







理解反向传播算法
了解神经网络最重要组成部分的具体细节

“A man is running on a highway” — photo by Andrea Leopardi on Unsplash
反向传播算法可能是神经网络中最基本的构建模块。它最早于 20 世纪 60 年代提出,近 30 年后(1989 年)由 Rumelhart、Hinton 和 Williams 在一篇名为*的论文中推广开来。*
***该算法用于通过一种称为链规则的方法有效地训练神经网络。*简单来说,在网络的每次正向传递之后,反向传播在调整模型参数(权重和偏差)的同时执行反向传递。
在本文中,我想回顾一下训练和优化一个简单的 4 层神经网络的数学过程。我相信这将帮助读者理解反向传播是如何工作的,并意识到它的重要性。
定义神经网络模型
4 层神经网络由 4 个用于输入层的神经元、4 个用于隐含层的神经元和 1 个用于输出层的神经元组成。

Simple 4-layer neural network illustration
输入层
紫色的神经元代表输入数据。这些可以像标量一样简单,也可以像向量或多维矩阵一样复杂。

Equation for input x_i
第一组激活( a )等于输入值。注意:“激活”是应用激活函数后神经元的值。见下文。
隐藏层
使用z^l*-层 l 中的加权输入,以及a^l-层 l 中的激活,计算隐藏神经元的最终值,以绿色、t29】表示。对于第 2 层和第 3 层,等式为:*
- l = 2

Equations for z² and a²
- l = 3

Equations for z³ and a³
W 和 W 是层 2 和层 3 中的权重,而 b 和 b 是这些层中的偏差。
使用激活函数 f 计算激活 a 和 a 。典型地,这个函数 f 是非线性的(例如 sigmoid 、 ReLU 、 tanh ),并且允许网络学习数据中的复杂模式。我们不会详细讨论激活函数是如何工作的,但是,如果感兴趣,我强烈推荐阅读这篇伟大的文章。
仔细观察,您会发现所有的 x、z、a、z、a、W、W、b 和 b 都缺少上面 4 层网络图中的下标。原因是我们已经将矩阵中的所有参数值组合起来,按层分组。这是使用神经网络的标准方式,人们应该对计算感到舒适。不过,我会检查一下方程式,以消除任何混淆。
让我们挑选第 2 层及其参数作为例子。相同的操作可以应用于网络中的任何层。
- W 是形状为 (n,m) 的权重矩阵,其中 n 是输出神经元(下一层神经元)的数量, m 是输入神经元(上一层神经元)的数量。对于我们来说, n = 2 和 m = 4 。

Equation for W¹
NB:任何权重下标中的第一个数字匹配下一层中神经元的索引(在我们的例子中,这是 Hidden_2 层 ) ,第二个数字匹配上一层中神经元的索引(在我们的例子中,这是输入层*)。*
- x 是形状 (m,1) 的输入向量,其中 m 是输入神经元的数量。对于我们来说, m = 4 。

Equation for x
- b 是形状 (n,1) 的偏置向量,其中 n 是当前层中神经元的数量。对于我们来说, n = 2 。

Equation for b¹
*根据 *z、的等式,我们可以使用上述 W、x 和 b 的定义来推导出“z 的等式”:

Equation for z²
现在仔细观察上面的神经网络图。

Input and Hidden_1 layers
你会看到 z 可以用( z_1) 和( z_2) 来表示,其中( z_1) 和( z_2) 是每个输入 x_i 与相应权重( W_ij)相乘的和。
这导致 z 的相同的“T14”方程,并证明 z、a、z 和 a 的矩阵表示是正确的。
输出层
神经网络的最后一部分是产生预测值的输出层。在我们的简单示例中,它被表示为单个神经元,以蓝色和着色,评估如下:

Equation for output s
同样,我们使用矩阵表示来简化方程。人们可以使用上述技术来理解底层逻辑。如果你发现自己迷失在方程式中,请在下面留下你的评论——我很乐意帮助你!
正向传播和评估
上述方程构成了网络的前向传播。下面是一个简短的概述:

Overview of forward propagation equations colored by layer
正向传递的最后一步是相对于预期输出 y 评估预测输出 s 。
输出 y 是训练数据集 (x,y) 的一部分,其中 x 是输入(正如我们在上一节中看到的)。
s 和 y 之间的评估通过成本函数*进行。这可以像 MSE (均方误差)一样简单,也可以像交叉熵一样复杂。*
我们将这个成本函数命名为 C ,并表示如下:

Equation for cost function C
如果成本可以等于 MSE、交叉熵或者任何其他成本函数。
基于 C 的值,模型“知道”调整其参数多少,以便更接近预期输出 y 。这是使用反向传播算法实现的。
反向传播和计算梯度
根据 1989 年的论文,反向传播:
重复地调整网络中连接的权重,以便最小化网络的实际输出向量和期望输出向量之间的差的度量。
和
创建有用的新功能的能力将反向传播与早期更简单的方法区分开来…
换句话说,反向传播旨在通过调整网络的权重和偏差来最小化成本函数。调整水平由成本函数相对于这些参数的梯度决定。
可能会出现一个问题——为什么要计算梯度?
要回答这个问题,我们首先需要重温一些微积分术语:
- 函数 C(x1,x2,…,x_m)在 x 点的梯度是 C 在 x 点的 偏导数 的向量

Equation for derivative of C in x
- 函数 C 的导数测量函数值(输出值)相对于其自变量 x(输入值)变化的敏感度 。换句话说,导数告诉我们 C 的方向。
- 梯度显示了参数 x 需要改变多少(正向或负向)以最小化 c。
使用一种叫做链式法则的技术来计算这些梯度。
*对于单个重量 *(w_jk)^l,的梯度为:

Equations for derivative of C in a single weight (w_jk)^l
类似的方程组可以应用于 (b_j)^l ):

Equations for derivative of C in a single bias (b_j)^l
两个方程中的公共部分通常被称为“局部梯度”,并表示如下:

Equation for local gradient
使用链式法则可以很容易地确定“局部梯度”。我现在不会重复这个过程,但是如果你有任何问题,请在下面评论。
梯度允许我们优化模型的参数:

Algorithm for optimizing weights and biases (also called “Gradient descent”)
- 随机选择 w 和 b 的初始值。
- ε(e)是学习率。它决定了渐变的影响。
- w 和 b 是权重和偏差的矩阵表示。 w 或 b 中的 C 的导数可以使用各个权重或偏差中的 C 的偏导数来计算。
- 一旦成本函数最小化,就满足终止条件。
我想把这一节的最后部分献给一个简单的例子,在这个例子中,我们将计算 C 相对于单个重量 (w_22) 的梯度。
让我们放大上面神经网络的底部:

Visual representation of backpropagation in a neural network
权重 (w_22) 连接(a _ 2)(z _ 2),因此计算梯度需要通过(z _ 2)(a _ 2)应用链式法则

Equation for derivative of C in (w_22)²
计算 (a_2) 中 C 的导数的最终值需要了解函数 C 。由于 C 依赖于 (a_2) ,计算导数应该相当简单。
我希望这个例子能够揭示计算梯度背后的数学原理。为了进一步提高你的技能,我强烈推荐观看斯坦福大学的 NLP 系列,其中理查德·索彻对反向传播给出了 4 个很好的解释。
结束语
在这篇文章中,我详细解释了反向传播是如何使用计算梯度、链式法则等数学技术进行工作的。了解这种算法的具体细节将巩固你的神经网络知识,并让你对更复杂的模型感到舒适。享受你的深度学习之旅!
谢谢你的阅读。希望你喜欢这篇文章🤩我祝你今天过得愉快!
理解量子计算中测量的基础

Measuring a Quantum bit
如果你对量子计算理论有更深入的了解,你可能会遇到这个叫做*测量的术语。*在顶层,测量本质上就是上图所描绘的:对一个量子位的某种操作(基向量|0 >和|1 >的某种叠加状态)以获得一个经典位(其过程是完全随机的)。
开始之前。如果你在理解量子位、叠加、基本向量等术语时遇到困难,我会建议你阅读这篇文章作为介绍、 bra 和 ket 符号以及这篇线性代数评论(并且不要省略特征向量和特征空间、正交性)。另外,参考其他关于(复)向量空间、内积、线性组合和相关概念的资料。
好吧,前提条件完成了。言归正传!
为什么是这篇文章?
当我开始学习量子测量的时候,事情并不是很顺利。数学没有那么难,但是基本的直觉为什么以他们的方式做事情却不见了,至少在我的消息来源里。当我最终将不同的部分组合在一起时,我认为这将有助于开辟一种不同的方法来理解量子测量(一种自上而下的方法— ,这意味着将数学保留到最后,同时首先理解更广泛的含义)并首先理解为什么我们需要区分我将在这里讨论的两种测量—一般和投影和 POVM。
等等!我没说的两种的和的三围和命名。别担心。把我的陈述解释成一种带有一定程度不确定性的量子陈述。通过这种方式,你会提出问题并更好地理解(整篇文章都是如此)。
我将从量子力学的前提假设开始:
假设 1
简单来说,如果你有一个孤立的量子系统,有一个内积定义的复向量空间附着在那个系统上,叫做态空间。
直观地,这样的空间被描述为将欧几里得(或主要是 2 维空间)微积分和线性代数的概念结合到多维空间。这允许像测量长度和角度的几个操作。
假设 2
给定一个封闭的量子系统,系统的演化用一个幺正变换来描述。

Unitary transformation of a quantum state
在上面的等式中,U 是一个酉矩阵(或者一个与其伴随矩阵的乘积产生单位矩阵的矩阵)。更一般地,对于连续时间,这种幺正变换可以写成:

You just got introduced to the Schrodinger’s equation!
这也是一个酉变换,尽管它需要一点理解。这里, H 称为哈密顿算符,是厄米算符。简单来说,厄米特的伴随就是算子本身,即 adj(H) = H. 求解上面关于时间的微分方程,得出下面的方程:

exp 部分中的术语需要更多解释。这里,H 是厄米算符。一个厄米算符乘以一个标量(本质上是时间和 Dirac-h 的差的比值)保持了厄米性质。无需深入数学,任何形式为 exp(-i.K) 的东西都会产生酉算子,其中 K 是厄米算子。
回到测量
我将避免在这里直接发起关于度量的正式讨论。我更愿意讨论一个更大的图片,并希望它能使普通和投影测量之间的区别更加清晰。
到目前为止,我们意识到了一件重要的事情:
这些假设适用于封闭、隔离的系统。
简单地说,这在现实世界中很难发生。这意味着你关于单一进化的正式观点(公设 2)不是很正确。你的哈密尔顿函数没有给你一个清晰的酉算符,可以完美地描述被观察系统的力学。两个非常简单的例子可以说明这一点:
- 在大多数情况下,测量会破坏量子态。
- 能量进入和离开系统。
如果你有一些 QM 的正式背景,你可能知道 1 本质上是正确的。一个系统保持在叠加状态,除非它被测量。举例?考虑一下这篇文章的顶部图片。

我们有一个由|0 >和|1 >的某种线性组合形成的量子位(叠加量子态)。测量后,它成为一个经典位(0 或 1)。
现在是时候介绍一下常规、POVM 和投影测量了。现在把这些测量系统看作是一种黑箱,所以我们可以着眼于更大的图景而不会被细节所困扰。
长话短说,系统是封闭的,并且由一个哈密顿量通过酉时间演化来描述,可以通过投影测量来测量。很明显,系统在现实中不是封闭的,因此使用投影测量是不可测量的。为了测量这样的系统,我们有两个选择:
- 将较小的开放系统视为较大系统的子部分,该系统关闭。在这种情况下,更大系统的演化可以用酉演化来描述,我们可以用射影测量到把东西测量出来。这将需要将关于完整的较大系统(姑且称之为环境)的完整细节添加到被观察的较小开放系统的哈密顿量中。但是这里有一个固有的缺陷。你知道 关于环境的一切 为了让它成为一个完全封闭的系统吗?这个很难确定。这个问题把我们引向第二种选择。
- 让系统打开,并从已知的投影测量中开发一些其他测量技术。
原来 POVM ( 正算子值度量)是对投影度量的限制,因此它包含除了环境之外的一切。简而言之,如果你采取了 POVM,你就不需要再关心环境了。或者换句话说,
我们可以从 POVMs 中得到投影测量,如果我们将环境因素考虑在内,使其成为酉时演化,即投影= POVMs +环境
这不正是我们要找的吗?一种不用关心环境就能测量系统的方法。而 POVM 就是答案。还有另外一个微妙的区别——尽管 POVMs 和一般测量在数学上看起来是一样的(事实上, POVMs 是通过将一个变量代入一般测量方程中获得的),但两者之间有一个重要的区别。然而,为了说明这一点,我需要引入关于这些测量的数学方程。
一般测量值
在量子测量场景中,测量算符本质上是一个矩阵(而不是一个精心选择的矩阵),它以数学方式操纵系统的初始状态。

Probability of the measurement to be m
上式给出了测量值与输出值的概率 m. 如果您熟悉 bra 和 ket 符号,最左边的符号表示原始系统状态的转置、复共轭行向量(原始系统状态是最右边的列向量)。中间是左边算符 M 乘以原算符 M 的伴随。

Post-measurement state
这个等式简单地是操作符对当前状态的应用,除以状态发生的概率。务必理解这一重要等式,因为这将被证明是常规和 POVM 测量之间的本质区别。
描述我们选择的操作符的性质的几个其他等式(基本上是对所有可能输出的求和,如果我们取伴随矩阵和原始矩阵的乘积,我们最终得到单位矩阵)。第二个方程是概率的基本假设,所有概率的总和本质上是一。

The ‘completeness equation’

我会休息一下,展示一个这些方程的例子。在这里更好地表示方程有点困难,因此我将把它写在纸上,并在这里贴一个屏幕。我已经展示了量子位前三个方程的必要计算。

需要注意的是这两个红色的简单计算语句。
- 每个操作员都是隐士
- 算符的平方就是算符本身。

An important result!!!
投影测量
记住这些是对经历酉进化的封闭系统的测量,,因此利用了最基本的直觉之一- 特征值和特征向量。
简单来说,特征向量的作用是将算子的操作分解成几个独立的向量方向。因此,现在可以在不同的方向上独立地和单独地观察操作者的动作。此外,算子在这些方向上的动作仅仅涉及特征向量的拉伸、压缩、翻转(或数学上的标量乘法)。
可能需要一段时间才能理解,但这是一个可以充分利用的非常强大的属性。

上面的等式是可观测 M 的谱分解,它只是将 M 分解成几个投影到 M 的本征空间,乘以 M 的本征值别担心,我会演示如何做。
其余所有来自一般测量值的方程得到相当简化:

Probability of the measurement yielding output as the eigenvalue m

The post-measurement state calculation equation
任何满足一般度量、要求的算子,如果遵循一个附加限制,就成为射影度量算子。**

Additional restriction for being projective!
不难将这些点联系起来,这里要注意的是,这个附加限制仅在封闭系统中得到满足,或者更具体地说,在这些系统中,测量是非破坏性测量,,即它们在测量时不会使量子态崩溃。为什么这样让我给出数学解:

可以看出,重复使用投影不会改变输出。一次又一次得到相同测量值的概率是 1。因此,投影不是我们在现实世界中可以使用的东西。
现在让我用一个例子演示一下投影计算的所有数学方面:

Note: The bottommost calculation wrongly computes using [0 1] instead of the previously assumed [1 0]. Thanks to Brian Droncheff for pointing this out in the comments.
上面的例子显示了一旦一个运算符 Z 被分解成一组向量,它的应用变得多么简单。这也展示了特征向量是如何相互独立地被分析和处理的,从而使事情变得简单得多。
POVM 测量
数学上,POVMs 由给定的一般测量概率分布:形成

Probability distribution of a general measurement
只需进行以下替换:

得到下面的等式:

Probability distribution

Completeness relation
我们结束了吗?好吧。号码
乍一看似乎很容易,但这里隐藏着一些东西。幸运的是,你已经知道我要求你记住的关于一般测量*和 POVMs 之间区别的关系。*

The post measurement state
现在,如果你从最初的运算符 M 开始,你就可以开始了。但是如果从关于 E 的初始知识开始呢?在这种情况下,将 E 分解成另一个矩阵 M 及其伴随矩阵是完全不可能的。因此,我们失去了 M,并因此失去了测量测量后状态的能力。在我们不需要知道任何关于测量后状态的情况下,POVMs 是惊人的。此外,这也是大多数标准文本倾向于仅从通用测量关系开发 POVMs 的原因。
另一个要联系的点是投影= POVM +环境,或者 POVM 是对不考虑环境的投影的限制。为此,请看下面的等式:

POVMs = projections. The extreme right P(m) comes from the middle expression utilising the fact that the operator P is Hermitian and square of the operator is the operator itself (statements in red ink in my handwritten example above in general measurements)
当且仅当:

The additional restriction for projections
这意味着关于POVM+environment = Projections的讨论仅仅意味着让操作者遵守上面描述的附加限制。此外,这也意味着同样的等式导致投影依赖于系统的单一时间演化和隔离,或者换句话说,给予系统对其环境足够的响应性。
结论
我希望这篇文章能帮助你抓住这些测量背后的基本直觉,以及它们在更大范围内是如何相互关联的。了解这些基础知识是理解量子力学公设 3 的关键。
祝你今天开心!玩的开心!
理解贝叶斯定理

