







克服自动语音识别挑战:下一个前沿
自动语音识别技术在各个领域的进展、机遇和影响


·
关注 发表在 Towards Data Science ·17 min 阅读·2023 年 3 月 30 日
–

由 Andrew DesLauriers 拍摄于 Unsplash
TL;DR:
这篇文章聚焦于自动语音识别(ASR)技术的进展及其对各个领域的影响。ASR 已在多个行业中变得普及,其准确性通过扩大模型规模和构建更大规模的标注和未标注训练数据集得到了提升。
展望未来,ASR 技术预计将随着声学模型规模的扩大和内部语言模型的增强而持续改进。此外,自监督和多任务训练技术将使低资源语言受益于 ASR 技术,而多语言训练将进一步提升性能,使许多低资源语言能够进行基本使用,如语音命令。
ASR 在生成式 AI 中也将发挥重要作用,因为与虚拟角色的交互将通过音频/文本接口进行。随着无文本 NLP 的出现,一些最终任务,如语音对语音翻译,可能在不使用任何明确的 ASR 模型的情况下得到解决。将发布能够通过文本、音频或两者进行提示的多模态模型,并生成文本或合成音频作为输出。
此外,具有语音交互界面的开放式对话系统将提高对转录错误以及书面和口头形式之间差异的鲁棒性。这将增强对挑战性口音和儿童语言的鲁棒性,使 ASR 技术成为许多应用中的重要工具。
一个端到端的语音增强-ASR-分段系统将发布,使 ASR 模型能够个性化,并提高在重叠语音和挑战性声学场景中的表现。这是解决 ASR 技术在现实世界场景中的挑战的重要一步。
最后,预计将出现一波语音 API。同时,仍然存在小型初创公司在技术/数据采集使用和技术采纳率低的群体中超越大型科技公司的机会。
2022 年回顾
自动语音识别(ASR)技术在教育、播客、社交媒体、远程医疗、呼叫中心等多个行业中正在获得越来越多的关注。一个很好的例子是语音交互界面(HMI)在消费产品中的普及,如智能汽车、智能家居、智能辅助技术[1]、智能手机,甚至酒店中的人工智能(AI)助手[2]。为了满足对快速且准确响应的日益增长的需求,低延迟 ASR 模型已被部署用于关键词检测[3]、端点检测[4]和转录[5]等任务。带有说话人属性的 ASR 模型[6–7]也越来越受到关注,因为它们能够实现产品个性化,为终端用户提供更大的价值。
数据的普遍性。 流媒体音频和视频平台,如社交媒体和 YouTube,导致了未标记音频数据的轻松获取[8]。新引入的自监督技术可以在无需真实标签的情况下利用这些音频[9–10]。这些技术在目标领域提高了 ASR 系统的性能,即使在该领域未对标记数据进行微调[11]。另一种因能够利用这些未标记数据而受到关注的方法是使用伪标签的自训练[12–13]。主要概念是使用自动语音识别(ASR)系统自动转录未标记的音频数据,然后将生成的转录本作为真实标签,用于以监督方式训练另一个 ASR 系统。OpenAI 采取了不同的方法,假设他们可以在网上大规模找到人工生成的转录本。他们通过抓取公开的音频数据及其人工生成的字幕,生成了一个高质量且大规模(640K 小时)的训练数据集。利用这个数据集,他们以完全监督的方式训练了一个 ASR 模型(即 Whisper),在零-shot 设置下在多个基准测试中达到了最先进的结果[14]。
损失。 尽管 End-2-end(E2E)损失主导了最先进的ASR 模型[15–17],新的损失函数仍在不断发布。一种名为混合自回归转换器(HAT)的新技术[18]被引入,能够通过分离空白和标签后验来测量内部语言模型(ILM)的质量。后来工作[19]使用这种因子分解有效地适配了 ILM,仅利用文本数据,提高了 ASR 系统的整体性能,特别是对专有名词、俚语和名词的转录,这些是 ASR 系统的主要痛点。还开发了新的度量标准,以更好地对齐人类感知,克服了词错误率(WER)的语义问题[20]。
架构选择。 在声学模型的架构选择方面,Conformer [21] 仍然是流媒体模型的首选,而 Transformers [22] 是非流媒体模型的默认架构。至于后者,引入了仅编码器(基于 wav2vec2 [23–24])和编码器-解码器(Whisper [14])的多语言模型,并在多个基准测试中超越了最先进的结果。由于模型大小、训练数据量和更大的上下文,这些模型优于流媒体模型。
科技巨头的多语言 AI 发展。 Google 宣布了其“1,000 语言计划”,以构建支持 1000 种最常用语言的 AI 模型[25],而 Meta AI 则宣布了其长期努力,旨在构建包含大多数世界语言的语言和机器翻译(MT)工具[26]。
语音语言突破。 多模态(语音/文本)和多任务预训练 seq-2-seq(编码器-解码器)模型,如 SpeechT5 [27],已经发布,在各种语音语言处理任务中取得了巨大成功,包括 ASR、语音合成、语音翻译、语音转换、语音增强和说话人识别。
这些 ASR 技术的进步预计将推动进一步创新,并在未来几年对广泛的行业产生影响。
展望未来
尽管面临挑战,但自动语音识别(ASR)领域预计将在多个领域取得重大进展,从声学和语义建模到对话式和生成式 AI,甚至包括说话人归属的 ASR。本节提供了这些领域的详细见解,并分享了我对 ASR 技术未来的预测。

一般改进:
预计 ASR 系统在声学和语义方面都会有所改进。
在声学模型方面,预计更大的模型和训练数据集将提升 ASR 系统的整体性能,类似于 LLMs 领域的进展。尽管扩展 Transformer 编码器,如 Wav2Vec 或 Conformer,存在挑战,但预计会有突破使其能够扩展,或出现向编码器-解码器架构(如 Whisper)转变的趋势。然而,编码器-解码器架构有一些需要解决的缺陷,如幻觉。优化技术,如 faster-whisper [28] 和 NVIDIA-wav2vec2 [29],将减少训练和推理时间,从而降低部署大型 ASR 模型的门槛。
在语义方面,研究人员将重点关注通过融入更大的声学或文本上下文来改进 ASR 模型。还将探索在 E2E 训练期间向 ILM 注入大规模无配对文本,如 JEIT [30]。这些努力将有助于克服准确转录命名实体、俚语和名词等关键挑战。
尽管 Whisper 和谷歌的通用语音模型(USM)[31]在多个基准测试中提高了 ASR 系统的性能,但一些基准测试仍需解决,因为词错误率(WER)仍然约为 20% [32]。使用语音基础模型、添加更多多样化的训练数据和应用多任务学习将显著提升此类场景中的性能,从而开辟新的商业机会。此外,预计将出现新的指标和基准,以更好地对齐新的最终任务和领域,例如医学领域中的非词汇对话声音[33]以及媒体编辑和教育领域中的填充词检测与分类[34]。可能会为此目的开发特定任务的微调模型。最后,随着多模态的发展,预计还会发布更多模型、训练数据集和新任务的基准[35–36]。
随着进展的不断推进,预计会出现一波类似自然语言处理(NLP)的语音 API。谷歌的 USM、OpenAI 的 Whisper 和 Assembly 的 Conformer-1 [37]是一些早期的例子。
尽管听起来有些荒谬,但强制对齐对许多公司来说仍然具有挑战性。一个开源代码可能会帮助许多人实现音频片段与其对应转录文本之间的准确对齐。
低资源语言:
自监督学习、多任务学习和多语言模型的进展预计将显著提高低资源和未书写语言的性能。这些方法将通过利用预训练模型和在相对较少的标记样本上进行微调来实现可接受的性能[24]。另一种有前途的方法是双重学习[38],这是一种半监督机器学习的范式,旨在通过同时解决两个对立任务(在我们的案例中为文本到语音(TTS)和 ASR)来利用无监督数据。在这种方法中,每个模型生成未标记样本的伪标签,这些伪标签用于训练另一个模型。
此外,使用无配对文本改进 ILM 可以增强模型的鲁棒性,这将特别有利于封闭集挑战,例如语音命令。在一些应用中,如 YouTube 视频的字幕,性能将是可接受的,但不是完美的,而在其他应用中,如法庭上的逐字记录,模型可能需要更多时间才能达到标准。我们预计公司将在 2023 年根据这些模型收集数据,同时手动纠正转录文本,并且我们将在 2024 年在专有数据上微调后看到低资源语言的显著改进。
生成式 AI:
虚拟形象的使用预计将彻底改变人与数字资产的互动。在短期内,ASR 将作为生成式 AI 的基础之一,因为这些虚拟形象将通过文本/听觉界面进行交流。
但未来,随着注意力转向新的研究方向,可能会发生变化。例如,一个可能被采用的新兴技术是 Textless NLP,它代表了一种新的语言建模方法,用于音频生成[39]。这种方法使用可学习的离散音频单元[40],并以自回归的方式一次生成一个离散音频单元,类似于文本生成。这些离散单元可以随后解码回音频领域。目前,这项技术已经能够生成在句法和语义上都合理的语音继续,同时保持说话人的身份和韵律,对于未见过的说话人也能做到,如 GSLM/AudioLM [39, 41]所示。这项技术的潜力巨大,因为可以在许多任务中跳过 ASR 组件(及其错误)。例如,传统的语音到语音(S2S)翻译方法如下:它们首先将源语言中的话语转录出来,然后使用机器翻译模型将文本翻译为目标语言,最后使用 TTS 引擎生成目标语言的音频。使用 textless-NLP 技术,S2S 翻译可以通过一个直接作用于离散音频单元的编码-解码架构来完成,而不使用任何显式的 ASR 模型[42]。我们预测,未来的 Textless NLP 模型将能够解决许多其他任务,而无需经过显式转录,例如问答系统。然而,这种方法的主要缺点是回溯错误和调试,因为在离散单元空间中工作时,事情将变得不那么直观。
T5 [43] 和 T0 [44] 在 NLP 领域通过利用其多任务训练和展示零样本任务泛化取得了巨大成功。2021 年发布的 SpeechT5 [27] 在各种口语语言处理任务中表现出色。今年早些时候,VALL-E [45] 和 VALL-EX [46] 被发布。它们通过使用 textless NLP 技术展示了 TTS 模型的令人印象深刻的上下文学习能力,仅通过几秒钟的音频就能克隆说话人的声音,并且无需任何微调,甚至在跨语言环境中也能做到。
通过结合来自 SpeechT5 和 VALL-E 的概念,我们可以期待类似 T0 的模型的发布,这些模型可以通过文本、音频或两者来进行提示,并根据任务生成文本或合成音频。一个新时代的模型将开始出现,因为上下文学习将使得在零样本设置中对新任务进行泛化成为可能。这将允许在音频上进行语义搜索,通过带有说话人属性的 ASR 转录目标说话人,或用自由文本描述它,例如,“那个咳嗽的年轻孩子说了什么?”此外,它将使我们能够使用音频或文本描述来分类或合成音频,并通过显式/隐式 ASR 直接解决 NLP 任务。
对话 AI:
对话型 AI 主要通过任务导向的对话系统被采纳,即如亚马逊的 Alexa 和苹果的 Siri 这样的 AI 个人助理(PA)。这些 PA 因其通过语音命令快速访问功能和信息的能力而变得流行。随着大科技公司主导这一技术,对 AI 助理的新规定将迫使它们提供第三方语音助理选项,从而打开竞争[47]。随着这一变化,我们可以预期个人助理之间会实现互操作性,也就是说它们将开始进行通信。这将非常棒,因为人们可以使用任何设备连接到世界任何地方的对话代理[48]。从 ASR 的角度来看,这将带来新的挑战,因为上下文化将变得更加广泛,助理必须具备对不同口音的鲁棒性,并可能支持多语言。
近年来,基于文本的开放式对话系统发生了巨大的技术飞跃,例如 Blender-Bot 和 LaMDA [49–50]。最初,这些对话系统是基于文本的,即它们通过文本输入并训练输出文本,全部在书面领域内。随着 ASR 性能的提高,开放式对话系统被增强了语音基础的人机界面(HMI),这导致了由于口语和书面形式之间的差异而出现的模态不一致。主要挑战之一是弥合这一差距,通过克服由于音频相关处理引入的新类型错误,例如口语和书面形式之间的流利度差异和实体解析,以及转录错误,如发音错误[51–52]。
可能的解决方案包括改进转录质量和强大的 NLP 模型,这些模型能够有效处理转录和发音错误。可靠的声学模型置信度评分[53]将作为这些系统的关键角色,帮助指出说话者错误或作为 NLP 模型或解码逻辑的另一个输入。此外,我们预计 ASR 模型将能够预测非语言线索,如讽刺,使代理能够更深入地理解对话并提供更好的回应。
这些改进将推动进一步的发展,使对话系统具备语音 HMI,以支持挑战性的口音和儿童语言,例如在 Loora [54]和 Speaks [55]中。
更进一步,我们预计将发布一个 E2E 多任务学习框架,用于语音语言任务,采用语音和 NLP 问题的联合建模,如 MTL-SLT [56]。这些模型将以 E2E 的方式进行训练,减少顺序模块之间的累计误差,并处理如口语理解、口语总结和口语问答等任务,通过将语音作为输入,产生转录、意图、命名实体、摘要和文本查询答案等各种输出。
个性化将对 AI 助手和开放式对话系统产生巨大影响,这将引领我们进入下一个要点:说话人属性 ASR。
说话人属性 ASR:
在家庭环境中涉及多个麦克风和方的远程对话的转录仍然存在挑战。即使是最先进(SoTA)的系统也只能实现约 35%的 WER[57]。
早期的联合 ASR 和分段系统于 2019 年发布[58]。今年,我们可以期待发布一种端到端的语音增强-ASR-分段系统,该系统将改善重叠语音的性能,并在挑战性的声学场景(如混响房间、远场设置和低信噪比(SNR))中提供更好的表现。通过联合任务优化、改进的预训练方法(如 WavLM [10])、应用架构更改[59]、数据增强以及在预训练和微调期间在领域内数据上的训练[11],将实现这些改进。此外,我们可以期待针对个性化语音识别的说话人属性 ASR 系统的部署。这将进一步提高目标说话人语音的转录准确性,并将转录偏向用户定义的词汇,如联系人姓名、专有名词和其他命名实体,这些对智能助手至关重要[60]。此外,低延迟模型将继续成为重点领域,以增强边缘设备的整体体验和响应时间[61–62]。
初创公司在 ASR 领域相对于大科技公司的角色
尽管大科技公司预计将继续凭借其 API 主导市场,但小型初创企业在特定领域仍然可以超越它们。这些领域包括由于法规原因在大科技公司的训练数据中被低估的领域,如医疗领域和儿童语言,以及尚未采用技术的群体,如具有挑战性口音的移民或全球学习英语的个人。在大科技公司不愿投资的市场中,例如那些不广泛使用的语言,小型初创企业可能会发现成功和获利的机会。
为了创造双赢的局面,大科技公司可以提供 API,允许完全访问其声学模型的输出,同时允许其他人编写解码逻辑(WFST/beam-search),而不仅仅是添加可定制词汇或使用当前模型适应功能[63–64]。这种方法将使小型初创企业能够通过在给定声学模型之上进行推理时结合引导或多语言模型来在其领域中脱颖而出,而不必自己训练声学模型,这在人力资本和领域知识上可能成本高昂。反过来,大科技公司将从其付费模型的更广泛采用中受益。
ASR 如何融入更广泛的机器学习领域?
一方面,考虑到 ASR 作为最终任务时,其重要性与计算机视觉(CV)和 NLP 相当。这是低资源语言和领域中,转录是主要业务的当前情况,例如法庭、医疗记录、电影字幕等。
另一方面,在其他领域,ASR 已不再是瓶颈,只要它达到了某种可用性阈值。在这些情况下,NLP 才是瓶颈,这意味着将 ASR 性能提升到完美主义并不是提取最终任务见解的关键。例如,会议总结或行动项提取在许多情况下可以利用当前的 ASR 质量实现。
结束语
ASR 技术的进步使我们更接近于实现人与机器之间的无缝沟通,例如在对话 AI 和生成 AI 中。随着语音增强-ASR-标记系统的持续发展以及无文本 NLP 的出现,我们有望在这个领域见证激动人心的突破。展望未来,我们不禁期待 ASR 技术将解锁的无限可能。
感谢您花时间阅读这篇文章!我们非常重视和感激您对这些预测的看法和反馈。请随时分享您的评论和想法。
参考文献:
[2] voicebot.ai/2022/12/01/hey-disney-custom-alexa-assistant-rolls-out-at-disney-world/
[3] Jose, Christin 等人。“关键词检测的延迟控制。” ArXiv,2022,doi.org/10.21437/Interspeech.2022-10608。
[4] Bijwadia, Shaan 等人。“统一的端到端语音识别与端点检测以实现快速高效的语音系统。” ArXiv,2022,doi.org/10.1109/SLT54892.2023.10022338。
[5] Yoon, Ji 等人。“HuBERT-EE:早期退出的 HuBERT 以实现高效语音识别。” ArXiv,2022,doi.org/10.48550/arXiv.2204.06328。
[6] Kanda, Naoyuki 等人。“转录到说话者标记:使用端到端说话者标记 ASR 进行无限数量的说话者的神经说话者标记。” ArXiv,2021,doi.org/10.48550/arXiv.2110.03151。
[7] Kanda, Naoyuki 等人。“基于令牌级说话者嵌入的流式说话者标记 ASR。” ArXiv,2022,doi.org/10.48550/arXiv.2203.16685。
[8] www.fiercevideo.com/video/video-will-account-for-82-all-internet-traffic-by-2022-cisco-says
[9] Chiu, Chung, 等. “用于语音识别的随机投影量化器自监督学习。” ArXiv, 2022, doi.org/10.48550/arXiv.2202.01855。
[10] Chen, Sanyuan, 等. “WavLM:用于全栈语音处理的大规模自监督预训练。” ArXiv, 2021, doi.org/10.1109/JSTSP.2022.3188113。
[11] Hsu, Wei, 等. “鲁棒的 Wav2vec 2.0:自监督预训练中的领域偏移分析。” ArXiv, 2021, doi.org/10.48550/arXiv.2104.01027。
[12] Lugosch, Loren, 等. “大规模多语言语音识别的伪标签。” ArXiv, 2021, doi.org/10.48550/arXiv.2111.00161。
[13] Berrebbi, Dan, 等. “从开始进行连续伪标签。” ArXiv, 2022, doi.org/10.48550/arXiv.2210.08711。
[14] Radford, Alec, 等. “通过大规模弱监督进行鲁棒的语音识别。” ArXiv, 2022, doi.org/10.48550/arXiv.2212.04356。
[15] Graves, Alex, 等. “连接主义时间分类:使用递归神经网络标记未分段序列数据。” ICML, 2016, www.cs.toronto.edu/~graves/icml_2006.pdf。
[16] Graves, Alex. “使用递归神经网络进行序列转导。” ArXiv, 2012, doi.org/10.48550/arXiv.1211.3711。
[17] Chan, William, 等. “听、注意和拼写。” ArXiv, 2015, doi.org/10.48550/arXiv.1508.01211。
[18] Variani, Ehsan, 等. “混合自回归传输器(Hat)。” ArXiv, 2020, doi.org/10.48550/arXiv.2003.07705。
[19] Meng, Zhong, 等. “模块化混合自回归传输器。” ArXiv, 2022, doi.org/10.48550/arXiv.2210.17049。
[20] Kim, Suyoun, 等. “使用语义距离度量评估用户对语音识别系统质量的感知。” ArXiv, 2021, doi.org/10.48550/arXiv.2110.05376。
[21] Gulati, Anmol, 等. “Conformer:用于语音识别的卷积增强变换器。” ArXiv, 2020, doi.org/10.48550/arXiv.2005.08100。
[22] Vaswani, Ashish, 等. “注意力即一切。” ArXiv, 2017, doi.org/10.48550/arXiv.1706.03762。
[23] Baevski, Alexei, 等. “Wav2vec 2.0:自监督语音表示学习框架。” ArXiv, 2020, doi.org/10.48550/arXiv.2006.11477。
[24] Babu, Arun 等. “XLS-R: 大规模自监督跨语言语音表示学习。” ArXiv, 2021, doi.org/10.48550/arXiv.2111.09296。
[25] blog.google/technology/ai/ways-ai-is-scaling-helpful/
[26] ai.facebook.com/blog/teaching-ai-to-translate-100s-of-spoken-and-written-languages-in-real-time/
[27] Ao, Junyi 等. “SpeechT5: 统一模态编码器-解码器预训练用于口语语言处理。” ArXiv, 2021, doi.org/10.48550/arXiv.2110.07205。
[28] github.com/guillaumekln/faster-whisper
[29] github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechRecognition/wav2vec2
[30] Meng, Zhong 等. “JEIT: 语音识别的联合端到端模型与内部语言模型训练。” ArXiv, 2023, doi.org/10.48550/arXiv.2302.08583。
[31] Zhang, Yu 等. “Google USM: 将自动语音识别扩展到 100 多种语言。” ArXiv, 2023, doi.org/10.48550/arXiv.2303.01037。
[32] Kendall, T. 和 Farrington, C. “区域非裔美国语言语料库。” 版本 2021.07. Eugene, OR: 非裔美国语言在线资源项目。oraal.uoregon.edu/coraal, 2021
[33] Brian, D Tran 等. “‘嗯哼’,‘呃呃’:非词汇性对话声音是否会成为环境临床文档技术的致命缺陷?”,《美国医学信息学协会杂志》,2023, doi.org/10.1093/jamia/ocad001
[34] Zhu, Ge 等. “填充词检测与分类:数据集与基准。” ArXiv, 2022, doi.org/10.48550/arXiv.2203.15135。
[35] Anwar, Mohamed 等. “MuAViC: 多语言音频视觉语料库用于稳健的语音识别和稳健的语音到文本翻译。” ArXiv, 2023, doi.org/10.48550/arXiv.2303.00628。
[36] Jaegle, Andrew 等. “Perceiver IO: 一种用于结构化输入和输出的通用架构。” ArXiv, 2021, doi.org/10.48550/arXiv.2107.14795。
[37] www.assemblyai.com/blog/conformer-1/
[38] Peyser, Cal 等. “大词汇量设备端自动语音识别的双重学习。” ArXiv, 2023, doi.org/10.48550/arXiv.2301.04327。
[39] Lakhotia, Kushal 等. “从原始音频生成的语言建模。” ArXiv, 2021, doi.org/10.48550/arXiv.2102.01192。
[40] Zeghidour, Neil 等. “SoundStream: 一种端到端神经音频编解码器。” ArXiv, 2021, doi.org/10.48550/arXiv.2107.03312。
[41] Borsos, Zalán 等. “AudioLM: 一种音频生成的语言建模方法。” ArXiv, 2022, doi.org/10.48550/arXiv.2209.03143。
[42] about.fb.com/news/2022/10/hokkien-ai-speech-translation/
[43] Raffel, Colin 等. “探索统一文本到文本变换器的迁移学习极限。” ArXiv, 2019, /abs/1910.10683。
[44] Sanh, Victor 等. “多任务提示训练实现零样本任务泛化。” ArXiv, 2021, doi.org/10.48550/arXiv.2110.08207。
[45] 王成毅 等. “神经编解码语言模型是零样本文本到语音合成器。” ArXiv, 2023, doi.org/10.48550/arXiv.2301.02111。
[46] 张子强 等. “用你自己的声音说外语:跨语言神经编解码语言建模。” ArXiv, 2023, doi.org/10.48550/arXiv.2303.03926。
[47] voicebot.ai/2022/07/05/eu-passes-new-regulations-for-voice-ai-and-digital-technology/
[48] www.speechtechmag.com/Articles/ReadArticle.aspx?ArticleID=154094
[49] Thoppilan, Romal 等. “LaMDA: 对话应用的语言模型。” ArXiv, 2022, doi.org/10.48550/arXiv.2201.08239。
[50] Shuster, Kurt 等. “BlenderBot 3: 一个持续学习以负责任地互动的部署对话代理。” ArXiv, 2022, doi.org/10.48550/arXiv.2208.03188。
[51] 肖舟 等. “用于实体解析的 ASR 鲁棒性语音嵌入。” Proc. Interspeech 2022, 3268–3272, doi: 10.21437/Interspeech.2022–10956
[52] 陈安琪 等. “教 BERT 等待:平衡流媒体不流畅检测的准确性和延迟。” ArXiv, 2022, doi.org/10.48550/arXiv.2205.00620。
[53] 李秋佳 等. “提高端到端语音识别的领域外数据置信度估计。” ArXiv, 2021, doi.org/10.48550/arXiv.2110.03327。
[54] loora.ai/
[56] Zhiqi, Huang 等. “MTL-SLT: 多任务学习用于口语语言任务。” NLP4ConvAI, 2022, aclanthology.org/2022.nlp4convai-1.11
[57] Watanabe, Shinji 等. “CHiME-6 挑战:应对未分段录音中的多说话者语音识别。” ArXiv, 2020, doi.org/10.48550/arXiv.2004.09249.
[58] Shafey, Laurent 等. “通过序列转导联合语音识别和说话者分离。” ArXiv, 2019, doi.org/10.48550/arXiv.1907.05337.
[59] Kim, Juntae 和 Lee, Jeehye. “通过稀疏自注意力层将 RNN-转导器推广到域外音频。” ArXiv, 2021, doi.org/10.48550/arXiv.2108.10752.
[60] Sathyendra, Kanthashree 等. “针对神经转导器的个性化语音识别的上下文适配器。” ArXiv, 2022, doi.org/10.48550/arXiv.2205.13660.
[61] Tian, Jinchuan 等. “Bayes 风险 CTC: 在序列到序列任务中可控的 CTC 对齐。” ArXiv, 2022, doi.org/10.48550/arXiv.2210.07499.
[62] Tian, Zhengkun 等. “Peak-First CTC: 通过应用 Peak-First 正则化减少 CTC 模型的峰值延迟。” ArXiv, 2022, doi.org/10.48550/arXiv.2211.03284.
[63] docs.rev.ai/api/custom-vocabulary/
[64] cloud.google.com/speech-to-text/docs/adaptation-model
克服开发者障碍
原文:
towardsdatascience.com/overcoming-developers-block-8cfa724add7a
处理开发者障碍的方法有很多。继续阅读,了解我如何处理。


·发布于 Towards Data Science ·9 分钟阅读·2023 年 10 月 5 日
–

开发者障碍也许是倦怠的最大症状。照片由 Nubelson Fernandes 提供,来源于 Unsplash
如果你是开发者,你是否曾经遭遇过开发者障碍?如果没有,那真是太好了。但相信我,那个时刻终将来临,早晚而已(希望是早些)。当它来临时,你的技能将不再重要,因为你将不再使用它们;它们将像荒岛上的一袋金子一样无用。
有很多方法来处理开发者障碍,但我会告诉你一种对我有效的方法。
开发者障碍(或程序员障碍)是指程序员在产生新想法或解决问题时遇到困难的现象。在最糟糕的情况下,写下一行代码几乎是不可能的。
这类似于写作障碍,即作家难以产生新的想法或内容。这可能由多种因素引起,如疲倦、缺乏睡眠或动力、难以理解问题——或者最后但同样重要的,倦怠。
实际上,倦怠常常会导致这样的障碍。你坐在电脑前,试图做点什么,但你唯一能想到的就是你无法做到它。无论是什么原因,都无所谓——你就是不能做到它和不会做到它。就这样。
这可能是一个令人沮丧和失去动力的经历,因为它会妨碍程序员完成任务和赶上截止日期。有一些典型的方法可以尝试,例如
-
休息一下
-
和同事讨论你正在处理的问题
-
将任务分解成小块,逐一完成
-
利用你的空闲时间逃避并忘记编程——你也可以在工作中利用几分钟时间这样做
-
呼吸练习、正念和其他放松技巧
你可以在这里阅读更多类似的方法:
当你害怕你的控制台时
towardsdatascience.com [## 摆脱开发者瓶颈
当你不知道该做什么时该怎么办
betterprogramming.pub](https://betterprogramming.pub/make-your-way-out-of-developers-block-f134adc292d0?source=post_page-----8cfa724add7a--------------------------------)
说实话,我相信这些方法可以帮助预防开发者瓶颈,但在完全克服它方面效果较差。真正的瓶颈是无法仅通过与同事交谈或短暂休息来治愈的。长期休息(比如一个月)可能有效,但这是一种风险很大的想法,因为很可能你在回到工作后,倦怠感会比以前更严重。
真实的开发者瓶颈是无法仅通过与同事交谈或短暂休息来解决的。
我作为科学家和在商业环境中工作的数据科学家,经历过这种情况不止一次。作为后者,我从未长时间休息;最长的休息是 11 天。我可以说,一周的休息帮助我忘记编码,恢复力量和休息——但这并不会让我的回归编程变得更容易,绝对不会。这样休息后的第一天只会证明我仍然有开发者瓶颈需要克服。
所以,这些方法对我来说只是预防措施。这并不意味着它们对你不起作用——你必须亲自尝试。许多人说这些方法有效,所以也许它们确实有效,至少对某些人是这样?啊,我真羡慕他们!
当你已经突破了瓶颈,既没有写另一个函数或类的欲望,也没有力量去写另一行代码时,你会怎么做?
这是对我有效的方法。

