




原文:RealPython
Python 中的 Minimax:学习如何输掉 Nim 游戏
游戏很好玩!他们定义明确的规则让你探索不同的策略,寻找必胜的方法。 minimax 算法用于选择游戏中任何一点的最佳走法。您将学习如何用 Python 实现一个可以完美地玩 Nim 游戏的 minimax 播放器。
在本教程中,您将关注极小极大。然而,为了形象化算法如何工作,用一个具体的游戏来工作是很好的。您将学习 Nim 的规则,这是一个规则简单、选择有限的游戏。在例子中使用 Nim 可以让你专注于极小极大原则,而不会迷失在游戏规则中。
随着您学习本教程,您将:
- 了解极大极小算法的原理
- 玩 Nim 的游戏的几个变种
- 实现极大极小算法
- 在与一名迷你游戏玩家的比赛中,输给了尼姆
- 使用阿尔法-贝塔剪枝优化极大极小算法
您可以下载本教程中使用的源代码,以及一个游戏模拟器,在那里您可以通过单击下面的链接与 minimax 对手玩不同的 Nim 变体:
源代码: 点击这里下载免费的源代码,你将使用它来输掉与你的 minimax 玩家的 Nim 游戏。
玩一个 Nim 的简化游戏
尼姆的根源可以追溯到很久以前。虽然历史上一直有人玩这种游戏的变体,但尼姆这个名字是在 1901 年查尔斯·l·波顿发表了尼姆,一种具有完整数学理论的游戏时获得的。
Nim 是两个人的游戏,总是以一个人赢而告终。该游戏由几个放在游戏桌上的计数器组成,玩家轮流移动一个或多个计数器。在本教程的前半部分,您将按照以下规则玩一个简化版的 Nim:
- 共享堆里有几个计数器。
- 两名玩家轮流玩**。**
*** 在他们的回合中,一名玩家从牌堆中移除个、个或个指示物。* 取得最后一个计数器的玩家输掉游戏。*
*你会把这个游戏称为 Simple-Nim 。稍后,你会学到常规 Nim 的规则。它们并不复杂,但很简单——尼姆更容易理解。
**注:**现在该上场了!你将从模拟版本开始,所以在你的桌子上清理出一个空间。玩几局简单的 Nim 游戏,了解一下规则。一路上,留意你遇到的任何获胜策略。
您可以使用任何碰巧可用的对象作为计数器,也可以使用记事本来记录当前计数器的数量。十到二十个柜台是一个游戏的好起点。
如果你附近没有对手,你可以暂时和自己打。在本教程结束时,你将会设计出一个你可以与之对战的对手。
为了演示规则,两名玩家——Mindy 和 Maximillian——将玩一个简单的 Nim 游戏,从 12 个计数器开始。明迪先来:
- 明迪拿了两个计数器,剩下十个。
- 马克西米利安拿走一个计数器,剩下九个。
- 明迪拿了三个计数器,剩下六个。
- 马克西米利安拿了两个指示物,剩下四个。
- 明迪拿了三个计数器,剩下一个。
- 马克西米利安拿到最后一个计数器,输掉游戏。
在这场游戏中,马克西米利安占据了最后一个柜台,所以明迪是赢家。
Nim,包括 Simple-Nim,是一个耐人寻味的游戏,因为规则足够简单,游戏完全可以分析。您将使用 Nim 来探索极大极小算法,它能够完美地玩这个游戏。这意味着,如果可能的话,极小极大玩家总是会赢得游戏。
了解 Minimax 算法
游戏已经成为发明和测试人工智能算法的沃土。游戏非常适合这种研究,因为它们有明确定义的规则。最著名的算法之一是极小极大。这个名字描述了一个玩家试图最大化他们的分数,而另一个玩家试图最小化他们的分数。
极大极小可以应用于许多不同的游戏和更一般的决策。在本教程中,你将学习如何教 minimax 玩尼姆。然而,你也可以在其他游戏中使用同样的原则,比如井字游戏和国际象棋。
探索游戏树
回想一下上一节 Mindy 和 Maximillian 玩的游戏。下表显示了游戏的所有步骤:
| 明迪(Minna 的异体)(f.) | 大量 | 姓氏 |
|---|---|---|
| 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 | ||
| 🪙🪙 | 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 | |
| 🪙🪙🪙🪙🪙🪙🪙🪙🪙 | 🪙 | |
| 🪙🪙🪙 | 🪙🪙🪙🪙🪙🪙 | |
| 🪙🪙🪙🪙 | 🪙🪙 | |
| 🪙🪙🪙 | 🪙 | |
| 🪙 |
这个游戏的表现明确地显示了每个玩家在他们的回合中移除了多少个指示物。然而,表中有一些冗余信息。您可以通过记录筹码堆中的筹码数量以及轮到谁来代表同一个游戏:
| 要移动的玩家 | 大量 |
|---|---|
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 (12) |
| 姓氏 | 🪙🪙🪙🪙🪙🪙🪙🪙🪙 (10) |
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙🪙🪙🪙🪙🪙 (9) |
| 姓氏 | 🪙🪙🪙🪙🪙 (6) |
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙 (4) |
| 姓氏 | (1) |
虽然每个玩家在他们的回合中移除的指示物的数量没有明确的说明,但是你可以通过比较回合前后的指示物数量来计算。
这种表示更加简洁。然而,你甚至可以完全避开桌子,用一系列数字来表示游戏: 12-10-9-6-4-1 ,明迪开始。你将把这些数字中的每一个称为游戏状态。
你现在有一些符号来谈论不同的游戏。接下来,把你的注意力转向赢得游戏的可能策略。例如,当马克西米利安的筹码堆里还剩六个筹码时,他会赢吗?
研究 Simple-Nim 的一个好处是博弈树不会大得令人望而生畏。游戏树描述了游戏中所有有效的走法。从一堆六个计数器开始,只有十三种可能的不同游戏可以玩:
| 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 |
|---|---|---|---|---|---|---|
| six | three | one | Zero | |||
| 6🪙 | 3🪙 | 2🪙 | 1🪙 | 0 | ||
| six | four | one | Zero | |||
| 6🪙 | 4🪙 | 2🪙 | 1🪙 | 0 | ||
| 6🪙 | 4🪙 | 3🪙 | 1🪙 | 0 | ||
| six | four | three | Two | one | Zero | |
| 6🪙 | 5🪙 | 2🪙 | 1🪙 | 0 | ||
| 6🪙 | 5🪙 | 3🪙 | 1🪙 | 0 | ||
| six | five | three | Two | one | Zero | |
| 6🪙 | 5🪙 | 4🪙 | 1🪙 | 0 | ||
| six | five | four | Two | one | Zero | |
| six | five | four | three | one | Zero | |
| 6🪙 | 5🪙 | 4🪙 | 3🪙 | 2🪙 | 1🪙 | 0 |
表格中的每一列代表一步棋,每一行代表十三种不同游戏中的一种。表格中的数字显示了在玩家行动之前,牌堆中有多少个指示物。粗体行是马克西米连会赢的游戏。
注:从技术上讲,可能的游戏比表中所列的要多一些。例如, 6-3 是一个有效的游戏,其中明蒂拿到最后三个指示物立即输掉游戏。但是在这个分析中,你只会考虑游戏结束时筹码数量减少到一个计数器,一个玩家被迫移除,因为你可以合理地假设一个玩家除非迫不得已,否则不会做出失败的举动。
例如,表格中的第一行代表游戏 6-3-1 ,明蒂获胜,而最后一行代表 6-5-4-3-2-1 ,每个玩家在他们的回合中只取一个计数器。该表显示了所有可能的游戏,但更有见地的表示是显示所有可能结果的游戏树:
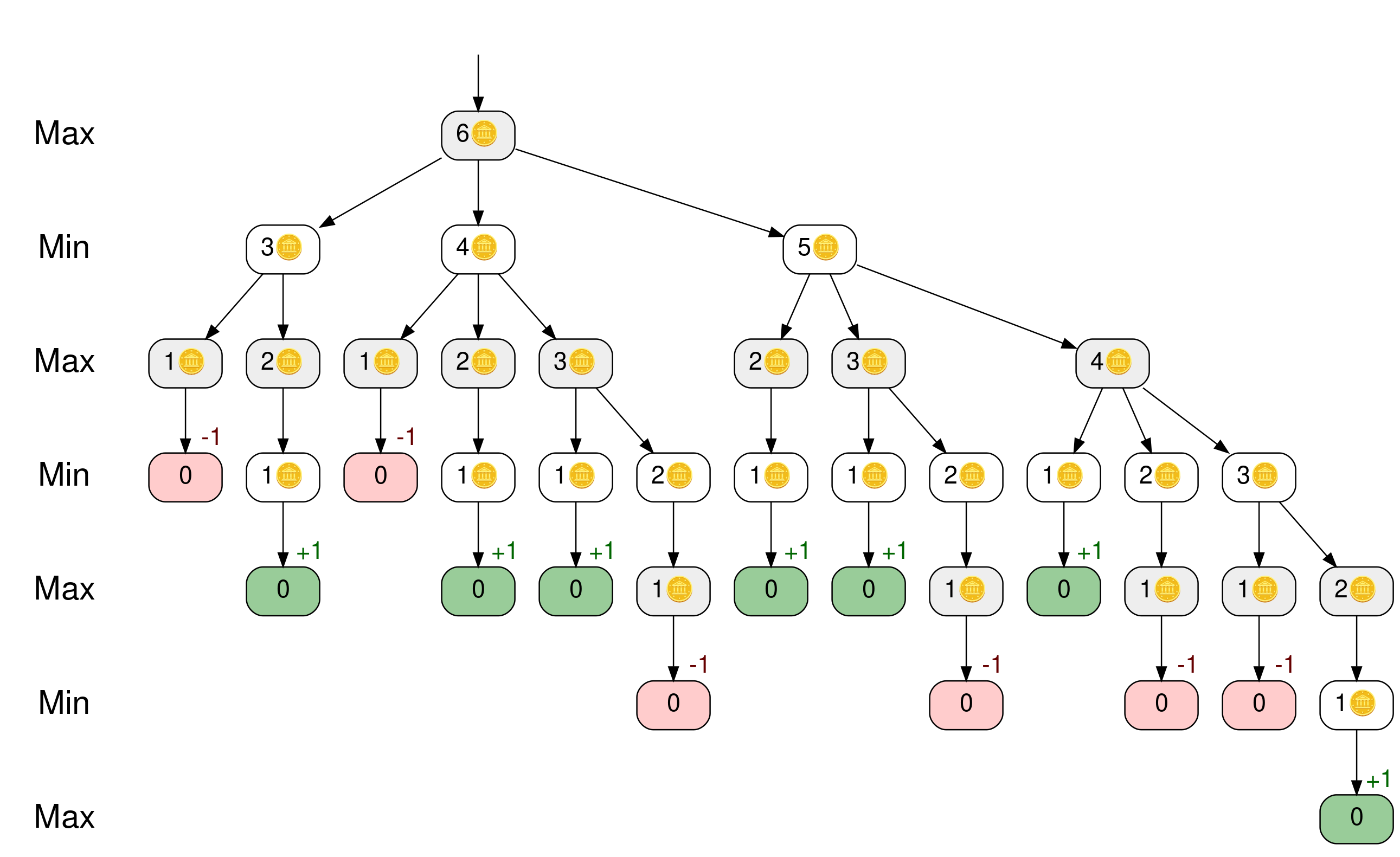
[外链图片转存中…(img-sncePYj2-1731342376586)]
在图中,马克西米利安的转弯用较暗的背景表示。彩色的节点是树上的叶子。它们代表游戏已经结束,剩下个零计数器。以红色节点结束的游戏由 Mindy 赢得,以绿色节点结束的游戏由 Maximillian 赢得。
你可以在树上找到和表中一样的十三个游戏。从树的顶部开始,沿着树枝,直到到达标记为 0 的叶子节点。每一关都代表进入一个新的游戏状态。顺着最左边的分支可以找到 6-3-1 游戏,再往最右边下降可以找到 6-5-4-3-2-1 。
马克西米利安赢了十三场比赛中的七场,而明迪赢了另外六场。看起来玩家们应该有几乎均等的机会获胜。尽管如此,马克西米利安有办法确保胜利吗?
找到最佳的下一步棋
把上面的问题重新表述如下:马克西米利安能走一步棋,这样无论明蒂下一步怎么走,他都能赢吗?在上面的树的帮助下,你可以计算出马克西米利安的每一个可能的第一步会发生什么:
- 取三个指示物,在牌堆中留下三个指示物:在这种情况下,明蒂可以取两个指示物,迫使马克西米利安输掉游戏。
- 取两个指示物,留四个指示物在这堆指示物中:在这种情况下,明蒂可以取三个指示物,迫使马克西米利安输掉游戏。
- 拿走一个指示物,留下五个指示物:在这种情况下,明迪没有立即获胜的行动。相反,马克西米利安对明迪的每一个选择都有制胜一招。
如果马克西米利安拿到一个计数器,并在筹码堆中留下五个筹码,他就能确保胜利!
