







调情——贝叶斯统计中的一个练习
求爱的仪式既多又奇怪。对一点都不好笑的事情的假笑。一缕头发。一句老套的搭讪台词。
这一切意味着什么?
答案就在贝叶斯统计中,因为调情可以被视为一种观察,然后相应地更新先前信念的练习。调情的核心是两件事:
1)试图通过观察某人在你身边时的行为/信号来判断他是否喜欢你(或者他们是否会成为一个好伴侣)。
2)向其他人发出信号,希望他们能够理解并得出你希望他们得出的结论(你对他们感兴趣,或者你会成为一个很好的合作伙伴)。
让我们借助贝叶斯定理,以一种更正式的方式来分解它。下面是:

The foundational theorem guiding this essay (Source: Towards Data Science)
这是什么意思?我们来分解一下。让我们看看方程中的两个变量——θ和数据。我们可以把θ看作一个结果。我们从 P(θ)开始,我们称之为先验,P(θ)的含义非常简单——它是我们认为我们的结果实际发生的概率。这里有一个真实的例子来说明。假设θ是抛硬币正面朝上的结果。假设我们的先验信念——我们在观察到任何数据之前开始相信的东西——是 50%。这意味着我们的先验信念是,掷硬币的结果是正面的概率等于 50%。P(θ)= P(抛硬币的结果=正面)= 50%。先验本质上可以是任何东西——它是你开始相信的任何东西。在这种情况下,我的生活经验和常识使我认为 P(θ)= 50%是合理的*先验,*我希望你同意。
现在我们已经有了初始信念 P(θ)set,让我们引入等式的下一部分 P(data |θ)。如果我们假设θ的先验分布为真,这就是观察到某些结果/数据的可能性。所以我们有了先验P(θ)= 50%。P(data |θ)是说,给定一个硬币是公平的(正面的结果是 50%),观察到一些数据的概率是 P(data |θ)。这些数据就是我们实际看到的东西——例如,如果我们观察到 30 次抛硬币,30 次正面朝上,那么 P(data |θ)= P(30 次抛 30 次正面朝上|θ= 0.5)→**如果硬币真的是公平的,那么我们在 30 次抛中得到 30 次正面朝上的可能性有多大?**观测数据出现在之前的可能性有多大?很明显,如果硬币真的是公平的,30 次投掷中 30 次正面朝上的可能性是非常低的。P(数据|θ)= P(30 次投掷 30 个头|θ= 0.5)几乎为 0。
综上所述,P(θ| data)是我们观察证据后的后验信念。这可以被视为根据我们在数据中观察到的情况更新我们的先验信念**。在这个例子的上下文中,这基本上意味着我们正在更新我们的先验信念,即硬币是公平的,到新的后验信念,即硬币倾向于正面。这只是常识——我们开始认为硬币是公平的,然后我们看到它在 30 次投掷中出现了 30 次正面,然后现在我们认为硬币没有我们最初认为的公平,而是更偏向正面。显然,从我们刚刚遵循的逻辑序列中,我们看到后验与*先验乘以从该先验产生的数据的可能性成比例。数学上,P(θ|数据)αP(θ) P(数据|θ)。

Fair or not? Observe data and use Bayes’ Rule to find out (Source: Public Domain)
很好,现在我们明白了贝叶斯法则。如果你想一想,我们实际上一直在我们的思维过程中实施贝叶斯法则。如果我们认为某件事是真的,然后我们看到影响先前信念的数据,我们会以某种方式改变我们最初的信念。如果我认为鲍勃是一个吝啬的人,然后我看到他在街上给乞丐钱,我会将我最初认为他吝啬的信念修正为一个新的信念,即他并不像我曾经认为的那样吝啬——因为如果我先前认为他吝啬的信念是真的,鲍勃给乞丐钱的可能性很低,这使得后来的信念更接近于鲍勃没有以前那么吝啬。每次你因为新的证据而改变主意时,你都在使用贝叶斯法则。
那么这和调情有什么关系呢?你现在可能已经猜到了。调情是贝叶斯法则的高风险、情绪化的表现。有几种方法可以考虑这个问题。
第一:你想弄清楚你的爱人是否也喜欢你。你一开始对之前的相对不了解,只是随意猜测他们是否喜欢你。可能你第一印象不好,你把先验设在 P(他们喜欢我)= 25%。这是一种不确定的方式,让你的品味去表达你的爱。你想先了解更多信息。
所以你们一起出去玩的时间越多,你们约会的时间越长,你们见面的次数越多,在每一种情况下,你们都在收集数据。也许他们紧紧地拥抱你——如果他们有 25%的机会喜欢你,这种情况发生的概率相当低——也许你一开始低估了自己,现在你将 25%的先验更新为 27%的后验。也许你碰了它们,它们本能地厌恶地退缩了→更新之前的并减少到 5%。我们继续前进。

This guy will update his prior belief on whether the woman likes him after he sees how she reacts to this touch (Source: Public Domain)
你正在收集所有这些数据,观察它们的每一个动作,并把它们代入贝叶斯法则,希望你能向上更新你的先验*。也许有一天你觉得你已经收集了足够多的数据,并说是的,他们喜欢你的概率其实真的很高——是时候表白了!或者有一天你得出结论,他们喜欢你的可能性非常低,现在你知道你应该放弃,继续前进。*
不管怎样,每次约会,你都在无意识地使用贝叶斯推理。对方也是。他们以完全相同的方式评价你和你的行为。你想引导他们走向正确的方向,帮助他们准确地更新他们的先验*——所以你轻拂你的头发,触摸他们的前臂,等等。或者,如果你不感兴趣,你会冷淡他们,取消约会,等等。让他们更接近你希望他们得出的结论。*
第二:同样的贝叶斯计算可以用于调情的另一个目的——评估潜在伴侣的质量或表明自己的质量。当你看到他们给服务生的小费很高时,你会修改之前的来反映这些数据——你的信念会更新,认为他们比你最初认为的更好。反之亦然,如果你的约会对象因为服务生晚了两分钟才把菜端上来而对他大喊大叫。**
有了这些知识,我们现在可以看到调情的关键。它们如下:
1)你需要收集数据。这是获得更多信息的唯一途径。所以去和你喜欢的人互动吧!
2)你的成功取决于你估算/计算 P(data |θ)项的能力有多强——你需要弄清楚,如果有人喜欢你,他们会如何行动,以及你的观察与这种预期有多大差异。
a.为了帮助计算,请你的朋友分析一下情况。当我们向朋友寻求建议时,我们所做的只是细化我们对 P(data |θ)的计算!
3)相应地更新后验。希望数据显示他们比你想象的更喜欢你!
希望这是有帮助的——带上贝叶斯法则,祝你的浪漫事业好运。
蜂拥而至
如何使用 Go 在你的终端上创建一个群集模拟
我写植绒模拟已经很久了。我用 Java 尝试过,但我仍有记录的最早版本是用 JRuby 和 Swing 开发的,名为 Utopia 。我用鞋写了一个,那是我的 用 R 和 Ruby 探索日常事物书中的那个。过了一段时间,(总体来说,我对鞋子不太满意),我用 2D 的一个 Ruby 和 C++游戏开发库 Gosu 重新写了一遍。这个版本可以在这里找到。
群集模拟基本上是一个模拟鸟类群集行为的软件程序。这种群集行为与昆虫的群集行为或鱼类的群集行为非常相似。这被认为是一种紧急行为——一种源于个体遵循简单规则的行为,不涉及任何中央协调。这种行为,尤其是在椋鸟或成群梭鱼的低语中看到的,可能是一种令人惊叹的现象。

Photo by James Wainscoat on Unsplash
Boids
群集最早是由程序员 Craig Reynolds 用软件模拟的,他开发了一个名为 boids 的软件程序,并于 1987 年在 ACM SIGGRAPH conference 上发表了一篇关于该主题的论文。从那以后,在模拟群集方面有了很多进步,但是基本思想仍然很简单。
Boids 本身使用三个基本规则来描述单个 boid 如何移动:
- 分离——避免拥挤附近的其他蜂群
- 对齐——向附近队友的平均方向移动
- 凝聚力——向附近队友的平均位置移动



这些规则得到了扩展,在某些情况下,添加了更多的规则,但基本思想是,个人遵循一些简单规则的局部反应可能会导致复杂的、意想不到的行为。
在围棋中做
虽然我已经认真地用 Go 编程几年了(它现在是我的主要编程语言),但我一直没有找到用 Go 编写群集模拟的好方法。最大的问题是,Go 主要是一种后端编程语言,并没有真正的 GUI 工具包。虽然有一些尝试,包括绑定到 GTK 和 QT,但没有一个符合我的要求。如果你正在寻找一个桌面应用程序,你可能会更好地使用 Electron 并在 Go 中构建一个 web 应用程序来支持它。
也就是说,直到我在我的帖子中摆弄遗传算法。在那篇文章中,我试图向终端显示一个图像,在我的例子中,是优秀的 iTerm2 。这就是我在 iTerm2 上偶然发现这个允许我在屏幕上显示图像的黑客的地方。
当然,如果我可以显示一个图像,我就可以显示多个图像。如果我可以显示多幅图像,我也可以将它们一幅接一幅地重叠显示。如果我能足够快地展示它们…
How to make a flip book (credits: Andymation https://www.youtube.com/watch?v=Un-BdBSOGKY)
黄金
当然,我称它们为黄金。一个Goid是一个简单的结构,带有位置、速度和颜色的信息。
*type Goid struct {
X int // position
Y int
Vx int // velocity
Vy int
R int // radius
Color color.Color
}*
位置和颜色很容易理解。这里的速度不仅仅是金子移动的速度,也是它移动的方向。在这种情况下,Vx和Vy是高尔夫球在下一个循环中将要离开的距离,也是它将要去的方向。从数学上来说,X和Y是标量位置(它告诉你在 2D 平面上离原点有多远),而Vx和Vy是 矢量 。
创建 goids 相对简单。每个 goid 必须在窗口内,并且它的起始速度小于它的大小。
*func createRandomGoid() (g Goid) {
g = Goid{
X: rand.Intn(windowWidth),
Y: rand.Intn(windowHeight),
Vx: rand.Intn(goidSize),
Vy: rand.Intn(goidSize),
R: goidSize,
Color: goidColor,
}
return
}*
大部分工作都在move函数中。
*// move the goids with the 3 classic boid rules
func move(goids []*Goid) {
for _, goid := range goids {
neighbours := goid.nearestNeighbours(goids)
separate(goid, neighbours)
align(goid, neighbours)
cohere(goid, neighbours) stayInWindow(goid)
}
}*
自 30 年前以来,群集模拟已经有了相当大的进步,但是对于这个简单的模拟,我使用了 boids 的 3 个经典规则。这三条规则都要求 goid 知道谁是它的邻居,所以首先弄清楚这一点是有意义的。
*// find the nearest neighbours
func (g *Goid) nearestNeighbours(goids []*Goid) (neighbours []Goid) {
neighbours = make([]Goid, len(goids))
for _, goid := range goids {
neighbours = append(neighbours, *goid)
}
sort.SliceStable(neighbours, func(i, j int) bool {
return g.distance(neighbours[i]) < g.distance(neighbours[j])
})
return
}// distance between 2 goids
func (g *Goid) distance(n Goid) float64 {
x := g.X - n.X
y := g.Y - n.Y
return math.Sqrt(float64(x*x + y*y))}*
首先,我们克隆整个 goid 群体,然后我们使用sort.SliceStable按照与所讨论的 goid 的距离对克隆的数组进行排序。找到距离只是一个使用毕达哥拉斯定理的问题。

这给了我们一个相邻高尔夫球的列表,按距离排序。让我们看看第一条规则。
分离规则
这就是个人空间法则。比方说,你和许多其他通勤者在一列火车上,它停在一个有许多人上车的车站。当他们进来的时候,他们会填满空间,会有一些人最终离你太近。你会怎么做?你会离开他们一点,但不会离其他人太近,最终会和其他人保持一个舒适的距离。这是规则。
*// steer to avoid crowding local goids
func separate(g *Goid, neighbours []Goid) {
x, y := 0, 0
for _, n := range neighbours[0:numNeighbours] {
if g.distance(n) < separationFactor {
x += g.X - n.X
y += g.Y - n.Y
}
}
g.Vx = x
g.Vy = y
g.X += x
g.Y += y
}*
我们只对有限数量的相邻 goids 感兴趣,这由参数numNeighbours指定。相邻的高尔夫球场也必须在参数separationFactor内(不是所有相邻的高尔夫球场都足够近,不会让人不舒服)。一旦这些金球进入那个空间,我们就远离它们。然后我们把速度更新到那个距离,然后用那个速度移动高尔夫球。
对齐规则
这就是同辈压力法则。同辈压力是同辈人对人们施加的直接影响,使他们改变行为以符合群体的要求。你可能对同辈压力很熟悉——当你看到你的邻居拥有闪亮的新 4K 电视或 iPhone X 时,你可能也会想给自己买一台。在我们的生活中,还有很多其他不需要进一步解释的同伴压力的例子,而这正是对齐规则。
*// steer towards the average heading of local goids
func align(g *Goid, neighbours []Goid) {
x, y := 0, 0
for _, n := range neighbours[0:numNeighbours] {
x += n.Vx
y += n.Vy
}
dx, dy := x/numNeighbours, y/numNeighbours
g.Vx += dx
g.Vy += dy
g.X += dx
g.Y += dy
}*
和以前一样,我们只对由numNeighbours指定的有限数量的相邻 goids 感兴趣。然而,这条规则并不影响高尔夫球的位置,而是改变高尔夫球的速度,我们将所有相邻高尔夫球的速度相加,然后除以相邻高尔夫球的数量。最终值会修改速度,而不是完全替换它,同时新值会修改 goid 的位置。
内聚规则
这就是方阵法则。希腊方阵是一个矩形的、紧密排列的步兵编队,作为一个整体行进和战斗。这是古代战争中最有效和持久的军事编队之一。它的效力在于密不透风的盾牌和长矛组成的紧密队形,缓慢地向前推进,突破敌人的行列。罗马人后来采取了同样的想法,创建了三线罗马军团,用于征服已知世界。
*// steer to move toward the average position of local goids
func cohere(g *Goid, neighbours []Goid) {
x, y := 0, 0
for _, n := range neighbours[0:numNeighbours] {
x += n.X
y += n.Y
}
dx, dy := ((x/numNeighbours)-g.X)/coherenceFactor, ((y/numNeighbours)-g.Y)/coherenceFactor
g.Vx += dx
g.Vy += dy
g.X += dx
g.Y += dy
}*
和其他规则一样,我们只对邻近的金子感兴趣。我们取所有这些邻居的平均位置(将所有邻居的位置相加,然后除以邻居的数量),并从中减去 goid 的位置。然后将这个值除以一个coherenceFactor,这个值决定了 goids 希望与其邻居保持一致的程度。如果coherenceFactor太高,高尔夫球将不会移动,如果太低,高尔夫球将会彼此贴得太近,形成紧密结合的高尔夫球簇。
呆在视野之内
现在我们有了规则,我们可以运行模拟,但由于我们的视图仅限于参数windowWidth和windowHeight,一旦黄金离开屏幕,我们就再也看不到它了。也就是说过一段时间,就只是一个空屏幕了。为了防止这种情况发生,如果一个黄金离开了屏幕,我们会神奇地把它转移到窗口的另一边。
*// if goid goes out of the window frame it comes back on the other side
func stayInWindow(goid *Goid) {
if goid.X < 0 {
goid.X = windowWidth + goid.X
} else if goid.X > windowWidth {
goid.X = windowWidth - goid.X
}
if goid.Y < 0 {
goid.Y = windowHeight + goid.Y
} else if goid.Y > windowHeight {
goid.Y = windowHeight - goid.Y
}
}*
显示框架
拼图的最后一块是画出金子本身。
*// draw the goids
func draw(goids []*Goid) *image.RGBA {
dest := image.NewRGBA(image.Rect(0, 0, windowWidth, windowHeight))
gc := draw2dimg.NewGraphicContext(dest)
for _, goid := range goids {
gc.SetFillColor(goid.Color)
gc.MoveTo(float64(goid.X), float64(goid.Y))
gc.ArcTo(float64(goid.X), float64(goid.Y), float64(goid.R), float64(goid.R), 0, -math.Pi*2)
gc.LineTo(float64(goid.X-goid.Vx), float64(goid.Y-goid.Vy))
gc.Close()
gc.Fill()
}
return dest
}*
每一帧都是宽windowWidth高windowHeight的图像。在这个框架中,我们将每个 goid 绘制为一个圆,然后我们绘制一条线来表示 goid 的尾巴。这条线与高尔夫球前进的方向相反,所以我们从高尔夫球的速度中减去它的位置。
显示模拟
我们现在已经有了所有需要的函数,所以让我们把它们放在main函数中。
*func main() {
clearScreen()
hideCursor() goids := make([]*Goid, 0)
for i := 0; i < populationSize; i++ {
g := createRandomGoid()
goids = append(goids, &g)
} for i := 0; i < loops; i++ {
move(goids)
frame := draw(goids)
printImage(frame.SubImage(frame.Rect))
fmt.Printf("\nLoop: %d", i) }
showCursor()
}*
还有几个你以前没见过的功能。什么是clearScreen、hideCursor、showCursor、printImage?这些是实际显示模拟的函数。
再来看clearScreen、hideCursor和showCursor。
*func hideCursor() {
fmt.Print("\x1b[?25l")
}func showCursor() {
fmt.Print("\x1b[?25h\n")
}func clearScreen() {
fmt.Print("\x1b[2J")
}*
那么我们用了哪些奇怪的转义序列呢?这些是 ANSI 转义序列,用于控制文本终端上的各种选项。它们大多是过去的遗留物,但仍在 iTerm2 等终端仿真器中广泛实现。所有序列都以ESC (27 或十六进制 0x1B)开头,后面是提供控制选项的第二个字节。特别是,ESC后跟[表示下一个字节是控制序列引入器(CSI),它是一组有用的序列。例如,?25h显示光标,?25l隐藏光标。您可能已经猜到了,2J清除整个屏幕并将光标移到屏幕的左上角。
让我们看看如何将图像打印到屏幕上。
*// this only works for iTerm!
func printImage(img image.Image) {
var buf bytes.Buffer
png.Encode(&buf, img)
imgBase64Str := base64.StdEncoding.EncodeToString(buf.Bytes())
fmt.Printf("\x1b[2;0H\x1b]1337;File=inline=1:%s\a", imgBase64Str)
}*
这是一个有趣的黑客行为,只在 iTerm2 中发现(据我所知)。这允许您获取二进制图像的 base64 表示,并在终端上内联打印出来。在行首的转义序列2;0H是一个 CSI,它将光标移动到第 2 行第 0 列,在那里我们要打印图像。
最终模拟
这是我运行它时的样子。

密码
这里找到的所有代码都可以在http://github.com/sausheong/goids找到。
我为什么要这么做?
群集模拟已经被做得死去活来,但是我喜欢写它。看到这些小家伙不是作为个体,而是作为一个有自己思想的群体四处活动,有一种禅意。在学习了群集和编写群集模拟之后,我开始做更多的模拟,将来我可能会写更多。
弗洛卡:监督学习,变得简单
机器学习模型的众包训练

图像识别是一个极其复杂的过程。这一过程中最困难的部分之一是获取数据并将其准确分类。在徒劳地寻找一种更实用的分类方法来节省时间和资源之后,我们开发了自己的解决方案。进来吧,弗洛卡,一个机器人。
Flokka 在今年的 Myriad Festival 上进行了尝试和测试,旨在众包一个简单图像识别模型的分类和训练。使用 Flokka slackbot,用户能够快速地将无序文件夹或列表中的文件排序为有序的文件结构——非常适合训练机器学习模型。
slackbot 是 Slack 平台独有的一种程序,它允许用户通过 Slack 聊天室与程序的界面进行交互。这可以通过自然语言来完成,例如“请为我获取最近 24 小时的最新头条”,或者通过命令来完成:“/获取新闻 10”。这有助于那些不知道如何使用某些程序/编程接口的用户轻松地使用它们。
我们选择开发 Flokka 作为 Slackbot,是因为 Slack 在 Max Kelsen 团队中扮演着不可或缺的角色。Slack 的多平台特性让我们可以随时随地轻松的对图像进行分类;在其他项目的短暂休息期间,甚至是在喝我们早晨的咖啡时。在办公室中,这种可访问性有助于简化图像分类过程,消除了数小时手动分类的需要。

弗洛卡是如何建成的? Flokka 是使用 SlackClient Python API(特别是 Events API)创建斜杠命令和处理交互消息而构建的。
使用/classify [number]命令,slackbot 从 training 文件夹中取出[number]张图像,并在指定的 Slack 通道中显示它们。显示后,用户可以使用每个图像下方的按钮输入选择适当的分类。然后,图像被分类到适当的文件结构中,以备在机器学习模型中使用。Flokka 为人们省去了将图像拖到桌面文件夹中的繁琐任务,并创建了一个更具吸引力和乐趣的整体过程。即使随着 slackbot 的发展,类别和图像变得更加复杂,一点一点分类的能力应该会提高执行任务的个人的准确性。
在接下来的几周里,我将会写一篇关于 Flokka 的更具技术性的文章。

测试模型
Myriad 是一个为期三天的技术和创新节,于 3 月 29 日至 31 日在布里斯班发电站举行。该活动鼓励企业家、投资者、企业主和技术爱好者之间的合作和交流。此外,Myriad 为我们提供了展示 Flokka 的机会,并让志同道合的人了解和测试 slackbot。我们邀请与会者帮助我们给未分类的四种珍奇动物贴上标签;一只熊,一只虎鲸,一只老虎和一只巨嘴鸟。这种标记的结果然后将被用作训练集来构建图像分类模型。

