







文章目录
www.aidoczh.com已经系统的将LangChain官网文档翻译成中文,您可以去http://www.aidoczh.com/langchain/v0.2/docs/introduction/ 查看文档,该网站www.aidoczh.com主要是将AI工具官方文档翻译成中文,还有其他工具文档可以看。
1. 检索器
检索器是一种接口,根据非结构化查询返回文档。它比向量存储更通用。检索器不需要能够存储文档,只需要返回(或检索)它们。向量存储可以用作检索器的支柱,但也有其他类型的检索器。
检索器接受字符串查询作为输入,并返回一个 Document 列表作为输出。
高级检索类型
LangChain 提供了几种高级检索类型。下面是完整列表,以及以下信息:
名称:检索算法的名称。
索引类型:依赖的索引类型(如果有)。
使用 LLM:此检索方法是否使用 LLM。
何时使用:我们对何时应考虑使用此检索方法的评论。
描述:此检索算法正在执行的描述。
| 名称 | 索引类型 | 使用 LLM | 何时使用 | 描述 |
|---|---|---|---|---|
| 向量存储 | 向量存储 | 否 | 如果您刚开始并正在寻找快速简单的东西。 | 这是最简单的方法,也是最容易入门的方法。它涉及为每个文本创建嵌入。 |
| 父文档 | 向量存储 + 文档存储 | 否 | 如果您的页面包含许多较小的不同信息片段,最好单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块。然后找到在嵌入空间中最相似的块,但检索整个父文档并返回(而不是单独的块)。 |
| 多向量 | 向量存储 + 文档存储 | 有时在索引期间 | 如果您能够从文档中提取信息,认为这些信息比文本本身更相关以进行索引。 | 这涉及为每个文档创建多个向量。每个向量可以以多种方式创建 - 例如,文本摘要和假设性问题。 |
| 自查询 | 向量存储 | 是 | 如果用户提出的问题最好通过基于元数据而不是与文本相似性的检索文档来回答。 | 这使用LLM将用户输入转换为两个内容:(1)要进行语义查找的字符串,(2)要与之配套的元数据过滤器。这很有用,因为通常问题是关于文档的元数据(而不是内容本身)。 |
| 上下文压缩 | 任意 | 有时 | 如果您发现检索到的文档包含太多无关信息,并且分散了LLM的注意力。 | 这在另一个检索器之上放置一个后处理步骤,并仅从检索到的文档中提取最相关的信息。这可以使用嵌入或LLM完成。 |
| 时间加权向量存储 | 向量存储 | 否 | 如果您的文档关联有时间戳,并且希望检索最近的文档 | 这根据语义相似性(与正常向量检索相同)和最新性(查看索引文档的时间戳)检索文档 |
| 多查询检索器 | 任意 | 是 | 如果用户提出的问题复杂,并且需要多个不同信息片段来回答 | 这使用LLM从原始查询生成多个查询。当原始查询需要关于多个主题的信息片段才能得到正确答案时,这很有用。通过生成多个查询,我们可以为每个查询获取文档。 |
| 集成 | 任意 | 否 | 如果您有多个检索方法,并希望尝试将它们结合在一起。 | 这从多个检索器中检索文档,然后将它们结合在一起。 |
| 长上下文重新排序 | 任意 | 否 | 如果您正在使用长上下文模型,并且注意到它没有关注检索文档中间的信息。 | 这从基础检索器中检索文档,然后重新排序它们,使得最相似的文档靠近开头和结尾。这很有用,因为已经证明对于较长的上下文模型,有时它们不会关注上下文窗口中间的信息。 |
第三方集成
LangChain 还与许多第三方检索服务集成。要查看所有这些的完整列表,请查看此列表的所有集成。
在 LCEL 中使用检索器
由于检索器是 Runnable,我们可以轻松地将它们与其他 Runnable 对象组合:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
template = """根据以下上下文回答问题:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
chain.invoke("总统对技术发表了什么看法?")
自定义检索器
由于检索器接口非常简单,编写自定义检索器非常容易。
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
class CustomRetriever(BaseRetriever):
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=query)]
retriever = CustomRetriever()
retriever.get_relevant_documents("bar")
2. 自查询
自查询检索器是指具有自我查询能力的检索器。正如其名称所示,它具有查询自身的能力。具体而言,对于任何自然语言查询,检索器使用查询构造的LLM链来编写结构化查询,然后将该结构化查询应用于其底层的VectorStore。这使得检索器不仅可以使用用户输入的查询与存储文档的内容进行语义相似性比较,还可以从用户查询中提取存储文档的元数据上的过滤器,并执行这些过滤器。
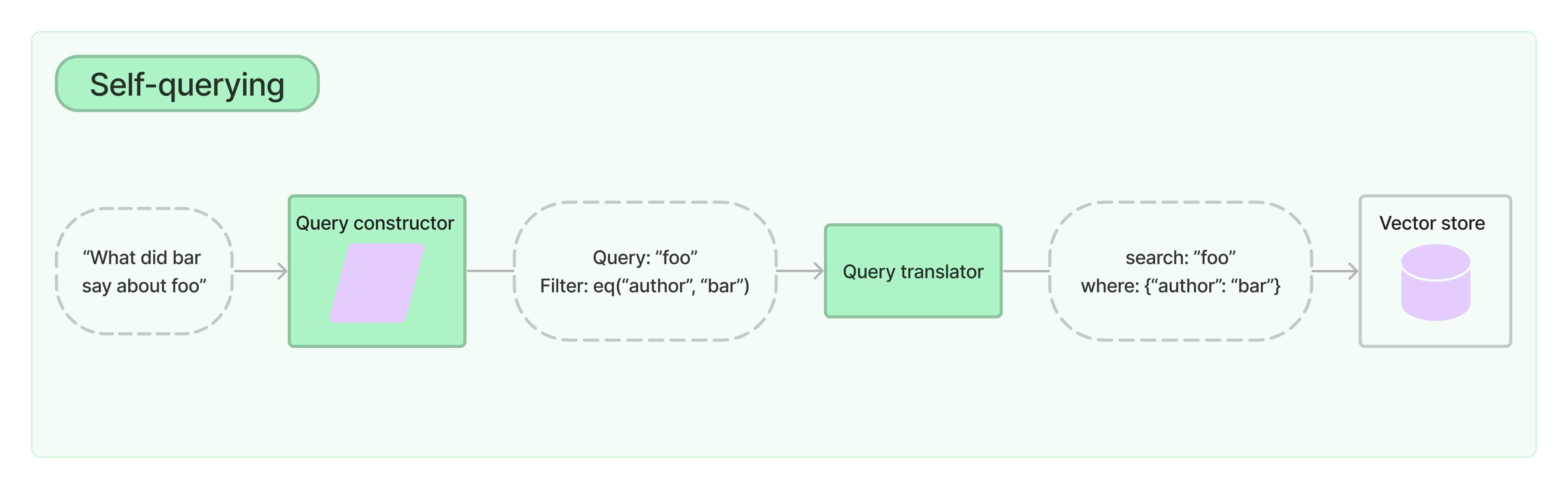
入门
为了演示目的,我们将使用Chroma向量存储。我们创建了一个包含电影摘要的小型演示文档集。
注意: 自查询检索器要求您已安装lark包。
%pip install --upgrade --quiet lark chromadb
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
docs = [
Document(
page_content="一群科学家复活了恐龙,混乱不堪",
metadata={"year": 1993, "rating": 7.7, "genre": "科幻"},
),
Document(
page_content="莱昂纳多·迪卡普里奥在梦中的梦中的梦中迷失了方向",
metadata={"year": 2010, "director": "克里斯托弗·诺兰", "rating": 8.2},
),
Document(
page_content="一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重复了这个想法",
metadata={"year": 2006, "director": "今敏", "rating": 8.6},
