







文章目录
4. Experiments
4.1. Datasets and Evaluation Protocols
\quad \quad CASIA-B是最流行的用于评估的步态数据集,包含 124 个受试者。共有三种步行条件:正常步行(NM,每个受试者 6 个序列)、提包步行(BG,每个受试者 2 个序列)和穿着不同衣服步行(CL,每个受试者 2 个序列)。在每种条件下,受试者在 11 个视角(0°180°,间隔 18°)中采样。为了评估性能,选取 74 个受试者进行训练,其余 50 个受试者进行测试。在测试过程中,NM条件(NM#1-4)的前4个序列被视为gallery,其余6个序列(NM#5-6、BG#1-2和CL#1-2)被视为probe。
\quad \quad OU-MVLP是最大的公共步态数据集。由10307个受试者(5153个训练受试者,5154个测试受试者)组成。然而,对于每个受试者,只有正常步行的序列(NM,每个受试者 2 个序列)可用。每个主体有14个视角,这14个视角以15°的间隔均匀分布在[0°,90°]和[180°,270°]之间。在测试阶段,索引#01 的序列被分组到gallery中,而索引#02 的序列被分组到probe中。
4.2. Implementation Details
\quad \quad
所有模型都在 PyTorch中实现并随机初始化。采样模块采用Mixture机制。为确保相邻帧的空间中心一致,使用前两帧对应部分的中心偏移量
(
Δ
x
,
Δ
y
)
(\Delta x, \Delta y)
(Δx,Δy)对每个部位的先验空间中心位置参数
(
c
x
,
c
y
)
\left(c_{x}, c_{y}\right)
(cx,cy)进行平滑,即,
c
^
x
t
=
c
x
t
+
(
Δ
x
t
−
1
+
Δ
x
t
−
2
)
/
2
,
c
^
y
t
=
\hat{c}_{x}^{t}=c_{x}^{t}+\left(\Delta x^{t-1}+\Delta x^{t-2}\right) / 2, \hat{c}_{y}^{t}=
c^xt=cxt+(Δxt−1+Δxt−2)/2,c^yt=
c
y
t
+
(
