







七、循环神经网络
随着深度学习的出现,自然语言处理(NLP)领域已经见证了显著的增长。这种运动很大程度上可以归功于循环神经网络(RNNs)及其变体。基于语音的 AI 助手、智能手机键盘中文本的自动完成以及基于情感分类的基于文本的评论都是 RNNs 有效解决的问题。
本章首先探讨与 RNNs 相关的基本概念。然后,我们探索更适合现代计算任务的香草 RNN 模型的几个变种。最后,我们将在从我们最喜欢的平台 Kaggle 借来的真实数据集上使用 PyTorch 研究 RNN 的实际实现。
让我们开始吧。
RNNs 简介
循环神经网络(RNNs)本质上是采用递归的神经网络,其使用来自神经网络上的前向传递的信息。本质上,所有的 rnn 都可以描述为一个递归关系。rnn 适用于这样的问题,并且在应用于这些问题时取得了令人难以置信的成功,在这些问题中,要对其进行预测的输入数据是序列形式的(顺序很重要的一系列实体)。序列数据的例子包括时间序列、自然语言处理、语音分析等。
图 7-1 展示了一个规则的 RNN 是如何展开(随时间)形成一个循环神经网络的。在下一节中,我们将探讨 RNN 利用的基础。
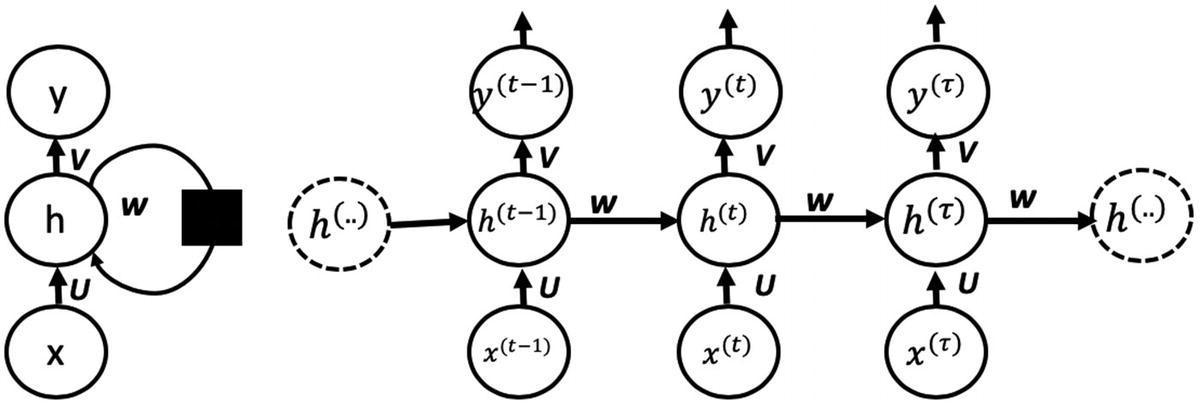
图 7-1
一个正规的 RNN 展开了(来源——深度学习www . Deep Learning book . org/contents/rnn . html
让我们从描述 RNN 的运动部件开始。首先,我们介绍一些符号。我们将假设输入由一系列实体组成x【1】, x (2) ,…,x()。对应于这个输入,我们需要产生一个序列y*【1】,y【2】,…,y(τ)或者整个输入序列 y (或者一个不同长度的序列)。不同架构的 RNN 将为不同的用例提供解决方案。图 7-2 展示了基于输入输出长度的 RNN 类型。*
*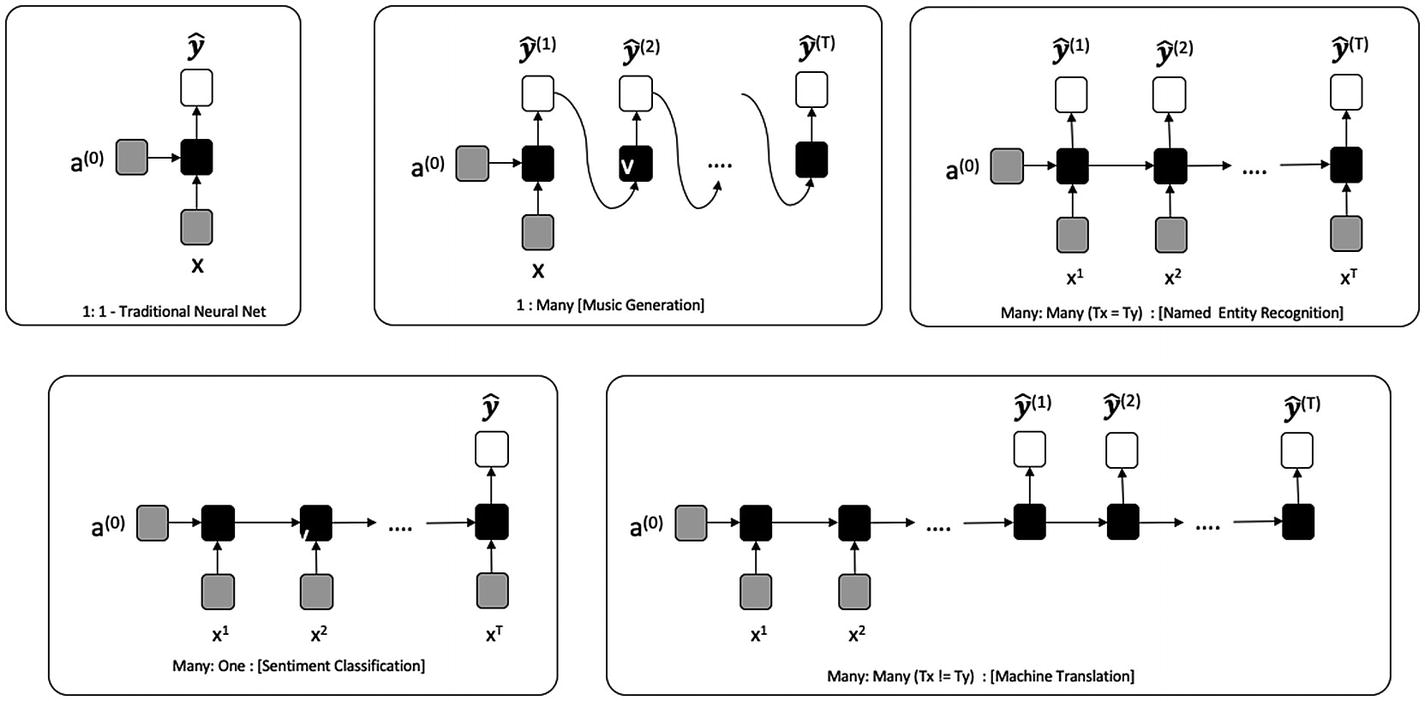
图 7-2
基于输入和输出长度的 RNN 类型
当我们有一个不利用来自先前状态的信息的 RNN 时,我们有一个传统的神经网络。然而,随着循环的出现,我们有了几种新的可能性。如今,NLP 中最常见的用例围绕着多对一和多对多模型。示例包括命名实体识别和机器翻译(例如,将文档从法语翻译成英语)。本章探索了几个简单的例子,但是深入讨论每个变体超出了本书的范围。强烈建议读者独立探索命名实体识别、机器翻译(以及可选的音乐生成)。
让我们从基础开始。
为了区分 RNN 生产的产品(即预测)和理想预期生产的产品(即实际),我们用 RNN 生产的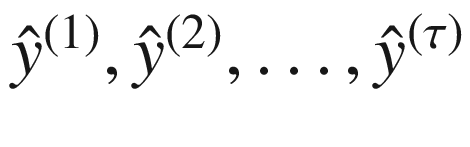 或
或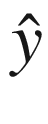 来表示预测。
来表示预测。
类似地,我们将表示基本事实,即 RNN 应该理想产生的实际值,表示为y【1】,y【2】,…, y ( τ ) 。图 7-3 显示了 RNN 产生的输出(预测)为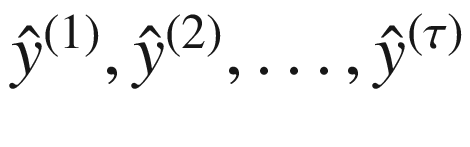 。为了计算与实际值的差异,我们将比较这些生成的输出与实际值,表示为y【1】,y【2】,…,y()。
。为了计算与实际值的差异,我们将比较这些生成的输出与实际值,表示为y【1】,y【2】,…,y()。
*rnn 或者为输入序列中的每个实体产生一个输出(多对多),或者为整个序列产生一个输出(多对一),如图 7-2 所示。让我们考虑一个 RNN,它为输入中的每个实体产生一个输出(本质上指的是图 7-1 中所示的展开的网络)。
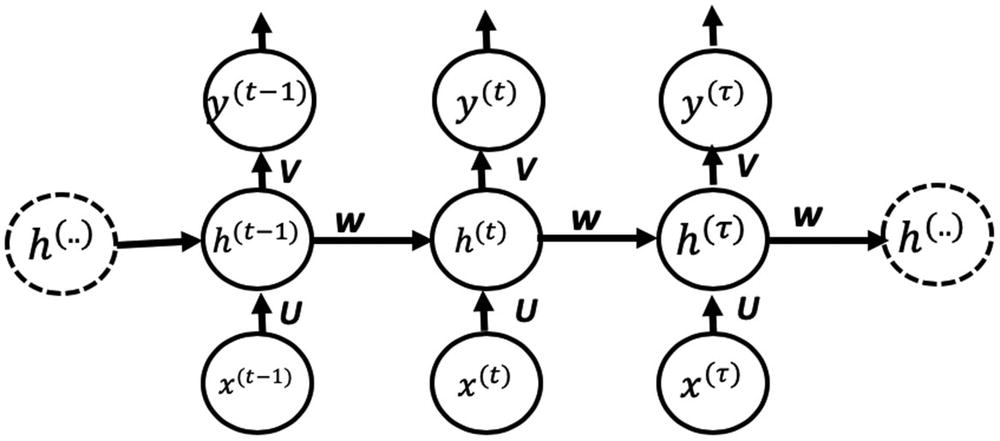
图 7-3
展开的 RNN(多对多),代表图形 7-1 的一部分
可以使用以下等式来描述 RNN:
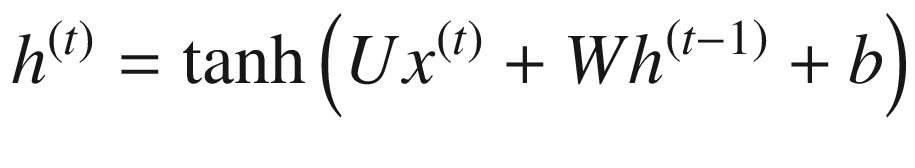
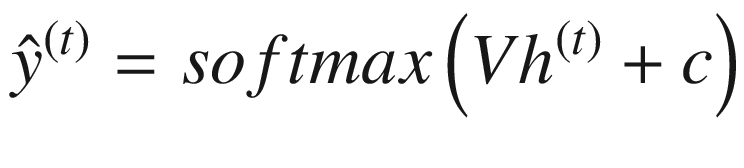
U 是网络输入的权重, V 是激活函数输出的权重, W 是当前隐藏状态的权重矩阵。
关于 RNN 方程,应注意以下几点:
-
RNN 计算包括计算序列中实体的隐藏状态。这用 h ( t ) 来表示。
-
h ( t ) 的计算使用实体 x ( t ) 处的相应输入和之前的隐藏状态h(t—1)。
-
使用隐藏状态h(t)计算输出
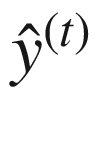 。
。 -
在计算当前隐藏状态时,一组权重与输入和前一隐藏状态相关联。这分别由 U 和 W 表示。还有一个偏差项,用 b 表示。
-
类似地,在计算输出时,一组权重也与当前隐藏状态相关联。这由 V 表示。还有一个偏差项,用 c 表示。
-
此外,在计算隐藏状态时,使用了
tanh激活函数(在前面的章节中介绍过)。 -
softmax激活功能用于输出的计算。 -
如等式所述,RNN 可以处理任意大的输入序列。
-
RNN 的参数— U 、 W 、 V 、 b 、 c 等。-在隐藏层和输出值的计算中共享(对于序列中的每个图元)。
图 7-4 显示了 RNN。注意隐藏状态下与自循环的递归关系。

图 7-4
RNN(使用以前的隐藏状态重复)
图 7-4 还描述了与每个输入相关的每个输出的损失函数。当讨论如何训练 rnn 时,我们将回头参考它。
将 RNN 与我们之前讨论的所有前馈神经网络(包括卷积网络)的不同内在化是至关重要的。关键的区别是隐藏状态,它表示过去看到的实体的汇总(对于同一序列)。
暂时忽略如何训练 RNN,应该清楚如何使用训练过的 RNN。对于给定的输入序列,RNN 将为输入中的每个实体生成一个输出。
现在让我们考虑 RNN 中的一种变化,其中我们使用前一状态产生的输出来代替使用隐藏状态的递归(图 7-5 )。
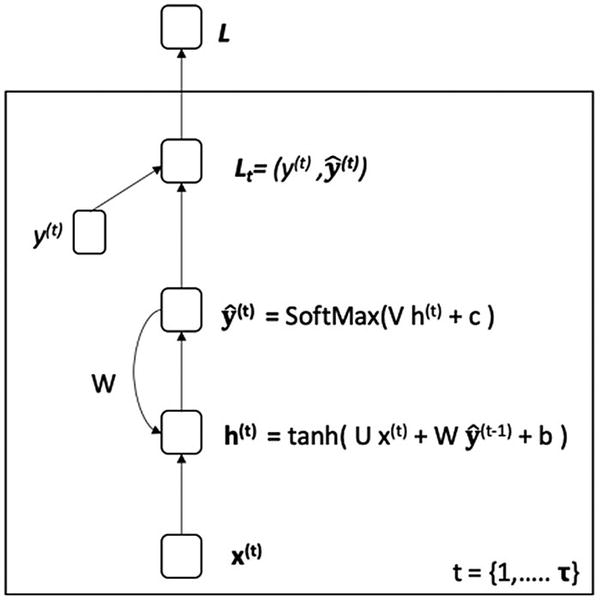
图 7-5
RNN(使用先前输出的递归)
描述这样一个 RNN 的方程式如下:
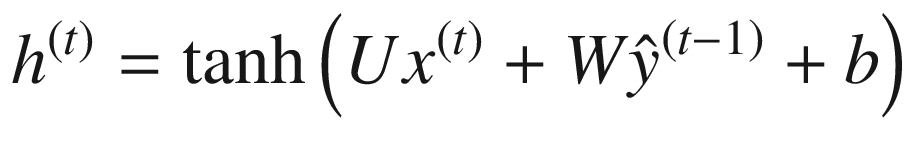
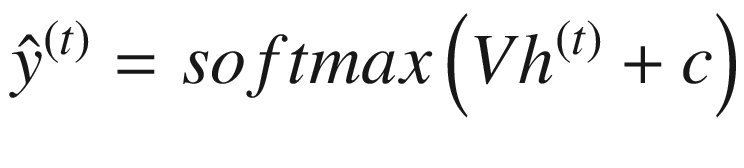
应注意以下几点:
-
RNN 计算包括计算序列中实体的隐藏状态。这用 h ( t ) 来表示。
-
h ( t ) 的计算使用实体 x ( t ) 的相应输入和先前的输出
