




深入计算机视觉世界:第 3 部分
YOLO,SSD,FPN 和 RetinaNet,比较统一的

刚开始看论文会很不舒服,很恐怖。克服这一点的一个方法是以更轻松的语气阅读一篇写得很好的文章。如果你选择的一篇论文难以消化,从解密视频或博客中获得一些直觉(比如这个😉).在你得到网络的核心概念后,再用原来的再试一次。读起来会变得更舒服,也更有趣,而不仅仅是一头扎进难读的书里。
这是“深入计算机视觉世界”的第三个故事,该系列的完整集如下:
- 从 VGG 开始,ResNet,Inception Network 和 MobileNet
- CNN 地区,让我们开始物体探测
- YOLO,SSD,FPN 和 RetinaNet,比较统一的
- 从对象检测到实例分割(TBU)
在前一篇文章中,我们讨论了对象检测网络——R-CNN、快速 R-CNN 和更快 R-CNN。这些都是基于两级架构。在第一阶段生成对象位置的候选,在第二阶段定位对象并对检测到的对象进行分类。
现在,下一个要探索的网络是 SSD、YOLO、FPN 和 RetinaNet。这些网络基于一级架构。最大的变化是,这些不再需要区域提案,从而形成一个更统一和完全卷积的网络,从而带来更快的性能。现在让我们一个一个地看看这是如何实现的。
(同 solid-statedisk)固态(磁)盘
SSD 代表**,**,其架构有三个要点。首先,这个网络可以在多个尺度进行检测。随着图层在基础网络之后出现,它产生了具有不同分辨率的多个特征地图,这使得网络能够在多尺度下工作。
第二,这些预测是以卷积的方式做出的。一组卷积过滤器对物体的位置和类别分数进行预测。这就是“单拍”这个名字的由来。取代了额外的分类器和回归器,现在检测是在一个单一的镜头!
最后,有固定数量的默认框与这些特征地图相关联。类似于更快的 R-CNN 的锚点,默认框应用于每个特征地图单元。

The architecture of SSD
网络的整体架构如上图所示。它使用 VGG-16 作为其基础网络,并有额外的功能层,规模逐渐减少。这个乍一看可以认为是相当复杂的,所以我们把它分成两部分。


在左图中,基础网络的特征层通过卷积滤波器进行检测。当要素图层的维度大小为 N x N 带 P 个通道时,这里的滤镜大小为 3x3xP 。现在,正如我上面所说的,每个单元格都有一组默认的边界框。因此,如果我们有 K 个盒子和 C 个类(包括“背景”类),我们计算原始默认盒子的四个偏移值,以及每个盒子的类分数。因此,滤波器的总数变为 (NxN)K(4+C) 。

SSD 使用卷积过滤器一次对边界框位置和类别分数进行所有预测。它不再需要区域提案网络。在不同比例的额外要素图层上执行相同的过程,从而显著提高精度。回想一下不同分辨率的特征地图,在一幅图像中看到不同大小的图形或物体(我用盗梦空间解释过这个)。因此,跨尺度预测在检测任务中变得至关重要。
在我们从所有这些层中获得结果后,我们将它们与地面真相框进行匹配,并选择最佳的一个。由于大部分的盒子会严重重叠,我们可以使用 非最大抑制 来选择一个。但是,仍然有一个相当具有挑战性的问题,阶级不平衡。当我们使用区域提案时,它们是有对象的合理候选。但在这里,网络从每个位置的一组默认框开始,具有多种比例和形状。结果是,大多数盒子的结果都是负面的。这就造成了阶层的不平衡。例如,“背景”类变成了一个简单的例子,而真正的“对象”类变成了困难的例子。简单的反例会淹没类的分布并使模型退化。(注意,这个问题将在 RetinaNet 中再次讨论)
为了补救这一点,SSD 只取一些负匹配,因此正匹配和负匹配之间的比率可以是 3:1。这叫硬负采。硬否定挖掘是对象检测中的一个经典问题,这意味着一个否定类很难被认为是否定的。一个模型应该把它归类为负面的,但是它给出了很高的可信度,因为负面的情况比正面的情况要多得多。我们只将正匹配输入到目标函数中,以便它计算地面真实和预测边界框之间的损失。

一件有趣的事情是,大约 80%的转发时间花在基础网络上,这表明更快的基础网络甚至可以进一步提高速度。并且数据扩充对于更高的准确性也起着重要的作用。与仅使用原始图像和水平翻转的更快的 R-CNN 相比,输入大小、形状和随机采样的变化提高了性能。此外,观察到各种默认的盒子形状对于准确性也是更好的。
YOLO
YOLO 是你只看一次的缩写。与 SSD 类似,YOLO 不使用区域提案,以“单次”方式工作。YOLO 有三种主要的变体。我不会涵盖所有的转换过程,而是将所有内容打包,并探索最终版本。如果你想知道所有的详细过程,请查看Jonathan Hui的这篇优秀文章。(从字面上看,这是我见过的最好的 YOLO 教程)。

The architecture of YOLO Ver.3. Let’s start from its tail where the predictions are made!
整个网络架构如上图。圆圈中的数字是层数。它使用 Darknet-53 作为它的基础网络,还有检测物体的附加层。让我们首先把注意力放在做出预测的尾部。YOLO 也是一个完全卷积网络,因此它通过卷积预测检测。经过几层后,对三种不同尺度的特征图进行 1x1 卷积检测。

Figures from Ver.1 (on the left) and Ver.3 (on the right)
当具有 P 个通道的特征图的大小为 N×N 时,应用 1x1xP 大小的滤波器。YOLO 也有默认的包围盒(原文中称之为 锚点 )。对于每个单元的每个框,预测 4 个边界框偏移值、对象性得分和类得分。客观性分数反映了该框包含一个对象的置信度。所以现在每个网格的预测数变成了 5+C 。所以如果盒子的数量是 K ,那么每一个音阶的滤镜总数就是 (NxN)K(5+C) 。

Now let’s see the main branch line. YOLO also operates in multi-scales like SSD, yet in a way a little bit different.
正如我所说的,随着深度的增加,特征地图的分辨率越来越小,当特征地图看到物体时,这会对比例产生影响。因此,为了实现多种比例,YOLO 只需通过一个穿透图层即可从上一个图层中获取更高分辨率的要素。ResNet 的快捷连接也是如此。
因此,在第 84 层,我们从前两层获取特征图,并将其向上采样 2 倍。然后,我们从第 36 层获得一个特征图,并将其与上采样特征连接起来。相同的过程在第 96 层重复一次,以得到最终的标度。通过这样做,我们可以在预测中添加更精细、更有意义的特征。


Figures from Ver.3 (on the left) and Ver. 2 (on the right)
第 1 版的基础网络是 AlexNet,第 2 版首次使用 Darknet,有 19 个卷积层。正如你在上面看到的,在第 3 版,这变成了 53 层。另一个值得一提的重要事情是,默认框是从 K-means 聚类中提取的,而不是手动选择的。网络在训练期间学会调整盒子,但是从一开始就有更好的先验知识肯定有助于网络。所以 YOLO 3 版通过聚类提取了 9 个默认框。通过连接前一层和一个穿透层的更高分辨率特征,与 SSD 相比,YOLO 可以更好地检测小物体。
FPN
FPN 代表特征金字塔网络。在此之前已经研究并使用了具有金字塔结构的网络。而且 SSD 也是类似金字塔的结构(垂直旋转试试)。但不能说是严格如图所示的金字塔式特征层次。因为它是从更高的层次开始形成金字塔,而不是从低层次开始。(记得 VGG Conv5_3 是用于检测的第一层)

有这种架构有什么意义?可以在网络的更深层次中检测到物体的精确位置信息。相反,语义在较低的级别变得更强。(我们将在下一个系列中讨论这个问题)。当一个网络有一种更深入的方式时,没有多少语义数据可以用来在像素级别上对对象进行分类。因此,通过实现特征金字塔网络,我们可以产生来自所有级别的多尺度特征地图,并且来自所有这些级别的特征在语义上是强的。

FPN 的建筑如上图所示。有三个方向,自下而上,自上而下,横向。自底向上路径是原始论文中使用的主干 ConvNet 和 ResNet 的前馈计算。有 5 个阶段,并且每个阶段的特征图的大小具有 2 的缩放步长。他们按尺寸区分,我们称他们为 C1、C2、C3、C4 和 C5 。图层越高,沿自下而上路径的特征地图的大小就越小。
现在在级别 C5 ,我们移动到自上而下的路径。上采样应用于每个级别的输出贴图。和具有来自自下而上路径的相同空间大小的对应地图,通过横向连接进行合并。在相加之前应用 1x1 卷积以匹配深度大小。然后,我们在合并的贴图上应用 3×3 卷积,以减少上采样的混叠效应。通过这样做,我们可以将低分辨率和语义强的特征(来自自顶向下路径)与高分辨率和语义弱的特征(来自自底向上路径)相结合。这意味着我们可以在所有尺度上拥有丰富的语义。如图所示,同样的过程被迭代并产生 P2,P3 P4 和 P5 。
现在网络的最后一部分是一个实际的分类。事实上,FPN 本身并不是一个物体探测器。探测器不是内置的,所以我们需要在这个阶段插入一个探测器。RPN 和 Fast R-CNN 在原图中使用,上图中只描绘了 RPN 情况下的 FPN。在 RPN 中,对象分类器和边界框回归器有两个兄弟层。所以在 FPN,这部分是附在 **P2、**P4、 P5 每一级的尾部。我在这里不会涉及太多,因为我选择 FPN 的原因是为了解释 RetinaNet。
RetinaNet
RetinaNet 更多的是提出一个新的损失函数来处理类不平衡,而不是发布一个新颖的新网络。让我们再把阶层失衡带回来。SSD 和 YOLO 等一级检测器明显更快,但与两级检测器相比,精度仍然落后。而阶层失衡问题是造成这一弊端的原因之一。

因此,作者通过对简单的例子进行加权,提出了一个新的损失函数,称为焦点损失。数学表达式如上图。这是交叉熵损失乘以一个调节因子。调节因子减少了简单例子对损失的影响。
比如比较 Pₜ = 0.9 和 γ = 2 时的损耗。如果我们说交叉熵损失为 CE,那么焦点损失变成-0.01CE。损失变成低 100 倍。而如果 Pₜ 变大,比如说 0.968,用常数 γ ,焦损就变成了-0.001 ce(as(1–0.968)=(0.032)≈0.001)。因此,它把简单的例子写得更难,并调整不平衡作为回报。而当 γ 增加时,如右图所示,当 Pₜ 不变时,损耗随着重量的增加而变小。

RetinaNet 的架构如上图。正如我们现在知道的 ResNet,RPN 的更快的 R-CNN 和 FPN,这里没有什么新的东西。网络可以分为两部分,一个主干网(a)和(b),两个子网用于分类和盒回归。主干网由雷斯内特和 FPN 组成,金字塔有 P3 到 P7 级。
与 RPN 一样,也有先前的锚盒。锚的大小根据它的级别而变化。在 P3 处,锚区域为 3232,在 P7 处为 512512。锚有三种不同的比例和三种不同的大小,所以每个等级的锚 A 的数量为 9。因此,盒回归子网的输出维数为**(N×N)x 4A。当数据集中的类别数为 K 时,分类子网的输出变为(N×N)x KA**。

Speed vs Accuracy on COCO dataset
结果相当引人注目。RetinaNet 在准确性和速度上都超过了以前的所有网络。retina net-101–500 表示具有 ResNet-101 和 500 像素图像比例的网络。与所有两阶段方法相比,使用更大的规模可以获得更高的精度,同时也足够快。
减去
有两种对象检测网络,一级和两级。各有利弊。两级网络,比如更快的 R-CNN,虽然准确,但是对于实际应用来说不切实际。一级网络,如 SSD、YOLO,速度够快但准确率相对较低。这就是 RetinaNet 的动机,开发一个一阶段网络实现两个兔子。
对象检测应该在多尺度上工作,因为对象的尺度不是恒定的。我们看到了网络使用什么策略进行尺度不变检测。固态硬盘有多层,在某种程度上缩小了分辨率。YOLO 在多尺度中有 3 个层,具有上采样和直通层。FPN 和 RetinaNet 制作了一个自上而下和横向工作的金字塔。
类别不平衡是物体探测任务中的另一个问题。有几种方法可以解决这个问题。SSD 使用了硬负挖掘但是有一个主要的缺点,那就是我们只能使用收集到的一些例子。RetinaNet 提出的另一个解决方案是聚焦损失。通过添加权重参数,我们可以抑制简单示例的贡献,并且有效地使用所有示例。
参考
- 刘威等人[ SSD:单次多盒探测器 ],2016
- Joseph Redmon 等人[ 你只看一次:统一的实时对象检测 ],2016
- 约瑟夫·雷德蒙等人[ YOLO9000:更好、更快、更强 ],2016
- 聪-林逸等[ 特征金字塔网络用于物体检测 ],2017
- 约瑟夫·雷德蒙等人[ 约洛夫 3:增量改进 ],2018 年
- 聪-林逸等人[ 密集物体探测的焦损失 ],2018 年
这个故事引起你的共鸣了吗?请与我们分享您的见解。我总是乐于交谈,所以请在下面留下评论,分享你的想法。我还在 LinkedIn上分享有趣和有用的资源,欢迎随时关注并联系我。下次我会带来另一个有趣的故事。一如既往,敬请期待!
使用 Git 深入研究版本控制
掌握 Git 实现高效的代码开发和协作

Git 是一个免费的工具,它通过提供一个分布式版本控制系统来实现高效的代码修改。这是我开始学习编程时学到的最有用的工具之一。无论我是在从事我的业余项目、与朋友合作,还是在专业环境中工作,Git 都证明了自己非常有用。我能给你的最好的类比是在 Google Doc 这样的平台上为一个小组项目写一份报告。您的同事可以同时处理他们自己的报告部分,而不必直接修改您的部分。Git 通过允许您从主分支创建分支并让多人在一个项目上协作来实现这个目标。在完成安装过程后,我将解释什么是 Git 分支。如果您刚刚开始或只是独自编写项目代码,Git 仍然可以帮助您跟踪您的编码历史,恢复变更,并维护一个高效的工作流。
使用 Git 时,您有多种选择。我是在本科学习期间作为学生开始 Github 之旅的。注册成为学生的好处是可以在 Github Education 获得一个免费的私人 Github 帐户。如果你是学生,请点击这里查看的交易。除了 Github,我还使用 Gitlab 进行项目合作。你可以选择 Github 或 Gitlab,因为它们都提供相似的功能。本教程将重点介绍如何设置 Github。如果你想将库从一个平台迁移到另一个平台,请参考迁移文档这里或者下面的评论,我很乐意写一个关于它的教程。
装置
Linux 操作系统
$ sudo apt install git-all
如果您有问题或者需要安装其他基于 Unix 的发行版,请访问这里的。
马科斯
首先,通过运行以下命令检查您是否已经安装了 Git:
$ git --version
如果您没有最新版本,应该会出现安装提示。否则,可以通过这里的获取最新版本的安装链接。
Windows 操作系统
对于 windows,请点击此处,下载将自动开始。这是 Git for windows,根据 Git 官方文档,Git for windows 不同于 Git 本身。Git windows 附带了 Git BASH,它有 BASH 模拟器,所以 Git 可以使用命令行特性在 windows 上轻松运行。这样,如果需要的话,您从在 windows 上运行 git 命令中获得的经验可以很容易地转移到其他系统。另一个安装选项是安装 Github 桌面。
创建 Github 帐户
进入注册流程并创建一个账户:【https://github.com/join?source=header-home
一旦你创建了一个 Github 帐户并登录,你现在可以创建库。存储库是您放置项目的地方。您可以决定每个存储库拥有一个项目,或者您可以拥有一个包含许多分支的存储库。对于后者,您的分支可以是相关的,但我见过用户在同一个存储库中创建不相关的分支,也称为孤儿分支。
分支
如果您是版本控制和 Git 的新手,这一切听起来会有点混乱。我喜欢把仓库想象成一顿饭。让我们把它当作感恩节晚餐。你的盘子里有火鸡、填料、蔓越莓酱和土豆泥。你将为自己提供各种食物的盘子就是储藏室。你可以选择拿起四个小盘子(四个储存库),把每样食物放在相应的盘子里。你的另一个选择可能是在一个更大的盘子(储存库)里为你自己提供四种食物中的每一种。分支是主分支的快照(主分支类似于我的项目的最接近的远景)。您获取这个特定的快照,并在不影响主分支的情况下添加额外的更改/特性。无论您喜欢哪种方法,您都可以选择使用 Git 以简洁明了的方式组织项目。我个人更喜欢用一个单一的存储库来代表一个项目,然后在这个项目的存储库中,我会创建一些分支来为我的项目添加特性。
一旦理解了 Git 数据存储的概念,Git 分支就更好理解了。当您做出更改并提交它们时,Git 将信息存储为一个对象,该对象保存了更改的快照。这是 Git 作为版本控制系统的一个特殊属性,因为其他版本控制系统将更改保存为基于文件的更改列表。
其他版本控制系统

Other Version Control Systems — Image taken from git-scm
Git 存储数据

Git storing data as a stream of snapshots — image taken from git-scm
这意味着,一旦您初始化了本地存储库,Git 就会知道其中的任何和所有更改(下面将详细介绍初始化)。
州
在给定的分支中,您有文件,并且在任何给定的时间,您的文件可能处于以下三种状态之一:
- 修改
- 上演
- 坚定的
已修改状态是指已经进行了更改,但没有任何更改被保存为其对应的快照。挑选修改过的文件,并将它们标识为您希望在下一个保存的快照中使用的项目,这被称为暂存。提交状态是指预期的更改安全地存储在本地数据库中。理解任何给定文件在本地存储库中的不同状态非常重要,这样才能安全地将更改推送到远程存储库。
创建您的第一个存储库
现在我们有了关于存储库和分支的背景知识,让我们创建我们的第一个存储库。点击右上角,打开“新建存储库”链接。

给存储库一个新名称,并选择隐私设置。此设置页面上的第三个选项使您能够使用自述文件初始化存储库。我们现在可以跳过它,但是 README.md 文件非常重要。这是一个文本文件,用户使用它来提供项目概述、功能、安装说明、许可证和学分。Github 将使用这个文件,如果可用的话,在主目录页面上为任何给定的存储库创建一个项目摘要。
一旦您创建了一个存储库,这就是所谓的远程存储库。Git 通常为您提供在本地创建新存储库或使用本地文件夹并将其初始化为存储库所涉及的选择和命令。对于本教程,假设已经有一个包含代码和文档的文件夹。您希望将内容添加到这个新创建的存储库中。
用本地文件填充远程存储库
$ git init
上面的命令在本地文件夹中创建一个空存储库,其中包含您要添加到远程存储库的文件。在将当前本地目录初始化为 git 存储库之后,如果您有文件存在于这个本地文件夹中,那么它们将处于修改过的状态(参见前面关于状态的讨论)。为了暂存这些修改过的文件,我们需要标记想要的文件。
因为我们是第一次添加到这个远程存储库中,所以您需要添加以下内容:
git remote add origin https://github.com/<username>/<your_repository_name>.git
对于此初始过程之后的提交,您可以使用以下命令之一添加文件:
$ git add <file_path>
# commit all files
$ git add .
此时,文件位于“暂存区”。
$ git commit -m “write your commit message here.”
文件现在应该安全地提交并记录到本地数据库。现在,提交最终可以通过以下方式推送到远程存储库:
$ git push
对于您的初始提交, git push 应该会毫无问题地推送您当前的更改。但是,可能会有多个分支的情况。您希望将所有本地分支推到一个特定的远程存储库。在这种情况下,请使用:
$ git push <remote> — all
随着你对 Git 的经验积累和项目的进展,你可能需要在 git 推送上使用 — force 标志。强烈建议只有在你对你的建议有绝对把握的时候才使用 — force 标志。
$ git push <remote> — force
当您推送您的更改时,Git 希望验证将更改推送至远程存储库的用户,并将要求您提供您在注册时创建的用户名和密码。如果您是全局用户,在全局 git 配置设置中配置用户名和密码,如下所示。
从远程存储库制作本地副本
上面的例子关注于这样一个场景,您在本地机器上完成了开发工作,然后您将这些工作推送到远程存储库。当您需要使用远程存储库的内容来开始本地开发时,情况正好相反。在这种情况下,您需要克隆感兴趣的存储库,为此,请确保您拥有访问权限。例如,您想使用 bootstrap 进行开发。你访问 bootstrap github 库:https://github.com/twbs/bootstrap。单击存储库上的克隆或下载按钮,复制远程存储库链接。