这种论证形成了极小极大算法的基础。你会给两个玩家中的每一个角色,要么是最大化玩家,要么是最小化玩家。当前玩家想要移动以最大化他们的获胜机会,而他们的对手想要用移动来反击以最小化当前玩家的获胜机会。在这个例子中,马克西米利安是最大化玩家,明蒂是最小化玩家。
为了跟踪游戏,画出所有可能移动的树。你已经为 Simple-Nim 从六个计数器开始做了这件事。然后,给树的所有叶节点分配一个极大极小值。在 Simple-Nim 中,这些是剩余零计数器的节点。分数将取决于叶节点所代表的结果。
如果最大化玩家赢了游戏,给叶子一个分数 +1 。类似地,如果最小化玩家赢了游戏,给叶子 -1 打分:
标记为 Max 的行中的叶节点——最大化玩家马克西米利安——标记为 +1 ,而明蒂行中的叶节点标记为 -1 。接下来,让极大极小值在树上冒泡。考虑一个节点,其中所有孩子都被分配了一个分数。如果该节点在一个 Max 行上,那么给它其子节点的最大值。否则,给它它的孩子的最低分。
如果您对树中的所有节点都这样做,那么您将得到下面的树:
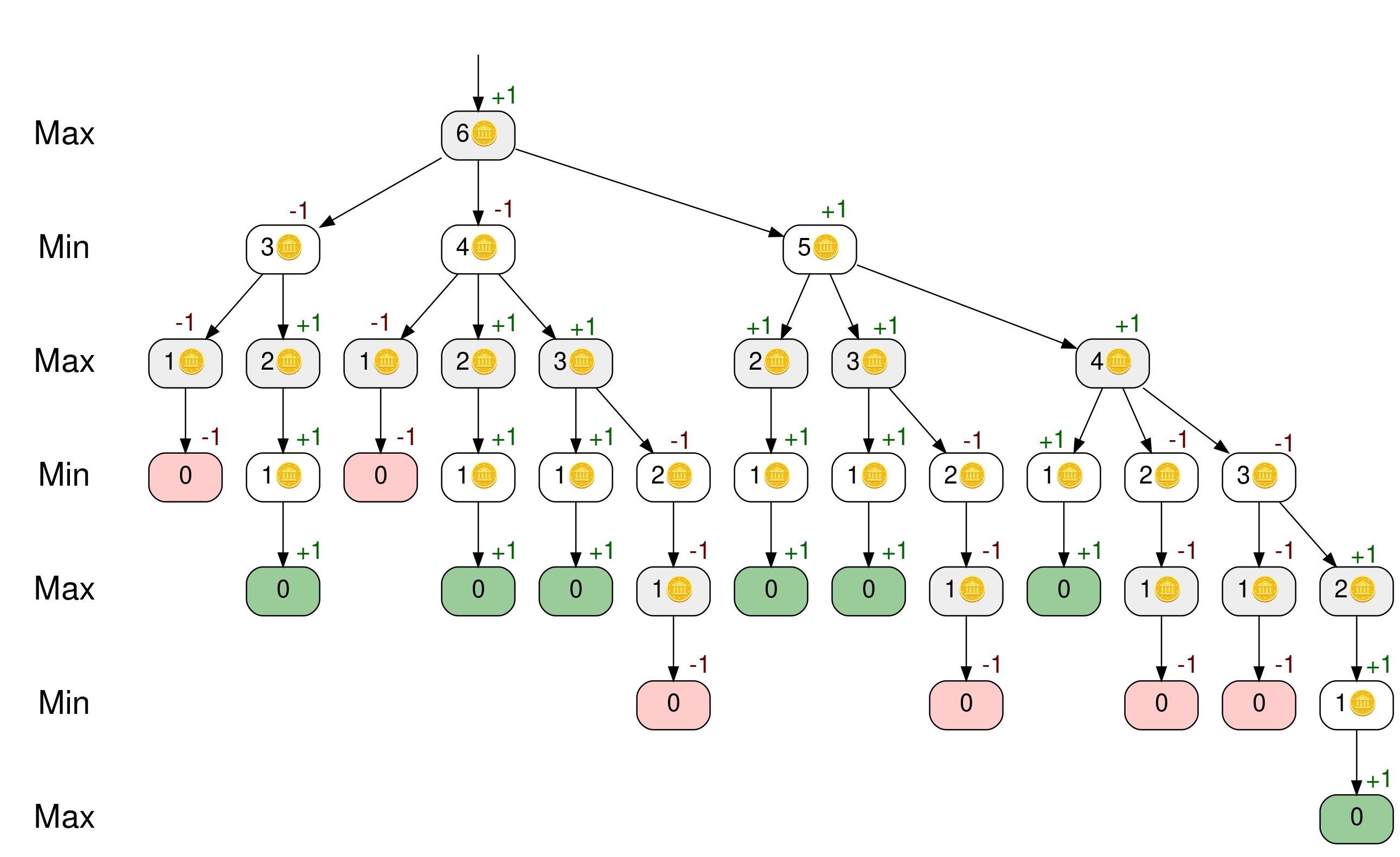
因为树的顶端节点 6🪙 的分数为正,所以马克西米利安可以赢得比赛。您可以查看顶层节点的子节点,以找到他的最佳移动。 3🪙 和 4🪙 节点的得分都是 -1 ,代表明蒂获胜。Maximillian 应该保留五个计数器,因为 5🪙 节点是得分为 +1 的顶层节点的唯一子节点。
虽然在为 Nim 优化时只使用了-1 和+1 的最小最大值,但通常可以使用任何范围的数字。例如,在分析像井字游戏这样可能以平局结束的游戏时,您可能希望使用-1、0 和+1。
许多游戏,包括国际象棋,有如此多不同的可能走法,以至于计算整个游戏树是不可行的。在这些情况下,您只需将树绘制到一定深度,并对这个截断树中的叶节点进行评分。由于这些游戏还没有结束,你不能根据游戏的最终结果来给树叶打分。相反,你会根据对当前职位的一些评估来给他们打分。
在下一节中,您将使用 Python 来计算极大极小分数。
在与 Python Minimax 玩家的 Nim 游戏中失败
你已经知道了极大极小算法的步骤。在本节中,您将在 Python 中实现 minimax。您将从直接为 Simple-Nim 游戏定制算法开始。稍后,您将重构您的代码,将算法的核心与游戏规则分离开来,这样您就可以稍后将您的 minimax 代码应用到其他游戏中。
实现 Nim 特定的 Minimax 算法
考虑与上一节相同的例子:轮到马克西米利安,桌上有六个计数器。您将使用极大极小算法来确认 Maximillan 可以赢得这场游戏,并计算他的下一步行动。
不过,首先考虑几个游戏后期情况的例子。假设轮到马克西米利安,他看到了下面的游戏情况:
- 零计数器表示 Mindy 已经使用了最后一个计数器。马克西米利安赢得了比赛。
- 一个计数器没有给 Maximillian 留下任何选择。他拿走了计数器,这样明迪就剩下零个计数器了。使用与上一个要点相同的逻辑,但是玩家的角色颠倒了,你会看到 Mindy 赢得了游戏。
- 两个计数器给了马克西米利安一个选择。他可以选择一个或两个指示物,这将分别给明迪留下一个或零个指示物。从 Mindy 的角度重做前面要点的逻辑。你会注意到,如果马克西米利安拿了一个指示物,他就会留下一个指示物,并赢得游戏。如果他拿了两个指示物,他就剩下零个指示物,明蒂赢得游戏。
请注意,您是如何重用前面要点中的逻辑来确定谁能从特定的游戏位置中胜出的。现在开始用 Python 实现逻辑。创建一个名为minimax_simplenim.py的文件。您将使用state来表示计数器的数量,使用max_turn来记录是否轮到马克西米利安。
第一个规则,对于零计数器,可以实现为条件if测试。如果马克西米利安赢了游戏,你返回1,如果他输了,你返回-1:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
# ...
接下来,思考如何处理一个或多个计数器的游戏情况。他们减少到一种或多种状态,有更少的指示物,对手先移动。例如,如果现在轮到马克西米利安,考虑他可能的走法的结果,并选择最佳走法:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
possible_new_states = [ state - take for take in (1, 2, 3) if take <= state ] if max_turn: scores = [ minimax(new_state, max_turn=False) for new_state in possible_new_states ] return max(scores)
# ...
你将首先列举可能的新状态,确保玩家不会使用超过可用数量的计数器。你通过再次调用minimax()来计算 Maximillian 可能的移动的分数,注意下一个将轮到 Mindy。因为 Maximillian 是最大化玩家,你将返回他可能得分的最大值。
同样,如果现在轮到 Mindy,考虑她可能的选择。因为-1表示她赢了,所以她会选择得分最低的结果:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
possible_new_states = [
state - take for take in (1, 2, 3) if take <= state
]
if max_turn:
scores = [
minimax(new_state, max_turn=False)
for new_state in possible_new_states
]
return max(scores)
else: scores = [ minimax(new_state, max_turn=True) for new_state in possible_new_states ] return min(scores)
minimax()函数不断调用自己,直到到达每局游戏结束。换句话说,minimax()是一个递归函数。
**注意:**实现一个递归函数是遍历树的一种直观方式,因为探索一棵树的一个分支与探索更大的树是相同的操作。
然而,递归函数有一些问题,特别是对于较大的树。在 Python 中,函数调用有一些开销,调用栈是有限的。
稍后您将看到如何应对这些问题。但是如果你需要优化极大极小算法的速度,极大极小的非递归实现可能是一个更好的选择。
首先确认minimax()按预期工作。打开REPLPython 和导入你的功能:
>>> from minimax_simplenim import minimax
>>> minimax(6, max_turn=True)
1
>>> minimax(5, max_turn=False)
1
>>> minimax(4, max_turn=False)
-1
你首先确认,如果马克西米利安在还剩六个指示物的情况下玩游戏,他可以赢,如1所示。同样,如果马克西米利安为明迪留下五个筹码,他仍然可以赢。相反,如果他给明迪留了四个柜台,那么她就赢了。
为了有效地找到 Maximillian 下一步应该走哪一步,您可以在一个循环中进行相同的计算:
>>> state = 6
>>> for take in (1, 2, 3):
... new_state = state - take
... score = minimax(new_state, max_turn=False)
... print(f"Move from {state} to {new_state}: {score}")
...
Move from 6 to 5: 1
Move from 6 to 4: -1
Move from 6 to 3: -1
寻找最高分,你看到马克西米利安应该拿一个计数器,在桌上留下五个。接下来,更进一步,创建一个可以找到 Maximillian 最佳移动的函数:
# minimax_simplenim.py
# ...
def best_move(state):
for take in (1, 2, 3):
new_state = state - take
score = minimax(new_state, max_turn=False)
if score > 0:
break
return score, new_state
你不断循环,直到找到一个给出正分数的走法——实际上,分数是1。你也可能在三个可能的走法中循环,却找不到获胜的走法。为了表明这一点,您需要返回分数和最佳移动:
>>> best_move(6)
(1, 5)
>>> best_move(5)
(-1, 2)
测试你的功能,你确认当面对六个指示物时,马克西米利安可以通过移除一个指示物并为明迪留下五个来赢得游戏。如果桌上有个计数器,那么所有的招式都有-1分。即使所有的移动都同样糟糕,best_move()建议它检查的最后一个移动:取三个指示物,留下两个。
回头看看你的minimax()和best_move()的代码。两个函数都包含处理 minimax 算法的逻辑和处理 Simple-Nim 规则的逻辑。在下一小节中,您将看到如何将它们分开。
重构为一般的极大极小算法
您已经将以下 Simple-Nim 规则编码到您的极大极小算法中:
- 玩家可以在他们的回合中使用一个、两个或三个指示物。
- 玩家不能使用比游戏中剩余数量更多的指示物。
- 当剩下零个计数器时,游戏结束。
- 拿到最后一个计数器的玩家输掉游戏。
此外,您已经使用max_turn来跟踪 Maximillian 是否是活动玩家。说得更笼统一点,你可以把现在的玩家想成是想把自己的分数最大化的人。为了表明这一点,您将用is_maximizing替换max_turn标志。
通过添加两个新函数开始重写代码:
# minimax_simplenim.py
# ...
def possible_new_states(state):
return [state - take for take in (1, 2, 3) if take <= state]
def evaluate(state, is_maximizing):
if state == 0:
return 1 if is_maximizing else -1
这两个函数实现了 Simple-Nim 规则。使用possible_new_states(),你计算可能的下一个状态,同时确保玩家不能使用比棋盘上可用的计数器更多的计数器。
你用evaluate()评估一个游戏位置。如果没有剩余的计数器,那么如果最大化玩家赢了游戏,函数返回1,如果另一个最小化玩家赢了,函数返回-1。如果游戏没有结束,执行将继续到函数结束并隐式返回 None 。
你现在可以重写minimax()来引用possible_new_states()和evaluate():
# minimax_simplenim.py
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None: return score
if is_maximizing:
scores = [
minimax(new_state, is_maximizing=False)
for new_state in possible_new_states(state) ]
return max(scores)
else:
scores = [
minimax(new_state, is_maximizing=True)
for new_state in possible_new_states(state) ]
return min(scores)
记住也要把max_turn重命名为is_maximizing。
只有当剩下零个计数器并且已经决定了赢家的时候,你才能在一个游戏状态中得分。所以你需要检查score是否为None来决定是继续调用minimax()还是退回游戏评价。您使用一个赋值表达式 ( :=)来检查和记忆评估的游戏分数。
接下来,观察您的if … else语句中的块非常相似。这两个模块之间的唯一区别是,您使用哪个函数 max()或min() 来寻找最佳得分,以及在对minimax()的递归调用中使用什么值作为is_maximizing。这两个都可以直接从is_maximizing的电流值计算出来。
因此,您可以将if … else块折叠成一条语句:
# minimax_simplenim.py
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
return (max if is_maximizing else min)( minimax(new_state, is_maximizing=not is_maximizing) for new_state in possible_new_states(state) )
您使用一个条件表达式来调用max()或min()。为了反转is_maximizing的值,您将not is_maximizing传递给对minimax()的递归调用。
minimax()的代码现在非常紧凑。更重要的是,Simple-Nim 的规则没有明确地编码在算法中。相反,它们被封装在possible_new_states()和evaluate()中。
通过用possible_new_states()和is_maximizing代替max_turn来表达best_move(),你完成了重构:
# minimax_simplenim.py
# ...
def best_move(state):
for new_state in possible_new_states(state): score = minimax(new_state, is_maximizing=False)
if score > 0:
break
return score, new_state
和以前一样,你检查每一步棋的结果,并返回第一个保证赢的棋。
**注意:**在best_move()中没有错误处理。特别是,它假设possible_new_states()至少返回一个新的游戏状态。如果没有,那么循环根本不会运行,并且score和new_state将是未定义的。
这意味着你应该只用一个有效的游戏状态来调用best_move()。或者,您可以在best_move()本身内部添加一个额外的检查。
在 Python 中,元组是逐元素比较的。您可以利用这一点直接使用max(),而不是显式检查可能的移动:
# minimax_simplenim.py
# ...
def best_move(state):
return max(
(minimax(new_state, is_maximizing=False), new_state)
for new_state in possible_new_states(state)
)
如前所述,您考虑并返回一个包含分数和最佳新状态的元组。因为包括max()在内的比较是在元组中一个元素一个元素地进行的,所以分数必须是元组中的第一个元素。
你仍然能够找到最佳的行动:
>>> best_move(6)
(1, 5)
>>> best_move(5)
(-1, 4)
和以前一样,best_move()建议如果你面对六个,你应该选择一个计数器。在失去五个指示物的情况下,你拿多少指示物并不重要,因为无论如何你都要输了。您基于max()的实现最终会在表上留下尽可能多的计数器。
您可以展开下面的框来查看您在本节中实现的完整源代码:
您已经在possible_new_states()和evaluate()中封装了 Simple-Nim 的规则。这些功能由minimax()和best_move()使用:
# minimax_simplenim.py
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
return (max if is_maximizing else min)(
minimax(new_state, is_maximizing=not is_maximizing)
for new_state in possible_new_states(state)
)
def best_move(state):
return max(
(minimax(new_state, is_maximizing=False), new_state)
for new_state in possible_new_states(state)
)
def possible_new_states(state):
return [state - take for take in (1, 2, 3) if take <= state]
def evaluate(state, is_maximizing):
if state == 0:
return 1 if is_maximizing else -1
使用best_move()找到给定游戏中的下一步棋。
干得好!您已经为 Simple-Nim 实现了一个极大极小算法。为了挑战它,你应该对你的代码玩几个游戏。从一些指示物开始,轮流自己移除指示物,并使用best_move()选择你的虚拟对手将移除多少指示物。除非你玩一个完美的游戏,否则你会输!
