







Deepfake 通过使用生成式对抗网络(GANs)来绕过面部识别

随着面部识别软件越来越多地用于解锁智能手机和电脑,仅举几个用例,Deepfakes 将使实现真正的面部识别成为可能。随着我们达到一个更高的水平,科技正在迅速进步,在这个水平上,很难区分欺骗和朋友。
Deepfake 使用深度学习 AI 将视频中一个人的面部和声音替换为他们自己的面部、声音或两者的组合。人工智能(AI)的进步是近年来人机交互领域最令人兴奋的发展之一,但还有很长的路要走。
目前有许多涉及虚假语言技巧的欺诈案例,例如试图说服公司的一名员工将钱转到一个欺诈账户[1]。欺诈者使用被称为生成式对抗网络(GANs)的分析技术,为此转向 Deepfake,创造了一种无法区分真实事物和 Deepfakes 的方法。这使得保证收费变得相当困难,因为无法区分合法和假冒[8]。
生成对抗网络(GANs) [2]是一种较新的分析技术,另一方面,它可以以虚假图像和视频的形式产生假阳性和假阴性。这种现象的一个更近的表现是 Deepfake,这是一种人工智能驱动的技术,可以产生极其逼真的文本、图像或视频,人类很难将其与赝品区分开来。

幸运的是,Deepfakes 背后的技术也是可以检测欺诈的技术[3]。随着计算能力的增长和算法变得更快,深度假货正在成为远程客户识别的越来越大的威胁。目前,由虚假视频驱动的技术还不足以推翻现有的生物识别技术。然而,已经有一些高调的尝试访问账户,并覆盖使用假视频的生物特征数据和身份验证解决方案[7]。
通过结合使用人工智能和生物面部识别,公司可以验证用户,而不必通过驾照或护照等身份证明来验证他们的实际存在。Deepfakes 的使用可以绕过这些生物特征和身份证明,获取个人数据[4]。
生物面部识别技术的使用被监管机构视为在入职过程中验证个人数字身份的一种手段。然而,这不足以防范在线身份识别,尤其是随着深度伪造技术的兴起[7]。
Deepfake 技术已被用于实施在线欺诈,并利用它来影响公众舆论和让政治官员难堪。这种技术对那些通过远程生物特征认证带来新客户的组织构成了明显的威胁。
客户 KYC onboarding 播放器嵌入了一种生命识别形式,作为身份验证流程的一部分。活体检查试图确认其身份的人是否是活的主体,而不是复制品或仿制品。结合了活性检测以减少欺骗尝试的成功机会。

一款名为 Zao 的应用程序使用人工智能将电影或电视剪辑中人物的脸替换为你上传到该应用程序的任何人的照片。使用 Zao 的面部交换技术可以绕过面部识别系统。用它来破解安全系统不是一件容易的事。在用户发现该应用背后有“中国开发者”,尽管有可疑的小字,人们开始猜测中国人出于邪恶的目的从手机上偷拍人脸和照片。幸运的是,事实证明这些面孔实际上在亚马逊位于美国本土的数据中心的服务器上,并在 48 小时内被删除了,但恐慌是巨大的[6]。
这项技术近年来取得了巨大的进步,有人担心它可能被用来创建妥协的照片和视频认证,以绕过语音和面部识别协议。
RemoteVerify 是一个身份验证解决方案,结合了 NorthRow 最流行的两项技术:活体检测和生物认证。在一个例子中,生物认证的成功关键在于识别“活动性”,生物认证试图确定你是坐在电脑前还是拿着智能手机并允许你创建和访问银行账户的真人。
活体检测有可能防止骗子在试图绕过验证协议时使用机器人、视频、照片和伪造的文档。相比之下,美国政府和欧盟(EU) 已经提倡使用经过认证的活体检测方法,这些方法反过来又被绑定到一个被称为 ISO 30107 的全球生物特征标准上。
引用来源
- [1]https://www . acuantcorp . com/blog/deep fakes-newest-threat-to-identity/
- [2]https://www . csoonline . com/article/3504740/prediction-2-anagements-to-generate-deep fakes-to-bypass-face-recognition . html
- [3]https://mgmt 3d . com/ai-deep fakes-and-face-recognition-raise-questions-about-security/
- [4]https://securityboulevard . com/2020/01/deep fakes-pose-new-security-challenges/
- [5]https://techno de . com/2019/09/11/deep fakes-is-not-a-threat-to-face-payments-for-now/
- [6]https://www . bobs guide . com/guide/news/2019/Nov/29/are-deep-fakes-a-threat-to-the-future-of-identity-verification/
- [7]https://www . cybersecasia . net/features/cyber security-predictions-2020-face-the-deep fake-threat/2
- [8]https://www . pym nts . com/authentic ation/2019/deep fakes-next-stop-banking/
Deepfakes 危害和威胁建模

Jr Korpa 在 Unsplash 上拍摄的照片
Deepfakes 使得人们有可能在未经同意的情况下制造媒体——交换面孔、对口型和木偶——并给心理安全、政治稳定和商业中断带来威胁。
与任何新的创新技术一样,它可以被用作改善人民生活的工具,也可以被邪恶的行为者用来通过将其武器化来造成伤害。Deepfakes 也不例外。deepfakes 的武器化会对经济和国家安全产生巨大影响,会对个人和民主造成伤害。Deepfakes 将进一步侵蚀已经下降的对媒体的信任。
在政策和立法真空中,Deepfakes 变得越来越容易制造,甚至更容易传播。
在过去两年中,利用人工智能模型创建的合成数据的潜在恶意使用已经开始引起技术专家、公民社会和立法者的警惕。这项技术现在已经发展到有可能被武器化,对个人、社会、机构和民主造成破坏和伤害。Deepfakes 可以促成事实相对论,让威权领导人得以茁壮成长。还可以帮助公众人物将自己的不道德行为隐藏在 deepfakes 和假新闻的面纱下,称自己的实际危害行为为虚假,这也被称为骗子的红利[ 1 ]。
对个人的威胁
恶意使用 deepfake 的第一个案例出现在色情行业,对个人(主要是女性)造成情感、名誉和某些情况下的暴力。根据深度追踪,现在的强度为。ai,关于 Deepfake[ 2 ]的报道,96%的 deepfakes 都是色情视频,仅色情网站就有超过 1.35 亿的浏览量。
Deepfake 色情专门针对女性。
2018 年 4 月,驻孟买的记者 Rana Ayyub 在写了一篇关于印度执政党 BJP 的批评文章后,面临了一场 deepfake 攻击将她的脸叠加在一个色情视频上,然后被 doxed,视频在社交媒体上传播。骚扰和羞辱使 Ayyub 因心悸被送往医院,并导致她退出网络生活。
2017 年,有人使用 deepfakes 制作了一段和其他名人的色情视频。诺埃尔·马丁(Noelle Martin)是澳大利亚珀斯的一名法学毕业生,她发现有人拍摄了她的社交媒体照片,并将其 PS 成裸照,以制作深度假视频。最近,基丝汀·贝尔开展了一项公共活动,讨论并提高对深度假冒色情及其对个人造成的伤害的认识。
色情假货可以威胁,恐吓,并对个人造成心理伤害。Deepfake 色情将女性降低为性对象,折磨她们,造成情绪困扰,名誉伤害,虐待,在某些情况下,还会造成经济损失等物质伤害和失业等附带后果。
Deepfake 可以描述一个人沉溺于反社会行为,说一些他们从未做过的卑鄙的事情。这些假货会严重影响他们的声誉。它会破坏他们现在和未来的生活,包括但不限于职业生涯、职业市场、政治、人际关系和爱情。即使受害者可以通过不在场证明或其他方式揭穿谎言,这种修复可能为时已晚,无法补救最初的伤害。
在许多情况下,消除对他们的声誉、代理和材料的间接损害是具有挑战性的。随着社交媒体的传播能力和人类对八卦和谎言的天生渴望,丑闻式的造假传播得更快,而不是反驳和纠正。大多数人都没有批判地审视谬误的欲望。
对基于人工智能的合成媒体 deepfakes 缺乏认识,导致印度村民认为 WhatsApp 上儿童绑架的虚假信息是准确的,虚假的图像和视频导致了几起暴民私刑和杀戮案件。
恶意行为者可以利用不知情的个人,使用音频和视频 deepfakes 骗取经济利益。Deepfake 可以用来勒索。虚假媒体,视频和音频,可以用来榨取金钱,机密信息,或从个人身上索取好处。
在娱乐和艺术领域,我们已经看到了一些 deepfakes 的例子,当一个演员在完成电影之前去世时,工作室已经使用 deepfakes 来完成电影。死者可能获利是一个复杂的法律问题,可能会在死后损害名誉。
语音技术已经发展到这样一个水平,只需几句话,人工智能就可以对任何人产生令人印象深刻的准确模仿,即使是在发出他们很可能从未说过的单词或短语时。对于画外音艺术家,合成语音可以用来增加或扩展艺术家的角色。如果 deepfake 内容是在未经艺人同意的情况下创作的,将会影响他们的业务,限制他们的代理。这也可能对他们的生计产生影响。
对社会的威胁
假货会造成短期和长期的社会危害。基于人工智能的合成媒体可能会加速对媒体已经下降的信任。这种侵蚀会助长事实相对主义的文化,磨损民间社会日益紧张的结构。数字平台已经取代了传统的新闻把关人。信息传播的民主化性质和社交媒体渠道的财务激励使对社会机构的不信任永久化。如果虚假在平台上流行并被进一步分享,它就是有利可图的。加上不信任,现有的偏见和政治分歧可以帮助创造回音室和过滤泡沫,在社会中制造不和谐。
深度造假有助于改变民主话语。由 deepfake 提供的关于机构、政策和公共领导人的虚假信息可以被用来歪曲信息和操纵信仰。Deepfakes 将使公共和私人机构面临挑战,以抵御声誉攻击并揭穿错误信息和虚假信息。
适时的深度造假会对人身财产和生命造成重大伤害,并可能引发社会动荡。
反堕胎组织 CMP(医学进步中心)发布了一系列经过大量编辑的视频,声称计划生育协会的代表非法出售胎儿组织牟利,生殖健康非营利组织对此予以强烈否认。此后的多次调查都没有发现计划生育有任何不当行为,而 CMP 的创始人和另一名成员面临的法律后果。
Deepfake 可以用来传播速度和规模的恶意虚假信息,以侵蚀对机构的信任。
2016 年总统大选前发布了一个虚假的故事,指控克林顿和她的竞选主席约翰·波德斯塔(John Podesta)在一家名为彗星乒乓球(Comet Ping Pong)的餐厅经营一个虐待儿童的团伙。随着这个故事的传播,乒乓彗星收到了来自该理论信徒的数百次威胁。华盛顿警方逮捕了一名北卡罗来纳州男子,据称他带着一支半自动步枪走进彗星披萨店“自我调查”这一理论,将枪对准一名员工,并至少开了一枪。虽然《假新闻》没有使用 deepfakes,但是一个真实的视频《假新闻》可能会导致可怕的结果。
Deepfakes 可以通过使用虚假视频和音频来传播关于某个社区的虚假信息,从而加剧社会分裂。南亚、缅甸和印度都有一些反对穆斯林的例子。
Deepfake 可能成为恶意民族国家破坏公共安全和制造不确定性和混乱的强大工具。2018 年初,一个关于弹道导弹来袭的假警报被发送给夏威夷居民和游客。这是一个人为的错误,误解了一个测试指令,导致发送了一个实时警报,引起了全州的恐慌和混乱。一个流氓演员用一枚弹道导弹击中美国一个州的深度假警报发出同样的现场警报,会使这个国家走上报复的道路,破坏公共安全和外交。
对民主的威胁
2018 年,加蓬人民怀疑他们的总统阿里·邦戈病重或已经死亡。为了揭穿这一猜测,政府宣布邦戈曾中风,但健康状况良好。政府很快发布了邦戈向加蓬人民发表新年致辞的视频。一周内,军方发动了一场不成功的政变,称该视频为 deepfake。事实上,这个视频从未被证实是伪造的,但是它会改变加蓬政府的进程。deepfakes 的想法足以加速已经岌岌可危的局面的瓦解。
政治候选人的深度造假可以破坏政治候选人的形象和声誉,还可能改变选举的进程。
在投票前几天,一个精心制作的政治领袖候选人散布种族歧视言论或从事不道德行为的假新闻会破坏他们的竞选。即使在有效揭穿人工智能生成的合成媒体虚假信息之后,竞选活动和候选人甚至可能没有时间从这一事件中恢复过来。美国 2016 年总统选举和 2017 年法国选举中出现了国家支持的虚假信息运动。高质量的 deepfake 可以注入引人注目的虚假信息,从而给投票过程和选举结果蒙上非法的阴影。
在许多国家,殖民时代的法律将同性活动视为犯罪。在社会保守的马来西亚,它们仍然被用于政治目的。2019 年,一段关于两名男子性爱视频的视频在 WhatsApp 上疯传,其中一人酷似经济事务部长阿兹明·阿里。视频中的另一名男子供认不讳,并声称该视频是在未经同意的情况下创作的。他随后因鸡奸指控被捕。阿里和包括马来西亚总理在内的其他人辩称,该视频纯属捏造。数字法医专家尚未断定该视频的真实性。这可能会毁了阿里的政治生涯。
一个比利时政党制作了一个美国总统的假视频,视频中特朗普呼吁比利时退出巴黎气候协定。发布该视频的佛兰德社会党(Flemish Socialist Party sp.a)声称,deepfake 旨在引起人们对气候变化的关注,因为该视频最终呼吁签署一份投资可再生能源、电动汽车和公共交通的请愿书。
在政治上,夸大事实,过度表现政策立场,为反对者提供替代事实是可以接受的策略。使用假货和合成媒体可能会对投票结果产生深远的影响。Deepfake 可以对选民和候选人产生影响。Deepfakes 还可能被用于错误归因、对候选人撒谎、错误地放大他们的贡献或对候选人造成名誉伤害。
说谎者红利是指一则真实的媒体报道或令人不快的真相可能会被领导者斥之为深度假消息或假新闻。
对企业的威胁
一项研究估计,由于虚假信息,企业每年损失大约 780 亿美元。其中包括 90 亿美元用于修复名誉损失,以及另外 170 亿美元因金融虚假信息造成的损失。
Deepfakes 被用来冒充商业领袖和高管的身份,以方便欺诈。2019 年 3 月,一家英国能源公司的首席执行官通过电话要求他的老板,即该公司德国母公司的首席执行官,向匈牙利供应商汇款 243,000 美元。英国首席执行官照办了。据能源公司的保险公司 Euler Hermes Group S.A .称,他们后来才意识到,基于人工智能的软件被用于模仿德国首席执行官的声音。
据赛门铁克称,三家公司被盗数百万美元,它们成为 deepfake 音频攻击的受害者。在每次攻击中,人工智能生成的合成声音会给高级财务官打电话,请求紧急转账。deepfakes 模型是根据 CEO 的公开演讲训练出来的。2020 年 2 月,一名宾夕法尼亚州的律师被他儿子的假声音愚弄了,声称他需要 9000 美元的保释金。
在一起不太复杂的诈骗案中,以色列诈骗犯在 Skype 视频通话中冒充法国外交部长,从一名商人那里窃取了约 900 万美元。冒名顶替者伪装成部长和办公厅主任,并重新创建了一个虚假的办公室环境来进行视频通话。如果他们用了 deepfakes,就不需要办公室和伪装了。Deepfakes 还可以在社交工程中用来欺骗员工以获取商业秘密。
Deepfakes 可能会带来独特的劳动和就业风险。员工越来越依赖秘密的视频和音频记录来支持他们对骚扰或虐待的指控。根据当地的规定,这些录音通常可以作为最可靠的证据,尽管许多雇主禁止在工作场所录音。一个从事不当行为的商业领袖的深度伪装可以被用来证实骚扰指控或支持集体诉讼。补救这些努力造成的声誉损害可能需要投入大量的时间和资源。
2017 年 8 月,一场使用星巴克字体和标志的逼真图形的虚假社交媒体活动在 twitter 上流行,标签为“ borderfreecoffee ”。这个骗局是为了散布虚假信息,说星巴克在所谓的梦想家日期间向无证移民提供免费饮料。同样,在 2019 年 8 月,一则关于连锁餐厅橄榄花园(Olive Garden)正在帮助资助川普总统竞选连任的谣言是以标签“抵制橄榄花园”开始的。两起案件都给橄榄园和星巴克造成了一时的名誉伤害。Deepfakes 将使影响成倍恶化。
一些恶作剧网站,如 Channel23News 允许用户创建自己看起来真实的假新闻文章,并直接发布到社交媒体上,降低了宣传者的进入成本,甚至使小企业也面临这样的危险。还有许多关于其他品牌的虚假故事,比如可口可乐因“明确的寄生虫”召回 Dasani 瓶装水,Xbox 游戏机杀死一名青少年,好事多结束会员计划。企业必须为这种潜在的额外法律和商业风险做好准备。
Deepfakes 可用于市场操纵。
在他们的报告中,来自 Wilmerhale 的 Ferraro、Chipman 和 Preston 确定了虚假信息和 deepfake 的法律和商业风险,并广泛关注了对公司的损害。他们特别指出,企业不仅会损失被骗资金的价值、声誉和商誉,还会受到股东的诉讼、监管机构的调查,并失去获得更多资本的机会。
摩根大通发表了一份关于使用基于帖子的交易算法的市场参与者的报告,头条新闻特别容易受到虚假信息操纵。有几个利用协同假情报活动的泵送和倾倒方案的例子。一个由虚假视频和音频支持的虚假故事很容易在短期内操纵市场。如果 deepfake 显示最近推出的自动驾驶汽车自发着火,或者首席执行官对某个种族群体发表贬低性评论,或者以明确的非自愿行为描绘一位商业领袖,消费者信心将会直线下降。这些威胁的危险性会对一家公司的估值产生破坏性的影响。
关于谁拥有你的声音,法律上的共识是有限的。美国许多州保护姓名和肖像,只有少数几个州保护声音。大多数州只为活着的人保护这些权利。美国只有少数几个州对可能性进行死后保护。还有讽刺和戏仿作品中合理使用的权利以及公众人物的定义和第一修正案权利的其他问题。音频 deepfakes 将冲击录音行业。
结论
与任何新技术一样,邪恶的行为者将利用这种创新,并利用它为自己谋利。未经同意的假货会对心理安全、政治稳定和商业破坏造成威胁。今天,deepfakes 主要用于色情行业,对个人(主要是女性)造成情感、名誉和某些情况下的暴力。除了 deepfake 色情,我们还没有看到任何相应的 deepfake 事件。专家指出,他们对 deepfakes 的主要担忧是,当一个不受欢迎的真相被斥为 deepfake 或假新闻时,骗子会从中获利。我坚信,从长远来看,deepfakes 对企业构成了重大威胁。
喜欢? 随便给我买本书
参考
[1]https://www.daniellecitron.com/ted-talk/
https://sensity.ai/mapping-the-deepfake-landscape/
DeepMind 刚刚发布了用于神经网络和强化学习的 Haiku 和 RLax