每只动物的图片都是从 http://www.image-net.org/的和 T4 的中挑选出来的,放在亚马逊 s3 的一个训练文件夹中。该文件夹中的图片用于分类过程的众包。与会者被邀请参观 Max Kelsen 展台,并一次对多达 20 幅图像进行分类。
在两次会议的过程中,2000 张图片被分为:712 只熊,790 只巨嘴鸟,154 只老虎和 286 只虎鲸。此外,58 张图片包含不相关的动物。

一旦图像被分类,我们就用它们来训练一个图像识别模型,以检测每种动物的新照片并对其进行分类。这个模型是通过重新训练一个张量流模型
创建的(有关教程,请参见此处 ) 。
然后,我们在模型中运行盲集(每个类别 50 张图片),该模型的结果显示在下图中:

该模型将 200 幅盲图像分为四类,每类图像的平均置信区间超过 99.8%。这一统计反映了程序比手工方法更有效、更准确地执行任务的能力。我们承认,这种准确性可能是由于图像类别在颜色、纹理、形状和模式方面有很大的差异,供模型辨别。认识到这一点,我们试图进一步测试该模型,并通过该模型运行该类别的亚种图像,包括黑熊、熊猫、北极熊和白虎。

这些图像的结果如下所示:

这项研究的结果进一步鼓励了这样一种观点,即对于识别来说,图案和形状被认为是比颜色更重要的因素。得出这一结论是因为白虎、北极熊和黑熊的图像颜色不同,但具有与其相应类别“原始”相似的图案和形状,并且在模型的图像识别中保持了高准确率。然而,该模型被发现在识别熊猫图像方面稍欠准确,熊猫图像在形状上具有最大的差异。
最终结果 Flokka 创造了一个图像分类过程,与以前的手动图像分类技术相比,它对用户来说既更快又更容易使用。虽然我们注意到人们似乎很喜欢 Flokka 的游戏特色,但我们也认识到,这可能是因为本研究中使用的生动而奇特的样本图像的性质而被放大了。与十个或更多类别的系统相比,由于四个类别系统的简单性,该过程也变得更容易,这可能会降低 Flokka 的生产率。
考虑到与会者能够快速分类也很重要,因为图像之间的视觉差异很大。较小的差异将带来更大的困难,个人可能难以以相同的速度和准确度对图像进行分类。尽管如此,Flokka 通过松散平台的可访问性和组织的便利性仍然会在该过程中产生整体效率增益。对于 Max Kelsen 来说,这是一个激动人心的时刻,因为我们不断开发 Flokka 等方法来改进我们的平台、技术和整体生产力。
Max Kelsen 团队目前正致力于改进和开发可用于任何工作场所和图像识别模型的 Flokka。敬请关注即将推出的 Flokka 开源版本,并通过Flokka . io订阅 Flokka 时事通讯,了解该项目的最新详情。
流动的概念和创造的可能性
通过概率规划的概念学习。
回到未来:人工智能大炒作时代的概念
“然后,‘人工智能’这个词就滑下了斜坡,最终变成了毫无意义的流行语和空洞的炒作。(……)幸运的是,一个新术语“认知科学”正在流行,我开始喜欢用这种方式来描述我的研究兴趣,因为它明确强调了对人类思维/大脑中实际发生的事情的忠诚。”—道格拉斯·霍夫施塔特(2000 年之前,只是为了说明一下)
我猜想有人带着下面的难题来找你:给定整数序列0, 1, 2, …,猜下一项。这似乎并不难,是吗?3将是我们显而易见的答案,因为我们会假设“生成器函数”可能像f(x) = x一样简单:
f(0) = 0
f(1) = 1
f(2) = 2
f(3) = ??? -> 3
...
事实证明,这是而不是生成这个序列的函数。序列继续如下:
f(0) = 0
f(1) = 1
f(2) = 2
f(3) = 720!
f(4) = ???
...
那么,f(4)是什么?
我们不会破坏这个惊喜(见解决方案的最后部分),但使用这个漂亮的难题来讨论一个更普遍的问题:给定由算术运算(加、减、乘等)构建的整数和函数的宇宙。),假设可能性的数目是无限的,如何学习一个数列的“生成函数”?
我们专门研究人类语言的形式模型——如果你认为求解整数序列是愚蠢的,你可以把英语语法想象成你现在正在阅读的内容的“生成器函数”,以及计算机对文本进行类似人类的推理是多么困难。关于语言,现在说够了,让我们回到整数!]
序列游戏是在探索概率编程 ( PP )时偶然想到的,这是经常解释的试图将通用编程与概率建模统一起来。我们对 PP 的兴趣在于明确推理结构的能力,以及在没有大量数据的情况下很好地处理不确定性的能力:祝“机器学习你的方法”好运;
f(1) = 1
f(2) = 4
f(3) = ???
序列游戏是令人惊奇的流动概念和创造性类比的一部分(有趣的事实:这是亚马逊上销售的第一本书!),一本由人工智能先驱、畅销书作家和认知科学家道格拉斯·霍夫施塔特(Douglas Hofstadter)于 1995 年出版的书( DH )。在他无与伦比的写作能力中,问题是这样引入的:
这一序列的数学起源表明,确实会有模式或顺序,但由于数学本身充满了极其多样的模式,这个领域仍然是敞开的。尽管如此,我们对简单和优雅有着固有的偏见,不管我们能否定义这些概念。那么,假设我们预期我们可能会找到一个简单而优雅的规则,那么接下来会发生什么呢?
在这篇简短的帖子中,我们将重新发现序列游戏,并用一些简单的 PP 程序讨论概念学习。一方面,这将是理解 PP 的一个很好的练习,因为我们将看到如何以令人满意和有原则的方式对待固有的偏见;另一方面,我们将使用 PP 来深入了解人工智能的最新进展。
免责声明:这篇文章既不是关于 PP 的教程,也不是学术著作(如果有的话,因为它带有明显的偏见),也不是生产就绪模型的集合 — 虽然包含了可运行的代码示例,但我们今天的兴趣几乎完全在于用标准 ML 工具难以实现的建模类型,而用 PP 来代替是自然的。作为奖励,我们将讨论关于概念学习的认知上合理的想法,这些想法超越了。
向前看,向后看:概率建模 101
“在纽约,百万分之一的几率一天发生八次.”—佩恩·吉列特
在我们作为人工智能从业者和创业公司创始人的生活中,我们多次发现,概率编程中的许多想法仍然远远不是数据科学社区的主流。被这个轶事证据所说服,我们决定包括对 PP 的概述,以及它对有趣的推理问题的特殊之处,比如你在向机器教授语言时遇到的问题(熟悉 PP/WebPPL 的读者可以快速跳过接下来的两节)。
我们将大量使用 WebPPL 示例并充分利用在浏览器中运行代码的可能性:所有示例都可以从这个简单的 HTML 页面中完全运行。
让我们从一个简单的例子开始(当然是用骰子)。如果我们有两个公平的骰子,当你扔的时候得到 8 的概率是多少?这个 WebPPL 程序(记住:你可以在这里运行它)以一个漂亮的直方图显示结果的分布(如果有些东西不清楚,不要惊慌:很快就会很明显了):

Frequency distribution for our dice model.
PP 最酷的地方在于做逆推论是多么容易:假设我们观察到和是 8,那么一个骰子是 2 的几率是多少?

Frequency distribution for our dice model, conditioned upon observation.
正如读者可能怀疑的那样,如果总数是 8,那么骰子#1 有 20%的机会是 2(给懒惰读者的小测验:为什么上面的直方图中没有 1?).
虽然这可能看起来像一个明显简单的例子,但理解“模型的力量”真的很重要,即生成我们感兴趣的数据的过程的简化版本。模型是世界复杂性的一个非常紧凑的表示:在一个单一的模型中,你实际上可以从原因推理到结果(当你计划时,向前),从结果推理到原因(当你进行有根据的猜测时,向后)。模型也是我们认知能力的核心:通过拥有一个"七巧板模型",孩子们知道如何用零散的碎片建造一只鸭子(向前),并且根据鸭子的形状,他们可以猜测哪些碎片是用来建造它的(向后)。

A Tangram duck — humans can easily reason from pieces to figures and from figures to pieces.
对于许多人来说,基于模型的推理是智能的关键,其适用性远远超出了七巧板(如直观物理学和视觉学习);
生成模型描述了一个过程,通常是生成可观察数据的过程,表示关于世界因果结构的知识。这些生成过程是一个领域的简化“工作模型”(…);通过询问心智模型,可以回答许多不同的问题。
对于今天比理解人类智力更温和的目的来说,理解 PP 如何帮助是非常重要的。正如我们所看到的,这些模型通常被称为“生成型模型”:不用太在意的技术细节,对我们来说重要的是以下两个考虑因素:
- 生成模型讲述了一个关于数据点如何生成的故事:它们有一个可以检查的结构,并且它们通常包含人类可以理解、质疑、辩论的因果假设;
- 生成模型可以用来生成我们目标数据的新实例*,这是一个并非所有机器学习模型都具备的特性。例如,如果我们训练生成模型来分类体育与金融中的新闻文章,我们可以使用它们来创建关于这些主题的新文章。*
当人们已经手工编写生成模型很久了的时候,概率建模的黄金时代才刚刚开始。PP 的兴起为实践者解决了两个主要问题:首先,PP 带来了编程语言的表达能力:通过使用熟悉的工具,数据科学家现在可以表达任意复杂的模型,而不是一些分布;其次,PP 将推理的负担推给了编译器(和相关工具):研究人员专注于建模,因为计算机将解决所需的推理挑战。
用 Javascript 表达生成模型:WebPPL 101
“我的编程语言的极限意味着我的世界的极限.”——(几乎)路德维希·维特斯坦根
既然我们已经有了一些关于为什么生成模型如此酷的共同背景,我们可以回到如何在 WebPPL 这样的语言中实现它们的问题。如果您还记得我们的第一个例子,模型被指定为一个简单的函数,包装在推断方法中:
*model() {
var die1 = randomInteger(6) + 1;
var die2 = randomInteger(6) + 1; return die1 + die2;
}*
当运行时会发生什么?由于enumerate是指定的推理方法,程序将对模型中随机变量的所有可能值运行一次函数(即每个骰子从 1 到 6 的随机整数),并收集分布结果(通过方便的viz实用程序可视化)。由于模型是可生成的,应该可以从中采样并创建新值(即模拟骰子滚动):sample函数正是这样做的,通过将以下语句添加到单元块中可以看到(它将打印从模型中采样的 5 个整数的数组):
*print(repeat(5, function() { sample(roll); }));*
第二个例子介绍了 PP 的一个关键思想:条件作用。该模型与之前的模型相同,但增加了一个新命令:
*condition(die1 + die2 == 8)*
它运行时会发生什么?condition告诉程序忽略不满足所需条件的运行:这就是为什么没有 1 出现在分布中——如果一个骰子是 1,则不存在总和是 8 的情况(因为 1+6=7)。
条件反射之所以重要,至少有三个原因:它让你从观察到原因进行推理;它有助于以有原则的方式陈述可能限制要考虑的程序运行空间的信息;最后,它可以用来模拟当代人工智能中一个非常重要的概念,学习,通过 18 世纪的一个被称为贝叶斯定理的想法:给定一些数据,你对一个假设HD 的信心应该与 a)你首先对 H 的信任程度有关,以及 b)你对 H 能够解释 D 的程度有关。
我们用一个稍微有趣的例子来结束我们对 WebPPL 的简短介绍。考虑一个年轻的领域语言学家——让我们称他为威拉德——在一个世界非常小的异国他乡(也叫本体论):

A toy universe with a tree-based ontology and 7 objects.
这个奇异的世界有七个物体(用整数 1-7 命名)组织成树状结构,概念是关于三个层次的共性*(例如一切都是哺乳动物,腊肠犬是一种狗,#3 是一种腊肠犬)。当#2 出现时,威拉德听到说本族语的人说basso to(1000 奖励点给期望本族语的人说 gavagai )的读者。巴索托是什么意思:腊肠犬、狗还是哺乳动物?更一般地说:*
给定一个未知的单词 W 和一组用 W 表示的物体,威拉德如何学习W 的适当的一般性水平?
不出所料,概率规划非常适合对此问题建模,如下图所示:
奇迹就发生在这里。我们可以区分三个主要部分:
- 首先,从假设空间取样:威拉德对什么可以用 W 来命名有一些先验的想法(在分布
ontologicalTree中总结);特别是,威拉德认为像狗和猫这样的“自然物种”比非常普通的哺乳动物更引人注目; - 二、似然函数:威拉德知道在给定观测值(一组对象)的情况下,如何对假设进行优先排序;公式中重要的是认识到 1)较低级别的概念(检索器)将比较高级别的概念(哺乳动物)赋予数据更大的可能性;2)随着一致事件数量的增加(
observedData.length),更低级别的概念更有可能以指数方式;** - 第三,实际观察数据,因为
mapData负责将 Willard 观察到的数据提供给评分函数。
[ 小技术说明:这个例子的最初想法来自于徐和 Tenenbaum 的工作——请参阅他们的论文,了解更多关于该模型背后的心理事实的背景以及关于先验和可能性的深入讨论。]
那么,回到我们观察到的单词的第二个例子,威拉德在想什么?运行代码会得到以下分布:****

Distribution over target concepts after one observation.
这似乎是一个合理的猜测,不是吗?威拉德更喜欢腊肠狗,但他仍然保持开放的心态;当然,与数据不符的假设(如寻回犬,其延伸不包括#2)根本不予考虑。当威拉德观察#2 + #3 和听到低音吉他时,这个场景变得非常有趣:

Distribution over target concepts after two observations.
发生了什么事?如果威拉德只是排除与数据不一致的假设,看到两只腊肠狗而不是一只不会增加有意义的信息:简单地说,威拉德不会学到任何新东西。相反,我们的概率模型允许捕捉威拉德的学习:在看到两只腊肠狗后,他更加确信 bassotto 是指腊肠狗,同时他几乎准备排除哺乳动物作为一种合理的解释(即使从纯粹的逻辑角度来看,与数据完全一致)。我们留给读者一个练习,以确保所有代码都是清楚的:尝试改变先验、可能性和观察以更好地理解幕后发生的事情!
如果你想在继续之前再玩一会儿,可以在 probmods 上找到一些关于向前和向后推理相互作用的有效例子。虽然该领域在数据科学社区中仍然相对小众,但事情正在快速发展:我们上周发现了这个出色的 WIP ,主要参与者正在进入 PP 。为了非懒惰读者的方便,我们在最后包含了一堆额外的书籍/链接。
现在让我们回到我们的序列游戏!
“寻找序列的来源”
“不要让一个人猜太久——他肯定会在别的地方找到答案的。”—梅·韦斯特
既然我们对 PP 背后的哲学有了更好的理解,我们可以试着将我们的序列游戏建模为一个在假设空间中的学习问题,假设空间是无限的。给定序列:
**f(1) = 1
f(2) = 4
f(3) = ???**
我们将尝试学习序列发生器 功能 调理(对!)对我们拥有的数据(f(1)和f(2)),然后将该函数应用于序列中的下一项(即 3)。即使我们只限于初等算术函数,也有许多函数符合我们的观察结果,例如:
**x * x
x ^ x
x ^ 2
x ^ (0 + x)
x * (x / 1)
0 + (x ^ x)
...**
换句话说,这是一个与我们之前的例子非常不同的场景:没有一个有限的假设集可以列出来,并以某种方式从最合理到最不合理进行评分。这个问题是 DH 在写的时候想到的:
由于数学本身充满了极其多样的模式,这个领域仍然是开放的。
既然我们不能列出我们的假设,我们需要把注意力转向能够产生无限假设的过程:幸运的是,我们的语言和语法知识来拯救我们。考虑这样定义的简单语言:
**1\. A, B, C ... Z are valid expressions
2\. If *X* is a valid expression, -*X* is also a valid expression
3\. If *X* and *Y* are valid expressions, *X&Y* is also a valid expression
4\. If *X* and *Y* are valid expressions, *X^Y* is also a valid expression**
根据语法可以生成多少个有效表达式?回答的关键是要认识到指令 2–4 以表达式为输入并产生新的表达式,这样任何一条指令的输出都可以成为另一条指令的输入(或者同一条!):
**A -> -A -> -A&B -> -A&B&A -> --A&B&A -> ...**
因此,即使像上面这样简单的语言也能够产生无数的表达式。
有了这种直觉,我们能通过一个语法来定义生成函数的空间吗?我们当然可以!我们只需要构建一个算术表达式的小语法,它可能会生成x * x、x ^ x、x ^ 2等。和它们之上的先验(记住空间是无限的,所以我们需要一种“生成”的方式来分配所有可能函数之上的先验)。这是第一次尝试(要点包含语法,而完整的可运行代码可以在这里找到):
代码应该非常容易理解(原始代码来自优秀的 Goodman & Tenenbaum ):以 50%的概率,通过挑选一个整数(1–9)或一个变量(x)组成一个表达式,否则将两个表达式合并成一个新的表达式(它将递归地随机挑选一个整数,以此类推)。我们将只强调模型上的“隐式”先验,这是关于简单性的先验:在其他条件相同的情况下,更简单的函数(现在定义为语法上更短的)应该是首选的。由于产生x * x比x * (x / 1)需要更少的概率选择,尽管在外延上是等价的(如x = x/1),前者被认为是一个更加可信的假设。显然,这在形式上等同于在一个模型中实施 DH 所说的:
倾向于简单和优雅的固有偏见
如果我们在序列上运行模型:
**f(1) = 1
f(2) = 4**
f(3)的首选建议是 9:

Guessing the third integer for the sequence 1, 4, …
正如古德曼&特南鲍姆所说,“许多人发现分配给27的高概率(……)是不直观的”。这表明,作为人类序列发现的认知模型,我们的先验可以使用一点修改:x times x似乎比x raised to the power of x更“自然”的想法(对非懒惰读者的练习:修改代码以反映这种偏差,并再次运行预测)。
这个模型能解决什么样的序列?下面是一些可以通过改变condition语句来测试的例子:
**1, 4, 9 -> ??? x * x
0, 3, 8 -> ??? (x * x) - 1
1, 3, 5 -> ??? x + (x - 1)**
[非懒惰读者的练习:有时学习生成器函数最简单的方法是采用高阶序列,即认识到1, 4, 9, 16, 25, ...产生一个3, 5, 7, ...的子序列作为数对之间的差;然后,您可以使用第二个序列(奇数)对原始序列进行预测。鼓励读者将现有的模型扩展到二阶序列:在这种情况下先验是什么样的?]
我们可能想做的最后一件事就是兜一圈:在流体概念和创造性类比中,“PP 方法”与原始想法有多接近?DH 在整本书中的一个要点是概念表征是人工智能的问题…如果你从人类指定的概念(像“符号化的人工智能”)开始,你在乞求那些概念最初是如何被学习的问题;另一方面,完全自下而上的表示(那时,今天的深度学习系统在计算机视觉等任务中可以做的事情的非常早期的版本)适用于低级别的感知任务,但缺乏与人类概念相关的大多数通用性。因此, Fluid Concepts 中介绍的架构是自上而下和自下而上过程的混合,其中较低级别的概念被随机组合以构建较高级别的概念,这反过来使得一些其他低级别的概念更有可能被用于解决给定的任务。****
与我们的 PP 模型相比,最显著的相似之处是 1)假设空间的概率性探索(由基本概念构成),以及 2)组合原则的应用,以重用低级概念来构建高级概念。
我们强烈邀请读者从书中获得未经过滤的体验,因为我们不会用我们的概述来公正地对待它。也就是说,我们想在结束前再探索一个“流体任务”:让我们开始(数字)绘图板吧!
通过“视觉”语法学习空间概念
“画字母‘A’的方法有成千上万种,但我们一眼就能认出其中的任何一种。对于任何心理范畴(……),尽管差异巨大,我们还是能立即识别出成千上万个例子。”道格拉斯·霍夫施塔特
流体概念和创造性类比的最后一部分致力于文字精神,这个项目的目标是“设计和实现一个计算机程序,它本身可以设计出成熟的字体”。
在 DH 特有的利用玩具问题启发重要认知现象的方法论中, Letter Spirit 是一项类人机器创造力的实验,产生了一些非常有趣的字体设计:

Examples of Letter Spirit fonts as printed in Fluid Concepts and Creative Analogies.
众所周知,视觉概念既非常灵活(例如,我们可以用无数种方式画出一个一个),又非常独特(例如,人类可以立即识别出一些图画是同一主题的变体)。因此,毫不奇怪,教机器如何理解视觉概念从根本上被视为对字母概念本质的“T2”探索:
要认识某个事物——也就是说,要将一个项目与恰当的柏拉图式抽象相匹配——必须有空间来伸缩柏拉图式抽象和事物本身的精神表征,让它们相遇。什么样的扭曲是合理的?内部边界的重新调整、连接强度的重新评估和部件的重新排列是识别过程的核心。
正如我们在这篇文章中多次看到的,概率方法强调了理解一个概念 C 和生成 C 的新实例实际上是密切相关的活动。在不试图重现文字精神的全部复杂性的情况下,我们能在 PP 范式中讨论一些有趣的视觉学习案例吗?我们将从 WebPPL 计算机视觉演示的一个变体开始:如果我们用 n 条线画一个(数字)多边形(三角形、正方形、五边形),一个概率程序能首先找出它是如何制作的吗?

