







六、并发与并行
多年来,计算机系统的处理能力呈指数增长。每个型号的处理器都变得越来越快,旨在挑战昂贵工作站硬件资源的程序被移植到笔记本电脑和手持设备上。这个时代在几年前就结束了,今天处理器的速度并没有指数级增长;他们的数量呈指数增长。当多处理器系统罕见且昂贵时,编写程序以利用多处理核心的 并不容易,今天,当智能手机配备双核和四核处理器时,这也变得不容易。
*在本章中,我们将开始在. NET 中的现代并行编程的世界中进行一次旋风式的旅行。尽管这一适度的章节不能开始描述并行编程今天的所有 API、框架、工具、缺陷、设计模式和架构模型,但是没有一本关于性能优化的书是不完整的,除非讨论一种明显最便宜的提高应用性能的方法,即扩展到多个处理器。
挑战和收获
利用并行性 的另一个挑战是多处理器系统日益增长的异构性。CPU 制造商以提供价格合理的面向消费者的四核或八核处理系统以及几十核高端服务器系统而自豪。然而,如今中档工作站或高端笔记本电脑通常配备了强大的图形处理单元(GPU),支持数百并发线程。似乎这两种并行还不够,基础设施即服务(IaaS)的价格每周都在下降,使得一眨眼就可以访问千核云。
 注 Herb Sutter 在他的文章《欢迎来到丛林》(2011)中对等待并行框架的异构世界进行了出色的概述。在 2005 年的另一篇文章“免费的午餐结束了”中,他塑造了日常编程中对并发和并行框架的兴趣的复苏。如果您发现自己渴望获得比这一章所能提供的更多的关于并行编程的信息,我们可以推荐以下关于并行编程主题的优秀书籍。特别是. NET 并行框架:Joe Duffy,“Windows 上的并发编程”(Addison-Wesley,2008);Joseph Albahari,“C# 中的线程化”(在线,2011)。为了更详细地了解操作系统围绕线程调度和同步机制的内部工作,马克·鲁西诺维奇、大卫·所罗门和亚历克斯·约内斯库的《Windows Internals,5 th Edition》(微软出版社,2009 年)是一篇很好的文章。最后,MSDN 是我们将在本章看到的 API 的一个很好的信息来源,比如任务并行库。
注 Herb Sutter 在他的文章《欢迎来到丛林》(2011)中对等待并行框架的异构世界进行了出色的概述。在 2005 年的另一篇文章“免费的午餐结束了”中,他塑造了日常编程中对并发和并行框架的兴趣的复苏。如果您发现自己渴望获得比这一章所能提供的更多的关于并行编程的信息,我们可以推荐以下关于并行编程主题的优秀书籍。特别是. NET 并行框架:Joe Duffy,“Windows 上的并发编程”(Addison-Wesley,2008);Joseph Albahari,“C# 中的线程化”(在线,2011)。为了更详细地了解操作系统围绕线程调度和同步机制的内部工作,马克·鲁西诺维奇、大卫·所罗门和亚历克斯·约内斯库的《Windows Internals,5 th Edition》(微软出版社,2009 年)是一篇很好的文章。最后,MSDN 是我们将在本章看到的 API 的一个很好的信息来源,比如任务并行库。
并行性带来的性能提升不容忽视。通过将 I/O 卸载到单独的线程,执行异步 I/O 以提供更高的响应能力,以及通过发出多个 I/O 操作 进行扩展,I/O 绑定的应用可以受益匪浅。通过利用所有可用的 CPU 内核,CPU 受限的应用可以在典型的消费类硬件上扩展一个数量级,或者通过利用所有可用的 GPU 内核扩展两个数量级。在这一章的后面,你将会看到一个执行矩阵乘法的简单算法是如何通过仅仅改变几行在 GPU 上运行的代码而被加速 130 倍的。
和往常一样,通往并行的道路充满了陷阱——死锁、竞争条件、饥饿和内存损坏在每一步都等着我们。最近的并行框架,包括任务并行库(。NET 4.0)和 C++ AMP ,我们将在本章中使用,目的是降低编写并行应用的复杂性,并获得成熟的性能收益。
为什么是并发和并行?
在应用中引入多线程控制有很多原因。这本书致力于提高应用的性能,事实上并发和并行的大部分原因在于性能领域。下面是一些例子:
- 发出异步 I/O 操作可以提高应用的响应能力。大多数 GUI 应用都有一个负责所有 UI 更新的控制线程;这个线程绝不能被长时间占用,以免 UI 对用户操作没有反应。
- 跨多个线程并行化工作可以更好地利用系统资源。配备了多个 CPU 内核甚至更多 GPU 内核的现代系统可以通过简单 CPU 限制算法的并行化获得数量级的性能提升。
- 一次执行几个 I/O 操作(例如,同时从多个旅游网站检索价格,或者更新几个分布式 Web 存储库中的文件)有助于提高整体吞吐量,因为大部分时间都在等待 I/O 操作完成,并且可以用于发出额外的 I/O 操作或者对已经完成的操作执行结果处理。
从线程到线程池再到任务
起初有线。线程是并行化应用和分配异步工作的最基本手段;它们是用户模式程序可用的最低级的抽象。线程在结构和控制方面提供的很少,编程线程直接类似于很久以前的非结构化编程,那时子例程、对象和代理还没有普及。
考虑下面这个简单的任务:给你一个大范围的自然数,要求你找出这个范围内的所有质数,并将它们存储在一个集合中。这是一个纯粹受 CPU 限制的任务,看起来很容易并行化。首先,让我们编写一个在单个 CPU 线程上运行的代码的简单版本:
//Returns all the prime numbers in the range [start, end)
public static IEnumerable < uint > PrimesInRange(uint start, uint end) {
List < uint > primes = new List < uint > ();
for (uint number = start; number < end; ++number) {
if (IsPrime(number)) {
primes.Add(number);
}
}
return primes;
}
private static bool IsPrime(uint number) {
//This is a very inefficient O(n) algorithm, but it will do for our expository purposes
if (number == 2) return true;
if (number % 2 == 0) return false;
for (uint divisor = 3; divisor < number; divisor += 2) {
if (number % divisor == 0) return false;
}
return true;
}
这里有什么需要改进的地方吗?也许算法太快了,试图优化它没有任何好处?嗯,对于一个相当大的范围,比如[100,200000],上面的代码在现代处理器上运行几秒钟,为优化留下了足够的空间。
您可能对算法的效率有很大的保留(例如,有一个微不足道的优化使它在 O (√ n )时间内运行,而不是线性时间),但不管算法的最优性如何,它似乎很可能很好地适应并行化。毕竟,发现 4977 是否是质数与发现 3221 是否是质数 是独立的,所以并行化上述代码的一个明显简单的方法是将范围划分为许多块,并创建一个单独的线程来处理每个块(如图 6-1 所示)。显然,我们必须同步对素数集合的访问,以防止它被多线程破坏。一种简单的方法是遵循以下原则:
public static IEnumerable < uint > PrimesInRange(uint start, uint end) {
List < uint > primes = new List < uint > ();
uint range = end - start;
uint numThreads = (uint)Environment.ProcessorCount; //is this a good idea?
uint chunk = range / numThreads; //hopefully, there is no remainder
Thread[] threads = new Thread[numThreads];
for (uint i = 0; i < numThreads; ++i) {
uint chunkStart = start + i*chunk;
uint chunkEnd = chunkStart + chunk;
threads[i] = new Thread(() = > {
for (uint number = chunkStart; number < chunkEnd; ++number) {
if (IsPrime(number)) {
lock(primes) {
primes.Add(number);
}
}
}
});
threads[i].Start();
}
foreach (Thread thread in threads) {
thread.Join();
}
return primes;
}

图 6-1 。在多线程之间划分质数的范围
在英特尔 i7 系统 上,顺序代码遍历范围【100,200000】平均需要 2950 ms,而并行版本平均需要 950 ms。从具有 8 个 CPU 内核的系统中,您期望获得更好的结果,但是这种特殊的 i7 处理器使用超线程,这意味着只有 4 个物理内核(每个物理内核托管两个逻辑内核)。4 倍的加速比是更合理的预期,我们获得了 3 倍的加速,这仍然是不可忽略的。然而,正如图 6-2 和 6-3 中并发分析器的报告所示,一些线程比其他线程完成得更快,导致整体 CPU 利用率远低于 100%(要在您的应用上运行并发分析器,请参考第二章)。

图 6-2 。总体 CPU 利用率上升到几乎 8 个逻辑核心(100%),然后在运行结束时下降到只有一个逻辑核心

图 6-3 。有些线程比其他线程完成得快得多。线程 9428 运行时间不到 200 毫秒,而线程 5488 运行时间超过 800 毫秒
事实上,这个程序可能比顺序版本运行得更快(尽管不会线性扩展),特别是如果你在混合中加入了很多内核。这招致几个疑问 ,然而:
- 多少线程是最佳的?如果系统有八个 CPU 核心,我们应该创建八个线程吗?
- 我们如何确保不独占系统资源或造成超额订阅?例如,如果我们的进程中有另一个线程需要计算质数,并试图运行与我们相同的并行算法,该怎么办?
- 线程如何同步对结果集合的访问?从多个线程访问一个列表< uint >是不安全的,会导致数据损坏,我们将在后面的章节中看到。然而,每当我们向集合中添加一个质数时(这是上面的天真解决方案所做的)获取一个锁将被证明是极其昂贵的,并且抑制了我们将算法扩展到更多处理核心的能力。
- 对于一个小范围的数字,是否值得产生几个新线程,或者在一个线程上同步执行整个操作可能是一个更好的主意?(在 Windows 上创建和销毁一个线程很便宜,但不如找出 20 个小数字是质数还是合数便宜。)
- 我们如何确保所有线程的工作量相等?有些线程可能比其他线程完成得更快,尤其是那些处理较小数量的线程。对于分成四等份的范围[100,100000],负责范围[100,25075]的线程的完成速度将是负责范围[75025,100000]的线程的两倍多,因为我们的素性测试算法在遇到大素数时会变得越来越慢。
- 我们应该如何处理其他线程可能出现的异常?在这种特殊情况下,IsPrime 方法似乎不会出现错误,但在现实世界的示例中,并行化工作可能会遇到潜在的陷阱和异常情况。(CLR 的默认行为是当线程因未处理的异常而失败时终止整个进程,这通常是一个好主意—快速失败语义—但根本不允许 PrimesInRange 的调用方处理异常。)
这些问题的好答案远非微不足道,开发一个允许并行工作执行而不产生太多线程的框架,避免超额订阅并确保工作在所有线程中均匀分布,可靠地报告错误和结果,并与流程中的其他并行资源合作,这正是任务并行库的设计者的任务,我们将在接下来处理。
从手动线程管理开始,自然的第一步是走向线程池 。线程池 ?? 是一个组件,它管理一组可用于工作项目执行的线程。不是创建一个线程来执行某个任务,而是将该任务排队到线程池中,线程池选择一个可用的线程并分派该任务来执行。线程池有助于解决上面强调的一些问题-它们降低了为极短的任务创建和销毁线程的成本,通过限制应用使用的线程总数来帮助避免资源独占和超额订阅,并自动决定给定任务的最佳线程数。
在我们的特殊情况下,我们可能决定将这个数字范围分成更大数量的块(在极端情况下,每个循环迭代一个块),并将它们排队到线程池中。下面是一个块大小为 100 的方法示例:
public static IEnumerable < uint > PrimesInRange(uint start, uint end) {
List < uint > primes = new List < uint > ();
const uint ChunkSize = 100;
int completed = 0;
ManualResetEvent allDone = new ManualResetEvent(initialState: false);
uint chunks = (end - start) / ChunkSize; //again, this should divide evenly
for (uint i = 0; i < chunks; ++i) {
uint chunkStart = start + i*ChunkSize;
uint chunkEnd = chunkStart + ChunkSize;
ThreadPool.QueueUserWorkItem(_ => {
for (uint number = chunkStart; number < chunkEnd; ++number) {
if (IsPrime(number)) {
lock(primes) {
primes.Add(number);
}
}
}
if (Interlocked.Increment(ref completed) == chunks) {
allDone.Set();
}
});
}
allDone.WaitOne();
return primes;
}
这个版本的代码比我们之前考虑的版本更具可伸缩性,执行速度也更快。它改进了简单的基于线程版本所需的 950 ms(范围为[100,300000]),平均在 800 ms 内完成(与顺序版本相比,几乎提高了 4 倍)。此外,正如图 6-4 的中的 所示,CPU 使用率一直保持在接近 100%的水平。
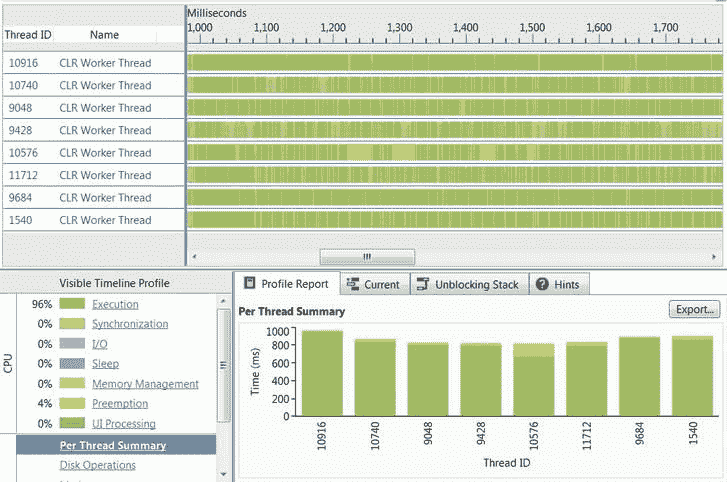
图 6-4 。在程序执行期间,CLR 线程池使用了 8 个线程(每个逻辑内核一个线程)。每个线程几乎运行了整个持续时间
从 CLR 4.0 开始,CLR 线程池由几个协同工作的组件组成。当一个不属于线程池的线程(比如应用的主线程)将工作项目分派到线程池时,它们会被放入一个全局 FIFO(先进先出)队列。每个线程池线程都有一个本地 LIFO(后进先出)队列,它会将在该线程上创建的工作项排入队列(参见图 6-5 )。当线程池线程寻找工作时,它首先查询自己的 LIFO 队列,只要工作项可用,就执行其中的工作项。如果一个线程的 LIFO 队列耗尽,它将尝试工作窃取——查询其他线程的本地队列,并从它们那里获取工作项目,按照 FIFO 的顺序。最后,如果所有的本地队列都是空的,线程将查询全局(FIFO)队列,并从那里执行工作项目。
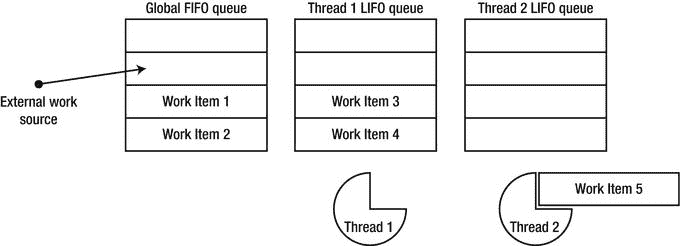
图 6-5 。线程#2 当前正在执行工作项目# 5;完成执行后,它将从全局 FIFO 队列中借用工作。线程#1 将在处理任何其他工作之前清空其本地队列
线程池 FIFO 和 LIFO 语义
明显古怪的 FIFO 和 LIFO 队列语义背后的原因如下:当工作在全局队列中排队时,没有特定的线程对执行该工作有任何偏好,公平是选择执行工作的唯一标准。这就是 FIFO 语义适合全局队列的原因。然而,当线程池线程将工作项排队以供执行时,它很可能使用与当前执行的工作项相同的数据和相同的指令;这就是为什么将它放入属于同一线程的 LIFO 队列是有意义的——它将在当前执行的工作项之后不久执行,并利用 CPU 数据和指令缓存。
此外,与访问全局队列相比,访问线程的本地队列上的工作项需要较少的同步,并且不太可能遇到来自其他线程的争用。类似地,当一个线程从另一个线程的队列中窃取工作时,它会按照 FIFO 的顺序进行窃取,这样就可以保持相对于原始线程处理器上的 CPU 缓存的 LIFO 优化。这种线程池结构对工作项层次结构非常友好,在这种层次结构中,加入全局队列的单个工作项将产生许多额外的工作项,并为几个线程池线程提供工作。
与任何抽象 一样,线程池从应用开发人员手中夺走了对线程生命周期和工作项目调度的一些粒度控制。虽然 CLR 线程池有一些控件 API,比如 thread pool。控制线程数量的 SetMinThreads 和 SetMaxThreads,它没有内置的 API 来控制其线程或任务的优先级。然而,通常情况下,应用在更强大的系统上自动伸缩的能力,以及不必为短期任务创建和销毁线程所带来的性能提升,大大弥补了这种控制的损失。
排队到线程池中的工作项目是极其不称职的;它们没有状态,不能携带异常信息,不支持异步延续和取消,也没有任何从已经完成的任务中获取结果的机制。任务平行库 中。NET 4.0 引入了任务*,这是线程池工作项之上的强大抽象。任务是线程和线程池工作项的结构化替代,就像对象和子例程是基于 goto 的汇编语言编程的结构化替代一样。
任务并行度
任务并行性是一种范式和一组 API,用于将一个大任务分解成一组较小的任务,并在多个线程上执行它们。任务并行库(TPL)拥有一流的 API,可以同时管理数百万个任务(通过 CLR 线程池)。第三方物流的核心是系统。Threading.Tasks.Task 类,代表一个任务。任务类 提供了以下功能:
- 为在未指定的线程上独立执行调度工作。(执行给定任务的特定线程由任务调度器决定;默认的任务计划程序将任务排入 CLR 线程池,但也有一些计划程序将任务发送到特定的线程,如 UI 线程。)
- 等待任务完成并获得其执行结果。
- 提供应该在任务完成后立即运行的延续。(这通常被称为回调,但我们将在本章通篇使用术语延续。)
- 处理单个任务中出现的异常,甚至是调度任务执行的原始线程上的任务层次结构中出现的异常,或者是对任务结果感兴趣的任何其他线程中出现的异常。
- 取消尚未开始的任务,并将取消请求传达给正在执行的任务。
因为我们可以将任务视为线程之上的高级抽象,所以我们可以重写用于素数计算的代码,以使用任务而不是线程。事实上,这将使代码更短——至少,我们不需要已完成任务计数器和 ManualResetEvent 对象来跟踪任务执行。然而,正如我们将在下一节中看到的,TPL 提供的数据并行性 API 甚至更适合于并行化在一个范围内寻找所有质数的循环。相反,我们应该考虑一个不同的问题。
有一种众所周知的基于递归比较的排序算法叫做 QuickSort,它非常容易实现并行化(并且平均 case 运行时复杂度为 O ( n log( n )),这是最优的——尽管目前很少有大型框架使用 QuickSort 来排序任何东西)。快速排序算法 如下进行:
public static void QuickSort < T > (T[] items) where T : IComparable < T > {
QuickSort(items, 0, items.Length);
}
private static void QuickSort < T > (T[] items, int left, int right) where T : IComparable < T > {
if (left == right) return;
int pivot = Partition(items, left, right);
QuickSort(items, left, pivot);
QuickSort(items, pivot + 1, right);
}
private static int Partition < T > (T[] items, int left, int right) where T : IComparable < T > {
int pivotPos = . . .; //often a random index between left and right is used
T pivotValue = items[pivotPos];
Swap(ref items[right-1], ref items[pivotPos]);
int store = left;
for (int i = left; i < right - 1; ++i) {
if (items[i].CompareTo(pivotValue) < 0) {
Swap(ref items[i], ref items[store]);
++store;
}
}
Swap(ref items[right-1], ref items[store]);
return store;
}
private static void Swap < T > (ref T a, ref T b) {
T temp = a;
a = b;
b = temp;
}
图 6-6 是分割方法 ?? 的一个单独步骤的示意图。选择第四个元素(其值为 5)作为轴心。首先,它被移到数组的最右边。接下来,所有大于轴心的元素都向数组的右侧传播。最后,定位枢轴,使其右侧的所有元素严格大于它,其左侧的所有元素小于或等于它。

图 6-6 。对 Partition 方法的单次调用的说明。
QuickSort 在每一步进行的递归调用必须设置并行化警报。对数组的左右部分进行排序是独立的任务,它们之间不需要同步,Task 类非常适合表达这一点。下面是使用任务并行化快速排序的首次尝试:
public static void QuickSort < T > (T[] items) where T : IComparable < T > {
QuickSort(items, 0, items.Length);
}
private static void QuickSort < T > (T[] items, int left, int right) where T : IComparable < T > {
if (right - left < 2) return;
int pivot = Partition(items, left, right);
Task leftTask = Task.Run(() => QuickSort(items, left, pivot));
Task rightTask = Task.Run(() => QuickSort(items, pivot + 1, right));
Task.WaitAll(leftTask, rightTask);
}
private static int Partition < T > (T[] items, int left, int right) where T : IComparable < T > {
//Implementation omitted for brevity
}
任务。Run 方法 创建一个新任务(相当于调用 new task())并调度它执行(相当于新创建任务的 Start 方法)。任务。WaitAll 静态方法等待两个任务都完成,然后返回。请注意,我们不必指定如何等待任务完成,也不必指定何时创建线程以及何时销毁线程。
有一种有用的实用方法叫做并行。调用 ,它执行提供给它的一组任务,并在所有任务完成后返回。这将允许我们用下面的代码重写快速排序方法的核心:
Parallel.Invoke(
() => QuickSort(items, left, pivot),
() => QuickSort(items, pivot + 1, right)
);
不管我们是否使用并行。手动调用或创建任务,如果我们尝试将这个版本与简单的顺序版本进行比较,我们会发现它的运行速度明显慢,尽管它似乎利用了所有可用的处理器资源。事实上,使用 1,000,000 个随机整数的数组,顺序版本运行(在我们的测试系统上)平均需要 250 ms,而并行版本平均需要将近 650 ms 才能完成!
