







 https://mp.weixin.qq.com/s?__biz=MzU1MjgyOTA5NQ==&mid=2247484928&idx=1&sn=e71886d2efb49e79116db99340dbc608&chksm=fbfd6fc8cc8ae6de614c1bbd5707c3a7b77f2c65557e401e69038b0c4e25d06687f8e426edcb&token=1414993605&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzU1MjgyOTA5NQ==&mid=2247484928&idx=1&sn=e71886d2efb49e79116db99340dbc608&chksm=fbfd6fc8cc8ae6de614c1bbd5707c3a7b77f2c65557e401e69038b0c4e25d06687f8e426edcb&token=1414993605&lang=zh_CN#rd前段时间OpenAI封禁国内调用API的事情,大伙都知道了吧?老美在芯片领域卡我们脖子,还想在人工智能领域继续卡我们脖子,简直欺人太甚!好在国产大模型比较争气,性能方面已经逐渐追赶上ChatGPT4了。
作为一个开发者,必须要支持国产大模型一波,所以最近在针对国产大模型做调研测试,尝试替换为国产大模型。对我来说,只关心一个核心点——性价比!通俗点来说,就是“既要好用”、“又要便宜”、“还要速度快”。

由于OpenAI API已经几乎成为全球的事实性标准,国产大模型基本都对OpenAI API做了兼容,再叠加前段时间的百模大战以及抢占OpenAI用户,API调用价格变得非常便宜了,所以核心测试点是模型回答速度测试。
参赛选手
经过一段时间调研,我选择了一些国内比较知名的大模型进行速度测评,按照模型参数量及API调用价格,分为了三个档次,分别对应经济型、高性价比型、旗舰型。
经济型
本次参与测评的选手有:
-
来自智谱的glm-4-Flash
-
来自讯飞星火的general
-
来自月之暗面的moonshot-v1-8k
-
来自阶跃星辰的step-1-8k
-
来自百度千帆的ERNIE-Speed-8K
高性价比型
本次参与测评的选手有:
-
来自智谱的glm-4-airx
-
来自通义千问的qwen-7b-chat
-
来自讯飞星火的generalv3
-
来自月之暗面的moonshot-v1-32k
-
来自阶跃星辰的step-1-32k
旗舰型
本次参与测评的选手有:
-
来自智谱的glm-4-0520
-
来自通义千问的qwen-turbo
-
来自讯飞星火的generalv3.5
-
来自月之暗面的moonshot-v1-128k
-
来自深度求索的deepseek-chat
-
来自阶跃星辰的step-1-128k
在看具体测评结果之前,做个小调查,你认为哪些选手会表现优异呢?
评测方法
挑选不同类型的问题,整理成评测问题集,采集相关指标来对比模型的回答速度。
为了避免单次测试结果的偶然性,分别对每个模型多次进行提问,取平均值。
计算公式:回答速度 = 每次回答token数汇总 / 总耗时
模型速度对比
我挑选了问答型、推理型和翻译型这三类问题,然后随机选了一个问题对每个模型进行多次提问,由于模型回答结果太长,回答的内容就不贴出来了,整体的测试结果如下。
类型1:问答型
我的预算是一万元而且喜欢打游戏,我该买什么样的电脑呢?
