









文章目录
介绍:使用Featuretools进行自动特征工程
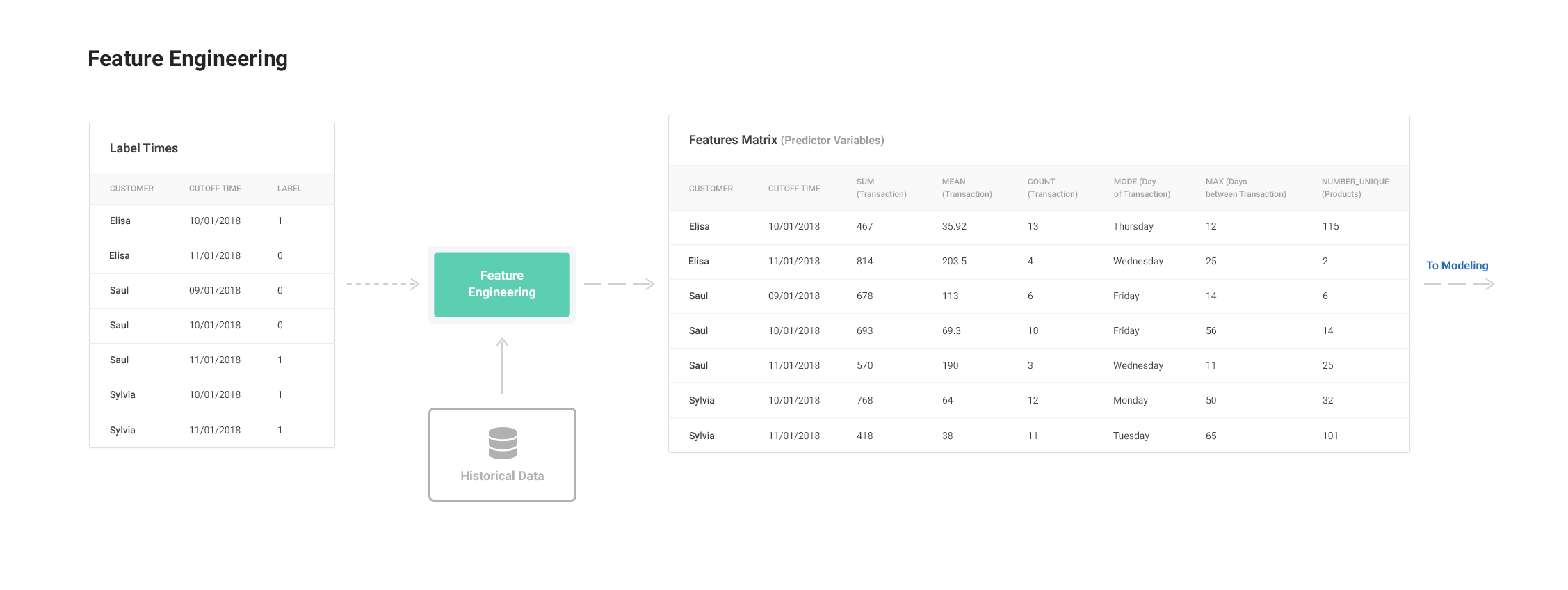
问题: 我们有一组截止时间和标签 - 在标签时间表中 - 我们需要为每个标签构建相关特征,仅使用截止时间之前的数据。传统上,我们会手动完成这个过程,这是一个费时且容易出错的过程,使得开发可用的机器学习解决方案非常困难。
解决方案: 使用Featuretools实现的自动特征工程,从可重用的框架中构建数百或数千个相关特征,从关系数据集中自动过滤数据基于截止时间。这种方法克服了手动特征工程的局限性,让我们在短时间内构建更好的预测模型。
特征工程的一般过程如下所示:
目前,使用多个相关表进行自动特征工程的唯一选择是Featuretools,这是一个开源的Python库。

在这个笔记本中,我们将使用Featuretools为客户流失数据集开发自动特征工程工作流程。最终的结果是一个函数,它接受客户数据集和标签时间,并构建一个特征矩阵,可用于训练机器学习模型。因为我们已经将数据分成了独立的子集(在“分区数据”中),所以我们将能够使用Spark和PySpark并行地将此函数应用于所有分区。
Featuretools资源
我们不会花太多时间在Featuretools的基础知识上,因此请参考以下资源获取更多信息:
基础知识相对容易掌握,如果您是新手,您可能可以跟随这里的所有代码!学习Featuretools只需要几分钟,它可以应用于任何关系数据集。
有了这个想法,让我们开始吧。
# 导入pandas和numpy库
import pandas as pd
import numpy as np
# 导入featuretools库
import featuretools as ft
# 导入os和warnings库,并忽略警告信息
import os
import warnings
warnings.simplefilter("ignore")
# 用于显示多个输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
/Users/nate.parsons/dev/open_source_demos/env/lib/python3.8/site-packages/statsmodels/compat/pandas.py:65: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
from pandas import Int64Index as NumericIndex
通常对于这样的项目,所有的数据都会存储在S3上。这样可以在任何计算机上直接读写,而不必担心如果计算机(在这种情况下是EC2实例)关闭会丢失数据。
对于这个示例,我们在Prediction Engineering笔记本中生成了分区并将其存储在本地。要改用S3,您可以在正确配置了AWS访问权限后,将文件路径替换为等效的S3路径。具体的操作步骤超出了本笔记本的范围。
另外,请注意在之前的笔记本中,我们生成了1000个数据分区,但为了节省时间和磁盘空间,我们只为这些分区中的前50个创建了标签。未来我们将使用这50个分区进行工作,但在真正的分布式环境中,您可以使用所有1000个分区。
# 定义分区数量
N_PARTITIONS = 50
# 获取当前工作目录
CWD = os.getcwd()
# 定义分区编号
PARTITION = '25'
# 定义基础目录
BASE_DIR = f'{CWD}/data/partitions/'
# 定义分区目录
PARTITION_DIR = BASE_DIR + 'p' + PARTITION
# 读取所有数据
members = pd.read_csv(f'{PARTITION_DIR}/members.csv',
parse_dates=['registration_init_time'],
infer_datetime_format = True,
dtype = {'gender': 'category'})
trans = pd.read_csv(f'{PARTITION_DIR}/transactions.csv',
parse_dates=['transaction_date', 'membership_expire_date'],
infer_datetime_format = True)
logs = pd.read_csv(f'{PARTITION_DIR}/logs.csv', parse_dates = ['date'])
cutoff_times = pd.read_csv(f'{PARTITION_DIR}/MS-31_labels.csv', parse_dates = ['time'])
数据表结构