问题是并行需要足够粗的粒度;尝试对三元素数组进行并行排序是徒劳的,因为创建任务对象、将工作项目调度到线程池以及等待它们完成执行所带来的开销完全超过了所需的少量比较操作。
递归算法中的节流并行
你打算如何抑制并行性,以防止这种开销减少我们优化的任何回报?有几种可行的方法:
- 只要要排序的数组的大小大于某个阈值(比如说 500 项),就使用并行版本,一旦它变小,就切换到顺序版本。
- 只要递归深度小于某个阈值,就使用并行版本,一旦递归非常深,就切换到顺序版本。(这个选项比前一个稍逊一筹,除非轴心总是正好位于数组的中间。)
- 只要未完成任务的数量(该方法必须手动维护)小于某个阈值,就使用并行版本,否则切换到顺序版本。(当没有其他限制并行性的标准(如递归深度或输入大小)时,这是唯一的选择。)
事实上,在上面的案例中,限制大于 500 个元素的数组的并行化在作者的英特尔 i7 处理器上产生了出色的结果,与顺序版本相比,执行时间提高了 4 倍。代码更改非常简单,尽管在生产质量的实现中不应该硬编码阈值:
private static void QuickSort < T > (T[] items, int left, int right) where T : IComparable < T > {
if (right - left < 2) return;
int pivot = Partition(items, left, right);
if (right - left > 500) {
Parallel.Invoke(
() => QuickSort(items, left, pivot),
() => QuickSort(items, pivot + 1, right)
);
} else {
QuickSort(items, left, pivot);
QuickSort(items, pivot + 1, right);
}
}
递归分解的更多例子
通过应用类似的递归分解 ,可以并行化许多附加算法。事实上,几乎所有将输入分成几个部分的递归算法都被设计成在每个部分上独立执行,然后组合结果。在本章的后半部分,我们将考虑不那么容易屈服于并行化的例子,但首先让我们来看几个这样做的例子:
- 斯特拉森矩阵乘法算法(概述见
http://en.wikipedia.org/wiki/Strassen_algorithm)。这种矩阵乘法的算法比我们将在本章后面看到的简单的立方算法提供了更好的性能。Strassen 的算法将一个大小为 2 n × 2 n 的矩阵递归分解成大小为 2 n-1 × 2 n-1 的四个相等的分块矩阵,并使用了一个依靠七次乘法而不是八次乘法的聪明绝招来获得渐近运行时间∽O(n2.807)。在快速排序的例子中,对于足够小的矩阵,Strassen 算法的实际实现通常会退回到标准的立方算法;当使用递归分解并行化 Strassen 算法时,为较小的矩阵设置一个并行化阈值甚至更为重要。 - 快速傅立叶变换(库利-图基算法,见
http://en.wikipedia.org/wiki/Cooley%E2%80%93Tukey_FFT_algorithm)。该算法通过将长度为 2 n 的向量递归分解为两个大小为 2 n-1 的向量来计算该向量的 DFT(离散傅立叶变换)。并行化这种计算是相当容易的,但是同样重要的是要警惕为足够小的向量设置并行化的阈值。 - 图形遍历(深度优先搜索或广度优先搜索)。正如我们在第四章中看到的,CLR 垃圾收集器遍历一个图,其中对象是顶点,对象之间的引用是边。使用 DFS 或 BFS 的图遍历可以从并行化以及我们考虑过的其他递归算法中受益匪浅;然而,与快速排序或 FFT 不同,当并行化图遍历的分支时,很难预先估计递归调用所代表的工作量。这种困难需要启发式方法来决定如何将搜索空间划分给多线程:我们已经看到服务器 GC 风格相当粗糙地执行这种划分,基于每个处理器分配对象的独立堆。
如果您正在寻找更多的例子来练习您的并行编程技能,也可以考虑 Karatsuba 的乘法算法,该算法依靠递归分解将∽O(n1.585)运算中的 n 位数字相乘;依赖递归分解进行排序的归并排序,类似于快速排序;以及许多动态编程算法,这些算法通常需要高级技巧来在并行计算的不同分支中采用记忆化(我们将在后面研究一个例子)。
例外和取消
我们还没有挖掘出任务类的全部能力。假设我们想要处理递归调用 QuickSort 时可能出现的异常,并在排序操作尚未完成时提供取消整个排序操作的支持。
任务执行环境提供了基础结构,用于将任务中出现的异常封送回到被认为适合接收它的任何线程。假设快速排序任务的一个递归调用遇到了一个异常,可能是因为我们没有仔细考虑数组的边界,给数组的任何一边引入了一个差 1 的错误。这个异常会在线程池线程上出现,线程池线程不受我们的显式控制,并且不允许任何总体异常处理行为。幸运的是,TPL 将捕获异常,并将其存储在 Task 对象中,供以后传播。
当程序试图等待任务完成(使用任务)时,任务中出现的异常将被重新抛出(包装在 AggregateException 对象中)。等待实例方法)或检索其结果(使用任务。结果属性)。这允许在创建任务的代码中进行自动和集中的异常处理,并且不需要将错误手动传播到中央位置和同步错误报告活动。下面的最小代码示例演示了 TPL 中的异常处理范例:
int i = 0;
Task < int > divideTask = Task.Run(() = > { return 5/i; });
try {
Console.WriteLine(divideTask.Result); //accessing the Result property eventually throws
} catch (AggregateException ex) {
foreach (Exception inner in ex.InnerExceptions) {
Console.WriteLine(inner.Message);
}
}
 注意当从现有任务的主体中创建任务时,TaskCreationOptions。AttachedToParent 枚举值在新子任务和创建它的父任务之间建立关系。我们将在本章后面看到,任务之间的父子关系影响任务执行的取消、继续和调试方面。然而,就异常处理而言,等待父任务完成意味着等待所有子任务完成,并且子任务的任何异常也会传播到父任务。这就是为什么 TPL 抛出一个 AggregateException 实例,该实例包含一个层次结构的异常,这些异常可能是从一个层次结构的任务中产生的。
注意当从现有任务的主体中创建任务时,TaskCreationOptions。AttachedToParent 枚举值在新子任务和创建它的父任务之间建立关系。我们将在本章后面看到,任务之间的父子关系影响任务执行的取消、继续和调试方面。然而,就异常处理而言,等待父任务完成意味着等待所有子任务完成,并且子任务的任何异常也会传播到父任务。这就是为什么 TPL 抛出一个 AggregateException 实例,该实例包含一个层次结构的异常,这些异常可能是从一个层次结构的任务中产生的。
取消现有工作是另一个需要考虑的问题。假设我们有一个任务层次结构,比如使用 TaskCreationOptions 时由 QuickSort 创建的层次结构。AttachedToParent 枚举值。即使可能有数百个任务同时运行,我们也可能希望向用户提供取消语义,例如,如果不再需要排序后的数据。在其他场景中,取消未完成的工作可能是任务执行的一个组成部分。例如,考虑使用 DFS 或 BFS 在图中查找节点的并行算法。当找到所需的节点时,应该调用执行查找的整个任务层次结构。
取消任务涉及 CancellationTokenSource 和 CancellationToken 类型,协同执行。换句话说,如果一个任务的执行已经在进行中,就不能使用 TPL 的取消机制粗暴地终止它。取消已经执行的工作需要执行该工作的代码的配合。然而,尚未开始执行的任务可以被完全取消,而不会产生任何不良后果。
下面的代码演示了一个二叉树查找,其中每个节点包含一个可能很长的需要线性遍历的元素数组;呼叫者可以使用 TPL 的取消机制来取消整个查找。一方面,未开始的任务将被 TPL 自动取消;另一方面,已经启动的任务将周期性地监视它们的取消令牌以获得取消指令,并在需要时协作停止。
public class TreeNode < T > {
public TreeNode < T > Left, Right;
public T[] Data;
}
public static void TreeLookup < T > (
TreeNode < T > root, Predicate < T > condition, CancellationTokenSource cts) {
if (root == null) {
return;
}
//Start the recursive tasks, passing to them the cancellation token so that they are
//cancelled automatically if they haven't started yet and cancellation is requested
Task.Run(() => TreeLookup(root.Left, condition, cts), cts.Token);
Task.Run(() => TreeLookup(root.Right, condition, cts), cts.Token);
foreach (T element in root.Data) {
if (cts.IsCancellationRequested) break; //abort cooperatively
if (condition(element)) {
cts.Cancel(); //cancels all outstanding work
//Do something with the interesting element
}
}
}
//Example of calling code:
CancellationTokenSource cts = new CancellationTokenSource();
Task.Run(() = > TreeLookup(treeRoot, i = > i % 77 == 0, cts);
//After a while, e.g. if the user is no longer interested in the operation:
cts.Cancel();
不可避免地,会有一些算法的例子需要一种更简单的方法来表达并行性。考虑我们开始的素性测试例子。我们可以手动将该范围划分为块,为每个块创建一个任务,然后等待所有任务完成。事实上,有一个完整的算法家族,其中有一个特定操作所应用的数据范围。这些算法要求比任务并行更高层次的抽象。我们现在转向这个抽象概念。
数据并行度
任务并行性主要处理任务,而数据并行性旨在将任务从直接视图中移除,并用更高级的抽象(并行循环)来取代它们。换句话说,并行性的来源不是算法的代码,而是它操作的数据。任务并行库提供了几个提供数据并行的 API。
平行。对于和平行。ForEach
for 和 foreach 循环 通常是并行化的绝佳选择。事实上,自从并行计算出现以来,已经有人尝试自动并行化这种循环。一些尝试已经走上了语言变化或语言扩展的道路,例如 OpenMP 标准(引入了#pragma omp parallel for 等指令来并行化 for 循环)。任务并行库通过显式 API 提供了循环并行性,尽管如此,它还是非常接近于它们的语言对应物。这些 API 是并行的。对于和平行。foreach,尽可能匹配语言中 for 和 ForEach 循环的行为。
回到并行化素性测试的例子,我们有一个在大范围数字上迭代的循环,检查每个数字的素性并将其插入到一个集合中,如下所示:
for (int number = start; number < end; ++number) {
if (IsPrime(number)) {
primes.Add(number);
}
}
将此代码转换为使用并行。因为几乎是一个机械的任务,尽管同步访问素数集合需要一些小心(还有更好的方法,比如聚合,我们稍后会考虑):
Parallel.For(start, end, number => {
if (IsPrime(number)) {
lock(primes) {
primes.Add(number);
}
}
});
通过用 API 调用替换语言级循环,我们获得了循环迭代的自动并行化。此外,平行。For API 不是一个直接的循环,它在每次迭代中生成一个任务,或者为范围内每个硬编码的块大小的部分生成一个任务。而是平行。For 缓慢适应单个迭代的执行速度,考虑当前正在执行的任务数量,并通过动态划分迭代范围来防止过于细粒度的行为。手动实现这些优化并不简单,但是您可以使用另一个并行重载来应用特定的定制(比如控制并发执行任务的最大数量)。这需要一个 ParallelOptions 对象,或者使用一个定制的分割器来确定如何在不同的任务之间划分迭代范围。
一个类似的 API 处理 foreach 循环,其中当循环开始时,数据源可能没有被完全枚举,并且实际上可能不是有限的。假设我们需要从 Web 上下载一组 RSS 提要,指定为 IEnumerable < string>。循环的骨架将具有以下形状:
IEnumerable < string > rssFeeds = . . .;
WebClient webClient = new WebClient();
foreach (string url in rssFeeds) {
Process(webClient.DownloadString(url));
}
这个循环可以通过机械转换来并行化,其中 foreach 循环被对 Parallel 的 API 调用所取代。ForEach 。注意,数据源(rssFeeds 集合)不必是线程安全的,因为它是并行的。ForEach 将在从几个线程访问它时使用同步。
IEnumerable < string > rssFeeds = . . .; //The data source need
*not*be thread-safe
WebClient webClient = new WebClient();
Parallel.ForEach(rssFeeds, url => {
Process(webClient.DownloadString(url));
});
 注意您可以表达对在无限数据源上执行操作的担忧。然而,事实证明,开始这样的操作并期望在满足某些条件时尽早终止它是非常方便的。例如,考虑一个无限的数据源,比如所有的自然数(在代码中由返回 IEnumerable < BigInteger >的方法指定)。我们可以编写并并行化一个循环,寻找一个数字和为 477 但不能被 133 整除的数。希望有这样一个数,我们的循环会终止。
注意您可以表达对在无限数据源上执行操作的担忧。然而,事实证明,开始这样的操作并期望在满足某些条件时尽早终止它是非常方便的。例如,考虑一个无限的数据源,比如所有的自然数(在代码中由返回 IEnumerable < BigInteger >的方法指定)。我们可以编写并并行化一个循环,寻找一个数字和为 477 但不能被 133 整除的数。希望有这样一个数,我们的循环会终止。
并行化循环并不像上面讨论的那样简单。在我们将这个工具牢牢地系在腰带上之前,我们需要考虑几个“缺失”的特征。首先,C# 循环有 break 关键字,它可以提前终止循环。当我们甚至不知道哪个迭代正在我们自己的线程之外的线程上执行时,我们如何终止一个已经跨多个线程并行化的循环呢?
ParallelLoopState 类表示并行循环的执行状态,并允许从循环中提前中断。这里有一个简单的例子:
int invitedToParty = 0;
Parallel.ForEach(customers, (customer, loopState) = > {
if (customer.Orders.Count > 10 && customer.City == "Portland") {
if (Interlocked.Increment(ref invitedToParty) > = 25) {
loopState.Stop(); //no attempt will be made to execute any additional iterations
}
}
});
注意,Stop 方法并不保证最后执行的迭代就是调用它的那个——已经开始执行的迭代将运行到完成(除非它们轮询 ParallelLoopState)。ShouldExitCurrentIteration 属性)。但是,已经排队的额外迭代将不会开始执行。
ParallelLoopState 的缺点之一。Stop 的一个缺点是,它不能保证直到某一次迭代的所有迭代都已执行。例如,如果有 1,000 个客户,则可能客户 1–100 已被完全处理,客户 101–110 根本没有被处理,而客户 111 是在调用 Stop 之前最后被处理的。如果您希望保证某个迭代之前的所有迭代都已经执行(即使它们还没有开始!),应该使用 ParallelLoopState。请改用 Break 方法。
平行 LINQ (PLINQ)
并行计算的最高抽象层次可能是这样的:你声明:“我希望这段代码并行运行”,剩下的留给框架来实现。这就是平行 LINQ 的意义所在。但是首先,应该对 LINQ 进行一个简短的回顾。LINQ(语言集成查询)是在 C# 3.0 和中引入的一个框架和一组语言扩展。NET 3.5,模糊了命令式编程和声明式编程在数据迭代方面的界限。例如,下面的 LINQ 查询从名为 customers 的数据源(可能是内存中的集合、数据库表或更奇特的来源)中检索在过去十个月中至少购买了三次 10 美元以上商品的华盛顿客户的姓名和年龄,并将其打印到控制台:
var results = from customer in customers
where customer.State == "WA"
let custOrders = (from order in orders
where customer.ID == order.ID
select new { order.Date, order.Amount })
where custOrders.Count(co => co.Amount >= 10 &&
co.Date >= DateTime.Now.AddMonths(−10)) >= 3
select new { customer.Name, customer.Age };
foreach (var result in results) {
Console.WriteLine("{0} {1}", result.Name, result.Age);
}
这里要注意的主要事情是,大多数查询都是以声明方式指定的——非常像 SQL 查询。它不使用循环来过滤对象或将来自不同数据源的对象组合在一起。通常,您不应该担心同步查询的不同迭代,因为大多数 LINQ 查询都是纯函数性的,没有副作用——它们将一个集合(IEnumerable < T>)转换为另一个集合,而不修改过程中的任何其他对象。
为了并行执行上述查询,唯一需要的代码更改是将源集合从通用 IEnumerable < T >修改为 ParallelQuery < T>。AsParallel 扩展方法 负责这一点,并允许以下优雅的语法:
var results = from customer in customers.AsParallel()
where customer.State == "WA"
let custOrders = (from order in orders
where customer.ID == order.ID
select new { order.Date, order.Amount })
where custOrders.Count(co => co.Amount >= 10 &&
co.Date > = DateTime.Now.AddMonths(−10)) >= 3
select new { customer.Name, customer.Age };
foreach (var result in results) {
Console.WriteLine("{0} {1}", result.Name, result.Age);
}
PLINQ 使用三级处理流水线来执行并行查询 ,如图图 6-7 所示。首先,PLINQ 决定应该使用多少线程来并行执行查询。接下来,工作线程从源集合中检索工作块,确保它在锁定状态下被访问。每个线程继续独立执行它的工作项,并且结果在每个线程内本地排队。最后,所有本地结果都被缓冲到一个结果集合中,在上面的示例中,这个结果集合由一个 foreach 循环进行轮询。
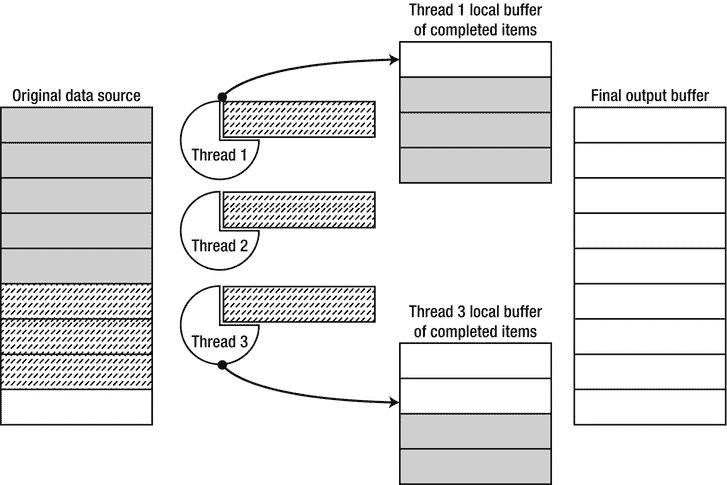
图 6-7 。PLINQ 中的工作项执行。实心灰色的工作项已经完成并被放置在线程本地缓冲区 中,它们随后从那里被移动到调用者可用的最终输出缓冲区。虚线工作项当前正在执行
PLINQ 相比并行的主要优势 。ForEach 源于这样一个事实,即 PLINQ 在执行查询的每个线程中本地自动处理临时处理结果的聚合。使用并行时。为了找到质数,我们必须访问一个质数的全局集合来聚合结果(在本章的后面,我们将考虑使用聚合的优化)。这种全局访问需要连续的同步,并且引入了大量的开销。我们可以通过使用 PLINQ 实现相同的结果,如下所示:
List < int > primes = (from n in Enumerable.Range(3, 200000).AsParallel()
where IsPrime(n)
select n).ToList();
//Could have used ParallelEnumerable.Range instead of Enumerable.Range(. . .).AsParallel()
定制并行循环和 PLINQ
并联回路 (并联。对于和平行。ForEach)和 PLINQ 有几个定制 API,这使它们非常灵活,在丰富性和表达性方面接近我们之前考虑过的显式任务并行 API。并行循环 API 接受具有各种属性的 ParallelOptions 对象,而 PLINQ 依赖于 ParallelQuery < T >的附加方法。这些选项包括:
- 限制并行度(允许并发执行的任务数量)
- 提供用于取消并行执行的取消令牌
- 强制并行查询的输出排序
- 控制并行查询的输出缓冲(合并模式)
对于并行循环,最常见的是使用 ParallelOptions 类来限制并行度,而对于 PLINQ,您通常会自定义查询的合并模式和排序语义。有关这些定制选项的更多信息,请参考 MSDN 文档。
C# 5 异步方法
到目前为止,我们考虑了丰富的 API,这些 API 允许使用任务并行库的类和方法来表达各种并行解决方案。然而,在 API 笨拙或不够简洁的地方,其他并行编程环境有时依赖语言扩展来获得更好的表达能力。在这一节中,我们将看到 C# 5 如何通过提供一种更容易表达延续的语言扩展来适应并发编程世界的挑战。但是首先,我们必须考虑异步编程世界中的延续。
通常,您会希望将一个延续 (或回调)与一个特定的任务相关联;当任务完成时,应该执行延续。如果您可以控制任务,也就是说,您可以调度任务的执行,那么您可以将回调嵌入到任务本身中,但是如果您从另一个方法接收任务,那么显式的 continuation API 是理想的。TPL 提供了 ContinueWith instance 方法和 continue when all/continue when any 静态方法(不言自明)来控制几种设置中的延续。可以仅在特定情况下(例如,仅当任务运行完成时或仅当任务遇到异常时)调度该继续,并且可以使用 TaskScheduler API 在特定线程或线程组上调度该继续。以下是各种 API 的一些示例:
Task < string > weatherTask = DownloadWeatherInfoAsync(. . .);
weatherTask.ContinueWith(_ => DisplayWeather(weatherTask.Result), TaskScheduler.Current);
Task left = ProcessLeftPart(. . .);
Task right = ProcessRightPart(. . .);
TaskFactory.ContinueWhenAll(
new Task[] { left, right },
CleanupResources
);
TaskFactory.ContinueWhenAny(
new Task[] { left, right },
HandleError,
TaskContinuationOptions.OnlyOnFaulted
);
延续是编写异步应用的一种合理方式,在 GUI 环境中执行异步 I/O 时非常有价值。例如,为了确保 Windows 8 Metro 风格的应用保持响应迅速的用户界面,Windows 8 中的 WinRT (Windows 运行时)API 只提供所有可能运行超过 50 毫秒的操作的异步版本。由于多个异步调用链接在一起,嵌套的延续变得有些笨拙,如下例所示:
//Synchronous version:
private void updateButton_Clicked(. . .) {
using (LocationService location = new LocationService())
using (WeatherService weather = new WeatherService()) {
Location loc = location.GetCurrentLocation();
Forecast forecast = weather.GetForecast(loc.City);
MessageDialog msg = new MessageDialog(forecast.Summary);
msg.Display();
}
}
//Asynchronous version:
private void updateButton_Clicked(. . .) {
TaskScheduler uiScheduler = TaskScheduler.Current;
LocationService location = new LocationService();
Task < Location > locTask = location.GetCurrentLocationAsync();
locTask.ContinueWith(_ => {
WeatherService weather = new WeatherService();
Task < Forecast > forTask = weather.GetForecastAsync(locTask.Result.City);
forTask.ContinueWith(__ => {
MessageDialog message = new MessageDialog(forTask.Result.Summary);
Task msgTask = message.DisplayAsync();
msgTask.ContinueWith(___ => {
weather.Dispose();
location.Dispose();
});
}, uiScheduler);
});
}
这种深度嵌套并不是显式基于延续的编程的唯一危险。考虑以下需要转换到异步版本 的同步循环:
//Synchronous version:
private Forecast[] GetForecastForAllCities(City[] cities) {
Forecast[] forecasts = new Forecast[cities.Length];
using (WeatherService weather = new WeatherService()) {
for (int i = 0; i < cities.Length; ++i) {
forecasts[i] = weather.GetForecast(cities[i]);
}
}
return forecasts;
}
//Asynchronous version:
private Task < Forecast[] > GetForecastsForAllCitiesAsync(City[] cities) {
if (cities.Length == 0) {
return Task.Run(() = > new Forecast[0]);
}
WeatherService weather = new WeatherService();
Forecast[] forecasts = new Forecast[cities.Length];
return GetForecastHelper(weather, 0, cities, forecasts).ContinueWith(_ => forecasts);
}
private Task GetForecastHelper( WeatherService weather, int i, City[] cities, Forecast[] forecasts) {
if (i >= cities.Length) return Task.Run(() => { });
Task < Forecast > forecast = weather.GetForecastAsync(cities[i]);
forecast.ContinueWith(task => {
forecasts[i] = task.Result;
GetForecastHelper(weather, i + 1, cities, forecasts);
});
return forecast;
}
转换这个循环需要完全重写原来的方法,并安排一个延续,本质上是以一种相当不直观和递归的方式执行下一次迭代。这是 C# 5 的设计者通过引入两个新的关键字 async 和 await 选择在语言层面上解决的问题。
异步方法必须用 async 关键字标记,并且可能返回 void、Task 或 Task < T>。在异步方法中,await 运算符可用于表示延续,而无需使用 ContinueWith API。考虑以下示例:
private async void updateButton_Clicked(. . .) {
using (LocationService location = new LocationService()) {
Task < Location > locTask = location.GetCurrentLocationAsync();
Location loc = await locTask;
cityTextBox.Text = loc.City.Name;
}
}
在此示例中,await locTask 表达式为 GetCurrentLocationAsync 返回的任务提供了延续。continuation 的主体是方法的其余部分(从对 loc 变量的赋值开始),await 表达式计算任务返回的内容,在本例中是 Location 对象。此外,延续是在 UI 线程上隐式调度的,这是我们之前使用 TaskScheduler API 时必须明确处理的事情。
C# 编译器负责与方法体相关的所有相关语法特性。比如在我们刚刚写的方法中,有一个尝试。。。隐藏在 using 语句后面的 finally 块。编译器重写延续,以便调用位置变量上的处置方法 ,而不管任务是成功完成还是发生异常。
这种智能重写允许将同步 API 调用转换为异步调用。编译器支持异常处理 、复杂循环、递归方法调用——难以与显式延续传递 API 结合的语言构造。例如,下面是先前给我们带来麻烦的预测-检索循环的异步版本:
private async Task < Forecast[] > GetForecastForAllCitiesAsync(City[] cities) {
Forecast[] forecasts = new Forecast[cities.Length];
using (WeatherService weather = new WeatherService()) {
for (int i = 0; i < cities.Length; ++i) {
forecasts[i] = await weather.GetForecastAsync(cities[i]);
}
}
return forecasts;
}
请注意,变化很小,编译器处理的细节是获取预测变量 (类型为 Forecast[])我们的方法返回并围绕它创建任务< Forecast[] >支架。
只有两个简单的语言特性 (其实现一点也不简单!),C# 5 极大地降低了异步编程的门槛,并使使用返回和操作任务的 API 变得更加容易。此外,await 操作符的语言实现没有绑定到任务并行库;Windows 8 中的本机 WinRT API 返回 IAsyncOperation < T >,而不是任务实例(这是一个托管概念),但仍可以等待,如下例所示,它使用了一个真正的 WinRT API:
using Windows.Devices.Geolocation;
. . .