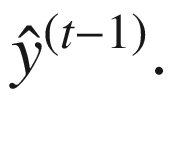
-
使用隐藏状态h(t)计算输出
 。
。 -
在计算当前隐藏状态时,一组权重与输入和先前输出相关联。这分别由 U 和 W 表示。还有一个偏差项,用 c 表示。
-
计算输出时,权重与隐藏状态相关联。这由 V 表示。还有一个偏差项,用 c 表示。
-
tanh激活函数用于隐藏状态的计算。 -
softmax 激活函数用于计算输出。
现在让我们考虑 RNN 的一种变体,其中整个序列只产生一个输出(图 7-6 )。这样的 RNN 是使用以下等式来描述的:
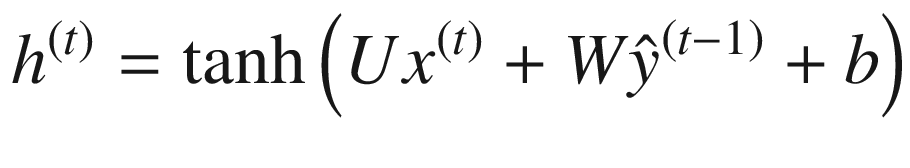
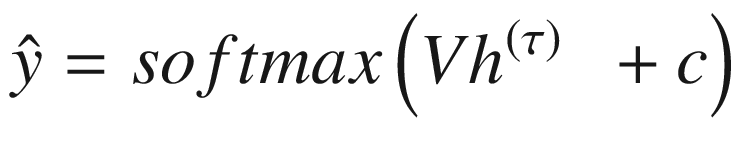
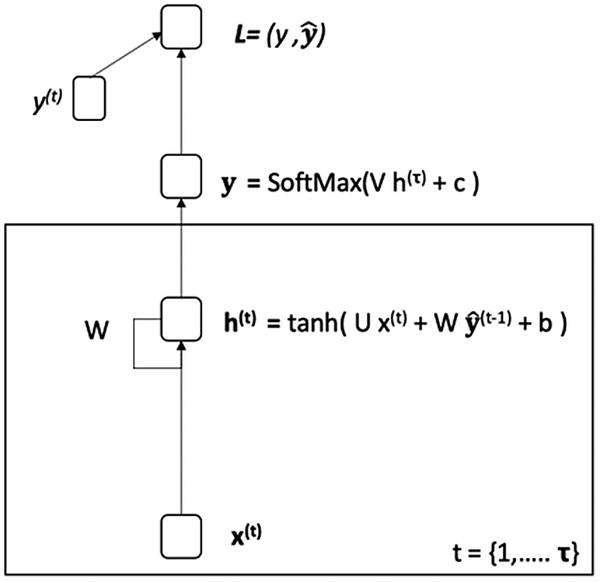
图 7-6
RNN(为整个输入序列产生单个输出)
应注意以下几点:
-
RNN 计算包括计算序列中实体的隐藏状态。这用 h ( t ) 来表示。
-
h ( t ) 的计算使用实体 x ( t ) 处的相应输入和之前的隐藏状态h(t—1)。
-
对输入序列x(1)x(2),…,x(τ)中的每个实体进行 h ( t ) 的计算。
-
仅使用最后一个隐藏状态h??(τ)来计算输出
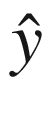 。
。 -
在计算当前隐藏状态时,一组权重与输入和前一隐藏状态相关联。这分别由 U 和 W 表示。还有一个偏差项,用 b 表示。
-
计算输出时,权重与隐藏状态相关联。这由 V 表示。还有一个偏差项,用 c 表示。
-
tanh激活函数用于隐藏状态的计算。 -
softmax 激活函数用于计算输出。
培训注册护士
本节描述了如何训练注册护士。我们首先需要看看当我们展开递归关系时,RNN 是什么样子的,递归关系是 RNN 的核心。展开对应于 RNN 的递归关系只是通过递归地替换定义递归关系的值来写出方程。
在图 7-1 中的 RNN 的情况下,这是h??(t)。也就是说, h ( t ) 的值由h(t—1)定义,依次由h(t—2)定义,以此类推,直到 h (0) 我们将假设 h (0) 或者由用户预定义,设置为零,或者作为另一个参数/权重被学习(像 W 、 V 或 b 一样被学习)。展开简单来说就是写出用 h (0) 描述 RNN 的方程。当然,为了做到这一点,我们需要确定序列的长度,用 τ 表示。在这一节中,我们将探索展开我们上面探索的几个不同的 rnn。我们将从展开 RNN 开始,之前的隐藏状态用于递归(如图 7-3 所示)。稍后,我们也将探索同样的 RNN 使用以前的输出进行递归,并最终展开一个单输出的 RNN。
图 7-7 示出了与图 7-4 中的 RNN 相对应的展开的 RNN,假设输入序列的大小为 4。类似地,图 7-8 和图 7-9 分别示出了与图 7-5 和图 7-6 所示的 rnn 相对应的展开的 rnn。
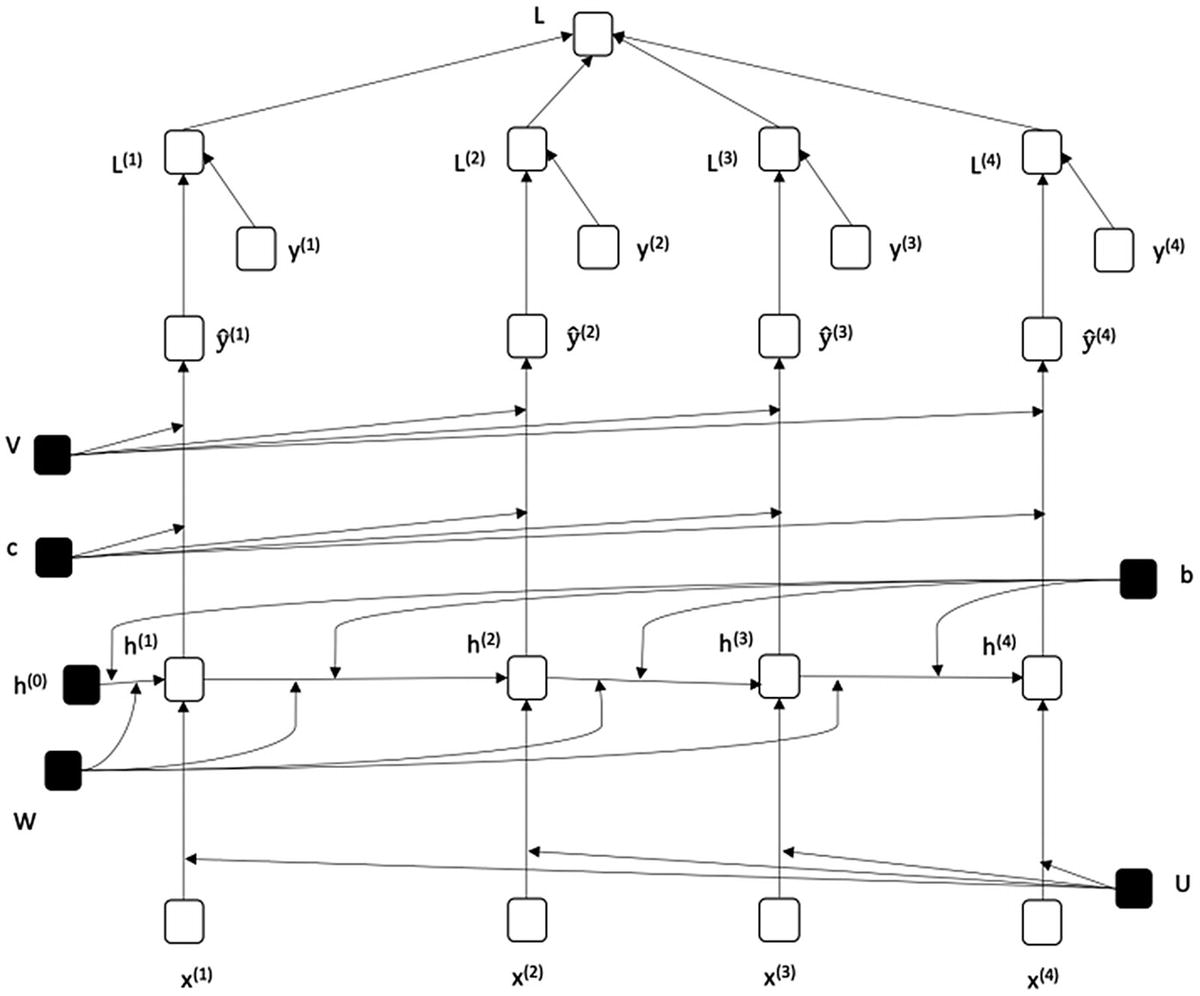
图 7-7
展开图 7-4 对应的 RNN
图 7-7 展开图 7-4 所示的递归网络——即递归单元从之前的隐藏状态开始添加。我们可以通过将 h 0 传递给 h 1 来注意到这一点,这是 x (1) 的隐藏状态。类似地,隐藏状态 h 3 被传递到 h 4 ,这是本图中的最后一步。权重 W 和偏差 b 在重复单元之间共享。
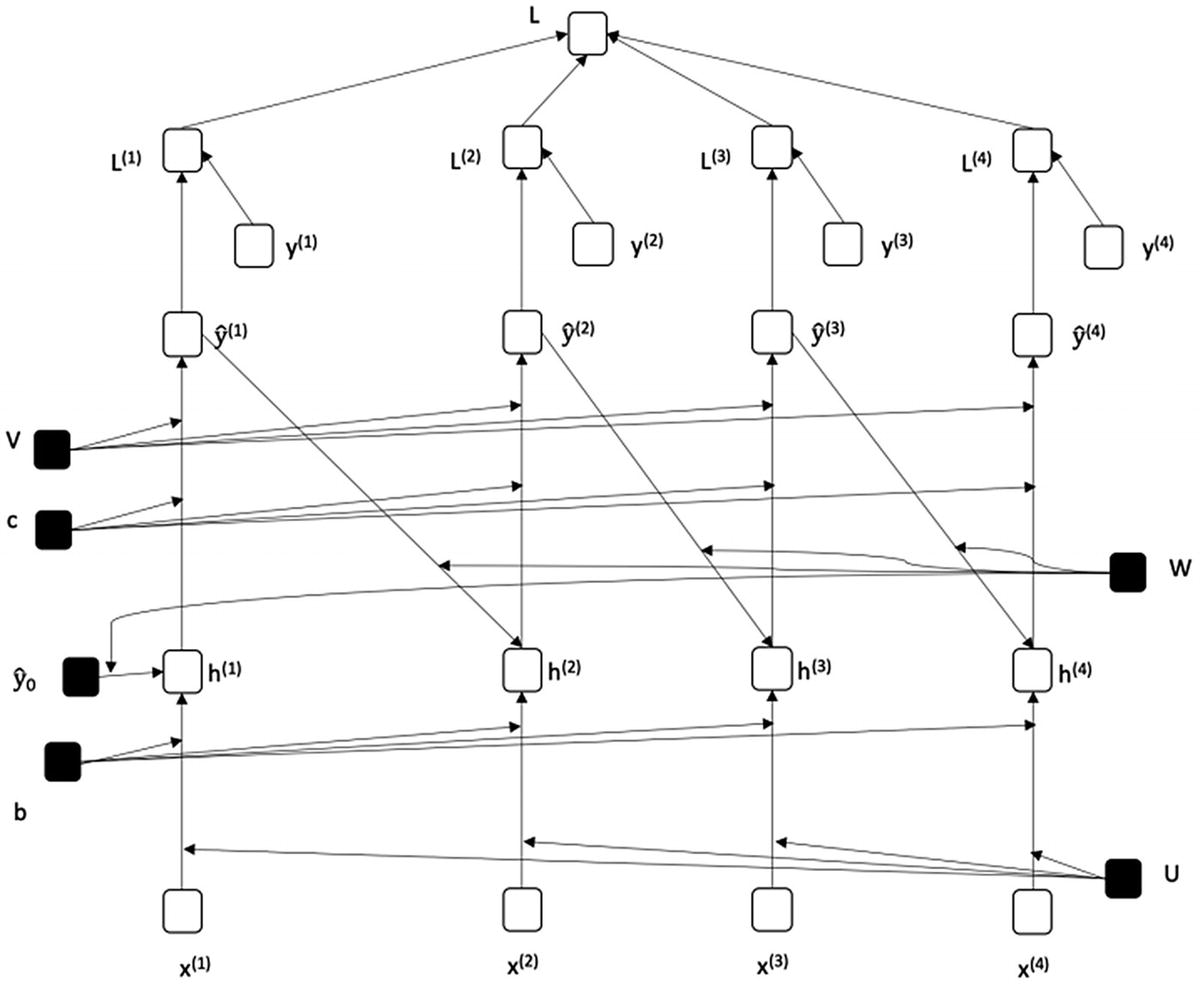
图 7-8
展开图 7-5 对应的 RNN
图 7-8 展开图 7-5 所示的递归网络——即从之前的输出状态增加递归单元。我们可以通过引用传递给 h 1 的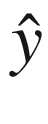 (0) 来注意到这一点,即 x (1) 的隐藏状态。类似地,输出状态
(0) 来注意到这一点,即 x (1) 的隐藏状态。类似地,输出状态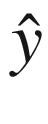 (3) 被传递到 h 4 ,这是本图中的最后一步。权重 W 和偏差 b 在重复单元之间共享。
(3) 被传递到 h 4 ,这是本图中的最后一步。权重 W 和偏差 b 在重复单元之间共享。

图 7-9
展开图 7-6 对应的 RNN(单输出)
展开过程基于输入序列的长度预先已知的假设进行操作,并基于此展开递归。一旦 RNN 展开,我们基本上就有了一个非循环神经网络。
需要学习的参数— U 、 W 、 V 、 b 、 c 等。(在图 7-9 中用黑色表示)-在隐藏层和输出值的计算中共享。我们之前在卷积神经网络的上下文中已经看到了这样的参数共享。
给定给定大小的输入和输出(例如, τ ,在图 7-7 到 7-9 中假设为 4),我们可以展开 RNN,并计算要学习的参数相对于损失函数的梯度(如前面章节所述)。
因此,训练 RNN 简单地首先展开给定大小的输入和相应的期望输出的 RNN,然后通过计算梯度和使用随机梯度下降来训练展开的 RNN。
如前所述,RNNs 可以处理任意长的输入;相应地,它们需要在任意长的输入上被训练。图 7-10 至 7-12 展示了如何针对不同尺寸的输入展开 RNN。请注意,一旦 RNN 展开,训练 RNN 的过程与训练常规神经网络的过程相同,如前几章所述。在图 7-101-7-11 . 1 . 3 中,图 7-4 中描述的 RNN 对于输入尺寸 1、2、3 和 4 展开。
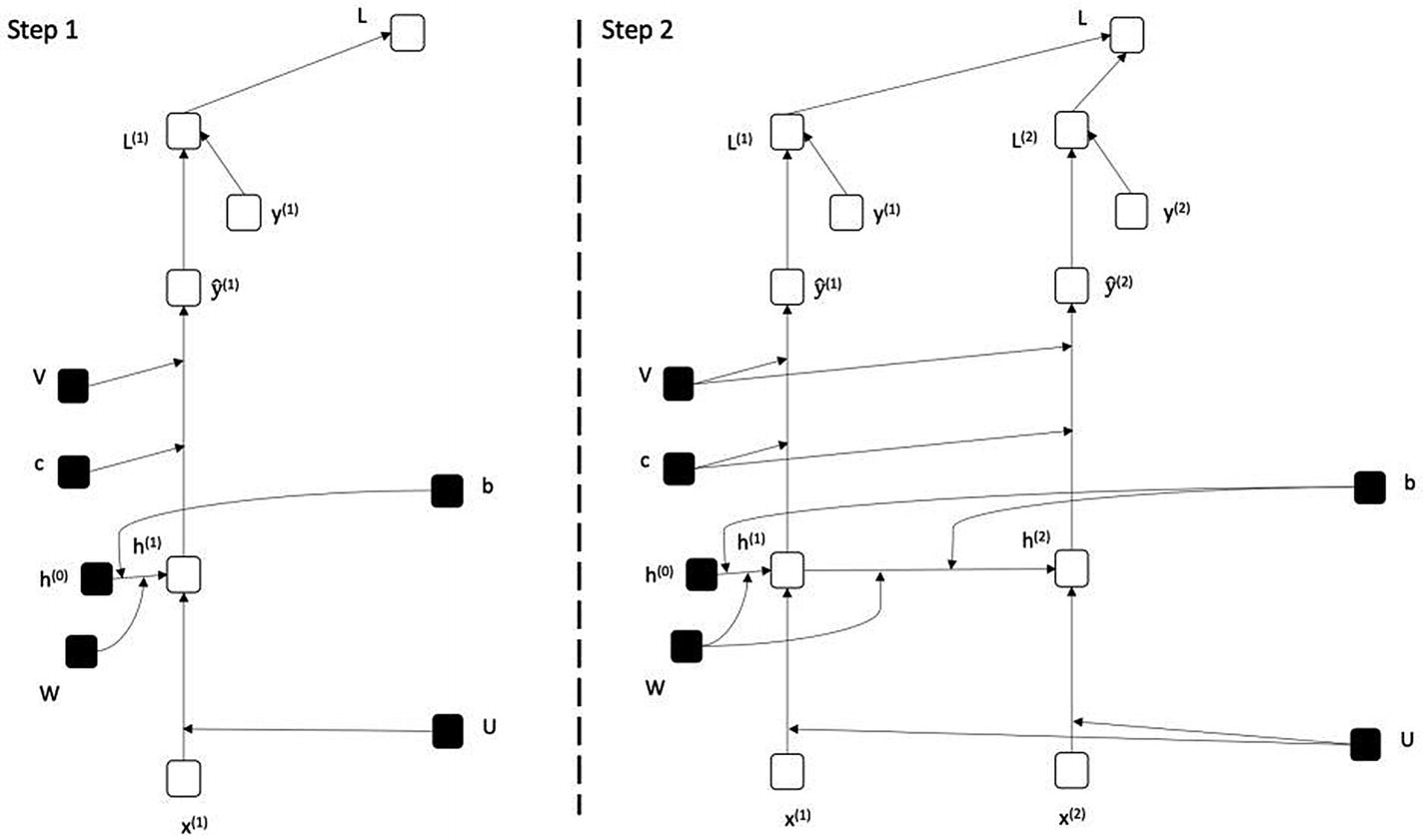
图 7-10
展开图 7-4 对应的 RNN(步骤 1 和步骤 2)
图 7-10 展示了步骤 1 和步骤 2——即依次展开输入序列 x (1) 和 x (2) 。在步骤 1 中,假设我们没有先前的隐藏状态,我们将 h (0) 传递给当前的隐藏状态。在图 7-10 中,我们将时间序列限制为展开,即τ= 4;因此,网络展开为 4 步。图 7-11 和图 7-12 依次演示了增量展开步骤。
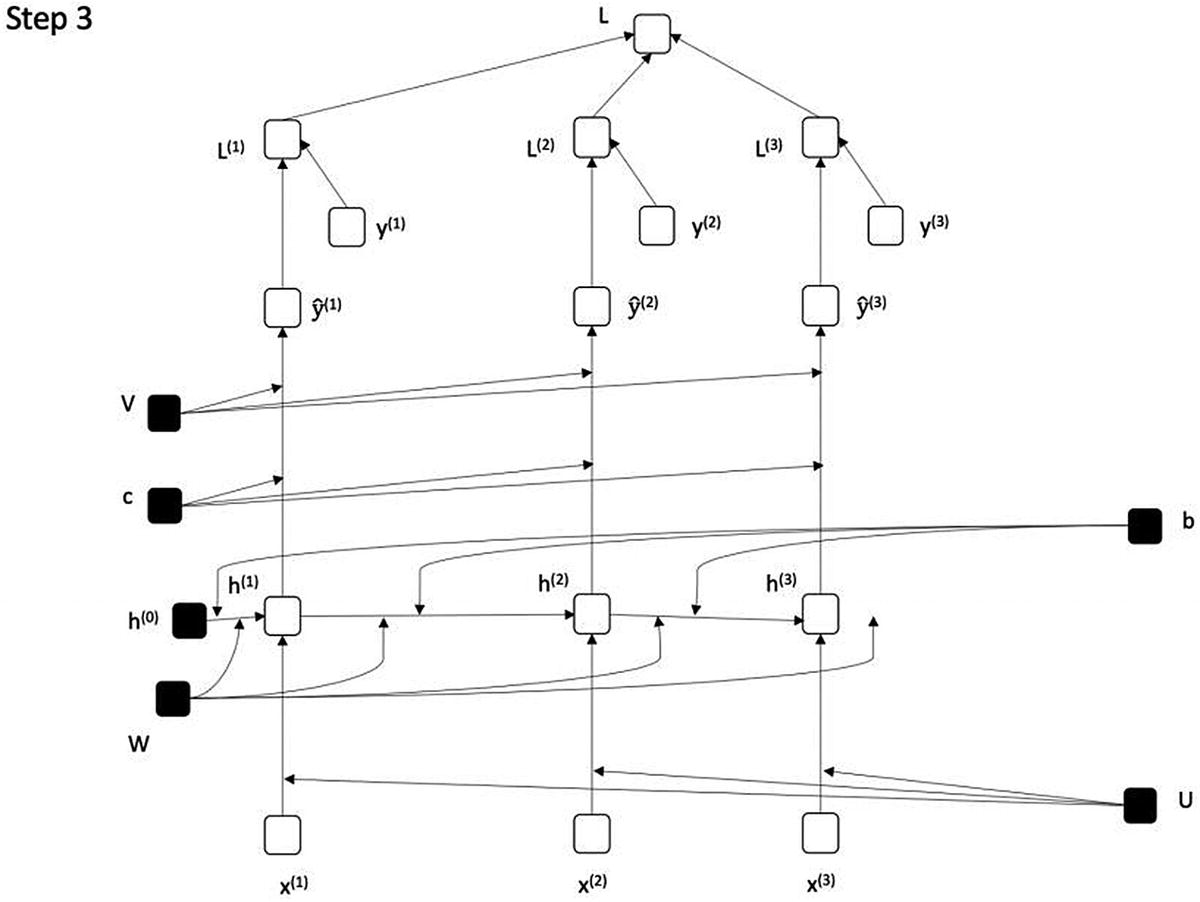
图 7-11
展开图 7-4 对应的 RNN(步骤 3)
这里,我们将第三个输入序列连接到展开的网络。权重 U、W 和 V 在整个网络中共享。在下一个也是最后一个步骤中,我们可以看到展开的网络与图 7-7 中所示的网络相同(即,针对四个输入序列展开)。
