






metaProbiotics:利用语言模型从宏基因组分箱数据中挖掘益生菌
metaProbiotics: a tool for mining probiotic from metagenomic binning data based on a language model

Article,2024-03-14,Briefings in Bioinformatics,[IF 9.5]
DOI:https://doi.org/10.1093/bib/bbae085
原文链接:https://academic.oup.com/bib/article/25/2/bbae085/7628548
第一作者:吴姝芳
通讯作者:周宏伟,hzhou@smu.edu.cn;方臻成,fangzc@smu.edu.cn
主要单位:
南方医科大学珠江医院检验医学部微生态医学中心 (Microbiome Medicine Center, Department of Laboratory Medicine, Zhujiang Hospital, Southern Medical University, Guangzhou, China)
2024年3月14日,南方医科大学珠江医院周宏伟团队在Briefings in Bioinformatics在线发表了题为 “metaProbiotics: a tool for mining probiotic from metagenomic binning data based on a language model” 的研究文章。本研究利用人工智能语言模型,引入了一种从宏基因组分箱数据中识别益生菌的新型计算方法。这种方法促进了新益生菌的发现,并提供了一个新颖的视角,系统地阐明了益生菌群落在维持宿主健康中的特性和异质性表现。
- 摘要 -
大量益生菌仍未被充分挖掘与研究。由于缺乏系统化的方法,理解益生菌群落的特性变得具有挑战性,不同文献对益生菌的益生效果往往会有不同的结论。我们开发了基于语言模型的metaProbiotics工具,该工具可从宏基因组中快速检测出来自益生菌的分箱(bins)。在模拟的基准数据集中,metaProbiotics显示出了优越的性能。在利用接受益生菌处理的个体的肠道宏基因组对metaProbiotics进行测试时,我们发现该工具可揭示源于干预菌的bins的益生属性,且能识别出不包含在训练数据中但展示出有益生功能的bins,例如一个质粒样的bin。对这些bins的基因功能分析表明,这些bins具有多种益生机制,且bai操纵子可能是具有益生功能的Ruminococcaceae科的潜在生物标志。我们在不同的健康-疾病队列中,发现上述bins在健康个体中的整体丰度更高,表明它们具有益生作用。然而,我们难以利用这些bins的丰度特征进行跨疾病类型的健康状态预测。为了更好地理解益生菌的异质性,我们使用metaProbiotics从全球肠道宏基因组数据中构建了一个全面的益生菌基因组集。对该集合的模块分析显示,患病个体通常缺少某些益生菌基因模块,并且不同疾病中缺失的模块存在显著差异。此外,同一益生菌上的不同基因模块对各种疾病有着异质性的影响。因此,我们认为,与仅仅增加特定基因的丰度相比,益生菌群落的基因功能完整性在维持肠道稳态中更为关键,盲目地增加特定益生菌可能不会促进健康。我们期望这种新颖的基于语言模型的metaProbiotics工具将促进基于大规模宏基因组数据的新型益生菌挖掘,并促进对细菌益生效应的系统研究。metaProbiotics程序可以在以下网址免费下载:https://github.com/zhenchengfang/metaProbiotics。
- 关键点 -
(1)metaProbiotics工具使用词向量语言模型来表征DNA序列,采用随机森林算法从宏基因组数据中迅速识别出来源于益生菌的分箱,并在模拟基准数据集中展示出优越的性能。