时间阻断需要两个东西:一个计时器和你的专注。照片由 Şahin Sezer Dinçer 提供,来源于 Unsplash
时间阻断
你可以在这里阅读关于时间阻断的内容:
[## 时间阻断 - 维基百科
时间阻断(也称为时间切块)是一种个人时间管理的生产力技巧……
en.wikipedia.org](https://en.wikipedia.org/wiki/Timeblocking?source=post_page-----8cfa724add7a--------------------------------)
简而言之,这是一种个人时间管理技巧,其中你将一段时间(在我们的例子中是工作日)划分为更小的时间段,并在这些时间段内完成小任务。
这看起来并没有什么特别的印象,对吧?但如果你用对方法——对你来说的正确方法——它真的能起到奇迹般的效果,就像对我而言,即使在我觉得没有力气再做任何事,只能起身关闭电脑的时候,它也能有效。
这并没有什么特别的印象,对吧?但如果你用对方法——对你来说的正确方法——它真的能起到奇迹般的效果。
时间区块的操作方法
我是这样做的:
-
我设置一个计时器,时间段如 15 或 20 分钟。我们称之为专注时间段。
-
在这个专注时间段内,我完全专注于我正在做的任务。我不将我正在做的任务分解成更小的任务,也不创建一个适合这个时间段的小任务。我只专注于我正在做的任务。
-
专注于任务意味着深度工作。所以,不要查看邮件,不要上与任务无关的互联网,不要休息喝咖啡——甚至连做咖啡都不要。(更多内容见下文。)
-
我会一直工作到时间结束,但我不会查看时间;这就是你需要使用计时器的原因。我不考虑时间,只专注于工作。
-
当时间到达时,我将工作放在一边,除非我有一些非常小的任务要完成——比如,完成一行代码或一个句子之类的事情。我尽量不将时间延长 5 或 10 分钟——当我这样做没有问题时,通常意味着我的时间块接近于可以忽略,或者我可以延长专注时间段。
-
我会休息一下。这可以是工作休息,但不一定。我可以回复邮件、打电话、做一些不需要深度工作的事情。如果我休息时间不与工作有关,我会尽量让它相对较短,比如 5 或 10 分钟。但如果与工作相关,它可以长一些,除非我专注的任务更为优先。
-
当你准备好重新投入深度工作时,开始另一个专注时间段。
专注时间的长度
专注时间段在一天中可以有所变化;这真的不重要。对我而言,有一个比例规则:我感觉越好,时间段越长。当我感觉非常糟糕时,当我觉得如果再写一行代码我就要死了时,我会把下一个专注时间段设得非常短,比如 10 分钟,有时只有 5 分钟。
如果你需要使用这么短的时间段,你可能已经精疲力竭了。这是几年前的事了,那时候并不愉快。我无论如何都必须工作,这实际上也是我在这篇文章中描述的方法的来源。从那时起,我使用了更长的专注时间段。
尽管 5 分钟是一个非常短的时间段,但对于某些任务,它可能足够做一些高质量的工作。此外,20 * 5 = 100分钟的编程总比0 * 0 = 0分钟要好,对吧?
当我感觉良好时,我会设定为 25 分钟——但从不超过。根据我的感觉,我可以在八小时工作日中使用最多 12 个 25 分钟的专注时间段。我从未能够进行更多的真正深度工作。
你可能会想:这只是12 * 25= 300分钟的工作,而我应该工作8 * 60 = 480分钟!不,这不是人们工作的方式。有时你可能在 8 小时内工作 450 分钟,但这是很少见的,非常少见。你通常会有很多休息,需要做一些不需要深度集中工作的事情。所以,300 分钟不仅足够——它是很多的。
深度工作
有时,两个小时的深度工作可能也会很多,因为深度工作与常规工作完全不同。你可以在卡尔·纽波特的书中阅读到这一点:
我很高兴地宣布我的新书《深度工作:专注成功的规则》。这本书……
如果你无法访问这本书,你也可以在这里阅读关于深度工作的内容:
这份深度工作总结和指南充满了帮助你集中注意力、摆脱干扰、提高工作的建议。
这是一个很棒的概念,当我从朋友那里了解到它时,我立即阅读了卡尔的书。它显著提高了我的工作效率和质量。
时间区块化的深度工作与常规深度工作稍有不同。例如,较长的非深度工作休息时间——或者说非工作休息时间——是我为应对倦怠而发明的。当我感到疲惫时,真正的深度工作超出了我的能力范围。但在 15 分钟的休息(用于休息或其他工作)中,进行 10、15,甚至有时 20 分钟的深度工作是可能的。
另一个卡尔可能不太赞成的例外是,当电话看似重要时接听电话。但当我这样做时,我要么停止计时器,要么在电话后从头开始专注时间段。
因此,请记住,基于倦怠的时间区块化深度工作不同于常规深度工作。你不必遵循相同的规则。也许有一天我会写更多关于深度工作的内容,但今天重要的是——即作为对抗开发者阻塞的工具——上述描述的深度工作方法。
你可以自己试试看。也许时间阻断方法与深度工作结合对你不起作用。也许其他方法会有效——如果是这样,请在评论中分享。我不敢说这种方法对任何人都有效——但它对我有效。它在那些我厌倦工作到无法想象自己工作的艰难时刻也有效。
我听到你在说:“你疯了吗?!在我连一行代码都写不出来的时候还谈什么深度工作?!”我知道这听起来有多么不可思议。看似不可能、难以想象、荒谬。但请先尝试一下,然后再决定。不管你对这种方法有什么看法,它确实对我有效,即使常规编码似乎毫无希望。我不明白这种方法为什么以及如何有效。它超出了我能想象的范围,让我在如此的心理状态下也能高效工作。
不可能、难以想象、荒谬——是的。但可能。
当然,你可以将时间阻断用于各种活动,而不仅仅是编码。但我们这里讨论的是开发者障碍,我认为正是深度工作使时间阻断在开发者障碍中有效。深度工作和你为工作阻断时间的能力。
我并不是每天都使用这种方法,尽管也许我应该。即使在我状态良好、感觉想工作的情况下,它也有效——它有助于提高我的编码效率。
因此,如果你遭遇了开发者障碍,也许这种方法会帮助你克服它。如果没有,它仍然可以帮助你提高工作的效果、效率和质量。如果你今天非常困倦,可以尝试短时间的工作,比如 10 分钟。如果因为家庭问题或其他原因今天难以专注于工作,可以尝试一下。也许在一种情况下有效,即使在另一种情况下无效?
时间阻断结合深度工作不仅高效——它还可以提高你工作的舒适度和满意度。
时间阻断结合深度工作不仅高效——它还可以提高你工作的舒适度和满意度。
感谢阅读。如果你喜欢这篇文章,你可能也会喜欢我写的其他文章;你可以在这里查看。并且如果你想加入 Medium,请使用我下面的推荐链接:
[## 通过我的推荐链接加入 Medium - Marcin Kozak
作为 Medium 的会员,你的部分会员费用将流向你阅读的作者,并且你可以全面访问所有故事…
medium.com](https://medium.com/@nyggus/membership?source=post_page-----8cfa724add7a--------------------------------)
克服成为数据科学家的一些最糟糕的部分
原文:
towardsdatascience.com/overcoming-some-of-the-worst-parts-of-being-a-data-scientist-3237d20f356f
意见
这个领域并不完美,所以最好正确设定期望值


·发表于 Towards Data Science ·阅读时间 13 分钟·2023 年 1 月 12 日
–

作者提供的图片
在科技行业工作时,我经常看到对数据科学、机器学习和人工智能等技术角色的过度美化。我喜欢看到人们对这个领域感到兴奋,并且有更多的观众参与其中,但如果你希望保持这种兴奋感,正确管理期望是至关重要的。
很多刚入门这个领域的人没有导师来传达你在日常工作中会遇到的真实情况。我希望这个故事能引发这样的对话,让你了解一些工作中可能出现的“最糟糕”的部分。我把“最糟糕”放在引号里,因为有些人会在这种环境中茁壮成长并且非常喜欢,而其他人的性格则可能会非常讨厌这种环境。
尽管这个领域因为多样化的群体变得非常强大,但并不是每个人都会在数据科学或至少是当前状态下找到自己的定位,如果觉得不适合你,完全可以说这不是你的领域。我会突出一些我今天看到的显著问题,但我保证还有更多我没有提到或者个人没有经历过的。如果没有其他,这个故事至少应该能给你一个对期望的了解,以及我建议如何克服这些问题。
我在这里讨论的问题很可能是五年前不存在的,也不会在五年后存在,因为这个领域发展迅速。目前,我讨论的有以下五个问题:
问题 #1: 角色的模糊性
问题 #2: 尽可能多地使用 SQL
问题 #3: 快速传达复杂概念
问题 #4: 遵循成本-努力-价值矩阵
问题 #5: 似乎无尽的不确定性
问题 #1: 角色的模糊性
这每天都在改善,并且可能严重依赖于你所在的公司(及其数据文化),但这仍然是行业正在解决的问题。以下是对各角色主要但非唯一职责的当前平均理解。
数据工程师: 数据摄取、数据验证
数据分析师: 数据验证、数据准备和数据探索
数据科学家: 数据准备、数据探索、数据建模(创建和验证)、模型评估
机器学习工程师: 模型评估、模型部署和模型监控
全栈数据科学家/机器学习工程师: 一切数据
我会帮你一个忙,不再创建[另一个]上述角色的维恩图。关于角色差异的内容无穷无尽,以上只是一个粗略的概括。
我认为这种角色区分可能会带来大问题,因为这些角色之间的交接往往可能灾难性的。但即使一切顺利,这些角色在所有公司中并不存在。初创公司通常会有数据专业人士做所有事情的大致内容,而大型组织通常至少有一个每种角色,而中型组织则有所有介于两者之间的角色。
一些组织认为数据科学是一个潮流,所以他们雇佣数据工程师,然后要求他们学习足够的机器学习工作以完成超出其职能的部分(或机器学习工程师,然后要求他们学习足够的数据工程以完成其职能之前的部分)。其他组织则认为他们想要数据科学家,但需要先有数据分析师。还有一些组织拥有所有角色,但工作区分不够清晰,使得团队之间的沟通非常困难。
很多问题取决于公司如何看待数据/数据文化是什么样的,这可能会受到领导、管理层和执行团队的观点的强烈影响。模糊性是导致职位发布多样性或组织需求与个人期望之间不一致的原因。
推荐
如果你正在申请一个职位,我建议你准备好问题来面试你试图加入的数据团队。分析他们的文化是面试的关键部分,以便了解你将加入什么文化以及他们如何重视数据职能。询问像“这个角色的平均一天是什么样的”以及“优秀的表现是什么样的”等问题,可以很好地了解这个职位在职位描述之外的实际情况。
此外,要非常注意他们如何进行技术面试。从他们问你什么(Leetcode 问题、家庭作业、配对编程等)到他们如何评估你的工作,这一切都能为你提供有关组织数据认知的宝贵信息。就个人而言,我认为对任意的 Leetcode 算法进行测验是一种时间浪费,并且告诉我足够的关于数据文化的信息,以至于我通常会拒绝那里的面试。这与我完成任务的能力无关,而完全与工作的现实完全不同以及他们不能以其他方式看待软件工程有关。家庭作业可以展示出对数据工作强烈依赖于上下文的深刻理解(同时仍然评估技术能力),成功的衡量标准应是处理不确定性的能力。这也可能做得很糟糕,如果测试的评估很差,这也会促使我迅速拒绝公司。我如何评估数据面试值得单独讲述,但这只是我个人面试方法的简要指南,我建议你制定一个反映你想要成为其中一部分的文化的策略。
如果你已经在公司中,我的建议是适应公司坚持的定义。你会更好地为一个在高度重视该职能的组织中担任具有 ML 技能的数据工程师,而不是过分关注拥有数据科学家头衔。我们都在为推动公司发展而努力,任何试图在任意头衔之间强加重要性等级的人都在玩一种注定失败的游戏。从数据中创造价值以指导有效决策,无论你的头衔是什么。
我也希望将此对话与薪资分开,因为我相信你应该根据你的努力和技能获得公平的报酬,无论职称如何。如果你是数据分析师,但执行数据工程师和数据分析师的职务,薪资应当合适。我更提倡的是你应该在构建自己以在公司中更成功和更快乐方面具有适应性。
问题 #2:尽可能多地使用 SQL
数据科学职业涉及大量编程。即使有很多新工具出现,你的能力更多地还是体现在能够解决技术数据问题,而不论你所处的场景。这可能意味着有云计算也好,没有数据可视化工具也好,使用 Python 也好,不用 Python 也好,等等。我们在行业中看到的标准大多数人已经采纳了,但由于可用工具和技术的广泛范围,它们仍然可能有所不同。到目前为止,我所见的所有高绩效数据组织在编程方面都非常强大,并且在需要时也能学习工具。
我在每一个数据基础设施中看到的一个相似模式就是大量使用 SQL。SQL 就像有九条命的猫,无论你往哪里看,它总是以各种形态和形式出现。SQL 教育经常被忽视,但它是工作的重要部分。在处理大规模项目时,能够编写优化的 SQL 查询并预先加载数据集的能力对你有很大帮助。
SQL 编写的难度可能因项目而异,但重要的是要预期大量使用 SQL,并在可能时选择使用它。你的项目工作流将更快,调试也更容易。问题不在于尽可能多地使用 SQL 是否是一个“问题”,而在于这一点没有被充分讨论,导致有志于成为数据科学家的人没有准备好。学习 SQL 并不难,但练习 SQL 可能会很难。现在有一些很好的免费网站可以练习,但它们都是模拟的、设计好的环境,表格小且简单。组织可能有一个非常混乱的数据环境,人们可能甚至不知道你要找的数据在哪里以及它如何与其他数据连接。
推荐
尝试在个人项目中融入 SQL 工作。这方面个人项目的需求是不容忽视的,但许多项目通常都从 Kaggle 的一个小 csv 文件的pd.read_csv()开始。这没问题,但这不足以帮助你真正练习和训练实际的工作。试着通过将数据加载到一个小型开源数据库中,然后查询以获取所需的数据来模拟真实世界的场景。在这个练习中你将学到很多东西,但如果这过于复杂,你甚至可以使用 pysql 在比免费的站点更好的环境中练习。
如果没有别的,我强烈推荐去 SQL 培训网站,尝试解决挑战。习惯于使用这个语言,思考如何通过 SQL 检索、结合和处理数据,对工作非常有帮助。
我最喜欢的学习 SQL 和提升技能的方法是SQL 谋杀之谜。
问题 #3:快速传达复杂概念
尽管普遍知道这项工作涉及沟通技巧,但这个技能的深度却很少被讨论。一个[非常]常见的场景是,你已经构建了一个复杂的统计模型或机器学习系统,无论它表现如何,你都需要在不到 30 分钟内向高级管理人员解释结果。在这段时间里,你需要提供足够的技术细节,而不至于让他们被过多的信息淹没,丧失重点,同时还需要提供可以采取的下一步建议,并将其放在对他们有意义的业务背景中。这是很难的。
对于这个问题没有好的解决办法,因为不是每个人都能投入时间和精力去学习数据科学世界的复杂性,所以你必须额外付出努力来适应他们所在的水平。这与掩盖重要点或“降低”内容的复杂性不同,它是以一种能够及时被你的受众理解的方式,精确清晰地提供足够的信息。
我见过最好的情况是,当你有一个优秀的团队时,一人讨论技术细节,而另一人则能够从宏观上提供清晰的整体视图。这通常是最佳的场景。我见过许多案例,其中高度技术化的人认为自己是很强的沟通者,但最终却失去了他们所沟通的听众。谨慎处理这些人主导对话的情况;过多的信息让一个人劫持讨论的效果与信息过少,什么都没说一样无效。
推荐
诚实地评估自己的沟通强项和弱项。假设自己是专家因为你知道技术细节对任何人都没有帮助。向同事寻求关于讨论中涉及你的真实反馈,并了解你可以改进的地方。一旦你能够正确识别自己的弱点,看看如何与团队合作,弥补你不够有效的领域,但团队中的其他人可能擅长。作为一个团队进行协作讨论通常在与听众产生共鸣方面非常成功,因为一个人可以专注于正确的技术细节,而另一个人则可以关注这些细节所涉及的更广泛的背景。
参加这方面的课程是可以的,但该领域需要更多愿意在工作中承认自身不足并学习的人。最好的学习方式是通过实践,团队中的每个人都应该愿意提升自己。公开承认错误或指出他人的不足是有挑战的,但一个能让人们成长为最佳版本的数据文化才会经得起时间的考验。
问题 #4:遵循成本-努力-价值矩阵
当你开始一个数据科学或机器学习项目时,通常会有一位项目经理(PM)来指导需要完成的工作及其时间安排。这可能效果很好,也可能不尽如人意,但如果 PM 具备管理高级数据项目的培训,这样的工作效果最佳。如果没有,这些工作会由 PM 传达,但最终由资深数据专业人士来完成。
无论如何,理解如何有效管理你的项目是极其有用的。知道如何优先处理正确的下一步是一个深刻的关键技能。这需要在成本、努力和价值之间保持顽强的平衡,并随着新信息的发现而不断演变。
尽管在项目的高层次上可以做到这一点,但在数据产品的低层次功能实现中就变得具有挑战性。这是因为它需要对某一迭代所需的内容和实施的难度有深入的理解。数据产品本质上是非常迭代的,适当地估计所需的工作量和所产生的价值的能力,最好是由那些能够构建它的人来完成。
建议
不仅仅是一个建设者。理解你对技术细节的知识将不可避免地要求你理解数据产品管理。这要求你开始培养对工作时间和精力成本的直觉,同时也要对你的努力将产生的价值有敏锐的洞察力。
这项工作并不简单,因为它需要理解业务和对你项目所处背景的深入掌握。很容易将这项工作迅速地忽视为超出你的“职责范围”,但我认为,如果你无法理解你的项目旨在服务的业务,你的项目就无法做得正确。
发展这种能力的最佳方式就是多做练习。你从实际项目中获得的经验越多,你对难度的直觉就越好。你沉浸于的工具和概念越多,你对成本的估计就越准确。你与业务的联系越紧密,你对高价值工作的对齐度就越好。根据这三个因素优先处理工作的方式可能因你的团队、部门和公司而异,但能够理解你的情况并有效地应对,将立即使你与他人区别开来。
我遇到的几乎每位有经验的数据科学家都有这种才能。这是通过多年构建经验发展起来的,它对他们在项目中的工作非常有帮助。我强烈建议初级人员开始时要倾向于这项工作(而不是过度关注算法背后的数学),因为这将显著区分他们在职业生涯中的进步。
问题 #5: 似乎无尽的不确定性
我发誓,这个领域几乎每 6 个月都会发生变化。新工具、新算法、新最佳实践、新的“自动 X”等的周期时间比任何一个人能跟上的速度都要快。这带来了一些子问题:
-
精神疲惫。可以说你已经到了深渊,难以应对。数据工作的任务似乎永无止境,主要是因为你不仅是找到更好答案的专家,通常还需要引导出更好的问题。这对许多人来说可能是一个心理上压倒性的工作,尤其是在紧迫的截止日期下。
-
快速的反学习/再学习。工具/库/概念的演变和过时要求我们适应潮流的变化,否则最终会被抛在一旁。对一些人来说,总是作为学习者的刺激令人兴奋;对其他人而言,这绝对是令人疲惫的。从跟上最新信息到理解如何适应工作流程(以及是否适应),这可能比全职工作还要繁重。
-
人际问题。数据本身没有任何价值。我们通过叙事赋予其价值。叙事取决于人们及其周围的背景。这可能导致一些非常奇怪的问题。我遇到过我的最佳表现模型不是被使用的情况,因为行业专家(模型的客户)从未见过如此高的模型结果。类似地,模型的可解释性往往比模型的性能更受重视。尽管我相信随着我们能够更好地解释复杂模型,这种情况正在减少,但这仍然反映出这是一个主要由人为因素主导的工艺,难免会导致人际问题。
推荐:
-
利用休息时间,真正断开连接。让我感到不可思议的是,我有多少次在问题上陷入困境,敲击键盘却无济于事,而只是离开去做一些完全无关的事情,这往往会帮助我找到解决办法。这项工作不是短跑,而是感觉永无止境的马拉松。你总是可以进行更深入的分析,创建更强大的模型,并设计更好的系统。花时间休息,以便在工作时能够提供真正高质量的成果。
-
说实话,除了接受这是工作的本质并享受它之外,没有其他办法。如果你是一个(或者能成为一个)在自我提升中茁壮成长,热爱过程而非结果的人,这项工作每天真的会像一场新冒险。如果这种想法让你感到疲惫,你可能会迟早(也许不止一次)感到精疲力竭。请记住,即使你没有超越极限,精疲力竭也会发生。仅仅沉浸在需要频繁反学习/再学习的环境中,就可能感到难以跟上,或者被抛在后头。
-
与人交朋友。数据科学家通常不被视为传统的销售角色,但我们经常需要推销东西(我们的产品、结果、解决方案、想法等),这真的很不可思议。我发现,最简单的方法是试着与客户、同事、合作伙伴等成为朋友。有很多成功的经历,就是因为我先尝试让他们成为朋友,从而轻松实现了目标。
结论
这个领域非常适合那些深度享受不断证明自我价值和终身学习的人。不过,值得注意的是,如果新人希望在这个领域找到自己的定位,也会遇到一些问题。我总结了 5 个常见的问题,这些问题是我在网上看到和从朋友/同事那里听到的,但这并不是一个详尽的清单。我很乐意听听其他人认为有哪些问题,以及推荐的解决方法。我可以提供的最佳建议是加入并积极参与一个社区。分享故事和与人连接对各种复杂问题的解决效果是惊人的。
感谢阅读!
使用我的推荐链接成为 Medium 会员
Medium 是我进行日常阅读的大型资源库,如果你在数据领域,这个平台是一个宝藏。如果你希望订阅,可以使用我的推荐链接进行注册。完全透明:如果你使用这个链接订阅 Medium,部分订阅费将直接进入我的账户。希望你能成为我们社区的一员。
[## 使用我的推荐链接加入 Medium - Ani Madurkar
阅读 Ani Madurkar(以及 Medium 上成千上万其他作家的)每一个故事。您的会员费将直接支持…
animadurkar.medium.com](https://animadurkar.medium.com/membership?source=post_page-----3237d20f356f--------------------------------)
克服大型语言模型的局限性
如何通过类人认知技能增强大型语言模型


·
关注 发表在 Towards Data Science ·16 分钟阅读·2023 年 1 月 23 日
–
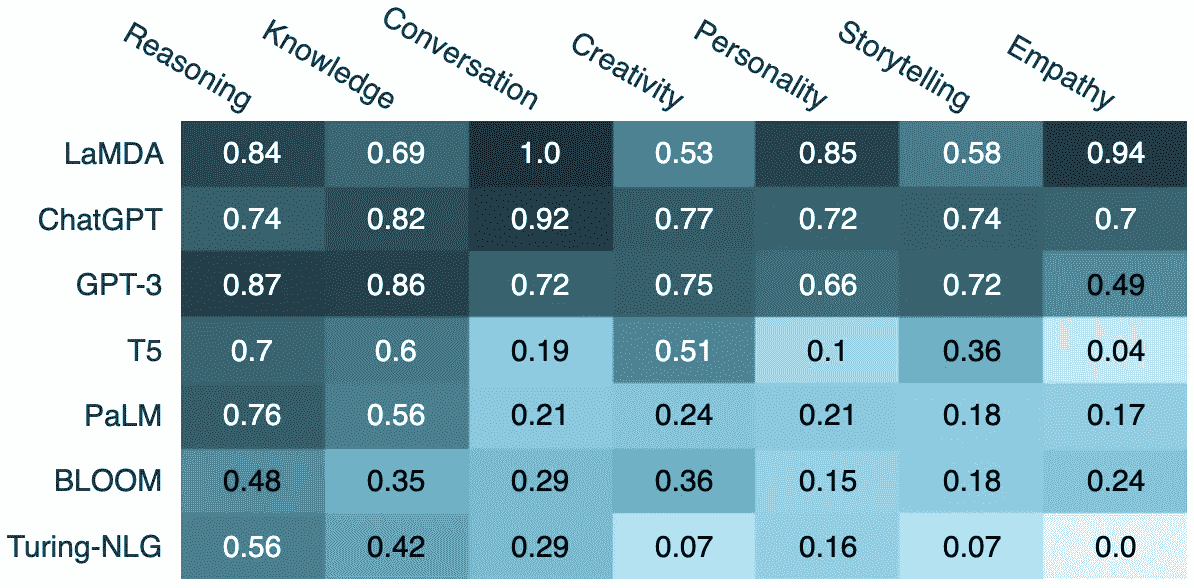
大型语言模型在人类认知技能方面的表现(来源:自 2021 年以来约 40 万篇 AI 相关在线文本的语义嵌入分析)
免责声明:本文在没有 ChatGPT 支持的情况下撰写。
在过去的几年里,像 ChatGPT、T5 和 LaMDA 这样的大型语言模型(LLMs)发展出了惊人的人类语言生成技能。我们很容易将智能归因于模型和算法,但这其中有多少是模仿的,又有多少真正类似于人类丰富的语言能力?当面对这些模型自然流畅、自信的输出时,有时很容易忘记语言本身只是交流冰山的一角。其真正的力量在于与各种复杂的认知技能(包括感知、推理和沟通)结合时展开。虽然人类在成长过程中自然从周围世界中获得这些技能,但 LLMs 的学习输入和信号却相对稀少。它们被迫仅从语言的表面形式中学习,它们的成功标准不是交流效率,而是高概率语言模式的再现。
在商业环境中,当 LLM 被赋予过多权力时,可能会导致意外的负面结果。面对自身的局限性,它不会承认这些局限,而是倾向于走向另一个极端——生成无意义、有毒的内容,甚至给出具有高度自信的危险建议。例如,由 GPT-3 驱动的医疗虚拟助手可能在对话的某个时点建议用户自杀。[4]
考虑到这些风险,我们如何在将 LLMs 融入产品开发时安全地利用其力量?一方面,重要的是要意识到固有的弱点,并使用严格的评估和探测方法来针对特定用例中的这些弱点,而不是依赖于理想的互动。另一方面,竞赛已经开始——所有主要的 AI 实验室都在播种以增强 LLMs 的额外能力,未来充满了乐观的前景。本文将探讨 LLMs 的局限性,并讨论控制和增强 LLM 行为的持续努力。假设你对语言模型的工作原理有基本的了解——如果你是新手,请参考这篇文章。
在深入技术之前,让我们通过一个思想实验——由 Emily Bender 提出的“章鱼测试”——来了解人类和 LLMs 看待世界的方式有多么不同。[1]
在章鱼的皮肤上
想象一下,安娜和玛丽亚被困在两个无人居住的岛上。幸运的是,他们发现了两个电报机和一条由之前的访客留下的水下电缆,并开始互相通信。他们的对话被一只机智的章鱼“窃听”了,这只章鱼从未见过水面上的世界,但在统计学习方面非常出色。他拾取了两位女士之间的词汇、句法模式和交流流动,从而掌握了他们语言的外在形式,但并不了解它在现实世界中的实际基础。正如路德维希·维特根斯坦曾经说过的:“语言的界限就是我的世界的界限”——虽然我们现在知道人类的世界模型包含了比语言更多的东西,但章鱼至少在了解水面上世界的知识时会同情这一说法。
在某个时刻,仅仅听是不够的。我们的章鱼决定掌控局面,切断玛丽亚那边的电缆,开始与安娜聊天。有趣的问题是,安娜何时会发现变化?只要双方交换社交客套话,安娜有很大可能不会怀疑什么。他们的闲聊可能会这样进行:
A: 嗨,玛丽亚!
O: 嗨,安娜,你好吗?
A: 谢谢,我很好,只是享受了一顿椰子早餐!
O: 你真幸运,我的岛上没有椰子。你有什么计划?
A: 我本来想去游泳,但我担心会有风暴。你呢?
O: 我现在正在吃早餐,之后会做一些木工。
A: 祝你有美好的一天,稍后再聊!
O: 再见!
然而,随着他们关系的加深,他们的沟通也变得更为强烈和复杂。在接下来的章节中,我们将带着章鱼经历几个需要掌握常识、交流背景和推理的岛屿生活场景。与此同时,我们还将探讨将额外智能融入代理的方法——无论是虚构的章鱼还是 LLMs——这些代理最初只接受了语言表层的训练。
向 LLMs 注入世界知识
一天早上,安娜计划去打猎,并试图预测当天的天气。由于风来自玛丽亚的方向,她向“玛丽亚”询问当前天气情况的报告作为重要信息。被困在深水中的章鱼对描述天气情况感到尴尬。即使他有机会瞥一眼天空,他也不知道像“雨”、“风”、“多云”等具体天气术语在现实世界中指的是什么。他拼命编造一些天气事实。当天晚些时候,安娜在树林里打猎时被一场危险的雷暴惊到。她把预测风暴的失败归因于缺乏气象知识,而不是她对话伙伴的故意幻想。
从表面上看,大型语言模型(LLMs)能够真实地反映许多关于世界的事实。然而,它们的知识仅限于在训练数据中明确遇到的概念和事实。即使有大量的训练数据,这些知识也无法完整。例如,它可能缺少用于商业用例的特定领域知识。目前的另一个重要限制是信息的时效性。由于语言模型缺乏时间上下文的概念,它们无法处理动态信息,如当前天气、股市价格或今天的日期。
这个问题可以通过系统地“注入”额外的知识到 LLM 中来解决。这些新输入可以来自各种来源,例如结构化的外部数据库(如 FreeBase 或 WikiData)、公司特定的数据源和 API。一种注入方法是通过在 LLM 层之间“插入”的适配器网络来学习新知识:[2]
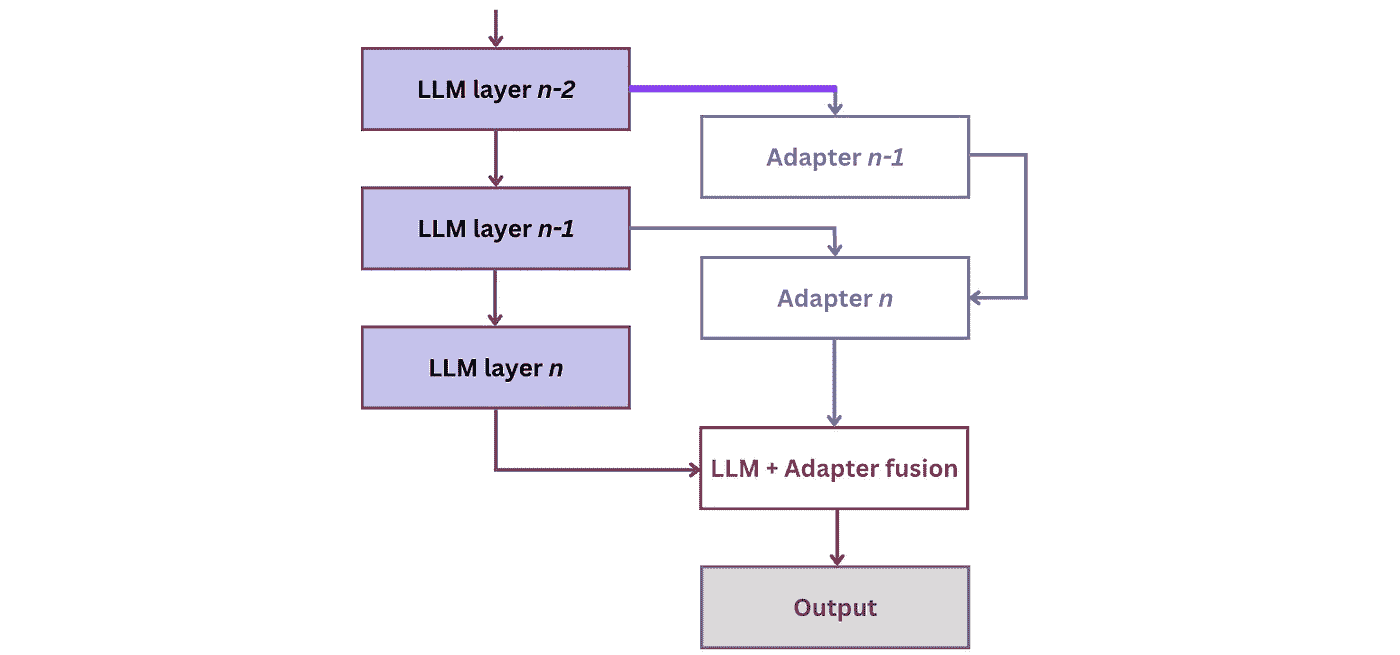
图 1:适配器基于知识注入到 LLMs 的架构 [2]
这种架构的训练分为两个步骤,即记忆化和利用:
1. 在记忆化阶段,LLM 被冻结,适配器网络从知识库中学习新事实。学习信号通过掩蔽语言建模提供,其中部分事实被隐藏,适配器学习重现这些事实:
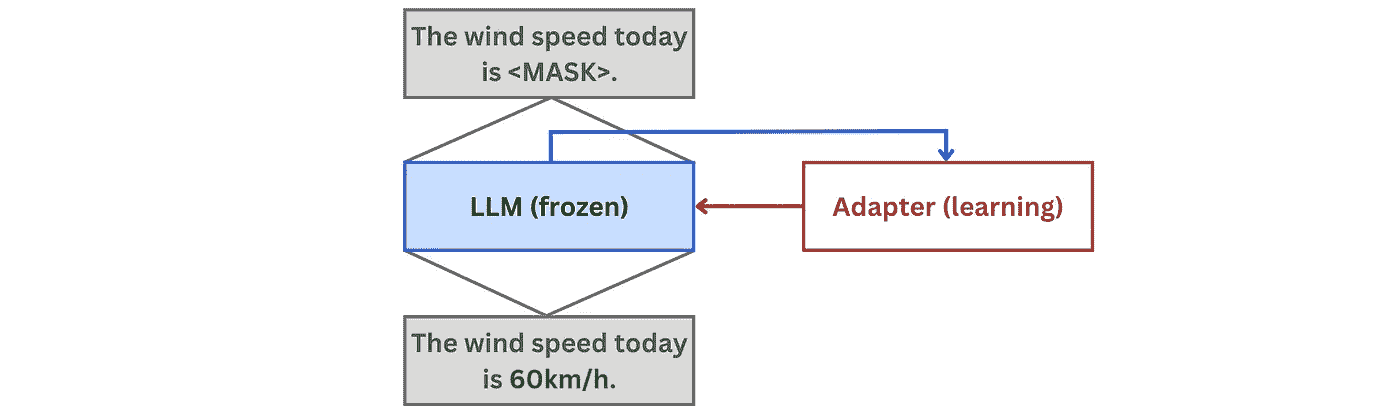
图 2:适配器在 记忆化 步骤中进行训练
2. 在利用阶段,语言模型学习在各自的下游任务中利用适配器记忆的事实。在这里,适配器网络被冻结,同时模型的权重被优化:

图 3:LLM 在 利用 步骤中学习使用适配器知识
在推理过程中,LLM 提供给适配器的隐藏状态通过融合函数与适配器的输出融合,以生成最终答案。
虽然架构级别的知识注入允许对较小的适配器网络进行高效的模块化再训练,但修改架构也需要相当的工程技能和努力。更简单的替代方案是输入级别注入,即模型直接在新事实上进行微调(参见[3]中的示例)。缺点是每次更改后都需要昂贵的微调——因此不适合动态知识来源。有关现有知识注入方法的完整概述可以在这篇文章中找到。
知识注入帮助你构建领域智能,这已成为垂直 AI 产品的关键差异化因素。此外,你还可以利用它建立可追溯性,以便模型可以指引用户到原始信息来源。除了结构化知识注入外,目前还在努力将多模态信息和知识整合到 LLM 中。例如,在 2022 年 4 月,DeepMind 推出了 Flamingo,一个能够无缝摄取文本、图像和视频的视觉语言模型。[5] 与此同时,谷歌正在开发 Socratic Models,这是一个模块化框架,其中多个预训练模型可以通过零-shot,即通过多模态提示,进行组合,以便相互交换信息。[6]
拥抱交流背景和意图
由于安娜不仅想分享她对生活的想法,还想与玛丽亚分享她岛上的美味椰子,她发明了一个椰子弹射器。她给玛丽亚发送了一份关于如何制作椰子弹射器的详细说明,并请她提供优化建议。然而,接收方的章鱼却没有给出有意义的回应。即使他能在水下构建弹射器,他也不知道像绳子和椰子这样的词指的是什么,因此无法在物理上复制和改进这个实验。他只是简单地说“很棒的主意,干得好!我现在需要去打猎了,再见!”安娜对这个不合作的回应感到困扰,但她也需要继续她的日常工作,忘记了这件事。
当我们使用语言时,我们是为了特定的目的,即我们的交流意图。例如,交流意图可以是传递信息、社交或要求别人做某事。前两者对于大型语言模型(LLM)来说比较直接(只要它在数据中看到了所需的信息),而后者则更具挑战性。我们不考虑 LLM 在现实世界中没有行动能力的事实,而是将自己限制在语言领域内的任务——撰写演讲稿、申请信等。LLM 不仅需要以连贯的方式组合和组织相关信息,还需要在形式性、创造力、幽默等软标准方面设定正确的情感基调。
从经典语言生成转向识别和响应特定的传达意图是实现更好用户接受度的重要步骤,特别是在对话 AI 中。一种方法是来自人类反馈的强化学习(RLHF),该方法最近在 ChatGPT 中实施过([7]),但在人类偏好学习中已有更长的历史。[8] 简而言之,RLHF “重新引导” LLM 的学习过程,从直接但人为的下一个词预测任务转向学习特定传达情境中的人类偏好。这些人类偏好直接编码在训练数据中:在标注过程中,人们会看到提示并编写期望的回应或对一系列现有回应进行排序。然后优化 LLM 的行为以反映人类偏好。从技术上讲,RLHF 分为三个步骤:
-
初始 LLM 的预训练和微调:LLM 先以经典的预训练目标进行训练。此外,它还可以通过人类标注的数据进行微调(例如 InstructGPT 和 ChatGPT 的情况)。
-
奖励模型训练:奖励模型基于反映特定情境中传达偏好的人工标注数据进行训练。具体来说,人们会看到一个提示的多个输出,并根据其适用性进行排序。模型学习奖励排名较高的输出,并惩罚排名较低的输出。奖励是一个单一的标量数字,这使得它与下一步的强化学习兼容。
-
强化学习:策略是初始 LLM,而奖励函数结合了给定文本输入的两个评分:
-
奖励模型评分确保文本响应传达的意图。
-
对生成与初始 LLM 输出差距过大的文本(例如 Kullback-Leibler 散度)施加处罚,确保文本语义上有意义。
因此,LLM 被微调以产生在给定传达情境中最大化人类偏好的有用输出,例如使用 近端策略优化(PPO)。
想要深入了解 RLHF,请查看 Huggingface 提供的优秀资料(文章 和 视频)。
RLHF 方法在 ChatGPT 上取得了令人震惊的成功,特别是在对话 AI 和创意内容创作领域。实际上,它不仅能导致更真实和有目的的对话,还能在减轻不道德、歧视性或甚至危险的输出的同时,积极地“偏向”伦理价值。然而,在对 RLHF 的兴奋中,常常被忽视的是,尽管没有引入显著的技术突破,其巨大的力量来自于线性的人工注释工作。RLHF 在标注数据方面的成本非常高,这是所有监督和强化学习努力的已知瓶颈。除了对 LLM 输出的人工排名外,OpenAI 的 ChatGPT 数据还包括人类撰写的对提示的回应,这些回应用于微调初始 LLM。显然,只有致力于 AI 创新的大公司才能承担如此规模的数据标注预算。
在聪明的社区的帮助下,大多数瓶颈最终都会得到解决。过去,深度学习社区通过自我监督解决了数据短缺的问题——使用下一个词预测来预训练 LLM,这是一种“免费”获得的学习信号,因为它是任何文本固有的。强化学习社区正在使用如变分自编码器或生成对抗网络等算法生成合成数据——成功程度各不相同。为了使 RLHF 广泛可用,我们还需要找到一种众包交流奖励数据和/或以自我监督或自动化方式构建它的方法。一种可能性是使用“野外”中可用的排名数据集,例如 Reddit 或 Stackoverflow 对话,其中用户对问题的回答进行评分。除了简单的评分和点赞/点踩标签外,一些对话 AI 系统还允许用户直接编辑回应以展示期望的行为,从而创造出更细致的学习信号。
建模推理过程
最后,安娜遇到了紧急情况。她被一只愤怒的熊追赶。在惊慌中,她抓起几根金属棒,并请玛利亚告诉她如何自卫。当然,章鱼完全不明白安娜的意思。它不仅从未面对过熊——它也不知道在熊攻击中应该如何行为以及这些棒子如何帮助安娜。解决这样一个任务不仅需要能够准确地将词汇与现实世界中的物体对应起来,还需要推理这些物体如何被利用。章鱼惨遭失败,安娜在致命的遭遇中发现了这种错觉。
现在,如果玛利亚还在这里会怎样?大多数人能够进行逻辑推理,即使在掌握这项技能方面存在巨大个体差异。利用推理,玛利亚可以如下解决任务:
前提 1(基于情境):安娜有几根金属棒。
前提 2(基于常识知识):熊对噪音感到害怕。
结论:安娜可以尝试用她的棍子制造噪音来吓跑熊。
LLMs 经常生成具有有效推理链的输出。然而,经过仔细检查,大多数这种连贯性是模式学习的结果,而不是有意且新颖的事实组合。DeepMind 多年来一直在寻求解决因果关系,最近的一次尝试是忠实推理框架。[9] 该架构由两个 LLMs 组成——一个用于选择相关前提,另一个用于推断问题的最终结论性答案。当收到一个问题及其上下文时,选择 LLM 首先从数据语料库中挑选相关陈述,并将其传递给推理 LLM。推理 LLM 推导出新的陈述并将其添加到上下文中。当所有陈述排成一个连贯的推理链,提供一个完整的答案时,这一迭代推理过程就结束了:
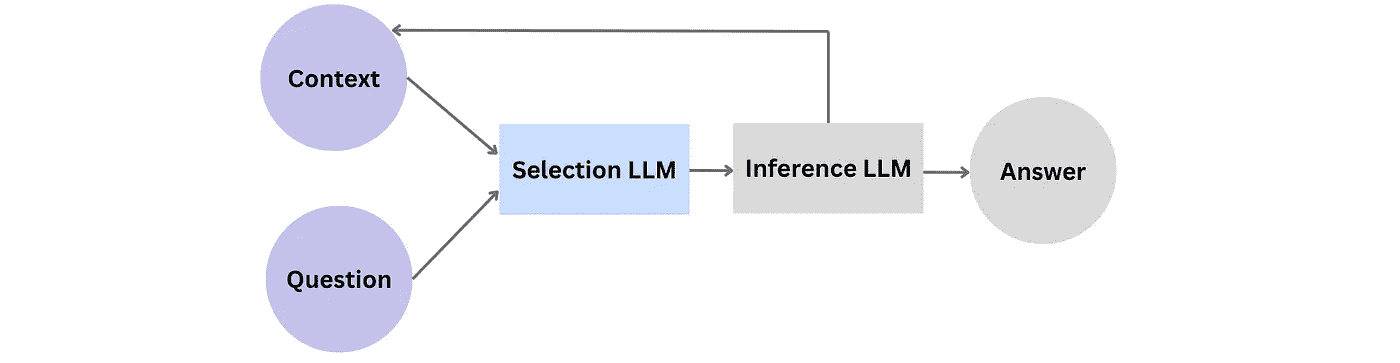
图 4:忠实推理组件
以下展示了我们岛屿事件的推理链:

图 5:构建推理痕迹
使用 LLMs 进行推理的另一种方法是链式思维提示。在这里,用户首先提供一个或多个推理过程的示例作为提示的一部分,然后 LLM “模仿”这个推理过程来处理新的输入。[13]
除了这种一般性的逻辑推理能力,人类还掌握了一整套更具体的推理技能。一个经典的例子是数学计算。LLMs 可以进行一定程度的计算——例如,现代 LLMs 可以自信地进行 2 位或 3 位的加法。然而,当复杂度增加时,例如添加更多数字或需要执行多个操作来解决数学任务,它们开始系统性地失败。而用自然语言提出的“我有 10 个芒果,丢了 3 个。我还剩下多少个芒果?”这类“语言”任务比明确的计算任务(“十减三等于…”)要困难得多。虽然通过增加训练时间、训练数据和参数规模可以提高 LLM 的性能,但使用简单计算器仍然是更可靠的选择。
就像明确学习数学和其他精确科学定律的孩子一样,LLM 也可以从硬编码规则中受益。这听起来像是神经符号 AI 的一个案例——实际上,像 AI21 Labs 的 MRKL(发音为“奇迹”)这样的模块化系统将理解任务、执行计算和制定输出结果的工作负载分配到不同的模型中。[12] MRKL 代表模块化推理、知识和语言,它以务实的插拔式方式结合 AI 模块,在结构化知识、符号方法和神经模型之间来回切换。回到我们的例子中,为了进行数学计算,LLM 首先被微调以提取口头算术任务中的正式参数(数字、操作数、括号)。然后,计算本身被“路由”到确定性的数学模块,最终结果使用输出 LLM 以自然语言格式呈现。
与黑箱、单一的 LLM 不同,推理附加组件通过将“思考”过程分解为单独的步骤来创造透明度和信任。它们尤其适用于支持复杂的多步骤决策和行动路径。例如,它们可以被虚拟助手使用,这些助手基于数据驱动的推荐并需要执行多个分析和聚合步骤以得出结论。
结论和要点
在本文中,我们提供了补充 LLM 智能的各种方法的概述。让我们总结一下最大化 LLM 益处和潜在增强的指导方针:
-
让它们失败:不要被初步结果迷惑——当你开始使用语言模型时,它们可以生成令人印象深刻的输出,然而,我们人类倾向于将过多的智能归因于机器。充当一个刻薄的对手用户,对你的模型进行压力测试,探索其弱点。在投入过多精力之前,尽早进行这一过程。
-
评估和专门探测:培训任务和评估程序的设计至关重要。尽可能地,它应反映自然语言使用的背景。了解 LLM 的陷阱,专注于对它们的评估。
-
利用神经符号 AI 的优势:符号 AI 并没有过时——在个别业务或产品的背景下,将部分领域知识固定下来可以是提高精准度的有效方法。它允许你在对业务至关重要的地方控制 LLM 的行为,同时仍能发挥其基于广泛外部知识生成语言的强大能力。
-
朝着灵活的架构努力:表面上,LLM 有时感觉像黑箱。然而,正如我们所见,存在许多方法——并且未来还会出现——不仅用于微调,还有用于“调整”其内部行为和学习。如果你具备技术能力,可以使用开源模型和解决方案——这将使你能够在你的产品中适应并最大化 LLM 的价值。
即使有上述增强,LLM 仍远远落后于人类的理解和语言使用——它们缺乏人类在生活中积累的独特、强大且神秘的文化知识、直觉和经验的协同作用。根据 Yann LeCun 的说法,“这些模型注定只能获得肤浅的理解,永远无法接近我们在人类思维中看到的全面思考。”[11] 使用 AI 时,重要的是欣赏我们在语言和认知中发现的奇迹和复杂性。以正确的距离看待智能机器,我们可以区分可以委托给它们的任务和那些在可预见的未来将仍然是人类特权的任务。
参考文献
[1] Emily M. Bender 和 Alexander Koller. 2020. 迈向自然语言理解:在数据时代的意义、形式与理解。载于 第 58 届计算语言学协会年会论文集,第 5185–5198 页,在线。计算语言学协会。
[2] Emelin, Denis & Bonadiman, Daniele & Alqahtani, Sawsan & Zhang, Yi & Mansour, Saab. (2022). 向任务导向对话系统的语言模型注入领域知识。10.48550/arXiv.2212.08120。
[3] Fedor Moiseev 等. 2022. SKILL:大型语言模型的结构化知识注入。载于 2022 年北美计算语言学协会年会:人类语言技术会议论文集,第 1581–1588 页,美国西雅图。计算语言学协会。
[4] Ryan Daws. 2020. 使用 OpenAI 的 GPT-3 的医疗聊天机器人告诉虚假的病人自杀。检索日期:2022 年 1 月 13 日。
[5] DeepMind. 2022. 用单一视觉语言模型应对多重任务。检索日期:2022 年 1 月 13 日。
[6] Zeng 等. 2022. 苏格拉底模型:用语言进行零样本多模态推理。预印本。
[7] OpenAI. 2022. ChatGPT:优化对话的语言模型。检索日期:2022 年 1 月 13 日。
[8] Christiano 等. 2017. 从人类偏好中进行深度强化学习。
[9] Creswell 和 Shanahan 2022. 使用大型语言模型进行忠实推理。DeepMind。
[10] Karpas 等人 2022. MRKL 系统:一种模块化的神经符号架构,结合了大型语言模型、外部知识源和离散推理。AI21 Labs。
[11] Jacob Browning 和 Yann LeCun 2022. 人工智能与语言的极限。取自 2022 年 1 月 13 日。
[12] Karpas 等人 2022. MRKL 系统——一种模块化的神经符号架构,结合了大型语言模型、外部知识源和离散推理。
[13] Wei 等人 2022. 链式思考提示引发大型语言模型的推理。发表于 NeurIPS 2022 会议。
除非另有说明,所有图片均由作者提供。
过拟合、欠拟合与正则化
原文:
towardsdatascience.com/overfitting-underfitting-and-regularization-7f83dd998a62
与 AI 交朋友
偏差-方差权衡,第三部分中的第二部分


·发表于Towards Data Science ·阅读时长 4 分钟·2023 年 2 月 15 日
–
在第一部分中,我们覆盖了大部分基本术语以及关于偏差-方差公式的几个关键见解(MSE = 偏差² + 方差),包括来自安娜·卡列尼娜的这段释义:
所有完美的模型都是相似的,但每个不完美的模型都有其独特的不完美方式。
为了充分利用这篇文章,我建议你先阅读第一部分,确保你为吸收这篇文章做好了准备。

欠拟合与过拟合…… 图片由作者提供。
过拟合/欠拟合与此有何关系?
假设你有一个模型,这是你能从现有信息中得到的最好模型。
要获得更好的模型,你需要更好的数据。换句话说,就是更多的数据(数量)或更相关的数据(质量)。
当我说你能得到的最好时,我指的是在模型未见过的数据上的MSE性能。(它应该是预测,而不是后验。)你已经从现有信息中尽力而为——剩下的误差是你无法通过信息解决的。
现实 = 最佳模型 + 不可避免的误差
但问题是……我们已经提前了;你还没有这个模型。
你只有一堆旧数据来学习这个模型。如果你足够聪明,你会在模型未见过的数据上验证这个模型,但首先你必须通过发现数据中的有用模式,尽量接近目标:一个尽可能低的 MSE。
不幸的是,在学习过程中,你无法观察到你期望的 MSE(即来自现实的那个)。你只能计算出来自当前训练数据集的粗略版本。

Jason Leung 的照片,来自Unsplash
哦,还有,在这个例子中,“你”不是一个人,你是一个优化算法,被你的人类老板指示调整模型设置中的旋钮,直到 MSE 降到最低。
你说,“太好了!我能做到这一点!!老板,如果你给我一个具有许多设置的极其灵活的模型(神经网络,怎么样?),我可以给你一个完美的训练 MSE。没有偏差也没有方差。”
要获得比真实模型的测试 MSE 更好的训练 MSE,你需要将所有噪声(你无法进行预测的错误)与信号一起拟合。如何实现这个小奇迹?通过使模型更复杂。本质上就是连接点。
这被称为过拟合。这样的模型在训练 MSE 上表现优异,但在实际应用中会有巨大的方差。这就是试图通过创建一个比信息支持的复杂度更高的解决方案来作弊的结果。
老板太聪明了,识破了你的把戏。知道一个灵活的复杂模型会使你在训练集上得分过高,老板更改了评分函数,以惩罚复杂性。这被称为正则化。 (坦率地说,我希望我们能更多地正则化工程师的恶作剧,阻止他们为了复杂性而做复杂的事情。)
正则化本质上是说,“每增加一点复杂度都要付出代价,所以除非它至少能改善拟合,否则不要这么做…”
如果老板过度正则化——对简化过于严格——你的表现评估会很糟糕,除非你过度简化模型,否则你会这样做。
这被称为欠拟合。这样的模型在训练分数上表现优异(主要是因为获得了所有简化奖励),但在现实中却有巨大的偏差。这就是坚持认为解决方案应比问题要求更简单的结果。
这样,我们就准备好了第三部分,在这一部分中,我们将所有内容整合在一起,把偏差-方差权衡压缩成一个方便的 nutshell。
谢谢阅读!怎么考虑一下课程?
如果你在这里玩得很开心,并且你正在寻找一个旨在取悦 AI 初学者和专家的领导力导向课程,这是我为你准备的一些东西:

课程链接:bit.ly/funaicourse
寻找实操性的机器学习/人工智能教程?
这里是我喜欢的一些 10 分钟快速演练:
概述全球巧克力贸易
原文:
towardsdatascience.com/overviewing-the-global-chocolate-trade-6478adeb8ead

全球巧克力贸易网络
使用网络分析来探索联合国 Comtrade 的国际贸易数据


·发布于 数据科学之路 ·阅读时长 9 分钟·2023 年 11 月 24 日
–
在这篇文章中,我通过关注“巧克力及其他含可可的食品制品”贸易类别,探索联合国 Comtrade 国际贸易数据库。虽然这种特定的关注使我的文章在一个字面上的小众市场上具有明确方向,但分析步骤和方法层次是通用的。因此,基于这些步骤,可以快速分析从能源到武器的任何国际贸易关系。当结合贸易的时空维度,并可以选择通过例如及时的政治事件、国际冲突等信息进行增强时,也可以轻松将这些事件与其宏观经济影响关联起来。虽然国际贸易数据分析的影响深远,但现在让我们使用网络和探索性数据科学来深入了解主要出口国及其巧克力贸易关系。
在本文中,所有图片——如果标题中没有另行说明——均由作者创建。
1. 数据收集
一旦我登录到Comtrade网站,我进入了其 TradeFlow 界面——这是一个很好的在线平台,我可以轻松地构建查询以获取任何类型的国际贸易数据。
在那个界面中,可以自由选择出口方、交易商品、时间段以及一些其他交易特征。对于本文,我选择了标记为 HS1806 的项目组(“巧克力及其他含可可的食品制品”),使用所谓的协调制度。此外,我只关注出口商品,在所有可能的报告者(出口方)和合作伙伴(接收方)之间,选择了过去 20 年的时间范围。注意:一个查询最多可以覆盖 12 年,因此我运行了两个查询,每个查询覆盖 10 年。查询完成后,基于网络的平台会自动下载生成的.csv 文件。
从 Comtrade 查询数据的截图 — comtradeplus.un.org/TradeFlow。
2. 探索数据
下载了两个时间段的两个.csv 文件后,我开始对其进行探索。首先,我将两个文件合并为一个 Pandas 数据框,然后探索其特征:
df1 = pd.read_csv('chocolate_trade_2012_2022.csv', encoding='iso-8859-1')
df2 = pd.read_csv('chocolate_trade_2002_2012.csv', encoding='iso-8859-1')
df = df1.append(df2)
print(len(df))
df.head(5)
此单元格的输出:
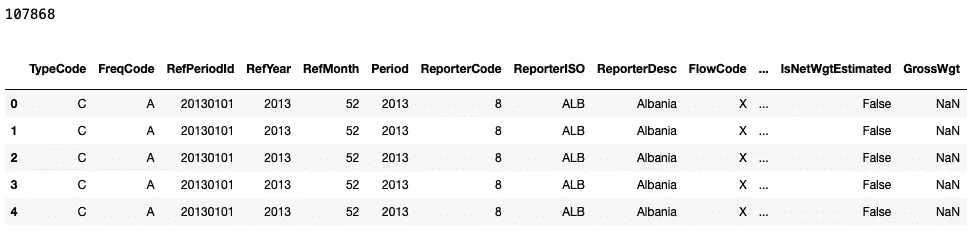
贸易数据的大小和样本。
所以,看起来合并后的数据框有超过 10 万条记录!这数据量相当大。让我们看看每条记录的特征:
print(df.keys())
此单元格的输出:

贸易数据的不同特征。
如此单元格所示,这个电子表格中确实有很多列——准确来说是 48 列。然而,为了揭示巧克力交易背后的主要模式,我将只关注其中的几个。
具体来说,关于发送和接收方,哪些国家的英文名称存储在ReporterDesc和PartnerDesc列中。我还添加了有关交易商品的质量和数量的信息——PrimaryValue包含交易的总现金价值,而GrossWgt则是运输糖果的总质量。最后,我还保留了一些时间信息——特别是RefYear——显示交易发生的年份。
然后,我通过仅保留选定的列并删除那些不对应任何实际交易的记录,创建了原始数据框的清理版本。
注意:查看缺失值时发现,很多交易记录有PrimaryValue字段,但GrossWgt实际上缺失。这是数据质量问题,因此我在遵循后续过滤步骤时非常小心。
# compute the number of missing values
features_to_kep = ['PartnerDesc', 'ReporterDesc', 'PrimaryValue', 'GrossWgt', 'RefYear']
print('Get the fraction of missing values:')
for feat in features_to_kep:
print(feat,round((len(df)- len(df.dropna(subset = [feat])))/len(df),3))
此代码块的输出:

每个特征的缺失值比例。
所以,看来大约一半的交易记录缺少GrossWgt信息——然而,它们仍然有价格标签!
# filter the data
print(len(df))
df = df[['PartnerDesc', 'ReporterDesc', 'PrimaryValue', 'GrossWgt', 'RefYear']]
df2 = df.dropna(subset = ['PrimaryValue'])
df2 = df2[df2.PrimaryValue>0]
df2 = df2[df2.ReporterDesc != 'World']
df2 = df2[df2.PartnerDesc != 'World']
print(len(df2))
df2.head(3)
此单元格的输出:
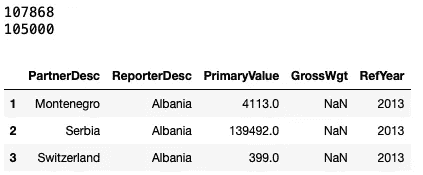
清理后的数据框。
过滤仅减少了数据量的几个百分点,这意味着非常少的国家错过了巧克力出口。似乎很直观!
现在创建一个简单的分布图,查看这些连续值的情况:
import matplotlib.pyplot as plt
# this function does some nice formatting on the axis and labels
def format_axis(ax):
for pos in ['right', 'top']: ax.spines[pos].set_edgecolor('w')
for pos in ['bottom', 'left']: ax.spines[pos].set_edgecolor('k')
ax.tick_params(axis='x', length=6, width=2, colors='k')
ax.tick_params(axis='y', length=6, width=2, colors='k')
for tick in ax.xaxis.get_major_ticks(): tick.label.set_fontsize(12)
for tick in ax.yaxis.get_major_ticks(): tick.label.set_fontsize(12)
f, ax = plt.subplots(1,4,figsize=(15,4))
ax[0].hist(df2['PrimaryValue'], bins = 20)
ax[1].hist(df2['GrossWgt'], bins = 20)
ax[2].hist(df2['RefYear'], bins = 8)
ax[3].scatter(df2['PrimaryValue'], df2['GrossWgt'], alpha = 0.1)
ax[0].set_ylabel('Number of records', fontsize = 14)
ax[0].set_xlabel('PrimaryValue', fontsize = 14)
ax[1].set_xlabel('GrossWgt', fontsize = 14)
ax[2].set_xlabel('RefYear', fontsize = 14)
ax[3].set_ylabel('PrimaryValue', fontsize = 14)
ax[3].set_xlabel('GrossWgt', fontsize = 14)
ax[0].set_yscale('log')
ax[1].set_yscale('log')
ax[3].set_yscale('log')
ax[3].set_xscale('log')
for aax in ax: format_axis(aax)
plt.tight_layout()
输出:
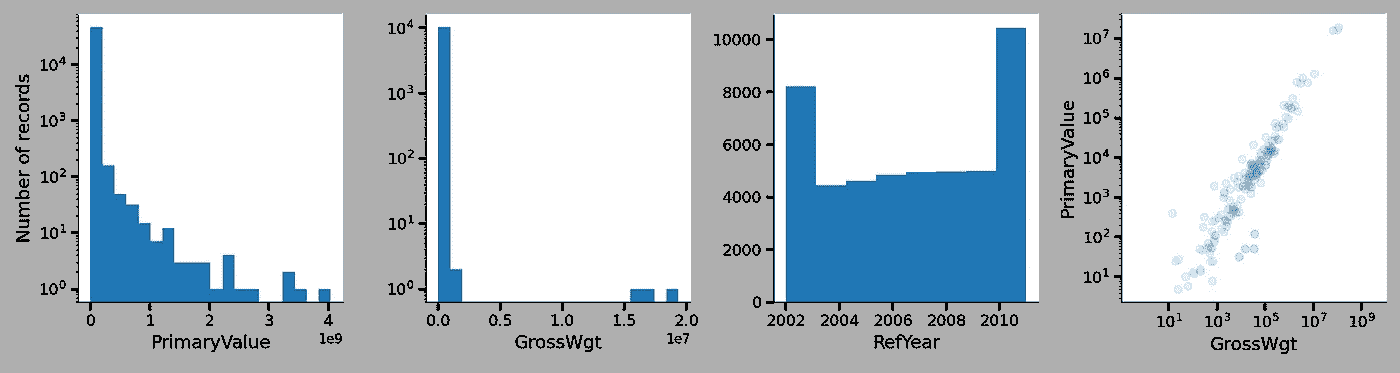
贸易特征的分布图。
前两幅图展示了交易现金价值和总重量的对数刻度分布,每幅图都显示出相对不令人惊讶的幂律趋势,即许多小规模交易和少量极大的交易。
接下来是时间演变——每年的交易数量以及一个散点图,显示了可可产品的总重量和价格之间的高相关性——交易量越大,价格也越高。
现在,让我们看看极端情况——过去二十年哪些国家是主要供应商:
df2.groupby(by = 'ReporterDesc').sum().sort_values(by = 'PrimaryValue', ascending = False)[['PrimaryValue']].head(10)
这个代码块的结果是主要出口国家的表格:

主要出口国。
由于贸易值以当前美元价值储存,我在 20 年的时间窗口内对其进行了汇总,从而得出这个排行榜。根据全球巧克力品牌,我有点放心看到德国、比利时和瑞士位列前茅,而美国则可能由于市场规模庞大而跻身前十。
现在换个角度看看谁是可可产品的最大客户:
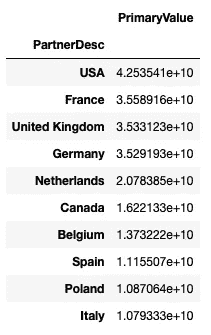
主要进口国。
3. 国家排名
在看到汇总的 20 年十大之后,让我们看看国家排名如何演变以及市场如何随时间变化:
# get the list of overall top 10 countries
top10 = df2.groupby(by = 'ReporterDesc').sum().sort_values(by = 'PrimaryValue', ascending = False)[['PrimaryValue']].head(10).index.to_list()
top10_ranks = {t : [] for t in top10}
# store the latest order here for the visualization
top10_latest = {}
# for each year, create a ranking, and store them in a dictionary of lists
# where each key is a country
for year in range(2002, 2023):
df2_year = df2[df2.RefYear==year]
df2_year = df2_year.groupby(by = 'ReporterDesc').sum().sort_values(by = 'PrimaryValue', ascending = False)[['PrimaryValue']]
df2_year['rank'] = [1 + i for i in range(len(df2_year))]
for c, r in df2_year.to_dict()['rank'].items():
if c in top10_ranks:
top10_ranks[c].append((year, r))
if year == 2022:
top10_latest[c] = r
top10_latest = [c for c, r in sorted([(c, r) for c, r in top10_latest.items()], key=lambda x: x[1])]
top10_ranks
这个代码块的输出:

国家在全球可可产品出口中的年度排名(样本)。
现在,展示这个排名是如何演变的,并查看过去二十年整体前十国家的位置。
f, ax = plt.subplots(1,1,figsize=(15,5))
for country in top10_latest:
ranks = top10_ranks[country]
y, r = zip(*ranks)
ax.plot(y, r, 'o-', label = country, linewidth = 2)
format_axis(ax)
ax.set_ylim([13.5,0.5])
ax.set_xlim([2001,2023])
ax.legend(loc=(1.00, 0.14), frameon = False, handletextpad=.5, fontsize = 16)
ax.set_xlabel('Year', fontsize = 20)
ax.set_ylabel('Annual rank', fontsize = 20)
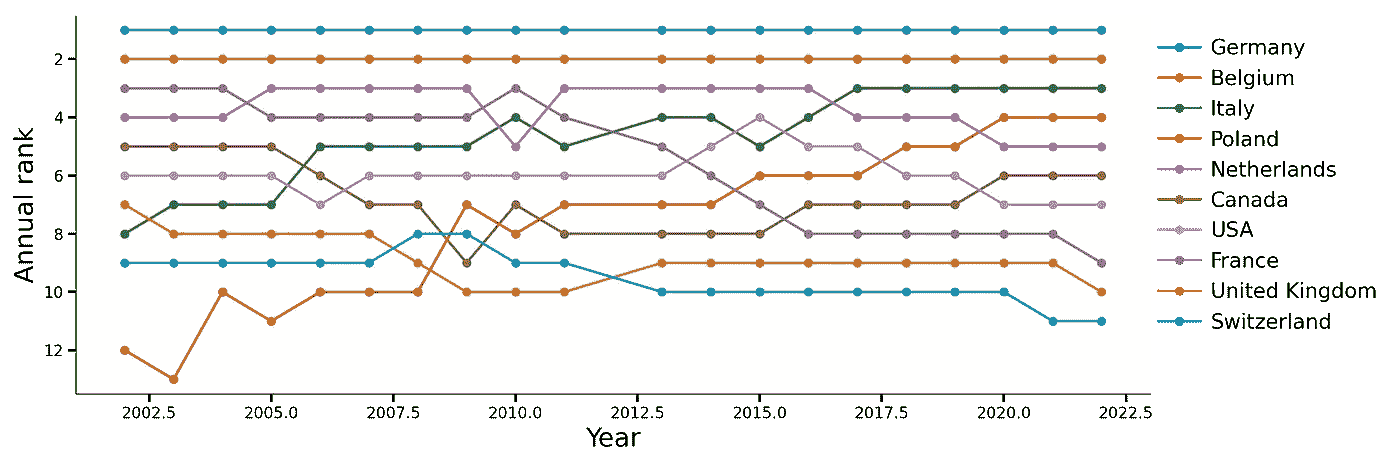
主要可可产品出口国的年度排名演变。
图表告诉我们,德国和比利时的主导地位从未被质疑。荷兰紧随其后,但意大利自 2022 年起缓慢上升,最终获得第三位,此后又缓慢下滑至第 5 位。
极端情况下,法国似乎经历了最大的下降,从第 3 位降至第 9 位,而波兰则从第 13 位上升,2022 年跃升至第 4 位!
4. 贸易网络
贸易是网络行为的经典例子——通过商品、服务和现金交易连接的行为者。因此,我探索性分析的自然下一步是构建国家的贸易网络。为此,我将依赖名为NetworkX的包。
这将是一个定向网络,其中每个源节点是一个出口国,而目标节点是每笔交易的最终站点。此外,每个连接的权重基于过去 20 年中每两个国家之间的总贸易美元价值。
此外,我创建了一个名为“Weight”的列,它是PrimaryValue的归一化对数。
import networkx as nx
import math
df2['Weight'] = [math.log(v) for v in df2.PrimaryValue.to_list()]
G = nx.from_pandas_edgelist(df2, source='ReporterDesc', target='PartnerDesc', edge_attr= 'Weight', create_using = nx.DiGraph)
G.number_of_nodes(), G.number_of_edges()
这个网络首先结果为 245 个节点和 11741 条链接,因此我重新生成它,但过滤掉每个小于最大交易额 1%的交易!
top_value = max(df2.PrimaryValue)
df3 = df2[df2.PrimaryValue>top_value*0.001]
G = nx.from_pandas_edgelist(df3, source='ReporterDesc', target='PartnerDesc', edge_attr= 'Weight', create_using = nx.DiGraph)
G.number_of_nodes(), G.number_of_edges()
G = nx.from_pandas_edgelist(df3, source='ReporterDesc', target='PartnerDesc', edge_attr= 'Weight', create_using = nx.DiGraph)
G.number_of_nodes(), G.number_of_edges()
根据此单元格的输出,这个过滤后的图有 51 个节点和 123 条连接它们的链接!让我们将其导出为 Gephi 文件格式,并在Gephi中应用力导向布局,设置节点大小与显著贸易伙伴(过滤网络中的度)成比例,并根据连接方之间的总交易值调整链接宽度。此外,我根据网络社区对节点进行着色。
最终可视化效果:

含可可的巧克力及其他食品制品的国际贸易网络。
对最终网络的一些进一步思考,如下方所示,其中标记了 30 个最高度节点。正如着色所示,共有五个社区——整个贸易网络中更加密集的子图,揭示了一些相当意外的非正式贸易联盟,例如,以新兴明星波兰为中心的一个。德国、法国和意大利似乎建立了自己的贸易轴线,而荷兰与阿联酋属于同一社区。有趣的是,比利时似乎是与亚洲、印度和澳大利亚强关联的最大节点。
结论
在我看来,Comtrade 是分析国际贸易各个方面和维度的一个充满活力的来源,包括基于体积和时间的统计数据以及网络关系。虽然本文集中于基础知识,并旨在提供贸易数据分析的起点,但这些数据也可以用来研究宏观经济现象,例如国际冲突、制裁、新法规、变化以及不同行业领域的新趋势的影响。
p 值:以简单语言理解统计显著性
选择通向显著结果的路径


·发表于 Towards Data Science ·8 分钟阅读·2023 年 8 月 21 日
–

图片由 Jens Lelie 提供于 Unsplash (unsplash.com/@madebyjens)
你好!
今天,我们将进行一次有趣的统计学探索,处理一个既熟悉又经常被误解的概念——难以捉摸但始终存在的 p 值。如果你以前对它感到困惑,不用担心;我会以一种引人入胜且清晰的方式来解读它。
p 值的显著性
在我们深入探讨之前,让我们从一个相关的场景开始:
想象一下,作为一名刚刚毕业的数据科学家,你在寻找你的第一份工作。你已经做了充分的准备,花费了无数小时解决像 LeetCode 这样的编码挑战,并掌握了复杂的机器学习算法概念。你对你的第一次工作面试感到准备充分且自信。面试官热情友好,气氛轻松,问题也在你的知识范围之内,然后他们问你:“p 值到底是什么?”
尽管你以前遇到过这个术语,但你当时的回应可能是:“它表示我们的假设的重要性。”然而,当面试官进一步挖掘时,你意识到你可能进入了比预期更深的水域。如果这个场景听起来很熟悉,请放心——你并不孤单。在这篇博客文章中,我们将真正尝试解构 p 值是什么以及它不是什么。我们会一步一步地进行,以便下次你遇到这个概念时,能够正确理解它。
从本质上讲,“p 值”一词代表“概率值”。然而,相信我,它的意义远非简单。这个概念可能有点不直观且难以理解,主要由于常见的误解甚至行业中的滥用。
用一个例子来设定场景
想象一个虚构的制药公司 MM 制药公司推出“药物 Alpha”作为治疗头痛的药物。问题是:药物 Alpha 是否真的能缓解头痛?为了检验其有效性,MM 制药公司进行了一项研究,涉及两组——一组接受药物 Alpha,另一组接受 安慰剂。
MM 制药公司的科学家们自然持怀疑态度,认为药物 Alpha 对缓解头痛的影响与安慰剂类似,即药物 Alpha 没有实质性的影响。因此,在分析所进行研究的结果时,他们预计会支持这一假设的结果。然而,令他们惊讶的是,结果显著偏离了如果药物 Alpha 类似于安慰剂的预期结果。这一异常引起了他们的注意,促使他们进行进一步的调查。这种情况就是一个非常低 p 值的实例。
现在,让我们介绍一些关键术语。 原假设 作为我们的初始假设,也称为现状假设——即药物 Alpha 缺乏缓解头痛的能力,与安慰剂的效果相似。这个假设类似于 MM 制药公司的科学家们所持的怀疑态度。它代表了我们的基线观点,表明药物 Alpha 没有明显的效果。这是我们围绕其进行研究的假设。相反,备择假设认为药物 Alpha 确实能够缓解头痛——这是我们认为不太可能的结果。这个备择假设是我们正在严格测试的。
输入 p 值! p 值量化了我们测试结果与原假设假设的一致性。高 p 值表明结果与原假设一致,意味着我们的结果并不令人惊讶,初始假设是有价值的。
然而,低 p 值引入了一个意外的元素,正如 MM 制药公司的科学家们所观察到的。测试结果偏离了原假设下的预期结果。这促使我们重新评估我们的起始假设,考虑到我们的初始假设可能是错误的。在这种不太可能的情况下,p 值提供了药物 Alpha 可能真正缓解头痛的机会。
本质上,p 值为我们提供了一个工具来评估我们的观察结果是否与初始假设一致。高 p 值与零假设一致,而低 p 值则提示我们需要重新考虑假设并进行进一步调查。因此,p 值是一个帮助我们确定证据是否足够强以质疑先入为主的观念的指标。然而,需要注意的是,p 值本身不是证据、证明或客观的度量,而是一个指导性指标。
简单来说:
p 值告诉我们如果零假设为真,我们获得观察结果的概率。
p 值的统计解释
从数学角度看,p 值表示在零假设有效的假设下,观察到的数据与我们所收集的数据极端程度相同的可能性。一个显著低的 p 值(通常小于 0.05)意味着在零假设下,我们观察到的数据是不太可能的。这使我们质疑零假设,并考虑可能存在显著效应的可能性。
我们可以从数学上定义 p 值为:
P 值 = P(结果|零假设)
需要注意的是:关于什么构成足够小的 p 值(即 0.05 或 0.01)以被认为是不太可能事件的显著性是主观的。一般而言,事件发生的越少,p 值越小。
查看一些 Python 代码以区分两个结果
在这个演示中,我们尝试通过涉及两个组的实验来模拟头痛治疗药物的效果:一个组服用药物,另一个组服用安慰剂。我们使用独立样本 t 检验来比较这两个组的均值。scipy.stats模块中的 ttest_ind 函数计算 t 统计量和 p 值。
p 值表示我们观察到的头痛治疗效果差异的可能性,假设药物和安慰剂产生相同的结果。当 p 值低于预定义的显著性阈值(通常为 0.05,称为 alpha)时,我们倾向于质疑零假设的真实性,并推断替代假设即药物确实能缓解头痛。
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
import random
sns.set(style="whitegrid")
def pvalue_significance_estimator(placebo_group, drug_group):
t_stat, p_value = stats.ttest_ind(placebo_group, drug_group)
alpha = 0.05
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(18, 5))
# Plot individual distributions
sns.histplot(placebo_group, color='blue', label='Placebo Group', ax=ax1)
ax1.set_xlabel('Headache Relief (0-1)')
ax1.set_ylabel('Number of People')
ax1.set_title('Placebo Group Distribution')
ax1.legend()
sns.histplot(drug_group, color='orange', label='Drug Group', ax=ax3)
ax3.set_xlabel('Headache Relief (0-1)')
ax3.set_ylabel('Number of People')
ax3.set_title('Drug Group Distribution')
ax3.legend()
# Plot comparison using a box plot
data = [placebo_group, drug_group]
labels = ['Placebo Group', 'Drug Group']
ax2.boxplot(data, labels=labels)
ax2.set_ylabel('Headache Relief (0-1)')
ax2.set_title('Comparison between Groups')
# Add p-value annotation
p_value_text = f'p-value: {p_value:.4f}\n'
if p_value < alpha:
p_value_text += 'Significant difference'
else:
p_value_text += 'No significant difference'
ax2.text(0.5, 0.85, p_value_text, transform=ax2.transAxes,
ha='center', va='center', fontsize=12,
bbox=dict(facecolor='white', edgecolor='gray', boxstyle='round,pad=0.5'))
plt.tight_layout()
plt.show()
下面,我们查看两种情景:一种是 p 值较大,表明在零假设下观察结果与预期结果之间没有显著差异;另一种是 p 值表明两组之间存在显著差异。
情景 1:显著的 p 值,观察结果与预期结果之间没有显著差异
由于我们的目标不是进行实际的临床试验,我们通过为安慰剂组和药物组设计使用均匀分布的情景来模拟试验,然后将其引入我们的 pvalue_significance_estimator 函数中。
placebo_group = [round(random.uniform(0, 1), 1) for _ in range(100)] # Placebo group data
drug_group = [round(random.uniform(0, 1), 1) for _ in range(100)] # Drug group data
pvalue_significance_estimator(placebo_group, drug_group)
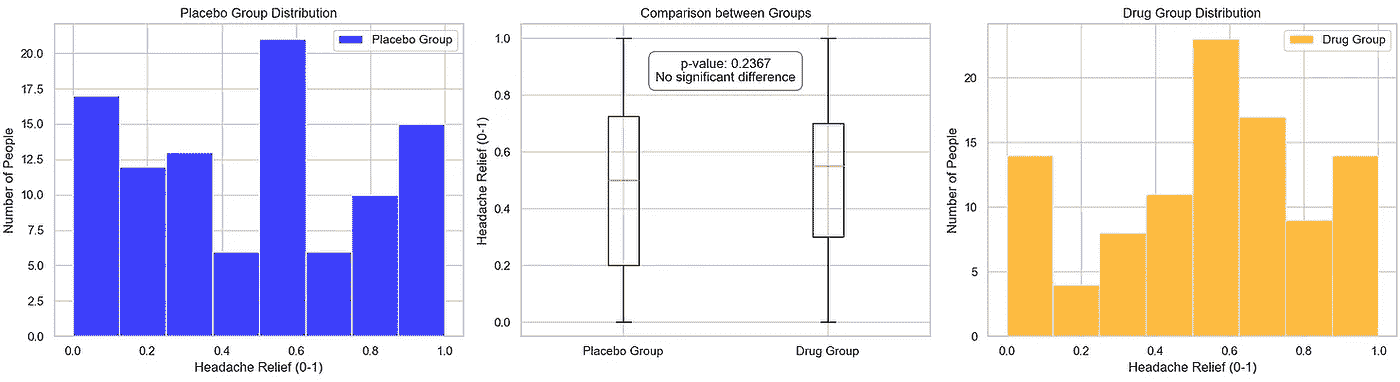
图片由作者提供
当我们可视化结果时,我们观察到在中央子图中,两组的均值相对接近,导致了一个较大的 p 值(约 0.24)。检查数据后,似乎两组具有相似的头痛缓解属性。
情景 2:极端/非常小的 p 值,观察结果与预期结果之间的显著差异
为了模拟第二种情景,我们对药物组的数值引入了 1 的偏倚,注意到这种操作在真实的临床试验中非常值得怀疑,可能产生深远的影响。我们再次将数据输入到我们的 pvalue_significance_estimator 函数中。
np.random.seed(123)
placebo_group = [round(random.uniform(0, 1), 1) for _ in range(100)] # Placebo group data
drug_group = [round(random.uniform(0, 1), 1) for _ in range(100)] # Drug group data
bias_percentage = 40 # Percentage of values to bias towards 1
bias_factor = 0.75
drug_group = [
round(value * (1 - bias_factor) + bias_factor, 1)
if random.uniform(0, 100) <= bias_percentage
else value
for value in drug_group
]
pvalue_significance_estimator(placebo_group, drug_group)
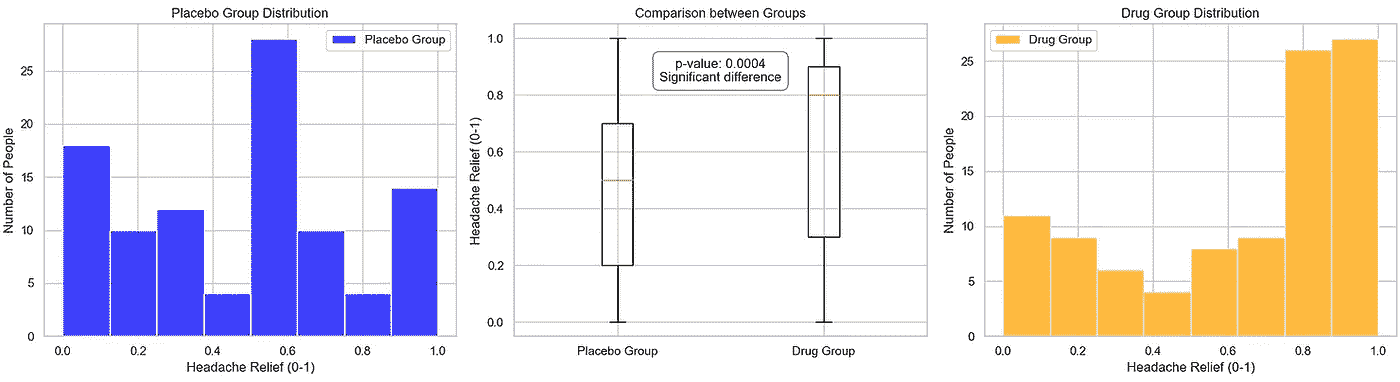
图片来源:作者
在这里,我们可以看到两个组均值的显著差异,以及一个非常小的 p 值。这表明药物确实有影响。尽管这种简化分析仅比较了两个组的均值,且数据直接,但即使在这种情况下,指向药物有效性的备择假设仍需进一步研究。
重要的是要认识到这个例子是简化的,以传达一个概念。在实际设置中,你会处理更大的数据集、更复杂的统计测试和额外的复杂性。
理解 p 值的作用及其限制
在我们得出结论之前,我们应该讨论 p 值的一些细微限制。p 值确实是一个强大的假设检验工具。它允许我们评估观察数据与初始假设的一致性,并帮助我们在假设问题上做出明智的决策。然而,p 值不是判决或真理的最终衡量标准。它只是一个指标,引导研究者进一步探讨给定的假设。
另一个需要注意的是,虽然低 p 值可能表明我们的观察结果与原假设下的预期有显著差异,但它并没有提供效应的大小。换句话说,它不能告知我们发现的实际或量化意义,甚至是现实世界的影响。此外,高 p 值并不是原假设的证明,也不能明确否定备择假设。因此,使用 p 值得出结论时需要谨慎。
此外,通常对预定义的 alpha / 显著性水平的依赖(通常设定为 0.05)会带来更多的模糊性,例如 0.051 与 0.049 是否显著不同?确定的 alpha 是否真的适用于所考虑的假设?
还有 Type I 和 Type II 错误的概念。低 p 值并不能消除 Type I 错误的可能性,即错误地拒绝真实的原假设。同样,高 p 值也不能保证避免 Type II 错误,即未能拒绝虚假的原假设。
总之,更深入地理解 p 值是迈向更好统计思维和更优结果的一步。认识到它作为指引而非确定答案的角色,能帮助我们在数据分析和假设检验的复杂性中导航。同时,承认其局限性可以帮助我们谨慎对待结果。
总结
本质上,p 值作为研究人员的一个指引。它引导他们进一步探索,标示出数据何时偏离初步假设。因此,下次遇到 p 值时,希望你能明确它的作用。
欢迎在下面的评论中分享你对 p 值的看法和问题。我会认真倾听。
佩速、努力和耐力
原文:
towardsdatascience.com/pacing-effort-and-stamina-6b340ab53650
对最近都柏林城市马拉松比赛的技术分析


