







十、语音到文本,反之亦然
在本章中,您将了解语音到文本和文本到语音转换的重要性。您还将了解进行这种类型的转换所需的函数和组件。
具体来说,我将介绍以下内容:
- 为什么你想把语音转换成文本
- 语音作为数据
- 将语音映射到矩阵的语音特征
- 光谱图,将语音映射成图像
- 利用梅尔倒谱系数(MFCC)特征构建语音识别分类器
- 通过频谱图建立语音识别的分类器
- 语音识别的开源方法
- 流行的认知服务提供商
- 文本话语的未来
语音到文本转换
语音转文本,通俗地说就是一个 app 识别一个人说的话,把语音转换成文字。有很多原因让你想使用语音到文本的转换。
- 盲人或残障人士可以仅使用语音控制不同的设备。
- 您可以通过将口头对话转换为文本记录来保存会议和其他事件的记录。
- 您可以转换视频和音频文件中的音频,以获得正在朗读的单词的字幕。
- 通过对着设备用一种语言说话,然后将文本转换成另一种语言的语音,可以将单词翻译成另一种语言。
语音作为数据
制造任何自动语音识别系统的第一步是获取特征。换句话说,你识别出了对识别语言内容有用的音频成分,并删除了所有其他无用的背景噪音。
每个人的语音都被他们声道的形状以及舌头和牙齿过滤。发出什么声音取决于这个形状。为了准确地识别正在产生的音素,你需要准确地确定这个形状。你可以说声道的形状表明它自己形成了短时功率谱的包络。MFCCs 的工作是准确地表示这个包络。
语音也可以通过转换成声谱图来表示为数据(图 10-1 )。
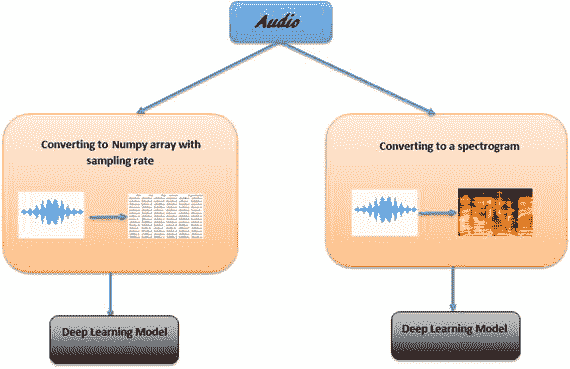
图 10-1
Speech as data
语音特征:将语音映射到矩阵
MFCCs 广泛用于自动语音和说话人识别。mel 标度将纯音的感知频率或音高与其实际测量频率相关联。
您可以使用以下公式将音频的频率标度转换为 mel 标度:
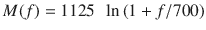
要将其转换回频率,请使用以下公式:
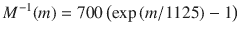
以下是 Python 中提取 MFCC 要素的函数:
def mfcc(signal,samplerate=16000,winlen=0.025,winstep=0.01,numcep=13, nfilt=26,nfft=512,lowfreq=0,highfreq=None,preemph=0.97, ceplifter=22,appendEnergy=True)
这些是使用的参数:
signal:这是需要计算 MFCC 特征的信号。应该是 N*1 的数组(读取 WAV 文件)。- 这是您正在工作的信号的采样率。
winlen:这是以秒为单位的分析窗口长度。默认情况下,它是 0.025 秒。winstep:这是连续的窗口步骤。默认情况下是 0.01 秒。numcep:这是函数应该返回的 ceptrum 的编号。默认情况下,它是 13。nfilt:这是滤波器组中滤波器的数量。默认情况下是 26。nfft:这是快速傅立叶变换(FFT)的大小。默认情况下,它是 512。- 这是最低的频带边缘,单位为赫兹。默认情况下,该值为 0。
- 这是最高频带边缘,单位为赫兹。默认情况下,它是采样速率除以 2。
preemph:应用以preemph为系数的预加重滤波器。0 表示没有过滤器。默认情况下,它是 0.97。ceplifter:将提升器应用于最终倒谱系数。0 表示没有升降机。默认情况下是 22。appendEnergy:如果设置为真,则第零倒谱系数被替换为总帧能量的对数。
这个函数返回一个包含特性的 Numpy 数组。每行包含一个特征向量。
频谱图:将语音映射到图像
光谱图是光谱的照片或电子图像。这个想法是将音频文件转换成图像,并将图像传递到深度学习模型,如 CNN 和 LSTM,以进行分析和分类。
频谱图被计算为窗口数据段的 FFT 序列。一种常见的格式是具有两个几何维度的图形;一个轴代表时间,另一个轴代表频率。第三维度使用点的颜色或大小来表示特定时间特定频率的振幅。光谱图通常用两种方法之一制作。它们可以近似为由一系列带通滤波器产生的滤波器组。或者,在 Python 中,有一个将音频映射到声谱图的直接函数。
利用 MFCC 特征构建语音识别分类器
要构建语音识别的分类器,您需要安装 python_speech_features Python 包。
您可以使用命令pip install python_speech_features来安装这个包。
mfcc函数为音频文件创建一个特征矩阵。为了建立一个识别不同人声音的分类器,你需要以 WAV 格式收集他们的语音数据。然后使用mfcc函数将所有音频文件转换成一个矩阵。从 WAV 文件中提取特征的代码如下所示:

如果您运行前面的代码,您将获得以下形式的输出:
[[ 7.66608682 7.04137131 7.30715423 ..., 9.43362359 9.11932984
9.93454603]
[ 4.9474559 4.97057377 6.90352236 ..., 8.6771281 8.86454547
9.7975147 ]
[ 7.4795622 6.63821063 5.98854983 ..., 8.78622734 8.805521
9.83712966]
...,
[ 7.8886269 6.57456605 6.47895433 ..., 8.62870034 8.79965464
9.67997298]
[ 5.73028657 4.87985847 6.64977329 ..., 8.64089442 8.62887745
9.90470194]
[ 8.8449656 6.67098127 7.09752316 ..., 8.84914694 8.97807983
9.45123015]]
这里,每一行代表一个特征向量。
尽可能多地收集一个人的录音,并在这个矩阵中附加每个音频文件的特征矩阵。
这将作为您的训练数据集。
对所有其他类重复相同的步骤。
一旦数据集准备好,你就可以将这些数据放入任何深度学习模型(用于分类)中,对不同人的声音进行分类。
Note
要查看使用 MFCC 功能的分类器的完整代码,您可以访问 www.navinmanaswi.com/SpeechRecognizer 。
通过声谱图建立用于语音识别的分类器
使用声谱图方法将所有音频文件转换为图像(图 10-2 ),因此您所要做的就是将训练数据中的所有声音文件转换为图像,并将这些图像馈送到深度学习模型,就像您在 CNN 中所做的那样。
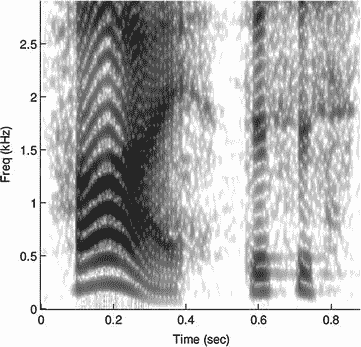
图 10-2
Spectogram of speech sample
下面是将音频文件转换为声谱图的 Python 代码:

开源方法
Python 有一些开源包可以执行语音到文本和文本到语音的转换。
以下是一些开源的语音到文本转换 API:
- PocketSphinx
- 谷歌语音
- 谷歌云演讲
- Wit.ai
- Houndify
- IBM 语音转文本 API
- 微软必应语音
在使用了所有这些之后,我可以说它们工作得相当好;美国口音特别清晰。
如果您对评估转换的准确性感兴趣,您需要一个度量:单词错误率(WER)。
在下一节中,我将讨论前面提到的每个 API。
使用每个 API 的示例
让我们看一下每个 API。
使用 PocketSphinx
PocketSphinx 是一个用于语音到文本转换的开源 API。这是一个轻量级的语音识别引擎,专门针对手持和移动设备进行了调整,尽管它在桌面上也同样适用。只需使用命令pip install PocketSphinx安装软件包。
import speech_recognition as sr
from os import path
AUDIO_FILE = "MyAudioFile.wav"
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source)
try:
print("Sphinx thinks you said " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))
===============================================================
使用谷歌语音 API
Google 提供了自己的语音 API,可以用 Python 代码实现,可以用来创建不同的应用。
# recognize speech using Google Speech Recognition
try:
print("Google Speech Recognition thinks you said " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service;{0}".format(e))
使用谷歌云语音 API
你也可以使用谷歌云语音 API 进行转换。在 Google Cloud 上创建一个帐户并复制凭证。
GOOGLE_CLOUD_SPEECH_CREDENTIALS = r"INSERT THE CONTENTS OF THE GOOGLE CLOUD SPEECH JSON CREDENTIALS FILE HERE" try: print("Google Cloud Speech thinks you said " + r.recognize_google_cloud(audio, credentials_json=GOOGLE_CLOUD_SPEECH_CREDENTIALS))
except sr.UnknownValueError:
print("Google Cloud Speech could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Cloud Speech service; {0}".format(e))
使用 Wit.ai API
Wit.ai API 使您能够制作语音到文本转换器。您需要创建一个帐户,然后创建一个项目。复制你的 Wit.ai 密钥,开始编码。
#recognize speech using Wit.ai
WIT_AI_KEY = "INSERT WIT.AI API KEY HERE" # Wit.ai keys are 32-character uppercase alphanumeric strings
try:
print("Wit.ai thinks you said " + r.recognize_wit(audio, key=WIT_AI_KEY))
except sr.UnknownValueError:
print("Wit.ai could not understand audio")
except sr.RequestError as e:
print("Could not request results from Wit.ai service; {0}".format(e))
使用 Houndify API
与前面的 API 类似,您需要在 Houndify 创建一个帐户,并获得您的客户机 ID 和密钥。这允许你建立一个对声音有反应的应用程序。
# recognize speech using Houndify
HOUNDIFY_CLIENT_ID = "INSERT HOUNDIFY CLIENT ID HERE" # Houndify client IDs are Base64-encoded strings
HOUNDIFY_CLIENT_KEY = "INSERT HOUNDIFY CLIENT KEY HERE" # Houndify client keys are Base64-encoded strings
try:
print("Houndify thinks you said " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))
使用 IBM 语音到文本 API
IBM 语音到文本 API 使您能够将 IBM 的语音识别功能添加到您的应用程序中。登录 IBM cloud 并启动您的项目,获取一个 IBM 用户名和密码。
# IBM Speech to Text
# recognize speech using IBM Speech to Text
IBM_USERNAME = "INSERT IBM SPEECH TO TEXT USERNAME HERE" # IBM Speech to Text usernames are strings of the form XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
IBM_PASSWORD = "INSERT IBM SPEECH TO TEXT PASSWORD HERE" # IBM Speech to Text passwords are mixed-case alphanumeric strings
try:
print("IBM Speech to Text thinks you said " + r.recognize_ibm(audio, username=IBM_USERNAME, password=IBM_PASSWORD))
except sr.UnknownValueError:
print("IBM Speech to Text could not understand audio")
except sr.RequestError as e:
print("Could not request results from IBM Speech to Text service; {0}".format(e))
使用 Bing 语音识别 API
这个 API 实时识别来自麦克风的音频。在 Bing.com 上创建一个帐户,并获得阿炳语音识别 API 密钥。
# recognize speech using Microsoft Bing Voice Recognition
BING_KEY = "INSERT BING API KEY HERE" # Microsoft Bing Voice Recognition API key is 32-character lowercase hexadecimal strings
try:
print("Microsoft Bing Voice Recognition thinks you said " + r.recognize_bing(audio, key=BING_KEY))
except sr.UnknownValueError:
print("Microsoft Bing Voice Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Bing Voice Recognition service; {0}".format(e))
一旦你把演讲转换成文本,你就不能指望百分之百的准确。要测量精确度,可以使用 WER。
文本到语音转换
本章的这一节重点介绍如何将书面文本转换为音频文件。
使用 pyttsx
使用名为 pyttsx 的 Python 包,可以将文本转换成音频。
Do a pip install pyttsx. If you are using python 3.6 then do pip3 install pyttsx3.
import pyttsx
engine = pyttsx.init()
engine.say("Your Message")
engine.runAndWait()
使用 SAPI
在 Python 中,还可以使用 SAPI 进行文本到语音的转换。
from win32com.client import constants, Dispatch
Msg = "Hi this is a test"
speaker = Dispatch("SAPI.SpVoice") #Create SAPI SpVoice Object
speaker.Speak(Msg) #Process TTS
del speaker
使用 SpeechLib
您可以从文本文件中获取输入,并使用 SpeechLib 将其转换为音频,如下所示:
from comtypes.client import CreateObject
engine = CreateObject("SAPI.SpVoice")
stream = CreateObject("SAPI.SpFileStream")
from comtypes.gen import SpeechLib
infile = "SHIVA.txt"
outfile = "SHIVA-audio.wav"
stream.Open(outfile, SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream = stream
f = open(infile, 'r')
theText = f.read()
f.close()
engine.speak(theText)
stream.Close()
很多时候,您必须编辑音频,以便从音频文件中删除声音。下一节将向您展示如何操作。
音频切割代码
制作一个包含音频详细信息的逗号分隔值的音频 CSV 文件,并使用 Python 执行以下操作:
import wave
import sys
import os
import csv
origAudio = wave.open('Howard.wav', 'r') #change path
frameRate = origAudio.getframerate()
nChannels = origAudio.getnchannels()
sampWidth = origAudio.getsampwidth()
nFrames = origAudio.getnframes()
filename = 'result1.csv' #change path
exampleFile = open(filename)
exampleReader = csv.reader(exampleFile)
exampleData = list(exampleReader)
count = 0
for data in exampleData:
#for selections in data:
print('Selections ', data[4], data[5])
count += 1
if data[4] == 'startTime' and data[5] == 'endTime':
print('Start time')
else:
start = float(data[4])
end = float(data[5])
origAudio.setpos(start*frameRate)
chunkData = origAudio.readframes(int((end-start)*frameRate))
outputFilePath = 'C:/Users/Navin/outputFile{0}.wav'.format(count) # change path
chunkAudio = wave.open(outputFilePath, 'w')
chunkAudio.setnchannels(nChannels)
chunkAudio.setsampwidth(sampWidth)
chunkAudio.setframerate(frameRate)
chunkAudio.writeframes(chunkData)
chunkAudio.close()
认知服务提供商
让我们看看一些帮助语音处理的认知服务提供商。
微软 Azure
Microsoft Azure 提供了以下功能:
- 自定义语音服务:这克服了语音识别的障碍,如说话方式、词汇和背景噪音。
- Translator Speech API:这支持实时语音翻译。
- 说话人识别 API:它可以根据给定音频数据中每个说话人的语音样本来识别说话人。
- Bing 语音 API:它将音频转换为文本,理解意图,并将文本转换回语音,以获得自然的响应。
亚马逊认知服务
亚马逊认知服务(Amazon Cognitive Services)提供亚马逊 Polly,一种将文本转化为语音的服务。Amazon Polly 允许您创建会说话的应用程序,使您能够构建全新类别的支持语音的产品。
- 可以使用 47 种语音和 24 种语言,并提供印度英语选项。
- 使用 Amazon effects,可以将耳语、愤怒等音调添加到讲话的特定部分。
- 您可以指示系统如何以不同的方式发出特定短语或单词的发音。例如,“W3C”读作万维网联盟,但是您可以将其改为只读作缩写。您还可以提供 SSML 格式的输入文本。
IBM 沃森服务
IBM Watson 提供了两种服务。
- 语音转文本:美国英语、西班牙语和日语
- 文本到语音转换:美国英语、英国英语、西班牙语、法语、意大利语和德语
语音分析的未来
语音识别技术已经取得了很大的进步。每年,它都比前一年精确 10%到 15%。未来,它将为计算机提供迄今为止最具交互性的界面。
你很快就会在市场上看到许多应用,包括交互式书籍、机器人控制和自动驾驶汽车界面。语音数据提供了一些令人兴奋的新的可能性,因为它是行业的未来。语音智能使人们能够发送信息、接受或下达命令、提出投诉,以及做任何他们过去需要手动输入的工作。它提供了很好的客户体验,也许这就是为什么所有面向客户的部门和企业都倾向于大量使用语音应用程序。我可以预见语音应用开发者的美好未来。
十一、开发聊天机器人
通过文本或语音作为人机交互界面的人工智能系统被称为聊天机器人。
与聊天机器人的交互可能简单,也可能复杂。直接互动的一个例子是询问最新的新闻报道。比如说,在对你的 Android 手机进行故障诊断时,交互会变得更加复杂。聊天机器人这个词在过去的一年里非常流行,已经成为用户互动和参与的最受欢迎的平台。机器人是聊天机器人的高级形式,有助于自动执行“用户执行的”任务。
关于聊天机器人的这一章将作为一个全面的指南,介绍聊天机器人的内容、方式、地点、时间和原因!
具体来说,我将介绍以下内容:
- 为什么你会想使用聊天机器人
- 聊天机器人的设计和功能
- 构建聊天机器人的步骤
- 使用 API 开发聊天机器人
- 聊天机器人的最佳实践
为什么是聊天机器人?
对于聊天机器人来说,理解用户在寻找什么信息,也就是所谓的意图,是非常重要的。假设一个用户想知道最近的素食餐馆;用户可以用许多可能的方式来问这个问题。聊天机器人(特别是聊天机器人内部的意图分类器)必须能够理解用户的意图,因为用户想要得到正确的答案。事实上,为了给出正确的答案,聊天机器人必须能够理解上下文、意图、实体和情感。聊天机器人甚至必须考虑会话中讨论的任何内容。例如,用户可能会问这样的问题“那里的鸡肉价格是多少?”尽管用户已经询问了价格,但是聊天引擎可能会误解并认为用户正在寻找一家餐馆。因此,作为响应,聊天机器人可以提供餐馆的名称。
聊天机器人的设计和功能
聊天机器人通过应用人工智能来刺激与人类的智能对话。
对话发生的界面通过口头或书面文本来实现。Facebook Messenger、Slack 和 Telegram 利用聊天机器人消息平台。它们有很多用途,包括网上订购产品、投资理财等等。聊天机器人的一个重要方面是它们使上下文对话成为可能。聊天机器人与用户交谈的方式类似于人类在日常生活中的交谈方式。尽管聊天机器人有可能根据上下文进行对话,但在根据上下文与任何事物进行交流方面,它们还有很长的路要走。但是聊天界面正在利用语言将机器与人连接起来,通过以上下文的方式提供信息,帮助人们以方便的方式完成事情。
此外,聊天机器人正在重新定义企业的经营方式。从接触消费者,到欢迎他们加入商业生态系统,再到向消费者提供各种产品及其功能的信息,聊天机器人都在提供帮助。它们正在成为及时和令人满意地与消费者打交道的最方便的方式。
构建聊天机器人的步骤
聊天机器人是为了与用户交流而构建的,让用户感觉他们是在与人交流,而不是与机器人交流。但是当用户输入时,通常他们不会以正确的方式输入。换句话说,他们可能会输入不必要的标点符号,或者可能会有不同的方式来问同一个问题。
例如,对于“我附近的餐馆?”用户可以输入“我旁边的餐馆?”或者“找一家附近的餐馆。”
因此,您需要对数据进行预处理,以便聊天机器人引擎能够轻松理解它。图 11-1 显示了该过程,这将在以下章节中详细描述。
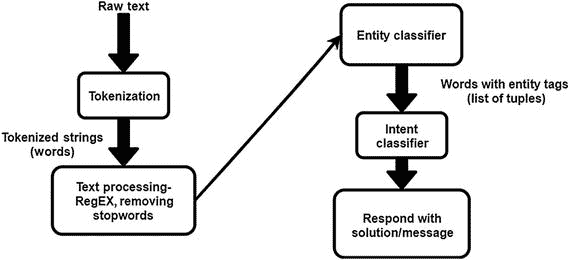
图 11-1
A flowchart to show how a chatbot engine processes an input string and gives a valid reply.