private async void updateButton_Clicked(. . .) {
Geolocator locator = new Geolocator();
Geoposition position = await locator.GetGeopositionAsync();
statusTextBox.Text = position.CivicAddress.ToString();
}
第三方物流中的高级模式
到目前为止,在这一章中,我们已经考虑了相当简单的并行算法的例子。在本节中,我们将简要介绍一些高级技巧,您可能会发现这些技巧在处理现实世界的问题时很有用;在一些情况下,我们可以从非常令人惊讶的地方获得性能提升。
当并行化具有共享状态的循环时,首先要考虑的优化是聚合 (有时也称为缩减 )。当在并行循环中使用共享状态时,由于共享状态访问上的同步,可伸缩性通常会丢失;添加到组合中的 CPU 内核越多,由于同步的原因,增益就越小(这种现象是阿姆达尔定律的直接推论,通常被称为收益递减定律)。在执行并行循环的每个线程或任务中聚合本地状态,并在循环执行结束时组合本地状态以获得最终结果,通常可以大幅提升性能。处理循环执行的 TPL APIs 配备了处理这种本地聚合的重载。
例如,考虑我们之前实现的素数计算。可伸缩性的主要障碍之一是需要将新发现的素数插入到共享列表中,这需要同步。相反,我们可以在每个线程中使用一个本地列表,并在循环完成时将这些列表聚集在一起:
List < int > primes = new List < int > ();
Parallel.For(3, 200000,
() => new List < int > (), //initialize the local copy
(i, pls, localPrimes) => { //single computation step, returns new local state
if (IsPrime(i)) {
localPrimes.Add(i); //no synchronization necessary, thread-local state
}
return localPrimes;
},
localPrimes => { //combine the local lists to the global one
lock(primes) { //synchronization is required
primes.AddRange(localPrimes);
}
}
);
在上面的例子中,使用的锁的数量比以前少得多——我们只需要为每个执行并行循环的线程使用一次锁,而不是为我们发现的每个素数使用一次锁。我们确实引入了将列表组合在一起的额外成本,但是与本地聚合获得的可伸缩性相比,这个成本可以忽略不计。
优化的另一个来源是循环迭代太小,无法有效地并行化。即使数据并行性 API 将多次迭代组合在一起,也可能有循环体完成得如此之快,以至于它们被调用每次迭代的循环体所需的委托调用所控制。在这种情况下,Partitioner API 可用于手动提取迭代块,从而最大限度地减少委托调用的数量:
Parallel.For(Partitioner.Create(3, 200000), range => { //range is a Tuple < int,int>
for (int i = range.Item1; i < range.Item2; ++i) . . . //loop body with no delegate invocation
});
有关自定义分区的更多信息,这也是数据并行程序可用的一个重要优化,请参考 MSDN 的文章“用于 PLINQ 和 TPL 的自定义分区器”,位于http://msdn.microsoft.com/en-us/library/dd997411.aspx。
最后,有些应用可以从定制的任务调度程序中受益。一些例子包括在 UI 线程上调度工作(我们已经使用 TaskScheduler 完成了一些工作。当前对 UI 线程的延续进行排队),通过将任务调度到更高优先级的调度器来区分任务的优先级,以及通过将任务调度到使用具有特定 CPU 关联的线程的调度器来将任务关联到特定 CPU。可以扩展 TaskScheduler 类来创建自定义任务计划程序。关于自定义任务调度器的例子,请参考 MSDN 的文章“如何:创建一个限制并发度的任务调度器”,位于http://msdn.microsoft.com/en-us/library/ee789351.aspx。
同步
对并行编程的处理至少需要粗略地提及同步这个庞大的主题。在贯穿本文的简单示例中,我们已经看到了许多多线程访问共享内存位置的情况,无论是复杂的集合还是单个整数。除了只读数据,对共享内存位置的每次访问都需要同步,但并非所有同步机制都具有相同的性能和可伸缩性成本。
在开始之前,让我们回顾一下访问少量数据时同步的必要性。现代的 CPU 可以对内存进行原子读写;例如,一个 32 位整数的写操作总是自动执行。这意味着,如果一个处理器将值 0xDEADBEEF 写入先前用值 0 初始化的存储器位置,另一个处理器将不会观察到部分更新的存储器位置,例如 0xDEAD0000 或 0x0000BEEF。不幸的是,对于较大的内存位置,情况就不一样了;例如,即使在 64 位处理器上,将 20 个字节写入内存也不是原子操作,不能以原子方式执行。
然而,即使在访问 32 位存储单元但发出多个操作时,同步问题也会立即出现。例如,操作++i(其中 I 是 int 类型的堆栈变量)通常被翻译成三个机器指令的序列:
mov eax, dword ptr [ebp-64] ;copy from stack to register
inc eax ;increment value in register
mov dword ptr [ebp-64], eax ;copy from register to stack
这些指令中的每一个都是自动执行的,但是如果没有额外的同步,两个处理器可能同时执行指令序列的一部分,导致丢失更新。假设变量的初始值是 100,检查下面的执行历史:
1 号处理器 2 号处理器
mov eax, dword ptr [ebp-64]
mov eax, dword ptr [ebp-64] inc eax
inc eax
mov dword ptr [ebp-64], eax
mov dword ptr [ebp-64], eax
在这种情况下,该变量的最终值将是 101,尽管两个处理器已经执行了递增操作,并且应该将它带到 102。这种竞争情况——希望是显而易见且容易检测到的——是保证小心同步的情况的典型例子。
其他方向
许多研究人员和编程语言设计人员认为,如果不完全改变编程语言、并行性框架或处理器内存模型的语义,就无法解决管理共享内存同步的情况。这一领域有几个有趣的方向:
- 硬件或软件中的事务性内存提出了一个围绕内存操作的显式或隐式隔离模型,以及一系列内存操作的回滚语义。目前,这种方法的性能成本阻碍了它们在主流编程语言和框架中的广泛采用。
- 基于代理的语言将并发模型深植于语言之中,并要求代理(对象)之间在消息传递方面进行显式通信,而不是共享内存访问。
- 消息传递处理器和内存架构使用私有内存范例来组织系统,其中对共享内存位置的访问必须通过硬件级的消息传递来明确。
在本节的其余部分,我们将假设一个更实用的观点,并试图通过提供一组同步机制和模式来解决共享内存同步的问题。然而,作者坚信同步比它应该的更困难;我们的共享经验表明,当今软件中的大多数疑难错误都源于通过不正确地同步并行程序来破坏共享状态的简单性。我们希望在几年或几十年后,计算社区会提出更好的替代方案。
无锁代码
同步的一种方法是将负担放在操作系统上。毕竟,操作系统提供了创建和管理线程的工具,并承担了调度线程执行的全部责任。然后很自然地期望它提供一组同步原语。尽管我们将很快讨论 Windows 同步机制,这种方法回避了操作系统如何实现 ?? 这些同步机制的问题。当然,Windows 本身需要同步访问其内部数据结构——甚至是代表其他同步机制的数据结构——并且它不能通过递归地遵从它们来实现同步机制。事实还证明,Windows 同步机制通常需要一个系统调用(用户模式到内核模式的转换)和线程上下文切换来确保同步,如果需要同步的操作非常廉价(例如增加一个数字或向链表中插入一个项目),这将是相对昂贵的。
所有可以运行 Windows 的处理器家族都实现了一个叫做比较交换(CAS) 的硬件同步原语。CAS 具有以下语义(在伪代码中),并且原子地执行*😗
WORD CAS(WORD* location, WORD value, WORD comparand) {
WORD old = *location;
if (old == comparand) {
*location = value;
}
return old;
}
简单地说,CAS 将内存位置与提供的值进行比较。如果内存位置包含提供的值,则用另一个值替换它;否则不变。在任何情况下,操作之前的存储单元的内容被返回。
例如,在 Intel x86 处理器上,LOCK CMPXCHG 指令实现了这个原语。翻译 CAS(&a,b,c)调用来锁定 CMPXCHG 是一个简单的机械过程,这就是为什么我们将满足于在本节的剩余部分使用 CAS。在。NET Framework 中,CAS 是使用一组称为 Interlocked 的重载实现的。比较交换。
//C# code:
int n = . . .;
if (Interlocked.CompareExchange(ref n, 1, 0) == 0) { //attempt to replace 0 with 1
//. . .do something
}
//x86 assembly instructions:
mov eax, 0 ;the comparand
mov edx, 1 ;the new value
lock cmpxchg dword ptr [ebp-64], edx ;assume that n is in [ebp-64]
test eax, eax ;if eax = 0, the replace took place
jnz not_taken
;. . .do something
not_taken:
单个 CAS 操作通常不足以确保任何有用的同步,除非理想的语义是执行一次性的检查和替换操作。但是,当与循环结构结合使用时,CAS 可以用于各种不可忽略的同步任务。首先,我们考虑一个简单的原地乘法的例子。我们希望以原子方式执行操作 x * = y,其中 x 是可能被其他线程同时写入的共享内存位置,y 是不被其他线程修改的常量值。以下基于 CAS 的 C# 方法执行此任务:
public static void InterlockedMultiplyInPlace(ref int x, int y) {
int temp, mult;
do {
temp = x;
mult = temp * y;
} while(Interlocked.CompareExchange(ref x, mult, temp) ! = temp);
}
每次循环迭代都是从将 x 的值读入一个临时堆栈变量开始的,该变量不能被另一个线程修改。接下来,我们找到乘法结果,准备放入 x 中。最后,当且仅当 CompareExchange 报告它成功地用乘法结果替换了 x 的值时,循环终止,假设原始值没有被修改。我们不能保证循环将在有限的迭代次数内终止;然而,即使在其他处理器的压力下,当试图用新值替换 x 时,单个处理器也不太可能被跳过多次。尽管如此,循环必须准备好面对这种情况(并重试)。考虑以下在两个处理器上 x = 3,y = 5 的执行历史:
Processor #1 Processor #2
temp = x; (3)
temp = x; (3)
mult = temp * y; (15)
mult = temp * y; (15)
CAS(ref x, mult, temp) == 3 (== temp)
CAS(ref x, mult, temp) == 15 (! = temp)
即使是这个极其简单的例子也非常容易出错。例如,以下循环可能会导致更新丢失:
public static void InterlockedMultiplyInPlace(ref int x, int y) {
int temp, mult;
do {
temp = x;
mult = x * y;
} while(Interlocked.CompareExchange(ref x, mult, temp) ! = temp);
}
为什么呢?快速连续读取 x 的值两次并不能保证我们看到相同的值!下面的执行历史演示了在两个处理器上 x = 3,y = 5 的情况下,如何产生不正确的结果——在执行结束时 x = 60!
Processor #1 Processor #2
temp = x; (3)
x = 12;
mult = x * y; (60!)
x = 3;
CAS(ref x, mult, temp) == 3 (== temp)
我们可以将这个结果推广到任何只需要读取一个变异的内存位置并用一个新值替换它的算法,不管它有多复杂。最通用的版本如下:
public static void DoWithCAS < T > (ref T location, Func < T,T > generator) where T : class {
T temp, replace;
do {
temp = location;
replace = generator(temp);
} while (Interlocked.CompareExchange(ref location, replace, temp) ! = temp);
}
用这个通用版本来表达乘法方法非常容易:
public static void InterlockedMultiplyInPlace(ref int x, int y) {
DoWithCAS(ref x, t => t * y);
}
具体来说,有一个简单的同步机制叫做自旋锁 ,可以使用 CAS 来实现。这里的想法如下:获取锁是为了确保试图获取它的任何其他线程都将失败并重试。因此,自旋锁是一种锁,它允许单个线程获取它,而所有其他线程在试图获取它时旋转(“浪费”CPU 周期):
public class SpinLock {
private volatile int locked;
public void Acquire() {
while (Interlocked.CompareExchange(ref locked, 1, 0) ! = 0);
}
public void Release() {
locked = 0;
}
}
记忆模型和易变变量
对同步的完整论述将包括对记忆模型的讨论和对易变变量的需求。然而,我们缺乏足够的空间来涵盖这一主题,只提供一个简短的说明。Joe Duffy 的书《Windows 上的并发编程》(Addison-Wesley,2008)提供了深入详细的描述。
一般来说,特定语言/环境的内存模型描述了编译器和处理器硬件如何对不同线程执行的内存操作进行重新排序——线程通过共享内存的交互。尽管大多数内存模型都同意在相同的内存位置上的读和写操作不能被重新排序,但是在不同的内存位置上的读和写操作的语义上很少有一致意见。例如,当从状态 f = 0,x = 13 开始时,下面的程序可能输出 13:
Processor #1 Processor #2
while (f == 0); x = 42;
print(x); f = 1;
产生这种不直观结果的原因是,编译器和处理器可以自由地对处理器#2 上的指令进行重新排序,使得对 f 的写入在对 x 的写入之前完成,并对处理器#1 上的指令进行重新排序,使得对 x 的读取在对 f 的读取之前完成。
在处理内存重新排序问题时,C# 开发人员可以采取几种补救措施。首先是 volatile 关键字,它防止编译器重新排序和大多数处理器围绕特定变量的操作重新排序。其次是一组互锁的 API 和线程。MemoryBarrier,它引入了一个就重新排序而言不能单向或双向跨越的栅栏。幸运的是,Windows 同步机制(包括一个系统调用)以及 TPL 中的任何无锁同步原语都会在必要时发出内存屏障。但是,如果您尝试实现您自己的低级同步的已经有风险的任务,您应该投入大量的时间来理解您的目标环境的内存模型的细节。
我们不能再强调这一点:如果你选择直接处理内存排序,那么理解你用来编写多线程应用的每种语言和硬件组合的内存模型是绝对重要的。将没有框架来守护你的脚步。
在我们的 spinlock 实现中,0 代表一个自由锁,1 代表一个被占用的锁。我们的实现试图用 1 替换它的内部值,前提是它的当前值为 0,即获取锁,前提是它当前没有被获取。因为不能保证拥有它的线程会很快释放锁,所以使用自旋锁意味着您可能会让一组线程不停地旋转,浪费 CPU 周期,等待锁变得可用。这使得自旋锁不适用于保护数据库访问、将大文件写到磁盘、通过网络发送数据包以及类似的长时间运行的操作。然而,当受保护的代码段非常快时,自旋锁非常有用——修改一个对象上的一组字段,在一行中增加几个变量,或者将一个项目插入一个简单的集合。
事实上,Windows 内核本身广泛使用自旋锁来实现内部同步。内核数据结构,例如调度程序数据库、文件系统高速缓存块列表、内存页帧号数据库和其他数据结构,由一个或多个自旋锁保护。此外,Windows 内核对上面描述的简单自旋锁实现引入了额外的优化,这带来了两个问题:
- 就 FIFO 语义而言,自旋锁是不公平的。一个处理器可能是十个处理器中最后一个调用 Acquire 方法并在其中旋转的,但也可能是第一个在它被所有者释放后实际获取它的。
- 当自旋锁所有者释放自旋锁时,它会使当前在 Acquire 方法中旋转的所有处理器的缓存失效,尽管实际上只有一个处理器会获取它。(我们将在本章后面重新讨论高速缓存失效。)
Windows 内核使用栈内排队自旋锁;栈内排队自旋锁维护一个等待锁的处理器队列,并且每个等待锁的处理器围绕一个独立的存储器位置旋转,该存储器位置不在其他处理器的高速缓存中。当自旋锁的所有者释放该锁时,它会找到队列中的第一个处理器,并向该特定处理器正在等待的位发出信号。这保证了 FIFO 语义,并防止了除成功获得锁的处理器之外的所有处理器上的缓存失效。
 注意自旋锁的生产级实现在遇到故障时可以更加健壮,避免自旋超过合理的阈值(通过将自旋转换为阻塞等待),跟踪拥有线程以确保自旋锁被正确获取和释放,允许递归获取锁,并提供额外的功能。任务并行库中的自旋锁类型是一个推荐的实现。
注意自旋锁的生产级实现在遇到故障时可以更加健壮,避免自旋超过合理的阈值(通过将自旋转换为阻塞等待),跟踪拥有线程以确保自旋锁被正确获取和释放,允许递归获取锁,并提供额外的功能。任务并行库中的自旋锁类型是一个推荐的实现。
有了 CAS 同步原语,我们现在实现了一个令人难以置信的工程壮举——无锁堆栈。在第五章中,我们已经考虑了一些并发集合,不再重复讨论,但是 ConcurrentStack < T >的实现仍然有些神秘。几乎不可思议的是,ConcurrentStack < T > 允许多个线程从其中推送和弹出项目,但从不需要阻塞同步机制(我们接下来会考虑)来这样做。
我们将通过使用一个单链表来实现一个无锁堆栈。堆栈的顶部元素是列表的头部;将一个项目压入堆栈或从堆栈中弹出一个项目意味着替换列表的头部。为了以同步的方式做到这一点,我们依赖 CAS 原语;事实上,我们可以使用之前介绍的 DoWithCAS < T> 助手:
public class LockFreeStack < T > {
private class Node {
public T Data;
public Node Next;
}
private Node head;
public void Push(T element) {
Node node = new Node { Data = element };
DoWithCAS(ref head, h => {
node.Next = h;
return node;
});
}
public bool TryPop(out T element) {
//DoWithCAS does not work here because we need early termination semantics
Node node;
do {
node = head;
if (node == null) {
element = default(T);
return false; //bail out – nothing to return
}
} while (Interlocked.CompareExchange(ref head, node.Next, node) ! = node);
element = node.Data;
return true;
}
}
Push 方法试图用一个新节点替换列表头,新节点的下一个指针指向当前列表头。同样,TryPop 方法试图用当前头的下一个指针所指向的节点替换列表头,如图图 6-8 所示。

图 6-8 。TryPop 操作试图用新列表头替换当前列表头
您可能会认为世界上的每一个数据结构都可以使用 CAS 和类似的无锁原语来实现。事实上,现在还有一些无锁集合被广泛使用的例子:
- 无锁双向链表
- 无锁队列(有头有尾)
- 无锁简单优先级队列
然而,有很多种集合无法使用无锁代码轻松实现,并且仍然依赖于阻塞同步机制。此外,有相当多的代码需要同步,但不能使用 CAS,因为执行时间太长。我们现在来讨论“真正的”同步机制,它包括由操作系统实现的阻塞。
Windows 同步机制
Windows 为用户模式程序提供了许多同步机制,比如事件、信号量、互斥和条件变量。我们的程序可以通过句柄和 Win32 API 调用来访问这些同步机制,它们代表我们发出相应的系统调用。那个。NET Framework 将大多数 Windows 同步机制包装在面向对象的瘦包中,如 ManualResetEvent、Mutex、Semaphore 等。在现有的同步机制之上。NET 提供了几个新的,比如 ReaderWriterLockSlim 和 Monitor。我们不会详尽地检查每一种同步机制,这是最好留给 API 文档来完成的任务;然而,理解它们的一般性能特征是很重要的。
当锁不可用时,Windows 内核通过阻塞试图获取锁的线程来实现我们现在讨论的同步机制。阻塞一个线程包括将它从 CPU 中移除,将其标记为等待,并调度另一个线程来执行。该操作涉及一个系统调用,这是一个用户模式到内核模式的转换,两个线程之间的上下文切换,以及在内核中执行的一小组数据结构更新(参见图 6-9 )以将线程标记为等待,并将其与它所等待的同步机制相关联。

图 6-9 。由操作系统调度程序维护的数据。准备执行的线程放在 FIFO 队列中,按优先级排序。被阻塞的线程通过称为等待块的内部结构引用它们的同步机制
总的来说,阻塞一个线程可能会花费数千个 CPU 周期,当同步机制可用时,需要类似数量的周期来解除阻塞。很明显,如果使用内核同步机制来保护长时间运行的操作,比如向文件写入一个大的缓冲区或执行网络往返,这种开销是可以忽略的,但是如果使用内核同步机制来保护++i 这样的操作,这种开销会导致不可原谅的速度下降。
同步机制窗口和。NET 提供给应用不同之处主要在于它们的获取和释放语义,也称为它们的信号状态。当同步机制收到信号时,它会唤醒一个线程(或一组线程)等待它变得可用。下面是当前可访问的一些同步机制的信号状态语义。网络应用:
表 6-1。一些同步机制的信号状态语义
| 同步机制 | 它什么时候变得有信号? | 哪些线程被唤醒? |
|---|---|---|
| 互斥(体)… | 当一个线程调用互斥时。释放互斥 | 正在等待互斥体的线程之一 |
| 旗语 | 当一个线程调用信号量时。释放;排放;发布 | 正在等待信号量的线程之一 |
| 手动重置事件 | 当线程调用 ManualResetEvent 时。一组 | 等待事件的所有线程 |
| 自动重置事件 | 当线程调用 AutoResetEvent 时。一组 | 正在等待事件的线程之一 |
| 班长 | 当线程调用 Monitor 时。出口 | 正在等待监视器的线程之一 |
| 屏障 | 当所有参与线程都调用了 Barrier。信号和等待 | 等待屏障的所有线程 |
| ReaderWriterLock—用于阅读 | 当没有编写器线程,或者最后一个编写器线程已经释放了用于写入的锁时 | 等待进入锁进行读取的所有线程 |
| ReaderWriterLock—用于写作 | 当没有读线程或写线程时 | 等待进入锁进行写入的线程之一 |
除了信号状态语义,一些同步机制在内部实现方面也有所不同。例如,Win32 临界区和 CLR 监视器实现了对当前可用锁的优化。通过这种优化,试图获取可用锁的线程可以直接获取它,而无需执行系统调用。另一方面,同步机制的读取器-写入器锁家族区分访问某个对象的读取器和写入器,当数据最常被读取时,这允许更好的可伸缩性。
从窗口和列表中选择合适的同步机制。NET 必须提供的功能通常是困难的,有时自定义同步机制可能提供比现有机制更好的性能特征或更方便的语义。我们将不再考虑同步机制;在编写并发应用时,您有责任在无锁同步原语和阻塞同步机制之间做出负责任的选择,并确定要使用的同步机制的最佳组合。
 注意如果不强调为并发性而从头设计的数据结构(集合),任何关于同步的讨论都是不完整的。这种集合是线程安全的——它们允许来自多个线程的安全访问——并且是可伸缩的,不会由于锁定而导致不合理的性能下降。关于并发集合的讨论,以及并发集合的设计,请参考第五章。
注意如果不强调为并发性而从头设计的数据结构(集合),任何关于同步的讨论都是不完整的。这种集合是线程安全的——它们允许来自多个线程的安全访问——并且是可伸缩的,不会由于锁定而导致不合理的性能下降。关于并发集合的讨论,以及并发集合的设计,请参考第五章。
高速缓存注意事项
我们之前已经在集合实现和内存密度的上下文中讨论过处理器缓存的主题。在并行程序中,考虑单个处理器上的缓存大小和命中率同样重要,但考虑多个处理器的缓存如何交互更为重要。我们现在将考虑一个有代表性的例子,它展示了面向缓存的优化的重要性,并强调了好工具在总体性能优化方面的价值。
首先,检查下面的顺序方法。它执行对二维整数数组中的所有元素求和的基本任务,并返回结果。
public static int MatrixSumSequential(int[,] matrix) {
int sum = 0;
int rows = matrix.GetUpperBound(0);
int cols = matrix.GetUpperBound(1);
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
sum + = matrix[i,j];
}
}
return sum;
}
我们的武器库中有一大套用于并行化这类程序的工具。然而,想象一下,我们没有 TPL,而是选择直接使用线程。以下并行化尝试可能看起来非常合理,足以收获多核执行的果实,甚至实现了一个粗略的聚合,以避免共享总和变量上的同步:
public static int MatrixSumParallel(int[,] matrix) {
int sum = 0;
int rows = matrix.GetUpperBound(0);
int cols = matrix.GetUpperBound(1);
const int THREADS = 4;
int chunk = rows/THREADS; //should divide evenly
int[] localSums = new int[THREADS];
Thread[] threads = new Thread[THREADS];
for (int i = 0; i < THREADS; ++i) {
int start = chunk*i;
int end = chunk*(i + 1);
int threadNum = i; //prevent the compiler from hoisting the variable in the lambda capture
threads[i] = new Thread(() => {
for (int row = start; row < end; ++row) {
for (int col = 0; col < cols; ++col) {
localSums[threadNum] + = matrix[row,col];
}
}
});
threads[i].Start();
}
foreach (Thread thread in threads) {
thread.Join();
}
sum = localSums.Sum();
return sum;
}
在英特尔 i7 处理器上分别执行这两种方法 25 次,对于 2,000 × 2,000 的整数矩阵产生了以下结果:顺序方法平均在 325 毫秒内完成,而并行方法平均耗时 935 毫秒,比顺序方法慢三倍!