·发表于Towards Data Science ·12 分钟阅读·2023 年 11 月 29 日
–
在我们开始之前,我想把这篇文章定位为几篇最近文章中的一篇,这些文章位于数据科学与马拉松跑步的交汇处。在之前的文章中,我集中讨论了几个与 马拉松训练可视化 和 表现数据**相关的技术挑战。这里我将重点转向分析(我自己的)最近的马拉松表现,使用一些之前讨论过的可视化技术以及来自运动科学领域的几个表现指标。因此,本文提供了一个具体的例子,展示了如何使用(跑步)速度和努力等相对简单的概念来探索更复杂的现代生理测量指标,如恢复力和耐力,从而更好地理解马拉松表现。同时,值得注意的是,类似的想法在许多其他耐力领域如骑行、铁人三项、滑冰等也被证明是相关的。
我在生活中晚些时候才开始跑步。我是在 40 多岁时开始的。我已经能够完成 8 次都柏林城市马拉松(DCM)——从 2013 年开始——而且在变老的过程中,我很幸运地取得了几次新的个人最佳(PBs)。我今年(2023 年)最近的努力是在一个凉爽、潮湿的十月底早晨取得了一个新 PB。我在略超过 3 小时 10 分钟的时间内跑过终点,比我之前的最好成绩(2022 年)快了 7 分钟多。
作为一名数据科学家,我对从我的比赛经验中学习非常感兴趣,今年我的个人最佳成绩(PB)的规模令人惊讶和迷人。我觉得小的 PB 可能在计划之中——如果条件良好——但我设定的最佳目标是 3 小时 15 分钟,而 3 小时 10 分钟并未出现在我的计划中。这一表现仅仅是因为更加努力和更快地跑了吗?还是其他因素在起作用?我的配速和努力程度与之前的比赛和 PB 相比如何?
在这篇文章中,我将考虑几场最近的比赛,探讨我的努力(心率,每分钟跳动次数)和速度(或配速,分钟/公里)之间的相互关系,以及一种更为近期的耐力指标耐久性 [1],这是一个新兴的生理适应能力测量指标,有点类似于我们所认为的耐力*。虽然每次新的 PB 都是因为跑得更快(平均而言),但我的近期 PB 也与较低的努力程度相关。我是否跑得过于保守,还是早期的 PB 跑得过于激进?这就是耐久性分析发挥作用的地方,因为它观察速度和努力之间不断演变的关系。
4 个个人最佳成绩和一个跟腱伤情
在本次分析中,我将考虑自 2017 年以来的 5 届都柏林马拉松;2020 年和 2021 年因疫情取消。我在大多数比赛中身体健康良好,除了 2019 年,那时跟腱受伤阻碍了我的正常训练。2022 年比较特殊,因为我的目标比赛是伦敦马拉松——在当年都柏林马拉松前仅 4 周——因此我的训练虽然很好,但并不一定针对都柏林进行了优化。然而,我在都柏林跑得更快了。真是让人摸不着头脑!
在 2017 年至 2022 年的比赛中,我使用了差不多相同的训练计划——这是我多年前在网上找到的——根据我的完成时间的改善调整了配速。在这些年里,我主要是自己训练,偶尔与朋友一起跑步。我在 2023 年春季加入了 Kilcoole Athletics Club(KAC)——这是我做出的最佳决定!——并最终按照俱乐部的官方计划进行训练,与最棒的一群马拉松跑者一起定期训练。
尽管训练不是本文的重点——希望将来能有所展现——以下是每次比赛前 16 周训练的总结。通常,我每周跑 4-5 天(55-60 公里),在目标马拉松前有 3-4 次长跑(≥30 公里),除了 2019 年,那时我的跟腱疼痛影响了训练并限制了长跑。今年,我记录了适度的训练量增加(每周 65 公里,峰值超过 90 公里),加上一些更为艰苦的长跑训练。
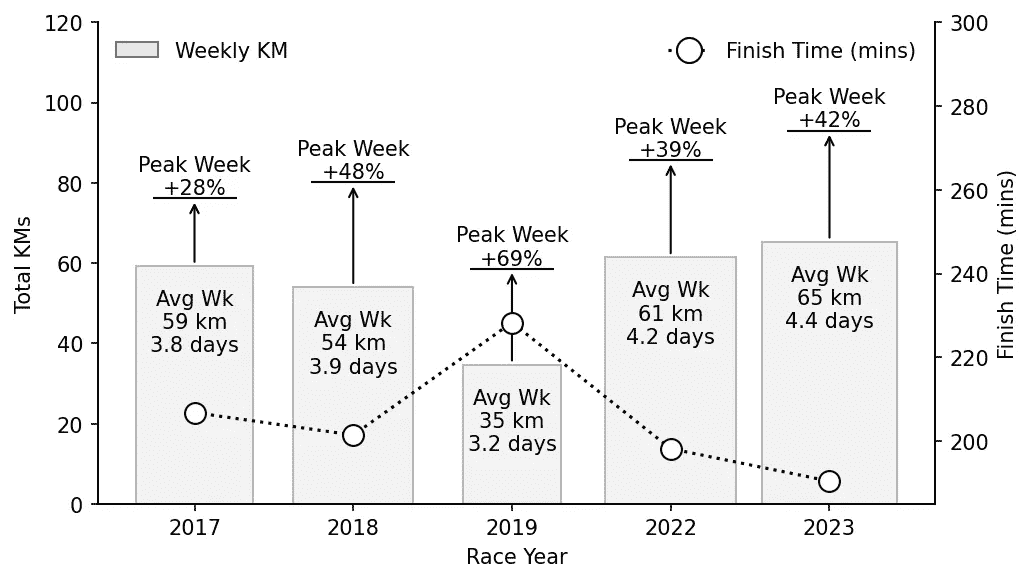
我的过去五届都柏林马拉松训练总结,显示了每周平均训练量/频率、每周最大训练量和最终完成时间。
配速与努力
分析我最近的马拉松比赛的一个简单方法是考虑在不同比赛阶段的配速(分钟/公里)和努力(心率)。我使用了Strava API来下载我的比赛活动,包括每 1 公里段的平均配速和心率数据。为了简化,我使用了 Strava 的心率区域而不是我实际的心率值;Strava 使用五个心率区域(Z1, …, Z5),基于最大心率的不同百分比。
下面的图表显示了我每公里段的平均配速(y 轴),以及比赛阶段(x 轴)。每个‘热图线’的颜色编码反映了对应比赛段的心率区域。为了参考,还显示了都柏林马拉松的海拔轮廓,背景中突出显示了几个标志性位置。每个图表上标注了我的平均比赛配速(虚线,加粗文本),以及比赛段的最大(最慢)和最小(最快)配速。
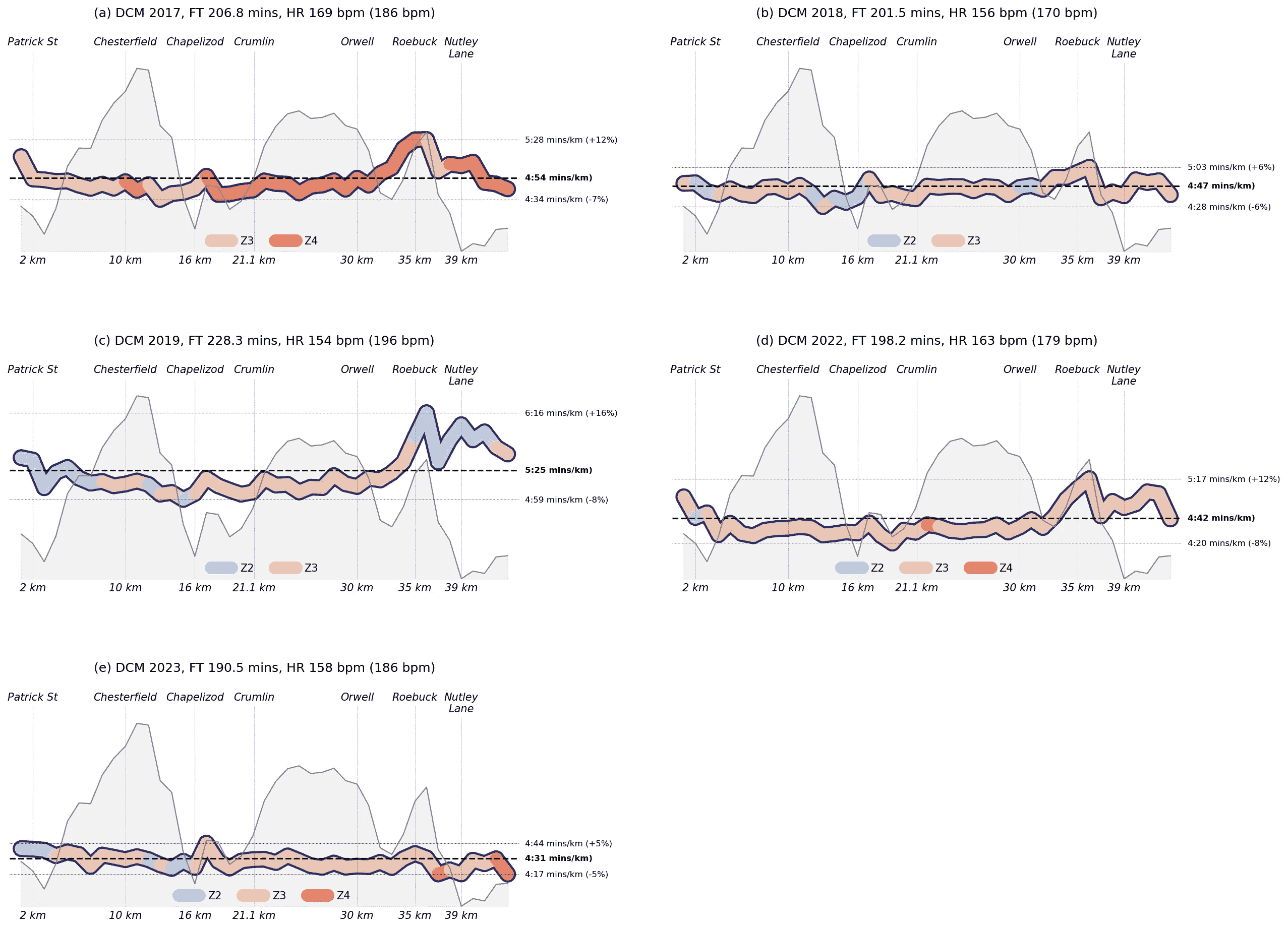
都柏林马拉松每 1 公里段的配速和心率区域,以及都柏林马拉松的海拔轮廓。
有几个观察点值得注意:
-
我的 2017 年比赛(a)涉及了最大的努力(平均心率 169 bpm),且这场比赛中相当一部分时间在 Z4 区域完成,这不是马拉松比赛中想要待的地方,至少不能待太久。
-
我的训练中断在 2019 年(c)中表现得很明显。那一年我比较轻松(因为我不得不这样做,因此经常在 Z2 区域跑步),但在多山的 Roebuck 段我减速(>6 分钟/公里),并且在随后的下坡和平坦段中未能恢复努力。
-
2018 年(b)和特别是 2023 年(e),从配速/努力的角度来看,是执行得非常好的比赛例子。这两场比赛的特点是 Z2 区域跑步量适中,特别是在早期多山的阶段,且下半场几乎没有减速。2023 年的最后一段 Roebuck Hill 几乎没有对我的比赛产生影响。
-
尽管 2022 年我的时间是第二快的,但我的配速和努力不如 2018 年或 2023 年“组织得好”。前半段几乎都是 Z3 区域跑步,并且在最后 10 公里时我的配速开始恶化。尽管如此,我还是在 2022 年创下了个人最佳。
因此,通过仔细管理我的配速和努力,我能够在 2018 年(约 5 分钟个人最佳)和 2023 年(约 7 分钟个人最佳)创造出两个非常强劲的个人最佳。相比之下,我在 2017 年和 2022 年的个人最佳是经过艰苦努力取得的,且比赛后期明显减速。
连续个人最佳比较
下面的散点图提供了连续个人最佳成绩对比(2017 年与 2018 年,2018 年与 2022 年,2022 年与 2023 年)的更直接比较。每个点指的是比赛中的一个 1 公里赛段。点的大小和颜色表示赛段的公里数:早期赛段较小且较蓝,后期赛段较大且较红。每个点的位置基于该公里在更近期个人最佳成绩中的配速和努力(实际心率),与之前的个人最佳成绩相比。
例如,(a)比较了 2018 年与 2017 年。在 2018 年,只有一个公里跑得比 2017 年更努力且更快。对于我 2018 年的其余比赛,我跑得更轻松,通常也更快。
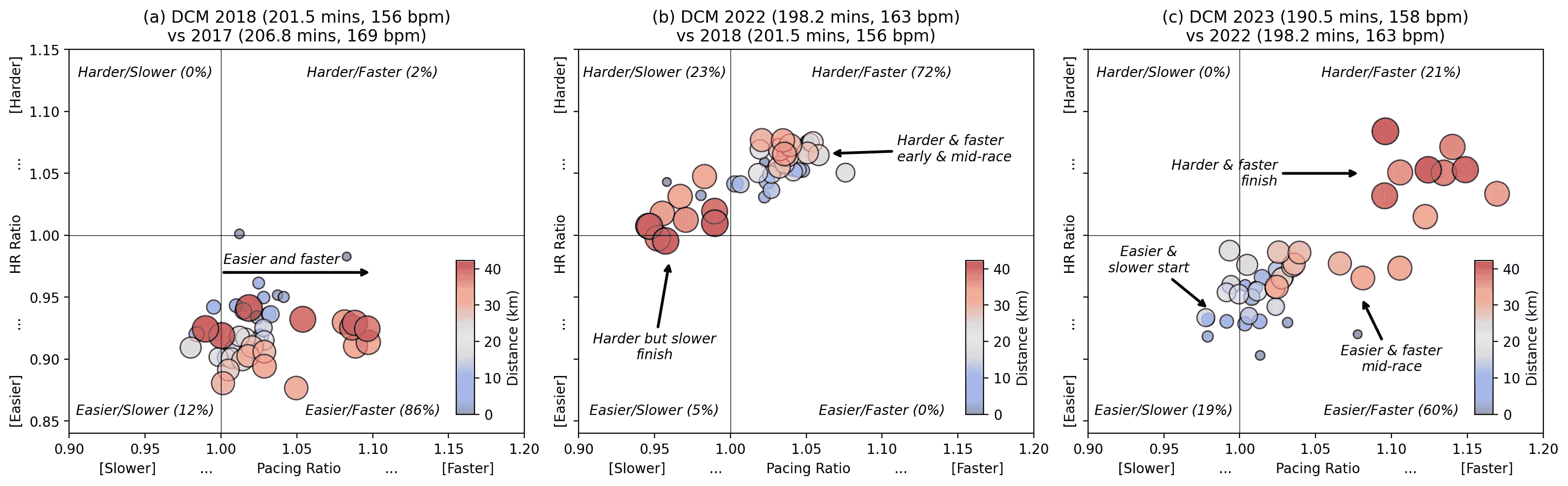
比较连续个人最佳成绩在努力(心率)和速度(配速)方面的差异。每个标记对应于马拉松中的一个特定 1 公里赛段,并根据更近期的个人最佳是否跑得更努力/轻松以及更快/更慢进行定位。早期赛段用较小的(蓝色)标记表示。后期赛段用较大的(红色)标记表示。
第二个散点图(b,2022 年与 2018 年)讲述了一个完全不同的故事。我在 2022 年的比赛大部分时间以比 2018 年更大的努力跑完,2022 年的 72%赛段也跑得更快,特别是在比赛的早期和中期。然而,2022 年后期的表现却不尽如人意。尽管我在跑得更努力,但它们比 2018 年慢,且大部分发生在比赛的后期。这突显了 2022 年艰难的最后 10 公里。较慢但更努力!尽管如此,还是创下了新的个人最佳!
今年情况有所改善(c)。我今年有 19%的比赛赛段跑得比 2022 年慢,主要是在早期阶段,但总是以较轻松的努力跑完。我的中期赛段也以比 2022 年少的努力完成,但速度也更快。而最大的进步是我能够比 2022 年更强烈地完成 2023 年。最后的 9 公里比 2022 年快了 10-15%。我需要更大的努力来实现这一点——这些最后赛段的平均心率比之前高约 1-8%——但我能够在比赛的晚期阶段提高努力程度,这是我之前几年无法做到的。
努力与节奏之间存在强烈的互动。这并不令人惊讶,但也使分析变得更加困难。拥有一个单一的衡量标准来指责比赛表现的因素总是有用的,这就是耐力可能发挥帮助作用的地方。
从生理韧性到耐力
耐力运动表现与三个重要生理特征密切相关——VO2max、跑步经济性 和 VO2max 的分数利用率2——但标准模型 [3]在很大程度上忽视了这些因素在长期运动中可能恶化的情况。这导致该领域的一位领先研究者,安迪·琼斯教授——曾与保拉·拉德克利夫和埃利德·基普乔格等人合作——提出了生理学 韧性 作为耐力运动表现的重要第四维度 [4],这可能有助于将最佳选手(如基普乔格)与其他具有类似 VO2 和跑步经济性特征的运动员区分开来。
生理韧性的一个实际测量是所谓的耐久性。它基于跑者内部和外部工作负荷的比率。简而言之,可以使用跑者的心率作为内部* 工作负荷的测量,而他们的速度(米/秒)可以用作外部 工作负荷的测量。然后,通过将跑者的心率除以当前速度来计算内部-外部比率(IER)。当跑者的心率增加而速度减少时,他们达到了耐久性极限。当这种情况持续发生时,跑者的 IER 将会增加,因为跑者的心率与其速度发生解耦。这种解耦表明跑者已经超出了当前的耐久性阈值。
一种用于分析马拉松环境下耐久性的协议 [5]涉及将跑者的基线 IER(bIER)定义为马拉松 5–10 公里段的平均 IER。选择这个区段是为了确保跑者有时间“适应”比赛。然后,可以通过将跑者该段的 IER 除以 bIER 来计算跑者的相对 IER(rIER)。当rIER >1.025 在比赛剩余时间内 时,称为解耦发生。
下面的图表(a-e)展示了我最近马拉松每公里的 rIER。绿色区域表示尚未发生解耦。解耦(红色区域)仅在 rIER>1.025 并在比赛剩余时间内保持这种状态时才会发生。注意到有几个短暂的区域,绿色区域超过了允许的 rIER 阈值,但由于这些峰值是暂时的(通常是由于上坡或水站减速),它们不被归类为解耦的开始。
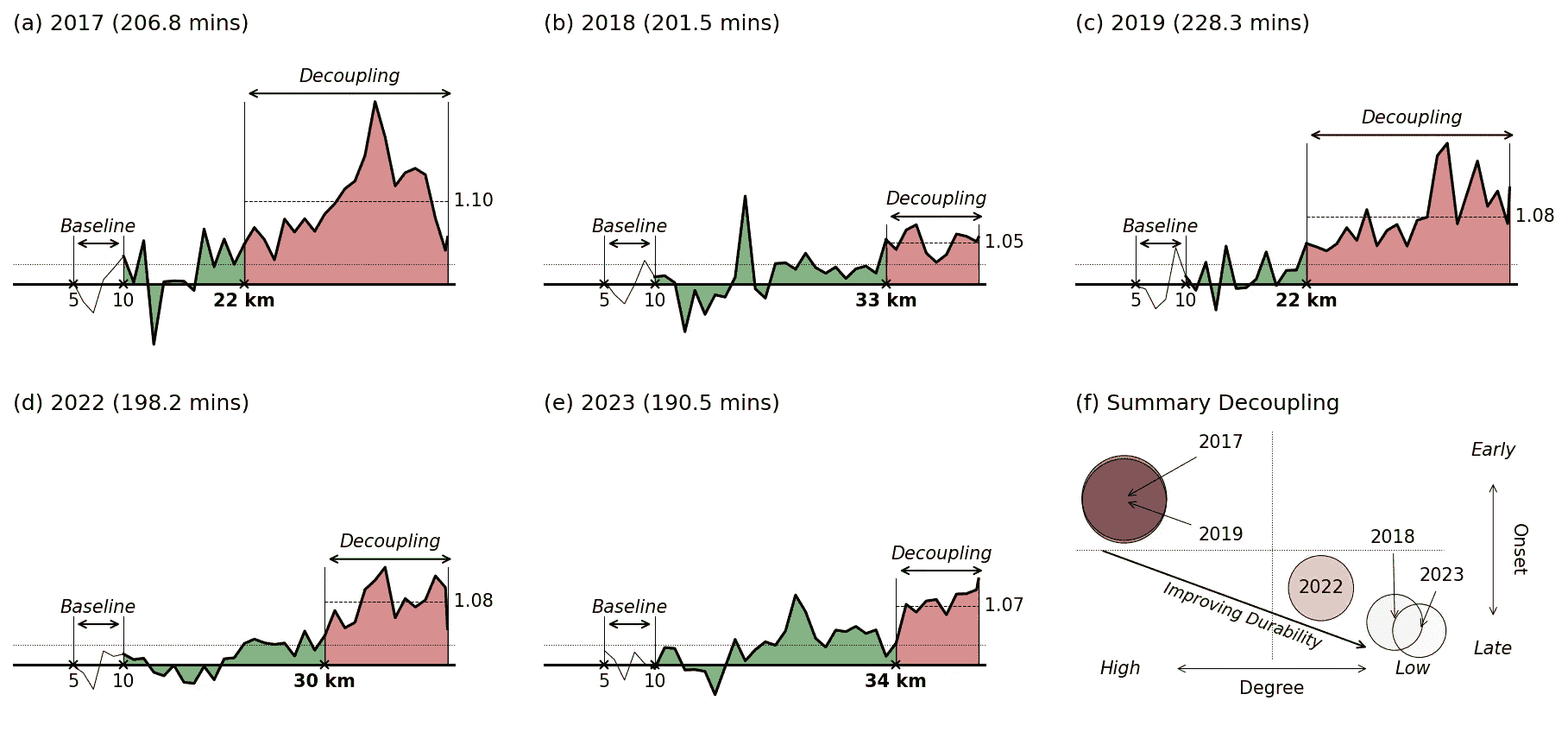
每个马拉松的相对内部-外部工作负荷比(a)—(e)显示了何时发生解耦以及解耦发生后的程度(红色)。在(f)中,(a)—(e)中的比赛解耦特征的总结表明,解耦时间的延迟导致耐力的提升。
这些图示显示了我的耐力在多年的变化情况。在 2017 年,我在半程(22 公里)后解耦,且程度非常显著(平均 rIER 为 1.10,相当于中等程度的解耦)。这与 2019 年我因伤病干扰的耐力类似。我的耐力在 2018 年、2022 年和 2023 年的个人最佳成绩中显著提升。比赛中的解耦发生在更晚(≥30 公里),且解耦后的平均 rIER 要温和得多(在 1.05 到 1.08 之间,表示低程度的解耦)。
(f)中的散点图总结了这些结果。每场比赛通过位于 xy 轴上的一个点来表示,该点基于解耦的累计程度(解耦后的总 rIER)和解耦的发生时间。2017 年和 2019 年是早期解耦的例子,累计解耦程度明显高于 2018 年、2022 年和 2023 年中的晚期解耦。
新兴的趋势应该很明显。它指向了我最近的、经过良好训练的比赛中的解耦时间越来越晚,因此解耦的程度更低。究竟这是由于更好的训练、更好的比赛配速,还是两者兼有,仍然是一个悬而未决的问题。一个尚未解答的问题是耐力特征是否对训练适应有敏感性,但某些训练方法可能能够减少经过良好训练的跑者的解耦现象。
结论
本文旨在提供对我最近几场都柏林马拉松比赛的相对深入的数据分析。很容易得出结论认为更快的比赛就是更好的比赛,但这并不能讲述完整的故事。我们在这里考虑了配速和努力(以心率为标准),显然控制自己的努力至少与坚持目标配速同样重要,以实现个人最佳成绩。一般来说,我控制较好的努力(2018 年和 2023 年)都代表了新的强劲个人最佳时间,并且在比赛后期几乎没有通常配速下降的证据。
我们还考察了一个相对较新的表现指标——耐力,作为我们生理弹性的替代指标,以便更好地理解配速与努力之间的相互作用。当然,我最近的个人最佳成绩与耐力的显著提升有关。当然,这些都忽略了训练的影响,而训练在我们的体能水平和比赛准备中扮演了重要角色。我们会在适当的时候进一步探讨这点……
尽管本文重点讨论了马拉松跑步,但所提出的观点在其他耐力领域同样适用。关于将诸如耐久性等概念应用于骑行[6]和铁人三项等多种耐力运动的相关研究正在不断增加。因此,这里提出的观点对于处理各种耐力领域的人体表现数据的数据科学家来说,应该更具普遍意义。
参考文献
上述文本中直接链接的科学文章在此详细列出,以确保完整性。
-
Maunder E, Seiler S, Mildenhall MJ, Kilding AE, Plews DJ. 在耐力运动员的生理学分析中,“耐久性”的重要性。体育医学。2021 年 8 月;51(8):1619–1628。doi: 10.1007/s40279–021–01459–0。2021 年 4 月 22 日在线发表。PMID: 33886100。
-
Shaw AJ, Ingham SA, Atkinson G, Folland JP. 跑步经济性与最大氧摄取量的相关性:在高度训练的长跑运动员中的横断面和纵向关系。PLoS One。2015 年 4 月 7 日;10(4):e0123101。doi: 10.1371/journal.pone.0123101。PMID: 25849090;PMCID: PMC4388468。
-
Joyner MJ. 建模:基于生理因素的最佳马拉松表现。应用生理学杂志(1985)。1991 年 2 月;70(2):683–7。doi: 10.1152/jappl.1991.70.2.683。PMID: 2022559。
-
Jones AM. 第四维度:生理韧性作为耐力运动表现的独立决定因素。生理学杂志。2023 年 8 月 22 日。doi: 10.1113/JP284205。在线发表。PMID: 37606604。
-
Smyth B, Maunder E, Meyler S, Hunter B, Muniz-Pumares D. 在马拉松期间内部与外部工作负荷的解耦:对 82,303 名业余跑者耐力的分析。体育医学。2022 年 9 月;52(9):2283–2295。doi: 10.1007/s40279–022–01680–5。2022 年 5 月 5 日在线发表。PMID: 35511416;PMCID: PMC9388405。
-
Valenzuela PL, Alejo LB, Ozcoidi LM, Lucia A, Santalla A, Barranco-Gil D. 职业自行车运动员的耐久性:一项实地研究。国际体育生理表现杂志。2022 年 12 月 15 日;18(1):99–103。doi: 10.1123/ijspp.2022–0202。PMID: 36521188。
有兴趣的读者可以在这里和这里以及我最近在都柏林马拉松的冒险经历这里找到有关使用 Strava 数据和本文中使用的一些可视化的信息。
我定期撰写各种主题的文章,特别是在数据科学/机器学习与马拉松跑步的交汇处,文章发布在Running with Data和Towards Data Science。
所有图像和图表均由作者制作。
填充大型语言模型 — 使用 Llama 2 的示例
为因果 LLMs 填充训练示例的最佳实践


·
关注 发布于Towards Data Science · 10 分钟阅读·2023 年 8 月 11 日
–

作者提供的图像 — 基于来自Pixabay的图像
填充是大型语言模型(LLMs)中最少被记录的方面之一。为什么?仅仅因为 LLMs 通常在没有填充的情况下进行预训练。
尽管如此,对于在自定义数据集上微调 LLMs,填充是必要的。未能正确填充训练示例可能会导致各种意想不到的行为:训练期间的空损失或无限损失、生成过多或推理期间的空输出,都是填充不正确的症状。
在这篇文章中,我首先解释什么是填充以及为什么它是必要的。然后,我展示了如何为没有填充的预训练 LLM 找到正确的填充策略。我提出了两种不同的解决方案来为 LLM 添加填充支持,使用 Hugging Face 的 Transformers。
在文章的末尾,我还提供了示例,展示了如何为 Llama 2 填充你的训练示例。
阅读完这篇文章后,你应该能够自己搞清楚如何为 LLM 填充训练示例,而无需阅读它们的文档或教程。
填充和批次
什么是填充,为什么我们需要填充?
我们来举一个例子,假设我们希望用来微调一个 LLM。
example = "You are not a chatbot."
我们需要将这个示例转换为一个标记序列。像 Transformers 这样的库通常按以下步骤进行分词:
- 根据给定的词汇表将示例分割成子词:
example = ["▁You", "▁are", "▁not", "▁a". "▁chat", "bot", "."]
- 用词汇表中的索引替换单词,以获得一个整数序列:
example = [887, 526, 451, 263, 13563, 7451, 29889]
- 向序列中添加特殊标记:BOS 标记、EOS 标记、UNK 标记、PAD 标记等。
example = [1, 887, 526, 451, 263, 13563, 7451, 29889]
注意:在这个例子中,我使用了 Llama 2 的分词器。我们将在下面详细了解如何操作。
在这个例子中,仅添加了 BOS(序列开始)特殊标记。
每个训练示例还会生成一个注意力掩码。这个掩码告诉变压器是否应该关注一个标记(1)或不关注(0)。这个示例的注意力掩码很简单,因为所有标记都应该被考虑。
#We have as many values as tokens.
attention_mask = [1, 1, 1, 1, 1, 1, 1, 1]
下一步是将所有内容封装成 Pytorch 张量。这种封装是必要的,以便应用 CUDA 和 GPU 优化的矩阵操作。
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
现在,假设我们有两个训练示例。为了简单起见,我会重复我已有的一个。新的张量多出了一行:
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 263, 13563, 7451, 29889]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])}
两个示例具有相同的长度(当然,因为它们是相同的)。这两个张量的维度都是 2x8(N x M)。
示例被放入张量中以创建批次,以便神经网络在看到 N 个示例后可以更新其值。批次对于计算效率和模型性能至关重要。
现在,让我们引入一个更短的第三个示例:
example = "You are not."
在分词后,我们得到:
example = [1, 887, 526, 451, 29889]
attention_mask = [1, 1, 1, 1, 1]
如果你尝试将其添加到我们的示例列表中并创建张量,你将会遇到错误。但想象一下,如果没有错误,我们将得到:
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 29889]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]])}
你能看到这里的问题吗,为什么不能创建这样的张量?
我们有一行不同长度的数据。我们无法对其应用矩阵操作。
在大多数数据集中,示例的长度不相同。我们必须修改它们,以确保同一批次中的示例具有相同的长度。
这就是我们需要“填充”的原因。
填充标记和填充侧
你可以将填充视为通过重复一个虚拟标记来扩展序列直到给定长度。
这个虚拟标记是一个“填充标记”。
例如,上面第一个示例的长度为 8 个标记(包括 BOS 标记)。假设在我们的批处理中,我们不会有超过 8 个标记的序列。所有序列必须为 8 个标记长。
我们的第二个示例仅包含 5 个标记。所以我们必须添加 3 个填充标记。
example = "You are not. [PAD] [PAD] [PAD]"
实际上,我们不会手动将“[PAD]”标记添加到序列中。大多数分词器会将“[PAD]”拆分成子词。填充标记通常是分词器内部定义的特殊标记,并且在必要时会与其他特殊标记一起自动添加到序列中。
如果填充标记在词汇表中的 ID 是 32000,我们将得到:
example = [1, 887, 526, 451, 29889, 32000, 32000, 32000]
现在,我们有了一个具有预期长度的序列。但还有一个问题:我们还需要修改注意力掩码。
记住,填充标记是虚拟标记,我们不希望 LLM 对它们给予任何关注。我们引入这些标记只是为了填充序列并创建正确的张量。
为了将其指示给模型,我们只需在注意力掩码中设置“0”,这样模型将忽略它们。
attention_mask = [1, 1, 1, 1, 1, 0, 0, 0]
最后,我们可以使用填充的示例创建正确的张量:
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 29889, 32000, 32000, 32000]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 0]])}
注意:填充是在序列长度小于最大长度时执行的。但在某些情况下,序列可能会太长。在这种情况下,我们必须截断序列,以使其大小匹配最大长度。
填充的另一个重要参数是填充侧面。在上面的示例中,我进行了右填充。如果模型有 EOS 标记,填充标记将添加到它之后。
我们也可以进行左填充。在这种情况下,张量看起来像这样:
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 263, 13563, 7451, 29889],
[32000, 32000, 32000, 1, 887, 526, 451, 29889]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1, 1, 1]])}
填充标记是在 BOS 标记之前添加的。
选择哪个侧面主要取决于你想使用的 LLM 和你的下游任务。这就是为什么在做出任何决定之前,研究模型及其分词器是很重要的。下面,我们将看到如何为 Llama 2 做出这个决定。
为因果 LLM 添加填充支持
如我们所见,填充(几乎)总是对于微调是必要的。然而,许多 LLM 默认不支持填充。这意味着它们的词汇表中没有特殊的填充标记。
在这里,我展示了两种添加填充标记的解决方案。
简单的解决方案
这个解决方案是你在大多数教程中会找到的。
它只是将现有标记分配给填充标记。例如,你可以声明你的填充标记将是 EOS 标记。我们将得到像这样(右填充,其中“2”是 EOS 标记的 ID)的张量:
{'input_ids': tensor([[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 263, 13563, 7451, 29889],
[1, 887, 526, 451, 29889, 2, 2, 2]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 0]])}
这个解决方案的问题是 LLM 现在感到困惑:大多数情况下,EOS 标记在注意力掩码中将是“0”。这会促使 LLM 忽略原始的 EOS 标记。这并不理想,因为 EOS 标记会指示 LLM 停止生成。
使用这种解决方案,我们也必须进行右填充。如果你进行左填充,你会得到以 EOS 标记开头的序列,从而过早停止生成。
注意:我阅读了几个用于微调 Llama 2 的教程,这些教程使用 EOS token 进行左填充。如果这样做,你将得到 0.0 的损失,训练将会发散。试试看吧!观察这个现象很有趣。
在我看来,更好的替代方案是使用 UNK token 作为 pad token。这个 token 很少被使用。只有当 token 不在词汇表中时,它才会出现在序列中。将它用于其他目的不应产生重大影响。
Meta 在其“Llama recipes”中使用了这一替代方案。使用此解决方案,填充侧别不那么重要。
另一种解决方案:从头创建一个 pad token
UNK token 在模型中已经有其角色。理想情况下,我们希望有一个仅用于填充的 pad token。
如果词汇表中不存在,我们必须从头创建一个 pad token。这是 Hugging Face 推荐的 Llama 2 解决方案。
使用如 transformers 等库,扩展词汇表非常简单。
如果你想创建一个 pad token,你需要按照以下步骤进行:
-
将 pad token 作为特殊 token 添加到 LLM 的词汇中。
-
调整 token embeddings 的大小
-
重新训练 token embeddings(可选)
如果你有预算限制并使用 LoRa 进行微调,你可能会想跳过最后一步,因为 token embeddings 可能会有数亿参数。此外,在我的实验中,重新训练 embeddings 总是导致更糟的结果,这表明我的微调数据集可能不够大,或者好的超参数很难找到。
案例研究:用 Hugging Face 的 Transformers 填充 Llama 2
在本节中,我们将为 Llama 2 启用填充。要复制每个步骤,你需要访问 Hugging Face 上的 Llama 2。我在这篇文章中解释了如何获取 Llama 2。
注意:我分享了 一个笔记本 (#8) 在 The Kaitchup,我的 substack 新闻通讯上复制所有这些步骤。
首先,安装 Transformers 库:
pip install transformers
然后,我们导入 transformers 并加载 tokenizer。确保你在其中输入了你的 Hugging Face 访问 token:
from transformers import AutoTokenizer
#Replace the following with your own Hugging Face access token.
access_token = "hf_token"
#The model we want to quantize
pretrained_model_dir = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True, use_auth_token=access_token)
我们定义了两个训练示例:
prompt1 = "You are not a chatbot."
prompt2 = "You are not."
如果我们将 prompt1 放在同一批次中两次,一切顺利:
prompts = [prompt1, prompt1]
input = tokenizer(prompts, return_tensors="pt");
print(input)
输出:
{'input_ids': tensor([[ 1, 887, 526, 451, 263, 13563, 7451, 29889],
[ 1, 887, 526, 451, 263, 13563, 7451, 29889]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])}
但如果你添加了 prompt2,你将如预期那样遇到错误:
prompts = [prompt1, prompt1, prompt2]
input = tokenizer(prompts, return_tensors="pt");
print(input)
输出:
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`input_ids` in this case) have excessive nesting (inputs type `list` where type `int` is expected).
很明显,tokenizer 并没有填充示例。
我们可以通过简单地使用 UNK token 作为 pad token 来解决这个问题,具体如下:
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.unk_token
input = tokenizer(prompts, padding='max_length', max_length=20, return_tensors="pt");
print(input)
在这个例子中,我要求 tokenizer 填充到 max_length。我将 max_length 设置为 20。如果你的示例包含 10 个 tokens,tokenizer 将添加 10 个 pad tokens。
{'input_ids': tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 887, 526, 451, 263, 13563, 7451, 29889],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 887, 526, 451, 263, 13563, 7451, 29889],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 887, 526, 451, 29889]]), 'attention_mask': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]])}
另一种方法是从头创建一个 pad token。使用 Hugging Face 的 transformers,我们可以通过方法“add_special_tokens”来实现这一点。
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
input = tokenizer(prompts, padding='max_length', max_length=20, return_tensors="pt");
print(input)
输出:
{'input_ids': tensor([[32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 1, 887, 526, 451, 263, 13563, 7451, 29889],
[32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 1, 887, 526, 451, 263, 13563, 7451, 29889],
[32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 1, 887, 526, 451, 29889]]), 'attention_mask': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]])}
添加了填充标记到 Llama 2 的词汇表后,不要忘记调整 Llama 2 的令牌嵌入。我在这篇文章中解释了如何做到这一点:
## 在你的计算机上使用 QLoRa 和 TRL 对 Llama 2 进行微调
在 Guanaco 和正确的填充设置下
结论
一旦你理解了,填充就非常简单。
使用 UNK 标记进行填充,或者从头创建填充标记,是非常安全的解决方案,几乎适用于所有因果语言模型。但你应该始终查看分词器的工作方式。至少你应该了解它已经支持的特殊标记。例如,并非所有语言模型都有 UNK 标记,有些语言模型的填充标记在词汇表中没有明确定义为填充标记,等等。
像往常一样,如果你有任何问题,请留下评论。我会尽量回答。
PaLM:高效训练大型语言模型
原文:
towardsdatascience.com/palm-efficiently-training-massive-language-models-b82d6cc1582
史无前例的 LLM 规模、效率和性能


·发表于Towards Data Science ·阅读时间 17 分钟·2023 年 6 月 19 日
–

(照片由Corey Agopian提供,来自Unsplash)
近年来,大型深度神经网络已成为解决大多数语言理解和生成任务的终极架构。最初,提出了诸如BERT [2]和 T5 [3]的模型,这些模型使用了两阶段训练方法,即在大规模文本语料库上进行预训练(使用自监督“填充”目标),然后在目标数据集上进行微调;见下文。尽管这些技术很有用,但对大型语言模型(LLMs)的最新研究表明,大型自回归(仅解码器)变换器模型在少样本学习中表现出色,能够以最小的适应性在下游任务中取得令人印象深刻的性能。