克隆存储库
$ git clone [https://github.com/twbs/bootstrap.git](https://github.com/twbs/bootstrap.git)
用远程中的更改更新本地副本
假设您已经提交了您的更改,但就在您的同事向同一分支机构提交更改之后。为了确保您的本地分支与这些变更保持同步,您需要将这些变更拉下来。
$ git pull <remote>
Git pull 通过使用(1) git fetch 和(2) git merge 从远程存储库中获取信息。获取从本地存储库与主分支发生分歧的节点开始。如果需要跟踪,您可以随时使用 git fetch 。Git fetch 下载本地存储库中没有的信息,然后 git merge 将这些信息集成到本地存储库中。另一个与 git merge 非常相似的命令是 git rebase 。使用 git rebase 优于 git merge 的主要优势在于,新信息的集成发生在分支上最后一次提交的末尾。这导致了更加线性的提交历史,而当使用 git merge 时,情况并非总是如此。在 git pull 的情况下,合并变更的第二个步骤也可以使用下面的代码与 rebase 交换:
$ git pull --rebase <remote>
当您对本地存储库进行更改时,您需要从远程存储库获取新的更改,切换到不同的分支,等等。您不希望您的本地更改受到直接影响,但是您希望有一个干净的工作树。在这种情况下,
# 1 - stash local changes
$ git stash
# 2 - pull remote changes
$ git pull
# 3 - view stashed list
$ git stash list
# 4 - access what you JUST stashed
$ git stash apply
# 5 - access an older stash from the stashed list on #3
$ git stash apply <stashed-id-from-list>
在这一点上,你可能会问我们在 **git clone 和 git pull 中试图实现的目标有什么不同?**第一,他们的目的不同。 Git 克隆获取远程存储库中的信息并制作本地副本。这是一次性操作。 Git pull 是一个命令,用于在远程分支更新时更新您的本地变更库。这将不止一次使用,最好是在您的本地分支落后的情况下提交变更的任何时候使用。
Git 配置
我们提到,在提交期间,Git 想要验证用户将变更提交到存储库的细节。每次提交时总是输入用户名和密码,这可能会变得重复。使用 Git 全局配置文件,您可以执行一些修改来减少重复性。
- 用户名:
$ git config — global user.name <username>
2.电子邮件:
$ git config — global user.email <email>
3.错认假频伪信号
$ git config --global alias.<alias> <git-command>
例如,将 git 状态别名化为 git s:
$ git config --global alias.s status
可能需要查看和手动编辑 git 用来保存上述指令的配置文件。
4.访问全局配置文件
$ git config --global --edit
查看历史记录
Git 最有用的特性之一是能够方便地查看您的提交历史,并不断地总结您的工作。工作日中,干扰时有发生。能够简单地运行 commit log 命令并查看整个提交历史有助于您获得所有更改的摘要。
$ git log
如果您只是运行 git log 命令,人眼可能会有点难以理解结果。但是,我们有修饰日志、传递单行提交消息和添加图形元素的选项。
# --all shows you the log history in its entirety
# --oneline compresses the commit messages to a single line.
# --decorate adds branch names and tags from commits
# --graph is a textual graph representation$ git log --all --decorate --oneline --graph
按模式搜索提交日志是另一个有用的特性。如果您想在一个有许多协作者的项目中找到您自己提交的特定变更,请执行以下操作:
$ git log — authors=<username>
如果是包含特定短语或模式的提交消息,请使用以下内容进行搜索:
$ git log --grep=”<pattern>”
每次提交的特定文件的更改可以用 stat:
$ git log --stat
改变历史
重定…的基准
使用 rebase,您也可以更改提交时间线。通常建议不要对已经被推送到公共存储库的提交进行重新排序。只传递 git rebase 将从当前分支获取提交,并自动将它们应用到传递的分支。我个人很欣赏交互式的基础特性,在这里你可以决定如何将提交转移到一个新的基础上。
# rebase current branch onto base(tag, commit ID, branch name, etc.)
$ git rebase <base>
# interactive changes
$ git rebase -i <base>
更改最后一次提交
历史最频繁的修改与更改最后的提交有关。在临时环境中,您可以决定不希望添加某个:
# change last commit message
$ git commit --amend
根据 Git 文档,建议您小心使用这个命令,并像对待一个小的 rebase 一样对待它。如果你已经推动了你的改变,就不要修改了。
从提交历史记录中删除文件
假设你养成了用 *git add 添加所有变更的习惯。*不小心添加了一个您想从所有提交历史中删除的敏感文件。使用分支过滤器流程,您可以实现以下目标:
$ git filter-branch --tree-filter 'rm -f sensitive_file.txt' HEAD
添加. gitignore
如果您创建了一个名为的文件,上述场景就不会发生。gitignore 并将你的“sensitive_file.txt”列为该文件中的一项。在您的本地目录中创建这个文件,然后添加备份文件、配置等。将使您免于将混乱推送到您的远程存储库。除了特定的文件名,您还可以指定模式。比如你有 *。txt 在你的。gitignore 文件,它将忽略所有文本文件。
观察差异
当前工作目录中的更改可以直接与远程分支上的最后一次提交进行比较:
$ git diff HEAD
HEAD 是指您所在的分支中的最后一次提交。
撤消更改
到目前为止,我们已经彻底讨论了 git 文件的三种不同状态。其中一个状态是 **staging。**如果您想要撤消暂存文件,请使用
$ git reset
# to reset specific files use a file path
$ git reset <file>
一旦分支被推送,我们仍然可以通过使用 **revert 更改特定的提交来撤销。**下面显示的<提交>参数是一个具体的提交参考。用 git log(如上所述)观察您的提交日志,然后对下面的命令使用 commit ref。
$ git revert <commit>
结论
从学习创建 Git 库到理解如何撤销我们的“错误”,我们已经走过了漫长的道路。理解 Git 并习惯本文中的命令列表可能需要一段时间,但这只是时间和实践的问题。如果有特定的命令无法记住,使用我们讨论过的别名方法(参见 Git 配置一节)。即使您目前没有使用 Git 的项目,也可以创建一个模拟存储库,并使用文本文件进行练习。确保你的项目用 README.md (参见创建你的第一个存储库一节)很好地记录,并且经常提交。有了这个教程,你就有足够的知识来进行项目合作,改变你的项目历史,并保持一个完美的投资组合。
计算机视觉中的深度域适应
在过去的十年中,计算机视觉领域取得了巨大的进步。这一进步主要是由于卷积神经网络(CNN)不可否认的有效性。如果用高质量的带注释的训练数据进行训练,CNN 允许非常精确的预测。例如,在分类设置中,您通常会使用标准网络架构之一(ResNet、VGG 等)。)并使用您的数据集对其进行训练。这可能会带来非常好的性能。
另一方面,如果您没有针对您的特定问题的大量人工注释数据集,CNN 还允许通过迁移学习来利用已经针对类似问题训练了网络的其他人。在这种情况下,您可以采用一个在大型数据集上进行预训练的网络,并使用您自己的小型带注释的数据集来调整它的一些上层。
这两种方法都假设您的训练数据(无论大小)代表了基本分布。但是,如果测试时的输入与定型数据显著不同,则模型的性能可能不会很好。例如,让我们假设你是一名自动驾驶汽车工程师,你想分割汽车摄像头拍摄的图像,以便了解前方的情况(建筑物、树木、其他汽车、行人、交通灯等)。).您的 NYC 数据集有很好的人工生成的注释,并且您使用这些注释训练了一个大型网络。你在曼哈顿的街道上测试你的自动驾驶汽车,一切似乎都很好。然后你在巴黎测试同样的系统,突然事情变得非常糟糕。汽车不再能够检测交通灯,汽车看起来非常不同(巴黎没有黄色出租车),街道也不再笔直。
您的模型在这些场景中表现不佳的原因是问题域发生了变化。在这种特殊情况下,输入数据的域发生了变化,而任务域(标签)保持不变。在其他情况下,您可能希望使用来自同一域的数据(为同一基础分布绘制)来完成一项新任务。类似地,输入和任务域可以同时不同。在这些情况下,领域适应会帮助你。领域自适应是机器学习的一个子学科,处理场景,其中在源分布上训练的模型被用于不同(但相关)目标分布的上下文中。一般来说,领域自适应使用一个或多个源领域中的标记数据来解决目标领域中的新任务。因此,源域和目标域之间的相关程度通常决定了适配的成功程度。
领域适应有多种方法。在**“浅”(非深)域适应中,通常使用两种方法:重新加权源样本并对重新加权的样本进行训练,并尝试学习共享空间以匹配源和目标数据集的分布**。虽然这些技术也可以应用于深度学习的环境中,但深度神经网络学习的深度特征( DNNs )通常会产生更多可转移的表示(通常在较低层中学习高度可转移的特征,而在较高层中可转移性急剧下降,参见例如 Donahue 等人的这篇论文)。在深度域适配中,我们尝试利用 DNNs 的这一特性。
领域适应类别
以下总结主要基于Wang 等人的这篇综述论文和Wilson 等人的这篇综述。在该工作中,作者根据任务的复杂性、可用的标记/未标记数据的数量以及输入特征空间的差异来区分不同类型的领域适应。他们特别将领域适应定义为一个问题,其中任务空间相同,差异仅在于输入领域发散。基于该定义,域自适应可以是同质的(输入特征空间是相同的,但是具有不同的数据分布)或者异质的(特征空间及其维度可以不同)。
域适配也可以在一个步骤中发生(一步域适配),或者通过多个步骤,在过程中遍历一个或多个域(多步域适配)。在这篇文章中,我们将只讨论一步域适应,因为这是最常见的域适应类型。
根据您从目标领域获得的数据,领域适应可以进一步分为监督的(您确实有来自目标领域的标记数据,尽管这个数量对于训练整个模型来说太小了)、半监督的(您有标记和未标记的数据),以及非监督的(您没有来自目标领域的任何标记数据)。
任务相关性
我们如何确定在源领域中训练的模型是否可以适应我们的目标领域?事实证明,这个问题并不容易回答,任务相关性仍然是一个活跃的研究课题。如果两个任务使用相同的特征进行决策,我们可以将它们定义为相似的。另一种可能性是,如果两个任务的参数向量(即分类边界)接近,则将这两个任务定义为相似的(参见薛等人的本文)。另一方面, Ben-David 等人提出,如果两个任务的数据可以使用一组变换 F 从固定的概率分布中生成,则这两个任务是 F 相关的
尽管有这些理论上的考虑,但在实践中,可能有必要在您自己的数据集上尝试域适应,看看您是否可以通过使用来自源任务的模型来为您的目标任务获得一些好处。通常,任务相关性可以通过简单的推理来确定,例如来自不同视角或不同照明条件的图像,或者在医学领域中,来自不同设备的图像等等。
一步域自适应技术及其应用
一步域适配有三种基本技术:
- 基于散度的域自适应,
- 使用生成模型(GANs)或使用领域混淆损失的基于对抗的领域适应,以及
- 使用堆叠自动编码器(SAE)或 GANs 的基于重构的域自适应。
基于散度的领域适应
基于散度的域自适应通过最小化源和目标数据分布之间的一些散度标准来工作,从而实现域不变特征表示。如果我们找到这样的特征表示,分类器将能够在两个域上同样好地执行。这当然假设这样的表示存在,这又假设任务以某种方式相关。
四种最常用的差异度量是最大平均差异(MMD)相关比对(CORAL)对比域差异 (CCD)和 Wasserstein 度量。
MMD 是一种假设检验,在将两个样本映射到再生核希尔伯特空间(RKHS)后,通过比较特征的平均值来检验这两个样本是否来自同一分布。如果均值不同,分布也可能不同。这通常通过使用内核嵌入技巧和使用高斯内核比较样本来实现。这里的直觉是,如果两个分布是相同的,则来自每个分布的样本之间的平均相似性应该等于来自两个分布的混合样本之间的平均相似性。在域自适应中使用 MMD 的一个示例是 Rozantsev 等人的这篇论文在这篇论文中,使用了双流架构,其权重不共享,但通过使用分类、正则化和域差异(MMD)损失的组合来产生相似的特征表示,如下图所示。

Two-stream architecture by Rozantsev et al.
因此,该设置可以是监督的、半监督的或者甚至是无监督的(在目标域中没有分类损失)。
CORAL ( 链接)类似于 MMD,但是它试图对齐源和目标分布的二阶统计量(相关性),而不是使用线性变换的平均值。Sun 等人的论文通过使用源和目标协方差矩阵之间的 Frobenius 范数构造可微分的 CORAL 损失,在深度学习的上下文中使用 CORAL。
CCD 也是基于 MMD,但也通过查看条件分布来利用标签分布。这确保了联合域特征仍然保持对标签的预测性。最小化 CCD 最小化类内差异,同时最大化类间差异。这需要源和目标域标签。为了摆脱这种约束, Kang 等人提出在联合优化目标标签和特征表示的迭代过程中使用聚类来估计丢失的目标标签。因此,通过聚类找到目标标签,然后最小化 CCD 以适应这些特征。
最后,源和目标域中的特征和标签分布可以通过考虑最优传输问题及其相应的距离,即 Wasserstein 距离来对齐。这是在 DeepJDOT (Damodaran 等人)中提出的。作者建议通过最佳传输来最小化联合深度特征表示和标签之间的差异。
基于对抗的领域适应
这种技术试图通过使用对抗训练来实现领域适应。
一种方法是使用生成对抗网络 (GANs)生成与源域有某种关联的合成目标数据(例如通过保留标签)。这些合成数据然后用于训练目标模型。
CoGAN 模型 试图通过为源和目标分布使用两个生成器/鉴别器对来实现这一点。生成器和鉴别器的一些权重被共享以学习域不变特征空间。以这种方式,可以生成标记的目标数据,其可以进一步用于诸如分类的任务中。

CoGAN architecture by Liu et al.
在另一个装置中, Yoo 等人试图通过使用两个鉴别器来学习源/目标转换器网络:一个用于确保目标数据是真实的,另一个用于保持源和目标域之间的相关性。发生器在此以源数据为条件。这种方法只需要目标域中未标记的数据。
除了用于当前任务的分类损失之外,如果我们使用所谓的域混淆损失,我们还可以完全去除生成器,并且一次执行域适应。域混淆损失类似于 GANs 中的鉴别器,因为它试图匹配源和目标域的分布,以便“混淆”高级分类层。这种网络最著名的例子可能是 Ganin 等人的域对抗神经网络 (DANN)。该网络包括两个损失,分类损失和域混淆损失。它包含一个梯度反转层来匹配特征分布。通过最小化源样本的分类损失和所有样本的域混淆损失(同时最大化特征提取的域混淆损失),这确保了样本对于分类器是相互不可区分的。

Domain-adversarial neural network architecture by Ganin et al.
基于重构的域适应
这种方法使用辅助重建任务来为每个域创建共享表示。例如, 深度重建分类网络【DRCN】试图同时解决这两个任务:(I)源数据的分类,和(ii)未标记目标数据的重建。这确保了网络不仅学会了正确区分,而且还保存了关于目标数据的信息。在该论文中,作者还提到重建管道学习将源图像转换成类似于目标数据集的图像,这表明为两者学习了共同的表示。

The DRCN architecture by Ghifary et al.
另一种可能性是使用所谓的循环杆。Cycle GANs 的灵感来源于机器翻译中双重学习的概念。这个概念同时训练两个相反的语言翻译者(A-B,B-A)。循环中的反馈信号由相应的语言模型和相互 BLEU 分数组成。使用 im2im 框架可以对图像进行同样的处理。在本文的中,从一个图像域到另一个图像域的映射是在不使用任何成对图像样本的情况下学习的。这是通过同时训练分别在两个域中生成图像的两个 gan 来实现的。为了确保一致性,引入了周期一致性损失。这确保了从一个域到另一个域的变换,以及从一个域到另一个域的变换,会产生与输入大致相同的图像。因此,两个配对网络的全部损耗是两个鉴别器的 GAN 损耗和周期一致性损耗的总和。
最后,通过对来自另一个域的图像的输入进行调节,GANs 也可以用于编码器-解码器设置。在 Isola 等人的论文中, 条件 GANs 用于通过在输入端调节鉴别器和发生器的输出,将图像从一个域转换到另一个域。这可以使用简单的编码器-解码器架构或者使用具有跳跃连接的 U-Net 架构来实现。

Several results from the conditional GAN by Isola et al.
结论
深度领域适应允许我们将特定 DNN 在源任务上学习的知识转移到新的相关目标任务。它已成功应用于图像分类或风格转换等任务中。在某种意义上,深度领域适应使我们能够在特定的新计算机视觉任务所需的训练数据量方面更接近人类水平的表现。因此,我认为这一领域的进展对整个计算机视觉领域至关重要,我希望它最终将引领我们在视觉任务中实现有效而简单的知识重用。
深度双重下降:当更多的数据是一件坏事
解决经典统计学和现代 ML 建议之间的根本冲突

Photo by Franki Chamaki on Unsplash
最近偶然看到一篇非常有意思的论文写于 OpenAI,题目是深度双下降。该论文触及了训练机器学习系统和模型复杂性的本质。我希望在这篇文章中以一种可接近的方式总结本文中的观点,并推进对模型大小、数据量和正则化之间权衡的讨论。
问题是
统计学习和现代最大似然理论之间存在着根本的冲突。经典统计学认为*太大的模型是不好的。*这是因为复杂的模型更容易过度拟合。事实上,经典统计学中经常应用的一个强有力的定理是奥卡姆剃刀,其本质是说 t 最简单的解释通常是正确的。
这可以用一个可视化来清楚地解释。

The green line is an example of a model overfitting the training data, while the black line is a simpler model that approximates the true distribution of the data.
尽管复杂性和可推广性之间存在明显的权衡,但你经常会看到现代 ML 理论认为更大的模型更好。有趣的是,这种说法在很大程度上似乎奏效了。来自世界上一些顶级人工智能研究团队的研究,包括来自谷歌和微软的团队,表明更深层次的模型尚未饱和。事实上,通过实施仔细的正则化和早期停止,似乎通常情况下,将您的模型的性能提高几个点的最佳方法是简单地添加更多的层或收集更多的训练数据。
深度双重下降
OpenAI 论文的焦点提供了经典统计学和现代 ML 理论之间的矛盾的实际调查。

Empirical evidence shows that the truth of how modern machine learning systems work is a mixture of both classical statistics and modern theory.
深度双下降是指性能提高,然后随着模型开始过度拟合而变得更差,最后随着模型大小、数据大小或训练时间的增加而进一步提高的现象。上图以图形方式说明了这种行为。
深度双下降现象在模型的复杂性、数据量和训练时间方面有多种含义。
有时,更大的型号更糟糕

Before the model hits the interpretation threshold, there is a bias-variance tradeoff. Afterwards, the current wisdom of “Larger models are better” is applicable
在对 ResNet18 进行实验时,OpenAI 的研究人员发现了一个关于偏差和方差之间权衡的有趣笔记。在模型的复杂性超过插值阈值之前,或者模型刚好大到足以适合训练集的点之前,较大的模型具有较高的测试误差。然而,在模型的复杂性允许它适合整个训练集之后,具有更多数据的更大模型开始表现得更好。
似乎有一个复杂的区域,在那里模型更容易过度拟合,但是如果在模型中捕捉到足够的复杂性,模型越大越好。
有时,样本越多越糟糕

There’s a point where models with more data actually perform worse on the test set. Again, however, there is a point near the interpolation threshold at which this reverses.
有趣的是,对于低于插值阈值的模型,似乎更多的训练数据实际上会在测试集上产生更差的性能。然而,随着模型变得更加复杂,这种权衡发生了逆转,现代智慧“数据越多越好”开始再次适用。
一个有效的假设是,不太复杂的模型可能无法捕获太大训练集中所需的一切,因此无法很好地推广到看不见的数据。然而,随着模型变得足够复杂,它能够克服这个限制。
有时,训练时间越长,过度适应就会消失

在上面关于被训练的时期数的图表中,训练和测试误差首先随着时期数的增加而急剧下降。最终,随着模型开始过度拟合,测试误差开始增加。最后,随着过度拟合奇迹般地被消除,测试误差再次减小。
在论文中,研究人员称之为划时代的双重下降。他们还注意到,测试误差的峰值正好在插值阈值处。这里的直觉是,如果一个模型不是非常复杂,那么只有一个模型最适合训练数据。如果模型符合噪声数据,其性能将大幅下降。但是,如果模型复杂到足以通过插值阈值,则有几个模型适合训练集和测试集,并且随着训练时间的延长,可以近似这些模型中的一个。发生这种情况的原因是一个公开的研究问题,并且对训练深度神经网络的未来非常重要。
如果你对这个研究问题感兴趣,看看启发了这篇文章的论文和相关总结。
CNN 内心深处:是不是听起来太复杂了?让我们用热图来观察体重吧!