在下一节中,您将为 Nim 的常规规则实现相同的算法。
享受 Nim 变体的乐趣
到目前为止,您已经使用并实现了 Simple-Nim。在这一部分,您将学习 Nim 的最常见规则。这会给你的游戏增加更多的变化。
尼姆——有其固定的规则——仍然是一个简单的游戏。但这也是一个令人惊讶的基础游戏。原来,一个名为公正游戏的游戏家族,本质上都是 Nim 的伪装。
玩 Nim 的常规游戏
是时候拉出 Nim 的常规了。你仍然可以认出这个游戏,但是它允许玩家有更多的选择:
- 有几个堆,每个堆里有若干个计数器。
- 两名玩家轮流玩**。**
*** 在他们的回合中,一个玩家可以移除任意多的指示物,但是指示物必须来自同一堆。* 取得最后一个计数器的玩家输掉游戏。*
*请注意,在一个回合中移除多少个指示物不再有任何限制。如果一堆包含二十个指示物,那么当前玩家可以拿走所有指示物。
作为一个例子,考虑一个游戏,以分别包含两个、三个和五个计数器的三个筹码开始。看看你的朋友 Mindy 和 Maximillian 在玩这个游戏:
- 明迪从第三堆拿走四个指示物,剩下两个、三个、一个指示物。
- 马克西米利安从第二堆拿走两个指示物,剩下两个、一个、一个指示物。
- 明迪从第一堆拿走一个计数器,剩下一个、一个、一个计数器。
- 马克西米利安没有留下任何有趣的选择,但从第三堆中取出一个计数器,剩下一个、一个和零个计数器。
- 明迪从第二堆中取出一个计数器,剩下一个、零个和零个计数器。
- 马克西米利安拿走最后一个剩余的指示物,输掉了这场游戏。
你可以用表格来表示游戏:
| 要移动的玩家 | 第一堆 | 第二堆 | 三号桩 |
|---|---|---|---|
| 明迪(Minna 的异体)(f.) | 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙🪙 |
| 姓氏 | 🪙🪙 | 🪙🪙🪙 | 🪙 |
| 明迪(Minna 的异体)(f.) | 🪙🪙 | 🪙 | 🪙 |
| 姓氏 | 🪙 | 🪙 | 🪙 |
| 明迪(Minna 的异体)(f.) | 🪙 | 🪙 | |
| 姓氏 | 🪙 |
就像在 Simple-Nim 游戏中一样,Maximillian 拿到了最后一个计数器,所以 Mindy 赢了。
注意:你应该玩几局 Nim,感受一下新规则是如何改变策略的。尝试不同数量的桩,比如三桩、四桩或五桩。每堆不需要很多计数器。三到九点是一个很好的起点。
考虑如何为这些新规则实现极大极小算法。记住你只需要重新实现possible_new_states()和evaluate()。
让你的代码适应常规 Nim
首先,将minimax_simplenim.py中的代码复制到一个名为minimax_nim.py的新文件中。然后,考虑如何从给定的游戏状态中列出所有可能的移动。比如明迪和马克西米利安,一开始是两个、三个、五个计数器。您可以列出所有可能的后续状态,如下所示:
| 第一桩:🪙🪙 | 第二桩:🪙🪙🪙 | 第三桩:🪙🪙🪙🪙🪙 |
|---|---|---|
| 🪙🪙🪙 | 🪙🪙🪙🪙🪙 | |
| 🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙🪙🪙 | |
| 🪙🪙 | 🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | |
| 🪙🪙 | 🪙🪙🪙 | 🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙 |
有十种可能的行动。你可以从第一堆中取出一到两个指示物;第二堆中的一个、两个或三个计数器;或者第三堆中的一个、两个、三个、四个或五个计数器。
在代码中,可以用嵌套循环列出所有可能的新状态。外循环将依次考虑每一堆,内循环将迭代每一堆的不同选择:
# minimax_nim.py
# ...
def possible_new_states(state):
for pile, counters in enumerate(state):
for remain in range(counters):
yield state[:pile] + (remain,) + state[pile + 1 :]
在这里,你用一组数字来表示游戏状态,每个数字代表一堆计数器的数量。比如上面的情况表示为(2, 3, 5)。然后循环遍历每一堆,使用 enumerate() 来跟踪当前堆的索引。
对于每一堆,你使用 range() 列出该堆中可以保留多少个指示物的所有可能选择。你通过复制除当前堆以外的state返回一个新的游戏状态。回想一下,元组可以用方括号([])分割,并用加号(+)连接。
你不用在一个列表中收集可能的走法,而是使用yield一次一个地将它们发送回去。这使得possible_new_states()成为发电机:
>>> from minimax_nim import possible_new_states
>>> possible_new_states((2, 3, 5))
<generator object possible_new_states at 0x7f1516ebc660>
>>> list(possible_new_states((2, 3, 5)))
[(0, 3, 5), (1, 3, 5), (2, 0, 5), (2, 1, 5), (2, 2, 5),
(2, 3, 0), (2, 3, 1), (2, 3, 2), (2, 3, 3), (2, 3, 4)]
仅仅调用possible_new_states()返回一个生成器,而不生成可能的新状态。您可以通过将生成器转换为一个列表来查看移动。
为了实现常规 Nim 的evaluate(),您需要考虑两个问题:
- 如何检测游戏结束
- 比赛结束后如何得分
赢得 Nim 的规则与赢得 Simple-Nim 的规则相同,因此您可以像前面一样为游戏评分。当所有的堆都空了,游戏就结束了。另一方面,如果任何一堆仍然包含至少一个计数器,那么游戏还没有结束。您使用 all() 来检查所有堆都包含零计数器:
# minimax_nim.py
# ...
def evaluate(state, is_maximizing):
if all(counters == 0 for counters in state): return 1 if is_maximizing else -1
如果游戏结束,那么如果最大化玩家赢了游戏,你就给游戏打分1,如果最小化玩家赢了,你就给游戏打分-1。和以前一样,如果游戏还没有结束,并且你还不能评估游戏状态,你隐式地返回None。
因为你已经在possible_new_states()和evaluate()中编码了所有的游戏规则,所以你不需要对minimax()或best_move()做任何改动。您可以展开下面的框来查看常规 Nim 所需的完整源代码:
以下代码可以计算常规 Nim 中的下一个最优移动:
# minimax_nim.py
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
return (max if is_maximizing else min)(
minimax(new_state, is_maximizing=not is_maximizing)
for new_state in possible_new_states(state)
)
def best_move(state):
return max(
(minimax(new_state, is_maximizing=False), new_state)
for new_state in possible_new_states(state)
)
def possible_new_states(state):
for pile, counters in enumerate(state):
for remain in range(counters):
yield state[:pile] + (remain,) + state[pile + 1 :]
def evaluate(state, is_maximizing):
if all(counters == 0 for counters in state):
return 1 if is_maximizing else -1
与minimax_simplenim.py相比,minimax()和best_move()没有变化。
您可以使用您的代码来检查 Mindy 在本节开头的示例中是否选择了一个好的第一步:
>>> from minimax_nim import best_move
>>> best_move((2, 3, 5))
(1, (2, 3, 1))
>>> best_move((2, 3, 1))
(-1, (2, 3, 0))
事实上,从第三堆中取出四个指示物是明迪的最佳选择。在筹码堆中有两个、三个、一个筹码的情况下,没有最优移动,由-1的分数表示。
您已经看到,在更改 Nim 规则时,您可以重用minimax()和best_move()。
尝试 Nim 的其他变体
尼姆有时被称为猜错游戏,因为目标是避免占据最后一个计数器。Nim 的一个流行变体改变了获胜条件。在这个变体中,拿到最后一个计数器的玩家赢得游戏。你会如何改变你的代码来玩这个版本的游戏?
尝试实现 Nim 的非 misre 变体的 minimax 算法。你只需要修改一行代码。
要修改您的代码,使其针对最后一个计数器进行优化,您需要更改评估游戏的方式:
def evaluate(state, is_maximizing):
if all(counters == 0 for counters in state):
return -1 if is_maximizing else 1
现在,如果没有剩余的指示物,最后一个移动的玩家已经赢得了游戏。为了表明这一点,您返回最差的分数:如果您最大化,则返回-1,如果您最小化,则返回1。
Nim 的另一个变体是将所有的计数器放在一堆:
- 有几个计数器,都是从一堆开始。
- 两名玩家轮流玩**。**
*** 轮到他们时,一名玩家将一堆分成两堆,这样这两堆新的筹码就有了不同的数量的指示物。* 第一个不能分裂任何一堆的玩家输掉游戏。*
*在这个变体中,每次移动都会产生一个新的堆。游戏持续到所有的堆都包含一个或两个指示物,因为那些堆不能被分开。
考虑一个从一堆六个计数器开始的游戏。请注意,有两种可能的开始移动:分裂到五比一或四比二。三-三不是合法的移动,因为两个新牌堆必须有不同数量的指示物。观看 Mindy 和 Maximillian 玩游戏:
- 明迪把这堆分成两堆,分别有四个和两个计数器。
- 马克西米利安将第一堆分成三堆,其中有三个、一个、两个计数器。
- 明迪将第一堆拆分成四堆,分别是两个、一个、一个、两个计数器。
- 马克西米利安不能拆分任何一堆,因为它们都包含一个或两个指示物,所以他输掉了这场游戏。
明蒂赢得了比赛,因为马克西米利安无法采取行动。你将如何实现一个能在这个变体中找到最佳走法的 minimax 版本?
实现 Nim 变体的规则,玩家轮流拆分一堆计数器。你应该思考四个问题:
- 你应该如何表现游戏状态?
- 在一次移动后,你如何列举可能的新状态?
- 你怎么能察觉到游戏结束了呢?
- 你应该如何评价一个游戏的结局?
您需要创建新的possible_new_states()和evaluate()函数。
复制您的minimax_nim.py文件,并将其命名为minimax_nim_split.py。然后您可以修改possible_new_states()和evaluate()来考虑新的规则:
# minimax_nim_split.py
# ...
def possible_new_states(state):
for pile, counters in enumerate(state):
for take in range(1, (counters + 1) // 2):
yield state[:pile] + (counters - take, take) + state[pile + 1 :]
def evaluate(state, is_maximizing):
if all(counters <= 2 for counters in state):
return -1 if is_maximizing else 1
为了列出可能的新状态,依次考虑每一堆。你需要考虑如何拆分一堆计数器。
请注意,拆分是对称的。你不需要把一堆3计数器拆分成(1, 2)和(2, 1)。这意味着您可以迭代大约一半数量的计数器。
更准确地说,你迭代了range(1, (counters + 1) // 2)。这隐含地考虑到您必须将一个堆分成两个具有不同计数器数量的堆。例如,5和6计数器都让take取值1和2。拆分的堆由元组(counters - take, take)表示。
你只评估游戏的最终状态。当所有的堆都包含一个或两个计数器时,游戏就结束了。当游戏结束时,当前玩家已经输了,因为他们不能再移动了。
Nim 还有很多其他的变种。享受实现其中一些的乐趣。
使用 Alpha-Beta 修剪优化 Minimax】
极大极小算法的一个挑战是博弈树可能很大。代表 Simple-Nim 的树中的节点数遵循一个类似 Fibonacci 的公式。例如,代表六个计数器的节点的子节点数量是代表三个、四个和五个计数器的树中节点的总和。
这些数字增长很快,如下表所示:
| Zero | one | Two | three | four | five | six | seven | … | Twenty-five |
|---|---|---|---|---|---|---|---|---|---|
| one | Two | three | six | Twelve | Twenty-two | Forty-one | Seventy-six | Four million four hundred and thirty-four thousand six hundred and ninety |
为了表示一个从 25 个计数器开始的游戏,你需要一个超过 400 万个节点的树。如果你试着计算minimax(25, True),你会注意到这需要几秒钟。
在 Simple-Nim 中,博弈树由许多重复的博弈状态组成。例如,您可以通过四种不同的方式从六个移动到三个计数器: 6-3 、 6-4-3 、 6-5-3 和 6-5-4-3 。所以同样的游戏状态被minimax()重复计算。您可以通过使用缓存来解决这个问题:
from functools import cache
@cache def minimax(state, is_maximizing):
# ...
这将大大加快你的代码,因为 Python 只为每个游戏状态计算一次最小最大值。
**注:**在常规 Nim 中,有很多等价的游戏状态。比如(2, 2, 3)、(2, 3, 2)、(3, 2, 2)都代表同一个位置。让游戏树变小的一个优化方法是在possible_new_states()中只列出一个对称的位置。你现在不会涉及这个,但是试着自己添加,并在评论中分享你的经验!
另一种提高算法效率的方法是避免不必要地探索子树。在这一部分,你将学习到 alpha-beta 修剪,你可以用它来减少游戏树的大小。
修剪你的游戏树
假设你在玩 Simple-Nim,还有三个计数器。你有两个选择可以考虑——留下一个或者留下两个柜台:
- 如果你留下一个计数器,那么你的对手需要拿走它,你将赢得这场游戏。
- 你不需要计算离开两个指示物的结果,因为你已经找到了赢得游戏的一步棋。
在这个争论中,你不需要考虑是否应该给留两个计数器。你已经修剪了游戏树。
现在回到轮到马克西米利安的例子,桌上有六个计数器。如果您考虑从左到右的分支,并且一旦确定了节点的极大极小值,就停止探索子树,那么您将得到下面的树:
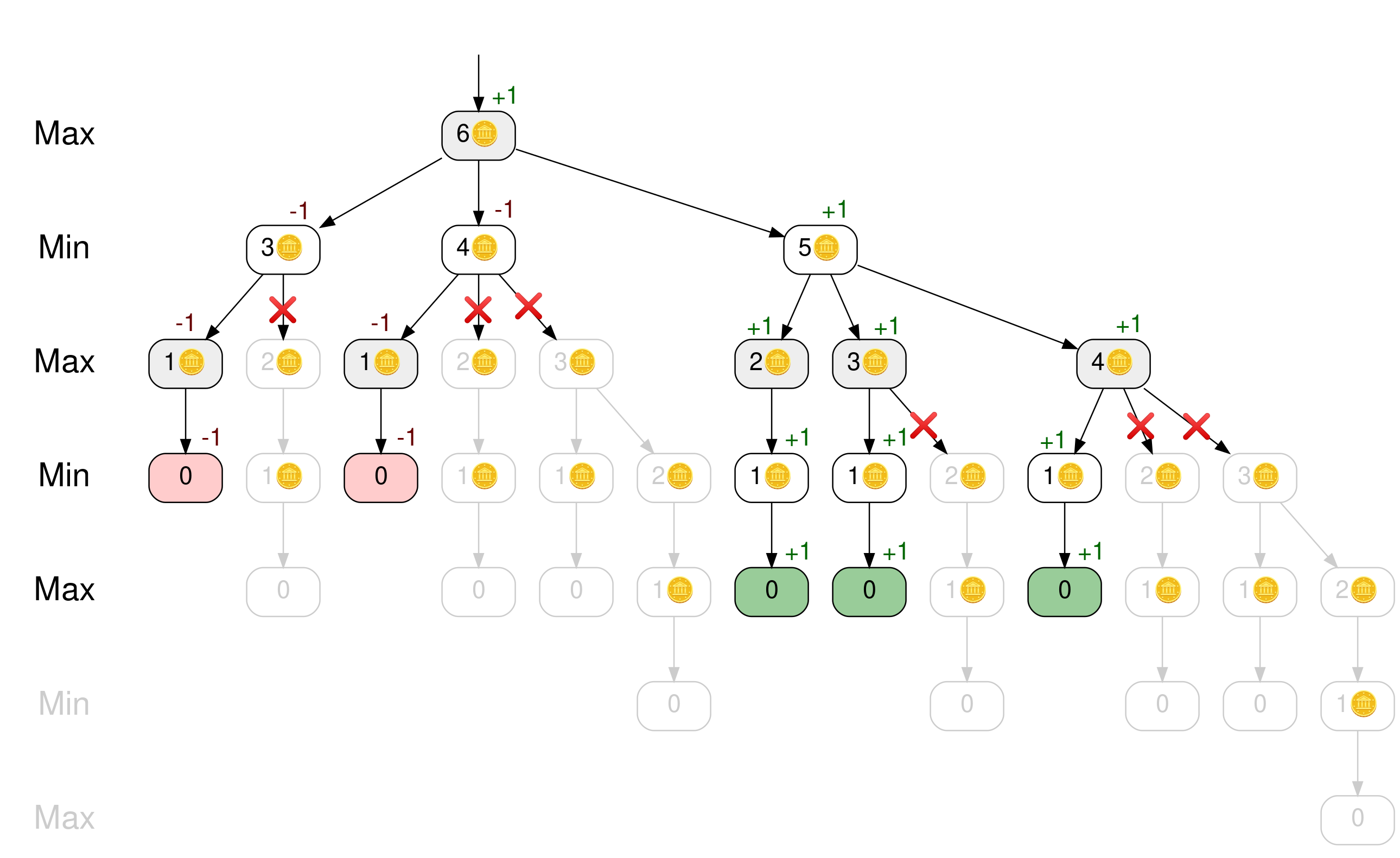
游戏树变得更小。最初的树有 41 个节点,而这个修剪过的版本只需要 17 个节点来代表游戏中的所有移动。
这个过程被称为α-β修剪,因为它使用两个参数,α和β,来跟踪一个分支何时可以被剪切。在下一节中,您将重写minimax()以使用 alpha-beta 修剪。
实施阿尔法-贝塔剪枝
您可以通过重构minimax()函数向代码添加 alpha-beta 修剪。您已经对minimax()进行了重构,使得相同的实现适用于 Nim 的所有变体。在前一小节中,您为 Simple-Nim 修剪了树。然而,您也可以为常规 Nim 实现 alpha-beta 修剪。制作一个minimax_nim.py的副本,命名为alphabeta_nim.py。
你需要一个标准来知道你什么时候可以停止探索。为此,您将添加两个参数,alpha和beta:
alpha将代表确保最大化玩家的最低分数。beta将代表确保最小化玩家的最高得分。
如果beta小于或等于alpha,那么玩家可以停止探索游戏树。最大化将已经找到比玩家通过进一步探索所能找到的更好的选择。
为了实现这个想法,您将从用一个显式的for循环替换您的理解开始。您需要显式循环,这样您就可以摆脱它并有效地修剪树:
# alphabeta_nim.py
from functools import cache
@cache
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
scores = [] for new_state in possible_new_states(state): scores.append(minimax(new_state, is_maximizing=not is_maximizing)) return (max if is_maximizing else min)(scores)