预处理文本和消息
文本和消息的预处理包括几个步骤,下面将介绍。
标记化
将句子分割成单个单词(称为标记)称为标记化。在 Python 中,通常字符串被标记化并存储在列表中。
- 例如,“人工智能就是应用数学”这句话变成了下面这句话:
- 【“人工”、“智能”、“是”、“所有”、“关于”、“应用”、“数学”】
- 以下是示例代码:
from nltk.tokenize import TreebankWordTokenizer
l = "Artificial intelligence is all about applying mathematics"
token = TreebankWordTokenizer().tokenize(l)
print(token)
删除标点符号
也可以去掉句子中不必要的标点符号。
- 例如,句子“我能得到送货上门的餐馆名单吗?”变成如下:
- “我能得到送货上门的餐馆名单吗?”
- 以下是示例代码:
from nltk.tokenize import TreebankWordTokenizer
from nltk.corpus import stopwords
l = "Artificial intelligence is all about applying mathematics!"
token = TreebankWordTokenizer().tokenize(l)
output = []
output = [k for k in token if k.isalpha()]
print(output)
删除停用词
停用词是存在于一个句子中的词,如果去掉,不会有太大的区别。尽管句子的格式改变了,但这对自然语言理解很有帮助(NLU)。
- 比如那句“人工智能可以改变人民的生活方式。”删除停用词后,变为以下内容:
- “人工智能改变人们的生活方式。”
以下是示例代码:
from nltk.tokenize import TreebankWordTokenizer
from nltk.corpus import stopwords
l = "Artificial intelligence is all about applying mathematics"
token = TreebankWordTokenizer().tokenize(l)
stop_words = set(stopwords.words('english'))
output= []
for k in token:
if k not in stop_words:
output.append(k)
print(output)
哪些词被认为是停用词可以有所不同。自然语言工具包(NLTK)、Google 等提供了一些预定义的停用词集。
命名实体识别
命名实体识别(NER),也称为实体识别,是将文本中的实体分类到预定义的类别(如国家名称、人名等)中的任务。您也可以定义自己的类。
- 例如,将 NER 应用于句子“今天的印度对澳大利亚板球比赛棒极了。”为您提供以下输出:
- [今天的]时间[印度]国家对[澳大利亚]国家[板球]比赛太精彩了。
要运行 NER 的代码,您需要下载并导入必要的包,如下面的代码所示。
使用斯坦福 NER
要运行代码,下载english.all.3class.distsim.crf.ser.gz和stanford-ner.jar文件。
from nltk.tag import StanfordNERTagger
from nltk.tokenize import word_tokenize
StanfordNERTagger("stanford-ner/classifiers/english.all.3class.distsim.crf.ser.gz",
"stanford-ner/stanford-ner.jar")
text = "Ron was the founder of Ron Institute at New york"
text = word_tokenize(text)
ner_tags = ner_tagger.tag(text)
print(ner_tags)
使用米蒂 NER(预训练)
下载 MITIE 的ner_model.dat文件运行代码。
from mitie.mitie import *
from nltk.tokenize import word_tokenize
print("loading NER model...")
ner = named_entity_extractor("mitie/MITIE-models/english/ner_model.dat".encode("utf8"))
text = "Ron was the founder of Ron Institute at New york".encode("utf-8")
text = word_tokenize(text)
ner_tags = ner.extract_entities(text)
print("\nEntities found:", ner_tags)
for e in ner_tags:
range = e[0]
tag = e[1]
entity_text = " ".join(text[i].decode() for i in range)
print( str(tag) + " : " + entity_text)
使用米铁 NER(自学)
下载米铁( https://github.com/mit-nlp/MITIE )的total_word_feature_extractor.dat文件运行代码。
from mitie.mitie import *
sample = ner_training_instance([b"Ron", b"was", b"the", b"founder", b"of", b"Ron", b"Institute", b"at", b"New", b"York", b"."])
sample.add_entity(range(0, 1), "person".encode("utf-8"))
sample.add_entity(range(5, 7), "organization".encode("utf-8"))
sample.add_entity(range(8, 10), "Location".encode("utf-8"))
trainer = ner_trainer("mitie/MITIE-models/english/total_word_feature_extractor.dat".encode("utf-8"))
trainer.add(sample)
ner = trainer.train()
tokens = [b"John", b"was", b"the", b"founder", b"of", b"John", b"University", b"."]
entities = ner.extract_entities(tokens)
print ("\nEntities found:", entities)
for e in entities:
range = e[0]
tag = e[1]
entity_text = " ".join(str(tokens[i]) for i in range)
print (" " + str(tag) + ": " + entity_text)
意图分类
意图分类是 NLU 的一个步骤,在这里你试图理解用户想要什么。以下是聊天机器人查找附近地点的两个输入示例:
- “我需要买些杂货。”:目的是寻找附近的杂货店。
- “我想吃素食。”:目的是寻找附近的餐馆,最好是素食餐馆。
基本上,你需要理解用户在寻找什么,并相应地将请求归类到特定的意图类别中(图 11-2 )。
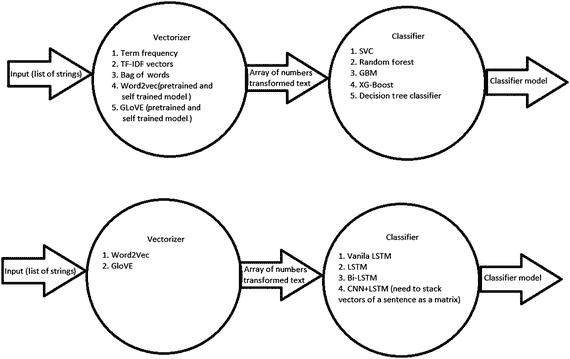
图 11-2
General flow of intent classification, from sentences to vectors to a model
要做到这一点,你需要训练一个模型来使用算法将请求分类成意图,从句子到向量再到模型。
单词嵌入
单词嵌入是将文本转换成数字的技术。在文本中很难应用任何算法。因此,你必须把它转换成数字。
以下是不同类型的单词嵌入技术。
计数向量
假设您有三个文档(D1、D2 和 D3 ),文档组中有 N 个唯一的单词。您创建了一个(D×N)矩阵,称为 C,这就是众所周知的计数向量。矩阵的每个条目都是该文档中唯一单词的频率。
- 让我们看一个例子。
- D1: Pooja 非常懒。
- D2:但是她很聪明。
- 她几乎不来上课。
这里,D=3,N=12。
独特的词很难,懒惰,但,Pooja,她,聪明,来,非常,类,是。
因此,计数向量 C 将如下:
| | 几乎不 | 懒惰的 | 但是 | 到 | 礼拜 | 她 | 聪明的 | 来 | 很 | 班级 | 存在 | | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | | D1 | Zero | one | Zero | Zero | one | Zero | Zero | Zero | one | Zero | one | | D2 | Zero | Zero | one | Zero | Zero | one | one | Zero | Zero | Zero | one | | D3 | one | Zero | Zero | one | Zero | one | Zero | one | Zero | one | Zero |术语频率-逆文档频率(TF-IDF)
对于这种技术,根据单词在句子中出现的次数以及文档,为句子中的每个单词指定一个数字。在句子中出现多次而在文档中不出现多次的单词将具有高值。
例如,考虑一组句子:
- “我是男生。”
- “我是女生。”
- “你住在哪里?”
TF-IDF 转换前面句子的特征集,如下所示:
| | 是 | 男孩 | 女孩 | 在哪里 | 做 | 你们 | 活着 | | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | | 1. | Zero point six | Zero point eight | Zero | Zero | Zero | Zero | Zero | | 2. | Zero point six | Zero | Zero point eight | Zero | Zero | Zero | Zero | | 3. | Zero | Zero | Zero | Zero point five | Zero point five | Zero point five | Zero point five |您可以导入 TFIDF 包并使用它来创建此表。
现在让我们看一些样本代码。您可以在请求字符串的 TF-IDF 转换特征上使用支持向量分类器。
#import required packages
import pandas as pd
from random import sample
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, accuracy_score
# read csv file
data = pd.read_csv("intent1.csv")
print(data.sample(6))
在继续编写代码之前,这里有一个数据集示例:
| 描述(消息) | 意图 _ 标签(目标) | | :-- | :-- | | 我附近有一家不错的非蔬菜餐馆 | Zero | | 我正在找医院 | one | | 心脏手术的好医院 | one | | 国际儿童学校 | Two | | 我周围的非素食餐馆 | Zero | | 小孩子的学校 | Two |在本例中,这些是要使用的值:
- 0 表示寻找餐厅。
- 1 表示找医院。
- 2 表示找学校。
现在让我们处理数据集。
# split dataset into train and test.
X_train, X_test, Y_train, Y_test = train_test_split(data["Description"], data["intent_label"], test_size=3)
print(X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
# vectorize the input using tfidf values.
tfidf = TfidfVectorizer()
tfidf = tfidf.fit(X_train)
X_train = tfidf.transform(X_train)
X_test = tfidf.transform(X_test)
# label encoding for different categories of intents
le = LabelEncoder().fit(Y_train)
Y_train = le.transform(Y_train)
Y_test = le.transform(Y_test)
# other models like GBM, Random Forest may also be used
model = SVC()
model = model.fit(X_train, Y_train)
p = model.predict(X_test)
# calculate the f1_score. average="micro" since we want to calculate score for multiclass.
# Each instance(rather than class(search for macro average)) contribute equally towards the scoring.
print("f1_score:", f1_score( Y_test, p, average="micro"))
print("accuracy_score:",accuracy_score(Y_test, p))
Word2Vec
有不同的方法来获得一个句子的单词向量,但是所有技术背后的主要理论是给相似的单词一个相似的向量表示。所以,像男人,男孩和女孩这样的词会有相似的向量。可以设置每个向量的长度。Word2vec 技术的例子包括 GloVe 和 CBOW(有或没有 skip grams 的 n-gram)。
您可以通过为自己的数据集训练 Word2vec 来使用它(如果您有足够的数据来解决问题),或者您可以使用预训练的数据。Word2vec 在网上有售。经过预训练的模型已经在维基百科数据、推文等大型文档上接受了训练,它们几乎总是对问题有好处。
可以用来训练意图分类器的一些技术的一个例子是,对句子中的单词的单词向量使用 1D-CNN,附加在每个句子的列表中。
# import required packages
from gensim.models import Word2Vec
import pandas as pd
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Input, Flatten
from keras.layers import Conv1D, MaxPooling1D, Embedding, Dropout
from keras.models import Model
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, accuracy_score
# read data
data = pd.read_csv("intent1.csv")
# split data into test and train
X_train, X_test, Y_train, Y_test = train_test_split(data["Description"], data["intent_label"], test_size=6)
# label encoding for different categories of intents
le = LabelEncoder().fit(Y_train)
Y_train = le.transform(Y_train)
Y_test = le.transform(Y_test)
# get word_vectors for words in training set
X_train = [sent for sent in X_train]
X_test = [sent for sent in X_test]
# by default genism.Word2Vec uses CBOW, to train word vecs. We can also use skipgram with it
# by setting the "sg" attribute to number of skips we want.
# CBOW and Skip gram for the sentence "Hi Ron how was your day?" becomes:
# Continuos bag of words: 3-grams {"Hi Ron how", "Ron how was", "how was your" ...}
# Skip-gram 1-skip 3-grams: {"Hi Ron how", "Hi Ron was", "Hi how was", "Ron how
# your", ...}
# See how: "Hi Ron was" skips over "how".
# Skip-gram 2-skip 3-grams: {"Hi Ron how", "Hi Ron was", "Hi Ron your", "Hi was
# your", ...}
# See how: "Hi Ron your" skips over "how was".
# Those are the general meaning of CBOW and skip gram.
word_vecs = Word2Vec(X_train)