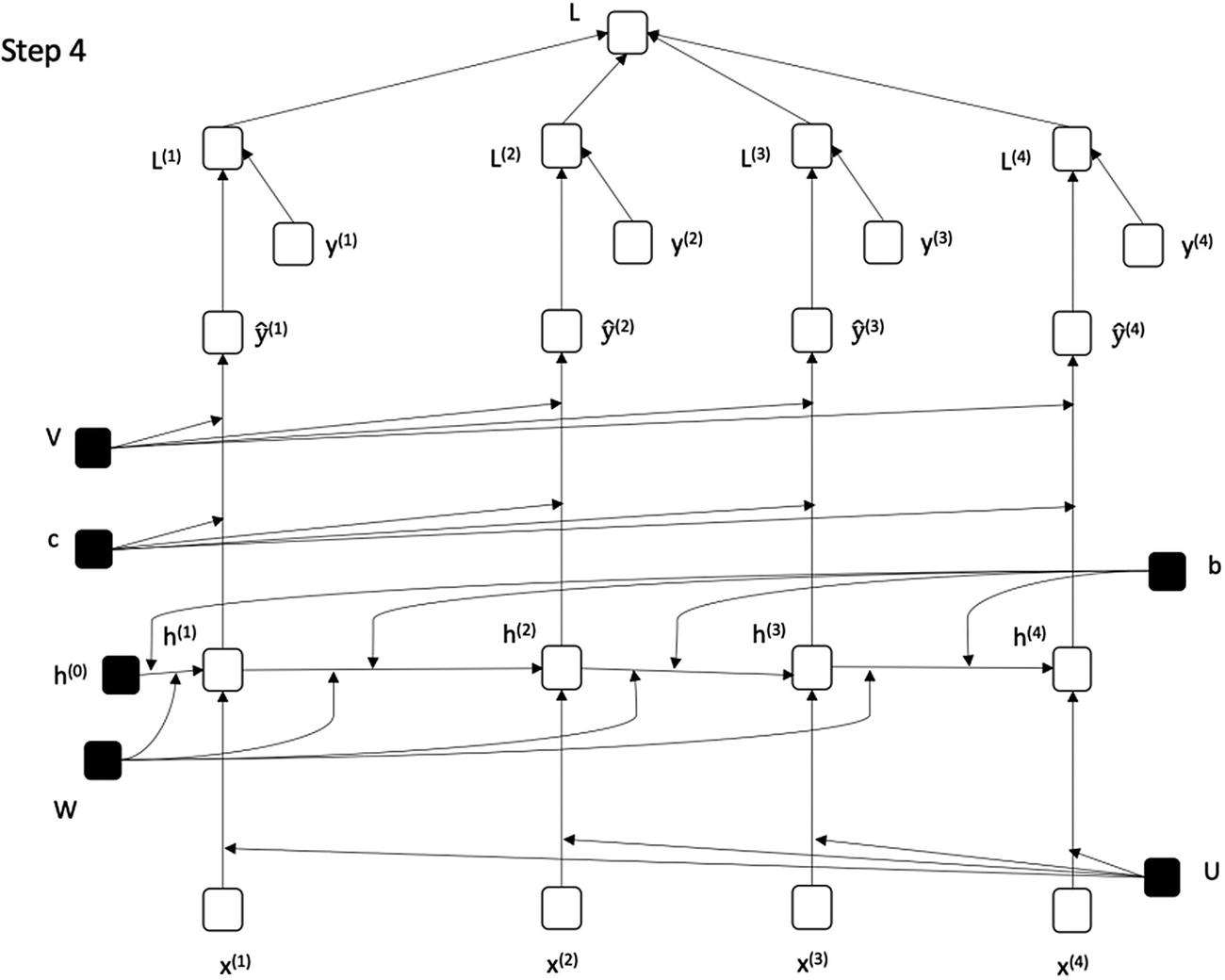
图 7-12
展开图 7-4 对应的 RNN(步骤 4) |与图 7-7 相同
假设要训练的数据集由不同大小的序列组成,输入序列被分组,使得相同大小的序列归入一组。然后,对于一个组,我们可以展开序列长度的 RNN 并训练它。针对不同组的训练将需要针对不同的序列长度展开 RNN。因此,可以通过展开来训练不同大小输入的 RNN,并根据序列长度展开来训练它。
必须注意的是,训练图 7-4 中所示的展开的 RNN 本质上是一个连续的过程,因为隐藏状态是相互依赖的。在递归超过输出而不是隐藏状态的 RNNs 的情况下(图 7-5 ,可以使用一种叫做老师强制的技术,如图 5-9 所示。这里的关键思想是训练时在h(t)的计算中用y(t—1)代替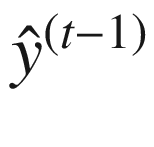 。然而,在进行预测时(当模型被部署使用时),使用了
。然而,在进行预测时(当模型被部署使用时),使用了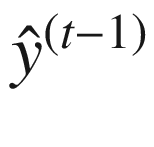 。
。
双向 RNNs
现在让我们看看 RNNs 的另一种变体,双向 RNN。双向 RNN 背后的关键思想是使用序列中位于更远处的实体来对当前实体进行预测。对于我们到目前为止考虑的所有 rnn,我们一直使用序列中的先前实体(由隐藏状态捕获)和当前实体来进行预测。然而,我们并没有利用序列中更靠后的实体的信息来进行预测。双向 RNN 利用这些信息,在许多情况下可以提高预测的准确性(图 7-13 )。
考虑下面这个简单的例子,它来自吴恩达的 Coursera 讲座:
-
他说,“泰迪熊是漂亮的玩具。”
-
他说,“泰迪·罗斯福,美国总统。”
在这些句子中,考虑到 NLP 的一个经典案例(预测下一个单词),没有办法正确预测“Teddy”之后的单词(假设单向向前 RNN)。来自右侧的上下文本质上揭示了对下一个单词的准确预测。考虑一个情感分析任务,其中一个模型试图将句子分类为肯定或否定。随着网络中左右语境的建立,双向模型可以有效地在句子中“向前看”,以查看“未来”标记是否会影响当前决策。在情绪分类(多对一 RNN)的情况下,有一些讽刺性的评论,其中肯定词后面的词否定了肯定词的存在——例如,“我喜欢这部电影,有史以来最大的笑话!”在这里,右边的上下文否定了“爱”这个词的存在。
双向 RNN 可以使用以下等式来描述:
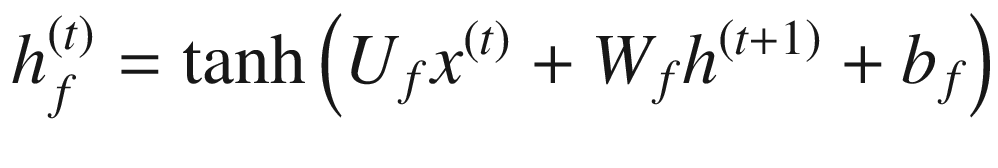
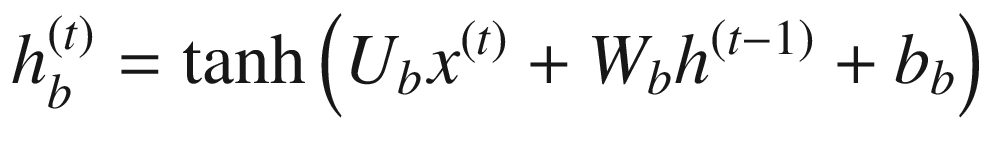
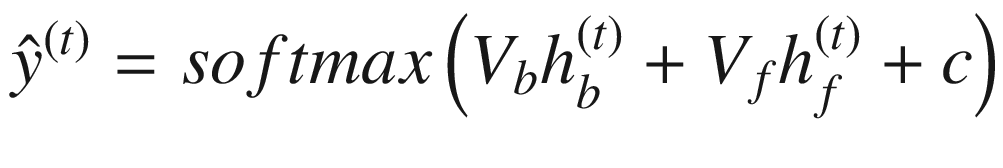
RNN 计算包括计算序列中实体的前向隐藏状态和后向隐藏状态。这分别由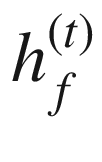 和
和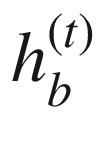 表示。
表示。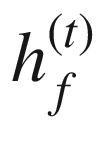 的计算使用实体x??(t)和先前隐藏状态
的计算使用实体x??(t)和先前隐藏状态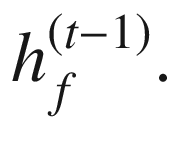 的相应输入
的相应输入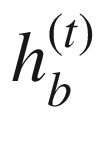 的计算使用实体x(t)和先前隐藏状态
的计算使用实体x(t)和先前隐藏状态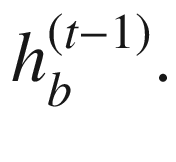 的相应输入
的相应输入
使用隐藏状态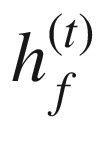 和
和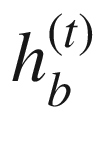 计算输出
计算输出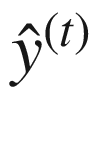 。在计算当前隐藏状态时,一组权重与输入和前一隐藏状态相关联。这分别用 U * f , W f , U b , W b 来表示。还有偏置项,分别用 b f 和 b b * 表示。
。在计算当前隐藏状态时,一组权重与输入和前一隐藏状态相关联。这分别用 U * f , W f , U b , W b 来表示。还有偏置项,分别用 b f 和 b b * 表示。
类似地,在计算输出时,一组权重与计算输出时的隐藏状态相关联。这用 V b 和 V f 来表示。还有一个偏置项,用 c 表示。tanh激活函数用于隐藏状态的计算。softmax 激活函数用于计算输出。
如等式所述,RNN 可以处理任意大的输入序列。RNN 的参数—Uf,Ub, W f , W b , V b , V -在隐藏层和输出值的计算中共享(对于序列中的每个图元)。
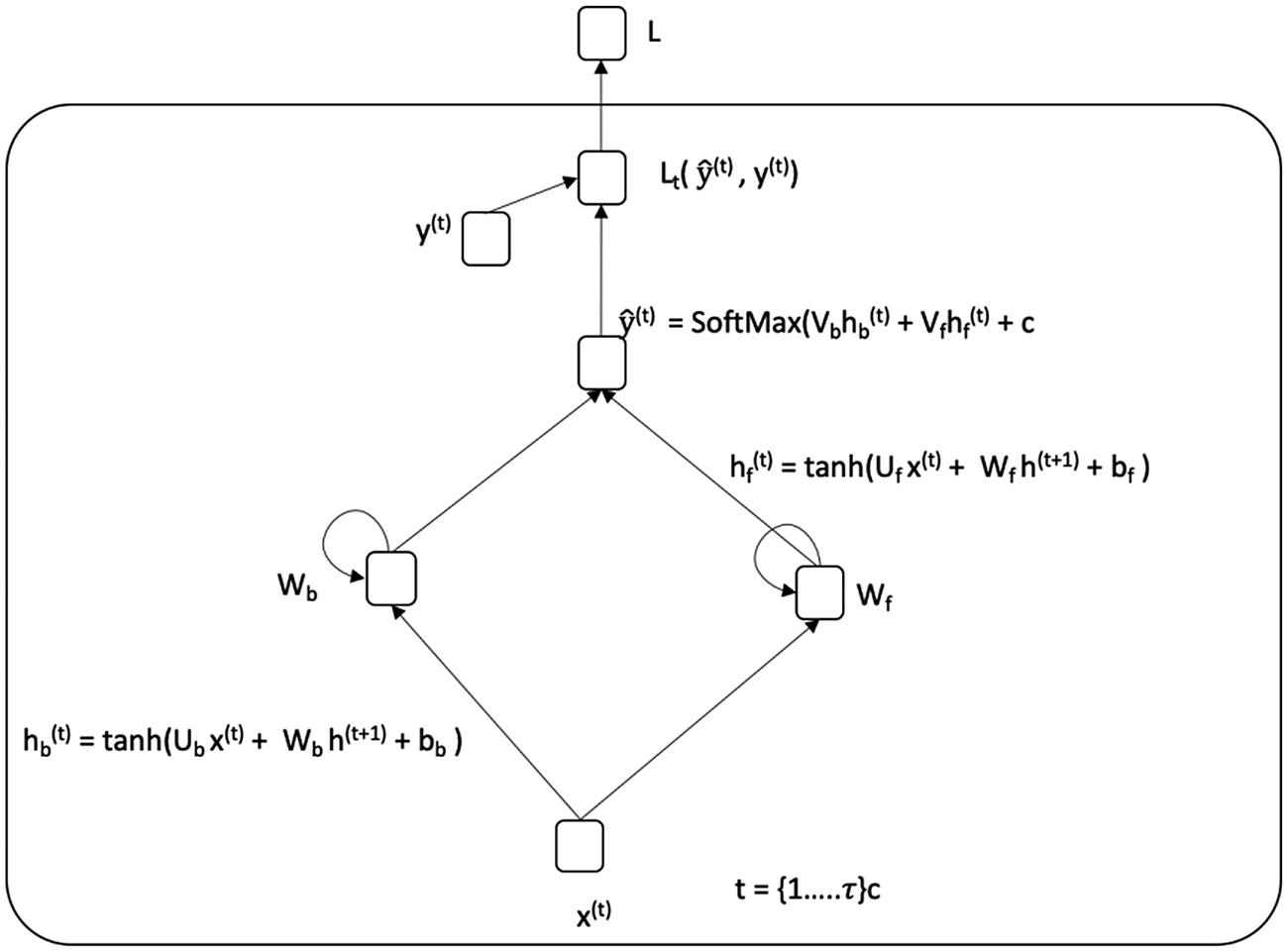
图 7-13
双向 RNN
消失和爆炸渐变
由于消失和爆炸梯度,训练 rnn 可能具有挑战性(图 7-14 )。消失梯度意味着当在展开的 rnn 上计算梯度时,梯度的值可以下降到非常小的数字(接近零)。类似地,梯度可以增加到非常高的值,这被称为爆炸梯度问题。在这两种情况下,训练 RNN 都是一个挑战。消失或爆炸梯度通常是为网络超参数和参数设置不适当或不需要的值的结果。因此,随着每次增量权重更新,网络需要花费异常长的时间来脱离斜率,并学习用例的最佳权重。
让我们再来看看描述 RNN 的方程。
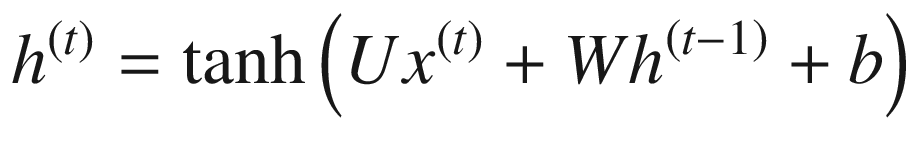
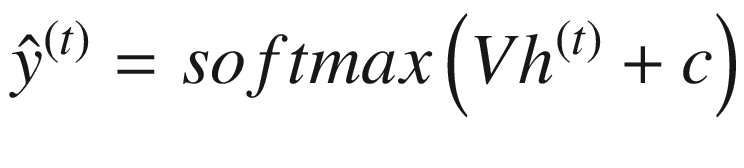
我们可以通过应用链式法则推导出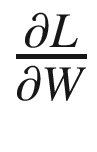 的表达式。如图 7-10 所示。
的表达式。如图 7-10 所示。
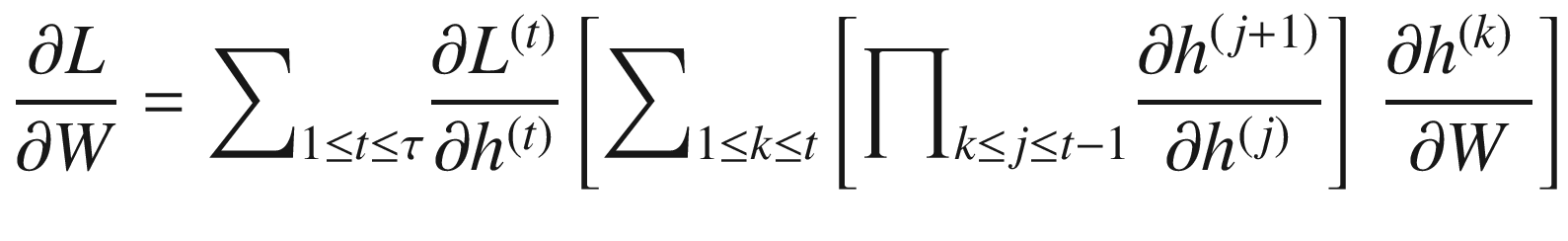
现在让我们关注表达式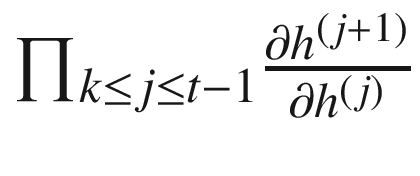 的部分,它涉及 W 的重复矩阵乘法,这有助于消失和爆炸梯度问题。直觉上,这类似于一个实数值一次又一次地相乘,这可能导致乘积缩小到零或爆炸到无穷大。
的部分,它涉及 W 的重复矩阵乘法,这有助于消失和爆炸梯度问题。直觉上,这类似于一个实数值一次又一次地相乘,这可能导致乘积缩小到零或爆炸到无穷大。