# ...
这里,在返回最佳分数之前,您在一个名为scores的列表中显式地收集子节点的分数。
接下来,您将添加alpha和beta作为参数。理论上,它们应该分别从负无穷大和正无穷大开始,代表两个玩家可能的最差分数。然而,由于 Nim 中唯一可能的分数是-1和1,您可以使用它们作为起始值。
对于每个 minimax 评估,您更新alpha和beta的值并比较它们。一旦beta变得小于或等于alpha,你就跳出了循环,因为你不需要考虑任何进一步的行动:
# alphabeta_nim.py
from functools import cache
@cache
def minimax(state, is_maximizing, alpha=-1, beta=1):
if (score := evaluate(state, is_maximizing)) is not None:
return score
scores = []
for new_state in possible_new_states(state):
scores.append(
score := minimax(new_state, not is_maximizing, alpha, beta) )
if is_maximizing: alpha = max(alpha, score) else: beta = min(beta, score) if beta <= alpha: break return (max if is_maximizing else min)(scores)
# ...
在递归步骤中,使用赋值表达式(:=)来存储minimax()的返回值并将其添加到分数列表中。
阿尔法-贝塔剪枝只是一种优化。它不会改变极大极小算法的结果。您仍然会看到与前面相同的结果:
>>> from alphabeta_nim import best_move
>>> best_move((2, 3, 5))
(1, (2, 3, 1))
>>> best_move((2, 3, 1))
(-1, (2, 3, 0))
如果你测量算法执行的时间,那么你会注意到极大极小法使用阿尔法-贝塔剪枝更快,因为它需要探索的博弈树更少。
您可以展开下面的框来查看使用 minimax 和 alpha-beta 剪枝来找到最佳 Nim 移动的完整 Python 代码:
Alpha-beta 修剪在minimax()中实现:
# alphabeta_nim.py
from functools import cache
@cache
def minimax(state, is_maximizing, alpha=-1, beta=1):
if (score := evaluate(state, is_maximizing)) is not None:
return score
scores = []
for new_state in possible_new_states(state):
scores.append(
score := minimax(new_state, not is_maximizing, alpha, beta)
)
if is_maximizing:
alpha = max(alpha, score)
else:
beta = min(beta, score)
if beta <= alpha:
break
return (max if is_maximizing else min)(scores)
def best_move(state):
return max(
(minimax(new_state, is_maximizing=False), new_state)
for new_state in possible_new_states(state)
)
def possible_new_states(state):
for pile, counters in enumerate(state):
for remain in range(counters):
yield state[:pile] + (remain,) + state[pile + 1 :]
def evaluate(state, is_maximizing):
if all(counters == 0 for counters in state):
return 1 if is_maximizing else -1
调用best_move()从一个给定的游戏状态中找到最优的移动。
即使minimax()现在做阿尔法-贝塔修剪,它仍然依靠evaluate()和possible_new_states()来实现游戏规则。因此,您也可以在 Simple-Nim 上使用新的minimax()实现。
结论
干得好!您已经了解了极大极小算法,并看到了如何使用它在 Nim 游戏中找到最佳移动。虽然 Nim 是一个简单的游戏,但 minimax 可以应用于许多其他游戏,如井字游戏和国际象棋。你可以将你探索的原则应用到许多不同的游戏中。
在本教程中,您已经学会了如何:
- 解释极大极小算法的原理
- 玩 Nim 的游戏的几个变种
- 实现极大极小算法
- 输了尼姆对一个极小极大玩家的游戏
- 使用阿尔法-贝塔剪枝优化极大极小算法
想一想如何将极大极小算法应用到你最喜欢的游戏中,以及如何用 Python 实现它。在评论中,让你的程序员同事知道你在与 minimax 的比赛中还输了哪些游戏。
源代码: 点击这里下载免费的源代码,你将使用它来输掉与你的 minimax 玩家的 Nim 游戏。*************
Python mmap:通过内存映射改进了文件 I/O
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python mmap:用内存映射做文件 I/O
Python 的禅有很多智慧可以提供。一个特别有用的想法是“应该有一个——最好只有一个——显而易见的方法去做。”然而,用 Python 做大多数事情有多种方法,而且通常都有很好的理由。比如在 Python 中有多种方式读取一个文件,包括很少使用的mmap模块。
Python 的mmap提供了内存映射的文件输入和输出(I/O)。它允许你利用底层操作系统的功能来读取文件,就好像它们是一个大的字符串或数组。这可以显著提高需要大量文件 I/O 的代码的性能。
在本教程中,您将学习:
- 电脑内存有哪些种类
- 用
mmap可以解决什么问题 - 如何使用内存映射来更快地读取大文件
- 如何改变文件的部分而不重写整个文件
- 如何使用
mmap到在多个进程间共享信息
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
了解计算机内存
内存映射是一种使用低级操作系统 API 将文件直接加载到计算机内存中的技术。它可以显著提高程序中的文件 I/O 性能。为了更好地理解内存映射如何提高性能,以及如何以及何时可以使用mmap模块来利用这些性能优势,首先学习一点关于计算机内存的知识是很有用的。
计算机内存是一个大而复杂的话题,但是本教程只关注你需要知道的如何有效地使用mmap模块。出于本教程的目的,术语存储器指的是随机存取存储器,或 RAM。
有几种类型的计算机内存:
- 身体的
- 虚拟的
- 共享的
当您使用内存映射时,每种类型的内存都会发挥作用,所以让我们从较高的层次来回顾一下每种类型的内存。
物理内存
物理内存是理解起来最简单的一种内存,因为它通常是与你的电脑相关的市场营销的一部分。(你可能还记得,当你买电脑时,它宣传的是 8g 内存。)物理内存通常位于连接到计算机主板的卡上。
物理内存是程序运行时可用的易失性内存总量。不应将物理内存与存储混淆,如硬盘或固态硬盘。
虚拟内存
虚拟内存是一种处理内存管理的方式。操作系统使用虚拟内存使你看起来比实际拥有的内存多,这样你就不用担心在任何给定的时间有多少内存可供你的程序使用。在幕后,您的操作系统使用部分非易失性存储(如固态硬盘)来模拟额外的 RAM。
为此,您的操作系统必须维护物理内存和虚拟内存之间的映射。每个操作系统都使用自己的复杂算法,通过一种叫做页表的数据结构将虚拟内存地址映射到物理内存地址。
幸运的是,这种复杂性大部分隐藏在您的程序中。用 Python 编写高性能 I/O 代码不需要理解页表或逻辑到物理的映射。然而,了解一点内存会让你更好地理解计算机和库在为你做什么。
mmap使用虚拟内存,让您看起来好像已经将一个非常大的文件加载到内存中,即使该文件的内容太大而不适合您的物理内存。
共享内存
共享内存是操作系统提供的另一种技术,允许多个程序同时访问相同的数据。在使用并发的程序中,共享内存是处理数据的一种非常有效的方式。
Python 的mmap使用共享内存在多个 Python 进程、线程和并发发生的任务之间高效地共享大量数据。
深入挖掘文件 I/O
现在,您已经对不同类型的内存有了一个较高的认识,是时候了解什么是内存映射以及它解决什么问题了。内存映射是执行文件 I/O 的另一种方式,可以提高性能和内存效率。
为了充分理解内存映射的作用,从底层角度考虑常规文件 I/O 是很有用的。当读取文件时,许多事情在幕后发生:
考虑以下执行常规 Python 文件 I/O 的代码:
def regular_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
text = file_obj.read()
print(text)
这段代码将整个文件读入物理内存,如果运行时有足够的内存可用的话,然后将它打印到屏幕上。
这种类型的文件 I/O 您可能在 Python 之旅的早期就已经了解过了。代码不是很密集或复杂。然而,在像read()这样的函数调用的掩盖下发生的事情是非常复杂的。请记住,Python 是一种高级编程语言,所以很多复杂性对程序员来说是隐藏的。
系统调用
实际上,对read()的调用意味着操作系统要做大量复杂的工作。幸运的是,操作系统提供了一种方法,通过系统调用,从你的程序中抽象出每个硬件设备的具体细节。每个操作系统将不同地实现这个功能,但是至少,read()必须执行几次系统调用来从文件中检索数据。
所有对物理硬件的访问都必须在一个名为内核空间的受保护环境中进行。系统调用是操作系统提供的 API,允许你的程序从用户空间进入内核空间,在内核空间管理物理硬件的底层细节。
在read()的情况下,操作系统需要几次系统调用才能与物理存储设备交互并返回数据。
同样,你不需要牢牢掌握系统调用和计算机架构的细节来理解内存映射。要记住的最重要的事情是,从计算上来说,系统调用相对昂贵,所以系统调用越少,代码可能执行得越快。
除了系统调用之外,对read()的调用还包括在数据返回到你的程序之前,在多个数据缓冲区之间进行大量潜在的不必要的数据复制。
通常情况下,这一切发生得如此之快,以至于人们察觉不到。但是所有这些层都增加了延迟并且会减慢你的程序。这就是内存映射发挥作用的地方。
内存映射优化
避免这种开销的一种方法是使用一个内存映射文件。您可以将内存映射想象成一个过程,在这个过程中,读写操作跳过上面提到的许多层,将请求的数据直接映射到物理内存中。
内存映射文件 I/O 方法牺牲内存使用来换取速度,这被经典地称为空间-时间权衡。然而,内存映射并不需要比传统方法使用更多的内存。操作系统非常聪明。它将根据请求缓慢地加载数据,类似于 Python 生成器的工作方式。
此外,由于虚拟内存,您可以加载比物理内存更大的文件。然而,当没有足够的物理内存存储文件时,您不会看到内存映射带来的巨大性能提升,因为操作系统将使用较慢的物理存储介质(如固态磁盘)来模拟它缺少的物理内存。
用 Python 的mmap 读取内存映射文件
现在,所有这些理论都已过时,您可能会问自己,“我如何使用 Python 的mmap来创建内存映射文件?”
下面是您之前看到的文件 I/O 代码的内存映射等价物:
import mmap
def mmap_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
text = mmap_obj.read()
print(text)
这段代码将整个文件作为一个字符串读入内存,并将其打印到屏幕上,就像早期的常规文件 I/O 方法一样。
简而言之,使用mmap与读取文件的传统方式非常相似,只有一些小的变化:
-
用
open()打开文件是不够的。您还需要使用mmap.mmap()向操作系统发送信号,表示您希望将文件映射到 RAM 中。 -
你需要确保你和
open()使用的模式和mmap.mmap()兼容。open()的默认模式是读,而mmap.mmap()的默认模式是读和写。所以,在打开文件时,你必须明确。 -
您需要使用
mmap对象而不是由open()返回的标准文件对象来执行所有的读写操作。
性能影响
内存映射方法比典型的文件 I/O 稍微复杂一些,因为它需要创建另一个对象。然而,当读取一个只有几兆字节的文件时,这一小小的改变可以带来巨大的性能优势。下面是读著名小说 《堂吉诃德的历史》 的原文对比,大致是 2.4 兆:
>>> import timeit
>>> timeit.repeat(
... "regular_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io, filename")
[0.02022400000000002, 0.01988580000000001, 0.020257300000000006]
>>> timeit.repeat(
... "mmap_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io, filename")
[0.006156499999999981, 0.004843099999999989, 0.004868600000000001]
这是使用常规文件 I/O 和内存映射文件 I/O 读取整个 2.4 兆字节文件所需的时间。如您所见,内存映射方法大约需要 0.005 秒,而常规方法大约需要 0.02 秒。当读取更大的文件时,这种性能提升甚至会更大。
**注意:**这些结果是使用 Windows 10 和 Python 3.8 收集的。因为内存映射非常依赖于操作系统的实现,所以您的结果可能会有所不同。
Python 的mmap文件对象提供的 API 与传统文件对象非常相似,除了一个额外的超级能力:Python 的mmap文件对象可以像字符串对象一样被切片!
