(struct sk _ buff * skb);
此方法是要转发的多播数据包的主要 Rx 处理程序。
int IPv6 _ dev _ MC _ Inc(struct net _ device * dev,const struct in 6 _ addr * addr);
该方法将指定的设备添加到由addr指定的多播组,或者如果没有找到,则创建这样的组。
int _ _ IPv6 _ dev _ MC _ dec(struct inet 6 _ dev * idev,const struct in 6 _ addr * addr);
此方法从指定的地址组中删除指定的设备。
bool IPv6 _ chk _ mcast _ addr(struct net _ device * dev,const struct in6_addr *group,const struct in 6 _ addr * src _ addr);
此方法检查指定的网络设备是否属于指定的多播地址组。如果第三个参数不为空,它还将检查源过滤是否允许从指定地址(src_addr)接收去往指定多播地址组的多播流量。
inline void addr conf _ addr _ solict _ mult(const struct in 6 _ addr * addr,struct in6_addr *solicited)
此方法计算链路本地请求节点多播地址。
void addr conf _ join _ solict(struct net _ device * dev,const struct in 6 _ addr * addr);
这个方法加入一个请求的地址多播组。
int IPv6 _ sock _ MC _ join(struct sock * sk,int ifindex,const struct in 6 _ addr * addr);
此方法处理多播组上的套接字连接。
int IPv6 _ sock _ MC _ drop(struct sock * sk,int ifindex,const struct in 6 _ addr * addr);
此方法处理多播组上的套接字离开。
int inet 6 _ add _ protocol(const struct inet 6 _ protocol * prot,无符号 char 协议);
此方法注册 IPv6 协议处理程序。它与 L4 协议注册(UDPv6、TCPv6 等)一起使用,也与扩展头(如片段扩展头)一起使用。
int IPv6 _ parse _ hopopts(struct sk _ buff * skb);
此方法解析逐跳选项标头,该标头必须是紧跟在 IPv6 标头之后的第一个扩展标头。
int ip6 _ local _ out(struct sk _ buff * skb);
此方法发送本地主机上生成的数据包。
int ip6 _ fragment(struct sk _ buff * skb,int(* output)(struct sk _ buff *));
此方法处理 IPv6 碎片。它是从ip6_finish_output()方法调用的。
参见 icmpv 6 _ param _ prob(struct sk _ buf * skb,u8 代码,int pos);
此方法发送 ICMPv6 参数问题(ICMPV6_PARAMPROB)错误。当解析扩展头或碎片整理过程中出现问题时,会调用该函数。
int do _ IPv6 _ setsockopt(struct sock * sk,int level,int optname,char __user *optval,signed int opt len);static int do _ IPv6 _ getsockopt(struct sock * sk、int level、int optname、char __user *optval、int __user *optlen、unsigned int flags);
这些方法是通用的 IPv6 处理程序,分别用于在 IPv6 套接字上调用setsockopt()和getsockopt()方法(net/ipv6/ipv6_sockglue.c)。
int igmp 6 _ event _ query(struct sk _ buff * skb);
此方法处理 MLDv2 和 MLDv1 查询。
void ip6 _ route _ input(struct sk _ buff * skb);
该方法通过基于指定的skb构建一个flow6对象并调用ip6_route_input_lookup()方法来执行路由查找。
宏指令
这是宏指令。
IPV6_ADDR_MC_SCOPE()
此宏返回指定 IPv6 多播地址的范围,该地址位于多播地址的第 11-14 位。
IPV6_ADDR_MC_FLAG_TRANSIENT()
如果设置了指定多播地址标志的 T 位,则该宏返回 1。
IPV6 _ ADDR _ MC _ FLAG _ 前缀( )
如果设置了指定多播地址标志的 P 位,此宏返回 1。
IPV6_ADDR_MC_FLAG_RENDEZVOUS()
如果设置了指定多播地址标志的 R 位,此宏返回 1。
桌子
这些是桌子。
表 8-2 显示了 IPv6 扩展报头的 Linux 符号、值和描述。您可以在本章的“扩展标题”一节中找到更多详细信息。
表 8-2 。IPv6 扩展标头
|Linux 符号
|
价值
|
描述
|
| — | — | — |
| nexthdr _ 跃点 | Zero | 逐跳选项头。 |
| NEXTHDR_TCP | six | TCP 段。 |
| NEXTHDR_UDP 文件 | Seventeen | UDP 消息。 |
| NEXTHDR_IPV6 | Forty-one | IPv6 中的 IPv6。 |
| NEXTHDR_ROUTING | Forty-three | 路由标题。 |
| NEXTHDR_FRAGMENT | forty-four | 分段/重组标题。 |
| NEXTHDR_GRE 版 | Forty-seven | GRE 标题。 |
| NEXTHDR_ESP | Fifty | 封装安全负载。 |
| NEXTHDR_AUTH 节 | Fifty-one | 认证头。 |
| NEXTHDR_ICMP | Fifty-eight | IPv6 的 ICMP。 |
| NEXTHDR_NONE(无) | Fifty-nine | 没有下一个标题。 |
| NEXTHDR_DEST | Sixty | 目标选项标题。 |
| NEXTHDR_MOBILITY | One hundred and thirty-five | 移动标题。 |
表 8-3 通过其 Linux 符号和值 ?? 显示了组播地址记录类型。有关更多详细信息,请参见本章中的“MLDv2 多播监听器报告”一节。
表 8-3 。多播地址记录(记录类型)
|Linux 符号
|
价值
|
| — | — |
| MLD2 _ 模式 _ 包含 | one |
| MLD2_MODE_IS_EXCLUDE | Two |
| MLD2 _ 更改为 _ 包含 | three |
| MLD2 _ 更改为 _ 排除 | four |
| MLD2_ALLOW_NEW_SOURCES | five |
| MLD2_BLOCK_OLD_SOURCES | six |
(include/uapi/linux/icmpv6.h)
表 8-4 按 Linux 符号和值显示了 ICMPv6“参数问题”消息的代码。这些代码提供了有关所发生问题类型的更多信息。
表 8-4 。ICMPv6 参数问题代码
|Linux 符号
|
价值
|
| — | — |
| icmp V6 _ HDR _ 字段 | 遇到 0 个错误的标头字段 |
| ICMPV6_UNK_NEXTHDR | 遇到 1 个未知的标题字段 |
| icmp V6 _ UNK _ 选项 | 2 遇到未知的 IPv6 选项 |
特殊地址
以下所有变量都是in6_addr结构的实例:
in6addr_any:表示未指定的全零器件(::)。in6addr_loopback:表示环回设备(::1)。in6addr_linklocal_allnodes:表示链路本地所有节点组播地址(ff02::1)。in6addr_linklocal_allrouters:表示链路本地所有路由器组播地址(ff02::2)。in6addr_interfacelocal_allnodes:表示接口本地所有节点(ff01::1)。in6addr_interfacelocal_allrouters:表示接口本地所有路由器(ff01::2)。in6addr_sitelocal_allrouters:表示本地所有路由器的地址(ff05::2)。
(include/linux/in6.h)
IPv6 中的路由表管理
像在 IPv4 中一样,我们可以使用iproute2的ip route命令和net-tools的route命令来管理添加和删除路由表:
- 通过
ip -6 route add添加路由是由inet6_rtm_newroute()方法通过调用ip6_route_add()方法来处理的。 - 通过调用
ip6_route_del()方法,由inet6_rtm_delroute()方法处理ip -6 route del删除路由。 - 通过
ip -6 route show显示路由表是由inet6_dump_fib()方法处理的。 - 通过调用
ip6_route_add()方法,发送由ipv6_route_ioctl()方法处理的 SIOCADDRT IOCTL 来实现由route -A inet6 add添加路由。 - 通过发送 SIOCDELRT IOCTL 来实现由
route -A inet6 del删除路由,这由ipv6_route_ioctl()方法通过调用ip6_route_del()方法来处理。
九、NetFilter
第八章讨论了 IPv6 子系统的实现。本章讨论 netfilter 子系统。netfilter 框架是由 Rusty Russell 于 1998 年创建的,他是最著名的 Linux 内核开发人员之一,是对旧版本的ipchains (Linux 2.2.x)和ipfwadm (Linux 2.0.x)的改进。netfilter 子系统提供了一个框架,允许在网络堆栈中数据包遍历的各个点(netfilter 挂钩)注册回调,并对数据包执行各种操作,如更改地址或端口、丢弃数据包、记录日志等。这些 netfilter 钩子 为注册回调的 netfilter 内核模块提供基础设施,以便执行 netfilter 子系统的各种任务。
Netfilter 框架
netfilter 子系统提供本章中讨论的以下功能:
- 数据包选择(iptables)
- 包过滤
- 网络地址转换(NAT)
- 数据包篡改(在路由之前或之后修改数据包报头的内容)
- 连接跟踪
- 收集网络统计数据
以下是一些基于 Linux 内核 netfilter 子系统的常见框架:
- IPVS (IP 虚拟服务器): 一种传输层负载均衡解决方案(
net/netfilter/ipvs)。很早的内核就支持 IPv4 IPVS,从内核 2.6.28 开始,支持 IPv6 中的 IPVS。对 IPVS 的 IPv6 内核支持是由谷歌的朱利叶斯·沃尔茨和文斯·布萨姆开发的。更多详情见 IPVS 官网,www.linuxvirtualserver.org。 - IP 集: 一个框架,由一个叫做
ipset的用户空间工具和一个内核部分(net/netfilter/ipset)组成。IP 集基本上是一组 IP 地址。IP sets 框架是由 Jozsef Kadlecsik 开发的。更多细节请见http://ipset.netfilter.org。 - iptables: 大概是最流行的 Linux 防火墙, iptables 是 netfilter 的前端,它为 netfilter 提供了一个管理层:比如添加和删除 netfilter 规则,显示统计数据,添加一个表,将一个表的计数器清零等等。
根据协议,内核中有不同的 iptables 实现:
- 【IPv4 的 iptables:(
net/ipv4/netfilter/ip_tables.c - 【IPv6 的 IP 6 tables:(
net/ipv6/netfilter/ip6_tables.c) - ARP 表用于 ARP: (
net/ipv4/netfilter/arp_tables.c) - 以太网的数据表😦
net/bridge/netfilter/ebtables.c)