渐变剪辑
处理爆炸梯度的一个简单技术是,每当梯度超过用户定义的阈值时,重新调整梯度的范数。具体来说,如果梯度用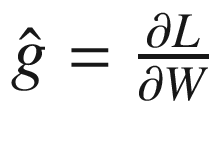 表示,如果
表示,如果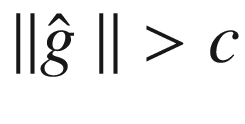 ,那么我们设置
,那么我们设置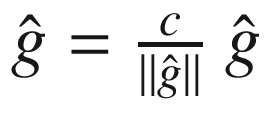 。这种技术既简单又计算高效,但它确实引入了一个额外的超参数。
。这种技术既简单又计算高效,但它确实引入了一个额外的超参数。
如果没有梯度裁剪,参数会大幅下降并流出所需区域。通过限幅,下降步长被限制,并且参数保持在期望的区域内。渐变裁剪将“裁剪”渐变,或者将它们限制在一个阈值,以防止它们变得太大。在图 7-14 中,梯度因过冲而被剪切,成本函数遵循虚线值,而不是其在期望区域外的原始轨迹。
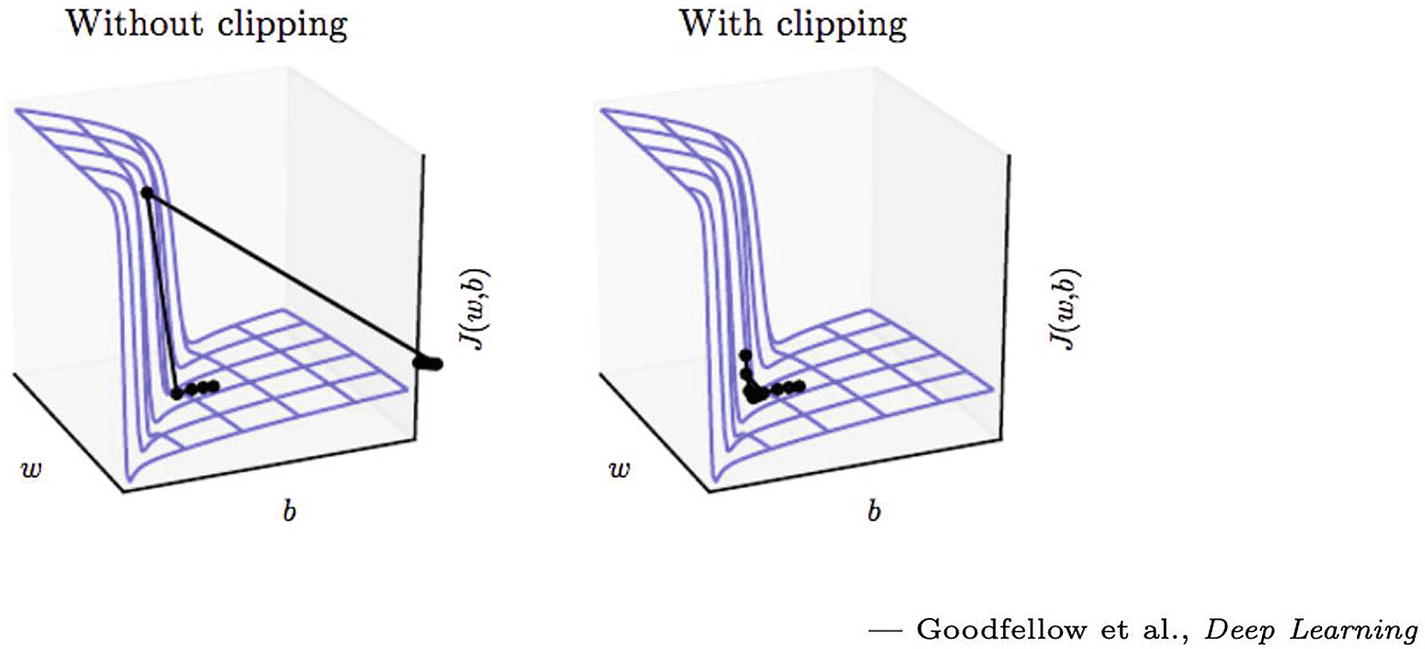
图 7-14
渐变剪辑
长短期记忆
让我们来看看 RNNs 的另一种变体,长短期记忆(LSTM)网络(见图 7-15 )。香草 RNN 有几个权衡,导致网络在学习序列之间的长相关性时表现不佳。总的来说,RNN 更容易产生噪音,在训练时容易过度疲劳。训练它们在计算上也非常昂贵。
LSTMs 非常适合通过使用更直观的方法来解决这些问题。与 rnn 相比,它们通常对噪声更鲁棒,并且更准确地捕捉短期和长期相关性,同时易于调整和训练。LSTMs 还具有比 rnn 更快的计算速度。LSTMs 具有配备便利功能的门,这些功能帮助网络记住长期依赖关系以及忘记无关紧要的依赖关系。在 RNNs 中,先前的隐藏状态是网络记得的唯一先前的记忆。有了 LSTMs,除了之前的隐藏状态,小区状态也被网络记住。
LSTM 网络的核心概念是单元状态和门(输入、输出和遗忘门)。这些门和单元状态包括几个操作,例如 sigmoid 和 tanh 激活、逐点乘法和加法以及向量连接。这些操作帮助单元状态和门训练网络忘记或通过网络传播重要信息。细胞状态连接整个网络的信息,从而有助于在需要时传递序列之间的长依赖性。
LSTM 可以用下面的一组等式来描述。请注意,⨀符号表示两个向量的逐点相乘——也就是说,如果 a = [1,1,2]并且 b = [0.5,0.5,0.5],那么 a ⨀ b = [0.5,0.5,1]。函数 σ 、 g 和 h 为非线性激活函数; W 和 R 为权重矩阵;并且 b 项是偏置项。
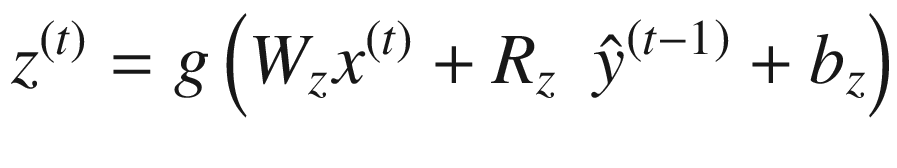
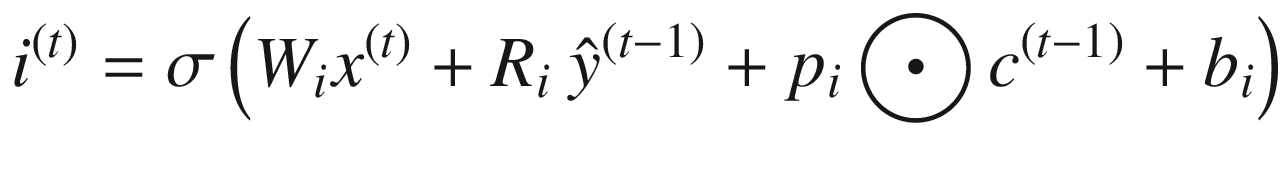
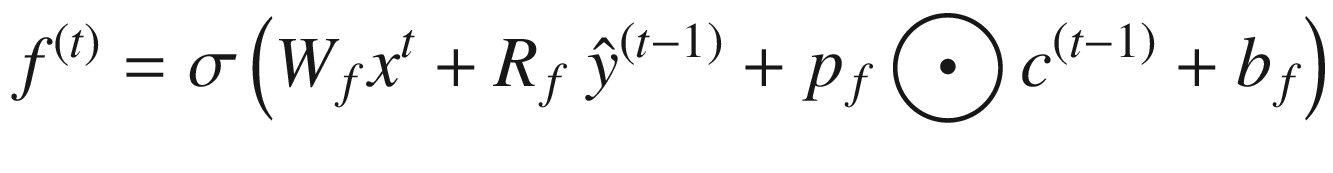
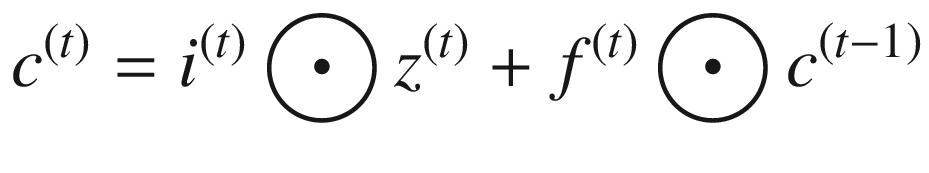
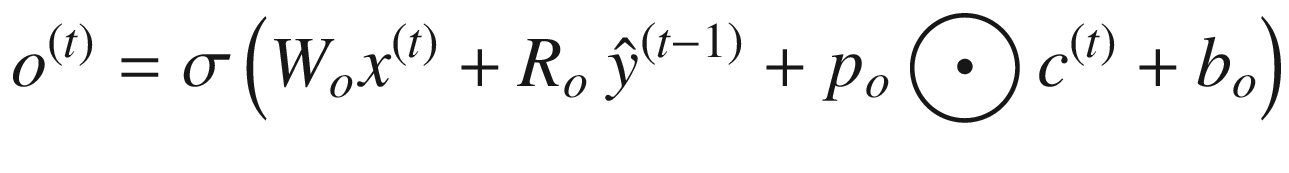
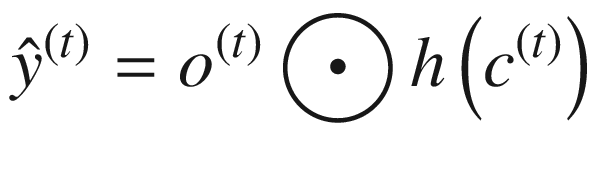
应注意以下几点:
-
LSTM 最重要的元素是细胞状态,用c(t)=I(t)⨀z(t)+f(t)⨀c基于块输入z(t)和先前单元状态c(t—1)更新单元状态。输入门It(t)确定块输入的哪一部分进入单元状态(因此称为门)。遗忘门f(t)决定了要保留多少先前的单元格状态。**
-
输出
 由单元状态c(t)和输出门 o ( * t * ) 决定,决定了单元状态对输出的影响程度。
由单元状态c(t)和输出门 o ( * t * ) 决定,决定了单元状态对输出的影响程度。 -
z ( t ) 项,称为块输入,根据当前输入和先前输出产生一个值。
-
i ( t ) 项,称为输入门,决定了在单元状态 c ( t ) 下保留多少输入。
-
所有的 p 项都是窥视孔连接,允许单元状态的一部分考虑到所讨论的项的计算中。
-
单元格状态 c ( i ) 的计算不会遇到渐变消失的问题。(这被称为恒定误差旋转。)然而,LSTMs 受到爆炸梯度的影响,并且在训练时使用梯度剪裁。
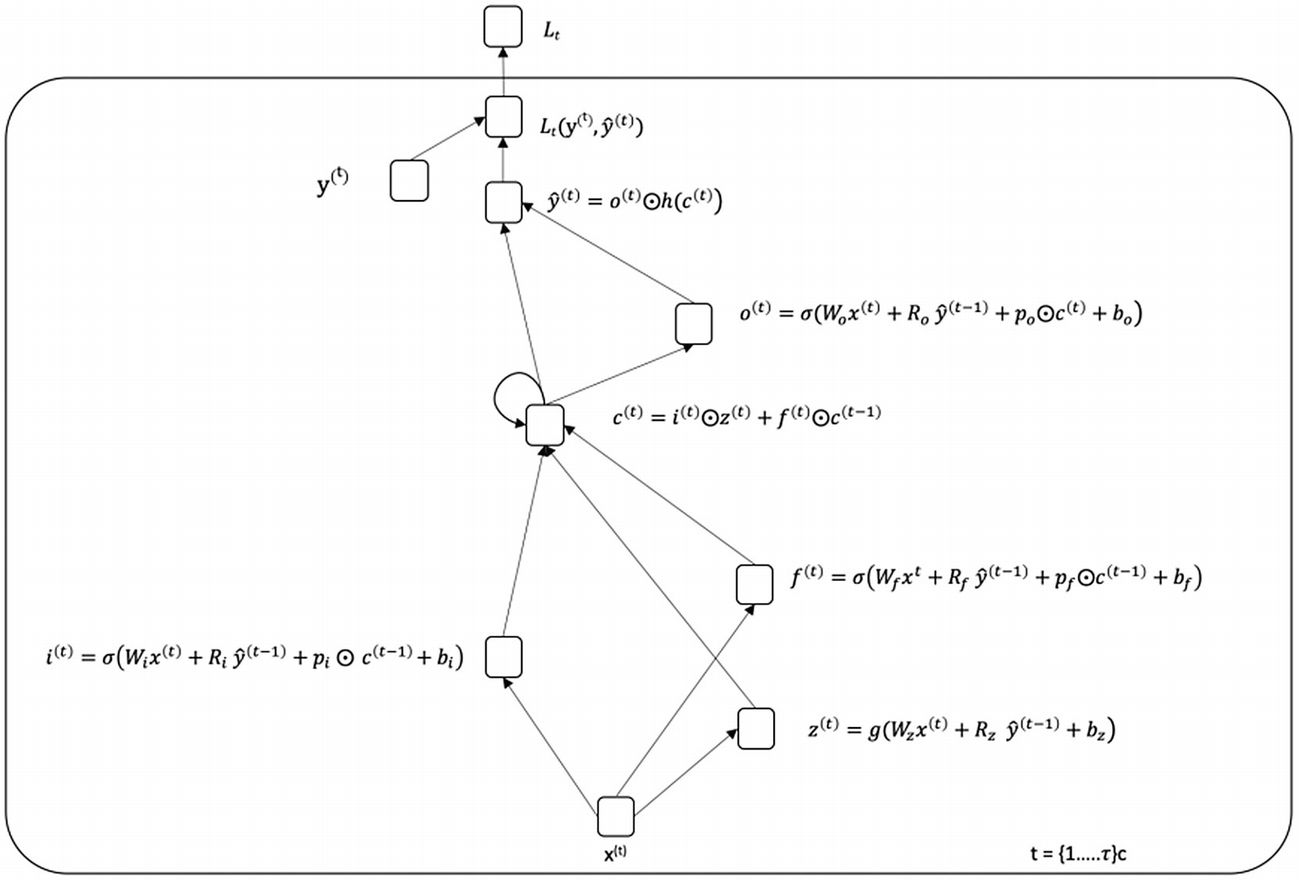
图 7-15
一个长短期记忆网络
实际实现
本节描述了一个用 PyTorch 实现 RNN 和 LSTM 的实例。我们将把练习分成两部分。首先,我们将只使用没有额外处理的普通 RNN 网络(来自 NLP 领域),并在情感分类数据集上训练网络。我们预计这种普通的网络性能会很差。第二,我们将对网络进行重大改进。我们将利用 LSTM 层,而不是 RNN 层,并使网络双向辍学正规化。这样的网络在我们的数据集上会表现得更好。
我们将使用 TorchText 包,它由数据处理工具和 NLP 的流行数据集组成。我们将利用位于 https://www.kaggle.com/columbine/imdb-dataset-sentiment-analysis-in-csv-format 的 Kaggle 上托管的数据集。
我们建议利用 Kaggle 笔记本进行练习(打开互联网选项并启用 GPU 加速器)。
让我们从导入基本包开始(清单 7-1 )。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import torch
from torch import nn,optim
import torchtext
from torchtext import data
#Check if we have GPU enabled
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print("Device =",device)
input_data_path = "/kaggle/input/imdb-dataset-sentiment-analysis-in-csv-format/"
Listing 7-1Importing the Packages for the RNN
首先,让我们使用 Pandas 在高层次上探索数据集。这里的目标是对数据集有一个粗略的了解。对于本练习的剩余部分,我们将使用基于 TorchText 的包装器来处理 NLP 领域内的训练和验证数据集。清单 7-2 将我们用例的数据读入内存。