mmap对象创建
在创建mmap对象的过程中,有一些细微之处值得仔细观察:
mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ)
mmap需要一个文件描述符,它来自一个常规文件对象的fileno()方法。文件描述符是一个内部标识符,通常是一个整数,操作系统用它来跟踪打开的文件。
mmap的第二个参数是length=0。这是存储器映射的字节长度。0是一个特殊的值,表示系统应该创建一个足够大的内存映射来保存整个文件。
access参数告诉操作系统你将如何与映射内存交互。选项有ACCESS_READ、ACCESS_WRITE、ACCESS_COPY和ACCESS_DEFAULT。这些有点类似于内置open()的mode参数:
ACCESS_READ创建一个只读内存映射。ACCESS_DEFAULT默认为可选prot参数中指定的模式,用于内存保护。ACCESS_WRITE和ACCESS_COPY是两种写模式,在下面你会了解到。
文件描述符、length和access参数表示创建一个内存映射文件所需的最低要求,该文件将在 Windows、Linux 和 macOS 等操作系统上工作。上面的代码是跨平台的,这意味着它将通过所有操作系统上的内存映射接口读取文件,而不需要知道代码运行在哪个操作系统上。
另一个有用的参数是offset,这是一种节省内存的技术。这指示mmap从文件中指定的偏移量开始创建一个内存映射。
mmap字符串形式的对象
如前所述,内存映射将文件内容作为字符串透明地加载到内存中。因此,一旦你打开文件,你就可以执行许多与使用字符串相同的操作,比如切片:
import mmap
def mmap_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj[10:20])
这段代码将十个字符从mmap_obj打印到屏幕上,并将这十个字符读入物理内存。同样,数据被缓慢地读取。
切片不会提升内部文件位置。所以,如果你在一个片后调用read(),那么你仍然会从文件的开始读取。
搜索内存映射文件
除了切片之外,mmap模块还允许其他类似字符串的行为,比如使用find()和rfind()在文件中搜索特定的文本。例如,有两种方法可以找到文件中第一次出现的" the ":
import mmap
def regular_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
text = file_obj.read()
print(text.find(" the "))
def mmap_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj.find(b" the "))
这两个函数都在文件中搜索第一次出现的" the ",它们之间的主要区别是第一个函数在字符串对象上使用find(),而第二个函数在内存映射文件对象上使用find()。
注意: mmap操作的是字节,不是字符串。
以下是性能差异:
>>> import timeit
>>> timeit.repeat(
... "regular_io_find(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find, filename")
[0.01919180000000001, 0.01940510000000001, 0.019157700000000027]
>>> timeit.repeat(
... "mmap_io_find(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find, filename")
[0.0009397999999999906, 0.0018005999999999855, 0.000826699999999958]
那可是差了好几个数量级啊!同样,您的结果可能会因操作系统而异。
内存映射文件也可以直接和正则表达式一起使用。考虑下面的示例,该示例查找并打印出所有五个字母的单词:
import re
import mmap
def mmap_io_re(filename):
five_letter_word = re.compile(rb"\b[a-zA-Z]{5}\b")
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
for word in five_letter_word.findall(mmap_obj):
print(word)
这段代码读取整个文件,并打印出其中正好有五个字母的每个单词。请记住,内存映射文件使用字节字符串,因此正则表达式也必须使用字节字符串。
下面是使用常规文件 I/O 的等效代码:
import re
def regular_io_re(filename):
five_letter_word = re.compile(r"\b[a-zA-Z]{5}\b")
with open(filename, mode="r", encoding="utf-8") as file_obj:
for word in five_letter_word.findall(file_obj.read()):
print(word)
这段代码还打印出文件中所有五个字符的单词,但是它使用传统的文件 I/O 机制,而不是内存映射文件。和以前一样,这两种方法的性能不同:
>>> import timeit
>>> timeit.repeat(
... "regular_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_re, filename")
[0.10474110000000003, 0.10358619999999996, 0.10347820000000002]
>>> timeit.repeat(
... "mmap_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_re, filename")
[0.0740976000000001, 0.07362639999999998, 0.07380980000000004]
内存映射方法仍然要快一个数量级。
作为文件的内存映射对象
内存映射文件是部分字符串和部分文件,因此mmap也允许您执行常见的文件操作,如seek()、tell()和readline()。这些函数的工作方式与常规的文件对象完全一样。
例如,下面是如何查找文件中的特定位置,然后执行单词搜索:
import mmap
def mmap_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
mmap_obj.seek(10000)
mmap_obj.find(b" the ")
这段代码将寻找文件中的位置10000,然后找到第一次出现" the "的位置。
seek()对内存映射文件的作用与对常规文件的作用完全相同:
def regular_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
file_obj.seek(10000)
text = file_obj.read()
text.find(" the ")
这两种方法的代码非常相似。让我们看看他们的表现如何比较:
>>> import timeit
>>> timeit.repeat(
... "regular_io_find_and_seek(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find_and_seek, filename")
[0.019396099999999916, 0.01936059999999995, 0.019192100000000045]
>>> timeit.repeat(
... "mmap_io_find_and_seek(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find_and_seek, filename")
[0.000925100000000012, 0.000788299999999964, 0.0007854999999999945]
同样,只需对代码进行一些小的调整,您的内存映射方法就会快得多。
用 Python 的mmap 写内存映射文件
内存映射对于读取文件最有用,但是您也可以使用它来写入文件。用于写文件的 API 与常规的文件 I/O 非常相似,除了一些不同之处。
下面是一个将文本写入内存映射文件的示例:
import mmap
def mmap_io_write(filename, text):
with open(filename, mode="w", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj.write(text)
这段代码将文本写入内存映射文件。但是,如果在创建mmap对象时文件是空的,它将引发一个ValueError异常。
Python 的mmap模块不允许空文件的内存映射。这是合理的,因为从概念上讲,一个空的内存映射文件只是一个内存缓冲区,所以不需要内存映射对象。
通常,内存映射用于读取或读/写模式。例如,下面的代码演示了如何快速读取文件并只修改其中的一部分:
import mmap
def mmap_io_write(filename):
with open(filename, mode="r+") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj[10:16] = b"python"
mmap_obj.flush()
该功能将打开一个至少包含 16 个字符的文件,并将字符 10 至 15 更改为"python"。
写入mmap_obj的更改在磁盘上的文件和内存中都是可见的。官方 Python 文档建议总是调用flush()来保证数据被写回磁盘。
写入模式
写操作的语义由access参数控制。编写内存映射文件和普通文件的一个区别是access参数的选项。有两个选项可以控制如何将数据写入内存映射文件:
ACCESS_WRITE指定直写语义,意味着数据将通过内存写入并持久存储在磁盘上。ACCESS_COPY不将更改写入磁盘,即使flush()被调用。
换句话说,ACCESS_WRITE写入内存和文件,而ACCESS_COPY只写入内存,不写入底层文件。
搜索和替换文本
内存映射文件将数据公开为一个字节字符串,但是这个字节字符串与常规字符串相比还有一个重要的优势。内存映射文件数据是一个由个可变字节组成的字符串。这意味着编写在文件中搜索和替换数据的代码要简单和高效得多:
import mmap
import os
import shutil
def regular_io_find_and_replace(filename):
with open(filename, "r", encoding="utf-8") as orig_file_obj:
with open("tmp.txt", "w", encoding="utf-8") as new_file_obj:
orig_text = orig_file_obj.read()
new_text = orig_text.replace(" the ", " eht ")
new_file_obj.write(new_text)
shutil.copyfile("tmp.txt", filename)
os.remove("tmp.txt")
def mmap_io_find_and_replace(filename):
with open(filename, mode="r+", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
orig_text = mmap_obj.read()
new_text = orig_text.replace(b" the ", b" eht ")
mmap_obj[:] = new_text
mmap_obj.flush()
这两个函数都将给定文件中的单词" the "更改为" eht "。如您所见,内存映射方法大致相同,但是它不需要手动跟踪额外的临时文件来进行适当的替换。
在这种情况下,对于这种文件长度,内存映射方法实际上会稍慢一些。因此,对内存映射文件进行完全搜索和替换可能是也可能不是最有效的方法。这可能取决于许多因素,如文件长度、机器的内存速度等。也可能有一些操作系统缓存扭曲了时间。正如您所看到的,常规 IO 方法在每次调用时都会加快速度。
>>> import timeit
>>> timeit.repeat(
... "regular_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find_and_replace, filename")
[0.031016973999996367, 0.019185273000005054, 0.019321329999996806]
>>> timeit.repeat(
... "mmap_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find_and_replace, filename")
[0.026475408999999672, 0.030173652999998524, 0.029132930999999473]
在这个基本的搜索-替换场景中,内存映射会使代码稍微简洁一些,但并不总是能大幅提高速度。正如他们所说,“你的里程可能会有所不同。”
用 Python 的mmap 在进程间共享数据
到目前为止,您只对磁盘上的数据使用内存映射文件。然而,你也可以创建没有物理存储的匿名内存映射。这可以通过传递-1作为文件描述符来实现:
import mmap
with mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj[0:100] = b"a" * 100
print(mmap_obj[0:100])
这在 RAM 中创建了一个匿名的内存映射对象,其中包含字母"a"的100个副本。
匿名内存映射对象本质上是内存中特定大小的缓冲区,由参数length指定。缓冲区类似于标准库中的 io.StringIO 或 io.BytesIO 。然而,一个匿名的内存映射对象支持跨多个进程的共享,io.StringIO和io.BytesIO都不允许。
这意味着您可以使用匿名内存映射对象在进程之间交换数据,即使这些进程具有完全独立的内存和堆栈。下面是一个创建匿名内存映射对象来共享可以从两个进程中读写的数据的示例:
import mmap
def sharing_with_mmap():
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
pid = os.fork()
if pid == 0:
# Child process
BUF[0:100] = b"a" * 100
else:
time.sleep(2)
print(BUF[0:100])
使用这段代码,您创建了一个100字节的内存映射缓冲区,并允许从两个进程中读取和写入该缓冲区。如果您希望节省内存,同时仍能在多个进程间共享大量数据,这种方法会很有用。
使用内存映射共享内存有几个优点:
- 数据不必在进程间复制。
- 操作系统透明地处理内存。
- 数据不必在进程间酸洗,节省了 CPU 时间。
说到酸洗,值得指出的是mmap与更高级、更全功能的 API 如内置multiprocessing模块不兼容。multiprocessing模块需要在进程间传递数据来支持 pickle 协议,而mmap不需要。
您可能会尝试使用multiprocessing而不是os.fork(),如下所示:
from multiprocessing import Process
def modify(buf):
buf[0:100] = b"xy" * 50
if __name__ == "__main__":
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
BUF[0:100] = b"a" * 100
p = Process(target=modify, args=(BUF,))
p.start()
p.join()
print(BUF[0:100])
在这里,您试图创建一个新的进程,并将内存映射缓冲区传递给它。这段代码将立即引发一个 TypeError ,因为mmap对象不能被酸洗,这是将数据传递给第二个进程所必需的。因此,要使用内存映射共享数据,您需要坚持使用底层的os.fork()。
如果您使用的是 Python 3.8 或更新版本,那么您可以使用新的 shared_memory模块来更有效地跨 Python 进程共享数据:
from multiprocessing import Process
from multiprocessing import shared_memory
def modify(buf_name):
shm = shared_memory.SharedMemory(buf_name)
shm.buf[0:50] = b"b" * 50
shm.close()
if __name__ == "__main__":
shm = shared_memory.SharedMemory(create=True, size=100)
try:
shm.buf[0:100] = b"a" * 100
proc = Process(target=modify, args=(shm.name,))
proc.start()
proc.join()
print(bytes(shm.buf[:100]))
finally:
shm.close()
shm.unlink()
这个小程序创建了一个100字符列表,并从另一个进程中修改前 50 个字符。
注意,只有缓冲区的名称被传递给第二个进程。然后,第二个进程可以使用该唯一名称检索同一个内存块。这是由mmap供电的shared_memory模块的一个特殊功能。在幕后,shared_memory模块使用每个操作系统独特的 API 为您创建命名的内存映射。
现在您已经知道了新的共享内存 Python 3.8 特性的一些底层实现细节,以及如何直接使用mmap!
结论
内存映射是文件 I/O 的另一种方法,Python 程序可以通过mmap模块使用它。内存映射使用低级操作系统 API 将文件内容直接存储在物理内存中。这种方法通常会提高 I/O 性能,因为它避免了许多昂贵的系统调用,并减少了昂贵的数据缓冲区传输。
在本教程中,您学习了:
- 物理、虚拟和共享内存有什么区别
- 如何优化内存使用与内存映射
- 如何使用 Python 的
mmap模块在你的代码中实现内存映射
mmap API 类似于常规的文件 I/O API,所以测试起来相当简单。在您自己的代码中尝试一下,看看您的程序是否能从内存映射提供的性能改进中受益。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python mmap:用内存映射做文件 I/O*****
了解 Python 模拟对象库
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Python 模拟对象库 改进您的测试
当您编写健壮的代码时,测试对于验证您的应用程序逻辑是正确的、可靠的和有效的是必不可少的。然而,您的测试的价值取决于它们在多大程度上证明了这些标准。诸如复杂的逻辑和不可预测的依赖关系这样的障碍使得编写有价值的测试变得困难。Python 模拟对象库unittest.mock,可以帮助你克服这些障碍。
本文结束时,你将能够:
- 使用
Mock创建 Python 模拟对象 - 断言你正在按照你的意图使用对象
- 检查存储在 Python 模拟中的使用数据
- 配置 Python 模拟对象的某些方面
- 使用
patch()将你的模型替换成真实的物体 - 避免 Python 模仿中固有的常见问题
您将从了解什么是嘲讽以及它将如何改进您的测试开始。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是嘲讽?
一个模拟对象在一个测试环境中替代并模仿一个真实对象。它是提高测试质量的一个通用且强大的工具。
使用 Python 模拟对象的一个原因是为了在测试过程中控制代码的行为。
例如,如果您的代码向外部服务发出 HTTP 请求,那么您的测试只有在服务的行为符合您的预期时才会可预测地执行。有时,这些外部服务行为的临时变化会导致测试套件中的间歇性故障。
因此,在一个受控的环境中测试您的代码会更好。用模拟对象替换实际的请求将允许您以可预测的方式模拟外部服务中断和成功的响应。
有时候,测试代码库的某些部分是很困难的。这样的区域包括难以满足的except块和if语句。使用 Python 模拟对象可以帮助您控制代码的执行路径以到达这些区域,并提高您的代码覆盖率。
使用模拟对象的另一个原因是为了更好地理解如何在代码中使用它们的真实对应物。Python 模拟对象包含关于其用法的数据,您可以检查这些数据,例如:
- 如果你调用了一个方法
- 您如何调用该方法
- 您调用该方法的频率
理解模拟对象的作用是学习如何使用它的第一步。
现在,您将看到如何使用 Python 模拟对象。
Python 模拟库
Python 模拟对象库是unittest.mock。它提供了一个简单的方法将模拟引入到你的测试中。
**注意:**标准库包括 Python 3.3 及以后版本中的unittest.mock。如果你使用的是旧版本的 Python,你需要安装库的官方后台。为此,从 PyPI 安装mock:
$ pip install mock
unittest.mock提供了一个名为Mock的类,你可以用它来模仿代码库中的真实对象。Mock提供令人难以置信的灵活性和深刻的数据。这个及其子类将满足您在测试中面临的大多数 Python 模仿需求。
该库还提供了一个名为patch()的函数,它用Mock实例替换代码中的真实对象。您可以使用patch()作为装饰器或上下文管理器,让您控制对象被模仿的范围。一旦指定的作用域退出,patch()将通过用它们原来的对应物替换被模仿的对象来清理你的代码。
最后,unittest.mock为模仿对象中固有的一些问题提供了解决方案。
现在,您已经更好地理解了什么是嘲讽,以及您将用来做这件事的库。让我们深入探讨一下unittest.mock提供了哪些特性和功能。
Mock对象
unittest.mock为模仿对象提供了一个基类,叫做Mock。因为Mock非常灵活,所以Mock的用例实际上是无限的。
首先实例化一个新的Mock实例:
>>> from unittest.mock import Mock
>>> mock = Mock()
>>> mock
<Mock id='4561344720'>
现在,您可以用新的Mock替换代码中的对象。您可以通过将它作为参数传递给函数或重新定义另一个对象来实现这一点:
# Pass mock as an argument to do_something()
do_something(mock)
# Patch the json library
json = mock
当你在代码中替换一个对象时,Mock必须看起来像它所替换的真实对象。否则,您的代码将无法使用Mock来代替原始对象。
例如,如果您正在模仿json库,并且您的程序调用了dumps(),那么您的 Python 模仿对象也必须包含dumps()。
接下来,您将看到Mock如何应对这一挑战。
惰性属性和方法
一个Mock必须模拟它替换的任何对象。为了实现这样的灵活性,当你访问属性时,它会创建它的属性:
>>> mock.some_attribute
<Mock name='mock.some_attribute' id='4394778696'>
>>> mock.do_something()
<Mock name='mock.do_something()' id='4394778920'>
由于Mock可以动态创建任意属性,因此适合替换任何对象。
使用前面的一个例子,如果您模仿json库并调用dumps(),Python 模仿对象将创建该方法,以便其接口可以匹配库的接口:
>>> json = Mock()
>>> json.dumps()
<Mock name='mock.dumps()' id='4392249776'>
请注意这个dumps()模拟版本的两个关键特征:
>>> json = Mock()
>>> json.loads('{"k": "v"}').get('k')
<Mock name='mock.loads().get()' id='4379599424'>
因为每个被模仿的方法的返回值也是一个Mock,所以您可以以多种方式使用您的模仿。
模拟是灵活的,但它们也能提供信息。接下来,您将学习如何使用模拟来更好地理解您的代码。
断言和检验
实例存储你如何使用它们的数据。例如,您可以查看是否调用了一个方法,如何调用该方法,等等。使用这些信息有两种主要方式。
首先,您可以断言您的程序使用了您所期望的对象:
>>> from unittest.mock import Mock
>>> # Create a mock object
... json = Mock()
>>> json.loads('{"key": "value"}')
<Mock name='mock.loads()' id='4550144184'>
>>> # You know that you called loads() so you can
>>> # make assertions to test that expectation
... json.loads.assert_called()
>>> json.loads.assert_called_once()
>>> json.loads.assert_called_with('{"key": "value"}')
>>> json.loads.assert_called_once_with('{"key": "value"}')
>>> json.loads('{"key": "value"}')
<Mock name='mock.loads()' id='4550144184'>
>>> # If an assertion fails, the mock will raise an AssertionError
... json.loads.assert_called_once()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 795, in assert_called_once
raise AssertionError(msg)
AssertionError: Expected 'loads' to have been called once. Called 2 times.