以下是3个数据表的模式。
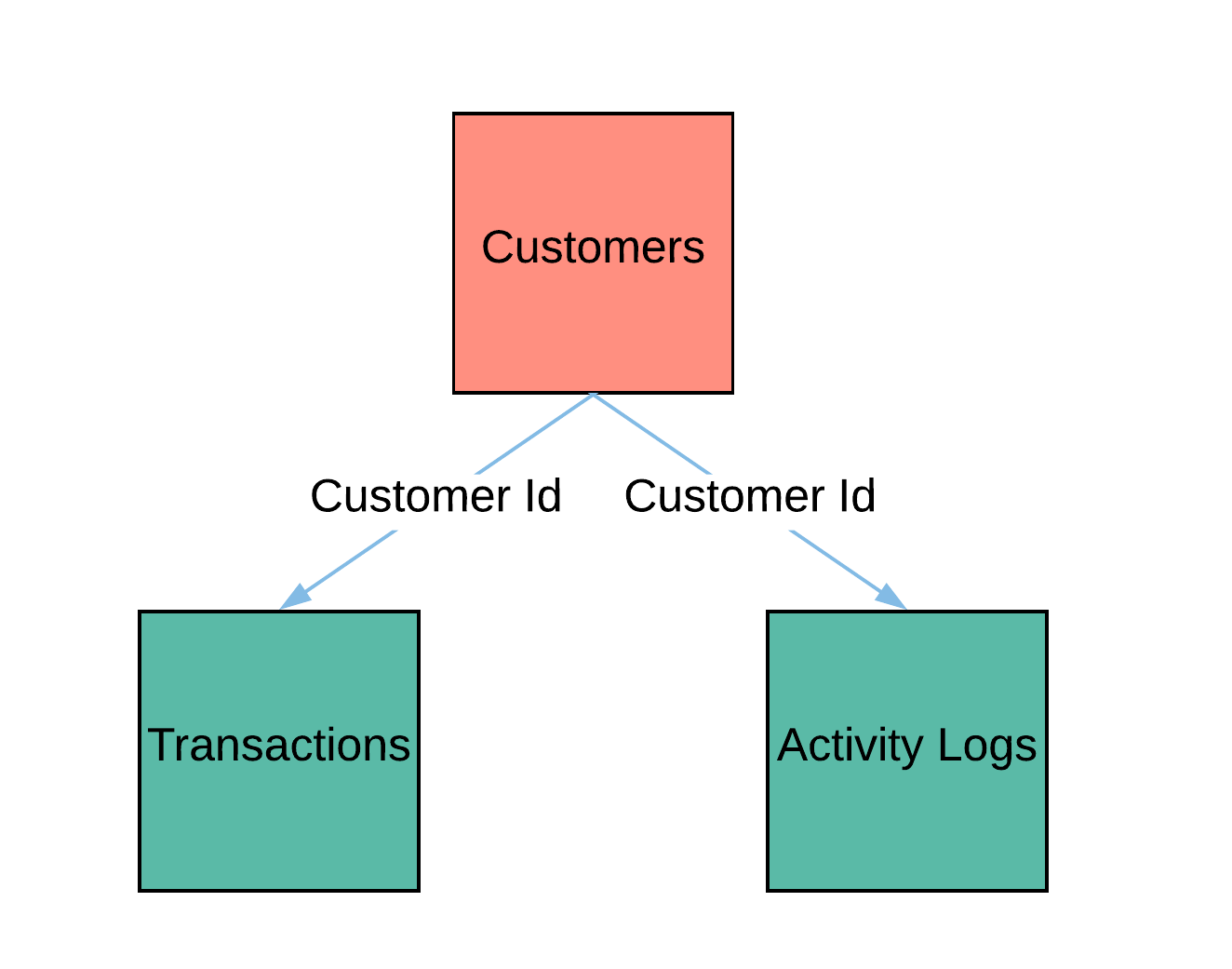
这个模式是在Featuretools中执行自动化特征工程所需的所有领域知识。
定义实体集
使用Featuretools的第一步是创建一个EntitySet并将所有数据框添加到其中。EntitySet是一个数据结构,它保存表格及其之间的关系。这使得在具有多个关系表的问题中更容易跟踪所有数据。
# 创建一个空的实体集合
es = ft.EntitySet(id = 'customers')
添加数据帧
在添加数据帧时,我们需要确保包括:
- 如果有索引,则包括
index或创建索引的名称。这是每个观察结果的唯一标识符。 - 如果没有索引,则需要在
index下提供名称并将其设置为True,以便使用make_index = True。 - 如果存在
time_index,则需要提供该时间,该时间表示行中的信息变为已知的时间。Featuretools 将使用time_index和cutoff_time为每个标签生成有效的特征。 logical_types。在某些情况下,我们的数据将具有应指定类型的列。例如,表示为浮点数的布尔值。这可以防止 Featuretools 生成 True/False 列的min或max等特征。
对于此问题,这些是我们需要的唯一参数。还有其他参数可用,如文档中所示。
成员表
members 表包含有关每个客户的基本信息。对于此表的重要点是指定 city 和 registered_via 列是离散的、分类的列,而不是数值列,并且 registration_init_time 是 time_index。msno 是唯一标识每个客户的索引。
# 查看DataFrame的前几行数据,默认为前5行
members.head()

# 检查'members'数据框中的'msno'列是否唯一
members['msno'].is_unique
# 创建一个实体集并将成员添加到实体集中
es.add_dataframe(dataframe_name='members', dataframe=members,
index='msno', time_index='registration_init_time',
logical_types={'city': 'Categorical',
'registered_via': 'Categorical'})
交易表
交易表包含客户所做的付款。每一行记录一笔付款。
# 显示数据集的前几行
trans.head()

# 导入matplotlib.pyplot库,并将其命名为plt
import matplotlib.pyplot as plt
# 在Jupyter Notebook中显示图形
%matplotlib inline
# 使用fivethirtyeight样式
plt.style.use('fivethirtyeight')
# 设置图形的大小为10x6
plt.rcParams['figure.figsize'] = (10, 6)
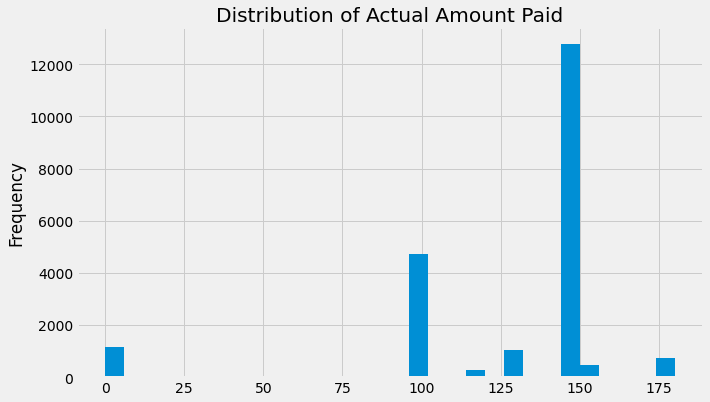
# 从trans数据框中选择actual_amount_paid列中小于250的值,并绘制直方图,将缺失值删除
trans.loc[trans['actual_amount_paid'] < 250, 'actual_amount_paid'].dropna().plot.hist(bins = 30);
# 设置图形的标题为'Distribution of Actual Amount Paid'
plt.title('Distribution of Actual Amount Paid');
领域知识特征
在添加这个数据框之前,我们可以基于领域知识创建一些新的列。仅仅因为我们将自动创建数百个特征并不意味着我们不能使用自己的专业知识。Featuretools将在我们定义的任何列上叠加更多的原语,以便在我们的知识基础上构建更多的特征。
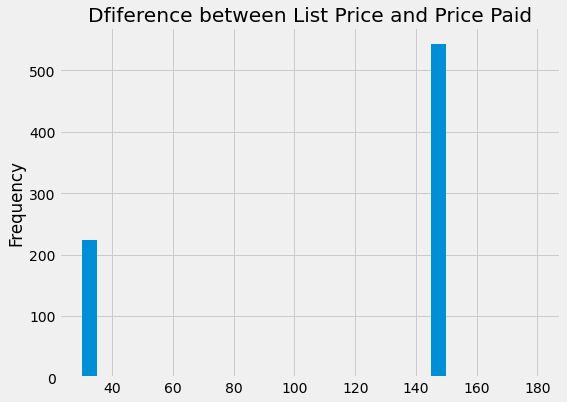
# 计算价格差异
trans['price_difference'] = trans['plan_list_price'] - trans['actual_amount_paid']
# 计划每天价格
trans['planned_daily_price'] = trans['plan_list_price'] / trans['payment_plan_days']
# 实际每天价格
trans['daily_price'] = trans['actual_amount_paid'] / trans['payment_plan_days']