),
Document(
page_content="一群普通身材的女性极其善良,一些男性为她们倾心",
metadata={"year": 2019, "director": "格蕾塔·葛韦格", "rating": 8.3},
),
Document(
page_content="玩具活了起来,并且玩得不亦乐乎",
metadata={"year": 1995, "genre": "动画"},
),
Document(
page_content="三个人走进区域,三个人走出区域",
metadata={
"year": 1979,
"director": "安德烈·塔尔科夫斯基",
"genre": "惊悚",
"rating": 9.9,
},
),
]
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
创建我们的自查询检索器
现在我们可以实例化我们的检索器。为此,我们需要提前提供有关文档支持的元数据字段以及文档内容的简短描述。
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
metadata_field_info = [
AttributeInfo(
name="genre",
description="电影的类型。其中之一为['科幻', '喜剧', '戏剧', '惊悚', '爱情', '动作', '动画']",
type="string",
),
AttributeInfo(
name="year",
description="电影上映年份",
type="integer",
),
AttributeInfo(
name="director",
description="电影导演的姓名",
type="string",
),
AttributeInfo(
name="rating", description="电影的1-10评分", type="float"
),
]
document_content_description = "电影简介"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
测试
现在我们可以实际尝试使用我们的检索器!
# 此示例仅指定一个过滤器
retriever.invoke("我想看一部评分高于8.5的电影")
[Document(page_content='三个人走进区域,三个人走出区域', metadata={'director': '安德烈·塔尔科夫斯基', 'genre': '惊悚', 'rating': 9.9, 'year': 1979}),
Document(page_content='一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重复了这个想法', metadata={'director': '今敏', 'rating': 8.6, 'year': 2006})]
# 此示例指定查询和过滤器
retriever.invoke("格蕾塔·葛韦格导演过关于女性的电影吗")
[Document(page_content='一群普通身材的女性极其善良,一些男性为她们倾心', metadata={'director': '格蕾塔·葛韦格', 'rating': 8.3, 'year': 2019})]
# 此示例指定复合过滤器
retriever.invoke("有哪些评分高于8.5的科幻电影?")
[Document(page_content='一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重复了这个想法', metadata={'director': '今敏', 'rating': 8.6, 'year': 2006}),
Document(page_content='三个人走进区域,三个人走出区域', metadata={'director': '安德烈·塔尔科夫斯基', 'genre': '惊悚', 'rating': 9.9, 'year': 1979})]
# 此示例指定查询和复合过滤器
retriever.invoke(
"1990年后但2005年前的关于玩具的电影,最好是动画片"
)
[Document(page_content='玩具活了起来,并且玩得不亦乐乎', metadata={'genre': '动画', 'year': 1995})]
过滤器 k
我们还可以使用自查询检索器来指定k:要获取的文档数量。
我们可以通过将enable_limit=True传递给构造函数来实现这一点。
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
)
# 此示例仅指定一个相关查询
retriever.invoke("有哪两部关于恐龙的电影")
[Document(page_content='一群科学家复活了恐龙,混乱不堪', metadata={'genre': '科幻', 'rating': 7.7, 'year': 1993}),
Document(page_content='玩具活了起来,并且玩得不亦乐乎', metadata={'genre': '动画', 'year': 1995})]
使用LCEL从头开始构建
为了了解底层发生了什么,并且具有更多的自定义控制,我们可以从头开始重建我们的检索器。
首先,我们需要创建一个查询构造链。该链将接受用户查询并生成一个StructuredQuery对象,该对象捕获用户指定的过滤器。我们提供了一些辅助函数来创建提示和输出解析器。这些函数有许多可调参数,为简单起见,我们将在此忽略。
from langchain.chains.query_constructor.base import (
StructuredQueryOutputParser,
get_query_constructor_prompt,
)
prompt = get_query_constructor_prompt(
document_content_description,
metadata_field_info,
)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
让我们看看我们的提示:
print(prompt.format(query="虚拟问题"))
您的目标是结构化用户的查询以匹配下面提供的请求模式。