>>> json.loads.assert_called_once_with('{"key": "value"}')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 824, in assert_called_once_with
raise AssertionError(msg)
AssertionError: Expected 'loads' to be called once. Called 2 times.
>>> json.loads.assert_not_called()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 777, in assert_not_called
raise AssertionError(msg)
AssertionError: Expected 'loads' to not have been called. Called 2 times.
.assert_called()确保您调用了被模仿的方法,而.assert_called_once()检查您只调用了该方法一次。
这两个断言函数都有变体,允许您检查传递给被模仿方法的参数:
.assert_called_with(*args, **kwargs).assert_called_once_with(*args, **kwargs)
要传递这些断言,您必须使用传递给实际方法的相同参数来调用模拟方法:
>>> json = Mock()
>>> json.loads(s='{"key": "value"}')
>>> json.loads.assert_called_with('{"key": "value"}')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 814, in assert_called_with
raise AssertionError(_error_message()) from cause
AssertionError: Expected call: loads('{"key": "value"}')
Actual call: loads(s='{"key": "value"}')
>>> json.loads.assert_called_with(s='{"key": "value"}')
json.loads.assert_called_with('{"key": "value"}')提出了一个AssertionError,因为它期望你用位置参数调用 loads() ,但你实际上用关键字参数调用了它。json.loads.assert_called_with(s='{"key": "value"}')这个断言是正确的。
其次,您可以查看特殊属性,以了解您的应用程序如何使用对象:
>>> from unittest.mock import Mock
>>> # Create a mock object
... json = Mock()
>>> json.loads('{"key": "value"}')
<Mock name='mock.loads()' id='4391026640'>
>>> # Number of times you called loads():
... json.loads.call_count
1
>>> # The last loads() call:
... json.loads.call_args
call('{"key": "value"}')
>>> # List of loads() calls:
... json.loads.call_args_list
[call('{"key": "value"}')]
>>> # List of calls to json's methods (recursively):
... json.method_calls
[call.loads('{"key": "value"}')]
您可以使用这些属性编写测试,以确保您的对象如您所愿地运行。
现在,您可以创建模拟并检查它们的使用数据。接下来,您将看到如何定制模拟方法,以便它们在您的测试环境中变得更加有用。
管理模拟的返回值
使用模拟的一个原因是为了在测试过程中控制代码的行为。一种方法是指定函数的返回值。让我们用一个例子来看看这是如何工作的。
首先,创建一个名为my_calendar.py的文件。添加is_weekday(),这个函数使用 Python 的datetime库来确定今天是否是工作日。最后,编写一个测试,断言该函数按预期工作:
from datetime import datetime
def is_weekday():
today = datetime.today()
# Python's datetime library treats Monday as 0 and Sunday as 6
return (0 <= today.weekday() < 5)
# Test if today is a weekday
assert is_weekday()
因为您正在测试今天是否是工作日,所以结果取决于您运行测试的日期:
$ python my_calendar.py
如果该命令没有产生输出,则断言成功。不幸的是,如果您在周末运行该命令,您将得到一个AssertionError:
$ python my_calendar.py
Traceback (most recent call last):
File "test.py", line 9, in <module>
assert is_weekday()
AssertionError
当编写测试时,确保结果是可预测的是很重要的。您可以使用Mock来消除测试过程中代码的不确定性。在这种情况下,您可以模仿datetime并将.today()的.return_value设置为您选择的日期:
import datetime
from unittest.mock import Mock
# Save a couple of test days
tuesday = datetime.datetime(year=2019, month=1, day=1)
saturday = datetime.datetime(year=2019, month=1, day=5)
# Mock datetime to control today's date
datetime = Mock()
def is_weekday():
today = datetime.datetime.today()
# Python's datetime library treats Monday as 0 and Sunday as 6
return (0 <= today.weekday() < 5)
# Mock .today() to return Tuesday
datetime.datetime.today.return_value = tuesday # Test Tuesday is a weekday
assert is_weekday()
# Mock .today() to return Saturday
datetime.datetime.today.return_value = saturday # Test Saturday is not a weekday
assert not is_weekday()
在这个例子中,.today()是一个被模仿的方法。通过给模拟的.return_value指定一个特定的日期,您已经消除了不一致性。这样,当你调用.today()时,它会返回你指定的datetime。
在第一个测试中,您确保tuesday是工作日。在第二个测试中,您验证了saturday不是工作日。现在,哪一天运行测试并不重要,因为你已经模仿了datetime,并且控制了对象的行为。
**延伸阅读:**虽然这样嘲讽datetime是使用Mock的一个很好的实践例子,但是已经有一个很棒的嘲讽datetime的库叫做 freezegun 。
在构建测试时,您可能会遇到这样的情况,仅仅模仿函数的返回值是不够的。这是因为函数通常比简单的单向逻辑流更复杂。
有时,当您不止一次调用函数或者甚至引发异常时,您会希望函数返回不同的值。您可以使用.side_effect来完成此操作。
管理模仿的副作用
您可以通过指定被模仿函数的副作用来控制代码的行为。一个.side_effect定义了当你调用被模仿的函数时会发生什么。
为了测试这是如何工作的,向my_calendar.py添加一个新函数:
import requests
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
get_holidays()向localhost服务器请求一组假期。如果服务器响应成功,get_holidays()将返回一个字典。否则,该方法将返回 None 。
您可以通过设置requests.get.side_effect来测试get_holidays()将如何响应连接超时。
对于这个例子,您只会看到来自my_calendar.py的相关代码。您将使用 Python 的 unittest 库构建一个测试用例:
import unittest
from requests.exceptions import Timeout
from unittest.mock import Mock
# Mock requests to control its behavior
requests = Mock()
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
class TestCalendar(unittest.TestCase):
def test_get_holidays_timeout(self):
# Test a connection timeout
requests.get.side_effect = Timeout with self.assertRaises(Timeout):
get_holidays()
if __name__ == '__main__':
unittest.main()
鉴于get()的新副作用,您使用.assertRaises()来验证get_holidays()是否引发了异常。
运行此测试以查看测试结果:
$ python my_calendar.py
.
-------------------------------------------------------
Ran 1 test in 0.000s
OK
如果您想更动态一点,您可以将.side_effect设置为一个函数,当您调用您模仿的方法时,Mock将调用该函数。mock 共享.side_effect函数的参数和返回值:
import requests
import unittest
from unittest.mock import Mock
# Mock requests to control its behavior
requests = Mock()
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
class TestCalendar(unittest.TestCase):
def log_request(self, url):
# Log a fake request for test output purposes
print(f'Making a request to {url}.')
print('Request received!')
# Create a new Mock to imitate a Response
response_mock = Mock()
response_mock.status_code = 200
response_mock.json.return_value = {
'12/25': 'Christmas',
'7/4': 'Independence Day',
}
return response_mock
def test_get_holidays_logging(self):
# Test a successful, logged request
requests.get.side_effect = self.log_request assert get_holidays()['12/25'] == 'Christmas'
if __name__ == '__main__':
unittest.main()
首先,您创建了.log_request(),它接受一个 URL,使用 print() 记录一些输出,然后返回一个Mock响应。接下来,您将get()的.side_effect设置为.log_request(),您将在调用get_holidays()时使用它。当您运行测试时,您会看到get()将其参数转发给.log_request(),然后接受返回值并返回它:
$ python my_calendar.py
Making a request to http://localhost/api/holidays.
Request received!
.
-------------------------------------------------------
Ran 1 test in 0.000s
OK
太好了! print()语句记录了正确的值。还有,get_holidays()返回了节假日字典。
.side_effect也可以是 iterable。iterable 必须由返回值、异常或两者的混合组成。每次调用被模仿的方法时,iterable 都会产生下一个值。例如,您可以测试在Timeout返回成功响应后的重试:
import unittest
from requests.exceptions import Timeout
from unittest.mock import Mock
# Mock requests to control its behavior
requests = Mock()
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
class TestCalendar(unittest.TestCase):
def test_get_holidays_retry(self):
# Create a new Mock to imitate a Response
response_mock = Mock()
response_mock.status_code = 200
response_mock.json.return_value = {
'12/25': 'Christmas',
'7/4': 'Independence Day',
}
# Set the side effect of .get()
requests.get.side_effect = [Timeout, response_mock] # Test that the first request raises a Timeout
with self.assertRaises(Timeout):
get_holidays()
# Now retry, expecting a successful response
assert get_holidays()['12/25'] == 'Christmas'
# Finally, assert .get() was called twice
assert requests.get.call_count == 2
if __name__ == '__main__':
unittest.main()
第一次调用get_holidays(),get()引出一个Timeout。第二次,该方法返回一个有效的假日字典。这些副作用符合它们在传递给.side_effect的列表中出现的顺序。
您可以直接在Mock上设置.return_value和.side_effect。但是,因为 Python 模拟对象需要灵活地创建其属性,所以有一种更好的方法来配置这些和其他设置。
配置您的模拟
您可以配置一个Mock来设置对象的一些行为。一些可配置的成员包括.side_effect、.return_value和.name。当您创建一个或者当您使用 .configure_mock() 时,您配置一个Mock。
您可以在初始化对象时通过指定某些属性来配置Mock:
>>> mock = Mock(side_effect=Exception)
>>> mock()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 939, in __call__
return _mock_self._mock_call(*args, **kwargs)
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 995, in _mock_call
raise effect
Exception
>>> mock = Mock(name='Real Python Mock')
>>> mock
<Mock name='Real Python Mock' id='4434041432'>
>>> mock = Mock(return_value=True)
>>> mock()
True
虽然.side_effect和.return_value可以在Mock实例本身上设置,但其他属性如.name只能通过.__init__()或.configure_mock()设置。如果您尝试在实例上设置Mock的.name,您将得到不同的结果:
>>> mock = Mock(name='Real Python Mock')
>>> mock.name
<Mock name='Real Python Mock.name' id='4434041544'>
>>> mock = Mock()
>>> mock.name = 'Real Python Mock'
>>> mock.name
'Real Python Mock'
.name是对象使用的常用属性。因此,Mock不允许您像使用.return_value或.side_effect那样在实例上设置值。如果您访问mock.name,您将创建一个.name属性,而不是配置您的模拟。
您可以使用.configure_mock()配置现有的Mock:
>>> mock = Mock()
>>> mock.configure_mock(return_value=True)
>>> mock()
True
通过将字典解包到.configure_mock()或Mock.__init__(),您甚至可以配置 Python 模拟对象的属性。使用Mock配置,您可以简化前面的例子:
# Verbose, old Mock
response_mock = Mock()
response_mock.json.return_value = {
'12/25': 'Christmas',
'7/4': 'Independence Day',
}
# Shiny, new .configure_mock()
holidays = {'12/25': 'Christmas', '7/4': 'Independence Day'}
response_mock = Mock(**{'json.return_value': holidays})
现在,您可以创建和配置 Python 模拟对象。您还可以使用模拟来控制您的应用程序的行为。到目前为止,您已经使用 mocks 作为函数的参数,或者在测试的同一个模块中修补对象。
接下来,您将学习如何在其他模块中用模拟对象替换真实对象。
patch()
unittest.mock提供了一个强大的模仿对象的机制,叫做 patch() ,它在给定的模块中查找一个对象,并用一个Mock替换那个对象。
通常,您使用patch()作为装饰器或上下文管理器来提供一个模仿目标对象的范围。
patch()当装潢师
如果你想在整个测试函数期间模仿一个对象,你可以使用patch()作为函数的装饰者。
要了解这是如何工作的,通过将逻辑和测试放入单独的文件来重新组织您的my_calendar.py文件:
import requests
from datetime import datetime
def is_weekday():
today = datetime.today()
# Python's datetime library treats Monday as 0 and Sunday as 6
return (0 <= today.weekday() < 5)
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
这些函数现在位于它们自己的文件中,与它们的测试分开。接下来,您将在名为tests.py的文件中重新创建您的测试。
到目前为止,您已经在对象所在的文件中对它们进行了猴子修补。猴子补丁是在运行时用一个对象替换另一个对象。现在,您将使用patch()来替换my_calendar.py中的对象:
import unittest
from my_calendar import get_holidays
from requests.exceptions import Timeout
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
@patch('my_calendar.requests') def test_get_holidays_timeout(self, mock_requests):
mock_requests.get.side_effect = Timeout
with self.assertRaises(Timeout):
get_holidays()
mock_requests.get.assert_called_once()
if __name__ == '__main__':
unittest.main()
最初,您在本地范围内创建了一个Mock并修补了requests。现在,你需要从tests.py进入my_calendar.py的requests图书馆。
对于这种情况,您使用了patch()作为装饰器,并传递了目标对象的路径。目标路径是由模块名和对象组成的'my_calendar.requests'。
您还为测试函数定义了一个新参数。patch()使用此参数将被模仿的对象传递到您的测试中。从那里,您可以根据需要修改 mock 或做出断言。
您可以执行这个测试模块来确保它按预期工作:
$ python tests.py
.
-------------------------------------------------------
Ran 1 test in 0.001s
OK
技术细节: patch()返回 MagicMock 的一个实例,是Mock的子类。MagicMock很有用,因为它为你实现了大部分魔法方法,比如.__len__()、.__str__()和.__iter__(),并且有合理的默认值。
在这个例子中,使用patch()作为装饰器效果很好。在某些情况下,使用patch()作为上下文管理器更易读、更有效或更容易。
patch()作为上下文管理器
有时,你会想要使用patch()作为上下文管理器而不是装饰器。您可能更喜欢上下文管理器的一些原因包括:
- 您只想在测试范围的一部分模拟一个对象。
- 您已经使用了太多的装饰器或参数,这会损害测试的可读性。
要将patch()用作上下文管理器,可以使用 Python 的with语句:
import unittest
from my_calendar import get_holidays
from requests.exceptions import Timeout
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
def test_get_holidays_timeout(self):
with patch('my_calendar.requests') as mock_requests: mock_requests.get.side_effect = Timeout
with self.assertRaises(Timeout):
get_holidays()
mock_requests.get.assert_called_once()
if __name__ == '__main__':
unittest.main()
当测试退出with语句时,patch()用原始对象替换被模仿的对象。
到目前为止,您已经模拟了完整的对象,但有时您只想模拟对象的一部分。
修补对象的属性
假设您只想模仿一个对象的一个方法,而不是整个对象。你可以使用 patch.object() 来完成。
比如,.test_get_holidays_timeout()真的只需要模仿requests.get(),将其.side_effect设置为Timeout:
import unittest
from my_calendar import requests, get_holidays
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
@patch.object(requests, 'get', side_effect=requests.exceptions.Timeout) def test_get_holidays_timeout(self, mock_requests):
with self.assertRaises(requests.exceptions.Timeout):
get_holidays()
if __name__ == '__main__':
unittest.main()
在这个例子中,你只模仿了get(),而不是所有的requests。其他所有属性保持不变。
object()采用与patch()相同的配置参数。但是不是传递目标的路径,而是提供目标对象本身作为第一个参数。第二个参数是您试图模仿的目标对象的属性。你也可以像使用patch()一样使用object()作为上下文管理器。
**延伸阅读:**除了对象和属性,还可以用 patch.dict() 的patch()字典。
学习如何使用patch()对于模仿其他模块中的对象至关重要。然而,有时目标对象的路径并不明显。
哪里打补丁
知道在哪里告诉patch()寻找你想要嘲笑的对象是很重要的,因为如果你选择了错误的目标位置,patch()的结果可能是你意想不到的。
假设你在用patch()嘲讽my_calendar.py中的is_weekday():
>>> import my_calendar
>>> from unittest.mock import patch
>>> with patch('my_calendar.is_weekday'):
... my_calendar.is_weekday()
...