Examples of target polygons for our visual challenge.
基本成分现在应该很简单了。首先,我们定义了一个多边形的生成模型——如果你愿意,可以称之为“视觉语法”;一个可能的生成配方如下:
- **线条是我们的原始元素;基于四个整数[x1,y1,x2,y2]绘制线条;
- 首先从分布[3,4,5]中取样,以选择要绘制的线的数量;可能的话,将取样偏向更简单的模型,即尽可能少的画线;
- 如果 N 是要画的线数,则挑选 N 个四元组整数得到 N 条线,并画在画布上。
为了熟悉我们的可视化生成模型,你可以尝试在一个单独的代码块中创建一些行(见小要点让你开始)。在运行时,我们然后使用 PP 的能力来进行反向推理:给定一个具有某某特征的绘图,可能是什么指令创建了它?

Forward and backward inference: from lines to polygons and back.
为了实现这一点,我们使用 WebPPL factor表达式根据我们的多边形(使用上面的方法生成)与我们试图解码的目标图像的接近程度来衡量迭代。一旦我们生成了我们的分布,我们就可以通过反复采样来检查程序对视觉概念的了解,比如说,正方形:
*map(drawSamples, repeat(6, function() {sample(m);}));*
并显示结果:

Sampling instances of the concept “square” as learned by the probabilistic program: pretty cool!
还不错!换句话说,我们可以使用这个模型来生成我们所学的视觉概念的无限实例:非常简洁,不是吗?像往常一样,鼓励不懒惰的读者扩展和改进现有的代码样本(去可能以前没有模型去过的地方!).
作为最后一个练习,受我们最喜欢的公司之一的启发,我们在上面的视觉语法中添加了一些想法,并完成了我们自己的“仅在我的笔记本电脑上运行”原型,以展示 PP 的强大功能:不需要大数据进行训练,不需要黑盒优化,不需要昂贵的 GPUs——一切都在标准的网络浏览器中几秒钟内完成。欣赏视频!
Learning complex visual concepts re-using simpler ones.
结束语的随机分发
“我们(……)希望我们在本书中描述的工作可以在遥远的未来有助于引导比我们更深入地捕捉真正的流体心理的架构,艾伦·图灵在他首次提出他当之无愧的著名测试时就清楚地预见了这一点。”道格拉斯·霍夫施塔特
我们(终于!)在我们的绝技的最后,透过“流动的人类概念”的镜头来看概率编程。然而,我们几乎没有触及表面,因为当试图在一个雄心勃勃但非常未知的领域,即机器学习的概念和类似人类的推理(即使在小领域)中概述有趣的想法和有前途的技术工具时,这是不可避免的。
在没有穷尽上述线索的前提下,以下是我们迄今为止在概念驱动的人工智能方面的一些离别想法和更多哲学思考:
- 与深度神经网络中当前的人工智能大趋势相比,更明确地讨论 PP 在热点问题上的立场可能是好的。在我们看来,概率编程有望成为一种原则性的方法,用更少的数据进行学习,并以更人性化的方式行事,即既更接近我们对人类认知的了解,更重要的是更容易理解:虽然最近在深度学习模型中的可解释性问题上做了很多工作,但可以肯定地说,PP 模型在这方面有优势。深度学习已经获得了令人难以置信的普及,它承诺消除图像分类等任务中繁琐的特征工程,即通过自动学习有用的表示;虽然这通常是正确的,但在许多真实世界的案例中,人类专家确实知道很多关于手头推理的相关信息,而 PP 有一种直接的方式将这些数据包含到正式模型中:在一个还没有准备好(也没有准备好)为你提供完全自动化的科幻生活的世界中,能够用一种共享语言与你的企业软件应用程序进行协作是一件大事正如我们已经看到的,概率建模是一种非常自然的方式来弥合人类可理解的想法和机器学习的知识之间的差距。
- 有一些非常有趣的尝试将 PP 应用于计算语义学和语用学的主题。在 Tooso,我们正在研究知识图的 PP 模型,即利用隐式本体结构对自然语言查询进行快速可靠的推理。然而,天空是极限,因为 PP 承诺结合迄今为止难以调和的两个语言理解原则:首先,语言是合成的*,因为复杂的表达(某种程度上)是由简单的表达组成的;第二,沟通是嘈杂的,以至于僵化的推论(例如纯粹的演绎)在几乎所有真实世界的用例中都将失败。真正的 - 而不是-有空闲时间的懒惰读者(学术界的朋友,有人吗?):反事实陈述要求我们根据没有发生的事实进行推理(“如果第一个骰子是 6,那么总和就不会是 5”)—有没有某种 PP(玩具)交流模型可以公正地解释这一点(贝叶斯建模和反事实之间的联系在相关文献中经常出现,但我们不知道反事实语义的具体应用,我们也没有太多地搜索)?*
- 我们在帖子中多次提到古德曼、特南鲍姆和 T21,如果没有他们的网络书籍《认知的概率模型》。如果你喜欢玩概念学习,你一定要看看 理性规则例子;如果你发现文字精神的视觉挑战特别有趣,那么你应该而不是惊讶于 Tenenbaum 等人的最近的工作从 PP 的角度解决了一个非常相似的问题:概率程序归纳是我们近年来看到的最令人兴奋的范例之一——最好的范例肯定(嗯,很可能即将到来。
- 我们在博文中多次提到道格拉斯·霍夫斯塔德(Douglas Hofstadter ),如果没有他的书《T2:流动的概念和创造性的类比》( T3 ),这肯定是不可能的。作为最后的怀旧笔记,请允许我们陈述我们是多么想念 DH!他是大多数时候不出现在主流媒体上,不怎么参与推特争斗 ( O tempora!哦,莫尔! ) 《当代人工智能》中引用不多。遗憾的是,霍夫施塔特的想法仍然发人深省,并能为整个领域提供急需的原创视角,以更好地理解智力。
- 腊肠犬的例子( bassotto 是意大利语中腊肠犬的单词)是我自己的爱的回忆, Omero 。
如果你熬过了这篇令人难以置信的长博文(包括怪异的引用、书呆子论文和笨拙的代码样本),你值得我们最深切的感谢。
我们确实希望,不管你之前的信念是什么,观察这篇文章中的数据能说服你更密切地关注我们在 Tooso 正在构建的东西。
再见,太空牛仔

如果你有请求、问题、反馈或者疯狂的想法,请将你的人工智能故事分享给jacopo . taglia bue @ tooso . ai。
别忘了在 Linkedin 、 Twitter 和 Instagram 上获取来自 Tooso 的最新消息。
感谢
特别感谢安德里亚·波洛尼奥利讲述了勇敢而令人敬畏的故事,感谢整个 Tooso 团队对本文之前的草稿提出了有益的评论;我们也感谢 人工智能的未来 见面会的组织者让我们在那里分享这些想法。
剩下的所有错误都是我的,而且只是我的。
关于 PP 的进一步阅读
我们的概率编程介绍很烂,尤其是在“编程”部分,因为我们只能介绍最少的 WebPPL 来说明我们的观点。从这里去哪里?不幸的是,对于脚本语言中的 PP(是的,我指的是 Python)来说,还没有太多完整的、从零开始的“计算机科学”介绍:**
- 这个曼宁本用的是费加罗(Scala);
- Pyro 最近已经开源了,但是社区仍然很小(这意味着:没有从 StackOverflow 复制+粘贴):将 WebPPL 模型移植到 Pyro 是一个很好的(尽管有时令人沮丧)入门方式;
- 这本“给黑客”的小书很有趣,非常实用,但没有涉及更抽象的人工智能应用(例如概念学习);
- 另一方面,认知的概率模型作为对 PP 的基于科学的介绍绝对是奇妙的*,但它是基于 Javascript 的(免责声明:我们基本上喜欢一切Goodman&tenen Baum做的事情,所以我们也可能有点偏颇)。*
最后,我们的建议是迷失在漂亮的例子和大量的研究论文中这里,这里这里和这里 ( 这个回购很神奇,但是大多数模型都不在 WebPPL 中:如果你喜欢自然语言语义,就从这个开始吧)。这个领域发展很快:如果你认为我们忘记了什么,请让我们知道。
720 的解决方案!难题
给定序列:
*f(0) = 0
f(1) = 1
f(2) = 2
f(3) = 720!
...*
发电机功能是什么?这是解决方案:
*0 -> 0 (0!)
1 -> 1!
2 -> 2!!
3 -> 3!!! (as 3! = 6 and [6! = 720](https://www.wolframalpha.com/input/?i=6!))
4 -> 4!!!!
...*
即对于每一个 x ,x-乘以阶乘 x (参见流体概念与创造性类比,第 46 页)。
#0014:度假袋鼠
一个持续的问题是,被机器人取代的制造业工人会发生什么。这篇文章指出,在某些情况下,使用机器人的成本现在比公司使用奴隶劳动力的成本要低。#autonomous #mechanised
自动驾驶汽车还没有真正为黄金时间做好准备,可能还需要一段时间。艺术家詹姆斯·布里德想出了一个新奇的点子:用一些道路油漆困住自动驾驶卡的方法。更多图片和视频这里。#autonomous
我们离第五级汽车自主驾驶还有多远还不清楚,但是优步今天能够做到的和宝马计划在 2021 年实现的与第五级汽车自主驾驶之间的差异是非常明显的。如果“每英里至少接管一次”是标准的话,我估计我现在的车只能算是“自动驾驶”了。至少在非常直的路上。#autonomous #mechanised
技术界一直在讨论颠覆的概念。这篇文章讨论了颠覆是如何在移动行业上演的。每当有人谈论颠覆,也值得参考本·汤姆森的聚合理论,我认为,这比克里斯滕森的原始颠覆论文中提出的更好地描述了面向消费者的技术中实际发生的事情。#autonomous #mechanised
机器会拥有自己的企业吗?#autonomous
需要在 60 英尺的积雪中清理出一条路吗?这些乡亲可以帮忙。#snow #wow
我们可能很快就会开着电动黑色出租车到处跑。#electric
这是一个非常棒的“人工智能介绍”演讲:吴恩达:人工智能是新的电力。#cognitive
增加人工智能潜在影响的赌注:神经科学家和哲学家山姆·哈里斯描述了一个既可怕又可能发生的场景。他说,这不是一个好的组合。如果唯一安全的前进方式是“将这项技术直接植入我们的大脑会怎么样?“我认为这有点道理。我不确定我们(目前)是否有一条通往人工智能的明确道路,但如果我们有,那么我认为融合的场景,即我们通过增强自己而不是与之斗争来“成为”智能机器的一员,可能是我们作为一个物种长期生存的最佳机会。#cognitive
机器人值得拥有权利吗?如果那些机器人变得有意识了呢?嗯。我们无力回答的棘手问题。下面是提出这些问题的一个短片。如果这个问题被提出来假设机器是有意识的,无论你想提出什么样的测试,那么除了认为这些“机器”应该被赋予与其他有意识的“实体”相同的权利之外,我看不出你如何能得出一个道德或伦理上合理的结论。也许我们应该更担心机器是否会给我们权利……#cognitive**
谷歌的 DeepMind 部门正在与英国国家电网进行谈判,以利用人工智能/人工智能技术减少 10%的能源使用,而无需改变基础设施。它还与英国国民保健服务系统合作。以及支持一个名为distilt的新(ish) AI/ML 研究出版物。#cognitive
目前有很多关于交通电气化的消息,但电池技术似乎没有同样快速的发展。锂电池的最初发明者约翰·古德诺的一项新发明可能会改变这种情况。他和三位合著者一起撰写了一篇新论文,描述了一种快速充电、不可燃电池的技术。然而,正如所有激进的技术进步一样,并不是每个人都信服。#battery
我不知道哪个更糟糕:由无知的人发布的假新闻,或者由人工智能语言工具启用的机器,机器人般地相互鸣叫。#cognitive #fakenews
哭泣、哭泣、情感撕裂——这是怎么回事? #tears #whatevenarethey
爱迪生是一台装在火柴盒里的 Linux 制造机。#mechanised #cognitive
这项技术使用加密技术来创造一个只能进行加密预测的人工智能。这不仅具有允许人工智能在敌对环境中训练的好处,还意味着从人工智能的角度来看,外部世界是加密的。这是一个非常深刻的结果,它可能会创造一个环境,让我们(即人类)安全地发展人工智能。#cognitive #agi #mindblown
只有在澳大利亚
甚至袋鼠有时也需要休假。#onlyinaustralia
周五预告
抱歉,这周晚了一天。
从 1 到 100 依次有 100 个人站成一圈。一号人物有一把剑。他杀死了他面前的人(即 2 号),然后把剑交给下一个人,在这种情况下,是 3 号。队列中的每个人都这样做,直到只有一个人幸存。活到最后的人的数量是多少?
像往常一样,在评论中向第一个正确答案敬献花束。
问候,
M@
#0025:伦敦笔记。AI8

我去了伦敦。艾 8 上周四晚上。它是在 Twitter 的伦敦办公室举行的,说得轻描淡写一点,这里相当豪华。
当晚有来自四家企业的推介和演讲,它们在人工智能和机器学习方面做着有趣的事情:
- 不可能的:一家总部位于伦敦的初创公司,创造了一种分布式、实时、持续模拟的技术。
- 桌面遗传学:带你经历基因组编辑实验的每一个方面,从设计到数据指导你,让你充分认识到 CRISPR 技术的效用。
- 夏洛克 ML :数据科学的操作系统。
- Vortexa :使用人工智能分析和解释大规模数据。它从数百个来源吸收了数十亿个数据点,以显示全球石油的过去、现在和未来流动。
不大可能的
不大可能专注于使用云基础设施的大规模模拟,以“实现规模和复杂性前所未有的虚拟世界”。他们刚刚从软银获得了一大笔现金注入,软银也对硬件进行了大量投资。
在我职业生涯的早期,我在飞行模拟器上做了一些工作,构建大规模离散事件模拟的挑战是非常真实的,演示展示了一些令人印象深刻的技术。这项技术在大型多人在线游戏中有明显的使用案例,但是其用途远远超出了游戏。
与人工智能/人工智能社区的相关性有点模糊。但是,如果你考虑一下 OpenAI 对宇宙所做的事情,然后将空间技术应用于同类问题,似乎会有很大的潜力。
这些人在未来绝对值得关注。
桌面遗传学
桌面遗传学是一个人工智能驱动的基因编辑平台。我对编辑基因一无所知,但是看起来它将会改变基因研究的游戏规则。
如果你给“ai@desktopgenetics.com”发一封电子邮件,你会得到一个回复,里面有一堆关于 CRISPR 和相关技术的有趣链接,而不是试图解释这些人在做什么。
夏洛克 ML
SherlockML 试图成为“数据科学的操作系统”。要理解这意味着什么,想想 Excel 为会计师和分析师做了什么,或者 Photoshop 为设计师做了什么,然后你就可以理解 SherlockML 试图为数据科学家做的事情了。
随着数据科学、人工智能和机器学习等学科的不断成熟,将会有很多这样的平台。
旋涡
Vortexa 使用人工智能来分析和解释大规模数据。它从数百个来源吸收了数十亿个数据点,以显示全球石油的过去、现在和未来流动。他们使用卫星图像和人工智能/人工智能技术的组合来创建全球能源供需视图。
这是“任何可以预测的事情,都将成为”大规模数据科学带来的必然性的一个例子。这里的天才洞察力是使用高分辨率卫星图像结合机器学习模型来预测世界各地的石油运动。
问候,
M@
#0028:来自认知 X 2017 的注释

Source: @heyerlein @ Unsplash
上周二有幸参加了 CognitionX 2017 的第一天。会议组织得很好,采用了主题演讲/小组讨论/分组讨论的新颖形式。主题演讲设置了一个主题,然后由 3-5 名专家组成的小组讨论了观众提出的互动问题(通过 Sli.do ),随后是详细的分组会议。
我所看到的主题的信噪比非常好,这些主题往往专注于人工智能和机器学习的社会、政治、经济和文化因素,而不是深度技术。在整个会议期间,大约 30%的与会者是女性,这比这类事情的正常情况要好得多。尽管组织者自己也承认,在这方面还有很多工作要做。
以下是我在第一天设法看到的 3 次会议的亮点:
人工智能的现状及其对社会的影响,第一部分
根据设计,会议有意关注窄/垂直 AI 的影响,并有意(在大多数情况下)避开关于人工通用智能 (AGI)或超级智能的讨论。
当会议简要谈到 AGI 和超级智能时,普遍的共识是没有达成共识。
汉森机器人公司的大卫·汉森认为,AGI 将在“5 到 10 年后”实现,届时将会有能感知周围环境的机器人帮助实现。大卫和索菲亚在一起,一个外表和声音都很逼真的机器人,并没有让我相信这些时间表。索菲娅和主持人之间的采访看起来完全是预先安排好的。
在第一个小组中,来自其他人(seánóHeigeartaigh)的经过深思熟虑的观点表明,AGI 可能还需要 20-50 年的时间,并且需要在多达 12 个独立的艰苦研究领域取得根本性的科学突破( Charlie Muirhead )。我不确定 12 是从哪里来的,但如果是 12,那很可能是 112 或 12000。很难预测科学研究的流向。
值得查阅的参考资料:
- 剑桥大学生存风险研究中心——生存风险研究中心是剑桥大学的一个跨学科研究中心,致力于研究和减轻可能导致人类灭绝或文明崩溃的风险。
- 汉森机器人——自己拿定主意索菲亚和其他机器人。
金融服务和经济
J Doyne Farmer 教授对复杂经济学和基于主体的建模领域进行了一次旋风式的访问。他认为目前在人工智能/人工智能领域进行的大部分工作都是“比回归分析好不了多少”(这不是一个不合理的描述),我们需要转向基于主体的模拟,以推动经济理论向前发展。与回归不同,回归从定义上讲是向后看的,这些技术允许您对以前从未遇到过的情况进行建模。
法默教授表示,他即将开发出一个可以模拟英国 2700 万个家庭的系统。他认为,这将为公共政策提供比民意调查更好的见解,民意调查在最近一段时间里出现了许多著名的失误。他还提到了“BINC”(生物、信息、纳米、认知)的概念,认为它掌握着人类未来的钥匙。或许有人应该成立一个 BINC 基金?
专家组会议中的一些选择(错误)引用:
- “人类是工业革命的机器人”J·多恩·法默教授——回避了一个问题:人类将在人工智能革命中扮演什么角色?
- “人工智能/自动化开始夺走认知技能”皮帕·马尔姆格伦——仅是轶事证据
- “英国 60%的经济是私营企业Damian Kimmelman,du edill——然而我们的大部分政策都是基于上市公司的数据
- “人们仍然认为机器没有”J·多恩·法默教授——也许永远不会有?
- “我们应该将市场的周期时间降到 1 秒钟,这样每个人都有时间做出明智的决定”J·多恩·法默教授 —这将使 HFT 的吸引力大打折扣,并消除某些特权玩家仅仅因为靠近交易所而获得的优势
- “在印度,只有不到 40%的人纳税,其他人都靠福利生活。”
在区块链理工大学的一次讨论中,皮帕·马尔姆格伦在回答观众提问时提到了一件有趣的轶事,关于 1834 年点燃计数棒导致威斯敏斯特教堂发生火灾。这一事件与区块链技术的推出有相似之处(在一些小组成员看来)。在我看来,这里的一些争论是基于对区块链技术到底是什么的根本误解,但这个轶事仍然很有趣。
值得查阅的参考资料:
- J . Doyne Farmer 教授—牛津马丁学院新经济思维研究院复杂性经济学联合主任。
- 经济模拟库 — ESL 是一个社区驱动的开源项目,旨在开发一个用户友好的建模库,用于构建基于代理的经济系统模型。
政治和治理
这里有一些关于人工智能在竞选中的作用的有趣讨论,特别是像最近美国大选中的剑桥分析和去年的#英国退出欧盟投票这样的组织的作用。专家组的一致意见是,像 CA(和其他组织)这样的组织的影响可能被夸大了,但他们参与的透明度确实令人担忧。
网络安全一瞥
由此得出的主要结论是“人工智能支持的数据窃取离还有很长的路要走”,这是个好消息。
还有一个非常有趣的线索,暗示了一个很好的研究主题:使用分布式版本控制系统中的版本历史作为训练数据的来源,来构建一个 AI/ML 系统,该系统可以自动找到并修复源代码中的 bug。这确实是软件工程的圣杯。这可能还有一段路要走,但是数据(在版本控制系统中)和过程(在人工智能/人工智能技术中)现在已经可以向前推进了。
人工智能的现状及其对社会的影响,第二部分
数字国务部长马特·汉考克讲述的重点是他自己讲述的事实,即卢德派领导人本杰明·汉考克是他的一个远亲。至少我认为看到了讽刺。
小组讨论的大部分集中在自动化渗透到各个层面时,经济会发生怎样的变化。作者卡勒姆·刘升对失业的 T2 人和失业的 T4 人进行了有趣的区分。他问了一些尖锐的问题,关于当 25%或更多的劳动力变得无法就业时,经济会是什么样子。他将这种(潜在的)暗淡的经济状态称为“经济奇点”。
值得查阅的参考资料:
摘要
总的来说,这是一个非常好的一天,内容非常棒(少一些技术,多一些社会/经济/政治/社会)。信噪比很好,没有任何形式的供应商推销演示(我看到的),并且受到了来自技术和商业社区各个部分的优秀、积极的观众的光顾。如果 CogX 2018 明年举行,它绝对值得参加。
问候,
M@
关注最终用户指标,走出你的舒适区