图片由 Gerd Altmann 从 Pixabay 拍摄
利用最新的 JAX 图书馆来促进你的人工智能项目
人工智能(AI)研究每天都在发展,其工具也是如此——尖端人工智能公司 DeepMind 刚刚发布了两个基于 JAX 的神经网络(NN)和强化学习(RL)库,分别是俳句和 RLax 、。由于两者都是开源的,我们可以利用这些最新的库来进行我们自己的人工智能工作。
JAX 是什么?
JAX 由谷歌于 2018 年发布,是一款开源工具,通过转化 Python 和 NumPy 程序生成高性能加速器代码。在幕后, JAX 高度集成了亲笔签名,可以有效区分原生 Python 和 NumPy 函数, XLA ,是一个线性代数编译器,可以优化 TensorFlow 模型。
因此, JAX 通过提供学习模型优化的集成系统,为高性能机器学习研究而构建。它在人工智能研究人员中越来越受欢迎。然而,这并不是最容易处理的事情,这可能导致 DeepMind 开发了俳句和 RLax 。
什么是俳句和 RLax?
俳句是为 JAX 准备的简单 NN 库,这个库是由十四行诗的一些作者开发的——为张量流准备的神经网络库。这个库通过提供面向对象的编程模型,允许人工智能研究人员完全访问 JAX 的纯函数转换。通过提供两个核心工具— hk.Module和hk.transform,Haiku 被设计用来管理 NN 模型参数和其他模型状态。
RLax 是为 JAX 设计的简单 RL 库。这个库没有为 RL 提供完整的算法,而是为实现特定的数学运算以构建全功能的 RL 代理提供了有用的构建块。RL 中的代理是学习与嵌入式环境交互的学习系统。通常,智能体与环境的交互有一些离散的步骤,包括智能体的动作,被称为观察的环境更新状态,以及被称为奖励的可量化反馈信号。RLax 专门用于改进代理如何更好地与环境交互,从而使 RL 更加有效。
为什么是他们?
由于这两个库都是开源的,开发人员可能会考虑在自己的项目中使用它们。当然,在生产项目中使用它们可能还为时过早,但是有两个主要因素可以证明我们应该开始试验它们。
- 整体质量高。这两个库都由 DeepMind 支持,并且已经在合理的规模上进行了测试。例如,俳句的作者也在开发 Sonnet,一个著名的tensor flowNN 库。
- *用户友好。*两个库都执行一组定义良好的易用操作。对于俳句来说,它的 API 和抽象非常接近于十四行诗,使得过渡到俳句变得不那么痛苦。如果您不熟悉 Sonnet,您仍然可以相对快速地学会使用它,因为它提供了面向对象的编程模型。
结论
这两个库都将通过在 JAX 保护伞下提供一个伟大的集成工具来促进 NN 和 ML 模型的开发。如果你喜欢尝试新事物,我肯定会推荐你考虑使用这些库,至少可能是为了实验的目的。
有用的链接
DeepMind 不断涌现,发布了 Acme 和 Reverb RL 库
Alphabet 子公司继续为机器学习研究社区提供有用的软件库。

要旨
Deepmind 现在完全是 Alphabeta 的子公司,是一家专注于人工智能的创新软件公司。你可能因为他们在训练 AlphaGo 和 AlphaGoZero 中的成就而知道他们。AlphaGoZero 强化学习代理从零开始学习,直到成为围棋世界冠军。
尽管取得了这样或那样的巨大成功,但由于缺乏可重复性,该公司的学术成就一直面临挫折。独立复制学术作品的能力是验证和进一步合作的生命线。因此,提供服务至关重要,尤其是在一个计算资源丰富的人和其他人之间的差距越来越大的世界里。
DeepMind 明白。
近年来,他们已经进入了一个凹槽,不断地发布模块化软件库来帮助其他研究人员。这些库有多种用途,包括:
- 再现性
- 简单
- 模块性
- 并行化
- 效率
随着他们的 Acme 和 Reverb 库的发布,这一趋势继续发展。事实上,该库的作者在他们的网站上明确提出了 Acme 的高层次目标:
1。使我们的方法和结果具有可重复性——这将有助于澄清是什么使 RL 问题变得困难或容易,这是很少显而易见的。
2。为了简化我们(以及整个社区)设计新算法的方式——我们希望下一个 RL 代理对每个人来说都更容易编写!
3。提高 RL 代理的可读性——当从一篇论文过渡到代码时,不应该有隐藏的惊喜。
好吧,但是怎么做?
他们实现这些目标的方法之一是通过适当的抽象层次。强化学习的领域就像一个洋葱,就其层次而言,它的使用效果最好。从表面上看,你有一个从数据中学习的代理。剥开数据部分,你会看到这个数据要么是一个存储的数据集,要么是一个活生生的体验序列。剥开代理,您会看到它计划并采取行动,从它的环境中产生一个有度量的响应。你可以再次剥离更多,深入研究政策,经验,重放等。下图很好地展示了这一点。

分层显示的强化学习问题[ 来源
Acme 实现其目标的另一种方式是通过一种可扩展的数据存储机制,实现为配套的混响库。为此,考虑代理的典型经验重放缓冲。这个缓冲区有多大?通常,它是在至少几万到几十万个经验元组的数量级上,这是针对每个代理的。当处理一个涉及数千到数百万代理的模拟时,你会得到…很多。
通过解耦数据生产者(代理)和数据消费者(学习者)的概念,一个有效的数据存储机制可以独立地位于两者之间。这正是混响的作用。作为一个公司支持的库,它有超过 70%的 C++代码和一个整洁的 python 界面,我真的很兴奋能够深入其中。
一名 R2D2 RL 代理人正在玩街机游戏 Breakout [ 来源
结论
通过不断发布类似这样的精彩开源库,DeepMind 有助于降低准入门槛,并为 ML 和 AI 研究创造公平的竞争环境。将此与低成本云计算解决方案相结合,任何人都可以直接加入进来!提交你用这些库做的任何酷项目。我迫不及待想见到他们。
跳进来
【极致】Github 资源库
【极致】白皮书
【极致】Google Colab 示例
【混响】Github 资源库
【混响】Google Colab 示例
保持最新状态
在学术界和工业界,事情发展得很快!用一般的 LifeWithData 博客和 ML UTD 时事通讯让自己保持最新状态。
如果你不是时事通讯的粉丝,但仍想参与其中,可以考虑将 lifewithdata.org/blog 的和 lifewithdata.org/tag/ml-utd 的添加到 Feedly 聚合设置中。
原载于 2020 年 6 月 1 日 https://lifewithdata.org。**
DeepMind:大规模 RL 的存在证明
大脑是普遍智能的存在证据——谷歌的 DeepMind 是我们在复制它方面取得进展的证据。

DeepMind 与 AlphaGo、AlphaZero 等的强化学习成功案例。正在为部署大规模人工智能项目的下一代科技公司铺平道路。理论上,DeepMind 远不是一个盈利的实体(尽管他们确实给了谷歌一个优势),但他们正在向世界展示如何使用人工智能,更令人印象深刻的是在特定任务中对过时的人类使用增强学习。既然它已经存在,它将被用来完成有利可图的任务。
DeepMind 是做什么的?
DeepMind 想解决智能。近年来,他们将世界上最优秀的机器学习研究人员与最优秀的计算机科学家融合在一起,创造出在游戏中击败人类的计算机。确切地说,是他们尝试过的任何游戏。 AlphaZero 在无人参与的情况下自行解决了无数游戏。DeepMind 瞄准了一个系统,并给了计算机掌握它的工具。在高层次上,这是一个美丽的暗示:计算机在没有人类输入的情况下可以做的事情每天都在扩展。
作为一名研究人员,我对前来参与前沿机器学习研究的科技巨头又爱又恨。DeepMind 在强化学习领域更有意图、更有影响力。人们应该模仿他们的方法。

美丽的岩石。来源,作者。
等等,什么是存在证明?
E 存在意味着有 是 一条通往某物的路径。人脑的存在意味着进化的确产生了一般的智力,但这并不意味着它会从目前的生物体或计算机中再次进化而来。存在证明通常比人们想要的要弱得多。
数学中的存在证明也很棘手。一个经典的例子是哥德尔的不完全性定理:他证明了数学中每一个公理的形式系统都能够展示所有的真理。工程师的外卖:每个系统都有限制(没有免费的午餐)。
也就是说,我对人工智能的看法要积极得多:
大脑是人工智能存在的证据,就像鸟类是飞行的证据一样。
解决一般智力问题可能来自我们无法预测的事件(研究突破),所以给它一个时间表是不值得的。除了希望 AGI(人工智能)被缺乏挑战动机的人发现之外,我正在寻找其他事情去做。
深度学习改变了人工智能领域,但它不会给我们人工通用…
towardsdatascience.com](/deep-learning-is-not-the-key-to-unlocking-the-singularity-913f960ac345) 
伯克利的钟楼。来源,作者。
RL 按比例
强化学习 (RL)最近在主流媒体上得到大量炒作。这是一个试图设计能够像人类婴儿一样学习完成任何任务的智能体的研究领域。在规模上,在技术上,意味着在一个项目上融合许多工程师来创造一些有价值的东西(通常是应用程序或算法)。研究人员研究强化学习,DeepMind 是第一个让他们在重要的事情上合作的公司(嗯,公开地说——另一家公司可能已经做了这件事,但没有告诉我们)。重要的是在人类时代最具历史意义的游戏中摧毁人类。
大规模研发是将研究中的创新应用到现有的问题中,以这种方式使人类做的工作变得无用。
在接下来的几年里,我认为人工智能的进步会在哪些领域引起轰动?
1 我未来的公司将从可穿戴设备和杂货账单中记录健康数据,并能够告诉某人如何饮食以 a)减肥,b)保持头脑清醒,或 c)保持肠道健康。
Batch RL 将使许多创业公司拥有的数据更具影响力。目前,这项研究受到数据不规则性和控制策略训练的不稳定性的限制,但只要再给它几年时间。
sascha Lange Thomas Gabel Martin ried miller 适应、学习和优化系列丛书的一部分(ALO,卷…
link.springer.com](https://link.springer.com/chapter/10.1007/978-3-642-27645-3_2)
2 体现智能:将机器学习创新从新闻传播到户外。赋予机器学习一个身体有时被称为体现智能。我们已经看到昂贵的机器人如何解决一些令人印象深刻的有用任务。下一步是让廉价的机器人完成更简单的任务——我认为我们正处于自动化指数的底部。在这个领域有很多地方可以成立一家公司。幸运的是,在这里做研究,我将继续前进,继续学习。
脸书人工智能正在进行机器人学习方面的研究项目,这将导致人工智能能够更有效地学习和…
ai.facebook.com](https://ai.facebook.com/blog/advancing-ai-by-teaching-robots-to-learn/)
3 我的公司将*提供一个平台,制药公司可以在这个平台上交叉引用他们的药物机制,并通过成为药物数据的中心枢纽,有可能省去设计阶段。*数据并不意味着知识,但它可以超级有用。
我以前写过一个关于这个的场景——如果一家公司得到了一个精确的人体模拟器,我们就可以为药物研发和许多其他产品进行强化学习。这将产生超乎想象的影响和收益。
一场基于机器学习的革命能否在人工全科医疗之前改变生物医学和治疗学
towardsdatascience.com](/the-bio-medicine-singularity-a9615708a925)
我接下来要写的将揭开炒作的面纱。 ai 全球创业公司——你可以在这里得到提示:
[## 解说:大部分‘AI’公司都不是 AI 公司。以下是辨别的方法
人工智能(AI)公司利用深度或机器学习,而不仅仅是基础数据分析。
fortune.com](https://fortune.com/2018/07/03/ai-artificial-intelligence-deep-machine-learning-data/)
像这样?请在https://robotic.substack.com/订阅我关于机器人、自动化和人工智能的直接通讯。
一个关于机器人和人工智能的博客,让它们对每个人都有益,以及即将到来的自动化浪潮…
robotic.substack.com](https://robotic.substack.com/)
Deepnote 将成为 Jupyter 黑仔

DeepNote 笔记本体验预览(来源)
DeepNote,一个位于旧金山的小型团队,想要在你的数据科学工作流程中取代 Jupyter。我想他们可能会这么做。
如果你像我一样是一名数据科学家,你可能会花更多时间在工程任务上,而不是实际研究上。安装库、管理数据库、跟踪你的实验、调试代码、耗尽内存……你明白了。
【关于】 页面 深注
Jupyter 笔记本非常适合数据科学原型开发。在一个单一的环境中,人们可以无缝地执行探索性分析,可视化数据,并建立 ML 模型原型。
也就是说,不久前,大多数数据科学家认为 Spyder IDE 是万能的。即使是最伟大的工具最终也会寿终正寝,不管是因为缺乏适应性、缺乏持续的支持,还是其他什么原因。
尽管 Jupyter 笔记本在数据科学社区广受欢迎,但许多人也指出了一些重要的弱点。新工具以更好或更快的方式解决现有工具中的弱点的能力通常使它们能够被现状工具集所采用。让我们来看看 DeepNote 提供的一些激动人心的竞争优势。
实时协作
谷歌的在线协作工具套件(文档、表格、幻灯片等)占据了微软 Office 的巨大市场份额,却没有增加多少功能。他们是怎么做到的?让世界踏上通往他们家门口的道路的主要区别在于实时协作。
通过在谷歌套件中与同事实时协作,你不再需要同步开发,也不再需要为融合差异而烦恼。此外,您总是知道您的合作者目前在哪里工作,这使得分工更加容易。
DeepNote 带来了开箱即用的功能,在共享计算环境中实现无缝协作。事实上,这确实会带来名称空间变化的问题。然而,我认为这是一个比共享 Jupyter 笔记本更好的问题,因为要获得给定的状态,必须重新运行这些笔记本。
在此查看实时 DeepNote 协作的运行。
此外,DeepNote 为每个协作者提供了不同的权限级别:查看、执行、编辑、管理和所有者。这允许对这些笔记本电脑的操作进行大量控制。
首先,想象一个师生场景。在线课程的教师可以在虚拟教室中浏览共享的笔记本。教师拥有管理员/所有者权限,而教室的其余部分仅包含查看权限。
作为另一个例子,考虑一个上级评估一个团队成员的工作。团队成员使用所有者权限来完全控制笔记本。上级使用编辑权限提供内联反馈,但不能执行任何单元格。通过只对团队成员保留执行权限,上级不能更改(读取:污染)团队成员的名称空间。
变量浏览器
Spyder IDEs 中我在 Jupyter 笔记本中真正错过的一个方面(至少,没有扩展/小部件)是易于访问的名称空间浏览器。当然,有who / whos魔法命令。然而,这些并不能真正与 Spyder 的产品相提并论。
我们再一次用 DeepNote 填补了空白!

DeepNote 笔记本为你的变量提供了漂亮的摘要(来源)
除了坚固的变量浏览器,没有漂亮的熊猫DataFrame显示器,任何有自尊的笔记本环境都是不完整的。

是的,DeepNote 笔记本也有漂亮的熊猫DataFrame显示屏(来源)
DeepNote 附着在云硬件上
我肯定你听说过经验法则(实际上,更多的是抱怨),大约 80%的数据科学是除了数学和统计之外的一切。在云计算环境中,这一比例变得更像 90/10,额外损失了 10%的时间来为您的笔记本电脑提供合适的计算能力。

轻松查看和选择笔记本电脑运行的硬件( source )
DeepNote 了解您的困难,并提供对基于云的硬件的无缝访问,以满足您的所有需求。所谓无缝,我的意思是你在笔记本界面上设置一切!哦,顺便说一下,他们不会关闭你的内核,除非它实际上是空闲的。
Python 包管理
Python 有一个很棒的包管理系统。DeepNote 意识到了这一点,并坚持使用其工作目录中的一个requirements.txt文件。即使这样,仍然很容易忘记预先安装一些依赖项。当这种情况发生时,直到我们尝试导入并失败时,我们才意识到遗漏!
为此,DeepNote 的笔记本会主动监控您的包导入,通知您声明的需求中缺少的依赖项。此外,如果需求文件还不存在,它会对该文件进行最好的猜测。剧透警告:猜测通常是正确的。

DeepNote 包管理器建议安装一个缺少的依赖项(源
DeepNote 集成了…很多

创建新项目的示例(来源
最后,DeepNote 提供了几乎所有你期望使用的集成。为了保持笔记本的有序,您可以选择不同的源代码控制库连接。这可以在笔记本创建过程中使用,也可以用于写回更新。
除了源代码控制,DeepNote 笔记本还允许连接到云计算数据存储,如 S3、GCS 和公共数据库引擎。

正式连接到各种云基础设施(来源)
暂时就这样了
虽然 DeepNote 还没有达到真正消灭 Jupyter 的境界,但这个轨迹肯定是存在的。我渴望看到他们如何继续!然而,不要只相信我的话。像我一样,报名参加他们的早期接入项目。他们在一周内做出了回应,从那以后我们就一直在漫不经心地讨论改进!不要只是抱怨现状,成为改善现状的一份子。
保持最新状态

学术界和工业界的事情发生得非常快!通过一般的 LifeWithData 博客、ML UTD 简讯和 Twitter feed 让自己保持最新状态。
如果你不是收件箱时事通讯的粉丝,但仍然想参与其中,可以考虑将这个 URL 添加到聚合设置中。
原载于 2020 年 2 月 23 日 https://lifewithdata.org。
DeepPavlov:自然语言处理的“Keras”回答 COVID 问题
使用 Azure 机器学习和 DeepPavlov 库在 COVID 论文数据集上训练开放域问答模型。

奥比·奥尼耶德在 Unsplash 上拍摄的照片
在与图像相关的深度学习领域,Keras 库发挥了重要作用,从根本上简化了迁移学习或使用预训练模型等任务。如果您切换到 NLP 领域,执行相对复杂的任务,如问题回答或意图分类,您将需要让几个模型一起工作。在这篇文章中,我描述了使 NLP 民主化的 DeepPavlov 库,以及如何使用它和 Azure ML 在 COVID 数据集上训练问答网络。
本帖是AI April倡议的一部分,四月的每一天我的同事都会在这里发布与 AI、机器学习和微软相关的新原创文章。看看 日历 找到其他已经发表的有趣的文章,并在这个月内继续查看那个页面。
在过去的几年里,我们见证了许多与自然语言处理相关的任务取得了重大进展,这主要归功于 transformer 模型和 BERT 架构。一般来说,BERT 可以有效地用于许多任务,包括文本分类,命名实体提取,预测上下文中的屏蔽词,甚至问答。
从头开始训练 BERT 模型是非常资源密集型的,大多数应用程序依赖于预先训练的模型,使用它们进行特征提取,或者进行一些温和的微调。因此,我们需要解决的原始语言处理任务可以分解为更简单步骤的管道,BERT 特征提取是其中之一,其他是标记化,将 TF-IDF 排名应用于一组文档,或者只是简单的分类。
这个流水线可以看作是由一些神经网络代表的一组处理步骤。以文本分类为例,我们将有提取特征的 BERT 预处理器步骤,然后是分类步骤。这一系列步骤可以组成一个神经架构,并在我们的文本数据集上进行端到端的训练。
DeepPavlov
DeepPavlov 图书馆来了。它主要为你做这些事情:
- 允许您通过编写一个配置,将文本处理管道描述为一系列步骤。
- 提供了许多预定义的步骤,包括预训练的模型,如 BERT 预处理器
- 提供了许多预定义的配置,您可以使用它们来解决常见的任务
- 从 Python SDK 或命令行界面执行管道训练和推理
这个库实际上做的远不止这些,它让你能够在 REST API 模式下运行它,或者作为微软机器人框架的 chatbot 后端。然而,我们将关注使 DeepPavlov 对自然语言处理有用的核心功能,就像 Keras 对图像一样。
您可以通过在https://demo . DeepPavlov . ai上玩一个交互式 web 演示来轻松探索 DeepPavlov 的功能。
用 DeepPavlov 进行 BERT 分类
再次考虑使用 BERT 嵌入的文本分类问题。 DeepPavlov 包含一些预定义的配置文件,例如,看看 Twitter 情感分类。在此配置中,chainer部分描述了管道,包括以下步骤:
simple_vocab用于将预期输出(y),即一个类名,转换成数字 id (y_ids)transformers_bert_preprocessor取输入文本x,产生一组伯特网络期望的数据transformers_bert_embedder实际上为输入文本生成 BERT 嵌入one_hotter将y_ids编码成分类器最后一层所需的一位热码keras_classification_model是分类模型,是定义了参数的多层 CNNproba2labels最终层将网络的输出转换成相应的标签
Config 还定义了dataset_reader来描述输入数据的格式和路径,以及train部分中的训练参数,以及其他一些不太重要的东西。
一旦我们定义了配置,我们就可以从命令行训练它,如下所示:
python -m deeppavlov install sentiment_twitter_bert_emb.json
python -m deeppavlov download sentiment_twitter_bert_emb.json
python -m deeppavlov train sentiment_twitter_bert_emb.json
install命令安装执行该过程所需的所有库(如 Keras、transformers 等)。),第二行download是所有预训练的模型,最后一行执行训练。
一旦模型经过训练,我们就可以从命令行与它进行交互:
python -m deeppavlov interact sentiment_twitter_bert_emb.json
我们也可以使用任何 Python 代码中的模型:
model **=** build_model(configs**.**classifiers**.**sentiment_twitter_bert_emb) result **=** model(["This is input tweet that I want to analyze"])
开放领域问答
可以使用 BERT 执行的最有趣的任务之一叫做 开放领域问答 ,简称 ODQA。我们希望能够给计算机一堆文本来阅读,并期望它对一般问题给出具体的答案。开放领域问答的问题指的是我们不是指一个文档,而是指一个非常广阔的知识领域。
ODQA 通常分两个阶段工作:
- 首先,我们试图为查询找到最匹配的文档,执行信息检索的任务。
- 然后,我们通过网络处理该文档,以从该文档中产生特定答案(机器理解)。