在用户空间中,有iptables和ip6tables命令行工具,分别用于设置、维护和检查 IPv4 和 IPv6 表。参见man 8 iptables和man 8 ip6tables。iptables和ip6tables都使用setsockopt() / getsockopt()系统调用从用户空间与内核通信。我应该在这里提到两个有趣的正在进行的 netfilter 项目。xtables2项目——主要由 Jan Engelhardt 开发,在撰写本文时仍在进行中——使用基于 netlink 的接口与内核 netfilter 子系统通信。详见项目网站http://xtables.de。第二个项目是nftables项目,它是一个新的包过滤引擎,可以替代iptables。nftables解决方案基于使用一个虚拟机和一个统一的实现,而不是前面提到的四个iptables对象(iptables、ip6tables、arptables和ebtables)。Patrick McHardy 在 2008 年的 netfilter 研讨会上首次提出了nftables项目。内核基础设施和用户空间实用程序是由 Patrick McHardy 和 Pablo Neira Ayuso 开发的。更多详细信息,请参见http://netfilter.org/projects/nftables和http://lwn.net/Articles/324989/的“Nftables:一个新的包过滤引擎”。
有许多 netfilter 模块扩展了核心 netfilter 子系统的核心功能;除了一些例子,我不在这里深入描述这些模块。从管理的角度来看,网上和各种管理指南中有许多关于这些 netfilter 扩展的信息资源。另见 netfilter 项目官方网站:www.netfilter.org。
Netfilter 挂钩
网络堆栈中有五个点有 netfilter 挂钩:在前面章节讨论 IPv4 和 IPv6 中的 Rx 和 Tx 路径时,您会遇到这些点。请注意,挂钩的名称对于 IPv4 和 IPv6 是通用的:
- NF_INET_PRE_ROUTING: 这个钩子在 IPv4 的
ip_rcv()方法中,在 IPv6 的ipv6_rcv()方法中。ip_rcv()方法是 IPv4 的协议处理器,ipv6_rcv()方法是 IPv6 的协议处理器。在路由子系统中执行查找之前,它是所有传入数据包到达的第一个挂钩点。 - NF_INET_LOCAL_IN: 这个钩子在 IPv4 的
ip_local_deliver()方法中,在 IPv6 的ip6_input()方法中。寻址到本地主机的所有传入分组在第一次通过 NF_INET_PRE_ROUTING 钩点之后以及在路由子系统中执行查找之后到达该钩点。 - NF_INET_FORWARD: 这个钩子在 IPv4 的
ip_forward()方法中,在 IPv6 的ip6_forward()方法中。所有转发的数据包在第一次通过 NF_INET_PRE_ROUTING 挂钩点并在路由子系统中执行查找后到达该挂钩点。 - NF_INET_POST_ROUTING: 这个钩子在 IPv4 的
ip_output()方法中,在 IPv6 的ip6_finish_output2()方法中。转发的数据包在通过 NF_INET_FORWARD 钩子点后到达这个钩子点。同样,在本地机器中创建并发送出去的数据包在通过 NF_INET_LOCAL_OUT 钩子点之后到达 NF_INET_POST_ROUTING。 - NF_INET_LOCAL_OUT: 这个钩子在 IPv4 的
__ip_local_out()方法中,在 IPv6 的__ip6_local_out()方法中。在本地主机上创建的所有传出数据包在到达 NF_INET_POST_ROUTING 挂钩点之前到达该点。
(include/uapi/linux/netfilter.h)
前几章提到的 NF_HOOK 宏在内核网络栈中数据包遍历的一些不同点被调用;它在include/linux/netfilter.h中定义:
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct sk_buff *))
{
return NF_HOOK_THRESH(pf, hook, skb, in, out, okfn, INT_MIN);
}
NF_HOOK()的参数如下:
pf:协议族。IPV4 的 NFPROTO_IPV4 和 IPV6 的 NFPROTO_IPV6。hook:前面提到的五个 netfilter 钩子之一(比如 NF_INET_PRE_ROUTING 或者 NF_INET_LOCAL_OUT)。skb:SKB 对象代表正在处理的数据包。in:输入网络设备(net_device对象)。out:输出网络设备(net_device对象)。存在输出设备为空的情况,因为它还是未知的;比如在ip_rcv()方法中,net/ipv4/ip_input.c,在执行路由查找之前调用,你还不知道哪个是输出设备;NF_HOOK()宏在这个方法中用一个空输出设备调用。- 一个指向延续函数的指针,当钩子终止时,这个函数将被调用。它有一个参数,SKB。
netfilter 挂钩的返回值必须是下列值之一(也称为 netfilter 判断):
- NF_DROP (0):无声地丢弃数据包。
- NF_ACCEPT (1):包照常继续在内核网络堆栈中遍历。
- NF _ stocked(2):不继续遍历。该数据包由钩子方法处理。
- NF_QUEUE (3):将数据包排入用户空间的队列。
- NF_REPEAT (4):应该再次调用钩子函数。
(include/uapi/linux/netfilter.h)
现在您已经了解了各种 netfilter 挂钩,下一节将介绍如何注册 netfilter 挂钩。
Netfilter 挂钩的注册
要在前面提到的五个挂钩点之一注册一个挂钩回调,首先要定义一个nf_hook_ops对象(或者一个nf_hook_ops对象的数组),然后注册它;nf_hook_ops结构在include/linux/netfilter.h中定义:
struct nf_hook_ops {
struct list_head list;
/* User fills in from here down. */
nf_hookfn *hook;
struct module *owner;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
下面介绍一些nf_hook_ops结构的重要成员:
-
hook:你要注册的钩子回调。它的原型是:unsigned int nf_hookfn(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *)); -
pf:协议族(IPV4 为 NFPROTO_IPV4,IPV6 为 NFPROTO_IPV6)。 -
hooknum:前面提到的五个 netfilter 钩子之一。 -
priority:同一个挂钩上可以注册多个挂钩回叫。首先调用优先级较低的钩子回调。nf_ip_hook_priorities enum定义了 IPv4 挂钩优先级的可能值(include/uapi/linux/netfilter_ipv4.h)。参见本章末尾“快速参考”部分的表 9-4 。
注册 netfilter 挂钩有两种方法:
int nf_register_hook(struct nf_hook_ops *reg):注册单个nf_hook_ops对象。int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n):注册一个由 n 个对象组成的数组;第二个参数是数组中元素的数量。
在接下来的两节中,您将看到两个注册一个nf_hook_ops对象数组的例子。下一节的图 9-1 说明了在同一个钩子点注册多个钩子回调时优先级的使用。
连接跟踪
在现代网络中,仅根据 L4 和 L3 报头过滤流量是不够的。您还应该考虑流量基于会话的情况,例如 FTP 会话或 SIP 会话。对于 FTP 会话,我指的是这一系列事件,例如:客户端首先在 TCP 端口 21 上创建一个 TCP 控制连接,这是默认的 FTP 端口。从 FTP 客户端发送到服务器的命令(例如列出目录的内容)在此控制端口上发送。FTP 服务器在端口 20 上打开一个数据套接字,其中客户端的目的端口是动态分配的。应该根据其他参数(如连接状态或超时)过滤流量。这是使用连接跟踪层的主要原因之一。
连接跟踪允许内核跟踪会话。连接跟踪层的主要目标是作为 NAT 的基础。如果未设置 CONFIG_NF_CONNTRACK_IPV4,则无法构建 IPv4 NAT 模块 ( net/ipv4/netfilter/iptable_nat.c)。同样,如果没有设置 CONFIG_NF_CONNTRACK_IPV6,则不能构建 IPv6 NAT 模块(net/ipv6/netfilter/ip6table_nat.c)。但是,连接跟踪不依赖于 NAT 您可以在不激活任何 NAT 规则的情况下运行连接跟踪模块。本章稍后将讨论 IPv4 和 IPv6 NAT 模块。
 注意本章末尾的“快速参考”部分提到了一些用于连接跟踪管理的用户空间工具(
注意本章末尾的“快速参考”部分提到了一些用于连接跟踪管理的用户空间工具(conntrack-tools)。这些工具可以帮助您更好地理解连接跟踪层。
连接跟踪初始化
称为ipv4_conntrack_ops的nf_hook_ops对象数组定义如下:
static struct nf_hook_ops ipv4_conntrack_ops[] __read_mostly = {
{
.hook = ipv4_conntrack_in,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_helper,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_HELPER,
},
{
.hook = ipv4_confirm,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_helper,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_HELPER,
},
{
.hook = ipv4_confirm,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};
(net/ipv4/netfilter/nf_conntrack_l3proto_ipv4.c)
您注册的两个最重要的连接跟踪挂钩是由ipv4_conntrack_in()方法处理的 NF_INET_PRE_ROUTING 挂钩和由ipv4_conntrack_local()方法处理的 NF_INET_LOCAL_OUT 挂钩。这两个钩子的优先级是 NF_IP_PRI_CONNTRACK (-200)。ipv4_conntrack_ops数组中的其他钩子具有 NF_IP_PRI_CONNTRACK_HELPER (300)优先级和 nf _ IP _ pri _ conntrack _ confirm(int _ max,2³¹-1)优先级。在 netfilter 挂钩中,首先执行具有较低优先级值的回调。(include/uapi/linux/netfilter_ipv4.h中的enum nf_ip_hook_priorities代表 IPv4 挂钩可能的优先级值)。ipv4_conntrack_local()方法和ipv4_conntrack_in()方法都调用nf_conntrack_in()方法,将相应的hooknum作为参数传递。nf_conntrack_in() 方法属于与协议无关的 NAT 核心,既用于 IPv4 连接跟踪,也用于 IPv6 连接跟踪;它的第二个参数是协议族,指定它是 IPv4 (PF_INET)还是 IPv6 (PF_INET6)。我从nf_conntrack_in()回调开始讨论。其他钩子回调函数ipv4_confirm()和ipv4_help()将在本节稍后讨论。
 注意当内核构建了连接跟踪支持(CONFIG_NF_CONNTRACK 已设置)时,即使没有激活 iptables 规则,也会调用连接跟踪钩子回调。自然,这需要一些性能成本。如果性能非常重要,并且您事先知道设备不会使用 netfilter 子系统,那么可以考虑构建没有连接跟踪支持的内核,或者将连接跟踪构建为内核模块而不加载它。
注意当内核构建了连接跟踪支持(CONFIG_NF_CONNTRACK 已设置)时,即使没有激活 iptables 规则,也会调用连接跟踪钩子回调。自然,这需要一些性能成本。如果性能非常重要,并且您事先知道设备不会使用 netfilter 子系统,那么可以考虑构建没有连接跟踪支持的内核,或者将连接跟踪构建为内核模块而不加载它。
IPv4 连接跟踪钩子的注册是通过调用nf_conntrack_l3proto_ipv4_init()方法(net/ipv4/netfilter/nf_conntrack_l3proto_ipv4.c)中的nf_register_hooks()方法来完成的:
in nf_conntrack_l3proto_ipv4_init(void) {
. . .