print("Word vectors trained")
# prune each sentence to maximum of 20 words.
max_sent_len = 20
# tokenize input strings
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)
sequences = tokenizer.texts_to_sequences(X_train)
sequences_test = tokenizer.texts_to_sequences(X_test)
word_index = tokenizer.word_index
vocab_size = len(word_index)
# sentences with less than 20 words, will be padded with zeroes to make it of length 20
# sentences with more than 20 words, will be pruned to 20.
x = pad_sequences(sequences, maxlen=max_sent_len)
X_test = pad_sequences(sequences_test, maxlen=max_sent_len)
# 100 is the size of wordvec.
embedding_matrix = np.zeros((vocab_size + 1, 100))
# make matrix of each word with its word_vectors for the CNN model.
# so each row of a matrix will represent one word. There will be a row for each word in
# the training set
for word, i in word_index.items():
try:
embedding_vector = word_vecs[word]
except:
embedding_vector = None
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
print("Embeddings done")
vocab_size = len(embedding_matrix)
# CNN model requires multiclass labels to be converted into one hot ecoding.
# i.e. each column represents a label, and will be marked one for corresponding label.
y = to_categorical(np.asarray(Y_train))
embedding_layer = Embedding(vocab_size,
100,
weights=[embedding_matrix],
input_length=max_sent_len,
trainable=True)
sequence_input = Input(shape=(max_sent_len,), dtype="int32")
# stack each word of a sentence in a matrix. So each matrix represents a sentence.
# Each row in a matrix is a word(Word Vector) of a sentence.
embedded_sequences = embedding_layer(sequence_input)
# build the Convolutional model.
l_cov1 = Conv1D(128, 4, activation="relu")(embedded_sequences)
l_pool1 = MaxPooling1D(4)(l_cov1)
l_flat = Flatten()(l_pool1)
hidden = Dense(100, activation="relu")(l_flat)
preds = Dense(len(y[0]), activation="softmax")(hidden)
model = Model(sequence_input, preds)
model.compile(loss='binary_crossentropy',optimizer='Adam')
print("model fitting - simplified convolutional neural network")
model.summary()
# train the model
model.fit(x, y, epochs=10, batch_size=128)
#get scores and predictions.
p = model.predict(X_test)
p = [np.argmax(i) for i in p]
score_cnn = f1_score(Y_test, p, average="micro")
print("accuracy_score:",accuracy_score(Y_test, p))
print("f1_score:", score_cnn)
模型拟合是一个简化的卷积神经网络,如下所示:
| 层(类型) | 输出形状 | 参数# | | :-- | :-- | :-- | | 输入 _20(输入层) | (无,20) | Zero | | 嵌入 _20(嵌入) | (无,20,100) | Two thousand eight hundred | | conv1d_19 (Conv1D) | (无,17,128) | Fifty-one thousand three hundred and twenty-eight | | max_pooling1d_19(最大池) | (无,4,128) | Zero | | 扁平化 _19(扁平化) | (无,512) | Zero | | 密集 _35(密集) | (无,100) | Fifty-one thousand three hundred | | 密集 _36(密集) | (无,3) | Three hundred and three |以下是参数的数量:
- 总参数:105731
- 可训练参数:105,731
- 不可训练的参数:0
下面是使用 Gensim 包的 Word2vec 的一些重要功能:
-
这就是你如何导入 Gensim 并加载预训练模型:
import genism #loading the pre-trained model model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)这是谷歌为英语语言提供的预训练模型,它有 300 个维度。
-
这是如何从一个预先训练好的模型中找到一个单词的单词向量:
# getting word vectors of a word lion = model['lion'] print(len(lion)) -
这是如何找到两个词之间的相似指数:
#Calculating similarity index print(model.similarity('King', 'Queen')) -
这就是如何从一组单词中找出一个奇怪的单词:
#Choose odd one out print(model.doesnt_match("Mango Grape Tiger Banana Strawberry".split())) -
这是如何找到最相似的单词:
print(model.most_similar(positive=[Prince, Girl], negative=[Boy]))word 2 vec 的一个独特的特点是,你可以得到向量,从其他向量使用向量运算。例如,“王子”的向量减去“男孩”的向量加上“女孩”的向量将几乎等于“公主”的向量。因此,当你计算这个的时候,你会得到一个“公主”的向量
Vec ("Prince") – Vec("boy") + Vec("girl") ≈ Vec("Princess")这只是一个例子。这种情况在许多其他情况下都是有效的。这是 Word2vec 的一个特点,在估计相似词、下一个词、自然语言生成(NLG)等方面非常有用。
表 11-1 显示了其他参数的预训练模型。
表 11-1
Different Pretrained Models with Other Parameters
| 模型文件 | 维度数量 | 语料库规模 | 词汇量 | 体系结构 | 上下文窗口大小 | 作者 | | :-- | :-- | :-- | :-- | :-- | :-- | :-- | | 谷歌新闻 | Three hundred | 100B | 3M | Word2Vec | 弓,~5 | 谷歌 | | 免费基本 id | One thousand | 100B | 1.4 米 | Word2Vec,Skip-gram | 弓,~10 | 谷歌 | | 免费基础名称 | One thousand | 100B | 1.4 米 | Word2Vec,Skip-gram | 弓,~10 | 谷歌 | | 维基百科+ Gigaword 5 | Fifty | 6B | Four hundred thousand | 手套 | 10+10 | 手套 | | 维基百科+ Gigaword 5 | One hundred | 6B | Four hundred thousand | 手套 | 10+10 | 手套 | | 维基百科+ Gigaword 5 | Two hundred | 6B | Four hundred thousand | 手套 | 10+10 | 手套 | | 维基百科+ Gigaword 5 | Three hundred | 6B | Four hundred thousand | 手套 | 10+10 | 手套 | | 普通爬行器 42B | Three hundred | 42B | 1.9 米 | 手套 | 阿达格拉德 | 手套 | | 公共爬行器 840B | Three hundred | 840B | 2.2 米 | 手套 | 阿达格拉德 | 手套 | | 维基百科依赖性 | Three hundred | - | One hundred and seventy-four thousand | Word2Vec | 句法依赖 | 利维-戈德堡公司 | | DBPedia 载体(wiki2vec) | One thousand | - | - | Word2Vec | 弓,10 | 白痴 |构建响应
回复是聊天机器人的另一个重要部分。根据聊天机器人的回答,用户可能会被它吸引。无论何时制造聊天机器人,都应该记住一件事,那就是它的用户。你需要知道谁将使用它,以及它将用于什么目的。例如,一个餐馆网站的聊天机器人将只被询问餐馆和食物。所以,你或多或少知道会被问到什么问题。因此,对于每个意图,您存储多个答案,这些答案可以在识别意图后使用,这样用户就不会重复得到相同的答案。对于任何断章取义的问题,你也可以有一个意图;该意图可以有多个答案,并且随机选择,聊天机器人可以回复。
例如,如果意图是“你好”,你可以有多个回复,如“你好!你好吗?”和“你好!你过得怎么样?”和“嗨!有什么可以帮你的吗?”
聊天机器人可以随机选择任何一个来回答。
在下面的示例代码中,您从用户那里获取输入,但是在最初的聊天机器人中,意图是由聊天机器人根据用户提出的任何问题来定义的。
import random
intent = input()
output = ["Hello! How are you","Hello! How are you doing","Hii! How can I help you","Hey! There","Hiiii","Hello! How can I assist you?","Hey! What's up?"]
if(intent == "Hii"):
print(random.choice(output))
使用 API 开发聊天机器人
创建聊天机器人不是一件容易的事情。你需要一双关注细节的眼睛和敏锐的思维来构建一个可以很好使用的聊天机器人。构建聊天机器人有两种方法。
- 基于规则的方法
- 一种机器学习方法,通过简化数据使系统自行学习
一些聊天机器人本质上是基础的,而另一些则是更高级的人工智能大脑。能够理解自然语言并做出反应的聊天机器人使用人工智能大脑,技术爱好者正在利用 Api.ai 等各种资源来创建这种人工智能丰富的聊天机器人。
程序员正在利用以下服务来构建机器人:
- 微软机器人框架
- Wit.ai
- Api.ai
- IBM 的沃森
其他编程技能有限或没有编程技能的 bot 构建爱好者正在利用如下 bot 开发平台来构建聊天机器人:
- 聊天燃料
- Texit.in
- 辛烷 AI
- Motion.ai
有不同的 API 来分析文本。三大巨头如下:
- 微软 Azure 的认知服务
- 亚马逊 Lex
- 沃森机器人
微软 Azure 的认知服务
先说微软 Azure。
- 语言理解智能服务(LUIS):这提供了简单的工具,使您能够构建自己的语言模型(意图/实体),允许任何应用程序/机器人理解您的命令并相应地采取行动。
- 文本分析 API:它评估情感和主题,以了解用户想要什么。
- Translator Text API:自动识别语言,然后实时将其翻译成另一种语言。
- Web 语言模型 API:这将自动在缺少空格的字符串中插入空格。
- Bing 拼写检查 API:这使用户能够纠正拼写错误;认识名字、品牌名称和俚语之间的区别;并且在他们打字的时候理解同音字。
- 语言分析 API:这允许您使用词性标记来识别文本中的概念和动作,并使用自然语言解析器来查找短语和概念。这对于挖掘客户反馈非常有用。
亚马逊 Lex
Amazon Lex 是一项为任何使用语音和文本的应用程序构建对话界面的服务。不幸的是,没有同义词选项,也没有适当的实体提取和意图分类。
以下是使用 Amazon Lex 的一些重要好处:
- 很简单。它指导你创建聊天机器人。
- 它有深度学习算法。聊天机器人实现了 NLU 和自然语言处理等算法。Amazon 已经将这一功能集中起来,以便于使用。
- 它具有易于部署和扩展的特性。
- 它内置了与 AWS 平台的集成。
- 这是有成本效益的。
沃森机器人
IBM 提供了 IBM Watson API 来快速构建您自己的聊天机器人。在实现中,接近旅程和旅程本身一样重要。通过沃森对话式人工智能学习对话式设计的企业基础知识及其对您业务的影响,对于制定成功的行动计划至关重要。这种准备工作将使您能够交流、学习和对照标准进行监控,从而使您的企业能够构建一个客户就绪的成功项目。
对话式设计是构建聊天机器人最重要的部分。首先要明白的是,用户是谁,想达到什么目的。
IBM Watson 有很多技术,你可以很容易地集成到你的聊天机器人中;其中一些是沃森对话,沃森声调分析器,语音到文本,等等。
聊天机器人开发的最佳实践
在构建聊天机器人时,了解可以利用某些最佳实践是很重要的。这将有助于创建一个成功的用户友好的机器人,它可以实现与用户进行无缝对话的目的。
在这种关系中,最重要的事情之一是充分了解目标受众。接下来是其他的事情,比如识别用例场景,设定聊天的基调,以及识别消息传递平台。
通过遵循以下最佳实践,确保与用户无缝对话的愿望可以成为现实。
了解潜在用户
彻底了解目标受众是构建成功 bot 的第一步。下一步是了解创建机器人的目的。
以下是需要记住的几点:
- 知道具体 bot 的目的是什么。它可以是一个娱乐观众、方便用户交易、提供新闻或作为客户服务渠道的机器人。
- 通过了解客户的产品,使机器人对客户更加友好。
阅读用户情感,让机器人在情感上更加丰富
聊天机器人应该像人类一样热情友好,这样才能让对话成为一次美好的经历。它必须聪明地阅读并理解用户的情绪,以推广能够提示用户继续对话的内容块。如果第一次的体验是丰富的,用户将被鼓励再次访问。
以下是需要记住的几点:
- 推广你的产品或利用积极情绪将用户转化为品牌大使。
- 迅速处理负面评论,以便在对话游戏中保持活力。
- 只要有可能,使用友好的语言,让用户感觉他们在和一个熟悉的人交流。
- 通过重复输入让用户感到舒服,并确保他们能够理解所讨论的一切。
十二、人脸检测和识别
人脸检测是在图像或视频中检测人脸的过程。
人脸识别是检测图像中的人脸,然后使用算法来识别人脸属于谁的过程。因此,人脸识别是一种身份识别形式。
你首先需要从图像中提取特征,用于训练机器学习分类器识别图像中的人脸。这些系统不仅是非主观的,而且是自动的——不需要手动标记面部特征。您只需从面部提取特征,训练您的分类器,然后使用它来识别后续的面部。
因为对于人脸识别,首先需要从图像中检测人脸,所以可以将人脸识别视为两个阶段。
- 阶段 1:使用诸如 Haar cascades、HOG +线性 SVM、深度学习或任何其他可以定位人脸的算法来检测图像或视频流中的人脸的存在。
- 第二阶段:取定位阶段检测到的每一张脸,了解这张脸属于谁——这是你实际上给一张脸命名的地方。
人脸检测、人脸识别和人脸分析
人脸检测、人脸识别和人脸分析是有区别的。
- 人脸检测:这是一种在图像中找到所有人脸的技术。
- 人脸识别:这是人脸检测之后的下一步。在人脸识别中,您可以使用现有的图像库来识别哪张脸属于哪个人。
- 面部分析:检查一张脸,从中推断出年龄、肤色等等。
开放计算机视觉
OpenCV 提供了三种人脸识别方法(见图 12-1 ):
- 特征脸
- 局部二元模式直方图
- 鱼脸