# 绘制价格差异的直方图
trans.loc[trans['price_difference'] > 0, 'price_difference'].plot.hist(bins = 30,
figsize = (8, 6));
plt.title('Dfiference between List Price and Price Paid');
在这个数据框中没有index,所以我们需要指定一个索引并传入一个名称。有一个time_index,即交易时间,在基于截止时间筛选数据以生成特征时非常重要。同样,我们还需要指定几个列类型。
在交易中存在一个小异常,即一些会员到期日期在交易日期之后,所以我们将过滤掉这些数据。
# 筛选异常数据
# 将trans数据框中membership_expire_date列大于transaction_date列的行筛选出来
trans = trans[trans['membership_expire_date'] > trans['transaction_date']]
# 添加交易数据框
es.add_dataframe(dataframe_name='transactions', dataframe=trans,
index='transactions_index', make_index=True, # 设置索引名称和是否创建索引
time_index='transaction_date', # 设置时间索引
logical_types={'payment_method_id': 'Categorical', # 设置逻辑类型
'is_auto_renew': 'Boolean', 'is_cancel': 'Boolean'}) # 设置逻辑类型
日志
logs 包含用户的听歌行为。和之前一样,我们会在添加到 EntitySet 之前创建一些领域知识列。
# 打印日志文件的前五行
logs.head()

# 创建一些手动特征
# 计算总数
logs['total'] = logs[['num_25', 'num_50', 'num_75', 'num_985', 'num_100']].sum(axis=1)
# 计算100%的比例
logs['percent_100'] = logs['num_100'] / logs['total']
# 计算唯一歌曲的比例
logs['percent_unique'] = logs['num_unq'] / logs['total']
# 计算每首歌曲的平均播放时间
logs['seconds_per_song'] = logs['total_secs'] / logs['total']
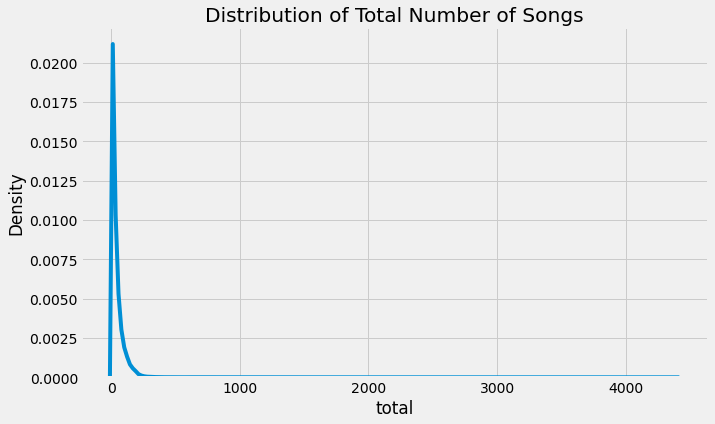
# 使用seaborn绘制总歌曲数量的分布图
sns.kdeplot(logs['total'])
plt.title('总歌曲数量的分布图')
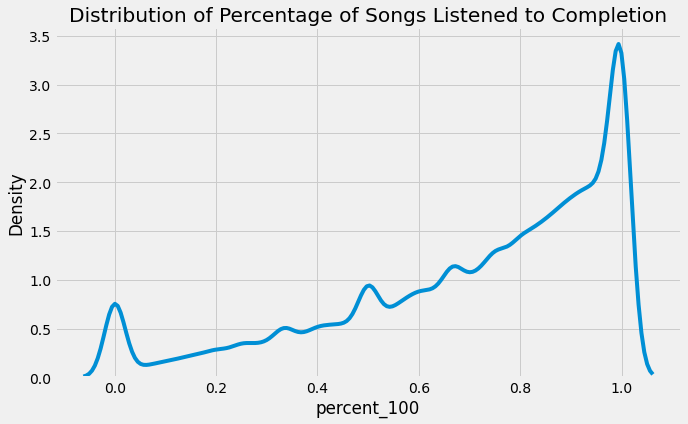
# 使用sns库的kdeplot函数绘制logs数据集中'percent_100'列的核密度估计图
sns.kdeplot(logs['percent_100'])
# 设置图表标题为"歌曲完整播放百分比的分布"
plt.title('歌曲完整播放百分比的分布')
在日志中有time_index,尽管没有index存在。
# 添加数据框到 Elasticsearch 中
es.add_dataframe(dataframe_name='logs', dataframe=logs,
index='logs_index', make_index=True,
time_index='date')
# 参数说明:
# - dataframe_name: 数据框的名称,用于在 Elasticsearch 中标识数据框
# - dataframe: 要添加的数据框
# - index: 数据框在 Elasticsearch 中的索引名称
# - make_index: 是否在 Elasticsearch 中创建索引,如果为 True,则会创建索引,如果为 False,则不会创建索引
# - time_index: 数据框中用作时间索引的列的名称,用于按时间排序数据
制作手工特征可能看起来与使用自动特征工程相矛盾,但在使用Featuretools之前这样做的好处是可以在其基础上构建深层特征。自动特征工程将利用我们已有的手工特征,并通过与其他特征的组合来提取更多的价值。
另一种提高深层特征合成能力的方法是通过有趣的值,这些值指定用于构建特征的条件语句。
有趣的值
为了创建条件特征,我们可以为数据中的现有列设置有趣的值。以下代码将用于根据交易数据中的is_cancel和is_auto_renew的值构建条件特征。在调用Deep Feature Synthesis时,用于条件特征的原语在where_primitives中指定。例如,如果我们使用mean原语以及以下有趣的值,我们将得到交易被取消时的平均值,以及交易未被取消时的平均值。