Δ
y
t
−
1
+
Δ
y
t
−
2
)
/
2
c_{y}^{t}+\left(\Delta y^{t-1}+\Delta y^{t-2}\right) / 2
cyt+(Δyt−1+Δyt−2)/2.使用 [27] 中提出的方法对轮廓进行预处理。在mini-batch中,CASIA-B 的受试者数量和每个受试者的序列数量设置为 (8, 16),OU-MVLP 设置为 (32, 16)。在训练阶段,根据[7]对序列进行采样,随机水平翻转。Adam优化器学习率设置为
1
e
−
4
1 e-4
1e−4。在 CASIA-B 中,模型经过
120
k
120k
120k次迭代训练。在 OU-MVLP 中,迭代次数设置为
250
k
250k
250k,在
150
k
150k
150k次迭代时学习率降低到
1
e
−
5
1e-5
1e−5。为了评估,采取步态序列的所有轮廓以获得最终表示。由于OU-MVLP的序列比CASIA-B多20倍,将卷积层中的通道数加倍(C1=C2=64,C3=C4=128,C5=C6=256)。为了与GLN进行公平比较,采用相同的紧凑块和交叉熵损失。详细信息可以在 [11] 中找到。CASIA-B 上的实验分别在两种输入尺寸(
64
×
44
64 \times 44
64×44 和
128
×
88
128 \times 88
128×88)上进行。
4.3. Comparison with State-of-the-Art Methods
\quad \quad CASIA-B. 表1展示了3D局部CNN与所有最先进模型相比的优势。与 GaitSet和GLN相比,3D 局部 CNN 在两种输入尺寸下明显表现出更好的性能。在最具挑战性的穿着不同衣服(CL)行走的条件下,3D局部CNN超过 GaitSet13.0%和GLN6.8%。GaitSet和GLN 都将轮廓视为一个集合,而不是一个序列。这一结果揭示了在序列中处理局部运动模式的优越性,而不是在没有顺序信息的集合中。
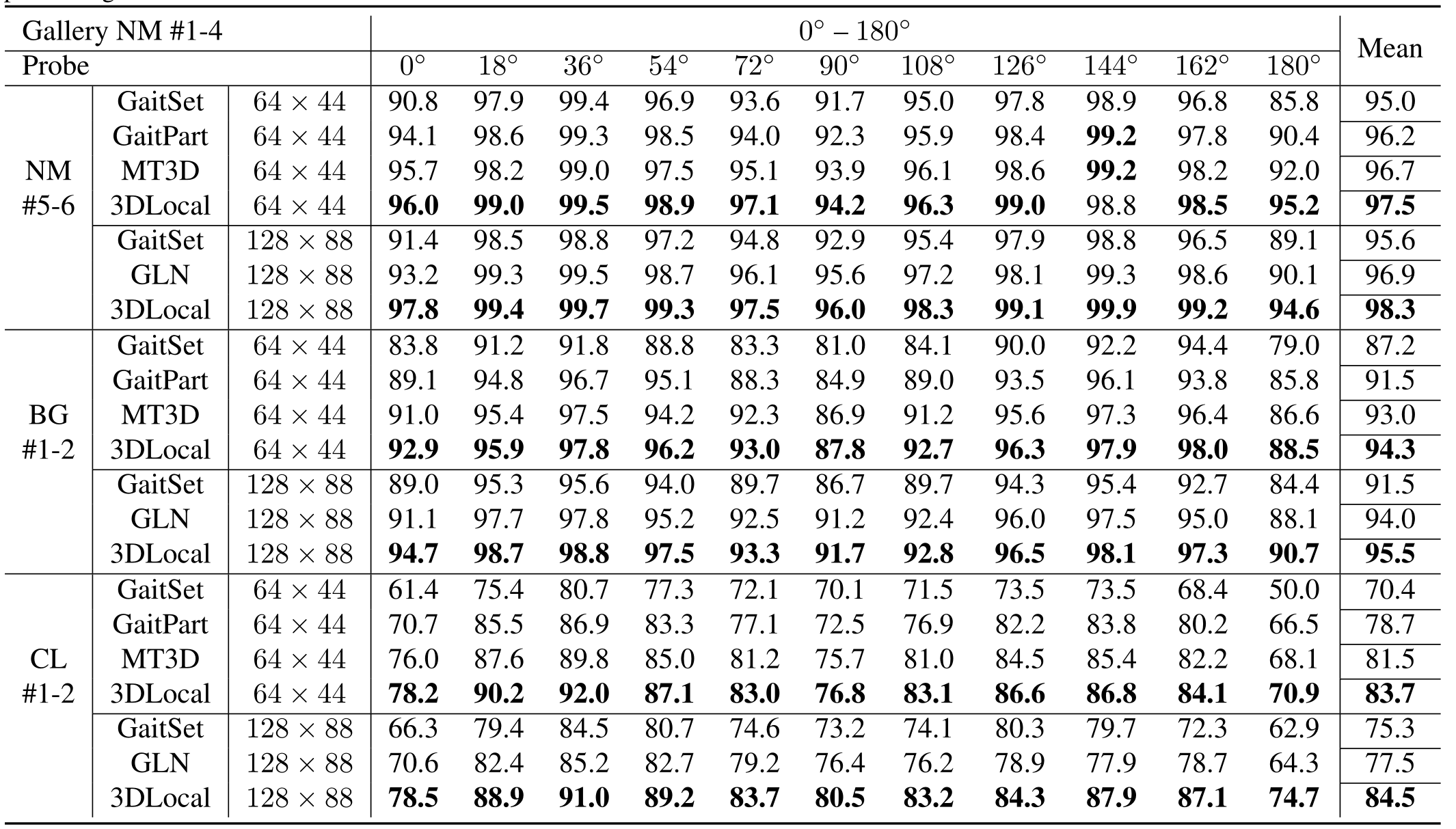