开放领域问答架构,来自 DeepPavlov 博客
在这篇博文中已经很好地描述了使用 DeepPavlov 进行 ODQA 的过程,然而,他们在第二阶段使用的是 R-NET,而不是 BERT。在本帖中,我们将把 ODQA 与 BERT 一起应用于新冠肺炎开放研究数据集,该数据集包含超过 52,000 篇关于新冠肺炎的学术文章。
使用 Azure ML 获取训练数据
为了训练,我将使用 Azure 机器学习,特别是笔记本。将数据放入 AzureML 的最简单方法是创建一个数据集。在语义学者页面可以看到所有可用的数据。我们将使用非商业子集,位于这里。
为了定义数据集,我将使用 Azure ML Portal ,并从 web 文件创建数据集**,选择文件作为数据集类型。我唯一需要做的就是提供网址。**

要访问数据集,我需要一台笔记本和计算机。因为 ODQA 任务相当密集,而且需要大量内存,所以我会用 112Gb 或 RAM 的 NC12 虚拟机创建一个大计算。这里描述了创建计算机和笔记本的过程。
要从我的笔记本中访问数据集,我需要以下代码:
from azureml.core import Workspace, Dataset
workspace **=** Workspace**.**from_config()
dataset **=** Dataset**.**get_by_name(workspace, name**=**'COVID-NC')
数据集包含一个压缩的.tar.gz文件。为了解压缩它,我将数据集挂载为一个目录,并执行 UNIX 命令:
mnt_ctx **=** dataset**.**mount('data')
mnt_ctx**.**start()
!tar **-**xvzf **./**data**/**noncomm_use_subset**.**tar**.**gz
mnt_ctx**.**stop()
所有文本以.json文件的形式包含在noncomm_use_subset目录中,在abstract和body_text字段中包含摘要和完整的纸质文本。为了将文本提取到单独的文本文件中,我将编写简短的 Python 代码:
from os.path import basename**def** **get_text**(s):
**return** ' '**.**join([x['text'] **for** x **in** s]) os**.**makedirs('text',exist_ok**=**True)
**for** fn **in** glob**.**glob('noncomm_use_subset/pdf_json/*'):
**with** open(fn) **as** f:
x **=** json**.**load(f)
nfn **=** os**.**path**.**join('text',basename(fn)**.**replace('.json','.txt'))
**with** open(nfn,'w') **as** f:
f**.**write(get_text(x['abstract']))
f**.**write(get_text(x['body_text']))
现在我们将有一个名为text的目录,所有的论文都以文本的形式存在。我们可以去掉原来的目录:
!rm **-**fr noncomm_use_subset
设置 ODQA 模型
首先,让我们在 DeepPavlov 中建立原始的预训练 ODQA 模型。我们可以使用名为en_odqa_infer_wiki的现有配置:
import sys
!{sys**.**executable} **-**m pip **--**quiet install deeppavlov
!{sys**.**executable} **-**m deeppavlov install en_odqa_infer_wiki
!{sys**.**executable} **-**m deeppavlov download en_odqa_infer_wiki
这将需要相当长的时间来下载,你将有时间意识到你是多么幸运地使用云资源,而不是你自己的电脑。下载云到云要快得多!
要从 Python 代码中使用这个模型,我们只需要从 config 构建模型,并将其应用到文本:
from deeppavlov import configs
from deeppavlov.core.commands.infer import build_model
odqa **=** build_model(configs**.**odqa**.**en_odqa_infer_wiki)
answers **=** odqa([ "Where did guinea pigs originate?",
"When did the Lynmouth floods happen?" ])
我们将得到的答案是:
['Andes of South America', '1804']
如果我们试图问网络一些关于冠状病毒的问题,下面是我们将得到的答案:
- 什么是冠状病毒?— 一种特定病毒的毒株
- 什么是新冠肺炎?— 在屋顶或教堂塔楼上筑巢
- 新冠肺炎起源于哪里?— 阿帕特北部海岸
- 上一次疫情是什么时候?— 1968 年
远非完美!这些答案来自旧的维基百科文本,该模型已被训练过。现在我们需要根据我们自己的数据重新训练文档提取器。
训练模型
用你自己的数据训练 ranker 的过程在 DeepPavlov 博客中有描述。因为 ODQA 模型使用en_ranker_tfidf_wiki作为排序器,我们可以单独加载它的配置,并替换用于训练的data_path。
from deeppavlov.core.common.file import read_json
model_config **=** read_json(configs**.**doc_retrieval**.**en_ranker_tfidf_wiki)
model_config["dataset_reader"]["data_path"] **=**
os**.**path**.**join(os**.**getcwd(),"text")
model_config["dataset_reader"]["dataset_format"] **=** "txt" model_config["train"]["batch_size"] **=** 1000
我们还减小了批量大小,否则训练过程将无法适应内存。再次意识到我们手头可能没有 112 Gb RAM 的物理机器。
现在让我们训练模型,看看它的表现如何:
doc_retrieval **=** train_model(model_config) doc_retrieval(['hydroxychloroquine'])
这将为我们提供与指定关键字相关的文件名列表。
现在让我们实例化实际的 ODQA 模型,看看它是如何执行的:
*# Download all the SQuAD models* squad **=** build_model(configs**.**squad**.**multi_squad_noans_infer,
download **=** True)
*# Do not download the ODQA models, we've just trained it* odqa **=** build_model(configs**.**odqa**.**en_odqa_infer_wiki,
download **=** False)
odqa(["what is coronavirus?","is hydroxychloroquine suitable?"])
我们将得到的答案是:
['an imperfect gold standard for identifying King County influenza admissions', 'viral hepatitis']
还是不太好…
使用 BERT 回答问题
DeepPavlov 有两个预先训练好的问答模型,在斯坦福问答数据集 (SQuAD): R-NET 和 BERT 上训练。在前面的例子中,使用了 R-NET。我们现在将它切换到 BERT。squad_bert_infer config 是使用 BERT Q & A 推论的良好起点:
!{sys**.**executable} **-**m deeppavlov install squad_bert_infer
bsquad **=** build_model(configs**.**squad**.**squad_bert_infer,
download **=** True)
如果你看 ODQA 配置,以下部分负责问答:
{
"class_name": "logit_ranker",
"squad_model": {
"config_path": ".../multi_squad_noans_infer.json" },
"in": ["chunks","questions"],
"out": ["best_answer","best_answer_score"]
}
为了改变整个 ODQA 模型中的问答引擎,我们需要替换 config:
odqa_config **=** read_json(configs**.**odqa**.**en_odqa_infer_wiki)
odqa_config['chainer']['pipe'][**-**1]['squad_model']['config_path'] **=**
'{CONFIGS_PATH}/squad/squad_bert_infer.json'
现在,我们以与之前相同的方式构建和使用模型:
odqa **=** build_model(odqa_config, download **=** False)
odqa(["what is coronavirus?",
"is hydroxychloroquine suitable?",
"which drugs should be used?"])
以下是我们从最终模型中获得的一些问题和答案:
- 什么是冠状病毒?— 呼吸道感染
- 羟氯喹合适吗?— 耐受性良好
- 应该使用哪些药物?— 抗生素、乳果糖、益生菌
- 潜伏期是多少?—3–5 天
- 患者在潜伏期有传染性吗?— 中东呼吸综合征不会传染
- 如何污染病毒?— 基于辅助细胞的拯救系统细胞
- 什么是冠状病毒类型?— 包膜单链 RNA 病毒
- 什么是 covid 症状?— 失眠、食欲不振、疲劳和注意力不集中
- 什么是生殖数?— 5.2
- 杀伤力如何?— 10%
- 新冠肺炎起源于哪里?— 葡萄膜黑色素细胞
- 抗生素疗法有效吗?— 不太有效
- 什么是有效的药物?— M2、神经氨酸酶、聚合酶、附着和信号转导抑制剂
- 对抗 covid 什么有效?— 神经氨酸酶抑制剂
- covid 和 sars 相似吗?— 所有冠状病毒的功能和结构基因都有非常相似的组织
- covid 类似于什么?— 血栓形成
结论
这篇文章的主要目的是演示如何使用 Azure 机器学习和 DeepPavlov NLP 库来做一些很酷的事情。我没有动力在 COVID 数据集中做出一些意想不到的发现——ODQA 方法可能不是最好的方法。然而,DeepPavlov 可以以类似的方式用于在该数据集上执行其他任务,例如,实体提取可以用于将论文聚类到主题组中,或者基于实体对它们进行索引。我绝对鼓励读者去看看 Kaggle 上的 COVID 挑战赛,看看你是否能提出可以使用 DeepPavlov 和 Azure 机器学习实现的原创想法。
Azure ML 基础设施和 DeepPavlov 库帮助我在几个小时内完成了我描述的实验。以这个例子为起点,你可以取得好得多的结果。如果有,请与社区分享!数据科学可以做很多奇妙的事情,但当许多人开始一起研究一个问题时,就更是如此了!
【https://soshnikov.com】原载于 2020 年 4 月 29 日。
DeepStyle(第 1 部分):使用最先进的深度学习生成现实的高级时尚服装和风格
提供纸和 github 代码!点击此处进入第二部分。

模特走秀(来源)
这是我在 2019 年春天在我的家乡大学 香港科技大学 为计算机视觉深度学习课程做的一个项目。那时候,我正在慢慢了解时尚和风格的世界:如何穿得更好,跟上现代潮流。我开始观看高级时尚奢侈品牌的时装秀,甚至街上随便一个人都知道。迪奥、古驰、路易威登、香奈儿、爱马仕、乔治·阿玛尼、卡地亚、博柏利等等。随着我看得越来越多,我开始逐渐融入时尚界。当我需要为我的计算机视觉课程想出一个最终项目主题的时候,我想,为什么不创建一个深度学习系统,它将能够生成好看且有创意的高级时装?想象一下会很有趣,对吗?
所以我和我的队友创造了深度风格。
什么是 DeepStyle?
简而言之, DeepStyle 就是具有生成高级时尚服装单品能力的定制深度学习框架。它可以作为时装设计师的灵感,也可以预测时装业的下一个流行项目。DeepStyle 吸收流行时尚图片,并创造新的产品,作为有效预测未来趋势的一种方式。
我们的研究包括两个部分:建立高级奢侈品时尚数据库,并使用人工智能生成类似的时尚物品。第一部分,我们需要一个可靠的来源,在那里我们可以收集所有来自 t 台的高级奢华时尚图片。但除此之外,我们还希望有一个模型,可以识别服装和裁剪出图像的其余部分,因为最终,如果我们在后台生成假的模型和观众,那会很奇怪😂。在我们将图像裁剪为仅包含服装本身之后,我们可以将图像输入到另一个模型中,该模型将能够从头开始生成新的服装。裁剪图像对于尽可能去除噪声至关重要。
框架
在简要分析了我们试图构建的东西之后,这里有一个粗略的框架。

深度风格框架
DeepStyle 的第一部分包含 更快的 R-CNN 这是一个实时对象检测模型,已经证明使用其 区域提议网络 可以达到最先进的准确性。你可以在这里阅读官方文件了解更多细节。我们将用香港中文大学发布的 深度时尚数据库 来训练我们更快的 R-CNN。
深度时尚数据库的快速介绍:这是迄今为止最大的时尚数据集,由大约 80 万张不同的时尚图片组成,这些图片具有不同的背景、角度、光线条件等。这个数据集由四个用于不同目的的基准组成,我们在项目中使用的是 类别和属性预测基准 。该基准具有 289,222 幅服装图像,每幅图像都由包围盒坐标和相应的服装类别标注。

deep fashion 数据库来源的类别和属性预测基准
在对 DeepFashion 数据库训练更快的 R-CNN 后,该网络将能够预测服装在哪里,给定任何测试图像。这就是 Pinterest 数据库 出现的地方。我们可以建立一个刮刀,从 Pinterest 上刮下几个大型奢侈品牌的高级时装秀,并将其用作我们更快的 R-CNN 的测试图像。我们之所以选择 Pinterest,是因为 Pinterest 提供了大量干净、高质量的图片,而且也很容易刮。
经过推理,Pinterest 图像的边界框将被预测,图像的其余部分可以被裁剪掉,因为我们只需要特定的项目。然后,我们最终将它传递给我们的时尚 GAN ,它将使用 DCGAN 或深度卷积生成对抗网络来实现。另一个甘的快速教程:一个生成式对抗网络基本上包含两个主要组件:生成器和鉴别器。生成器努力创建看起来真实的图像,而鉴别器试图区分真实图像和虚假图像。在训练过程中,随着时间的推移,发生器在生成真实图像方面变得更好,而鉴别器在辨别真假方面变得更好。当鉴别者不再能判断出发生器产生的图像是真是假时,就达到了最终的平衡。
最终结果是由 DCGAN 产生的一组图像。希望它们看起来很时尚!
履行
步骤 1 安装 Detectron 和 DeepFashion 数据集
为了实现更快的 R-CNN,我们将使用由脸书 AI 提供的 Detectron 库。Detectron 库包含用于实现最先进的对象检测算法的代码,如更快的 R-CNN、Mask R-CNN、Retina-Net 等。可以通过以下步骤安装官方库:
根据您的 CUDA 版本安装 Caffe2
- 对于支持 CUDA 9 和 CuDNN 7 的 Caffe2:
conda install pytorch-nightly -c pytorch
2.对于支持 CUDA 8 和 CuDNN 7 的 Caffe2:
conda install pytorch-nightly cuda80 -c pytorch
安装了 Caffe2 之后,现在继续安装 COCO API。
# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python setup.py install --user
现在,你可以下载官方回购并安装 Detectron。
git clone [https://github.com/facebookresearch/Detectron.git](https://github.com/facebookresearch/Detectron.git)
您可以通过以下方式安装 Python 依赖项:
cd Detectron
pip install -r requirements.txt
通过以下方式设置 Python 模块:
make
您可以通过以下方式验证 Detectron 是否已成功安装:
python detectron/tests/test_spatial_narrow_as_op.py
更多安装细节,可以参考这里。
注:脸书 AI 最近发布了Detectron 2,是 Detectron 的更新版本。我在做这个项目的时候用过 Detectron,如果你愿意,你可以看看 Detectron 2。
接下来,我们要下载 DeepFashion 数据集。你可以从他们的主页阅读更多关于数据集的细节。你可以从谷歌硬盘上下载数据集。我们想要的是类别和属性预测基准,可以从这里下载。
步骤 2 将 DeepFashion 数据集转换为 COCO 格式
为了使用 Detectron 的自定义数据集训练模型,我们必须首先将数据集转换成 COCO 格式。COCO 是一个大规模的对象检测、分割和字幕数据集,也是对象检测数据集的标准格式。我们可以使用以下代码将 DeepFashion 数据集转换为 COCO 格式:
COCO 基本上将数据集的轮廓保存在一个.json文件中,该文件包括关于对象检测数据集的基本信息。最值得注意的是coco_dict['images']和coco_dict['annotations'],它们分别给出了图像及其相应注释的信息。

DeepFashion 数据库到 COCO 输出
在 DeepFashion 上训练更快的 R-CNN 模型
在成功地将数据集转换成 COCO 格式后,我们终于可以训练我们更快的 R-CNN 模型了!在此之前,我们需要首先选择我们想要使用的更快的 R-CNN 的具体变体。有大量端到端更快的 R-CNN 变体供我们选择:

支持更快的 R-CNN 型号(来源)
当时,我训练了三种不同的变体:R-50-FPN_1x,R-101-FPN_1x,X-101–32x8d-FPN _ 1x。然而,为了简单说明的目的,我将只告诉你如何训练 R-50-FPN,因为步骤是相同的。你可以通过访问这里获得 Detectron 支持的型号列表。
在我们决定使用更快的 R-CNN R-50-FPN_1x 后,我们可以前往configs/12_2017_baselines/查看提供的现有模型配置。我们可以找到我们想要的——它被命名为[e2e_faster_rcnn_R-50-FPN_1x.yaml](https://github.com/facebookresearch/Detectron/blob/master/configs/12_2017_baselines/e2e_faster_rcnn_R-50-FPN_1x.yaml)。在那里你可以看到并根据我们的意愿修改模型和训练配置。
最重要的是将训练和测试数据集改为我们的 DeepFashion 数据集,它已经是 COCO 格式了。我们还可以将规划求解参数更改为我们想要的参数。我的看起来像这样:
在我们选择完模型及其配置后,现在我们终于可以开始训练这个模型了!根据您拥有的 GPU 数量,您可以通过执行以下命令开始培训:
- 单 GPU 训练
python tools/train_net.py \
--cfg configs/12_2017_baselines/e2e_faster_rcnn_R-50-FPN_1x.yaml \
OUTPUT_DIR [path/to/output/]
2.多 GPU 支持
python tools/train_net.py \
--multi-gpu-testing \
--cfg configs/12_2017_baselines/e2e_faster_rcnn_R-50-FPN_1x.yaml \
OUTPUT_DIR [path/to/output/]
运行上面的任何一个命令后,指定为--cfg的模型将开始训练。包括模型参数、验证集检测等的输出。会保存在/tmp/detectron-output下。更多训练细节,可以参考这里。
第四步建立高级时装的 Pinterest 数据库

注意:由于版权问题,上面的图片实际上不是 Pinterest 数据库中的项目,而只是作为项目一般外观的参考。
在我们测试我们更快的 R-CNN 定位服装商品的能力之前,我们首先需要有我们自己的测试数据库。我们可以建立一个刮刀,从 Pinterest 上刮下时装秀的图片。当时,我们搜索了 2017 年,2018 年和 2019 年的秋冬时装秀。我们搜集的品牌包括:博柏利、香奈儿、克洛伊、迪奥、纪梵希、古驰、爱马仕、Jimmy Choo、路易威登、迈克高仕、普拉达、范思哲、圣罗兰。我们最终收集了分散在所有这些品牌中的总共 10,095 张时尚图片。
尽管我很想给出 Pinterest 的 scraper 代码,我已经没有代码了:()。因为我不再能够访问我们当时在这个项目中使用的虚拟机。然而,使用 BeautifulSoup 可以很容易地构建这个刮刀,因为 Pinterest 图片都是静态的,而不是使用 Javascript 动态生成的。
恭喜你走了这么远!下一步是在 Pinterest 数据库上运行我们速度更快的 R-CNN。在那之后,我们可以开始构建一个 DCGAN,它将能够获取服装图像,并生成与它们相似的好东西。因为这篇文章已经很长了,我们将把它留到第 2 部分。
要继续,请点击此处查看第 2 部分:
第 2 部分继续:构建 DCGAN 以生成逼真的服装
towardsdatascience.com](/deepstyle-part-2-4ca2ae822ba0)
时尚的甘(下)
构建 DCGAN 以生成逼真的高级时尚服装
如果您还没有阅读第 1 部分,请先阅读它,因为本文假设您已经阅读了第 1 部分。
[## DeepStyle:使用最先进的深度学习生成现实的高级时装服装和…
提供论文和 Github 代码
towardsdatascience.com](/deepstyle-f8557ab9e7b)
现在假设您已经阅读了第 1 部分,让我们继续。
在 Pinterest 数据库和 Crop 上运行更快的 R-CNN
在收集了 Pinterest 数据库之后,现在我们可以使用我们之前训练的更快的 R-CNN 对这些图像进行推理。但在我们这样做之前,我们需要首先添加功能,我们将裁剪检测到的对象并保存结果图像,因为该功能不是开箱即用的。你可以去这个项目的 github repo 下载vis.py来完成。然后,导航到detectron/utils,用下载的版本替换现有的vis.py。新的vis.py与已经提供的相同,但有一个主要的不同——裁剪检测到的对象并将其保存在一个目录中。
添加的代码预测检测到的对象的类别,如果类别是“Full ”,即全身衣服,那么它将裁剪图像并将其保存在指定的目录中。我们只保存全身服装,因为我们希望能够生成全身服装,而不仅仅是简单的衬衫或裙子。
经过微小的修改后,我们就可以在 Pinterest 数据集上运行我们的模型了!我们可以在之前通过以下方式训练的更快的 R-CNN 上运行推理:
python tools/infer.py \
--im [path/to/image.jpg] \
--rpn-pkl [path/to/rpn/model.pkl] \
--rpn-cfg configs/12_2017_baselines/e2e_faster_rcnn_R-50-FPN_1x.yaml \
--output-dir [path/to/output/dir]
[path/to/image.jpg]是我们存储 Pinterest 图像的目录,--rpn-pkl是我们之前保存模型.pkl文件的地方,--rpn-cfg是我们存储配置文件的地方,最后,--output-dir是我们想要保存预测的地方。然而,这个--output-dir并不重要,因为它将包含带有预测的未剪裁图像。我们要寻找的是我们在vis.py中指定的目录,因为那是保存裁剪图像的地方。

在对模型进行推断之后,我们应该得到以服装为中心的裁剪图像,并且模型以及背景大部分被移除。即使仍然有一些噪音,我们已经足够好了。

将裁剪后的图像传递给时尚 GAN ( 来源)
第 6 步将预测和图像传递给 DCGAN 进行生成

DCGAN 架构(来源)
现在我们终于有了高质量的服装图像,我们可以开始构建 DCGAN 模型了!
注意:代码基于 Pytorch 的官方 DCGAN 教程,您可以从这里的 访问 。代码就不解释太详细了,更详细的解释可以参考教程。
我们开始吧。首先,我们必须导入所有必需的库:
接下来,我们设置稍后需要的所有变量:
设置完变量后,我们现在创建数据集和数据加载器,稍后我们将把它们输入到模型中。我们调整图像的大小,将它们居中裁剪到所需的图像大小,并使它们正常化。我们的图像尺寸设置为 64,因为较小的尺寸通常更一致。
我们还绘制了一些训练图像来可视化:

样本训练图像
之后,我们定义了生成器上的权重初始化和待构建的鉴别器:
我们制造发电机:

发电机架构
还有鉴别器!