<< 结构化请求模式 >>
在回复时,使用一个带有JSON对象的Markdown代码片段,格式如下:
{
"query": string \ 文本字符串,用于与文档内容进行比较
"filter": string \ 用于过滤文档的逻辑条件语句
}
查询字符串应仅包含预计与文档内容匹配的文本。过滤器中的任何条件也不应在查询中提及。
逻辑条件语句由一个或多个比较和逻辑操作语句组成。
比较语句采用以下形式:comp(attr, val):
comp(eq | ne | gt | gte | lt | lte | contain | like | in | nin):比较器attr(string):应用比较的属性名称val(string):比较值
逻辑操作语句采用op(statement1, statement2, ...)的形式:
op(and | or | not):逻辑运算符statement1、statement2等(比较语句或逻辑操作语句):应用操作的一个或多个语句
确保仅使用上述列出的比较器和逻辑运算符,不要使用其他任何内容。
确保过滤器仅涉及数据源中存在的属性。
确保过滤器仅使用带有其函数名称的属性名称,如果对其应用了函数。
确保过滤器仅在处理日期数据类型值时使用格式YYYY-MM-DD。
确保过滤器考虑属性的描述,并仅进行可能的数据类型存储的比较。
确保根据需要仅使用过滤器。如果没有应用过滤器,为过滤器值返回“NO_FILTER”。
<< 示例1。 >>
数据源:
{
"content": "一首歌的歌词",
"attributes": {
"artist": {
"type": "string",
"description": "歌曲艺术家的姓名"
},
"length": {
"type": "integer",
"description": "歌曲的长度(秒)"
},
"genre": {
"type": "string",
"description": "歌曲风格,为“流行”、“摇滚”或“说唱”之一"
}
}
}
用户查询:
泰勒·斯威夫特或凯蒂·佩里演唱的关于十几岁恋情的歌曲中,长度不超过3分钟,属于舞蹈流行风格的有哪些
结构化请求:
{
"query": "teenager love",
"filter": "and(or(eq(\"artist\", \"Taylor Swift\"), eq(\"artist\", \"Katy Perry\")), lt(\"length\", 180), eq(\"genre\", \"pop\"))"
}
示例2
数据源:
{
"content": "一首歌的歌词",
"attributes": {
"artist": {
"type": "string",
"description": "歌手的名字"
},
"length": {
"type": "integer",
"description": "歌曲长度(秒)"
},
"genre": {
"type": "string",
"description": "歌曲流派,可以是 '流行'、'摇滚' 或 '说唱' 中的一种"
}
}
}
用户查询:
哪些歌曲没有在Spotify上发布
结构化请求:
{
"query": "",
"filter": "NO_FILTER"
}
示例3
数据源:
{
"content": "一部电影的简要概述",
"attributes": {
"genre": {
"description": "电影的流派,可以是 ['科幻', '喜剧', '戏剧', '惊悚', '爱情', '动作', '动画'] 中的一种",
"type": "string"
},
"year": {
"description": "电影上映年份",
"type": "integer"
},
"director": {
"description": "电影导演的名字",
"type": "string"
},
"rating": {
"description": "电影的1-10评分",
"type": "float"
}
}
}
用户查询:
虚拟问题
结构化请求:
我们的完整链路生成的结果如下:
query_constructor.invoke(
{
"query": "What are some sci-fi movies from the 90's directed by Luc Besson about taxi drivers"
}
)
结构化查询(query=‘taxi driver’, filter=Operation(operator=<Operator.AND: ‘and’>, arguments=[Comparison(comparator=<Comparator.EQ: ‘eq’>, attribute=‘genre’, value=‘science fiction’), Operation(operator=<Operator.AND: ‘and’>, arguments=[Comparison(comparator=<Comparator.GTE: ‘gte’>, attribute=‘year’, value=1990), Comparison(comparator=<Comparator.LT: ‘lt’>, attribute=‘year’, value=2000)]), Comparison(comparator=<Comparator.EQ: ‘eq’>, attribute=‘director’, value=‘Luc Besson’)]), limit=None)
查询构造器是自查询检索器的关键元素。要创建一个出色的检索系统,您需要确保您的查询构造器能够正常工作。通常需要调整提示、提示中的示例、属性描述等。有一个示例通过对酒店库存数据的查询构造器进行细化的步骤,请查看这个食谱。
下一个关键元素是结构化查询转换器。这个对象负责将通用的 StructuredQuery 对象转换为您正在使用的向量存储语法中的元数据过滤器。LangChain 提供了许多内置的转换器。要查看它们,请转到集成部分。
from langchain.retrievers.self_query.chroma import ChromaTranslator
retriever = SelfQueryRetriever(
query_constructor=query_constructor,
vectorstore=vectorstore,
structured_query_translator=ChromaTranslator(),