经济型
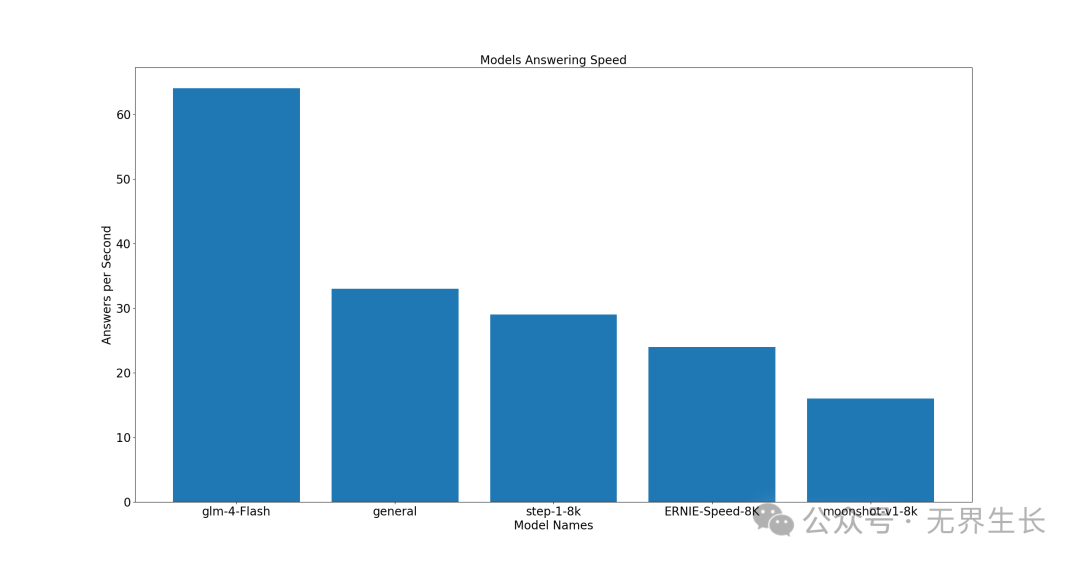
前三名分别是 glm-4-Flash、general、step-1-8k,其中 glm-4-Flash 表现亮眼。
高性价比型
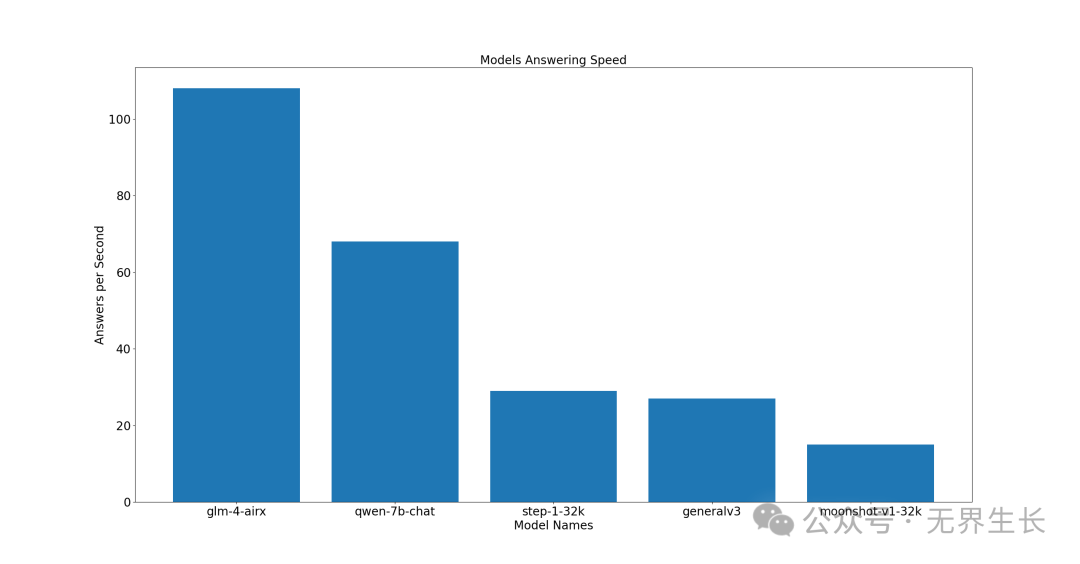
前三名分别是 glm-4-arix、qwen-7b-chat、step-1-32k。
旗舰型
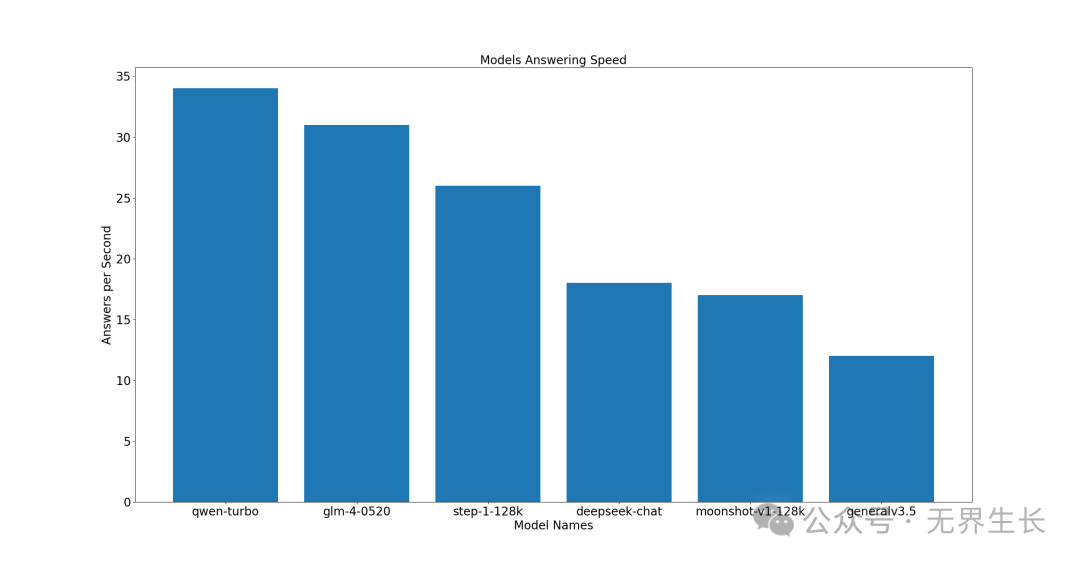
前三名分别是 qwen-turbo、glm-4-0520、step-1-128k。
类型2:推理型
答非所问就是回答;敬而远之就是不喜欢;沉默不语就是拒绝;冷战就是不怕失去;闪烁不定就是撒谎。有的事情没必要追问,因为你慢慢会发现,所有的细节都是答案。而你只是不想接受罢了。这是正方辩手描述的观点,如果你是反方辩手,该如何回答?