ret = nf_register_hooks(ipv4_conntrack_ops,
ARRAY_SIZE(ipv4_conntrack_ops))
. . .
}
在图 9-1 中,可以看到连接跟踪回调 ( ipv4_conntrack_in()、ipv4_conntrack_local()、ipv4_helper()、ipv4_confirm()),根据它们注册的钩子点。
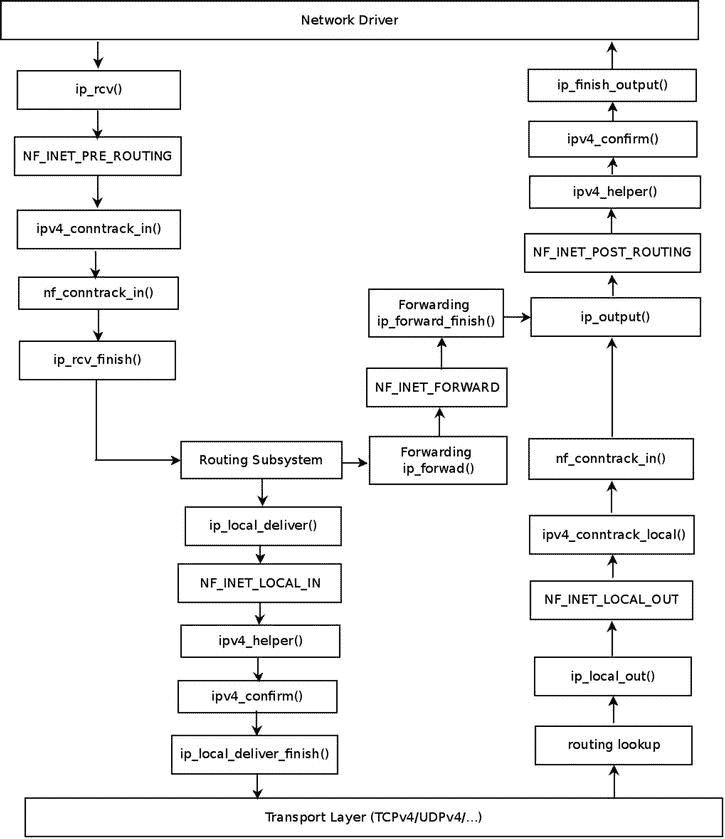
图 9-1 。连接跟踪挂钩(IPv4)
 注为了简单起见,图 9-1 没有包括更复杂的场景,比如使用 IPsec 或者分片或者组播的时候。为了简单起见,它还省略了在本地主机上生成并发送出去的数据包所调用的函数(如
注为了简单起见,图 9-1 没有包括更复杂的场景,比如使用 IPsec 或者分片或者组播的时候。为了简单起见,它还省略了在本地主机上生成并发送出去的数据包所调用的函数(如ip_queue_xmit()方法或ip_build_and_send_pkt()方法)。
连接跟踪的基本元素是nf_conntrack_tuple结构:
struct nf_conntrack_tuple {
struct nf_conntrack_man src;
/* These are the parts of the tuple which are fixed. */
struct {
union nf_inet_addr u3;
union {
/* Add other protocols here. */
__be16 all;
struct {
__be16 port;
} tcp;
struct {
__be16 port;
} udp;
struct {
u_int8_t type, code;
} icmp;
struct {
__be16 port;
} dccp;
struct {
__be16 port;
} sctp;
struct {
__be16 key;
} gre;
} u;
/* The protocol. */
u_int8_t protonum;
/* The direction (for tuplehash) */
u_int8_t dir;
} dst;
};
(include/net/netfilter/nf_conntrack_tuple.h)
nf_conntrack_tuple结构表示一个方向的流程。dst结构中的联合包括各种协议对象(如 TCP、UDP、ICMP 等等)。对于每个传输层(L4)协议,都有一个连接跟踪模块,它实现协议特定的部分。因此,举例来说,TCP 协议有net/netfilter/nf_conntrack_proto_tcp.c,UDP 协议有net/netfilter/nf_conntrack_proto_udp.c,FTP 协议有net/netfilter/nf_conntrack_ftp.c,等等;这些模块支持 IPv4 和 IPv6。在本节的后面,您将看到连接跟踪模块的特定于协议的实现如何不同的示例。
连接跟踪条目
nf_conn结构表示连接跟踪条目:
struct nf_conn {
/* Usage count in here is 1 for hash table/destruct timer, 1 per skb,
plus 1 for any connection(s) we are `master' for */
struct nf_conntrack ct_general;
spinlock_t lock;
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* Have we seen traffic both ways yet? (bitset) */
unsigned long status;
/* If we were expected by an expectation, this will be it */
struct nf_conn *master;
/* Timer function; drops refcnt when it goes off. */
struct timer_list timeout;
. . .
/* Extensions */
struct nf_ct_ext *ext;
#ifdef CONFIG_NET_NS
struct net *ct_net;
#endif
/* Storage reserved for other modules, must be the last member */
union nf_conntrack_proto proto;
};
(include/net/netfilter/nf_conntrack.h)
以下是对nf_conn结构中一些重要成员的描述:
ct_general:参考计数。tuplehash:有两个tuplehash对象:tuplehash[0]是原方向,tuplehash[1]是回复。它们通常分别被称为tuplehash[IP_CT_DIR_ORIGINAL]和tuplehash[IP_CT_DIR_REPLY]。status:条目的状态。当你开始跟踪一个连接条目时,它是 IP _ CT _ NEW 稍后,当连接建立时,它变成 IP_CT_ESTABLISHED。参见include/uapi/linux/netfilter/nf_conntrack_common.h中的ip_conntrack_info enum。master:预期的连接。由init_conntrack()方法设置,当一个期望的包到达时(这意味着由init_conntrack()方法调用的nf_ct_find_expectation()方法找到一个期望)。另请参阅本章后面的“连接跟踪助手和期望”一节。timeout:连接条目的定时器。当没有流量时,每个连接条目在一段时间间隔后到期。时间间隔根据协议确定。当用__nf_conntrack_alloc()方法分配一个nf_conn对象时,超时定时器被设置为death_by_timeout()方法。
现在您已经了解了nf_conn struct及其一些成员,让我们来看看nf_conntrack_in()方法:
unsigned int nf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum,
struct sk_buff *skb)
{
struct nf_conn *ct, *tmpl = NULL;
enum ip_conntrack_info ctinfo;
struct nf_conntrack_l3proto *l3proto;
struct nf_conntrack_l4proto *l4proto;
unsigned int *timeouts;
unsigned int dataoff;
u_int8_t protonum;
int set_reply = 0;
int ret;
if (skb->nfct) {
/* Previously seen (loopback or untracked)? Ignore. */
tmpl = (struct nf_conn *)skb->nfct;
if (!nf_ct_is_template(tmpl)) {
NF_CT_STAT_INC_ATOMIC(net, ignore);
return NF_ACCEPT;
}
skb->nfct = NULL;
}
首先,您尝试确定网络层(L3)协议是否可以被跟踪:
l3proto = __nf_ct_l3proto_find(pf);
现在,您尝试确定是否可以跟踪传输层(L4)协议。对于 IPv4,通过ipv4_get_l4proto()方法(net/ipv4/netfilter/nf_conntrack_l3proto_ipv4)完成:
ret = l3proto->get_l4proto(skb, skb_network_offset(skb),
&dataoff, &protonum);
if (ret <= 0) {
. . .
ret = -ret;
goto out;
}
l4proto = __nf_ct_l4proto_find(pf, protonum);
/* It may be an special packet, error, unclean...