)
retriever.invoke(
"What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
[Document(page_content=‘Toys come alive and have a blast doing so’, metadata={‘genre’: ‘animated’, ‘year’: 1995})]
3. 上下文压缩
在信息检索中的一个挑战是,当您将数据导入系统时,通常不知道系统将面对的具体查询。这意味着与查询相关的信息可能被埋在大量无关文本的文档中。将完整文档传递到应用程序可能导致更昂贵的LLM调用和更差的响应。
上下文压缩旨在解决这个问题。其思想很简单:与其立即返回检索到的文档,您可以利用给定查询的上下文对其进行压缩,以便只返回相关信息。这里的“压缩”既指对单个文档内容进行压缩,也指批量过滤文档。
要使用上下文压缩检索器,您需要:
- 一个基础检索器
- 一个文档压缩器
上下文压缩检索器将查询传递给基础检索器,获取初始文档并将其通过文档压缩器传递。文档压缩器接收文档列表,并通过减少文档内容或直接丢弃文档来缩短列表。
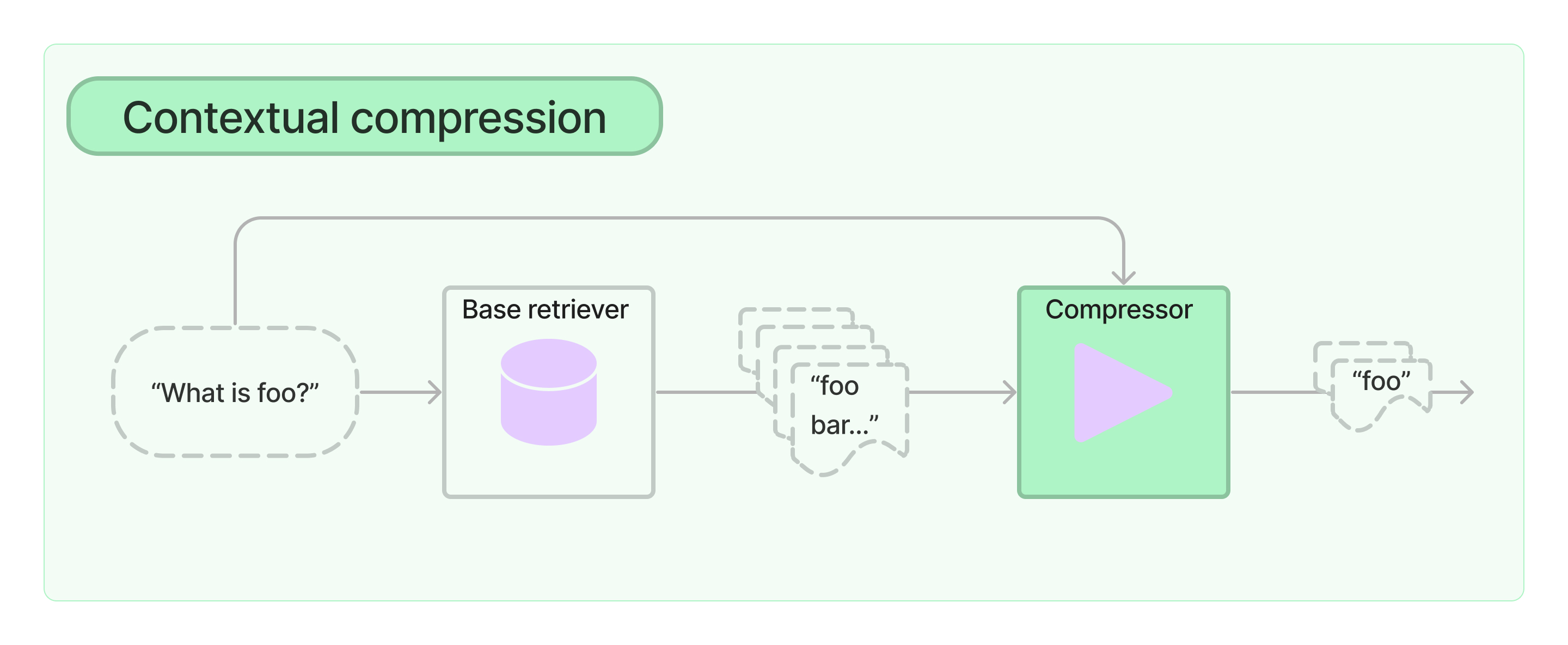
开始
# 用于打印文档的辅助函数
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)
使用简单的向量存储检索器
让我们从初始化一个简单的向量存储检索器开始,并存储2023年国情咨文(分块)。我们可以看到,给定一个示例问题,我们的检索器返回了一个或两个相关文档以及一些不相关文档。即使相关文档中也包含大量无关信息。
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
documents = TextLoader("../../state_of_the_union.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
docs = retriever.get_relevant_documents(
"What did the president say about Ketanji Brown Jackson"
)
pretty_print_docs(docs)
Document 1:
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
----------------------------------------------------------------------------------------------------
Document 2:
A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.
And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.
We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling.
We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers.
We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster.
We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.
----------------------------------------------------------------------------------------------------
Document 3:
And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong.
As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential.
While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice.
And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things.
So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together.
First, beat the opioid epidemic.
----------------------------------------------------------------------------------------------------
Document 4:
Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers.
And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up.
That ends on my watch.
Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect.
We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees.
Let’s pass the Paycheck Fairness Act and paid leave.
Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty.
Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
使用LLMChainExtractor添加上下文压缩
现在让我们用ContextualCompressionRetriever包装我们的基础检索器。我们将添加一个LLMChainExtractor,它将遍历最初返回的文档,并仅提取与查询相关的内容。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
Document 1:
I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson.