Photo by Daniel Gaffey on Unsplash
过分专注于优化算法对任何产品都是有害的——打破这种专注,着眼于解决方案的整体情况,往往会以模型优化的一小部分成本为最终用户带来更好的性能。
理解全局是一项艰巨的工作,需要大量的时间。由于这些原因,它经常被搁置,以获得更多的数学改进。专注于一个模型的独特性和容易性对数据科学家来说可能是有吸引力的-因此,对于数据科学家来说,走出我们的舒适区更为重要。
关注最终用户
在我看来, 最重要的 数据科学家工作的一部分是了解最终用户,并从他们工作领域的专家那里吸收尽可能多的领域知识。我经常把自己的工作看作是算法的老师和向导,我应该给他们一切成功的机会。拥有领域知识并作为产品所有者,允许我站在用户的角度考虑问题,并允许我在优化之外找到改进产品的方法。让我们看一个简单的例子。
想象一下,在一个项目中,你试图从成千上万张照片中预测狗的品种。你不可避免地会构建一个深度学习模型,并拥有成千上万(或潜在的数百万)带注释的例子。当你和你的团队专注于该算法时,你将开始触及与边际收益递减规律相冲突的性能上限。
当您达到性能上限时,您可以将几个简单的步骤放入您的 ML 管道中以提高性能——并且这些步骤很可能会超过仅在您的模型上花费昂贵的开发人员时间所带来的增量改进。
- 为狗建立一个分类器,并从训练和测试集中删除所有不包含狗的例子。
- 使用模型的输出来识别分数很低的带注释的图像,或者在太多类别上分数很高而不真实的图像。使用此数据清理您的培训数据。这可以迭代完成,可以显著提高性能。如果你做的方法正确,你甚至可以自动完成大部分工作。
- 寻找人们不感兴趣的课程。也许人们对秘鲁印加兰花不感兴趣——把它们从你试图识别的类别中移除。
- 花时间了解假阳性与假阴性的成本。理解用户的这种成本效益,并将其构建到你的算法中。这可能不会提高您的精确度,但也许这没关系——通过优化正确的指标,而不是与最终结果脱节的东西,您可能会获得很大的价值提升。
- 构建一个分类器,对极有可能被错误分类的图像进行分类。这样做的时候,往往会发现系统性的问题。在图像分类中,这可能是镜头着色、相机故障或其他原因。
在一天结束时,你应该有一个可定义的,客观的标准来判断你的产品。在许多情况下,精确度、召回率、AUC、对数损失和其他标准度量是不够的。精确度的价值可能是回忆的十倍,也可能是回忆的一半——关键是如果你不尝试理解最终用例,你永远不会知道。通常,定制指标对于构建最好的产品至关重要。
通过梯度下降进行食品成分逆向工程

DeepNutella — Neural Style Transfer (base image: nutella.com)
带着另一个奇怪的想法回来,这总是另一个学习新东西的借口。这个故事是关于我做的一个快速实验,猜测包装食品中每种成分的不同含量。基于成分列表和营养事实标签,我将任务公式化为线性回归问题,其中成分百分比是参数。为了执行优化(梯度下降),我使用了官方的 hipster 深度学习库,又名 PyTorch 。代码可以在这里找到。
我喜欢烹饪。我并不总是有时间做饭,但当我有时间时,我会尝试使用非常科学的方法。例如,我喜欢简化和揭开老祖母食谱的神秘面纱。在这个过程中,我可能不得不处理食物数据,尤其是营养数据(也就是碳水化合物、蛋白质、脂肪、盐等的含量)。).
在这个实验中,我试图通过使用大多数包装食品上要求的营养成分标签来找到食谱中(缺失的)成分百分比。我的直觉是,这些数据足以找到真正的配方。
注:显然还有一些其他的方法可以找到食材,但是在这个 炼金 的时代,为什么不针对问题扔点渐变下降呢?
就拿我们钟爱的棕榈油涂抹酱 Nutella 来说吧。
以下是配料:

砝码
在我的线性回归模型中,参数(重量)是不同成分的克数:
- w1 是 100 克果仁糖的含量,
- w2 是 100 克果仁中棕榈油的含量,
- 诸如此类…
在某些情况下,某些百分比是已知的。欧洲 Nutella 就是这种情况,我们知道其健康成分(榛子、可可等)的含量。).在这种情况下,重量是固定的,不可训练。
输入和输出
现在营养事实标签:

每个营养成分成为一个训练观察/例子(x,y)。
让我们以“总脂肪”组件为例,它给了我们一个(x,y)元组。
x 是包含每种成分中脂肪百分比的行向量:
- x1 是糖中脂肪的百分比(0%)
- x2 棕榈油中脂肪的百分比(100%)
- …
这些很简单。但对于某些成分,猜测其成分变得越来越难(卵磷脂有人知道吗?).在这个实验中,我使用了美国农业部国家营养数据库,其中包含了大多数基本成分的信息。
注意:这个数据库并不是万能的,营养成分会有很大的不同(榛子有不同的种类,你可以选择是否烘焙它们,可可可以是生的或脱脂的……)
在我的非常深的 1 层神经网络的另一边,y 是一个标量,包含最终产品中的脂肪量。这些信息很容易在营养事实表中找到:
每份 Nutella 含有 12g 脂肪,或者,在一个更文明的营养标签系统中:31%(谢谢法国)
由于这种标记非常冗长,我们可以得到大约十个(x,y)样本。
培养
当然,在模型中,线性单位没有偏差。在食物成分中找不到暗物质,所有的东西都被计算在数量的加权和中。
在 PyTorch 中声明所有这些相对容易(这是我的第一次),这个库非常自然和直接,我想我现在理解炒作了。现在,我们应该只是减少原始 L2 损失吗?不,我们必须在模型上设置很多约束,使它收敛到一个看似合理的局部最小值,而不是一个我必须放入负量可可的奇怪配方。
特定域约束
- 质量不能是负的(不是开玩笑)
- 一些权重是固定的(当百分比已知时)
- 质量的总和必须等于 100 克
- 最重要的是,重量要按降序排列(与包装上食品成分按降序排列的方式相同)
这些约束中的一些是在更新权重时强制实施的,一些是通过损失函数中的炼金术士技巧实施的。恐怕这些都不是什么好东西。
我使用整个数据集(批量梯度下降)来计算每一步的损失函数。结果如下:


**配料:**糖(50.8%)、棕榈油(19.7%)、榛子(13.0%)、可可(7.4%)、脱脂奶粉(6.6%)、乳化剂(1%*)
()充分披露:乳化剂保持在 1%以下(它只是一种添加剂)*
我承认结果并不令人印象深刻。但是我想把它看完,通常,旅程比目的地更重要:)希望你喜欢它!

source: hersheys.com
奖金:里斯的花生酱杯
我还试图找到里斯著名的花生酱杯子的原料。
这是一项更艰巨的任务:10 种不同的成分,但没有一种是已知的。
此外,还有两种“复合”配料,每种都有自己的配料表:牛奶巧克力涂层和花生酱夹心。

Here, a clear example of ingredients getting stuck between their left and right neighbors
**配料:**牛奶巧克力(62%)【糖(20.3 克)、可可脂(16.0 克)、可可液块(6.3 克)、脱脂牛奶(6.3 克)、乳脂(6.3 克)、乳糖(6.3 克)、乳化剂(0.3 克)】花生馅(38%)【花生(18.7 克)、葡萄糖(18.7 克)、盐(0.7 克)】
这个故事到此结束。如果你喜欢,可以关注我的 中 或 推特 获取最新消息。如果你喜欢唐纳德·特朗普,你可能会喜欢阅读 这篇文章 。如果你更喜欢《权力的游戏》, 去那里 。
另外,如果你觉得有什么不对,或者有什么问题,欢迎在下面评论。
使用机器学习的足球提示:添加玩家数据
我是如何停止担忧,学会获取、汇总和重塑 AFL 球员数据的。

Photo by Scott Webb on Unsplash
我试图开发一个关于小费的数据模型,这是系列文章的第四部分。你可以在这里阅读第三部**。本帖使用的 Jupyter 笔记本可以在* 这里找到 。*
当我开始这个项目时,我的主要目标之一是将玩家数据整合到我的足球小费模型中。我上个赛季的模特 Footy Tipper 将投注和团队比赛数据整合到一个整体中,但我不太明白如何以增强性能的方式包含基于球员的功能。我尝试按字母顺序对球员名单进行排序,将球员姓名视为分类变量,然后在我的神经网络中添加嵌入层,但这只是增加了噪声,实际上稍微降低了准确性。由于 AFL 赛季很快就要来临,我没有太多的时间进行实验,所以我暂时放弃了使用球员名单的想法,发誓要带着更多的人、马和钢铁回来。随着 Tipresias 的出现,我带着一些新武器向路障发起了另一次攻击。
菲茨罗伊不错,但我是个皮托尼斯塔
在最近的 AFL 赛季,我开始关注强大的 AFL 统计社区,在我的美国沙文主义中,我认为这个社区并不存在。什么?在一个人口仅占美国 7.6%的国家,一个地区性职业体育联盟足以支撑一大批痴迷于数据的粉丝,他们能够撰写足够多的博客帖子和推文,来告知我对足球统计数据的新兴趣?就当我卑微吧。我在推特上关注了几个账号,读了一些关于统计数据的帖子,然后开始将我的模特的表现与那些在网上参赛的名人进行比较。
除了教会我足球的优点,我的研究还收获了这个小宝贝:菲茨罗伊。fitzRoy 是一个 R 包,它避开了流行的 AFL 统计网站,清理了数据,并在 good china 上提供了数据框架。它甚至有像样的文档!我对以最小的努力获得大量数据的前景感到非常兴奋,因为使用开源包比维护自己的网站抓取器容易得多,尤其是当面对导航 AFL 表的 borgesian 噩梦时。唯一的问题是,我所有的工作都是用 Python 完成的,而 fitzRoy 是严格针对 R 的,我每隔几年就要学习它的基础知识,但由于缺乏实践,很快就忘记了。我在 R 中有一个很棒的数据源;我在 Python 中有一个数据消耗的机器学习模型;我怎么才能让这两个人见面呢?
幸运的是,什么都有一个工具,甚至是让你的工具更好工作的工具。稍微搜索了一下,我就找到了 Python 包 rpy2 ,它的全部目的是让您在 Python 上下文中运行 R,无论这意味着将 R 包作为 Python 模块导入,直接在.py文件中运行您自己的 R 代码,还是将 R 数据帧转换成 pandas。不幸的是,这给我的项目依赖性增加了额外的复杂性:我不仅使用了更多的包,而且我现在需要在我的开发环境中有两种完整的语言可用。解决这个问题的最好的工具肯定是 Docker(对于代码,它是一路向下的工具),特别是如果您计划在不同的机器上运行这样的代码或者与其他人合作。这不是 Docker 教程(如果你感兴趣,你可以在 GitHub 上查看 Docker 对 Tipresias 的设置),但基本思想是它创建了一个隔离的虚拟环境(即“容器”),你可以在其中运行你的代码。这意味着您可以安装所有依赖项的精确版本,而不用担心与计算机上的其他库冲突。此外,合作者只需输入几个命令,就可以轻松地创建一个已经安装了所有东西的开发环境。
我没想到福蒂做了这么多坏事
121 年来,很多人在 VFL 和 AFL 打了很多比赛:619,751 场(加上比芒格更容易输掉的几轮循环赛中的 100 场左右),给或拿。该数据集的规模带来了新的挑战,超出了更长的处理时间。首先,当我清理和转换数据时,我的 Jupyter 笔记本电脑一直在崩溃,这导致我花了整整一个周末来解决如何批量处理数据的问题,结果才意识到我所需要的只是增加 Docker 的内存限制。
至于弄清楚如何让球员数据成为对比赛预测有用的形状,本着总是从 MVP(在这种情况下是“最小可行产品”)开始的精神,我决定采用一种简单的方法:计算每个球员统计数据的滚动平均值(例如,踢球、得分、进球),然后将参加给定比赛的给定球队的所有球员的平均统计数据相加。这类似于使用一个球队在比赛中的统计数据的滚动平均值,但增加了一个细微的差别,只包括实际比赛的球员最近的表现。因此,如果一个球队的最佳球员没有参加他们的下一场比赛,总的统计数据将反映该队预期表现的下降。
在董事会上得到一个模型
现在,我已经将我的球员数据聚合并组织到团队比赛行中,就像我的其他模型的数据集一样,我可以开始查看各种机器学习模型的相对性能。与基于其他数据集的模型一样,我发现包括一支球队的统计数据和他们对手的统计数据可以提高模型的性能,最低的交叉验证平均绝对误差(MAE)在没有对手统计数据的情况下为 31.79,在有对手统计数据的情况下为 30.95。以下是使用球队及其对手的聚合球员数据的各种模型的 MAEs。

与博彩数据一样,尽管这次不那么明显,但线性模型的表现优于花哨的集合。然而,前五名都非常接近,如果不是按升序排列,很难选出最好的。下面的准确度分数进一步证明了这些模型的性能有多接近。

当考虑模型的准确性时,LinearSVR 和 Ridge 仍然是最高的,但它们现在落后于 MAE 分数排名第三至第五的集合模型。值得庆幸的是,至少相同的模型在 MAE 和准确性方面都排在前五位,这限制了我在逐年细分的性能中需要比较的数量。

Ridge 和 XGBoost 似乎有最好的年度 MAEs,每个都有两年内的最低值,但与 CV/test 分数一样,没有明显的赢家,因为 2015 年和 2016 年的误差分数非常接近,XGBoost 和 Ridge 在任何给定的年份都没有持续排名前二。

不管我用多少种不同的方法分割数据,我总是得到混杂的结果。在这一点上有点直觉,但 XGBoost 往往是跨不同度量和数据段的较好模型之一。这不是一个明显的赢家(Ridge 和 GradientBoost 的性能大致相当),但我过去使用 XGBoost 取得了不错的结果,这足以让它占据优势。
玩家评级模型
受到 HPN 的 PAV 的启发,但我对足球不够了解,无法应用必要的严谨性来创建我自己的球员评级系统,我想知道我是否能找到一种算法来为我创建一个。我没有像上面那样汇总玩家的比赛统计数据,而是将它们和一些汇总的对手统计数据一起输入一个回归变量,试图估计每个玩家对最终得分的贡献。这是一种简单的方法,但我只是想看看它是否有潜力作为一种使用球员数据来预测比赛结果的手段。
我通过几个线性算法(当我试图使用 scikit-learn 集合时,waaaay 花了太长时间来训练)来处理未聚合的球员数据,以根据每个球员的游戏内统计数据来估计每场比赛的最终得分差距。然后,我采用了表现最佳的模型,并使用其预测创建了一个球员评级特征,我将该特征按每场比赛的球队进行汇总(即每场比赛有两行,每个参赛队一行),以用于最终模型。这种堆叠整体的最终表现并不太糟糕,但表现最好的模型仍然比基于聚合球员统计数据的简单模型多几个点的 MAE 和低几个百分点的准确性,即使相对表现更接近,在原始球员数据上训练模型所花费的时间也是令人痛苦的。说真的,我的笔记本偶尔会在计算交叉验证分数的过程中挂起,这就像西西弗斯的巨石滚回冥河深处一样。有可能使用类似这样的东西向主玩家数据模型添加一个特性,但是我想我会通过添加 PAV 来获得更好的性能,所以这个想法对于未来的实验来说优先级很低。
3D 玩家数据
鉴于球员数据给我的初始团队比赛数据结构增加了一个额外的部分,我想知道,除了汇总统计数据,我是否可以将球员分成他们自己的维度,将维度为[team-matchxaggregated feature的矩阵转换为[team-matchxplayerxfeature]的矩阵。获得正确的数据形状需要比我希望的更多的工作,但是我能够在 Footy Tipper 中重用递归神经网络(RNN)的一些代码来完成它。对我来说,最大的挑战是总是以正确的排序顺序获取数据,并计算出正确的维度,以便 numpy 的reshape按照我想要的方式工作。一旦我超越了二维,我的大脑开始崩溃,但我最终还是到达了那里。
与玩家评级模型一样,这只是一个实验,所以我实现了一个尽可能简单的版本,选择了一维卷积层和常见的池层。由于对 RNNs 有了更多的经验,我对 CNN 模型在数据上训练的速度感到惊喜,但即使在退出或正则化参数的情况下,过度拟合也是一个主要问题。训练集的误差随着每个时期持续下降,而验证误差将在两个或三个时期达到峰值,然后继续上升。这导致了与玩家评级模型相似的性能,即,在最好的情况下,MAE 在 30-32 的范围内,准确性在 64-66%的范围内,这两个指标都明显比基于聚合玩家数据训练的线性模型差。将这一点添加到集合中或以某种方式扩展数据以减少过度拟合是有一定潜力的,但就目前而言,与玩家评级模型一样,这种实验的优先级低于其他改进,如特征工程和在完整数据集上实现 RNN。
我们今天学到了什么?
我感觉这一系列博文的叠句就是“保持简单,笨蛋”。尽管我不后悔花时间去试验更复杂的方法,但基本的线性模型一直表现得和花哨的集合模型一样好,甚至更好。即使万能的 XGBoost 是最好的模型,当使用正确的随机种子时,总有至少两个线性模型稍微差一点,有时可能更好。已经看到了从几个不同的模型类型创建集合的可测量的收益,然而,我认为稍微更细微的教训是在移动到构建整个城堡之前从简单的构建块开始。重要的是要有一个好的基础来比较未来变化的影响。
为了你的皮肤美丽:用散景映射化妆品
根据化妆品的化学成分给出建议

每当我想尝试一种新的化妆品时,都很难选择。实际上不仅仅是困难。这有时很可怕,因为我从未尝试过的新东西最终给我带来了皮肤问题。我们知道我们需要的信息在每个产品的背面,但是除非你是一个化学家,否则很难解释那些成分表。因此,我不再担心我的新选择,而是决定自己建立一个简单的化妆品推荐。
第一步,我从丝芙兰网站搜集信息。为了专注于护肤项目,我只选择了六个不同的类别——润肤霜、面部护理、洁面乳、面膜、眼部护理和防晒。数据集总共有 1472 个项目。它也有关于品牌、价格、等级、皮肤类型和每件物品的化学成分的信息。我将跳过网页抓取这一步,但完整的代码和数据集可以在我的 Github 上找到。
按成分推荐
本文假设您已经对推荐系统有了基本的了解。如果你不熟悉推荐系统或余弦相似度,我推荐你阅读艾玛·马尔迪的 这篇 文章,它能给你这方面的直觉。在构建推荐引擎的各种方法中,基于内容的推荐被应用于本项目。选择的原因主要有两个。
首先,根据我过去用过的物品来预测一个新产品有多合适是不合适的。那是因为训练集(过去的产品)比测试集小很多。想象一下,与世界上存在的化妆品数量相比,一个人尝试了多少产品。
其次,关于皮肤病的美容建议是一个复杂的问题。可能有些人对化妆品有着非常相似的品味。而且有了用户-用户协同过滤,我们就可以根据这个邻近群体的排名值来推荐新产品。然而,一个人的皮肤类型和特征是一个比仅仅推荐你今晚的电影更敏感和棘手的问题。要得到推荐中的可靠性和稳定性,我们需要关注每种产品的真实含量,或者产品的成分,并基于它们得到相似度。
进入之前的一些预处理步骤。
现在让我们从检查数据集开始。抓取后的几个预处理步骤已经完成,我们将从这里开始。无重复项 1472 项,17 列。

下一步是清除Ingredients列中的文本数据。数据是从 Sephora 页面上刮下来的。正如你在下面看到的,有两个部分——一些特定成分的描述,所有成分的列表,以及附加信息。


这里只需要食材部分(左边第二段或者右边第一段)。由于行被'\r\n\r\n'分隔,我们将使用此模式分割文本。
*# Split the ingredients with '\r\n\r\n'*
a = [t.split('\r\n\r\n') for t in cosm['Ingredients']]
结果将是列表中的列表。换句话说,分开的部分被放在一个列表中,每个条目的列表被收集在一个列表中。那么我们如何只提取成分的一部分呢?我的策略是使用几种模式来检测不需要的部分。
*# Take onle the part with the real ingredients*
pattern = ['\r\n', '-\w+: ', 'Please', 'No Info',
'This product','Visit']**for** i **in** range(len(cosm)):
num = len(a[i])
**for** j **in** range(num):
**if** all(x not in a[i][j] for x in patern):
cosm['Ingredients'][i] = a[i][j]
遍历每一项,我们可以只取一个不包含模式词的项,放入Ingredients列的相应行。现在我们准备开始标记化了。
将 NLP 概念应用于化学品
我们的数据中有六类产品(保湿霜、洁面乳、面膜、眼霜、和防晒),还有五种不同的皮肤类型(混合性、干性、中性、油性和敏感性)。我们正在制作的地图是带有可选选项的绘图,以便用户可以获得更详细的结果。会有两种选择。一种用于化妆品类别,如保湿剂和清洁剂。另一类针对干性和油性等皮肤类型的用户。为了清楚起见,让我们先关注一个选项,即针对干性肤质的 保湿剂 ,然后将相同的过程应用于其他选项。
**# Making the two options*
option_1 = cosm.Label.unique().toarray()
option_2 = ['Combination', 'Dry', 'Normal', 'Oily', 'Sensitive']*# Filter the data by the given options*
df = cosm[cosm['Label'] == 'Moisturizer'][cosm['Dry'] == 1]
df = df.reset_index()*
过滤后的数据有 190 项。为了达到我们比较每个产品成分的最终目标,我们首先需要做一些预处理工作,并记录每个产品成分列表中的实际单词。第一步是标记Ingredients列中的成分列表。将它们拆分成记号后,我们将制作一个二进制单词包。然后我们将创建一个带有标记ingredient_idx的字典,如下所示。
**# Tokenization*
ingredient_idx = {}
corpus = []
idx = 0
**for** i **in** range(len(df)):
ingredients = df['Ingredients'][i]
ingredients_lower = ingredients.lower()
tokens = ingredients_lower.split(', ')
corpus.append(tokens)
**for** ingredient **in** tokens:
**if** ingredient **not** **in** ingredient_idx:
ingredient_idx[ingredient] = idx
idx += 1*
一个一个的经过,我们先把所有的字母放低,把文字拆分。将所有标记化的单词放入语料库。然后准备另一个循环。这个是用来把单词放进我们事先编好的字典里的。它首先检查重复,如果一个单词还没有找到,就用索引把它放进字典。指数的值会一个一个增加。
下一步是制作一个文档术语矩阵(DTM)。在这里,每个化妆品对应一个文档,每个化学成分对应一个术语。这意味着我们可以把矩阵想象成一个“化妆品成分”矩阵。矩阵的大小应该如下图所示。