* inverse of the return code tells to the netfilter
* core what to do with the packet. */
现在您可以检查特定于协议的错误条件(例如,参见net/netfilter/nf_conntrack_proto_udp.c中的udp_error()方法,它检查格式错误的数据包、带有无效校验和的数据包等等,或者参见net/netfilter/nf_conntrack_proto_tcp.c中的tcp_error()方法):
if (l4proto->error != NULL) {
ret = l4proto->error(net, tmpl, skb, dataoff, &ctinfo,
pf, hooknum);
if (ret <= 0) {
NF_CT_STAT_INC_ATOMIC(net, error);
NF_CT_STAT_INC_ATOMIC(net, invalid);
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->nfct)
goto out;
}
此后立即调用的resolve_normal_ct()方法执行以下操作:
-
通过调用
hash_conntrack_raw()方法计算元组的散列。 -
通过调用
__nf_conntrack_find_get()方法执行元组匹配的查找,将散列作为参数传递。 -
如果没有找到匹配,它通过调用
init_conntrack()方法创建一个新的nf_conntrack_tuple_hash对象。这个nf_conntrack_tuple_hash对象被添加到未确认的 tuplehash 对象列表中。该列表嵌入在网络名称空间对象中;net结构包含一个netns_ct对象,它由网络名称空间特定的连接跟踪信息组成。它的成员之一是unconfirmed,是未确认的tuplehash对象列表(见include/net/netns/conntrack.h)。稍后,在__nf_conntrack_confirm()方法中,它将从未确认列表中删除。我将在本节的后面讨论__nf_conntrack_confirm()方法。 -
每个 SKB 都有一个名为
nfctinfo的成员,它代表连接状态(例如,它是新连接的 IP_CT_NEW),还有一个名为nfct(nf_conntrack struct的一个实例)的成员,它实际上是一个引用计数器。resolve_normal_ct()方法初始化这两者。ct = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum, l3proto, l4proto, &set_reply, &ctinfo); if (!ct) { /* Not valid part of a connection */ NF_CT_STAT_INC_ATOMIC(net, invalid); ret = NF_ACCEPT; goto out; }
if (IS_ERR(ct)) {
/* Too stressed to deal. */
NF_CT_STAT_INC_ATOMIC(net, drop);
ret = NF_DROP;
goto out;
}
NF_CT_ASSERT(skb->nfct);
您现在调用nf_ct_timeout_lookup()方法来决定您想要对这个流应用什么超时策略。例如,对于 UDP,单向连接的超时为 30 秒,双向连接的超时为 180 秒;参见net/netfilter/nf_conntrack_proto_udp.c中udp_timeouts数组的定义。对于复杂得多的协议 TCP,在tcp_timeouts数组(net/netfilter/nf_conntrack_proto_tcp.c)中有 11 个条目:
/* Decide what timeout policy we want to apply to this flow. */
timeouts = nf_ct_timeout_lookup(net, ct, l4proto);
您现在调用特定于协议的packet()方法(例如,UDP 的udp_packet()或 TCP 的tcp_packet()方法)。udp_packet()方法通过调用nf_ct_refresh_acct()方法根据连接的状态延长超时时间。对于未应答的连接(未设置 IPS_SEEN_REPLY_BIT 标志),它将被设置为 30 秒,而对于应答的连接,它将被设置为 180。同样,在 TCP 的情况下,tcp_packet()方法要复杂得多,这是由于 TCP 高级状态机的缘故。此外,udp_packet()方法总是返回 NF_ACCEPT 的结论,而tcp_packet()方法有时可能会失败:
ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum, timeouts);
if (ret <= 0) {
/* Invalid: inverse of the return code tells
* the netfilter core what to do */
pr_debug("nf_conntrack_in: Can't track with proto module\n");
nf_conntrack_put(skb->nfct);
skb->nfct = NULL;
NF_CT_STAT_INC_ATOMIC(net, invalid);
if (ret == -NF_DROP)
NF_CT_STAT_INC_ATOMIC(net, drop);
ret = -ret;
goto out;
}
if (set_reply && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl) {
/* Special case: we have to repeat this hook, assign the
* template again to this packet. We assume that this packet
* has no conntrack assigned. This is used by nf_ct_tcp. */
if (ret == NF_REPEAT)
skb->nfct = (struct nf_conntrack *)tmpl;
else
nf_ct_put(tmpl);
}
return ret;
}
在 NF_INET_POST_ROUTING 钩子和 NF_INET_LOCAL_IN 钩子中调用的ipv4_confirm()方法通常会调用__nf_conntrack_confirm()方法,该方法会将元组从未确认列表中移除。
连接跟踪助手和期望
有些协议有不同的数据流和控制流,例如,FTP(文件传输协议)和 SIP(会话发起协议,即 VoIP 协议)。通常在这些协议中,控制信道与另一端协商一些配置设置,并就数据流使用哪些参数达成一致。netfilter 子系统更难处理这些协议,因为 netfilter 子系统需要知道流是相互关联的。为了支持这些类型的协议,netfilter 子系统提供了连接跟踪帮助程序,它扩展了连接跟踪的基本功能。这些模块创建期望(nf_conntrack_expect对象),这些期望告诉内核它应该在指定的连接上期待一些流量,并且两个连接是相关的。知道两个连接是相关的,就可以在主连接上定义也适用于相关连接的规则。您可以使用基于连接跟踪状态的简单 iptables 规则来接受其连接跟踪状态相关的数据包:
iptables -A INPUT -m conntrack --ctstate RELATED -j ACCEPT
 注意联系不仅是期望的结果。例如,如果 netfilter 找到与嵌入 ICMP 的 L3/L4 报头中的元组相匹配的
注意联系不仅是期望的结果。例如,如果 netfilter 找到与嵌入 ICMP 的 L3/L4 报头中的元组相匹配的conntrack条目,则诸如“需要 ICMP 碎片”之类的 ICMPv4 错误包将是相关的。更多细节见icmp_error_message()方法,net/ipv4/netfilter/nf_conntrack_proto_icmp.c。
连接跟踪助手由nf_conntrack_helper结构(include/net/netfilter/nf_conntrack_helper.h)表示。它们分别通过nf_conntrack_helper_register()方法和nf_conntrack_helper_unregister()方法进行注册和取消注册。因此,例如,nf_conntrack_ftp_init() ( net/netfilter/nf_conntrack_ftp.c)调用nf_conntrack_helper_register()方法来注册 FTP 连接跟踪助手。连接跟踪助手保存在哈希表中(nf_ct_helper_hash)。ipv4_helper()钩子回调在两个钩子点注册,NF_INET_POST_ROUTING 和 NF_INET_LOCAL_IN(参见前面“连接跟踪初始化”一节中ipv4_conntrack_ops数组的定义)。因此,当 FTP 数据包到达 NF_INET_POST_ROUTING 回调函数ip_output()或 NF_INET_LOCAL_IN 回调函数ip_local_deliver()时,调用ipv4_helper()方法,该方法最终调用注册的连接跟踪帮助器的回调函数。在 FTP 的情况下,注册的帮助器方法是help()方法,net/netfilter/nf_conntrack_ftp.c。这个方法寻找特定于 FTP 的模式,比如“PORT”FTP 命令;参见下面的代码片段(net/netfilter/nf_conntrack_ftp.c)中对help()方法中find_pattern()方法的调用。如果匹配,通过调用nf_ct_expect_init()方法创建一个nf_conntrack_expect对象:
static int help(struct sk_buff *skb,
unsigned int protoff,
struct nf_conn *ct,
enum ip_conntrack_info ctinfo)
{
struct nf_conntrack_expect *exp;
. . .
for (i = 0; i < ARRAY_SIZE(search[dir]); i++) {
found = find_pattern(fb_ptr, datalen,
search[dir][i].pattern,
search[dir][i].plen,
search[dir][i].skip,
search[dir][i].term,
&matchoff, &matchlen,
&cmd,
search[dir][i].getnum);
if (found) break;
}
if (found == -1) {
/* We don't usually drop packets. After all, this is
connection tracking, not packet filtering.
However, it is necessary for accurate tracking in
this case. */
nf_ct_helper_log(skb, ct, "partial matching of `%s'",
search[dir][i].pattern);
 注意正常情况下,连接跟踪不会丢包。在某些情况下,由于某些错误或异常情况,数据包会被丢弃。下面是这种情况的一个例子:早先对
注意正常情况下,连接跟踪不会丢包。在某些情况下,由于某些错误或异常情况,数据包会被丢弃。下面是这种情况的一个例子:早先对find_pattern()的调用返回–1,这意味着只有部分匹配;并且由于没有找到完全的模式匹配,该分组被丢弃。
ret = NF_DROP;
goto out;
} else if (found == 0) { /* No match */
ret = NF_ACCEPT;
goto out_update_nl;
}
pr_debug("conntrack_ftp: match `%.*s' (%u bytes at %u)\n",
matchlen, fb_ptr + matchoff,
matchlen, ntohl(th->seq) + matchoff);
exp = nf_ct_expect_alloc(ct);
. . .
nf_ct_expect_init(exp, NF_CT_EXPECT_CLASS_DEFAULT, cmd.l3num,
&ct->tuplehash[!dir].tuple.src.u3, daddr,
IPPROTO_TCP, NULL, &cmd.u.tcp.port);
. . .