图 12-1
Applying OpenCV methods to faces
这三种方法都是通过将人脸与一些已知人脸的训练集进行比较来识别人脸的。为了训练,你给算法提供人脸,并用他们所属的人给他们贴上标签。当你使用该算法来识别某个未知人脸时,它使用在训练集上训练的模型来进行识别。上述三种方法中的每一种使用的训练集都略有不同。
拉普拉斯人脸可以是识别人脸的另一种方式。
特征脸
eigenfaces 算法使用主成分分析来构建人脸图像的低维表示,您将使用它作为相应人脸图像的特征(图 12-2 )。

图 12-2
Applying Eigenvalue decomposition and extracting 11 eigenfaces with the largest magnitude
为此,您可以收集一个人脸数据集,其中包含您想要识别的每个人的多张人脸图像,这就像您想要在图像分类中标记的一个图像类有多个训练样本一样。有了这个面部图像的数据集,假定它们具有相同的宽度和高度,并且理想情况下它们的眼睛和面部结构在相同的(x,y)坐标上对齐,您可以应用数据集的特征值分解,保留具有最大相应特征值的特征向量。
给定这些特征向量,人脸就可以表示为 Kirby 和 Sirovich 所说的特征脸的线性组合。特征脸算法查看整个数据集。
LBPH 值
您可以在 LBPH 中独立分析每张图像。LBPH 方法稍微简单一些,因为您可以在本地描述数据集中每个图像的特征;当提供新的未知图像时,您对其执行相同的分析,并将结果与数据集中的每个图像进行比较。分析图像的方法是描述图像中每个位置的局部模式。
本征脸算法依靠 PCA 来构建人脸图像的低维表示,而局部二进制模式(LBP)方法,顾名思义,依靠特征提取。
Ahonen 等人在 2006 年的论文“使用局部二进制模式进行人脸识别”中首次介绍了这种方法,该方法建议将人脸图像划分为 7×7 大小相等的网格(图 12-3 )。