经济型
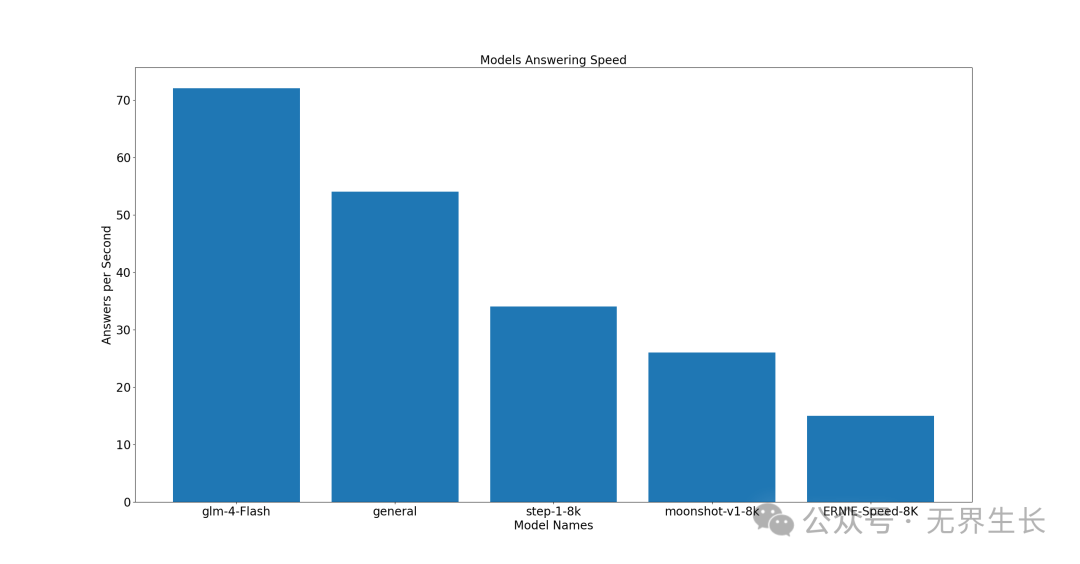
前三名分别是 glm-4-Flash、general、step-1-8k。
高性价比型
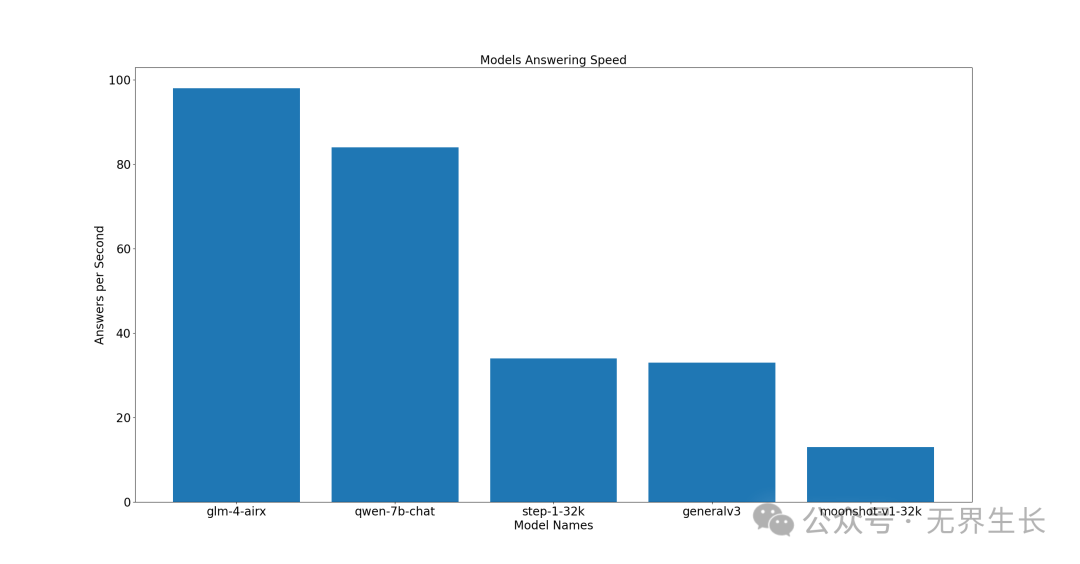
前三名分别是 glm-4-airx、qwen-7b-chat、step-1-32k。
旗舰型
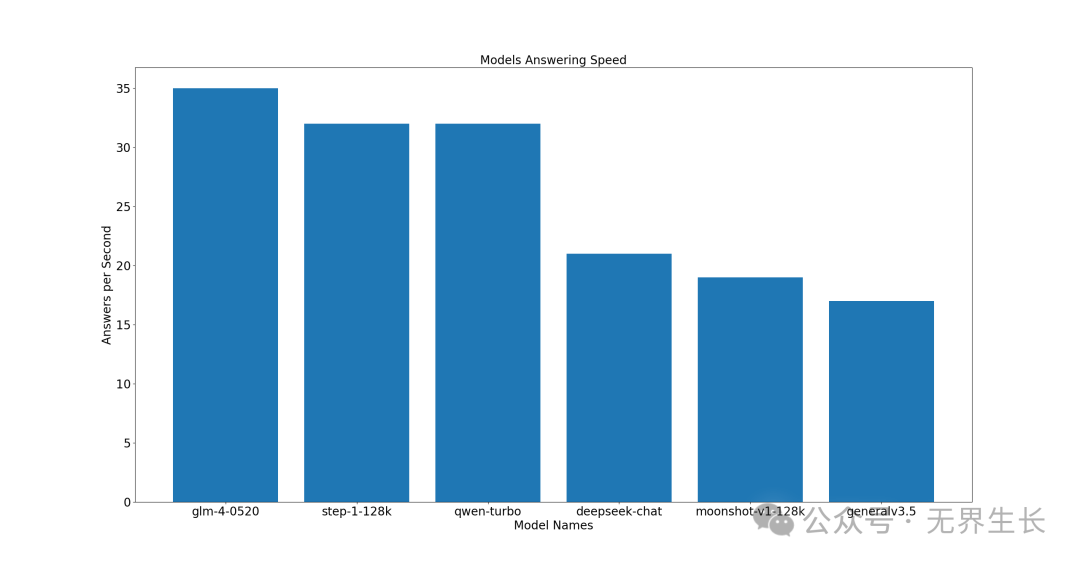
前三名分别是 glm-4-0520、step-1-128k、qwen-turbo。
类型3:翻译型
床前明月光,疑是地上霜。举头望明月,低头思故乡。把这首诗翻译成英文。
经济型
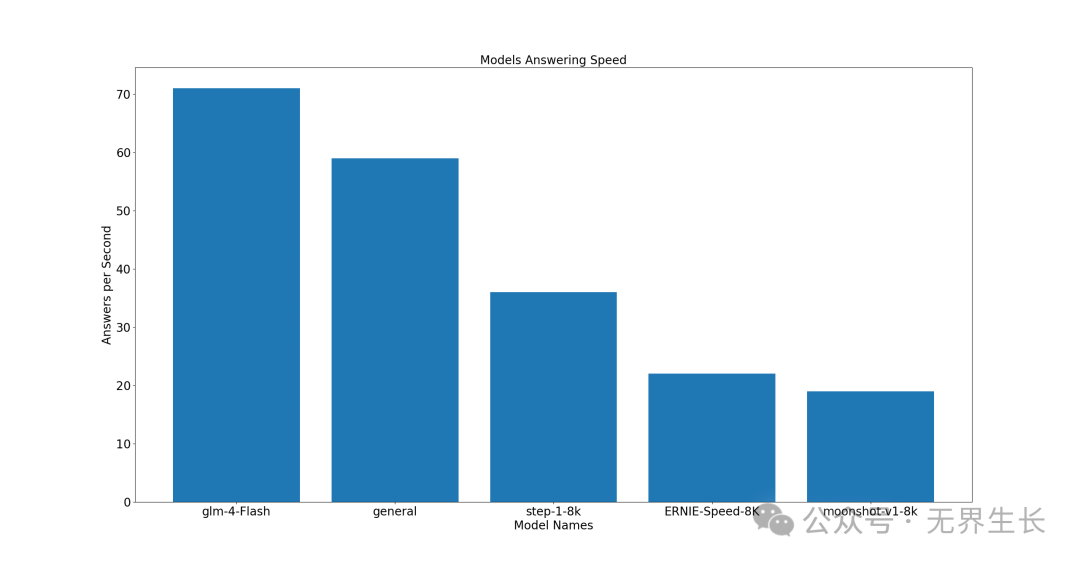
前三名分别是 glm-4-Flash、general、step-1-8K。
高性价比型
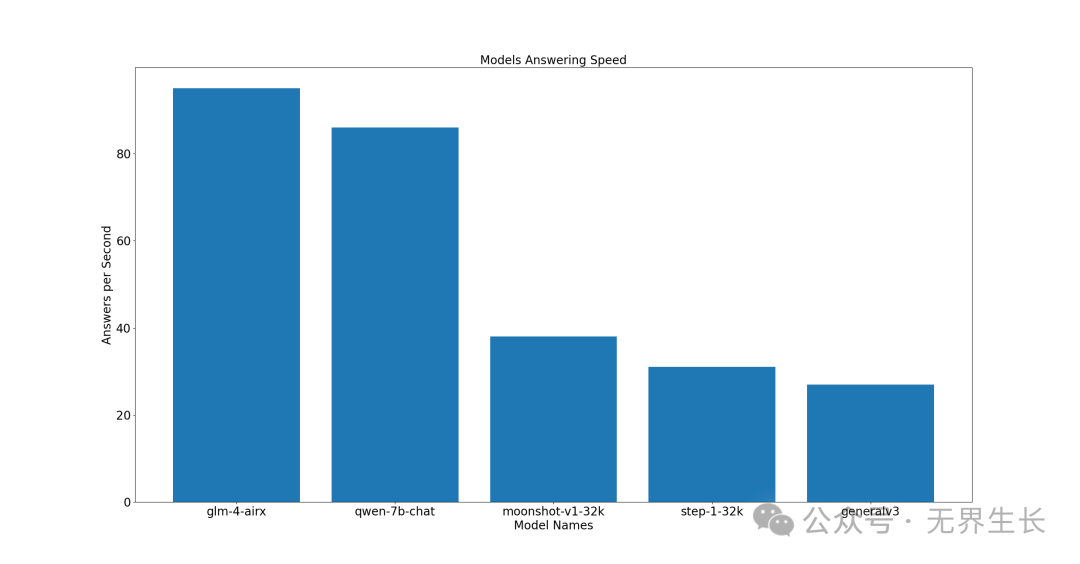
前三名分别是 glm-4-airx、qwen-7b-chat、moonshot-v1-32k。
旗舰型
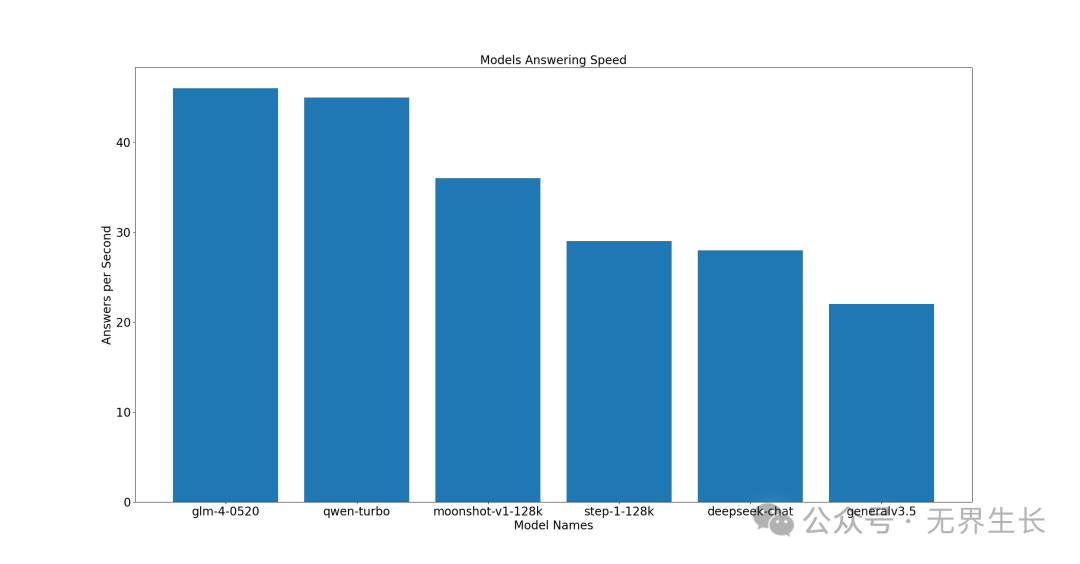
前三名分别是 glm-4-0520、qwen-turbo、moonshot-v1-128k。