\quad \quad 与GaitPart相比,本文的方法也有很大的优势。这一结果表明,本文的三维局部体积操作具有自适应的时空位置、尺度和长度,比水平地将特征图分割成条带作为部位,能更有效地捕捉局部部位信息。更重要的是,本文的方法在CL情况下超过了其他方法,具有很大的性能优势。在CL场景中,与视觉上的外观相比,大的外观变化使得时间变化特征(步态的核心概念)在识别中占主导地位。因此,本文的3D局部CNN在学习核心步态表示方面比 SOTA 方法要好得多。
\quad \quad
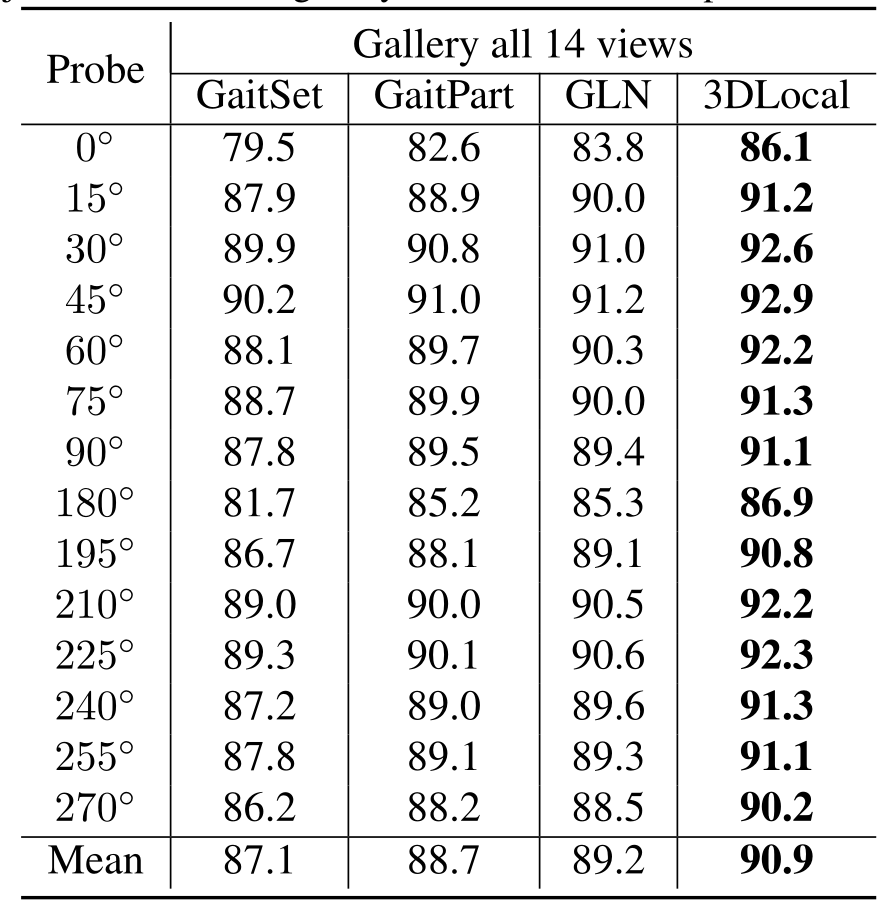
OU-MVLP. 如表 2 所示,3D 局部 CNN 在所有跨视角条件下都实现了最佳性能。对于某些probe序列,gallery中没有对应的序列。如果丢弃probe中没有相应样本的受试者,则所有probe视角的平均rank1准确率为96.5%,而GaitSet为93.3%,GaitPart为95.1%,GLN为95.6%。
表2. OU-MVLP的平均rank-1准确性,排除了GaitSet、GaitPart和GLN的相同视角情况。为了评估,每个受试者的第一个正常行走(NM)的序列被作为gallery,其余的作为probe。
4.4. Ablation Experiments
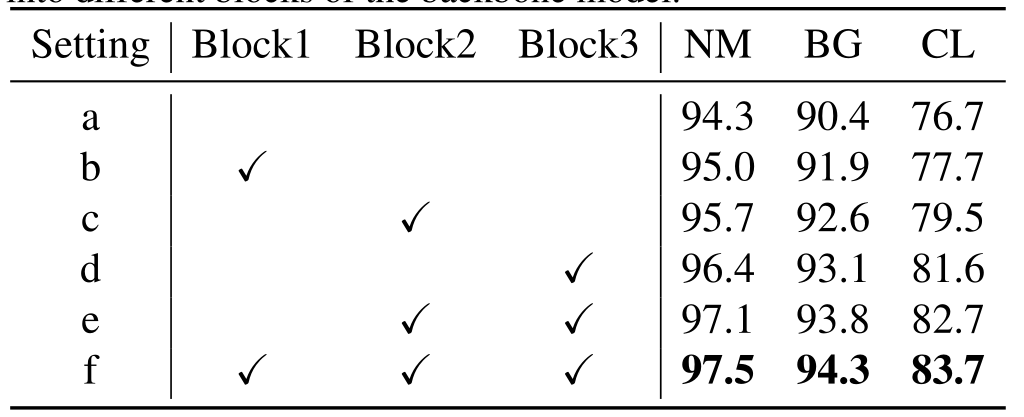
\quad \quad Architecture. 首先研究将提出的局部操作插入到主干模型的不同块时的性能。结果总结在表3中。将本文的 3D 局部块插入主干模型的任何块都可以带来显著的性能提升。这验证了在构建块中合成全局和 3D 局部信息的设计是合理的。将 3D 局部块插入较高层往往比将它们插入较低层表现更好。这是因为在更高层中,学习特征的表达能力足以传达明确定义的人体部位的语义概念。
\quad \quad Sampling. 在第3.2.2节中,叙述了采样模块的三种变体:高斯(Gaussian)、三线性(Trilinear)和混合(Mixture)。表 4 显示了分别应用这三种采样机制的结果。可以看到这三种设置具有比较好的性能,这表明本文的3D局部操作是通用的,并且本文的模型对采样模块的特定实现不敏感。

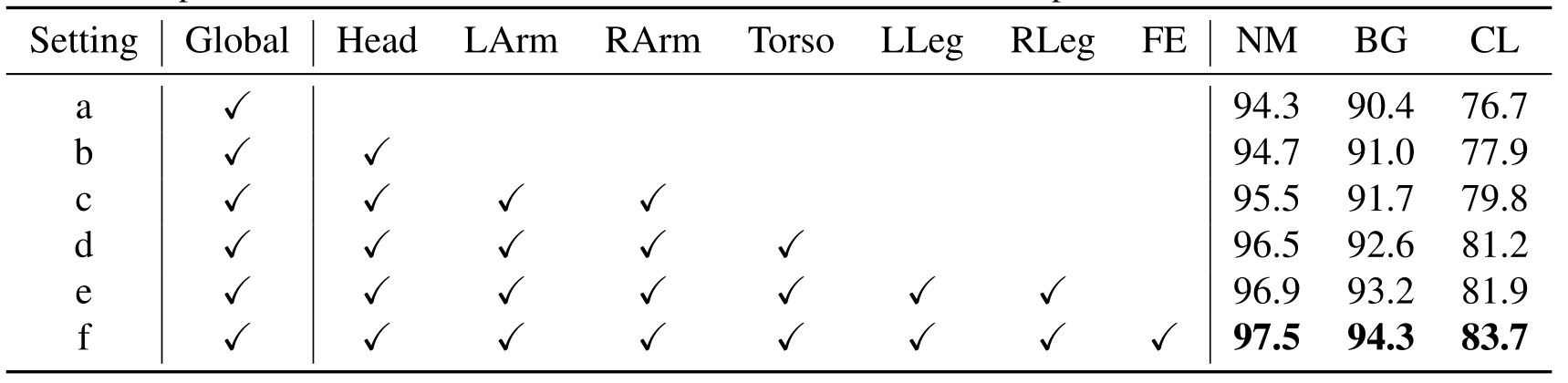