<MagicMock name='is_weekday()' id='4336501256'>
首先,你导入my_calendar.py。然后你修补is_weekday(),用一个Mock替换它。太好了!这是预期的工作。
现在,让我们稍微修改一下这个例子,直接导入函数:
>>> from my_calendar import is_weekday
>>> from unittest.mock import patch
>>> with patch('my_calendar.is_weekday'):
... is_weekday()
...
False
**注意:**根据您阅读本教程的日期,您的控制台输出可能会显示True或False。重要的是,输出不是像以前一样的Mock。
注意,即使您传递给patch()的目标位置没有改变,调用is_weekday()的结果也是不同的。这种差异是由于导入函数的方式发生了变化。
将实函数绑定到局部范围。因此,即使您稍后patch()该函数,您也会忽略模仿,因为您已经有了对未模仿函数的本地引用。
一个好的经验法则就是patch()被仰望的物体。
在第一个例子中,模仿'my_calendar.is_weekday()'是可行的,因为您在my_calendar模块中查找函数。在第二个例子中,您有一个对is_weekday()的本地引用。因为您使用了在局部范围内找到的函数,所以您应该模仿局部函数:
>>> from unittest.mock import patch
>>> from my_calendar import is_weekday
>>> with patch('__main__.is_weekday'):
... is_weekday()
...
<MagicMock name='is_weekday()' id='4502362992'>
现在,你牢牢掌握了patch()的力量。你已经看到了如何patch()对象和属性,以及在哪里修补它们。
接下来,您将看到对象模仿中固有的一些常见问题以及unittest.mock提供的解决方案。
常见嘲讽问题
模仿对象会给你的测试带来几个问题。有些问题是嘲讽固有的,有些问题是unittest.mock特有的。请记住,本教程中没有提到嘲讽的其他问题。
这里讨论的问题彼此相似,因为它们引起的问题基本上是相同的。在每种情况下,测试断言都是不相关的。虽然每个模仿的意图是有效的,但模仿本身却是无效的。
对象接口的变化和拼写错误
类和函数定义一直在变化。当一个对象的接口改变时,任何依赖于该对象的Mock的测试都可能变得无关紧要。
例如,您重命名了一个方法,但是忘记了一个测试模拟了这个方法并调用了.assert_not_called()。变化之后,.assert_not_called()依然是True。但是这个断言没有用,因为这个方法已经不存在了。
不相关的测试听起来可能不重要,但是如果它们是您唯一的测试,并且您认为它们工作正常,那么这种情况对您的应用程序来说可能是灾难性的。
一个特定于Mock的问题是拼写错误会破坏测试。回想一下,当您访问一个Mock的成员时,它会创建自己的接口。因此,如果您拼错了属性的名称,就会无意中创建新属性。
如果你调用.asert_called()而不是.assert_called(),你的测试将不会产生AssertionError。这是因为您已经在 Python 模拟对象上创建了一个名为.asert_called()的新方法,而不是评估一个实际的断言。
**技术细节:**有趣的是,assret是assert的特殊拼错。如果您试图访问一个以assret(或assert)开头的属性,Mock将自动引发一个AttributeError。
当您在自己的代码库中模仿对象时,会出现这些问题。当您模仿与外部代码库交互的对象时,会出现一个不同的问题。
外部依赖关系的变化
再想象一下,您的代码向外部 API 发出请求。在这种情况下,外部依赖是 API,它容易在未经您同意的情况下被更改。
一方面,单元测试测试代码的独立组件。因此,模拟发出请求的代码有助于您在受控条件下测试隔离的组件。然而,这也带来了一个潜在的问题。
如果一个外部依赖改变了它的接口,你的 Python 模拟对象将变得无效。如果发生这种情况(并且接口变化是破坏性的),您的测试将会通过,因为您的模拟对象已经屏蔽了这种变化,但是您的生产代码将会失败。
不幸的是,这不是一个unittest.mock提供解决方案的问题。嘲笑外部依赖时,你必须运用判断力。
所有这三个问题都可能导致测试无关性和潜在的代价高昂的问题,因为它们威胁到您的模拟的完整性。给你一些处理这些问题的工具。
使用规范避免常见问题
如前所述,如果您更改了一个类或函数定义,或者拼错了 Python 模拟对象的属性,那么您的测试就会出现问题。
出现这些问题是因为当您访问属性和方法时,Mock会创建它们。这些问题的答案是防止Mock创建与您试图模仿的对象不一致的属性。
当配置一个Mock时,您可以将一个对象规范传递给spec参数。spec参数接受一个名称列表或另一个对象,并定义 mock 的接口。如果您试图访问一个不属于规范的属性,Mock将引发一个AttributeError:
>>> from unittest.mock import Mock
>>> calendar = Mock(spec=['is_weekday', 'get_holidays'])
>>> calendar.is_weekday()
<Mock name='mock.is_weekday()' id='4569015856'>
>>> calendar.create_event()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
这里,您已经指定了calendar具有名为.is_weekday()和.get_holidays()的方法。当你访问.is_weekday()时,它返回一个Mock。当您访问.create_event()时,一个与规范不匹配的方法Mock会引发一个AttributeError。
如果用对象配置Mock,规格的工作方式相同:
>>> import my_calendar
>>> from unittest.mock import Mock
>>> calendar = Mock(spec=my_calendar)
>>> calendar.is_weekday()
<Mock name='mock.is_weekday()' id='4569435216'>
>>> calendar.create_event()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
.is_weekday()对calendar可用,因为您配置了calendar来匹配my_calendar模块的接口。
此外,unittest.mock提供了自动指定Mock实例的接口的便利方法。
实现自动规格的一种方法是create_autospec:
>>> import my_calendar
>>> from unittest.mock import create_autospec
>>> calendar = create_autospec(my_calendar)
>>> calendar.is_weekday()
<MagicMock name='mock.is_weekday()' id='4579049424'>
>>> calendar.create_event()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
像以前一样,calendar是一个Mock实例,它的接口匹配my_calendar。如果您正在使用patch(),您可以向autospec参数发送一个参数来获得相同的结果:
>>> import my_calendar
>>> from unittest.mock import patch
>>> with patch('__main__.my_calendar', autospec=True) as calendar:
... calendar.is_weekday()
... calendar.create_event()
...
<MagicMock name='my_calendar.is_weekday()' id='4579094312'>
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
结论
你已经学到了很多关于使用unittest.mock模仿物体的知识!
现在,您能够:
- 在你的测试中使用
Mock来模仿物体 - 检查使用数据以了解如何使用对象
- 定制模拟对象的返回值和副作用
- 整个代码库中的对象
- 查看和避免使用 Python 模拟对象的问题
您已经建立了理解的基础,这将帮助您构建更好的测试。您可以使用模拟来深入了解您的代码,否则您将无法获得这些信息。
我留给你最后一个免责声明。当心过度使用模仿对象!
很容易利用 Python 模拟对象的强大功能,并且模拟得如此之多,以至于实际上降低了测试的价值。
如果你有兴趣了解更多关于unittest.mock的信息,我鼓励你阅读它优秀的文档。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Python 模拟对象库 改进您的测试******
Python 模块和包——简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模块和包:简介
本文探索了 Python 模块和 Python 包,这两种机制促进了模块化编程。
模块化编程指的是将一个庞大、笨拙的编程任务分解成独立、更小、更易管理的子任务或模块的过程。然后,可以像构建模块一样将各个模块拼凑在一起,创建一个更大的应用程序。
在大型应用程序中,模块化代码有几个优点:
-
简单性:一个模块通常专注于问题的一个相对较小的部分,而不是关注手头的整个问题。如果你在一个模块上工作,你将会有一个更小的问题域去思考。这使得开发更容易,更不容易出错。
-
**可维护性:**模块通常被设计成在不同的问题域之间强制执行逻辑边界。如果以最小化相互依赖性的方式编写模块,那么对单个模块的修改对程序的其他部分产生影响的可能性就会降低。(您甚至可以在不了解模块之外的应用程序的情况下对模块进行更改。)这使得一个由许多程序员组成的团队在一个大型应用程序上协作工作变得更加可行。
-
**可重用性:**在单个模块中定义的功能可以很容易地被应用程序的其他部分重用(通过适当定义的接口)。这消除了复制代码的需要。
-
**作用域:**模块通常定义一个单独的 命名空间 ,这有助于避免程序不同区域的标识符之间的冲突。(Python 的禅的信条之一是名称空间是一个非常棒的想法——让我们做更多这样的事情吧!)
函数、模块和包都是 Python 中促进代码模块化的构造。
免费 PDF 下载: Python 3 备忘单
Python 模块:概述
在 Python 中,实际上有三种不同的方式来定义模块:
- 一个模块可以用 Python 本身编写。
- 一个模块可以用 C 编写,在运行时动态加载,像
re( 正则表达式 )模块。 - 一个内置的模块本质上包含在解释器中,就像
itertools模块一样。
一个模块的内容在所有三种情况下都以相同的方式被访问:用import语句。
这里,重点将主要放在用 Python 编写的模块上。用 Python 编写的模块最酷的一点是它们非常容易构建。您所需要做的就是创建一个包含合法 Python 代码的文件,然后给这个文件起一个扩展名为.py的名字。就是这样!不需要特殊的语法或巫术。
例如,假设您创建了一个名为mod.py的文件,其中包含以下内容:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
在mod.py中定义了几个对象:
s(一个字符串)a(一个列表)foo()(一种功能)Foo(一类)
假设mod.py在一个合适的位置,稍后您将了解到更多,这些对象可以通过导入模块来访问,如下所示:
>>> import mod
>>> print(mod.s)
If Comrade Napoleon says it, it must be right.
>>> mod.a
[100, 200, 300]
>>> mod.foo(['quux', 'corge', 'grault'])
arg = ['quux', 'corge', 'grault']
>>> x = mod.Foo()
>>> x
<mod.Foo object at 0x03C181F0>
模块搜索路径
继续上面的例子,让我们看看 Python 执行语句时会发生什么:
import mod
当解释器执行上述import语句时,它在从以下来源汇编的目录的列表中搜索mod.py:
- 运行输入脚本的目录或当前目录**(如果解释器交互运行)**
- 包含在
PYTHONPATH环境变量中的目录列表,如果设置了的话。(PYTHONPATH的格式依赖于操作系统,但应该模仿PATH环境变量。) - 安装 Python 时配置的依赖于安装的目录列表
结果搜索路径可在 Python 变量sys.path中访问,该变量从名为sys的模块中获得:
>>> import sys
>>> sys.path
['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib',
'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib',
'C:\\Python36', 'C:\\Python36\\lib\\site-packages']
注意:sys.path的确切内容取决于安装。上述内容在您的计算机上看起来几乎肯定会略有不同。
因此,要确保找到您的模块,您需要执行以下操作之一:
- 将
mod.py放入输入脚本所在的目录或者当前目录,如果是交互的话 - 在启动解释器之前,修改
PYTHONPATH环境变量以包含mod.py所在的目录- **或:**将
mod.py放入已经包含在PYTHONPATH变量中的一个目录中
- **或:**将
- 将
mod.py放在一个依赖于安装的目录中,根据操作系统的不同,您可能有也可能没有写权限
实际上还有一个额外的选项:您可以将模块文件放在您选择的任何目录中,然后在运行时修改sys.path,使其包含该目录。例如,在这种情况下,您可以将mod.py放在目录C:\Users\john中,然后发出以下语句:
>>> sys.path.append(r'C:\Users\john')
>>> sys.path
['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib',
'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib',
'C:\\Python36', 'C:\\Python36\\lib\\site-packages', 'C:\\Users\\john']
>>> import mod
一旦模块被导入,您可以使用模块的__file__属性来确定它被发现的位置:
>>> import mod
>>> mod.__file__
'C:\\Users\\john\\mod.py'
>>> import re
>>> re.__file__
'C:\\Python36\\lib\\re.py'
__file__的目录部分应该是sys.path中的一个目录。
import语句
模块的内容通过import语句提供给调用者。import语句有许多不同的形式,如下所示。
import <module_name>
最简单的形式是上面已经显示的形式:
import <module_name>
注意这个并不使模块内容直接可被调用者访问。每个模块都有自己的私有符号表,作为模块中定义的所有对象的全局符号表。因此,正如已经提到的,一个模块创建了一个单独的名称空间。
语句import <module_name>只将<module_name>放在调用者的符号表中。在模块中定义的对象保留在模块的私有符号表中。
从调用者那里,模块中的对象只有在通过点符号以<module_name>为前缀时才是可访问的,如下所示。
在下面的import语句之后,mod被放入局部符号表。因此,mod在呼叫者的当地语境中有意义:
>>> import mod
>>> mod
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
但是s和foo保留在模块的私有符号表中,在本地上下文中没有意义:
>>> s
NameError: name 's' is not defined
>>> foo('quux')
NameError: name 'foo' is not defined
要在本地上下文中访问,模块中定义的对象名必须以mod为前缀:
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.foo('quux')
arg = quux
几个逗号分隔的模块可以在单个import语句中指定:
import <module_name>[, <module_name> ...]
from <module_name> import <name(s)>
另一种形式的import语句允许将模块中的单个对象直接导入调用者的符号表:
from <module_name> import <name(s)>
在执行上述语句之后,<name(s)>可以在调用者的环境中被引用,而没有前缀<module_name>:
>>> from mod import s, foo
>>> s
'If Comrade Napoleon says it, it must be right.'
>>> foo('quux')
arg = quux
>>> from mod import Foo
>>> x = Foo()
>>> x
<mod.Foo object at 0x02E3AD50>
因为这种形式的import将对象名直接放入调用者的符号表中,任何已经存在的同名对象将被覆盖:
>>> a = ['foo', 'bar', 'baz']
>>> a
['foo', 'bar', 'baz']
>>> from mod import a
>>> a
[100, 200, 300]
甚至有可能一下子不加选择地从一个模块中取出所有内容:
from <module_name> import *
这将把来自<module_name>的所有对象的名称放到本地符号表中,除了任何以下划线(_)字符开头的对象。
例如:
>>> from mod import *
>>> s
'If Comrade Napoleon says it, it must be right.'
>>> a
[100, 200, 300]
>>> foo
<function foo at 0x03B449C0>
>>> Foo
<class 'mod.Foo'>
这在大规模生产代码中不一定被推荐。这有点危险,因为你正在把名字一起输入到本地符号表中。除非你对它们都很了解,并且确信不会有冲突,否则你很有可能无意中覆盖了一个已有的名字。然而,当您只是在使用交互式解释器进行测试或发现时,这种语法非常方便,因为它可以让您快速访问模块提供的所有内容,而无需大量键入。
from <module_name> import <name> as <alt_name>
也可以import单个对象,但用备用名输入到本地符号表中:
from <module_name> import <name> as <alt_name>[, <name> as <alt_name> …]
这使得可以将名称直接放入局部符号表,但避免与先前存在的名称冲突:
>>> s = 'foo'
>>> a = ['foo', 'bar', 'baz']
>>> from mod import s as string, a as alist
>>> s
'foo'
>>> string
'If Comrade Napoleon says it, it must be right.'
>>> a
['foo', 'bar', 'baz']
>>> alist
[100, 200, 300]
import <module_name> as <alt_name>
您也可以用另一个名称导入整个模块:
import <module_name> as <alt_name>
>>> import mod as my_module
>>> my_module.a
[100, 200, 300]
>>> my_module.foo('qux')
arg = qux
模块内容可以从函数定义中导入。在这种情况下,import不会发生,直到函数被调用:
>>> def bar():
... from mod import foo
... foo('corge')
...