es.add_interesting_values(dataframe_name='transactions',
values={'is_cancel': [False, True],
'is_auto_renew': [False, True]})
关系
表关系对于任何使用关系数据库的人来说应该是很熟悉的,在Featuretools中的概念也是一样的。我们使用关系来指定一个表中的示例与其他表中的示例之间的关系。对于这个问题,实体集的结构相当简单,只有三个数据框和两个关系。members是logs和transactions的父表。在这两个关系中,父列和子列都是msno,即客户ID。
这两个关系是:一个将members与transactions关联起来,另一个将members与logs关联起来。在featuretools中,关系的顺序是实体集、父数据框名称、父列、子数据框名称、子列。
# 定义关系r_member_transactions,表示members和transactions之间的关系
r_member_transactions = ft.Relationship(es, 'members', 'msno', 'transactions', 'msno')
# 定义关系r_member_logs,表示members和logs之间的关系
r_member_logs = ft.Relationship(es, 'members', 'msno', 'logs', 'msno')
# 将关系添加到实体集中
es.add_relationships([r_member_transactions, r_member_logs])
截止时间
cutoff_times 是任何基于时间的机器学习问题中的关键部分。标签时间数据框包含了成员ID、截止时间和标签的列。对于每个截止时间,只能使用截止时间之前的数据来构建该标签的特征。 这是Featuretools相对于手动特征工程的最大优势之一:Featuretools会根据截止时间自动过滤我们的数据,以确保所有特征对于机器学习都是有效的。 通常情况下,我们需要非常小心地确保所有特征都是有效的,但是Featuretools能够在幕后为我们实现过滤逻辑。
我们只需要确保传入正确的标签时间来解决我们想要解决的预测问题。
# 去除重复行,根据'msno'和'time'两列进行去重
cutoff_times = cutoff_times.drop_duplicates(subset=['msno', 'time'])
# 显示前5行数据
cutoff_times.head()

深度特征合成
在实体集完全定义好之后,我们准备运行深度特征合成(DFS)。这个过程将称为特征原语的特征工程构建块应用于数据集,以构建数百个特征。特征原语是两种类型的基本操作——转换和聚合——它们堆叠起来构建深度特征(有关更多信息,请参见前面链接的资源)。这包括许多我们传统上手动执行的操作,但自动特征工程使我们不必一次实现这些特征。
调用ft.dfs需要包含所有表格和它们之间关系的实体集,target_dataframe_name以确定要为其构建特征的表格,特定的原语,原语的最大堆叠(max_depth),cutoff_times以及一些可选参数。
首先,我们将使用默认的聚合和转换原语以及两个where_primitives,看看这将生成多少特征。为了仅生成特征的定义,我们传入features_only = True。
有关深度特征合成的完整详细信息,请查看文档。
# 使用特征工程库的dfs函数进行特征生成
# entityset参数指定实体集,target_dataframe_name参数指定目标数据帧名称
# cutoff_time参数指定截止时间
# where_primitives参数指定要使用的聚合函数
# max_depth参数指定特征生成的最大深度
# features_only参数设置为True,表示只返回特征定义
feature_defs = ft.dfs(entityset=es, target_dataframe_name='members',
cutoff_time = cutoff_times,
where_primitives = ['sum', 'mean'],
max_depth=2, features_only=True)
# 打印语句,输出将会生成feature_defs列表的长度个数的特征
print(f'This will generate {len(feature_defs)} features.')
This will generate 186 features.