#Read the csv dataset using pandas
df = pd.read_csv("/input/imdb-dataset-sentiment-analysis-in-csv-format/Train.csv")
print("DF.shape :\n",df.shape)
print("df.label = ",df.label.value_counts())
df.head()
Output[]
DF.shape : (40000, 2)
df.label = 0 20019
1 19981
Name: label, dtype: int64
Listing 7-2Reading Data into Memory
我们在数据集中只有两列:“文本”,包含实际的注释,“标签”,包含值 0(负)和 1(正)。正负之间的分布相当均匀。
接下来,我们将使用 TorchText 数据集包装器,它将帮助我们创建基于迭代器的数据集,简化我们需要的数据处理任务。如清单 7-3 所示,我们从定义训练和验证数据集所需的原始数据类型开始。
#Define a custom tokenizer
my_tokenizer = lambda x:str(x).split()
#Define fields for our input dataset
TEXT = data.Field(sequential=True, lower= True,tokenize = my_tokenizer,use_vocab=True)
LABEL = data.Field(sequential = False,use_vocab = False)
#Define inut fields as a list of tuples of fields
trainval_fields = [("text",TEXT),("label",LABEL)]
#Contruct dataset
train_data, val_data = data.TabularDataset.splits(path = input_data_path, train = "Train.csv", validation = "Valid.csv", format = "csv", skip_header = True, fields = trainval_fields)
#Build vocabulary
MAX_VOCAB_SIZE = 25000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
#Define iterators for train and validation
train_iterator = data.BucketIterator(train_data, device = device
, batch_size = 32
, sort_key = lambda x:len(x.text)
,sort_within_batch = False
,repeat = False)
val_iterator = data.BucketIterator(val_data, device = device,
batch_size= 32
, sort_key = lambda x:len(x.text)
, sort_within_batch = False
, repeat = False)
print(TEXT.vocab.freqs.most_common()[:10])
Output[]
[('the', 511112), ('a', 253702), ('and', 251397), ('of', 229381), ('to', 211883)
, ('is', 164005), ('in', 143530), ('i', 113576), ('this', 110892), ('that', 104153)]
Listing 7-3Defining the Tokenizer, Fields, and Dataset for Training and Validation
在清单 7-3 中,我们处理了一些我们的网络所必需的东西。对于 NLP 用例,在使用数据进行网络训练之前,作为文本处理的一部分,我们需要对数据进行标记化和数值化。你可能已经猜到了,神经网络只处理数字数据。上述两项操作都由 PyTorch 内部巧妙处理。我们可以提供一个现有的标记器——例如 SpaCy(一个开源的高级 NLP 库)PyTorch 会完成剩下的工作。在这个例子中,我们使用一个定制的简单的。接下来,我们为数据集定义必要的字段(原始数据)。Field类对可以用张量表示的常见文本处理数据类型进行建模。此外,它还保存了一个Vocab对象,该对象定义了承载字段中出现的所有单词的数字表示的向量。我们的数据集有两列,“文本”和“标签”,前者是简单的英文注释,后者是数字标签(0/1)。因此,我们将 TEXT 和 LABEL 定义为代表我们的列的两个单独的字段。我们添加了一个参数来定义这个字段所需的标记化函数,一个布尔标志来将文本转换为小写,一个布尔标志来指示这个字段中的数据是连续的。对于标签字段,我们没有顺序数据;因此,我们将其设置为 False。
接下来,我们定义创建数据集时需要的数据字段列表。该列表表示数据集中的每一列。如果我们计划不使用这个数据集中的某个特定列,那么在定义列的列表时,我们需要将列名指定为“None”。我们将这个列表分配给trainval_fields变量。然后,我们创建一个TabularDataset对象,其中包含对数据列进行必要操作的精简列表。请注意,splits()函数实际上并不分割现有的数据集。只有当路径中已经有单独分离的数据集时,才应该使用它。
接下来,我们需要构建词汇表(在我们的字段文本中出现的唯一单词的数字化表示)。这一步非常重要,有几种执行手段。我们可以使用预训练的单词嵌入来创建词汇,或者我们可以定制一个。使用预训练的很简单,所以我们将在下一个例子中使用它。我们将最大词汇量设置为 25,000。该函数还将创建两个额外的单词,总数为 25,002—一个用于所有未知的标记(例如,新单词),另一个用于填充(用于生成等长的句子)。