Source: Freepik
大家好!
我们都使用一些深度学习工具为我们的项目创建应用程序。因为在我们的时代,构建计算机视觉应用非常容易,不像过去的时代,有时这些工具会阻止我们学习算法的工作机制。
我们相信理解它如何工作的最好方法,就是在它工作的时候观察它!
因此,我们将实验 CNN 如何工作,以及它如何使用热图进行分类。这将使我们更好地理解神经网络中使用的卷积,以及权重在我们算法中的重要性。
在这个例子中,我们将遵循 Fastai DL-1 课程中的说明。多亏了他们的 让神经网络再次变得不酷 !
帖子的上下文:
- 选择数据集
- 探索性数据分析和数据扩充
- 创建模型和学习者
- 培训
- 使用热图分析结果
1。选择数据集
当尝试新事物时,最好的方法是使用预清洗数据集。因为我们不想在为模型清理和准备数据时失去动力。寻找高质量数据集以尝试新事物的最佳地点是!
在这个例子中,我使用了一个名为 植物幼苗分类 的图像分类数据集。我想简单解释一下我为什么选择这个数据集;因为这是一个平衡的分类问题,而且竞赛的目的也适合我的算法。
在这次比赛中,我们被要求创建一个模型,成功地完成属于 12 个不同物种的图像的分类任务。该数据集包含 960 幅图像。

Images from different species in the dataset.
我选择这个数据集的另一个原因是,对我来说,从这些图像中分类植物类型似乎是一项艰巨的任务。它们看起来非常熟悉,而且有着相同的背景(土壤),我认为这种算法不会真正成功地识别植物类别。我真的很想知道卷积在这个特定问题中是如何工作的。
2。探索性数据分析和数据扩充
在决定库、架构和其他项目需求之前,最重要的步骤是探索数据集。虽然 Kaggle 竞争数据集确实准备充分,但作为一名数据科学家,在创建解决方案之前,您始终需要首先了解问题。
*tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
data = ImageDataBunch.from_folder(
path = path,
valid_pct = 0.2,
bs = 16,
size = 224,
ds_tfms = tfms,
).normalize(imagenet_stats)
data
print(data.classes)
data.show_batch()*

因此,在观察了来自我们数据集的图像后,我准备了一个数据模型用于训练。在这里,我想简单解释一下我在这篇代码博客中所做的事情:
- 首先,我决定了数据增强规格。我应用了垂直翻转和一些扭曲来增强图像。另外,由于一些图像比较暗,而且有微小的植物,我使用了一些灯光效果和缩放。
- 为了观察我的训练,我留出了 20%的数据集作为验证。
- 我在这个任务中使用了迁移学习,所以用 imagenet 统计数据对图像进行了标准化。也像原始 imagenet 数据集一样调整它们的大小。
3。创建模型和学习者
Fastai 是一个非常棒的深度学习库,具有易于使用和理解的特点。在这个实验中,我使用了一个 CNN 学习器来训练我的模型。所以我们在图书馆有一个很棒的功能叫做 cnn_learner() 。但我们不仅仅是复制和粘贴代码的工具用户;我们想深入了解桥下到底发生了什么。我们的库中还有另一个名为 doc() 的函数。那么让我们用它来理解 cnn_learner()函数:
*doc(cnn_learner)Result:cnn_learner(**data**:[DataBunch](https://docs.fast.ai/basic_data.html#DataBunch), **base_arch**:Callable, **cut**:Union[int, Callable]=***None***, **pretrained**:bool=***True***, **lin_ftrs**:Optional[Collection[int]]=***None***, **ps**:Floats=***0.5***, **custom_head**:Optional[[Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)]=***None***, **split_on**:Union[Callable, Collection[ModuleList], NoneType]=***None***, **bn_final**:bool=***False***, **init**=***'kaiming_normal_'***, **concat_pool**:bool=***True***, ********kwargs**:Any)*
所以现在我们可以研究这个函数中的每个变量了!
之后,我们可以创建我们的学习者。在这个问题中,我并不关注准确性。我想要一个好的结果,但不会花太多时间进行微调和其他步骤。我选择了一个预先训练好的模型,它是 resnet34。该模型有 34 层,在 imagenet 数据集上进行训练。由于我的任务中有植物,我相信结果对我来说足够了。
让我们创建学习者:
*learn = cnn_learner(data, models.resnet34, metrics=accuracy)*
4.培养
我们准备了模型和学习者。现在是决定学习速度的时候了。为此,我们将使用另一个强大的函数:
*learn.recorder.plot()*

Learning rate plot.
让我们来训练这个模型:
*lr = 0.01
learn.fit_one_cycle(5, slice(lr))*

Training result.
我们有 93%的准确率,这对我来说足够了。如果我参加这次比赛,我会使用一个更复杂的架构,并进行微调,还会进行一些数据预处理,但因为我们专注于了解正在发生的事情,所以这个结果已经足够了。
5。使用热图分析结果
为了准备热图函数,我们使用了另一个很棒的 Fastai 规范。在库中,我们有回调和钩子库,用它们我们可以研究训练,如反向传播,并对它们进行评估。
*def show_heatmap(hm):
_,ax = plt.subplots()
xb_im.show(ax)
ax.imshow(hm, alpha=0.6, extent=(0,224,224,0),
interpolation='bilinear', cmap='magma')*
我使用 0.6 alpha 值和 magma 方法为我们的 224–224 像素大小的图像创建了热图函数。让我们在一张图片上试试:
*show_heatmap(avg_acts)*

Heatmap on an example image.
结果比我想的要好。图像左上方的土壤对结果几乎没有影响。这很好,因为在那个区域没有植物的任何部分。此外,我们可以清楚地看到,植物的中心对结果的影响最大。之后,位于图像右上方和左下方的植物外部对结果有很大影响。
热图是了解卷积函数内部情况的绝佳可视化工具。我们可以将它们应用到其他研究领域。
这篇文章旨在用一种有趣的方法来解释卷积中的权重。我会继续写其他的例子。请和我分享你的想法!
分类变量的深度嵌入(Cat2Vec)
对表格数据使用深度学习

在这篇博客中,我将带你了解在 keras 上使用深度学习网络创建分类变量嵌入的步骤。这个概念最初是由杰瑞米·霍华德在他的 fastai 课程中提出的。更多详情请看链接。
传统嵌入
在我们使用的大多数数据源中,我们会遇到两种主要类型的变量:
- **连续变量:**通常是整数或十进制数,有无限多的可能值,如计算机存储单元,如 1GB、2GB 等…
- **分类变量:**这些是离散变量,用于根据某些特征分割数据。例如计算机存储器的类型,即 RAM 存储器、内部硬盘、外部硬盘等。
当我们建立一个最大似然模型的时候,在我们能够在算法中使用它之前,我们需要转换分类变量。所应用的转换对模型的性能有很大的影响,尤其是当数据具有大量高基数的分类要素时。应用的一些常见转换示例包括:
One-Hot encoding: 这里我们将每个类别值转换成一个新列,并为该列分配一个1或0 (True/False)值。
二进制编码:这创建了比一个热点更少的特性,同时保留了列中值的一些唯一性。它可以很好地处理高维有序数据。
然而,这些通常的变换并不能捕捉分类变量之间的关系。有关不同类型的编码方法的更多信息,请参见以下链接。
数据
为了演示深度嵌入的应用,让我们以 Kaggle 的自行车共享数据为例。这里的也链接到 git 回购。

Data — Bike Sharing
正如我们所看到的,数据集中有许多列。为了演示这个概念,我们将只使用来自数据的 date_dt、cnt 和 mnth 列。

Selected Columns
传统的一键编码会产生 12 列,每个月一列。然而,在这种类型的嵌入中,一周中的每一天都具有同等的重要性,并且每个月之间没有关系。

One hot encoding of the mnth column
我们可以在下图中看到每个月的季节性模式。正如我们所见,第 4 到 9 个月是高峰期。0 月、1 月、10 月和 11 月是自行车租赁需求较低的月份。

Monthly Seasonality
此外,当我们用不同的颜色表示每个月的日使用量时,我们可以看到每个月内的一些周模式。

Daily usage trends
理想情况下,我们期望通过使用嵌入来捕获这种关系。在下一节中,我们将使用构建在 keras 之上的深层网络来研究这些嵌入的生成。
深度编码
代码如下所示。我们将建立一个具有密集层网络和“relu”激活功能的感知器网络。
网络的输入,即’ x '变量是月份号。这是一年中每个月的数字表示,范围从 0 到 11。因此,input_dim 被设置为 12。
网络的输出,即’ y ‘是’ cnt '的缩放列。然而,可以增加“y”以包括其他连续变量。这里我们使用一个连续变量,我们将输出密集层的最后一个数字设置为 1。我们将为 50 个迭代或时期训练模型。
embedding_size = 3model = models.Sequential()
model.add(Embedding(input_dim = 12, output_dim = embedding_size, input_length = 1, name="embedding"))
model.add(Flatten())
model.add(Dense(50, activation="relu"))
model.add(Dense(15, activation="relu"))
model.add(Dense(1))
model.compile(loss = "mse", optimizer = "adam", metrics=["accuracy"])
model.fit(x = data_small_df['mnth'].as_matrix(), y=data_small_df['cnt_Scaled'].as_matrix() , epochs = 50, batch_size = 4)
网络参数

Model Summary
嵌入层:我们在这里指定分类变量的嵌入大小。在本例中,我使用了3**,**如果我们增加这个值,它将捕获分类变量之间关系的更多细节。杰瑞米·霍华德建议采用以下方法来选择嵌入尺寸:
# m is the no of categories per featureembedding_size = min(50, m+1/ 2)
我们使用一个具有均方误差损失函数的“adam”优化器。Adam 优于 sgd(随机梯度下降),因为它的自适应学习速率更快更优化。你可以在这里找到关于不同类型优化器的更多细节。
结果
每个月的最终嵌入结果如下。这里“0”代表一月,“11”代表十二月。

Embedding Table
当我们用一个 3D 图将它可视化时,我们可以清楚地看到月份之间的关系。具有相似“计数”的月份更接近地分组在一起,例如,第 4 个月到第 9 个月彼此非常相似。

Embeddings — Months of the year
结论
总之,我们已经看到,通过使用 Cat2Vec(类别变量到向量),我们可以使用低维嵌入来表示高基数类别变量,同时保留每个类别之间的关系。
在接下来的几篇博客中,我们将探讨如何使用这些嵌入来构建具有更好性能的监督和非监督机器学习模型。
Python 中基于深度 CNN 的图像质量盲预测器
介绍
在本教程中,我们将实现 Jongio Kim、Anh-Duc Nguyen 和 Sanghoon Lee [1]提出的基于深度 CNN 的盲图像质量预测器(DIQA) 方法。此外,我将介绍以下 TensorFlow 2.0 概念:
- 使用 tf.data.Dataset 构建器下载并准备数据集。
- 使用 tf.data API 定义一个 TensorFlow 输入管道来预处理数据集记录。
- 使用 tf.keras 函数 API 创建 CNN 模型。
- 为客观误差图模型定义自定义训练循环。
- 训练客观误差图和主观评分模型。
- 使用训练好的主观评分模型进行预测。
注:部分功能在utils . py中实现,不在本指南讨论范围内。
迪迦是什么?
DIQA 是一项原创提案,专注于解决将深度学习应用于图像质量评估(IQA)的一些最受关注的挑战。相对于其他方法的优势是:
- 该模型不限于专门处理自然场景统计(NSS)图像[1]。
- 通过将训练分为两个阶段(1)特征学习和(2)将学习到的特征映射到主观分数,防止过度拟合。
问题
生成 IQA 数据集的成本很高,因为它需要专家的监督。因此,基本的 IQA 基准仅由几千条记录组成。后者使深度学习模型的创建变得复杂,因为它们需要大量的训练样本来进行归纳。
例如,让我们考虑最频繁使用的数据集来训练和评估 IQA 方法 Live , TID2008 , TID2013 , CSIQ 。下表包含每个数据集的总体摘要:

其中任何一个样本的总量都不超过 4,000 条记录。
资料组
IQA 基准只包含有限数量的记录,可能不足以训练 CNN。然而,出于本指南的目的,我们将使用实时数据集。它由 29 幅参考图像和 5 种不同的失真组成,每种失真有 5 种严重程度。

Fig 1. An example of a reference image in Live dataset.
第一项任务是下载和准备数据集。我为图像质量评估创建了几个 TensorFlow 数据集构建器,并在图像质量包中发布了它们。构建器是由 tensorflow-datasets 定义的接口。
注意:由于数据集的大小(700 兆字节),这个过程可能需要几分钟。

下载并准备好数据后,将构建器转换成数据集,并对其进行洗牌。请注意,批次等于 1。原因是每个图像都有不同的形状。增加批量大小将导致错误。

输出是发电机;因此,使用括号运算符访问样本会导致错误。有两种方法可以访问发生器中的图像。第一种方法是将生成器转换成迭代器,并使用 next 函数提取单个样本。

输出是包含失真图像、参考图像和主观分数(dmos)的张量表示的字典。另一种方法是通过 for 循环从生成器中提取样本:

方法学
图像标准化
DIQA 的第一步是预处理图像。图像被转换成灰度,然后应用低通滤波器。低通滤波器定义为:

其中低频图像是以下算法的结果:
- 模糊灰度图像。
- 将它缩小 1 / 4。
- 把它放大到原来的大小。
这种标准化的主要原因是(1)人类视觉系统(HVS)对低频带的变化不敏感,以及(2)图像失真几乎不影响图像的低频分量。


Fig 2. On the left, the original image. On the right, the image after applying the low-pass filter.
客观误差图
对于第一个模型,使用客观误差作为代理,以利用数据增加的影响。损失函数由预测误差图和地面真实误差图之间的均方误差定义。

而 err( ) 可以是任何误差函数。对于这种实现,作者建议使用

用 p=0.2 。后者是为了防止误差图中的值很小或接近零。


Fig 3. On the left, the original image. In the middle, the pre-processed image, and finally, the image representation of the error map.
可靠性地图
根据作者的说法,该模型很可能无法预测具有同质区域的图像。为了防止它,他们提出了一个可靠性函数。假设模糊区域比纹理区域可靠性低。可靠性函数定义为

其中α控制可靠性图的饱和特性。sigmoid 的正部分用于将足够大的值分配给低亮度的像素。

之前的定义可能会直接影响预测得分。因此,使用平均可靠性图来代替。

对于 Tensorflow 函数,我们只需计算可靠性图,并除以其均值。


Fig 4. On the left, the original image, and on the right, its average reliability map.
损失函数
损失函数被定义为可靠性图和客观误差图之间的乘积的均方误差。误差是预测误差图和地面实况误差图之间的差异。

损失函数要求将误差乘以可靠性图;因此,我们不能使用默认的 loss 实现TF . loss . meansquaerror。

创建自定义损耗后,我们需要告诉 TensorFlow 如何区分它。好的一面是我们可以利用自动微分使用 tf。梯度胶带。

【计算机】优化程序
作者建议使用学习速率为 2e-4 的那达慕优化器。

培养
客观误差模型
对于训练阶段,利用 tf.data 输入管道来生成更清晰易读的代码是很方便的。唯一的要求是创建应用于输入的函数。

然后,将 tf.data.Dataset 映射到 calculate_error_map 函数。

几乎很快就可以应用转换。原因是处理器还没有对数据执行任何操作,它是按需发生的。这个概念通常被称为懒惰评估。
到目前为止,已经实施了以下组件:
- 预处理输入并计算目标的生成器。
- 定制训练循环所需的损失和梯度函数。
- 优化器功能。
唯一缺少的是模型的定义。

Fig 5. The architecture for the objective error map prediction. The red and blue arrows indicate the flows of the first and stage. Source: http://bit.ly/2Ldw4PZ
在上图中,描述了如何:
- 预处理后的图像进入卷积神经网络(CNN)。
- 它用 Relu 激活函数和“相同”填充进行 8 次卷积变换。这被定义为 f()。
- f()的输出通过与线性激活函数的最后卷积来处理。这被定义为 g()。

对于自定义训练循环,有必要:
- 定义度量标准来衡量模型的性能。
- 计算损耗和梯度。
- 使用优化器更新权重。
- 印刷精度。

注意:使用斯皮尔曼的等级相关系数(SRCC)或皮尔逊的线性相关系数(PLCC)作为准确性指标是一个好主意。
主观评分模型
为了创建主观评分模型,让我们使用 f()的输出来训练回归变量。


使用 tf.keras.Model 的 fit 方法训练模型需要返回两个参数的数据集。第一个是输入,第二个是目标。

然后,拟合主观评分模型。

预言;预测;预告
使用已经训练好的模型进行预测很简单。在模型中使用预测方法即可。

结论
在本文中,我们学习了如何利用 tf.data 模块来创建易于阅读且节省内存的数据管道。此外,我们使用功能性 Keras API 实现了基于深度 CNN 的盲图像质量预测器(DIQA)模型。该模型通过使用 TensorFlow 的自动微分功能的自定义训练循环进行训练。
下一步是找到最大化 PLCC 或 SRCC 准确性度量的超参数,并评估模型相对于其他方法的整体性能。
另一个想法是使用更大的数据集来训练客观误差图模型,并查看最终的整体性能。
Jupyter 笔记本
更新 2020/04/15: 包图像质量和笔记本更新修复了 LiveIQA 和 Tid2013 TensorFlow 数据集的一个问题。现在一切正常,检查一下!
Image quality 是一个用于自动图像质量评估(IQA)的开源软件库。该包是公共的…
github.com](https://github.com/ocampor/image-quality.git)
文献学
[1] Kim,j .,Nguyen,A. D .,& Lee,S. (2019)。基于深度 CNN 的图像质量盲预测器。神经网络和学习系统汇刊。https://doi.org/10.1109/TNNLS.2018.2829819
深入到端到端的神经共指模型

Credit to Victor Vasarely
在之前关于端到端神经共指模型的文章中,我们已经看到了结果及其在 chatbot 上的应用。您想更深入地了解模型的工作原理吗?这篇文章将满足你的好奇心。
这篇文章包含了更详细的公式,但是我已经尽力使论文中理论部分的描述更容易理解。Medium 不支持上标、下标或类似 latex 的语法,这给阅读本文带来了一些不便。
在我们开始了解这个模型之前,关于共指的几个概念有助于我们的理解。
1.共指消解研究
一些重要的共指模型被建立起来,如提及对模型和提及排序模型。
1.1 提及对模型
提及对模型是受监督的。根据共指数据集,对名词短语共指进行标注。该模型提出了一个二元分类器来预测两个名词短语是否相关。然而,就以下问题而言,该模型并不实用。首先,不能保证共指关系中的传递性。然后,对于大多数非共指名词短语,非共指标签的数量远远多于共指标签。因此,带标签的数据集可能具有偏斜的类分布。为了实现该模型,需要特征、训练实例创建方法和聚类算法。
1.2 提及排名模型
给定一个要解决的 NP,提及排序模型考虑最可能的候选先行词。对于每个提及,计算该提及和先行候选项的成对共指得分。将选择得分最高的先行词来匹配该提及。成对共指得分由提及得分和先行得分组成。提及分数意味着表达式被提及的可能性。类似地,先行词得分表明先行候选词是该提及的真实先行词的可能性。机器学习方法从数据集中训练一些标准。这允许我们训练一个提及排序器,而不是对所有候选人的经历进行排序。提及排序模型优于提及对模型。但是,它不能利用集群级别的功能。
Rahman 和 Ng (2009)提出了另一种改进的聚类排序模型。不是仅对候选前因进行排序,而是对前面的聚类进行排序。提及排名模型的一个缺省是只对候选先行词进行排名,所以如果提及实际出现在某些候选先行词之前,非回指 NP 就会被错误解析。这不是我们所期望的。模型本身不能决定提及是否是回指。其他几个决议被提出来识别非照应名词短语。
1.3 最先进的共指消解模型
该论文(Clark 和 Manning,2016a)提出了一种基于神经网络的基于实体的模型,该模型为共指聚类对产生高维向量表示。该系统通过使用从学习到搜索的算法来学习如何使聚类合并,从而提供高分的最终共指划分。因为真实的观察依赖于先前的动作,所以在这种情况下不能支持共同的 i.i.d .假设。学习搜索算法可以通过优化策略分数来解决这个问题。最终结果是 F1 得分的平均值为 65.29%。
在 Clark 和 Manning (2016b)的论文中,通过两种方法优化了提及排名模型,即强化学习和奖励重标度最大利润目标。应用了 Clark 和 Manning (2016a)的论文中描述的相同提及排名模型。代替从学习到搜索的算法,强化学习被提议作为学习算法,以直接针对共指度量来优化模型。最后,使用奖励重标最大间隔目标的模型优于增强算法,也优于 Clark 和 Manning 的先前论文,在英语任务中给出 65.73%。
2.端到端神经共指模型
第一个端到端共指消解模型优于以前的最先进的模型,这些模型使用手动提及检测、语法分析器和大量特征工程。它将所有跨度(即表达式)视为潜在提及,并为每个跨度找出可能的前因。通过结合上下文相关的边界表示和头部寻找注意机制来表示跨度。对于每个跨度,跨度排序模型提供了前一个跨度是一个好的前因的决定。训练一个剪枝函数来消除较少可能的提及。最终模型是具有不同参数的 5 模型集合。与提及排序模型相比,跨度排序模型具有更大的发现提及空间。跨度由单词嵌入来表示。这些表示考虑了两个重要部分:围绕提及区间的上下文和区间内的内部结构。LSTMs 和字符上的一维卷积神经网络(CNN)由向量表示组成。代替通常在共指消解中使用的句法分析器,对每个区间中的词应用了一种寻找中心的注意机制。在学习过程中,黄金聚类中所有正确前件的边际对数似然被优化。在优化目标的过程中,跨度被修剪。设置跨度的长度、要考虑的前提的数量。并且对跨度进行排序,并且仅取那些具有最高提及分数的跨度。
集成模型的最终结果是 68.8%,优于以往的所有论文。现在,更好的结果是通过由粗到细推理的高阶共指消解给出的(Lee 等人,2018)。出于实际考虑,我们实现了端到端模型,而不是最新的模型。
2.1 任务介绍
端到端共指消解是为文档中每个可能的跨度构建的。任务是为每个跨度找出最可能的先行词 yi 。可能的前件集合是一个虚拟前件ε和所有前面的跨度。两种情况导致虚拟先行词ε: (1)跨度不是实体提及或(2)跨度是实体提及,但它不与任何先前的跨度共指。我们假设文档是 D ,它包含 T 个单词以及用于特性的元数据。文档中可能的
跨度数为 N = T(T + 1) / 2 。我们用 START(i) 和 END(i) 、 1≤i≤N 来表示 D 中一个区间 i 的开始和结束索引。
2.2 跨度表示
跨度表示是端到端神经共指模型的核心。强大的跨度表示可以提取提及跨度周围的上下文和跨度内部结构的语义和句法信息。该模型可以根据跨度表示提供的单词相似性来理解单词之间的关系。首先,矢量嵌入是至关重要的。每个单词都有它的向量嵌入。向量表示, {x1,…,xT} ,由固定的预训练单词嵌入(300 维手套嵌入和 50 维图瑞安嵌入)和字符上的 1 维卷积神经网络(CNN)组成。
2.3 双向 LSTMs
单向 LSTMs 只能感知来自过去的信息。但是,以前的词不能提供表达的所有信息或它所指的内容,这将造成歧义。而双向 LSTMs 可以获得过去和未来的信息。这对于共指消解来说是一个很大的优势,因为对单词之间关系的理解很大程度上依赖于周围的上下文。
除了具有两个 lstm 之外,双向 lstm 具有与 lstm 几乎相同的组件。其中一个接受正向序列,而另一个接受反向序列作为输入。该架构如图所示。