}
(net/netfilter/nf_conntrack_ftp.c)
稍后,当通过init_conntrack()方法创建一个新连接时,您检查它是否有期望,如果有,您设置 IPS_EXPECTED_BIT 标志并设置连接的主节点(ct->master)来引用创建期望的连接:
static struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
struct nf_conntrack_l3proto *l3proto,
struct nf_conntrack_l4proto *l4proto,
struct sk_buff *skb,
unsigned int dataoff, u32 hash)
{
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conntrack_tuple repl_tuple;
struct nf_conntrack_ecache *ecache;
struct nf_conntrack_expect *exp;
u16 zone = tmpl ? nf_ct_zone(tmpl) : NF_CT_DEFAULT_ZONE;
struct nf_conn_timeout *timeout_ext;
unsigned int *timeouts;
. . .
ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC,
hash);
. . .
exp = nf_ct_find_expectation(net, zone, tuple);
if (exp) {
pr_debug("conntrack: expectation arrives ct=%p exp=%p\n",
ct, exp);
/* Welcome, Mr. Bond. We've been expecting you... */
__set_bit(IPS_EXPECTED_BIT, &ct->status);
ct->master = exp->master;
if (exp->helper) {
help = nf_ct_helper_ext_add(ct, exp->helper,
GFP_ATOMIC);
if (help)
rcu_assign_pointer(help->helper, exp->helper);
}
. . .
请注意,助手监听预定义的端口。例如,FTP 连接跟踪助手监听端口 21(参见include/linux/netfilter/nf_conntrack_ftp.h中的 FTP_PORT 定义)。您可以通过两种方式之一设置不同的端口:第一种方式是通过模块参数——您可以通过向modprobe命令提供单个端口或逗号分隔的端口列表来覆盖默认端口值:
modprobe nf_conntrack_ftp ports=2121
modprobe nf_conntrack_ftp ports=2022,2023,2024
第二种方法是使用 CT 目标:
iptables -A PREROUTING -t raw -p tcp --dport 8888 -j CT --helper ftp
请注意,CT 目标(net/netfilter/xt_CT.c)是在内核 2.6.34 中添加的。
 注意 Xtables 目标扩展由
注意 Xtables 目标扩展由xt_target结构表示,并通过xt_register_target()方法注册单个目标,或者通过xt_register_targets()方法注册一个目标数组。Xtables 匹配扩展由xt_match结构表示,并由xt_register_match()方法注册,或者由xt_register_matches()注册一个匹配数组。匹配扩展根据由匹配扩展模块定义的一些标准来检查分组;因此,例如,xt_length匹配模块(net/netfilter/xt_length.c)根据数据包的长度(IPv4 数据包情况下的 SKB 的tot_len)检查数据包,而xt_connlimit模块(net/netfilter/xt_connlimit.c)限制每个 IP 地址的并行 TCP 连接数。
本节详细介绍了连接跟踪初始化。下一节讨论 iptables,这可能是 netfilter 框架中最广为人知的部分。
防火墙
iptables 有两个部分。内核部分 IPv4 的内核在net/ipv4/netfilter/ip_tables.c中,IPv6 的内核在net/ipv6/netfilter/ip6_tables.c中。还有用户空间部分,它提供了访问内核 iptables 层的前端(例如,用iptables命令添加和删除规则)。每个表由xt_table结构表示(在include/linux/netfilter/x_tables.h中定义)。表的注册和注销分别由ipt_register_table()和ipt_unregister_table()方法完成。这些方法在net/ipv4/netfilter/ip_tables.c中实现。在 IPv6 中,您也可以使用xt_table结构来创建表,但是表的注册和注销分别由ip6t_register_table()方法和ip6t_unregister_table()方法来完成。
网络名称空间对象包含特定于 IPv4 和 IPv6 的对象(分别为netns_ipv4和netns_ipv6)。而netns_ipv4和netns_ipv6对象又包含指向xt_table对象的指针。对于 IPv4,在struct netns_ipv4中你有例如iptable_filter、iptable_mangle、nat_table等等(include/net/netns/ipv4.h)。在struct netns_ipv6中你有,比如说ip6table_filter、ip6table_mangle、ip6table_nat等等(include/net/netns/ipv6.h)。有关 IPv4 和 IPv6 网络名称空间 netfilter 表以及相应内核模块的完整列表,请参见本章末尾“快速参考”部分的表 9-2 和表 9-3 。
为了理解 iptables 是如何工作的,让我们看一个使用过滤器表的真实例子。为了简单起见,让我们假设过滤器表是唯一构建的,并且日志目标也是受支持的;我使用的唯一规则是用于日志记录,您很快就会看到。首先,我们来看看过滤表的定义:
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \
(1 << NF_INET_FORWARD) | \
(1 << NF_INET_LOCAL_OUT))
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = FILTER_VALID_HOOKS,
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.priority = NF_IP_PRI_FILTER,
};
(net/ipv4/netfilter/iptable_filter.c)
首先通过调用xt_hook_link()方法完成表的初始化,该方法将iptable_filter_hook()方法设置为packet_filter表的nf_hook_ops对象的钩子回调:
static struct nf_hook_ops *filter_ops __read_mostly;
static int __init iptable_filter_init(void)
{
. . .
filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook);
. . .
}
然后调用ipt_register_table()方法(注意,IPv4 netns对象net->ipv4,保存一个指向过滤表的指针iptable_filter):
static int __net_init iptable_filter_net_init(struct net *net)
{
. . .
net->ipv4.iptable_filter =
ipt_register_table(net, &packet_filter, repl);
. . .
return PTR_RET(net->ipv4.iptable_filter);
}
(net/ipv4/netfilter/iptable_filter.c)
请注意,过滤器表中有三个挂钩:
- 本地网络
- 网络转发
- 本地输出
对于本例,您使用iptable命令行设置以下规则:
iptables -A INPUT -p udp --dport=5001 -j LOG --log-level 1
此规则的含义是,您将把目标端口为 5001 的传入 UDP 数据包转储到 syslog 中。log-level修饰符是 0 到 7 范围内的标准系统日志级别;0 表示紧急,7 表示调试。注意,当运行一个iptables命令时,您应该用–t修饰符指定您想要使用的表;例如,iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE会向 NAT 表中添加一条规则。当没有用–t修饰符指定表名时,默认情况下使用过滤表。因此,通过运行iptables -A INPUT -p udp --dport=5001 -j LOG --log-level 1,您向过滤器表添加了一个规则。
 注意你可以给 iptables 规则设置目标;通常这些可以是来自 Linux netfilter 子系统的目标(参见前面使用日志目标的例子)。您还可以编写自己的目标,并扩展 iptables 用户空间代码来支持它们。参见 Jan Engelhardt 和 Nicolas Bouliane 的“编写 Netfilter 模块”。
注意你可以给 iptables 规则设置目标;通常这些可以是来自 Linux netfilter 子系统的目标(参见前面使用日志目标的例子)。您还可以编写自己的目标,并扩展 iptables 用户空间代码来支持它们。参见 Jan Engelhardt 和 Nicolas Bouliane 的“编写 Netfilter 模块”。
注意,为了在 iptables 规则中使用日志目标,必须设置 CONFIG_NETFILTER_XT_TARGET_LOG,如前面的示例所示。你可以参考net/netfilter/xt_LOG.c的代码作为iptables 目标模块的例子。
当一个目的端口为 5001 的 UDP 包到达网络驱动,上行到网络层(L3)时,遇到的第一个钩子是 NF_INET_PRE_ROUTING 钩子;过滤表回调没有在 NF_INET_PRE_ROUTING 中注册一个钩子。它只有三个钩子:NF_INET_LOCAL_IN、NF_INET_FORWARD 和 NF_INET_LOCAL_OUT,如前所述。所以您继续使用ip_rcv_finish()方法,在路由子系统中执行查找。现在有两种情况:数据包打算传送到本地主机或打算转发(让我们忽略数据包将被丢弃的情况)。在图 9-2 中,你可以看到两种情况下的数据包遍历。
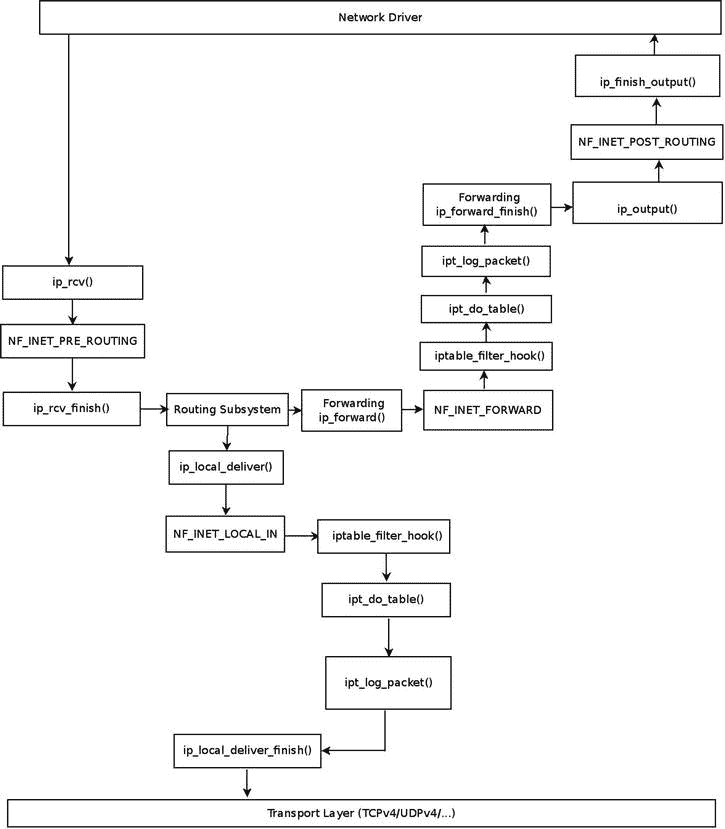
图 9-2 。我的流量和转发流量采用过滤表规则
交付给本地主机
首先你到达ip_local_deliver()方法;简单看一下这个方法:
int ip_local_deliver(struct sk_buff *skb)
{
. . .