评测结果
这个测评结果打破了我的固有观念,总结如下:
-
经济型:glm-4-Flash 表现亮眼,稳居第一名
-
高性价比型:glm-4-airx 表现亮眼,稳居第一名,qwen-7b-chat表现不错
-
旗舰型:qwen-turbo、glm-4-0520 表现不错,稳居前三名
如果你追求经济实惠型,glm-4-Flash 是个不错的选择;如果你追求高性价比的话,glm-4-airx 和 qwen-7b-chat 是个不错的选择;如果你追求质量,qwen-turbo、glm-4-0520 都可以考虑。
总结
我个人比较追求性价比,所以打算使用 glm-4-airx 了。原因有以下几点:
-
好用:智谱的GLM系列大模型全面对标OpenAI产品体系,可以对ChatGPT无缝替换,其他厂商都是做的兼容,代码需要额外处理
-
便宜:10元/百万tokens,还提供不设上限的Token赠送计划及专属搬家服务
-
速度快:在高性价比型测评中,稳居第一
glm-4-airx使用案例
glm-4-airx 推理过程耗时相对同类模型更少,可能是智谱有针对性做优化。为了让大家直观的感受,我在文章最后放三个glm-4-airx的使用案例。
案例1:数值比较
先来个最近比较经典的模型翻车问题,glm-4-airx 回答正确,逻辑条理清晰。
9.11和9.9哪个更大
glm-4-airx(输出174个token,耗时1.46秒)
在比较两个小数 9.11 和 9.9 的时候,首先比较它们的整数部分,都是 9,所以整数部分相同。接下来比较小数部分,首先看十分位,9.11 的十分位是 1,而 9.9 的十分位是 9。由于 9.9 的十分位大于 9.11 的十分位,所以不需要再比较后面的位数。因此,9.9 更大。
案例2:写代码
让模型写代码的问题也来一个,glm-4-airx 提供的代码非常简洁。
以123为随机种子,随机生成10个介于1(含)到999(含)之间的随机数,每个随机数后跟随一个逗号进行分隔,屏幕输出这10个随机数。
glm-4-airx(输出113个token,耗时1.29秒)
```pythonimport random# 设置随机数种子random.seed(123)# 生成10个随机数并输出random_numbers = [random.randint(1, 999) for _ in range(10)]print(','.join(str(num) for num in random_numbers) + ',')```
案例3:解读古诗词