鉴别器架构
然后我们定义培训流程。我们使用 BCELoss 函数,因为鉴别器的工作是识别图像是真是假。我们为生成器和鉴别器设置了 Adam 优化器。然后,我们逐批更新两个网络:
这将开始培训过程。输出是:

培训产出
培训过程需要一段时间。训练后,我们可以绘制训练期间的发生器和鉴频器损耗:

生成器和鉴别器训练损失与迭代
完成所有这些工作后,这是最后一步——将图像保存到本地硬盘:
结果
最后,伙计们,在所有这些工作之后!我们将看到生成的结果:

DCGAN 生成的图像!
现在,我们可以并排绘制并比较数据集的真实图像和生成的图像。

真实服装和生成的服装的并排比较
不错吧?假图像与真实图像相差不远。事实上,有些在我眼里看起来相当时尚😁。
就是这样,伙计们!希望你们都喜欢我的文章,并希望再次见到你。同样,本文中显示的全部代码以及我写的论文可以在我的 github repo 中获得!如果你喜欢我的内容,请在 Medium 上关注我,我会定期发布关于深度学习的话题!
参考
Detectron 已被弃用。请参阅 detectron2,这是 PyTorch 中 detectron 的全新重写版本。侦探是脸书·艾…
github.com](https://github.com/facebookresearch/Detectron) [## 更快的 R-CNN:用区域提议网络实现实时目标检测
最先进的目标检测网络依靠区域提议算法来假设目标位置…
arxiv.org](https://arxiv.org/abs/1506.01497) [## 深度时尚数据库
我们贡献了 DeepFashion 数据库,一个大规模的服装数据库,它有几个吸引人的特性:首先…
mmlab.ie.cuhk.edu.hk](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion.html) [## COCO -上下文中的常见对象
编辑描述
cocodataset.org](https://cocodataset.org/#home) [## 深度卷积生成对抗网络的无监督表示学习
近年来,卷积网络的监督学习(CNN)在计算机视觉领域得到了广泛应用…
arxiv.org](https://arxiv.org/abs/1511.06434) [## DCGAN 教程- PyTorch 教程 1.5.1 文档
本教程将通过一个例子对 DCGANs 进行介绍。我们将训练一个生成性的对抗网络…
pytorch.org](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html)
DeepWalk:它的行为和如何实现它

使用 Python、Networkx 和 Gensim 快速分析和评估图网络关系的备忘单
图形数据结构表示复杂交互的能力带来了新的方法来分析和分类由它们的共同交互定义的实体。虽然这些分析在发现社区内的不同结构方面是强大的,但是它们缺乏对图形的各个方面进行编码以输入到传统的机器学习算法中的能力。随着 DeepWalk 的提出,[1]图中的相互作用可以被简单的神经网络捕获并编码到可由上述 ML 算法使用的嵌入中。然而,虽然有文章简单介绍了 DeepWalk 算法,但我能找到的很少文章提供了代码并讨论了这些系统的实现细节。细节包括模型参数化、部署考虑和处理不可见数据。
在这篇短文中,我将提供对图网络、Word2Vec / Skip-Gram 和 DeepWalk 过程的高级概述。为了帮助解决这个问题,我将给出一个多类分类的例子来演示这个算法。之后,我将考虑不同的参数配置,并展示它们对算法性能的影响。最后,我将概述在系统中部署和处理不可见数据的一些注意事项。
图形网络
图是有效地表示生态系统中两个或多个对象之间的交互的数据结构。该结构由两个对象定义,一个节点或顶点定义系统内的实体。在本文中,我将使用一个电子商务网站上的购物网络示例,图中的节点是正在销售的产品。

作者图片
图的另一个方面是连接它们的东西:一条边,它定义了连接两个节点的交互。一条边可以是有向的,显示出一种 to-from 关系——想象一个人 A 给人 b 发了一封电子邮件。一条边也可以有一个定义他们交互的权重。在我们的例子中,我们可以定义一个边缘权重,代表在我们的电子商务网站上购买了和两种产品的消费者的比例。
深度行走算法:
DeepWalk 是一种图形神经网络*【1】*—一种直接在目标图形结构上操作的神经网络。它使用随机路径遍历技术来洞察网络中的局部结构。它通过利用这些随机路径作为序列来做到这一点,然后使用这些序列来训练 Skip-Gram 语言模型。为了简单起见,本文中我们将使用 Gensim 包 Word2Vec 来训练我们的 Skip-Gram 模型。
Word2Vec
DeepWalk 算法的这个简单实现非常依赖于 Word2Vec 语言模型[2]。由谷歌在 2013 年推出的 Word2Vec 允许将单词嵌入到 n 维空间中,相似的单词彼此靠近。这意味着经常一起使用/在类似情况下使用的单词将具有较小的余弦距离。

单词嵌入行为的三维示例,作者的图片
Word2Vec 通过使用 Skip-Gram 算法将目标单词与其上下文进行比较来实现这一点。在高层次上,Skip-Gram 使用滑动窗口技术进行操作——在给定中间目标单词的情况下,它试图预测周围的单词。对于我们试图将图中的相似节点编码为在 n 维空间中彼此靠近的用例,这意味着我们有效地试图猜测我们网络中目标节点周围的邻居*。*

一个来自 S. Doshi [3]的 Skip-Gram 示例,修改了取自原作者的图像[2]
深度行走
DeepWalk 通过图使用随机路径来揭示网络中的潜在模式,然后这些模式被神经网络学习和编码,以产生我们的最终嵌入。这些随机路径以极其简单的方式生成:从目标根开始,随机选择那个节点的一个邻居,并将其添加到路径中,接下来,随机选择那个节点的一个邻居,并继续遍历,直到已经走了期望的步数。以电子商务为例,这种对网络路径的重复采样产生了一个产品 id 列表。然后,这些 ID 被视为句子中的标记,使用 Word2Vec 模型从这些 ID 中学习状态空间。更简洁地说,DeepWalk 过程遵循以下步骤:
DeepWalk 过程分几个步骤进行:
- 对于每个节点,从该节点开始执行 N 个“随机步骤”
- 将每次遍历视为一系列节点 id 字符串
- 给定这些序列的列表,使用 Skip-Gram 算法对这些字符串序列训练一个 word2vec 模型

作者图片
这在代码中看起来像什么?
我们从核心的 networkx 数据结构开始,它定义了一系列产品,这些产品由它们的 ID 给出。两个产品之间的顶点是在电子商务生态系统中共同购买的产品。首先,我们要定义一个函数 get_random_walk (Graph,Node_Id):
# Instantiate a undirected Networkx graph
G = **nx.Graph**()
G.**add_edges_from**(list_of_product_copurchase_edges)**def get_random_walk**(graph:nx.Graph, node:int, n_steps:int = 4)->List[str]:
""" Given a graph and a node,
return a random walk starting from the node
""" local_path = [str(node),]
target_node = node **for** _ **in** **range**(n_steps):
neighbors = **list**(**nx.all_neighbors**(graph, target_node))
target_node = **random.choice**(neighbors)
**local_path.append**(**str**(target_node)) **return** local_pathwalk_paths = []**for** node **in** **G.nodes**():
**for** _ **in** **range**(10):
walk_paths.**append**(**get_random_walk**(G, node))
walk_paths[0]
***>>>*** *[‘10001’, ‘10205’, ‘11845’, ‘10205’, ‘10059’]*
这些随机漫步提供给我们的是一系列字符串,它们充当从起始节点开始的路径——沿着列表从一个节点随机漫步到下一个节点。我们接下来要做的是将这个字符串列表视为一个句子,然后利用这些字符串序列来训练一个 Word2Vec 模型
# Instantiate word2vec model
embedder = **Word2Vec**(
window=4, sg=1, hs=0, negative=10, alpha=0.03, min_alpha=0.0001,
seed=42
)# Build Vocabulary
**embedder.build_vocab**(walk_paths, progress_per=2)# Train
**embedder.train**(
walk_paths, total_examples=embedder.corpus_count, epochs=20,
report_delay=1
)
调谐和参数
现在我们已经有了 DeepWalk 的基本结构,在 Word2Vec 模型的一般模型参数的之外,还有许多方面是可参数化的*。这些可能包括:*
- 为 W2V 训练数据执行的随机行走的次数
- 从节点开始的每次行走的深度
我将利用一个样本数据集上的通用分类方法来展示这些参数如何影响模型的性能。在上面描述的图表中——利用一系列产品,用一个图表定义共同购买的产品——我们试图将产品分类到它们各自的 10 个类别。

作者图片
上面显示了在我们的 Word2Vec 模型的节点向量上训练的分类器的分类性能(精确度),在 y 轴上使用增加的随机行走次数,在 x 轴上使用增加的随机行走深度。我们看到的是,准确性随着两个参数的增加而增加,但随着两个参数的增加,回报率逐渐降低。需要注意的一点是,随着行走次数的增加,训练时间**线性增加,**所以训练时间会随着行走次数的增加而激增。例如,左上角的训练时间只相差 15 秒,而右下角的训练时间则相差一个多小时。
部署系统:
热启动再培训
既然我们知道了它的行为方式,我们如何让它变得实用呢?在大多数图形系统中,核心问题是更新和维护系统,而不必立刻重新训练整个模型。幸运的是,由于 DeepWalks 与 NLP 的关系,我们可以依赖类似的更新过程。使用 gensim 时,更新算法更加简单,其流程如下:
- 将目标节点添加到图中
- 从该节点执行随机行走
- 使用这些序列来更新 Word2Vec 模型
# Add new nodes to graph from their edges with current nodes
**G.add_edges_from**([new_edges])# From a list of the new nodes' product_ids (unknown_nodes) get rw's
sequences = [**get_random_walks**(G, node) **for** node **in** unknown_nodes]**model.build_vocab**(new_nodes, update=True)
**model.train**(sequences,total_examples=model.corpus_count, epochs=model.epochs)
不需要再培训
或者,有一种更简单的方法来处理系统中的新节点。您可以利用模型的已知嵌入来推断未知节点的嵌入。遵循与前面的实现类似的模式:
- 将目标节点添加到图中
- 从该节点执行随机行走
- 聚集来自随机行走的嵌入,然后使用该聚集来代替未知节点嵌入
# Add new nodes to the graph from their edges with current nodes
**G.add_edges_from**([new_edges])sequences = [**get_random_walk**(G, node) **for** node **in** unknown_nodes]**for** walk **in** sequences:
nodes_in_corpus = [
node **for** node **in** walk **if** node **in** word2vec
]
node_embedding = [ # here we take the average of known embeddings
**np.mean**(embedder[nodes_in_corpus])
]
这里,我们的嵌入是从未知节点开始的随机行走中已知节点的平均值。这种方法的好处是它的速度,我们不需要重新训练任何东西,并且正在执行几个对 Gensim 中类似字典的数据结构的 O ( 1 )调用。缺点是它的不精确性,在没有重新训练模型的情况下,新节点和它的邻居之间的交互是近似的,并且只和你的聚合函数一样好。要更深入地了解这些方法,您可以查阅讨论此类聚合功效的论文,如 TF-IDF 平均等。[4]
在过去的 10 分钟里,我们走过了[哈。】DeepWalk 的核心组件,如何实现,以及在自己的工作中实现的一些考虑。对于图网络的评估,有许多可能性可以考虑,鉴于其简单性和可伸缩性,DeepWalk 当然应该在其他可用的算法中加以考虑。下面你可以找到一些上面概述的算法的参考,以及一些关于单词嵌入的进一步阅读。
来源:
[1] Perozzi 等人。深度行走:在线学习社交表征https://arxiv.org/pdf/1403.6652.pdf
[2]米科洛夫等人。向量空间中单词表示的有效估计https://arxiv.org/pdf/1301.3781.pdf
[3] S .多希。 Skip-Gram: NLP 上下文单词预测算法:https://towardsdatascience . com/Skip-Gram-NLP-context-words-prediction-algorithm-5 bbf 34 f 84 e0c?gi = 8 ff 2 eada 829
[4] Levy 等人。**利用从单词嵌入中吸取的经验教训改进分布相似性【https://www.aclweb.org/anthology/Q15-1016/**T22
捍卫数据科学大师
支持数据科学研究生学位的考虑
简介
(本文中的任何陈述均为本人所作,不代表任何其他实体、个人或组织)
尽管数据科学可以被定义为一个领域,但它是一个不断发展的领域。凭借其独特的计算机科学、统计学、科学探索、可视化以及在一系列跨领域领域的巨大增长潜力,美国的大学和学院开设数据科学课程应该不足为奇。但是数据科学硕士课程包括什么呢?值得有人在这个项目上花两年时间吗?我刚刚在 GWU 大学获得理学硕士学位,我可以提供我的经验,我认为它最终会如何发展,以及我在申请这样一个项目时所做的主要考虑,以及为什么有人应该考虑这样一个项目,而不是编码训练营或 MOOCs 自学和其他非学位导向的学习。

我为什么这么做
首先,当我试图进入数据科学领域时,我开始关注数据科学项目。尽管我已经在从事数据科学的入门级工作,但我知道我还有很多东西要学(并且我不确定我会学到在我当时的角色中有效工作所需的一切)。但更重要的是,我没有看起来像数据科学家或任何其他组织的学术背景。但我一直在学习 Python,并投身于这个领域,我知道我需要强化训练。那么如何获得呢?对我来说,MOOCs 是不够的,因为我觉得我需要一个显示能力的高级学位。但是发现一个程序比我想象的要难。
许多程序似乎是由校园内其他系提供的课程组合而成,而不仅仅是统计和计算机科学系。有时他们需要商业课程,更接近于数据分析 MBA,但被更名为数据科学。通常,这些项目不会包括明确的深度学习、分布式计算、高级技术或研究方法类型的课程。这是一个问题,对我来说,内容似乎非常肤浅。对我来说,唯一可以确认的方法就是与程序对话。
四处打听
当我与这些数据科学硕士项目交流时,我对几个领域感兴趣,这些领域可以归纳为以下几个问题:
1)可获得何种经济资助(包括助教奖学金):
这个项目将会是你的首选。由于这是一个硕士项目,你可能已经有学生债务,你想确保你的钱花得值。让财务变得有意义可能不是你知道的事情,直到你得到一个报价和财务包。
2)学生是全日制还是非全日制?
如果学生是兼职或全职,你知道你有多少支持工作和参与该计划。绝大多数好处不会在课堂上出现,当你进入就业市场时,你将需要专业经验,最好是真实世界的数据集,而不仅仅是 MNIST 数据集。
3)核心教师(兼职教师等)的任期状况如何?)?
如果教职员工是兼职教授,或者终身职位不能反映他们的教学质量。然而,你可以从这个答案中推断出两件事。教员研究的重点(主要是终身职位)还是申请(主要是兼职)?教员是主要的区别,他们的行业经验将为你提供比课堂材料更多的信息。
4)学生成果(如果他们不能清晰表达,这是一个巨大的危险信号):
为什么一个项目最终可能不会给你提供一份工作?如果这个项目太新,不能告诉你,或者对讨论这些结果不感兴趣(这就是为什么一个电话会有所不同),那就回答了你所有的问题。
5)覆盖哪种材料?有没有更广阔的视野/教学原则?
坦率地说,其他问题都无关紧要。课程包括哪些内容?他们能和你分享教学大纲吗?他们教图书馆还是教概念?有深度学习课吗?他们是否深入到作为所有机器学习基础的线性代数、统计学和微积分中?有什么样的重点课程内容,如何教授?他们是否有针对高级 NLP、时间序列分析、贝叶斯方法、分布式或高性能计算的特定课程,或者任何其他重要的深入研究的主题领域,这些领域是基础的,但不是头条新闻?他们是打算教那些能让你在职业生涯中适应的技能,还是基于表面?在这里,课程的进步是一件好事,但是忽视高级课程所涵盖的内容是一个重大错误。
6)存在什么样的校园组织来支撑?
类似于教职员工的终身职位,这个问题更多的是关于项目的支持和文化。这个项目位于什么部门?什么样的专用资源可用于该计划?有职业顾问吗?一般来说,这些问题的答案会告诉你,这是一个他们打算发展和投资的项目(为你的学位增加价值),还是一个在大肆宣传期间快速获得财务收益的项目。
即使有这些问题,当你第一次看它的时候,还是有一些危险信号需要注意。
红旗
1)21 世纪最性感的工作!学习构建未来的人工智能!他们在哪里提到过这些短语吗?这个项目对与他们学校无关的权威有吸引力吗?问问你自己为什么他们会这样做,他们对他们的教员、学校或项目没有信心吗?他们说 AI 吗?说真的,如果他们一直说 AI,那就有问题了。如果他们参考的是这些项目,而不是数据科学的应用,该计划可能不会给你带来很好的结果,或者提供超出你自己能力范围的教育。这是我个人最讨厌的,也让我对说话人的知识产生了怀疑。
2)学生成绩有限,课程设置古怪
他们分享结果吗?你对你所听到的满意吗?他们列出的课程是否有意义,听起来是否会填补你的空白?请记住,你将填补你技能组合中的空白,并在你的所有技能中获得认证。
3)缺乏清晰度
他们似乎不愿意深入回答问题吗?学校想要吸引新的学生,尤其是研究生项目。问问自己为什么他们不把问题告诉你,一直把你发给新人回答问题。他们把你和现在的学生联系起来了吗?当我决定我选择的硕士项目时,我已经和项目管理员、项目主管、一名教师、一名学生和另一名教师谈过了。这些人中的每一个人都把我和下一个人联系起来,并对我的后续行动保持开放,而且会及时把我要求的信息发给我。一些和我交谈过的程序一直把我指向他们的网站,而没有把我发送给另一个人,这让我很担心。
4)非常新的程序
让我们面对现实吧,数据科学是新定义的,高等教育很难适应一切。一个学术项目在最初的 2-3 个阶段会有很大的变化。你想加入那些实验小组吗?我可能是一个相对规避风险的人,但你的里程可能会有所不同。
5)商业项目(我不喜欢,但你的里程数可能会有所不同)
我不愿参与商学院的课程。数据分析有用,但不是数据科学。如果在数据可视化和通信上没有强调机器学习,它就不是一个数据科学项目。这是商业分析。这不是一个问题,除非你想做数据科学的发展需求,而不是通信方面。
那么,为什么我最终加入了这个项目呢?从根本上说,我选择的程序对上述所有问题提供了满意的答案,危险信号是有限的。
注意事项:
硕士不应该是你进入这个领域的第一步,但如果你的目标是改变职业,它应该是你考虑的主要一步。最终,像硕士学位这样的学术证书会有持久的影响力,而 MOOC 或编码训练营可能不会对你的职业生涯有持久的影响力。尽管专业经验比课堂更有价值,但它会让你获得一个可以毫无疑问地向前传递的证书,并且会勾选相关领域的高级学位(以及博士学位的时间和资金限制相对较低)。
硕士不应该是你进入这个领域的第一步,但如果你的目标是改变职业,它应该是你考虑的主要一步。最终,像硕士学位这样的学术证书会有持久的影响力,而 MOOC 或编码训练营可能不会对你的职业生涯有持久的影响力。尽管专业经验比课堂更有价值,但它会让你获得一个可以毫无疑问地向前传递的证书,并且会勾选相关领域的高级学位(以及博士学位的时间和资金限制相对较低)。
防御性查询编写