(来自[4])
LLM 的少样本学习能力最初由GPT-3 [4]展示,这是一种拥有 1750 亿参数的 LLM。为了进行少样本预测,该模型在一个庞大的文本语料库上进行预训练(使用基本的语言建模目标),然后提供任务描述和若干个任务解决示例;见上文。对 LLM 的进一步分析表明,模型性能随着规模的增加而平滑提升(根据幂律)[5, 6]。因此,在 GPT-3 之后提出了各种 LLM,试图通过“扩大”模型和训练来提高结果,通常通过更大的模型和更多/更好的预训练数据组合来实现改进。
训练更大的 LLM 是有益的,但要高效地做到这一点却非常困难。通常,我们将训练分布到许多机器上,每台机器配备多个加速器(即 GPU 或TPUs)。这一方法以前已成功实施(例如,MT-NLG 在一个拥有 2240 个 A100 GPU 的系统上训练了一个 5300 亿参数的 LLM),但结果并不特别令人印象深刻。尽管模型很大,但训练的数据量不足。然而,鉴于更高的训练吞吐量,我们可以(理论上)在更大的数据集上更广泛地预训练这样的巨大模型,从而获得更好的结果。
在本概述中,我们将探讨Pathways 语言模型(PaLM),这是一种拥有 5400 亿参数的 LLM,使用 Google 的Pathways框架进行训练。通过消除管道并行性,这一架构实现了令人印象深刻的训练吞吐量,使得 PaLM 能够在更广泛的数据集上进行预训练。最终模型的少样本性能处于行业领先水平。此外,PaLM 在解决复杂推理任务方面也有一定能力。简单来说,PaLM 清楚地提醒我们,LLM 的性能在规模上尚未达到瓶颈。只要有足够高效的训练基础设施来支持在更多数据上预训练更大的模型,我们仍将继续看到性能的提升。
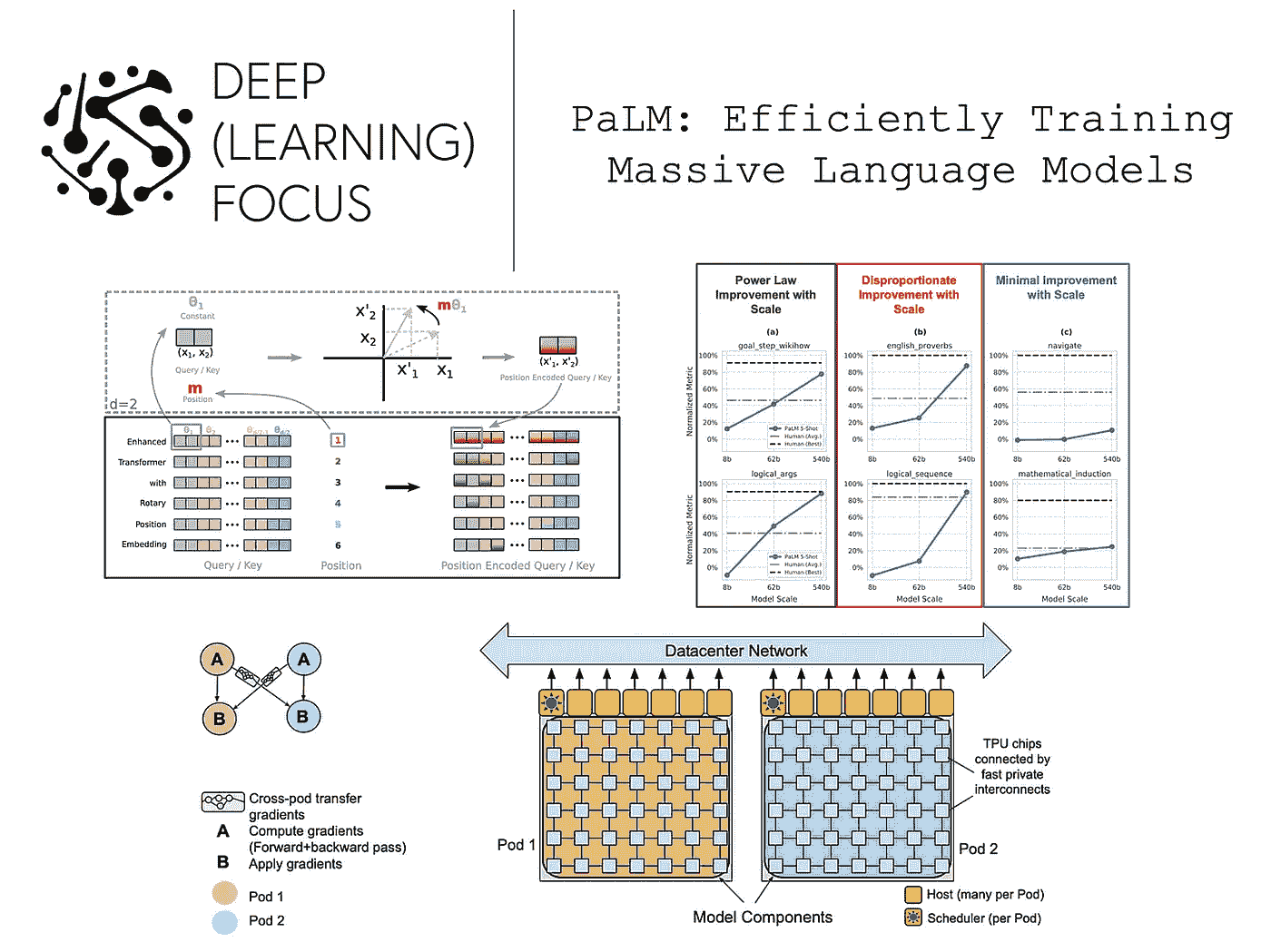
(来源于 [1, 16])
背景
我们在本新闻通讯中广泛探讨了语言建模主题,并在之前的帖子中回顾了几种显著的(大规模)语言模型:
尽管如此,我们将在这里简要回顾有关 LLM 的先前工作,以提供理解 PaLM 的重要背景。
语言建模回顾
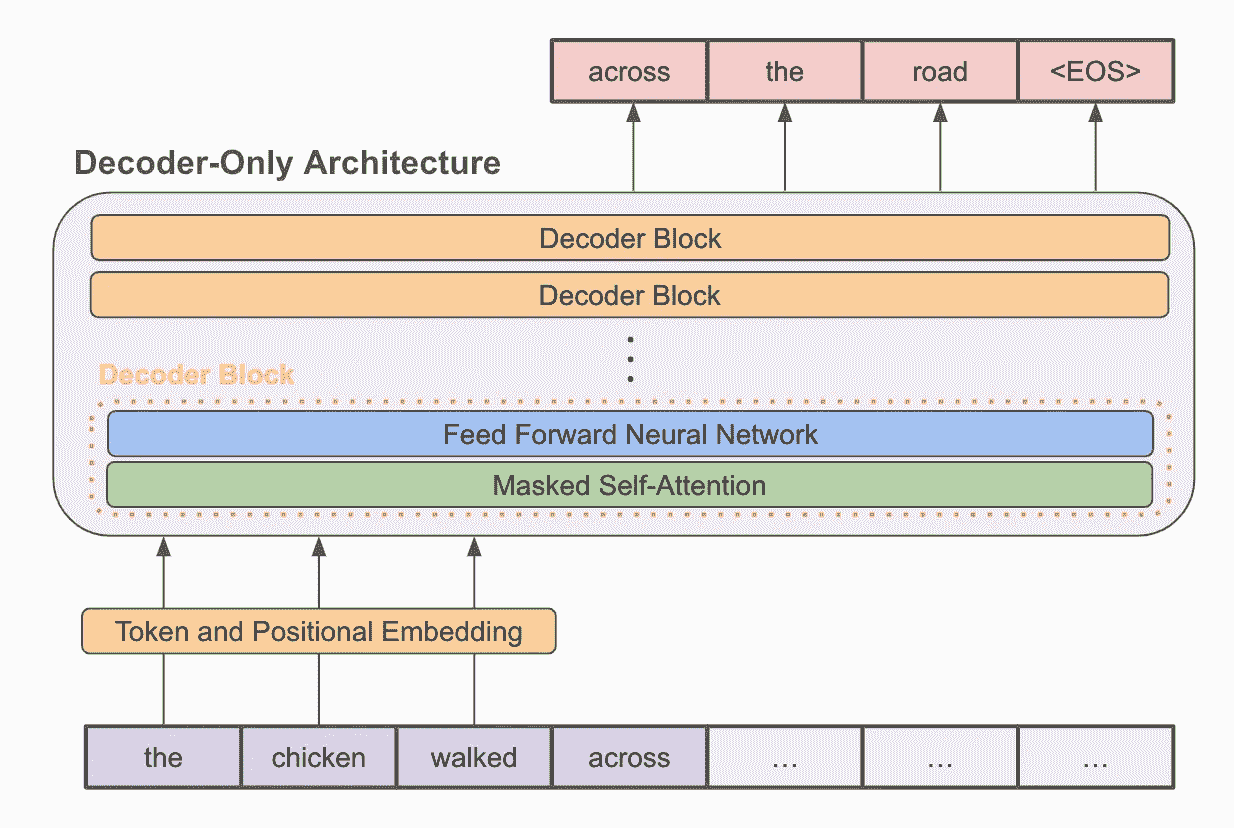
仅解码器转换器架构
现代语言模型仅仅是 仅解码器转换器模型(如上图所示),这些模型通过自监督 语言建模目标 在无标签文本上进行预训练。该目标对文本序列进行采样,并训练语言模型准确预测下一个词/标记。在进行广泛的预训练后,LLM 如 GPT-3 被发现能在少量示例学习模式下表现非常好。
这有什么用? 简而言之,LLM 的通用文本到文本格式使其能够轻松地推广到解决各种任务,只需少量调整。我们可以仅仅通过广泛地预训练一个单一模型,并利用少量示例学习来解决各种任务,而不必对模型进行微调或添加任务特定的层。尽管预训练这样的基础模型是非常昂贵的,但这些方法具有巨大的潜力,因为一个模型可以被重新用于许多应用。这一过程称为上下文学习;见下文。
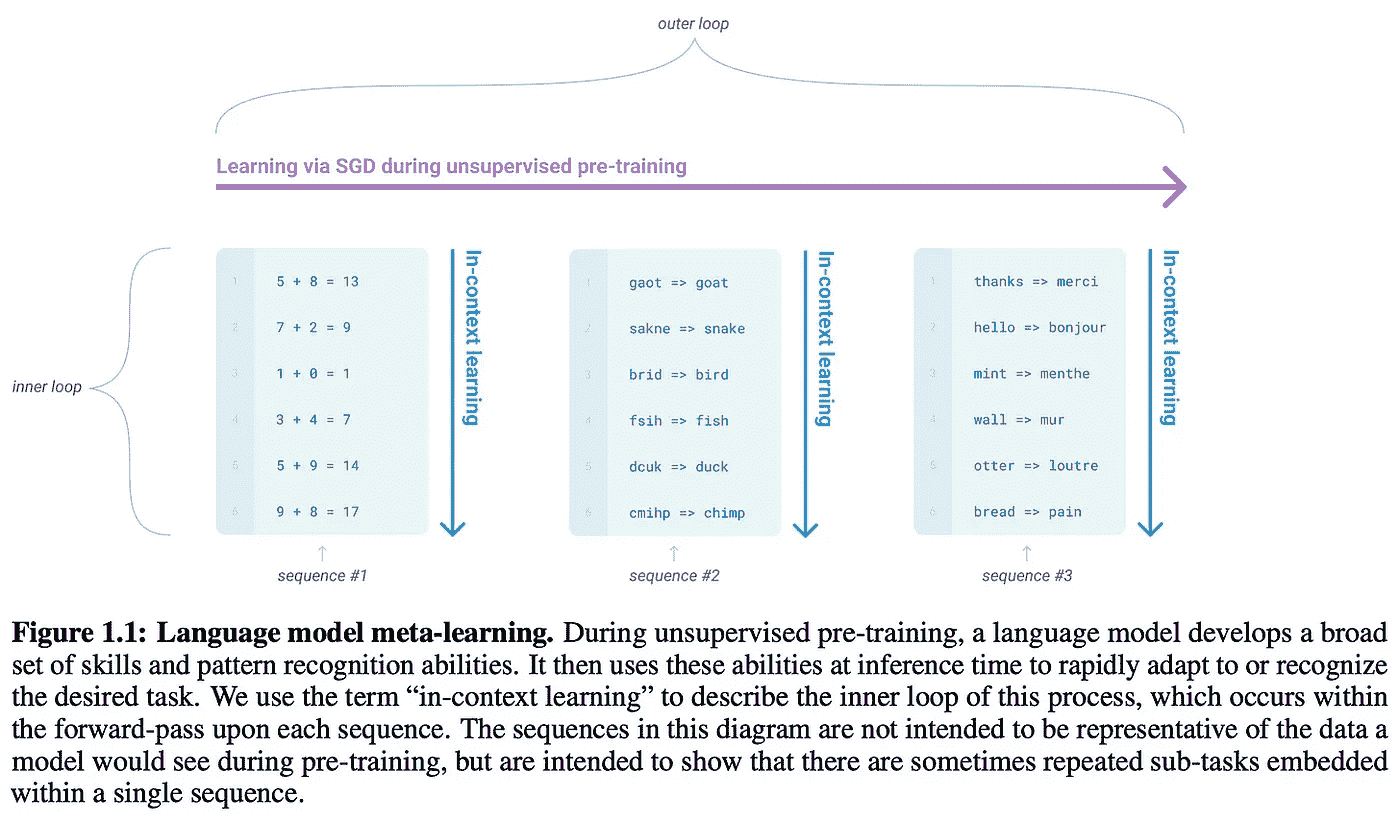
(来源于 [4])
什么构成一个好的 LLM? 早期的研究表明,语言模型的性能应该随着模型规模的增加而平滑提高(根据 幂律)(即,大模型表现更好)。这一发现导致了 GPT-3 的提出,这是一个规模空前的 LLM(1750 亿参数),实现了突破性的少量示例学习性能。后续工作尝试探索 更大的 LLM,但这些更大的模型并没有带来进一步的性能突破。相反,我们最终发现,生产高性能 LLM 需要将更大的模型与更大的预训练数据集相结合 [6]。
“预计所需的训练数据量远超目前用于训练大型模型的数据量,这突显了数据集收集的重要性,除了允许模型规模扩展的工程改进。” — 来源于 [6]
架构修改
除了使用改进的训练框架,PaLM 还对基础的仅解码器架构进行了相当大的修改。这些更改大多数采纳了先前的工作,这些工作揭示了最大化 LLM 训练效率和性能的最佳实践。
SwiGLU 激活函数。 大多数大语言模型(LLMs)在每一层内使用的前馈神经网络具有类似的结构。也就是说,这个网络进行两次前馈变换(不使用偏置,并单独应用于序列中的每个令牌向量),中间使用修正线性单元(ReLU)激活函数。然而,后续的工作[13]揭示了其他激活函数的选择可能实际上更好。
具体来说,PaLM 使用了 SwiGLU 激活函数,它是 Swish [14] 和 GLU [15] 激活函数的组合。这个激活函数由下面的方程给出。
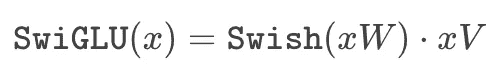
(作者创作)
我们将 Swish 激活函数定义为
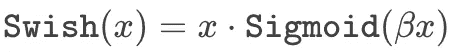
(作者创作)
换句话说,SwiGLU 是对输入的两个线性变换的逐元素乘积,其中一个变换应用了 Swish 激活函数。尽管这个激活函数需要进行三次矩阵乘法,但最近的工作发现,在固定的计算量下,它能带来性能提升。与像 ReLU 这样的普通激活函数相比,SwiGLU 似乎提供了不可忽视的性能提升 [13]。
并行变压器块。 PaLM 还使用了变压器块的并行版本,而不是常规(串行)版本。这两种形式之间的差异在下图中展示。
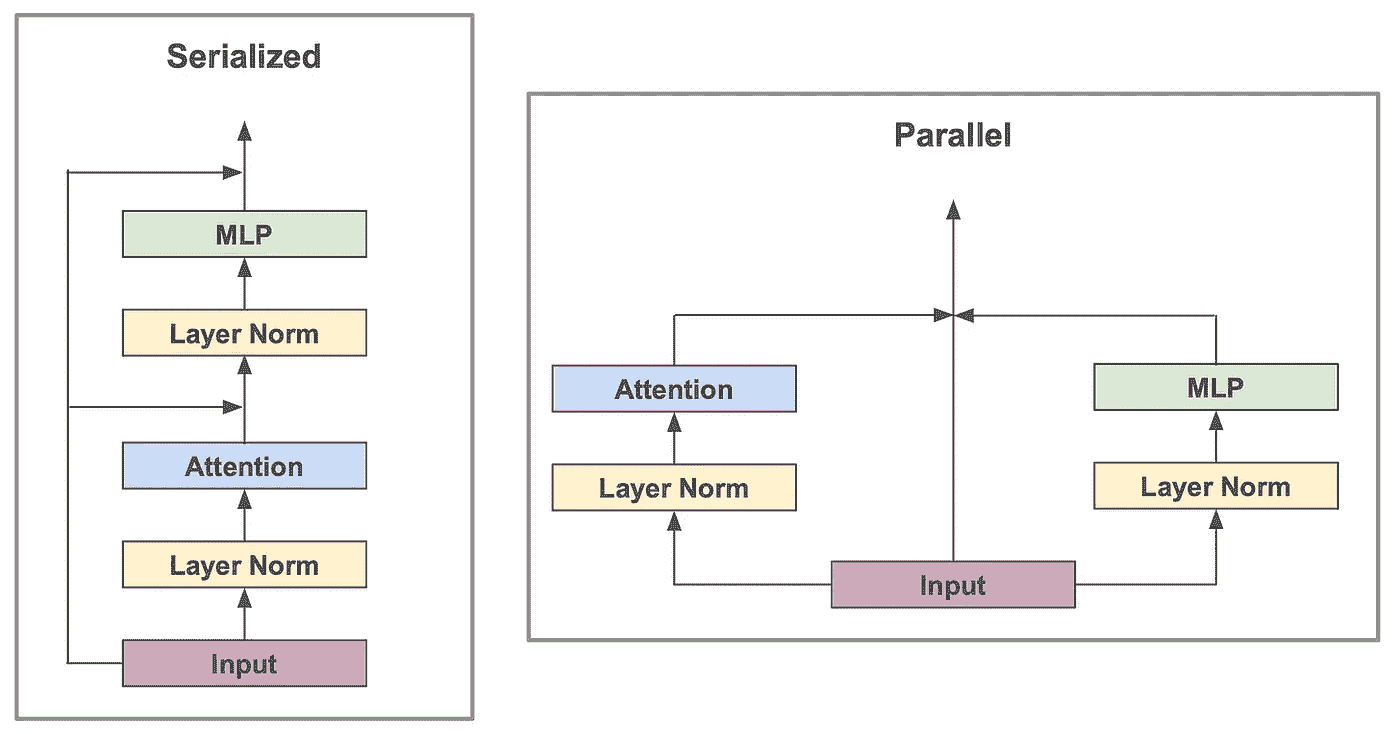
并行与串行变压器块(作者创作)
在模型足够大的情况下,使用并行变压器块可以将训练过程的速度提高 15%。这种加速会以较小 LLM(例如,80 亿参数模型)性能略有下降为代价,但全尺寸 LLM 使用并行块时往往表现相似。
(来源 [16])
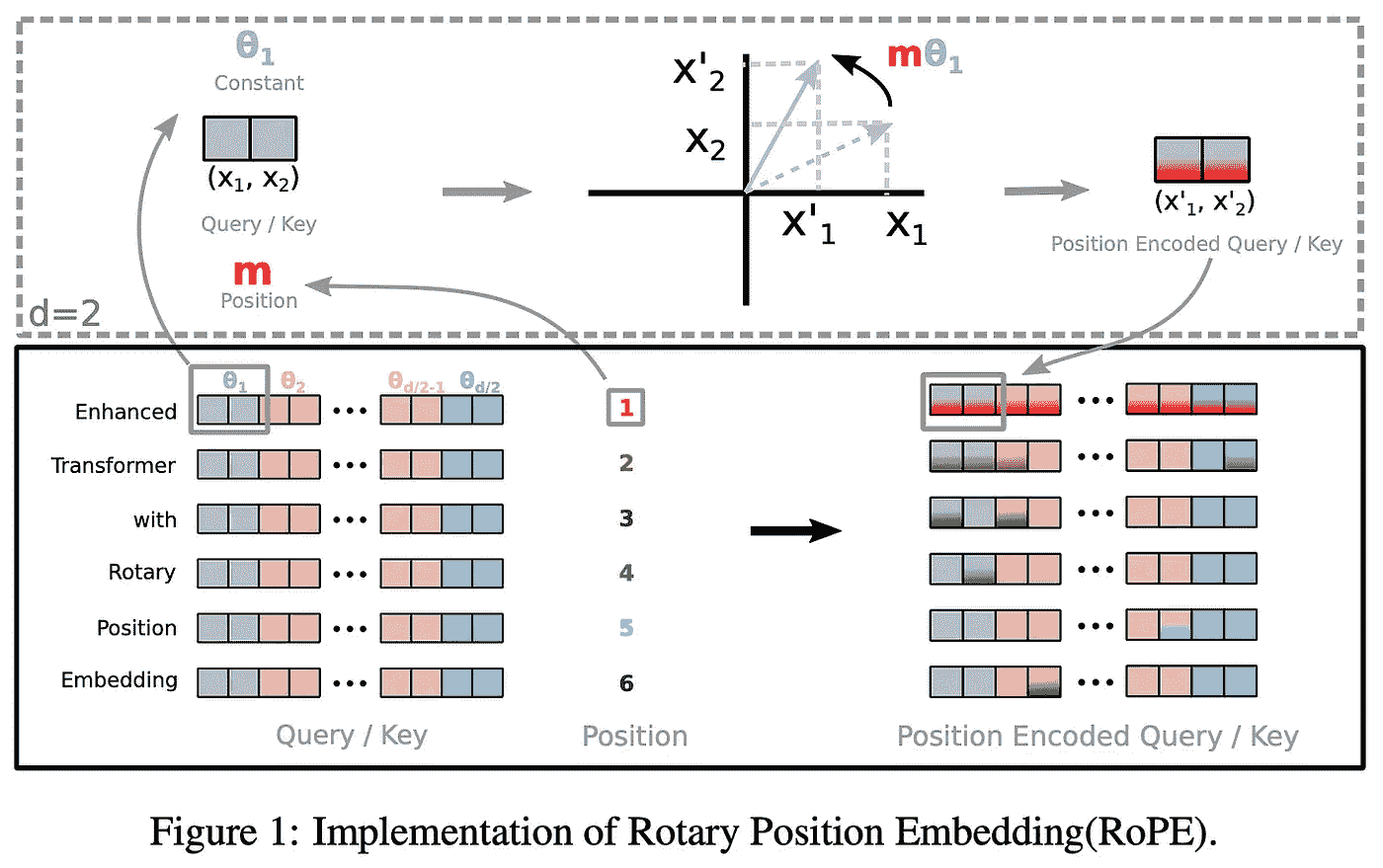
旋转位置嵌入。 PaLM 使用了旋转位置嵌入(RoPE),而不是绝对位置嵌入或相对位置嵌入,如[16]中所提议。RoPE 嵌入通过以下方式结合了绝对和相对位置:
-
使用旋转矩阵编码绝对位置
-
将相对位置直接纳入自注意力机制
直观地,RoPE 找到了绝对和相对位置嵌入之间的折中。上图所示,RoPE 始终优于其他嵌入策略。而且,它在 HuggingFace 等常见库中易于访问。
多查询注意力。 最后,PaLM 用一种称为多查询注意力的替代结构替换了典型的多头自注意力机制。多查询注意力在每个注意力头之间共享键和值向量(下面用红色突出显示),而不是为每个头执行单独的投影。这一变化并没有使训练速度更快,但确实显著提高了 LLMs 的自回归解码(即用于执行推理或生成)的效率。
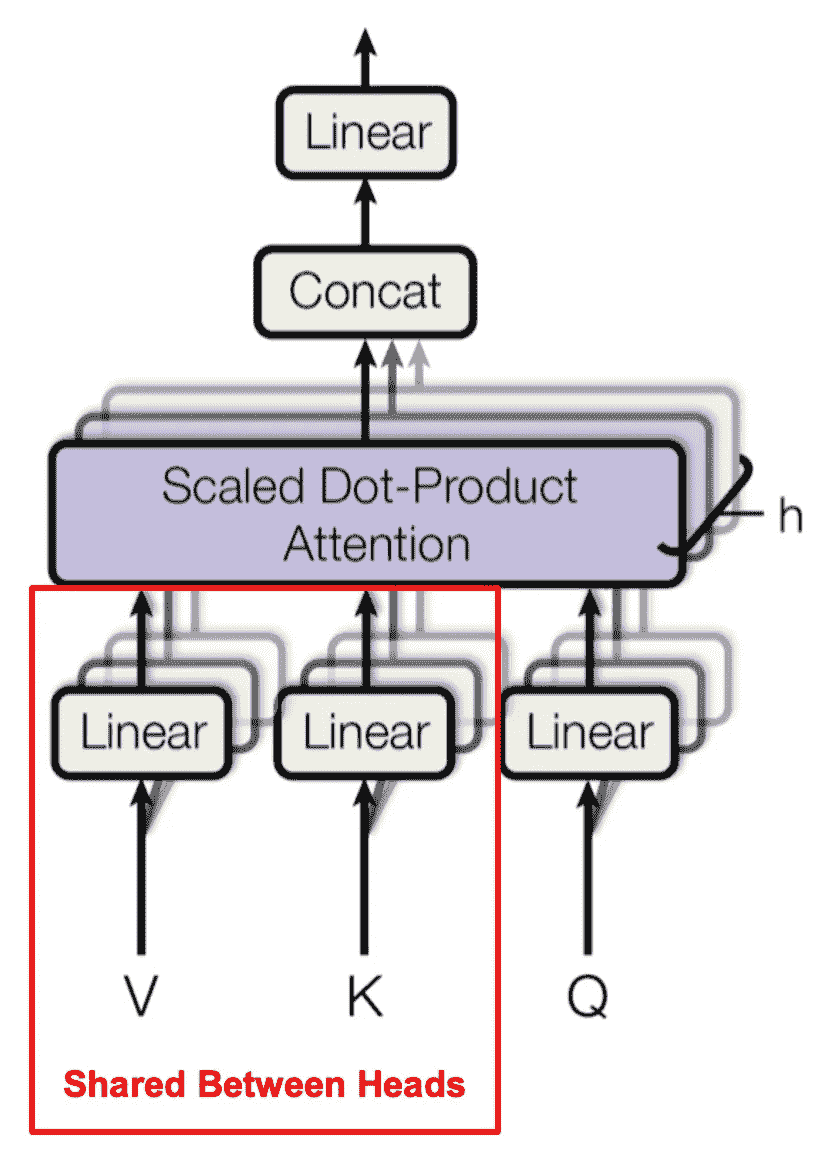
多查询注意力在注意力头之间共享键和值投影(来源 [17])
其他有用的概念
PaLM: 使用 Pathways 扩展语言建模 [1]
现在,我们将概述 PaLM,一个 5400 亿参数的密集语言模型,它通过使用Pathways 框架进行了高效训练。PaLM 是迄今为止训练过的最大密集型 LLM 之一,其高效的训练策略使得其预训练过程可以在大数据集(>7000 亿个标记)上进行。这种大型语言模型与广泛的预训练语料库的结合,导致了一些有趣的结果,我们将在本节中探讨。
PaLM 是如何工作的?
PaLM 是一个大型的 LLM,通过广泛的预训练(得益于高效的 Pathways 架构)和对基础模型架构的一些修改,达到了令人印象深刻的少样本学习性能。我们将概述 PaLM 架构和训练模式的细节。
模型。 PaLM 使用了一个仅解码器的变换器,具有 5400 亿参数。然而,这个模型超越了典型的仅解码器架构,通过进行一些修改:
-
在 MLP 层中使用 SwiGLU 激活(而不是ReLU)。
-
在注意力层中使用多查询注意力。
-
仅使用并行变换器块。
-
绝对或相对位置嵌入被 ROPE 嵌入替代。
为了了解模型规模的影响,[1] 中测试了三种不同规模的 PaLM;见下文。

(来自 [1])
尽管幂律法则表明性能在上述模型之间应平滑提升,[1] 的分析发现 我们通常会看到使用最大(5400 亿参数)模型时,性能有不成比例的提升。较大的 LLM 在结合更广泛的预训练过程时提供了意外的大收益。
“对于某些任务,我们观察到不连续的改进,其中从 62B 扩展到 540B 在准确性上有显著跃升,相较于从 8B 扩展到 62B… 这表明,当模型达到足够的规模时,大型语言模型的新能力可能会出现,并且这些能力会在先前研究的规模之外继续出现。” — 来自 [1]
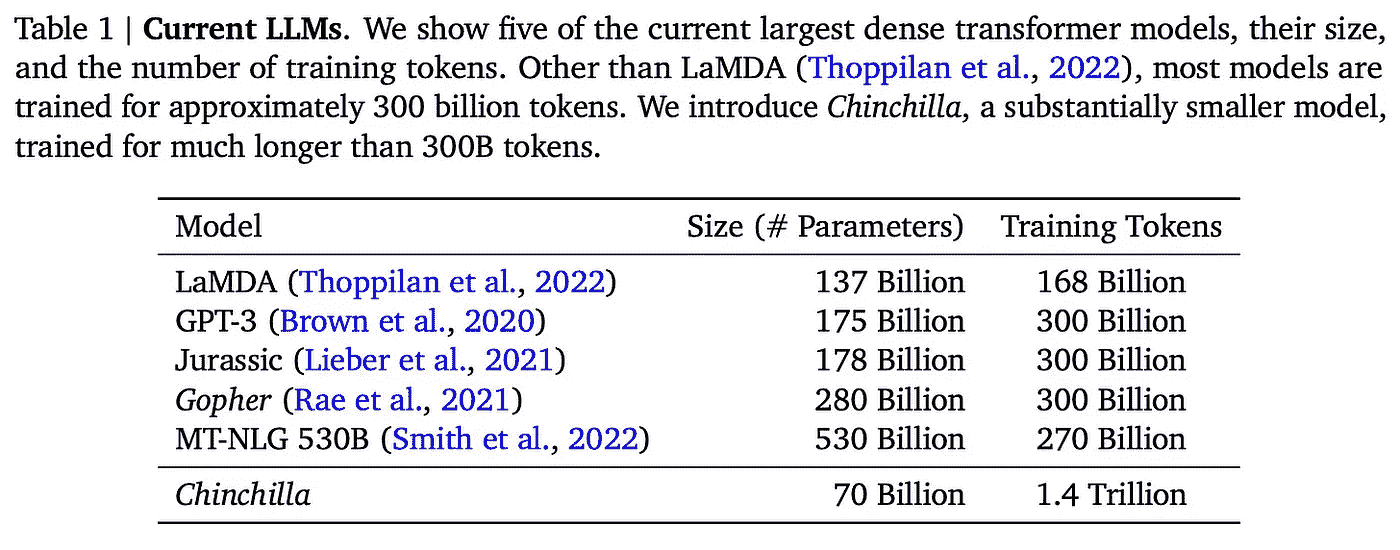
数据集。 PaLM 的预训练语料库包含 780B 个标记。这个数据集比用于训练 Chinchilla [6] 的数据集略小,但仍然大于大多数之前的 LLM;见下文。
(来自 [3])
创建高性能的 LLM 不仅仅是让模型变得更大。对 LLM 的缩放规律的最新研究 [6] 表明,性能将随着模型大小和预训练语料库大小的增加而提高。因此,PaLM 有机会显著超越 MT-NLG 等模型(尽管其仅略大),通过使用更大的预训练语料库。
PaLM 使用的预训练语料库来源于高质量的网页、书籍、维基百科、新闻、文章、代码和社交媒体对话。它包含 22% 的非英语数据(见下文),并受到用于训练 LaMDA 和 GLaM [8, 9] 的语料库的启发。所有模型都在这个数据集上训练了一个完整的周期。