为了创建这个矩阵,我们将首先创建一个用零填充的空矩阵。矩阵的长度是数据中化妆品的总数。矩阵的宽度是成分的总数。初始化这个空矩阵后,我们将在下面的任务中填充它。
**# Get the number of items and tokens*
M = len(df) # The number of the items
N = len(ingredient_idx) # The number of the ingredients
*# Initialize a matrix of zeros*
A = np.zeros((M, N))*
在填充矩阵之前,让我们创建一个函数来计算每一行的令牌数(例如,一个成分列表)。我们的最终目标是用 1 或 0 填充矩阵:如果一种成分在化妆品中,值就是 1。如果不是,则保持为 0。这个函数的名字oh_encoder,接下来将变得清晰。
**# Define the oh_encoder function*
**def** oh_encoder(tokens):
x = np.zeros(N)
**for** ingredient **in** tokens:
*# Get the index for each ingredient*
idx = ingredient_idx[ingredient]
*# Put 1 at the corresponding indices*
x[idx] = 1
**return** x*
现在我们将把oh_encoder()函数应用到corpus中的记号上,并在这个矩阵的每一行设置值。所以结果会告诉我们每样东西是由什么成分组成的。例如,如果一个化妆品项目包含水、烟酸、癸酸酯和sh-多肽-1* ,该项目的结果将如下。*

这就是我们所说的一次性编码。通过对物品中的每种成分进行编码,化妆品成分矩阵将用二进制值填充。
**# Make a document-term matrix*
i = 0
**for** tokens **in** corpus:
A[i, :] = oh_encoder(tokens)
i += 1*
用 t-SNE 降维
现有矩阵的维数是(190,2215),这意味着我们的数据中有 2215 个特征。为了形象化,我们应该把它缩小成二维。我们将使用 t-SNE 来降低数据的维度。
【T-分布式随机邻居嵌入(t-SNE) 是一种非线性降维技术,非常适合于在二维或三维的低维空间中嵌入用于可视化的高维数据。具体来说,这种技术可以降低数据的维度,同时保持实例之间的相似性。这使我们能够在坐标平面上绘图,这可以说是矢量化。我们数据中的所有这些装饰项目都将被矢量化为二维坐标,点之间的距离将表明项目之间的相似性。
**# Dimension reduction with t-SNE*
model = TSNE(n_components = 2, learning_rate = 200)
tsne_features = model.fit_transform(A)
*# Make X, Y columns*
df['X'] = tsne_features[:, 0]
df['Y'] = tsne_features[:, 1]*
我将结果值与价格、品牌名称和排名等其他列相结合。因此生成的数据帧如下所示。

用散景映射装饰项目
我们现在准备开始创建我们的情节。有了 t-SNE 值,我们可以在坐标平面上绘制所有的项目。这里最酷的部分是,它还会向我们显示每个项目的名称、品牌、价格和排名。让我们使用散景制作一个散点图,并添加一个悬停工具来显示这些信息。请注意,我们还不会显示该图,因为我们将对其进行更多的添加。
**# Make a source and a scatter plot*
source = ColumnDataSource(**df_all**)
plot = figure(x_axis_label = 'T-SNE 1',
y_axis_label = 'T-SNE 2',
width = 500, height = 400)
plot.circle(x = 'X', y = 'Y', source = source,
size = 10, color = '#FF7373', alpha = .8)plot.background_fill_color = "beige"
plot.background_fill_alpha = 0.2*# Add hover tool*
hover = HoverTool(tooltips = [
('Item', '@name'),
('brand', '@brand'),
('Price', '$ @price'),
('Rank', '@rank')])
plot.add_tools(hover)*
这里的数据df_all是所有可能的选择组合的数据。到目前为止,我们已经完成了相同的过程。我只是将所有可能的选项合并到一个数据框中。因此,当我们创建一个回调函数并给它一个可选选项时,它将获取给定条件下的数据并更新绘图。
**# Define the callback*
**def** update(op1 = option_1[0], op2 = option_2[0])**:**
a_b = op1 + '_' + op2
new_data = {
'X' : df[df['Label'] == a_b]['X'],
'Y' : df[df['Label'] == a_b]['Y'],
'name' : df[df['Label'] == a_b]['name'],
'brand' : df[df['Label'] == a_b]['brand'],
'price' : df[df['Label'] == a_b]['price'],
'rank' : df[df['Label'] == a_b]['rank'],
}
source.data = new_data
push_notebook()*# interact the plot with callback*
interact(update, op1 = option_1, op2 = option_2)
show(plot, notebook_handle = True)*
终于,表演时间到了!让我们看看我们制作的地图是什么样子的。🙌🙌

图上的每个点对应于化妆品项目。那这些轴在这里是什么意思?根据原始数据,SNE 霸王龙图的坐标轴不容易解释。如上所述,t-SNE 是一种在低维空间绘制高维数据的可视化技术。因此,定量解释 t-SNE 图是不可取的。
相反,我们从这张地图上能得到的是点与点之间的距离(哪些项目距离近,哪些项目距离远)。两个项目之间的距离越近,它们的组成就越相似。因此,这使我们能够在没有任何化学背景的情况下比较这些项目。
比较具有余弦相似性的项目
最后,让我们比较每个点之间的相似性。 余弦相似度 是衡量两个非零向量之间相似度的一种方式。我们用余弦值代替两者之间的距离是什么原因?使用距离也是可以的,但是如果我们将向量之间的角度加入到距离概念中,这个值将代表比长度更多的信息。它甚至可以包含带有符号的方向数据。所以取余弦相似度基本上能提供更多信息。
*df_2 = df[df.Label == 'Moisturizer_Dry'].reset_index()
df_2['dist'] = 0.0*
比如有个产品叫泥炭奇迹复活霜。让我们比较一下它和其他干性皮肤保湿产品的性能。
**# Find the product named Peat Miracle Revital*
myItem = df_2[df_2.name.str.contains('Peat Miracle Revital')]*# getting the array for myItem*
X = myItem.SVD1.values
Y = myItem.SVD2.values
Point_1 = np.array([X, Y]).reshape(1, -1)*# cosine similarities with other items*
for i in range(len(df_2)):
P2 = np.array([df_2['SVD1'][i], df_2['SVD2'][i]]).reshape(-1, 1)
df_2.dist[i] = (P1 * P2).sum() / (np.sqrt(np.sum(P1))*np.sqrt(np.sum(P2)))*
如果我们将结果按升序排序,我们可以看到前 5 个最接近的化妆品,如下所示。
**# sorting by the similarity*
df_2 = df_2.sort_values('dist')
df_2[['name', 'dist']].head(5)*

这是与myItem性质相似的前 5 名化妆品。也许我下次应该买娇兰。有了这份清单,我们可以为新产品做推荐。如果我们按降序排列,那么这个列表可以被用作‘对你来说最差的选择’。
结论
基于产品属性的推荐可以应用于任何领域。它也可以应用于一本书或葡萄酒推荐。我们可以根据产品特点制作各种地图。在坐标平面上可视化产品有助于我们以直观的方式理解项目之间的关系。
通过这种分析,我们可以进一步实现更精细的服务。它可以显示商品的图片和评论,或者提供订购页面的直接链接。我们也可以画一个不同的图,它的轴代表化学属性。例如,如果我们添加一些专业的化学知识,我们可以设置水合作用或毒性的坐标轴。在这种情况下,它将能够看到每个项目的毒性有多大。这些类型的应用将提供更高水平的产品分析。
资源
- 准备好学习更多关于推荐系统的知识了吗?解释四种不同推荐算法的最佳文章作者James Le:https://medium . com/@ James _ aka _ Yale/the-4-recommendation-engines-that-can-predict-your-movie-tastes-bbec 857 b 8223
- 准备好用散景构建您的精彩情节了吗?Datacamp 上的这个课程将是最好的起点:https://www . data camp . com/courses/interactive-data-visualization-with-bokeh
感谢您的阅读,希望您对这篇文章感兴趣。如果有需要改正的地方,请分享你的见解!如果您想鼓励一位有抱负的数据科学家,请点击👏 👏 👏!我总是乐于交谈,所以请随时在 LinkedIn 上留下评论或联系我。我会带着另一个令人兴奋的项目回来。在那之前,机器学习快乐!
用递归神经网络预测空气污染

Photo by Carolina Pimenta on Unsplash
在完成了公民科学项目之后,我想了解更多关于空气污染的知识,看看我是否可以用它来做一个数据科学项目。在欧洲环境署的网站上,你可以找到大量关于空气污染的数据和信息。
在这本笔记本中,我们将关注比利时的空气质量,更具体地说是二氧化硫(SO2) 造成的污染。数据可以通过https://www . EEA . Europa . eu/data-and-maps/data/aqe reporting-2/be下载。zip 文件包含不同空气污染物和聚集水平的单独文件。第一个数字代表污染物 ID,如词汇表中所述。这个笔记本用的文件是BE _ 1 _ 2013–2015 _ aggregated _ time series . CSV这是比利时的 SO2 污染情况,但是你也可以找到其他欧洲国家的类似数据。
在数据下载页面上可以找到 CSV 文件中字段的描述。更多关于空气污染物的背景信息可以在维基百科上找到。
项目设置
*# Importing packages*
**from** **pathlib** **import** Path
**import** **pandas** **as** **pd**
**import** **numpy** **as** **np**
**import** **pandas_profiling**
%**matplotlib** inline
**import** **matplotlib.pyplot** **as** **plt**
**import** **warnings**
warnings.simplefilter(action = 'ignore', category = **FutureWarning**)
**from** **sklearn.preprocessing** **import** MinMaxScaler
**from** **keras.preprocessing.sequence** **import** TimeseriesGenerator
**from** **keras.models** **import** Sequential
**from** **keras.layers** **import** Dense, LSTM, SimpleRNN
**from** **keras.optimizers** **import** RMSprop
**from** **keras.callbacks** **import** ModelCheckpoint, EarlyStopping
**from** **keras.models** **import** model_from_json
*# Setting the project directory*
project_dir = Path('/Users/bertcarremans/Data Science/Projecten/air_pollution_forecasting')
加载数据
date_vars = ['DatetimeBegin','DatetimeEnd']
agg_ts = pd.read_csv(project_dir / 'data/raw/BE_1_2013-2015_aggregated_timeseries.csv', sep='**\t**', parse_dates=date_vars, date_parser=pd.to_datetime)
meta = pd.read_csv(project_dir / 'data/raw/BE_2013-2015_metadata.csv', sep='**\t**')
print('aggregated timeseries shape:**{}**'.format(agg_ts.shape))
print('metadata shape:**{}**'.format(meta.shape))
数据探索
让我们使用 pandas_profiling 来检查数据。
pandas_profiling.ProfileReport(agg_ts)
为了不与图表混淆,我不会在本文中显示 pandas_profiling 的输出。但是你可以在我的 GitHub 回购里找到。
pandas_profiling 报告告诉我们:
- 有 6 个常量变量。我们可以把这些从数据集中去掉。
- 不存在缺失值,因此我们可能不需要应用插补。
- 有一些零,但这可能是完全正常的。另一方面,这些变量有一些极值,可能是空气污染的不正确记录。
- 共有 53 个空气质量站,可能与采样点相同。airqualitystationoicode 只是 AirQualityStation 的一个较短的代码,因此变量也可以被删除。
- AirQualityNetwork 有 3 个值(布鲁塞尔、佛兰德和瓦隆)。大多数测量来自佛兰德斯。
- DataAggregationProcess :大多数行包含作为一天测量(P1D)的 24 小时平均值聚集的数据。关于其他值的更多信息可以在这里找到。在这个项目中,我们将只考虑 P1D 值。
- DataCapture :平均周期内有效测量时间相对于总测量时间(时间覆盖)的比例,以百分比表示。几乎所有行都有大约 100%的有效测量时间。一些行的数据捕获率略低于 100%。
- DataCoverage :平均周期内聚合过程中包含的有效测量的比例,以百分比表示。在这个数据集中,我们至少有 75%。根据该变量的定义,低于 75%的值不应包括在空气质量评估中,这解释了为什么这些行不出现在数据集中。
- TimeCoverage :与数据覆盖率高度相关,将从数据中删除。
- 单位空气污染等级 : 423 行有一个单位计数。为了有一个一致的目标变量,我们将删除这种类型的单位的记录。
- 日期时间开始和日期时间结束:柱状图在这里没有提供足够的细节。这需要进一步分析。
日期时间开始和日期时间结束
pandas_profiling 中的直方图结合了每个 bin 的多个天数。让我们看看这些变量在日常水平上的表现。
每个日期多个汇总级别
- datetime begin:2013、2014、2015 年 1 月 1 日和 2013、2014 年 10 月 1 日的大量记录。
- datetime end:2014、2015、2016 年 1 月 1 日和 2014、2015 年 4 月 1 日的大量记录。
plt.figure(figsize=(20,6))
plt.plot(agg_ts.groupby('DatetimeBegin').count(), 'o', color='skyblue')
plt.title('Nb of measurements per DatetimeBegin')
plt.ylabel('number of measurements')
plt.xlabel('DatetimeBegin')
plt.show()

Number of rows per date
记录数量中的异常值与多个聚合级别(DataAggregationProcess)有关。这些日期的 DataAggregationProcess 中的值反映了 DatetimeBegin 和 DatetimeEnd 之间的时间段。例如,2013 年 1 月 1 日是一年测量期的开始日期,直到 2014 年 1 月 1 日。
由于我们只对每日汇总级别感兴趣,过滤掉其他汇总级别将解决这个问题。为此,我们也可以删除 DatetimeEnd。
每日汇总级别缺少时间步长
正如我们在下面看到的,并非所有采样点都有三年期间内所有日期时间 Begin 的数据。这是 DataCoverage 变量低于 75%的最有可能的日子。所以在这些日子里,我们没有足够的有效测量。在本笔记本的后面,我们将使用前几天的测量值来预测当天的污染情况。
为了获得类似大小的时间步长,我们需要为每个采样点插入缺失的 DatetimeBegin 行。我们将用有效数据插入第二天的测量数据。
其次,我们将删除太多丢失时间步长的采样点。这里我们将任意取 1.000 个时间步长作为所需时间步长的最小数目。
ser_avail_days = agg_ts.groupby('SamplingPoint').nunique()['DatetimeBegin']
plt.figure(figsize=(8,4))
plt.hist(ser_avail_days.sort_values(ascending=**False**))
plt.ylabel('Nb SamplingPoints')
plt.xlabel('Nb of Unique DatetimeBegin')
plt.title('Distribution of Samplingpoints by the Nb of available measurement days')
plt.show()

Distribution of SamplingPoints by the number of available measurement days
数据准备
数据清理
基于数据探索,我们将执行以下操作来清理数据:
- 仅保留 P1D 的 DataAggregationProcess 记录
- 正在删除计数为 UnitOfAirPollutionLevel 的记录
- 删除一元变量和其他冗余变量
- 移除少于 1000 个测量日的采样点
df = agg_ts.loc[agg_ts.DataAggregationProcess=='P1D', :]
df = df.loc[df.UnitOfAirPollutionLevel!='count', :]
df = df.loc[df.SamplingPoint.isin(ser_avail_days[ser_avail_days.values >= 1000].index), :]
vars_to_drop = ['AirPollutant','AirPollutantCode','Countrycode','Namespace','TimeCoverage','Validity','Verification','AirQualityStation',
'AirQualityStationEoICode','DataAggregationProcess','UnitOfAirPollutionLevel', 'DatetimeEnd', 'AirQualityNetwork',
'DataCapture', 'DataCoverage']
df.drop(columns=vars_to_drop, axis='columns', inplace=**True**)
为缺失的时间步长插入行
对于每个采样点,我们将首先插入(空)没有 DatetimeBegin 的行。这可以通过在最小和最大 DatetimeBegin 之间的范围内创建包含所有采样点的完整多索引来实现。然后, reindex 将插入丢失的行,但是对于列使用 NaN。
其次,我们使用 bfill 并指定用有效数据的下一行的值来估算缺失值。bfill 方法应用于 groupby 对象,以将回填限制在每个采样点的行内。这样,我们就不会使用另一个采样点的值来填充缺失的值。
测试该操作是否正确工作的样本点是日期为2013–01–29的 SPO-BETR223_00001_100 。
dates = list(pd.period_range(min(df.DatetimeBegin), max(df.DatetimeBegin), freq='D').values)
samplingpoints = list(df.SamplingPoint.unique())
new_idx = []
**for** sp **in** samplingpoints:
**for** d **in** dates:
new_idx.append((sp, np.datetime64(d)))
df.set_index(keys=['SamplingPoint', 'DatetimeBegin'], inplace=**True**)
df.sort_index(inplace=**True**)
df = df.reindex(new_idx)
*#print(df.loc['SPO-BETR223_00001_100','2013-01-29']) # should contain NaN for the columns*
df['AirPollutionLevel'] = df.groupby(level=0).AirPollutionLevel.bfill().fillna(0)
*#print(df.loc['SPO-BETR223_00001_100','2013-01-29']) # NaN are replaced by values of 2013-01-30*
print('**{}** missing values'.format(df.isnull().sum().sum()))
处理多个时间序列
好了,现在我们有了一个干净的数据集,不包含任何丢失的值。使这个数据集特别的一个方面是我们有多个采样点的数据。所以我们有多个时间序列。
一种处理方法是为采样点创建虚拟变量,并使用所有记录来训练模型。另一种方法是为每个采样点建立一个单独的模型。在本笔记本中,我们将采用后者。但是,我们将限制笔记本电脑只能在一个采样点上这样做。但是同样的逻辑可以应用于每个采样点。
df = df.loc['SPO-BETR223_00001_100',:]
分割训练、测试和验证集
为了评估模型的性能,我们划分了一个测试集。在训练阶段将不使用该测试集。
- 列车组:截至 2014 年 7 月的数据
- 验证集:2014 年 7 月至 2015 年 1 月之间的 6 个月
- 测试集:2015 年的数据
train = df.query('DatetimeBegin < "2014-07-01"')
valid = df.query('DatetimeBegin >= "2014-07-01" and DatetimeBegin < "2015-01-01"')
test = df.query('DatetimeBegin >= "2015-01-01"')
缩放比例
*# Save column names and indices to use when storing as csv*
cols = train.columns
train_idx = train.index
valid_idx = valid.index
test_idx = test.index
*# normalize the dataset*
scaler = MinMaxScaler(feature_range=(0, 1))
train = scaler.fit_transform(train)
valid = scaler.transform(valid)
test = scaler.transform(test)
保存已处理的数据集
这样,我们就不需要在每次重新运行笔记本时重复预处理。
train = pd.DataFrame(train, columns=cols, index=train_idx)
valid = pd.DataFrame(valid, columns=cols, index=valid_idx)
test = pd.DataFrame(test, columns=cols, index=test_idx)
train.to_csv('../data/processed/train.csv')
valid.to_csv('../data/processed/valid.csv')
test.to_csv('../data/processed/test.csv')
建模
首先,我们读入经过处理的数据集。其次,我们创建一个函数来绘制我们将构建的不同模型的训练和验证损失。
train = pd.read_csv('../data/processed/train.csv', header=0, index_col=0).values.astype('float32')
valid = pd.read_csv('../data/processed/valid.csv', header=0, index_col=0).values.astype('float32')
test = pd.read_csv('../data/processed/test.csv', header=0, index_col=0).values.astype('float32')
**def** plot_loss(history, title):
plt.figure(figsize=(10,6))
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Validation')
plt.title(title)
plt.xlabel('Nb Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
val_loss = history.history['val_loss']
min_idx = np.argmin(val_loss)
min_val_loss = val_loss[min_idx]
print('Minimum validation loss of **{}** reached at epoch **{}**'.format(min_val_loss, min_idx))
使用时间序列生成器准备数据
Keras 的 TimeseriesGenerator 帮助我们以正确的格式构建数据用于建模。
- **长度:**生成序列中的时间步长数。这里我们想回顾任意数量的 n_lag 时间步。实际上,n_lag 可能取决于如何使用预测。假设比利时政府可以采取一些措施来减少采样点周围的 SO2 污染(例如在一定时间内禁止柴油车进入某个城市)。假设政府在纠正措施生效前需要 14 天。那么将 n_lag 设置为 14 是有意义的。
- sampling_rate: 生成序列中连续时间步之间的时间步数。我们希望保留所有的时间步长,因此我们将其保留为默认值 1。
- **步距:**该参数影响生成的序列重叠的程度。由于我们没有太多的数据,我们将其保留为默认值 1。这意味着相继生成的两个序列与除一个时间步长之外的所有时间步长重叠。
- batch_size: 每批生成的序列数
n_lag = 14
train_data_gen = TimeseriesGenerator(train, train, length=n_lag, sampling_rate=1, stride=1, batch_size = 5)
valid_data_gen = TimeseriesGenerator(train, train, length=n_lag, sampling_rate=1, stride=1, batch_size = 1)
test_data_gen = TimeseriesGenerator(test, test, length=n_lag, sampling_rate=1, stride=1, batch_size = 1)
递归神经网络
传统的神经网络没有记忆。因此,在处理当前输入时,它们不会考虑以前的输入。在时序数据集中,如时间序列,先前时间步骤的信息通常与当前步骤的预测相关。因此需要保持关于先前时间步的状态和状态。
在我们的例子中,时间 t 的空气污染可能受到先前时间点的空气污染的影响。所以我们需要考虑到这一点。递归神经网络或 rnn 有一个内部循环,通过它它们保持先前时间步长的状态。然后,该状态用于当前时间步长中的预测。当一个新的序列被处理时,该状态被复位。关于 RNNs 的图解指南,你绝对应该阅读 Michael Nguyen 的文章。
在我们的例子中,我们使用 Keras 包的一个 SimpleRNN 。我们还指定了一个提前停止回调,当有 10 个时期没有任何验证损失的改善时停止训练。模型检查点允许我们保存最佳模型的权重。模型架构仍然需要单独保存。
simple_rnn = Sequential()
simple_rnn.add(SimpleRNN(4, input_shape=(n_lag, 1)))
simple_rnn.add(Dense(1))
simple_rnn.compile(loss='mae', optimizer=RMSprop())
checkpointer = ModelCheckpoint(filepath='../model/simple_rnn_weights.hdf5'
, verbose=0
, save_best_only=**True**)
earlystopper = EarlyStopping(monitor='val_loss'
, patience=10
, verbose=0)
**with** open("../model/simple_rnn.json", "w") **as** m:
m.write(simple_rnn.to_json())
simple_rnn_history = simple_rnn.fit_generator(train_data_gen
, epochs=100
, validation_data=valid_data_gen
, verbose=0
, callbacks=[checkpointer, earlystopper])
plot_loss(simple_rnn_history, 'SimpleRNN - Train & Validation Loss')