照片来自 Pexels
数据工程
使用防御性编码原则编写 SQL 查询
源自防御性编程,防御性查询编写是一种尝试确保查询运行不会失败的实践。就像在应用程序开发中一样,尽量避免愚蠢的错误,控制不可预见的情况。有时,您需要决定是希望查询失败,还是希望查询即使有一些不正确的数据也能运行。我将分享几个简单的例子,在这些例子中,我们可以在编写查询时使用这些实践。
检查数据库对象是否存在
以创建和删除数据库对象为例。不要使用CREATE TABLE xyz,使用CREATE TABLE IF NOT EXISTS xyz (id int)或者如果你想重新创建丢失所有数据的表,你可以运行DROP TABLE IF EXISTS xyz,然后运行CREATE TABLE IF NOT EXISTS xyz (id int)。
同样的实践可以用于创建和删除数据库、视图、索引、触发器、过程、函数等等。我开始意识到,在大多数情况下,使用这个是有帮助的。
使用数据库和列别名
防止自己出现不明确的列错误。参见下面的例子,列city可能同时出现在TABLE_1和TABLE_2中。你如何期望数据库知道你希望它选择哪个字段?
通常,为数据库对象创建别名,然后使用别名而不是完整名称来访问这些数据库对象及其子对象是一个非常好的做法。显然,为了高效地完成这项工作,您需要遵循 SQL 样式表。我在这里写了更多关于它的内容—
让您的 SQL 代码更易读、更容易理解
towardsdatascience.com](/how-to-avoid-writing-sloppy-sql-43647a160025)
使用极限,偏移
不,我不是在说使用LIMIT来限制最终查询中的记录数量。相反,我说的是这样的查询。
返回列的子查询中的LIMIT子句很重要,因为如果子查询返回多行,即对于TABLE_1中的每条记录,如果TABLE_2中有多条记录,它可以防止查询失败。这是编写更好的查询的一个非常有用的技巧。
使用LIMIT有一个警告。如果你不确定数据的质量或者你对数据库不够了解,使用LIMIT经常会给你错误的答案。在某些情况下,您更希望作业失败时抛出错误,而不是查询返回不正确的结果集。
使用存储过程和预准备语句
信不信由你,SQL 注入仍然非常流行。近年来,许多受欢迎的公司发现自己受到了黑客攻击 SQL 注入的摆布。有非常具体的方法来防止您的应用程序受到这种攻击。关于这个话题最有资源的网站是 OWASP。
SQL 注入攻击包括通过从客户端到客户端的输入数据插入或“注入”SQL 查询
owasp.org](https://owasp.org/www-community/attacks/SQL_Injection)
防止这些攻击背后的想法是通过使用准备好的语句或使用存储过程来安全地参数化您的查询。即使这些解决方案也要求在运行查询之前进行严格的验证检查——使用特殊字符、转义字符等等。
小心使用触发器
我有触发器的问题。我曾经试图在生产数据库触发的触发器上构建一个轻量级的数据转换管道。我在想什么,对吧?它是轻量级的,它本来可以工作更长时间,但由于应用程序中的一些 bug(很可能是关于事务边界的),它没有得到解决。即使那没有成功,我仍然真的非常喜欢触发器,但它们确实会带来自己的痛苦。
必须格外小心,确保触发器不是相互依赖的,并且在数据库应用程序中不可能有循环触发器。
执行前模拟 DML 语句
总是试图将您的生产查询模拟成SELECT语句,即使您正在尝试DELETE或UPDATE。这样做会给你一个公平的想法,当你DELETE或UPDATE时,你实际上要做什么。这些年来,我发现这个方法真的很有用。这无疑增加了另一个耗费时间的步骤,但我认为这比额外的成本有好处。
除了嘲讽之外,您还必须在您的开发/测试环境中运行相同的DELETE和UPDATE语句,这样您就可以在生产中做任何激烈的事情之前签署它们。
这些是我的一些建议。我发现这些在处理数据系统时非常有用。类似地,我在这里也谈到了许多提高数据库查询性能的好的、简单的 SQL 技巧
查询任何传统关系数据库的经验法则
towardsdatascience.com](/easy-fixes-for-sql-queries-ff9d8867a617)
快乐阅读!
定义数据科学、机器学习和人工智能
有可能区分它们吗?
随着可用数据的数量、种类和速度不断增加,科学学科为我们提供了先进的数学工具、过程和算法,使我们能够以有意义的方式使用这些数据。数据科学(DS)、机器学习(ML)和人工智能(AI)就是三个这样的学科。在许多与数据相关的讨论中经常出现的一个问题是,DS、ML 和 AI 之间的区别是什么?它们能被比较吗?根据你和谁交谈,他们有多少年的经验,以及他们做过什么项目,你可能会得到上述问题的非常不同的答案。在这篇博客中,我将尝试根据我的研究、学术和行业经验来回答这个问题;并促成了许多关于这一主题的对话。然而,这仍然是一个人的意见,应该被视为如此。我还将提到,这篇文章旨在提供这三个领域之间的概念差异;因此,一般情况下,肯定会有边缘情况。
如果你把 DS、ML 或 AI 看作是一套工具和技术,要恰当地区分它们几乎是不可能的。它们重叠;然而,它们是 而不是彼此的适当子集 。例如,如果有人使用“聚类”算法,他们可能正在进行 DS、ML 或 AI 工作,甚至可能是 ML+DS、DS+AI、ML+AI 或三者的组合!我希望您考虑一种定义这些领域的替代方法,将它们与工具和技术分开,并将其与最终目标联系起来。尽管它们可能使用重叠的技能、工具和技术,但是 DS、ML 和 AI 可以通过它们对实现不同最终目标的关注来区分。
以下是概括的重点领域:
数据科学是关于使用数据提供价值(金钱、增长、声誉等)。)到一个组织。
机器学习是关于使用数据进行优化的推理和预测。
人工智能是利用数据将类似人类的决策传递给机器。

有了这些定义,很容易看出这些字段非常有趣地重叠在一起。例如,能够做出类似人类的决定可能包括让更好 推论等等。向一个组织提供价值可能涉及创造具有类人决策的数字代理。类似地,在创建学习模型以使更好地预测时,人们可能希望致力于将为组织提供最大价值的指标。你可以想象,这三个学科之间的界限变得混乱,我们经常用一个为另一个服务。真正的“为什么”是你正在做的,你正在用数据做什么,这可以帮助确定你当前的工作是否应该归入数据科学、机器学习或人工智能。需要记住的另一点是,在数据科学中几乎总是有一个人类代理人参与其中。你可能会听到“这台计算机正在运行机器学习算法”或“这个数字代理正在展示人工智能”,但你不会听到“这台机器正在做数据科学。”数据科学几乎总是由人类来完成。
下面我们考虑一个简化的例子来把这些概念结合起来。
考虑一个正在研究为老年患者制造辅助机器人的医疗机构。机器人的任务是在没有人护理的情况下帮助老年病人行走。机器人需要知道这个人什么时候起床,这样它才能开始行动。这种确定可以通过观察手和腿的运动来进行。医疗保健机构将这个项目外包给另一家公司,要求他们设计一种算法(模型),可以对一个人的站立意图进行准确预测。这可以通过对图像和视频进行训练来完成,以预测哪些手和腿的运动可能表明这个人正在起床。这是一个 机器学习 项目。
一旦人起来了,机器人的任务就是帮助他们行走。最好的帮助方式是什么?那么,在这种情况下,一个训练有素的人类护理人员会怎么做呢?他们可能会走近病人,根据病人走路需要多少帮助,提供一只或两只手臂或手来依靠。此外,护理人员可以温和地抓握虚弱的人,并且更牢固地抓握,将脚牢牢地放在地上以支撑肥胖的人。让机器人模仿训练有素的人类护理员的行为是人工智能的领域。
现在考虑医疗保健机构想要决定是否继续投资这个项目。这种确定可以通过从各种来源收集数据来进行,例如老年人跌倒造成的伤害率、人类护理人员的工作时间和工资、通过使用新机器人减少的跌倒率、训练机器人的成本、技术采用率、由于减少伤害而节省的医疗费用等。一旦对数据进行了整合、建模和分析,就可以向医疗保健机构提出几项建议,例如,辅助机器人导致 80%(虚构数字)的较少跌倒,并且该机构可以在 5 年内收回其投资(虚构数字)。这个以数据开始,以对决策者有价值的见解结束的过程就是 数据科学 。
我希望下一次你看到这些术语时,你会比它们所使用的工具和技术看得更深。工具和技术随着时间而发展;意图依然存在。
在 Python 中定义函数
定义 Python 函数

在计算机科学中,函数提供了执行特定任务的一组指令。函数是软件程序的重要组成部分,因为它们是我们今天使用的大多数应用程序的核心。在这篇文章中,我们将讨论如何在 python 中定义不同类型的函数。
我们开始吧!
定义一个简单函数
首先,让我们定义一个简单的函数。我们使用“def”关键字来定义 python 中的函数。让我们定义一个函数来打印引用自托马斯·品钦的万有引力的彩虹:
def print_quote():
print("If they can get you asking the wrong questions, they don't have to worry about the answers.")
现在,如果我们调用我们的函数,它应该显示我们的报价:
print_quote()

如果我们愿意,我们可以让函数使用 return 关键字返回字符串:
def print_quote():
return "If they can get you asking the wrong questions, they don't have to worry about the answers."
然后,我们可以将函数返回值存储在一个变量中,并打印存储的值:
quote = print_quote()
print(quote)

编写函数的一种更简洁的方式是将字符串存储在函数范围内的一个变量中,然后返回该变量:
def print_quote():
quote = "If they can get you asking the wrong questions, they don't have to worry about the answers."
return quote
让我们将函数返回值存储在一个变量中,并打印存储的值:
my_quote = print_quote()
print(my_quote)

用输入定义函数
现在,让我们讨论如何用输入定义函数。让我们定义一个函数,它接受一个字符串作为输入,并返回该字符串的长度。
def quote_length(input_quote):
return len(input_quote)
我们可以定义一些变量来存储不同长度的报价。让我们引用威廉·加迪斯的中的几句话:
quote_one = "The most difficult challenge to the ideal is its transformation into reality, and few ideals survive."quote_two = "We've had the goddamn Age of Faith, we've had the goddamn Age of Reason. This is the Age of Publicity."quote_three = "Reading Proust isn't just reading a book, it's an experience and you can't reject an experience."
让我们用这些引用来调用我们的函数:
quote_length(quote_one)
quote_length(quote_two)
quote_length(quote_three)

我们还可以对输入字符串执行各种操作。让我们定义一个函数,将我们的引号组合成一个字符串。我们可以使用“join()”方法将一系列字符串组合成一个字符串:
quote_list = [quote_one, quote_two, quote_three]def combine_quote(string_list):
return ''.join(string_list)
如果我们用“quote_list”作为输入来打印函数,我们会得到以下结果:
print(combine_quote(quote_list))

我们的函数中也可以有多个输入值。让我们的函数接受一个指定作者姓名的输入字符串。在函数的范围内,让我们打印作者的名字:
def combine_quote(string_list, author_name):
print("Author: ", author_name)
return ''.join(string_list)
现在,让我们调用我们的函数并打印它的返回值:
print(combine_quote(quote_list, 'William Gaddis'))

返回多个值
在一个函数中返回多个值也非常简单。让我们定义一个函数,它接受一段引文、书名、作者姓名和书中的页数。在我们的函数中,我们将创建一个数据框,其中包含报价、书名、作者和页数等列。该函数将返回数据帧及其长度。
首先,让我们定义一个引用、对应作者、书名和页数的列表:
quote_list = ["If they can get you asking the wrong questions, they don't have to worry about the answers.", "The most difficult challenge to the ideal is its transformation into reality, and few ideals survive.", "The truth will set you free. But not until it is finished with you."]book_list = ['Gravity's Rainbow', 'The Recognitions', 'Infinite Jest'] author_list = ["Thomas Pynchon", "William Gaddis", "David Foster Wallace"]number_of_pages = [776, 976, 1088]
接下来,让我们用适当的键将每个列表存储在字典中:
df = {'quote_list':quote_list, 'book_list':book_list, 'author_list':author_list, 'number_of_pages':number_of_pages}
现在,让我们将字典从 Pandas 库中传递到数据框构造函数中:
import pandas as pd
df = pd.DataFrame({'quote_list':quote_list, 'book_list':book_list, 'author_list':author_list, 'number_of_pages':number_of_pages})
让我们放松对使用 Pandas 的显示列数量的限制,并打印结果:
pd.set_option('display.max_columns', None)
print(df)

现在让我们将这段代码包装在一个函数中。让我们将我们的函数命名为“get_dataframe”。我们的函数将返回数据帧及其长度:
def get_dataframe(quote, book, author, pages):
df = pd.DataFrame({'quotes':quote, 'books':book, 'authors':author, 'pages':pages})
return df, len(df)
现在让我们用列表调用函数,并将返回值存储在两个独立的变量中:
df, length = get_dataframe(quote_list, book_list, author_list, number_of_pages)
print(df)
print("Data Frame Length: ", length)

我们可以自由选择在函数中返回哪些值和多少个值。让我们也返回对应于“报价”和“书籍”列的熊猫系列:
def get_dataframe(quote, book, author, pages):
df = pd.DataFrame({'quotes':quote, 'books':book, 'authors':author, 'pages':pages})
return df, len(df), df['books'], df['quotes']
现在,让我们再次调用我们的函数:
df, length, books, quotes = get_dataframe(quote_list, book_list, author_list, number_of_pages)
我们可以印刷书籍:
print(books)

和报价:
print(quotes)

我就讲到这里,但是您可以自己随意摆弄代码。
结论
总之,在这篇文章中,我们讨论了如何在 python 中定义函数。首先,我们展示了如何定义一个打印字符串的简单函数。对应一本书的引用。接下来,我们讨论了如何定义一个接受输入值、操作输入并返回值的函数。最后,我们展示了如何定义一个返回多个值的函数。我希望你觉得这篇文章有用/有趣。这篇文章中的代码可以在 GitHub 上找到。感谢您的阅读!
P 值到底是什么?
数据科学概念
解释 P 值

彼得·德·格兰迪在 Unsplash 上拍摄的照片
O 作为一名数据科学家,你必须学会的第一件事是 P 值。如果你没有统计学背景,并且希望进入数据科学领域,你会遇到 P 值的概念。你最终还会发现的另一件事是,在你可能进行的任何技术面试中,你都必须解释 P 值。p 值的重要性永远不会被低估,因为它经常被用于大多数(如果不是全部)数据科学项目。
这里我们将解释 P 值的概念以及如何解释它的值。即使您没有统计学和数学背景,在本文结束时,您也应该能够理解 P 值的概念和目的。
P 值是多少?

斯文·米克在 Unsplash 上拍摄的照片
让我们从解释 P 值到底是多少开始。P 值中的*“P”表示概率*。它所指的值是从 0 到 1 的数值。到目前为止,这是 P 值的最基本情况。
数值的计算是由一个叫做 的东西决定的 z 值 。而 z-score 是从另一个计算 标准差 的公式推导出来的。这些都一起工作,以检索 P 值。
在这里注册一个中级会员,可以无限制地访问和支持像我这样的内容!在你的支持下,我赚了一小部分会费。谢谢!
P 值有什么用?

进行统计或假设检验时,p 值用于确定结果是否具有统计显著性。这是什么意思?换句话说,这个结果是由于其他一些因素和而不是随机的。这个因素可能就是您第一次开始测试时所寻找的因素。
P 值中的数字

当我们进行这些统计假设检验时,我们通常会寻找一个小于我们期望阈值的 P 值。该阈值通常小于 0.05%或 5%。为什么会有这些数字?因为这些数字在统计学上已经足够低了,而且通常是大多数统计学家设定他们统计显著性水平的地方。
该数字表示由于随机性或偶然性而获得结果的可能性。如果这个值小于 0.05,那么我们可以有把握地说,这个结果不是随机的。仅凭这一点可能还不足以得出结论,但这是一个开始。
P 值的简单示例
让我们通过提供一个示例,用更多的上下文来解释 P 值:

照片由 Rai Vidanes 在 Unsplash 上拍摄
假设你是一个面包师,刚进了一批生蜂蜜。但问题是,你以前从未吃过或听说过蜂蜜。人们告诉你,它会让你的饼干变甜,就像糖一样,但你不相信他们,你会自己尝试。所以你开始用蜂蜜做你自己的实验或测试。
首先,你把两种不同的饼干食谱放在一边。一杯加蜂蜜,一杯不加蜂蜜。然后,你混合并烘烤它们。在烤箱中烘烤后,你把它们拿出来品尝每一个,看看甜度是否有差异。你可以比没有蜂蜜的饼干更能尝到蜂蜜饼干里的甜味。然而,因为你是一个固执而传统的面包师,从不远离糖,你认为这个测试可能是侥幸的。所以你做了另一个测试,但是用了更多的饼干。

Erol Ahmed 在 Unsplash 上拍摄的照片
在接下来的测试中,你要烘烤 200 块饼干:100 块有蜂蜜,100 块没有蜂蜜。这些是很多饼干,但你要确保蜂蜜实际上是一种甜味剂。所以你在测试开始时简单陈述一下你的总体信念,统计学家称之为零假设:
“蜂蜜不会让这些饼干变得更甜”
因此,另一种替代说法,也就是统计学家所说的替代假说:
“蜂蜜会让这些饼干更甜吗”
混合、烘焙,最后品尝并给每块饼干一个甜度分数后,你开始计算 P 值:
- 你找到了饼干甜度分数的标准偏差。
- 你找到了 Z 值。
- 你通过知道 Z 值来找到 P 值。
在这一切之后,你得出一个 P 值,像 0.001 这样小得可笑的值。由于 p 值远低于 0.05 的统计显著性阈值,您别无选择,只能拒绝您在开始时声明的一般陈述或无效假设。你已经得出结论,根据统计概率,蜂蜜确实使你的饼干更甜。
从现在开始,你可以考虑时不时地在你的食谱中加入蜂蜜。
结论
以上是一个简单的例子,说明了人们可能如何进行假设检验,以及他们可能如何解释实验结束时的 P 值。通过使用从面包师测试结束时得出的 P 值,他们能够以足够的统计概率确定饼干中有蜂蜜会更甜。
希望你对 P 值以及如何解读 P 值有更清晰的理解。理解它们的重要性很重要,因为它们在数据科学中无处不在,最终会在面试中出现。如果你愿意,用这篇文章来准备和理解。希望你喜欢学习数学和统计学!
人工智能产品战略的 7 个要素
构建 ML 驱动的产品、团队和业务的剧本

资料来源:Anne Nygå rd,Unsplash
构建和销售机器学习(ML)产品很难。底层技术不断发展,要求组织时刻保持警觉……而关于成功和盈利产品的规则手册仍在编写中,导致不确定的结果。
我们在 Semantics3 与机器学习产品合作了 5 年多,不得不应对许多源于行业不景气的挑战。在这篇文章中,我从这些经历中提炼出一组考虑因素,用于主动预测和处理这些突发事件。仔细考虑这些因素有助于我们调整产品以取得长期成功。
以下观点涵盖了总体趋势;当然,规范总会有例外。
#1 —人工智能/人工智能在您的产品中扮演什么角色?