最后,我们创建迭代器对象。sort_within_batch参数根据sort_key对每个小批量内的数据进行降序排序。当我们想将pack_padded_sequence用于填充的序列数据并将填充的序列张量转换为PackedSequence对象时,这是必要的。我们不会在第一个练习中利用这个特性,但是我们将在下一个练习中使用它,在下一个练习中我们将改进我们的模型。本质上,PyTorch 在序列中添加了填充符,这样所有序列的长度都相等。通过按关键字的降序对数据进行排序,该过程变得高效,并确保网络不会学习填充。最后一行打印 vocab 中最常用的单词,并返回与向量中每个单词相关的索引(嵌入)。
准备好要处理的数据后,我们将构建我们的 RNN 类,如清单 7-4 所示。
class RNNModel(nn.Module):
def __init__(self,embedding_dim,input_dim,hidden_dim,output_dim):
super().__init__()
self.Embedding = nn.Embedding(input_dim,embedding_dim)
self.rnn = nn.RNN(embedding_dim,hidden_dim)
self.fc = nn.Linear(hidden_dim,output_dim)
def forward(self,text):
embed = self.Embedding(text)
output, hidden = self.rnn(embed)
out = self.fc(hidden.squeeze(0))
return(out)
#Define model
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
#Create model instance
model = RNNModel(EMBEDDING_DIM, INPUT_DIM,HIDDEN_DIM, OUTPUT_DIM)
Listing 7-4Defining the RNN Class
这段代码的很大一部分与我们在第 5 和 6 章中的实验非常相似。这里新增加的是嵌入层和 RNN 层。RNN 层返回输出以及隐藏层计算(不像我们到目前为止探索的其他层)。输入维度是我们的 vocab 列表的长度。嵌入维数是我们决定在数字上最能代表一个单词的一个值。我们这里用 100,但也可能是 200,300,或者更高。更大的数字并不总是有价值的,而且会显著增加计算量。此外,我们为隐藏层选择 256 维,为输出层选择 1 维(因为结果是二进制的)。
接下来,在清单 7-5 中,我们定义了两个函数,这两个函数将包装给定时期的训练步骤和评估步骤。随后,我们通过另一个函数为每个时期编排训练步骤和评估步骤。
#Define training step
def train(model, data_iterator,optimizer,loss_function):
epoch_loss,epoch_acc,epoch_denom = 0,0,0
model.train() #Explicitly set model to train mode
for i, batch in enumerate(data_iterator):
optimizer.zero_grad()
predictions = model(batch.text)
loss = loss_function(predictions.reshape(-1,1), batch.label.float().reshape(-1,1))
acc = accuracy(predictions.reshape(-1,1), batch.label.reshape(-1,1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
epoch_denom += len(batch)
return epoch_loss/epoch_denom,epoch_acc, epoch_denom
#Define evaluation step
def evaluate(model, data_iterator,loss_function):
epoch_loss,epoch_acc,epoch_denom = 0,0,0
model.eval() #Explcitly set model to eval mode
for i, batch in enumerate(data_iterator):
with torch.no_grad():
predictions = model(batch.text)
loss = loss_function(predictions.reshape(-1,1), batch.label.float().reshape(-1,1))
acc = accuracy(predictions.reshape(-1,1), batch.label.reshape(-1,1))
epoch_loss += loss.item()
epoch_acc += acc.item()
epoch_denom += len(batch)
return epoch_loss/epoch_denom, epoch_acc, epoch_denom
Listing 7-5Defining the Training and Evaluation Step
在这里,内容与前面的实验相似。我们为训练循环创建必要的样板代码。注意,我们在 evaluate 函数中需要一个助手函数来计算精度(在我们的例子中是二进制结果)。这一部分不是强制性的,但它有助于在每个时期后准确地查看中间结果。清单 7-6 为我们的网络定义了功能和必要的位。
#Compute binary accuracy
def accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
#Count the number of correctly predicted outcomes
correct = (rounded_preds == y).float()
acc = correct.sum()
return acc
#Define optimizer, loss function
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.BCEWithLogitsLoss()
#Transfer components to GPU, if available.