更多内置压缩器:过滤器
LLMChainFilter
LLMChainFilter是一个稍微简单但更强大的压缩器,它使用LLM链来决定最初检索到的文档中哪些要被过滤掉,哪些要返回,而不会操纵文档内容。
from langchain.retrievers.document_compressors import LLMChainFilter
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/Users/harrisonchase/workplace/langchain/libs/langchain/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
Document 1:
今晚,我想向一个致力于为这个国家服务的人致敬:司法部长史蒂芬·布雷耶(Stephen Breyer)——一位陆军退伍军人、宪法学者,也是美国最高法院即将退休的法官。布雷耶司法部长,感谢您的服务。
总统拥有的最严肃的宪法责任之一就是提名人选担任美国最高法院的法官。
而我在4天前提名了联邦上诉法院法官凯坦吉·布朗·杰克逊(Ketanji Brown Jackson)。她是我国顶尖的法律智囊,将延续布雷耶司法部长卓越的传统。
EmbeddingsFilter
对每个检索到的文档进行额外的LLM调用既昂贵又慢。EmbeddingsFilter提供了一种更便宜、更快速的选择,通过嵌入文档和查询,只返回那些与查询具有足够相似嵌入的文档。
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"总统关于凯坦吉·杰克逊·布朗的讲话内容是什么"
)
pretty_print_docs(compressed_docs)
文档1:
今晚,我呼吁参议院:通过《自由选举法》。通过《约翰·刘易斯选举权法》。而且,在此期间,通过《披露法案》,以便美国人了解谁在资助我们的选举。
今晚,我想向一个致力于为这个国家服务的人致敬:司法部长史蒂芬·布雷耶——一位陆军退伍军人、宪法学者,也是美国最高法院即将退休的法官。布雷耶司法部长,感谢您的服务。
总统拥有的最严肃的宪法责任之一就是提名人选担任美国最高法院的法官。
而我在4天前提名了联邦上诉法院法官凯坦吉·布朗·杰克逊。她是我国顶尖的法律智囊,将延续布雷耶司法部长卓越的传统。
文档2:
曾是私人执业中的顶尖诉讼律师。曾是联邦公共辩护人。来自一家公立学校教育工作者和警察的家庭。一个达成共识的人。自她被提名以来,她得到了广泛的支持——从警察兄弟会到由民主党和共和党任命的前法官。
如果我们要推进自由和正义,我们需要保护边境并修复移民系统。
我们可以做到。在我们的边境,我们安装了新技术,如尖端扫描仪,以更好地检测走私毒品。
我们与墨西哥和危地马拉建立了联合巡逻,以抓捕更多的人口贩子。
我们正在设立专门的移民法官,以便那些逃离迫害和暴力的家庭能够更快地得到审理。
我们正在承诺并支持南美和中美的合作伙伴,以接纳更多的难民并保护他们自己的边界。
文档3:
对于我们的 LGBTQ+ 美国人,让我们最终将两党支持的《平等法案》送到我的办公桌上。针对跨性别美国人及其家人的一系列州法律的袭击是错误的。
正如我去年所说,特别是对我们年轻的跨性别美国人,作为你们的总统,我将永远支持你们,这样你们就可以做自己,并发挥上帝赋予你们的潜力。
虽然我们经常看起来永远无法达成一致,但事实并非如此。去年我签署了80项两党法案。
从防止政府关门到保护亚裔免受仍然普遍存在的仇恨犯罪,再到改革军事司法。
很快,我们将加强我三十年前首次起草的《反对妇女暴力法》。对我们来说,向全国展示我们可以团结一致,做出重大贡献是很重要的。
因此,今晚我提出了一个国家的团结议程。我们可以一起做的四件大事。
首先,战胜阿片类药物流行病。
将压缩器和文档转换器串联起来
使用DocumentCompressorPipeline,我们还可以轻松地将多个压缩器依次组合在一起。除了压缩器,我们还可以向我们的管道中添加BaseDocumentTransformer,它们不执行任何上下文压缩,而只是对一组文档执行一些转换。例如,TextSplitter可以用作文档转换器,将文档分割成更小的片段,EmbeddingsRedundantFilter可用于根据文档之间的嵌入相似性过滤出冗余文档。
下面我们通过首先将文档分割成较小的块,然后删除冗余文档,最后根据与查询的相关性进行过滤,创建一个压缩器管道。
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"总统关于凯坦吉·杰克逊·布朗的讲话内容是什么"
)
pretty_print_docs(compressed_docs)
文档1:
总统拥有的最严肃的宪法责任之一就是提名人选担任美国最高法院的法官。
而我在4天前提名了联邦上诉法院法官凯坦吉·布朗·杰克逊
文档2:
正如我去年所说,特别是对我们年轻的跨性别美国人,作为你们的总统,我将永远支持你们,这样你们就可以做自己,并发挥上帝赋予你们的潜力。
虽然我们经常看起来永远无法达成一致,但事实并非如此。去年我签署了80项两党法案
文档3:
曾是私人执业中的顶尖诉讼律师。曾是联邦公共辩护人。来自一家公立学校教育工作者和警察的家庭。一个达成共识的人
文档4:
自她被提名以来,她得到了广泛的支持——从警察兄弟会到由民主党和共和党任命的前法官。
如果我们要推进自由和正义,我们需要保护边境并修复移民系统。
我们可以做到。
4. 基于向量存储的检索器
向量存储检索器是一种利用向量存储来检索文档的检索器。它是对向量存储类的轻量级封装,使其符合检索器接口。它利用向量存储实现的搜索方法,如相似性搜索和最大边际相关性(MMR),来查询向量存储中的文本。
一旦构建了向量存储,构建检索器就非常容易。让我们通过一个示例来了解一下。
from langchain_community.document_loaders import TextLoader
loader = TextLoader("../../state_of_the_union.txt")
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
docs = retriever.get_relevant_documents("what did he say about ketanji brown jackson")
最大边际相关性检索
默认情况下,向量存储检索器使用相似性搜索。如果底层向量存储支持最大边际相关性搜索,您可以将其指定为搜索类型。
retriever = db.as_retriever(search_type="mmr")
docs = retriever.get_relevant_documents("what did he say about ketanji brown jackson")
相似性分数阈值检索
您还可以设置一个检索方法,设置相似性分数阈值,并且仅返回分数高于该阈值的文档。
retriever = db.as_retriever(
search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}
)
docs = retriever.get_relevant_documents("what did he say about ketanji brown jackson")
指定前 k 个
您还可以指定搜索参数,比如 k,用于进行检索。
retriever = db.as_retriever(search_kwargs={"k": 1})
docs = retriever.get_relevant_documents("what did he say about ketanji brown jackson")
len(docs)
5. 多向量检索器
通常,为每个文档存储多个向量是有益的。有多种情况下这种做法是有利的。LangChain 提供了一个基础的 MultiVectorRetriever,使得查询这种设置变得简单。很多复杂性在于如何为每个文档创建多个向量。本文介绍了创建这些向量和使用 MultiVectorRetriever 的一些常见方法。
创建每个文档多个向量的方法包括:
- 较小的块:将文档分割成较小的块,并嵌入这些块(这是 ParentDocumentRetriever)。
- 摘要:为每个文档创建摘要,将其与文档一起嵌入(或者替代文档)。
- 假设问题:创建每个文档适合回答的假设问题,将其与文档一起嵌入(或者替代文档)。
需要注意的是,这也可以通过另一种方法来添加嵌入 - 手动添加。这很棒,因为您可以明确添加应导致文档被检索的问题或查询,从而使您拥有更多的控制。
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loaders = [
TextLoader("../../paul_graham_essay.txt"),
TextLoader("../../state_of_the_union.txt"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)
较小的块
通常情况下,检索较大块的信息,但嵌入较小块可能是有用的。这允许嵌入尽可能准确地捕获语义含义,但同时传递尽可能多的上下文。请注意,这就是 ParentDocumentRetriever 的作用。下面我们展示了内部运行情况。
# 用于索引子块的向量存储
vectorstore = Chroma(
collection_name="full_documents", embedding_function=OpenAIEmbeddings()
)
# 父文档的存储层
store = InMemoryByteStore()
id_key = "doc_id"
# 检索器(初始为空)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
import uuid
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 用于创建较小块的分割器
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = []
for i, doc in enumerate(docs):
_id = doc_ids[i]
_sub_docs = child_text_splitter.split_documents([doc])
for _doc in _sub_docs:
_doc.metadata[id_key] = _id
sub_docs.extend(_sub_docs)
retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 仅使用向量存储检索小块
retriever.vectorstore.similarity_search("justice breyer")[0]
# 检索器返回较大块
len(retriever.get_relevant_documents("justice breyer")[0].page_content)
检索器在向量数据库上执行的默认搜索类型是相似性搜索。LangChain 向量存储还支持通过最大边际相关性进行搜索,因此,如果您希望使用此功能,只需将 search_type 属性设置为如下所示:
from langchain.retrievers.multi_vector import SearchType
retriever.search_type = SearchType.mmr
len(retriever.get_relevant_documents("justice breyer")[0].page_content)
摘要
通常,摘要可能更准确地概括了一个块的内容,从而导致更好的检索结果。下面我们展示了如何创建摘要,然后嵌入它们。
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")
| ChatOpenAI(max_retries=0)
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 5})
# 用于索引子块的向量存储
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())
# 父文档的存储层
store = InMemoryByteStore()
id_key = "doc_id"
# 检索器(初始为空)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
sub_docs = vectorstore.similarity_search("justice breyer")
sub_docs[0]
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
假设查询
LLM 还可以用于生成可能针对特定文档提出的假设问题列表。然后可以嵌入这些问题。
functions = [
{
"name": "hypothetical_questions",
"description": "Generate hypothetical questions",
"parameters": {
"type": "object",
"properties": {
"questions": {
"type": "array",
"items": {"type": "string"},
},
},
"required": ["questions"],
},
}
]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
chain = (
{"doc": lambda x: x.page_content}
# 仅要求生成 3 个假设问题,但这可以调整
| ChatPromptTemplate.from_template(
"Generate a list of exactly 3 hypothetical questions that the below document could be used to answer:\n\n{doc}"
)
| ChatOpenAI(max_retries=0, model="gpt-4").bind(
functions=functions, function_call={"name": "hypothetical_questions"}
)
| JsonKeyOutputFunctionsParser(key_name="questions")
)
chain.invoke(docs[0])
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5})
# 用于索引子块的向量存储
vectorstore = Chroma(
collection_name="hypo-questions", embedding_function=OpenAIEmbeddings()
)
# 父文档的存储层
store = InMemoryByteStore()
id_key = "doc_id"
# 检索器(初始为空)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
question_docs = []
for i, question_list in enumerate(hypothetical_questions):
question_docs.extend(
[Document(page_content=s, metadata={id_key: doc_ids[i]}) for s in question_list]
)
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
sub_docs = vectorstore.similarity_search("justice breyer")
sub_docs
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
9194
6. 基于时间加权的向量存储检索器
这个检索器结合了语义相似性和时间衰减的方法。
计算它们的算法如下:
语义相似性 + (1.0 - 衰减率) ^ 经过的小时数
值得注意的是,经过的小时数 指的是自检索器中的对象上次被访问以来经过的小时数,而不是自创建以来经过的小时数。这意味着频繁访问的对象保持“新鲜”。
from datetime import datetime, timedelta
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.retrievers import TimeWeightedVectorStoreRetriever
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
低衰减率
低的 衰减率(在这里,为了极端,我们将其设定接近于 0)意味着记忆将被“记住”更长时间。衰减率为 0 意味着记忆永远不会被遗忘,使得这个检索器等同于向量查找。
# 定义您的嵌入模型
embeddings_model = OpenAIEmbeddings()
# 将向量存储初始化为空
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model, index, InMemoryDocstore({}), {})
retriever = TimeWeightedVectorStoreRetriever(
vectorstore=vectorstore, decay_rate=0.0000000000000000000000001, k=1
)
yesterday = datetime.now() - timedelta(days=1)
retriever.add_documents(
[Document(page_content="hello world", metadata={"last_accessed_at": yesterday})]
)
retriever.add_documents([Document(page_content="hello foo")])
# "Hello World" 被首先返回,因为它最显著,而衰减率接近于 0,意味着它仍然足够新鲜
retriever.get_relevant_documents("hello world")
高衰减率
当 衰减率 较高(例如,多个 9),最近性分数 快速降至 0!如果将其设置为 1,所有对象的 最近性 都为 0,再次使其等同于向量查找。
# 定义您的嵌入模型
embeddings_model = OpenAIEmbeddings()
# 将向量存储初始化为空
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model, index, InMemoryDocstore({}), {})
retriever = TimeWeightedVectorStoreRetriever(
vectorstore=vectorstore, decay_rate=0.999, k=1
)
yesterday = datetime.now() - timedelta(days=1)
retriever.add_documents(
[Document(page_content="hello world", metadata={"last_accessed_at": yesterday})]
)
retriever.add_documents([Document(page_content="hello foo")])
# "Hello Foo" 被首先返回,因为 "hello world" 大部分被遗忘
retriever.get_relevant_documents("hello world")
虚拟时间
使用 LangChain 中的一些工具,您可以模拟时间组件。
import datetime
from langchain.utils import mock_now
# 注意最后访问时间是那个日期时间
with mock_now(datetime.datetime(2024, 2, 3, 10, 11)):
print(retriever.get_relevant_documents("hello world"))
7. 长文本上下文重排序
无论您的模型架构如何,当您包含10个以上的检索文档时,性能会显著下降。简而言之:当模型必须在长文本的中间访问相关信息时,它们往往会忽略提供的文档。
详见:https://arxiv.org/abs/2307.03172
为避免这个问题,您可以在检索后重新排序文档,以避免性能下降。
%pip install --upgrade --quiet sentence-transformers > /dev/null
from langchain.chains import LLMChain, StuffDocumentsChain
from langchain.prompts import PromptTemplate
from langchain_community.document_transformers import (
LongContextReorder,
)
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAI
# 获取嵌入
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
texts = [
"篮球是一项伟大的运动。",
"带我飞往月球是我最喜欢的歌曲之一。",
"凯尔特人队是我最喜欢的球队。",
"这是一份关于波士顿凯尔特人队的文件。",
"我简直喜欢去看电影。",
"波士顿凯尔特人队以20分的优势赢得比赛。",
"这只是一段随机文本。",
"《埃尔登之环》是过去15年中最好的游戏之一。",
"L·科内特是最优秀的凯尔特人队球员之一。",
"拉里·伯德是一名标志性的NBA球员。",
]
# 创建一个检索器
retriever = Chroma.from_texts(texts, embedding=embeddings).as_retriever(
search_kwargs={"k": 10}
)
query = "你能告诉我关于凯尔特人队的情况吗?"