这显然是不可接受的,但为什么呢?这不是另一个太细粒度并行的例子,因为线程的数量只有 4 个。如果您接受这个问题在某种程度上与缓存相关的前提(因为这个例子出现在“缓存注意事项”一节),那么测量由这两种方法引入的缓存未命中的数量是有意义的。Visual Studio 探查器(在每 2,000 次缓存未命中时采样)在并行版本中报告了 963 个独占样本,而在顺序版本中仅报告了 659 个独占样本;绝大多数样本位于从矩阵读取的内环线上。
再问一次,为什么?为什么写入 localSums 数组的代码行将比写入 sum 局部变量的代码行引入更多的缓存未命中?简单的答案是,对共享阵列的写入使其他处理器的缓存线无效,导致阵列上的每个+ =操作都是缓存未命中。
正如您在第五章中回忆的那样,处理器缓存是按缓存行组织的,相邻的内存位置共享同一个缓存行。当一个处理器写入另一个处理器的缓存中的内存位置时,硬件会导致缓存失效,将另一个处理器的缓存中的缓存线标记为无效。访问无效的高速缓存线会导致高速缓存未命中。在我们上面的例子中,很可能整个 localSums 数组适合一个缓存行,并且同时驻留在应用的线程正在其上执行的所有四个处理器的缓存中。在任一处理器上对数组的任何元素执行的每一次写操作都会使所有其他处理器上的缓存行无效,从而导致缓存无效的持续往复(参见图 6-10 )。

图 6-10 。CPU 1 写入 localSums[1],而 CPU 2 写入 localSums[2]。因为两个数组元素是相邻的,并且适合两个处理器高速缓存中的同一高速缓存行,所以每次这样的写入都会导致另一个处理器上的高速缓存无效
为了确保问题完全与缓存失效相关,可以使阵列跨度足够大,以使缓存失效不会发生,或者将对阵列的直接写入替换为对每个线程中的局部变量的写入,该写入最终在线程完成时刷新到阵列。这两种优化都恢复了世界的健全性,并使并行版本在足够多的内核上比顺序版本更快。
缓存失效(或缓存冲突)是一个令人讨厌的问题,在实际的应用中非常难以检测,即使有强大的分析器帮助。在设计受 CPU 限制的算法时,提前考虑这一点将会为您节省大量时间,并减少以后的麻烦。
 注意作者在一个生产场景中遇到了一个类似的缓存失效案例,在两个不同的处理器上执行的两个线程之间有一个共享的工作项队列。当对队列类的字段的内部结构进行了某些微小的更改时,在后续的构建中会检测到显著的性能下降(大约 20%)。经过长时间的详细检查,很明显,对 queue 类中的字段进行重新排序是导致性能下降的原因;由不同线程写入的两个字段靠得太近,被放置在同一高速缓存行上。在字段之间添加填充符将队列的性能恢复到可接受的水平。
注意作者在一个生产场景中遇到了一个类似的缓存失效案例,在两个不同的处理器上执行的两个线程之间有一个共享的工作项队列。当对队列类的字段的内部结构进行了某些微小的更改时,在后续的构建中会检测到显著的性能下降(大约 20%)。经过长时间的详细检查,很明显,对 queue 类中的字段进行重新排序是导致性能下降的原因;由不同线程写入的两个字段靠得太近,被放置在同一高速缓存行上。在字段之间添加填充符将队列的性能恢复到可接受的水平。
通用图形处理器计算
到目前为止,我们对并行编程的报道只局限于 CPU 内核。事实上,我们掌握了多种技能,可以在多个内核上并行化程序,同步访问共享资源,并使用高速 CPU 原语实现无锁同步。正如我们在本章开始时提到的,我们的程序还有另一个并行来源——GPU,它在现代硬件上提供了比高端 CPU 多得多的内核。GPU 核非常适合数据并行算法,其庞大的数量弥补了在其上运行程序的笨拙。在这一节中,我们将研究一种在 GPU 上运行程序的方法,使用一组名为 C++ AMP 的 C++语言扩展。
 注意 C++ AMP 是基于 C++的,这也是为什么本节会使用 C++代码示例的原因。然而,通过使用适量的。NET 互操作性,您可以在您的。NET 应用也是如此。我们将在这一节的最后回到这个主题。
注意 C++ AMP 是基于 C++的,这也是为什么本节会使用 C++代码示例的原因。然而,通过使用适量的。NET 互操作性,您可以在您的。NET 应用也是如此。我们将在这一节的最后回到这个主题。
C++简介 AMP
从本质上来说,GPU 是一种与其他处理器一样的处理器,具有特定的指令集、众多内核和内存访问协议。然而,现代 GPU 和 CPU 之间存在显著差异,理解它们对于编写高效的基于 GPU 的程序至关重要:
- 现代 CPU 只有一小部分指令可以在 GPU 上使用。这意味着一些限制:没有函数调用,数据类型有限,库函数缺失,等等。其他操作,如分支,可能会带来 CPU 无法比拟的性能成本。显然,这使得将大量代码从 CPU 移植到 GPU 是一项相当大的工作。
- 与中档 CPU 插槽相比,中档显卡上的内核数量要多得多。有些工作单元太小,或者不能分成足够多的部分,无法从 GPU 上的并行化中适当受益。
- 很少支持执行任务的 GPU 核之间的同步,也不支持执行不同任务的 GPU 核之间的同步。这需要在 CPU 上执行 GPU 工作的同步和编排。
什么任务适合在 GPU 上执行?
并不是每个算法都适合在 GPU 上执行。例如,GPU 不能访问其他 I/O 设备,所以你几乎不能通过使用 GPU 来提高从 Web 获取 RSS 提要的程序的性能。然而,许多 CPU 绑定的数据并行算法可以移植到 GPU,并从中获得大规模并行化。以下是一些例子(该列表绝非详尽无遗):
- 图像模糊、锐化和其他变换
- 快速傅里叶变换
- 矩阵转置和乘法
- 数字排序
- 强力哈希反转
Microsoft Native Concurrency team blog(http://blogs.msdn.com/b/nativeconcurrency/)是其他示例的一个很好的来源,其中有示例代码和对已经移植到 C++ AMP 的各种算法的解释。
C++ AMP 是 Visual Studio 2012 附带的一个框架,它为 C++开发人员提供了在 GPU 上运行计算的简单方法,并且只需要运行 DirectX 11 驱动程序。微软已经发布了 C++ AMP 作为一个开放的规范(在撰写本文时可以在线获得),任何编译器供应商都可以实现它。在 C++ AMP 中,代码可以在代表计算设备的加速器上执行。C++ AMP 使用 DirectX 11 驱动程序动态发现所有加速器。开箱即用,C++ AMP 还附带了一个执行软件仿真的参考加速器和一个基于 CPU 的加速器 WARP,WARP 是没有 GPU 或有 GPU 但没有 DirectX 11 驱动程序并使用多核和 SIMD 指令的计算机上的合理后备。
事不宜迟,让我们考虑一个可以在 GPU 上轻松并行化的算法。下面的算法取两个相同长度的向量,计算逐点结果。没有什么比这更简单的了:
void VectorAddExpPointwise(float* first, float* second, float* result, int length) {
for (int i = 0; i < length; ++i) {
result[i] = first[i] + exp(second[i]);
}
}
在 CPU 上并行化该算法需要将迭代范围分成几个块,并创建一个线程来处理每个部分。事实上,我们已经花了相当多的时间在我们的素性测试示例上——我们已经看到了如何通过手动创建线程、向线程池发出工作项以及使用并行来实现并行化。用于自动并行化功能。此外,回想一下,当在 CPU 上并行化类似的算法时,我们非常小心地避免了过于细粒度的工作项目(例如,每次迭代一个工作项目是不行的)。
在 GPU 上,不需要这样的小心。GPU 配备了许多可以非常快速地执行线程的内核,上下文切换的成本明显低于 CPU。下面是使用 C++ AMP 的 parallel_foreach API 所需的代码:
#include < amp.h>
#include < amp_math.h>
using namespace concurrency;
void VectorAddExpPointwise(float* first, float* second, float* result, int length) {
array_view < const float,1 > avFirst (length, first);
array_view < const float,1 > avSecond(length, second);
array_view < float,1> avResult(length, result);
avResult.discard_data();
parallel_for_each(avResult.extent, = restrict(amp) {
avResult[i] = avFirst[i] + fast_math::exp(avSecond[i]);
});
avResult.synchronize();
}
我们现在分别检查代码的每个部分。首先,保持了主循环的一般形状,尽管原来的 for 循环被替换为对 parallel_foreach 的 API 调用。事实上,将循环转换成 API 调用的原理并不新鲜——我们已经在 TPL 的 Parallel 中看到了同样的原理。对于和平行。ForEach APIs。
接下来,传递给方法的原始数据(第一个、第二个和结果参数)被包装在 array_view 实例中。array_view 类包装必须移动到加速器(GPU)的数据。它的模板参数是数据的类型及其维度。如果我们希望 GPU 执行访问最初在 CPU 上的数据的指令,一些实体必须负责将数据复制到 GPU,因为当今的大多数 GPU 都是具有自己的内存的分立设备。这是 array_view 实例的任务,它们确保按需复制数据,并且只在需要时复制。
当 GPU 上的工作完成时,数据被复制回其原始位置。通过创建带有 const 模板类型参数的 array_view 实例,我们确保第一个和第二个实例仅从 GPU 的复制到,而不必从 GPU 的复制回*。类似地,通过调用 discard_data 方法,我们确保 result 不会从 CPU 复制到 GPU,而只会在有值得复制的结果时从 GPU 复制到 CPU。*
parallel_foreach API 接受一个范围,这是我们正在处理的数据的形状,以及一个为该范围中的每个元素执行的函数。我们在上面的代码中使用了 lambda 函数,这是 2011 ISO C++标准(C++11)中对 C++的一个受欢迎的补充。restrict(amp)关键字指示编译器验证函数体是否可以在 GPU 上执行,从而禁止大部分 C++语法——不能编译为 GPU 指令的语法。
lambda 函数的参数是一个 index < 1 >对象,表示一个一维索引。这必须与我们使用的范围相匹配—如果我们声明一个二维范围(如矩阵的数据形状),索引也必须是二维的。我们很快就会看到这样的例子。
最后,方法末尾的 synchronize 方法调用确保在 VectorAdd 返回时,CPU 上对 avResult array_view 所做的更改被复制回其原始容器 Result array 中。
这就结束了我们对 C++ AMP 世界的第一次探索,我们准备更深入地研究正在发生的事情,以及一个更好的示例,它将从 GPU 并行化中获得好处。向量加法不是最令人兴奋的算法,也不是卸载到 GPU 的好选择,因为内存传输超过了计算的并行化。在接下来的小节中,我们来看两个更有趣的例子。
矩阵乘法
我们要考虑的第一个“真实世界”的例子是矩阵乘法。我们将优化矩阵乘法的简单立方时间算法,而不是运行在亚立方时间的 Strassen 算法。给定两个适当维数的矩阵,A 是 m 乘 w,B 是 w 乘 n,下面的顺序程序产生它们的乘积,矩阵 C 是 m 乘 n:
void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) {
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
int sum = 0;
for (int k = 0; k < w; ++k) {
sum + = A[i*w + k] * B[k*w + j];
}
C[i*n + j] = sum;
}
}
}
这里有几个并行性的来源,如果您愿意在 CPU 上并行化这段代码,那么建议我们并行化外部循环并完成它可能是正确的。然而,在 GPU 上,有足够多的内核,如果我们只并行化外部循环,我们可能无法为所有内核创建足够的工作。因此,并行化两个外部循环是有意义的,同时为内部循环留下一个丰富的算法:
void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) {
array_view < const int,2 > avA(m, w, A);
array_view < const int,2 > avB(w, n, B);
array_view < int,2> avC(m, n, C);
avC.discard_data();
parallel_for_each(avC.extent, = restrict(amp) {
int sum = 0;
for (int k = 0; k < w; ++k) {
sum + = avA(idx[0]*w, k) * avB(k*w, idx[1]);
}
avC[idx] = sum;
});
}
除了索引是二维的,由内部循环使用[]操作符访问之外,一切都与我们前面看到的顺序乘法和向量加法非常相似。与顺序 CPU 相比,这个版本怎么样?为了乘以两个 1024 × 1024 的整数矩阵,CPU 版本平均需要 7350 毫秒,而 GPU 版本——抓紧——平均需要 50 毫秒,提高了 147 倍!
n-体模拟
到目前为止,我们看到的例子在 GPU 上调度的内部循环中有非常琐碎的代码。显然,情况不一定总是如此。我们提到的 Native Concurrency team 博客上的一个例子演示了一个 N 体模拟,它模拟了重力作用下粒子之间的相互作用。模拟由无限数量的步骤组成;在每一步中,它必须确定每个粒子的更新的加速度矢量,然后确定它的新位置。这里的可并行化组件是粒子向量——有了足够多的粒子(几千个或更多),所有 GPU 核心都有足够的工作要同时完成。
决定两个物体之间交互结果的内核是以下代码,这些代码可以非常容易地移植到 GPU:
//float4 here is a four-component vector with pointwise operations
void bodybody_interaction(
float4& acceleration, const float4 p1, const float4 p2) restrict(amp) {
float4 dist = p2 – p1;
float absDist = dist.x*dist.x + dist.y*dist.y + dist.z*dist.z; //w is unused here
float invDist = 1.0f / sqrt(absDist);
float invDistCube = invDist*invDist*invDist;
acceleration + = dist*PARTICLE_MASS*invDistCube;
}
每个模拟步骤都采用一组粒子位置和速度,并根据模拟结果生成一组新的粒子位置和速度:
struct particle {
float4 position, velocity;
//ctor, copy ctor, and operator = with restrict(amp) omitted for brevity
};
void simulation_step(array < particle,1 > & previous, array < particle,1 > & next, int bodies) {
extent < 1 > ext(bodies);
parallel_for_each(ext, & restrict(amp) {
particle p = previous[idx];
float4 acceleration(0, 0, 0, 0);
for (int body = 0; body < bodies; ++body) {
bodybody_interaction(acceleration, p.position, previous[body].position);
}
p.velocity + = acceleration*DELTA_TIME;
p.position + = p.velocity*DELTA_TIME;
next[idx] = p;
});
}
有了合适的 GUI,这个模拟非常有趣。C++ AMP 团队提供的完整示例可以在 Native Concurrency 博客上找到。在作者的系统上,英特尔 i7 处理器配有 ATI 镭龙 HD 5800 显卡,10,000 个粒子的模拟从顺序 CPU 版本产生了 2.5 帧每秒(步数)和从优化 GPU 版本产生了 160 帧每秒(步数)(见图 6-11 ),这是一个令人难以置信的改进。
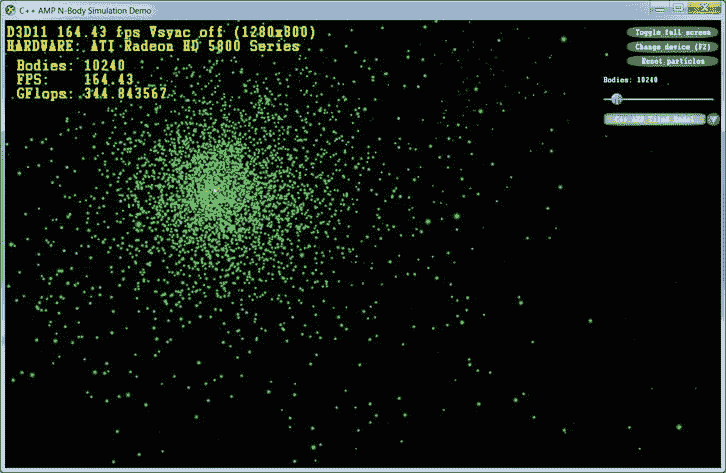
图 6-11 。N-body 模拟 UI 演示,展示了使用优化的 C++ AMP 实现和 10,240 个模拟粒子时>每秒 160 帧(模拟步骤)
图块和共享内存
在我们结束本节之前,C++ AMP 有一个非常重要的优化,可以进一步提高我们的 GPU 代码的性能。GPU 提供可编程数据缓存(通常称为共享内存)。存储在其中的值在同一个瓦片中的所有线程之间共享。通过使用分块内存,C++ AMP 程序可以将数据从 GPU 的主内存中一次性读取到共享的分块内存中,然后从同一个分块中的多个线程快速访问它,而无需从 GPU 的主内存中重新读取它。访问共享的 tile 内存比访问 GPU 的主内存快 10 倍左右——换句话说,你有理由继续阅读。
为了执行并行循环的分块版本,parallel_for_each 方法接受 tiled_extent 域和 tiled_index lambda 参数,前者将多维范围细分为多维分块,后者指定范围内的全局线程 ID 和分块内的本地线程 ID。例如,一个 16 × 16 的矩阵可以被细分成 2 × 2 的块(见图 6-12 ),然后被传递到 parallel_for_each :
extent < 2 > matrix(16,16);
tiled_extent < 2,2 > tiledMatrix = matrix.tile < 2,2 > ();
parallel_for_each(tiledMatrix,=restrict(amp){。。。});
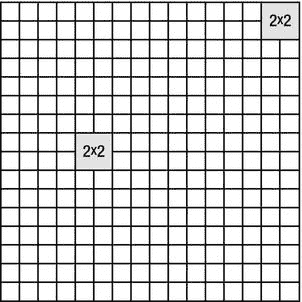
图 6-12 。一个 16 × 16 的矩阵被分成 2 × 2 的小块。属于同一瓦片的每四个线程可以在它们之间共享数据
在 GPU 内核中,idx.global 可以用来代替我们之前在矩阵上执行操作时看到的标准索引< 2 >。但是,巧妙使用本地图块内存和本地图块索引可以获得显著的性能优势。为了声明在同一个 tile 中的所有线程之间共享的 tile 特定的内存,tile_static storage 说明符可以应用于内核内部的局部变量。通常声明一个共享内存位置,并让 tile 中的每个线程初始化其中的一小部分:
parallel_for_each(tiledMatrix, = restrict(amp) {
tile_static int local[2][2]; //32 bytes shared between all threads in the tile
local[idx.local[0]][idx.local[1]] = 42; //assign to this thread's location in the array
});
显然,只有当所有线程都能够同步它们对共享内存的访问时,才可能从同一个块中的其他线程共享的内存中获得任何好处;即,在它们的相邻线程初始化它们之前,它们不应该试图访问共享存储器位置。tile_barrier 对象同步 tile 中所有线程的执行——它们可以在调用 tile_barrier.wait 之后继续执行,只有在 tile 中的所有线程也调用 tile_barrier.wait 之后(这类似于 TPL 的 barrier 类)。例如:
parallel_for_each(tiledMatrix, [](tiled_index < 2,2 > idx) restrict(amp) {
tile_static int local[2][2]; //32 bytes shared between all threads in the tile
local[idx.local[0]][idx.local[1]] = 42; //assign to this thread's location in the array
idx.barrier.wait(); //idx.barrier is a tile_barrier instance
//Now this thread can access "local" at other threads' indices!
});
现在是时候将所有这些知识应用到一个具体的例子中了。我们将重新讨论之前在没有平铺的情况下实现的矩阵乘法算法,并在其中引入基于平铺的优化。让我们假设矩阵维数可被 256 整除——这允许我们使用 16 × 16 的线程块。矩阵乘法包含固有的阻塞,这可以为我们所用(事实上,CPU 上极大矩阵乘法最常见的优化之一是通过使用阻塞来获得更好的缓存行为)。主要的观察可以归结为以下几点。为了找到 C i,j (结果矩阵中行 i 和列 j 的元素),我们必须找到 A i,** (第一个矩阵的整个I*-第行)和 B **,j* 之间的标量积但是,这相当于求部分行和部分列的标量积,并将结果相加。我们可以用它来将我们的矩阵乘法算法转换成平铺的版本:
void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) {
array_view < const int,2 > avA(m, w, A);
array_view < const int,2 > avB(w, n, B);
array_view < int,2> avC(m, n, C);
avC.discard_data();
parallel_for_each(avC.extent.tile < 16,16 > (), = restrict(amp) {
int sum = 0;
int localRow = idx.local[0], localCol = idx.local[1];
for (int k = 0; k < w; k += 16) {
tile_static int localA[16][16], localB[16][16];
localA[localRow][localCol] = avA(idx.global[0], localCol + k);
localB[localRow][localCol] = avB(localRow + k, idx.global[1]);
idx.barrier.wait();
for (int t = 0; t < 16; ++t) {
sum + = localA[localRow][t]*localB[t][localCol];
}
idx.barrier.wait(); //to avoid having the next iteration overwrite the shared memory
}
avC[idx.global] = sum;
});
}
分块优化的本质是分块中的每个线程(有 256 个线程,分块为 16 × 16)在来自 A 和 B 输入矩阵的子块的 16 × 16 本地副本中初始化它自己的元素(参见图 6-13 )。瓦片中的每个线程只需要这些子块的一行和一列,但是所有线程一起将访问每行 16 次和每列 16 次,显著减少了主存储器访问的次数。
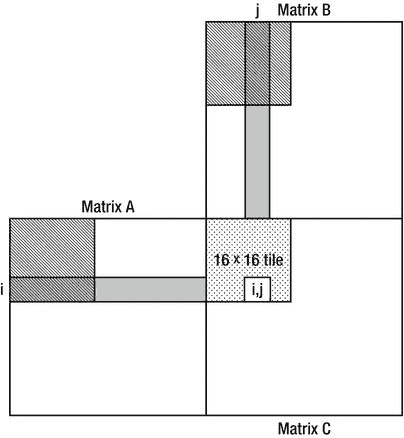
图 6-13 。为了找到结果矩阵中的元素(I,j ),该算法需要第一个矩阵的整个第 I 行和第二个矩阵的第 j 列。当图中所示的 16 × 16 tile 中的线程执行且 k = 0 时,第一个和第二个矩阵中的阴影区域最终将被读入共享内存。负责结果矩阵中第(I,j)个元素的线程将具有来自第 I 行的前 k 个元素与来自第 j 行的前 k 个元素的部分标量积
在这种情况下,平铺是一种值得的优化。矩阵乘法的平铺版本比简单版本的执行速度快得多,平均需要 17 毫秒才能完成(使用相同的 1024 × 1024 矩阵)。与 CPU 版本相比, 的速度提升了 430 倍!