Photo by Antoine Dautry on Unsplash
理解著名定理背后的基本原理
这是统计和概率世界中最著名的方程式之一。即使你不从事定量领域的工作,你也可能不得不在某个时候为了考试而记忆它。
P(A|B) = P(B|A) * P(A)/P(B)
但这意味着什么,为什么会起作用?在今天的帖子中找出我们深入探索贝叶斯定理的地方。
更新我们信念的框架
不管怎样,概率(和统计学)的意义是什么?**它最重要的应用之一是不确定情况下的决策。**当你决定采取一项行动时(假设你是一个理性的人),你在打赌完成这项行动会让你比没做时过得更好。但是赌注本身是不确定的,所以你如何决定是否继续?
含蓄地或明确地,你估计成功的概率——如果概率高于某个阈值,你就勇往直前。
因此,能够准确估计这一成功概率对于做出好的决策至关重要。虽然机会总是在结果中发挥作用,但如果你能持续地积累对你有利的机会,那么随着时间的推移,你会做得很好。
这就是贝叶斯定理的用武之地——它为我们提供了一个量化框架,当我们周围的事实发生变化时,我们可以更新我们的信念,这反过来允许我们随着时间的推移改进我们的决策。
让我们试试这个公式
让我们再看一下公式:
P(A|B) = P(B|A) * P(A)/P(B)
- P(A|B) —是给定 B 已经发生的概率。
- P(B|A) —是给定 A 已经发生的情况下,B 的概率。它现在看起来是循环的和任意的,但是我们很快就会明白为什么它会起作用。
- P(A)—A 发生的无条件概率。
- P(B) —是 B 发生的无条件概率。
P(A|B)是条件概率的一个例子——只测量世界上某些状态(B 出现的状态)的概率。P(A)是一个无条件概率的例子,在世界上所有的州都可以测量。
让我们通过一个例子来看看贝叶斯定理。假设你是一名刚刚毕业的数据科学训练营的学生。你还没有收到一些你面试过的公司的回复,你开始紧张了。因此,你决定计算一家特定公司向你发出要约的概率,因为已经过去 3 天了,他们仍然没有给你打电话。
让我们根据我们的例子重写公式。在这里,结果 A 是“收到一个提议”(编辑:这篇文章的早期版本错误地将 A 标识为“没有提议”——现在已经被更正为“收到一个提议”),结果 B 是“3 天没有电话”。所以我们可以把公式写成:
P(Offer | NoCall)= P(NoCall | Offer)* P(Offer)/P(NoCall)
P(Offer|NoCall)的值,即 3 天没有电话的情况下收到 Offer 的概率,很难估计。
但是反过来,P(NoCall|Offer),或者说如果你收到了公司的邀请,3 天内没有电话的可能性,更像是我们可以合理确定价值的东西。从与朋友、招聘人员和工作顾问的交谈中,你了解到,如果一家公司打算给你一份工作,它不太可能保持沉默长达 3 天,但这并不罕见。所以你估计:
p(无呼叫|报价)= 40%
40%还不错,好像还有希望!但是我们还没完。现在我们需要估计 P(Offer),即在一段时间内获得工作机会的概率。每个人都知道找工作是一个漫长而艰难的过程,在得到那份工作之前,你可能至少需要面试几次,所以你估计:
p(报价)= 20%
现在我们只需要估算 P(NoCall),3 天没有接到公司回电的概率。一家公司可能三天不给你打电话有很多原因——他们可能决定放弃你,或者他们可能还在面试其他候选人,或者招聘经理可能感冒了。哇,他们可能没有打电话的原因有很多,所以你估计的最后一个可能性是:
P(NoCall) = 90%
现在把它们全部插入,我们可以计算 P(Offer|NoCall):
p(Offer | NoCall)= 40% * 20%/90% = 8.9%
这相当低——所以不幸的是,我们不应该抱太大希望(我们绝对应该继续投简历)。如果这看起来有点武断,不要担心。当我第一次学习贝叶斯定理时,我也有同样的感觉。现在让我们来解释一下我们是如何以及为什么会达到 8.9%(记住你最初估计的 20%已经很低了)。
公式背后的直觉
还记得我们说过贝叶斯定理是更新我们信念的框架吗?那么我们的信仰从何而来?他们通过先验的 P(A)进来,在我们的例子中是 P(Offer)——这是我们关于有多大可能收到要约的先验信念。在我们的例子中,你可以认为先验是我们对你在走出面试室的那一刻收到工作机会的可能性的信念。
现在,新的信息来了——3 天过去了,公司还没有给你打电话。所以我们用等式的其他部分来调整我们对已经发生的新事件的先验。
让我们检查 P(B|A),在我们的例子中是 P(NoCall|Offer)。当你第一次学习贝叶斯定理时,很自然会想知道 P(B|A)项的意义是什么。如果我不知道 P(A|B ),那么我怎么能神奇地知道 P(B|A)是什么呢?这让我想起了查理·孟格曾经说过的话:
“反转,一直反转!”—查理·孟格
他的意思是,当试图解决一个具有挑战性的问题时,更容易把问题反过来看——这正是贝叶斯定理正在做的。让我们用统计术语重新定义贝叶斯定理,使它更容易解释(我首先在这里读到这个):

Bayes’ Theorem reframed so that it is more intuitive
对我来说,这是一种更直观的思考公式的方式。我们有一个假设(我们得到了这份工作),一个先验,并观察到一些证据(3 天没有电话)。现在我们想知道在给定证据的情况下,我们的假设为真的概率。正如我们上面讨论的,我们已经有了 20%的优先权。
反转时间到了!**我们用 P(证据|假设)来反过来问这个问题:“在我们的假设为真的世界里,观察到这个证据的概率是多少?”因此,在我们的例子中,我们想知道在一个公司已经明确决定向你发出邀请的世界里,3 天没有电话的可能性有多大。**在上面公式的注释图中,我称 P(证据|假设)为缩放器,因为这正是它的作用。当我们将它与先验相乘时,定标器会根据证据是有助于还是有损于我们的假设来放大或缩小先验——在我们的例子中,定标器会缩小先验,因为没有电话的日子越来越多,这将是一个越来越糟糕的迹象。3 天的无线电沉默已经不好了(它减少了我们 60%的先验),但 20 天的沉默会彻底摧毁我们得到这份工作的任何希望。因此,我们积累的证据越多(没有打电话的天数越多),缩放器就越能减少我们的先验。定标器是贝叶斯定理用来调整我们先验信念的机制。
编辑:在这篇文章的最初版本中,我有些纠结的一件事是阐明为什么 P(证据|假设)比 P(假设|证据)更容易估计。这是因为 p(证据|假设)是一种更受约束的思考世界的方式——通过缩小范围,我们简化了我们的问题。一个简单的方法是用流行的火和烟的例子,火是我们的假设,观察烟是证据。p(火|烟)更难估计,因为很多东西都可能引起烟——汽车尾气、工厂、有人在炭火上烤汉堡。 P(烟|火)更容易估计——在一个有火的世界里,几乎肯定会有烟。

The value of the scaler decreases as more days pass with no call — the lower the scaler, the more it reduces the prior as they are multiplied together
**我们公式的最后一部分,P(B),又名 P(证据)是规格化器。顾名思义,它的目的是归一化先验和定标器的乘积。**如果我们不除以规格化器,我们将得到以下等式:

注意,prior 和 scaler 的乘积等于一个联合概率。因为其中一个术语是 P(证据),联合概率会受到证据稀有性的影响。
**这是有问题的,因为联合概率是一个考虑了世界上所有状态的值。但是我们不关心所有的州——我们只关心证据出现的州。**换句话说,我们生活在一个证据已经发生的世界,我们证据的丰富或稀缺不再相关(所以我们根本不希望它影响我们的计算)。将 prior 和 scaler 的乘积除以 P(Evidence)使其从联合概率变为条件概率——条件概率是只考虑证据发生的世界状态的概率,这正是我们所希望的。
**编辑:考虑为什么我们用规格化器除定标器的另一种方式是,它们回答了两个不同的重要问题——它们的比值以一种有用的方式组合了信息。**让我们用我关于朴素贝叶斯的新帖中的一个例子。比方说,我们试图根据单一特征敏捷性来判断被观察的动物是否是猫。我们只知道这种动物很敏捷。
- 标度告诉我们猫敏捷的比例——这应该很高,比如说 0.90。
- 标准化器告诉我们总体上有多少比例的动物是敏捷的——这应该是中等的,比如 0.50。
- 比率 0.90/0.50 = 1.8 告诉我们扩大我们的先验——它说无论你以前相信什么,现在是时候修改它了,因为看起来你可能在和一只猫打交道。之所以这么说,是因为我们观察到一些证据表明这种动物很敏捷。然后我们发现猫的敏捷比例大于所有动物的敏捷比例。鉴于我们目前只知道这一条证据,其他一无所知,合理的做法是修正我们的信念,即我们正在与一只猫打交道。
把所有的放在一起
现在我们知道了如何考虑公式的各个部分,让我们最后一次从头到尾回顾一下我们的例子:
- 面试结束后,我们从先前开始——有 20%的机会你会得到你刚刚面试的工作。
- 随着时间的推移,我们使用缩放器来缩小我们的先验。例如,三天过去了,我们估计在你得到这份工作的世界里,只有 40%的机会公司会等这么久才给你打电话。将 scaler 和 prior 相乘,我们得到 20% * 40% = 8%。
- 最后,我们认识到 8%是对世界上所有国家进行计算的。但是我们只关心你面试后 3 天没有接到公司电话的情况。为了只捕捉这些状态,我们估计 3 天没有接到电话的无条件概率为 90% —这是我们的标准。我们将之前计算的 8%除以规格化器,8% / 90% = 8.9%,得到最终答案。因此,在世界上那些你已经三天没有收到公司回复的州,你有 8.9%的几率会收到一份工作邀请。
希望这是有帮助的,干杯!
更多数据科学与分析相关帖子由我:
理解伯努利分布和二项式分布

每当你处理随机变量时,识别与它们相关的概率函数是很重要的。后者是一个函数,它给随机变量 X 的每个可能结果分配一个 0 到 1 之间的数。这个数字是与结果相关的概率,它描述了结果发生的可能性。
在离散随机变量中(也就是说,随机变量的支持是可计数的值),可能最重要的概率分布是伯努利分布和二项式分布。
在这篇文章中,我将通过证据和例子来解释每个分布背后的思想,它们的相关值(期望值和方差)。
二项分布
伯努利分布是随机变量的离散概率分布,采用二进制布尔输出:1 表示概率 p,0 表示概率(1-p)。这个想法是,每当你在进行一个可能导致成功或失败的实验时,你可以将你的成功(标为 1)与概率 p 联系起来,而你的不成功(标为 0)将具有概率(1-p)。
与伯努利变量相关的概率函数如下:

成功概率 p 是伯努利分布的参数,如果离散随机变量 X 遵循该分布,我们写为:

想象一下,你的实验由抛硬币组成,如果输出是尾巴,你就赢了。再者,既然硬币是公平的,你就知道有尾巴的概率是 p=1/2。因此,一旦设置 tail=1,head=0,就可以按如下方式计算成功的概率:

再一次,假设你要掷骰子,你把钱押在数字 1 上:因此,数字 1 将是你的成功(标为 1),而任何其他数字都将是失败的(标为 0)。成功的概率是 1/6。如果你想计算失败的概率,你会这样做:

最后,让我们计算期望值(EV)和方差。已知离散随机变量的 EV 和 V 由下式给出:

接下来,对于伯努利随机变量 X :


现在,伯努利分布背后的想法是,实验只重复一次。但是如果我们运行不止一个试验,假设试验是相互独立的,会发生什么呢?
二项分布
这个问题的答案是二项分布。这个分布描述了 n 个随机实验的输出行为,每个实验都有一个概率为 p 的伯努利分布。
让我们回忆一下之前抛公平硬币的例子。我们说过我们的实验包括抛一次硬币。现在让我们稍微修改一下,假设我们将掷硬币 5 次。在这些试验中,我们会有一些成功(尾部,标为 1)和一些失败(头部,标为 0)。每次试验都有 1/2 的成功概率和 1/2 的失败概率。我们可能有兴趣知道获得给定数量的成功的概率是多少。我们将如何进行?
让我们想象一下这个实验:

所以我们掷了 5 次硬币,前 3 次我们输了,后 2 次我们赢了。既然我们说成功=尾部=1,失败=头部=0,我们可以重新架构如下:

现在,每个试验都是一个伯努利随机变量,因此如果它等于 1,它的发生概率就是 p,否则就是 0。因此,如果我们想计算发生上述情况(3 次失败和 2 次成功)的概率事前,我们会得到这样的结果:

由于试验是相互独立的:

概括这一推理,如果我们已经进行了 n 次试验并取得了 x 次成功:

现在需要引入一个进一步的概念。实际上,到目前为止,我们已经计算了按照上面显示的顺序成功两次的概率。然而,由于我们对给定数量的成功感兴趣,而不考虑它们给我们的顺序,我们需要考虑所有可能的 x 次成功的组合。
也就是说,假设我们掷硬币三次,我们想计算三次试验中有一次出现尾巴的概率。因此,我们将在以下情况中胜出:

如你所见,有三种不同的结果组合会导致成功。我们如何将这一概念纳入我们的概率函数?答案是二项式系数,由下式给出:

其中 n 是试验的次数,而 x 是我们想要知道发生概率的成功次数。
因此,当我们运行 n 个独立实验时,每个实验都有一个参数为 *p、*的伯努利分布,我们想知道有 x 个成功的概率,概率函数将是:

这样一个随机变量是这样表达的:

现在让我们计算 EV 和 v,首先回想一下,对于二项式定理:

因此:


注意,如果二项式分布的 n=1(只进行试验),那么它就变成了一个简单的伯努利分布。此外,二项式分布也很重要,因为如果 n 趋于无穷大,并且 p 和(1-p)都不是无限小的,那么它很接近高斯分布。因此,后者是二项分布的一种极限形式。
您可以很容易地将其形象化,如下所示:

正如你所看到的,试验次数 n 越高,我们的二项随机变量的形状就越能回忆起众所周知的高斯分布的钟形曲线。
如果你对伯努利分布和二项式分布的所谓“对应物”感兴趣,它们是几何和逆二项式分布,请查看我的下一篇文章这里!
理解 BERT:它是 NLP 中的游戏改变者吗?

自然语言处理领域最具突破性的发展之一是由伯特的发布(被认为是自然语言处理的 ImageNet 时刻),这是一个革命性的自然语言处理模型,与传统的自然语言处理模型相比是最棒的。它还启发了许多最近的 NLP 架构、训练方法和语言模型,如 Google 的 TransformerXL、OpenAI 的 GPT-2、ERNIE2.0、XLNet、RoBERTa 等。
让我们深入了解 BERT 及其转变 NLP 的潜力。
伯特是什么?
**BERT(来自变压器的双向编码器表示)**是谷歌的研究人员在 2018 年开发的开源 NLP 预训练模型。作为 GPT(广义语言模型)的直接后裔,BERT 在 NLP 中的表现超过了几个模型,并在问答(SQuAD v1.1)、自然语言推理(MNLI)和其他框架中提供了顶级结果。
它建立在预训练上下文表示的基础上,包括半监督序列学习(由 Andrew Dai 和 Quoc Le 完成)、 ELMo(由 Matthew Peters 和来自和 CSE 的研究人员完成)、 ULMFiT(由 fast.ai 创始人和 Sebastian Ruder 完成)、OpenAI Transformer(由 open ai 研究人员、Narasimhan、Salimans 和 Sutskever 完成)以及 Transformer ( Vaswani
它与其他模型的独特之处在于,它是第一个深度双向、无监督的语言表示,仅使用纯文本语料库进行预训练。由于它是开源的,任何具有机器学习知识的人都可以很容易地建立 NLP 模型,而不需要为训练模型寻找大量数据集,从而节省时间、精力、知识和资源。
最后,BERT 在一个大型未标记文本语料库上接受预训练,其中包括整个维基百科(大约 25 亿字)和一本书语料库(8 亿字)。
它是如何工作的?
传统的上下文无关模型(如 word2vec 或 GloVe)为词汇表中的每个单词生成单个单词嵌入表示,这意味着单词**“右”**在“我确定我是对的”和“向右转”中将具有相同的上下文无关表示。“然而,BERT 将基于上一个和下一个上下文进行表示,使其成为双向的。虽然双向的概念已经存在很长时间了,但 BERT 是第一个在深度神经网络中成功预训练双向的。
他们是如何做到这一点的?

Source: BERT [Devlin et al., 2018]
他们使用两种策略——屏蔽语言模型(MLM)——通过屏蔽掉输入中的一些单词,然后双向调节每个单词来预测被屏蔽的单词。在将单词序列输入 BERT 之前,每个序列中 15%的单词被替换为一个[MASK]标记。然后,该模型尝试根据序列中其他未屏蔽单词提供的上下文来预测屏蔽单词的原始值。

第二种技术是下一个句子预测(NSP) ,在这里 BERT 学习对句子之间的关系进行建模。在训练过程中,模型接收句子对作为输入,并学习预测句子对中的第二个句子是否是原始文档中的后续句子。让我们考虑两个句子 A 和 B,B 是语料库中 A 后面的实际下一个句子,还是只是一个随机的句子?例如:

当训练 BERT 模型时,两种技术被一起训练,从而最小化两种策略的组合损失函数。
架构

BERT is deeply bidirectional, OpenAI GPT is unidirectional, and ELMo is shallowly bidirectional. Image Source: Google AI Blog
BERT 架构建立在 Transformer 之上。有两种变型可供选择:
伯特基础:12 层(变压器块),12 个注意头,和 1.1 亿个参数
BERT Large: 24 层(变压器块),16 个注意头,3.4 亿个参数
结果

在 SQuAD v1.1 上,BERT 获得了 93.2%的 F1 分数(一种准确性衡量标准),超过了之前 91.6%的最高分数和 91.2%的人类水平分数:在极具挑战性的 GLUE benchmark(一组 9 个不同的自然语言理解(NLU)任务)上,BERT 还将最高分数提高了 7.6%。
伯特来了——但他准备好面对现实世界了吗?
BERT 无疑是机器学习用于自然语言处理的一个里程碑。但是我们需要反思如何在各种 NLP 场景中使用 BERT。
文本分类是自然语言处理的主要应用之一。例如,该概念已在票证工具中使用,以根据简短描述/电子邮件对票证进行分类,并将票证分类/发送给正确的团队进行解决。同样,它也可以用于分类电子邮件是否是垃圾邮件。
你可以在日常生活中找到它的一些应用。