Bi-LSTMs — Credit to Colah’s Blog
双向 LSTMs 的每一层都是独立的 LSTMs。而输出是两个输出向量的连接。因此,双向 lstm 的公式不同于 lstm,因为它也取决于方向。我们假设方向由方向指示器δ= {-1,1}表示。

formulas of Bi-LSTMs
2.4 注意机制
句法中心是一段时间内最重要的句法信息,由注意机制检测。在以往的研究中,句法中心被表示为特征。注意机制的基本思想是决定一段时间内最重要的部分,即一段时间内最重要的信息。注意机制的输入是双向 LSTMs 的输出。通过前馈神经网络,向量表示被转化为单词得分 αt 。接下来,每个单词 ai,t 的权重由对齐模型计算,该模型测量该单词在该跨度中的重要性。单词向量的加权和是一个区间的注意机制的最终结果。

formulas of Attention Mechanism
最终的跨度表示是边界表示、软头词向量和特征向量的组合。

formula of the final span representation
2.5 评分和修剪策略
我们提醒,任务是为每个跨度找到最可能的前因。根据由提及分数 sm 和前因分数 sa 组成的成对共指分数 s 对前因候选项进行排序。提及分数暗示了 span 是否是提及。而先行词得分表示 span 是否是先行词。提及得分 sm 和前因得分 sa 都是通过标准的前馈神经网络计算的。

formulas of the scores sm and sa
成对共指分数考虑一对跨度,跨度 i 和跨度 j :

formula of the coreference score
虚拟先行词ε用于两种情况。第一,span 不是一个实体。第二个是跨度是一个实体提及,但它不与任何先前的跨度共指。一旦我们有了共指得分,即输出层,softmax 将决定哪一个先行词更有可能用于区间 i 。
在训练和评估期间,模型不会保留第一步中生成的所有跨度。原因是模型的记忆复杂度高达 O(T4) 。应用修剪策略可以删除不太可能包含在共指聚类中的区间。span 是否会被修剪取决于提及分数 sm 。我们只考虑宽度不超过 10 的跨度,并计算它们的提及分数 sm 。仅保留提及分数最高的 λT 个区间。对于每个跨度,只考虑最多 K 个前件。根据这篇论文,即使我们使用这些积极的剪枝策略,当 λ = 0.4 时,我们仍然保持高提及召回率,超过 92%。
2.6 学习和优化步骤
在学习过程中,gold 聚类所隐含的所有正确前因的边际对数似然性:

formula of the marginal log-likelihood for the learning process
该模型的输出层是一个 softmax,它依赖于成对共指得分。我们将学习一个条件概率分布 P(y1,…,yN|D) ,这意味着这个分布的配置可以找到正确的聚类。对于每个区间,寻找其前因的过程独立于其他区间,我们可以将该分布分解为每个区间的多项式的乘积:

formula of the distribution of the coreference clustering
2.7 模型的架构
现在我们知道这个模型是如何工作的了。至于模型的架构,由两部分组成。一部分是跨度,另一部分是乐谱架构。

The Architecture of Generating Span Representations
拿一句话来说,“通用电气说是邮政联系了公司。”首先,这个句子中的每个单词将被表示为一个向量嵌入,它由一个单词嵌入和一个 CNN 字符嵌入组成。在下一步中,向量嵌入作为双向 LSTMs 的输入,lst ms 为每个单词输出另一个向量嵌入。注意机制将双向 LSTMs 的输出作为其在跨度级的输入,并提供向量嵌入。此外,嵌入特定维度的特征也将在跨度表示中发挥作用。

The Score Architecture
最后,我们利用区间的边界信息、由注意机制生成的表示和特征嵌入来实现区间表示。我们只考虑一定数量的单词来计算提及分数。通过应用修剪策略,我们可以保持一定数量的跨度。
然后我们计算前因得分和共指得分。softmax 输出层将决定为每个跨度选择哪个先行项。
参考资料:
[1]凯文·克拉克和克里斯托弗·曼宁。通过学习实体级分布式表示提高共指消解。计算语言学协会第 54 届年会论文集(第 1 卷:长篇论文),2016。
[2]凯文·克拉克和克里斯托弗·曼宁。提及排序共指模型的深度强化学习。2016 自然语言处理经验方法会议论文集,2016。
[3] Kenton Lee,Luheng He,,和 Luke Zettlemoyer。端到端的神经共指消解。2017 自然语言处理经验方法会议论文集,2017。
我对数据科学、人工智能和区块链方面的商业合作机会感兴趣:
https://www.linkedin.com/in/lingjin2016/
如果你觉得我的文章有用,请用可爱的比特币多鼓励我:
3 ay dni 2 tocphslr 9 pdb 3 hcxkdcuxpdz 4h
感谢阅读和支持!
深度 Java 库(DJL)——面向 Java 开发人员的深度学习工具包
现实世界中的数据科学
亚马逊发布深度 Java 库(DJL ),为 Java 开发者提供深度学习的快速入门

Deep Java Library (DJL) ,是亚马逊创建的开源库,用于在 Java 中本地开发机器学习(ML)和深度学习(DL)模型,同时简化深度学习框架的使用。
我最近用 DJL 开发了一个鞋类分类模型,发现这个工具包超级直观和易用;很明显,在设计和 Java 开发人员将如何使用它上花了很多心思。DJL API 抽象出常用的功能来开发模型和编排基础设施管理。我发现用于训练、测试和运行推理的高级 API 允许我使用 Java 和 ML 生命周期的知识,用最少的代码在不到一个小时的时间内开发一个模型。
鞋类分类模型
鞋类分类模型是使用监督学习训练的多类分类计算机视觉(CV)模型,它将鞋类分类为四类标签之一:靴子、凉鞋、鞋子或拖鞋。

Image 1: footwear data (source UT Zappos50K)
关于数据
开发精确的 ML 模型最重要的部分是使用来自可靠来源的数据。鞋类分类模型的数据源是由德克萨斯大学奥斯汀分校提供的数据集,可免费用于学术和非商业用途。鞋子数据集由从Zappos.com收集的 50,025 张带标签的目录图片组成。
训练鞋类分类模型
训练是通过给学习算法训练数据来产生 ML 模型的过程。术语模型是指在训练过程中产生的工件;该模型包含在训练数据中发现的模式,并可用于进行预测(或推断)。在开始培训过程之前,我设置了本地开发环境。你将需要 JDK 8(或更高版本),IntelliJ,一个用于训练的 ML 引擎(像 Apache MXNet ),一个指向你的引擎路径的环境变量和 DJL 的构建依赖。
dependencies **{**compile "org.apache.logging.log4j:log4j-slf4j-impl:2.12.1"compile "ai.djl:api:0.2.0"compile "ai.djl:basicdataset:0.2.0"compile "ai.djl:examples:0.2.0"compile "ai.djl:model-zoo:0.2.0"compile "ai.djl.mxnet:mxnet-model-zoo:0.2.0"runtimeOnly "ai.djl.mxnet:mxnet-native-mkl:1.6.0-a:osx-x86_64"**}**
通过成为引擎和深度学习框架不可知者,DJL 忠于 Java 的座右铭,“编写一次,在任何地方运行(WORA)。开发人员可以编写一次运行在任何引擎上的代码。DJL 目前提供了 Apache MXNet 的实现,这是一个简化深度神经网络开发的 ML 引擎。DJL API 使用 JNA,Java 原生访问,来调用相应的 Apache MXNet 操作。从硬件的角度来看,培训是在我的笔记本电脑上使用 CPU 进行的。然而,为了获得最佳性能,DJL 团队建议使用至少带有一个 GPU 的机器。如果你没有可用的 GPU,总有一个选项可以在亚马逊 EC2 上使用 Apache MXNet。DJL 的一个很好的特性是,它提供了基于硬件配置的自动 CPU/GPU 检测,以始终确保最佳性能。
从源加载数据集
鞋类数据保存在本地,并使用 DJL ImageFolder数据集加载,该数据集可以从本地文件夹中检索图像。用 DJL 的术语来说,一个Dataset只是保存训练数据。有些数据集实现可用于下载数据(基于您提供的 URL)、提取数据以及自动将数据分成定型集和验证集。自动分离是一个有用的功能,因为绝不使用训练模型所用的相同数据来验证模型的性能是很重要的。训练验证数据集用于在数据中查找模式;验证数据集用于在训练过程中估计鞋类模型的准确性。
*//identify the location of the training data*String trainingDatasetRoot = **"src/test/resources/imagefolder/train"**;*//identify the location of the validation data*String validateDatasetRoot = **"src/test/resources/imagefolder/validate"**;//create training ImageFolder dataset
ImageFolder trainingDataset = initDataset(trainingDatasetRoot);//create validation ImageFolder dataset
ImageFolder validateDataset = initDataset(validateDatasetRoot);**private** ImageFolder initDataset(String datasetRoot) **throws** IOException { ImageFolder dataset = **new** ImageFolder
.Builder()
.setRepository(**new** SimpleRepository(Paths.get(datasetRoot))).optPipeline( *// create preprocess pipeline* **new** Pipeline()
.add(**new** Resize(NEW_WIDTH, NEW_HEIGHT))
.add(**new** ToTensor()))
.setSampling(BATCH_SIZE,**true**)
.build(); dataset.prepare();
**return** dataset;
}
当在本地构建数据时,我没有深入到 UTZappos50k 数据集确定的最细粒度级别,如脚踝、膝盖高、小腿中部、膝盖以上等。靴子的分类标签。我的本地数据保存在最高级别的分类中,只包括靴子、凉鞋、鞋子和拖鞋。

Image 2: structure of local training data
训练模型
现在,我已经将鞋类数据分为训练集和验证集,我将使用神经网络来训练模型。
**public** final class **Training** extends **AbstractTraining** { . . . **@Override**
**protected** **void** **train**(Arguments arguments) **throws** IOException {
. . . **try** (Model model = Models.getModel(NUM_OF_OUTPUT,
NEW_HEIGHT, NEW_WIDTH)) { TrainingConfig config = setupTrainingConfig(loss); **try** (Trainer trainer = model.newTrainer(config)) {
trainer.setMetrics(metrics);
trainer.setTrainingListener(**this**);
Shape inputShape = **new** Shape(1, 3, NEW_HEIGHT,
NEW_WIDTH);
*// initialize trainer with proper input shape* trainer.initialize(inputShape); *//find the patterns in data* fit(trainer, trainingDataset,
validateDataset, **"build/logs/training"**); *//set model properties* model.setProperty(**"Epoch"**,
String.valueOf(EPOCHS));
model.setProperty(**"Accuracy"**,
String.format(**"%.2f"**,
getValidationAccuracy())); *//save the model after done training for
//inference later model saved
//as shoeclassifier-0000.params* model.save(Paths.get(modelParamsPath),
modelParamsName); }
}
}
通过将训练数据输入到模块开始训练。用 DJL 的术语来说,Block是形成神经网络的可组合单元。你可以组合积木(就像乐高积木一样)形成一个复杂的网络。在训练过程的最后,一个Block代表一个完全训练好的模型。第一步是通过调用Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH)获得一个模型实例。getModel()方法创建一个空模型,构造神经网络,将神经网络设置到模型上。
*/*
Use a neural network (ResNet-50) to train the model**ResNet-50 is a deep residual network with 50 layers; good for image classification
*/***public class** Models {
**public static** ai.djl.Model getModel(**int** numOfOutput,
**int** height, **int** width)
{
*//create new instance of an empty model* ai.djl.Model model = ai.djl.Model.newInstance(); *//Block is a composable unit that forms a neural network;
//combine them like Lego blocks to form a complex network* Block resNet50 = **new** ResNetV1.Builder()
.setImageShape(**new** Shape(3, height, width))
.setNumLayers(50)
.setOutSize(numOfOutput)
.build(); *//set the neural network to the model* model.setBlock(resNet50);
**return** model; }
}
下一步是通过调用model.newTrainer(config)方法来设置和配置一个Trainer。config 对象是通过调用setupTrainingConfig(loss)方法初始化的,该方法设置训练配置(或超参数)来确定如何训练网络。
**private static** TrainingConfig setupTrainingConfig(Loss loss) {
*// epoch number to change learning rate* **int**[] epoch = {3, 5, 8}; **int**[] steps = Arrays
.stream(epoch)
.map(k -> k * 60000 / BATCH_SIZE).toArray(); *//initialize neural network weights using Xavier initializer* Initializer initializer = **new** XavierInitializer(
XavierInitializer.RandomType.UNIFORM,
XavierInitializer.FactorType.AVG, 2); *//set the learning rate
//adjusts weights of network based on loss* MultiFactorTracker learningRateTracker = LearningRateTracker
.multiFactorTracker()
.setSteps(steps)
.optBaseLearningRate(0.01f)
.optFactor(0.1f)
.optWarmUpBeginLearningRate(1e-3f)
.optWarmUpSteps(500)
.build(); *//set optimization technique
//minimizes loss to produce better and faster results
//Stochastic gradient descent* Optimizer optimizer = Optimizer
.sgd()
.setRescaleGrad(1.0f / BATCH_SIZE)
.setLearningRateTracker(learningRateTracker)
.optMomentum(0.9f)
.optWeightDecays(0.001f)
.optClipGrad(1f)
.build(); **return new** DefaultTrainingConfig(initializer, loss)
.setOptimizer(optimizer)
.addTrainingMetric(**new** Accuracy())
.setBatchSize(BATCH_SIZE);
}
为训练设置了多个超参数:
**newHeight**和**newWidth**—图像的形状。**batchSize**—用于训练的批量;根据你的模型选择合适的尺寸。**numOfOutput**—标签的数量;鞋类分类有 4 个标签。**loss**—损失函数根据衡量模型好坏的真实标签评估模型预测。**Initializer**—标识初始化方法;在这种情况下,Xavier 初始化。**MultiFactorTracker**—配置学习率选项。**Optimizer**:最小化损失函数值的优化技术;在这种情况下,随机梯度下降(SGD)。
下一步是设置Metrics,一个训练监听器,并用正确的输入形状初始化Trainer。Metrics在培训期间收集和报告关键绩效指标(KPI ),这些指标可用于分析和监控培训绩效和稳定性。接下来,我通过调用fit(trainer, trainingDataset, validateDataset, **“build/logs/training”**) 方法开始训练过程,该方法迭代训练数据并存储在模型中找到的模式。
**public void** fit(Trainer trainer, Dataset trainingDataset, Dataset validateDataset,String outputDir) **throws** IOException { *// find patterns in data* **for** (**int** epoch = 0; epoch < EPOCHS; epoch++)
{
**for** (Batch batch : trainer.iterateDataset(trainingDataset))
{
trainer.trainBatch(batch);
trainer.step();
batch.close();
}
*//validate patterns found* **if** (validateDataset != **null**) {
**for** (Batch batch:
trainer.iterateDataset(validateDataset)){
trainer.validateBatch(batch);
batch.close();
}
} *//reset training and validation metric at end of epoch* trainer.resetTrainingMetrics(); *//save model at end of each epoch* **if** (outputDir != **null**) {
Model model = trainer.getModel();
model.setProperty(**"Epoch"**, String.valueOf(epoch));
model.save(Paths.get(outputDir), **"resnetv1"**);
}
}
}
在训练的最后,使用model.save(Paths.get(modelParamsPath), modelParamsName)方法,一个运行良好的经验证的模型工件及其属性被保存在本地。培训过程中报告的指标如下所示。

Image 3: metrics reported during training
运行推理
现在我有了一个模型,我可以用它对我不知道分类(或目标)的新数据进行推断(或预测)。在设置了模型和要分类的图像的必要路径之后,我使用Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH)方法获得一个空的模型实例,并使用model.load(Paths.get(modelParamsPath), modelParamsName)方法初始化它。这将加载我在上一步中训练的模型。接下来,我使用model.newPredictor(translator)方法,用指定的Translator初始化一个Predictor。你会注意到我将一个Translator传递给了Predictor。在 DJL 术语中,Translator提供模型预处理和后处理功能。例如,对于 CV 模型,需要将图像重塑为灰度;a Translator可以帮你做到这一点。Predictor允许我使用predictor.predict(img)方法对加载的Model进行推理,传入图像进行分类。我做的是单个预测,但是 DJL 也支持批量预测。推理存储在predictResult中,其中包含每个标签的概率估计。一旦推理完成,模型自动关闭,使得 DJL 记忆有效。
**private** Classifications predict() **throws** IOException, ModelException, TranslateException {
*//the location to the model saved during training* String modelParamsPath = **"build/logs"**; *//the name of the model set during training* String modelParamsName = **"shoeclassifier"**; *//the path of image to classify* String imageFilePath = **"src/test/resources/slippers.jpg"**; *//Load the image file from the path* BufferedImage img =
BufferedImageUtils.fromFile(Paths.get(imageFilePath)); *//holds the probability score per label* Classifications predictResult; **try** (Model model = Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH)) { *//load the model* model.load(Paths.get(modelParamsPath), modelParamsName); *//define a translator for pre and post processing* Translator<BufferedImage, Classifications> translator =
**new** MyTranslator(); *//run the inference using a Predictor* **try** (Predictor<BufferedImage, Classifications> predictor =
model.newPredictor(translator)) {
predictResult = predictor.predict(img);
}
} **return** predictResult;
}
推论(每张图片)及其相应的概率得分如下所示。