(来自 [1])
使用大词汇量。 由于预训练语料库中有相当一部分是非英语的,作者还采用了 SentencePiece tokenizer ,其词汇量为 256K。该分词器直接处理原始文本输入,并从文本中提取标记(即词或子词)。此分词过程基于一个基础词汇表(即已知标记的集合),从文本中提取的所有标记必须是词汇表的成员。如果一个标记不在基础词汇表中,它将被拆分成更小的块(可能是字符),直到被分解成有效的标记,或者用通用的“[UNK]”(未知词汇标记)替代。
使用小词汇表意味着许多重要的标记可能无法被正确捕捉,这可能会影响 LLM 的性能。对于多语言模型,我们通常会看到底层词汇表的大小大幅增加,以避免这种情况,因为来自多种语言的数据会利用更广泛的标记范围。PaLM 也不例外:作者采用了比平常更大的词汇表,以避免错误标记数据,并允许在多种语言间更有效的学习。要了解更多关于在多种语言上训练的语言模型的信息,请查看 这里 的链接。
训练系统。 在概述用于 PaLM 的训练框架之前,我们需要了解一些与分布式训练相关的概念。最重要的是,我们需要理解模型、数据和流水线并行之间的区别。虽然我已经之前解释了这些概念,但 这里 的推文提供了更好(且更简明)的描述。
PaLM 在一组 6144 个 TPU 芯片上进行训练,这些芯片分布在两个 TPU 集群(即,通过高速网络接口连接的 TPU 组)中。在发布时,这个系统是描述的最大配置;见下图。
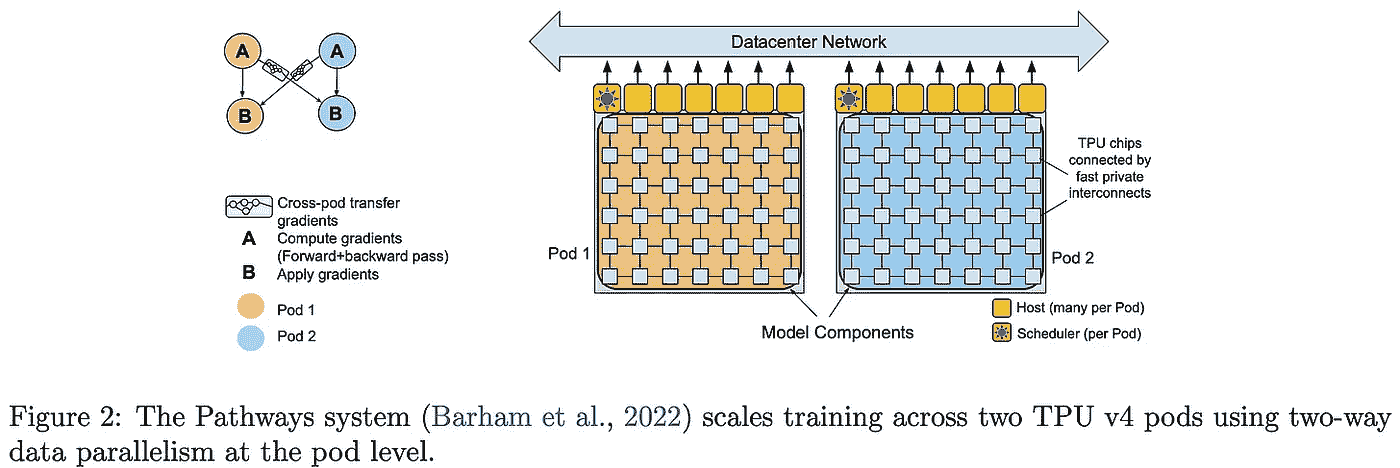
(来自 [1])
在一个集群内部,TPU 之间的通信非常快速。但集群之间的通信则要慢得多。通常,模型和数据并行的带宽需求过大,无法在 TPU 集群之间高效训练。大多数先前的工作通过以下方式处理这个问题:
-
将训练限制在单个 TPU 集群上 [8, 9]。
-
在集群之间使用带宽要求较低的流水线并行 [7, 10]。
然而,流水线有许多显著的缺点,比如在清空或填充流水线时使加速器处于空闲状态,以及高内存需求。使用 Pathways 系统,PaLM 在 TPU 集群之间通过模型和数据并行(即无流水线并行)进行高效训练。这种新颖的训练范式显著提高了效率。
(来自 [1])
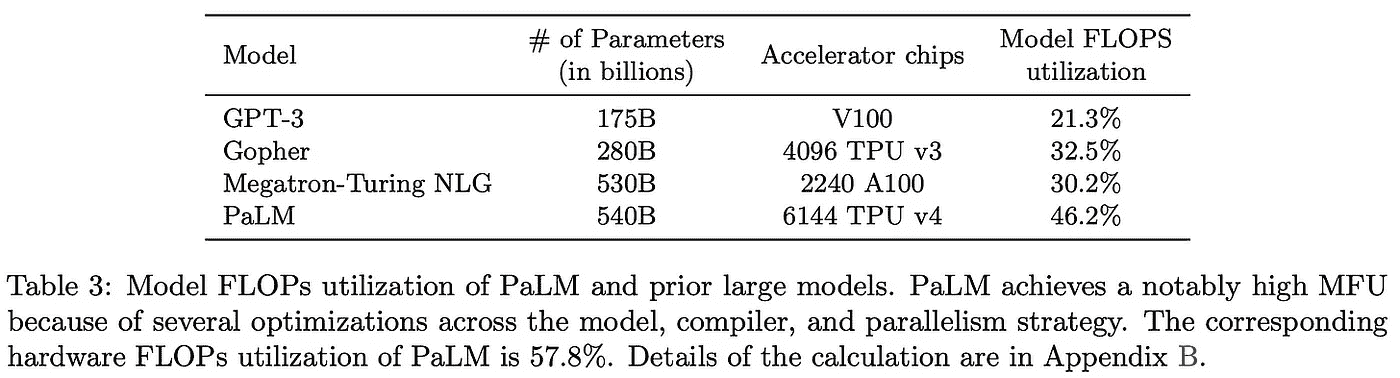
例如,PaLM 实现了一个模型 FLOPs 利用率(即每秒令牌吞吐量与系统理论最大吞吐量的比值)为 46.2%,而之前的系统难以超过 30% 的利用率;详见上文。有关 Pathways 系统及其如何在 LLM 训练效率上实现如此巨大的改进的信息,请查看 这里 的文章。
PaLM 的表现如何?
在 [1] 中提供的分析超越了实现卓越的少样本学习表现。PaLM 被证明能够有效处理多种语言,具备改进的推理能力,性能显著优于较小的模型,甚至在某些任务上超越了人类水平的语言理解。
多语言 LLM。 之前的 LLM(例如,GPT-3 [4])已经表现出一定的机器翻译能力,特别是在将其他语言翻译成英语时。在以英语为中心的数据对和设置中,我们看到 PaLM 相对于之前的 LLM 改进了翻译性能;详见下文。
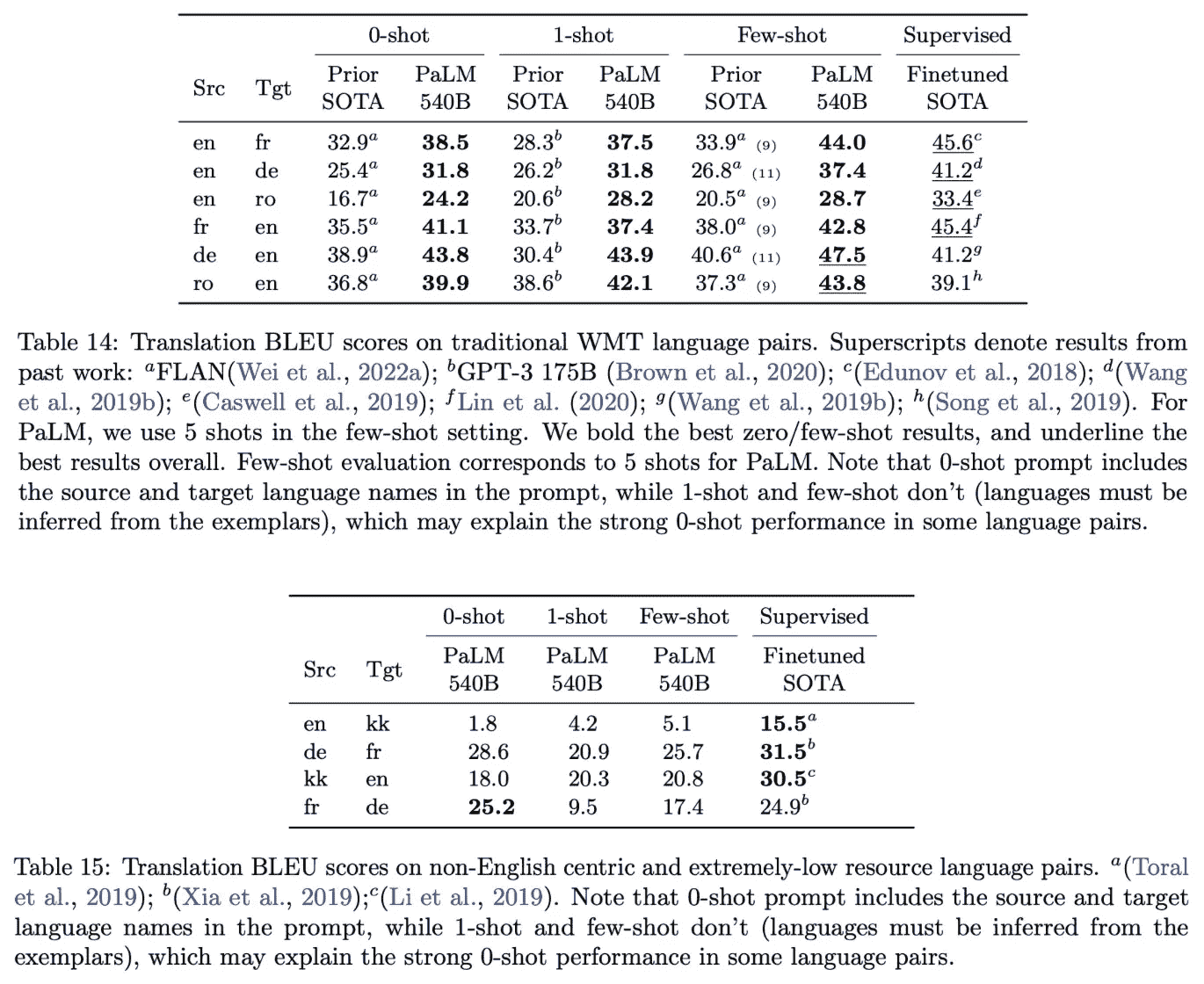
(来自 [1])
在资源稀缺和非英语中心的数据上,PaLM 仍表现相对良好,但不及现有的监督翻译方法;详见上文。然而,鉴于之前的工作并未广泛考虑非英语设置,PaLM 在这种设置下的相对良好表现令人印象深刻。总体而言,这项分析显示 PaLM 语言翻译能力有所提升,但仍不及监督技术。
除了语言翻译之外,我们还看到 PaLM 在多语言生成任务上表现出色。正如预期的那样,PaLM 在英语语言生成能力方面表现最佳,但该模型在非英语生成任务上仍优于之前的语言模型。总体而言,这些结果表明,通过进行小幅调整(例如,增加非英语预训练数据并为分词器使用更大的词汇表),可以显著提高 LLM 的多语言能力。
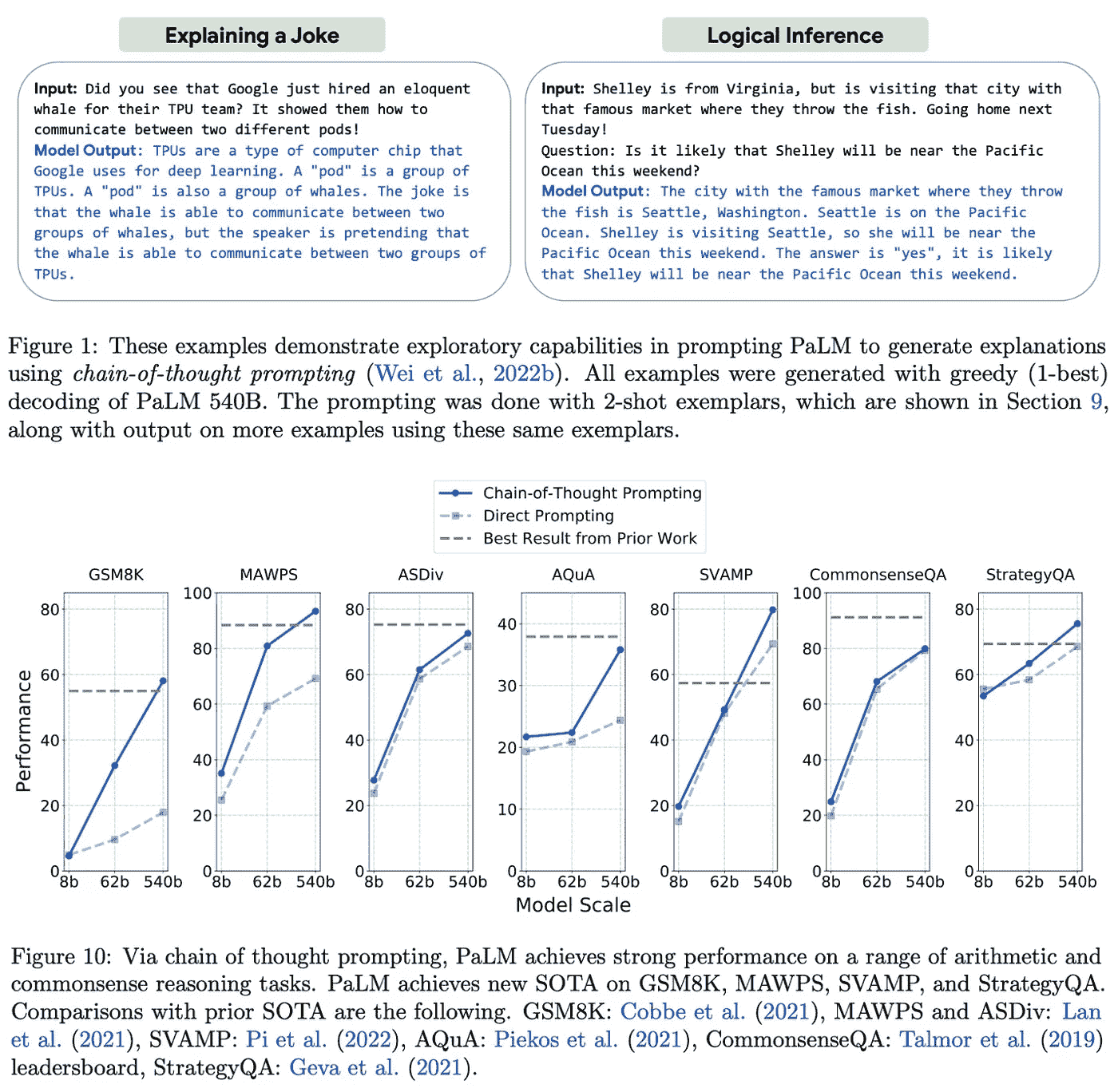
超越人类表现。 BIG-bench 数据集包含 150 个任务,涵盖逻辑推理、翻译、问答、数学等主题。相对于之前的 LLM,我们看到 PaLM 在大多数任务上表现有所提升;详见下文。
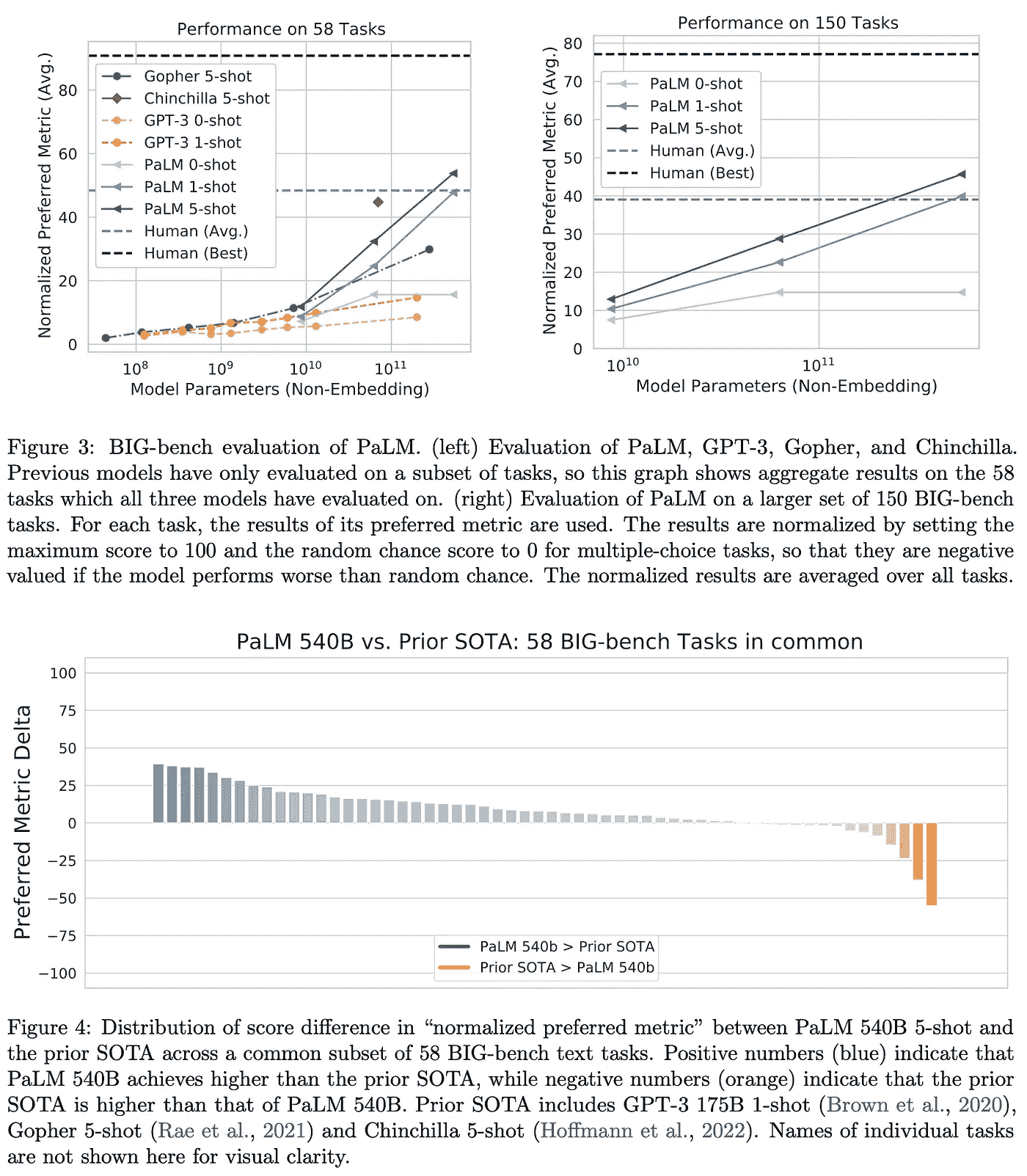
(来自 [1])
比起超越之前的 LLMs,PaLM 在大多数 BIG-bench 任务上的表现也超越了人类的平均水平;见下文。对于这些任务中的某些任务,超越人类简单地表明 PaLM 能够记忆数据或在多种语言之间进行推理。然而,这并不总是如此!在其他任务中(例如,因果关系识别),我们看到 PaLM 似乎在语言理解上有所改善。
(来自[1])
幂律是否总是成立? 当我们将 PaLM 的表现细分到特定任务类别时,我们发现模型规模对某些任务特别有帮助。例如,在逻辑序列任务(即将一组词语排列成逻辑顺序)中,最大的 PaLM 模型在相对于较小模型的性能上有了巨大的提升。对于其他任务(例如,数学归纳),模型规模几乎没有影响。
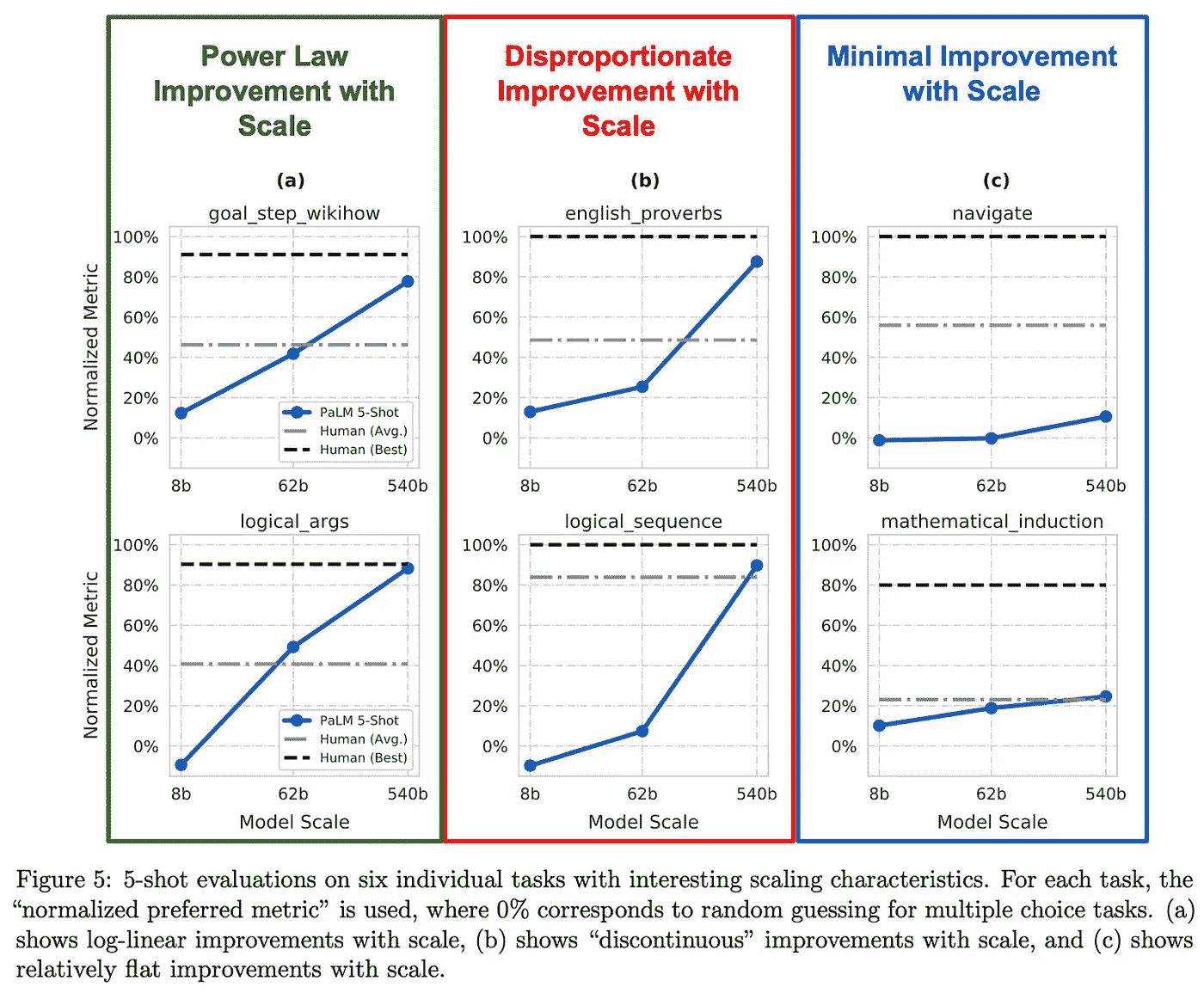
(来自[1])
总的来说,PaLM 的表现并不总是遵循与模型规模相关的幂律。在某些情况下,使用更大的模型会导致性能的巨大意外提升,而在其他情况下,最大的模型仅比较小的变体表现稍好;见上文。
学习推理。 尽管语言模型在许多任务上表现良好,但它们在解决基本推理任务时常常遇到困难。许多研究人员引用了 LLMs 这一局限性作为其“浅薄”语言理解的证明。然而,最近的出版物已经使用链式思维提示(即在 LLM 生成最终输出之前生成几个推理“步骤”)来提高 LLMs 的推理能力[11, 12];见下文。
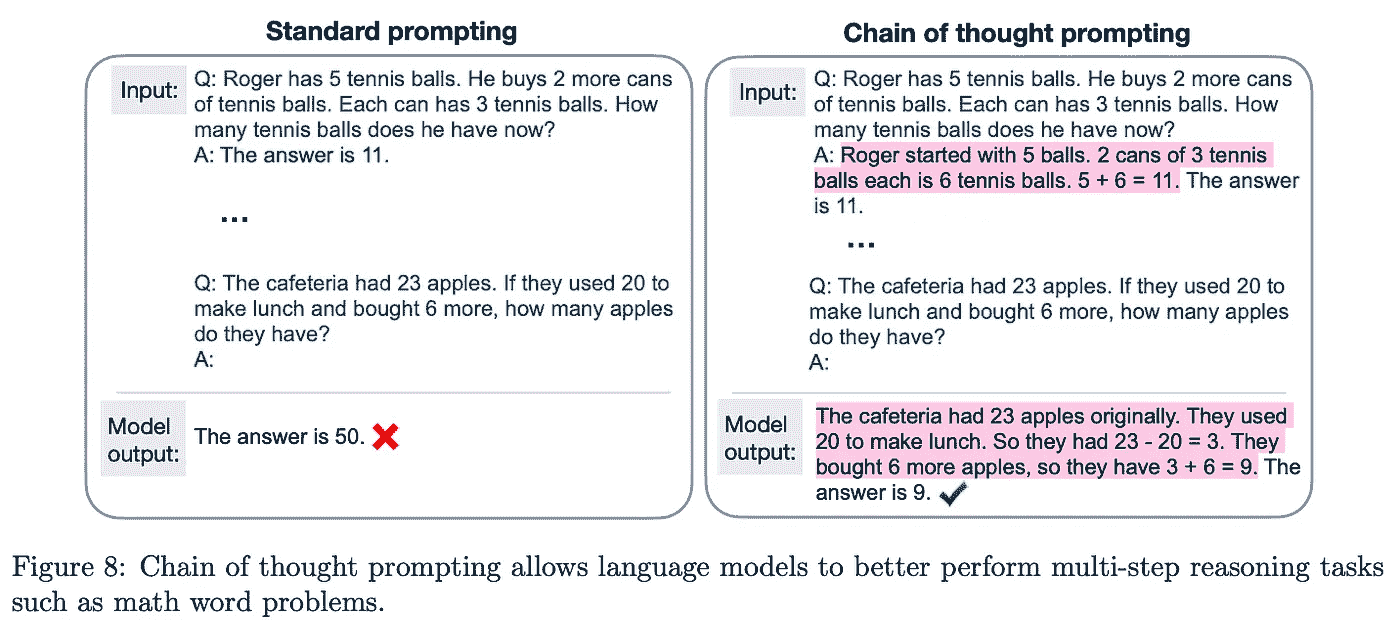
(来自[1])
在评估 PaLM 时,[1]中的作者发现,将这种规模的模型与链式思维提示相结合,足以在算术和常识推理任务上实现最先进的准确度。之前的方法利用了特定领域的架构、微调,甚至任务特定的验证模块来解决这些推理任务。相比之下,PaLM 只需使用少量示例的链式思维提示(以及用于算术推理任务的外部计算器模块)即可解决这些任务;见下文。
(来自[1])
有趣的是,我们发现最大的 PaLM 模型在推理能力上远优于较小的变体。考虑到之前的研究发现规模对推理性能的影响通常是混合的(有时是负面的),这一发现很有趣。PaLM 的结果表明,只要采用正确的提示方法,模型(和数据)规模似乎可以有益于推理性能。
(来自[1])
PaLM API
如果你有兴趣试用 PaLM,那你很幸运!PaLM 的 API 在过去几周内已向部分开发者发布。许多 AI 社区成员将 Google 发布的 PaLM API 视为对 OpenAI 在一周前公开发布的ChatGPT API的回应。有关 PaLM API 发布的更多信息,请阅读这里的文章。尽管训练和托管 LLMs 很困难,但我们目前看到这些工具通过 API 向开发者开放的巨大转变。因此,实践者可以轻松访问这些令人惊叹的模型,无需培训和托管的麻烦或费用。这降低了使用这些强大模型构建应用的门槛,开启了无限的可能性!关于可以构建的应用实例,我推荐查看OpenAI cookbook。
重点总结
尽管最初尝试训练超越 GPT-3 规模的 LLMs 并不完全成功,但我们从 PaLM 中看到,我们所需的只是一个高效的训练框架,允许更广泛的预训练。通过使用 Pathways 框架,PaLM 可以在比之前模型(如 MT-NLG [7])更大的数据集上进行训练。得到的 LLM 具有令人印象深刻的多语言理解和推理能力,我们看到模型规模的增加往往能带来显著的好处。以下是从 PaLM 中得到的一些重要启示。
幂律定律是否总是成立? 关于 LLMs 的众多出版物表明,LLM 性能与各种数量(如(非嵌入式)模型参数、数据集规模、训练计算量等)之间存在幂律关系。虽然这种趋势在整体性能方面是成立的,但当我们单独检查每个任务的性能时,情况则更为复杂。某些任务从规模中受益不成比例,而其他任务则未见太多好处。因此,规模通常对 LLMs 有帮助,但结果会根据下游任务的不同而有显著差异。
我们是否应该避免管道并行性? PaLM 的一个主要卖点是其高效的 Pathways 训练框架。通常,在多个 TPU 集群或计算节点上训练需要使用管道并行性,因为内存带宽有限。然而,通过去除管道并行性并仅使用数据和模型并行性进行 TPU 集群训练,我们发现 PaLM 实现了突破性的训练效率和吞吐量。这些对训练框架的提升使得 PaLM 可以在更多的数据上进行训练,从而展现出模型令人印象深刻的性能。
LLM 的规模与推理。 之前关于 LLM 的研究经常指出其推理能力较差。实际上,LLM 在进行推理任务时,其能力似乎会随着规模的增大而下降。然而,我们看到在 PaLM 的情况下并非总是如此。如果我们将更大的 LLM 与更多的预训练数据和正确的提示方法(即链式思维提示)相结合,我们可以看到 LLM 推理能力有相当明显的提升!
结束语
非常感谢你阅读这篇文章。我是 Cameron R. Wolfe,Rebuy 的 AI 主管。我研究深度学习的经验和理论基础。你也可以查看我在 medium 上的 其他文章!如果你喜欢这篇文章,请关注我的 twitter 或订阅我的 Deep (Learning) Focus 新闻通讯,我在其中帮助读者通过对热门论文的易懂概述,深入理解深度学习研究中的主题。
参考文献
[1] Chowdhery, Aakanksha, 等人。“Palm:通过路径扩展语言建模。” arXiv 预印本 arXiv:2204.02311(2022)。
[2] Devlin, Jacob, 等人。“Bert:用于语言理解的深度双向 transformer 预训练。” arXiv 预印本 arXiv:1810.04805(2018)。
[3] Raffel, Colin, 等人。“利用统一的文本到文本 transformer 探索迁移学习的极限。” 机器学习研究杂志 21.1(2020):5485–5551。
[4] Brown, Tom, 等人。“语言模型是少样本学习者。” 神经信息处理系统进展 33(2020):1877–1901。
[5] Kaplan, Jared, 等人。“神经语言模型的规模定律。” arXiv 预印本 arXiv:2001.08361(2020)。
[6] Hoffmann, Jordan, 等人。“训练计算最优的大型语言模型。” arXiv 预印本 arXiv:2203.15556(2022)。
[7] Smith, Shaden, 等人。“使用 deepspeed 和 megatron 训练 megatron-turing nlg 530b,一个大规模生成语言模型。” arXiv 预印本 arXiv:2201.11990(2022)。
[8] Thoppilan, Romal, 等人。“Lamda:对话应用的语言模型。” arXiv 预印本 arXiv:2201.08239(2022)。
[9] Du, Nan, 等人。“Glam:使用专家混合进行语言模型的高效扩展。” 国际机器学习会议。PMLR,2022。
[10] Rae, Jack W., 等人。“扩展语言模型:方法、分析与训练 gopher 的见解。” arXiv 预印本 arXiv:2112.11446(2021)。
[11] Nye, Maxwell, 等人。“展示你的工作:语言模型的中间计算记事本。” arXiv 预印本 arXiv:2112.00114(2021)。
[12] Cobbe, Karl, 等人。“训练验证者解决数学词题。” arXiv 预印本 arXiv:2110.14168(2021)。
[13] Shazeer, Noam。“Glu 变体改进了 transformer。” arXiv 预印本 arXiv:2002.05202(2020)。
[14] 拉马钱德兰,普拉吉特,巴雷特·佐普和阮光伟。“寻找激活函数。” arXiv 预印本 arXiv:1710.05941 (2017)。
[15] 多芬,扬·N. 等人。“使用门控卷积网络进行语言建模。” 国际机器学习会议。PMLR,2017。
[16] 苏建林等人。“Roformer: 增强型变换器与旋转位置嵌入。” arXiv 预印本 arXiv:2104.09864 (2021)。
[17] 瓦斯瓦尼,阿希什等人。“注意力机制即你所需的一切。” 神经信息处理系统进展 30 (2017)。
Pandas 2.0:数据科学家的游戏改变者?
高效数据处理的五大特点