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
可以看到,你在这个方法中有 NF_INET_LOCAL_IN 钩子,前面也提到过,NF_INET_LOCAL_IN 是过滤表钩子之一;所以 NF_HOOK()宏将调用iptable_filter_hook()方法。现在看一看iptable_filter_hook()方法:
static unsigned int iptable_filter_hook(unsigned int hook, struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
const struct net *net;
. . .
net = dev_net((in != NULL) ? in : out);
. . .
return ipt_do_table(skb, hook, in, out, net->ipv4.iptable_filter);
}
(net/ipv4/netfilter/iptable_filter.c)
实际上,ipt_do_table()方法调用了日志目标回调函数ipt_log_packet(),它将数据包报头写入 syslog。如果有更多的规则,他们会在这个时候被调用。因为没有更多的规则,您继续使用ip_local_deliver_finish()方法,数据包继续遍历到传输层(L4)由相应的套接字处理。
转发数据包
第二种情况是,在路由子系统中进行查找后,您发现该数据包将被转发,因此调用了ip_forward()方法:
int ip_forward(struct sk_buff *skb)
{
. . .
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev,
rt->dst.dev, ip_forward_finish);
. . .
因为过滤表在 NF_INET_FORWARD 中有一个注册的钩子回调函数,正如前面提到的,您再次调用了iptable_filter_hook()方法。因此,和以前一样,您再次调用了ipt_do_table()方法,它将再次调用ipt_log_packet()方法。你会继续到ip_forward_finish()方法(注意ip_forward_finish是上面 NF_HOOK 宏的最后一个参数,代表 continuation 方法)。然后调用ip_output()方法,因为过滤表没有 NF_INET_POST_ROUTING 钩子,所以继续到ip_finish_output()方法。
 注意你可以根据连接跟踪状态过滤数据包。下一个规则将转储到连接跟踪状态已建立的 syslog 数据包中:
注意你可以根据连接跟踪状态过滤数据包。下一个规则将转储到连接跟踪状态已建立的 syslog 数据包中:
iptables -A INPUT -p tcp -m conntrack --ctstate ESTABLISHED -j LOG --log-level 1
网络地址转换(NAT)
网络地址转换(NAT)模块主要处理 IP 地址转换,顾名思义,即端口操作。NAT 最常见的用途之一是使局域网中拥有私有 IP 地址的一组主机能够通过某个住宅网关访问互联网。例如,您可以通过设置 NAT 规则来做到这一点。安装在网关上的 NAT 可以使用这样的规则,并为主机提供访问 Web 的能力。netfilter 子系统具有针对 IPv4 和 IPv6 的 NAT 实现。IPv6 NAT 实现主要基于 IPv4 实现,并且从用户的角度来看,提供了类似于 IPv4 的接口。IPv6 NAT 支持在内核 3.7 中被合并。它提供了一些功能,如简单的负载平衡解决方案(通过在传入流量上设置 DNAT)等。IPv6 NAT 模块在net/ipv6/netfilter/ip6table_nat.c中。NAT 设置有很多种类型,网上也有很多关于 NAT 管理的文档。我讲两种常见的配置:SNAT 是源 NAT,源 IP 地址改变,DNAT 是目的 NAT,目的 IP 地址改变。您可以使用–j标志来选择 SNAT 或 DNAT。DNAT 和 SNAT 的实现都在net/netfilter/xt_nat.c。下一节讨论 NAT 初始化。
NAT 初始化
NAT 表和上一节中的过滤器表一样,也是一个xt_table对象。除了 NF_INET_FORWARD 钩子之外,它在所有钩子点上都被注册:
static const struct xt_table nf_nat_ipv4_table = {
.name = "nat",
.valid_hooks = (1 << NF_INET_PRE_ROUTING) |
(1 << NF_INET_POST_ROUTING) |
(1 << NF_INET_LOCAL_OUT) |
(1 << NF_INET_LOCAL_IN),
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
};
(net/ipv4/netfilter/iptable_nat.c)
NAT 表的注册和注销分别通过调用ipt_register_table()和ipt_unregister_table()(net/ipv4/netfilter/iptable_nat.c)来完成。网络名称空间(struct net)包括一个 IPv4 特定对象(netns_ipv4),该对象包括一个指向 IPv4 NAT 表(nat_table)的指针,如前面的“IP 表”部分所述。这个由ipt_register_table()方法创建的xt_table对象被分配给这个nat_table指针。您还定义了一个nf_hook_ops对象的数组并注册它:
static struct nf_hook_ops nf_nat_ipv4_ops[] __read_mostly = {
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_in,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_out,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_local_fn,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_fn,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
nf_nat_ipv4_ops数组的注册在iptable_nat_init()方法中完成:
static int __init iptable_nat_init(void)
{
int err;
. . .
err = nf_register_hooks(nf_nat_ipv4_ops, ARRAY_SIZE(nf_nat_ipv4_ops));
if (err < 0)
goto err2;
return 0;
. . .
}
(net/ipv4/netfilter/iptable_nat.c)
NAT 钩子回调和连接跟踪钩子回调
有一些钩子同时注册了 NAT 回调和连接跟踪回调。例如,在 NF_INET_PRE_ROUTING 钩子(传入数据包到达的第一个钩子)上,有两个注册的回调:连接跟踪回调ipv4_conntrack_in() 和 NAT 回调nf_nat_ipv4_in()。连接跟踪回叫的优先级ipv4_conntrack_in()是 NF_IP_PRI_CONNTRACK (-200),NAT 回叫的优先级nf_nat_ipv4_in()是 NF_IP_PRI_NAT_DST (-100)。因为优先级较低的同一个钩子的回调被首先调用,所以优先级为–200 的连接跟踪ipv4_conntrack_in()回调将在优先级为–100 的 NAT nf_nat_ipv4_in()回调之前被调用。ipv4_conntrack_in()方法位置见图 9-1 图nf_nat_ipv4_in()位置见图 9-4;两者都在同一个地方,在 NF_INET_PRE_ROUTING 点。这背后的原因是 NAT 在连接跟踪层执行查找,如果没有找到条目,NAT 不执行任何地址转换操作:
static unsigned int nf_nat_ipv4_fn(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
struct nf_conn *ct;
. . .
/* Don't try to NAT if this packet is not conntracked */
if (nf_ct_is_untracked(ct))
return NF_ACCEPT;
. . .