>>> bar()
arg = corge
然而, Python 3 不允许在函数内部使用不加选择的import *语法:
>>> def bar():
... from mod import *
...
SyntaxError: import * only allowed at module level
最后,带有except ImportError 子句的 try语句可用于防止不成功的import尝试:
>>> try:
... # Non-existent module
... import baz
... except ImportError:
... print('Module not found')
...
Module not found
>>> try:
... # Existing module, but non-existent object
... from mod import baz
... except ImportError:
... print('Object not found in module')
...
Object not found in module
dir()功能
内置函数dir()返回名称空间中已定义名称的列表。如果没有参数,它会在当前的本地符号表中产生一个按字母顺序排序的名称列表:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> qux = [1, 2, 3, 4, 5]
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux']
>>> class Bar():
... pass
...
>>> x = Bar()
>>> dir()
['Bar', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux', 'x']
注意上面对dir()的第一次调用是如何列出几个名称的,这些名称是自动定义的,并且在解释器启动时已经存在于名称空间中。随着新名称的定义(qux、Bar、x),它们会出现在后续的dir()调用中。
这对于确定 import 语句向名称空间添加了什么非常有用:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> import mod
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'mod']
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.foo([1, 2, 3])
arg = [1, 2, 3]
>>> from mod import a, Foo
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'mod']
>>> a
[100, 200, 300]
>>> x = Foo()
>>> x
<mod.Foo object at 0x002EAD50>
>>> from mod import s as string
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'mod', 'string', 'x']
>>> string
'If Comrade Napoleon says it, it must be right.'
当给定一个作为模块名称的参数时,dir()列出模块中定义的名称:
>>> import mod
>>> dir(mod)
['Foo', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__',
'__name__', '__package__', '__spec__', 'a', 'foo', 's']
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from mod import *
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'foo', 's']
将模块作为脚本执行
任何包含一个模块的.py文件本质上也是一个 Python 脚本,没有任何理由它不能像这样执行。
这里又是上面定义的mod.py:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
这可以作为脚本运行:
C:\Users\john\Documents>python mod.py
C:\Users\john\Documents>
没有错误,所以它显然是有效的。当然,这不是很有趣。正如所写的,只有定义了对象。T2 不会对它们做任何事情,也不会产生任何输出。
让我们修改上面的 Python 模块,使它在作为脚本运行时生成一些输出:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
print(s)
print(a)
foo('quux')
x = Foo()
print(x)
现在应该更有趣一点了:
C:\Users\john\Documents>python mod.py
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<__main__.Foo object at 0x02F101D0>
不幸的是,现在它在作为模块导入时也会生成输出:
>>> import mod
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<mod.Foo object at 0x0169AD50>
这可能不是你想要的。模块在导入时通常不会生成输出。
如果您能够区分文件何时作为模块加载,何时作为独立脚本运行,这不是很好吗?
有求必应。
当一个.py文件作为模块导入时,Python 将特殊的 dunder 变量 __name__ 设置为模块的名称。然而,如果一个文件作为独立脚本运行,__name__被(创造性地)设置为字符串'__main__'。利用这一事实,您可以在运行时辨别出哪种情况,并相应地改变行为:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
if (__name__ == '__main__'):
print('Executing as standalone script')
print(s)
print(a)
foo('quux')
x = Foo()
print(x)
现在,如果您作为脚本运行,您会得到输出:
C:\Users\john\Documents>python mod.py
Executing as standalone script
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<__main__.Foo object at 0x03450690>
但是如果您作为模块导入,您不会:
>>> import mod
>>> mod.foo('grault')
arg = grault
模块通常被设计为能够作为独立脚本运行,以测试模块中包含的功能。这被称为 单元测试。例如,假设您创建了一个包含阶乘函数的模块fact.py,如下所示:
fact.py
def fact(n):
return 1 if n == 1 else n * fact(n-1)
if (__name__ == '__main__'):
import sys
if len(sys.argv) > 1:
print(fact(int(sys.argv[1])))
该文件可以作为一个模块,导入的fact()函数:
>>> from fact import fact
>>> fact(6)
720
但是也可以通过在命令行上传递一个整数参数来独立运行,以便进行测试:
C:\Users\john\Documents>python fact.py 6
720
重新加载模块
出于效率的原因,一个模块在每个解释器会话中只加载一次。这对于函数和类定义来说很好,它们通常构成了模块的大部分内容。但是模块也可以包含可执行语句,通常用于初始化。请注意,这些语句只会在第一次导入模块时执行。
考虑下面的文件mod.py:
mod . pyT3】
a = [100, 200, 300]
print('a =', a)
>>> import mod
a = [100, 200, 300]
>>> import mod
>>> import mod
>>> mod.a
[100, 200, 300]
在后续导入中不执行print()语句。(就此而言,赋值语句也不是,但正如最后显示的mod.a值所示,这无关紧要。一旦任务完成,它就生效了。)
如果您对一个模块进行了更改,并且需要重新加载它,您需要重新启动解释器或者使用模块importlib中的一个名为reload()的函数:
>>> import mod
a = [100, 200, 300]
>>> import mod
>>> import importlib
>>> importlib.reload(mod)
a = [100, 200, 300]
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
Python 包
假设您开发了一个包含许多模块的非常大的应用程序。随着模块数量的增长,如果将它们放在一个位置,就很难跟踪所有的模块。如果它们具有相似的名称或功能,尤其如此。您可能希望有一种方法来对它们进行分组和组织。
包允许使用点符号对模块名称空间进行层次化构造。同样,模块有助于避免全局变量名之间的冲突,包有助于避免模块名之间的冲突。
创建一个包非常简单,因为它利用了操作系统固有的层次文件结构。考虑以下安排:

这里有一个名为pkg的目录,包含两个模块mod1.py和mod2.py。这些模块的内容包括:
mod1.py
def foo():
print('[mod1] foo()')
class Foo:
pass
mod2.py
def bar():
print('[mod2] bar()')
class Bar:
pass
给定这种结构,如果pkg目录位于可以找到它的位置(在sys.path中包含的一个目录中),您可以引用带有点符号 ( pkg.mod1,pkg.mod2)的两个模块,并用您已经熟悉的语法导入它们:
import <module_name>[, <module_name> ...]
>>> import pkg.mod1, pkg.mod2
>>> pkg.mod1.foo()
[mod1] foo()
>>> x = pkg.mod2.Bar()
>>> x
<pkg.mod2.Bar object at 0x033F7290>
from <module_name> import <name(s)>
>>> from pkg.mod1 import foo
>>> foo()
[mod1] foo()
from <module_name> import <name> as <alt_name>
>>> from pkg.mod2 import Bar as Qux
>>> x = Qux()
>>> x
<pkg.mod2.Bar object at 0x036DFFD0>
您也可以使用这些语句导入模块:
from <package_name> import <modules_name>[, <module_name> ...]
from <package_name> import <module_name> as <alt_name>
>>> from pkg import mod1
>>> mod1.foo()
[mod1] foo()
>>> from pkg import mod2 as quux
>>> quux.bar()
[mod2] bar()
从技术上讲,您也可以导入包:
>>> import pkg
>>> pkg
<module 'pkg' (namespace)>
但这无济于事。虽然严格来说,这是一个语法正确的 Python 语句,但它并没有做多少有用的事情。特别是,它不会将pkg中的任何模块放入本地名称空间:
>>> pkg.mod1
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
pkg.mod1
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod1.foo()
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
pkg.mod1.foo()
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod2.Bar()
Traceback (most recent call last):
File "<pyshell#36>", line 1, in <module>
pkg.mod2.Bar()
AttributeError: module 'pkg' has no attribute 'mod2'
要实际导入模块或它们的内容,您需要使用上面显示的表单之一。
包初始化
如果包目录中有一个名为__init__.py的文件,当导入包或包中的一个模块时,它会被调用。这可用于执行包初始化代码,例如包级数据的初始化。
例如,考虑下面的__init__.py文件:
init。pyT3】
print(f'Invoking __init__.py for {__name__}')
A = ['quux', 'corge', 'grault']
让我们将这个文件添加到上面示例中的pkg目录中:
[外链图片转存中…(img-90jddP3n-1731342376588)]
现在,当包被导入时,全局列表A被初始化:
>>> import pkg
Invoking __init__.py for pkg
>>> pkg.A
['quux', 'corge', 'grault']
包中的模块可以通过依次导入来访问全局变量:
mod1.py
def foo():
from pkg import A
print('[mod1] foo() / A = ', A)
class Foo:
pass
>>> from pkg import mod1
Invoking __init__.py for pkg
>>> mod1.foo()
[mod1] foo() / A = ['quux', 'corge', 'grault']
__init__.py也可用于实现从包中自动导入模块。例如,前面您看到语句import pkg只将名字pkg放在调用者的本地符号表中,没有导入任何模块。但是如果pkg目录中的__init__.py包含以下内容:
init。pyT3】
print(f'Invoking __init__.py for {__name__}')
import pkg.mod1, pkg.mod2
然后当您执行import pkg时,模块mod1和mod2被自动导入:
>>> import pkg
Invoking __init__.py for pkg
>>> pkg.mod1.foo()
[mod1] foo()
>>> pkg.mod2.bar()
[mod2] bar()
注意:很多 Python 文档都指出,当创建一个包时,__init__.py文件必须存在于包目录中。这曾经是真的。过去,__init__.py的出现对 Python 来说意味着一个包正在被定义。该文件可以包含初始化代码,甚至可以是空的,但是它必须有存在。
从 Python 3.3 开始,隐式名称空间包被引入。这些允许创建一个没有任何__init__.py文件的包。当然,如果需要包初始化,它可以仍然存在。但是不再需要了。
从包中导入*
出于以下讨论的目的,前面定义的包被扩展为包含一些附加模块:
现在在pkg目录中定义了四个模块。它们的内容如下所示:
mod1.py
def foo():
print('[mod1] foo()')
class Foo:
pass
mod2.py
def bar():
print('[mod2] bar()')
class Bar:
pass
mod3.py
def baz():
print('[mod3] baz()')
class Baz:
pass
mod4.py
def qux():
print('[mod4] qux()')
class Qux:
pass
(很有想象力,不是吗?)
您已经看到,当import *用于模块,时,模块中的所有对象都被导入到本地符号表中,除了那些名称以下划线开头的对象,一如既往:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg.mod3 import *
>>> dir()
['Baz', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'baz']
>>> baz()
[mod3] baz()
>>> Baz
<class 'pkg.mod3.Baz'>
一个包的类似陈述如下:
from <package_name> import *
那有什么用?
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
嗯。不多。您可能期望(假设您有任何期望)Python 会深入到包目录中,找到它能找到的所有模块,并导入它们。但是正如你所看到的,默认情况下并不是这样。
相反,Python 遵循这样的约定:如果包目录中的__init__.py文件包含一个名为__all__的列表,那么当遇到语句from <package_name> import *时,它被认为是应该导入的模块列表。
对于本例,假设您在pkg目录中创建了一个__init__.py,如下所示:
pkg/init。pyT3】
__all__ = [
'mod1',
'mod2',
'mod3',
'mod4'
]
现在from pkg import *导入所有四个模块:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'mod1', 'mod2', 'mod3', 'mod4']
>>> mod2.bar()
[mod2] bar()
>>> mod4.Qux
<class 'pkg.mod4.Qux'>
使用import *仍然不被认为是很好的形式,对于包比对于模块更是如此。但是这个工具至少给了包的创建者一些控制,当指定了import *时会发生什么。(事实上,它提供了完全不允许它的能力,简单地拒绝定义__all__。正如您所看到的,包的默认行为是不导入任何东西。)
顺便说一下,__all__也可以在模块中定义,其目的相同:控制用import *导入的内容。例如,将mod1.py修改如下:
pkg/mod1.py
__all__ = ['foo']
def foo():
print('[mod1] foo()')
class Foo:
pass
现在来自pkg.mod1的import *语句将只导入包含在__all__中的内容:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg.mod1 import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'foo']
>>> foo()
[mod1] foo()
>>> Foo
Traceback (most recent call last):
File "<pyshell#37>", line 1, in <module>
Foo
NameError: name 'Foo' is not defined
foo()(函数)现在在本地名称空间中定义,但是Foo(类)没有,因为后者不在__all__中。
总之,__all__被包和模块用来控制当import *被指定时导入什么。但是默认行为不同:
- 对于一个包,当没有定义
__all__时,import *不导入任何东西。 - 对于一个模块,当没有定义
__all__时,import *会导入所有内容(除了——你猜对了——以下划线开头的名字)。
子包
包可以包含任意深度的嵌套子包。例如,让我们对示例包目录进行如下修改:
四个模块(mod1.py、mod2.py、mod3.py和mod4.py)的定义如前。但是现在,它们没有被集中到pkg目录中,而是被分成两个子包目录,sub_pkg1和sub_pkg2。
导入仍然与前面所示的一样。语法是相似的,但是额外的点符号被用来分隔包名和子包名:
>>> import pkg.sub_pkg1.mod1
>>> pkg.sub_pkg1.mod1.foo()
[mod1] foo()
>>> from pkg.sub_pkg1 import mod2
>>> mod2.bar()
[mod2] bar()
>>> from pkg.sub_pkg2.mod3 import baz
>>> baz()
[mod3] baz()
>>> from pkg.sub_pkg2.mod4 import qux as grault
>>> grault()
[mod4] qux()
此外,一个子包中的模块可以引用一个兄弟子包中的对象(如果兄弟子包包含您需要的一些功能)。例如,假设您想从模块mod3中导入并执行函数foo()(在模块mod1中定义)。您可以使用绝对导入:
pkg/sub _ _ pkg 2/mod 3 . pyT3】
def baz():
print('[mod3] baz()')
class Baz:
pass
from pkg.sub_pkg1.mod1 import foo
foo()
>>> from pkg.sub_pkg2 import mod3
[mod1] foo()
>>> mod3.foo()
[mod1] foo()
或者你可以使用一个相对导入,这里..指的是上一级的包。从mod3.py内部,也就是在sub_pkg2子包中,
..评估为父包(pkg),并且..sub_pkg1评估为父包的子包sub_pkg1。
pkg/sub _ _ pkg 2/mod 3 . pyT3】
def baz():
print('[mod3] baz()')
class Baz:
pass
from .. import sub_pkg1
print(sub_pkg1)
from ..sub_pkg1.mod1 import foo
foo()
>>> from pkg.sub_pkg2 import mod3
<module 'pkg.sub_pkg1' (namespace)>
[mod1] foo()
结论
在本教程中,您学习了以下主题:
- 如何创建一个 Python 模块
- Python 解释器搜索模块的位置
- 如何使用
import语句访问模块中定义的对象 - 如何创建可作为独立脚本执行的模块
- 如何将模块组织成包和子包
- 如何控制包的初始化
免费 PDF 下载: Python 3 备忘单
这有望让您更好地理解如何获得 Python 中许多第三方和内置模块的可用功能。
此外,如果你正在开发自己的应用程序,创建自己的模块和包将帮助你组织和模块化你的代码,这使得编码、维护和调试更容易。
如果您想了解更多信息,请在Python.org查阅以下文档:
快乐的蟒蛇!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模块和包:简介*****

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










![[外链图片转存中…(img-sncePYj2-1731342376586)]](https://files.realpython.com/media/minimax_nim_tree_plain.73395737874a.png){kind=link}
![[外链图片转存中…(img-90jddP3n-1731342376588)]](https://files.realpython.com/media/pkg2.dab97c2f9c58.png){kind=link}