Model = model.to(device)
criterion = criterion.to(device)
Listing 7-6Defining the Accuracy Function, Loss Function, and Optimizer, and Instantiating the Model
最后,在清单 7-7 中,我们用定义损失函数和优化器在五个时期的循环中训练上面实例化的模型。我们在这里定义 5 只是为了说明的目的;对于实际的例子,我们建议根据数据的大小和网络的复杂性增加历元的数量。
n_epochs = 5
for epoch in range(n_epochs):
#Train and evaluate
train_loss, train_acc,train_num = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc,val_num = evaluate(model, val_iterator,criterion)
print("Epoch-",epoch)
print(f'\tTrain Loss: {train_loss: .3f} | Train Predicted Correct : {train_acc}
| Train Denom: {train_num} |
PercAccuracy: {train_acc/train_num}')
print(f'\tValid Loss: {valid_loss: .3f} | Valid Predicted Correct: {valid_acc}
| Val Denom: {val_num}|
PercAccuracy: {train_acc/train_num}')
Output[]
Epoch -0
Train Loss: 0.022 | Train Predicted Correct : 20149.0 | Train Denom: 40000 | PercAccuracy: 0.503725
Valid Loss: 0.022 | Valid Predicted Correct: 2537.0 | Val Denom: 5000| PercAccuracy: 0.503725
Epoch -1
Train Loss: 0.022 | Train Predicted Correct : 20048.0 | Train Denom: 40000 | PercAccuracy: 0.5012
Valid Loss: 0.022 | Valid Predicted Correct: 2497.0 | Val Denom: 5000| PercAccuracy: 0.5012
Epoch -2
Train Loss: 0.022 | Train Predicted Correct : 20023.0 | Train Denom: 40000 | PercAccuracy: 0.500575
Valid Loss: 0.022 | Valid Predicted Correct: 2507.0 | Val Denom: 5000| PercAccuracy: 0.500575
Epoch -3
Train Loss: 0.022 | Train Predicted Correct : 20143.0 | Train Denom: 40000 | PercAccuracy: 0.503575
Valid Loss: 0.022 | Valid Predicted Correct: 2556.0 | Val Denom: 5000| PercAccuracy: 0.503575
Epoch -4
Train Loss: 0.022 | Train Predicted Correct : 19996.0 | Train Denom: 40000 | PercAccuracy: 0.4999
Valid Loss: 0.022 | Valid Predicted Correct: 2492.0 | Val Denom: 5000| PercAccuracy: 0.4999
Listing 7-7Training the Model for Five Epochs
我们可以看到该模型的性能几乎没有提高。虽然五个纪元其实太少了,但我们应该已经看到了小的变化。整体准确性并没有真正增加模型的任何价值。性能差。为了改善我们的结果,我们将在第二次实验中采取更全面的方法。
在我们的第二个实验中,我们将利用 Spacy 的标记器(而不是使用我们的自定义标记器)和预训练的单词嵌入(而不是从头开始训练),并添加双向 LSTM 层(而不是单向 RNN 层)。我们还将增加辍学,以减少过度拟合。
我们实际上需要从头开始,而不是继续使用相同的代码库(尽管变化很小)。
像往常一样,我们从导入所需的包开始,如清单 7-8 所示。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import torch,torchtext
from torch import nn, optim
from torch.optim import Adam
from torchtext import data
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print("Device =",device)
input_data_path = " /input/imdb-dataset-sentiment-analysis-in-csv-format/"
#Define fields for our input dataset
TEXT = data.Field(sequential=True, lower= True,tokenize = 'spacy', include_lengths = True)
LABEL = data.Field(sequential = False,use_vocab = False)
#Define a list of tuples of fields
trainval_fields = [("text",TEXT),("label",LABEL)]
#Contruct dataset
train_data, val_data = data.TabularDataset.splits(path = input_data_path, train = "Train.csv", validation = "Valid.csv", format = "csv", skip_header = True, fields = trainval_fields)
#Build Vocab using pretrained
MAX_VOCAB_SIZE = 25000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE, vectors = 'fasttext.simple.300d')
BATCH_SIZE = 64
train_iterator, val_iterator = data.BucketIterator.splits(
(train_data, val_data),
batch_size = BATCH_SIZE,
sort_key = lambda x:len(x.text),
sort_within_batch = True,
device = device)
Listing 7-8Importing the Required Packages
我们将只关注前面代码片段中的变化。在定义数据字段时,我们使用了 Spacy 的 tokenizer。使用字符串spacy作为 tokenize 参数就足够了;PyTorch 在后端管理必要的繁重工作。我们还添加了参数include_length作为true。这是必要的,因为我们稍后会添加填充并对一批中的样本进行排序。为了利用这一点,我们现在需要将样本的长度和文本一起传递给 RNN 模型的类定义中的 forward 函数。
在构建词汇表时,我们使用vectors = 'fasttext.simple.300d'告诉 PyTorch 下载预先训练好的 fasttext 向量,并为我们的文本字段中的单词创建一个嵌入向量。(如果使用的是 Kaggle 内核,应该在笔记本环境设置中开启互联网选项)。这个预训练的向量有 300 个维度。在创建网络实例时,我们需要注意这一变化。这一步可能需要一段时间,取决于你的网速。最后,我们还启用了排序并定义了排序键。PyTorch 下载已定义的预训练向量(通常为 300MN 或更多),并基于 25,000 个令牌为我们的用例创建一个子集。
现在让我们定义我们改进的序列模型,如清单 7-9 所示。
class ImprovedRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
embedded = self.dropout(self.embedding(text))
#pack sequence
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths)
packed_output, (hidden, cell) = self.lstm(packed_embedded)
#unpack sequence
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
return self.fc(hidden)
Listing 7-9Defining the (Improved) RNN Class
请注意,我们在这里做了相当多的添加。我们现在有一个 LSTM 层,而不是香草 RNN。当bidirectional标志被设置为True时,它使我们能够捕捉前向和后向上下文。线性层的尺寸现在将是原始层的两倍,因为我们有一个串联的前向和后向网络。我们最初在定义最初的FIELD;时添加了include_lengths=True,因此,我们的转发函数现在将接受一个额外的参数。在从嵌入输出接收数据后,在将数据传递到线性层之前,打包和解包数据时,此信息是必需的。隐藏层现在将前向和后向网络的输出连接起来,然后再传递给下一层。清单 7-10 定义了模型属性并复制了预训练的权重。
#Define model input parameters
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 300
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
#Create model instance
model = ImprovedRNN(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
#Copy pretrained vector weights
model.embedding.weight.data.copy_(pretrained_embeddings)
#Initialize the embedding with 0 for pad as well as unknown tokens
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)
Output []
torch.Size([25002, 300])
Listing 7-10Defining the Model Properties and Copying the Pretrained Weights
接下来,我们定义训练和评估函数,类似于我们之前的练习。唯一的区别是,我们需要将text_lengths作为模型中的一个附加参数来处理。我们还将定义计算二进制精度所需的精度函数,定义模型的损失函数、优化器,并在 GPU 上加载模型和损失函数(如果可用)。这些步骤与我们之前的练习相同。在清单 7-11 中,我们训练我们改进的模型定义。
#Define train step
def train(model, iterator, optimizer, criterion):
epoch_loss,epoch_acc,epoch_denom = 0,0,0
model.train()
for batch in iterator:
optimizer.zero_grad()
text, text_lengths = batch.text
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions.reshape(-1,1), batch.label.float().reshape(-1,1))
acc = accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
epoch_denom += len(batch)
return epoch_loss/epoch_denom, epoch_acc, epoch_denom
#Define evaluate step
def evaluate(model, iterator, criterion):
epoch_loss,epoch_acc,epoch_denom = 0,0,0
model.eval()
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label.float())
acc = accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
epoch_denom += len(batch)
return epoch_loss/epoch_denom, epoch_acc, epoch_denom
#Define optimizer, loss funciton and load to GPU
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
#similar to previous exercise, we deifne our accuracy function
def accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float()
acc = correct.sum()
return acc
#Finally lets train our model for 5 epochs
N_EPOCHS = 5
for epoch in range(N_EPOCHS):
train_loss, train_acc,train_num = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc,val_num = evaluate(model, val_iterator, criterion)
print("Epoch-",epoch)
print(f'\tTrain Loss: {train_loss: .3f} | Train Predicted Correct : {train_acc}
| Train Denom: {train_num} |
PercAccuracy: {train_acc/train_num}')
print(f'\tValid Loss: {valid_loss: .3f} | Valid Predicted Correct: {valid_acc}
| Val Denom: {val_num}|
PercAccuracy: {train_acc/train_num}')
Output[]
Train Loss: 0.005 | Train Predicted Correct : 34911.0 | Train Denom: 40000 | PercAccuracy: 0.872775
Valid Loss: 0.003 | Valid Predicted Correct: 4558.0 | Val Denom: 5000| PercAccuracy: 0.872775
Epoch- 1
Train Loss: 0.003 | Train Predicted Correct : 37193.0 | Train Denom: 40000 | PercAccuracy: 0.929825
Valid Loss: 0.004 | Valid Predicted Correct: 4557.0 | Val Denom: 5000| PercAccuracy: 0.929825
Epoch- 2