在我们结束 C++ AMP 之前,有必要提一下可供 C++ AMP 开发人员使用的开发工具(Visual Studio)。Visual Studio 2012 有一个 GPU 调试器,可以用来在 GPU 内核中放置断点,检查模拟调用栈,读取和修改局部变量(有些加速器支持 GPU 调试;对于其他应用,Visual Studio 使用软件仿真器)和一个分析器,该分析器可用于评估您的应用从使用 GPU 并行化中获得了什么。有关 Visual Studio GPU 调试体验的更多信息,请参考 MSDN 的文章“演练:调试 C++ AMP 应用”,位于http://msdn.microsoft.com/en-us/library/hh368280(v=VS.110).aspx。
。GPGPU 计算的 NET 替代方案
尽管到目前为止,这一整节都专门讨论了 C++,但是从托管应用中利用 GPU 的能力有几种选择。一种选择是使用托管-本机互操作性(在第八章中讨论过),遵从本机 C++组件来实现 GPU 内核。如果您喜欢 C++ AMP,或者有一个可重用的 C++ AMP 组件,既可以在托管应用中使用,也可以在本地应用中使用,那么这是一个合理的选择。
另一种选择是使用一个库,直接从托管代码中使用 GPU。有几个这样的库可用,例如 GPU.NET 和 CUDAfy.NET(都是商业提供)。这里有一个来自 GPU.NET GitHub 库的例子,展示了两个向量的标量积:
[Kernel]
public static void MultiplyAddGpu(double[] a, double[] b, double[] c) {
int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X;
int TotalThreads = BlockDimension.X * GridDimension.X;
for (int ElementIdx = ThreadId; ElementIdx < a.Length; ElementIdx += TotalThreads) {
c[ElementIdx] = a[ElementIdx] * b[ElementIdx];
}
}
在作者看来,语言扩展(C++ AMP 方法)比纯粹在库级别上试图弥合差距或通过引入重要的 IL 重写更有效,也更容易学习。
这一节几乎没有触及 C++ AMP 提供的可能性的表面。我们只看了一些 API,并行化了一两个算法。如果你对 C++ AMP 的更多细节感兴趣,我们强烈推荐 Kate Gregory 和 Ade Miller 的书《C++ AMP:用 Microsoft Visual C++加速大规模并行性》(微软出版社,2012)。
摘要
通过本章的学习,并行化已经成为性能优化工作的重要工具。在世界各地的许多服务器和工作站上,CPU 和 GPU 闲置并浪费了宝贵的硬件资源,因为应用未能发挥机器的全部计算能力。有了任务并行库,利用所有可用的 CPU 内核比以前更容易了,尽管同步问题、超额订阅和不平等的工作分配留下了一些有趣的问题和陷阱需要处理。在 GPU 方面,C++ AMP 和其他通用 GPU 计算库正在蓬勃发展,它们的算法和 API 可以在数百个 GPU 核心上并行化您的代码。最后,本章未探讨的是分布式计算带来的性能提升,即云,这是当今 IT 的最大趋势。****
七、网络、I/O、串行化
本书的大部分内容集中在优化应用性能的计算方面。我们已经看到了无数的例子,比如调优垃圾收集,并行化循环和递归算法,甚至通过提出更好的算法来降低运行时成本。
对于某些应用,只优化计算方面会导致有限的性能提升,因为性能瓶颈在于 I/O 工作,如网络传输或磁盘访问。根据我们的经验,现场遇到的相当一部分性能问题并不是由未优化的算法或过度的 CPU 利用率引起的,而是由于系统 I/O 设备的低效利用。让我们考虑优化 I/O 可以带来性能提升的两种情况:
- 由于 I/O 的低效使用,应用可能会产生大量的计算(CPU)开销,这是以有用功为代价的。更糟糕的是,这种开销可能非常高,以至于成为实现 I/O 设备全部潜在容量的限制因素。
- I/O 设备可能未得到充分利用,或者由于低效的使用模式而浪费了其容量,例如进行许多小型 I/O 传输,或者未能保持通道得到充分利用。
本章讨论提高 I/O 性能的一般策略,特别是网络 I/O 性能。此外,我们还讨论了序列化性能,并比较了几种序列化程序。
通用输入/输出概念
本节探讨了 I/O 概念,并提供了与任何类型的 I/O 相关的性能指南。这个建议适用于网络应用、繁重的磁盘访问过程,甚至是为访问定制的高带宽硬件设备而设计的软件。
同步和异步输入/输出
对于同步 I/O,I/O 传递函数(例如 ReadFile、WriteFile 或 DeviceIoControl Win32 API 函数)会一直阻塞,直到 I/O 操作完成。这种模式虽然用起来很方便,但是效率不是很高。在发出连续 I/O 请求的时间间隔内,设备可能处于空闲状态,因此可能未得到充分利用。同步 I/O 的另一个问题是,对于每个并发的 I/O 请求,线程都被“浪费”了。例如,在一个并发服务于许多客户机的服务器应用中,您可能最终会为每个会话创建一个线程。这些线程基本上都是空闲的,它们正在浪费内存,并可能造成一种称为线程颠簸的情况,其中许多线程在 I/O 完成时醒来,并相互竞争 CPU 时间,导致许多上下文切换和较差的可伸缩性。
Windows I/O 子系统(包括设备驱动程序)是内部异步的——当 I/O 操作正在进行时,程序流的执行可以继续。几乎所有现代硬件本质上都是异步的,不需要轮询来传输数据或确定 I/O 操作是否完成。相反,大多数设备依靠直接内存访问(DMA)控制器在设备和计算机 RAM 之间传输数据,在传输过程中不需要 CPU 的注意,然后发出中断信号以表示数据传输完成。只有在应用级别,Windows 才允许内部实际异步的同步 I/O。
在 Win32 中,异步 I/O 被称为重叠I/O(参见图 7-1 比较同步和重叠 I/O)。一旦应用发出重叠的 I/O,Windows 要么立即完成 I/O 操作,要么返回指示 I/O 操作仍处于挂起状态的状态代码。然后线程可以发出更多的 I/O 操作,或者它可以做一些计算工作。程序员有几种选择来接收关于 I/O 操作完成的通知:

图 7-1 。同步和重叠 I/O 的比较
- Win32 事件的信号:当 I/O 完成时,对此事件的等待操作也将完成。
- 通过异步过程调用(APC)机制调用用户回调例程:发布线程必须处于 alertable wait 状态才能允许 APC。
- 通过 I/O 完成端口通知:这通常是最有效的机制。我们将在本章后面详细探讨 I/O 完成端口。
 注意如果应用可以保持少量 I/O 请求挂起,一些 I/O 设备(例如以无缓冲模式打开的文件)会受益(通过提高设备利用率)。推荐的策略是预先发出一定数量的 I/O 请求,并且对于每个完成的请求,重新发出另一个请求。这确保了设备驱动程序可以尽快启动下一个 I/O,而无需等待应用发出下一个 I/O 响应。但是,不要夸大挂起数据的数量,因为它会消耗有限的内核内存资源。
注意如果应用可以保持少量 I/O 请求挂起,一些 I/O 设备(例如以无缓冲模式打开的文件)会受益(通过提高设备利用率)。推荐的策略是预先发出一定数量的 I/O 请求,并且对于每个完成的请求,重新发出另一个请求。这确保了设备驱动程序可以尽快启动下一个 I/O,而无需等待应用发出下一个 I/O 响应。但是,不要夸大挂起数据的数量,因为它会消耗有限的内核内存资源。
输入输出完成端口
Windows 提供了一种高效的异步 I/O 完成通知机制,称为 I/O 完成端口 (IOCP) 。它是通过。NET 线程池。BindHandle 方法。几个。处理 I/O 的. NET 类型在内部利用这种功能:FileStream、Socket、SerialPort、HttpListener、PipeStream 等等。NET 远程处理信道。
一个 IOCP(见图 7-2 )与零个或多个以重叠模式打开的 I/O 句柄(套接字、文件和专用设备驱动程序对象)以及用户创建的线程相关联。一旦相关联的 I/O 句柄的 I/O 操作完成,Windows 将完成通知排队到适当的 IOCP,并且相关联的线程处理完成通知 。通过拥有服务于完成的线程池和智能地控制线程唤醒,减少了上下文切换并最大化了多处理器并发性。高性能服务器(如 Microsoft SQL Server)使用 I/O 完成端口不足为奇。

图 7-2 。I/O 完成端口的结构和操作
通过调用 CreateIoCompletionPortWin32 API 函数、传递最大并发值、完成键并可选地将其与支持 I/O 的句柄相关联,来创建完成端口。完成键是用户指定的值,用于在完成时区分不同的 I/O 句柄。通过再次调用 CreateIoCompletionPort 并指定现有的完成端口句柄,可以将更多的 I/O 句柄与相同或不同的 IOCP 相关联。
然后,用户创建的线程调用 GetCompletionStatus 绑定到指定的 IOCP 并等待完成。一个线程一次只能绑定到一个 IOCP。GetQueuedCompletionStatus 会一直阻塞,直到有可用的 I/O 完成通知(或超时时间已过),此时它会返回 I/O 操作的详细信息,如传输的字节数、完成键和 I/O 期间传递的重叠结构。如果另一个 I/O 在所有关联线程都忙时完成(即,在 GetQueuedCompletionStatus 上没有阻塞),IOCP 会按 LIFO 顺序唤醒另一个线程,直到达到最大并发值。如果线程调用 GetQueuedCompletionStatus 并且通知队列不为空,则调用会立即返回,而不会在 OS 内核中阻塞线程。
 还可以通过调用 PostQueuedCompletionStatus 来手动发布完成通知,而不涉及 I/O。
还可以通过调用 PostQueuedCompletionStatus 来手动发布完成通知,而不涉及 I/O。
下面的代码清单显示了一个使用 ThreadPool 的示例。Win32 文件句柄上的 BindHandle。首先来看 TestIOCP 方法 。在这里,我们调用 CreateFile,这是一个 P/Invoke’d Win32 函数,用于打开或创建文件或设备。我们必须指定 EFileAttributes。调用中的 Overlapped 标志,以使用任何类型的异步 I/o。create file 如果成功,将返回 Win32 文件句柄,然后我们将绑定到该句柄。我们通过调用 ThreadPool.BindHandle 来创建一个自动重置事件,该事件用于在进行中的 I/O 操作太多的情况下临时阻止线程发出 I/O 操作(限制由 MaxPendingIos 常量设置)。
然后,我们开始一个异步写操作循环。在每次迭代中,我们分配一个包含要写入的数据的缓冲区。我们还分配了一个 Overlapped 结构,其中包含文件偏移量(在这里,我们总是写入偏移量 0)、一个在 I/O 完成时发出信号的事件句柄(不用于 I/O 完成端口)以及一个可选的用户创建的 IAsyncResult 对象,该对象可用于将状态传递给完成函数。然后我们调用 Overlapped structure 的 Pack 方法 ,它以完成函数和数据缓冲区作为参数。它从非托管内存中分配一个等效的本机重叠结构,并固定数据缓冲区。本机结构必须手动释放,以释放它所占用的非托管内存,并取消固定托管缓冲区。
如果没有太多正在进行的 I/O 操作,我们调用 WriteFile,同时指定本机重叠结构。否则,我们会一直等待,直到事件变为有信号状态,这表明挂起的 I/O 操作数已降至限制以下。
I/O 完成函数 WriteComplete 由调用。当 I/O 完成时,NET I/O 完成线程池线程。它接收指向本机重叠结构的指针,该指针可以被解包以将其转换回托管重叠结构 。
using System;
using System.Threading;
using Microsoft.Win32.SafeHandles;
using System.Runtime.InteropServices;
[DllImport("kernel32.dll", SetLastError = true, CharSet = CharSet.Auto)]
internal static extern SafeFileHandle CreateFile(
string lpFileName,
EFileAccess dwDesiredAccess,
EFileShare dwShareMode,
IntPtr lpSecurityAttributes,
ECreationDisposition dwCreationDisposition,
EFileAttributes dwFlagsAndAttributes,
IntPtr hTemplateFile);
[DllImport("kernel32.dll", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
static unsafe extern bool WriteFile(SafeFileHandle hFile, byte[] lpBuffer,
uint nNumberOfBytesToWrite, out uint lpNumberOfBytesWritten,
System.Threading.NativeOverlapped *lpOverlapped);
[Flags]
enum EFileShare : uint {
None = 0x00000000,
Read = 0x00000001,
Write = 0x00000002,
Delete = 0x00000004
}
enum ECreationDisposition : uint {
New = 1,
CreateAlways = 2,
OpenExisting = 3,
OpenAlways = 4,
TruncateExisting = 5
}
[Flags]
enum EFileAttributes : uint {
//Some flags not present for brevity
Normal = 0x00000080,
Overlapped = 0x40000000,
NoBuffering = 0x20000000,
}
[Flags]
enum EFileAccess : uint {
//Some flags not present for brevity
GenericRead = 0x80000000,
GenericWrite = 0x40000000,
}
static long _numBytesWritten;
static AutoResetEvent _waterMarkFullEvent; // throttles writer thread
static int _pendingIosCount;
const int MaxPendingIos = 10;
//Completion routine called by .NET ThreadPool I/O completion threads
static unsafe void WriteComplete(uint errorCode, uint numBytes, NativeOverlapped* pOVERLAP) {
_numBytesWritten + = numBytes;
Overlapped ovl = Overlapped.Unpack(pOVERLAP);
Overlapped.Free(pOVERLAP);
//Notify writer thread that pending I/O count fell below watermark
if (Interlocked.Decrement(ref _pendingIosCount) < MaxPendingIos)
_waterMarkFullEvent.Set();
}
static unsafe void TestIOCP() {
//Open file in overlapped mode
var handle = CreateFile(@"F:\largefile.bin",
EFileAccess.GenericRead | EFileAccess.GenericWrite,
EFileShare.Read | EFileShare.Write,
IntPtr.Zero, ECreationDisposition.CreateAlways,
EFileAttributes.Normal | EFileAttributes.Overlapped, IntPtr.Zero);
_waterMarkFullEvent = new AutoResetEvent(false);
ThreadPool.BindHandle(handle);
for (int k = 0; k < 1000000; k++) {
byte[] fbuffer = new byte[4096];
//Args: file offset low & high, event handle, IAsyncResult object
Overlapped ovl = new Overlapped(0, 0, IntPtr.Zero, null);
//The CLR takes care to pin the buffer
NativeOverlapped* pNativeOVL = ovl.Pack(WriteComplete, fbuffer);
uint numBytesWritten;
//Check if too many I/O requests are pending
if (Interlocked.Increment(ref _pendingIosCount) < MaxPendingIos) {
if (WriteFile(handle, fbuffer, (uint)fbuffer.Length, out numBytesWritten,
pNativeOVL)) {
//I/O completed synchronously
_numBytesWritten + = numBytesWritten;
Interlocked.Decrement(ref _pendingIosCount);
} else {
if (Marshal.GetLastWin32Error() ! = ERROR_IO_PENDING) {
return; //Handle error
}
}
} else {
Interlocked.Decrement(ref _pendingIosCount);
while (_pendingIosCount > = MaxPendingIos) {
_waterMarkFullEvent.WaitOne();
}
}
}
}
总之,当使用高吞吐量 I/O 设备时,使用带有完成端口的重叠 I/O,方法是直接在非托管库中创建和使用自己的完成端口,或者将 Win32 句柄与。NET 的完成端口。
网络线程池
那个。NET 线程池 有多种用途,每种用途由不同种类的线程提供服务。第六章展示了线程池 API,我们用它来挖掘线程池的能力,以并行处理 CPU 受限的计算。然而,线程池适用于许多类型的工作:
- 工作线程处理用户委托的异步调用(例如 BeginInvoke 或 ThreadPool。QueueUserWorkItem)。
- I/O 完成线程处理全局 IOCP 的完成。
- 等待线程处理注册等待。注册等待通过将几个等待合并为一个等待(使用 WaitForMultipleObjects)来节省线程,最多可达 Windows 限制(MAXIMUM_WAIT_OBJECTS = 64)。注册等待用于不使用 I/O 完成端口的重叠 I/O。
- 定时器线程组合等待多个定时器。
- Gate thread 监控线程池线程的 CPU 使用情况,并增加或减少线程数量(在预设限制内)以获得最佳性能。
 注意你可以发出一个看似异步的 I/O 操作,尽管它实际上并不是。比如调用 ThreadPool。委托上的 QueueUserWorkItem,然后执行同步 I/O 操作并不能使它成为真正的异步,并不比在常规线程上执行更好。
注意你可以发出一个看似异步的 I/O 操作,尽管它实际上并不是。比如调用 ThreadPool。委托上的 QueueUserWorkItem,然后执行同步 I/O 操作并不能使它成为真正的异步,并不比在常规线程上执行更好。
复制内存
通常,从硬件设备接收的数据缓冲区被一遍又一遍地复制,直到应用完成对它的处理。复制会成为 CPU 开销的重要来源,因此,对于高吞吐量 I/O 代码路径,应该避免复制。我们现在调查一些复制数据的场景以及如何避免复制。
非托管内存
英寸 NET 中,使用非托管内存缓冲区比使用托管字节【】更麻烦,所以程序员通常采取简单的方法,只是将缓冲区复制到托管内存中。
如果您的 API 或库允许您指定自己的内存缓冲区或具有用户定义的分配器回调,请分配一个托管缓冲区并固定它,以便可以通过指针和托管引用来访问它。如果缓冲区太大(> 85,000 字节),它被分配在大型对象堆中,请尝试重用该缓冲区。如果由于不确定的对象生存期而导致重用不重要,那么使用内存池,如第八章中的所述。
在其他情况下,API 或库坚持分配自己的(非托管)内存缓冲区。您可以使用指针(需要不安全的代码)或使用包装类(如 UnmanagedMemoryStream 或 UnmanagedMemoryAccessor)直接访问它。但是,如果您需要将缓冲区传递给一些只处理 byte[]或 string 对象的代码,复制可能是不可避免的。
即使您无法避免复制内存,如果您的部分或大部分数据在早期被过滤(例如网络数据包),也可以通过先检查数据是否有用而不复制它来避免不必要的内存复制。
暴露缓冲区的部分
正如第八章所解释的,程序员有时会假设一个字节[]只包含所需的数据,并且从开始一直延续到结束,迫使调用者拼接缓冲区(分配一个新的字节[]并只复制所需的部分)。这种情况经常在解析协议栈时出现。相比之下,等效的非托管代码将接受一个指针,不知道它是否指向分配的开始,并且必须接受一个长度参数来告诉它数据的结束位置。
为了避免不必要的内存复制,在使用 byte[]参数的地方使用 offset 和 length 参数。使用 length 参数代替数组的 Length 属性,并将偏移量值添加到索引中。
分散–收集 I/O
scatter–gather 是一种 Windows I/O 功能,支持 I/O 在一组不连续的内存位置之间来回传输,就像它们是连续的一样。Win32 通过 ReadFileScatter 和 WriteFileGather 函数公开了这一功能。Windows Sockets 库也通过自己的函数支持分散-聚集:WSASend、WSARecv 以及其他函数。
分散-聚集在以下情况下很有用:
- 每个数据包的有效载荷前都有一个固定的报头。这使您不必每次都复制头来创建连续的缓冲区。
- 您希望通过在一个系统调用中对多个缓冲区执行 I/O 来节省系统调用开销。
虽然 ReadFileScatter 和 WriteFileGather 有局限性,因为每个缓冲区必须正好是系统页面大小,并且这些函数要求句柄以重叠和无缓冲的方式打开(这施加了更多的约束),但基于套接字的分散收集更实用,因为它没有这些限制。那个。NET Framework 通过套接字的 Send 和 Receive 方法的重载来公开套接字分散-收集,但不公开一般的分散/收集函数。
分散-聚集用法的一个例子是 HttpWebRequest。它将 HTTP 头和有效负载结合在一起,而不需要构建一个连续的缓冲区来保存这两者。
文件输入/输出
通常,文件 I/O 通过文件系统缓存,这有一些性能优势:缓存最近访问的数据、预读(推测性地从磁盘预取数据)、后写(异步地将数据写入磁盘)以及合并小型写入。通过向 Windows 提示您期望的文件访问模式,您可以获得更高的性能。如果您的应用确实有重叠的 I/O,并且能够智能地处理一些复杂的缓冲区,那么完全绕过缓存会更有效。
缓存提示
创建或打开文件时,您可以为 CreateFile Win32 API 函数指定标志和属性,其中一些会影响缓存行为:
- FILE_FLAG_SEQUENTIAL_SCAN 向缓存管理器提示文件是顺序访问的,可能会跳过某些部分,但很少随机访问。缓存将进一步提前读取。
- FILE_FLAG_RANDOM_ACCESS 提示文件是以随机顺序访问的,因此缓存管理器提前读取的数据较少,因为应用实际上不太可能会请求这些数据。
- FILE_ATTRIBUTE_TEMPORARY 提示文件是临时的,因此可以延迟刷新磁盘写入(以防止数据丢失)。
NET 通过接受 FileOptions 枚举参数的 FileStream 构造函数重载来公开这些选项(最后一个选项除外)。
 注意随机存取不利于性能,尤其是在磁盘介质上,因为读/写磁头必须物理移动。从历史上看,磁盘吞吐量随着平均存储密度的增加而提高,但延迟却没有。现代磁盘可以智能地(将磁盘旋转考虑在内)对随机存取 I/O 进行重新排序,从而最大限度地减少磁头移动的总时间。这被称为本地命令队列(NCQ)。为了有效地工作,磁盘控制器必须预先知道几个 I/O 请求。换句话说,如果可能的话,应该有几个异步 I/O 请求挂起。
注意随机存取不利于性能,尤其是在磁盘介质上,因为读/写磁头必须物理移动。从历史上看,磁盘吞吐量随着平均存储密度的增加而提高,但延迟却没有。现代磁盘可以智能地(将磁盘旋转考虑在内)对随机存取 I/O 进行重新排序,从而最大限度地减少磁头移动的总时间。这被称为本地命令队列(NCQ)。为了有效地工作,磁盘控制器必须预先知道几个 I/O 请求。换句话说,如果可能的话,应该有几个异步 I/O 请求挂起。
无缓冲输入/输出
无缓冲 I/O 完全绕过 Windows 缓存。这既有好处也有坏处。与缓存提示一样,无缓冲 I/O 是在文件创建期间通过“标志和属性”参数启用的,但是。NET 不公开此功能:
- FILE_FLAG_NO_BUFFERING 防止读取或写入的数据被缓存,但对磁盘控制器的硬件缓存没有影响。这避免了内存复制(从用户缓冲区到缓存)并防止缓存污染(以牺牲更重要的数据为代价用无用的数据填充缓存)。但是,读取和写入必须遵守对齐要求。以下参数必须与磁盘扇区大小对齐,或者其大小是磁盘扇区大小的整数倍:I/O 传输大小、文件偏移量和内存缓冲区地址。通常,扇区大小为 512 字节长。最近的高容量磁盘驱动器具有 4,096 字节扇区(称为“高级格式”),但它们可以在模拟 512 字节扇区的兼容模式下运行(以性能为代价)。
- FILE_FLAG_WRITE_THROUGH 指示缓存管理器刷新缓存的写入(如果 FILE_FLAG_NO_BUFFERING 未指定),并指示磁盘控制器立即将写入提交到物理介质,而不是将它们存储在硬件缓存中。
预读通过保持磁盘利用率来提高性能,即使应用进行同步读取,并且读取之间有延迟。这取决于 Windows 正确预测应用下一步将请求文件的哪一部分。通过禁用缓冲,您还可以禁用预读,并通过挂起多个重叠的 I/O 操作来保持磁盘繁忙。
Write-behind 还通过给人一种磁盘写入很快完成的错觉,提高了进行同步写入的应用的性能。应用可以更好地利用 CPU,因为它阻塞的时间更少。当禁用缓冲时,写入会在将其写入磁盘的实际时间内完成。因此,当使用无缓冲 I/O 时,进行异步 I/O 变得更加重要。
建立关系网
网络访问是大多数现代应用的基本功能。处理客户端请求的服务器应用努力最大化可伸缩性及其吞吐能力,以便更快地为客户端提供服务,并在每台服务器上为更多的客户端提供服务,而客户端的目标是最小化网络访问延迟或减轻其影响。本节提供了最大限度提高网络性能的建议和提示。
网络协议
应用网络协议(OSI 第 7 层)的构建方式对性能有着深远的影响。本节探讨了一些优化技术,以更好地利用可用的网络容量并最小化开销。
流水线作业
在非流水线协议中,客户端向服务器发送请求,然后等待响应到达,然后才能发送下一个请求。使用这种协议,网络容量没有得到充分利用,因为在网络往返时间(即网络数据包到达服务器并返回所需的时间)期间,网络是空闲的。相反,在管道连接中,客户端可以继续发送更多的请求,甚至在服务器处理完之前的请求之前。更好的是,服务器可以决定不按顺序响应请求,首先响应琐碎的请求,而推迟处理计算要求更高的请求。
管道化 越来越重要,因为尽管互联网带宽在全球范围内持续增长,但延迟的改善速度却慢得多,因为它受到光速所施加的物理限制的限制。
HTTP 1.1 是真实协议中管道的一个例子,但是由于兼容性问题,它在大多数服务器和 web 浏览器上通常是默认禁用的。Google SPDY,一个实验性的类似 HTTP 的协议,由 Chrome 和 Firefox web 浏览器以及一些 HTTP 服务器支持,以及即将到来的 HTTP 2.0 协议要求管道支持。
流式传输
流媒体不仅仅用于视频和音频,还可以用于信息传递。通过流式传输,应用甚至在完成之前就开始通过网络发送数据。流式传输减少了延迟并提高了网络通道利用率。
例如,如果服务器应用为响应请求而从数据库中获取数据,它可以将数据一个一个地读入数据集(这会消耗大量内存),也可以使用 DataReader 一次检索一条记录。在前一种方法中,服务器必须等到整个数据集到达后才能开始向客户机发送响应,而在后一种方法中,服务器可以在第一个 DB 记录到达后立即开始向客户机发送响应。
消息分块
通过网络一次发送一小块数据是一种浪费。以太网、IP 和 TCP/UDP 报头并没有变小,因为有效负载变小了,所以尽管带宽利用率仍然很高,但最终您会将它浪费在报头上,而不是实际的数据上。此外,Windows 本身的每次调用开销与数据块大小无关或很少相关。一个协议可以通过允许几个请求被组合来减轻这个问题。例如,域名服务(DNS)协议允许客户端在一个请求中解析多个域名。
闲聊协议
有时,即使协议允许,客户端也不能通过管道发送请求,因为下一个请求取决于前面的回复的内容。
考虑一个聊天式协议会话 的例子。当您浏览到一个网页时,浏览器通过 TCP 连接到 web 服务器,发送一个 HTTP GET 请求来请求您要访问的 URL,并接收一个 HTML 页面作为响应。然后,浏览器解析 HTML,确定需要检索哪些 JavaScript、CSS 和图像资源,并分别下载它们。然后执行 JavaScript 脚本,它可以获取更多的内容。总之,客户机并不立即知道它必须检索来呈现页面的所有内容。相反,它必须反复获取内容,直到发现并下载所有内容。
为了缓解这个问题,服务器可能会提示客户端需要检索哪些 URL 来呈现页面,甚至可能在客户端没有请求的情况下发送内容。