(2)在利用接受益生菌干预的个体的肠道宏基因组进行测试时,metaProbiotics能够更好地识别具有益生性能的分箱,包括一个显示出与干预菌株具有协同益生功能的质粒样分箱。
(3)基因功能分析结果显示,metaProbiotics识别出的益生菌分箱具有多种益生机制,而bai操作子是一些具有益生活性的Ruminococcaceae的潜在关键标记。
(4)metaProbiotics识别出的益生菌分箱可以作为抵抗多种疾病的保护因子,标志着它们的益生作用。
(5)使用metaProbiotics进行的大规模益生菌分析显示,与仅仅增加特定基因的丰度相比,益生菌群落的基因功能完整性在维持肠道稳态方面更为关键;由于同一益生菌上的不同基因模块对各种疾病有着异质性影响,盲目添加益生菌可能不会促进健康。
- 引言 -
根据世界卫生组织(WHO)的定义,益生菌是一种活的微生物,当以足够的量给予宿主时,可以对宿主产生健康益处。一些研究相对充分的细菌显示出了多种不同的益生菌特性,例如保护肠道屏障、免疫调节、调节肠道菌群、代谢调控以及通过肠脑轴缓解精神疾病。鉴于益生菌对宿主的健康益处,近年来为发现新的益生菌及理解其益生机制做出了巨大努力,预计到2027年,益生菌市场将达到854亿美元。
然而,确定一个微生物是否为益生菌可能需要基于多个复杂因素进行全面评估,并且需要长时间的临床试验。目前,许多益生菌的分子机制仍然未知。特别是,许多肠道共生细菌是下一代益生菌(NGPs)的潜在候选者,但其培养上的困难常常阻碍了生理学研究。在临床上,选择和验证一个益生菌菌株通常涉及一个耗时的随机对照试验(RCT),而且出于安全性的考虑,只有某些常见的属,例如Lactobacillus(已被重新分类为25个属,即修正后的Lactobacillus属、Paralactobacillus属和23个新属)和Bifidobacterium,能用于进行大规模的RCT。令人困惑的是,不同的研究和报告中关于某些细菌的益生效果常常出现冲突的结果。由于细菌与宿主之间复杂的相互作用,如果没有一套系统的方法在微生物群落中对益生菌进行表征,阐明它们在维持宿主健康中的具体作用将是一项挑战。
随着大量宏基因组数据的积累,机器学习方法使得绕过上述困难、通过脱氧核糖核酸(DNA)数据进行系统的、大规模的益生菌挖掘成为可能。这种技术可以从带标签的数据集中提取决策规则,并对新数据进行有效评估。它们近期在微生物基因组注释任务中的应用,以及目前已知益生菌基因组数据量的持续积累,凸显了这些方法在益生菌挖掘领域的潜力。
Sun等人开发了一种相关工具,iProbiotics,它利用k-mer频率来表征完整的细菌基因组,并采用支持向量机算法进行益生菌的识别。尽管iProbiotics在完整细菌基因组的验证中已被证明有效,但其在宏基因组中的基因组草图的效果仍然不确定。尽管k-mer频率模型在各种生物信息学任务中得到应用,但它主要捕捉寡核苷酸出现频率,可能无法反映序列功能。k-mer的局限性包括保守区域的冗余、缺乏特异性以及高k值时特征空间维度过高。由于序列拼接的困难,宏基因组序列经常是碎片化的,这可能导致k-mer频率的波动。近年来,自然语言处理(NLP)技术提供了新颖的生物序列表示方法。在这种模型中,寡核苷酸或寡氨基酸被视为“单词”,而DNA或蛋白质序列被视为“句子”。通过在大型数据集上进行无监督预训练,每个“单词”都映射到一个基于上下文的特征向量,具有提供比k-mer频率更有信息量的表示的潜力。这种方法在如抗菌肽预测、分泌效应物识别、微生物基因功能预测以及人类-病毒-蛋白质相互作用预测等任务中显示出优越性。