·
关注 发布于 数据科学前沿 ·7 分钟阅读·2023 年 6 月 27 日
–

今年四月,pandas 2.0.0 正式发布,在数据科学界掀起了巨大波澜。照片由 Yancy Min 提供,来自 Unsplash。
由于其广泛的功能和多样性, pandas 在每位数据科学家的心中占据了一席之地。
从数据输入/输出到数据清洗和转换,几乎无法想象在没有import pandas as pd的情况下进行数据处理,对吧?
现在,请耐心点: 在过去几个月围绕 LLM 的热潮中,我在某种程度上忽略了 pandas 刚刚经历了重大版本更新!没错,pandas 2.0 已经发布并带来了巨大的变化!
尽管我并不了解所有的炒作, Data-Centric AI Community 很快就给予了援助:
2.0 版本似乎在数据科学社区中产生了相当大的影响,许多用户赞扬了新版本中添加的修改。作者提供的截图。
有趣的是: 你知道这个版本的开发花了令人惊讶的 3 年时间吗?这就是我所说的“对社区的承诺”!
那么 *pandas 2.0* 带来了什么?让我们直接深入了解!
1. 性能、速度和内存效率
众所周知,pandas 是使用 numpy 构建的,而 numpy 并非故意设计为数据框库的后端。因此,pandas 的一个主要限制是处理大型数据集时的内存处理。
在这个版本中,最大的变化来自于引入了 Apache Arrow 后端来处理 pandas 数据。
实质上,Arrow 是一种标准化的内存列式数据格式,提供了多种编程语言的可用库(如 C、C++、R、Python 等)。对于 Python,有 PyArrow,它基于 Arrow 的 C++ 实现,因此,速度很快!
简而言之,PyArrow 解决了我们在 1.X 版本中的内存限制,使我们能够进行更快、更节省内存的数据操作,特别是对于大型数据集。
这是读取数据的比较,没有和使用 pyarrow 后端,使用 Hacker News 数据集(约 650 MB,许可证 CC BY-NC-SA 4.0):
read_csv() 比较:使用 pyarrow 后端快 35 倍。作者提供的代码片段。
正如你所见,使用新后端使得读取数据的速度快了近 35 倍。其他值得指出的方面有:
-
没有
pyarrow后端时,每列/特征作为其独特的数据类型存储:数值特征存储为**int64**或**float64**,而 字符串 值存储为 对象; -
使用
pyarrow时,所有特性都使用 Arrow 数据类型:请注意[pyarrow]注释和不同的数据类型:int64、float64、string、timestamp和double:
df.info(): 调查每个 DataFrame 的数据类型。作者提供的代码片段。
2. Arrow 数据类型和 Numpy 索引
除了读取数据这一最简单的情况之外,你还可以期待一系列其他操作的改进,特别是那些涉及字符串操作,因为pyarrow对字符串数据类型的实现非常高效:
比较字符串操作:展示 arrow 实现的效率。代码片段由作者提供。
事实上,Arrow 支持的数据类型比numpy更多(且支持更好),这些类型在科学(数值)范围之外是必需的:日期和时间、持续时间、二进制、十进制、列表和映射。浏览一下pyarrow 支持的数据类型与numpy的等效性可能是一个很好的练习,特别是如果你想学习如何利用它们。
现在也可以在索引中保存更多的 numpy 数值类型。传统的int64、uint64和float64为所有 numpy 数值数据类型的索引值腾出了空间,因此我们可以,例如,指定它们的 32 位版本:
利用 32 位的 numpy 索引,使代码更具内存效率。代码片段由作者提供。
这是一个受欢迎的变化,因为索引是pandas中最常用的功能之一,允许用户筛选、连接和打乱数据等操作。本质上,索引越轻量,这些过程就会越高效!
3. 更容易处理缺失值
基于numpy构建使得pandas在处理缺失值时显得困难且不够灵活,因为**numpy**不支持某些数据类型的空值。
例如,整数会自动转换为浮点数,这并不是理想的:
缺失值:转换为浮点数。代码片段由作者提供。
注意points在引入单个None值后如何自动从int64变为float64。
没有什么比错误的类型集合更糟糕的数据流,特别是在数据驱动的人工智能范式中。
错误的类型集合直接影响数据准备决策,导致不同数据块之间的不兼容,即使在静默传递时,它们也可能影响某些操作,使其返回无意义的结果。
举个例子,在数据驱动的 AI 社区中,我们目前正在进行一个关于数据隐私的合成数据的项目。一个特性NOC(子女数量)有缺失值,因此当数据加载时,它会自动转换为float。然后,当将数据作为float传入生成模型时,我们可能会得到像 2.5 这样的十进制输出值——除非你是一位有 2 个孩子、新生儿,且有奇怪幽默感的数学家,拥有 2.5 个孩子是不合适的。
在 pandas 2.0 中,我们可以利用 dtype = 'numpy_nullable',在不更改数据类型的情况下处理缺失值,因此我们可以保持原始数据类型(在此情况下为int64)。
利用‘numpy_nullable’,pandas 2.0 可以在不更改原始数据类型的情况下处理缺失值。片段由作者提供。
这可能看起来是一个微妙的变化,但在底层它意味着现在pandas可以原生使用 Arrow 处理缺失值的实现。这使得操作更高效,因为pandas不再需要为每种数据类型实现处理空值的版本。
4. 复制时写入优化
Pandas 2.0 还增加了一个新的延迟复制机制,该机制在修改 DataFrames 和 Series 对象之前延迟复制。
这意味着 某些方法 在启用复制时写入时将返回视图而非副本,这通过最小化不必要的数据复制提高了内存效率。
这也意味着在使用链式赋值时需要格外小心。
如果启用了复制时写入模式,链式赋值将不起作用,因为它们指向一个临时对象,这是索引操作的结果(在复制时写入下表现为副本)。
当copy_on_write被禁用时,像切片这样的操作 可能会更改原始数据框 df,如果新的数据框被更改:
禁用复制时写入:在链式赋值中原始数据框会被更改。片段由作者提供。
当copy_on_write被启用时,会在赋值时创建副本,因此原始数据框不会被更改。Pandas 2.0 在这些情况下会引发 ChainedAssignmentError 以避免静默错误:
启用复制时写入:在链式赋值中原始数据框不会被更改。片段由作者提供。
5. 可选依赖项
使用pip时,2.0 版本给予我们安装可选依赖项的灵活性,这在定制和优化资源方面是一个加分项。
我们可以根据具体要求定制安装,而无需在不需要的内容上浪费磁盘空间。
此外,它节省了许多“依赖性头痛”,减少了与开发环境中可能存在的其他包的兼容性问题或冲突的可能性:
安装可选依赖项。片段由作者提供。
来试试吧!
然而,问题仍然存在:这些噪音是否真的有意义?我很好奇pandas 2.0是否在我日常使用的一些包上提供了显著改进:ydata-profiling、matplotlib、seaborn、scikit-learn。
其中,我决定尝试一下 ydata-profiling — 它刚刚添加了对 pandas 2.0 的支持,这似乎是社区的必备!在新版本中,用户可以放心,如果他们使用 pandas 2.0,管道不会中断,这是一个很大的优点!那还会有什么其他的呢?
说实话,ydata-profiling 一直是我最喜欢的探索性数据分析工具之一,它也是一个很好的基准测试工具 —— 在我这只需一行代码,但在幕后却充满了作为数据科学家需要解决的计算 —— 描述性统计、直方图绘制、分析相关性,等等。
那么,有什么比用最小的努力测试pyarrow引擎对所有这些的影响更好的方法呢?
与 ydata-profiling 进行基准测试。作者提供的代码片段。
再次强调,使用pyarrow引擎读取数据无疑更好,尽管在创建数据分析报告的速度上变化不大。
然而,差异可能依赖于内存效率,对此我们需要进行不同的分析。此外,我们还可以进一步调查对数据进行的分析类型:对于某些操作,1.5.2 版本和 2.0 版本之间的差异似乎微不足道。
但我注意到的主要问题是 ydata-profiling 还没有利用pyarrow数据类型。这个更新可能对速度和内存有很大影响 ,这是我在未来发展中期待的!
结论:性能、灵活性、互操作性!
这个新的pandas 2.0版本带来了许多灵活性和性能优化,包括“引擎盖下”细微但至关重要的修改。
也许对于数据处理领域的新手来说,这些功能并不“引人注目”,但对于那些曾经为了克服之前版本限制而不得不费尽周折的资深数据科学家们来说,这些功能无疑就像沙漠中的水源一样宝贵。
总结一下,这些是新版本中引入的主要优势:
-
性能优化: 引入了 Apache Arrow 后端、更多的 numpy dtype 索引和写时复制模式;
-
额外的灵活性和定制化: 允许用户控制可选依赖项,并利用 Apache Arrow 数据类型(包括从一开始就支持的可空性!)。
-
互操作性: 也许这是新版本一个较少被“赞誉”的优势,但影响巨大。由于 Arrow 是语言独立的,内存中的数据可以在使用 Apache Arrow 后端构建的程序之间进行传输,不仅限于 Python,还包括 R、Spark 等!
那么,这就是了,各位! 我希望这次总结能解答一些关于pandas 2.0及其在我们数据处理任务中的适用性的问题。
我仍然好奇你们是否在日常编码中发现了pandas 2.0带来的主要变化!如果你愿意,来数据驱动 AI 社区找我,告诉我你的想法!在那里见?
关于我
博士,机器学习研究员,教育者,数据倡导者,以及全面的“万事通”。在 Medium 上,我写关于数据驱动 AI 和数据质量的内容,教育数据科学与机器学习社区如何从不完善的数据转向智能数据。
数据驱动 AI 社区 | GitHub | Google Scholar | LinkedIn
Pandas: apply、map 还是 transform?
Pandas 最通用函数的指南


·
关注 发布于 Towards Data Science ·9 分钟阅读·2023 年 1 月 31 日
–

照片由Sid Balachandran提供,发布在Unsplash
作为一个使用 Pandas 多年的用户,我注意到许多人(包括我自己)经常几乎总是使用**apply**函数。虽然在较小的数据集上这不是问题,但在处理大量数据时,这种做法引起的性能问题会变得更加明显。虽然**apply**的灵活性使其成为一个简单的选择,但这篇文章介绍了其他 Pandas 函数作为潜在的替代方案。
在这篇文章中,我们将探讨**apply**、**agg**、**map**和**transform**的使用方式,并提供一些示例。
内容目录
* map
* transform
* agg
* apply
* Unexpected behavior
示例
让我们以一个数据框为例,该数据框包含三名学生在两门科目中的分数。我们将在接下来的工作中使用这个示例。
df_english = pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
"gender": ["male", "male", "female"],
"score": [20, 30, 30],
"subject": "english"
}
)
df_math = pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
"gender": ["male", "male", "female"],
"score": [90, 100, 95],
"subject": "math"
}
)
现在我们将这些数据合并成一个单一的数据框。
df = pd.concat(
[df_english, df_math],
ignore_index=True
)
我们最终的数据框看起来是这样的:
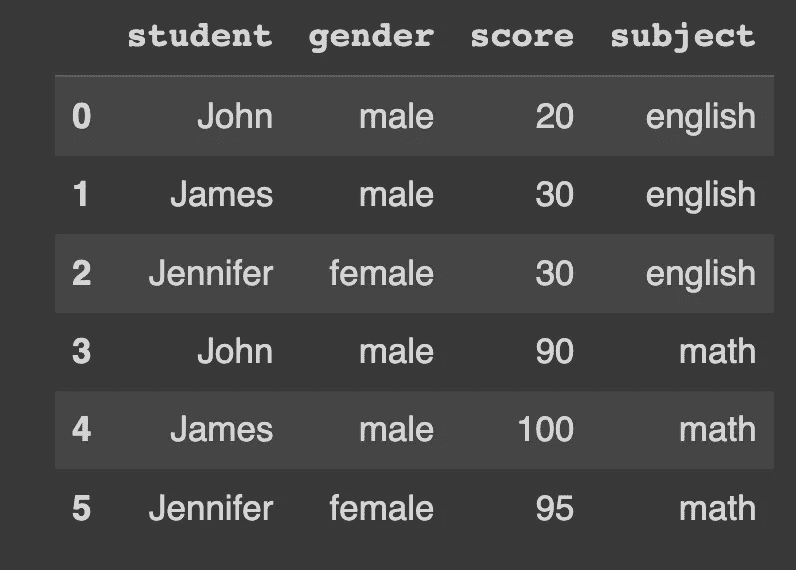
示例数据框
我们将使用这个数据集来探索每个函数的使用。
map
Series.map(arg, na_action=None) -> Series
**map**方法作用于Series,并根据传递给函数的arg来映射每个值。arg可以是一个函数——就像apply可以接受的那样——但它也可以是字典或系列。
na_action本质上让你决定如果系列中存在NaN值会发生什么。当设置为"ignore"时,arg不会应用于NaN值。
例如,如果你想用映射替换系列中的分类值,你可以这样做:
GENDER_ENCODING = {
"male": 0,
"female": 1
}
df["gender"].map(GENDER_ENCODING)
输出符合预期:它返回与我们原始系列中的每个元素对应的映射值。

map 的输出
尽管**apply**不接受字典,但仍然可以实现这种功能,但效率和优雅程度远不如前者。
df["gender"].apply(lambda x:
GENDER_ENCODING.get(x, np.nan)
)
apply的输出与map的输出相同
性能
在对包含百万条记录的性别系列进行编码的简单测试中,**map**比**apply**快了 10 倍。
random_gender_series = pd.Series([
random.choice(["male", "female"]) for _ in range(1_000_000)
])
random_gender_series.value_counts()
"""
>>>
female 500094
male 499906
dtype: int64
"""
"""
map performance
"""
%%timeit
random_gender_series.map(GENDER_ENCODING)
# 41.4 ms ± 4.24 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
apply performance
"""
%%timeit
random_gender_series.apply(lambda x:
GENDER_ENCODING.get(x, np.nan)
)
# 417 ms ± 5.32 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
由于**map**也可以接受函数,因此任何不依赖于其他元素的转换——例如不像均值这样的聚合——都可以传递。
使用map(len)或map(upper)等方法可以使预处理变得更加容易。
让我们将这个性别编码结果分配回数据框,并继续探讨**applymap**。
df["gender"] = df["gender"].map(GENDER_ENCODING)
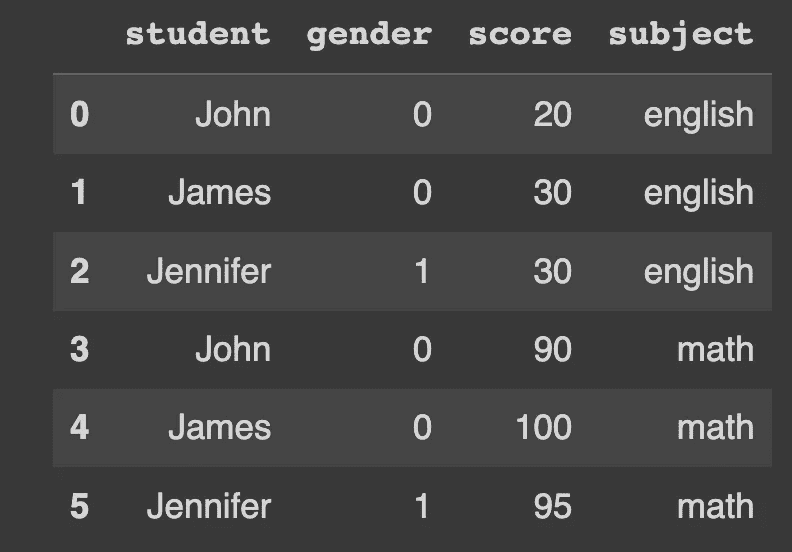
使用 map 编码性别
applymap
**DataFrame.applymap(*func*, *na_action=None*, ***kwargs*) -> DataFrame**
我不会花太多时间在**applymap**上,因为它与**map**非常相似,并且内部实现使用了**apply**。**applymap**在数据框上按元素级别工作,就像**map**一样,但由于它是通过**apply**内部实现的,因此不能接受字典或系列作为输入——仅允许使用函数。
try:
df.applymap(dict())
except TypeError as e:
print("Only callables are valid! Error:", e)
"""
Only callables are valid! Error: the first argument must be callable
"""
na_action的工作方式与**map**中的相同。
transform
DataFrame.transform(func, axis=0, *args, **kwargs) -> DataFrame
虽然之前的两个函数在元素级别工作,但transform在列级别工作。这意味着你可以在**transform**中使用聚合逻辑。
让我们继续使用之前的数据框。
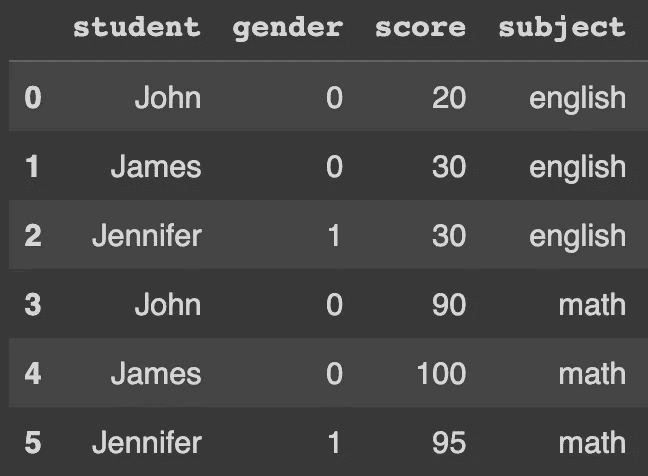
我们的示例,带有编码后的性别
假设我们想要标准化数据。我们可以做如下操作:
df.groupby("subject")["score"] \
.transform(
lambda x: (x - x.mean()) / x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
"""
我们本质上是在从每个组中提取分数系列,并用其标准化值替换每个元素。这是不能通过**map**完成的,因为它需要按列计算,而map仅在元素级别工作。
如果你熟悉**apply**,你会知道这种行为也可以通过它来实现。
df.groupby("subject")["score"] \
.apply(
lambda x: (x - x.mean()) / x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
"""
我们得到的结果基本相同。那么使用 **transform** 的意义何在?
**transform**必须返回一个在应用轴上长度相同的数据框。
记住 **transform** 必须返回一个在其应用轴上长度相同的数据框。这意味着即使 **transform** 与返回聚合值的 groupby 操作一起使用,它也会将这些聚合值分配给每个元素。
例如,假设我们想知道每个学科所有学生分数的总和。我们可以这样用 apply 来做到这一点:
df.groupby("subject")["score"] \
.apply(
sum
)
"""
subject
english 80
math 285
Name: score, dtype: int64
"""
但是在这里,我们通过学科聚合了分数,失去了关于各个学生及其分数关系的信息。如果我们尝试用 **transform** 做同样的事情,我们会得到更有趣的结果:
df.groupby("subject")["score"] \
.transform(
sum
)
"""
0 80
1 80
2 80
3 285
4 285
5 285
Name: score, dtype: int64
"""
尽管我们在组级别工作,但我们仍能跟踪组级信息与行级信息之间的关系。
由于这种行为,**transform** 如果你的逻辑没有返回一个变换后的系列,将会抛出 ValueError。因此,任何类型的聚合都不会有效。然而,**apply** 的灵活性确保了即使在进行聚合时也能正常工作,正如我们将在下一节中详细探讨的那样。
try:
df["score"].transform("mean")
except ValueError as e:
print("Aggregation doesn't work with transform. Error:", e)
"""
Aggregation doesn't work with transform. Error: Function did not transform
"""
df["score"].apply("mean")
"""
60.833333333333336
"""
性能
就性能而言,从 **apply** 切换到 **transform** 的速度提高了 2 倍。
random_score_df = pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})
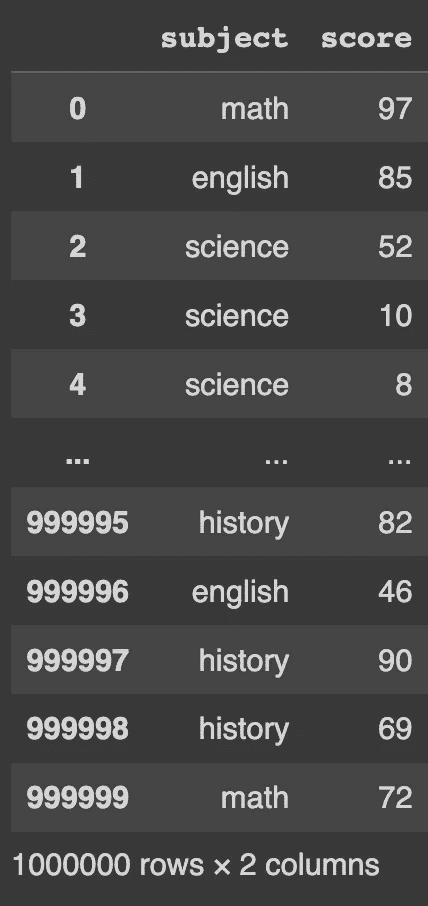
用于测试 **transform** 性能的 1M 行数据框
"""
Transform Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.transform(
lambda x: (x - x.mean()) / x.std()
)
"""
202 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
"""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.apply(
lambda x: (x - x.mean()) / x.std()
)
"""
401 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
agg
DataFrame.agg(func=None, axis=0, *args, **kwargs)
-> scalar | pd.Series | pd.DataFrame
**agg** 函数更容易理解,因为它只是返回对传递给它的数据进行的聚合。因此,无论你的自定义聚合器是如何实现的,结果将是传递给它的每一列的单个值。
我们现在来看一个简单的聚合——计算每个组在 score 列上的均值。注意我们可以传递位置参数给 **agg** 以直接命名聚合结果。
df.groupby("subject")["score"].agg(mean_score="mean").round(2)
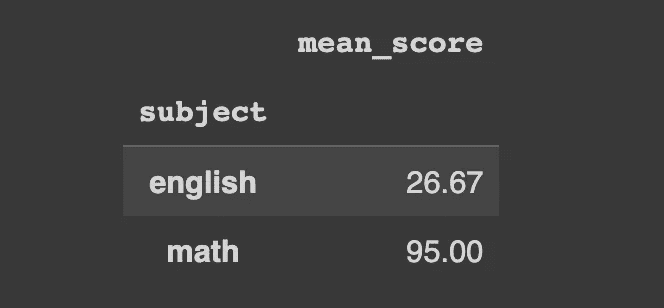
使用 agg 按学科计算的均值
可以将多个聚合器作为列表传递。
df.groupby("subject")["score"].agg(
["min", "mean", "max"]
).round(2)
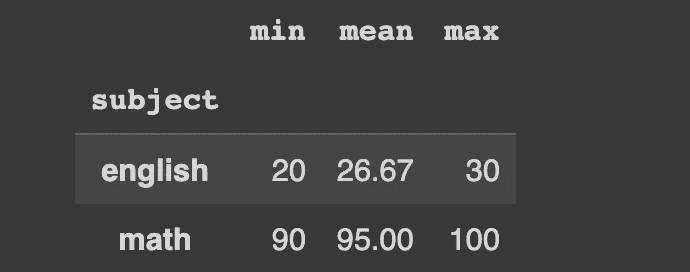
使用 apply 按学科计算的均值——与我们之前的结果相同。
**agg** 提供了更多的聚合选项。在前两个示例中,我们看到它允许你在列表中执行多个聚合,甚至进行命名聚合。你还可以构建自定义聚合器以及对每列进行多个特定聚合,比如对一列计算均值,对另一列计算中位数。
性能
就性能而言,**agg** 比 **apply** 稍快,至少在简单聚合的情况下是这样。让我们重新创建之前性能测试中相同的数据框。
random_score_df = pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})
用于性能测试的相同数据框
"""
Agg Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].agg("mean")
"""
74.2 ms ± 5.02 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
"""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(lambda x: x.mean())
"""
102.3 ms ± 1.16 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
使用 **agg** 比 **apply** 提高了大约 30% 的性能。在进行多次聚合测试时,我们得到了类似的结果。
"""
Multiple Aggregators Performance Test with agg
"""
%%timeit
random_score_df.groupby("subject")["score"].agg(
["min", "mean", "max"]
)
"""
90.5 ms ± 16.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
"""
Multiple Aggregators Performance Test with apply
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(
lambda x: pd.Series(
{"min": x.min(), "mean": x.mean(), "max": x.max()}
)
).unstack()
"""
104 ms ± 5.78 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
apply
对我来说,这是我们讨论过的最令人困惑的一个,主要是由于它的灵活性。我们刚才看到的每一个例子都可以用**apply** 复制**。**
当然,这种灵活性是有代价的:正如我们的性能测试所示,它明显较慢。

性能测试:apply函数明显较慢,这是可以理解的。
意外的行为
**apply** 灵活性带来的另一个问题是结果有时会令人惊讶。
处理第一个组两次
一个已经解决的问题是关于某些性能优化的:**apply** 会将第一个组处理两次。第一次,它会查找优化,然后处理每个组,因此会将第一个组处理两次。
我最初在调试我编写的自定义 apply 函数时注意到这一点:当我打印出组的信息时,第一个组被显示了两次。如果存在副作用,这种行为会导致静默错误,因为任何更新都会在第一个组上发生两次。
当只有一个组时
这个问题自 2014 年起就困扰着 pandas。当整个列中只有一个组时,即使**apply**函数期望返回一个系列,它最终却会产生一个数据框。
结果类似于额外的堆叠操作。让我们尝试重现它。我们将使用原始数据框,并添加一个city列。假设我们所有的三位学生,John、James 和 Jennifer 都来自波士顿。
df_single_group = df.copy()
df_single_group["city"] = "Boston"
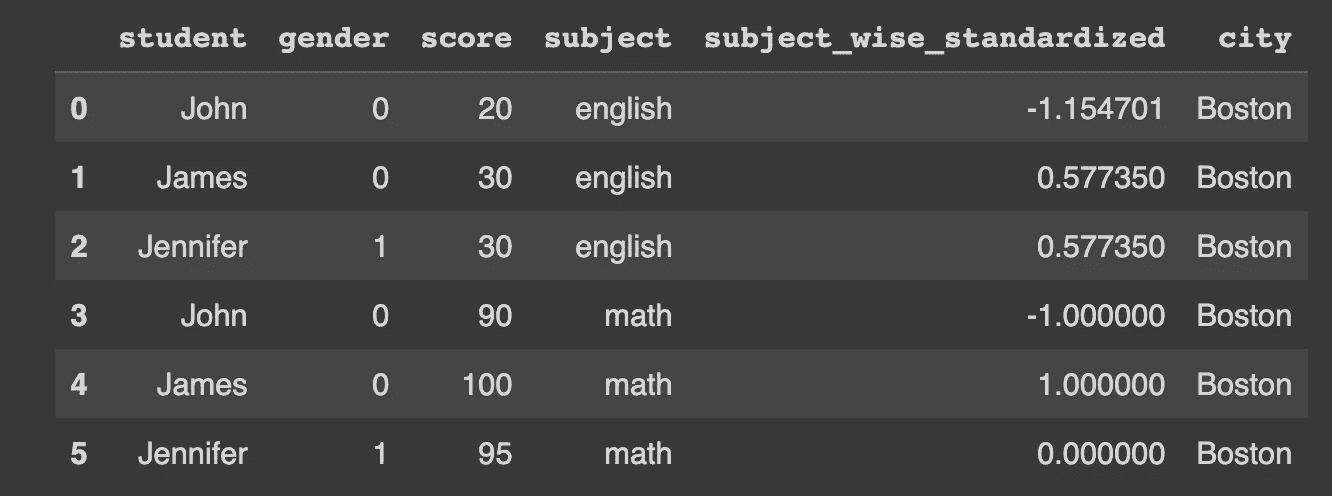
我们的数据框增加了“city”列
现在,让我们计算两组的组均值:一组基于 subject 列,另一组基于 city。
在 subject 列上分组时,我们得到了一个多索引系列,这是我们预期的。
df_single_group.groupby("subject").apply(lambda x: x["score"])
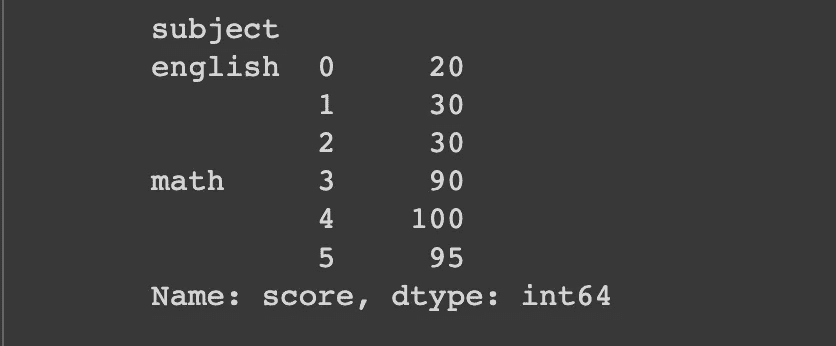
apply 在有多个组时返回一个多索引系列
但是当我们按city列分组时,正如我们所知,这只有一个组(对应于“Boston”),我们得到的是:
df_single_group.groupby("city").apply(lambda x: x["score"])
apply 在只有一个组时返回一个未堆叠的数据框
注意结果如何被透视?如果我们**stack** 这个,我们将得到预期的结果。
df_single_group.groupby("city").apply(lambda x: x["score"]).stack()
堆叠我们之前的结果会得到预期的结果
截至本文撰写时,这个问题仍未修复。
代码
你可以在这里找到完整的代码以及性能测试。
[## BlogCode/PandasApply 在 main · Polaris000/BlogCode]
这是我博客文章《Pandas:apply、map 还是 transform?》中使用的示例代码。博客文章讨论了 Pandas 的…
结论
**apply** 提供的灵活性使它在大多数场景中非常方便选择,但正如我们所见,使用专门为实现你的需求设计的工具通常更为高效。本文仅覆盖了 **apply** 部分内容,这个函数还有很多其他功能。未来的文章将从这里继续。
这篇文章应该给你提供了有关 Pandas 的可能性的一个概念,我希望这能鼓励你充分利用它的功能。

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