}
(net/ipv4/netfilter/iptable_nat.c)
 注意
注意nf_nat_ipv4_fn ()方法是从 NAT PRE_ROUTING 回调中调用的,nf_nat_ipv4_in()。
在 NF_INET_POST_ROUTING 钩子上,有两个注册的连接跟踪回调:回调ipv4_helper()(优先级为 NF_IP_PRI_CONNTRACK_HELPER,300)和回调ipv4_confirm()(优先级为 NF_IP_PRI_CONNTRACK_CONFIRM,INT_MAX,优先级最高的整数值)。你还有一个注册的 NAT 钩子回调,nf_nat_ipv4_out(),优先级为 NF_IP_PRI_NAT_SRC,为 100。这样一来,当到达 NF_INET_POST_ROUTING 钩子时,首先会调用 NAT 回调,nf_nat_ipv4_out(),然后会调用ipv4_helper()方法,ipv4_confirm()是最后被调用的。参见图 9-4 。
让我们来看看一个简单的 DNAT 规则,看看转发的包的遍历以及连接跟踪回调和 NAT 回调的调用顺序(为了简单起见,假设这个内核映像中没有构建过滤器表)。在图 9-3 所示的设置中,中间主机(AMD 服务器)运行 DNAT 规则:
iptables -t nat -A PREROUTING -j DNAT -p udp --dport 9999 --to-destination 192.168.1.8
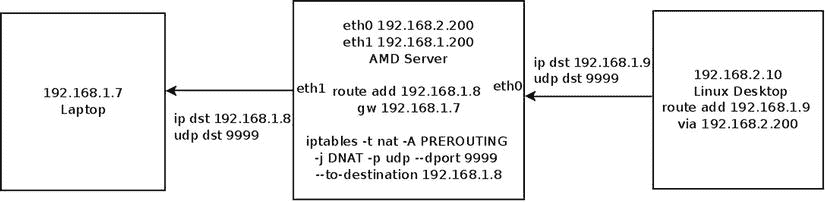
图 9-3 。一个简单的 DNAT 规则设置
此 DNAT 规则的含义是,在 UDP 目标端口 9999 上发送的传入 UDP 数据包会将其目标 IP 地址更改为 192.168.1.8。右侧机器(Linux 桌面)将 UDP 数据包发送到 192.168.1.9,UDP 目的端口为 9999。在 AMD 服务器中,目的 IPv4 地址被 DNAT 规则更改为 192.168.1.8,数据包被发送到左边的笔记本电脑。
在图 9-4 中,您可以看到第一个 UDP 包的遍历,它是根据前面提到的设置发送的。
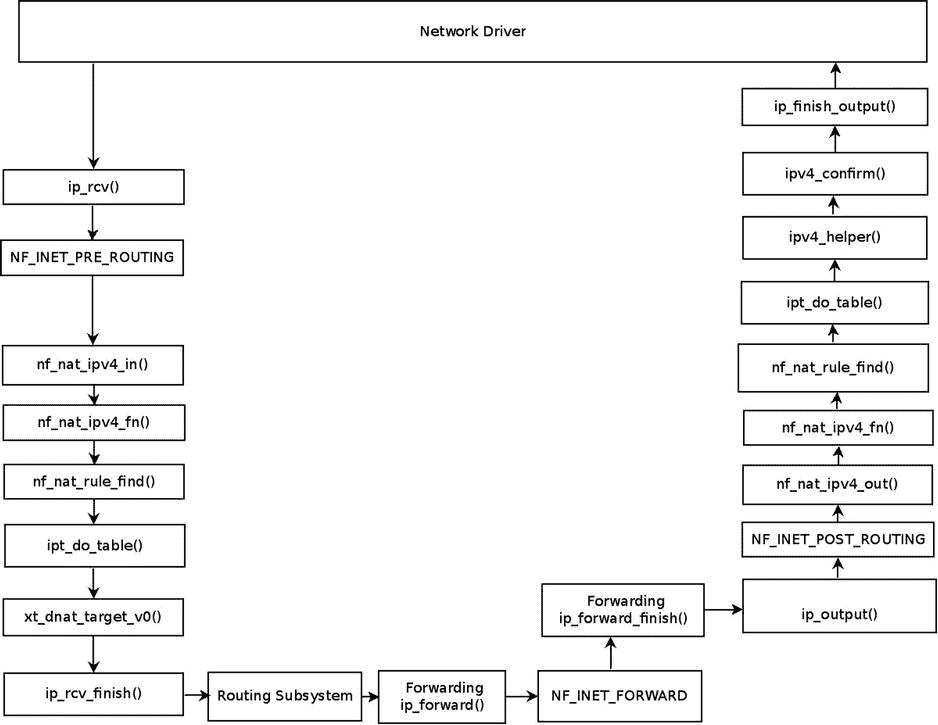
图 9-4 。NAT 和 netfilter 挂钩
通用的 NAT 模块是net/netfilter/nf_nat_core.c。NAT 实现的基本元素是nf_nat_l4proto结构(include/net/netfilter/nf_nat_l4proto.h和nf_nat_l3proto结构。在 3.7 之前的内核中,您将会遇到nf_nat_protocol结构,而不是这两个结构,这两个结构作为添加 IPv6 NAT 支持的一部分取代了它们。这两种结构提供了独立于协议的 NAT 核心支持。
这两种结构都包含一个manip_pkt()函数指针,用于改变数据包报头。让我们看一个 TCP 协议的manip_pkt()实现的例子,在net/netfilter/nf_nat_proto_tcp.c中:
static bool tcp_manip_pkt(struct sk_buff *skb,
const struct nf_nat_l3proto *l3proto,
unsigned int iphdroff, unsigned int hdroff,
const struct nf_conntrack_tuple *tuple,
enum nf_nat_manip_type maniptype)
{
struct tcphdr *hdr;
__be16 *portptr, newport, oldport;
int hdrsize = 8; /* TCP connection tracking guarantees this much */
/* this could be an inner header returned in icmp packet; in such
cases we cannot update the checksum field since it is outside of
the 8 bytes of transport layer headers we are guaranteed */
if (skb->len >= hdroff + sizeof(struct tcphdr))
hdrsize = sizeof(struct tcphdr);
if (!skb_make_writable(skb, hdroff + hdrsize))
return false;
hdr = (struct tcphdr *)(skb->data + hdroff);
根据maniptype设置newport:
- 如果需要更改源端口,
maniptype是 NF_NAT_MANIP_SRC。所以您从tuple->src中提取端口。 - 如果需要更改目的端口,
maniptype是 NF_NAT_MANIP_DST。所以您从tuple->dst中提取端口:
if (maniptype == NF_NAT_MANIP_SRC) {
/* Get rid of src port */
newport = tuple->src.u.tcp.port;
portptr = &hdr->source;
} else {
/* Get rid of dst port */
newport = tuple->dst.u.tcp.port;
portptr = &hdr->dest;
}
你要改变 TCP 头的源端口(当maniptype为 NF_NAT_MANIP_SRC 时)或者目的端口(当maniptype为 NF_NAT_MANIP_DST 时),所以你需要重新计算校验和。您必须保留旧端口用于校验和重新计算,这将通过调用csum_update()方法和inet_proto_csum_replace2()方法立即完成:
oldport = *portptr;
*portptr = newport;
if (hdrsize < sizeof(*hdr))
return true;
重新计算校验和:
l3proto->csum_update(skb, iphdroff, &hdr->check, tuple, maniptype);
inet_proto_csum_replace2(&hdr->check, skb, oldport, newport, 0);
return true;
}
NAT 钩子回调
特定于协议的 NAT 模块对于 IPv4 协议是net/ipv4/netfilter/iptable_nat.c,对于 IPv6 协议是net/ipv6/netfilter/ip6table_nat.c。这两个 NAT 模块各有四个钩子回调,如表 9-1 所示。
表 9-1 。IPv4 和 IPv6 NAT 回调
|钩
|
挂机回拨(IPv4)
|
挂钩回调(IPv6)
|
| — | — | — |
| NF _ INET _ 预路由 | 网络地址转换 ipv4 输入 | 网络地址转换协议 ipv6 协议 |
| 物流配送 | nf_nat_ipv4_out | nf_nat_ipv6_out |
| 本地输出 | nf_nat_ipv4_local_fn | nf_nat_ipv6_local_fn |
| 本地网络 | nf_nat_ipv4_fn | nf_nat_ipv6_fn |
nf_nat_ipv4_fn()是这些方法中最重要的(对于 IPv4)。其他三个方法,nf_nat_ipv4_in()、nf_nat_ipv4_out()和nf_nat_ipv4_local_fn(),都调用了nf_nat_ipv4_fn()方法。让我们来看看nf_nat_ipv4_fn()方法:
static unsigned int nf_nat_ipv4_fn(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
struct nf_conn_nat *nat;
/* maniptype == SRC for postrouting. */
enum nf_nat_manip_type maniptype = HOOK2MANIP(hooknum);
/* We never see fragments: conntrack defrags on pre-routing
* and local-out, and nf_nat_out protects post-routing.
*/
NF_CT_ASSERT(!ip_is_fragment(ip_hdr(skb)));
ct = nf_ct_get(skb, &ctinfo);
/* Can't track? It's not due to stress, or conntrack would
* have dropped it. Hence it's the user's responsibilty to
* packet filter it out, or implement conntrack/NAT for that
* protocol. 8) --RR
*/
if (!ct)
return NF_ACCEPT;
/* Don't try to NAT if this packet is not conntracked */
if (nf_ct_is_untracked(ct))
return NF_ACCEPT;
nat = nfct_nat(ct);
if (!nat) {
/* NAT module was loaded late. */
if (nf_ct_is_confirmed(ct))
return NF_ACCEPT;
nat = nf_ct_ext_add(ct, NF_CT_EXT_NAT, GFP_ATOMIC);
if (nat == NULL) {
pr_debug("failed to add NAT extension\n");
return NF_ACCEPT;
}
}
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
if (ip_hdr(skb)->protocol == IPPROTO_ICMP) {
if (!nf_nat_icmp_reply_translation(skb, ct, ctinfo,
hooknum))
return NF_DROP;
else
return NF_ACCEPT;
}
/* Fall thru... (Only ICMPs can be IP_CT_IS_REPLY) */
case IP_CT_NEW:
/* Seen it before? This can happen for loopback, retrans,
* or local packets.