# 导入random模块,用于生成随机数
import random
# 设置随机数种子为42,保证每次运行结果一致
random.seed(42)
# 从feature_defs中随机抽取10个元素作为样本
random.sample(feature_defs, 10)
我们可以看到,Featuretools使用表关系和特征原语自动为我们构建了近200个特征。如果手动构建,每个特征都需要几分钟的工作时间,总共需要花费数小时来构建186个特征。此外,尽管这些特征不一定直观,但它们很容易用自然语言解释,因为它们是简单的操作叠加在一起。
指定基元
现在我们将调用 ft.dfs 并指定要使用的基元。通常,这些基元将取决于问题并可能涉及领域知识。选择基元的最佳方法是尝试各种基元并查看哪些表现最佳。像许多机器学习操作一样,选择基元仍然主要是经验性的,而不是理论性的实践。
聚合原语
# 获取所有特征原语
all_p = ft.list_primitives()
# 筛选出类型为“transform”的特征原语
trans_p = all_p.loc[all_p['type'] == 'transform'].copy()
# 筛选出类型为“aggregation”的特征原语
agg_p = all_p.loc[all_p['type'] == 'aggregation'].copy()
# 设置 Pandas 显示列宽的最大值
pd.options.display.max_colwidth = 100
# 显示前五个聚合特征原语
agg_p.head()

# 指定聚合原语
agg_primitives = ['sum', 'time_since_last', 'avg_time_between', 'num_unique', 'min', 'last',
'percent_true', 'max', 'count']
转换原语
# 查看数据的后几行
trans_p.tail()

# 指定转换原语
trans_primitives = ['is_weekend', 'cum_sum', 'day', 'month', 'time_since_previous']
Where原语
这些原语应用于interesting_values以构建条件特征。
# 指定基本操作的位置
where_primitives = ['sum', 'mean', 'percent_true']
自定义原语
自定义原语是Featuretools中最强大的选项之一。我们使用自定义原语基于领域知识编写自己的函数,然后像其他原语一样将它们传递给dfs。Featuretools将把我们的自定义原语与其他原语堆叠在一起,从而有效地增强我们的领域知识。
对于这个问题,我编写了一个自定义原语,用于计算截止时间之前一个月内某个值的总和。实际上,这是我为另一个问题编写的原语,但我可以将其应用于这个问题,因为原语是数据不可知的。这是特征原语的一个好处之一:它们可以适用于任何问题,并且编写自定义原语将会多次得到回报。
# 导入make_agg_primitive函数
from featuretools.primitives import make_agg_primitive
# 定义一个函数,计算在给定时间之前一个月内numeric列的总和
def total_previous_month(numeric, datetime, time):
# 创建一个包含numeric和datetime列的DataFrame
df = pd.DataFrame({'value': numeric, 'date': datetime})
# 获取给定时间的前一个月份和年份
previous_month = time.month - 1
year = time.year
# 处理一月份的情况
if previous_month == 0:
previous_month = 12
year = time.year - 1
# 过滤数据并计算总和
df = df[(df['date'].dt.month == previous_month) & (df['date'].dt.year == year)]
total = df['value'].sum()
return total
# 导入datetime模块
from datetime import datetime
# 导入pandas模块
import pandas as pd
# 定义一个数字列表
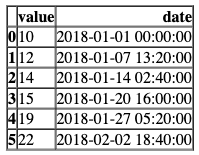
numeric = [10, 12, 14, 15, 19, 22, 9, 8, 8, 11]
# 生成日期范围,从'2018-01-01'到'2018-03-01',个数与数字列表的长度相同
dates = pd.date_range('2018-01-01', '2018-03-01', periods=len(numeric))
# 创建一个DataFrame,包含'value'列和'date'列,前6行
df = pd.DataFrame({'value': numeric, 'date': dates}).head(6)
# 调用total_previous_month函数,传入数字列表、日期列表和指定日期(2018年2月1日)
total_previous_month(numeric, dates, datetime(2018, 2, 1))
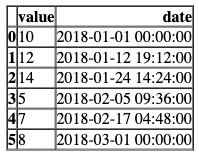
# 定义一个数字列表
numeric = [10, 12, 14, 5, 7, 8]
# 生成日期范围,长度为数字列表的长度
dates = pd.date_range('2018-01-01', '2018-03-01', periods=len(numeric))
# 创建一个数据框,包含数字和日期两列,并显示前6行
pd.DataFrame({'value': numeric, 'date': dates}).head(6)
# 调用total_previous_month函数,传入数字列表、日期列表和日期时间对象
total_previous_month(numeric, dates, datetime(2018, 3, 1))
自定义原始实现
制作自定义原始实现很简单:首先我们定义一个函数(total_previous_month),然后使用input_type[s]、return_type以及uses_calc_time来创建make_agg_primitive。
这个原始实现是一个聚合原始实现,因为它接收多个数字(上个月的交易)并返回一个数字(交易总额)。
# 导入Woodwork ColumnSchema对象,用于定义输入和返回类型
from woodwork.column_schema import ColumnSchema
from woodwork.logical_types import Datetime
# 定义一个聚合原语,接收一个数字和一个日期时间类型的输入,返回一个数字类型的输出
total_previous = make_agg_primitive(total_previous_month,
input_types=[ColumnSchema(semantic_tags={'numeric'}), ColumnSchema(logical_type=Datetime)],
return_type=ColumnSchema(semantic_tags='numeric'),
uses_calc_time=True)
现在只需要将其作为另一个聚合原语传递给Featuretools,以便在计算中使用它。
第二个自定义原语用于查找自上一个真值以来的时间。这最初是针对transactions数据帧中的is_cancel列设计的,但它也适用于任何布尔列。它只是找到True示例之间的时间。
def time_since_true(boolean, datetime):
"""计算上一个真值之后的时间"""
if np.any(np.array(list(boolean)) == 1):
# 创建按日期从旧到新排序的数据框
df = pd.DataFrame({'value': boolean, 'date': datetime}).\
sort_values('date', ascending = False).reset_index()
older_date = None
# 逆序遍历每个日期
for date in df.loc[df['value'] == 1, 'date']:
# 如果没有更早的真值
if older_date == None:
# 子集为真值及之后的时间
times_after_idx = df.loc[df['date'] >= date].index
else:
# 子集为真值及之后但在前一个真值之前的时间
times_after_idx = df.loc[(df['date'] >= date) & (df['date'] < older_date)].index
older_date = date
# 计算上一个真值之后的时间
df.loc[times_after_idx, 'time_since_previous'] = (df.loc[times_after_idx, 'date'] - date).dt.total_seconds()
return list(df['time_since_previous'])[::-1]
# 处理没有真值的情况
else:
return [np.nan for _ in range(len(boolean))]
# 创建一个空的布尔列表
booleans = []
# 创建一个空的日期列表
dates = []
# 使用pandas库创建一个DataFrame,其中包含两列:'value'和'date',分别对应布尔列表和日期列表
df = pd.DataFrame({'value': booleans, 'date': dates})
# 调用time_since_true函数,传入DataFrame的'value'列和'date'列作为参数,并返回结果
time_since_true(df['value'], df['date'])
# 创建一个布尔值列表
booleans = [1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0]
# 根据布尔值列表创建日期范围
dates = pd.date_range('2018-01-01', '2018-03-01', periods=len(booleans))
# 创建一个包含布尔值和日期的数据框
df = pd.DataFrame({'value': booleans, 'date': dates})
# 调用函数time_since_true,传入布尔值列和日期列作为参数
time_since_true(df['value'], df['date'])
# 定义一个布尔型列表
booleans = [1, 0, 0]
# 生成一个日期范围,长度与booleans列表相同
dates = pd.date_range('2018-01-01', '2018-03-01', periods=len(booleans))
# 调用time_since_true函数,传入booleans和dates参数,并打印结果
print(time_since_true(booleans, dates))
# 定义一个列表booleans,包含两个元素0和0
booleans = [0, 0]
# 使用pd.date_range函数生成一个日期范围,起始日期为'2018-01-01',结束日期为'2018-03-01',长度与booleans列表的长度相同
dates = pd.date_range('2018-01-01', '2018-03-01', periods=len(booleans))
# 调用time_since_true函数,传入booleans列表和dates日期范围作为参数,并返回结果
time_since_true(booleans, dates)
这是一个转换原语,因为它作用于同一表中的多个列。返回的列表与原始列具有相同的长度。
# 导入所需的库
from featuretools.primitives import make_trans_primitive
from woodwork.logical_types import Boolean
# 指定输入和返回类型
time_since = make_trans_primitive(time_since_true,
input_types = [ColumnSchema(logical_type=Boolean), ColumnSchema(logical_type=Datetime)],
return_type = ColumnSchema(semantic_tags={'numeric'}))
让我们将这两个自定义原语添加到各自的列表中。在最终版本的特征工程中,我没有使用time_since原语。我在实现过程中遇到了问题,但我鼓励任何人尝试修复它或构建自己的自定义原语。
agg_primitives.append(total_previous)
# trans_primitives.append(time_since)
使用指定的基元进行深度特征合成
这次我们将再次运行深度特征合成,使用选定的基元和自定义基元来生成特征定义。
# 使用特征工具包的dfs函数生成特征定义
# entityset参数指定实体集
# target_dataframe_name参数指定目标数据帧的名称
# cutoff_time参数指定截止时间
# agg_primitives参数指定聚合原语
# trans_primitives参数指定转换原语
# where_primitives参数指定条件原语
# chunk_size参数指定块大小
# cutoff_time_in_index参数指定截止时间是否在索引中
# max_depth参数指定最大深度
# features_only参数指定是否只返回特征
feature_defs = ft.dfs(entityset=es, target_dataframe_name='members',
cutoff_time = cutoff_times,
agg_primitives = agg_primitives,
trans_primitives = trans_primitives,
where_primitives = where_primitives,
chunk_size = len(cutoff_times),
cutoff_time_in_index = True,
max_depth = 2, features_only = True)
# 打印语句,输出将会生成feature_defs列表的长度个数的特征
print(f'This will generate {len(feature_defs)} features.')
This will generate 401 features.
# 从feature_defs列表中随机选择15个元素
random.sample(feature_defs, 15)
我们可以看到,我们的自定义原语TOTAL_PREVIOUS_MONTH已被应用于创建更多特征。自定义原语的好处是可以将特定领域知识编码到特征工程过程中。此外,我们不仅得到了自定义原语本身,还得到了叠加在原语之上的特征。
运行深度特征合成
一旦我们对将要生成的特征满意,我们就可以运行深度特征合成来生成实际的特征。我们需要将 features_only 改为 False,然后就可以开始了。
# 导入所需的库
from timeit import default_timer as timer
# 记录开始时间
start = timer()
# 使用featuretools的dfs函数生成特征矩阵和特征定义
# entityset为实体集,target_dataframe_name为目标数据框的名称
# cutoff_time为截止时间,agg_primitives为聚合原语,trans_primitives为转换原语
# where_primitives为条件原语,max_depth为最大深度,features_only为是否只返回特征
# verbose为是否显示详细信息,chunk_size为块大小,cutoff_time_in_index为截止时间是否在索引中
feature_matrix, feature_defs = ft.dfs(entityset=es, target_dataframe_name='members',
cutoff_time = cutoff_times,
agg_primitives = agg_primitives,
trans_primitives = trans_primitives,
where_primitives = where_primitives,
max_depth = 2, features_only = False,
verbose = 1, chunk_size = 1000,
cutoff_time_in_index = True)
# 记录结束时间
end = timer()
# 输出运行时间
print(f'{round(end - start)} seconds elapsed.')
Built 401 features
Elapsed: 51:33 | Progress: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████
3094 seconds elapsed.