再看看模型对古诗词理解能力,glm-4-airx 的回答也很不错。
窗前明月光,疑是地下霜。举头望明月,低头思故乡。解读这首诗
glm-4-airx(输出219个token,耗时3.05秒)
这首诗是唐代诗人李白的名作《静夜思》。以下是这首诗的解读:诗的开头“窗前明月光,疑是地上霜”描绘了作者夜晚在窗前,看到明亮的月光照进屋内,地面上的月光反射出如霜般的光芒,给人一种清冷寂静的感觉。“举头望明月”表达了诗人抬头仰望天空中的明月,月亮的明亮和圆满常常引起人们的感慨和联想。最后一句“低头思故乡”,诗人在欣赏月色的同时,内心涌起了对故乡的思念之情。低头这个动作,既可以理解为诗人因为思念故乡而感到心情沉重,也可以理解为诗人在月光下沉思。整首诗通过简洁的语言,将诗人夜晚独处时的心境和对故乡的深深思念表达得淋漓尽致。这首诗体现了诗人对自然美景的细腻感受以及浓郁的乡愁情感,是中国古典诗歌中表达乡愁情感的经典之作。
我是无界生长,关注我,带你一起玩转AI!如果你觉得我分享的内容对你有帮助,麻烦点赞、分享、在看,你的支持是我创作的最大动力!

















 2247
2247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