象限 A(左上):以 ML 模型为核心的独立黑盒产品
你销售的是一个黑盒 ML 模型,在这个模型中,客户决定如何最好地利用所提供的智能(例如,像 Amazon Transcribe 或 Google Speech-To-Text 这样的转录服务)。
如果你的产品属于这一类,仔细想想顾客可能会给你的所有输入的怪癖。您的模型可能已经在特定的上下文中进行了训练,在您的训练数据集中有所表示,您需要防止客户测试边缘情况、接收到较差的输出并得出您的服务没有达到标准的结论。
在 Semantics3,当我们发布我们的电子商务分类 API 时,我们遇到了这一挑战…同时我们的系统被训练为接收产品名称(“苹果 iPhone X — 64GB 黑色”),客户发送的不兼容的通用输入(“iPhone”,“手机”)。
有三种方法可以防止这种情况。
- 确保您的产品被正确使用,要么通过定义输入的自由度(强制使用某种格式的输入),要么通过教育客户(通过文档、培训材料和直接沟通渠道)。
- 通过构建检测图层来拒绝不符合标准的输入(通过与训练数据进行比较来检测异常值的非监督方法效果很好)。
- 构建一个处理所有边缘情况的产品。这是困难的,并且可能在超过一个阈值后收益递减。但是,如果你的客户对所有人都有很强的亲和力——欢迎谷歌搜索框用户体验,它可能会带你度过难关。
象限 B(右上):以 ML 模型为核心的端到端解决方案
机器学习是你的产品的核心,没有它你的产品就无法运行,但你已经将它打包成一个更广泛的解决方案,旨在解决特定的需求(例如无人驾驶汽车)。
使用这样的产品,您可以控制自由度,从而避免黑盒方法的陷阱。您还可以获得更多的价值,并有可能扩大您的市场,为不太精明的客户提供服务。
但另一方面,自由度的减少意味着理解客户需求和设计所需体验的责任落在了你身上。您的开发团队的需求也可能更加多样化——您可能需要投资构建支持硬件、软件和数据层以及可定制的组件。我的经验是,这些挑战比前一组更容易应付。
象限 C(右下角):采用 ML 技术的端到端解决方案
机器学习实现了你产品的一个关键特性,但是即使没有任何机器学习的参与,你的产品也有显著的效用(例如网飞推荐)。
从数据科学家的角度来看,这些产品为部署 ML 模型提供了最有利的环境。由于机器学习的附加值是递增的,即使没有这一功能,客户也能获得效用,因此逐步推广和迭代是可能的。最棒的是,该产品本身通常会生成构建模型所需的训练数据集。
在这些生态系统中,机器学习有可能增加产品的价值,并建立更强的防御能力……但产品基本面需要由数据科学领域以外的举措来驱动。
象限 D(左下角):具有 ML 供电功能的独立黑盒产品
如果你的产品落入这个桶里,你就看错文章了!
#2 —您的产品如何影响客户的工作流程?
a]该产品是否通过取代相关人员来实现手动流程的自动化?
完全取代人类是一件非常困难的事情。人类有能力处理边缘情况和细微差别,这种方式对编程到模型中是一种挑战。您的模型将总是根据这个基准来衡量,并且很可能在经验上(如果不是统计上)达不到要求。
此外,减少人力成本节约的角度没有你想象的那么吸引人。客户不会主动裁员来实现节约,除非他们真的被迫这样做,并且确信你的解决方案是一个时代的解决方案,因为这种激烈的措施很难收回。即使你越过了这个障碍,你所能控制的收入上限也将永远是以节省的成本而不是交付的价值来衡量的。
如果允许预算有限的组织大规模执行原本只能在子集上完成的任务,这种策略通常效果最佳。
该产品是否能让参与手工流程的人更快地完成任务?
支持人类活动通常是更好的策略。使用这种方法,您可以利用帕累托原则并调整您的模型来处理最常见的决策类型。有了正确的产品工作流程,您可以进行设置,以便在遇到边缘情况时,人在回路中可以介入并覆盖。同样,缺点是你的附加值将会以节约成本为框架,而你的产品将会以人力来衡量。
c】该产品是否解决了以前没有类似手动替代方案的问题?
这包括以下产品:
- 解决人类根本无法解决的问题(例如人工智能药物发现)
- 在需要的地方释放人力(例如自动驾驶汽车)
- 以比人快得多的速度执行决策,从而实现迄今为止无法实现的新用例(例如实时 HS 代码估计)
这些问题更像是绿地,因此争议更少,更有利于价值捕捉。
#3 —你的独特辩护销售主张(USP)是什么?
有很多原因可以让顾客发现你的产品的价值,其中一些比另一些更有说服力。
一个获得数据科学的人才
向技术采用缓慢的老行业销售可以帮助获得早期回报,但这种策略不能提供强大的防御能力。如果合同规模变得太大,产品开始变得对客户的需求太重要,或者市场上出现了新的竞争对手,那么你的立足点将开始变得薄弱。这也不是快速增长的咒语,所以不要被早期采用所迷惑。
b]唯一数据集
如果你可以访问独特的数据集,你训练的模型可能比你的竞争对手带来的更有效。但是,您应该认识到数据集的独特性:
- 最强有力的保护形式是从一个独特的来源长期合法地保证你的访问。
- 如果建立训练数据集的成本是阻止竞争对手的原因,那么你可以肯定,如果市场有利可图,你的蓝海不会长期没有鲨鱼。
- 如果这种独特性源于你的先发优势或你最初客户群的规模,那么请再想一想——已经有很多关于数据网络效应 是否会形成强大的护城河的文章。
c】创新的模型架构
有时,你的数据科学团队可能非常有能力,在一个普遍可用的数据集上获得比其他任何人都好得多的结果。然而,这几乎从来不是长期防御的来源。由于该行业的开源基因,新的创新迅速扩散。更重要的是,由于创新的速度,看似开创性的技术很快就会被新的浪潮完全淹没。
通常,这三个选项中没有一个足以确保增长和防御。从长远来看,造成差异的是你如何将它们结合在一起,来制作你的过程和产品。流程是指如何将模型和数据集与人在回路中、分类法、试探法和分析法编织在一起,以解决手头的问题。产品是指如何以满足客户需求的方式使这些过程对客户可用。
#4 —人类在你的循环中扮演什么角色?
“每当你有歧义和错误时,你需要考虑如何将人置于循环中,并升级到人来做出选择。对我来说,这是人工智能产品的艺术形式。如果你有歧义和错误率,你必须能够处理异常。但首先你必须检测出异常,幸运的是,在人工智能中,你有信心、概率和分布,所以你必须利用所有这些让人类参与进来。”——塞特亚·纳德拉
具有讽刺意味的是,人工智能需要人类才能使其可用,无论是处理边缘案件,建立训练数据集,生成启发式或量化样本准确性。在这些人类活动中,有些活动比其他活动影响力更大,成本更低。你如何将人的角色设计到你的产品工作流程中,将决定你的成本和你的用户体验。一些需要思考的观点:
- 你有没有在你的产品中建立反馈环,让你的用户间接地“训练”你的模型?还是所有识别和提供反馈的成本都由您的后端注释团队承担?
- 您的注释团队是否处理单个数据点,或者您是否有一种机制让他们交流他们在数据中看到的更广泛的模式?
- 你会像一个庞然大物一样解决潜在的问题吗?还是使用智能采样技术和主动学习模型将人的注意力集中在可以提供最高 RoI 的地方?
#5 —您的客户如何衡量您产品的质量?
在学术界,ML 系统的质量是通过对 ImageNet 等标准化数据集进行基准测试来衡量的,精确度越高,模型越好。
然而在工业界,这些标准化的基准并不存在。您训练的数据集是自定义的,可能不代表手头的问题-事实上,最大的挑战通常是建立一个准确模拟问题的数据集。此外,没有两个客户从同一个角度看待问题,因此单一精度/召回基准的想法是象征性的,最多可能是指示性的。加上像数据漂移和概念漂移这样的现象,你会发现自己漂浮在海上,没有锚。
你面临的挑战是不仅要找到一种方法来衡量每个客户的质量,还要找到一种方法来将这个数字传达给客户,以管理他或她对你产品的看法。我们使用 5 个步骤来处理这个问题:
a】统计教育
让你的客户了解统计思维和经验思维的区别。无论你采取什么样的措施,边缘案例和断层线总是存在的。虽然从统计数据来看,完美几乎从来不是一个要求,但问题是人类倾向于凭经验思考。客户对个别例子的负面反应并不少见(导致数据科学家发泄他们的统计愤怒)。
然而,统计教育说起来容易做起来难,即使你与客户有直接的沟通渠道。我倾向于从与客户的第一次营销互动开始,并确保这种想法渗透到您的销售组织的推销中。顾客通常会接受合理的论点,即使竞争对手向他们许下种种承诺。根据你的业务性质,以及你与客户的接触程度,你可能需要找到创新的方法来做到这一点。
b】确定代表性数据集
寻找或建立一个数据源,定量地获取客户使用产品的方式。通常,这包括跟踪和记录客户行为,无论是输入到您的模型中,还是基于反应的反馈循环。该数据集代表了客户的问题空间。
c】抽样方法
如果代表性数据集的大小太大而无法进行分析或标注,则决定一种采样方法来放大到更小的子集。
d】评估方法
确定最能抓住客户优先事项的指标。如果要对数据集进行注释,就要包含一组简单且一致的规则来定义如何进行注释。此外,决定执行这些评估的频率。
e】设定目标和补救措施
确定每个指标的最小阈值,以及如果没有达到这些阈值将采取的补救措施。
f】获得客户认可并定期报告
这是关键部分——尽你所能,让客户了解你选择采用的方法,并且最好将他们的反馈反馈反馈到流程中。然后,定期严格地主动向客户提供这些指标,以消除任何不满。
如果您从事销售企业合同的业务,并且每个客户的毛利润很高,请将这些指标用作合同中保证的 SLA。虽然这给你的团队带来了更多的挑战,但它确保了任何关于质量的讨论都是通过一个共同的统计透镜来简化的。
讨论了所有这些之后,统计教育说起来容易做起来难。由于各种各样的原因,观察者偏差很难克服。我们遇到过很多这样的情况,我们产品的日常用户对我们的方法很满意,但是当一个高级主管(和产品的零星用户)遇到一个边缘情况并敲响了所有的警钟时,他们就变得手忙脚乱了。要处理这种情况,请考虑内置覆盖机制来根据症状处理问题。你的数据科学团队中的清教徒可能会不高兴,但这是一个你可能想要做出的权衡,以确保对你的产品功效的感知不会被变幻莫测的机会所左右。
此外,客户特定的调整和测量并不便宜。您必须考虑质量和成本之间的权衡,并配置您的定价模型,以将这些“支持”成本转嫁给客户。
# 6——你是否接受了过多的挑战?
ML 产品团队在两种项目上花费了大量的时间,这两种项目损害了用户体验并增加了运营成本。
解决不属于产品核心价值主张核心的“模糊”问题
可以用机器学习解决的问题范围很广。然而,这并不意味着你遇到的所有问题都应该用机器学习来解决。在构建您的产品时,您可能会遇到许多挑战,数据科学团队对此的第一反应是使用 ML。在这样的时刻,有必要问一下,是否有不那么优雅、效率可能更低、但更简单的解决方案可供选择。
机器学习通常被视为必须尽可能撒在任何地方的魔法灰尘,即使是那些理解它的人也是如此。训练第一组模型来解决一个新问题,甚至交付有希望的结果,可能是非常容易和令人兴奋的。但是如上所述,部署到生产环境需要的不仅仅是一个有好结果的模型。因此,在实践中,尽可能少用魔法,求助于不那么令人兴奋但肯定有效的替代方法,比如启发式……或者尽可能完全放弃产品功能,这可能不是一个坏主意。
b】内部构建工具以弥补开源或云生态系统中的空白
Tensorflow 和 PyTorch 是两个领先的深度学习框架,还不到 5 岁。像 Sagemaker 和 Kubeflow 这样的基础设施工具还不到 2 岁。开源工具的生态系统才刚刚兴起,每隔几个月就会有新的改变游戏规则的库出现。
当您开始使用这些工具时,您经常会发现您的特定开发工作流或产品特性所必需的某些组件不见了。对于一个有进取心的工程师团队来说,这可能是一个建立新工具来填补空白的号召。在 Semantics3,这些年来我们已经这样做了很多次。我们已经建立了一个并行处理暨缓存层,用于处理需要大量预处理的训练数据集…最近,我们使用脸书的 FAISS 库创建了我们自己的网络数据库。
不过,这种暴跌应该仔细考虑,并通过构建 vs 购买 vs 等待演算。如果你发现开源或云生态系统中有一个巨大的需求需要满足,很可能你不是唯一的一个,其他人也在做这件事——询问周围的人以获得早期访问是值得的。如果你没有其他选择或者发现你的需求很紧急,记住这些工具需要定期维护,尤其是当它们被放在你的书架上的时候。
#7 —您的数据科学团队是否具备完成手头任务的合适 DNA?
一旦你理解了你的产品是什么,你就可以反过来确定你需要组建什么样的团队:
- 你正在解决绿色领域的问题吗?这些问题要求你在这一领域的工作中聘请最前沿的博士。
- 您的增值是否来自调整模型架构—您是否需要一群数据科学家整天训练模型和优化超参数?
- 钉住边缘案例对你的用户体验至关重要吗——你是否需要有黑客心态的测试人员来放弃注释思想、启发式框架和其他合适的工具?
- 在这里,对领域的深刻理解是必不可少的吗——你需要对你的问题领域有多年经验的人吗?
- 您的销售和售后流程的结构化程度如何?您是否需要通才数据科学家与整个组织的员工合作,以确保流程正确?
- 优化运营执行的云成本是否是获得合理毛利润的瓶颈——您是否需要同时拥有基础架构头衔的数据科学家?
- 如果 ML 模型只是一个更大整体的一个组成部分,那么在预算有限的情况下,你需要在产品经理和前端工程师身上投资多少
我见过一些产品是由大批 ML 工程师在发布前制造的,还有一些是由游击队员组成的迷你披萨团队制造的。一个和另一个是不一样的,每个群体对挑战的反应都不一样。拥有正确的 DNA 会带来巨大的不同。
总之,企业主对价值主张、防御能力和成本的计划越多,增长的可预测性就越大。产品经理对他们的方法考虑得越周到,ML 模型、环中人和客户工作流之间的和谐就越大。数据科学经理对工具选择和团队构成越慎重,代码和愿景之间的协同作用就越大。客户负责人在衡量质量和管理认知方面越系统,你的流失率就越低。
“人工智能行业”不是一个整体——有许多方法来构建机器学习支持的产品。虽然现在还为时尚早,这方面的剧本还在继续编写,但如果你正着手在这个领域开发一款产品,那么系统地考虑可能影响你成功的各种决策会有所帮助。
绝对不要点击这个点击诱饵

由 Unsplash 上的 Mael BALLAND 拍摄的照片
社交媒体的政治
互联网政策假新闻技术算法伤害社会
W 社交媒体出现之前的世界是什么样的?在六度、Friendster、LinkedIn、MySpace、Twitter、Snapchat、Reddit、Instagram 和脸书出现之前,社会是什么样子的?
2004 年,MySpace 成为首个月活跃用户达到 100 万的社交媒体网站。如今,脸书拥有超过 1.62 亿 日活跃用户。虽然 Instagram、WhatsApp 和 Messenger 等公司帮助这一数字增长,但不可否认的是,社交媒体已经深深嵌入社会。
快速的技术变革不是没有代价的。用户慢慢发展社交媒体平台,以适应他们的 UX 需求,但人们往往忘记了社交媒体如何同样影响社会。
“技术不仅是人类活动的辅助工具,也是重塑人类活动及其意义的强大力量。”—兰登·温纳
听过煮青蛙的古老寓言吗?
要煮一只活青蛙,把它放在一锅沸水里是行不通的——它会直接从锅里跳出来。相反,必须将它放入一壶室温的水中,随着时间的推移慢慢加热。青蛙不会意识到它舒适的炉顶热水浴缸已经成为一个坟墓,直到为时已晚。
社交媒体就像一口烧开的锅
每个社交媒体平台都有被黑客操纵的风险。算法多年来一直受到攻击。每天有超过 10 亿的活跃用户,这些算法有能力引导社会走向更好或更坏。一些平台比其他平台面临更大的攻击风险。
1.Twitter 趋势
Twitter 最脆弱的算法是允许标签、事件和短语免费到达数百万观众的算法。虽然 Twitter 趋势最初是为了显示用户周围的实际上是趋势信息而创建的,但它已经成为参与度操纵的一个大目标。
对于黑客来说,Twitter 的趋势比简单的 #throwbackthursday 要强大得多。数百万的观众很容易就足以左右选举,传播假新闻,隐藏重要的真相。
2011 年,垃圾邮件即服务市场攻击 Twitter 趋势,审查关于俄罗斯议会选举结果的公众意见。2012 年,墨西哥竞选总统的政客雇佣了成千上万的墨西哥公民通过推特操纵趋势来影响公众舆论。2015 年,趋势算法被用于试图让公众脱离伊朗核谈判,也被用于推动委内瑞拉公众的政治观点。
黑客们发现了如何人为夸大虚假趋势和人为缩小真实趋势来操纵公众知识和参与度。甚至还存在秘密市场和团体,它们可以被雇佣来以低廉的价格人为地创造一种 Twitter 趋势。
换句话说,黑客、垃圾邮件制造者和政客已经找到了非常有效的方法来控制哪些内容会出现在 Twitter 的首页。尽管 Twitter 在打击其平台上的虚假趋势和机器人方面做得很好,但决定什么时候成为趋势的算法仍然是专有的。这意味着用户没有办法知道 Twitter 趋势是真是假。*
2.剑桥分析和脸书公司

2015 年至 2018 年间的扎克伯格迷因和大数据流行语让许多数字公民感到害怕、有趣和严重困惑。脸书和剑桥分析公司之间到底发生了什么,出了这么大的问题?
这是几年前开始的。剑桥分析公司最初并没有违反任何法律。脸书也没有。剑桥分析公司只是一家战略传播公司。他们利用潜在选民的数据来战略性地与他们交流选举细节(并希望说服他们投票给他们的客户)。然而,他们做了一些错误的决定。
2013 年,剑桥分析公司开始通过完全合法的手段收集脸书用户的数据。他们最初收集的每个用户的账户都是经过同意的。这不成问题。
当分析公司开始滥用这种同意时,问题就出现了。对于每一个同意的用户,他们也可以从他们账户上的所有朋友那里获得所有的个人资料信息,而不需要征得同意。
他们开始收集数据;大量的数据。
数据变成了力量。他们对人们了解得越多,就越能影响他们。
“今天在美国,我们在每个人身上有近四五千个数据点……所以我们对美国大约 2.3 亿成年人的个性进行建模。”——剑桥分析公司首席执行官亚历山大·尼克斯,2016 年 10 月。
2015 年,特德·克鲁兹竞选团队聘请剑桥分析公司帮助他影响目标潜在选民。2016 年,川普竞选团队做了同样的事情。2018 年,一名举报者将这一政治活动公之于众。
剑桥分析公司违法了吗?关于这个还有争论。
剑桥分析公司的行为不道德吗?这就更清楚一点了。简而言之:
- 该公司从没有明确表示同意的不知情的社交媒体用户那里收集数据。这些用户也没有被告知他们的数据是在事后收集的。
- 这些数据是打着*【学术目的】的幌子收集的,而它却被用于完全不同的用途。*
说到研究,大多数伦理问题都不是法律问题。
在第二次世界大战期间对人进行了不人道的科学实验后,机构审查委员会(IRB)成立,为科学家提供伦理指导。
在大学,IRB 委员会管理研究伦理。社交媒体数据挖掘很难监管,因为很难知道什么被认为是“公开可用的数据”。例如,收集和分析公开的 Twitter 帖子进行研究通常不需要征得同意。但是,下载一个脸书朋友的私人帖子需要得到同意。
如果剑桥分析公司要求 IRB 批准他们的活动,他们会被拒绝。未经同意,他们不可能收集任何“朋友”的个人资料。他们也不可能将人类数据用于与其最初意图不同的目的。
一些人仍在争论剑桥分析公司是否真的对美国选举进程产生了那么大的影响。截至目前,还没有办法衡量其影响。
然而,不可否认的是,剑桥分析公司收集的数据是危险的和强大的。**
我们是青蛙