Training and validation loss for a SimpleRNN
长短期记忆网络
RNN 人记性很差。很难记住许多时间点以前的信息。当序列非常长时会出现这种情况。其实是因为消失渐变问题。梯度是更新神经网络权重的值。当你的 RNN 中有很多时间步长时,第一层的梯度会变得非常小。结果,第一层的权重的更新可以忽略。这意味着 RNN 不能学习早期地层中的东西。
因此,我们需要一种方法将第一层的信息传递给后面的层。LSTMs 更适合考虑长期依赖性。Michael Nguyen 写了一篇关于 LSTMs 的视觉描述的优秀文章。
简单 LSTM 模型
simple_lstm = Sequential()
simple_lstm.add(LSTM(4, input_shape=(n_lag, 1)))
simple_lstm.add(Dense(1))
simple_lstm.compile(loss='mae', optimizer=RMSprop())
checkpointer = ModelCheckpoint(filepath='../model/simple_lstm_weights.hdf5'
, verbose=0
, save_best_only=**True**)
earlystopper = EarlyStopping(monitor='val_loss'
, patience=10
, verbose=0)
**with** open("../model/simple_lstm.json", "w") **as** m:
m.write(simple_lstm.to_json())
simple_lstm_history = simple_lstm.fit_generator(train_data_gen
, epochs=100
, validation_data=valid_data_gen
, verbose=0
, callbacks=[checkpointer, earlystopper])
plot_loss(simple_lstm_history, 'Simple LSTM - Train & Validation Loss')

Training and validation loss for a simple LSTM
堆叠 LSTM 模型
在这个模型中,我们将堆叠多个 LSTM 层。这样,模型将随着时间的推移学习输入数据的其他抽象。换句话说,表示不同时间尺度的输入数据。
在 Keras 中要做到这一点,我们需要在另一个 LSTM 层之前的 LSTM 层中指定参数 return_sequences 。
stacked_lstm = Sequential()
stacked_lstm.add(LSTM(16, input_shape=(n_lag, 1), return_sequences=**True**))
stacked_lstm.add(LSTM(8, return_sequences=**True**))
stacked_lstm.add(LSTM(4))
stacked_lstm.add(Dense(1))
stacked_lstm.compile(loss='mae', optimizer=RMSprop())
checkpointer = ModelCheckpoint(filepath='../model/stacked_lstm_weights.hdf5'
, verbose=0
, save_best_only=**True**)
earlystopper = EarlyStopping(monitor='val_loss'
, patience=10
, verbose=0)
**with** open("../model/stacked_lstm.json", "w") **as** m:
m.write(stacked_lstm.to_json())
stacked_lstm_history = stacked_lstm.fit_generator(train_data_gen
, epochs=100
, validation_data=valid_data_gen
, verbose=0
, callbacks=[checkpointer, earlystopper])
plot_loss(stacked_lstm_history, 'Stacked LSTM - Train & Validation Loss')

Training and validation loss for a stacked LSTM
评估绩效
基于最小验证损失,SimpleRNN 似乎优于 LSTM 模型,尽管度量标准彼此接近。使用 evaluate_generator 方法,我们可以对测试数据(生成器)上的模型进行评估。这会给我们带来测试数据上的损失。我们将首先从 JSON 文件中加载模型架构和最佳模型的权重。
**def** eval_best_model(model):
*# Load model architecture from JSON*
model_architecture = open('../model/'+model+'.json', 'r')
best_model = model_from_json(model_architecture.read())
model_architecture.close()
*# Load best model's weights*
best_model.load_weights('../model/'+model+'_weights.hdf5')
*# Compile the best model*
best_model.compile(loss='mae', optimizer=RMSprop())
*# Evaluate on test data*
perf_best_model = best_model.evaluate_generator(test_data_gen)
print('Loss on test data for **{}** : **{}**'.format(model, perf_best_model))
eval_best_model('simple_rnn')
eval_best_model('simple_lstm')
eval_best_model('stacked_lstm')
- simple_rnn 的测试数据的损失:0 . 54686 . 38686868661
- simple_lstm 的测试数据损失:0 . 54686 . 68686868661
- stacked_lstm 的测试数据损失:0 . 46866 . 38886888661
结论
在这个故事中,我们为 LSTM 使用了一个递归神经网络和两种不同的架构。最佳性能来自于由几个隐藏层组成的堆叠 LSTM。
肯定有许多事情值得进一步研究,以提高模型性能。
- 使用每小时的数据(EEA 网站上的另一个 CSV 文件),尝试除每日数据之外的其他采样策略。
- 使用关于其他污染物的数据作为特征来预测 SO2 污染。也许其他污染物与二氧化硫污染有关。
- 基于日期构建其他特征。在驱动数据的幂律预测竞赛的获胜者之一的 PDF 中可以找到一篇很好的文章
通过做这个项目,我学到了很多递归神经网络。我希望你喜欢它。欢迎留下任何评论!
在 Python 中使用 ARIMA 预测汇率
ARIMA 如何预测汇率时间序列数据
几乎所有部门都使用时间序列数据来预测未来的时间点。预测未来可以帮助分析师和管理层做出更好的决策,以实现回报最大化和风险最小化。我将在本文中演示我们如何预测汇率。如果你是金融新手,想了解什么是汇率,那么请阅读我的文章“学习金融的最佳途径?了解市场数据”。它提供了市场数据的基本概述。汇率取决于一系列因素,如供求关系、政府政策、国家增长率等。想了解更多关于影响汇率的经济指标的信息,请看看我的文章“评估和比较国家需要知道的一切”。
预测汇率
最近,引入了许多技术进步,可以快速、高效和准确地预测未来时间点。其中之一是在 Python 中引入统计和机器学习(ML)模型。在我的文章“ python 从头开始”中,我提供了 Python 基础知识的概述。
在本文中,我将使用 ARIMA 模型来预测汇率。
在我的博客“我如何预测时间序列?”和“理解自回归移动平均模型— ARIMA ”,我概述了时间序列的概念和 ARIMA 的工作方式。在这篇博客中,我将结合 Jupyter notebook 使用 python 编程语言来解释如何在 Python 中使用 ARIMA 来预测汇率。
请阅读 fintech 解释 d isclaimer 。
使用 Pandas 加载汇率数据
Pandas 是最流行的 Python 库之一。它建立在 Numpy python 库的基础上,提供了一系列功能,包括:
对象创建、数据分析和数据加载。它有内置的统计功能,可以合并/加入/联合多个集合。它还可以帮助我们分组、旋转和绘制数据。此外,Pandas 是一个非常有效的库,可以从 csv、HDF5 和 excel 加载数据。最后,可以对数据应用一系列样式和格式。
我们将利用熊猫来:
1.从 csv(逗号分隔)文件中加载时间序列汇率
2.查看前 10 条记录
3.查看数据的基本统计信息
从 csv 文件加载时间序列汇率
我准备了一份文件,其中包括自 1998 年 12 月 31 日以来英镑/美元的每日收盘汇率。文件存储在这里。该文件包含两列数据:数据和英镑/美元收盘
确保文件保存在与 python 笔记本相同的位置。
键入以下行以加载文件并查看前 10 条记录:
要导入一个库,做:将导入为 >
注意:GetData(fileName)是一个接受文件名作为参数的方法。
按 Alt + Enter 查看数据的基本统计信息
下图通过调用 GetData(fileName)方法显示了 csv 文件的前 10 条记录:

让我们找出有用的统计数据,并绘制出汇率图
键入:exchangeRatesSeries.describe()以查看如下所示的统计信息:

describe()显示了许多有用的指标,包括:
count —记录数, mean —期望值, std —告诉我们平均值周围数据的离差的标准偏差, min —集合中的最小值, max —集合中的最大值以及一个百分比范围。百分位数可以帮助我们理解数据的概率分布。
绘制加载的数据
可以添加 Html 样式来改变 Python 的感觉和外观。我将绘图颜色设置为绿色:
#绘制时间序列数据
exchange rates series . plot(color = ’ green ')

注意,传递 color='green '会创建一个绿色线图。
键入:exchangeRatesSeries.hist()以显示 historgram。
直方图可以帮助我们理解数据的分布,反过来帮助我们预测变量:

matplotlib 可以帮助我们绘制数据。我们也可以通过编写以下代码来导入 matplotlib:
从 matplotlib 导入 pyplot
然后写出时间序列:
py plot . plot(exchange rate series)
带 StatsModels 套装的 ARIMA
StatsModels 是一个功能强大的 python 库,包含丰富的统计模型。StatsModels 库包含许多可用于预测和预测数据的模型。这个库也包含许多诊断工具。我们将使用 StatsModels 软件包中的 ARIMA 模型来预测汇率。
ARIMA 简介
ARIMA 模型有 3 个参数:
P —模型的自回归特征
d——差分顺序
Q —模型的移动平均特征
导入 statsmodels 后,使用 tsa.arima_model 并给它一个别名 arima:
从 statsmodels.tsa.arima_model 导入 ARIMA
有关参数的详细信息,请访问:http://www . stats models . org/dev/generated/stats models . TSA . ARIMA _ model。ARIMA.html
ARIMA 参数可以改变,以获得不同的预测行为。我已经定义了一个用户定义的方法,它接受三个参数的训练集和值。该函数首先创建 ARIMA 模型。然后对模型执行 fit()和 forecast()。Forecast()返回预测值。
将这几行复制并粘贴到您的笔记本上:
ARIMA(……)创造了 ARIMA 模式。Fits()通过卡尔曼滤波器以最大似然法拟合 ARIMA(p,d,q)模型,Forecast()返回基于拟合的 ARIMA 模型的估计值。
我们可以认为 Fit()是一个生成误差最小的最佳拟合曲线的过程。关于这个话题的更多内容,请见我的博客:我的预测模型——回归分析有多好?
p,q,d 参数可以调整以获得更好的结果。
这是一个我们如何传递时间序列数据并使用 ARIMA 根据实际观察数据预测值的示例:
通过运行该脚本,我们可以看到预测值:

我们传入随机值作为训练集。然后 ARIMA 模型进行拟合,预测下一个值为 15.219305
我们还可以将外生变量、日期、时间序列的频率等传递给 ARIMA 模型。

最后,让我们使用 Python 中的 ARIMA 来预测汇率
既然我们已经了解了如何使用 python Pandas 来加载 csv 数据,以及如何使用 StatsModels 来预测价值,那么让我们结合本博客中获得的所有知识来预测我们的样本汇率。
复制并粘贴这段代码。它是我们在这个博客中学到的所有概念的结合。
按 Alt+Enter。Python 将开始用实际数据循环调用 ARIMA 模型。70%的数据用于训练模型,其余 30%用于测试准确性。每次产生新的预测值。
实际值和预测值将打印在笔记本上。
最后,实际值与预测值将绘制在图表上
查看均方误差
我还导入了一个额外的库 sklearn ,我将在未来的博客中使用它。
复制粘贴这一行:
“从 sklearn.metrics 导入 mean_squared_error”导入库。
最后打印均方差:
均方误差计算实际数据和预测数据之间差异的平均值,并告诉您您的模型有多好。更多信息可以在我的博客里找到: 我的预测模型—回归分析 有多好
通过运行下面的代码,我们可以查看实际值、预测值以及折线图和总均方误差:

如您所见,我们打印了实际值和预测值。此外,我们用红色绘制了 MSE 为 1.551 的预测值。
完整的笔记本,请访问这里。
进一步的改进
预测汇率可以通过以下方式改进:
- 不断更新模型参数
- 通过输入影响汇率及其相关性的其他因素
- 模型参数也可以通过机器学习和优化技术来更新。
- 最后,可以强调因素及其相关性,以确保预测的汇率考虑到极端情况。
最终注释
本文演示了如何使用 python 通过 ARIMA 模型预测汇率。金融市场可以向任何方向移动,这使得准确预测汇率变得非常困难,如果不是不可能的话。话虽如此,通过 ARIMA 预测汇率的唯一目的是帮助我们做出精心计算的决定,以实现回报最大化和风险最小化。预测汇率取决于 ARIMA 模型的假设,该模型基于自回归、综合和移动平均概念。
ARIMA 是一个简单而强大的模型。它假设历史价值决定现在的行为。它还假设数据不包含异常,是稳定的,并且模型参数以及误差项是恒定的。
尽管 ARIMA 没有将市场数据中的压力、经济和政治条件或所有风险因素的相关性作为预测汇率的输入,但上面展示的简单示例可用于预测正常情况下稳定货币的运动,在正常情况下,过去的行为决定了现在和价值。
如果您有任何反馈,请告诉我。
在构建预测模型之前,您应该了解的预测基础知识
预测,还是不预测,这是一个问题。
人类文明史与我们尝试预测方法的历史交织在一起。当我们的祖先观察天空来预测天气时,数据科学家开发并训练机器学习模型来预测销售、风险、事件、趋势等。准确的预测是一项重要的组织能力,做得好的企业将会有很大的生存优势。
应该预测什么
在预测项目的早期阶段,需要决定应该预测什么,什么时候可以准确预测,以及什么时候预测不会比扔硬币好。
例如,如果需要对房地产市场进行预测,则有必要询问是否需要对以下方面进行预测:
- 任何类型的财产,或独立/半独立/联排别墅/公寓分开?
- 是按地区分组的房产平均销售价格,还是仅针对总销售额?
- 周数据,月数据还是年数据?
需要注意的关键是并不是所有的预测都比掷硬币好。事件或价值的可预测性取决于几个因素,包括:
- 我们是否发现并理解了影响结果的大部分因素?
- 这些因素有“大”数据吗?
- 预测是否会影响我们试图预测的事情?
例如,24 小时天气预报可以非常准确,因为这三个条件通常都满足。另一方面,很难预测下一滴雨滴落入你眼中的概率,明天的并发汇率会上升或下降或下周的比特币价格。
时间跨度和数据可用性方面的预测类型
是否需要提前几分钟、6 个月或 10 年的预测?就时间跨度而言,有 3 种类型的预测:
- 短期预测:一至三个月的正常范围
- 中期预测:时间周期一般为一年
- 长期预测:预测超过两年的结果
在大多数预测情况下,随着事件的临近,与我们预测的事物相关的不确定性会减少。换句话说,我们预测的越近,我们就越准确。
根据数据可用性,预测可以分为两种类型。
- 定性预测:如果没有可用数据,或者可用数据与预测无关。
- 定量预测(时间序列预测):如果过去的数字信息可用;过去的模式将延续到未来。
用于定量预测(时间序列预测)的数据通常以固定的时间间隔观察,例如每小时、每天、每周、每月、每季度、每年。目标是估计历史观察序列将如何延续到未来。
预测方法
方法的选择取决于可用的数据和事件的可预测性或要预测的价值。
由于缺乏历史数据,判断性预测是定性预测的唯一选择。例如,预测新政策、新产品或新竞争对手的影响。
最简单的时间序列预测方法仅使用待预测变量的历史值,并排除可能影响其行为的因素,如竞争对手的活动、环境或经济条件的变化等。下图显示了使用过去 10 年的销售数据对 2017 年的房屋销售预测。

house sales prediction for 2017 with past 10-year sales data
在本文中,我们将讨论什么是预测、预测类型和预测方法。预测显然是一项具有挑战性的活动。在以后的文章中,我将探讨一些常用的预测方法,包括指数平滑法、ARIMA 模型、动态回归模型、LSTM 等。
“你看到这些伟大的建筑了吗?没有一块石头留在另一块石头上,不被拆毁。”( 马克 13:1–2)
让预测在未来到来之前向你展示它。
预测欧元区的 GDP

使用欧盟统计局数据和 ARIMA 模型预测欧元区季度 GDP(国内生产总值)
这一分析使用了欧盟统计局的公共数据集来预测所有欧元区国家未来的季度 GDP 总量。欧盟统计局是位于卢森堡的欧盟统计局。它的任务是为欧洲提供高质量的统计数据。欧盟统计局提供了一系列重要而有趣的数据,政府、企业、教育部门、记者和公众可以在工作和日常生活中使用这些数据。特别是,使用了欧元区(欧盟 19 国)季度 GDP(国内生产总值)数据集。欧元区由 19 个国家组成:奥地利、比利时、塞浦路斯、爱沙尼亚、芬兰、法国、德国、希腊、爱尔兰、意大利、拉脱维亚、立陶宛、卢森堡、马耳他、荷兰、葡萄牙、斯洛伐克、斯洛文尼亚和西班牙。
国内生产总值(GDP)是在一段时间(季度或年度)内生产的所有最终商品和服务的市场价值的货币度量。它通常用于确定一个国家或地区的经济表现。
用于获取数据集的欧盟统计局软件包和用于 ARIMA 建模的预测软件包。
关于 ETL 步骤的更多细节可以在实际代码中找到,在文章结尾的链接中。
探索性分析
在探索性分析期间,我们试图发现时间序列中的模式,例如:
- 趋势时间序列中涉及长期增减的模式
- 季节性由于日历(如季度、月份、工作日)
- 周期性存在一种模式,其中数据呈现非固定周期(持续时间通常至少为两年)的上升和下降
下面是 1995 年以来欧元区国家季度 GDP 的时间序列图。

上面的时间序列图中有一些输出:
-我们可以说总体趋势是积极的
-趋势中没有明显的增加/减少的可变性
-看起来有一些季节性,但需要进一步调查
-没有周期性
-在 2008-2009 年左右,GDP 增长出现了明显的中断
下面用一个季节性图来研究季节性。季节图类似于时间图,只是数据是根据观察数据的单个“季节”绘制的。

这增强了我们对时间序列中季节性的信心。似乎每年的第四季度总是最高的,而第一季度是最低的。第二次和第三次差不多。
滞后图将帮助我们了解时间序列中是否存在自相关。查看时间序列数据的另一种方法是将每个观察值与之前某个时间发生的另一个观察值进行对比。例如,您可以根据 yt1 绘制 yt。这被称为滞后图,因为你是根据时间序列本身的滞后来绘制的。基本上,它是时间序列和时间序列滞后值之间的散点图。

滞后 4 (1 年)有很强的季节性,因为所有季度线图遵循几乎相同的路径。
下面是自相关函数图。与滞后图相关的相关性形成了所谓的自相关函数(ACF)。超出置信区间(蓝线)的香料表明具有特定滞后的自相关具有统计显著性(不同于零)

看起来在所有滞后上都有显著的自相关,这表明了时间序列中的趋势和/或季节性。
我们还可以使用 Ljung-Box 检验来检验时间序列是否是白噪声。白噪声是一个纯粹随机的时间序列。下面是第四阶段的测试。
## Box-Ljung test
##
## data: gdp_ts
## X-squared = 319.62, df = 4, p-value < 2.2e-16
Ljung-Box 检验 p 值很小< 0.01, so there is strong evidence that the time series is not white noise and has seasonality and/or trend.
Modelling
ARIMA (Auto-regressive integrated moving average) models provide one of the main approaches to time series forecasting. It is the most widely-used approach to time series forecasting, and aim to describe the autocorrelations in the data.
The final fitted model was produced by the auto.arima() function of the forecast library. It rapidly estimates a series of model and return the best, according to either AIC, AICc or BIC value. After fitting the ARIMA model, it is essential to check that the residuals are well-behaved (i.e., no outlines or patterns) and resemble white noise. Below there are some residual plots for the fitted ARIMA model.