Gmail’s Suggested Replies, Smart Compose & Google Search Autocomplete
聊天机器人凭借其回答用户查询和处理各种任务的能力,正在颠覆信息产业。然而,最大的限制之一是意图识别和从句子中捕获实体。
问答模型是自然语言处理的基本系统之一。在 QnA 中,基于机器学习的系统从知识库或文本段落中为作为输入提出的问题生成答案。BERT 可以用在聊天机器人中吗?当然可以。BERT 现在被用在许多对话式人工智能应用中。所以,你的聊天机器人应该变得更聪明。
然而,BERT 只能用于回答非常短的段落中的问题,并且需要解决许多关键问题。作为一项常规任务,NLP 太复杂了,有更多的含义和微妙之处。BERT 只解决了一部分问题,但肯定会很快改变实体识别模型。
今天的伯特只能解决有限的一类问题。然而,还有许多其他任务,如情感检测,分类,机器翻译,命名实体识别,摘要和问题回答需要建立。现在一个常见的批评是,这种任务是基于对表示的操纵,没有任何理解,添加简单的对抗性内容来修改原始内容会使其混淆。
只有在运营中得到更广泛的采用,现场场景得到改善,从而支持跨组织和用户的广泛应用时,才能实现 BERT 在 NLP 中的真正优势。
然而,随着一波基于变压器的方法(GPT-2,罗伯塔,XLNet)的出现,事情正在迅速变化,这些方法通过展示更好的性能或更容易的训练或其他一些特定的好处来不断提高标准。
让我们看看在伯特的介绍之后出现的其他一些发展
罗伯塔
RoBERTa 由脸书开发,基于 BERT 的语言掩蔽策略,并修改了 BERT 中的一些关键超参数。为了改进训练过程,RoBERTa 从 BERT 的预训练中移除了下一句预测(NSP)任务,并引入了动态屏蔽,使得屏蔽的令牌在训练时期期间改变。它还在比 BERT 多一个数量级的数据上接受了更长时间的训练。
蒸馏酒
由 HuggingFace 开发的 DistilBERT 学习了 BERT 的一个蒸馏(近似)版本,在 GLUE 上保留了 95%的性能,但只使用了一半数量的参数(只有 6600 万个参数,而不是 1.1 亿个)。这个概念是,一旦一个大的神经网络被训练,它的全部输出分布可以用一个较小的网络来近似(像后验近似)。
XLM/姆伯特
由脸书开发的 XLM 使用已知的预处理技术(BPE)和双语言训练机制与 BERT 一起学习不同语言中单词之间的关系。在多语言分类任务中,该模型优于其他模型,并且当预训练的模型用于翻译模型的初始化时,显著提高了机器翻译。
艾伯特
由谷歌研究院和丰田技术研究所联合开发的 **ALBERT(一个用于自我监督语言表示学习的 Lite BERT)**将成为 BERT 的继任者,它比 BERT 小得多,轻得多,也更智能。两个关键的架构变化使得 ALBERT 不仅表现出色,而且显著减小了模型的大小。第一个是参数的数量。它通过跨所有层共享所有参数来提高参数效率。这意味着前馈网络参数和注意力参数都是共享的。
研究人员还从词汇嵌入的大小中分离出隐藏层的大小。这是通过将一个热点向量投影到低维嵌入空间,然后投影到隐藏空间来实现的,这使得在不显著增加词汇嵌入的参数大小的情况下增加隐藏层大小变得更加容易。
谈到预训练,艾伯特有自己的训练方法,叫做句序预测(SOP) ,与 NSP 相反。作者提出的 NSP 理论的问题是,它将主题预测与连贯性预测混为一谈。
ALBERT 代表了 NLP 在几个基准上的新水平,以及参数效率的新水平。这是一个惊人的突破,它建立在 BERT 一年前所做的伟大工作的基础上,并在多个方面推进了 NLP。
伯特和像它这样的模型肯定是 NLP 的游戏规则改变者。机器现在可以更好地理解语音,并实时做出智能响应。许多基于 BERT 的模型正在开发中,包括 VideoBERT、ViLBERT(视觉和语言 BERT)、PatentBERT、DocBERT 等。
你对 NLP 和 BERT 的状态有什么看法?
理解偏差和方差
用一点插图和一点代码简化这些概念
任何学习数据科学 101 课程的人都会遇到这些定义机器学习模型准确性的术语偏差和方差。我发现它周围的一些材料令人困惑,所以我想我会尝试用一些插图和代码来解释。
在我开始写代码之前,基本上偏差只不过是应用于不同测试数据集时模型中的预期误差(误差的平均值)。让我用飞镖靶来类比。圆圈中的数字代表误差,直到圆圈的圆周处。

Board A
在电路板 A 中,平均误差或偏置等于(0 + 0 + 0 + 1 + 2) / 5 = 0.6

Board B
尽管电路板 B 看起来与电路板 A 不同,但它具有相同的平均误差或偏差= (0 + 0 + 1 + 1 + 1) / 5= 0.6
现在的问题是你会赌哪个飞镖手?一个使用板 A 或板 b,这就是差异的来源。
方差是应用于不同测试数据点时误差的方差。现在让我们分别用 A 板和 B 板试着把这个概念应用到两个投掷飞镖的人身上。
棋盘 A 的方差= (0 + 0 + 0 + 1 + 2 ) / 5 = 1.0
棋盘 B 的方差= (0 + 0 + 1 + 1 + 1 ) / 5 = 0.6
这表明,虽然板 A 飞镖投掷者击中靶心的次数比板 B 飞镖投掷者多 50%,但当他不正确时,他更加不稳定。另一方面,B 板飞镖手稳稳的,总是在靶心标上或靶心标周围盘旋。在机器学习模型的世界中,通常类似于棋盘 B 飞镖投掷者的模型是优选的,因为它避免了令人尴尬的错误并且更加稳定。
事实证明,类似于棋盘 B 的行为发生在过度拟合的机器学习模型中(相对于训练集过度拟合),即,即使模型的偏差较低,方差也会较高。因此,差异越大,你就越担心把它推向生产,因为一旦出了问题,它会变得非常糟糕。
在一个没有过度拟合(可能是正则化)的模型中,方差将会很低——这意味着在测试集上遇到的错误不会是荒谬的。
我已经通过将线性和三次回归应用于具有随机扰动的线性数据集说明了这一点。

Universe of data points

Points sampled for training

Cubic regression

Linear Regression
浏览下面的代码(希望是不言自明的)将帮助您看到,尽管三次和线性回归的平均误差(偏差)有些相似(类似于我们的飞镖游戏),但是三次回归的方差太高,这使它类似于 a 板上出色但不稳定的飞镖游戏。
在这种情况下,这意味着数据科学家应该选择线性回归模型来推广到生产中。
总之,作为数据科学家,重要的是不要看平均误差(偏差),还要注意方差。方差越大,意味着虽然有些情况下模型是超级准确的,但也有一些情况下模型会出现严重错误,这是您希望避免的。
在 3 分钟内了解偏差-方差权衡
机器学习照明讲座—2019 年 10 月 11 日

Balancing them is like magic
躲在付费墙后面?点击这里阅读完整的故事与我的朋友链接。
偏差和方差是在训练机器学习模型时要调整的核心参数。
当我们讨论预测模型时,预测误差可以分解成两个主要的子分量:由于偏差、造成的误差和由于方差造成的误差。
偏差-方差权衡是偏差引入的误差和方差产生的误差之间的张力**。为了理解如何最大限度地利用这种权衡,并避免我们的模型过拟合或欠拟合,让我们首先学习偏差方差。**
偏差引起的误差
由于 偏差 产生的误差是模型的预测值 和真实值 的 之间的距离。在这种类型的错误中,模型很少关注训练数据,并且 过度简化 模型,并且不学习模式。模型通过不考虑所有特征来学习错误的关系****
由于差异导致的误差
给定数据点或数值的模型预测可变性 告诉我们数据的分布 。在这种类型的错误中,模型在训练数据 中花费了 l ot 的注意力,以至于记住它而不是从中学习。方差误差较大的模型不能灵活地对以前没有见过的数据进行归纳。
如果偏见和差异是阅读的行为,那就像略读课文和记忆课文一样
我们希望我们的机器模型从它接触到的数据中学习,而不是*“知道它是关于什么的”或一个字一个字地记住它。*
偏差—方差权衡
偏差-方差权衡是关于平衡,而 是关于在偏差引起的误差和方差引起的误差之间找到最佳平衡点** 。
这是一个适配不足和适配过度的两难选择

Plot by Jake VanderPla
如果模型用灰色线表示,我们可以看到高偏差模型是一个过度简化数据的模型,而高方差模型是一个过于复杂而过度拟合数据的模型。
简而言之:
- 偏差是模型做出的简化假设,使目标函数更容易逼近。
- 方差是在给定不同训练数据的情况下,目标函数的估计将改变的量。
- 偏差-方差权衡是我们的机器模型在偏差和方差引入的误差之间执行的最佳点。
在本帖中,我们讨论了 c 偏差和方差的概念含义 。接下来,我们将探讨 代码中的概念。
未来阅读:
理解偏差-方差权衡 斯科特·福特曼-罗著
《统计学习的要素》 作者:特雷弗·哈斯蒂、罗伯特·蒂布拉尼和杰罗姆·弗里德曼
理解二进制数据
让我们说些咒语。

“You get used to it, I don’t even see the code, All I see is blond, brunette, redhead”
在这篇文章中,我解释了真实存在于我们电脑中的数据。如果你想知道 1 和 0 的序列是如何产生有意义的信息的,这篇文章就是为你准备的。
比特和字节
计算机中的所有数据都表示为一系列 1 和 0。取决于数据存储的位置—内存、固态硬盘、硬盘、DVD 等。—1 和 0 的物理编码不同,但从概念上讲,它们是两种不同的状态——这就是全部。

Hard drives and computer memory just stores ones and zeros. Photo by Patrick Lindenberg on Unsplash
一个这样的数据片段——0 或 1——被称为 位 。八位组成一个 字节 。字节作为一个单元是相关的,因为——一般来说——它们是最小的可寻址内存单元。
假设你有 40 位数据,那么 5 个字节:
01001000``01100101 01101100``01101100
您可以通过指定从起始点的偏移量来请求读取或写入其中一个字节的数据。你总是一次读或写一个完整的字节,而不是单个的位。因此,除了压缩机制之外,大多数信息都是以字节为基本单位进行编码的,而不是以比特为单位。
顺便说一句,在文章的最后你将能够回到上面的 40 位,并弄清楚它们的意思。当你到了那里,试着回来看看。你会想出办法的。我保证。
为什么一个字节是 8 位,而不是 10 位?
历史和现实的原因交织在一起。
我会试着暗示潜在的实际问题。让我们后退一步:对我们来说,乘以或除以 10 的幂是微不足道的,只需添加零或移动小数点,对吗?
3.1415 ✕ 100 = 314.15
这在我们的十进制系统中是正确的——一个基于 10 的幂的数字系统。
计算机内部做二进制运算。二进制算术以 2 的幂为基础。在二进制算术中,像 8 = 2 这样的 2 的幂同样方便。
让我们看一个二进制算术的例子:
13 ✕ 8 = 104对应00001101 ✕ 1000 = 01101000
它只是将输入向左移动三位。先不要试图理解编码。只要注意到结果是通过将数字向左移动而简单地计算出来的。
总之:如果数据单元的大小是 2 的幂,比如 8 = 2,那么计算机需要做的许多内部计算就比其他情况简单得多。
一千字节有多少字节?
好问题。没有关于千字节、兆字节、千兆字节等的官方标准。直到 1998 年。然而,这些设备在技术人员和消费者中被广泛使用。你买了一个硬盘,它的大小以千兆字节为单位。
技术人员正在计算 2 ⁰ =每千字节 1024 字节,每兆字节 1024 千字节,每千兆字节 1024 兆字节,等等。正如我们所了解的,当你使用计算机内存时,2 的幂是很实用的。
众所周知,销售硬盘的营销人员有一个巧妙的想法,即缺乏官方标准,他们可以声称“他们的”单位是基于 1000,因此“他们的”千兆字节是 1000 = 1,000,000,000 字节——而不是 1024 = 1,073,741,824,这样他们就可以在空间上少给你一笔钱。驱动力越大,差异越大。

您购买了 500GB 的硬盘,并一直想知道为什么您的计算机一直声称它只有 465.66 GB。
嗯,标准化最终于 1998 年发生。可惜的是,企业贪婪成为了官方标准,原来基于 2 ⁰=1024 的单位变成了‘bi’单位: kibibytes,mebibytes,gibibytes 等。更糟糕的是,通常的缩写形式,KB,MB,GB 等。也被吸引住了。最初的 base-2 单位现在是 KiB、MiB 和 GiB。

It’s kibibytes, not kilobytes. You’re a professional. Sound like a Teletubbie!
在学术界之外,大多数技术人员仍然认为一千字节是 1024 字节。软件世界分裂了,一些公司开始采用这个“标准”,一些没有。有些让你选择。

For me, kilobytes will also always have 1024 bytes. Byte me!
但是我跑题了。
剖析一个字节
让我们来看一个样本字节值:01101101
大声读出该值,并根据记忆重复一遍。不太容易,是吧?
当与人类交流二进制数据时,1 和 0 的效率非常低。让我们将一个字节值分成两组,每组 4 位——这些组被称为半字节——并为一个半字节可以采用的所有位模式分配一个符号。
我们可以开始使用符号来代替位模式。我们的字节值01101101变成了6D。
这被称为十六进制记法,简称 hex,因为有 16 种不同的符号。此外,由于十进制数可能会产生歧义,因此十六进制值通常会以 0x 作为前缀来消除这种歧义。所以我们在看0x6D。
这还不是一种解释,只是一种更简洁的方式来书写和表达价值。
解释二进制数据
无论 1 和 0 代表什么,都完全取决于上下文。

“那么 0x6D 的信息量是多少呢?”
“这是一种 1 和 0 的模式”
“是啊,但这意味着什么?”
“这只是 1 和 0”
“我明白了”
如果您将 0x6D 解释为一个 ASCII 字符,它将是m。如果你把它解释为一个二进制补码数,那么它就是 T1。如果你要把它解释成一个有三个小数的定点数,那就是13.625。
当给定一段二进制数据时,通常必须给出上下文才能理解它。对于文本文件来说,它是编码,目前主要是UTF-8——一种兼容 ASCII 的文本字符编码。对于其他类型的文件,比如说 PNG 文件,你必须在相应的文件格式规范中查找数据的含义。
二进制整数
一个字节(或一个字节序列)的第一种和默认解释是正整数。在解释字节值时,文档通常暗示您知道如何将字节作为整数读取。
来自 PNG 文件格式规范:
" PNG 数据流的前八个字节总是包含下列(十进制)值:
137 80 78 71 13 10 26 10"
那么…这些十进制值的位模式是什么?暂时还是坚持我们的0x6D值吧。我们会找到答案的。十六进制值0x6D就是数字109,但是我怎么知道这个呢?
我们习惯于十进制系统。但是选择10作为基数和0–9作为数字是完全任意的。
我们只是手上有 10 个手指的动物,这使得数量在计算时既熟悉又方便——比如牲畜或大米袋。数字 10 本身并不特别,只是对我们人类来说很实用。
十进制系统
当我们写下数字时,我们写下一个范围在0-9内的数字,代表我们的基数10的每个幂,从右边的 10⁰开始。我们在左边增加了 10 的额外幂的数字,只要我们需要它们来表达我们的数字。
numbers in the decimal system
八进制系统
我们可以用更小的基数8来代替使用数字0–7。它被称为八进制系统。这不是一个完全虚构的例子。其实是用过的。也许你已经在 Linux 系统上的文件权限的上下文中见过了。正如十六进制数通常以 0x 为前缀以消除歧义一样,八进制数通常以 0 为前缀。
numbers in the octal system
十六进制系统
所以我们把基数从 10 降到了 8。我们也可以上去,去说基地16。不过,我们会在数字上遇到麻烦。
我们需要0–15和过去 9 的数字,我们没有既定的惯例。让我们使用十六进制数字:A=10, B=11, C=12, D=13, E=14, F=15
numbers in the hexadecimal system
二进制
只要我们手头有商定的数字,基数的选择完全是任意的。让我们完全简化,使用基数2,数字0–1。
numbers in the binary system
整数摘要
现在你可以看到01101101、0x6D和109 are对同一个整数的不同表示法。现在看一下像这样的 ASCII 表应该就明白了,它们是用各种格式索引的。这只是一种礼貌,所以你可以在手边的任何系统中使用索引来查找这个字符。
二进制文本
打开一个文本编辑编辑器,创建一个新文件,把“Hello World”放进去,保存为一个简单的文本文件。
现在得到一个十六进制编辑器。十六进制编辑器只是一个文件编辑器,它不会为您解释文件的内容——它只是向您显示原始的二进制内容。任何基本的免费十六进制编辑器都可以。你也可以使用在线十六进制编辑器。
在十六进制编辑器中打开文本文件。它会显示文件的二进制内容。它应该看起来像这样。

binary contents of a simple text file
十六进制编辑器通常显示三列:从文件开始的偏移量(通常是十六进制)、文件的二进制内容(也是十六进制),第三列显示被解释为 ASCII 字符的文件字节。
如果您的文件内容在开头有一些额外的字节,很可能您的文本编辑器在您的文件中保存了一个 BOM 。别担心。
还记得我们之前的 40 比特吗?你现在知道了你需要弄清楚它说什么的一切。
01001000``01100101 01101100``01101100
更深入
我们已经有了基本的东西。以下每个主题都值得写一篇自己的文章。但是我们已经在空间、时间和读者的注意力上捉襟见肘了,所以我把你引向稍后阅读的资源。
我知道你还有疑问!🤓
固有整数
到目前为止,我们只讨论了正整数,一次只讨论一个字节。但是…
“编码大于 255 的整数怎么样?一个字节中没有足够的位来存储更高的值。而负数呢?”
好问题。您使用固定长度的连续字节—通常是 2 字节、4 字节和 8 字节—这扩展了 2 的幂。对有符号整数使用二进制补码编码。
大多数非玩具计算器带有正常的、科学的和程序员的观点。在研究这些东西时,打开计算器上的“程序员视角”。

A “Programmer” view of your system calculator probably supports hex and binary views
一旦你开始使用不止一个字节来表示一个值,字节序就变得很重要,尤其是从文件或网络中读取字节时,所以要记住这一点。
分数
到目前为止,我们只讨论了整数。关于:
π=3.1415926535…
有一个标准化的,硬件支持浮点小数的表示。最常用的版本是 4 字节单精度,通常称为’浮点型’,以及 8 字节版本,通常称为’双精度型’。

The interpretation of bits in a 4 byte a float
大致思路如下:
符号存储在最左边的位。0 代表正数,1 表示负数。我们的示例编号是正数。
红色阴影表示一个分数,即1加上所选的负 2 次方的和——如二分之一、四分之一、八分之一等。…在上面的示例中,我们仅在四分之一位置设置了一个位。所以分数是1.25
请注意,分数将始终介于1.0和2.0之间。
在下一步中,您将计算由绿色阴影部分给出的指数。我们的指数是124。标准要求我们将分数乘以2^(exp-127),所以在我们的例子中,我们乘以2^-3 = 1/8。
最后,我们的位模式编码的数字是:
1.25 × 1/8 = 0,15625
您可能想知道如何使用这种编码有效地将十进制数转换为浮点数。在实践中,您永远不需要手动操作,生态系统——就像您的编程语言标准库——会为您处理好。
哦,关于π,试着解释一下这个模式:
0 10000000 10010010000111111011011
你可能也想知道对小数的近似有多精确,现在我们用的是 1/2 而不是 1/10。很多人做,连做的那帮家伙都比优秀。
结论
我们的数据只是 1 和 0。它被分组和解释的方式使它有意义。在这种情况下,如果您曾经被要求处理二进制数据,您现在应该有足够的信息来正确理解它所附带的文档。
为了测试你的理解,试着看一下形状文件格式规范,看看它是否有意义。