消息编码和冗余
网络带宽通常是一种有限的资源,而浪费的消息格式对性能没有帮助。以下是优化消息格式的一些技巧:
- 不要一遍又一遍地发送相同的内容,保持标题较小。
- 对数据使用智能编码或表示。例如,字符串可以用 UTF 8 编码,而不是 UTF-16。二进制协议比人类可读的协议要简洁许多倍。如果可能,避免封装,如 Base64 编码。
- 对高度可压缩的数据(如文本)使用压缩。对于不可压缩的数据,如已经压缩的视频、图像和音频,请避免使用它。
网络插座
套接字 API 是应用使用网络协议(如 TCP 和 UDP)的标准方式。最初,sockets API 是在 BSD UNIX 操作系统中引入的,此后几乎成为所有操作系统的标准,有时还带有专有扩展,如微软的 WinSock。在 Windows 中有许多方法可以实现套接字 I/O:阻塞、带有轮询的非阻塞和异步。使用正确的 I/O 模型和套接字参数可以实现更高的吞吐量、更低的延迟和更好的可扩展性。本节概述了与 Windows 套接字相关的性能优化。
异步套接字
。NET 通过 Socket 类支持异步 I/O。然而,异步 API 有两个家族:BeginXXX 和 XXXAsync,其中 XXX 代表接受、连接、接收、发送和其他操作。前者使用。NET 线程池的注册等待功能来等待重叠的 I/O 完成,而后者使用。NET 线程池的 I/O 完成端口机制,这是更高的性能和可伸缩性。后面的 API 是在中引入的。NET 框架 2.0 SP1。
套接字缓冲区
Socket 对象公开了两个可设置的缓冲区大小:ReceiveBufferSize 和 SendBufferSize,它们指定 TCP/IP 堆栈分配的缓冲区大小(在 OS 内存空间中)。默认情况下,两者都设置为 8,192 字节。接收缓冲区用于保存应用尚未读取的接收数据。发送缓冲区用于保存应用已经发送但尚未被接收方确认的数据。如果需要重新传输,来自发送缓冲区的数据将被重新传输。
当应用从套接字读取数据时,它会根据读取的数据量来填充接收缓冲区。当接收缓冲区变空时,调用要么阻塞,要么挂起,这取决于使用的是同步还是异步 I/O。
当应用写入套接字时,它可以无阻塞地写入数据,直到发送缓冲区已满而无法容纳数据,或者直到接收方的接收缓冲区变满。接收方通过每个确认通告其接收缓冲区大小有多满。
对于高带宽、高延迟的连接,如卫星链路,默认的缓冲区大小可能太小。发送端很快填满其发送缓冲区,并不得不等待确认,由于等待时间长,确认到达的速度很慢。等待时,管道不会保持满,端点仅利用可用带宽的一部分。
在完全可靠的网络中,理想的缓冲区大小是带宽和延迟的乘积。例如,在往返时间为 5 毫秒的 100Mbps 连接中,理想的缓冲区窗口大小应为(100,000,000 / 8) × 0.005 = 62,500 字节。数据包丢失会降低该值。
纳格尔算法
如前所述,小数据包是一种浪费,因为与有效负载相比,数据包报头可能很大。Nagle 的算法 通过将应用的多次写入合并成一个完整数据包的数据,提高了 TCP 套接字的性能。然而,这项服务并不是免费的,因为它会在发送数据之前引入延迟。对延迟敏感的应用应该通过设置套接字来禁用 Nagle 的算法。NoDelay 属性设置为 true。一个编写良好的应用一次会发送大量缓冲区,不会从 Nagle 的算法中受益。
注册输入输出
Registered I/O (RIO) 是 WinSock 在 Windows Server 2012 中的新扩展,提供了非常高效的缓冲区注册和通知机制。RIO 消除了 Windows I/O 中最严重的低效问题:
- 用户缓冲区探测(检查页面访问权限)、锁定和解锁(确保缓冲区驻留在 RAM 中)。
- 句柄查找(将 Win32 句柄翻译成内核对象指针)。
- 进行的系统调用(例如,将 I/O 完成通知出队)。
这些是为了将应用与操作系统和其他应用隔离开来而支付的“税”,目的是确保安全性和可靠性。如果没有力拓,你需要为每笔交易支付这些税,在高 I/O 率的情况下,这些税变得很重要。相反,在 RIO 中,您只需在初始化期间支付一次“税收”成本。
RIO 要求注册缓冲区,这将缓冲区锁定在物理内存中,直到它们被注销(当应用或子系统取消初始化时)。由于缓冲区保持分配并驻留在内存中,Windows 可以跳过每次调用的探测、锁定和解锁。
RIO 请求和完成队列驻留在进程的内存空间中,并且可以被它访问,这意味着不再需要系统调用来轮询队列或使完成通知出队。
里约支持三种通知机制:
- 轮询:这具有最低的延迟,但意味着逻辑处理器专用于轮询网络缓冲区。
- 输入输出完成端口。
- 发出 Windows 事件的信号。
在写这篇文章的时候,力拓还没有被曝光。NET 框架,但它可以通过标准。NET 互操作性机制(在第八章中讨论)。
数据序列化和反序列化
序列化是以一种可以写入磁盘或通过网络发送的格式来表示对象的行为。反序列化是从序列化表示中重建对象的行为。例如,哈希表可以序列化为键值记录的数组。
串行器基准
那个。NET Framework 附带了几个通用序列化程序,可以序列化和反序列化用户定义的类型。本节从序列化吞吐量和序列化消息大小的角度衡量了每种基准序列化程序的优缺点。
首先,我们回顾一下可用的序列化器:
-
系统。XML . serialize . XML serializer
-
序列化为 XML,文本或二进制。
-
处理子对象,但不支持循环引用。
-
仅适用于公共字段和属性,明确排除的除外。
-
只使用一次反射来代码生成序列化程序集,以提高操作效率。您可以使用 sgen.exe 工具预先创建序列化程序集。
-
允许自定义 XML 架构。
-
要求事先知道参与序列化的所有类型:它自动推断出这些信息,除非使用继承类型。
-
系统。runtime . serialization . formatters . binary . binary formatter
-
序列化为专有的二进制格式,只能由使用。NET BinaryFormatter。
-
由使用。NET 远程处理,但也可以独立用于一般序列化。
-
在公共和非公共领域工作。
-
处理循环引用。
-
不需要要序列化的类型的先验知识。
-
要求通过应用[Serializable]属性将类型标记为可序列化。
-
系统。runtime . serialization . formatters . soap . soap formatter
-
在功能上类似于 BinaryFormatter,但序列化为 SOAP XML 格式,这种格式更具互操作性,但不太紧凑。
-
不支持泛型和泛型集合,因此在。NET 框架。
-
系统。runtime . serialization . datacontractserializer
-
序列化为 XML,文本或二进制。
-
由 WCF 使用,但也可以独立用于常规序列化。
-
通过使用[DataContract]和[DataMember]属性将类型和字段序列化为选择性加入:如果类由[Serializable]属性标记,则所有字段都将被序列化。
-
要求事先知道参与序列化的所有类型:它自动推断出这些信息,除非使用继承类型。
-
系统。runtime . serialization . netdatacontractserializer
-
类似于 DataContractSerializer,只是它嵌入了。序列化数据中特定于. NET 的类型信息。
-
不需要参与序列化的类型的先验知识。
-
需要共享包含序列化类型的程序集。
-
系统。runtime . serialization . datacontractjsonserializer
-
类似于 DataContractSerializer,但序列化为 JSON 格式而不是 XML 格式。
图 7-3 展示了前面列出的序列化程序的基准测试结果。有些序列化程序针对文本 XML 输出和二进制 XML 输出测试了两次。基准测试涉及高复杂性对象图的序列化和反序列化,该对象图由 5 种类型的 3,600 个实例组成,具有树状引用模式。每种类型都由 string 和 double 字段及其数组组成。不存在循环引用,因为并非所有序列化程序都支持循环引用。然而,那些支持循环引用的序列化器在它们存在的情况下运行速度要慢得多。此处显示的基准测试结果运行于。NET Framework 4.5 RC,它比。NET Framework 3.5,用于使用二进制 XML 的测试,但在其他方面没有明显的区别。
基准测试结果显示,DataContractSerializer 和 XmlSerializer 在处理二进制 XML 格式时总体上是最快的。
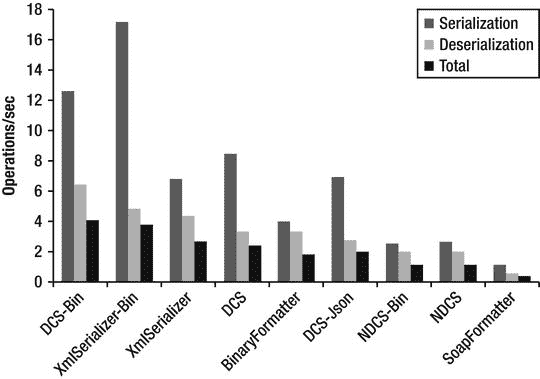
图 7-3 。序列化程序吞吐量基准结果,以操作/秒为单位
接下来,我们比较序列化器的序列化数据大小(参见图 7-4 )。在这个度量中,有几个彼此非常接近的序列化器。这可能是因为对象树的大部分数据都是字符串形式的,这在所有序列化程序中都以相同的方式表示。
最紧凑的序列化表示由 DataContractJsonSerializer 生成,当与二进制 XML 编写器一起使用时,紧随其后的是 XmlSerializer 和 DataContractSerializer。也许令人惊讶的是,BinaryFormatter 的表现优于大多数其他序列化程序。
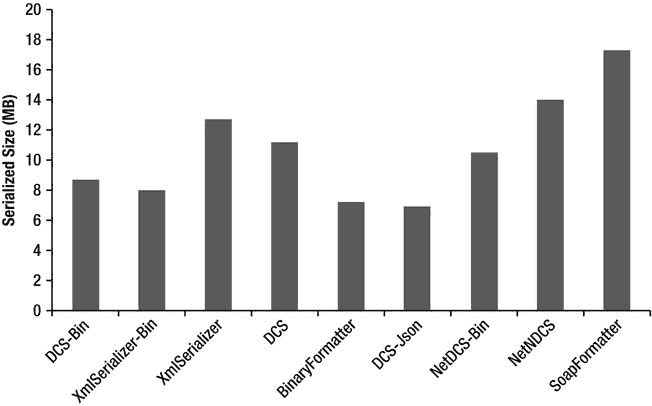
图 7-4 。序列化数据大小的比较
数据集序列化
数据集是通过 DataAdapter 从数据库中检索的数据的内存缓存。它包含 DataTable 对象的集合,这些对象包含数据库架构和数据行,每个数据行包含序列化对象的集合。数据集对象很复杂,消耗大量内存,并且序列化时计算量很大。然而,许多应用在应用的不同层之间传递它们。减少序列化开销的技巧包括:
- 调用数据集。序列化数据集之前应用 Changes 方法。数据集存储原始值和更改后的值。如果不需要序列化旧值,请调用 ApplyChanges 来丢弃它们。
- 仅序列化您需要的数据表。如果数据集包含您不需要的其他表,请考虑只将所需的表复制到新的 DataSet 对象中,并将其序列化。
- 使用列名别名(作为关键字)来给出较短的名称并减少序列化的长度。例如,考虑以下 SQL 语句:选择 EmployeeID 作为 I,Name 作为 N,Age 作为 A
Windows 通信基础
Windows 通信基金会(WCF),发布于。NET 3.0 正迅速成为大多数网络需求的事实上的标准。NET 应用。它提供了无与伦比的网络协议和定制选择,并不断通过新的。净释放量。本节介绍 WCF 性能优化。
节流
WCF,尤其是以前。默认情况下,NET Framework 4.0 具有保守的限制值。这些都是为了防止拒绝服务(DoS)攻击而设计的,但不幸的是,在现实世界中,它们通常被设置得太低而没有用。
可以通过编辑 app.config(针对桌面应用)或 web.config(针对 ASP.NET 应用)中的 system.serviceModel 部分来修改限制设置:
<system.serviceModel>
<behaviors>
<serviceBehaviors>
<behavior>
<serviceThrottling>
<serviceThrottling maxConcurrentCalls = "16"
maxConcurrentSessions = "10" maxConcurrentInstances = "26" />
更改这些参数的另一种方法是在服务创建期间设置 ServiceThrottling 对象的属性:
Uri baseAddress = new Uri("http://localhost:8001/Simple");
ServiceHost serviceHost = new ServiceHost(typeof(CalculatorService), baseAddress);
serviceHost.AddServiceEndpoint(
typeof(ICalculator),
new WSHttpBinding(),
"CalculatorServiceObject");
serviceHost.Open();
IChannelListener icl = serviceHost.ChannelDispatchers[0].Listener;
ChannelDispatcher dispatcher = new ChannelDispatcher(icl);
ServiceThrottle throttle = dispatcher.ServiceThrottle;
油门。MaxConcurrentSessions**=**10;
油门。MaxConcurrentCalls**=**16;
油门。MaxConcurrentInstances**=**26;
让我们来理解这些参数是什么意思。
- maxConcurrentSessions 限制 ServiceHost 上当前处理的消息数。超过限制的呼叫将被排队。的默认值为 10。NET 中处理器数量的 3.5 倍和 100 倍。NET 4。
- maxConcurrentCalls 限制在 ServiceHost 上一次执行的 InstanceContext 对象的数量。创建额外实例的请求被排队,并在低于限制的位置可用时完成。
- 的默认值为 16。NET 中处理器数量的 3.5 和 16 倍。NET 4。
- maxConcurrentInstances 限制 ServiceHost 对象可以接受的会话数。该服务接受超过限制的连接,但只有低于限制的通道是活动的(从通道中读取消息)。
- 的默认值是 26。NET 中处理器数量的 3.5 倍和 116 倍。NET 4。
另一个重要的限制是每个主机允许的应用并发连接数,默认情况下是两个。如果您的 ASP.NET 应用调用外部 WCF 服务,这个限制可能是一个严重的瓶颈。这是一个设置这些限制的配置示例:
<system.net>
<connectionManagement>
<add address = "*" maxconnection = "100" />
</connectionManagement>
</system.net>
流程模型
编写 WCF 服务时,您需要确定其激活和并发模型。这分别由 ServiceBehavior 属性的 InstanceContextMode 和 ConcurrencyMode 属性控制。InstanceContextMode 值的含义如下:
- per call–为每个呼叫创建一个服务对象实例。
- PerSession(默认)–为每个会话创建一个服务对象实例。如果通道不支持会话,这类似于 PerCall。
- 单一–单一服务实例可重复用于所有呼叫。
并发模式值的含义如下:
- Single(默认)–服务对象是单线程的,不支持重入。如果 InstanceContextMode 设置为 Single,并且它已经为一个请求提供了服务,那么其他请求必须等待轮到它们。
- 可重入——服务对象是单线程的,但可重入。如果该服务调用另一个服务,它可能会被重新输入。在调用另一个服务之前,您有责任确保对象状态保持一致。
- multiple——不保证同步,服务必须自己处理同步,以确保状态的一致性。
不要将 Single 或 Reentrant ConcurrencyMode 与 Single InstanceContextMode 一起使用。如果使用多并发模式,请使用细粒度的锁定,以便实现更好的并发性。
WCF 从。NET 线程池 I/O 完成线程,在本章前面已经介绍过。如果在服务期间执行同步 I/O 或 do 等待,您可能需要通过编辑 ASP.NET 应用的 system.web 配置部分(见下文)或调用 thread pool 来增加线程池线程的数量。SetMinThreads 和 ThreadPool。桌面应用中的 SetMaxThreads。
<system.web>
<processModel
...
enable = "true"
autoConfig = "false"
**maxworkerthread =**80
**maxIoThreads =**80
minWorkerThreads ="40
**miniothhreads =**40
/>
缓存
WCF 没有内置缓存支持。即使您将 WCF 服务托管在 IIS 中,默认情况下它仍无法使用其缓存。要启用缓存,请使用 aspnetcompatibility requirements 属性标记您的 WCF 服务。
[AspNetCompatibilityRequirements(RequirementsMode = AspNetCompatibilityRequirementsMode.Allowed)]
此外,通过编辑 web.config 并在 system.serviceModel 部分下添加以下元素来启用 ASP.NET 兼容性:
<serviceHostingEnvironment aspNetCompatibilityEnabled = "true" />
从……开始。NET Framework 4.0,可以使用新系统。实现缓存的缓存类型。它不依赖于系统。网络大会,所以它不仅限于 ASP.NET。
异步 WCF 客户端和服务器
WCF 允许你在客户端和服务器端发布异步操作。每一方都可以独立地决定是同步操作还是异步操作。
在客户端,有两种异步调用服务的方式:基于事件的和。基于 NET 异步模式。基于事件的模型与使用 ChannelFactory 创建的通道不兼容。要使用基于事件的模型,请使用带有/async 和/tcv:Version35 开关的 svcutil.exe 工具来生成服务代理:
svcutil /n:http://Microsoft.ServiceModel.Samples,Microsoft.ServiceModel.Sampleshttp://localhost:8000/servicemodelsamples/service/mex /async /tcv:Version35
然后,可以按如下方式使用生成的代理:
// Asynchronous callbacks for displaying results.
static void AddCallback(object sender, AddCompletedEventArgs e) {
Console.WriteLine("Add Result: {0}", e.Result);
}
static void Main(String[] args) {
CalculatorClient client = new CalculatorClient();
client.AddCompleted + = new EventHandler < AddCompletedEventArgs > (AddCallback);
client.AddAsync(100.0, 200.0);
}
在基于 IAsyncResult 的模型中,您使用 svcutil 创建一个指定/async 开关但不指定/tcv:Version35 开关的代理。然后调用代理上的 BeginXXX 方法,并提供一个完成回调,如下所示:
static void AddCallback(IAsyncResult ar) {
double result = ((CalculatorClient)ar.AsyncState).EndAdd(ar);
Console.WriteLine("Add Result: {0}", result);
}
static void Main(String[] args) {
ChannelFactory < ICalculatorChannel > factory = new ChannelFactory < ICalculatorChannel > ();
ICalculatorChannel channelClient = factory.CreateChannel();
IAsyncResult arAdd = channelClient.BeginAdd(100.0, 200.0, AddCallback, channelClient);
}
在服务器上,异步是通过创建契约操作的 BeginXX 和 EndXX 版本来实现的。您不应该有另一个名称相同但没有开始/结束前缀的操作,因为 WCF 将调用它。遵循这些命名约定,因为 WCF 要求这样做。
BeginXX 方法应该接受输入参数并返回 IAsyncResult,几乎不做任何处理;I/O 应该异步完成。BeginXX 方法(只有它)应该应用 OperationContract 属性,并将 AsyncPattern 参数设置为 true。
EndXX 方法应该接受一个 IAsyncResult,具有所需的返回值,并具有所需的输出参数。IAsyncResult 对象(从 BeginXX 返回)应该包含返回结果所需的所有信息。
此外,WCF 4.5 在服务器和客户端代码中都支持新的基于任务的异步/等待模式。例如:
//Task-based asynchronous service
public class StockQuoteService : IStockQuoteService {
async public Task<double> GetStockPrice(string stockSymbol) {
double price = await FetchStockPriceFromDB();
return price;
}
}
//Task-based asynchronous client
public class TestServiceClient : ClientBase < IStockQuoteService>, IStockQuoteService {
public Task<double> GetStockPriceAsync(string stockSymbol) {
return Channel.GetStockPriceAsync();
}
}
绑定
设计 WCF 服务时,选择正确的绑定非常重要。每个绑定都有自己的功能和性能特征。选择最简单的绑定,并使用满足您需求的最少数量的绑定功能。可靠性、安全性和身份验证等特性会增加大量开销,所以只在必要时才使用它们。
对于同一台机器上的进程之间的通信,命名管道绑定提供了最佳性能。对于跨机器双向通信,Net TCP 绑定提供了最佳性能。但是,它不能互操作,只能与 WCF 客户端一起工作。它也不是负载平衡器友好的,因为会话变得与特定的服务器地址密切相关。
您可以使用自定义二进制 HTTP 绑定来获得 TCP 绑定的大部分性能优势,同时保持与负载平衡器的兼容性。下面是配置此类绑定的示例:
<bindings>
< customBinding>
<binding name = "NetHttpBinding">
<reliableSession />
<compositeDuplex />
<oneWay />
<binaryMessageEncoding />
<httpTransport />
</binding>
</customBinding>
<basicHttpBinding>
<binding name = "BasicMtom" messageEncoding = "Mtom" />
</basicHttpBinding>
<wsHttpBinding>
<binding name = "NoSecurityBinding">
<security mode = "None" />
</binding>
</wsHttpBinding>
</bindings>
<services>
<service name = "MyServices.CalculatorService">
<endpoint address = " " binding = "customBinding" bindingConfiguration = "NetHttpBinding"
contract = "MyServices.ICalculator" />
</service>
</services>
最后,选择基本的 HTTP 绑定,而不是 WS 兼容的。后者的消息格式更加冗长。
摘要
正如您在本章中所看到的,通过提高应用的 I/O 性能,您可以带来巨大的变化,并避免任何与计算相关的优化。本章内容:
- 研究了同步和异步 I/O 之间的区别。
- 探索了各种 I/O 完成通知机制。
- 给出了关于 I/O 的一般技巧,比如最小化内存缓冲区复制。
- 讨论了特定于文件 I/O 的优化。
- 检查了特定于套接字的优化。
- 展示了如何优化网络协议以充分利用可用的网络容量。
- 比较和基准测试了内置于。NET 框架。
- 涵盖 WCF 优化。
八、不安全代码和互操作性
很少有真实世界的应用是严格由托管代码组成的。取而代之的是,他们经常使用内部的或者第三方的用本地代码实现的 ?? 库。那个。NET 框架提供了多种机制来与本地代码进行互操作,这些本地代码是通过多种广泛使用的技术 实现的:
- P/Invoke:支持与导出 C 风格函数的 dll 的互操作性。
- COM Interop:允许托管代码使用 COM 对象以及公开。NET 类作为供本机代码使用的 COM 对象。
- C++/CLI 语言:通过混合编程语言实现与 C 和 C++的互操作性。
事实上,基础类库(BCL)是。NET 框架(mscorlib.dll 是主要的)包含。NET Framework 的内置类型使用所有上述机制。因此,可以说,任何重要的托管应用实际上都是一个混合应用,在某种意义上,它调用本机库。
虽然这些机制非常有用,但是理解与每个互操作机制相关的性能含义以及如何最小化它们的影响是很重要的。
不安全代码
托管代码提供了类型安全、内存安全和安全保证,从而消除了本机代码中普遍存在的一些最难诊断的错误和安全漏洞,如堆损坏和缓冲区溢出。通过禁止使用指针直接访问内存,转而使用强类型引用,检查数组访问边界,并确保只对对象进行合法的强制转换,就可以做到这一点。
但是,在某些情况下,这些约束可能会使原本简单的任务变得复杂,并通过迫使您使用安全的替代方法来降低性能。例如,一个人可能将数据从一个文件读入一个 byte[]中,但希望将该数据解释为一个双精度值数组。在 C/C++中,您可以简单地将 char 指针转换为 double 指针。相比之下在保险箱里。NET 代码中,可以用 MemoryStream 对象包装缓冲区,并在前者之上使用 BinaryReader 对象将每个内存位置作为双精度值读取;另一种选择是使用 BitConverter 类。这些解决方案是可行的,但是它们比在非托管代码中实现要慢。幸运的是,C# 和 CLR 通过指针和指针转换支持不安全的内存访问。其他不安全的特性是堆栈内存分配和结构中的嵌入式数组。不安全代码的缺点是安全性受到损害,这可能导致内存损坏和安全漏洞,因此在编写不安全代码时应该非常小心。
要使用不安全代码,必须先在 C# 项目 设置中启用编译不安全代码(参见图 8-1 ),这导致将/unsafe 命令行参数传递给 C# 编译器。接下来,您应该标记允许不安全代码或不安全变量的区域,这可以是整个类或结构、整个方法或方法中的一个区域。

图 8-1 。在 C# 项目设置中启用不安全代码(Visual Studio 2012)
锁定和垃圾收集句柄
因为位于 GC 堆上的托管对象在不可预知的时间发生垃圾收集期间可能会被重新定位,所以您必须固定它们,以便获得它们的地址,并防止它们在内存中被四处移动。
锁定可以通过使用 C# 中的固定作用域(参见清单 8-1 中的例子)或者分配一个锁定 GC 句柄(参见清单 8-2 中的)来完成。 P/Invoke 存根,我们将在后面介绍,也以一种等同于 fixed 语句的方式固定对象。如果固定要求可以限制在函数的范围内,请使用 fixed,因为它比 GC 句柄方法更有效。否则,使用 GCHandle。Alloc 分配一个锁定句柄来无限期锁定一个对象(直到您通过调用 GC handle 显式释放 GC 句柄。免费)。堆栈对象(值类型)不需要固定,因为它们不受垃圾收集的影响。通过使用&符号(&)引用操作符,可以直接获得堆栈定位对象的指针。
清单 8-1。 使用固定范围和指针强制转换来重新解释缓冲区中的数据
using (var fs = new FileStream(@"C:\Dev\samples.dat", FileMode.Open)) {
var buffer = new byte[4096];
int bytesRead = fs.Read(buffer, 0, buffer.Length);
unsafe {
double sum = 0.0;
fixed (byte* pBuff = buffer) {
double* pDblBuff = (double*)pBuff;
for (int i = 0; i < bytesRead / sizeof(double); i++)
sum + = pDblBuff[i];
}
}
}
 注意从 fixed 语句中获得的指针一定不能在 fixed 作用域之外使用,因为当作用域结束时,被钉住的对象会被解除钉住。您可以在值类型数组、字符串和托管类的特定值类型字段上使用 fixed 关键字。请务必指定结构内存布局。
注意从 fixed 语句中获得的指针一定不能在 fixed 作用域之外使用,因为当作用域结束时,被钉住的对象会被解除钉住。您可以在值类型数组、字符串和托管类的特定值类型字段上使用 fixed 关键字。请务必指定结构内存布局。
GC 句柄是一种通过不可变的指针大小的句柄值(即使对象的地址发生变化)来引用驻留在 GC 堆上的托管对象的方法,该句柄值甚至可以由本机代码存储。GC 句柄有四种类型,由 GCHandleType 枚举指定:弱、WeakTrackRessurection、普通和固定。Normal 和 Pinned 类型防止对象被垃圾回收,即使没有对它的其他引用。Pinned 类型还会固定对象,并允许获取其内存地址。Weak 和 WeakTrackResurrection 不会阻止对象被回收,但是如果对象还没有被垃圾回收,则可以获得正常(强)引用。它由 WeakReference 类型使用。
清单 8-2。 使用锁定 GCHandle 进行锁定和指针转换来重新解释缓冲区中的数据
using (var fs = new FileStream(@"C:\Dev\samples.dat", FileMode.Open)) {
var buffer = new byte[4096];
int bytesRead = fs.Read(buffer, 0, buffer.Length);