## Ljung-Box test
##
## data: Residuals from ARIMA(2,1,1)(0,1,1)[4]
## Q* = 6.1916, df = 4, p-value = 0.1853
##
## Model df: 4\. Total lags used: 8
We can say that the model is fairly good, since the residuals are closely normally distributed, have no real pattern and autocorrelations are not significant.
最终模型是一个季节性 ARIMA(2,1,1)(0,1,1)【4】。季节性差异和第一次差异都被使用,由模型每个部分的中间槽表示。此外,选择了一个滞后误差和一个季节性滞后误差,由模型每个部分的最后一个槽表示。使用了两个自回归项,由模型中的第一个槽表示。没有使用季节性自回归术语。
最后,对预测模型的准确性进行了检验。下面是对模型准确性的测试,使用 2017 年所有四个季度和 2018 年第一季度作为测试集。
## ME RMSE MAE MPE MAPE MASE
## Training set -1763.393 18524.64 13332.4 -0.08197817 0.6440916 0.1939318
## Test set 47152.498 49475.29 47152.5 1.68398118 1.6839812 0.6858757
## ACF1 Theil's U
## Training set 0.06526246 NA
## Test set 0.09563655 0.6768184
测试集的 MAPE(平均绝对百分比误差)为 1.68,因此我们可以得出模型的预测精度在 98.3 % 左右。
下面是欧元区国家 2018-19 年季度 GDP 预测的时间序列图。

- 看起来国内生产总值将在未来几年保持增长。特别是对未来几个季度的预测是:
Quarter Forecast Lo 80 Hi 80 Lo 95 Hi 95
2018 Q2 2887406 2853687 2921524 2835996 2939748
2018 Q3 2892970 2841213 2945670 2814191 2973955
2018 Q4 2990005 2917818 3063978 2880312 3103876
2019 Q1 2888631 2805996 2973700 2763213 3019742
2019 Q2 2973066 2870171 3079650 2817151 3137610
2019 Q3 2976688 2859234 3098966 2798945 3165717
2019 Q4 3076720 2939974 3219827 2870063 3298258
- 到 2019 年底,国内生产总值很有可能在今年的一个或多个季度突破三万亿€的关口
使用其他预测方法开发的模型更多,如指数平滑(具有趋势和季节性 Holt-Winters 的指数平滑方法)& 指数三次平滑,但 ARIMA 模型表现更好。
用蒙特卡罗模拟预测软件项目的完成日期

Photo by Jonathan Petersson on Unsplash
如今,我们正在使用一种比确定性方法更具概率性的方法来管理我们的过程。这意味着我们使用不同的统计方法来预测未来,而不是盲目的估计。但是等等…不可预测性难道不是让我们从瀑布式转变为敏捷的主要原因之一吗?
是的,不确定性是软件开发所固有的。例如,一个人不可能在一个项目的开始就预测一个系统的所有特性。
但是,如果我们能预测接下来几周的行为会怎样呢?
这就是我们试图通过收集指标并对其进行蒙特卡洛模拟来实现的目标。
要了解我们如何收集指标,我建议您阅读以下帖子:
大多数人不使用任何度量来管理他们的项目。你可以想象有多少人使用复杂的统计模型来预测项目的完成。然而,在你当前的项目中拥有这些知识将会帮助你更快更好的交付。
在本帖中,你将看到我们如何使用蒙特卡罗模拟从一个简单的预测方法到一个更加精确和稳健的方法。此外,我们将以简单明了的方式解释蒙特卡罗模拟是如何工作的,然后在这个简单的例子和我们的现实世界方法之间进行类比。知道你的项目什么时候可能结束可以帮助你管理项目的预算,给利益相关者更好的反馈,给你信心,你确实在控制你的项目。
为什么不是其他方法?
长期以来,我们一直在尝试其他的预测方法,但它们都有一些缺点。在这里,我们列出了其中的一些,以及我们如何和为什么选择使用蒙特卡洛。
平均吞吐量
你们中的一些人可能已经想到了一个简单的方法,我们将使用平均吞吐量来预测项目的结束。然而,正如你在这篇博文中看到的 指标的力量:不要用平均值来预测最后期限 ,那将是一个极其幼稚的方法,而且它不起作用。
线性回归方法
作为第一种方法,我们使用线性回归,基于我们累积的吞吐量,来预测项目何时结束:

但是,我们发现了两个不同的问题,我们在进行分析时没有考虑到:
- 我们必须保持待办事项列表中的项目数量不变,以便进行预测,这非常有偏差。
- 经过一些分析后,我们发现吞吐量和交付时间都不符合正态分布,因此计算线性回归是没有意义的(参见 以不同的方式看待交付时间 和 线性回归 的假设)。
手动设置方法
首先,我们专注于避免第二个问题,我们开始使用一个更节俭的模型,它使用了我们知道有些倾斜的方法,但是我们可以更好地控制它们。

我们手动添加了吞吐量性能,这将导致每个不同的预测在某个日期到达积压。这种预测方法来自对我们吞吐量历史的百分位数的研究。
我们有了更好的结果,因为我们可以手动更改预测,因此可以根据项目的当前状态进行调整。但是第一个问题,事实上我们没有考虑到积压订单的变化,这让我们更进一步,尝试蒙特卡罗模拟。
蒙特 卡罗模拟
维基百科将蒙特卡洛方法定义为
蒙特卡罗方法各不相同,但往往遵循一种特定的模式:
定义可能输入的域。
根据域内的概率分布随机生成输入。
对输入执行确定性计算。
汇总结果。
乍一看,这似乎很难或很复杂,但实际上比看起来要简单得多。你可以把它看作是预测的强力方法。我们将给出一个简单的例子,然后展示我们在现实世界中的表现。Larry Maccherone 做了一个很好的模拟,可以更好地解释这一点。
骰子游戏
假设你在玩一个骰子游戏,目标是用最少的掷数得到 12 点。这里最好的玩法是连续两次掷骰子,你都得到 6,最差的是 12 次掷骰子得到 1。我们要计算的是 N 次运行后结束博弈的概率。
考虑到每一次掷骰子有 6 种可能的结果,即骰子的 6 个面,那么在 1 次掷骰子中完成游戏的概率是多少?
零。因为如果骰子只到 6 点,你就不能到 12 点。
第二卷呢?
就是连续得到两个 6 的概率,这是基本统计:

第三卷呢?
现在你可以用很多方法达到 12 点,其中一些是:(3,3,6),(3,4,5),(3,5,4),(3,4,6),(5,5,2),(4,4,4)等等。这个计算背后的统计数据并不简单,对吗?这就是蒙特卡罗模拟派上用场的时候。
蒙特卡洛模拟成千上万次掷骰子,然后分析结果。例如,要知道在第三轮完成游戏的概率,它将掷骰子三次,将点数相加并存储结果。之后,它将重复这些步骤 5000 次,并总结每一个点数总和得到的掷数:

现在它所做的是将所有产生大于 12 的和的事件相加,然后除以事件总数。在这种情况下:

同样的方式,我们做了第三轮,我们可以做第四,第五,等等。
现实世界
现实世界的解决方案非常类似于掷骰子的例子。唯一的区别是,我们也改变了目标(游戏场景中的 12 分),以考虑待办事项中的变化。
所以现在每一轮的可能结果(骰子的两面)就是我们的吞吐量历史。同样,我们是吞吐量的“滚动骰子”,我们需要滚动积压的骰子,以便给它增长的机会。在这种情况下,可能的结果将是积压的增长率(BGR)。
让我们慢慢开始。假设我们的项目历史是这样的:

因此,我们每一轮的吞吐量可能是集合{2,3,0,2,5,0,1,3,3},积压可能是{0,2,1,1,2,1,0,2,0}。我们不排除重复的数字,因为有了它们,我们可以保持拥有一个数字而不是其他数字的更高概率。
现在,我们可以将相同的基本原理应用到骰子游戏中。在第一周,总吞吐量达到积压量或更多的概率是多少?一些可能的结果如下:

然后,我们将运行许多这样的程序,看看有多少程序的吞吐量总和大于 backlog 总和,然后将结果除以运行次数。这样做,我们就有可能在第一周结束项目。在接下来的一周,我们将做同样的事情,但是每一轮掷骰子两次,然后对吞吐量和积压量求和。
这种方法的一个问题是,在项目开始时,backlog 的行为不同于在项目中间或结束时。在开始时,通常增长要快得多,因为我们更好地理解了我们项目的问题和细微差别,在最后,增长基本上来自于精炼的故事。
为了解决这个问题,我们不考虑整个 BGR 历史作为可能的结果,而只考虑积压的最后 10 个 bgr,这将使我们对积压最近的表现有更好的了解。
使用新的最后 10 个 BGR 方法得出的未来 10 周的结果显示在图表中:

如您所见,我突出显示了图表的三个不同区域,以说明我认为可以从图表中获得的信息:
- 第一个区域,红色的,是我们完成项目的概率低于 50%的几周。这意味着告诉项目的利益相关者你将在接下来的 4 周内完成它是非常危险的。
- 下一个区域,橙色区域,显示了我们完成项目的概率在 50%到 75%之间的几周。我要说的是,如果利益相关者向你施压,要求你快速交付,那么这几周,如果你有信心,你就能完成。
- 绿色区域是一个更无风险的区域,在那里你完成项目的概率大于 75%。我建议你总是优先考虑基于这个领域而不是其他领域来估计你的项目的结束,但是我们都知道我们不能总是那么安全。
我们在过去的项目中测试了蒙特卡洛模拟,它看起来工作得很好,但是,和任何其他统计方法一样,在项目中几周后,它比开始时好得多。
摘要
预测一个项目什么时候可能结束看起来太“胡说八道”了,但是这个方法真的很容易实现,并且让我们对我们的项目有更好的预测和理解。重要的是要弄清楚,这种方法是一种统计方法,因此它不是失败证明。主要目标是在我们的工具包中增加一个元素,让项目管理变得简单一点。
为了帮助你预测软件项目的完成日期,我们制作了一个简单版本的电子表格供你下载,这样你不用做太多工作就可以运行模拟。
要了解更多关于蒙特卡洛模拟的信息,我推荐以下参考资料:
- Troy Magennis 的书— 预测和模拟软件开发项目:使用蒙特卡罗模拟对看板& Scrum 项目进行有效建模
- 丹尼尔·瓦坎蒂的网站、书籍和博客:可操作的敏捷
- Joel Spolsky 关于循证计划的博客文章
预测可变差旅费用的准确率达到 95%
首席财务官的自动机器学习
更新:我开了一家科技公司。你可以在这里找到更多
组织每年在差旅费上花费数百万美元,其中很大一部分是可变的,很难估计。除了在预订时已知的机票和住宿之外,餐饮和杂费等额外费用是未知的,可能对总费用有很大影响。
在本文中,我们将在几分钟内建立一个模型,该模型可以根据员工的职位、目的、目的地、住宿和机票计算出可变费用,对公布的数据有 95%的准确性,并且无需编写任何代码。数据准备和模型构建将由 AuDaS 处理,AuDaS 是由 [Mind Foundry](http://mind foundry.ai) 构建的自动化数据科学团队。
数据准备
费用数据是从安大略省养老金委员会下载的,包含其员工自 2010 年以来的费用报销。目标是使用截至 2017 年的数据来预测 2018 年的总支出。

Uploading the data into AuDaS
特征工程
数据集包含每次旅行的开始和结束日期,因此我们将要求 AuDaS 计算持续时间,因为这可能会对总花费产生很大影响。

然后,我们将使用 RegEx 转换删除数据中的$符号,以便进行格式化。

然后,我们将删除包含可变费用的列,以避免数据泄露,因为它们已经包含在我们希望预测的总支出中。这样做之后,AuDaS 检测到有一些丢失的值,并建议用户如何纠正它。

在整个过程中,AuDaS 在工作流程中增加了一些步骤,作为审计跟踪。您可以返回到数据集的先前版本,也可以导出工作流。在我们的例子中,我们将把这个工作流导出到包含 2018 年养老基金支出的测试集中。这将自动重现数据准备步骤,并允许我们在对其进行训练后,轻松地在其上部署我们的模型。

数据探索
现在我们已经清理了数据,我们可以访问直方图视图来提取初始的洞察力。我们也可以改变比例来查看稀疏分布的值。


我们的直接收获是,最常见的目的地是多伦多,董事会成员出差最多。似乎没有一个关键的模式,这就是为什么我们要使用机器学习来揭示更复杂的关系。
自动化建模
我们将要求 AuDaS 建立一个回归模型来预测总支出。

AuDaS 自动保留训练集的 10%用于最终验证。它还使用 10 重交叉验证来训练模型,以避免过度拟合。这保证了由 AuDaS 训练的模型在生产中表现良好。一旦我们满意了,我们现在就可以按开始按钮开始训练了。
训练是使用 Mind Foundry 的专有贝叶斯优化器 OPTaaS 实现的,opta as 允许 AuDaS 有效地在可能的回归管道的大搜索空间中导航。

AuDaS 提供了所选管道、模型和参数值以及性能统计的完全透明性。AuDaS 还为找到的最佳模型提供了特征相关性。


在这种情况下,住宿和机票费用以及目的地和目的地城市伦敦是可变费用的最强预测因素。首席信息官的头衔似乎也是总支出的一个很好的指标。既然我们对模型的准确性感到满意,我们就可以查看它的模型健康状况了。在我们的情况下,它是好的,我们可以放心地将其应用于测试数据集。

在测试数据集上运行训练好的模型之后,我们得到了每个条目的预测。AuDaS 会自动忽略模型训练中未使用的列。这意味着我们可以很容易地将实际总支出与预测支出进行比较。为此,我们可以导出数据并在 excel 中访问它。


在计算了每一列的总数后,我们可以看到 AuDaS 达到了 95%的准确率。
为什么这很重要
能够在一定程度上准确预测总支出对首席财务官来说是非常有价值的。在大公司,每季度的差旅支出可能达到 1 亿美元,甚至更多。可能会有相当大差异,分析人员通常会使用电子表格,根据不同部门的累积输入来估计预算需求。部门经理做了大量工作来积累有关未完成项目和过去支出的信息,增加了一些应急余量。同样的方法不仅适用于差旅费,也适用于许多成本预测情况。通过机器学习,业务线经理和财务可以在几分钟内做出更加准确的预测。最重要的是,这些模型可以实时运行,并在情况变化时提供高级警告。这避免了在关键的季度最后几周臭名昭著的旅行和成本禁运,因为预算已经达到。
了解更多信息
如果你想知道澳洲是否能解决你的问题,请填写这张简短的表格。如果你对 OPTaaS 感兴趣,你可以使用这个更短的表格获得一周免费试用的资格!
以下是这一过程的完整视频:
你可以在下面阅读更多 AuDaS 案例研究教程:
营销人员面临的首要挑战是了解他们的销售对象。当你知道你的买家…
towardsdatascience.com](/credit-card-clustering-6a92657ac99) [## 利用自动化机器学习优化您的电子邮件营销策略
对于全球超过 1 万亿美元的企业来说,优化销售营销支出是一个价值 10 亿美元的问题…
towardsdatascience.com](/optimize-your-email-marketing-strategy-with-automated-machine-learning-e1bfb8cc171b) [## 利用 AuDaS 在几分钟内解决 Kaggle Telco 客户流失挑战
AuDaS 是由 Mind Foundry 开发的自动化数据科学家,旨在允许任何人,无论是否有…
towardsdatascience.com](/solving-the-kaggle-telco-customer-churn-challenge-in-minutes-with-audas-2273fed19961)
团队和资源
Mind Foundry 是牛津大学的一个分支机构,由斯蒂芬·罗伯茨(Stephen Roberts)和迈克尔·奥斯本(Michael Osborne)教授创建,他们在数据分析领域已经工作了 35 年。Mind Foundry 团队由 30 多名世界级的机器学习研究人员和精英软件工程师组成,其中许多人曾是牛津大学的博士后。此外,Mind Foundry 通过其分拆地位,拥有超过 30 名牛津大学机器学习博士的特权。Mind Foundry 是牛津大学的投资组合公司,其投资者包括牛津科学创新、牛津技术与创新基金、、牛津大学创新基金和 Parkwalk Advisors 。
使用 Python 和 Tableau 进行预测

我写了一本关于脸书先知的书,已经由 Packt 出版社出版了!这本书在亚马逊上有售。
这本书涵盖了使用 Prophet 的每个细节,从安装到模型评估和调整。十几个数据集已经可用,并用于演示 Prophet 功能,从简单到高级,代码完全可用。如果你喜欢这篇中帖,请考虑在这里订购:【https://amzn.to/373oIcf】T4!在超过 250 页的篇幅中,它涵盖的内容远远超过了媒体所能教授的内容!
非常感谢你支持我的书!
我是 Greg Rafferty,湾区的数据科学家。你可以在我的 github 上查看这个项目的代码。如有任何问题,请随时联系我!
在这篇文章中,我将展示如何在 Tableau 中使用 Python 代码来构建一个实现时间序列预测的交互式仪表板。如果你只是想先玩一下仪表盘,探索一下 SARIMAX 算法,请在这里下载完整的 python 实现的仪表盘,或者在 Tableau Public 上下载这个稍微有点笨的版本(Tableau Public 明智但令人失望地不允许上传外部脚本,所以我不得不用硬编码的数据集来伪造 Python 脚本)。
因为当你想不出一个好名字的时候,试试一个旅行箱

去年,Tableau 发布了 10.2 版本,其中包括与 Python 的集成。不过,如何使用它并不是非常简单,所以当一个客户要求一个时间序列预测仪表板时,我想我会弄清楚的。 ARIMA 模型没有内置到 Tableau 中(Tableau 的预测模块使用指数平滑,在这种特殊情况下,我确实需要使用 ARIMA 算法的更高预测能力,所以tabby似乎是我唯一的选择。
我不会详细介绍如何安装 TabPy(提示:pip install tabpy-server),也不会详细介绍如何安装 Python(我想,如果你想在 Tableau 中运行 Python 代码,你可能已经知道如何使用 Python 了。如果没有,从这里开始。)
一旦安装了 TabPy 发行版,您将需要导航到包含在 /site-packages 中的源代码,然后进入 tabpy-server 目录(在我的例子中,是在默认位置安装了 Anaconda 3 的 MacOS 上,/anaconda3/lib/python3.7/site-packages/tabpy_server)。从那里运行sh startup.sh或python tabpy.py来启动服务器。您需要指示 Tableau 不断地嗅探端口 9004,这是 Tableau 和 Python 的通信方式。为了做到这一点,在 Tableau 内部,
- 转到帮助→设置和性能→管理外部服务连接…
- 输入服务器(如果在同一台计算机上运行 TabPy,则为 localhost)和端口(默认为 9004)。

And you’re off to the races!
如果到目前为止你有任何困难,试试这个教程。
ARIMA:如果你的公文包听起来笨重,那就用首字母缩略词
ARIMA 代表一个独立的整体平均值。在本教程中,我使用了它的更高级的兄弟,SARIMAX(SeasonalAuto-RegressiveIintegratedMovingAaverage with eXogen 回归变量)。好吧,那是什么?
先从回归说起。你知道那是什么,对吧?基本上,给定一组点,它会计算出最能解释图案的直线。
接下来是 ARMA 模型(自回归移动平均)。自回归部分意味着它是一个基于以前的值预测未来值的回归模型。这类似于说明天会很暖和,因为前三天都很暖和。(附注:这就是时间序列模型比标准回归复杂得多的原因。数据点不是相互独立的!).均线部分其实根本不是均线(别问我为什么,我也不知道)。这仅仅意味着回归误差可以建模为误差的线性组合。
如果 ARMA 模型不太符合你的数据,你可以试试 ARIMA。额外的 I 代表集成。这个术语解释了先前值之间的差异。直觉上,这意味着明天很可能和今天一样的温度,因为过去一周没有太大变化。
最后,我们转到萨里马克斯。S 代表季节性-它有助于对重复模式进行建模。这些季节性模式本身并不一定每年都会发生;例如,如果我们在一个繁忙的城市地区模拟地铁交通,模式将每周重复一次。而 X 代表外源性的(抱歉。这个不是我想出来的)。这个术语允许将外部变量添加到模型中,比如天气预报(尽管我在本教程中的模型没有添加任何外部变量)。
一个 SARIMAX 模型采用 SARIMAX(p,D,q) x (P,D,Q)m 的形式,其中 P 是 AR 项,D 是 I 项,Q 是 MA 项。大写的 P、D 和 Q 是相同的术语,但与季节成分有关。小写的 m 是模式重复之前的季节周期数(因此,如果您正在处理月度数据,就像在本教程中一样,m 将是 12)。在实现时,这些参数都是整数,数字越小越好(即不太复杂)。对于我的模型,我选择的最适合模型的参数是 SARIMAX(2,1,2) x (0,2,2)12。
我进行了网格搜索以得出这些术语。我试图最小化的错误是赤池信息标准 (AIC)。AIC 是一种衡量模型与数据拟合程度的方法,同时降低了复杂性。在 Tableau 仪表板中,我报告均方误差,因为这更直观。
这样一来,让我们看看如何在 Tableau 中实现它!
航空乘客数据
如果你想跟进,你可以在我的 github 上下载打包的 Tableau 工作簿。我使用的是航空乘客数据集(https://www.kaggle.com/rakannimer/air-passengers),其中包含了 1949 年至 1961 年间航空乘客数量的月度数据。让我们来看看发生了什么:
(舞台上由人扮的)静态画面
我希望我的仪表板是完全交互式的,这样我可以更改所有的 p、d 和 q,同时观察它们对模型的影响。因此,首先(这里的“第一”,我指的是“第二,在您连接到上面链接的航空乘客数据集之后”),让我们为这些变量创建参数。