# 获取相关文档按相关性得分排序
docs = retriever.get_relevant_documents(query)
docs
# 重新排序文档:
# 不太相关的文档将位于列表中间,而更相关的元素将位于开头/结尾。
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
# 确认4个相关文档位于开头和结尾。
reordered_docs
# 我们准备并运行一个自定义 Stuff 链,以重新排序后的文档作为上下文。
# 覆盖提示
document_prompt = PromptTemplate(
input_variables=["page_content"], template="{page_content}"
)
document_variable_name = "context"
llm = OpenAI()
stuff_prompt_override = """给定以下文本摘录:
-----
{context}
-----
请回答以下问题:
{query}"""
prompt = PromptTemplate(
template=stuff_prompt_override, input_variables=["context", "query"]
)
# 实例化链
llm_chain = LLMChain(llm=llm, prompt=prompt)
chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt,
document_variable_name=document_variable_name,
)
chain.run(input_documents=reordered_docs, query=query)
8. 多查询检索器
基于距离的向量数据库检索将查询嵌入到高维空间中,并根据“距离”找到相似的嵌入文档。但是,如果查询措辞略有变化,或者嵌入未能很好地捕捉数据的语义,检索可能会产生不同的结果。有时会进行提示工程/调整来手动解决这些问题,但这可能会很繁琐。
MultiQueryRetriever 通过使用 LLM 从不同角度为给定用户输入查询生成多个查询,自动化提示调整过程。对于每个查询,它检索一组相关文档,并对所有查询的唯一并集进行处理,以获得一个更大的潜在相关文档集。通过从同一问题的多个角度生成不同视角,MultiQueryRetriever 可能能够克服基于距离的检索的一些限制,并获得更丰富的结果集。
# 构建示例向量数据库
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载博客文章
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# 向量数据库
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
简单用法
指定用于生成查询的 LLM,检索器将完成剩下的工作。
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
# 设置用于查询的日志记录
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
len(unique_docs)
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be approached?', '2. What are the different methods for Task Decomposition?', '3. What are the various approaches to decomposing tasks?']
5
提供自定义提示
您还可以提供一个提示以及一个输出解析器,将结果拆分为查询列表。
from typing import List
from langchain.chains import LLMChain
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from pydantic import BaseModel, Field
# 输出解析器将LLM结果拆分为查询列表
class LineList(BaseModel):
# "lines" 是解析输出的关键(属性名称)
lines: List[str] = Field(description="Lines of text")
class LineListOutputParser(PydanticOutputParser):
def __init__(self) -> None:
super().__init__(pydantic_object=LineList)
def parse(self, text: str) -> LineList:
lines = text.strip().split("\n")
return LineList(lines=lines)
output_parser = LineListOutputParser()
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines.
Original question: {question}""",
)
llm = ChatOpenAI(temperature=0)
# 链
llm_chain = LLMChain(llm=llm, prompt=QUERY_PROMPT, output_parser=output_parser)
# 其他输入
question = "What are the approaches to Task Decomposition?"
# 运行
retriever = MultiQueryRetriever(
retriever=vectordb.as_retriever(), llm_chain=llm_chain, parser_key="lines"
) # "lines" 是解析输出的关键(属性名称)
# 结果
unique_docs = retriever.get_relevant_documents(
query="What does the course say about regression?"
)
len(unique_docs)
INFO:langchain.retrievers.multi_query:Generated queries: ["1. What is the course's perspective on regression?", '2. Can you provide information on regression as discussed in the course?', '3. How does the course cover the topic of regression?', "4. What are the course's teachings on regression?", '5. In relation to the course, what is mentioned about regression?']