Image 4: Inference for boots

Image 5: Inference for sandals

Image 6: Inference for shoes

Image 7: Inference for slippers
外卖和后续步骤
我从 90 年代末开始开发基于 Java 的应用程序,并在 2017 年开始了我的机器学习之旅。如果当时 DJL 在的话,我的旅程会容易得多。我强烈建议希望过渡到机器学习的 Java 开发人员给 DJL 一个机会。在我的例子中,我从头开始开发了鞋类分类模型;然而,DJL 也允许开发人员以最小的努力部署预先训练好的模型。DJL 还提供了现成的流行数据集,允许开发人员立即开始使用 ML。在开始学习 DJL 之前,我建议你对 ML 生命周期有一个牢固的理解,并且熟悉常见的 ML 术语。一旦你对 ML 有了一个基本的理解,你就可以很快熟悉 DJL API。
亚马逊有开源的 DJL,在那里可以在 DJL 网站和 Java 库 API 规范页面找到关于该工具包的更多详细信息。鞋类分类模型的代码可以在 GitLab 上找到。祝您的 ML 之旅好运,如果您有任何问题,请随时联系我。
深层潜在变量模型:揭示隐藏结构

source: Unsplash
理解真实世界数据的底层结构是机器学习中最引人注目的任务之一。但是随着深度生成模型的出现,研究者和实践者有了一个强有力的方法来解开它。
真实世界的数据通常是复杂和高维的。传统的数据分析方法在大多数情况下是无效的,并且只能模拟非常简单的数据分布。现在,我们可以使用机器学习模型来直接学习我们数据的结构。机器学习中最常见的方法是监督学习 ,其中我们要求模型学习从输入到输出变量的映射,例如图像 x 到标签 y。然而,带标签的数据是昂贵的,并且容易被人类注释者产生错误或偏见。并且监督模型仅能够根据训练数据的质量来概括其映射函数。为了测试其推广性,使用了来自相同分布的验证集,该验证集将具有相同的误差。使用这种模型,可以执行分类或回归任务,但我们无法了解数据的实际基本组织。
机器学习社区开始关注 无监督学习 模型的开发。通过结合概率建模和深度学习,最近取得了一些进展。我们称这类模型为 生成型模型 。根据这句名言,
“我不能创造的东西,我不明白。”—理查德·费曼
生成模型应该能够发现底层结构,例如数据的有趣模式、聚类、统计相关性和因果结构,并生成类似的数据。
目前,该领域中的一个著名模型是生成式广告网络(GANs)【1】,例如,它能够从学习到的数据分布中生成人脸的真实图像。这一类的另一个模型被称为变分自动编码器(VAE)【2】,它也用于复杂高维分布的无监督学习,将是本文的重点。甘的训练仍然是实验性的,因为他们的训练过程缓慢且不稳定。但是他们也在进步,请看这篇关于 Wasserstein GANs 的博客文章。
一般来说,非监督学习比监督学习困难得多,因为这些模型不是预测给定输入的标签或值,而是学习数据分布本身的隐藏结构。本文将介绍我们如何实现这一点的概念,重点是静态数据,如没有序列性质的图像。学习顺序数据的底层结构是一个更困难的问题,我打算将来写一篇关于这个问题的后续文章。
在第一部分中,我们将定义潜在变量模型,在第二部分中,我们将了解如何使用深度神经网络来学习它们的参数。我试图尽可能保持一切直观,但一些概率论和深度学习的先验知识肯定是有帮助的。
潜在变量模型
机器学习中的一个中心问题就是学习一个复杂的概率分布p(x),只需要从这个分布中抽取有限的一组高维数据点 x 。例如,为了学习猫的图像的概率分布,我们需要定义一个分布,该分布可以模拟形成每个图像的所有像素之间的复杂相关性。直接模拟这种分布是一项具有挑战性的任务,甚至在有限的时间内是不可行的。
与其直接建模p(x),我们可以引入一个不可观测的潜在变量 z 并为数据定义一个条件分布p(x|z,这就叫做可能性用概率术语 z 可以解释为连续的随机变量*。对于猫图像的例子, z 可以包含猫的类型、颜色或形状的隐藏表示。*
有了 z ,我们可以进一步引入潜在变量的先验分布p(z)来计算观察变量和潜在变量的联合分布:

Joint distribution over observed and latent variables; Equation (1)
这种联合分布让我们可以用更易处理的方式来表达复杂的分布p(x)*。其组成部分,*p(x|z)和p(z)的定义通常要简单得多,例如通过使用中的分布
为了获得数据分布p(x)我们需要对潜在变量进行边缘化

Marginalized data distribution p(x); Equation (2)
此外,利用贝叶斯定理我们可以计算后验分布p(z|x)为

Posterior distribution p(z|x); Equation (3)
后验分布允许我们推断给定观测值的潜在变量。注意,对于我们处理的大多数数据,方程(2)中的积分没有解析解,我们必须应用某种方法来推断方程(3)中的后验概率,这将在下面解释。
为什么我们要做这个练习并引入一个潜在变量?优势在于,具有潜在变量的模型可以表达数据被创建的生成过程(至少这是我们的希望)。这被称为生成模型。一般来说,这意味着如果我们想要生成一个新的数据点,我们首先需要获得一个样本**【z】~p(z),然后使用它从条件分布x***|中采样一个新的观察值在这样做的同时,我们还可以评估该模型是否为数据分布p()x**)提供了良好的近似。*****
根据定义,包含潜在变量的数学模型是潜在变量模型。这些潜在变量的维数比观察到的输入向量低得多。这产生了数据的压缩表示。您可以将潜在变量视为一个瓶颈,生成数据所需的所有信息都必须通过这个瓶颈。从 流形假设 中我们知道,高维数据(例如真实世界的数据)位于嵌入在这个高维空间中的低维流形上。这证明了低维潜在空间的合理性。
后验推断
后验分布p(z|x),是概率推理中的一个关键组成部分,在观察到一个新的数据点后,更新我们对潜在变量的信念。然而,真实世界数据的后验常常是难以处理的,因为它们对于出现在方程(3)分母中的方程(2)中的积分没有解析解。有两种方法可以近似这种分布。一种是叫做 马尔可夫链蒙特卡罗方法的抽样技术。然而,这些方法在计算上是昂贵的,并且不能很好地扩展到大型数据集。第二种方法是确定性近似技术。在这些技术中,VAE 使用的是所谓的(VI)【4】。注意,这种方法的缺点是,即使在无限的计算时间内,它们也不能产生精确的结果。
VI 的总体思路是从一个易处理的分布族(例如多元高斯)中取一个近似值q(z),然后使这个近似值尽可能接近真实的后验p(z|x)。这通常通过最小化两个分布之间的 Kullback-Leibler (KL)散度来实现,定义为**

Kullback-Leibler Divergence; Equation (4)
这减少了对优化问题的推断[5]。越相似的q()p(z|x)KL 的散度越小。请注意,这个量不是数学意义上的距离,因为如果我们交换分布,它就不是对称的。此外,在我们的例子中,交换分布意味着我们需要获取关于p(z|x)的期望,这被认为是难以处理的。
现在,方程(4)在对数内的分子中仍然有难以处理的后验概率。使用(3),我们可以将(4)改写为:
 ****
****
Evidence Lower Bound (ELBO) F(q); Equation (5)
*边际可能性log p(x)可以从期望中取出,因为它不依赖于 z 。量F(q)就是所谓的证据下界 (ELBO)。KL 总是≥ 0,因此它表示对*证据日志 p(x)的下限。ELBO 越接近边际似然,变分近似就越接近真实的后验分布。因此,复杂的推理问题被简化为更简单的优化问题。
变分自动编码器
我们还没有提到它,但是可能性和先验属于依赖于一些未知参数的分布族。为了使这一点更清楚,请看等式(1)的参数联合分布:

Parametric joint distribution; Equation (6)
θ表示模型的未知参数,可以使用深度神经网络(或使用传统方法,如 期望最大化 算法)来学习。
VAE 使用这种深度神经网络来参数化定义潜在变量模型的概率分布。此外,它提供了一个有效的近似推理过程,规模大的数据集。它由一个生成模型(潜在变量模型)、一个推理网络(变分近似)和一种如何学习 VAE 参数的方法来定义。关于 VAE 在 Keras 的非常好的介绍和实现,你可以访问这个漂亮的博客帖子。
生成模型由等式(6)给出,这里 z 是具有 K- 维的连续潜变量。它的先验通常是具有零均值和单位协方差矩阵的高斯,

Gaussian prior with zero mean and identity covariance; Equation (7)
这种可能性被称为解码器,它通常是连续数据的高斯分布,其参数θ通过将潜在状态 z 传递通过深度神经网络来计算。这种可能性看起来如下,

Likelihood as continuous Gaussian distribution; Equation (8)
均值和方差由两个深度神经网络参数化,其输出向量的维数为 D ,即观测值的维数xT5。参数θ是解码器神经网络的权重和偏差。****
推理网络被称为编码器,允许我们计算后验近似的参数。变分参数φ在所有数据点上共享,而不是每个数据点都有一组参数。同样,在 VAE 设置中,我们使用深度神经网络,该网络获取输入数据点并输出相应高斯变分近似的均值和对角协方差矩阵,

Posterior approximation of VAE; Equation (9)
共享的变分参数φ是编码器神经网络的权重和偏差。
参数学习和 VAE 的目标函数
如上所述,边际分布p(x)(由θ参数化)在很多情况下是难以处理的,需要近似。使用 ELBO 可以获得一个近似值。为了明确 ELBO 依赖于某个参数,我们可以将它重写为

ELBO parametized by theta; Equation (10)
为了学习参数,我们可以使用期望最大化(EM)使 ELBO 相对于其参数最大化。对于 VAE 设置来说,最大化反而是超过参数φ的 q 。因此,我们可以将 ELBO 分解为两项:

Objective Function. The left term represents the reconstruction loss and the right term represents the regularization loss; Equation (11)
F 的第一项是重构损失,鼓励似然和推理网络准确重构数据。第二项是正则化损失并惩罚与先验相差太远的后验近似。具有参数φ和θ的两个神经网络都可以通过具有反向传播的梯度下降来有效地计算。此外,参数是联合更新的,而不是像 EM 那样迭代更新。
结论
*在这篇文章中,我介绍了潜在变量模型的概念,以及用深度神经网络来参数化定义潜在变量模型的概率分布。在这里,我们关注了变分自动编码器(一种生成模型)所使用的对后验分布*p(z|x)的近似的变分推断。VAE 的真正力量在于,它们可以在完全无人监督的情况下接受训练,并学习捕捉数据自然特征的潜在空间。
如果我们能够将复杂的高维数据嵌入到一个潜在空间中,从这个潜在空间中我们能够生成与原始数据非常相似的新数据,我们可以假设我们的模型捕捉到了数据的主要特征。这可以给研究人员和从业人员提供许多有用的信息来研究感兴趣的数据,并确定模式、相关性甚至因果结构。
参考
[1] Goodfellow,Ian,et al. “生成性对抗性网络”,NIPS (2014)
[2]迪德里克·p·金马,马克斯·韦林。自动编码变分贝叶斯,arXiv 预印本 arXiv:1312.6114 (2014)。
[3] Martin Arjovsky、Soumith Chintala 和 Léon Bottou。《瓦瑟斯坦甘》,arXiv 预印本 arXiv:1701.07875 (2017)。
[4]戴维·布莱、阿尔普·库库尔比尔、乔恩·麦考利夫。"变分推断:统计学家回顾,arXiv 预印本 arXiv:1601.00670
[5]凯文·p·墨菲,“机器学习:概率观点”,麻省理工学院出版社(2012 年)
关于变分自动编码器的进一步阅读
阿古斯蒂斯·克里斯蒂的博客 : 变分自动编码器:直觉与实现
JAAN ALTOSAAR 博客 : 教程——什么是变分自动编码器?
关于转录因子-DNA 结合的“深度学习”
使用卷积神经网络测量转录因子-DNA 结合

如果我们能解开基因表达的秘密,我们就能真正解开自己的秘密。
我们淹没在基因信息中。

Except, imagine the coins as DNA nucleotides.
事实上,你现在就可以花大约 100 美元(如果你再等一段时间,这个价格会更低)去获取你的整个基因组序列。
**你可以自己解开背后的密码。**每一个特性、特征、不好的突变都是从你的曾曾祖父那里传下来的,但不知何故在你之前跳过了几代人(遗传统计学万岁)。
但是有个问题。
我们连一半是什么意思都不知道。
(一半很可能是高估)。
这就像试图学习一种可以编码生物生命的编码语言。你只知道这些位是四个碱基对:A,C,T,g。
对于所谓的“经典数据”,我们已经进入了一个疯狂兴奋的阶段,试图建立机器学习模型,从中提取模式。现在,如果我们用机器来尝试理解基因组数据会怎么样?
如果我们尝试使用机器学习来解开基因表达的秘密会怎么样?
我们拥有的每一个行为或特征最终都可以归结为某些基因的开启和关闭。基因表达几乎控制着我们身体的一切。我们的细胞执行什么功能。你头发的颜色。它还决定了你何时、如何或是否患有致命疾病。我们可以黑掉我们自己。根除疾病。增进我们的健康。改变我们的特征。
如果基因表达是一部电影,那么转录因子(TF),一种类型的蛋白质,将是导演。哪些基因开启或关闭由与调控元件(启动子、增强子等)结合的转录因子决定。)——这在不同的细胞类型中是不同的。
让我们进一步分析一下。
转录因子- DNA 结合
转录因子直接转录— 将遗传信息从 DNA 复制到信使 RNA 。把信使 RNA 想象成邮差。它将信息(遗传密码)从 DNA 传递到核糖体,以翻译成蛋白质。

Transcription and translation of proteins. Source: Khan Academy
因此,转录因子控制着哪些信息被复制并转化为蛋白质,从而影响细胞的功能或特性。
好吧,酷。但是实际上有成千上万不同的变体。我们如何知道一个组织因子是否会与某个 DNA 序列结合?或者如果另一个 TF 会结合同样的 DNA 序列?或者说TF 与该序列的结合有多好?
等等…不是也有上百种不同的 TF 吗?我们究竟该如何预测呢?猜猜看?
没错。

Excuse me?
但是不要担心,我们从现在开始不会再做猜测和检查……我们会让机器学习来帮我们做这件事 😉

Take a deep breath. The hard stuff is coming soon.
如果我们可以使用机器学习来预测转录因子与特定 DNA 序列结合的可能性有多大呢?
基于过去预测 TF-DNA 相互作用的深度学习尝试,如 DeepSEA,我想看看我是否可以建立自己的算法,该算法可以预测给定转录因子与特定 DNA 序列结合的可能性。然而,我想更进一步,用量化这个值。
如何量化转录因子与 DNA 的结合?“非常好”或“不太好”可能不是最好的标签。
和芯片序列来拯救!
ChIP-seq 代表与下一代测序相结合的染色质免疫沉淀** (ChIP)分析。如果你不知道这意味着什么,这里有一个复习。**
基本上,芯片测序 ( 芯片 - 序列)是识别转录因子和其他蛋白质的全基因组 DNA 结合位点的有力方法。它告诉我们 TF 将结合在 DNA 的什么位置。

Notice the “peaks” or spikes on the graph = lot of gene activity in that area
现在,峰值区域是图上的黑色/彩色部分,本质上意味着在那个特定区域有大量的基因表达。每个峰都有一个信号值(来自该基因组位置的序列读数)。
信号值量化了 TF 与 DNA 的结合程度。
我们能用 ChIP-seq 做什么?
如果我们比较患病和非患病细胞的 ChIP-seq 峰区域,我们可以确定导致或促成该疾病的遗传变异!
我们可以使用它的另一种方式是确定基因表达如何从一种细胞类型变化到另一种细胞类型——这可以给我们一个巨大的洞察力,让我们知道如何区分诱导多能干细胞!
我们将如何使用机器学习?
如果给定一个特定的基因序列,我们可以预测特定转录因子的信号值,会怎么样?
基本上:
输入:原始 DNA 序列(没有关于变体的先验知识)
输出:实值码片序列信号值
机器将通过深度学习来学习这些。
所以今天,我们将应用一个卷积神经网络算法。你已经看到他们擅长图像分类,但现在看到他们擅长基因组数据分析。如果图像只是一个数字矩阵,从技术上来说,基因组数据只是一个 A、T、C 和 Gs 的矩阵。他们擅长模式识别。
深度学习模型概述
首先,原始 DNA 序列被输入到模型中。每个输入序列被转换成一个具有 4 行 300 列的独热矩阵。4 行代表 4 个碱基对(A、C、T、G ),而序列长度为 300 b.p(核苷酸)。
因为 DNA 是双螺旋,TFs 可以识别给定位置的任何一条 DNA 链,所以模型被输入正向序列和反向互补序列。

It would be a more accurate representation if one of the spidermen were flipped upside down.
同样,因为 TFs 可以在给定的位置识别 DNA 的任意一条链*,所以两个序列的卷积层共享同一套过滤器。使用 DeFine 提出的体系结构,该体系结构看起来像这样:*

The convolutional neural network architecture in DeFine.
- 首先,我们有两个卷积层,它们将自动从数据中提取特征
- 接下来是 ReLU 层,过滤高于阈值的结果(在训练中学习到的)
- 然后,它们同时通过最大池和平均池层。最大池为每个滤波器输出序列中最显著的激活信号,而平均池通过取序列中每个位置的滤波器扫描结果的平均值来考虑整个序列上下文
- 两个输出被组合成一个向量
- 然后经过批量归一化
- 然后是全连接层
- 然后应用删除层(概率为 0.5)——帮助减轻过度拟合
- 又一个最终完全连接的层
- 以及最后的回归层——其预测芯片序列信号强度
现在让我们回到我们如何预处理数据。(我知道,大家最喜欢的关于机器学习的部分)。
数据预处理!

牛逼的ENCODE(DNA 元素百科)项目编译了一个开源的数据库,里面有很多细胞系,各种测序。
他们有几个细胞系有 ChIP-seq 和全基因组测序。我将使用 K562 细胞系(有 79 个转录因子)。整个基因组测序从这里的开始。参考基因组是 GRCh37。注意:模型必须对每个转录因子分别进行训练。
为了准备用于训练的数据,从峰调用结果中提取每个转录因子的峰区域(信号值)。所以现在我们有了显示基因活性的每个区域的 TF 信号值。
- 每个 TF 的前 1%信号值被丢弃(异常值具有极高的信号值)
- 然后对信号值进行对数变换,并通过 0-1 之间的最小-最大标度进行归一化。我们这样做是为了让我们的数字更容易使用!
- 然后,根据峰区域从参考基因组中提取峰的基因组序列
- 通过添加 Ns(代表任何核苷酸)或删除核苷酸,将峰序列固定在 300 bp(然后我们可以将其输入到我们的模型中)
最后,为了帮助数据扩充**,我们做最后一步:**
- 从与已知 TF 没有结合的区域中随机取出序列,并将它们的信号值设置为零****
- 具有零值的随机选择序列的数量应该等于具有信号强度值的码片序列峰值序列的数量
最后,数据分成 70%用于训练,15%用于验证和调整超参数,15%用于测试。
评估准确性
对于这个模型,一个简单的百分比精度是不够的。我们将引入一些统计相关性测量!
该模型将基于皮尔逊相关系数和斯皮尔曼相关系数进行评估。它们都衡量两个数字是如何相互关联的。相关性越高=两者关系越强! 这里有一个链接快速回顾这两个术语。
你刚刚“深度学习”了如何预测转录因子-DNA 结合!
简单回顾一下…
- 基因表达控制着我们身体里发生的一切
- 基因表达受转录因子结合调节元件(DNA)** 的调节**
- 深度学习可以帮助我们预测转录因子与 DNA** 结合的可能性——通过**预测芯片序列强度值****
- 比较 ChIP-seq 值(或总的来说 TFs 与 DNA 的结合亲和力)可以帮助我们了解导致疾病的不同变体,帮助我们了解干细胞分化,并总的来说教会我们更多关于基因表达的知识!****
这个项目背后的代码将很快发布在我的 GitHub 上,敬请关注!
有什么问题吗?
如果您有任何问题,请随时联系:
- 电子邮件:gracelyn@gracelynshi.com
- **领英:【https://www.linkedin.com/in/gracelynshi/ **
- **推特:【https://twitter.com/GracelynShi **
- 网站:gracelynshi.com
来源
[1] M. Wang,C. Tai,L. Wei,定义:深度卷积神经网络精确量化转录因子-DNA 结合的强度,并促进功能性非编码变体的评估(2018)
动态跨网格深度学习—第 1 部分:无人机
深度学习无人机
AI 会飞会怎么样?