图 12-3
Applying LBPH for face recognition starts by dividing the face image into a 7x7 grid of equally sized cells
然后,从 49 个单元中的每一个提取局部二进制模式直方图。通过将图像划分为单元,您将局部性引入到最终的特征向量中。此外,中心的单元具有更大的权重,因此它们对整体表示的贡献更大。与网格中心的细胞(包含眼睛、鼻子和嘴唇结构)相比,角落的细胞携带的识别面部信息较少。最后,您连接来自 49 个单元的加权 LBP 直方图,以形成您的最终特征向量。
鱼脸
主成分分析(PCA)是本征脸方法的核心,它寻找使数据的总方差最大化的特征的线性组合。虽然这显然是表示数据的一种强有力的方法,但它没有考虑任何类,因此在丢弃组件时可能会丢失许多有区别的信息。想象一种情况,你的数据中的差异是由外部来源产生的,让它成为光。由 PCA 识别的成分不一定包含任何区别信息,因此投影的样本被涂抹在一起,分类变得不可能。
线性判别分析执行特定类别的维度缩减,由伟大的统计学家 R. A. Fisher 爵士发明。分类问题中多重测量的使用。为了找到在类之间分离得最好的特征组合,线性判别分析最大化类间与类内分散的比率,而不是最大化整体分散。这个想法很简单:相同的类应该紧密地聚集在一起,而不同的类在低维表示中彼此尽可能地远离。
检测人脸
执行人脸识别所需的第一个功能是检测当前图像中人脸出现的位置。在 Python 中,您可以使用 OpenCV 库的 Haar 级联过滤器来有效地做到这一点。
对于这里展示的实现,我将 Anaconda 与 Python 3.5、OpenCV 3.1.0 和 dlib 19.1.0 一起使用。要使用以下代码,请确保您拥有这些(或更新的)版本。
要进行面部检测,必须进行一些初始化,如下所示:
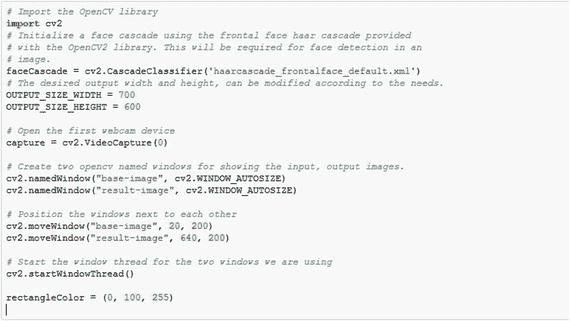
剩下的代码将是一个无限循环,不断从网络摄像头获取最新的图像,检测检索到的图像中的所有人脸,在检测到的最大人脸周围绘制一个矩形,然后最终在一个窗口中显示输入、输出图像(图 12-4 )。