GCHandle gch = GCHandle.Alloc(buffer, GCHandleType.Pinned);
unsafe {
double sum = 0.0;
double* pDblBuff = (double *)(void *)gch.AddrOfPinnedObject();
for (int i = 0; i < bytesRead / sizeof(double); i++)
sum + = pDblBuff[i];
gch.Free();
}
}
 警告如果触发了垃圾收集(即使是由另一个并发运行的线程触发),钉住可能会导致托管堆碎片。碎片浪费内存并降低垃圾收集器算法的效率。为了最大限度地减少碎片,不要将对象固定得过长。
警告如果触发了垃圾收集(即使是由另一个并发运行的线程触发),钉住可能会导致托管堆碎片。碎片浪费内存并降低垃圾收集器算法的效率。为了最大限度地减少碎片,不要将对象固定得过长。
生命周期管理
在许多情况下,本机代码在函数调用中继续持有非托管资源,并且需要显式调用来释放资源。如果是这种情况,除了终结器之外,还要在包装托管类中实现 IDisposable 接口。这将使客户端能够确定性地释放非托管资源,而终结器应该是在您忘记显式释放时的最后一道安全屏障。
分配非托管内存
占用超过 85,000 字节的托管对象(通常是字节缓冲区和字符串)被放在大对象堆(LOH)上,它与 GC 堆的 Gen2 一起被垃圾收集,这是非常昂贵的。LOH 也经常变得支离破碎,因为它从未被压缩;如果可能的话,相当自由的空间被重新使用。这两个问题都会增加垃圾收集器对内存和 CPU 的使用。因此,使用托管内存池或从非托管内存中分配这些缓冲区(例如,通过调用 Marshal)会更有效。AllocHGlobal)。如果以后需要从托管代码中访问非托管缓冲区,请使用“流”方法,即将非托管缓冲区的小块复制到托管内存中,一次处理一个块。你可以使用系统。UnmanagedMemoryStream 和 System。UnmanagedMemoryAccessor 使工作更容易。
内存池
如果您大量使用缓冲区与本机代码通信,您可以从 GC 堆或从非托管堆分配它们。对于高分配率和缓冲区不是很小的情况,前一种方法变得低效。需要固定托管缓冲区,这会导致碎片。后一种方法也有问题,因为大多数托管代码希望缓冲区是托管字节数组(byte[])而不是指针。如果不复制,就不能将指针转换为托管数组,但这对性能不利。
 提示你可以在 GC 下的性能计数器中查找% Time。NET CLR 内存性能计数器类别来估计被 GC“浪费”的 CPU 时间,但是这并不能告诉您是什么代码造成的。在投入优化工作之前,使用一个分析器(参见第二章),并参见第四章以获得更多关于垃圾收集性能的提示。
提示你可以在 GC 下的性能计数器中查找% Time。NET CLR 内存性能计数器类别来估计被 GC“浪费”的 CPU 时间,但是这并不能告诉您是什么代码造成的。在投入优化工作之前,使用一个分析器(参见第二章),并参见第四章以获得更多关于垃圾收集性能的提示。
我们提出了一个解决方案(见图 8-2 ),它提供了从托管和非托管代码的免复制访问,并且不会给 GC 带来压力。其思想是分配位于大型对象堆上的大型托管内存缓冲区(段)。固定这些段不会带来任何损失,因为它们已经是不可重定位的了。
一个简单的分配器,其中一个段的分配指针(实际上是一个索引)在每次分配时只向前移动,然后分配不同大小的缓冲区(直到段大小),并返回这些缓冲区周围的包装器对象。一旦指针接近末尾,分配失败,就从段池中获得一个新的段,并再次尝试分配。
段有一个引用计数,该计数在每次分配时递增,在包装对象被释放时递减。一旦它的引用计数达到零,就可以通过将指针设置为零来重置它,并且可以选择用零填充存储器,然后将其返回到段池。
包装对象存储段的 byte[]、数据开始的偏移量、长度和一个非托管指针。实际上,包装器是进入段的大缓冲区的窗口。它还将引用该段,以便在包装被释放后减少段使用计数。包装器可以提供方便的方法,例如安全的索引器访问,它考虑了偏移量并验证访问是否在界限内。
自从。NET 开发人员习惯于假设缓冲区数据总是从索引 0 开始,并持续整个数组长度,您将需要修改代码,而不是假设,而是依赖于将与缓冲区一起传递的附加偏移量和长度参数。大多数。使用缓冲区的. NET BCL 方法具有显式接受偏移量和长度的重载。
这种方法的主要缺点是失去了自动内存管理。为了回收段,您必须显式地释放包装对象。实现终结器不是一个好的解决方案,因为这将抵消更多的性能优势。

图 8-2 。提出内存池方案
p/调用
平台调用,更好的说法是 P/Invoke ,支持调用 C 风格的函数,这些函数由 dll 从托管代码中导出。要使用 P/Invoke,托管调用方声明一个静态 extern 方法,其签名(参数类型和返回值类型)等同于 C 函数的签名。然后用 DllImport 属性标记该方法,同时至少指定导出该函数的 DLL。
// Native declaration from WinBase.h:
HMODULE WINAPI LoadLibraryW(LPCWSTR lpLibFileName);
// C# declaration:
class MyInteropFunctions {
[DllImport("kernel32.dll", SetLastError = true)]
public static extern IntPtr LoadLibrary(string fileName);
}
在前面的代码中,我们将 LoadLibrary 定义为一个函数,它接受一个字符串并返回一个 IntPtr ,这是一个不能直接取消引用的指针类型,因此使用它不会导致代码不安全。DllImport 属性指定该函数由 kernel32.dll(它是主 Win32 API DLL)导出,并且 Win32 上一个错误代码应保存在线程本地存储中,以便不会被未显式完成的对 Win32 函数的调用覆盖(例如,在 CLR 内部)。DllImport 属性 也可以用来指定 C 函数的调用约定、字符串编码、导出名称解析选项等。
如果本机函数的签名包含复杂类型,如 C 结构,则等效的结构或类必须由托管代码定义,对每个字段使用等效的类型。相对结构字段顺序、字段类型和对齐方式必须符合 C 代码的要求。在某些情况下,您需要对字段、函数参数或返回值应用 MarshalAs 属性来修改默认的封送处理行为。例如,受管系统。布尔(bool)类型在本机代码中可以有多种表示形式:Win32 BOOL 类型有四个字节长,true 值是任何非零值,而在 C++中,BOOL 值有一个字节长,true 值等于 1。
在下面的代码清单中,应用于 WIN32 _ FIND _ DATAstruct 的 StructLayout 属性指定需要一个连续的内存中字段布局。没有它,CLR 可以自由地重新排列字段以提高效率。应用于 cFileName 和 cAlternativeFileName 字段的 MarshalAs 属性指定字符串应该作为嵌入在结构中的固定大小的字符串进行封送,而不仅仅是指向结构外部的字符串的指针。
// Native declaration from WinBase.h:
typedef struct _WIN32_FIND_DATAW {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
WCHAR cFileName[MAX_PATH];
WCHAR cAlternateFileName[14];
} WIN32_FIND_DATAW;
HANDLE WINAPI FindFirstFileW(__in LPCWSTR lpFileName,
__out LPWIN32_FIND_DATAW lpFindFileData);
// C# declaration:
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
struct WIN32_FIND_DATA {
public uint dwFileAttributes;
public FILETIME ftCreationTime;
public FILETIME ftLastAccessTime;
public FILETIME ftLastWriteTime;
public uint nFileSizeHigh;
public uint nFileSizeLow;
public uint dwReserved0;
public uint dwReserved1;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 260)]
public string cFileName;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 14)]
public string cAlternateFileName;
}
[DllImport("kernel32.dll", CharSet = CharSet.Auto)]
static extern IntPtr FindFirstFile(string lpFileName, out WIN32_FIND_DATA lpFindFileData);
当您在前面的代码清单中调用 FindFirstFile 方法 时,CLR 会加载导出函数的 DLL(kernel 32 . DLL),定位所需的函数(FindFirstFile),并将参数类型从其托管表示形式转换为本机表示形式(反之亦然)。在此示例中,输入 lpFileName 字符串参数被转换为本机字符串,而对 lpFindFileData 参数所指向的 WIN32_FIND_DATAW 本机结构的写入被转换为对托管 WIN32_FIND_DATA 结构的写入。在下面的章节中,我们将详细描述每个阶段。
PInvoke.net 和 P/调用互操作助手
创建 P/Invoke 签名可能既困难又乏味。有很多规则要遵守,有很多细微差别要知道。产生不正确的签名会导致难以诊断的错误。幸运的是,有两个资源可以使这变得更容易:PInvoke.net 网站和 P/Invoke Interop Assistant 工具。
PInvoke.net 是一个非常有用的维基风格的网站,在那里你可以找到并贡献各种微软 API 的 P/Invoke 签名。PInvoke.net 是由亚当·内森创造的,他是微软的高级软件开发工程师,曾在。NET CLR 质量保证小组,并撰写了大量关于 COM 互操作性的书籍。您还可以下载一个免费的 Visual Studio 加载项,以便在不离开 Visual Studio 的情况下访问 P/Invoke 签名。
P/Invoke Interop Assistant 是微软的一个免费工具,可从 CodePlex 下载,并附带源代码。它包含一个数据库(一个 XML 文件),描述用于生成 P/Invoke 签名的 Win32 函数、结构和常数。给定 C 函数声明,它还可以生成 P/Invoke 签名;给定托管程序集,它还可以生成本机回调函数声明和本机 COM 接口签名。

图 8-3 。显示 CreateFile 的 P/Invoke 签名的 P/Invoke 互操作实例的屏幕截图
图 8-3 显示了微软的 P/Invole Interop Assistant 工具,在左侧显示了“CreateFile”的搜索结果,P/Invoke 签名以及相关的结构显示在右侧。P/Invoke Interop Assistant 工具(以及其他有用的 CLR interop 相关工具)可以从 http://clrinterop.codeplex.com/获得。
装订
当您第一次调用 P/Invoke 函数时,本机 DLL 及其依赖项通过 Win32 LoadLibrary 函数加载到进程中(如果它们尚未加载)。接下来,搜索所需的导出函数,可能首先搜索损坏的变量。搜索行为取决于 DllImport 的 CharSet 和 ExactSpelling 字段的值。
-
如果 ExactSpelling 为 true,P/Invoke 只搜索具有确切名称的函数,只考虑调用约定混乱。如果失败,P/Invoke 将不会继续搜索其他名称变体,并将抛出 EntryPointNotFoundException。
-
如果 ExactSpelling 为 false,则行为由 CharSet 属性决定:
-
如果设置为字符集。Ansi(默认),P/Invoke 首先搜索精确的(未混淆的)名称,然后搜索被破坏的名称(附加“A”)。
-
如果设置为字符集。Unicode,P/Invoke 首先搜索损坏的名称(附加“W”),然后搜索非托管名称。
对于 C# 来说,ExactSpelling 的默认值是 false,对于 value 来说是 True。字符集。Auto value 的行为类似于 CharSet。任何现代操作系统(比 Windows ME 更晚)上的 Unicode。
 提示使用 Unicode 版本的 Win32 函数。Windows NT 和更高版本本身是 Unicode (UTF16)。如果调用 ANSI 版本的 Win32 函数,字符串将被转换为 Unicode,这会导致性能下降,并且调用 Unicode 版本的函数。那个。NET 字符串表示形式本身也是 UTF16,因此如果字符串参数已经是 UTF16,则封送字符串参数会更快。设计您的代码,尤其是接口要与 Unicode 兼容,这也有全球化的好处。将 ExactSpelling 设置为 true,这将通过消除不必要的函数搜索来加快初始加载时间。
提示使用 Unicode 版本的 Win32 函数。Windows NT 和更高版本本身是 Unicode (UTF16)。如果调用 ANSI 版本的 Win32 函数,字符串将被转换为 Unicode,这会导致性能下降,并且调用 Unicode 版本的函数。那个。NET 字符串表示形式本身也是 UTF16,因此如果字符串参数已经是 UTF16,则封送字符串参数会更快。设计您的代码,尤其是接口要与 Unicode 兼容,这也有全球化的好处。将 ExactSpelling 设置为 true,这将通过消除不必要的函数搜索来加快初始加载时间。
编组员存根
当您第一次调用 P/Invoke’d 函数时,在加载本机 DLL 之后,将根据需要生成 P/Invoke 封送拆收器存根,并将在后续调用中重用。一旦被调用,编组器执行以下步骤:
- 检查调用方的非托管代码执行权限。
- 将托管参数转换为其适当的本机内存表示形式,可能会分配内存。
- 将线程的垃圾收集模式设置为先发制人,这样垃圾收集无需等待线程到达安全点即可发生。
- 调用本机函数。
- 将线程 GC 模式恢复为合作模式。
- 可以选择将 Win32 错误代码保存在线程本地存储中,供 Marshal.GetLastWin32Error 以后检索。
- 可以选择将 HRESULT 转换为异常并引发它。
- 如果引发到托管异常,则转换本机异常。
- 将返回值和输出参数转换回它们的托管内存表示形式。
- 清理所有临时分配的内存。
P/Invoke 也可以用来从本机代码调用托管代码。可以为委托生成反向封送拆收器存根(通过封送。GetFunctionPointerForDelegate),如果它作为参数在对本机函数的 P/Invoke 调用中传递。本机函数将接收一个代替委托的函数指针,它可以调用该指针来调用托管方法。函数指针指向一个动态生成的存根,除了参数封送,它还知道目标对象的地址(这个指针)。
英寸 NET Framework 1.x 中,封送拆收器存根由生成的汇编代码(用于简单签名)或生成的 ML(封送处理语言)代码(用于复杂签名)组成。ML 是内部字节码,由内部解释器执行。随着中 AMD64 和安腾支持的引入。NET Framework 2.0 之后,微软意识到为每个 CPU 架构实现并行 ML 基础设施将是一个巨大的负担。相反,64 位版本的。NET Framework 2.0 专门在生成的 IL 代码中实现。虽然 IL 存根比解释的 ML 存根快得多,但它们仍然比 x86 生成的程序集存根慢,所以微软选择保留 x86 实现。英寸 NET Framework 4.0 中,IL 存根生成基础结构得到了显著优化,这使得 IL 存根甚至比 x86 程序集存根更快。这允许微软完全移除 x86 特定的存根实现,并在所有架构上统一存根生成。
 提示跨越托管到本机边界的函数调用至少比相同环境中的直接调用慢一个数量级。如果您同时控制本机代码和托管代码,则以最小化本机代码到托管代码的往返行程的方式构造接口(聊天式接口)。尝试将几个“工作项目”合并成一个呼叫(分块接口)。类似地,将几个简单函数的调用(例如简单的 Get/Set 函数)组合成一个外观,在一个调用中完成相同的工作。
提示跨越托管到本机边界的函数调用至少比相同环境中的直接调用慢一个数量级。如果您同时控制本机代码和托管代码,则以最小化本机代码到托管代码的往返行程的方式构造接口(聊天式接口)。尝试将几个“工作项目”合并成一个呼叫(分块接口)。类似地,将几个简单函数的调用(例如简单的 Get/Set 函数)组合成一个外观,在一个调用中完成相同的工作。
微软从 CodePlex 提供了一个名为 IL Stub Diagnostics 的免费下载工具以及源代码。它订阅 CLR ETW IL 存根生成/缓存命中事件,并在 UI 中显示生成的 IL 存根代码。
下面我们展示一个带注释的示例 IL 封送处理存根,由五个代码部分组成:初始化、输入参数的封送处理、调用、返回值和/或输出参数的封送处理以及清理。封送拆收器存根用于以下签名:
// Managed signature:
[DllImport("Server.dll")]static extern int Marshal_String_In(string s);
// Native Signature:
unmanaged int __stdcall Marshal_String_In(char *s)
在初始化部分,存根声明局部(堆栈)变量,获取存根上下文并要求非托管代码执行权限。
// IL Stub:
// Code size 153 (0x0099)
.maxstack 3
// Local variables are:
// IsSuccessful, pNativeStrPtr, SizeInBytes, pStackAllocPtr, result, result, result
.locals (int32,native int,int32,native int,int32,int32,int32)
call native int [mscorlib] System.StubHelpers.StubHelpers::GetStubContext()
// Demand unmanaged code execution permissioncall void [mscorlib] System.StubHelpers.StubHelpers::DemandPermission(native int)
在封送处理部分,存根封送处理输入参数本机函数。在这个例子中,我们封送一个字符串输入参数。封送拆收器可以调用系统下的帮助器类型。StubHelpersnamespace 或系统。帮助将特定类型和类型类别从托管表示形式转换到本机表示形式以及从本机表示形式转换回来的类。在本例中,我们调用 CSTRMarshaler::convert native 来封送字符串。
这里有一个小小的优化:如果托管字符串足够短,它将被封送到堆栈上分配给的内存中(这样更快)。否则,必须从堆中分配内存。
ldc.i4 0x0 // IsSuccessful = 0 [push 0 to stack]
stloc.0 // [store to IsSuccessful]
IL_0010:
nop // argument {
ldc.i4 0x0 // pNativeStrPtr = null [push 0 to stack]
conv.i // [convert to an int32 to "native int" (pointer)]
stloc.3 // [store result to pNativeStrPtr]
ldarg.0 // if (managedString == null)
brfalse IL_0042 // goto IL_0042
ldarg.0 // [push managedString instance to stack]
// call the get Length property (returns num of chars)
call instance int32 [mscorlib] System.String::get_Length()
ldc.i4 0x2 // Add 2 to length, one for null char in managedString and
// one for an extra null we put in [push constant 2 to stack]
add // [actual add, result pushed to stack]
// load static field, value depends on lang. for non-Unicode
// apps system setting
ldsfld System.Runtime.InteropServices.Marshal::SystemMaxDBCSCharSize
mul // Multiply length by SystemMaxDBCSCharSize to get amount of
// bytes
stloc.2 // Store to SizeInBytes
ldc.i4 0x105 // Compare SizeInBytes to 0x105, to avoid allocating too much
// stack memory [push constant 0x105]
// CSTRMarshaler::ConvertToNative will handle the case of
// pStackAllocPtr == null and will do a CoTaskMemAlloc of the
// greater size
ldloc.2 // [Push SizeInBytes]
clt // [If SizeInBytes > 0x105, push 1 else push 0]
brtrue IL_0042 // [If 1 goto IL_0042]
ldloc.2 // Push SizeInBytes (argument of localloc)
localloc // Do stack allocation, result pointer is on top of stack
stloc.3 // Save to pStackAllocPtr
IL_0042:
ldc.i4 0x1 // Push constant 1 (flags parameter)
ldarg.0 // Push managedString argument
ldloc.3 // Push pStackAllocPtr (this can be null)
// Call helper to convert to Unicode to ANSI
call native int [mscorlib]System.StubHelpers.CSTRMarshaler::ConvertToNative(int32,string, native int)
stloc.1 // Store result in pNativeStrPtr,
// can be equal to pStackAllocPtr
ldc.i4 0x1 // IsSuccessful = 1 [push 1 to stack]
stloc.0 // [store to IsSuccessful]
nop
nop
nop
在下一节中,存根从存根上下文获得本机函数指针并调用它。call 指令实际上做了比我们在这里看到的更多的工作,例如改变 GC 模式和捕捉本机函数的返回,以便在 GC 正在进行并且处于需要暂停托管代码执行的阶段时暂停托管代码的执行。
ldloc.1 // Push pStackAllocPtr to stack,
// for the user function, not for GetStubContext
call native int [mscorlib] System.StubHelpers.StubHelpers::GetStubContext()
ldc.i4 0x14 // Add 0x14 to context ptr
add // [actual add, result is on stack]
ldind.i // [deref ptr, result is on stack]
ldind.i // [deref function ptr, result is on stack]
calli unmanaged stdcall int32(native int) // Call user function
下面的部分实际上由两部分组成,分别处理返回值和输出参数的“解组”(本机类型到托管类型的转换)。在本例中,本机函数返回一个不需要封送处理的 int,它只是按原样复制到一个局部变量。由于没有输出参数,后一部分是空的。
// UnmarshalReturn {
nop // return {
stloc.s 0x5 // Store user function result (int) into x, y and z
ldloc.s 0x5
stloc.s 0x4
ldloc.s 0x4
nop // } return
stloc.s 0x6
// } UnmarshalReturn
// Unmarshal {
nop // argument {
nop // } argument
leave IL_007e // Exit try protected block
IL_007e:
ldloc.s 0x6 // Push z
ret // Return z
// } Unmarshal
最后,清理部分释放为了封送而临时分配的内存。它在 finally 块中执行清理,这样即使本机函数抛出异常,清理也会发生。它也可能只在出现异常的情况下执行一些清理。在 COM interop 中,它可以将指示错误的 HRESULT 返回值转换为异常。
// ExceptionCleanup {
IL_0081:
// } ExceptionCleanup
// Cleanup {
ldloc.0 // If (IsSuccessful && !pStackAllocPtr)
ldc.i4 0x0 // Call ClearNative(pNativeStrPtr)
ble IL_0098
ldloc.3
brtrue IL_0098
ldloc.1
call void [mscorlib] System.StubHelpers.CSTRMarshaler::ClearNative(native int)
IL_0098:
endfinally
IL_0099:
// } Cleanup
.try IL_0010 to IL_007e finally handler IL_0081 to IL_0099
总之,即使对于这个简单的函数签名,IL 封送拆收器存根也不是简单的。复杂的签名会导致更长更慢的 IL 封送拆收器存根。
可直接复制到本机结构中的类型
大多数本机类型与托管代码共享一个公共的内存表示形式。这些类型称为可直接复制到本机结构中的类型,不需要转换,并且按原样跨托管到本机的边界传递,这比封送非可直接复制到本机结构中的类型要快得多。事实上,封送拆收器存根可以通过固定托管对象并将指向托管对象的直接指针传递给本机代码来进一步优化这种情况,从而避免一两次内存复制操作(每个所需的封送方向一次)。
可直接复制到本机结构中的类型是下列类型之一:
- 系统。字节(字节)
- 系统。SByte
- 系统。Int16(短)
- 系统。UInt16 (ushort)
- 系统。Int32(整数)
- 系统。UInt32 (uint)
- -系统。Int64(长)
- 系统。UInt64 (ulong)
- 系统。句柄
- System.UIntPtr
- 系统。单一(浮动)
- 系统。双倍(双倍)
此外,可直接复制到本机结构中的类型的一维数组(其中所有元素的类型都相同)也是可直接复制到本机结构中的,只包含可直接复制到本机结构中的字段的结构或类也是如此。
一个系统。Boolean (bool)不是 blittable,因为它在本机代码(系统)中可以有 1、2 或 4 个字节的表示形式。Char (char)不是 blittable,因为它可以表示 ANSI 或 Unicode 字符和系统。String(字符串)不是 blittable,因为它的本机表示可以是 ANSI 或 Unicode,它可以是 C 风格的字符串或 COM BSTR,并且托管字符串需要是不可变的(如果本机代码修改了字符串,这是有风险的,会破坏不变性)。包含对象引用字段的类型不是可直接复制到本机结构中的,即使它是对可直接复制到本机结构中的类型或其数组的引用。封送非直接复制到本机结构中的类型包括分配内存来保存参数的转换版本,适当地填充它,最后释放以前分配的内存。
通过手动封送字符串输入参数,可以获得更好的性能(有关示例,请参见下面的代码)。本机被调用方必须接受一个 C 样式的 UTF-16 字符串,并且它不应该写入该字符串所占用的内存,因此这种优化并不总是可行的。手动封送处理包括固定输入字符串,修改 P/Invoke 签名以采用 IntPtr 而不是字符串,并传递一个指向固定字符串对象的指针。
class Win32Interop {
[DllImport("NativeDLL.DLL", CallingConvention = CallingConvention.Cdecl)]
public static extern void NativeFunc(IntPtr pStr); // takes IntPtr instead of string
*}*
//Managed caller calls the P/Invoke function inside a fixed scope which does string pinning:
unsafe
{
string str = "MyString";
fixed (char *pStr = str) {
//You can reuse pStr for multiple calls.