L et 创造了一个微型无人机群,它利用人工智能和网状网络来模仿自然界中常见的群体行为。
坚持住!不要走!听我说完这个概念。通过利用这些时髦的技术,我们可以创造出非常酷,而且我敢说,非常有用的东西?
当然,小型无人机有可怕的飞行时间(以及其他事情),是的,微处理器可能不是人工智能处理的最佳解决方案。然而,如果我们保持项目的小范围,那么我们可能能够完成它。比如用装有传感器阵列的多架四轴飞行器在室内环境中模仿群体行为。
还觉得我满口胡言吗?如果我告诉你我已经造出了第一个原型呢?
让我们开始吧!
无人机是怎么做出来的?
当开始任何需要硬件的项目时,你应该做的第一件事就是确定你想要使用什么组件。
在这种情况下,我选择使用 PCB 作为四轴飞行器的底座。这将最大限度地减少项目所需的零件数量。它还可以让我快速原型化各种设计并做出改变,而不必制作多个零件。

四轴飞行器的上述底座尺寸为 100 毫米乘 100 毫米。它被印刷在一个两层的 PCB 上,包含了让四轴飞行器飞行所需的一切!
是时候决定飞行控制器、惯性测量单元以及如何控制马达了。
对于我的概念无人机,我选择了 ESP32 作为主飞行控制器。我选择 ESP32 是因为它的多功能性、多核、大量 PWM 引脚(用于控制螺旋桨速度的脉宽调制)和网状网络功能。ESP32 还可以针对最低功耗进行优化,同时为给定任务提供足够的功率。
如果您还没有使用过 ESP32 模块,那您就错过了。
对于我的惯性测量单元,我选择了 MPU6050 。MPU6050 是一个六轴陀螺仪和加速度计 IC 。MPU6050 非常适合确定无人机的俯仰、偏航、滚动和加速度。该芯片还通过一个双线接口(不能说是 I2C,因为它是有商标的),并且非常容易从 ESP32 访问。
最后,我们需要一个电压调节器和电机电路。
稳压器是德州仪器的超低压差稳压器,具体来说就是 TLV117LV33DCYR (Yikes!那是一个很长的数字)。
对于电机控制器,我采用二极管/MOSFET/电阻设置。我还附加了一个 100uf 电容用于平滑。
- 二极管:621–1n 5819 HW-F
- 电容器: 581-F980J107MSA
- MOSFET: 781-SI2302CDS-E3
- 电阻器:1K 电阻器

Circuit diagram for the drone’s motors
上面的配置是最佳的,因为它允许 ESP32(3.3V 芯片)控制从电池接收全部 3.7V 电压的电机。电容器将有助于防止电池上的过电流保护由于突然的电流尖峰而触发。这些电流尖峰通常会在电机首次启动时或速度急剧上升时出现。
示意图,示意图,示意图!
零件清单做好了,无人机的基本概念也有了,是时候开始组装了!
我首先关注的是将 ESP32 连接到 MPU6050 和电机。由于许多在线参考,MPU6050 相当容易连接。然而,我犯了一个致命的错误,阻止了 ESP32 与 MPU6050 的通信-…我在 3.3V 线上使用了 10K 上拉电阻。这导致线路低于信号阈值,被视为高电平,ESP32 无法与我的概念无人机上的 MPU6050 通信。我已经修复了错误,并使用 2.2K 电阻代替,但它引起了一个主要问题,我们将在稍后讨论。
这是飞行控制器的示意图:

很酷,对吧?这是无人机最复杂的部分(到目前为止)。
在我完成了飞行控制器之后,我开始研究电源电路。它只是连接到输入线路的 3.3V 超低压差稳压器和两个 0.1uF 电容。

然后是电机控制器。

最后,连接到四轴飞行器每个臂上的发光二极管。

所有这些电路不可避免地成为第一个概念四轴飞行器。
有趣的部分是设计四轴飞行器本身和路由所有的组件。

Slimmed-down version of the 100x100mm drone to reduce weight
组装无人机
无人机完成后,一切都被送去生产,并在两周内回来。我花了大约 40 美元买了一架无人机(不是很好,但也不可怕)。

Baby steps……
经过一个漫长的夜晚焊接所有的东西,一次测试一个转子,我让一切正常工作!MPU6050 除外…力量…稳定性到此为止了吧。
即使没有工作的 MPU6050 -…我能够让所有四个马达都运转起来,并动态调整速度,看看无人机是否能离开地面。
下面是我使用的测试代码。
超级简单的代码片段。在这里,我只是配置所需的引脚使用 PWM,然后慢慢调整功率输出,直到电池因过流保护而断电。
这是因为我使用了锂离子电池,而不是锂聚合物。锂聚合物电池通常比锂离子轻得多,可以输出更大的电流。虽然它们更轻,但锂电池的外壳通常也更厚。
第一次飞行
在充满期待之后,我上传了测试代码,并检查了无人机是否会飞。

First…flight?
剧透警报:它没飞起来。
还记得我之前提到的 MPU6050 的问题吗?没有稳定,我们不会走得很远。
我们在这里学到了什么?这些四轴飞行器太重了,飞行控制器需要一个合适的控制回路来稳定自身和悬停。
无人机的下一次迭代将被印刷在更薄更小的 PCB 上,我将使用锂电池代替。这将允许四轴飞行器利用发动机的全油门,获得相当大的升力。与此同时,我将创建一个更合适的控制环路,它可以与 MPU6050 接口,并调整四轴飞行器的俯仰、偏航和滚动,以保持稳定。
所有这些修复将允许建立一个工作的四轴飞行器,并让我继续这个项目的深度学习和网状网络方面。
深度学习和群体行为
我知道,我知道,我没有在这篇文章中详细介绍这个项目的深度学习方面。
那只是因为我还没有走到那一步。这是一个多次迭代的项目,因此,我们必须从小处着手,逐步推进。
我概述的当前步骤是:
- 原型一个能飞的 PCB 微型无人机
- 将网状网络与无人机上的 ESP32 模块结合在一起
- 创造第二代带距离传感器的微型无人机
- 训练神经网络以允许在模拟环境中的群体行为
- 将经过训练的模型应用于微型无人机
这将是一个真正的深度学习项目,即使四轴飞行器必须连接到更强大的基站进行数据处理。然而,我们的目标是看看利用分布式网络方法,我们能把这些微处理器推进到什么程度。
我希望最终产品看起来像下面显示的英特尔无人机灯光秀:

Credit: Intel
当然,规模要小得多,而且可能只是在室内环境中。
对于深度学习部分,无人机将利用深度强化学习来即时做出关于如何在周围环境中机动的决定。
深层加固网络将在模拟环境中使用 Unity3D 进行训练。通过这种方式,丢失无人机或手指的风险可以通过预先训练的模型来减轻。
增强模型将在连接到无人机网状网络的基站上运行,或者在每个无人机上运行。该网络将依靠网状网络中所有无人机的传感器读数来计算单个无人机的最佳可能行动。通过这种方式,他们要么能够根据其他人正在做的事情进行协调,要么网络中的中央管理器将监视无人机并指挥它们。
单一基站是这个项目的一个有吸引力的选择,但会挫败将 ESP32 推向绝对边缘的目的。然而,如果没有基站来提供神经网络所需的广泛计算能力,无人机的能力将受到明显的限制。
下一步是什么?
无人驾驶飞机、控制回路和网格功能。
本系列的下一篇文章将关注如何让无人机真正飞行。它还将介绍一个 ESP32 网状网络的基本实现,作为概念验证,在节点之间传递数据。
所有代码和原理图将很快可用!在传给你们之前,我想确保我有一个可行的设计!
深度学习算法和脑机接口

作为研究团队的一员,我想解释近年来深度学习(DL)如何显著提升了脑机接口系统(BCI)的性能。
对于那些不熟悉脑机接口的人来说,BCI 是一个将人脑的活动模式翻译成消息或命令以与其他设备通信的系统。
可以想象,设计 BCI 是一项复杂的任务,需要计算机科学、工程学、信号处理、神经科学等多学科知识。
要使用 BCI,通常需要两个阶段:

在 BCI 进行校准很有挑战性,因为信噪比(SNR)不理想,而且受试者之间的差异很大。根据所选范式的类型,校准所需的时间可能不同。尽管如此,校准时间可以部分减少。
BCI 的关键挑战是在大脑信号信噪比很低的情况下准确识别人类的意图。事实是低分类精度和低泛化能力限制了 BCI 的实际应用。

为了克服上述挑战,在过去几年中,深度学习技术已经被用于处理大脑信息。与传统的机器学习算法不同,深度学习可以从大脑信号中学习特定的高级特征,而无需人工选择特征,其准确性与训练集的大小成正比。此外,深度学习模型已经应用于几种类型的 BCI 信号(例如,自发 EEG、ERP、fMRI)。
为什么要深度学习?
首先,大脑信号容易被各种生物(例如,眨眼、肌肉伪影、疲劳和注意力水平)和环境伪影(例如,环境噪声)破坏。
使用脑电图有许多困难。由于 BCI 的主要任务是脑信号识别,因此区分性深度学习模型是最流行和最强大的算法。
一个 BCI 可以通过多种方式监控大脑活动,大致可以分为侵入式和非侵入式 - 侵入式。大多数非 - 有创 BCI 系统使用脑电信号;即从放置在头皮上的电极记录的脑电活动。
很难理解大脑活动的意义,这种活动从神经元相互交流,通过头骨,通过头皮,勉强进入 EEG 传感器。一般来说,EEG 数据是非常嘈杂的,因为很难获得特定事物的清晰信号。
因此,从受损的大脑信号中提取有用的数据并建立一个在不同情况下都能工作的健壮的 BCI 系统是至关重要的。
此外,由于电生理脑信号的非平稳特性,BCI 具有低信噪比。
在脑机接口(BCI)中对脑电图(EEG)数据进行分类的准确性取决于测量通道的数量、用于训练分类器的数据量以及信噪比(SNR)。在所有这些因素中,信噪比是现实应用中最难调整的。
虽然已经开发了几种预处理和特征工程方法来降低噪声水平,但是这些方法(例如,时域和频域中的特征选择和提取)非常耗时,并且可能导致提取的特征中的信息丢失。
第三,特征工程高度依赖于人类在特定领域的专业知识。人类经验可能有助于捕捉某些特定方面的特征,但在更普遍的情况下证明是不够的。因此,需要一种算法来自动提取代表性特征。
深度学习为自动提取可区分特征提供了更好的选择。
此外,当前大多数机器学习研究都专注于静态数据,因此无法准确地对快速变化的大脑信号进行分类。在 BCI 系统中,通常需要新的学习方法来处理动态数据流。
到目前为止,深度学习已经在 BCI 应用中得到广泛应用,并在解决上述挑战方面显示出成功。
深度学习有三个优势。首先,它通过直接在原始脑信号上工作来通过反向传播学习可区分的信息,从而避免了耗时的预处理和特征工程步骤。此外,深度神经网络可以通过深度结构捕捉代表性的高级特征和潜在的依赖性。
最后,深度学习算法被证明比支持向量机(SVM)和线性判别分析(LDA)等传统分类器更强大。这是有道理的,因为几乎所有的 BCI 问题都可以被视为一个分类问题。

BCI 使用的 DL 算法
CNN 是 BCI 研究中最流行的 DL 模型,可以用来挖掘输入脑信号(如 fMRI 图像、自发脑电等)之间潜在的空间相关性。
CNN 在一些研究领域取得了巨大的成功,这使得它非常“可扩展”和可行(通过可用的公共代码)。因此,BCI 的研究人员有更多的机会了解 CNN 并将其应用到他们的工作中。
生成式深度学习模型主要用于生成训练样本或数据扩充。换句话说,生成式深度学习模型在 BCI 地区起到了辅助作用,提高了训练数据的质量和数量。在 BCI 范围内,生成算法主要用于重建或生成一批脑信号样本来增强训练集。BCI 常用的生成模型包括变分自动编码器(VAE)、生成对抗网络(GANs)等。
深度信念网络也在 BCI 用于特征提取。尽管越来越多的出版物关注于采用 CNN 或混合模型来进行特征学习和分类。
RNN 和 CNN 都具有很好的时间和空间特征提取能力,将它们结合起来进行时间和空间特征学习是很自然的。
未来的挑战
基于深度学习的 BCI 的一个有前景的研究领域是开发一个通用框架,该框架可以处理各种 BCI 信号,而不管用于信号收集的通道数量、样本维度和刺激类型(视觉或听觉刺激)等。
总体框架需要两种关键能力:
- 注意机制
- 捕捉潜在特征的能力。
前者保证该框架能够集中于输入信号的最有价值的部分,而后者使该框架能够捕获独特的和信息丰富的特征。
到目前为止,大多数 BCI 分类任务都集中在与人相关的场景,其中训练集和测试集来自同一个人。未来的方向是实现与人无关的分类,使测试数据永远不会出现在训练集中。高性能的独立于个人的分类对于 BCI 系统在现实世界中的广泛应用是必不可少的。
实现这一目标的一个可能的解决方案是建立一个具有迁移学习的个性化模型。
BCI 的未来
当谈到更先进的想法时,我们可能仍然需要几年的时间,因为大脑的功能更加复杂,不容易理解。我们仍在学习大脑如何创造这些复杂的功能,尽管有些人已经在非人类物种中进行了非常初步的尝试,但结果并没有达到我们的预期。
根据一些研究,目前只有不到 100 人在使用这项技术的一些早期形式。
就方法论而言,复杂网络理论现在正处于早期阶段…它需要达到成熟,我们才能看到对我们理解复杂网络(如大脑)的内在机制的影响。目前的技术只能让我们接触到神经系统的某些部分。
在计算机科学中,在用更有效的算法和数据结构以省时的方式解码神经数据方面还有许多事情要做。
要了解更多信息,我推荐你阅读这项出色的研究,它对我写这篇文章帮助很大:
-“基于深度学习的脑机接口调查:最新进展和新前沿”
使用大模型支持的深度学习分析
借助 IBM 大型模型支持,优化您的深度学习模型内存消耗。

(Source: https://miro.medium.com/max/3512/1*d-ZbdImPx4zRW0zK4QL49w.jpeg)
介绍
内存管理现在是机器学习中一个非常重要的话题。由于内存限制,使用 Kaggle 和谷歌 Colab 等云工具训练深度学习模型变得非常普遍,这要归功于它们免费的 NVIDIA 图形处理单元(GPU)支持。尽管如此,在云中处理大量数据时,内存仍然是一个巨大的限制。
在我的上一篇文章中,我解释了如何加速机器学习工作流的执行。相反,本文旨在向您解释如何在实现深度学习模型时有效地减少内存使用。通过这种方式,你可能能够使用相同数量的内存来训练你的深度学习模型(即使之前因为内存错误而无法训练)。
模型导致内存不足的主要原因有三个:
- 模型深度/复杂度 =神经网络的层数和节点数。
- 数据大小 =使用的数据集中样本/特征的数量。
- 批量大小 =通过神经网络传播的样本数量。
这个问题的一个解决方案传统上是通过在预处理阶段试图去除不太相关的特征来减小模型大小。这可以使用特征重要性或特征提取技术(如 PCA、LDA)来完成。
使用这种方法可能会降低噪声(减少过度拟合的机会)并缩短训练时间。不过这种方法的一个缺点是准确性会持续下降。
如果模型需要很高的复杂度来捕捉数据集的所有重要特征,那么减少数据集的大小实际上不可避免地会导致更差的性能。在这种情况下,大模型支持可以解决这个问题。
大型模型支持
大型模型支持(LMS)是 IBM 最近推出的一个 Python 库。这个库的构想是为了训练无法容纳在 GPU 内存中的大型深度学习模型。事实上,与中央处理器(CPU)相比,GPU 通常具有更小的内存空间。
当使用 Tensorflow 和 PyTorch 等库实现神经网络时,会自动生成一组数学运算来构建该模型。这些数学运算可以用计算图来表示。
计算图是一个有向图,其中节点对应于操作或变量。变量可以将它们的值提供给操作,操作可以将它们的输出提供给其他操作。这样,图中的每个节点都定义了变量的函数。
—深刻的想法[1]
计算图中进出节点的值称为张量(多维数组)。
图 1 给出了一个简单的例子,说明如何使用计算图形(z =(x+y)∫(X5))来表示数学运算:

Figure 1: Computational Graph [2]
LMS 能够通过重新设计神经网络计算图来缓解 GPU 内存问题。这是通过在 CPU(而不是 GPU)上存储中间结果来实现张量运算的。
IBM 文档概述了使用 Tensorflow 库支持大型模型的三种不同方法:
- 基于会话的培训。
- 基于估计器的训练。
- 基于 Keras 的培训。
在本文中,我将提供一个使用基于 Keras 的培训的例子。如果您有兴趣了解其他两种方法的更多信息,IBM 文档是一个很好的起点[3]。
使用 LMS 时,我们可以调整两个主要参数来提高模型效率。目标是能够找出我们需要交换的最少数量的张量,而不会导致内存错误。
要调整的两个主要参数是:
- n_tensors =交换张量的数量(例如,刷出比所需更多的张量,会导致通信开销)。
- lb =张量在使用前多久换回(例如,使用较低的 lb 值会使 GPU 训练暂停)。
示范
现在,我将通过一个简单的例子向您介绍 LMS。这个练习使用的所有代码都可以在这个 Google 协作笔记本和我的 GitHub 上找到。
在这个例子中,我将训练一个简单的神经网络,首先使用具有大模型支持的 Keras,然后只使用普通的 Keras。如果是这两种情况,我将记录培训所需的内存使用情况。
预处理
为了按照这个例子安装所有需要的依赖项,只需在您的笔记本上运行以下单元,并启用您的 GPU 环境(例如 Kaggle、Google Colab)。
! git clone [https://github.com/IBM/tensorflow-large-model-support.git](https://github.com/IBM/tensorflow-large-model-support.git)
! pip install ./tensorflow-large-model-support
! pip install memory_profiler
一旦一切就绪,我们就可以导入所有必要的库了。
为了记录内存使用情况,我决定使用 Pythonmemory _ profiler。
随后,我定义了将在培训中使用的 LMS Keras 回调。根据 Keras 文档,回调的定义是:
回调是在训练过程的给定阶段应用的一组函数。在训练期间,您可以使用回调来查看模型的内部状态和统计数据。
— Keras 文档[4]
回调通常用于通过在每个训练迭代期间自动化某些任务来控制模型训练过程(在这种情况下,通过添加大型模型支持优化)。
然后,我决定使用由三个特征和两个标签(0/1)组成的高斯分布来构建一个 200000 行的简单数据集。
已经选择了分布的平均值和标准偏差值,以便使这个分类问题相当容易(线性可分数据)。

Figure 2: Dataset Head
创建数据集后,我将其分为要素和标注,然后定义一个函数对其进行预处理。
现在我们有了训练/测试集,我们终于准备好开始深度学习了。因此,我为二元分类定义了一个简单的序列模型,并选择了 8 个元素的批量大小。
Keras 和大型模型支持
使用 LMS 时,使用 Keras fit_generator 函数训练 Keras 模型。这个函数需要的第一个输入是一个生成器。生成器是一种功能,用于在多个内核上实时生成数据集,然后将其结果输入深度学习模型[5]。
为了创建本例中使用的生成器函数,我参考了这个实现。
如果你对 Keras 发电机的更详细的解释感兴趣,可以在这里找到。
一旦定义了我们的生成器函数,我就使用之前定义的 LMS Keras 回调来训练我们的模型。
在上面的代码中,我在第一行额外添加了 %%memit 命令来打印出运行这个单元的内存使用情况。结果如下所示:
Epoch 1/2 200000/200000 [==============================]
- 601s 3ms/step - loss: 0.0222 - acc: 0.9984 Epoch 2/2 200000/200000 [==============================]
- 596s 3ms/step - loss: 0.0203 - acc: 0.9984 peak memory: 2834.80 MiB, increment: 2.88 MiB
使用 LMS 训练此模型的注册峰值内存等于 2.83GB,增量为 2.8MB
最后,我决定测试我们的训练模型的准确性,以验证我们的训练结果。
Model accuracy using Large Model Support: 99.9995 %
克拉斯
使用普通 Keras 重复相同的程序,获得以下结果:
Epoch 1/2 1600000/1600000 [==============================]
- 537s 336us/step - loss: 0.0449 - acc: 0.9846 Epoch 2/2 1600000/1600000 [==============================]
- 538s 336us/step - loss: 0.0403 - acc: 0.9857 peak memory: 2862.26 MiB, increment: 26.15 MiB
使用 Keras 训练该模型的注册峰值内存等于 2.86GB,增量为 26.15MB
测试我们的 Keras 模型反而导致 98.47%的准确性。
Model accuracy using Sklearn: 98.4795 %
估价
比较使用 Keras + LMS 与普通 Keras 获得的结果,可以注意到,使用 LMS 可以减少内存消耗,并提高模型精度。如果给予更多的 GPU/CPU 资源(可用于优化训练)并使用更大的数据集,LMS 的性能甚至可以得到改善。
除此之外,IBM 和 NVIDIA 还决定创建一个由 27000 个 NVIDIA TESLA GPU组成的深度学习计算机集群,以进一步发展这方面的研究人员。如果你有兴趣了解更多,你可以在这里找到更多信息。
联系人
如果你想了解我最新的文章和项目,请通过媒体关注我,并订阅我的邮件列表。以下是我的一些联系人详细信息:
文献学
[1]从零开始的深度学习 I:计算图——深度思想。访问网址:http://www . deep ideas . net/deep-learning-from scratch-I-computational-graphs/
[2] TFLMS:通过图重写在张量流中支持大模型。董丁乐,今井春树等访问:https://arxiv.org/pdf/1807.02037.pdf
TensorFlow 大型模型支持(TFLMS)入门— IBM 知识中心。访问地址:https://www . IBM . com/support/knowledge center/en/ss5sf 7 _ 1 . 5 . 4/navigation/pai _ TF LMS . html
[4] Kears 文件。文档->回调。访问地点:【https://keras.io/callbacks/?source=post_page -
[5]如何将数据生成器用于 Keras 的详细示例。
谢尔文·阿米迪。访问地址:https://Stanford . edu/~ sher vine/blog/keras-how-to-generate-data-on-the-fly
深度学习和碳排放
由 Emma Strubell、Ananya Ganesh 和 Andrew McCallum 撰写的一篇颇具争议的论文《NLP 中深度学习的能源和政策考虑》最近正在流传。虽然论文本身是深思熟虑和有分寸的,但标题和推文一直具有误导性,比如“深度学习模型有大量的碳足迹”。一篇特别是不负责任的文章将该发现总结为“一个普通的现成深度学习软件可以排放超过 626,000 磅的二氧化碳”,这是一个惊人的误解。