*/
if (!nf_nat_initialized(ct, maniptype)) {
unsigned int ret;
nf_nat_rule_find()方法调用ipt_do_table()方法,该方法遍历指定表中条目的所有匹配项,如果有匹配项,则调用目标回调:
ret = nf_nat_rule_find(skb, hooknum, in, out, ct);
if (ret != NF_ACCEPT)
return ret;
} else {
pr_debug("Already setup manip %s for ct %p\n",
maniptype == NF_NAT_MANIP_SRC ? "SRC" : "DST",
ct);
if (nf_nat_oif_changed(hooknum, ctinfo, nat, out))
goto oif_changed;
}
break;
default:
/* ESTABLISHED */
NF_CT_ASSERT(ctinfo == IP_CT_ESTABLISHED ||
ctinfo == IP_CT_ESTABLISHED_REPLY);
if (nf_nat_oif_changed(hooknum, ctinfo, nat, out))
goto oif_changed;
}
return nf_nat_packet(ct, ctinfo, hooknum, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
连接跟踪扩展
内核 2.6.23 中添加了连接跟踪(CT)扩展。连接跟踪扩展的要点是只分配所需的内存,例如,如果没有加载 NAT 模块,则不会分配连接跟踪层中 NAT 所需的额外内存。有些扩展是由sysctls启用的,甚至取决于某些 iptables 规则(例如,-m connlabel)。每个连接跟踪扩展模块应该定义一个nf_ct_ext_type对象,并通过nf_ct_extend_register()方法执行注册(取消注册通过nf_ct_extend_unregister()方法完成)。每个扩展应该定义一个方法,将它的连接跟踪扩展附加到一个连接(nf_conn)对象,该对象应该从init_conntrack()方法中调用。因此,例如,您有用于时间戳 CT 扩展的nf_ct_tstamp_ext_add()方法和用于标签 CT 扩展的nf_ct_labels_ext_add()方法。连接跟踪扩展基础设施在net/netfilter/nf_conntrack_extend.c中实现。这些是撰写本文时的连接跟踪扩展模块(全部在net/netfilter下):
nf_conntrack_timestamp.cnf_conntrack_timeout.cnf_conntrack_acct.cnf_conntrack_ecache.cnf_conntrack_labels.cnf_conntrack_helper.c
摘要
本章描述了 netfilter 子系统的实现。我介绍了 netfilter 挂钩以及它们是如何注册的。我还讨论了一些重要的主题,比如连接跟踪机制、iptables 和 NAT。第十章讲述了 IPsec 子系统及其实现。
快速参考
本节涵盖了与本章中讨论的主题相关的顶级方法,按其上下文排序,后面是三个表和一个关于工具和库的简短部分。
方法
下面是 netfilter 子系统的重要方法的简短列表。本章提到了其中一些。
struct XT _ table * ipt _ register _ table(struct net * net,const struct xt_table *table,const struct ipt _ replace * repl);
此方法在 netfilter 子系统中注册一个表。
void ipt _ unregister _ table(struct net * net,struct XT _ table * table);
此方法在 netfilter 子系统中注销一个表。
int nf _ register _ hook(struct nf _ hook _ ops * reg);
这个方法注册一个单独的nf_hook_ops对象。
int nf _ register _ hooks(struct nf _ hook _ ops * reg,unsigned int n);
该方法注册一个由 n 个 nf_hook_ops对象组成的数组;第二个参数是数组中元素的数量。
void nf _ unregister _ hook(struct nf _ hook _ ops * reg);
这个方法注销一个单独的nf_hook_ops对象。
void nf _ unregister _ hooks(struct nf _ hook _ ops * reg,unsigned int n);
此方法注销一个由 n nf_hook_ops个对象组成的数组;第二个参数是数组中元素的数量。
静态内联 void nf _ conntrack _ get(struct nf _ conntrack * nfct);
该方法增加相关nf_conntrack对象的引用计数。
静态内联 void nf _ conntrack _ put(struct nf _ conntrack * nfct);
该方法减少相关nf_conntrack对象的引用计数。如果达到 0,就调用nf_conntrack_destroy()方法。
int nf _ conn track _ helper _ register(struct nf _ conn track _ helper * me);
这个方法注册一个nf_conntrack_helper对象。
静态内联结构 nf _ conn * resolve _ normal _ CT(struct net * net,struct nf_conn *tmpl,struct sk_buff *skb,unsigned int dataoff,u_int16_t l3num,u_int8_t protonum,struct nf _ conn track _ L3 proto * L3 proto,struct nf _ conn track _ l4 proto * l4 proto,int *set_reply,enum IP _ conn track _ info * ctinfo);
这个方法试图通过调用__nf_conntrack_find_get()方法根据指定的 SKB 找到一个nf_conntrack_tuple_hash对象,如果没有找到这样的条目,就通过调用init_conntrack()方法创建一个。从nf_conntrack_in()方法(net/netfilter/nf_conntrack_core.c)调用resolve_normal_ct()方法。
struct nf _ conntrack _ 元组 _ hash * init _ conntrack(struct net * net,struct nf_conn tmpl,const struct nf _ conntrack _ 元组元组,struct nf _ conntrack _ L3 proto * L3 protocol,struct nf _ conntrack _ l4 proto * l4 proto,struct sk _ buff * skb,signed int dataoff,u32 hash);
这个方法分配一个连接跟踪nf_conntrack_tuple_hash对象。从resolve_normal_ct()方法中调用,它试图通过调用nf_ct_find_expectation()方法来寻找这个连接的期望。
static struct nf _ conn * _ _ _ nf _ conntrack _ alloc(struct net * net,u16 区域,const struct nf _ conntrack _ tuple * orig,const struct nf _ conntrack _ tuple * repl,gfp_t gfp,u32 hash);
这个方法分配一个nf_conn对象。将nf_conn对象的超时计时器设置为death_by_timeout()方法。
int XT _ register _ target(struct XT _ target * target);
这个方法注册一个 Xtable 目标扩展。
void XT _ unregister _ target(struct XT _ target * target);
此方法注销 Xtable 目标扩展。
int XT _ register _ targets(struct XT _ target * target,unsigned int n);
此方法注册 Xtable 目标扩展的数组; n 是目标数量。
void XT _ unregister _ targets(struct XT _ target * target,unsigned int n);
此方法注销 Xtable 目标扩展的数组; n 是目标数量。
int XT _ register _ match(struct XT _ match * target);
此方法注册一个 Xtable 匹配扩展。
void XT _ unregister _ match(struct XT _ match * target);
此方法注销 Xtable 匹配扩展。
int XT _ register _ matches(struct XT _ match * match,unsigned int n);
此方法注册 Xtable 匹配扩展的数组; n 是匹配的次数。
void XT _ unregister _ matches(struct XT _ match * match,unsigned int n);
此方法注销 Xtable 匹配扩展的数组; n 是匹配的次数。
int nf _ CT _ extend _ register(struct nf _ CT _ ext _ type * type);
此方法注册连接跟踪扩展对象。
void nf _ CT _ extend _ unregister(struct nf _ CT _ ext _ type * type);
此方法注销连接跟踪扩展对象。
int _ _ init iptable _ NAT _ init(void);
此方法初始化 IPv4 NAT 表。
int __init nf_conntrack_ftp_init(请参阅):
此方法初始化连接跟踪 FTP 帮助程序。调用nf_conntrack_helper_register()方法来注册 FTP 助手。
巨
让我们看看本章中使用的宏。
NF_CT_DIRECTION(哈希)
这是一个宏,获取一个nf_conntrack_tuple_hash对象作为参数,返回关联元组(include/net/netfilter/nf_conntrack_tuple.h)的目的(dst对象)的方向(IP_CT_DIR_ORIGINAL,为 0,或者 IP_CT_DIR_REPLY,为 1)。
桌子
下面是表格,显示了 IPv4 网络名称空间和 IPv6 网络名称空间中的 netfilter 表以及 netfilter 挂钩优先级。
表 9-2 。IPv4 网络命名空间(netns_ipv4)表(xt_table 对象)
|Linux 符号( netns_ipv4)
|
Linux 模块
|
| — | — |
| iptable_filter | net/IP v4/netfilter/iptable _ filter . c |
| iptable_mangle | net/IP v4/netfilter/iptable _ mangle . c |
| iptable_raw | net/IP v4/netfilter/iptable _ raw . c |
| ARP 表 _ 过滤器 | net/IP v4/netfilter/ARP _ tables . c |
| nat_table | net/IP v4/netfilter/iptable _ NAT . c |
| iptable_security | net/IP v4/netfilter/iptable _ SECURITY . c(注意:要设置 CONFIG_SECURITY)。 |
表 9-3 。IPv6 网络命名空间(netns_ipv6)表(xt_table 对象)
|Linux 符号( netns_ipv6)
|
Linux 模块
|
| — | — |
| ip6 表格 _ 过滤器 | net/IPv6/netfilter/IP 6 table _ filter . c |
| ip6table_mangle | net/IPv6/netfilter/IP 6 table _ mangle . c |
| ip6table_raw | net/IPv6/netfilter/IP 6 table _ raw . c |
| ip6table_nat | net/IPv6/netfilter/IP 6 table _ NAT . c |
| ip6table_security | net/IPv6/netfilter/IP 6 table _ SECURITY . c(注意:要设置 CONFIG_SECURITY)。 |
表 9-4。 Netfilter 挂钩优先级
|Linux 符号
|
值
|
| — | — |
| NF _ IP _ 优先级 _ 优先 | INT_MIN |
| nf _ ip _ pri _ conntrack _ 碎片整理 | -400 |
| NF_IP_PRI_RAW 格式 | -300 |
| NF _ IP _ 优先级 _ SELINUX _ 优先 | -225 |
| nf _ IP _ pri _ conntrack _ 连线轨迹 | -200 |
| S7-1200 可编程控制器 | -150 |
| NF_IP_PRI_NAT_DST 文件 | -100 |
| 网络过滤协议优先级过滤器 | Zero |
| NF_IP_PRI_SECURITY | Fifty |
| NF_IP_PRI_NAT_SRC | One hundred |
| 最后一个 | Two hundred and twenty-five |
| NF_IP_PRI_CONNTRACK_HELPER | Three hundred |
| NF _ IP _ PRI _ CONNTRACK _ 确认 | INT_MAX |
| NF _ IP _ 优先级 _ 最后 | INT_MAX |
参见include/uapi/linux/netfilter_ipv4.h中的nf_ip_hook_priorities enum定义。
工具和库
conntrack-tools由一个用户空间守护进程conntrackd和一个命令行工具conntrack组成。它提供了一个工具,系统管理员可以使用该工具与 netfilter 连接跟踪层进行交互。参见:http://conntrack-tools.netfilter.org/。
有些库是由 netfilter 项目开发的,允许您执行各种用户空间任务;这些库以“libnetfilter”为前缀;比如libnetfilter_conntrack、libnetfilter_log、libnetfilter_queue。更多详情见 netfilter 官网,www.netfilter.org。

















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