“chunk_size”是一个可能需要调整以优化计算的参数。我建议尝试调整这个参数,找到最佳值。通常我发现,较大的值可以加快计算速度,尽管这取决于使用的机器和唯一截止时间的数量。
# 查看DataFrame的前五行数据
feature_matrix.head()
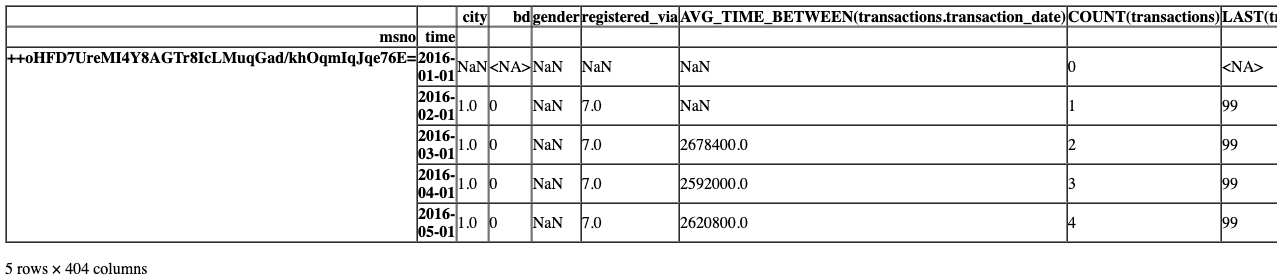
我们可以将这些特征定义保存为二进制文件,这样我们就可以为另一个相同格式的实体集创建完全相同的特征。当我们有多个分区并且希望为每个分区创建相同的特征时,这非常有用。我们不需要重新创建特征定义,只需将相同的特征定义传递给calculate_feature_matrix函数的调用即可。
# 将特征定义保存到文件中
ft.save_features(feature_defs, f'{CWD}/data/features.txt')
# 读取特征矩阵
feature_matrix = pd.read_csv('feature_matrix.csv')
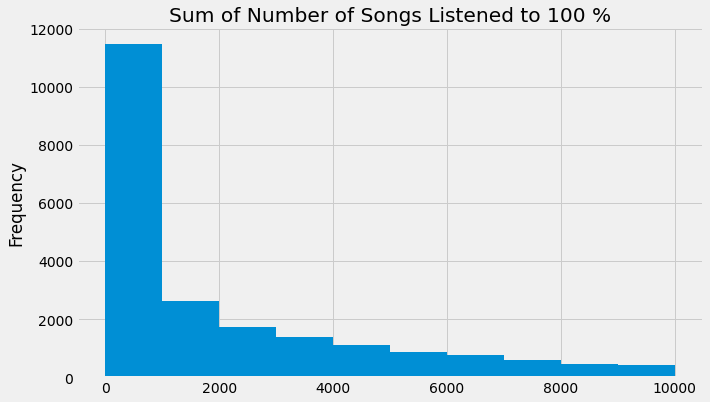
# 选择“SUM(logs.num_100)”列中小于10000的行,并绘制直方图
feature_matrix.loc[feature_matrix['SUM(logs.num_100)'] < 10000, 'SUM(logs.num_100)'].plot.hist()
# 设置图表标题
plt.title('Sum of Number of Songs Listened to 100 %')
# 特征工程
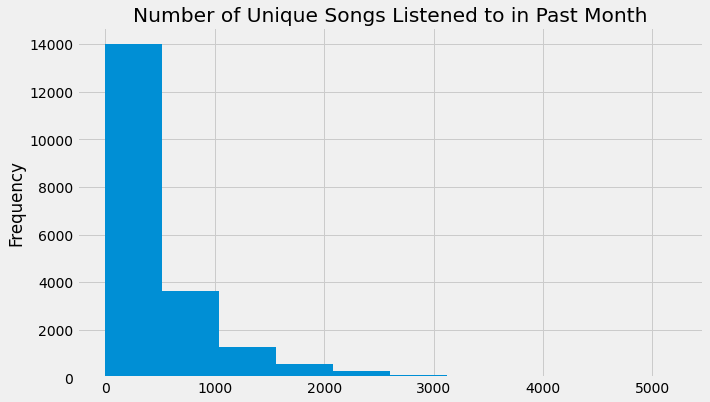
# 创建一个新的特征,表示用户在上个月听过的独特歌曲数量的对数
feature_matrix['TOTAL_PREVIOUS_MONTH(logs.num_unq, date)'] = np.log(data.groupby('msno').agg({'num_unq': 'sum'}).shift())
# 绘制直方图
feature_matrix['TOTAL_PREVIOUS_MONTH(logs.num_unq, date)'].plot.hist()
# 设置标题
plt.title('Number of Unique Songs Listened to in Past Month')
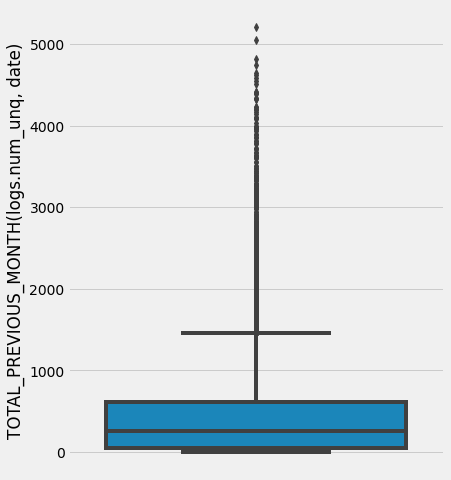
# 对 feature_matrix 中的 'TOTAL_PREVIOUS_MONTH(logs.num_unq, date)' 进行描述性统计分析
feature_matrix['TOTAL_PREVIOUS_MONTH(logs.num_unq, date)'].describe()
# 设置图形的大小为6x8
plt.figure(figsize=(6, 8))
# 绘制箱线图,y轴为feature_matrix中的'TOTAL_PREVIOUS_MONTH(logs.num_unq, date)'列的值
sns.boxplot(y=feature_matrix['TOTAL_PREVIOUS_MONTH(logs.num_unq, date)'])
并行化特征工程
为了并行运行特征工程,我们需要编写一个函数,可以一次处理一个分区。
现在我们将编写一个函数,该函数接受分区号、特征定义和特定的截止时间文件名,读取数据,计算特征矩阵,并将特征矩阵保存回分区目录。由于所有分区都是独立的 - 一个分区的特征不依赖于任何其他分区的数据 - 我们可以稍后使用此函数来并行计算所有特征矩阵。
# 加载特征定义文件
feature_defs = ft.load_features(f'{CWD}/data/features.txt')
# 打印特征数量
print(f'There are {len(feature_defs)} features.')
There are 401 features.