Photo by Scott Blake on Unsplash
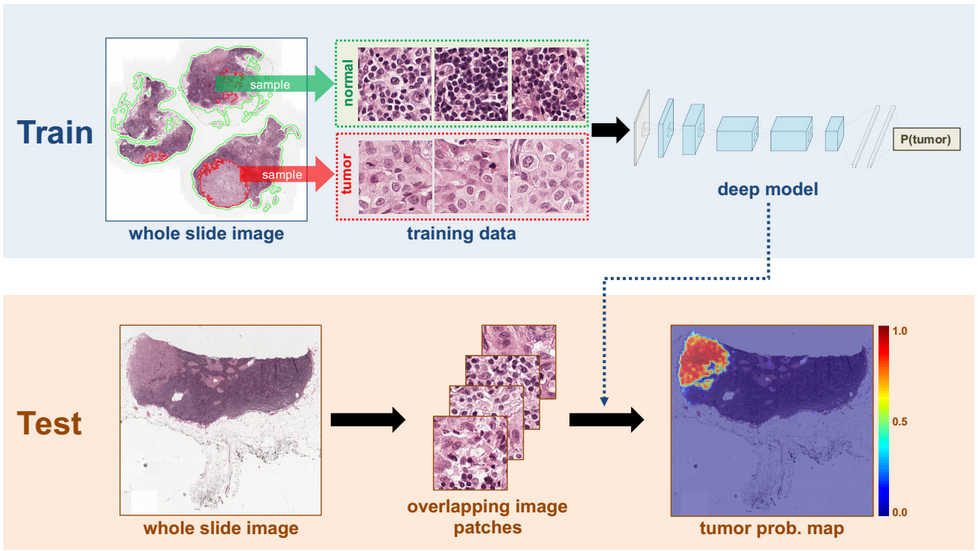
理解碧溪通勤者:用 Python 分析蒙特利尔的自行车共享系统
蒙特利尔的自行车共享系统 BIXI 于 2009 年问世。当时,这是自行车共享系统的早期尝试之一。它的模型后来被出口到世界其他城市,如纽约和伦敦。作为一名蒙特利尔人、自行车爱好者和软件工程学生,我很好奇去探索其公开可用的数据,所以我下载了【2018 年以来的 530 万次 BIXI 旅行。
通过此分析,您将了解蒙特利尔人何时何地使用碧溪自行车,气温等因素如何影响骑行量,以及骑行量在社区内和社区间如何变化。在接下来的部分中,我将更详细地介绍这些见解和代码(可在 GitHub 上获得):
- 数据
- 乘客偷看,想象全天的交通流量
- 高峰时段通勤者的空间进出流量
- 预测骑行习惯和温度之间的或关系
- 数据的聚类和图形分析
数据
BIXI 提供的两个数据集:
车站:
- 密码
- 名字
- 纬度
- 经度
旅行:
- 开始日期
- 起点站代码
- 结束日期
- 终点站代码
- 持续时间秒
- 是成员
我开始使用 2019 年 5 月的数据进行分析,以评估全天的客流量和地点(第 2 节和第 3 节)。然后使用 2018 年全年的数据将乘客量与温度相关联,并根据我需要的更多粒度形成聚类(第 4 和第 5 节)。
在清理数据时,持续时间不到 2 分钟的行程被删除,因为任何人都很难在这么短的时间内到达另一个站点。
每个月的数据发布在不同的 csv 文件中,但是可以使用 Pandas(一个用于数据操作的 python 库)轻松合并这些数据。它预装了 Anaconda。Pandas 也在整个项目中使用,因为它使操作数据成为一个用户友好的过程。代码读取并合并 2018 年与熊猫的所有数据。
import pandas as pd#read CSV file
def read_trips():
data_files = glob.glob(‘data2018/OD_2018-*.csv’)
li = []
for filename in data_files:
df = pd.read_csv(filename, index_col=None, header=0)
li.append(df)
#convert argument to datetime
data = pd.concat(li, axis=0, ignore_index=True)
data[‘start_date’] = pd.to_datetime(data[‘start_date’], format=’%Y-%m-%d’, errors=’coerce’)
data[‘end_date’] = pd.to_datetime(data[‘end_date’], format=’%Y-%m-%d’, errors=’coerce’)
#filtering out trips that were less than 2 min
data = data.drop(data[data[‘duration_sec’] < 120].index)
#adding a day number column to identify days of the week
data[‘day_number’] = pd.to_datetime(data[‘start_date’]).dt.dayofweek
data = data.drop(data[data[‘day_number’].isin([5, 6])].index)
return data
可视化全天的交通状况
首先要调查的是 BIXI 用户的个人资料。通过绘制数据可以看出,该系统在一周内的使用量比周末多。此外,通过查看一周中的使用高峰(图 1),可以假设许多用户通过使用 BIXIs** 在早上 7 点到 9 点之间上下班,在下午 4 点到 6 点之间下班。在周末(图 2),分布更加平稳,用户大多在下午骑自行车,这可能表明骑自行车的人使用 BIXIs 进行休闲。**
 ****
****
通过使用 python 库 Pandas 处理数据并使用 Matplotlib 绘制数据,很容易创建这样的可视化,如下所示。
import pandas as pd
import matplotlib.pyplot as plt#creates a bar chart with the departures per hour during the week
def visualizePerHourWeek(data, column_name, color=’#0000FF’, title=’Avreage Number of Trips Per Hour During the Week — May 2019'):
dataWeek = data.drop(data[data[‘week_day_b’] == 0].index)
plt.figure(figsize=(20, 10))
ax = ((dataWeek[column_name].groupby(dataWeek[column_name].dt.hour)
.count())/23).plot(kind=”bar”, color=color)
ax.set_xlabel('Hour')
ax.set_ylabel('Number of Trips')
ax.set_title(title)
plt.rcParams.update({‘font.size’: 22})
plt.show()
高峰时间通勤者的空间流入和流出
查看一周内每小时出行次数的条形图,通过尝试确定 BIXI 骑手在早上和晚上往返的区域来完善这一分析是很有趣的。
为此,计算了 2019 年 5 月每个车站的净流入量。出行净流入量由特定时间窗口内某个站点的进入出行量减去离开出行量确定。绿色站点有净流入量,红色站点有净流出量。圆圈的大小基于净流入或流出流量计数。
查看下图(图 3 和图 4)可以看到用户主要在一英里终点进出市区。这并不奇怪,因为这些地区有很多办公室。

Each circle is a station. Red stations have a net outflux of trips. Green stations have a net influx of trips. The size of the circle is [= (trips in — trips out)]. The analysis was performed for May 2019.
上面的可视化效果是使用 were 创建的。Folium 允许用户创建地理可视化,它可以使用 pip 安装。上面的可视化效果是使用下面的代码创建的。应当注意,传递给该功能的数据帧包含与特定时隙的每个站相关的净流入或流出流量。
import folium
def densityMap(stations):
#generate a new map
Montreal = [45.508154, -73.587450]
map = folium.Map(location = Montreal,
zoom_start = 12,
tiles = “CartoDB positron”)
#calculate stations radius
stations[‘radius’] = pd.Series( index=data.index)
stations[‘radius’] = np.abs(stations[‘net_departures’])
stations[‘radius’] = stations[‘radius’].astype(float) #set stations color
stations[‘color’] = ‘#E80018’ # red
stations.loc[stations[‘net_departures’].between(-10000,0), ‘color’] = ‘#00E85C’ # green
lat = stations[‘latitude’].values
lon = stations[‘longitude’].values
name = stations[‘name’].values
rad = stations[‘radius’].values
color = stations[‘color’].values
net_dep = stations[‘net_departures’]
#populate map
for _lat, _lon, _rad, _color, _name, _nd in zip(lat, lon, rad, color, name, net_dep):
folium.Circle(location = [_lat,_lon],
radius = _rad/5,
color = _color,
tooltip = _name + “ / net. dep:” +str(_nd),
fill = True).add_to(map)
#save map
f = ‘maps/map_density.html’
map.save(f)
骑车习惯与温度的相关性
现在已经确定骑自行车的人使用 BIXI 上下班,让我们看看其他的预测因素。蒙特利尔是一个温度变化很大的城市,夏天很容易达到 30 摄氏度,冬天则低至零下 30 摄氏度。来自碧溪的自行车在 11 月从街上拿走,然后在 4 月被带回来。值得一问的是,温度在多大程度上预测了网络的使用情况。

Each dot is the count of trips on a given day in 2018
从上面的图中可以看出,随着气温变暖,日客流量增加,预计出行次数在 0 到 20 摄氏度之间增加了两倍,从 10,000 次增加到 30,000 次**。可以认为,三次多项式回归提供了这种情况下的最佳拟合,因为人们会预计,随着温度接近冰点,日客流量将保持较低水平。当气温变暖时,日客流量会迅速增加,但当天气太热时,客流量会停滞甚至下降。从图上看,每天的旅行次数似乎在 22 摄氏度左右开始减少。这种减少也可能是因为人们在炎热的月份里度假。**
从 R 平方得分可以看出,70%的可变性是用三阶多项式回归的温度来解释的,其他要考虑的因素可能是周末与一周。我也尝试过关联离地铁站的距离,但结果并不确定。
Variance r2 score linear: 0.63
Variance r2 score poly2: 0.65
Variance r2 score poly3: 0.70
可以使用库 Sklearn 在 python 中执行回归。用于该分析的日平均温度来自加拿大政府的公开的数据集。下面是用来执行这个线性回归的代码。
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import r2_scoredef scatterPlot(dataDay):
X = dataDay[[‘Mean Temp (°C)’]].values
X_1 = dataDay[[‘Mean Temp (°C)’]].values
X_2 = dataDay[[‘Mean Temp (°C)’]].values
X_3 = dataDay[[‘Mean Temp (°C)’]].values
Y = dataDay[[‘departures_cnt’]].values
#Linear regression
linear_regressor = LinearRegression()
linear_regressor.fit(X, Y)
Y_pred_linear = linear_regressor.predict(X)
print(‘Variance score linear: %.2f’ % r2_score(Y, Y_pred_linear))
#polynmial degree 2 regression
polynomial_feat = PolynomialFeatures(degree=2)
x_poly_2 = polynomial_feat.fit_transform(X)
polynomial_regressor = LinearRegression()
polynomial_regressor.fit(x_poly_2, Y)
Y_pred_poly_2 = polynomial_regressor.predict(x_poly_2)
print(‘Variance score poly2: %.2f’ % r2_score(Y, Y_pred_poly_2))
#polynmial degree 3 regression
polynomial_feat_3 = PolynomialFeatures(degree=3)
x_poly_3 = polynomial_feat_3.fit_transform(X)
polynomial_regressor_3 = LinearRegression()
polynomial_regressor_3.fit(x_poly_3, Y)
Y_pred_poly_3 = polynomial_regressor_3.predict(x_poly_3)
print(‘Variance score poly3: %.2f’ % r2_score(Y, Y_pred_poly_3))#Ploting the data
plt.figure(figsize=(20, 10))
plt.title(‘Daily Bike Ridership With Regards to Temperature’)
plt.scatter(X_1,Y,c=’blue’,marker=’o’)
plt.xlabel(‘Mean Temperature (°C)’)
plt.ylabel(‘Number of Daily Trips’)
plt.plot(X_1, Y_pred_linear, color=’red’)
sort_axis = operator.itemgetter(0)
sorted_zip = sorted(zip(X_2,Y_pred_poly_2), key=sort_axis)
X_2, Y_pred_poly_2 = zip(*sorted_zip)
plt.plot(X_2, Y_pred_poly_2, color=’green’)
sort_axis = operator.itemgetter(0)
sorted_zip = sorted(zip(X_3,Y_pred_poly_3), key=sort_axis)
X_3, Y_pred_poly_3 = zip(*sorted_zip)
plt.plot(X_3, Y_pred_poly_3, color=’magenta’)
plt.plot(X_1, Y_pred_linear, ‘-r’, label=’degree=1')
plt.plot(X_2, Y_pred_poly_2, ‘-g’, label=’degree=2')
plt.plot(X_3, Y_pred_poly_3, ‘-m’, label=’degree=3')
plt.legend(loc=’upper left’)
plt.rcParams.update({‘font.size’: 22})
plt.show()
数据的聚类和图形分析
此分析的最后一部分是关于估计整个网络的流量。为了做到这一点,这些站点形成了光谱簇。谱聚类是一种来自图论的技术。它试图通过使用连接节点的边来识别节点组,在这种情况下是站点,在这种情况下是行程。为此,它最大限度地减少不同集群之间的出行次数,最大限度地增加集群内部的出行次数。最后,它给出了骑车人从车站骑车时所处地理区域的概念。
从下面的地图可以看出,2018 年 53%的出行发生在蓝色集群内,表明网络中的大部分交通发生在高原社区和市中心之间。此外可以看出,大多数集群由地理特征界定,这些地理特征通常是高速公路或火车轨道。例如,红色和蓝色集群之间的分裂主要发生在火车轨道上。此外,市中心区和老港口社区沿着 Ville-Marie 高速公路分为蓝色和紫色两部分。

Each dot on the map is a station and its color identifies to cluster to which it pertains. On the graph on the right the color of the nodes identifies the cluster and the vertices identify the percentage of the traffic that occurred within or between clusters in 2018. for Instance 5.02% or the traffic occurred from a red station to a blue station in 2018. Edges representing less than 0.5% of yearly traffic have been removed.
查看下图,我们可以假设,为了促进蒙特利尔的自行车运动,该市应该投资巩固自行车爱好者已经存在的网络,在这种情况下,蓝色集群,并促进与其他集群的联系。例如,城市应该确保在蓝色集群中有安全的自行车道可用,骑车人也可以高效、安全地穿过高速公路或火车轨道,这些道路会将他们与其他相邻集群隔开。
上面的图形分析是使用库 fleur 和库 Graphviz 中的 Diagraph 进行的。这两者都必须使用 pip 安装。地图的绘制与上面的相似。使用 Pandas 数据框,通过下面的代码可以快速生成 Graphviz。
def create_graphviz(data):
#create the graph
G = Digraph(format=’png’)
G.attr(rankdir=’LR’, size=’10')
G.attr(‘node’, shape=’circle’)
nodelist = [] #prepare the data
data = data.drop([‘count’], axis=1)
data[‘from’] = pd.to_numeric(data[‘from’], downcast=’integer’)
data[‘to’] = pd.to_numeric(data[‘to’], downcast=’integer’)
data[‘from’] = data[‘from’].apply(str)
data[‘to’] = data[‘to’].apply(str)
#add the nodes and edges to the graph
for idx, row in data.iterrows():
node1, node2, weight = [str(i) for i in row] if node1 not in nodelist:
G.node(node1)
nodelist.append(node2)
if node2 not in nodelist:
G.node(node2)
nodelist.append(node2) #transform the edge label to XX,XX% format
percent = float(weight)
percent = percent*100
percent = round(percent, 2)
percent = str(percent)
G.edge(node1,node2, label = (“”+ percent +” %”)) #show graph
G.render(‘bixi_graph’, view=True)
结论
总之,这一探索性分析是使用 2018 年和 2019 年 5 月的 BIXI 数据进行的。人们已经看到通勤者在工作日使用碧溪上下班,周末使用碧溪休闲。此外,网络的使用受到温度的严重影响,因为天气变冷时用户会减少。此外,大部分网络用户仍然停留在市中心、高原和周边地区。这可能是因为地理障碍,如高速公路和火车轨道,使得他们很难通勤到附近的社区。
进一步的分析也有助于了解趋势和模式,例如用户在早上和晚上通勤的具体路径。这也将为自行车手对自行车道网络的需求提供深刻的见解。访问站点容量等其他数据将有助于更好地了解网络的局限性和重新平衡的需求(通过卡车将自行车运送到其他站点)。因此,描绘一幅完整的形势图,以优化蒙特利尔的 BIXI 和自行车运动。
最后,我要感谢其他开发者和作家,他们用自己的分析启发了我的工作,更具体地说是托德·w·施耐德、伊登·奥和乔恩·诺德比。
了解加拿大的算法影响评估工具
这是与联邦政府做生意的必备条件

From Unsplash.
(注:我不隶属于加拿大联邦政府。我们的公司是一家 合格的 AI 厂商 ,但是我这篇文章的目标仅仅是展示如何解释和执行我认为将是任何厂商项目向前发展的强制性要求。)
随着最近新的加拿大政府的预先合格的人工智能供应商名单和关于自动决策的指令的出现,已经投入了同等的努力来刺激护栏内的创新,这似乎是一个充满政府创新的未来。
这种方法的基础是一个(某种程度上)集中的框架,它允许技术人员和非技术人员就部署的解决方案的可持续性和长期影响以及他们在各自组织中的角色进行透明的讨论。
虽然领导和执行团队的努力值得称赞,但是有可能扩展它的覆盖范围,以帮助确保高度技术性的项目的更少的长期暴露。经过一定的修改(见下文),我建议您在自己的项目中使用该工具,以帮助确保商业和生产准备就绪,无论政府是否参与。
背景
已经有一篇透彻的文章解释了算法影响评估需求背后的基本原理,所以这里是关键的要点:
- 早在 2018 年 12 月,财政委员会秘书处更新了他们关于自动化决策的任务。
- 开发该工具是为了帮助组织“通过提供适当的治理、监督和报告以及审计要求,更好地理解和减轻与自动化决策(ADM)系统相关的风险。”(摘自超治篇)。)
- 从 2019 年 2 月开始,有一个不言而喻的期望,即任何政府实体都将使用该工具(或其版本)来监督、控制和缓解 ADM 系统部署的潜在问题。

The website of the ADM directive as it came out in February 2019.
等等——财政委员会秘书处是做什么的?
对于加拿大以外的人来说(即使是在加拿大境内,也不直接与联邦政府打交道),国库委员会秘书处有点像一个神话人物。