图 12-4
A sample output showing detected face
您可以在无限循环中使用以下代码来实现这一点:



跟踪面部
以前的人脸检测代码有一些缺点。
- 该代码可能计算量很大。
- 如果被检测的人稍微转头,哈尔级联可能检测不到面部。
- 很难在帧间跟踪一张脸。
更好的方法是检测一次人脸,然后利用优秀的 dlib 库中的相关跟踪器来逐帧跟踪人脸。
为此,您需要导入另一个库并初始化其他变量。

在无限for循环中,您现在将确定 dlib 关联跟踪器当前是否正在跟踪图像中的一个区域。如果不是这种情况,您将使用与前面类似的代码来查找最大的面,但不是绘制矩形,而是使用找到的坐标来初始化相关性跟踪器。


现在,无限循环中的最后一点是再次检查相关性跟踪器是否正在主动跟踪人脸(即,它是否刚刚检测到具有先前代码的人脸,trankingFace=1?)。如果追踪器正在积极追踪图像中的人脸,您将更新追踪器。根据更新的质量(例如,追踪器对是否仍在追踪同一张脸有多大把握),您可以在追踪器指示的区域周围画一个矩形,或者指示您不再追踪一张脸。

从代码中可以看出,每次再次使用检测器时,都会向控制台打印一条消息。如果您在运行该应用程序时查看控制台的输出,您会注意到,即使您在屏幕上移动了相当多的距离,追踪器也会很好地跟踪检测到的人脸。
人脸识别
人脸识别系统通过将每帧视频中的人脸与训练图像进行匹配来识别视频帧中出现的人的姓名,如果帧中的人脸匹配成功,则返回标签(并写入 CSV 文件中)。现在你将看到如何一步一步地创建一个人脸识别系统。
首先,导入所有需要的库。face_recognition 是一个简单的库,使用 dlib 最先进的人脸识别技术构建,也是通过深度学习构建的。

Argparse 是一个 Python 库,允许您向文件中添加自己的参数;然后,它可以用于在执行时输入任何图像目录或文件路径。

在前面的代码中,在运行这个 Python 文件时,您必须指定以下内容:训练输入图像目录、我们将用作数据集的视频文件,以及用于在每个时间帧写入输出的输出 CSV 文件。


通过使用上述功能,可以读取指定文件夹中的所有图像文件。
以下函数使用已知的训练图像测试输入帧:

现在您定义函数来提取匹配的已知图像的标签。

读取输入视频以提取测试帧。

现在定义训练集的标签。然后匹配从给定输入视频中提取的帧,以获得所需的结果。

基于深度学习的人脸识别
导入必要的包。

初始化变量。

label_img()函数用于创建标签数组,detect_faces()函数检测图像中的人脸部分。

create_train_data()函数用于预处理训练数据。

process_test_data()函数用于对测试数据进行预处理。
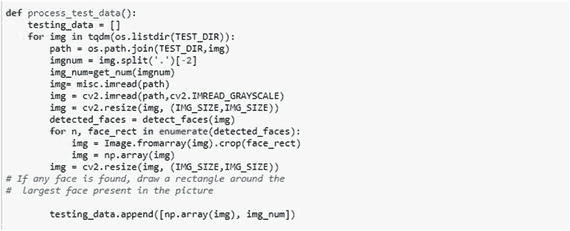
然后创建模型,并在模型中拟合训练数据。

最后,您准备测试数据并预测输出。

迁移学习
迁移学习利用在解决一个问题时获得的知识,并将其应用于另一个不同但相关的问题。
在这里,您将看到如何使用名为 Inception v3 模型的预训练深度神经网络对图像进行分类。
Inception 模型能够从图像中提取有用的信息。
为什么要转学?
众所周知,卷积网络需要大量的数据和资源来训练。
使用迁移学习和微调(也就是说,将在以前的项目(如 ImageNet)中训练的网络权重转移到新的任务中)已经成为研究人员和实践者的规范。
您可以采取两种方法。
- 迁移学习:你可以拿一个已经在 ImageNet 上预先训练好的 CNN,去掉最后一个完全连接的层,然后把 CNN 的其余部分当作新数据集的特征提取器。一旦提取了所有图像的特征,就可以为新的数据集训练一个分类器。
- 微调:您可以在 CNN 上替换和重新训练分类器,还可以通过反向传播微调预训练网络的权重。
迁移学习示例
在这个例子中,首先您将尝试通过直接加载 Inception v3 模型来对图像进行分类。
导入所有需要的库。

现在为模型定义存储目录,然后下载 Inception v3 模型。

加载预训练的模型并定义函数来对任何给定的图像进行分类。
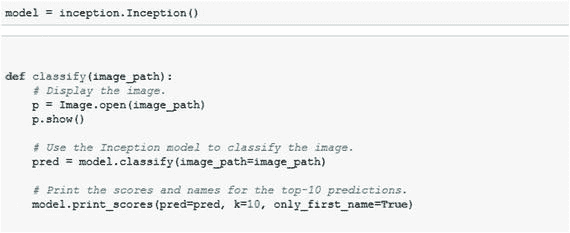
现在模型已经定义好了,让我们检查一些图片。

这给出了 91.11%的正确结果,但是现在如果你检查某个人,你会得到这样的结果:
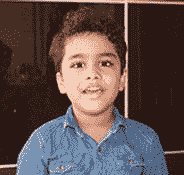
是 48.50%的网球!
不幸的是,盗梦空间模型似乎无法对人的图像进行分类。这样做的原因是用于训练初始模型的数据集,它对于类有一些令人困惑的文本标签。
相反,您可以重用预训练的初始模型,仅仅替换最终分类的层。这就是所谓的迁移学习。
首先,您使用 Inception 模型输入并处理一个图像。就在初始模型的最终分类层之前,您将所谓的转移值保存到一个缓存文件中。
使用缓存文件的原因是,使用 Inception 模型处理图像需要很长时间。当新数据集中的所有图像都已经通过初始模型进行了处理,并且所得到的传递值被保存到缓存文件中时,那么您可以使用这些传递值作为另一个神经网络的输入。然后,您将使用新数据集中的类来训练第二个神经网络,以便网络学习如何基于来自初始模型的转移值来对图像进行分类。
这样,初始模型用于从图像中提取有用的信息,然后另一个神经网络用于实际的分类。
计算转移价值
从初始文件中导入transfer_value_cache函数。
到目前为止,传输值存储在缓存文件中。现在您将创建一个新的神经网络。
定义网络。
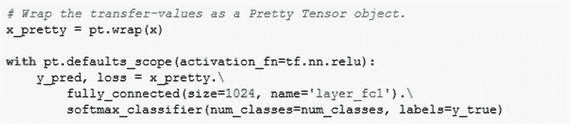
下面是优化方法:

下面是分类精度:

下面是 TensorFlow 运行:

下面是执行批量训练的帮助器函数:

为了优化,下面是代码:


为了绘制混淆矩阵,下面是代码:

以下是计算分类的辅助函数:





现在让我们运行它。
from datetime import timedelta
optimize(num_iterations=1000)
Global Step: 13100, Training Batch Accuracy: 100.0%
Global Step: 13200, Training Batch Accuracy: 100.0%
Global Step: 13300, Training Batch Accuracy: 100.0%
Global Step: 13400, Training Batch Accuracy: 100.0%
Global Step: 13500, Training Batch Accuracy: 100.0%
Global Step: 13600, Training Batch Accuracy: 100.0%
Global Step: 13700, Training Batch Accuracy: 100.0%
Global Step: 13800, Training Batch Accuracy: 100.0%
Global Step: 13900, Training Batch Accuracy: 100.0%
Global Step: 14000, Training Batch Accuracy: 100.0%
Time usage: 0:00:36
print_test_accuracy(show_example_errors=True,
show_confusion_matrix=True)
Accuracy on Test-Set: 83.2% (277 / 333)
Example errors:
Confusion Matrix:
[108 3 5] (0) Aamir Khan
[0 83 22] (1) Salman Khan
[4 22 86] (2) Shahrukh Khan
(0) (1) (2)
蜜蜂
许多易于使用的 API 也可用于人脸检测和人脸识别任务。
以下是面部检测 API 的一些示例:
- piclab
- Trueface.ai
- 决定的吉时
- 微软计算机视觉
以下是面部识别 API 的一些示例:
- Face++
- 拉姆达实验室
- KeyLemon
- piclab
如果你想从一个提供商那里获得人脸检测、人脸识别和人脸分析,目前有三大巨头在这方面领先。
- 亚马逊的亚马逊识别 API
- 微软 Azure 的 Face API
- IBM Watson 的视觉识别 API
亚马逊的亚马逊识别 API 可以做四种类型的识别。
- 对象和场景检测:识别识别各种有趣的对象,如车辆、宠物或家具,并提供置信度得分。
- 面部分析:您可以在图像中定位面部并分析面部属性,如面部是否微笑或眼睛是否睁开,并具有一定的置信度。
- 面部对比:亚马逊的亚马逊识别 API 可以让你测量两张图片中的面部是同一个人的可能性。不幸的是,同一个人的两张脸的相似性度量取决于照片拍摄时的年龄。此外,面部照明的局部增加会改变面部比较的结果。
- 面部识别:API 使用私有存储库识别给定图像中的人。它又快又准。
微软 Azure 的 Face API 将返回一个置信度分数,以确定这两张脸属于一个人的可能性有多大。微软还有其他 API,如下所示:
- 计算机视觉 API:这个特性返回图像中可视内容的信息。它可以使用标记、描述和特定于领域的模型来识别内容并满怀信心地对其进行标记。
- 内容审核 API:这可以检测潜在的攻击性或不需要的图像、各种语言的文本和视频内容。
- Emotion API:它分析人脸来检测一系列的感觉,并个性化你的应用程序的响应。
- 视频 API:这产生稳定的视频输出,检测运动,创建智能缩略图,检测和跟踪人脸。
- 视频索引器:这可以在视频中发现一些见解,例如语音实体、语音的情感极性和音频时间轴。
- 定制视觉服务:这将根据内置模型或通过您提供的训练数据集构建的模型来标记新图像。
IBM Watson 的视觉识别 API 可以进行一些特定的检测,例如:
- 它可以确定人的年龄。
- 它可以确定人的性别。
- 它可以确定一个面周围的边界框的位置。
- 它可以返回在图像中检测到的名人的信息。(未检测到名人时不返回此信息。)

















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