\quad \quad Local Path and Feature Extraction. 为了验证本文的局部操作的有效性,在CASIA-B上展示了带有和不带有局部路径或特征提取模块的模型的性能。在表5中,(a)表示没有局部操作。从(b)到(e),逐渐添加局部路径。(f) 使用特征提取模块表示特征。可以看到,具有局部操作的模型始终优于不具有局部操作的模型,这表明对局部操作的设计是合理的。有FE的模型比没有FE的模型取得了更好的性能。目前,FE模块的实现非常简单。作者相信,更复杂的FE架构将带来更多的性能增益。
表5. 在CASIA-B上,不同设置下的局部操作的性能。“Head”、“LArm”、“RArm”、“Torso”、"LLeg "和 "RLeg "表示六个不同的局部路径。"FE "表示所有局部路径的特征提取模块。尺寸: 64 × 44 64\times 44 64×44。
\quad \quad Sampled Sequences. 除了部位体积中心的先验位置,定位模块是以完全无监督的方式学习的。图4(a)显示了不同局部路径的采样模块的结果。由于空间有限,选择了三个最有区别的分支:右臂、左腿和右腿。对于左腿的运动轨迹来说,可以是一个原始的步态周期。左腿和右腿的采样序列来自不同的时间段。这表明,即使在很少的监督下,3D局部CNN也能成功地学习不同部位的自适应空间位置、尺度和时间长度。
\quad \quad
Fusion of Global and Local Paths. 为了检查该模块如何合成全局和局部特征,将输入特征图、输出特征图和特征融合模块中卷积层的权重可视化。图4(b)显示了输出特征图和输入特征图,表明不同的分支是相互补充的,因为它们关注的是不同的区域。综合不同分支的特征可以使输出特征更具信息性和区分性。平均融合权重附在每个相应的特征图上,显示每条路径都对输出有贡献(所有系数都是非零)。

图4. 不同局部路径的可视化。(a): 三维局部CNN块中的右臂、左腿和右腿路径的采样序列。不同的局部部分有不同的空间位置、尺度和时间长度。(b): 带有最大系数的全局和局部特征图,以及输出特征图。不同的分支是相互补充的,因为它们专注于不同的区域。平均的融合权重 w w w附在每个特征图上方。每条路径都对输出有贡献(所有系数都是非零)。
5. Conclusion
\quad \quad
本文提出了一个新的三维CNN的构建模块,其中包含了局部信息,被称为三维局部卷积神经网络。本文的局部操作可以与任何现有的架构相结合。展示了局部操作在步态识别任务上的优越性,其中 3D 局部 CNN 始终优于最先进的模型。希望这项工作能对引入简单而有效的局部操作作为现有卷积构件的子模块的更多研究有所启示。
参考文献
[7] Chao Fan, Yunjie Peng, Chunshui Cao, Xu Liu, Saihui Hou, Jiannan Chi, Yongzhen Huang, Qing Li, and Zhiqiang He. Gaitpart: Temporal part-based model for gait recognition. In CVPR, pages 14225–14233, 2020. 2, 6, 7
[11] Saihui Hou, Chunshui Cao, Xu Liu, and Yongzhen Huang. Gait lateral network: Learning discriminative and compact representations for gait recognition. In ECCV, pages 382– 398. Springer International Publishing, 2020. 2, 3, 6, 7
[27] Noriko Takemura, Yasushi Makihara, Daigo Muramatsu, Tomio Echigo, and Yasushi Yagi. On input/output architectures for convolutional neural network-based cross-view gait recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2017. 7


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