尽管它的主要任务是“就政府如何在项目和服务上花钱向财政部长委员会提供咨询和建议”(来自网站),但它不同于英国内阁办公室和美国创新办公室。它列出了下列义务:
- 政府开支和运作的透明度
- 政策、标准、指令和指南
- 开放式政府
- 公共服务的创新
- 公共服务的价值观和道德
- 公共服务中的专业发展
这不同于你的标准行政部门。他们正在通过加速和简化政府职能来试验和寻找为加拿大人服务的新方法。现在不用看政治,你就能明白为什么他们非常适合在政府内部颁布使用人工智能的最佳实践。
工具——保险清单
算法影响评估工具是一种记分卡,旨在引起人们对可能被忽略的设计和部署决策的注意。它提出了许多关于为什么、做什么以及如何建立一个系统的问题,以避免陷阱和问题(以及对政府的潜在指责,这在选举季节总是一个风险)。
这个工具可以在 github.io 上交互使用,从一开始就已经做了大量的修改。这无疑是对其早期基于 Excel 的记分卡(可从 AIA 原始网站获得)的升级。该工具的新版本与现有的和未来的政府政策更加紧密地联系在一起,因此为了清楚起见,让我们探讨一下早期版本。

The clumsy-but-specific spreadsheet-based system.
主要影响评估包括 4 个主要部分:
- **商业案例。**你是想加快速度吗?您是否正在尝试清理积压的活动?你正在努力使你的组织现代化吗?
- **系统概述。**主要的技术基础是什么?图像识别、文本分析,还是流程和工作流自动化?
- **决策失察。**它是否与健康、经济利益、社会援助、出入和流动性或许可证和执照有关?
- **数据源。**是否来自多个来源?它是否依赖于个人(潜在可识别的)信息?安全分类是什么,由谁控制?
这些支票避免了明显的“我认为这很酷”的问题,浪费了金钱。它还意外地设定了衡量成功的总体标准,通常与部门的关键绩效指标挂钩。
(关于新友邦保险的完整问题列表,您可以参考 github repo 的问卷调查的 raw JSON 。)
好的,坏的和丑陋的
这篇文章的大部分内容是对所完成的工作的持续缓慢的点头,就像有人向米开朗基罗竖起大拇指让他继续前进。下面列出了需要更多注意的几点。
好的—最佳实践在前面和中间
很多问题涵盖了这个工具应该涵盖的内容。它询问临时部署的关键功能,以便进行检查和平衡。以下是一些例子:
“你会维护一个日志,详细记录对模型和系统所做的所有更改吗?”
“当需要时,系统能够为它的决定或建议提供理由吗?”
“是否有授予、监控和撤销系统访问权限的流程?(是/否)"
“该系统是否允许人工干预系统决策?是否有适当的流程来记录执行覆盖时的实例?”
太好了,这正是它需要问的。但是仍然有很多东西需要修复。
不好的方面——缺乏量化或精确性
当我们使用记分卡时,不强迫回答的能力会比仅仅填补空白更有帮助。以下是一些例子:
“决策的风险很高吗?(是/否)"
“决策对个人经济利益的影响可能是:(很少或没有影响/中度影响/高度影响/非常高度影响)”
“在你的机构中,你是否对系统的设计、开发、维护和改进赋予了责任?(是/否)"
现在,“利害关系”、“风险”和“责任”可以在每个部门的基础上量化和定义,但我希望看到一个标准的定义(如 ISO 的影响与概率计算)。
还有一个让我有点困惑的令人惊讶的问题:
“您是否有记录在案的流程来针对偏见和其他意外结果测试数据集?这可能包括应用框架、方法、准则或其他评估工具的经验。”
这就是这个工具的目的。我承认其崇高的包罗万象的性质不允许每一种可能的情况下的细节,但至少应该提到或提及“这是你如何知道你在正确的轨道上”的参考。
丑陋的政治化
与旧版本相比,这是该工具当前版本令我惊讶的一个方面。它旨在帮助各部门为现在和即将成为公民的人提供更好的服务,而不是通过不搅动罐子来帮助一个政党获得或保持权力。问题是:
“项目是否处于公众严格审查(例如,出于隐私考虑)和/或频繁诉讼的范围内?”
虽然我知道,从表面上看,这似乎是一个适当的问题,但这样一个问题的历史背景确实有很多政治含义。(对于那些好奇的人来说,首席审计员称联邦雇员的薪资改革是一次“不可理解的失败”。值得带着一袋爆米花去读。)
如果某个特定的领域受到公众的密切关注,并且经常被提起诉讼,那么它就应该被更新和创新。
我真心希望我读错了。我不希望政府内部的创新能力被政治动荡拖慢。
面向未来的约定
在不影响到目前为止在建立一个全面彻底的框架方面所做的巨大努力的情况下,我建议修改检查表,添加以下内容。
1.对问题的简单修改
将许多是/否问题移到“示范”文档中,有助于更彻底地检查解决方案。例如:
- Change " 您会开发一个流程来记录数据质量问题在设计过程中是如何解决的吗?“to " 您计划如何记录和传达已发现的数据质量问题?”
- "您是否在您的机构中分配了系统设计、开发、维护和改进的责任?"应该变成“谁是系统的设计、开发、维护、*修复、重构、*和改进的责任方?”
- "您是否有记录在案的流程来测试数据集是否存在偏差和其他意外结果?"可以"针对偏见和其他意外结果测试数据集的所有记录流程是什么?
2.长期所有权和变革管理
谁将拥有算法?该工具现在有一个简单的责任问题。然而,我的好朋友 Jen 说,最好的流程和技术是那些像员工一样管理的流程和技术:它们在某人的监督下,并且有明确的成功衡量标准。因此:
- 谁来维护?此人/这些人的工作职责是否已更新,以包括此特定系统?
- 就人员、预算和时间而言,未来用于维护 it 的资源有多少?
- 是否为预期的技术变化制定了维护计划?(至少每季度或每两年一次。)
3.翻译和评估成功的衡量标准
我过去曾在智能系统环境中谈论过“正确构建事物”与“构建正确的事物”,深受 ISO 13485 的启发。这适用于功能系统与业务案例脱节的情况,因为它在技术上得到了维护(例如,本周发布的 VueJS 的任何版本),但没有重新处理以回答核心组织问题。
如果没有对每个团队和部门如何建立和度量进展(更不用说成功)的清晰理解,就不可能评估一个系统是否在不投入大量资金的情况下产生了实质性的差异。
花额外的一两个月时间为项目构建定制的记分卡,这样在初始部署后就不会出现太多意外。
结论
AIA 工具满足了政府创新任务中的一个关键需求,即建立探索性项目的监督机制。
具有讽刺意味的是,目前与该工具相关的最大风险与它试图评估的每个项目相同——好主意,糟糕的执行。在这种特殊情况下,执行是关于更新和教育的,这样每个人都知道什么是向前发展的最佳实践集。
如果应用正确,这个工具将确保您的项目可以承受未来几年,而不需要在更具支持性的基础上从头开始重建。如果做错了,貌似合理的否认会导致诉讼(或者更糟),所以现在就花额外的时间来确保你的项目有一个坚实的基础。
如果您对本文或我们的 AI 咨询框架有其他问题,请随时通过LinkedIn或通过 电子邮件 联系。
你可能喜欢的其他文章
我的首席技术官丹尼尔·夏皮罗(Daniel Shapiro)的其他文章您可能会喜欢:
使用机器学习了解癌症
机器学习(ML)在医学中的应用变得越来越重要。一个应用实例可以是癌症检测和分析。

(Source: https://news.developer.nvidia.com/wp-content/uploads/2016/06/DL-Breast-Cancer-Detection-Image.png)
注来自《走向数据科学》的编辑: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
介绍
正如许多研究人员所证明的[1,2],机器学习(ML)在医学中的应用现在变得越来越重要。研究人员现在将 ML 用于 EEG 分析和癌症检测/分析等应用中。例如,通过检查生物数据,如 DNA 甲基化和 RNA 测序,就有可能推断哪些基因会导致癌症,哪些基因反而能够抑制其表达。在这篇文章中,我将向你介绍我是如何检查关于 TCGA 肝癌、宫颈癌和结肠癌的 9 个不同数据集的。所有的数据集都是由 UCSC 谢轩(加州大学圣克鲁兹分校网站)提供的。对于所考虑的 3 种不同类型的癌症中的每一种,使用了三个数据集,包含关于 DNA 甲基化(甲基化 450k)、基因表达 RNAseq (IlluminaHiSeq)和最终外显子表达 RNAseq (IlluminaHiSeq)的信息。然后,这些数据集按信息类型而不是按癌症进行分组。我决定使用这些数据集,因为它们具有所有的共同特征,并且共享相似数量的样本。此外,我决定选择这些类型的癌症,因为它们提供了人体基因和染色体特征的不同观点,因为不同的癌症位于身体的不同部位。这样,在这项工作中获得的分类结果可以推广到其他形式的癌症。DNA 甲基化在基因表达的调节中起着重要作用,其修饰可以导致癌细胞的产生或抑制[3]。
分类
每个数据集都必须进行转置和预处理。在形成最终的三个数据集之后,进行不同类型癌症之间的分类。为了产生这些结果,使用了 70%训练,30%测试的分割比率。如表 1 所示,考虑了许多分类算法。这些结果是利用整个数据集和旨在正确区分三种不同类型癌症的分类器获得的。

特征抽出
我对 3 个给定的数据集执行了主成分分析(PCA ),以查看仅使用前两个主成分会如何影响分类精度结果(表 2)。主成分分析旨在降低数据集的维数,同时尽可能多地保留方差。从表 2 中可以注意到,将数据维数减少到两个特征并没有导致准确性的急剧下降。

图 1 提供了使用逻辑回归的 PCA 分类结果,两个轴代表 PCA 产生的两个主要成分。外显子表达数据集似乎受五氯苯甲醚的影响最大,最高准确率为 65%。这一结果的原因是不同类别之间的主要重叠,如图 1©所示。

最后,我决定应用另一种特征提取技术,如 t-SNE。这种技术可以实现将高维数据可视化到低维空间中,从而最大化不同类别之间的分离。结果如图 2 所示,双轴代表由 t-SNE 设计的两个主要组件。三种不同类型的癌症中的每一种都用不同的颜色标记(TCGA 肝癌= 0,宫颈癌= 1,结肠癌= 2)。从图 2 中可以看出,t-SNE 创造了两个能够很好地区分三个不同类别的特征。

特征选择
前面几节向我们展示了使用整个数据集可以获得非常好的分类结果。使用特征提取技术,如主成分分析和 t-SNE,已经表明有可能减少维数,同时仍然产生可观的分类分数。由于这些结果,我决定绘制一个决策树,代表分类中使用的主要特征(权重最大的特征),以便更仔细地研究最重要的特征。由于决策树在所有三个数据集中的分类性能,我决定使用决策树进行分析。结果见图 3 (DNA 甲基化)、图 4(基因表达)和图 5(外显子表达)。

在每个图中,不同的癌症类型用不同的颜色表示(TCGA 肝癌= 0,宫颈癌= 1,结肠癌= 2)。所有三种癌症的特征分布都表示在树的起始节点中。只要我们向下移动每个分支,算法就会尝试使用每个节点图下面描述的功能来最好地分离不同的分布。沿着分布生成的圆表示在跟随某个节点之后被正确分类的元素的数量,元素的数量越大,圆的大小就越大。

为了生成这些图形,我使用了 Terence Parr 和 Prince Grover 创建的 dtreeviz.trees 库。我决定使用这个库,因为它使我能够可视化树的每个分支中的特性分布。当试图分析类别之间的差异以及观察算法如何做出分类决策时,这在生物学领域可能特别重要。

估价
表 3 总结了三个不同树的顶部(前两层)使用的特性。经过仔细研究,查看在线可用数据库,为每个特性添加了一系列相关注释(表 3)。对于 cg27427318 和 chr 10:81374338–81375201,无法找到任何相关信息。

从分析的特征中推断出的一些最有趣的结果是:
- PFN3 已被鉴定为与 cg06105778 最接近的基因。根据邹丽、丁志杰等人在 2010 年进行的一项研究,轮廓蛋白(Pfns)可能被归类为乳腺癌中的一种肿瘤抑制蛋白[4]。
- 根据诺埃尔·j·埃亨、古汉·兰加斯瓦米等人的“Holt-Oram 综合征男性前列腺癌:TBX5 突变的首次临床关联”,TBX5 基因“被认为在突变时上调肿瘤细胞增殖和转移”[5]。Yu J,Ma X 等人的另一项研究证明,患有 TBX5 结肠癌的患者存活率低得多[6]。
- Alexa Hryniuk、Stephanie Grainger 等人开展的研究强调,“Cdx1 的缺失导致远端结肠肿瘤发病率显著增加”[7]。
仅使用表 3 中列出的各个数据集的特征,我最终决定使用 PCA 和线性判别分析(LDA)将数据减少到二维,并执行朴素贝叶斯(NB)和支持向量机(SVM)分类,以查看覆盖了多少数据方差。结果如表 4 所示,该表显示,仅使用数据集中最重要的特征即可获得出色的分类结果(由于噪声降低)。在所有考虑的情况下,原始数据差异的 83%到 99%被保留。

结论
总来说,这个项目产生了很好的结果。作为进一步的发展,尝试替代的特征选择技术,如递归特征选择(RFS)或 SVM(如我的另一篇文章中所解释的),看看是否可以识别其他类型的基因/染色体,这将是有趣的。这种分析的另一个可能的改进是使用包含来自健康受试者的数据的数据集来交叉验证所获得的结果。
我要感谢 Adam Prugel-Bennett 教授给我这个机会来实施这个项目。
联系人
如果你想了解我最新的文章和项目,请通过媒体关注我,并订阅我的邮件列表。以下是我的一些联系人详细信息:
文献学
[1]维里戴安娜·罗梅罗·马丁内斯。使用深度学习检测组织病理学图像中的乳腺癌。访问:https://medium . com/datadriveninvestor/detecting-breast-cancer-in-organism-photo-images-using-deep learning-a 66552 AEF 98,2019 年 4 月。
[2]胡子龙嘎,唐金山,等.基于图像的癌症检测和诊断的深度学习,一项调查。查阅网址:https://www . science direct . com/science/article/ABS/pii/s 0031320318301845,2019 年 5 月。
[3] Luczak MW,Jagodzi nski PP . DNA 甲基化在癌症发展中的作用。访问时间:https://www.ncbi.nlm.nih.gov/pubmed/16977793, 2019 年 5 月。
[4]邹丽、丁志杰和帕萨·罗伊。Profilin-1 过表达抑制 MDA-MB-231 乳腺癌细胞增殖部分通过 p27kip1 上调获得:https://www . NCBI . NLM . NIH . gov/PMC/articles/PMC 2872929/pdf/NIH ms-202017 . pdf,2019 年 5 月。
[5]诺埃尔·埃亨、古汉·兰加斯瓦米和皮埃尔·蒂里翁。Holt-Oram 综合征男性患者的前列腺癌:TBX5 突变的首次临床关联于 2019 年 5 月在https://www.hindawi.com/journals/criu/2013/405343/获得。
[6]于军,马 X,等.一种新的肿瘤抑制基因 T-box 转录因子 5 的表观遗传失活与结肠癌相关.访问时间:https://www.ncbi.nlm.nih.gov/pubmed/20802524, 2019 年 5 月。
[7] Alexa Hryniuk,Stephanie Grainger 等。Cdx1 和 Cdx2 具有肿瘤抑制功能。访问时间:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4246091/, 2019 年 5 月。
使用等曲线了解分类阈值
你在一个会议室里,展示你的一个分类问题。您展示了您在特征工程、预测器选择、模型选择、超参数调整和集成方面的所有神奇之处。你用预测概率和 ROC 曲线以及奇妙的 AUC 来结束你的陈述。你坐下来,对自己出色的工作充满信心。
经理说,“我该怎么处理这些概率和 ROC 之类的东西?我只是想知道我应该做 x 还是 y 。”x 可能在哪里,我是否应该将此邮件归类为垃圾邮件?还是面对这种路况我的特斯拉应该踩刹车?或者我该不该批准这笔贷款?