社交媒体公司可能是公开交易的,但它们是私有的。用户可以免费玩游戏,那么这些大型科技巨头是如何赚钱的呢?
如果你不是顾客,你就是产品。
UX 设计最初并不是为了让用户满意而创造的。它是为用户保留期创建的。社交媒体用户不用钱支付,他们用数据支付。用户就是产品。真正的客户是那些想要数据、想要喜欢和想要参与的人。
对于剑桥分析公司来说,参与就是投票率。对脸书来说,互动吸引了广告商。对于 Twitter 趋势来说,参与影响了从选举到公共审查的一切。
社会还能怎样被社交媒体无声地伤害?
每天都有数十亿人使用社交平台。数以万亿计的文字被发布、点赞、分享、发推特,并传播给大众。算法操纵只是众多危险之一。最近的研究强调了社交媒体上出现的一些有趣现象:
- 过滤气泡和回音室:社交媒体用户经常上网,让自己置身于类似的社区中,有效地将自己置于一个重申其信仰/观点的内容“气泡”中。当推荐与兴趣相匹配时,过滤泡沫就会加剧,思想的多样性就会消失。当用户被推入极端分子的回音室时,这变得更加危险。
- 反馈回路:

clickbait 的示例。这些能激起你的兴趣吗?
从心理学上来说,人类更容易传播吸引两样东西的信息:情感和信任。情感是由点击诱饵和极端主义引发的。某样东西看起来越令人兴奋,就越能引发我们的注意。社交媒体上的信任以喜欢和分享的形式出现。又名:人们信任那些被分享和喜欢的帖子。
具有讽刺意味的是,假新闻引发争议。争议滋生情绪。情绪引发更多的喜欢和分享。喜欢和分享创造信任。直接导致人们信任误传。
总之,社交媒体上的内容总是主观的,而且经常是假的。但是用户没有办法衡量它的主观性或有效性。
青蛙正在享受温水。
如何走出沸腾的锅

第一步:背书
大约一年前,我把手机换成了西班牙语,为去南美旅行做准备。虽然切换语言让我对优秀的 UX 设计有了新的欣赏,但它也让我在一天早上滚动 LinkedIn feed 时获得了有趣的见解。
在英语中,当我想对 LinkedIn 上某人的帖子做出反应时,我会点击“ like ”按钮。然而,在我的西班牙语手机上,我注意到“喜欢”按钮在西班牙语中没有被动词“ gustar ”(喜欢)取代。取而代之的是“建议者”。
这种区别非常重要。
**在社交媒体上喜欢某件事并不一定等同于同意某件事。如果我喜欢一条推文或一个帖子,我很容易讨厌那个帖子。我可以对一个帖子有各种各样的情绪,但仍然喜欢它。我可能会喜欢一篇让我感到非常愤怒的虚假政治新闻文章。我会喜欢一个点击诱饵,因为它有一个有趣的标题。
在西班牙语中,recomendar 的意思是推荐*,建议,或者建议。*
如果我看到一篇假新闻文章,我会推荐别人看吗?我会建议我的朋友受它的影响吗?我会建议向公众传播吗?大概不会。
这让我想知道,如果“喜欢”按钮变成了“认可”按钮,社交媒体会发生怎样的变化。当参与等同于认可时,用户传播的错误信息就少了,假新闻也不再像以前那样有那么大的影响力。
第二步:脸书的内部评级法
《剑桥分析》并不是脸书第一次被置于公众监督之下。2016 年,一个 A/B 测试出错的案例凸显了一个怪异的未来。脸书的研究人员发表了一篇关于脸书情绪传染能力的论文。
这篇文章强调了一些可怕的事实,其中之一是脸书时间线的内容严重影响了用户的离线情绪。研究人员通过随机选择一组脸书用户作为更多负面时间线内容的实验对象,而另一组则被给予更多正面时间线内容,从而发现了这一点。不足为奇的是,结果证明了脸书供稿中内容的情感确实与消费该内容的用户的情感相关。又名:负面的社交媒体信息会产生负面的人,反之亦然。
这项研究发表后,公众强烈反对。脸书用户对该公司在未经他们同意的情况下将他们的在线生活用作实验室感到愤怒。讽刺的是,这些研究一直都在发生。私企每天都在用户身上做 A/B 测试,没有问过他们。这是用户在签署社交媒体最畅销的条款和条件文档时同意的许多事情之一。
不管怎样,公众对脸书在他们身上做实验感到愤怒。幸运的是,脸书像大学一样,创建了自己的内部 IRB 委员会。脸书的 IRB 由五名员工组成,他们审查提交的研究来决定它们是否符合伦理。
虽然脸书的内部评级法还有很大的改进空间,但这是朝着非常好的方向迈出的一步。
目前,在不道德行为成为法律问题之前,私有公司不会被追究责任。当涉及到社交媒体时,这个概念可能会非常危险,原因有两个:(1)对于数据隐私,大多数道德问题都不是法律问题。(2)在操纵参与度的情况下,当技术丑闻成为法律问题时,伤害通常已经造成了。
针对私营科技公司的内部评级法可以消除这些担忧。如果政策不支持技术伦理,那么公共关系可以为合规提供动力。对于社交媒体公司来说,如果 IRB 意味着增加用户保留率,那么道德就是性感的。
第三步:正念
多年来,特朗普一直在发动一场反对媒体的战争。这是一个危险的游戏。如果新闻机构失去了全体民众的信任,还有可能区分现实和诱饵吗?
即使是现在,当你登录你的脸书、Twitter、LinkedIn 或者你喜欢的社交媒体时,是什么让你相信你所看到的是真实的呢?你真的确定你上周分享的文章不是假的吗?你的 feed 里那些推荐的文章呢,你能相信那些吗?Twitter 上的这种趋势是由人还是由机器人发起的呢?
在一个充满误传的世界里,真理的源泉在哪里?有吗?
我不认为特朗普应该与媒体机构开战。当所有的新闻都被看做假新闻,社会就不知道该相信谁了。
然而,怀疑并不一定是一件坏事。
许多主观的真理拼凑在一起,可以描绘出一幅类似客观的画面。
这就是为什么做一个负责任的数字公民是如此重要,尤其是在社交媒体网站上。假新闻没有。私营科技公司没有内部评级法。剩下的只有直觉和信任。
以下是我的主观建议:
如果你的新闻订阅中出现了一篇有争议的文章,在点击分享按钮之前做一些研究。不要相信 clickbait,除非你知道它会把你带到哪里。在网上要小心。为信息丰富的互联网做出贡献,而不是有害的互联网。
不要做开水锅里的青蛙。
不要相信你看到的一切。
不要相信你所相信的一切。
脚注:
召集所有编码员!!如果你有兴趣成为一个更用心的数字公民,请随意查看我制作的这个教程。在这个回购中,您将获得尝试逆向设计 Twitter 趋势算法所需的所有资源,以更好地了解是什么推动了我们的在线参与。*
欢迎光临!在您开始之前,我建议您阅读这项研究的报告。在本存储库/教程中…
github.com](https://github.com/jesmith14/TwitterTrends)*
可变形卷积及其在视频学习中的应用
实践教程
利用带有稀疏标记数据的视频帧

(来源
卷积层是卷积神经网络的基本层。虽然它广泛应用于计算机视觉和深度学习,但它有几个缺点。例如,对于特定的输入特征图,核权重是固定的,并且不能适应局部特征变化,因此我们需要更多的核来建模特征图的复杂上下文,这是多余的并且效率不高。此外,由于输出像素的感受野总是矩形,作为分层卷积的累积效应,感受野变得更大,其中将包含一些与输出像素无关的上下文背景。不相关的背景会给输出像素的训练带来噪声。
想象一下,为了克服上述问题,你想对传统的卷积层做一个小小的改变:核可以适应局部特征变化,感受野可以收敛到与输出像素对应的语义背景。幸运的是,它已经实现了,细化卷积层的名称叫做可变形卷积层。
在本帖中,我将介绍这些话题:
- 可变形卷积
- 利用可变形卷积提高关键点估计的性能
- 使用可变形卷积增强实例分割的性能
可变形卷积

(可变形卷积)
可变形卷积是卷积层加偏移学习。如上所示,对于卷积核的每个足迹,学习 2D 偏移,以便将足迹引导到对训练最优化的位置。偏移学习部分也是卷积层,其输出通道的数量是输入通道数量的两倍,因为每个像素有两个偏移坐标。基于该方法,核可以适应局部特征变化,有利于语义特征学习。

(覆盖区偏移示例)
这是偏移学习的一个例子。a 是传统的卷积,其中内核足迹完全不移动。b、c 和 d 表示足迹的移动。

(可变形卷积的感受野细化)
结果,在可变形卷积中,深像素的感受野集中于相应的物体。如上图,在 a 中,深蓝色像素(上图)属于大羊。然而,它的矩形感受野(底部)包含左下方的小绵羊,这可能会为实例分割等任务带来模糊性。b 中感受野变形,集中在大羊上,其中避免了歧义。
理解可变形卷积中的偏移
如上所述,偏移有助于局部特征的核心适应和感受野的集中。顾名思义,offset 用于使内核足迹局部变形,从而使感受野整体变形。
现在棘手的部分来了:既然可以学习偏移来适应当前图片中的对象,我们是否可以通过提供偏移来使当前图片中的对象适应另一张图片中的对象?
让我们把它具体化。假设我们有一个视频,其中每一帧都与其相邻帧相似。然后,我们稀疏地选择一些帧,并在像素级对它们进行标记,如语义分割或关键点等。既然这几类像素级的标签都很贵,那我们能不能用无标签的相邻帧来提高概化的精度呢?具体来说,用一种方法将未标记帧的特征图变形到其相邻的标记帧,以补偿标记帧中缺失的信息?
从稀疏标记视频中学习时间姿态估计

(特征地图扭曲模型)
这项研究很好地解决了上面讨论的问题。由于标记是昂贵的,所以在视频中只有少量的帧被标记。然而,标记帧图像中的固有问题,如遮挡、模糊等。阻碍模型训练的准确性和效率。为了解决这个问题,作者使用可变形卷积将未标记帧的特征映射变形为它们相邻的标记帧的特征映射,以补偿上面讨论的固有问题。偏移量就是已标记帧与其未标记相邻帧之间的优化特征差异。可变形部分由多分辨率特征金字塔构成,其中使用了不同的膨胀。这种方法的优点是,我们可以利用相邻的未标记帧来增强标记帧的特征学习,因此我们不需要标记视频的每一帧,因为相邻的帧是相似的。这种变形方法,也被作者称为“扭曲”方法,比其他一些视频学习方法,如光流或 3D 卷积等,更便宜,更有效。

(扭曲模型的训练和推断)
如上所示,在训练期间,未标记帧 B 的特征图被扭曲到其相邻的标记帧 A 的特征图。在推断期间,帧 A 的基本事实可以使用训练的扭曲模型来传播,以获得帧 B 的关键点估计。此外,可以扭曲更多的相邻帧,聚集它们的特征图,以提高关键点估计的准确性。
具有掩模传播的视频中的实例分割

(基于掩码 RCNN 的掩码传播)
作者还通过在现有的 Mask-RCNN 模型中添加掩模传播头,提出了用于实例分割的掩模传播,其中在时间 t 的预测实例分割可以传播到其相邻的帧 t + δ。

(掩模传播的网络结构)
网络结构类似于上面讨论的姿态估计网络,但有点复杂。它有三个部分:1)帧 t 的实例分割预测;2)帧 t 和 t + δ之间的偏移优化和分割变形;3)用于帧 t + δ处实例分割的最终预测的特征图聚集。在这里,作者还使用乘法层来过滤噪声,只关注对象实例存在的特征。利用来自相邻帧的特征集合,可以减轻遮挡、模糊的问题。
结论
可变形卷积可以被引入到具有给定偏移的视频学习任务中,其中标签传播和特征聚集被实现以提高模型性能。与传统的一帧一标签学习方式相比,作者提出了多帧一标签学习方式,利用相邻帧的特征图来增强表征学习。因此,模型可以被训练来从相邻帧中看到被其他眼睛遮挡或模糊的内容。
参考
可变形卷积网络,2017
从稀疏标记的视频中学习时间姿态估计,2019
利用掩模传播对视频中的对象实例进行分类、分割和跟踪,2020
阅读陈数·杜(以及媒体上成千上万的其他作家)的每一个故事。您的会员费直接支持…
dushuchen.medium.com](https://dushuchen.medium.com/membership)
去神秘化的可变形卷积
可变形卷积越来越受欢迎,并被应用于复杂的计算机视觉任务,如物体检测。在这篇文章中,我将尝试详细解释它们,并阐明它们在未来计算机视觉应用中的重要性。

(来源)
先决条件:
帖子的读者必须对卷积神经网络有一个基本的了解。如果你不熟悉这个话题,你可以参考这个链接 如果你想了解更多关于卷积运算的知识,它实际上是从基本的图像处理中派生出来的,你也可以阅读这个 博客 。
介绍
简而言之,卷积神经网络或 CNN 是人工智能研究在一个非常艾龙的冬天之后复兴的主要原因之一。基于它们的应用首次展示了人工智能或深度学习的力量,并恢复了该领域的信心。在马文·明斯基指出感知器只能处理线性可分数据,而不能处理最简单的非线性函数(如 XOR)后,这种信心已经丧失。
卷积神经网络在计算机视觉领域非常流行,几乎所有最新的应用程序,如谷歌图像、无人驾驶汽车等,都基于它。在非常高的水平上,它们是一种神经网络,其关注局部空间信息,并使用权重共享以分层方式提取特征,这些特征最终以某种特定于任务的方式聚集,以给出特定于任务的输出。
虽然 CNN 在视觉识别任务方面表现出色,但在对物体比例、姿态、视点和部分变形的几何变化或几何变换建模时却非常有限。
几何变换是将图像的位置和方向变换为另一个位置和方向的基本变换。
一些基本的几何变换包括缩放、旋转、平移等。
卷积神经网络缺乏模拟几何变化的内部机制,只能使用固定且受用户知识限制的数据扩充来模拟几何变化,因此 CNN 无法学习用户未知的几何变换。
为了克服这个问题并增加 CNN 的能力,微软亚洲研究院推出了。在他们的工作中,他们引入了一种简单的、高效的和端到端的机制,使得 CNN 能够根据给定的数据学习各种几何变换。
为什么卷积神经网络无法模拟几何变换?

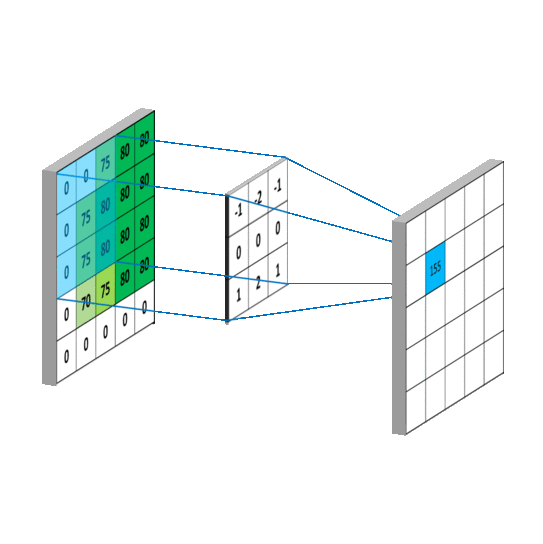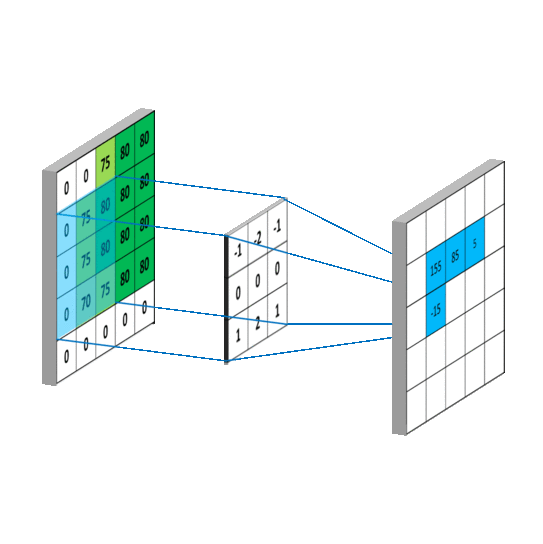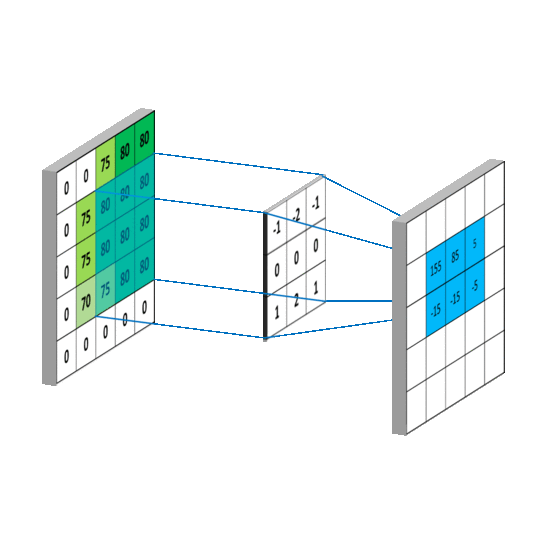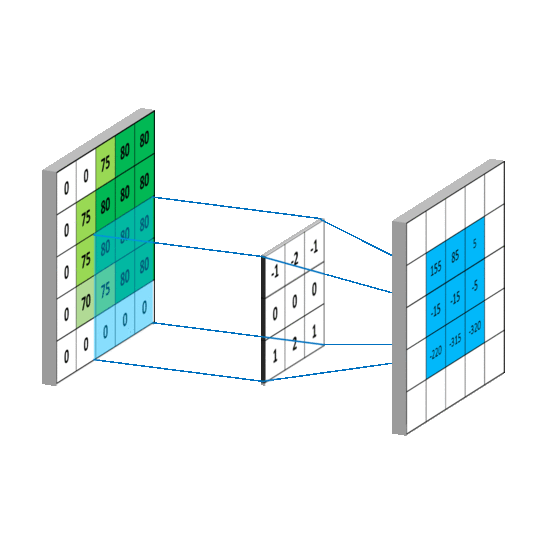
****图一。简单卷积运算 ( 来源 )

图二。2x2 矩形内核的最大池操作(来源)
CNN 对模型几何变换的限制源于用于从特征图采样的核的固定结构。CNN 内核使用固定的矩形窗口(图 1 )在固定位置从输入特征地图中进行采样,汇集层使用相同的矩形内核(图 2 )以固定比率降低空间分辨率。这引入了各种问题,例如给定 CNN 层中的所有激活单元具有相同的感受野,即使在不同的空间位置可能存在不同尺度的对象。对于需要精细定位的视觉识别任务,例如物体检测、分割等,需要适应物体的比例并对不同的物体具有不同的感受野大小。
可变形卷积
高级解释:
在可变形卷积中,为了将不同对象的尺度考虑在内并根据对象的尺度具有不同的感受野,在标准卷积运算中,将 2D 偏移添加到规则网格采样位置,从而使前面激活单元的恒定感受野变形。使用额外的卷积层,添加的偏移可以从前面的特征图中获知。因此,所应用的变形以局部、密集和自适应的方式取决于输入特征。添加的可变形卷积层向现有模型添加了非常小的参数和计算,并且可以使用正常的反向传播进行端到端训练。

****图 3。正常卷积运算(a)与可变形卷积运算(b,c,d)的采样位置。
详解:
为了详细解释可变形卷积,我将首先讨论正常的卷积运算,然后解释将它们转换为可变形卷积的简单思想。
正常的卷积运算包括两个基本步骤:
- 使用矩形核对输入图像或特征图的小区域进行采样。
- 将采样值乘以矩形核的权重,然后在整个核上对它们求和,以给出单个标量值。
我会用方程式和视觉的形式来解释以上两个概念。
让我们先试着用数学方程式来理解。
设 R 是一个 3×3 的核,用于对输入特征图的一个小区域进行采样。

****方程式 1。采样内核
那么正常的二维卷积运算的等式将如下图所示,其中 w 是核的权重, x 是输入特征图, y 是卷积运算的输出, p₀ 是每个核的起始位置, pₙ 是 r 中所有位置的枚举

****方程式 2。普通卷积运算
该等式表示卷积运算,其中采样网格上的每个位置首先乘以权重矩阵的相应值,然后求和以给出标量输出,并且在整个图像上重复相同的运算给出了新的特征图。
下面直观地描述了上面解释的操作,其中绿色内核滑过由蓝色矩阵描述的图像,并且相应的权重值与来自图像的采样值相乘,然后求和以给出输出特征图中给定位置的最终输出。