你需要创建 8 个参数: AR(时滞)、 I(季节性)、 MA(移动平均线)、月预测、期、季节性 AR(时滞)、季节性 I(季节性)、季节性 MA(移动平均线)。确保所有的数据类型都是整数,否则 Python 稍后会抛出一些错误(并且 TabPy 非常无益地拒绝为您提供错误行号)。对于月预测和期间,我使用了一个允许值范围,从 1 到 48(对于月预测)和 1 到 24(对于期间)。接下来我们需要创建一个名为预测日期的计算字段,这样 Tableau 将扩展 x 轴以包含预测值。在计算字段中,输入:
DATE(DATETRUNC('month', DATEADD('month', [Months Forecast], [Month])))
我们还将创建一个乘客数量计算字段,以确保我们的 SARIMAX 数据与实际数据相符:
LOOKUP(SUM([#Passengers]), [Months Forecast])
最后,还有一个名为过去与未来的计算字段,我们稍后将使用它将预测格式化为不同的颜色:
IF LAST() < [Months Forecast]
THEN 'Model Forecast'
ELSE 'Model Prediction'
END
计算机编程语言
好了,终于!在蟒蛇身上。让我们创建我们的第一个脚本。创建一个计算字段并将其命名为预测。在字段中,粘贴以下代码:
我们还将创建一个名为均方误差的计算字段,这样我们就可以在图表上有一个漂亮的动态标题:
现在,将预测日期拖到列架上,将乘客数量和预测拖到列架上。使其成为双轴图表,并使轴同步。将过去与未来放在预测卡的色标上,就大功告成了!那很容易,不是吗?(不,实际上不是。令人尴尬的是,我花了很长时间才弄明白如何让这些脚本工作,而且 Tableau 极其无益的不显示错误发生在哪里的习惯使得故障排除成为一项令人沮丧的工作。为了增加一点趣味,将这些参数添加到侧栏中,这样您就可以交互地更改它们。哦!我差点忘了那个时髦的标题。右键单击标题→编辑标题… →并键入以下代码:

下面是最终的仪表板应该是什么样子。如果你想让它看起来和我的一样,你会有一些格式化任务要处理,或者你可以下载我的仪表板在这里并完成它。Tableau Public 不允许上传任何外部脚本,很遗憾,这意味着我不能分享如下所示的确切版本。相反,我只是运行了数百个 SARIMAX 参数的排列,并将每个预测保存到一个 csv 文件中,这个版本虽然没有那么漂亮,也没有那么酷,但可以直接在 Tableau Public 这里上玩。

如你所见,模型相当不错!这就是 SARIMAX 的强大之处:它准确地模拟了随着时间推移的总体增长趋势,全年季节的起伏,甚至是随着时间的推移数据的增长方差(波峰高点和波谷低点之间的距离增加)。你需要小心选择你的参数,如果你不小心,一些有趣的事情会发生。例如,我表现最差的模型是这样的(看看这个误差幅度!):

法医深度学习:Kaggle 相机模型识别挑战
数据扩充的重要性

From https://habr.com/company/ods/blog/415571/
大约一年前,在 kaggle.com 举办了一场名为 IEEE 信号处理学会——相机型号识别的计算机视觉挑战赛。任务是分配哪种类型的相机用于捕捉图像。比赛结束后,亚瑟·库津、阿图尔·法塔霍夫、伊利亚·基巴尔丁、鲁斯兰·道托夫和我决定写一份技术报告,描述如何解决这个问题,并分享我们在这个过程中获得的一些见解。它被接受参加在西雅图举行的第二届网络犯罪调查大数据分析国际研讨会,我将于 2018 年 12 月 10 日在那里发表演讲。在这篇博文中,我想写一个文本的扩展版本。
这篇论文有五位作者:
亚瑟·法塔霍夫、亚瑟·库津、伊利亚·基布丁和其他队员以 0.987 的成绩获得第二名。
我是以 0.985 分获得第九名的队伍中的一员。
我们的解决方案非常相似,所以我们决定写一份技术报告。深圳大学大数据研究所的研究生鲁斯兰(Ruslan )自愿帮我做文本,这对这篇论文至关重要。
在下文中,我将把第二名团队的方法称为“我们的”解决方案。此外,我将跳过一些对整体信息不重要的技术细节。第二名解决方案的代码可在 GitHubhttps://GitHub . com/iki bardin/ka ggle-camera-model-identificati on上获得。比赛结束后,我们使用我们开发的洞察力进行了一系列单独的实验。这里的工作主要是基于这一进一步的调查。
图像处理的许多应用之一是相机模型检测。例如,在法医学领域,可能至关重要的是要知道一张图片是使用谷歌 Pixel 还是 iPhone 拍摄的,以确定谁可能是非法或有罪照片的所有者,甚至确定谁是知识产权的合法所有者。这种系统还可以用于检测诽谤、中伤或传播假新闻的肇事者。
计算机中的图像存储为数字矩阵和附带的元数据。在最简单的情况下,相机模型应该存储在图像元数据中,这使得相机识别成为一个基本问题。但是图像元数据可能不可靠,并且很容易被恶意用户操纵。
还有另一种更复杂但更可靠的方法。采集完成后,数码相机中的图像将经过一系列后处理步骤,从而生成图像保真度和内存占用优化的图像。这些算法非常复杂,高度非线性。例子可以包括去马赛克、噪声过滤、修正镜头失真等。不同的算法用于各种相机模型,这意味着它们中的每一个都创建特定于模型的工件,人们可以将其用作机器学习管道的特征。
当然,有很多关于这个主题的文献。它的大部分提出了手动特征提取的步骤,在此基础上使用 SVM 或类似的分类算法。例如,当我面对这个问题时,我想到的第一个想法是拍摄一张图像,减去它的平滑版本,并计算这种差异的不同统计数据,如均值、中值、标准差和不同的量,并在其上训练 xgboost。关于如何进行这种相机型号检测的第一篇论文之一非常接近我刚才描述的内容。其他文章提出了一些更复杂的东西,但方法非常相似,基于领域知识的手动特征提取,并在此基础上使用逻辑回归、决策树或 SVM。
将这种方法推广到新的相机型号也很困难。假设我们想为一个新的、刚刚发布的模型进行相机检测。专家应该花多长时间来找出哪些特征有助于将它与其他模型区分开来?
另一方面,深度学习方法可以解决这两个问题。总的来说,深度学习是一头强大的野兽,如果你知道如何驯服它,它可能会帮助你创建高度准确的黑盒模型。
当你在查阅文献并试图理解哪种方法是“最好的”时,这是不可能的。几乎每篇论文都告诉你它们是最先进的。处理的方法是在同一个数据集上评估不同的方法。这种比较不会给你一个总体上哪种算法更好的答案,而是在给定的数据集上,哪种算法更好。这并不意味着在相似的数据集上算法排名是相同的,比如在 CIFAR 上最先进的架构可能在 ImageNet 上表现不佳,反之亦然。但这样的统一对比总比没有好。
对于相机检测任务,IEEE 信号处理协会组织了一次挑战,其中 582 个团队有两个月的时间和一个实时排行榜来比较他们的方法。582 是一个很大的数字,这确保了问题会被不同背景和技能的人所攻击。一些参与者在工业界和学术界从事法医工作,以此谋生。其他人,比如我,有使用计算机视觉技术的经验,但是没有意识到甚至存在像相机识别这样的问题,并且有人有兴趣解决它。
组织者准备了一个由 2750 张图片组成的训练集,这些图片来自 10 台相机——每台相机 275 张。
我们需要区分的相机型号有:
- 索尼 NEX-7
- 摩托罗拉摩托 X
- 摩托罗拉 Nexus 6
- 摩托罗拉 DROID MAXX
- LG Nexus 5x
- 苹果 iPhone 6
- 苹果 iPhone 4s
- HTC One M7
- 三星银河 S4
- 三星 Galaxy Note 3
为了让这个问题不那么无聊,组织者使用了 20 部不同的手机来收集图像:10 部用于训练,10 部用于测试。这意味着在训练期间,您的模型可能不会学习与后处理算法相关的相机模型特定的功能,而是过度适应特定手机特定的伪像。
测试集中的图像是用相同的 10 个相机模型捕获的,但是使用第二个设备。例如,如果 iPhone 6 的火车数据图片是用 Ben Hamner 的设备(相机 1)拍摄的,那么测试数据中的图像是用 Ben Hamner 的第二个设备(相机 2)拍摄的,因为他在风筝冲浪时丢失了海湾中的第一个设备。
此外,火车中的图像是全尺寸的,而在测试中,只使用了中央 512x512 作物。其原因是径向失真在图像的侧面更加明显。一些论文显示了纯粹基于径向畸变特征的有希望的结果。他们能增加多少附加值还不清楚,但组织者决定阻止参与者利用他们。
这还不是全部。在许多情况下,通常存储在电脑上的图像会受到不同转换的影响,如 jpeg 压缩、gamma 转换、对比度、亮度、调整大小等。
从实践的角度来看,有一个健壮的模型来进行这样的转换是很好的。以下类似的逻辑组织者用以下变换之一修改了一半的测试图像:
- 质量因子= 70 的 JPEG 压缩
- 质量因子= 90 的 JPEG 压缩
- 通过因子 0.5 调整大小(通过双三次插值)
- 通过因子 0.8 调整大小(通过双三次插值)
- 通过因子 1.5 调整大小(通过双三次插值)
- 通过因子 2.0 调整大小(通过双三次插值)
- 使用 Gamma = 0.8 进行 gamma 校正
- 使用 Gamma = 1.2 进行 gamma 校正

Jpeg compression with quality [5, 15, 25, 35, 45, 55, 65, 75, 85, 95]

Gamma Transform with quality [0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75]
正如我上面提到的,在不同的图像主机上有数 Pb 的图像,我们可以从中提取相机模型。Kaggle 的各种比赛对外部数据有不同的规则,但在这种情况下,这是允许的。一般来说,所有允许外部数据的竞赛都有一条规则,强制所有参与者也可以访问这些数据。在任何此类比赛中,论坛上都有一个主题,参与者可以分享他们计划使用的数据和预先训练的模型。
这次比赛是个例外。管理员忘记在规则中加入关于共享数据的句子。这改变了游戏。
深度学习模型的好处在于,由于容量大,它们通常会受益于用于训练的数据量。同样重要的是,许多火车标签可能是错误的。这很好。只要错误标签的百分比低于 15%,你就没事。你使用的数据越多,你的模型就越好。
参与者可能不是法医专家,但他们肯定知道更多数据对 DL 更好的事实。这改变了竞争的态势。通常,在竞争中,您会试图从给定的数据集中获取最多的信息。经过一些实验后,你选择一个性能良好的模型,聪明地选择你的增强,探索领域知识,花时间制定一个智能训练计划,损失函数等。如果你没有更好的选择,所有这些都很重要。但是我们做到了。
Flickr,Yandex,Fotki,Wikipedia commons 都被废弃了,该团队拥有的原始图像数据总量约为 500Gb。我们可以使用所有这些数据,但是为了加速训练并潜在地提高模型的质量,我们进行了过滤。
对于训练,我们想要未经处理的数据,这意味着不受 Photoshop 或 LightRoom 或类似图像编辑软件的影响,不调整大小,并且是高质量的。
首先,我们删除了元数据中包含 Photoshop 和 LightRoom 的图像。其次,我们删除了 Jpeg 质量低于 95 的图像。第三,我们知道不同的相机以固定的尺寸拍摄照片。如果图像的大小与我们预期的不匹配,我们认为它被调整了大小。我们删除了不符合这些标准的图片。
这并不意味着我们得到的所有图像都是未经处理的,比如有人可能使用 10%质量的 jpeg 压缩,然后再使用 99%质量的 jpeg 压缩。实际上它仍然是 10%,但是对于我们的软件来说,很难发现它是 10 而不是 99。我不想说“困难”,我想说不可能,但是回想一下,在研究这个问题时,我看到过试图识别“双重 jpeg 压缩”的论文。再说一次,我甚至不知道有这样的问题存在。
过滤后,我们有 78807 个废弃的图像,它们被认为是原始的和未经处理的。阶级分布不均匀。正如人们所料,并非所有手机都同样受欢迎,或者手机型号与机主拍照并上传到互联网的频率之间存在相关性。因此,对于某些类,我们有更少的图像。

Camera model classes with the number of samples each part of the dataset. The table presents the final dataset, which contains external and organizers datasets.

From https://habr.com/company/ods/blog/415571/
总的来说,这是一个从 ImageNet 学习的过程。你拿一个预先训练好的网络,去掉预测 1000 个类的最后一层,换成预测你需要什么的一层。在我们的例子中,这个数字是 10。在此之后,您使用分类交叉熵来计算您的损失,并训练网络。第一名和第 50 名的区别通常不在于你使用的网络类型,而在于培训程序和进行培训的人。从实践的角度来看,深度学习仍然是炼金术多于科学。因此,当一个人从事不同的工作时,发展出来的直觉是至关重要的。
对 PyTorch 有影响力的网络有一个很好的列表,那就是雷米·卡登 https://github.com/Cadene/pretrained-models.pytorch的回购。人们可以使用类似的 API 访问不同的网络和预先训练的权重,从而快速进行实验。这种回购被挑战的参与者广泛使用。团队试验了 Resnet、VGG、DPN 和所有其他类型的网络。
对于这个问题,一个经验主义的结论是 DenseNet 工作得稍微好一点,但是团队之间的差异是如此之小,以至于它是真是假还不清楚。
什么是 DenseNet?DenseNet 是一种体系结构,它将在 Resnet 类型的网络中使用跳过连接的思想推进了一步。

https://arthurdouillard.com/post/densenet/ https://arxiv.org/abs/1608.06993
更多被跳过的连接给被跳过的连接之神!
DenseNet 论文的作者将卷积块中的所有层连接起来。跳跃连接简化了梯度的流动,使得训练深度网络成为可能。在 skip connections 成为主流之前,处理只有 19 层的 VGG19 是一件痛苦的事情。在引入它们之后,具有 100 层以上的网络可以处理非常高级的抽象功能,不再是训练的问题。
还认为损失曲面变得更平滑,防止训练陷入许多局部最小值。

https://arxiv.org/abs/1712.09913
除此之外,网络比较规范。一组卷积块,具有批范数和 ReLu 层,在块之间有最大池。全球平均池和密集层在最后。有必要提及的是,存在全局平均池层的事实允许我们使用不同大小的图像作为输入。
有些人认为 DenseNet 总是优于 Resnet,因为它是后来推出的,并成为 2017 年 CVPR 最佳论文。事实并非如此。在最初的文章中,DenseNet 在 CIFAR 上显示了良好的结果,但是在更多样化的 ImageNet 数据集上,更深的 Densenet 需要在准确性上匹配更浅的 ResNet 网络。

DenseNet 比 Resnet 好/差?看情况。在星球:从太空挑战中了解亚马逊,DenseNet,我们的团队在 900+中获得了第 7 名,在这个相机检测问题上表现更好。但在 ImageNet 上,情况更糟。
我与我的合作者进行了一次讨论,有人提出跳过连接不仅提供了良好的光滑损失表面,而且还降低了模型容量。这可能解释了为什么 DenseNet 在像 CIFAR 这样的非多样性问题中表现得更好。尽管如此,人们需要增加网络的深度,以弥补更多样化的 ImageNet 数据集的容量损失。基于这种推测,人们可能会想到 DenseNets 工作良好的用例是当数据集不是非常多样化并且不需要大容量时。尽管如此,区别性特征是高水平的,这可能需要非常深的网络。
摄像机检测任务属于这一类吗?我不知道。经验上是的,但是证据不足。
将智能正则化添加到训练过程的标准方法是使用增强。不同的问题可能受益于不同的增强,同样,你的直觉越好,你就可以选择更好的增强及其参数。
对于这个问题,我们使用:
- 二面角组 D4 变换:旋转 90 度、180 度、270 度和翻转。
- 伽玛变换。我们从[80,120]范围内统一选择伽马参数。
- 参数从 70 到 90 均匀采样的 JPEG 压缩。
- 重新缩放变换,从[0.5,2]范围中选择比例。
在代码中,使用相册库,它可以被描述为:
import albumentations as albu def train_transform(image, p=1):
aug = albu.Compose([albu.RandomRotate90(p=0.5),
albu.HorizontalFlip(p=0.5),
albu.RandomGamma(gamma_limit=(80, 120), p=0.5),
albu.JpegCompression(quality_lower=70, quality_upper=90, p=0.5),
albu.RandomScale(scale_limit=(0.5, 2), interpolation=cv2.INTER_CUBIC, p=1)
], p=p)
return aug(image=image)['image']

Left is the original image from my recent rock-climbing trip to Bishop, and right is flipped and a bit darker. The latter is the effect of the gamma transformation. Jpeg compression was also applied, but it is hard to find its effects because quality [70:90] is relatively high.
组织者告诉我们,他们使用三次插值来调整大小。如果我们没有这些信息,我们可以在不同插值之间交替使用。一般来说,竞争激烈的 ML 社区经常使用这个技巧,但是我还没有在文献中看到它。
无论如何,如果我们想要添加这种改变,代码会更复杂,但仍然相对透明。
import albumentations as albu def train_transform(image, p=1):
scale_limit = (0.5, 2) aug = albu.Compose([
albu.RandomRotate90(p=0.5),
albu.HorizontalFlip(p=0.5),
albu.RandomGamma(gamma_limit=(80, 120), p=0.5),
albu.JpegCompression(quality_lower=70, quality_upper=90, p=0.5),
albu.OneOf([albu.RandomScale(scale_limit=scale_limit, interpolation=cv2.INTER_NEAREST, p=0.5),
albu.RandomScale(scale_limit=scale_limit, interpolation=cv2.INTER_LINEAR, p=0.5),
albu.RandomScale(scale_limit=scale_limit, interpolation=cv2.INTER_CUBIC, p=0.5),
albu.RandomScale(scale_limit=scale_limit, interpolation=cv2.INTER_AREA, p=0.5),
albu.RandomScale(scale_limit=scale_limit, interpolation=cv2.INTER_LANCZOS4, p=0.5),
], p=0.5),
], p=p)
return aug(image=image)['image']
原始图像的分辨率很高。在全分辨率下重新调整它们是不明智的。因此我们连续收获了两季。一个在调整大小之前,一个在调整大小之后。
import albumentations as albu def train_transform(image, p=1):
aug = albu.Compose([
albu.RandomCrop(height=960, width=960, p=1),
albu.RandomRotate90(p=0.5),
albu.HorizontalFlip(p=0.5),
albu.RandomGamma(gamma_limit=(80, 120), p=0.5),
albu.JpegCompression(quality_lower=70, quality_upper=90, p=0.5),
albu.RandomScale(scale_limit=(0.5, 2), interpolation=cv2.INTER_CUBIC, p=1)
albu.RandomCrop(height=480, width=480, p=1),
], p=p)
return aug(image=image)['image']
使用初始学习率为 0.001 的 Adam optimizer 对网络进行 100 个时期的训练。
为了获得更好的精度,当学习率在不同值之间振荡时,我们还使用了循环学习率方法。

正如你从这张图片中所猜测的,学习率在 17 世纪左右下降了。
同时,在 42°左右和 53°左右有两个连续衰减的损耗峰。在训练过程中,网络往往会陷入局部最小值,而这些振荡有助于摆脱它们。
在推断时,我们执行测试时间增加,平均来自测试图像的不同 480x480 裁剪的预测。
我们还对估计不同的转换如何在推理时降低模型的准确性感兴趣。

绿色表示训练中使用的参数范围。
正如预期的那样,在模型被训练的范围内,精确度没有显著降低。这表明,如果使用深度学习方法并拥有足够数量的数据,增加所应用的增强的范围可能会导致更稳健的模型。
我们想要回答的另一个问题是,如果我们在测试时减少输入到网络的作物的输入大小,精确度会如何?

我会认为网络正在学习的特性是如此的局部化,以至于不需要大规模的裁剪,但是看起来事实并非如此。为了使 10 个类别的准确率达到 90%以上,人们需要至少 250x250 的作物,这可能意味着后处理算法会在网络捕捉的像素之间创建长距离相关性。
我们还希望验证,当训练数据量增加时,模型的准确性也会提高。从图中可以看出,这种情况并没有发生。我想我们的最低数据点 25k 对于高质量的模型来说已经足够了。如果我们需要检测的不是 10 个,而是 1000 个类别,那么作为训练数据的函数,模型质量的提高可能会更明显。
总结:
- 来自 ImageNet 的迁移学习即使对于像照相机检测任务中的那些低级特征也工作得很好。
- DenseNet 表现更好,但我们认为,人们可以从 Cadene 的列表中选择任何预训练网络,它会表现类似。
- 在训练期间应用增强可能有助于使模型更健壮。
- 如果你能得到更多的标签数据,那就去得到它。在许多(但不是全部)问题中,使用大量数据的蛮力可能比复杂的解决方案更容易使用。尽管利用领域知识可以增加重要的额外推动力。
课文中跳过的内容:
- 添加额外的输出来判断图像是否被操纵有意义吗?
- 像检查点平均这样的技巧。
- 其他架构表现如何?
- 如何完成这项任务?
- 如何利用测试中的类是平衡的?
- 如何将伪标签应用于此任务。
- 讨论我们尝试了什么,但它在这个任务中不起作用。
- 网络了解到的特征有哪些?
- 此问题评估标准的细微差别。
所有这些话题都很重要,但我并不认为它们有很大的影响力,或者我更愿意对每一个话题进行单独的讨论。
P.S .参加 2018 年 12 月 10-13 日在美国西雅图举行的 2018 年 IEEE 大数据国际会议的人。参观第二届网络犯罪调查和预防大数据分析国际研讨会的研讨会并问好:)
帮助编辑:埃里克·加塞德伦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










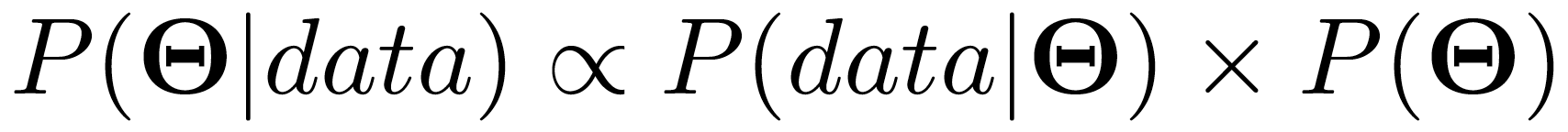{kind=link}