下面的函数接受一个单独的分区号,检索数据,使用预定义的特征集合使用calculate_feature_matrix计算特征矩阵,并将特征矩阵保存回分区。这是对上述独立步骤的重构。
%%capture
def partition_to_feature_matrix(partition, feature_defs = feature_defs,
cutoff_time_name = 'MS-31_labels.csv', write = True):
"""根据给定的分区号创建特征矩阵,并保存到Amazon S3
参数
--------
partition (int): 分区号
feature_defs (list of ft features): 需要为分区创建的特征
cutoff_time_name (str): 截止时间文件的名称
write: (boolean): 是否将数据写入分区。默认为True
返回
--------
None: 将特征矩阵保存到Amazon S3
"""
partition_dir = BASE_DIR + 'p' + str(partition)
# 读取数据文件
members = pd.read_csv(f'{partition_dir}/members.csv',
parse_dates=['registration_init_time'],
infer_datetime_format = True,
dtype = {'gender': 'category'})
trans = pd.read_csv(f'{partition_dir}/transactions.csv',
parse_dates=['transaction_date', 'membership_expire_date'],
infer_datetime_format = True)
logs = pd.read_csv(f'{partition_dir}/logs.csv', parse_dates = ['date'])
# 确保删除重复项
cutoff_times = pd.read_csv(f'{partition_dir}/{cutoff_time_name}', parse_dates = ['time'])
cutoff_times = cutoff_times.drop_duplicates(subset = ['msno', 'time'])
# 用于保存
cutoff_spec = cutoff_time_name.split('_')[0]
# 创建空的实体集
es = ft.EntitySet(id = 'customers')
# 添加members父表
es.add_dataframe(dataframe_name='members', dataframe=members,
index = 'msno', time_index = 'registration_init_time',
logical_types = {'city': 'Categorical',
'registered_via': 'Categorical'})
# 在transactions中创建新特征
trans['price_difference'] = trans['plan_list_price'] - trans['actual_amount_paid']
trans['planned_daily_price'] = trans['plan_list_price'] / trans['payment_plan_days']
trans['daily_price'] = trans['actual_amount_paid'] / trans['payment_plan_days']
# 添加transactions子表
es.add_dataframe(dataframe_name='transactions', dataframe=trans,
index = 'transactions_index', make_index = True,
time_index = 'transaction_date',
logical_types = {'payment_method_id': 'Categorical',
'is_auto_renew': 'Boolean',
'is_cancel': 'Boolean'})
# 添加transactions的有趣值
es.add_interesting_values(dataframe_name="transactions",
values={'is_cancel': [False, True],
'is_auto_renew': [False, True]})
# 在logs中创建新特征
logs['total'] = logs[['num_25', 'num_50', 'num_75', 'num_985', 'num_100']].sum(axis = 1)
logs['percent_100'] = logs['num_100'] / logs['total']
logs['percent_unique'] = logs['num_unq'] / logs['total']
logs['seconds_per_song'] = logs['total_secs'] / logs['total']
# 添加logs子表
es.add_dataframe(dataframe_name='logs', dataframe=logs,
index = 'logs_index', make_index = True,
time_index = 'date')
# 添加关系
r_member_transactions = ft.Relationship(es, 'members', 'msno', 'transactions', 'msno')
r_member_logs = ft.Relationship(es, 'members', 'msno', 'logs', 'msno')
es.add_relationships([r_member_transactions, r_member_logs])
# 使用预先计算的特征计算特征矩阵
feature_matrix = ft.calculate_feature_matrix(entityset=es, features=feature_defs,
cutoff_time=cutoff_times, cutoff_time_in_index = True,
chunk_size = 1000)
if write:
# 保存到分区目录
bytes_to_write = feature_matrix.to_csv(None).encode()
with open(f'{partition_dir}/{cutoff_spec}_feature_matrix.csv', 'wb') as f:
f.write(bytes_to_write)
# 导入计时器模块
from timeit import default_timer as timer
# 记录开始时间
start = timer()
# 调用函数partition_to_feature_matrix,传入参数40、feature_defs,设置cutoff_time_name为'MS-31_labels.csv',并将结果写入文件
partition_to_feature_matrix(40, feature_defs, cutoff_time_name='MS-31_labels.csv', write=True)
# 记录结束时间
end = timer()
# 打印运行时间
print(f'{round(end - start)} seconds elapsed.')
3111 seconds elapsed.
# 读取csv文件,并将其存储在名为feature_matrix的变量中
# csv文件的路径为BASE_DIR/p40/MS-31_feature_matrix.csv
# low_memory参数设置为False,以便在读取文件时不考虑内存限制
feature_matrix = pd.read_csv(f'{BASE_DIR}/p40/MS-31_feature_matrix.csv', low_memory=False)
# 显示feature_matrix的前几行数据
feature_matrix.head()
我们可以看到该函数适用于单个特征矩阵。稍后我们将在Spark中实现并行计算。
给定计算一个特征矩阵所需的时间,如果按顺序计算所有1000个特征矩阵,将需要数天的时间。幸运的是,由于我们将数据分成了独立的子集,我们可以使用分布式框架(如Dask或Spark)并行计算特征矩阵。
(有关如何在Spark中使用PySpark分发特征工程的教程,请参阅“Featuretools on Spark”笔记本。这种方法适用于单机和集群环境)。
结论
自动特征工程在时间和建模性能方面都比手动特征工程有了显著的改进。在这个笔记本中,我们使用Featuretools为客户流失问题实现了一个自动特征工程的工作流程。给定客户数据和标签时间,我们现在可以计算一个包含几百个相关特征的特征矩阵,用于预测客户流失,同时确保我们的特征是基于每个截止时间的有效数据生成的。
在此过程中,我们实现了一些Featuretools的概念:
- 实体集
- 数据帧之间的关系
- 截止时间
- 特征原语
- 自定义原语
- 深度特征合成
这些概念将在我们未来的机器学习项目中发挥重要作用,我们可以利用自动特征工程来解决这些项目。
下一步
虽然我们经常听到“数据是机器学习的燃料”,但数据并不完全是燃料,更像是原油。_特征_是我们输入机器学习模型以进行准确预测的精炼产品。在进行预测工程和自动特征工程之后,下一步是将这些特征与标记的历史示例一起使用,训练一个机器学习模型来预测使用这些特征的标签。
自动生成数百个特征是令人印象深刻的,但如果这些特征不能让模型学习到我们的预测问题,那么它们就没有太大的帮助!下一步是使用我们的特征和带有标签的历史示例来训练一个机器学习模型,以预测客户流失。我们将确保使用一个保留测试集来测试我们的模型,以估计在新数据上的性能。然后,在验证我们的模型之后,我们可以通过特征工程过程将其应用于新的示例数据。
如果您想了解如何在Spark中并行化特征工程,请参阅“Feature Engineering on Spark”笔记本。否则,下一个笔记本是“Modeling”,在那里我们将开发一个机器学习模型,使用历史标记示例和自动化生成的特征来预测流失。


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