图 4 。卷积运算的直观演示
可变形卷积不是使用简单的固定采样网格,而是将 2D 偏移引入到上述正常卷积运算中。
如果 R 是正常网格,则可变形卷积运算将学习到的偏移增加到网格,从而使网格的采样位置变形。
可变形卷积运算由下面的等式描述,其中δpₙ表示添加到正常卷积运算的偏移。

方程式 3 。变形卷积运算
现在,由于采样是在不规则和偏移位置上进行的,并且δpₙ通常是分数,我们使用双线性插值来实现上述等式。
使用双线性插值是因为当我们向现有采样位置添加偏移时,我们获得的分数点不是网格上定义的位置,为了估计它们的像素值,我们使用双线性插值,使用相邻像素值的 2x2 网格来估计新变形位置的像素值。
****下面给出了用于执行双线性插值和估计分数位置处的像素值的等式,其中 p(**p₀+pₙ+****δpₙ)**是变形位置, q 列举了输入特征图上的所有有效位置,而 G(…)是双线性插值核。

****方程式 4。双线性插值运算
注: G(…)是二维的,并且可以根据轴分解成两个一维内核,如下所示。

****方程式 5。轴向双线性插值内核
从视觉上看,可变形卷积的实现如下图所示。

****图五。可变形卷积运算的可视化表示
如图图 5 所示,通过在输入特征地图上应用卷积层获得偏移。所使用的卷积核具有与当前卷积层相同的空间分辨率和膨胀。输出偏移字段的分辨率与输入要素地图的分辨率相同,具有 2N 个通道,其中 2N 对应于 N 个 2d 偏移。
网络修改详细信息
可变形卷积层主要应用于卷积网络的最后几层,因为与提取更多基本特征如形状、边缘等的早期层相比,它们更可能包含对象级语义信息。实验结果表明,将可变形卷积应用于最后 3 个卷积层在诸如对象检测、分割等任务中提供了最佳性能。

图 6。标准卷积中固定感受野和变形卷积运算中自适应感受野的图示。
使用可变形卷积的优点

****图 7。描绘每个对象的适应性感受野的三联图像。
使用可变形卷积运算的优势在图 7 中有清晰的描述。如您所见,有 4 个图像三元组,其中特定三元组中的每个图像描绘了关于特定对象的感受野。如果这是一个正常的卷积运算,那么给定图像中所有物体的感受野应该是相同的。但是正如你所注意到的,在可变形卷积的情况下,感受野根据物体的大小是自适应的。与大尺寸物体相比,小尺寸物体(例如第一组中的汽车)具有较小的感受野。你可以注意到,背景物体的感受野是最大的,与前景物体相比,需要大的感受野来检测背景物体。
结论:
在这篇文章中,我试图解释可变形卷积,这种卷积在当前新颖的对象检测和分割模型中很容易应用。它们获得动力的主要原因是它们提供了内部机制,使卷积神经网络能够模拟各种空间变换。它们提供了自适应感受野的优势,该感受野从数据中学习并根据对象的规模而变化。
希望你喜欢这篇文章,如果你有任何疑问或建议,请使用 Twitter 或 LinkedIn 联系我。
参考文献:
- 可变形卷积网络。戴,齐,熊,李,张,胡,魏
通过 NLP & R 提供即时商业价值
让我们面对现实吧——我们不能整天坐在那里训练神经网络

照片: 弗洛伦西亚 Viadana ,Unsplash
作为数据科学家,我们的工作是为企业提供切实的底线结果。虽然我喜欢整天训练神经网络,但关键是我们要与业务部门建立稳固的关系,并找到交付易于理解和量化的价值的方法。
除非你在一家大型科技公司工作,否则你的团队很可能有大量的分析用例。在这个简短的教程中,我将为您提供代码,并概述如何利用基本的自然语言处理(NLP)来交付真实、可沟通、有价值的分析。
关于从互联网上收集必要的文本数据的教程(和一些警告),请查看我关于 web 爬行的文章:
完全初学者的第 1 部分可以在这里找到和第 2 部分,在那里我们采取了一种更加面向对象和可重用的方法,可以在这里找到。
TL;博士-给我密码
让我们来分解一下:语料库
语料库是我们将用于 NLP 的核心数据结构。因为我们将一个字符向量传递给 Corpus()函数,所以我们需要指定源是一个向量源。使用 inspect()方法将允许您查看新创建的语料库。
在语料库创建之后,我们使用一些常用的方法清理文本数据。我们的 cleaner()函数做了一些基本的操作,比如删除数字,但是它也删除了所有的停用词,这些词本身没有什么意义。流行的停用词是“the”和“a”
请注意,删除停用字词时可能会丢失一些信息。这就是分析变得更像艺术而不是科学的地方。你可以选择只删除基本术语,也可以决定删除特定行业术语,等等。

产品的原始评论(图片由作者提供)

去掉了停用词。请注意,“它没有”不再出现在句子中(图片由作者提供)
TDM 和词云
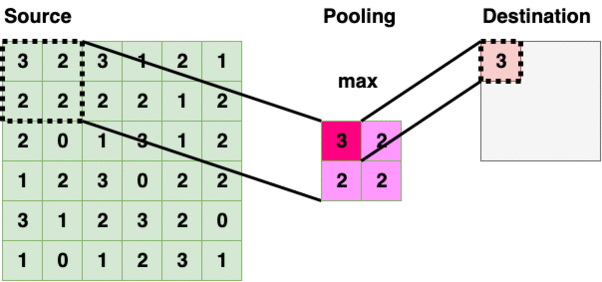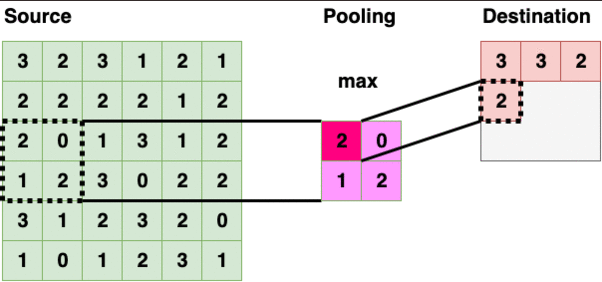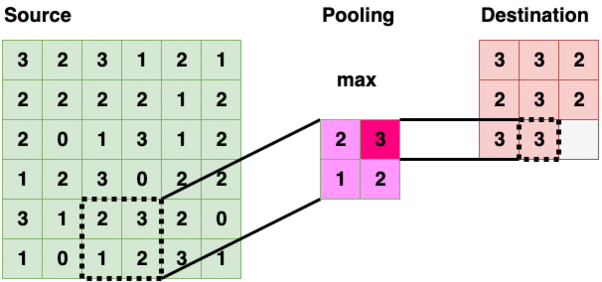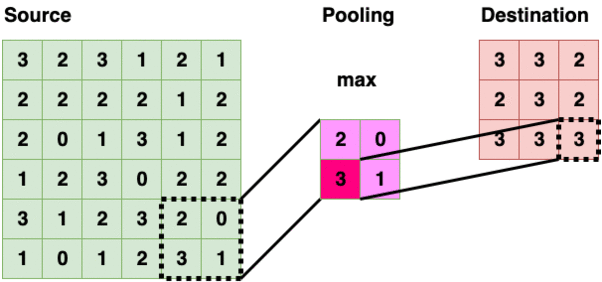
当我们创建语料库时,R 基本上将每篇评论编码为一个单独的文本文档。术语文档矩阵(TDM)采用语料库,并对每个单词制作一个的矢量化频率表。下面是一个 TDM 中包含 3 个虚拟评论的示例:****

TDM 是如何制作的示例(图片由作者提供)
从这个 TDM 中,我们可以创建一个矩阵,按行和(词频)排序,然后使用词云可视化结果。这是我们分析的第一部分。

药品评论的文字云(图片由作者提供)
单词相关性
云这个词是一个很好的开始,但却是一个很基础的起点。我们可以通过评估单词之间的相关性来增强我们的分析。单词相关性利用 R 的 base cor()函数使用的相同方法,Pearson 相关性是默认的。这是皮尔逊相关公式:

皮尔逊相关系数®公式,
因为我们的 TDM 是矢量化的,所以 R 可以有效地执行这些比较。在我们的主代码中,我们需要输入一个感兴趣的项和一个相关下限。如果你看到大多数单词的相关度都在 15%以下,不要惊讶。事实上,由于我们数据集的庞大规模,15%可能是一个显著的相关性。即使我们的数据集很小(按 ML 标准),我们的 TDM 也非常大(2300 万个元素——3107 条评论 x 750 个单词)。
让我们看一下单词“Pain”和我们的 TDM 的其余部分之间的相关图,施加 18%的相关下限:

TDM 和“疼痛”之间的关联图,18%关联下限(图片由作者提供)
这张图表立刻向我们展示了一些见解。例如,我们看到“神经”与疼痛有很高的相关性,相关性为 22%。这可以产生直接、即时的业务影响;我们有效地总结了 3000 多篇评论,并找出了一个常见的问题。
情感分析
虽然有许多复杂的方法来执行情感分析,但在本文中,我们将重点关注合理执行的开箱即用的方法。对于情感分析的详细概述,请查看这个维基百科页面。对于快速启动,我们基本上利用了微软情感词典中大量预先标记的消极/积极词汇。我们用我们的单词列表加入词典,然后只计算正面和负面单词的比率。

来自我们合并列表的片段(图片由作者提供)
N-Grams
但是等等,还有呢!虽然我们可以更仔细地观察单个词频,但这表面上是我们在词云中可视化的条形图/表格形式。单个单词也有信息缺失的问题。类似于我们在讨论停用词时看到的,我们可能会用这种方法丢失句子中的重要修饰语。例如,我们可以将“粉丝”作为我们的首选词之一,但可能有一半的句子也包括“我不是一个…

作者图片
我们可以用 N-gram 分析来应对这种信息丢失。一个 N-gram 基本上是在我们的数据集中同现的“N”个单词。在这个代码模板中,我们需要做的就是将方法中的“n”改为我们想要的大小。以下是运行二元和三元模型分析并清理数据集后的结果。

几乎是瞬间,我们对热门话题有了一个很好的了解(图片由作者提供)
太好了,我怎么卖?
这个代码模板有几个很大的技术和非技术优势:
- ****战斗偏见&显著性:采用程序化方法的最重要优势之一是消除了人为因素。对于公司来说,让一个关键人员审查报告的药物副作用、内部调查等是很常见的。这是一个问题。人都是有偏见的,不管自己知不知道。潜意识偏见会导致一种类型的评论保持突出或直接影响结果的交付。像这样的程序可以很容易地扩展和大规模共享(见#4),消除了孤立的偏见/突出的影响。
- ****谁不喜欢字云?由此产生的视觉效果易于理解,看起来很漂亮,是建立业务方对您的分析的信心的好方法。
- 速度:**当然,不是完全优化,但是这个代码是快。从开始到结束,这个程序在我的电脑上运行 6.25 秒。诚然,我的电脑比大多数工作机器快一点,但也没快多少。一个人仔细梳理这 3100 条评论可能需要几天时间。

脚本计时(图片由作者提供)
4.没有分析基础设施?没问题!该模板可以回收用于任何文本分析,几乎不需要用户交互。基础设施有所帮助,但并不是真正必要的。如果我们想对此类代码进行“软部署”:
- 添加您想要查看的任何导出条件(图表、n-gram 等。)
- 创建引用此脚本的. bat 文件
- 安排一个 windows 进程在数据更新时每“X”天运行一次可执行文件,或者只需单击。蝙蝠
戴尔 EMC 和 Comet 宣布机器学习平台合作

为数据科学团队提供全栈解决方案的领先提供商戴尔 EMC 和行业领先的元机器学习实验平台 Comet 发布了一个参考体系结构,供希望利用戴尔 EMC 基础架构与 Comet 元机器学习平台的强大功能的数据科学团队使用。阅读由 Comet 和戴尔共同撰写的白皮书,了解 Comet 与戴尔 EMC 人工智能基础架构的配合使用。
借助 Dell EMC PowerEdge 参考体系结构,组织可以部署人工智能工作负载优化的机架系统,比设计正确的配置和部署解决方案大约快 6 到 12 个月。组织现在可以依赖由我们的戴尔工程师测试和验证的体系结构,并且知道服务可以在您需要的时间和地点提供。
Comet 联合创始人/首席执行官 Gideon Mendels 表示:“对于我们的许多客户来说,协调和管理企业数据科学团队的堆栈是一个巨大的难题。“戴尔 EMC 的 Kubeflow 和 Kubernetes 解决方案是同类最佳的解决方案,是任何希望构建强大且可扩展的 ML 平台的数据科学团队的绝佳选择。”
Comet 是一个元机器学习实验平台,允许用户自动跟踪他们的指标、超参数、依赖性、GPU 利用率、数据集、模型、调试样本等。通过利用 Comet,数据科学团队产生了更快的研究周期,以及更加透明和协作的数据科学。Comet 还提供了内置的超参数优化服务、交互式混淆矩阵、完整的代码跟踪和可再现性特性。Comet 本地安装可以支持任何规模的团队,从单台机器到分布式微服务。

“这是一种让你质疑没有它你如何运作的产品。“Comet 为数据科学团队提供了他们需要的所有自动化和生产力功能,但他们从来没有时间开发自己,”戴尔 EMC 高级首席工程师兼杰出技术人员菲尔·胡梅尔说。
参考体系结构利用戴尔 EMC 支持人工智能的 Kubernetes 解决方案,由 Canonical 的charged Kubernetes和 Kubeflow 提供支持,符合人工智能工作负载的所有要求。该解决方案包括 100%上游 Kubernetes 的最新代码,这些代码被打包成易于使用的包,并由 Canonical 提供支持。
戴尔 EMC 和 Comet 的参考体系结构和数据科学团队用户案例说明了我们的联合解决方案如何为团队提供管理其机器学习工作流(数据存储、实验和模型构建以及部署)所需的工具和基础架构,同时随着团队的扩展提供灵活而强大的部署选项。要了解有关戴尔 EMC 支持人工智能的 Kubernetes 集群选项的更多信息,请阅读更多信息此处或直接联系戴尔 EMC安排电话。要了解更多关于 Comet 的元机器学习平台的信息,请阅读更多关于 Comet 的信息这里或者联系 Comet 的客户解决方案团队以获取更多信息或安排演示。
点击此处阅读完整白皮书,该白皮书涵盖(a)将 Comet 与戴尔 EMC 人工智能基础架构结合使用,以及(b)技术安装说明。
三角洲湖在行动:Upsert &时间旅行
在 Apache spark 中使用 Delta lake 的初学者指南

这是我介绍 Delta Lake with Apache Spark 文章的后续文章,请继续阅读,了解如何使用 Delta Lake with Apache Spark 来执行操作,如更新现有数据、检查以前版本的数据、将数据转换为 Delta 表等。
在深入研究代码之前,让我们试着理解什么时候将 Delta Lake 与 Spark 一起使用,因为这并不像我某天醒来就将 Delta Lake 包含在架构中:P
可使用三角洲湖泊:
- 当处理同一个数据集的*【覆盖】*时,这是我处理过的最头疼的问题,Delta Lake 在这种情况下真的很有帮助。
- 当处理有更新的数据时,Delta Lake 的*“merge”*功能有助于处理数据中的更新(再见,混乱的连接/过滤操作!!)
当然,有许多使用 Delta Lake 的用例,但这是两个场景,它们真正帮助了我。
说够了,让我们深入代码!
如何用 Apache Spark 运行 Delta Lake
首先,要开始使用 Delta Lake,需要将其添加为 Spark 应用程序的一个依赖项,可以这样做:
- 对于
pyspark外壳
pyspark --packages io.delta:delta-core_2.11:0.6.1 --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
- 作为 maven 的依赖项,delta lake 可以包含在
pom.xml中,如下所示
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-core_2.11</artifactId>
<version>0.6.1</version>
</dependency>
注意事项:
- 在这里,
2.11是scala版本,如果使用 scala2.12相应地修改版本。 0.6.1是 Delta Lake 版本,是支持Spark 2.4.4的版本。- 截止到
20200905,delta lake 的最新版本是0.7.0,支持Spark 3.0 - *AWS EMR 特定:*不要将 delta lake 与
EMR 5.29.0一起使用,它有已知问题。建议升级或降级 EMR 版本,以便与 Delta Lake 配合使用。
如何将数据写成 Delta 表?
Delta lake 使用存储为 Delta 表的数据,因此数据需要以 Delta 表的形式写入。
- 要将现有数据转换为增量表,需要一次完成。
df = spark.read.parquet("path/of/some/data") # Read existing datadf.coalesce(5).write.format("delta").save("path/of/some/deltaTable")
- 将新数据写入增量表
df.coalesce(5).write.format("delta").save("path/of/some/deltaTable")
注意事项:
- 当数据保存为增量表时,该路径包含跟踪增量表元数据的
_delta_log目录。 - 编写使用某些列进行分区的 DeltaTable,如下所示:
df.coalesce(5).write.partitionBy("country").format("delta").save("path/of/some/deltaTable")
如何读取增量表?
- 作为火花数据帧:
df = spark.read.format("delta").load("path/of/some/deltaTable")As DeltaTable:
将 DeltaTable 作为 Spark 数据帧读取允许对 DeltaTable 进行所有数据帧操作。
- 作为增量表:
deltaTable = DeltaTable.*forPath*("path/of/some/deltaTable")
将数据读取为 DeltaTable 仅支持 DeltaTable 特定函数。此外,DeltaTable 可以转换为 DataFrame,如下所示:
df = deltaTable.toDF
阿帕奇斯帕克的三角洲湖
DeltaTable 上的 UPSERT 操作允许数据更新,这意味着如果 DeltaTable 可以与一些新的数据集合并,并且在一些join key的基础上,可以在 delta 表中插入修改后的数据。这是在 DeltaTable 上进行向上插入的方法:
val todayData = # new data that needs to be written to deltaTableval deltaTable = DeltaTable.*forPath*("path/of/some/deltaTable")deltaTable.alias("oldData")
.merge(
todayData.alias("newData"),
"oldData.city_id = newData.city_id")
.whenMatched()
.updateAll()
.whenNotMatched()
.insertAll()
.execute()
似乎很简单,对吗?就是这样!所以接下来会发生的是,如果城市已经存在于deltaTable中,那么todayData中带有城市更新信息的行将在deltaTable中被修改,如果城市不存在,那么行将被插入到deltaTable中,这是我们的基本更新!
注意事项:
- 可以使用分区来修改 Upsert 操作,例如,如果需要合并特定的分区,可以指定它来优化合并操作,如:
deltaTable.alias("oldData")
.merge(
todayData.alias("newData"),
"(country = 'India') AND oldData.city_id = newData.city_id")
.whenMatched()
.updateAll()
.whenNotMatched()
.insertAll()
.execute()
- 当
deltaTable中的行与连接键匹配或不匹配时,要执行的操作是可配置的,详情请参考文档。 - 默认情况下,合并操作会写很多小文件,为了控制小文件的数量,相应地设置下面的
spark conf属性,详细信息请参考文档。
spark.delta.merge.repartitionBeforeWrite true
spark.sql.shuffle.partitions 10
- 在成功的合并操作之后,将在
_delta_log目录中创建一个日志提交,浏览其内容以了解 Delta Lake 的工作方式可能会很有趣。 - 合并只支持一对一的映射,即只有一行应该尝试更新
DeltaTable中的一行,如果多行尝试更新DeltaTable中的同一行,则合并操作失败。预处理数据来解决这个问题。
阿帕奇星火中的三角洲湖时光旅行
Delta Lake 支持返回到先前数据版本的功能,同样可以通过指定要读取的数据版本来实现:
df= spark.read.format("delta").option("versionAsOf", 0).load("path/of/some/deltaTable")
版本化从0开始,在delta_log 目录中有多少日志提交,就会有多少数据版本。
似乎,简单吧?
供参考:
[## 欢迎来到三角洲湖文档
学习如何使用三角洲湖。
文档增量 io](https://docs.delta.io/latest/index.html)
下次见,
Ciao。

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}