作为一个非常关心深度学习和环境的人,我很高兴看到机器学习从业者写的一篇关于这个主题的深思熟虑的文章,但很遗憾看到它在媒体上被严重歪曲。
我开了一家公司,Weights and Biases,帮助机器学习从业者跟踪他们的模型和实验。我已经直接看到了冗余模型训练的代价,我希望权重和偏见可以在帮助机器学习从业者更明智地使用他们的资源方面发挥作用。
结论
- 模型训练的实际碳足迹可能不是什么大问题,但在未来可能是。
- 模型推理的碳足迹现在是一个更大的问题。
- 快速增长的 CPU/GPU 培训成本是今天的一个问题,原因有几个,我预计它会变得更糟。
- 机器学习从业者在冗余训练上浪费了大量资源。
如今,模型训练可能不是碳排放的重要来源(但它正呈指数增长)
论文中的示例模型“具有神经架构搜索的变压器”在 2019 年几乎任何人真正做的计算成本方面都遥遥领先。例如,一个更具代表性的任务,在 imagenet 上训练一个标准的神经网络初始,以 95%的准确率识别图片中的对象,需要大约 40 个 GPU 小时,这将消耗大约 10 千瓦时并产生大约 10 磅的二氧化碳,这相当于运行一个中央空调大约 2-3 个小时。
我们看到的使用 Weights & Biases 的典型机器学习实践者可能有八个 GPU 可供其使用,它们的利用率不会接近 100%。即使他们这样做,能源消耗将在 2kW 左右。如果有 100,000 名机器学习从业者(可能很慷慨),总的培训消耗将是 200 兆瓦。这并不比让一架 747 飞机停留在空中多多少能源,也可能更少碳排放。
另一种看待深度学习影响的方式是看英伟达的销售额,因为英伟达提供了大多数人用于培训的处理器。在 Q1 2019 年,他们的数据中心收入为 7.01 亿美元,这意味着他们为数据中心销售了大约 100,000 个 GPU。即使所有这些 GPU 都是训练模型(同样,不太可能),我们也会得出类似的结论。

为什么机器学习可能成为未来碳排放的重要组成部分
仅仅因为模型训练可能不是今天的主要碳生产者,并不意味着我们不应该关注它在未来可能产生的影响。
尽管典型的机器学习实践者可能只使用八个 GPU 来训练模型,但在谷歌、脸书、OpenAI 和其他大型组织中,使用率可能会高得多。
美国能源部为他们的橡树岭超级计算机购买了 27,648 个 Volta GPU ,他们计划用于深度学习,在 100%利用率的情况下将消耗大约 1 兆瓦。
深度学习的最近趋势显然是计算量增加几个数量级。这意味着更多数量级的能源和气候影响。因为今天的影响可能很小,如果趋势继续下去,它可能会迅速改变。OpenAI 有一篇出色的博客文章, AI 和 Compute 展示了构建最先进模型的计算成本的快速增长。

来源:人工智能和计算
GPU 性能功耗比也呈指数级增长,但它似乎更像是每 10 年增长 10 倍,而先进模型性能所需的计算每年增长 10 倍。

https://github.com/karlrupp/cpu-gpu-mic-comparison
模型推理比模型训练消耗更多的能量(现在如此,可能永远如此)
模型不仅仅在训练时消耗能量,今天更大的能量消耗来源于它们被部署之后。Nvidia 估计,在 2019 年,一款机型80–90%的成本都在推论中。目前还不清楚神经网络进行自动驾驶需要多少功率,但一些原型需要多达 2500 瓦,如果在世界上的每辆汽车上部署,将产生相当大的影响,尽管这比实际移动汽车要小一个数量级。
一个更直接的能源使用问题是数据中心今天使用超过 200 瓦,而且这个数字还在增长。谷歌在数据中心的能源使用足以激励他们设计自己的处理器,用于被称为 TPU 的推理,他们现在也将它作为谷歌云的一部分提供。
经济激励大多与模特培训的环境激励一致
模特培训变得极其昂贵。在云中运行模型,单个 GPU 的成本约为 1 美元/小时,产生约 0.25 磅的二氧化碳——以 10 美元/吨的声誉良好的碳抵消计算,抵消这些二氧化碳将花费约 0.1 美分,仅增加我的账单 0.1%。为碳中和模型培训支付的小额增量价格。
对于深度学习中快速增长的计算需求来说,环境影响甚至可能不是最糟糕的事情
Ananya 的论文提到了这一点,但它值得强调:训练艺术模型的高成本有许多令人担忧的影响。如今,研究人员和初创公司很难与谷歌和脸书等公司竞争,甚至复制它们的工作,因为培训成本太高。
直到最近,模型通常被认为是数据绑定的,许多人担心大公司在拥有最多数据方面具有不容置疑的优势。但是研究人员仍然能够在像 ImageNet 这样的高质量开放数据集上取得进展。创业公司能够在他们可用的数据上建立最好的机器学习应用程序。
在一个研究人员和公司都受限于计算的世界里,很难想象他们将如何与大公司竞争甚至合作。如果最先进的模型花费数百万美元来训练,还会有人试图复制彼此的结果吗?
即使在研究人员中,更高知名度的实验室也拥有不成比例的资金和资源,导致他们发表更令人兴奋的结果,这反过来增加了他们的计算能力。这可能导致极少数机构成为唯一能够进行基础深度学习研究的机构,
大量浪费和冗余的计算正在不断增加
这篇文章有几个极好的结论,我都同意。第一个是“作者应该报告训练时间和对超参数的敏感性”。为什么这如此重要?一个非从业者可能不会从这篇文章中意识到的一件事是,相同的深度学习模型是如何被一遍又一遍地训练的。从业者通常从现有的艺术模型开始,并尝试训练它。
例如,像脸书的 mask rcnn 视觉模型这样受欢迎的机器学习知识库已经被标星超过 5000 次,分叉超过 1500 次。很难说有多少人使用这种模式进行了训练,但我认为合理的估计可能是恒星数量的十倍,也就是说,有 25,000 名不同的人尝试过这种模式。有人会对模型做的第一件事就是训练它,看看它表现如何。然后他们通常会训练它更多次,尝试不同的超参数。但是所有这些信息都丢失了,而且大多数训练都是多余的。
这是我创办公司《重量与偏见》的原因之一。我们会保存您运行的所有实验,这样您就不必再次运行它们,而那些接手您工作的人也不必再次运行它们。当我看到研究人员在我们的系统中跟踪他们的实验时,我真的很兴奋。
论文中提出的另一个要点是“NLP 和机器学习软件开发人员可以帮助减少与模型调整相关的能量的另一个途径是通过提供易于使用的 API 来实现更有效的替代超参数调整的强力网格搜索,例如随机或贝叶斯超参数搜索技术。”
换句话说,研究人员不用尝试所有可能的超参数集,而是通过让算法智能地挑选有前途的超参数来节省资金、时间和环境影响。我们真的试图让做更智能的超参数搜索变得非常简单。
考虑抵消你的模特训练对环境的影响
与在亚马逊上购买 GPU 小时相比,购买碳补偿是便宜的。那么为什么不碳中和呢?有些人不认为碳补偿真的有效,但这超出了我的专业领域。非营利的碳基金对此进行了大量的思考,并提供了我认为大多数人会认为是高质量的碳补偿,即使他们可能会对确切的“补偿”吹毛求疵。向像地球正义这样的组织捐款可能不那么直接,但可能更有影响力。如果你左右为难,也许可以两者兼而有之。
一个简单的公式是,2019 年在加利福尼亚州的 Nvidia GPU 上训练一小时产生大约 0.25 磅二氧化碳当量的排放。
如果你想帮助计算你的模型训练碳足迹,我很乐意帮助你。
感谢
感谢詹姆斯·查姆、埃德·麦卡洛、克里斯·范·代克、布鲁斯·比沃德、斯泰西·斯维特拉奇尼亚和诺加·莱维纳的有益反馈。
神经网络的自然同伦

流形学习
在流形假设下,现实世界的高维数据集中在一个非线性的低维流形附近**【2】。换句话说,数据大致位于一个比输入空间维度低得多的流形上,一个可以被检索/学习的流形【8】**
为了应对维数灾难,流形假设是至关重要的:如果我们期望机器学习算法学习在高维空间中有有趣变化的函数,许多机器学习模型问题似乎是没有希望的**【6】**
幸运的是,经验证明,人工神经网络由于其分级、分层的结构**【3】,能够捕捉普通数据的几何规律。[3]** 展示了证明处理位于低维流形上或附近的数据的能力的实验。
然而,ANN 层如何识别原始数据空间到合适的低维流形之间的映射(表示)?
同胚线性嵌入
根据**【10】提供的定义,**一个同胚,也叫连续变换,是两个几何图形或拓扑空间中的点之间在两个方向上连续的等价关系和一一对应关系。
- 同样保持距离的同胚叫做等距。
- 仿射变换是另一种常见的几何同胚。

A continuous deformation between a coffee mug and a doughnut (torus) illustrating that they are homeomorphic. But there need not be a continuous deformation for two spaces to be homeomorphic — only a continuous mapping with a continuous inverse function [4]
**【1】**看 tanh 图层。tanh 层 tanh(Wx+b) 包括:
- 通过“权重”矩阵 W 进行线性变换
- 甲由矢乙翻译
- tanh 的逐点应用
虽然流形学习方法明确地学习低维空间,但是神经网络层是到不一定是低维空间的非线性映射。实际情况就是这样:我们来看具有 N 个输入和 N 个输出的双曲正切层。
在这样的 tanh-layers 中,每一层都拉伸和挤压空间,但它从不切割、破坏或折叠空间。直观上,我们可以看到它保留了拓扑性质[…如果权矩阵 W 是非奇异的,则具有 N 个输入和 N 个输出的 Tanh 层是同胚的。(尽管需要注意领域和范围)【1】。

A four-hidden-layers tanh ANN discriminates between two slightly entangled spirals by generating a new data representation where the two classes are linearly separable [1]
同胚和可逆的概念与可解释性深深交织在一起:理解特征空间中的变换如何与相应的输入相关是迈向可解释深度网络的重要一步,可逆深度网络可以在这种分析中发挥重要作用,因为例如,人们可以潜在地从特征空间回溯属性到输入空间**【11】**

An example of problems that arise in mapping manifolds not diffeomorphic to each other. The “holes” in the first manifold prevent a smooth mapping to the second [12]. It is a good idea to characterize the learnability of different neural architectures by computable measures of data complexity such as persistent homology [13]
不幸的是,并不总是可能找到同胚映射。如果数据集中在具有非平凡拓扑的低维流形附近,则不存在到斑点状流形(先验质量集中的区域)的连续可逆映射**【12】**
让我们回到描述 ANN 层中发生的事情的目标。通过构造同伦,我们可以分析激活函数中非线性程度的增加如何改变 ANN 层将数据映射到不同空间的方式。
自然同伦
两个映射 f0 和 f1 是同伦的,f0 ≃ f1,如果存在一个映射,同伦 F : X × I → Y 使得 f0(x) = F(x,0)和 f1(x) = F(x,1)对于所有的 x∈x**【9】**
**【6】**通过将单层感知器中的节点传递函数从线性映射转换为 s 形映射来构造同伦:
通过使用将线性网络变形为非线性网络的自然同伦,我们能够探索通常用于分析线性映射的几何表示如何受到网络非线性的影响。具体地,输入数据子空间被网络转换成曲线嵌入数据流形“【6】

The data manifold for L=3, s=2 and three weights at 𝜏=1 [6]

An intuition of how curvature relates to the existence of multiple projections of y on Z [6]

An example data manifold Z with boundaries Pa,b = Z ± (1/ |k|max)n where n is the normal to the surface. For all desired vectors y in the region between Pa and Pb, there exists only one solution. It is important to remark that the mapping is not homeomorphic: the mapping is not invertible and Z folds on itself, infinitely [6]
结论
在流形假设下,学习相当于发现一个非线性的、低维的流形。在这篇简短的博客中,我试图提供一个简短的、直观的、当然不完全全面的直觉,来说明人工神经网络如何将原始数据空间映射到一个合适的低维流形。
对于不同的人工神经网络体系结构和分类问题,在层级别可视化映射(表示)的一个很好的工具是可用的这里**【15】**它是令人敬畏的。
免责声明:本博客中的观点是我的,可能的错误和误解也是我的
参考
【1】http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
**【2】**劳伦斯·凯顿。流形学习算法。“加州大学圣地亚哥分校。代表 12.1–17(2005 年):1。()
**【3】**巴斯里,罗嫩,大卫雅各布。"使用深度网络有效表示低维流形。arXiv 预印本 arXiv:1602.04723 (2016)。
【4】https://en.wikipedia.org/wiki/Homeomorphism
库切、弗兰斯·m 和弗吉尼亚·l·斯通尼克。“关于线性和非线性单层网络之间的自然同伦。”神经网络汇刊 7.2(1996):307–317。
**【6】**Coetzee,Frans Martin,“神经网络和其他非线性方程组的分析和求解的同伦方法。博士论文,卡耐基·梅隆大学,5 月 (1995)。
**【7】**阿迪卡里,玛希玛·兰詹。基本代数拓扑及其应用。斯普林格,2016。
**【8】**Pierre Geurts,Gilles Louppe,Louis Wehenkel,迁移学习及相关协议,讲义,2018
**【9】**杰斯珀·莫勒,初学者同伦理论,课堂讲稿
http://mathworld.wolfram.com/Homeomorphism.html
雅各布森、约恩-亨里克、阿诺德·斯默德斯和爱德华·奥雅伦。i-revnet:深度可逆网络。“arXiv 预印本 arXiv:1802.07088 (2018)。
****【12】法洛西,卢卡等.同胚变分自动编码的探索。“arXiv 预印本 arXiv:1807.04689 (2018)。
古斯、威廉·h 和鲁斯兰·萨拉胡季诺夫。关于用代数拓扑来表征神经网络的能力。“arXiv 预印本 arXiv:1802.04443 (2018)。
****【14】古德菲勒、伊恩、约舒阿·本吉奥和亚伦·库维尔。深度学习。麻省理工学院出版社,2016 年。
****【15】https://cs . Stanford . edu/people/karpathy/convnetjs//demo/classify 2d . html
fastai 用于疟疾检测的深度学习和医学图像分析
学习使用高级深度学习环境对血液涂片图像进行分类

Jimmy Chan/Pexels free images
在国家医学图书馆(NLM)的一部分 Lister Hill 国家生物医学通信中心(LHNCBC)提供了一个健康和受感染的血液涂片疟疾图像的注释数据集之后,各种帖子和论文已经发表,展示了如何使用卷积神经网络的图像分类来学习和分类这些图像。
该数据集中的图像看起来像我们下面收集的图像:寄生的涂片将显示一些彩色点,而未感染的涂片将倾向于均匀着色。

对这些涂片进行分类应该不是一件非常困难的事情。下面列出的帖子中描述的结果表明,96%到 97%的分类准确率是可行的。
在这篇文章中,我们将展示如何使用 fast.ai CNN 图书馆来学习分类这些疟疾涂片。Fast.ai 是一个库,基于 PyTorch 构建,使得编写机器学习应用程序变得更快更简单。Fast.ai 还提供了一门在线课程,涵盖了 fast.ai 和深度学习的一般使用。与较低级别的“高级”库相比,如 Keras 、 TensorFlow 。无论是 Keras 还是 pure PyTorch ,fast.ai 都极大地减少了制作最先进的神经网络应用程序所需的样板代码数量。
本公告基于以下材料:
- PyImagesearch::深度学习和医学图像分析与 Keras —以疟疾图像为例,作者 Adrian Rosebrock,2018 年 12 月 3 日;
- 来自 NIH 的疟疾数据集——来自疟疾筛查者研究活动的薄血涂片图像的分割细胞库;
- TowardsDataScience::利用深度学习检测疟疾——人工智能造福社会——医疗保健案例研究——Dipanjan(DJ)Sarkar 对上述内容的评论;
- PeerJ::Sivaramakrishnan Raja Raman 等人的预训练卷积神经网络作为特征提取器,用于改进薄血涂片图像中的疟原虫检测 —上述帖子的作者基于其工作的原始科学论文。
我已经改编了这个材料,以便在 2019 年 5 月与 PyTorch/fast.ai 一起使用。被评论的代码作为谷歌合作笔记本免费提供。
我们去看代码吧…
初始化
每次运行此笔记本时,请执行以下部分中的操作一次…
%reload_ext autoreload
%autoreload 2
%matplotlib inline
在 Google Colab 上测试您的虚拟机…
只是为了确定,看看哪一个 CUDA 驱动和哪一个 GPU Colab 已经为你提供了。GPU 通常是:
- 一个 11 GB 内存的 K80 或者(如果你真的幸运的话)
- 一个 14 GB 内存的特斯拉 T4
如果谷歌的服务器很拥挤,你最终只能访问 GPU 的一部分。如果您的 GPU 与另一台 Colab 笔记本共享,您将看到可供您使用的内存量减少。
小贴士:避开美国西海岸的高峰期。我住在 GMT-3,我们比美国东海岸早两个小时,所以我总是试图在早上进行繁重的处理。
!/opt/bin/nvidia-smi
!nvcc --version
当我开始运行这里描述的实验时,我很幸运:我有一个 15079 MB RAM 的完整 T4!我的输出如下所示:
Thu May 2 07:36:26 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.79 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 63C P8 17W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
图书馆进口
在这里,我们导入所有必需的包。我们将使用 fast.ai V1 库,它位于 Pytorch 1.0 之上。fast.ai 库提供了许多有用的功能,使我们能够快速轻松地建立神经网络并训练我们的模型。
from fastai.vision import *
from fastai.metrics import error_rate
from fastai.callbacks import SaveModelCallback# Imports for diverse utilities
from shutil import copyfile
import matplotlib.pyplot as plt
import operator
from PIL import Image
from sys import intern # For the symbol definitions
实用功能:导出和恢复功能
导出用于部署的网络并创建副本
def exportStageTo(learn, path):
learn.export()
# Faça backup diferenciado
copyfile(path/'export.pkl', path/'export-malaria.pkl')
#exportStage1(learn, path)
恢复部署模型,例如为了继续微调
def restoreStageFrom(path):
# Restore a backup
copyfile(path/'export-malaria.pkl', path/'export.pkl')
return load_learner(path)
#learn = restoreStage1From(path)
下载疟疾数据
我上面列出的作者使用了 NIH 疟疾数据集。让我们做同样的事情:
!wget --backups=1 -q [https://ceb.nlm.nih.gov/proj/malaria/cell_images.zip](https://ceb.nlm.nih.gov/proj/malaria/cell_images.zip)
!wget --backups=1 -q [https://ceb.nlm.nih.gov/proj/malaria#/malaria_cell_classification_code.zip](https://ceb.nlm.nih.gov/proj/malaria/malaria_cell_classification_code.zip)
# List what you've downloaded:
!ls -al
wget 的 backups=1 参数将允许您在下载失败的情况下多次重复命令行,而无需创建大量新版本的文件。
最后一行应该产生以下输出:
total 345208
drwxr-xr-x 1 root root 4096 May 2 07:45 .
drwxr-xr-x 1 root root 4096 May 2 07:35 ..
-rw-r--r-- 1 root root 353452851 Apr 6 2018 cell_images.zip
drwxr-xr-x 1 root root 4096 Apr 29 16:32 .config
-rw-r--r-- 1 root root 12581 Apr 6 2018 malaria_cell_classification_code.zip
drwxr-xr-x 1 root root 4096 Apr 29 16:32 sample_data
现在解压缩 NIH 疟疾细胞图像数据集:
!unzip cell_images.zip
这将产生一个非常大的详细输出,如下所示:
Archive: cell_images.zip
creating: cell_images/
creating: cell_images/Parasitized/
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_162.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_163.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_164.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_165.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_166.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_167.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_168.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_169.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_170.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_171.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_138.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_139.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_140.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_141.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_142.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_143.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144348_cell_144.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144823_cell_157.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144823_cell_158.png
extracting: cell_images/Parasitized/C100P61ThinF_IMG_20150918_144823_cell_159.png
....
....
....
...and so on...
准备您的数据
将 cell_images 文件夹的名称改为 train ,然后将 mv 放在一个新的 data 文件夹上面,这样 fast.ai 就可以用它来自动生成 train,验证和测试集合,而不用再大惊小怪了…
!mv cell_images train
!mkdir data
!mv train data
看看你的文件夹
如果还没有安装 tree 命令,使用来安装 tree :
!apt install tree
现在运行它:
!tree ./data --dirsfirst --filelimit 10
这将显示文件树的结构:
./data
└── train
├── Parasitized [13780 exceeds filelimit, not opening dir]
└── Uninfected [13780 exceeds filelimit, not opening dir]3 directories, 0 files
不要忘记设置一个文件限制,否则你会有大量的输出…
初始化一些变量
bs = 256 # Batch size, 256 for small images on a T4 GPU...
size = 128 # Image size, 128x128 is a bit smaller than most
# of the images...
path = Path("./data") # The path to the 'train' folder you created...
创建您的培训和验证数据集
在使用 Keras 的 PyImagesearch 的原始资料中,有一个很长的例程从数据中创建训练、验证和测试文件夹。有了 fast.ai 就没必要了:如果你只有一个‘train’文件夹,你可以在创建 DataBunch 时通过简单地传递几个参数来自动分割它。我们将把数据分成一个训练集 (80%)和一个验证集 (20%)。这是通过*imagedatabunch . from _ folder()*构造函数方法中的 valid_pct = 0.2 参数完成的:
# Limit your augmentations: it's medical data!
# You do not want to phantasize data...
# Warping, for example, will let your images badly distorted,
# so don't do it!
# This dataset is big, so don't rotate the images either.
# Lets stick to flipping...
tfms = get_transforms(max_rotate=None, max_warp=None, max_zoom=1.0)
# Create the DataBunch!
# Remember that you'll have images that are bigger than 128x128
# and images that are smaller, o squish them all in order to
# occupy exactly 128x128 pixels...
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=size, resize_method=ResizeMethod.SQUISH, **valid_pct = 0.2**, bs=bs)
#
print('Transforms = ', len(tfms))
# Save the DataBunch in case the training goes south...
# so you won't have to regenerate it..
# Remember: this DataBunch is tied to the batch size you selected.
data.save('imageDataBunch-bs-'+str(bs)+'-size-'+str(size)+'.pkl')
# Show the statistics of the Bunch...
print(data.classes)
data
print() 将输出转换和类:
Transforms = 2
['Parasitized', 'Uninfected']
最后一行, data 将简单地输出 ImageDataBunch 实例的返回值:
ImageDataBunch;Train: LabelList (22047 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Uninfected,Uninfected,Uninfected,Uninfected,Uninfected
Path: data;Valid: LabelList (5511 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Parasitized,Uninfected,Parasitized,Uninfected,Uninfected
Path: data;Test: None
查看您的数据集群,看看增加是否可以接受…
data.show_batch(rows=5, figsize=(15,15))