Train Loss: 0.002 | Train Predicted Correct : 38079.0 | Train Denom: 40000 | PercAccuracy: 0.951975
Valid Loss: 0.003 | Valid Predicted Correct: 4591.0 | Val Denom: 5000| PercAccuracy: 0.951975
Epoch- 3
Train Loss: 0.002 | Train Predicted Correct : 38659.0 | Train Denom: 40000 | PercAccuracy: 0.966475
Valid Loss: 0.004 | Valid Predicted Correct: 4569.0 | Val Denom: 5000| PercAccuracy: 0.966475
Epoch- 4
Train Loss: 0.001 | Train Predicted Correct : 39030.0 | Train Denom: 40000 | PercAccuracy: 0.97575
Valid Loss: 0.004 | Valid Predicted Correct: 4564.0 | Val Denom: 5000| PercAccuracy: 0.97575
Listing 7-11Training the Improved Model
如你所见,性能提高了很多。我们只训练了五个纪元的网络,但结果令人印象深刻。建议读者通过对网络进行更改来进行试验。实验可以包括改变预先训练的向量(可能是 glove 而不是 fasttext),在输入数据上处理更多 NLP 相关的动作,添加更多积极的退出,添加更多的纪元,等等。
我们的第二个练习到此结束,在这个练习中,我们试图提高序列模型的性能。我们使用了普通的 RNN 网络、LSTM 网络和双向网络。我们还利用预先训练的嵌入来实现单词的量化表示。(对于几乎所有与 NLP 相关的任务,强烈建议这样做。)还存在门控循环单元(gru ),其非常类似于 LSTMs,但是其计算速度稍快,因为它们具有较少的运算。然而,当谈到性能时,大多数研究人员发现 LSTMs 和 GRUs 非常相似。在 NLP 实验中,使用 LSTMs 和 GRUs 迭代,取其精华是很常见的。你可以在 https://arxiv.org/abs/1412.3555 阅读更多关于这项研究的内容。
讨论 GRUs 的细节超出了本章的范围。鼓励读者自己进一步探索这个话题。
摘要
在本章中,我们介绍了循环神经网络(RNNs)的基础知识。本章的要点是隐藏状态的概念,通过展开(通过时间的反向传播)训练 RNNs,消失和爆炸梯度的问题,以及长短期记忆(LSTM)网络。重要的是内在化 rnn 如何包含允许它们对一系列输入进行预测的内部/隐藏状态——这是一种超越传统神经网络的能力。**
八、深度学习的最新进展
到目前为止,这本书已经讨论了深度学习领域的重要主题:前馈网络,卷积神经网络和循环神经网络。我们描述了它们的实际方面,包括使用 PyTorch 改进的实现、培训、验证和调优模型。尽管我们在基础方面覆盖了很多领域,但仍有大量领域没有触及。深度学习领域最近见证了研究、贡献者和业界对尖端解决方案的采用的巨大增长。更新和变化的绝对速度(增量的和突破性的)是巨大的。即使你一直在读这本书,也可能有几篇突破性的研究论文发表,为深度学习领域的下一门课程量身定制。
在这最后一章,我们介绍了一些与深度学习相关的额外主题,这些主题应该可以帮助你以更有意义的方式研究这个主题。本章仅作为简要介绍,并不深入任何实现细节。建议您探索与这些主题相关的其他资源,以加强您的学术、个人和行业职业感兴趣的领域。
让我们开始吧。
超越计算机视觉中的分类
在第五章中,我们研究了使用卷积神经网络解决的深度学习中的计算机视觉问题。这个想法是新颖的和开创性的。第五章只关注一个关键领域——分类。我们研究了 MNIST 手写数字的经典例子,其中我们将给定的图像分类为 0-9 之间的数字[10 类]。在另一个练习中,我们看了猫和狗之间的二元分类。虽然使用计算技术将图像分类为有意义的标签的能力确实很有价值,但更进一步,它打开了几个对现代用例有深远价值的用例。
本节通过进一步扩展卷积神经网络的概念来探索一些可能性。
目标检测
物体检测,一种与计算机视觉相关的技术,试图区分一幅图像或视频中的一个或多个物体。例如,在猫与狗的分类练习中,对象检测将更进一步,并预测最能捕捉感兴趣对象的矩形边界框。在更复杂的用例中,对象检测可以用于检测图像/视频中的几个对象。
图 8-1 显示了一个复杂的物体检测算法。每个被识别的对象都有边界框来区分它们。

图 8-1
计算机视觉图像中的物体检测来源-github . com/face book research/detectron 2
针对每个人(多个人被识别)的边界框是来自对象检测的结果。
物体检测的现实使用案例包括从 CCTV 视频流中识别汽车,从而跟踪重要路线上的交通状况,在智能手机上使用面部检测,以便自动对焦可以精确地聚焦在重要物体上,从而改善照片,等等。
图象分割法
继物体检测之后,计算机视觉的下一个逻辑步骤是图像分割。图像分割是一种标记技术,将给定的图像分割成多个片段(一组像素),以更精确地定义物体。图像分割和对象检测之间的区别在于,在图像分割下,在图像中识别的对象的定义更精确。也就是说,我们将拥有物体的实际像素轮廓,而不是像物体检测中那样的矩形边界框(见图 8-2 )。

图 8-2
计算机视觉中的图像分割图片来源-github . com/face book research/detectron 2
取代了边界框,我们现在有了更精细的轮廓来捕捉实际的物体。图像分割的实际应用包括交通监控、医疗成像、智能手机相机中的人像模式(数字模拟散景效果——识别人物以模糊背景)。
现代智能手机实现了语义图像分割——识别图像中的对象,并根据所识别的对象类型进一步处理它们。例如,一张脸将被处理以获得美感(平滑瑕疵/阴影等)。);添加模糊效果后,天空会变得不那么清晰;大自然将被彩色处理,以具有一种充满活力的感觉;诸如此类。
要了解更多关于语义图像分割的信息,请访问 https://developer.apple.com/videos/play/wwdc2019/225/ 。
姿态估计
姿态估计是一种预测和跟踪人或物体位置的计算机视觉技术。本质上,姿态估计使用给定人/物体的姿态和方向的组合从图像或视频预测人的身体部分或关节位置。
姿势估计的更复杂版本——也是更难解决的计算机视觉问题——是多人姿势估计(见图 8-3 )。

图 8-3
多人姿势估计图片来源-github . com/face book research/detectron 2
姿态估计的实际应用类似于图像分割和对象检测,尽管姿态估计的应用更有意义和针对性——例如,跟踪人的活动,如跑步、骑自行车等。活动跟踪使安全监控更上一层楼。姿态估计的另一个重要应用涉及电影和增强现实领域。将人类的动作捕捉转换为三维图形角色,其中动作被精确捕捉和转换(称为 VFX 或 VFX),经常用于电影。
要了解更多关于姿态估计的信息,请访问 http://neuralvfx.com/tag/facial-pose-estimation/ 。
生成计算机视觉
除了分类、对象检测、图像分割和姿态估计,我们在计算机视觉中还有另一个热门领域— 生成对抗网络 (GANs)。计算机视觉中的生成模型首先学习训练集的分布,然后生成一些具有小变化的新样本。这些新图像是由模型在监督设置中使用随机噪声和先前学习的模型权重合成生成的。图 8-4 为 GAN 模型生成的图像样本示例。

图 8-4
GAN 生成的样本图像
大多数图像看起来相当逼真,易于辨认,例如马、船、汽车等。训练 GANs 一直是个难题,通常需要大量的计算资源。制作更大尺寸的图像会进一步增加复杂性。然而,GANs 是近年来计算机视觉领域最大的发展之一。ACM 图灵感知奖获得者 Yann LeCun 将它们描述为“过去 10 年机器学习中最有趣的想法”。
gan 的实际应用是无限的。最简单的应用程序是基于文本描述渲染图像的产品。例如,键入“设计一个白天人比车多的繁忙街道的图像”将得到显示这些事情的图像。反之亦然——即,输入图像并接收关于该图像的基于文本的自然语言描述。科技公司百度设计了一种原型设备,它通过一个用自然语言描述周围环境的摄像头来帮助盲人。欲了解更多关于原型的信息,请访问 https://www.youtube.com/watch?v=Xe5RcJ1JY3c 。
一些新兴的电子商务企业正在利用 GANs 设计图形 t 恤。例如,流行的照片编辑应用 Prisma 和 FaceApp,一个有争议但直观的应用,可以将你现有的照片变成你更老或更年轻的自己,在 2019 年席卷了互联网。
Deepfake 视频现在(或即将)是互联网上的一个主要问题。Deepfakes 可以制作几乎真实的视频,让名人用真实的语音和手势讲述您的输入内容。
具有深度学习的自然语言处理
第七章讨论了循环神经网络(RNNs)和长短期记忆(LSTM)网络,它们可以用来解决现代自然语言处理(NLP)问题。序列模型在语音识别和自然语言处理中的相关任务中也非常有效。近年来,语音数字助理有了显著的进步,比如苹果的 Siri 和亚马逊的 Alexa。这些助手现在可以理解更多带有地域影响和各种口音的语言和讲话,并以非常真实的声音做出回应。他们也能理解并区分你的声音和其他人的声音,当然,准确性的问题仍然存在。在早期,这些改进是通过 LSTM 和门控循环单元(GRUs),另一种类似于 LSTM 的变体。
LSTM 和 GRU 模型仍然有局限性。它们在计算上非常昂贵,并且顺序地处理输入。长期依赖问题仍然存在,尽管这比普通的 RNN 要好得多。
变压器型号
2017 年底,谷歌发表了关于 Transformer network 的研究结果,这是 NLP 的一个开创性的深度学习模型。这篇名为“注意力是你所需要的全部”( https://arxiv.org/pdf/1706.03762.pdf )的论文揭示了语言模型研究领域的一个新转变。
有一段时间,rnn 是处理顺序数据的最佳选择。然而,顺序处理和相对较差的长期依赖性能给大型 NLP 任务带来了各种挑战。变压器网络在这类用例中发挥着至关重要的作用。变压器网络可以并行训练,从而大幅减少计算时间。它们基于自我关注机制,完全免除了递归和卷积(因此,计算速度更快)。
Transformer 模型在 WMT 2014 年英德翻译任务中获得了 28.4 的双语评估替角(BLEU)分数,比现有的最佳结果(包括合奏)提高了两个 BLEU 以上。
来自变压器的双向编码器表示
2018 年,在发布 Transformer networks 一年后,谷歌人工智能语言的研究人员从 Transformers (BERT)开源了一项名为双向编码器表示的 NLP 新技术。
BERT 依赖于一个变压器,但有一些变化。标准变压器由编码器和解码器架构组成;编码器读取文本输入,而解码器产生预测。然而,BERT 只利用编码器部分。因为 BERT 的目标是生成一个语言表示模型,所以这是理想的。BERT 的独特优势之一是其半监督设置。在这种情况下,该过程首先集中在预训练(无监督的),其中使用大量文本数据(主要通过互联网获得)来训练语言表示模型。接下来,针对感兴趣的特定用例,以受监督的方式对模型进行训练和微调。我们在第七章探索的情感分类用例就是一个例子。
你可以在 https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html 找到更多关于伯特的细节。
BERT 使用两种策略进行训练:掩蔽语言建模和下一句预测。对于屏蔽语言建模,在将单词序列输入 BERT 时,每个序列中大约有 15%的单词被替换为[MASK]标记。然后,该模型试图根据序列中其他未屏蔽单词提供的上下文来预测屏蔽单词的原始值。
AllenNLP 发布了一个在后台使用 BERT 的有趣工具(见 https://demo.allennlp.org/masked-lm )。图 8-5 展示了一个简单的演示;该模型以 72%的概率将[MASK]中的单词预测为 car。

图 8-5
allennlp 演示
格罗涅特
我们到目前为止所探讨的计算机视觉课题都与单任务学习有关。也就是说,我们专门设计了一个具有一个损失函数和一个期望结果的网络——将一幅图像分成 n 个不同的类别。数字时代的现代问题有更复杂的要求,需要更全面的方法。考虑一个电子商务市场。当用户上传一张图片来列出一个待售产品时,他们可能不会添加关于该产品的详细和全面的描述。在大多数情况下,上传者会为产品添加一行描述和一个宽泛的类别(这可能不完全正确)。
为了更好地理解这个问题,考虑一个椅子的样本产品列表:“出售一把结实的椅子,仅用了一年,状况像新的一样”这种用户起草的描述缺乏大量信息,而这些信息可能是买家做出更明智决策的理想信息。对买方(以及市场)来说理想的信息属性包括椅子的颜色、椅子的品牌和型号、制造年份等。从工程的角度来看,根据针对提要的基于用户的搜索查询对这样的产品列表进行排序将是一项困难的任务,因为它可能不匹配大多数相关的信息字段。
这个问题的解决方案是通过几个单独的计算机视觉任务来增加额外的信息,例如,一个将图像分类到一个大的类别(家具/工具/车辆/书籍等)的任务。),然后使用另一个型号在一个垂直方向(品牌和型号年份)内进行更具体的分类,依此类推。可能还会出现为每个垂直产品(例如,服装、家具、书籍等)提供个性化模型的需求。考虑到广泛的可能性,我们可能经常面临构建和维护数百个不同模型的挑战。
考虑到 Facebook Marketplace 是一个问题,该公司发布了 GrokNet ,这是一个单一、统一的模型,全面覆盖所有产品。借助统一的模型,该公司能够减少维护和计算成本,并通过消除对每个垂直应用程序的单独模型的需求来提高覆盖率。GrokNet 利用多任务学习方法来训练单个计算机视觉主干。该模型使用 80 个分类损失函数和 3 个嵌入损失,在几个商业垂直行业的 7 个不同数据集上进行训练。
最终模型对给定图像预测如下:
-
对象类别:“吧台凳”、“围巾”、“地毯”等。
-
家居属性:物品颜色、材质、装饰风格等。
-
时尚属性:款式、颜色、材质、袖长等。
-
车辆属性:品牌、型号、外观颜色、年代等。
-
搜索查询:用户可能用来在市场搜索中找到产品的文本短语
-
图片嵌入:一个 256 位的哈希码,用于识别确切的产品,查找相似的产品并进行排序,提高搜索质量
有了对给定图像的如此丰富的预测,给定用户的搜索结果的市场馈送可以用高度相关的结果来定制和定制。预测的图像嵌入可以进一步用于呈现相似的产品列表,使得用户可以做出更明智的决定。此外,整个增强任务是由单个模型而不是模型的集合来执行的。
欲了解更多关于 GrokNet 的信息,请访问 https://ai.facebook.com/research/publications/groknet-unified-computer-vision-model-trunk-and-embeddings-for-commerce/ 。
其他值得注意的研究
本节描述了一些与深度学习领域相关的研究出版物,这些出版物非常令人兴奋,可供人们独立探索,作为该领域的下一步发展。讨论这项研究的任何细节都超出了本书的范围,因此鼓励读者独立探索以下研究论文:
-
点唱机:音乐的生成模型
Jukebox 是一个神经网络,它生成音乐,包括基本的歌唱,作为各种流派和艺术家风格的原始音频。OpenAI 发布了模型的权重和代码,以及一个探索生成样本的工具。
-
图像 GPT–生成相干图像完成
经过语言训练的基于转换器的模型可以生成连贯的文本。在像素序列上训练的相同模型可以生成连贯的图像完成和样本。
论文:
https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf -
通用音乐翻译网
一种基于深度学习的跨乐器和风格翻译音乐的方法。该技术基于多域波网自编码器的无监督训练,具有共享编码器和在波形上端到端训练的域独立潜在空间。
-
视频中的实时人脸去识别
该方法使用前馈编码器-解码器网络架构,以人的面部图像的高级表示为条件,在全自动设置中以高帧速率对实况视频进行面部去识别。
总结想法
我们想感谢你,读者,感谢你花时间和兴趣通过阅读这本书来研究深度学习的主题。我们真诚地感谢您为这本书付出的努力,并希望我们能够满足您的期望。
深度学习的主题是如此广泛和动态,以至于人们需要进行持续的研究以跟上创新的步伐。我们对这本书的关注一直是传递关于这个主题的抽象而直观的信息的健康组合(用最少的数学运算;抱歉,如果方程是压倒性的),同时使用业界和学术界的领先工具(PyTorch)将急需的实际实现与真实数据集相结合。
我们将感谢您的想法和反馈!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