11
9. 集成检索器
EnsembleRetriever 接受一个检索器列表作为输入,并根据Reciprocal Rank Fusion算法合并它们的 get_relevant_documents() 方法的结果,并重新排列结果。
通过利用不同算法的优势,EnsembleRetriever 可以比任何单一算法都实现更好的性能。
最常见的模式是将稀疏检索器(如 BM25)与密集检索器(如嵌入相似度)结合起来,因为它们的优势是互补的。这也被称为“混合搜索”。稀疏检索器擅长基于关键词查找相关文档,而密集检索器擅长基于语义相似性查找相关文档。
%pip install --upgrade --quiet rank_bm25 > /dev/null
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
doc_list_1 = [
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]
# 初始化 bm25 检索器和 faiss 检索器
bm25_retriever = BM25Retriever.from_texts(
doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2
doc_list_2 = [
"You like apples",
"You like oranges",
]
embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(
doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# 初始化集成检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.invoke("apples")
docs
[Document(page_content='You like apples', metadata={'source': 2}),
Document(page_content='I like apples', metadata={'source': 1}),
Document(page_content='You like oranges', metadata={'source': 2}),
Document(page_content='Apples and oranges are fruits', metadata={'source': 1})]
运行时配置
我们也可以在运行时配置检索器。为了做到这一点,我们需要将字段标记为可配置的
from langchain_core.runnables import ConfigurableField
faiss_retriever = faiss_vectorstore.as_retriever(
search_kwargs={"k": 2}
).configurable_fields(
search_kwargs=ConfigurableField(
id="search_kwargs_faiss",
name="Search Kwargs",
description="The search kwargs to use",
)
)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
config = {"configurable": {"search_kwargs_faiss": {"k": 1}}}
docs = ensemble_retriever.invoke("apples", config=config)
docs
请注意,这只返回来自 FAISS 检索器的一个来源,因为我们在运行时传入了相关配置
10. 父文档检索器
在拆分文档以进行检索时,通常存在着相互冲突的需求:
- 您可能希望拥有小型文档,以便它们的嵌入可以最准确地反映它们的含义。如果太长,那么嵌入可能会失去意义。
- 您希望拥有足够长的文档,以保留每个块的上下文。
ParentDocumentRetriever 通过拆分和存储小块数据来取得平衡。在检索过程中,它首先获取小块,然后查找这些块的父 ID,并返回那些更大的文档。
请注意,“父文档”指的是小块来源的文档。这既可以是整个原始文档,也可以是更大的块。
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loaders = [
TextLoader("../../paul_graham_essay.txt"),
TextLoader("../../state_of_the_union.txt"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
检索完整文档
在这种模式下,我们希望检索完整文档。因此,我们只指定一个子拆分器。
# 此文本拆分器用于创建子文档
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 用于索引子块的向量存储
vectorstore = Chroma(
collection_name="full_documents", embedding_function=OpenAIEmbeddings()
)
# 用于父文档的存储层
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
这应该返回两个键,因为我们添加了两个文档。
list(store.yield_keys())
[‘cfdf4af7-51f2-4ea3-8166-5be208efa040’,
‘bf213c21-cc66-4208-8a72-733d030187e6’]
现在让我们调用向量存储搜索功能 - 我们应该看到它返回小块(因为我们存储了小块)。
sub_docs = vectorstore.similarity_search("justice breyer")
print(sub_docs[0].page_content)
今晚,我想向一个致力于为这个国家服务的人致敬:司法部长史蒂芬·布雷耶(Stephen Breyer)——一位陆军退伍军人、宪法学者,也是美国最高法院即将退休的法官。布雷耶司法部长,感谢您的服务。
总统拥有的最严肃的宪法责任之一是提名某人担任美国最高法院法官。
现在让我们从整体检索器中检索。这应该返回大型文档 - 因为它返回了包含小块的文档。
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
38540
检索更大的块
有时,完整文档可能太大,我们不希望按原样检索它们。在这种情况下,我们真正想要做的是首先将原始文档拆分为较大的块,然后将其拆分为小块。然后我们索引小块,但在检索时我们检索较大的块(但仍不是完整文档)。
# 此文本拆分器用于创建父文档
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# 此文本拆分器用于创建子文档
# 它应创建比父文档小的文档
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 用于索引子块的向量存储
vectorstore = Chroma(
collection_name="split_parents", embedding_function=OpenAIEmbeddings()
)
# 用于父文档的存储层
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(docs)
现在我们可以看到不止两个文档 - 这些是较大的块。
len(list(store.yield_keys()))
66
让我们确保底层向量存储仍然检索小块。
sub_docs = vectorstore.similarity_search("justice breyer")
print(sub_docs[0].page_content)
今晚,我想向一个致力于为这个国家服务的人致敬:司法部长史蒂芬·布雷耶(Stephen Breyer)——一位陆军退伍军人、宪法学者,也是美国最高法院即将退休的法官。布雷耶司法部长,感谢您的服务。
总统拥有的最严肃的宪法责任之一是提名某人担任美国最高法院法官。
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
1849
print(retrieved_docs[0].page_content)
在一个又一个州,新法律的通过不仅压制了选举权,还颠覆了整个选举。
我们不能让这种事情发生。
今晚,我呼吁参议院:通过《自由选举法案》。通过《约翰·刘易斯选举权法案》。而且,顺便说一句,通过《披露法案》,这样美国人就可以知道谁在资助我们的选举。
今晚,我想向一个致力于为这个国家服务的人致敬:司法部长史蒂芬·布雷耶(Stephen Breyer)——一位陆军退伍军人、宪法学者,也是美国最高法院即将退休的法官。布雷耶司法部长,感谢您的服务。
总统拥有的最严肃的宪法责任之一是提名某人担任美国最高法院法官。
而我在4天前就做到了,当时我提名了联邦上诉法院法官凯坦吉·布朗·杰克逊。她是我们国家顶尖的法律智囊之一,将继续布雷耶司法部长的卓越传统。
她曾是私人执业的顶级诉讼律师。曾是联邦公共辩护律师。来自一家公立学校教育工作者和警察的家庭。一个建立共识的人。自提名以来,她得到了广泛的支持——从警察兄弟会到民主党和共和党任命的前法官。
如果我们要推进自由和正义,我们需要保护边境并修复移民制度。
我们可以做到。在我们的边境,我们安装了新技术,如尖端扫描仪,以更好地检测毒品走私。
我们与墨西哥和危地马拉建立了联合巡逻,以抓捕更多的人口贩子。
我们正在设立专门的移民法官,以便那些逃离迫害和暴力的家庭能够更快地得到审理。
我们正在确保承诺并支持南美和中美的合作伙伴,以接纳更多的难民并保护他们自己的边界。


















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