培训:resnet34
如果你不知道用什么,从 34 层的剩余网络开始是一个好的选择。不要太小也不要太大…在上面列出的教程中,作者使用了:
- 一个自定义的小 ResNet (PyImagesearch)
- VGG19(面向数据科学)
我们将采用现成的 fast.ai 残差网络(ResNets)。让我们创建我们的第一个网络:
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.model
最后一行将以文本流的形式输出网络的架构。它看起来会像这样:
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
....and so on....
即使像 ResNet34 这样的“小”网络也仍然非常大。不要费心去理解输出。你可以稍后阅读更多关于剩余网络的内容。有许多关于 ResNets 的介绍性帖子。
培训策略
fast.ai 的一大区别就来了:易用的 HYPOs(超参数优化策略)。超参数优化是 CNN 的一个有点神秘的分支学科。这是因为 CNN 有如此多的参数,试图通过设置一些非标准值来选择我们将改变的参数,以便为我们的网络提供更好的性能,这是一个非常复杂的问题,也是一项研究本身。fast.ai 库提供了一些非常先进但易于使用的 HYPOs,它们对快速实现更好的 CNN 有很大的帮助。
我们将采用 Leslie N. Smith 开发的 fit1cycle 方法,详情如下:
- https://docs.fast.ai/callbacks.one_cycle.html
- 神经网络超参数的训练方法:第一部分——学习速率、批量大小、动量和权重衰减——https://arxiv.org/abs/1803.09820
- 超级收敛:使用大学习率快速训练残差网络—https://arxiv.org/abs/1708.07120
- 有一篇来自 Nachiket Tanksale 的非常有趣的文章,名为寻找好的学习率和单周期政策,其中讨论了周期学习率和动量。
由于这种方法很快,我们将在第一个迁移学习阶段仅使用 10 个时期。如果性能变得更好,我们也将在每个时期保存网络:https://docs.fast.ai/callbacks.html#SaveModelCallback
learn.fit_one_cycle(10, callbacks=[SaveModelCallback(learn, every='epoch', monitor='accuracy', name='malaria-1')])
# Save it!
learn.save('malaria-stage-1')
# Deploy it!
exportStageTo(learn, path)
这将生成一个如下所示的表作为输出:

上表显示,验证集的准确率为 96.4%,而且这仅仅是在迁移学习的情况下! error_rate fast.ai 显示您将始终看到与训练集相关联的那个。作为比较,Adrian Rosebrock 在 PyImagesearch 帖子中使用他的自定义 ResNet 实现了 97%的搜索率。
ResNet34 的结果
让我们看看我们得到了什么额外的结果。我们将首先查看哪些是模型相互混淆的实例。我们将尝试看看模型预测的结果是否合理。在这种情况下,错误看起来是合理的(没有一个错误看起来明显幼稚)。这表明我们的分类器工作正常。
此外,我们将绘制混淆矩阵。这在 fast.ai 中也很简单。
interp = ClassificationInterpretation.from_learner(learn)losses,idxs = interp.top_losses()len(data.valid_ds)==len(losses)==len(idxs)
看看你的 9 个最差结果(首先不使用热图):
interp.plot_top_losses(9, figsize=(20,11), heatmap=False)

现在,进行同样的操作,但使用热图突出显示导致错误分类的原因:
interp.plot_top_losses(9, figsize=(20,11), heatmap=True)

显示混淆矩阵
fast.ai 的ClassificationInterpretation类有一个高级实例方法,允许快速轻松地绘制混淆矩阵,以更好的方式向您显示 CNN 的表现有多好。只有两个类并没有多大意义,但我们还是要这么做:它生成了漂亮的图片…你可以设置结果图的大小和分辨率。我们将 5x5 英寸设置为 100 dpi。
interp.plot_confusion_matrix(figsize=(5,5), dpi=100)

展示你的学习曲线:
观察学习和验证曲线是很有趣的。它将向我们显示网络是否以稳定的方式学习,或者它是否振荡(这可能表明质量差的数据),以及我们是否有一个好的结果,或者我们是否过度拟合或欠拟合我们的网络。
再说一次 fast.ai 有高级方法可以帮助我们。每个 fast.ai cnn_learner 都有一个自动创建的记录器实例。记录器记录训练期间的历元、损失、最优和度量数据。*plot _ loss()*方法将创建一个带有训练和验证曲线的图形:
learn.recorder.plot_losses()

这个结果看起来真的太好了,网络微调没有意义。如果我们仔细观察,我们会发现在大约 500 个批次时,验证损失比训练损失更严重,这表明网络可能在这一点上开始过度拟合。这表明我们已经接受了足够的培训,至少对于这个 ResNet 模型是如此。
我们观察到的过度拟合可能表明我们采用的网络模型对于数据的复杂性来说是过度的,这意味着我们正在训练一个学习单个实例而不是数据集泛化的网络。测试这一假设的一个非常简单实用的方法是尝试用一个更简单的网络学习数据集,看看会发生什么。
让我们使用一个更小的网络,再试一次…
ResNet18
这个网络简单多了。让我们看看它是否有效。
ResNet18 要小得多,所以我们会有更多的 GPU RAM。我们将再次创建数据群发,这一次批量更大…
# Limit your augmentations: it's medical data!
# You do not want to phantasize data...
# Warping, for example, will let your images badly distorted,
# so don't do it!
# This dataset is big, so don't rotate the images either.
# Lets stick to flipping...
tfms = get_transforms(max_rotate=None, max_warp=None, max_zoom=1.0)
# Create the DataBunch!
# Remember that you'll have images that are bigger than 128x128
# and images that are smaller, so squish them to occupy
# exactly 128x128 pixels...
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=size, resize_method=ResizeMethod.SQUISH, valid_pct = 0.2, **bs=512**)
#
print('Transforms = ', len(tfms))
# Save the DataBunch in case the training goes south... so you won't have to regenerate it..
# Remember: this DataBunch is tied to the batch size you selected.
data.save('imageDataBunch-bs-'+str(bs)+'-size-'+str(size)+'.pkl')
# Show the statistics of the Bunch...
print(data.classes)
data
注意,我们坚持使用我们的 valid_pct = 0.2 :我们仍然让 fast.ai 随机选择数据集的 20%作为验证集。
上面的代码将输出如下内容:
Transforms = 2
['Parasitized', 'Uninfected']
并且:
ImageDataBunch;Train: LabelList (22047 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Uninfected,Uninfected,Uninfected,Uninfected,Uninfected
Path: data;Valid: LabelList (5511 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Parasitized,Uninfected,Parasitized,Uninfected,Parasitized
Path: data;Test: None
现在,创建学习者:
learn18 = cnn_learner(data, models.resnet18, metrics=error_rate)
如果您的 Colab 环境没有 ResNet18 的预训练数据,fast.ai 会自动下载它:
Downloading: "https://download.pytorch.org/models/resnet18-5c106cde.pth" to /root/.torch/models/resnet18-5c106cde.pth
46827520it [00:01, 28999302.58it/s]
看模型:
learn18.model
这将列出你的网的结构。它比 ResNet34 小得多,但仍然有很多层。输出将如下所示:
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
...and so on...
让我们训练它
我们将再次使用 fit_one_cycle HYPO 训练策略。将训练限制在 10 个时期,以观察这个较小网络的行为:
learn18.fit_one_cycle(10, callbacks=[SaveModelCallback(learn, every='epoch', monitor='accuracy', name='malaria18-1')])
# Save the network
learn18.save('malaria18-stage-1')
# Deploy it also
exportStageTo(learn18, path)

该表显示网络学习到大约 96.1%的准确度,并且建议网络不应该被进一步训练:时段#8 和#9 之间的损失显示出 0.005 的减少,但是准确度保持不变,这表明网络已经开始过拟合。
让我们生成一个分类解释并查看混淆矩阵和损失曲线。
interp = ClassificationInterpretation.from_learner(learn18)
losses,idxs = interp.top_losses()interp.plot_confusion_matrix(figsize=(5,5), dpi=100)

这个混淆矩阵比我们为 ResNet34 生成的稍微差一点,但只是非常差一点。ResNet18 是否不太适合这个问题?
让我们来看看损失:

该图显示,ResNet18 在大约 290 批次后开始有点过度拟合。记住我们的 bs 在这里是 512,在 ResNet34 是 256。
让我们看看我们能否更好地微调网络。
微调一下!
这里我们将介绍另一个 fast.ai HYPO:自动选择的可变学习率。我们将让 fast.ai 为每个历元和每个层选择使用哪个学习速率,提供一个我们认为足够的学习速率范围。我们将训练 30 个纪元的网络。
# Unfreeze the network
learn18.unfreeze()
# Learning rates range: max_lr=slice(1e-4,1e-5)
learn18.fit_one_cycle(30, **max_lr=slice(1e-4,1e-5)**,
callbacks=[SaveModelCallback(learn,
every='epoch', monitor='accuracy',
name='malaria18')])
# Save as stage 2...
learn18.save('malaria18-stage-2')
# Deploy
exportStageTo(learn18, path)

**97%的准确率!**这正是 Adrian Rosebrock 在 PyImagesearch 帖子中使用他的定制 Keras ResNet 实现所实现的,该帖子在上述三篇参考文献中提供了最佳的准确性结果。
然而,验证失败在过去的时代变得更糟。这表明我们从大约第 20 纪元开始就已经过度拟合。如果你想部署这个网络,我建议你从 epoch 20 加载结果并生成一个部署网络。它似乎没有变得更好,没有这个网络。
看看结果
interp = ClassificationInterpretation.from_learner(learn18)
losses,idxs = interp.top_losses()interp.plot_confusion_matrix(figsize=(5,5), dpi=100)

这比我们以前吃过的要好。让我们看看损失曲线:

在这里,我们看到网络似乎在 500 批次后开始过度拟合,这将证实我们从上面的结果表中推断的怀疑。如果你看上面的曲线,你会看到验证损失在训练的最后三分之一开始增加,表明这部分训练只是过度拟合了网络。
如果培训中途中断,我该怎么办?
如果你的训练被打断了,你会怎么做?这可能是因为你在 Google Colab 笔记本上达到了连续 12 小时的“免费”操作时间,或者因为你的计算机由于某种原因停止了。我住在巴西,电力短缺是常事…
fit_one_cycle 方法适用于变化的自适应学习速率,遵循速率先增大后减小的曲线。如果您在第 10 个时期(比如说 20 个时期)中断训练,然后重新开始 9 个时期以上的训练,您将不会得到与不间断训练 20 个时期相同的结果。您必须能够记录您停止的位置,然后从该点重新开始训练周期,并使用该周期部分的正确超参数。

A fit_one_cycle training session divided into three subsessions. Image by PPW@GitHub
你要做的第一件事就是保存你的网络:
learn.fit_one_cycle(20, max_lr=slice(1e-5,1e-6),
callbacks=[SaveModelCallback(learn, every='epoch',
monitor='accuracy', name=***<callback_save_file>***)])
这将使您的网络在每个时期都被保存,您提供的名称后跟*_ #时期*。所以在纪元#3,文件 saved_net_3.pth 将被写入。您可以在完成以下操作后加载此文件:
- 重新创建了数据束和
- 用它重新实例化了网络。
重新加载后。pth 文件,你可以重新开始你的训练,只是你要告诉 fit_one_cycle 考虑 20 个历元,但是要从历元#4 开始训练。
要了解这是如何做到的,请看这里:
你是怎么做到的?
fast.ai 中的 fit_one_cycle 方法已经开发出来,允许您告诉它从周期的哪个部分恢复中断的训练。恢复培训的代码如下所示:
# Create a new net if training was interrupted and you had to
# restart your Colab sessionlearn = cnn_learner(data, models.<your_model_here>,
metrics=[accuracy, error_rate])# If you're resuming, only indicating the epoch from which to
# resume, indicated by ***start_epoch=<epoch#>*** will load the last
# saved .pth, it is not necessary to explicitly reload the last
# epoch, you only should **NOT** change the name given in
# name=<callback_save_file>:
# when resuming fast.ai will try to reload
# ***<callback_save_file>_<previous_epoch>.pth***
# Unfreeze the network
learn50.unfreeze()# Use start_epoch=<some_epoch> to resume training...
learn.fit_one_cycle(20, max_lr=slice(1e-5,1e-6),
***start_epoch=<next_epoch#>***,
callbacks=[SaveModelCallback(learn,
every='epoch', monitor='accuracy',
***name=<callback_save_file>***)])
fast.ai 会告诉你“已加载<回调 _ 保存 _ 文件> _ <上一个 _ 纪元# > ”,恢复训练。
您可以在此查看 fit_one_cycle 方法支持的所有参数:
我们学到了什么?
与其他方法相比,作者分别使用纯 Keras 和 TensorFlow。Keras 为了解决这个问题,借助 fast.ai 我们能够使用更少的代码解决同样的疟疾血液涂片分类问题,同时使用高级超参数优化策略,使我们能够更快地进行训练。同时,一组高级功能也允许我们以表格和图形的形式轻松检查结果。
利用 fast.ai 提供的现成残差网络模型,在 ImageNet 上进行预训练,我们获得的精度结果比上面三篇文章中的两篇(包括发表在 PeerJ 上的科学论文)高出 1%,相当于上面文章的最佳表现。这表明 fast.ai 是更传统的 CNN 框架的一个非常有前途的替代方案,特别是如果手头的任务是一个“标准”的深度学习任务,如图像分类、对象检测或语义分割,可以通过微调现成的预训练网络模型来解决。
想看看更有野心的例子吗?
用 fast.ai 看我们的皮肤癌检测教程:
- towards data science:利用 fastai 进行皮肤图像诊断的深度学习——学习从皮肤镜图像中识别皮肤癌和其他病症 作者 Aldo von Wangenheim
在本例中,我们将向您展示如何处理更大的数据集并调整最佳学习率。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










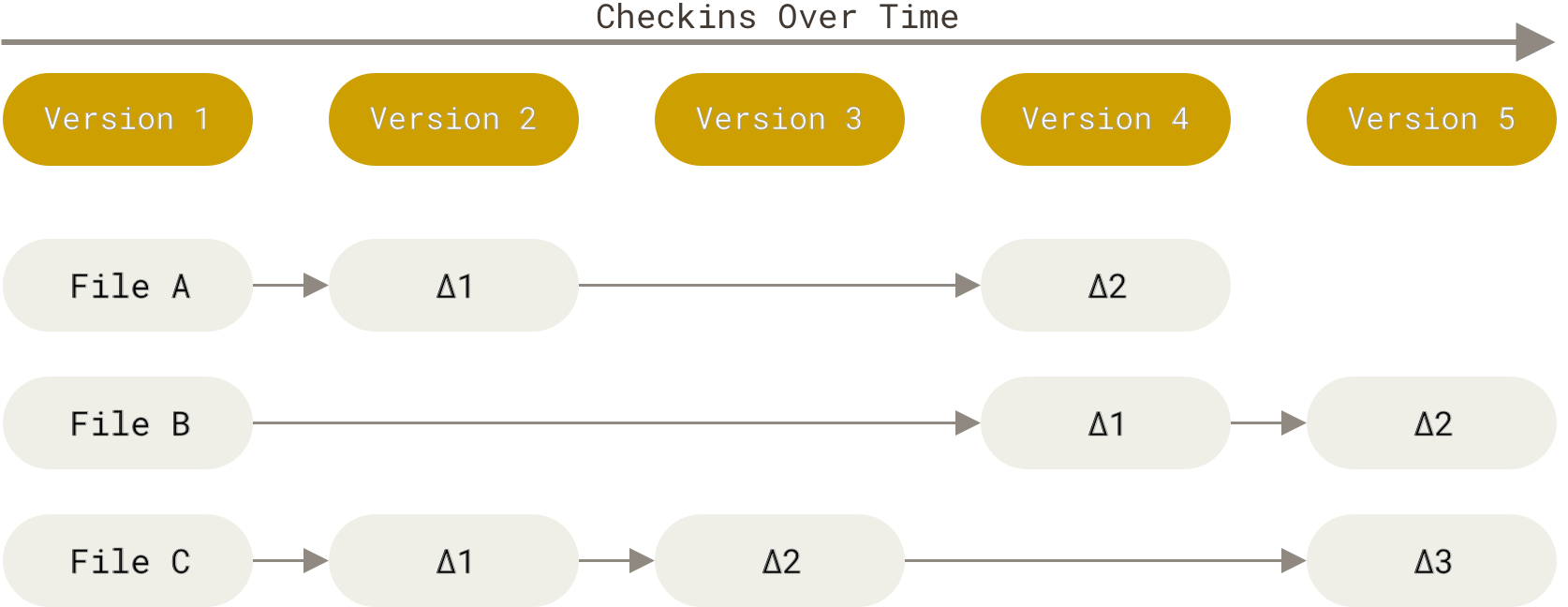{kind=link}
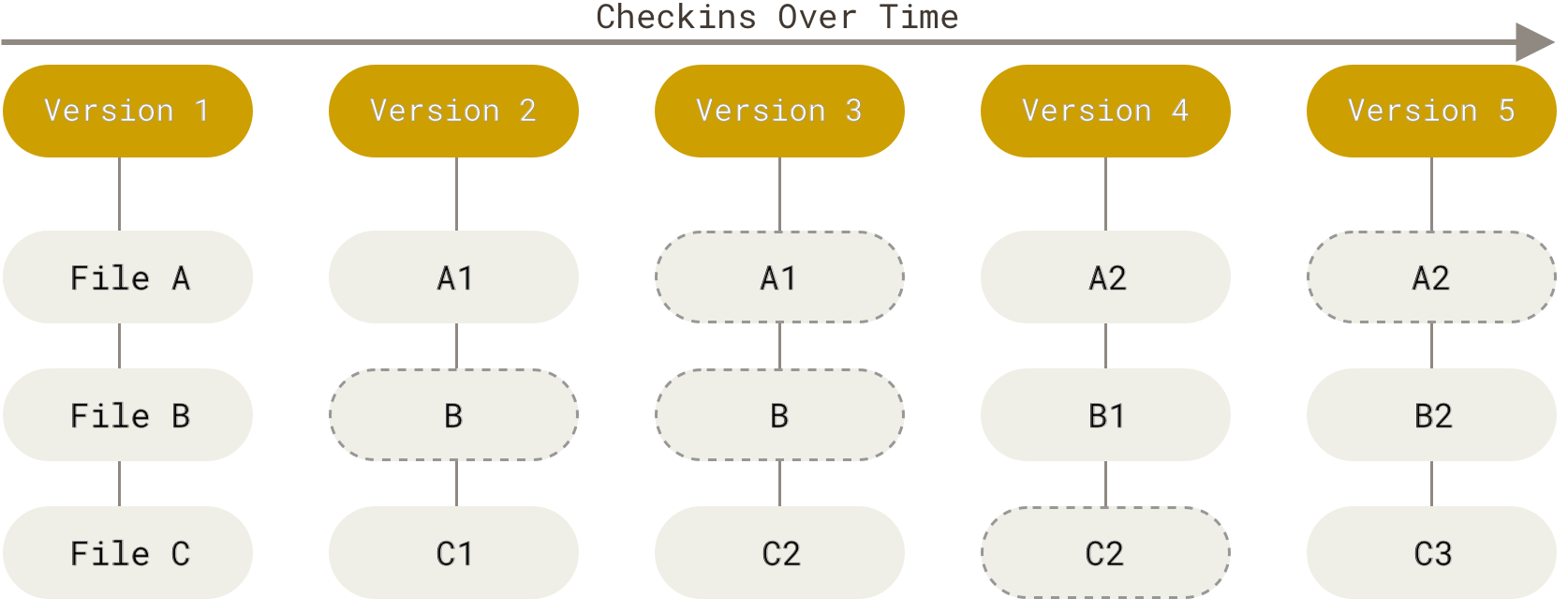{kind=link}
{kind=link}