Optimal thresholds using different metrics, with isocurves
在你解释如何解释模型并应用它之前,你作为数据科学家的工作还没有结束。这意味着为激励模型的商业决策选择阈值。
作为一名数据科学家,你可能会说… “一篇关于阈值的博文?这甚至不是一个数据科学问题,而是一个业务问题。”
你是对的!阈值选择缺乏吸引力,比如说,生成性对抗网络。
但这也是橡胶遇到道路的地方,在这里你用奇特的算法做的所有创造性的东西与现实世界的决策相互作用。
它受到了冷遇。因此,这里有一个深入的阈值选择,包括 F1 分数及其与其他指标的比较。让我们开始吧!
1.你需要一个度量或者一个成本函数来优化。
企业不关心 Kaggle 指标。企业在数据科学上投资的唯一正当理由是:1)获得并留住客户,2)降低成本,3)更好地开展业务,从而 4)增加利润。如果您了解模型的业务目标,模型可以改进哪些关键绩效指标(KPI ),并应用科学方法来提出正确的问题并改进这些 KPI,您可能会成为 A-team 数据科学家。
在预测观察值属于正类的概率的算法的情况下,阈值选择是必要的。这是大多数(但不是全部)分类算法的工作方式。接下来的问题是,如果我们需要根据建模的概率进行离散预测,那么将一个观察结果归类为阳性的最佳阈值是什么?
要问的第一个问题是:您能使用企业关心的 KPI 量化第一类和第二类错误的成本吗?什么是假阳性的边际成本,什么是假阴性的边际成本?如果你能确定正确的成本函数,你的工作基本上就完成了。
选择使交叉验证中的假阳性和假阴性的总成本最小化的阈值。(始终处于交叉验证中:永远不要选择超参数或使用训练数据或测试数据对您的模型做出任何决定;分类阈值可以被认为是一个超参数。)
假设我们预测一个借款人是否会拖欠信用卡。提供本应被拒绝的信贷会造成 50,000 美元的信贷损失和管理成本。拒绝本应提供的信贷会导致客户损失 10,000 美元的终身价值(LTV)。选择在交叉验证集合(或折叠)中假阳性和假阴性总成本最低的阈值。
2.当您改变分类阈值时,ROC 曲线可视化了一组可行的解决方案,隐含地改变了假阳性相对于假阴性的成本。
如果阳性类别代表检测到停车标志或医疗状况,则假阴性的成本很高。你需要一个低门槛来最大限度地减少假阴性,这些假阴性会导致你冲过十字路口,与交通相撞,或者无法获得进一步的救命诊断或治疗。
如果您的问题是垃圾邮件检测,阻止一封重要的电子邮件比让垃圾邮件通过的成本更高。所以你倾向于使用更高的阈值来将邮件标记为垃圾邮件,以减少误报。
图一。ROC 曲线
这是来自 Kaggle 数据集的 ROC 图。

我们来回顾一下如何解读 ROC 剧情:
- 真阳性是被正确预测为真的真实观察。
- 真阳性率(TPR) 是真阳性/真阳性的数量(也称为召回或灵敏度)。地面真阳性=真阳性+假阴性:TPR = tp / (tp+fn)
- 假阳性是错误预测为真的错误观察。
- 假阳性率(FPR) 是假阳性/真阴性数 (1 — FPR 是特异性)。地面真阴性=真阴性+假阳性:FPR = fp / (tn + fp)
- ROC 图上最好的点是左上角,100% TPR,灵敏度或回忆,0% FPR,或 100%特异性。
- 最佳可行点在 ROC 曲线上。当你从左向右移动时,你降低了将一个观察归类为积极的阈值。你得到更多的真阳性,但也有更多的假阳性。
- 一个很好的类比是用网捕鱼:当你使用更细的网时,漏网的鱼会更少,但你也会捕获更多的海藻和垃圾。这个价值 64,000 美元的问题是如何使用一张网来获得最好的结果。
3.ROC 曲线的斜率反映了每接受一个假阳性,您获得了多少个真阳性。
我们来讨论一下如何解读 ROC 曲线的斜率。
图二。ROC 曲线斜率

我们把 TPR 放在左轴,把 FPR 放在底轴。我们也用虚线画出了 45 度线。45 线是 ROC 曲线,如果你用基本比率对你的观察值进行随机分类,你会得到这条曲线。在这个例子中,大约 20.8%的观察结果是基本事实。如果您使用随机分类器将 20.8%随机分类为阳性,您的 ROC 曲线将大致遵循 45°线。这是你不用做任何建模就能得到的最好的 AUC(ROC 曲线下面积)。或建模尝试失败的最坏情况 AUC,其不能找到任何预测信号。
回想一下,TPR 是真阳性,作为基础真阳性的百分比,我们将实际真阳性计数放在右轴上。同样,由于 FPR 是假阳性占地面真实阴性的百分比,所以实际的假阳性计数在顶轴上。
这有助于我们解释斜率:斜率是通过接受一个额外的假阳性而获得的额外的真阳性的数量。(近似值,记住 ROC 曲线是由离散点组成的)。
45°线在 TPR/FPR 空间中的斜率为 1(FPR 每增加一个百分点,TPR 增加一个百分点)。在原始真阳性/假阳性空间中,45°线的斜率是阳性总数/阴性总数。如果正类以概率 p 出现,则斜率为 p / (1 — p) 。
如果你有一个理想的 ROC 曲线,斜率连续下降(凹下),你可以从左下开始,一直向右上,只要假阴性表达的额外真阳性的成本是可接受的。
(真实世界的 roc 通常更混乱,可能没有连续递减的斜率。但是 ROC 曲线总是正倾斜的,除了在边缘处,从不平坦或垂直。这将意味着两点,其中一点在一个维度上更好,而在另一个维度上相等。那么只有一个可能是最优解,而且只有那个应该在 ROC 曲线上。此外,最合理的阈值选择度量将忽略不在“外壳”上但暂时向左下角倾斜的区域中的点。所以考虑一条斜率连续下降的 ROC 曲线是合理的。)
4.精确度、召回率和 F1 分数
现在,如果您不能确定假阳性和假阴性的真实成本,会发生什么?
一个常用的指标是 F1-score ,它是精确度和召回率的调和平均值。
- 精度是真阳性/预测阳性,即我们正确预测的阳性预测的百分比。
- 回忆一下是 TPR:真阳性/基本事实阳性,即我们正确预测的基本事实阳性的百分比。
- 为了计算谐波平均值,我们反转输入,计算它们的平均值,然后反转平均值。

为了获得关于调和平均值的直觉:如果车辆以速度 x ( 例如 60 km/h 向外行驶距离 d ,并以速度 y ( 例如 20 km/h 返回相同的距离,那么其平均速度是 x 和的调和平均值
这并不等于算术平均值(40 km/h ),如果您在两个不同速度的路段中行驶了相同的时间,则算术平均值是适用的。
如果任一条腿上的速度接近 0,则无论另一条腿上的速度如何,整个距离的调和平均值都将接近 0。如果任何一段的速度正好为 0,你就永远不会到达目的地,所以整个行程的平均速度为 0。
F1 分数平衡了精确性和回忆性,惩罚了其中任何一个方面的极端弱点。
F1 的分数是不对称的。我们有不平衡的 79.2%/20.8%的负面/正面比率。假设我们的分类器预测一切都是积极的。那么召回率是 1,精度是 0.208,F1 是 0.344。现在假设标签反了,你预测一切都是正的,回忆是 1,精度是 0.792,F1 是 0.884。这看起来很棒,但事实并非如此,因为我们所做的只是将所有东西归类为多数类。由于这种不对称性,我们总是小心翼翼地将少数类标记为正类来计算 F1 分数。
不对称有时是好的。有时业务问题是不对称的。在一个搜索引擎应用程序中,我们不太关心我们没有检索到的所有文档。
我们可以通过使用加权平均值而不是等加权平均值来将阈值向精确度或召回率倾斜,在这种情况下,我们称之为 F2-score 等。
F-score 似乎是合理的,虽然调和平均值的适用性对我来说不是完全直观的。我从未遇到过假阳性和假阴性的真实成本函数是调和平均值的业务问题。
5.等曲线可帮助您可视化任何评分或成本函数,如 F1
如果你想要最好的折衷,用等曲线可视化折衷是有帮助的。等值成本曲线或无差别曲线描绘了一组具有相同成本或度量值的点:例如,F1 值为 0.5 的所有点。这可以让您直观地看到当您沿着 ROC 曲线移动时,指标是如何演变的。
对于 F1 指标,等曲线看起来像这样。
图 3。f1-得分等曲线

- 底部轴:回忆= 0,F1 = 0
- 左上角:我们完美地分类了:召回率= 1,精确度= 1,F1 = 1
- 右上方:我们对所有阳性进行分类:召回率= 1,精确度= 0.208,F1 = 0.344
要选择具有最高 F1 的点,选择 ROC 曲线上位于最佳 F1 等曲线上的点,即最接近左上的等曲线。
6.线性成本等值线
F-score 是一个非线性成本函数。如果成本函数是 TPR 和 FPR(或假阳性和假阴性)的线性函数,用一个假阳性换一个假阴性的相对成本是常数,并且你有均匀间隔的线性等曲线。
图四。线性成本等值线

再次选择 ROC 曲线上的点,该点也在最靠近左上方的等曲线上。在这个例子中,相对价格是 p/(1-p) 。所以等曲线平行于 45°线,对应于使用基本速率 p 的随机分类器。
与 F1 等曲线相比,当你上升时,F1 在左侧上升得更快。因此,当你提高 ROC 时,在其他条件相同的情况下,连接最佳 F1 点的路径将向左弯曲(凹下)。连接最佳线性成本的路径将是一条直线。就像他们说的,证据是作为练习留下的。
我们可以衡量假阳性对假阴性的相对成本。当我们这样做时,等曲线的斜率会发生变化,我们会倾向于精度高于回忆,反之亦然。
7.圆形或“最接近左上”等曲线
假设我们希望通过欧几里德距离尽可能接近左上。对应于圆形等曲线。成本函数是从左上角开始的距离:

图五。最靠近左上角:圆形等曲线

我们还可以对平方根下的项进行加权,以提高精确度或召回率,并将曲线做成水平或垂直的椭圆。
与恒定成本等曲线相比,圆形等曲线倾向于将最佳点保持在中间,靠近对角脊,从而平衡精确度和召回率。
8.交互信息
最后再来看互信息。互信息是一种信息论度量,就像 日志损失 。Log loss 可以解释为我们的预测与实际结果之间的错误或意外,用比特来衡量。 互信息 可以解释为我们预测中的正确信息量,用比特来衡量。
互信息是我们用来测量电话线或无线信道上信号的带宽容量的。我们可以把预测看作是关于未来的信号。在同样的意义上,互信息衡量的是一个信道上可以传输多少有用的信号,互信息告诉我们有多少关于未来的有用信息。
如果我们用互信息作为我们的成本函数,我们会得到这样的等值线。
图 6。互信息等曲线

在信息论的意义上,最大化互信息可以最小化预测中的意外或错误,并最大化“正确”信息。由于没有假阳性和假阴性的明确成本,互信息似乎是一个自然的度量选择。
然而,互信息等曲线符合 ROC 曲线的一般形状。所以他们在选择是偏向精确还是偏向回忆方面可能不是很稳定。
倾向于精确还是召回的选择是基于算法在精确还是召回方面更好,而不是任何现实世界的成本。因此,阈值的选择可能是任意的,很难解释。
同样值得注意的是,完全错误的预测与完全正确的预测包含相同的互信息,因为您可以从该信号中提取正确的预测。这也有点违反直觉。
互信息具有理论吸引力,但可解释性具有挑战性。
9.结论
当我开始建立分类模型时,我经常使用 F1 分数。现在,我一般用 AUC 进行模型选择和超参数调优。对于阈值选择,我尝试识别最相关的真实世界度量。
我发现线性等曲线最容易解释。在没有一个好的先验成本函数的情况下,我还发现证明 p/(1-p) 比 F1 或其他更复杂的指标更容易。圆形等曲线更难解释,但有利于精确度和召回率之间的平衡。但从经验上看,F1 表现不错。
要选择一个门槛,就要把某个东西最大化。您最大化的指标应该是可解释的,并与现实世界的成本相关联。
外卖:
- 阈值选择是数据科学与现实决策相结合的地方。
- 不要自动使用 50%的阈值,甚至 F1 分数;考虑假阴性和假阳性的真实成本。
- 要选择一个阈值,你必须优化一些指标:一个成本函数。
- 业务环境决定了您正在优化的成本函数:您愿意在第一类和第二类错误之间做出的真实世界的权衡;为了以假阳性为代价获得更多的真阳性,您应该将阈值降低到什么程度。
- 等曲线等高线图是一种可视化,每当您必须权衡两个变量时,它都可以为您的成本函数提供良好的直觉。
- 最小化成本函数时,选择 ROC 曲线与最低成本(或最高度量)等曲线相交的最佳分类阈值。
等曲线可用于在任何一组竞争的备选方案之间做出合理的选择,而不仅仅是分类阈值。这篇文章涵盖了大约 30%最重要的经济学原理:人们面临权衡;某物的成本是你为了得到它而放弃的东西;理性的人在边际思考;你必须选择最大化什么。
选择优化 KPI 和实现业务目标的阈值,可以最大化您作为数据科学家的价值…这是一个真正的最佳结果。
可视化的代码在 GitHub 这里。
另请参见:
福塞特,汤姆。" ROC 图:研究人员的注意事项和实际考虑."机器学习 31.1(2004):1–38。【https://www.hpl.hp.com/techreports/2003/HPL-2003-4.pdf
《通过科学做出更好的决策》《科学美国人》, 2000 年第 283 卷第 4 期,第 82-87 页。JSTOR,www.jstor.org/stable/26058901。
grandenberger,评估分类模型,第 3 部分:Fᵦ和其他加权毕达哥拉斯方法的精确度和召回率
了解 CNN(卷积神经网络)
数据科学家的技术说明
你学习图像分类深度学习的第一步

Source Unsplash
想象一下 Google 相册:对于你所有的图片,你是如何用物体来标记的?要不要一个一个贴标签?可以搜索一下你最新的马里兰鸡快照吗?进入 CNN!
理解图像分类
图像分类定义图像对象,并从标记的例子中标记这些图像。
我们的大脑是快速判断物体的大师。当你进入一家杂货店时,你可以把香蕉和鞋子等其他商品分开。我 2 岁的侄女知道如何区分猫和狗。
然而,用计算机来教这些分类是非常困难的。

My search for the word “cat”
看看这些图片。在几个惊鸿一瞥之内,你应该已经意识到,在猫的形象中间,有几个来自音乐剧《猫》的女演员。也有一些是猫涂鸦的图片,但不是猫。那么我们如何教会我们的计算机理解这些图像呢?
经典图像分类
过去,图像分类模型使用原始像素对图像进行分类。您可以通过颜色直方图和边缘检测对猫进行分类,边缘检测允许您通过颜色和耳朵形状对猫进行分类。这种方法是成功的,但是直到该方法遇到更复杂的变体。



Imagine if our classifiers only specify cats by their black color and ear shape. Are all of these pictures cats?
这就是经典图像识别失败的地方,因为模型没有考虑其他特征。但是这些的其他特征是什么呢?需要一个一个讲型号吗?你会发现这即使不是不可能,也是一件非常麻烦的事。
介绍卷积神经网络(CNN)

CNN Architecture
CNN 是一种神经网络模型,它允许我们提取图像内容的更高表示。与传统的图像识别不同,在传统的图像识别中,您需要自己定义图像特征,CNN 获取图像的原始像素数据,训练模型,然后自动提取特征以进行更好的分类。
让我们来看看下面的视错觉,了解 CNN 是如何工作的。
CNN 的直觉——想象一个视错觉


Psychologist Edwin Boring introduced the painting of “My Wife and My Mother-in-Law” where the figure seems to morph from young lady to old woman, to the public in 1930. (Source)
考虑这个图像。你看到一位年轻女士还是一位老奶奶?如果你把焦点放在图像中间的一个点上,你会看到一位年轻的女士。然而,如果你把焦点放在图像中下方的黑色条纹上,你会看到一位老太太。请看图片上的红色方框。
这张图片提供了人类如何识别图像的见解。因为人类的大脑被设计用来捕捉模式以对物体进行分类,所以改变你观察的焦点也会改变你对整体图像的理解。
与人类大脑的工作方式类似,CNN 区分图像中有意义的特征,以便对图像进行整体分类。
CNN 原理
盘旋
卷积通过图像扫描窗口,然后计算其输入和过滤点积像素值。这允许卷积强调相关特征。

1D Convolution Operation with features(filter)
看看这个输入。我们将用一个小窗口包住窗口元素,用点乘它与过滤器元素,并保存输出。我们将重复每个操作以导出 5 个输出元素作为[0,0,0,1,0]。从这个输出中,我们可以知道序列 4 中的特征变化(1 变成 0)。过滤器很好地识别了输入值。同样,这也发生在 2D 卷积。

2D Convolution Operation with features(filter) — Source
通过这种计算,您可以从输入图像中检测出特定的特征,并生成强调重要特征的特征图(卷积特征)。这些卷积特征将总是根据受梯度下降影响的滤波器值而变化,以最小化预测损失。
此外,部署的过滤器越多,CNN 提取的特征就越多。这允许发现更多的特征,但是代价是更多的训练时间。有一个甜蜜点的层数,通常,我会把 150 x 150 大小的图像 6。

Feature map in each layer of CNN (source)
然而,边角值呢。它们没有足够的相邻块来适合过滤器。我们应该移除它们吗?
不,因为你会丢失重要信息。因此,你要做的反而是**填充;**用 0 填充相邻的特征图输出。通过将 0 插入其相邻像素,您不再需要排除这些像素。
本质上,这些卷积层促进了权重共享来检查内核中的像素,并开发视觉上下文来对图像进行分类。与权重独立的神经网络(NN)不同,CNN 的权重被附加到相邻像素,以提取图像每个部分的特征。
最大池化

We take the maximum max pooling slices of each 2x2 filtered areas (source)
CNN 使用 max pooling 用 max summary 替换输出,以减少数据大小和处理时间。这使您可以确定产生最大影响的特征,并降低过度拟合的风险。
最大池有两个超参数:步幅和大小。步幅将决定价值池的跳跃,而大小将决定每次跳跃中价值池的大小。
激活函数(ReLU 和 Sigmoid)
在每个卷积和最大池操作之后,我们可以应用校正线性单元(ReLU)。ReLU 函数模拟我们的神经元在“足够大的刺激”下的激活,从而为值 x>0 引入非线性,如果不满足条件,则返回 0。这种方法对于解决梯度递减是有效的。在 ReLU 激活功能后,非常小的权重将保持为 0。
CNN 大图+全连接层

CNN architectures with convolutions, pooling (subsampling), and fully connected layers for softmax activation function
最后,我们将使用全连接图层(FCL)提供卷积和最大池要素地图输出。我们将特征输出展平为列向量,并将其前馈到 FCL。我们用 softmax 激活函数包装我们的特征,该函数为每个可能的标签分配十进制概率,其总和为 1.0。前一层中的每个节点都连接到最后一层,并表示要输出哪个不同的标签。
**最终结果如何?**你将能够对狗和猫的图片进行如下分类。

Finding the perfect image classification with softmax (Source)
CNN 中的清洗和防止过拟合
不幸的是,CNN 也不能幸免于过度拟合。如果没有适当的监控,模型可能会被训练得太多,以至于不能概括看不见的数据。通过我的经验,我犯了许多初学者过度拟合的错误,我是如何解决它们的如下:
使用测试集作为验证集来测试模型
即使我们不使用测试集来训练模型,模型也可以用测试集来调整损失函数。这将使训练基于测试数据集,并且是过度拟合的常见原因。因此,在训练过程中,我们需要使用验证集,然后用看不见的测试集最终测试完成的模型。
数据集相对较小
当数据集很小时,很容易专注于几组规则而忘记概括。例如,如果您的模型只将靴子视为鞋子,那么下次您展示高跟鞋时,它不会将其识别为鞋子。
因此,在训练数据集很小的情况下,你需要人为地提振训练样本的多样性和数量。这样做的一个方法是添加图像增强并创建新的变体。这些包括转换图像和创建尺寸变化,如缩放、裁剪、翻转等。

Image augmentation Source
过度记忆
过多的神经元、层和训练时期会促进记忆并抑制概括。你训练你的模型越多,它就越有可能变得过于专业化。为了解决这个问题,你可以通过去除一些隐藏层和每层的神经元来降低复杂度。
或者,您也可以使用正则化技术,如 Dropout 来移除每个梯度步长训练中的激活单元。每个历元训练去激活不同的神经元。
因为梯度步骤的数量通常很高,所以所有神经元将平均具有相同的丢失发生率。直觉上,你退出的越多,你的模型记忆的可能性就越小。