Win32Interop.NativeFunc((IntPtr)pStr);
}
}
将本机 C 样式的 UTF-16 字符串转换为托管字符串也可以通过使用 System。String 的构造函数以 char*作为参数。系统。字符串构造函数将制作缓冲区的副本,以便在创建托管字符串后可以释放本机指针。请注意,没有进行任何验证来确保字符串只包含有效的 Unicode 字符。
封送方向、值和引用类型
如前所述,封送拆收器存根可以单向或双向封送函数参数。参数的封送方向由许多因素决定:
- 参数是值类型还是引用类型。
- 参数是通过值传递还是通过引用传递。
- 该类型是否可直接复制到本机结构中。
- 是否封送方向修改属性(系统。属性和系统。RuntimeInteropService . out attribute)应用于该参数。
出于讨论的目的,我们将“in”方向定义为托管到本机封送方向;相反,“向外”方向是管理方向的原生方向。下面是默认封送方向规则的列表:
-
通过值传递的参数,不管它们是值类型还是引用类型,都只按“入”的方向进行封送。
-
您不需要手动应用 In 属性。
-
StringBuilder 是这个规则的一个例外,它总是被“in/out”封送。
-
通过引用传递的参数(通过 ref C# 关键字或 ByRef VB。NET 关键字),不管它们是值类型还是引用类型,都被“入/出”封送。
单独指定 OutAttribute 将禁止“in”封送,因此本机被调用方可能看不到调用方完成的初始化。C# out 关键字的行为类似于 ref 关键字,但增加了一个 OutAttribute。
 提示如果参数在 P/Invoke 调用中不可直接复制到本机结构中,并且您只需要在“out”方向上封送,那么您可以通过使用 out C# 关键字而不是 ref 关键字来避免不必要的封送。
提示如果参数在 P/Invoke 调用中不可直接复制到本机结构中,并且您只需要在“out”方向上封送,那么您可以通过使用 out C# 关键字而不是 ref 关键字来避免不必要的封送。
由于上面提到的可直接复制到本机结构中的参数固定优化,可直接复制到本机结构中的引用类型将获得有效的“入/出”封送,即使上面的规则另有说明。如果您需要“out”或“in/out”封送处理行为,则不应该依赖于此行为,而是应该显式指定方向属性,因为如果您稍后添加了一个非直接复制到本机结构中的字段,或者这是一个跨越单元边界的 COM 调用,则此优化将停止工作。
封送值类型和引用类型之间的差异体现在它们在堆栈上的传递方式上。
- 由值传递的值类型作为副本被推送到堆栈上,因此不管修改属性如何,它们总是被有效地封送到“in”中。
- 通过引用传递的值类型和通过值传递的引用类型通过指针传递。
- 通过引用传递的引用类型作为指针传递给指针。
 注意通过值传递大的值类型参数(十几个字节长)比通过引用传递开销更大。对于大的返回值也是如此,其中 out 参数是一种可能的选择。
注意通过值传递大的值类型参数(十几个字节长)比通过引用传递开销更大。对于大的返回值也是如此,其中 out 参数是一种可能的选择。
代码访问安全性
的。NET 代码访问安全 机制支持在沙箱中运行部分受信任的代码,对运行时功能(例如 P/Invoke)和 BCL 功能(例如文件和注册表访问)的访问受到限制。调用本机代码时,CAS 要求其方法出现在调用堆栈中的所有程序集都具有 UnmanagedCode 权限。封送拆收器存根将为每个调用要求此权限,这包括遍历调用堆栈以确保所有代码都具有此权限。
 提示如果您只运行完全受信任的代码,或者您有其他方法来确保安全性,您可以通过将 SuppressUnmanagedCodeSecurityAttribute 放在 P/Invoke 方法声明、类(在这种情况下,它适用于包含的方法)、接口或委托上来获得显著的性能提升。
提示如果您只运行完全受信任的代码,或者您有其他方法来确保安全性,您可以通过将 SuppressUnmanagedCodeSecurityAttribute 放在 P/Invoke 方法声明、类(在这种情况下,它适用于包含的方法)、接口或委托上来获得显著的性能提升。
COM 互操作性
COM 的设计目的就是用任何支持 COM 的语言/平台编写组件,并在任何(其他)支持 COM 的语言/平台上使用这些组件。。NET 也不例外,它允许您轻松地使用 COM 对象并公开。NET 类型作为 COM 对象。
对于 COM interop,基本思想与 P/Invoke 相同:声明 COM 对象的托管表示,CLR 创建处理封送处理的包装对象。有两种包装器:运行时可调用包装器(RCW ) ,使托管代码能够使用 COM 对象(参见图 8-4 ),以及 COM 可调用包装器(CCW) ,使 COM 代码能够调用托管类型(参见图 8-5 )。第三方 COM 组件通常附带一个主互操作程序集,该程序集包含供应商批准的互操作定义,并且具有强名称(签名)并安装在 GAC 中。其他时候,您可以使用 tlbimp.exe 工具,它是 Windows SDK 的一部分,根据类型库中包含的信息自动生成互操作程序集。
COM interop 重用 P/Invoke 参数封送处理基础结构,但在默认情况下有一些更改(例如,默认情况下将字符串封送到 BSTR),因此本章 P/Invoke 部分提供的建议也适用于此处。
COM 有其自身的性能问题,这是由特定于 COM 的特性造成的,如单元线程模型和 COM 的引用计数特性与。NET 垃圾收集方法。
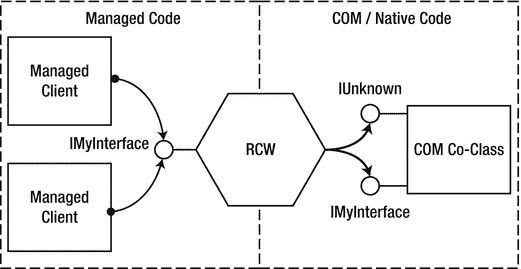
图 8-4 。托管客户端调用非托管 COM 对象
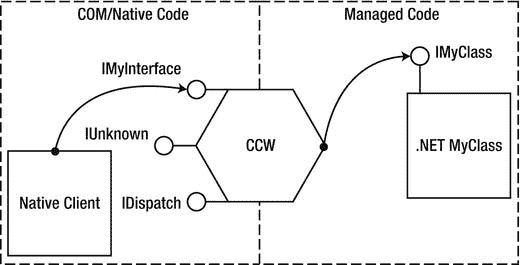
图 8-5 。非托管客户端调用托管 COM 对象
生命周期管理
中保存对 COM 对象的引用时。NET,您实际上持有对 RCW 的引用。RCW 总是保存对基础 COM 对象的单个引用,并且每个 COM 对象只有一个 RCW 实例。RCW 维护自己的引用计数,与 COM 引用计数分开。该引用计数的值通常为 1,但是如果已经封送了多个接口指针,或者如果同一接口已经被多个线程封送,则该值可以更大。
通常,当对 RCW 的最后一个托管引用消失,并且在 RCW 驻留的代上有后续的垃圾收集时;RCW 的终结器运行,并通过调用 COM 基础对象的 IUnknown 接口指针上的释演法来减少 COM 对象的引用计数(为 1)。COM 对象随后自我销毁并释放其内存。
自从。NET GC 在不确定的时间运行,并且不知道由它保持 rcw 和随后的 COM 对象活动所引起的非托管内存负担,它不会加速垃圾回收,并且内存使用率可能会变得非常高。
如果有必要,你可以打电话给法警。方法显式释放对象。每次调用都会减少 RCW 的引用计数,当它达到零时,底层 COM 对象的引用计数也会减少(就像 RCW 的终结器正在运行的情况一样),从而释放它。您必须确保在调用 Marshal.ReleaseComObject 后不继续使用 RCW。如果 RCW 引用计数大于零,您将需要调用 Marshal。循环中的 ReleaseComObject,直到返回值等于零。最佳做法是调用 Marshal。finally 块中的 ReleaseComObject,以确保即使在 COM 对象的实例化和释放之间的某个地方引发了异常,也会发生释放。
公寓编组
COM 实现了自己的线程同步机制来管理跨线程调用,甚至是针对不是为多线程设计的对象。如果没有意识到这些机制,它们会降低性能。虽然这个问题不是与的互操作性所特有的。尽管如此,它仍然值得讨论,因为这是一个常见的陷阱,可能是因为开发人员习惯了典型的。NET 线程同步约定可能不知道 COM 在幕后做什么。
COM 分配对象和线程单元 ,它们是 COM 调度调用的边界。COM 有几种公寓类型:
- 单线程单元(STA) ,每个单元都托管一个线程,但是可以托管任意数量的对象。一个流程中可以有任意数量的 STA 单元。
- 多线程单元(MTA) ,托管任意数量的线程和任意数量的对象,但是在一个进程中只有一个 MTA 单元。这是的默认设置。网螺纹。
- 中性线程单元(NTA) ,托管对象而不是线程。只有一个 NTA 公寓在处理中。
当调用 CoInitialize 或 CoInitializeEx 来初始化线程的 COM 时,该线程被分配给一个单元。调用 CoInitialize 会将线程分配给一个新的 STA 单元,而 CoInitializeEx 允许您指定 STA 或 MTA 分配。英寸 NET 中,不直接调用这些函数,而是用 STAThread 或 MTAThread 属性标记线程的入口点(或 Main)。或者,您可以调用 Thread。SetApartmentState 方法或线程。线程启动前的 ApartmentState 属性。如果没有特别说明,。NET 将线程(包括主线程)初始化为 MTA。
COM 对象根据 ThreadingModel 注册表值分配给单元,该值可以是:
- 单一对象驻留在默认 STA 中。
- 单元(STA)-对象必须驻留在任何 STA 中,并且只允许该 STA 的线程直接调用该对象。不同的实例可以驻留在不同的 STA 中。
- 自由(MTA)-对象位于 MTA。任何数量的 MTA 线程都可以直接并发地调用它。对象必须确保线程安全。
- 两者——对象位于创建者的公寓(STA 或 MTA)。本质上,它一旦被创造出来,就变成类似 STA 或类似 MTA 的物体。
- neutral–对象驻留在中性单元中,从不需要封送。这是最有效的模式。
关于单元、线程和对象的可视化表示,参见图 8-6 。
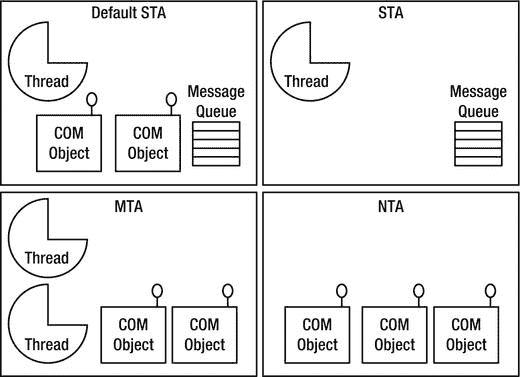
图 8-6 。进程划分成 COM 单元
如果你创建一个对象,它的线程模型与创建者线程单元的线程模型不兼容,你将收到一个接口指针,它实际上指向一个代理。如果需要将 COM 对象的接口传递给属于不同单元的不同线程,则不应直接传递接口指针,而是需要封送处理。COM 将根据需要返回一个代理对象。
封送处理包括将函数调用(包括参数)转换成消息,该消息将被发送到接收方 STA 单元的消息队列。对于 STA 对象,这被实现为一个隐藏窗口,其窗口过程接收消息并通过存根将调用发送到 COM 对象。这样,STA COM 对象总是由同一个线程调用,这显然是线程安全的。
当调用者的单元与 COM 对象的单元不兼容时,会发生线程切换和跨线程参数封送处理。
 提示通过将 COM 对象的单元与创建线程的单元相匹配来避免线程间的性能损失。在 STA 线程上创建和使用单元线程(STA) COM 对象,在 MTA 线程上创建和使用自由线程 COM 对象。标记为支持这两种模式的 COM 对象可以在任一线程中使用,而不会受到影响。
提示通过将 COM 对象的单元与创建线程的单元相匹配来避免线程间的性能损失。在 STA 线程上创建和使用单元线程(STA) COM 对象,在 MTA 线程上创建和使用自由线程 COM 对象。标记为支持这两种模式的 COM 对象可以在任一线程中使用,而不会受到影响。
从 ASP.NET 调用 STA 对象
默认情况下,ASP.NET 在 MTA 线程上执行页面。如果您调用 STA 对象,它们将经历封送处理。如果您主要调用 STA 对象,这将降低性能。您可以通过用 ASPCOMPAT 属性标记页面来解决这个问题,如下所示:
<%@Page Language = “vb” AspCompat = “true” %>
请注意,页面构造函数仍然在 MTA 线程中执行,因此将 STA 对象的创建推迟到 Page_Load 和 Page_Init 事件。
TLB 导入和代码访问安全性
代码访问安全性执行与 P/Invoke 中相同的安全检查。您可以将/unsafe 开关与 tlbimp.exe 实用工具一起使用,该实用工具将对生成的类型发出 SuppressUnmanagedCodeSecurity 属性。仅在完全信任的环境中使用此选项,因为这可能会带来安全问题。
诺比
之前。在. NET Framework 4.0 中,您不得不将互操作程序集或主互操作程序集(PIA)与您的应用或外接程序一起分发。这些程序集往往很大(与使用它们的代码相比更是如此),并且它们通常不是由 COM 组件的供应商安装的;相反,它们是作为可再发行的软件包安装的,因为 COM 组件本身的操作并不需要它们。不安装 pia 的另一个原因是,它们必须安装在 GAC 中,这使得. NET Framework 依赖于完全本机应用的安装程序。
从……开始。NET Framework 4.0 中,C# 和 VB.NET 编译器可以检查哪些 COM 接口和其中的哪些方法是必需的,并且可以仅将必需的接口定义复制和嵌入到调用程序集中,从而消除了分发 PIA DLLs 的需要并减小了代码大小。微软将这一功能称为 NoPIA。它对主互操作程序集和一般的互操作程序集都有效。
PIA 程序集有一个重要的特性,叫做类型等价。由于它们有一个强名称并被放入 GAC,不同的托管组件可以交换 rcw,并从。从. NET 的角度来看,它们应该有等价的类型。相比之下,由 tlbimp.exe 生成的互操作程序集没有此功能,因为每个组件都有自己独特的互操作程序集。对于 NoPIA,因为没有使用强名称程序集,所以 Microsoft 提出了一个解决方案,只要接口具有相同的 GUID,就将来自不同程序集的 rcw 视为相同的类型。
要启用 NoPIA,选择引用下的互操作程序集的属性,并将“嵌入互操作类型”设置为真(参见图 8-7 )。
图 8-7 。在互操作程序集引用属性中启用 NoPIA
例外情况
大多数 COM 接口方法通过 HRESULT 返回值报告成功或失败。负的 HRESULT 值(设置了最高有效位)表示失败,而零(S_OK)或正值表示成功。此外,通过调用 SetErrorInfo 函数,传递通过调用 CreateErrorInfo 创建的 IErrorInfo 对象,COM 对象可以提供更丰富的错误信息。当通过 COM interop 调用 COM 方法时,封送拆收器存根根据 HRESULT 值和 IErrorInfo 对象中包含的数据将 HRESULT 转换为托管异常。由于引发异常的代价相对较高,因此频繁失败的 COM 函数会对性能产生负面影响。可以通过用 PreserveSigAttribute 标记方法来禁止自动异常转换。您必须更改托管签名以返回一个 int,retval 参数将成为一个“out”参数。
C++/CLI 语言扩展
C++/CLI 是一组 C++语言扩展,支持创建混合托管和本机 dll。在 C++/CLI 中,即使在同一个中,也可以有托管和非托管类或函数。cpp 文件。您可以使用托管类型以及本机 C 和 C++类型,就像在普通 C++中一样,即通过包含一个头文件并链接到库。这些强大的功能可用于构造可从任何。NET 语言以及本机包装类和函数(公开为。dll,。lib 和。h 文件),这些文件可由本机 C/C++代码调用。
C++/CLI 中的封送处理是手动完成的,开发人员可以更好地控制封送处理,并且更清楚封送处理的性能损失。C++/CLI 可以成功用于 P/Invoke 无法应对的场景,比如可变长度结构的封送。C++/CLI 的另一个优势 是,即使您不控制被调用者的代码,您也可以通过重复调用本机方法来模拟粗块接口方法,而不必每次都跨越托管到本机的界限。
在下面的代码清单中,我们实现了一个本机 NativeEmployee 类和一个托管 Employee 类,包装了前者。只有后者可以从托管代码中访问。
如果查看清单,您会看到 Employee 的构造函数展示了两种托管到本机字符串转换的技术:一种是分配需要显式释放的 GlobalAlloc 内存 ,另一种是将托管字符串临时固定在内存中并返回一个直接指针。后一种方法速度更快,但只有在本机代码需要 UTF-16 空终止字符串的情况下才有效,并且您可以保证指针所指向的内存不会发生写操作。此外,长时间锁定被管理对象会导致内存碎片(见第四章),所以如果不能满足上述要求,你将不得不求助于复制。
Employee 的 GetName 方法 展示了三种本机到托管字符串转换的技术:一种使用系统。runtime . interop services . marshal 类,一个使用在 msclr/marshal.h 头文件中定义的 marshal_as 模板函数(我们将在后面讨论),最后一个使用 System。String 的构造函数,这是最快的。
Employee 的 DoWork 方法 接受一个托管数组或托管字符串,并将其转换为一个 wchar_t 指针数组,每个指针指向一个字符串;本质上,它是一个 C 风格的字符串数组。托管到原生字符串的转换是通过 marshal_context 的 marshal_as 方法完成的。与 marshal_as 全局函数不同,marshal_context 用于需要清理的转换。通常这些都是托管到非托管转换,在调用 marshal_as 期间分配非托管内存,一旦不再需要就需要释放。marshal_context 对象包含一个清理操作的链表,当它被销毁时执行这些操作。
#include <msclr/marshal.h>
#include <string>
#include <wchar.h>
#include <time.h>
using namespace System;
using namespace System::Runtime::InteropServices;
class NativeEmployee {
public:
NativeEmployee(const wchar_t *employeeName, int age)
: _employeeName(employeeName), _employeeAge(age) { }
void DoWork(const wchar_t **tasks, int numTasks) {
for (int i = 0; i < numTasks; i++) {
wprintf(L"Employee %s is working on task %s\n",
_employeeName.c_str(), tasks[i]);
}
}
int GetAge() const {
return _employeeAge;
}
const wchar_t *GetName() const {
return _employeeName.c_str();
}
private:
std::wstring _employeeName;
int _employeeAge;
};
#pragma managed
namespace EmployeeLib {
public ref class Employee {
public:
Employee(String ^employeeName, int age) {
//OPTION 1:
//IntPtr pEmployeeName = Marshal::StringToHGlobalUni(employeeName);
//m_pEmployee = new NativeEmployee(
// reinterpret_cast<wchar_t *>(pEmployeeName.ToPointer()), age);
//Marshal::FreeHGlobal(pEmployeeName);
//OPTION 2 (direct pointer to pinned managed string, faster):
pin_ptr<const wchar_t> ppEmployeeName = PtrToStringChars(employeeName);
_employee = new NativeEmployee(ppEmployeeName, age);
}
∼Employee() {
delete _employee;
_employee = nullptr;
}
int GetAge() {
return _employee->GetAge();
}
String ^GetName() {
//OPTION 1:
//return Marshal::PtrToStringUni(
// (IntPtr)(void *) _employee->GetName());
//OPTION 2:
return msclr::interop::marshal_as<String ^>(_employee->GetName());
//OPTION 3 (faster):
return gcnew String(_employee->GetName());
}
void DoWork(array<String^>^ tasks) {
//marshal_context is a managed class allocated (on the GC heap)
//using stack-like semantics. Its IDisposable::Dispose()/d’tor will
//run when exiting scope of this function.
msclr::interop::marshal_context ctx;
const wchar_t **pTasks = new const wchar_t*[tasks->Length];
for (int i = 0; i < tasks->Length; i++) {
String ^t = tasks[i];
pTasks[i] = ctx.marshal_as<const wchar_t *>(t);
}
m_pEmployee->DoWork(pTasks, tasks->Length);
//context d’tor will release native memory allocated by marshal_as
delete[] pTasks;
}
private:
NativeEmployee *_employee;
};
}
总之,C++/CLI 提供了对封送处理的精细控制,并且不需要容易出错的重复函数声明,尤其是当您经常更改本机函数签名时。
marshal_as 助手库
在本节中,我们将详细介绍作为 Visual C++ 2008 和更高版本的一部分提供的 marshal_as 帮助器库。
marshal_as 是一个模板库,用于简化和方便地将托管类型封送到本机类型,反之亦然。它可以将许多本机字符串类型(如 char *、wchar_t *、std::string、std::wstring、CStringT 、CStringT <wchar_t>、BSTR、bstr_t 和 CComBSTR)封送到托管类型,反之亦然。它处理 Unicode/ANSI 转换,并自动处理内存分配/释放。</wchar_t>
该库是在 marshal.h(对于基类型)、marshal_windows.h(对于 windows 类型)、marshal_cppstd.h(对于 STL 数据类型)和 marshal_atl.h(对于 atl 数据类型)中内联声明和实现的。
marshal_as 可以扩展为处理用户定义类型的转换。这有助于在许多地方封送同一类型时避免代码重复,并允许对不同类型的封送使用统一的语法。
下面的代码是一个扩展 marshal_as 以处理托管字符串数组到等效的本机字符串数组的转换的示例。
namespace msclr {
namespace interop {
template<>
ref class context_node<const wchar_t**, array<String^>^> : public context_node_base {
private:
const wchar_t** _tasks;
marshal_context _context;
public:
context_node(const wchar_t**& toObject, array<String^>^ fromObject) {
//Conversion logic starts here
_tasks = NULL;
const wchar_t **pTasks = new const wchar_t*[fromObject->Length];
for (int i = 0; i < fromObject->Length; i++) {
String ^t = fromObject[i];
pTasks[i] = _context.marshal_as<const wchar_t *>(t);
}
toObject = _tasks = pTasks;
}
∼context_node() {
this->!context_node();
}
protected:
!context_node() {
//When the context is deleted, it will free the memory
//allocated for the strings (belongs to marshal_context),
//so the array is the only memory that needs to be freed.
if (_tasks != nullptr) {
delete[] _tasks;
_tasks = nullptr;
}
}
};
}
}
//You can now rewrite Employee::DoWork like this:
void DoWork(array<String^>^ tasks) {
//All unmanaged memory is freed automatically once marshal_context
//gets out of scope.
msclr::interop::marshal_context ctx;
_employee->DoWork(ctx.marshal_as<const wchar_t **>(tasks), tasks->Length);
}
IL 代码与本机代码
默认情况下,非托管类将被编译为 C++/CLI 中的 IL 代码,而不是机器代码。相对于优化的本机代码,这可能会降低性能,因为 Visual C++编译器比 JIT 更能优化代码。
您可以在一段代码前使用#pragma unmanaged 和#pragma managed 来重写复杂行为。此外,在 VC++项目中,您还可以为单个编译单元启用 C++/CLI 支持。cpp 文件)。
Windows 8 WinRT Interop
Windows Runtime (WinRT) 是专为 Windows 8 Metro 风格应用设计的新平台。WinRT 以本机代码实现(即 WinRT 不使用. NET Framework),但是可以从 C++/CX 针对 WinRT,。NET 语言或 JavaScript。WinRT 取代了 Win32 和。NET BCL,它变得不可访问。WinRT 强调异步,对于任何可能需要 50 毫秒以上才能完成的操作,它都是强制性的。这样做是为了确保流畅的 UI 性能,这对于像 Metro 这样基于触摸的用户界面尤其重要。
WinRT 是建立在 COM 的高级版本之上的。以下是 WinRT 和 COM 之间的一些区别:
- 对象是使用 RoCreateInstance 创建的。
- 所有对象都实现 IInspectable 接口,该接口又派生自我们熟悉的 IUnknown 接口。
- 支持。NET 样式的属性、委托和事件(而不是接收器)。
- 支持参数化接口(“泛型”)。
- 使用。NET 元数据格式(。winmd 文件)而不是 TLB 和 IDL。
- 所有类型都是从 Platform::Object 派生的。
尽管借鉴了很多。由于 WinRT 完全是在本机代码中实现的,因此从非。NET 语言。
微软实现了语言投影,将 WinRT 概念映射到特定于语言的概念,无论是 C++/CX、C# 还是 JavaScript。例如,C++/CX 是 C++的新语言扩展,它自动管理引用计数,将 WinRT 对象激活(RoActivateInstance)转换为 C++构造函数,将 HRESULTs 转换为异常,将“retval”参数转换为返回值,等等。
当调用者和被调用者都被管理时,CLR 足够聪明,可以直接进行调用,而不涉及内部操作。对于跨越本机到托管边界的调用,会涉及常规 COM 互操作。当调用方和被调用方都用 C++实现,并且被调用方的头文件可供调用方使用时,不涉及 COM 互操作,调用非常快,否则,需要进行 COM 查询接口。
互操作的最佳实践
以下是高性能互操作的最佳实践摘要列表:
- 通过分块(组合)工作,设计接口以避免本机管理的转换。
- 用立面减少往返行程。
- 如果非托管资源跨调用持有,则实现 IDisposable。
- 考虑使用内存池或非托管内存。
- 考虑使用不安全代码来重新解释数据(例如在网络协议中)。
- 显式命名您调用的函数,并使用 ExactSpelling=true。
- 尽可能使用 blittable 参数类型。
- 尽可能避免 Unicode 到 ANSI 的转换。
- 手动整理进出 IntPtr 的字符串。
- 使用 C++/CLI 可以更好地控制 C/C++和 COM 互操作并提高性能。
- 指定[In]和[Out]属性以避免不必要的封送处理。
- 避免固定对象的长寿命。
- 考虑调用 ReleaseComObject。
- 考虑将 SuppressUnmanagedCodeSecurityAttribute 用于性能关键的完全信任方案。
- 对于性能关键的完全信任方案,考虑使用 TLBIMP /unsafe。
- 减少或避免跨公寓呼叫。
- 如果合适,在 ASP.NET 中使用 ASPCOMPAT 属性来减少或避免 COM 跨单元调用。
摘要
在本章中,您已经了解了不安全代码,各种互操作机制是如何实现的,每个实现细节如何对性能产生深远的影响,以及如何减轻这种影响。已经向您介绍了提高互操作性能和使编码更容易、更不容易出错的最佳实践和技术(例如,帮助生成 P/Invoke 签名和 marshal_as 库)。

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