Drop out images
处理彩色图像
您还可以轻松地包含具有 3 层颜色通道的图像:红绿蓝(RGB)。在卷积过程中,您为每个颜色通道使用 3 个单独的卷积,并训练 3 级过滤器堆栈。这允许您检索 3D 要素地图。
我们如何做得更好?—迁移学习
随着用例变得复杂,模型的复杂性也需要提高。有了几层 CNN,你可以确定简单的特征来分类狗和猫。然而,在深度学习阶段,你可能希望从图像中分类更复杂的对象,并使用更多的数据。因此,迁移学习允许你利用现有的模型快速分类,而不是自己训练它们。
迁移学习是一种将现有模型重新用于当前模型的技术。你可以在现有模型的基础上制作,这些模型是由专家精心设计的,并用数百万张图片进行了训练。
然而,你需要遵循一些注意事项。首先,您需要修改最终层以匹配可能的类的数量。第二,您需要冻结参数,并将训练好的模型变量设置为不可变的。这阻止了模型的显著变化。
你可以使用的一个著名的迁移学习工具是 MobileNet。它是为内存和计算资源较少的移动设备创建的。你可以在 Tensorflow Hub 找到 MobileNet,里面聚集了很多预训练的模型。你可以简单地在这些模型上添加你自己的 FCL 层。
结论:CNN 感知我们的视觉世界
CNN 是一门很难的课程,但却是一门值得学习的技术。它教会我们如何感知图像,并学习对图像和视频进行分类的有用应用。在学习了 CNN 之后,我意识到我可以在谷歌的项目中使用这个来检测网络钓鱼攻击。
我也意识到对 CNN 的了解很深。多年来,CNN 变体有许多改进,包括最新的 ResNet,它甚至在 ImageNet 分类中击败了人类评论者。
- 乐网(杨乐村,1998 年)
- 亚历克斯·奈特(2012 年)
- VGGNet (2014) —深度神经网络
- 初始模块 Google Net (2014) —堆栈模块层
- ResNet (2015) —首个超过人类图像网络的网络
对我来说,我写这篇文章是为了我在谷歌工作的一个项目探索我对 CNN 的基本理解。因此,如果我在写作中犯了任何错误或知识空白,请随时给我反馈。索利·迪奥·格洛丽亚。
参考
我真诚地希望这能激起你更深入了解 CNN 的兴趣。如果你有,这里有一些你可能会觉得非常有用的资源:
最后…
我真的希望这是一本很棒的读物,是你发展和创新的灵感来源。
请在下面评论以获得建议和反馈。就像你一样,我也在学习如何成为一名更好的数据科学家和工程师。请帮助我改进,以便我可以在后续的文章发布中更好地帮助您。
谢谢大家,编码快乐:)
关于作者
Vincent Tatan 是一名数据和技术爱好者,拥有在 Google LLC、Visa Inc .和 Lazada 实施微服务架构、商业智能和分析管道项目的相关工作经验。
Vincent 是土生土长的印度尼西亚人,在解决问题方面成绩斐然,擅长全栈开发、数据分析和战略规划。
他一直积极咨询 SMU BI & Analytics Club,指导来自不同背景的有抱负的数据科学家和工程师,并为企业开发他们的产品开放他的专业知识。
文森特还在 10 日至 8 日开放了他的一对一导师服务,指导你如何在谷歌、Visa 或其他大型科技公司获得你梦想中的数据科学家/工程师工作。
- 如果你需要转介到谷歌,请通知他。谷歌在招人!
- 如果你正在寻找良师益友,请在这里预约你和他的约会。
最后,请通过LinkedIn,Medium或 Youtube 频道 联系文森特
理解置信区间
思考频率主义者,而不是贝叶斯:在 Udacity 参与度数据集上模拟一百万次实验

“我们有 95%的把握总体均值落在置信区间内.”
事实证明,上述说法具有误导性。置信区间是一个源于频率统计的概念,而陈述表达了贝叶斯信念。在本文中,我们将通过对真实数据的模拟实验来找出置信区间的真正含义。
频率主义者和贝叶斯统计之间的区别是根本性的。教科书上的例子是抛硬币。一个经常光顾的统计学家会将硬币抛 100 万次,如果观察到 50 万个头像,他会宣布硬币是公平的。贝叶斯统计学家会从硬币是否公平的先验信念开始,当他抛硬币时,根据证据逐渐调整他的信念。
在实验背景下,频率主义者认为,无论你相信什么,都只有一个正确的总体均值,而贝叶斯主义者认为总体均值是一个随机变量:你假设它在一个可能值的范围内,你用概率来对冲你的信念。在下面的模拟中,我们将看到为什么置信区间只能用频率主义的方式来解释。
Udacity 参与度数据集
我们将使用来自 Udacity 的参与度数据集。每个数据点都是学生观看视频教程的时间片段。如果一个学生看完了整个课程,他是 100%投入的,他的数据点是 1。啮合遵循指数分布。大多数学生一开始就辍学,只有少数学生完成了整个课程,这并不奇怪。

在现实世界中,我们会将该数据集视为大小为 8702 的样本。但是在这个模拟中,我们将它视为整个人口,并从中抽取 100 万个大小为 300 的样本(这个过程称为 Bootstrap 抽样)。因为我们这里有完整的总体,我们可以很容易地看出,抽样分布的均值是总体均值的无偏估计量(0.07727)。此外,很容易确认经验计算的标准误差与分析的标准误差相同(0.0062)。

总体分布显然不是正态的,但是中心极限定理保证了抽样分布是正态的,给定足够大的样本量(300 就足够了)。如密度图所示,抽样分布确实非常正常。我添加了两条垂直线,标记平均值上下 1.96 的标准误差。这是双尾显著性水平为 0.05 的 z 得分。在正态分布中,有 2.5%以上的概率,和 2.5%以下的概率。
在我们的例子中,我们有 2.06%的下尾部和 2.83%的上尾部。抽样分布是正偏的,因为我们不能有负值。这和 QQ 剧情一致。在低端,极值出现的频率低于正常预期,而在高端,极值出现的频率高于正常预期。
但实际上,这种抽样分布不仅仅满足正态假设:大多数数据点恰好落在 QQ 图对角线上。这是一个重要的健全性检查:正态抽样分布是 z-检验和 t-检验的基本假设(稍后将详细介绍 t-检验)。如果抽样分布不正态,所有测试结果无效。

事实上,我们不知道总体均值或标准误差。毕竟知道了总体均值,就不需要统计检验或者置信区间了!此外,我们不能成为常客。没有人有钱或时间去画一百万个样本,或者把一枚硬币掷一百万次。我们通常只获得一个样本,计算样本平均值和平均值的标准误差,加上和减去一些标准误差的 t 分数倍数,以获得我们的置信区间。
一个常客模拟
如果我们能提取几十万个样本呢?我们已经模拟了一百万个样本。在下面的代码中,我们为每个样本建立了一个置信区间,并检查总体均值是否在置信区间内。请记住,我们已经精确地计算出人口平均值为 0.07727。
结果是 94.4%的置信区间捕捉到了总体均值。这就是置信区间的真正含义:如果我们无限次重复抽样程序,大约 95%的置信区间将包含总体均值。
换句话说,大约有 5%的置信区间没有捕捉到总体均值。在下图中,当蓝色点(上限)低于总体平均值时,或者当橙色点(下限)高于总体平均值时,就会发生这种情况。

Visualizing upper and lower bounds of confidence intervals
那么为什么贝叶斯解释不准确呢?给定任何一个置信区间,我们都不能对总体均值本身做出任何陈述。我们不知道它是属于包含总体均值的 95%区间,还是不属于总体均值的剩余 5%。我们甚至不能推断数据在置信区间内的分布。置信区间可以包含细尾的一部分,或者正好位于总体均值的中心。

A confidence interval could cover any part of the distribution
总之,我们对数据如何在置信区间内分布一无所知,更不用说它是否包含总体均值了。我们能做的陈述是关于置信区间的边界,而不是总体均值的位置。
结论
本文主要研究总体均值的置信区间。我们经常会遇到关于比例(z 检验)和线性回归参数的置信区间。尽管如此,解释是一样的。
我们生活在一个贝叶斯世界。一个人说“我们 95%有信心……”你的经理毕竟不想重复一百万次实验,这很容易被原谅,但是当我们告诉别人这意味着什么时,我们不应该忘记置信区间是一个频繁出现的概念。
延伸阅读
下面的博客涵盖了与 AB 测试相关的主题,以及对本文中提到的关键概念的更深入的回顾。
理解卷积神经网络:CNN——Eli 5 方式
ELI5 项目机器学习

Photo by Efe Kurnaz on Unsplash
通用逼近定理表示,前馈神经网络(也称为多层神经元网络)可以作为强大的逼近器来学习输入和输出之间的非线性关系。但是前馈神经网络的问题是,由于网络内存在许多要学习的参数,网络容易过度拟合。
我们是否可以拥有另一种类型的神经网络,它可以学习复杂的非线性关系,但参数较少,因此容易过拟合?。卷积神经网络 (CNN)是另一种类型的神经网络,可用于使机器能够可视化事物并执行任务,如图像分类、图像识别、对象检测、实例分割等,这是 CNN 最常用的一些领域。
概述
在本文中,我们将深入探讨卷积神经网络的工作原理。本文大致分为两个部分:
- 在第一部分中,我们将讨论卷积运算在不同输入(1D、2D 和 3D 输入)中的工作原理。
- 在第二部分,我们将探讨卷积神经网络的背景以及它们与前馈神经网络的比较。之后,我们将讨论 CNN 的关键概念。
引用说明:本文的内容和结构基于四分之一实验室——pad hai的深度学习讲座。
1D 卷积运算
让我们从基础开始。在本节中,我们将了解什么是卷积运算,它实际上是做什么的!。
想象一下,有一架飞机从阿里格纳安娜国际机场(印度钦奈)起飞,向英迪拉·甘地国际机场(印度新德里)飞去。通过使用某种仪器,你可以定期测量飞机的速度。在典型的情况下,我们的设备可能不是 100%准确,因此我们可能希望采用过去值的平均值,而不是依赖设备的最新读数。

Readings of aircraft
由于这些读数是在不同的时间步长获取的,而不是简单的平均读数,我们希望给予最近的读数比以前的读数更大的重要性,即…给当前读数分配更大的权重,给以前的读数分配较小的权重。
假设在当前时间步分配给读数的权重是 w₀,先前读数的权重是 w₋₁,依此类推。权重按递减顺序分配。从数学的角度来看,想象一下,我们有无限多的飞机读数,在每一个时间步,我们都有分配给该时间步的权重,一直到无穷大。那么当前时间步长的速度由(Sₜ)给出,

The weighted sum of all values
让我们举一个简单的例子,看看如何使用上面的公式计算当前时间步长的读数。

从上图可以看出,我们想计算飞机在当前时间步(t₀).)的速度我们从仪器中得到的实际速度是 1.90,我们不相信这个值,所以我们将通过取以前读数的加权平均值以及它们的重量来计算一个新值。我们从这个操作中获得的新读数是 1.80。
在卷积运算中,我们得到一组输入,我们根据所有先前输入及其权重计算当前输入的值。
在这个例子中,我没有谈到我们如何获得这些权重,不管这些权重是对还是错。现在,我们只关注卷积运算是如何工作的。
2D 卷积运算
在上一节中,我们已经了解了卷积运算在 1D 输入中的工作原理。简而言之,我们将特定输入的值重新估计为其周围输入的加权平均值。让我们讨论一下如何将同样的概念应用于 2D 输入。

Convolution with 2D filter
为了便于解释,我把上面显示的图像看作只有一个颜色通道的灰度图像。想象一下,上图中的每个像素都是由照相机拍摄的读数。如果我们想要重新估计任何像素的值,我们可以取其邻居的值,并计算这些邻居的加权平均值,以获得重新估计的值。该操作的数学公式由下式给出:

哪里有,
k-表示分配给像素值的权重的矩阵。它有两个索引 a,b——a 表示行,b 表示列。
I-包含输入像素值的矩阵。
sᵢⱼ-某一位置像素的重新估计值。
让我们举个例子来理解公式的工作原理。假设我们有一个泰姬陵的图像和 3x3 的权重矩阵(也称为内核)。在卷积运算中,我们对图像施加核,使得感兴趣的像素与核的中心对齐,然后我们将计算所有邻域像素的加权平均值。然后,我们将从左到右滑动内核,直到它通过整个宽度,然后从上到下计算图像中所有像素的加权平均值。卷积运算看起来像这样,

模糊图像
考虑我们将使用 3×3 单位核矩阵来重新估计图像中的像素值。我们这样做的方法是系统地检查图像中的每个像素,并放置内核,使像素位于内核的中心。然后将该像素的值重新估计为其所有邻居的加权和。

blur
在这个操作中,我们平均取 9 个邻居,包括像素本身。因此,合成的图像会变得模糊或平滑。
使用 3D 滤波器的 2D 卷积
在 3D 输入的情况下,如何执行卷积运算?
到目前为止,我们看到的任何图像都是 3D 图像,因为有 3 个输入通道——红色、绿色和蓝色(RGB ),但为了便于解释,我们忽略了这一点。但是,在本节中,我们将考虑原始形式的图像,即… 3D 输入。在 3D 图像中,每个像素都有 3 个值,分别代表红色、绿色和蓝色值。
在 2D 输入中,我们在水平和垂直方向滑动内核(也是 2D)。在 3D 输入中,我们将使用 3D 内核,这意味着图像和内核的深度是相同的。由于内核和图像具有相同的深度,因此内核不会随深度移动。

类似于 2D 卷积运算,我们将在水平方向上滑动内核。每次我们移动内核时,我们都要对整个 3D 邻域进行加权平均,即 RGB 值的加权邻域。因为我们只在两个维度上滑动内核——从左到右和从上到下,所以该操作的输出将是 2D 输出。
尽管我们的输入是 3D 的,核是 3D 的,但是我们执行的卷积运算是 2D 的,这是因为滤波器的深度与输入的深度相同。
我们可以对同一个图像应用多个滤镜吗?
实际上,我们可以在同一幅图像上一个接一个地应用具有不同值的多个核,而不是应用一个核,这样我们就可以获得多个输出。

Application of Multiple Filters
所有这些输出可以堆叠在一起,形成一个卷。如果我们对输入应用三个过滤器,我们将得到深度等于 3 的输出。卷积运算的输出深度等于应用于输入的过滤器数量。
计算输出尺寸
到目前为止,在前面的章节中,我们已经了解了卷积运算在不同输入情况下的工作原理。在这一节中,我们将讨论如何计算卷积运算后输出的维数?。
假设我们有大小为 7x7 的 2D 输入,我们从图像的左上角开始对图像应用 3x3 的过滤器。当我们在图像上从左到右从上到下滑动内核时,很明显输出小于输入,即… 5x5。

为什么产量变小了?
因为我们不能把内核放在角落,因为它会穿过输入边界。图像外的像素值是不确定的,所以我们不知道如何计算该区域像素的加权平均值。

对于输入中的每个像素,我们不是计算加权平均值和重新估计像素值。这适用于图像中存在的所有阴影像素(至少对于 3x3 内核),因此输出的大小将会减小。这个操作被称为有效填充。

如果我们希望输出和输入的大小相同呢?
原始输入的大小是 7x7,我们也希望输出大小是 7x7。因此,在这种情况下,我们可以在输入周围均匀地添加一个带有零的人工填充,这样我们就可以将内核 K (3x3)放在角点像素上,并计算邻居的加权平均值。

通过在输入周围添加这种人工填充,我们能够保持输出的形状与输入相同。如果我们有一个更大的内核( K 5x5),那么我们需要应用的填充量也会增加,这样我们就能够保持相同的输出大小。在此过程中,输出的大小与输出的大小相同,因此得名 Same Padding § 。
到目前为止,我们已经在图像中看到,我们以一定的间隔从左到右滑动内核(过滤器),直到它通过图像的宽度。然后我们从上到下滑动,直到整个图像横向移动。步距**【S】**定义应用过滤器的间隔。通过选择大于 1 的步幅(间隔),当我们计算邻居的加权平均值时,我们跳过了几个像素。步幅越高,输出图像的尺寸越小。
如果我们将本节所学的内容结合到一个数学公式中,就可以帮助我们找到输出图像的宽度和深度。公式应该是这样的,

最后,对于输出的深度,如果我们对输入应用’ K ‘滤波器,我们将得到’ K '这样的 2D 输出。因此,输出的深度与过滤器的数量相同。
卷积神经网络
我们是如何得到卷积神经网络的?
在我们讨论卷积神经网络之前,让我们回到过去,了解在前深度学习时代如何进行图像分类。这也是为什么我们更喜欢卷积神经网络用于计算机视觉的一个动机。

Photo by Dominik Scythe on Unsplash
让我们以图像分类为例,我们需要将给定的图像分类到其中一个类别中。实现这一点的早期方法是展平图像,即将 30×30×3 的图像展平为 2700 的向量,并将该向量输入到任何机器学习分类器,如 SVM、朴素贝叶斯等。此方法的关键要点是,我们将原始像素作为输入输入到机器学习算法,并学习图像分类的分类器参数。

从那以后,人们开始意识到并不是图像中的所有信息对于图像分类都是重要的。在这种方法中,我们不是将原始像素传递到分类器中,而是通过应用一些预定义或手工制作的过滤器(例如,在图像上应用边缘检测器过滤器)来预处理图像,然后将预处理的表示传递到分类器。
一旦特征工程(预处理图像)开始给出更好的结果,像 SIFT/HOG 这样的改进算法就被开发出来,以生成图像的精确表示。由这些方法生成的特征表示是静态的,即……在生成表示时不涉及学习,所有的学习都被推送到分类器。

而不是手动生成图像的特征表示。为什么不将图像展平成 2700×1 的向量,并将其传递到前馈神经网络或多层神经元网络(MLN)中,以便网络也可以学习特征表示?
与 SIFT/HOG、边缘检测器等静态方法不同,我们不固定权重,而是允许网络通过反向传播进行学习,从而降低网络的整体损耗。前馈神经网络可以学习图像的单个特征表示,但是在复杂图像的情况下,神经网络将不能给出更好的预测,因为它不能学习图像中存在的像素依赖性。

卷积神经网络可以通过应用不同的滤波器/变换来学习图像的多层特征表示,使得它能够保持图像中存在的空间和时间像素依赖性。在 CNN 中,网络要学习的参数数量明显低于 MLN,因为稀疏连接和网络中的权重共享允许 CNN 传输得更快。
稀疏连接和权重共享
在第节中,我们将了解前馈神经网络和卷积神经网络在稀疏连接和权重共享方面的区别。

假设我们正在执行一项数字识别任务,我们的输入是 16 个像素。在前馈神经网络的情况下,输入/隐藏层中的每个神经元都连接到前一层的所有输出,即…它对连接到该神经元的所有输入进行加权平均。

在卷积神经网络中,通过在图像上叠加核,我们一次只考虑几个输入来计算所选像素输入的加权平均值。使用稀疏得多的连接而不是考虑所有连接来计算输出 h₁₁。

请记住,当我们试图计算输出 h₁₁时,我们只考虑了 4 个输入,对于输出 h₁₂.也是如此需要注意的重要一点是,我们使用相同的 2x2 内核来计算 h₁₁和 h₁₂,即使用相同的权重来计算输出。不像在前馈神经网络中,隐藏层中存在的每个神经元将具有单独的权重。这种利用输入的相同权重来计算加权平均值的现象被称为权重共享。
汇集层

考虑我们有一个长度、宽度和深度为 3 个通道的输入体积。当我们对输入应用相同深度的滤波器时,我们将得到 2D 输出,也称为输入的特征图。一旦我们得到了特征图,我们通常会执行一个叫做汇集操作的操作。因为学习图像中存在的复杂关系所需的隐藏层的数量将是巨大的。我们应用池操作来减少输入特征表示,从而减少网络所需的计算能力。
一旦我们获得了输入的特征映射,我们将在特征映射上应用一个确定形状的过滤器,以从特征映射的该部分获得最大值。这就是所谓的最大池。它也被称为子采样,因为我们从内核覆盖的整个特征图部分采样一个最大值。

类似于最大池,平均池计算内核覆盖的特征图的平均值。
全连接层

LeNet — 5
一旦我们对图像的特征表示进行了一系列卷积和汇集操作(最大汇集或平均汇集)。我们将最终池层的输出展平为一个向量,并通过具有不同数量的隐藏层的完全连接的层(前馈神经网络)来学习特征表示中存在的非线性复杂性。
最后,完全连接的层的输出通过所需大小的 Softmax 层。Softmax 层输出一个概率分布向量,帮助执行图像分类任务。在数字识别器的问题中(如上所示),输出 softmax 层有 10 个神经元,用于将输入分类为 10 个类别(0-9 个数字)中的一个。

Photo by Fab Lentz on Unsplash
继续学习
如果你想用 Keras & Tensorflow 2.0 (Python 或者 R)学习更多关于人工神经网络的知识。查看来自 Starttechacademy的 Abhishek 和 Pukhraj 的人工神经网络。他们以一种简单化的方式解释了深度学习的基础。
结论
在这篇文章中,我们已经讨论了卷积运算如何在不同的输入上工作,然后我们继续讨论了一些导致 CNN 的图像分类的原始方法。之后,我们讨论了 CNN 的工作,也了解了卷积神经网络的一些重要技术方面。最后,我们看了在 CNN 的《学习复杂关系》的末尾附上 MLN 的来解决图像分类问题背后的原因。
推荐阅读
你的第一个深度神经网络
medium.com](https://medium.com/hackernoon/deep-learning-feedforward-neural-networks-explained-c34ae3f084f1) [## 使用免费 GPU 在 Google Collab 中开始使用 Pytorch
在 CUDA 支持下学习 Colab 中的 Pytorch
medium.com](https://medium.com/hackernoon/getting-started-with-pytorch-in-google-collab-with-free-gpu-61a5c70b86a)
在我的下一篇文章中,我们将讨论如何使用 Pytorch 可视化卷积神经网络的工作。所以确保你在媒体上跟踪我,以便在它下降时得到通知。
直到那时和平:)
NK。
你可以在 LinkedIn 上联系我,或者在 twitter 上关注我,了解关于深度学习和人工智能的最新文章。
免责声明 —这篇文章中可能有一些相关资源的附属链接。你可以以尽可能低的价格购买捆绑包。如果你购买这门课程,我会收到一小笔佣金。
利用大数据分析了解客户流失
如何利用数据科学为您的企业带来价值的实例

Photo by Matt Hoffman on Unsplash
猜猜看。目前世界上最有价值的资产是什么?
不是黄金,不是原油……是数据。您一定听说过流行的术语“大数据”,并且想知道这个术语到底是什么意思。想想你最喜欢的音乐流媒体服务——Spotify、Pandora 等。在世界各地,每秒钟都有许多不同的用户登录到该服务,与该服务进行公平的交互。由于每一次移动都对应一个可收集的数据点,所以您可以想象存储如此大的数据会面临怎样的挑战。
幸运的是,如果以正确的方式使用,这些大型数据集可以为企业带来真正的价值。在这篇博文中,我们将讨论这些大数据集的一个常见用例——预测客户流失。
了解流失
客户流失指的是从大量客户中悄悄流失客户的行为。一些客户可能会转向竞争对手,而一些人可能会永远离开服务。

开始时可能不明显,但随着时间的推移,这种损失的影响会逐渐积累。作为这些音乐流媒体服务提供商的决策者,我们希望了解这种搅动行为的成因,这将成为我们今天项目的主要目标。
我们将从检查可用的数据集开始。
完整的数据集是存储在 12 GB 中的用户日志。json 文件——这个大小只能由一些大数据工具处理,比如 Spark。为了充分理解可用的字段,我们将从获取数据的一个小子集(大约 128 MB)开始,以便在单台机器上进行探索性的数据分析。我们将通过以下命令加载数据集,
# create a Spark session
**spark = (SparkSession.builder
.master("local")
.appName("Creating Features")
.getOrCreate())**# Read in .json file as events **events = spark.read.json('mini_sparkify_event_data.json')
events.persist()**
Spark 有一个很棒的单行快捷方式,可以显示所有字段及其各自的数据类型
**events.printSchema()**root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: long (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
在查看数据集的头部后,我们会发现所有的用户交互都记录在页面的列中。
当大多数用户继续播放下一首歌曲时,有一些用户进入了“取消”页面——他们都通过“取消确认”页面确认了他们的取消(参见相同数量的“取消”和“取消确认”.我们将搅动活动具体定义为取消确认的数量。第页列有“取消确认”的用户将是我们特别感兴趣的搅动用户。
特征工程
我们已经成功地识别了流失的用户,现在是时候用我们的商业思维来思考用户流失的影响因素了。 如果你真的很讨厌你的音乐流媒体服务,你会怎么做? 我想出了下面 7 个特性,
- 代表性用户互动

我们有理由期待其他一些用户互动最终会导致我们的用户流失。我们可以使用箱线图来执行第一级过滤。箱线图将有效地帮助我们可视化特定数据分布的最小值、第 25 个百分点、平均值、第 75 个百分点和最大值。通过绘制搅动和非搅动用户的箱线图,我们可以清楚地解释特定交互中两类用户之间的差异。
以下相互作用显示了两组之间的显著分布差异,
- 添加好友——喝醉的用户不太可能添加好友
- 添加到播放列表 —喝醉的用户不太可能添加到播放列表
- 升级 —被搅动的用户有各种各样的升级活动
- 下一首歌——喝醉的用户不太可能播放下一首歌
- 拇指朝上——喝醉的用户不太可能竖起大拇指
- 滚动广告——被搅动的用户在滚动广告上有更广泛的传播
- 设置 —搅动的用户不太可能访问设置页面
- 注销 —大量用户不太可能注销(由于登录次数减少)
- 帮助——不焦虑的用户更有可能寻求帮助
- 首页——不安的用户不太可能访问主页
请注意,我们所有的用户交互都在同一列中,我们需要透视和聚合每个客户的某个交互的总数。基于以上筛选,我们将去掉一些不太重要的交互。
**events = events.drop('firstName', 'lastName', 'auth',
'gender', 'song','artist',
'status', 'method', 'location',
'registration', 'itemInSession')****events_pivot = (events.groupby(["userId"])
.pivot("page")
.count()
.fillna(0))****events_pivot = events_pivot.drop('About', 'Cancel', 'Login',
'Submit Registration','Register',
'Save Settings')**
2.平均音乐播放时间
对我自己来说,我使用它的时间可能会比普通用户短。因此,用户花在播放音乐上的平均时间长度将是一个非常重要的因素。一个简单的可视化显示确认结果如下。

我们将把这个特性添加到我们的 events_pivot 表中,
# filter events log to contain only next song
**events_songs = events.filter(events.page == 'NextSong')**# Total songs length played
**total_length = (events_songs.groupby(events_songs.userId)
.agg(sum('length')))**# join events pivot
**events_pivot = (events_pivot.join(total_length, on = 'userId',
how = 'left')
.withColumnRenamed("Cancellation Confirmation",
"Churn")
.withColumnRenamed("sum(length)",
"total_length"))**
3.活动天数
我们还期望搅动组和非搅动组之间活动天数的差异。由于 datetime 列只包含以秒为单位的单位,我们将需要使用一个窗口函数来合计每个客户的总活动时间,并将该值转换为天数。我们将把这个特性添加到 events_pivot 中。
**convert = 1000*60*60*24** # conversion factor to days# Find minimum/maximum time stamp of each user
**min_timestmp = events.select(["userId", "ts"])
.groupby("userId")
.min("ts")****max_timestmp = events.select(["userId", "ts"])
.groupby("userId")
.max("ts")**# Find days active of each user
**daysActive = min_timestmp.join(max_timestmp, on="userId")
daysActive = (daysActive.withColumn("days_active",
(col("max(ts)")-col("min(ts)")) / convert))****daysActive = daysActive.select(["userId", "days_active"])**# join events pivot
**events_pivot = events_pivot.join(daysActive,
on = 'userId',
how = 'left')**
4.付费用户的天数
类似地,我们也可以通过使用窗口函数来计算付费用户的天数,我们只需要为要成为付费用户的客户添加一个过滤器。
# Find minimum/maximum time stamp of each user as paid user
**paid_min_ts = events.filter(events.level == 'paid')
.groupby("userId").min("ts")****paid_max_ts = events.filter(events.level == 'paid')
.groupby("userId").max("ts")**# Find days as paid user of each user**daysPaid = paid_min_ts.join(paid_max_ts, on="userId")
daysPaid = (daysPaid.withColumn("days_paid",
(col("max(ts)")-col("min(ts)")) / convert))****daysPaid = daysPaid.select(["userId", "days_paid"])**# join events pivot
**events_pivot = events_pivot.join(daysPaid,
on = 'userId',
how='left')**
5.免费用户的天数
现在使用免费用户过滤器,我们可以找到每个客户作为免费用户的天数,
# Find minimum/maximum time stamp of each user as paid user
**free_min_ts = events.filter(events.level == 'free')
.groupby("userId").min("ts")
free_max_ts = events.filter(events.level == 'free')
.groupby("userId").max("ts")**# Find days as paid user of each user
**daysFree = free_min_ts.join(free_max_ts, on="userId")
daysFree = (daysFree.withColumn("days_free",
(col("max(ts)")-col("min(ts)")) / convert))****daysFree = daysFree.select(["userId", "days_free"])**# join events pivot
**events_pivot = events_pivot.join(daysFree,
on = 'userId',
how='left')**
6.会议次数
音乐播放的次数也可能是一个影响因素。由于这个数据集中有 sessionId ,我们可以使用 groupby 子句直接计算每个用户的惟一 Id 的数量。
# count the number of sessions **numSessions = (events.select(["userId", "sessionId"])
.distinct()
.groupby("userId")
.count()
.withColumnRenamed("count", "num_session**s"))# join events pivot
**events_pivot = events_pivot.join(numSessions,
on = 'userId',
how = 'left')**
7.用户访问代理
流服务在不同的用户代理上可能具有不同的性能。我们将尝试在模型中加入这一因素。由于有 56 个不同的用户代理,我们将使用 Spark 的 one-hot 编码器将这些不同的用户代理转换成一个向量。
# find user access agents, and perform one-hot encoding on the user
**userAgents = events.select(['userId', 'userAgent']).distinct()
userAgents = userAgents.fillna('Unknown')**# build string indexer
**stringIndexer = StringIndexer(inputCol="userAgent",
outputCol="userAgentIndex")****model = stringIndexer.fit(userAgents)
userAgents = model.transform(userAgents)**# one hot encode userAgent column
**encoder = OneHotEncoder(inputCol="userAgentIndex",
outputCol="userAgentVec")
userAgents = encoder.transform(userAgents)
.select(['userId', 'userAgentVec'])**# join events pivot
**events_pivot = events_pivot.join(userAgents,
on = 'userId',
how ='left')**
模型构建
在我们设计了适当的功能后,我们将构建三个模型——逻辑回归、随机森林和梯度推进树。为了避免编写冗余代码,我们将构建 stage 对象,并在管道末端用不同的分类器构建管道。
# Split data into train and test set
**events_pivot = events_pivot.withColumnRenamed('Churn', 'label')
training, test = events_pivot.randomSplit([0.8, 0.2])**# Create vector from feature data
**feature_names = events_pivot.drop('label', 'userId').schema.names
vec_asembler = VectorAssembler(inputCols = feature_names,
outputCol = "Features")**# Scale each column
**scalar = MinMaxScaler(inputCol="Features",
outputCol="ScaledFeatures")**# Build classifiers
**rf = RandomForestClassifier(featuresCol="ScaledFeatures",
labelCol="label",
numTrees = 50,
featureSubsetStrategy='sqrt')****lr = LogisticRegression(featuresCol="ScaledFeatures",
labelCol="label",
maxIter=10,
regParam=0.01)****gbt = GBTClassifier(featuresCol="ScaledFeatures",
labelCol="label")**# Consturct 3 pipelines
**pipeline_rf = Pipeline(stages=[vec_asembler, scalar, rf])
pipeline_lr = Pipeline(stages=[vec_asembler, scalar, lr])
pipeline_gbt = Pipeline(stages=[vec_asembler, scalar, gbt])**# Fit the models
**rf_model = pipeline_rf.fit(training)
lr_model = pipeline_lr.fit(training)
gbt_model = pipeline_gbt.fit(training)**
现在三个对象 rf_model 、 lr_model 、 gbt_model ,代表了 3 种不同的拟合模型。
车型评价
我们将测试拟合模型的性能,并选择具有最佳性能的模型作为最终模型。我们将首先构建一个专门用于此目的的函数,
**def modelEvaluations(model, metric, data):**
""" Evaluate a machine learning model's performance
Input:
model - pipeline object
metric - the metric of the evaluations
data - data being evaluated
Output:
[score, confusion matrix]
"""
# generate predictions
**evaluator = MulticlassClassificationEvaluator(
metricName = metric)
predictions = model.transform(data)**
# calcualte score
**score = evaluator.evaluate(predictions)
confusion_matrix = (predictions.groupby("label")
.pivot("prediction")
.count()
.toPandas())
return [score, confusion_matrix]**
我们将调用上面的函数来评估上面的模型
**f1_rf, conf_mtx_rf = modelEvaluations(rf_model, 'f1', test)
f1_lr, conf_mtx_lr = modelEvaluations(lr_model, 'f1', test)
f1_gbt, conf_mtx_gbt = modelEvaluations(gbt_model, 'f1', test)**



梯度推进模型在测试集中表现出最好的性能(F1 分数)。F1 分数定义为精确度和召回率的调和平均值,计算如下

精度是计算正确的正类标识的比例,在数学表达式中是这样的
精度= tp/(tp + fp)
召回是计算实际正类样本被正确识别的比例,在数学表达式中,
召回= tp/(tp + fn)
您可能想知道为什么我们选择更复杂的度量标准而不是最直观的准确性,这是因为数据集中存在不平衡的类分布。由于只有一小部分用户最终会流失,我们希望我们的模型能够正确识别他们,而不是追求高整体性能。想象一下,如果只有 6%的客户会在真实的人口分布中流失,预测每个人都不会流失仍然会给我们 94%的准确性。另一方面,F1 分数将惩罚单个班级的不良表现,这将有效地缓解这些问题。不平衡类特征将出现在每个流失预测问题中——F1 将始终是未来使用的指标。
特征重要性
我们将利用特征重要性函数,并可视化我们构建的每个特征的相对重要性等级。由于最后一个特性 userAgentVec 实际上是一个热编码向量,我们将把 userAgentVec 特性视为一个。下面的代码将对从独热编码向量获得的所有子特征的所有特征重要性值求和。
**feature_importances = np.array(gbt_model.stages[-1]
.featureImportances)****userAgentVec = feature_importances[len(feature_names) :].sum()
feature_importances = feature_importances[:len(feature_names)]
+ [userAgentVec]**
现在我们绘制梯度推进树的特征重要性。

我们构建的大多数功能都是用户流失的重要因素,其中 days_active 是最重要的因素。
全数据集运行
我们已经构建了适当的框架——我们准备按照上面相同的步骤,使用 AWS 的 EMR 服务让模型在完整的 12 GB 数据集上运行。我们将通过以下方式初始化会话
# Create spark session
**spark = (SparkSession
.builder
.appName("Sparkify")
.getOrCreate())**# Read in full sparkify dataset
**event_data = "s3n://dsnd-sparkify/sparkify_event_data.json"
events = spark.read.json(event_data)**
我们不再重复这些步骤——我已经在 nbviewer 网站上附上了完整的脚本。
最终,梯度推进模式产生了 0.8896 的 F1 成绩,这是一个很棒的表现。
+-----+----+---+
|label| 0.0|1.0|
+-----+----+---+
| 0|1612| 70|
| 1| 163|344|
+-----+----+---+
经营战略
我们经历了怎样的旅程——但我们还没有完成我们的使命。在数据科学领域,每个模型背后都有一个商业意图。有了我们创造的功能重要性,我们肯定可以想出一些商业策略来应对客户的抱怨。我们将简要讨论两种可能的策略,它们将真正为我们的提供商带来一些价值。
我们知道活跃天数是最重要的因素,我们可以建议高层管理人员建立一个奖励系统,鼓励低活跃度用户长时间保持在线。
此外,由于用户用来访问服务的代理也很重要,我们还可以找出表现不佳的代理,并让我们的工程团队专门解决这个问题。
我希望你能像我喜欢写这篇文章一样喜欢读这篇文章。我们一起使用大数据分析框架 Spark 来构建端到端的机器学习工作流,以从用户日志中识别潜在的音乐流媒体服务客户。我们执行了以下步骤,
- 探索性数据分析
- 特征工程
- 模型结构
- 模型评估
- 模型放大
- 商业策略
由于我们正在处理的数据规模庞大,执行超参数搜索变得尤为困难。可以想象,让笔记本电脑长时间开着并不是使用资源的最有效方式。使用 ssh 来保持程序运行的一些好技巧肯定有助于应对这一挑战。
如果说我们应该从这篇文章中学到什么的话,那就是我们在故事开始时提到的那一点。作为杰出的工程师,我们经常被吸引去通过各种技术构建最好的高性能模型,但是我们的模型需要解决商业问题才能有价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}