在这项研究中,我们开发了metaProbiotics工具,该工具使用词向量对宏基因组分箱(bin)中的DNA序列进行数字化表征,并采用随机森林来识别来源于益生菌的分箱。在使用序列组装和分箱工具对宏基因组原始数据进行拼接与分箱后,用户可以利用metaProbiotics来从分箱数据中识别益生菌。我们的目标是克服用于益生菌发现的传统方法(如湿实验和临床试验)的局限性。这种方法为生物学家提供了一种高效、系统的方法来表征益生菌群落。metaProbiotics程序可以在https://github.com/zhenchengfang/metaProbiotics免费下载。
- 结果 -
通过无监督预训练构建用于序列表征的词向量
The unsupervised pretrained word vector for sequence representatio
metaProbiotics的构建过程主要分为两个步骤,如图1所示。在无监督预训练过程中,我们使用NCBI数据库中的120个原核生物参考基因组序列(https://ftp.ncbi.nlm.nih.gov/genomes/GENOME_REPORTS/prok_reference_genomes.txt)作为‘语料库’。我们采用skip-gram算法,基于DNA中的核苷酸序列的上下文信息,将每8个核苷酸的组合(8-mer)映射到一个100维的词向量上。对于给定的DNA序列(包括来自完整的基因组、宏基因组片段,以及宏基因组bin中一组片段的DNA序列),我们使用序列上所有8-mer的平均词向量来表示这些序列。
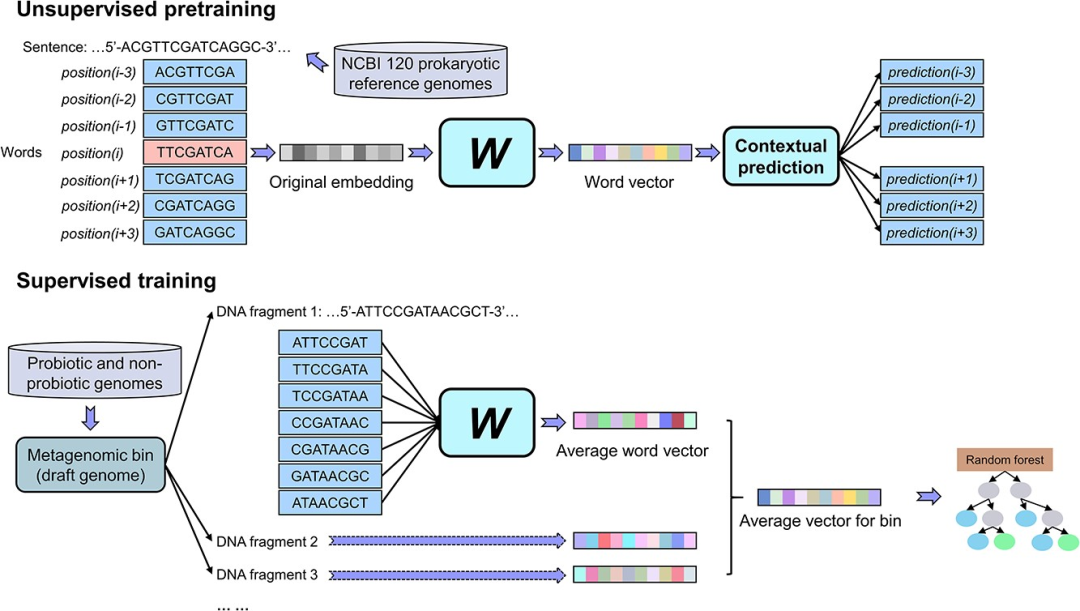
图1 metaProbiotics的构建流程。
metaProbiotics的开发主要分为两个步骤。在无监督预训练的步骤中,我们使用skip-gram算法将每个8-mer转换为一个词向量语言模型。在有监督训练的步骤中,我们将词向量作为DNA序列的数学模型,并利用经过实验验证的益生菌和非益生菌基因组数据,构建了一个用于在宏基因组中识别益生菌分箱的随机森林算法。
采用词向量模型,我们对Sun等人收集的覆盖69个物种的237个经过实验验证的益生菌基因组、以及覆盖105个物种的470个非益生菌基因组进行了特征向量的构建(数据链接:http://bioinfor.imu.edu.cn/iprobiotics/public/Download,以下简称Sun数据集)。
传统的k-mer模型只是对DNA中各种核苷酸字符串的频率进行量化,无法捕获不同核苷酸组合中的生物化学特性。相较之下,词向量模型通过在不同序列中分析核苷酸字符串上下文,将上下文相似的核苷酸字符串映射到相似的空间坐标。这种空间表征能够有效地反映出核苷酸序列的生物化学特性,从而增强了对物种生物功能的表征能力。为了比较词向量模型与传统k-mer模型的优势,我们对益生菌和非益生菌的8-mer词向量和8-mer模型进行了tSNE降维和可视化分析,并重点关注它们的空间分布特性(如图S1A、S1C所示)。我们发现,在两种模型中,益生菌都明显地聚集在一起。在8-mer模型和词向量的tSNE图中,益生菌基本上都聚成了四簇。然而,在8-mer模型中,有一个益生菌聚类簇被非益生菌包围,并且在使用k-means聚类后,该簇倾向于与周围的非益生菌聚在一起(如图S1C、S1D所示),这表明8-mer模型不能在坐标空间中完美地区分益生菌。相较之下,在词向量的tSNE图中,益生菌聚类并未明显地被非益生菌包围,并且在k-means聚类后,形成了相对独立的分组(如图S1A、S1B所示)。我们进一步使用与标签信息无关的轮廓系数和依赖于标签信息的互信息来评估聚类效果。词向量模型中每个聚类簇的轮廓系数显著高于8-mer模型(如图S1E所示,采用秩和检验,p=9.42e-19***),词向量模型聚类的互信息分值也大于8-mer模型(如图S1F所示),这体现了词向量模型在表征益生菌功能方面的优越性。
我们进一步采用自然语言处理中的余弦相似度方法,来评估词向量模型是否能够准确地表现出益生菌的基本特性。作为临床前评估的重要项目,益生菌应具备在肠道内强大的生存和定殖能力。我们发现,与细菌定殖能力相关的基因(包括与胆汁酸耐受性相关的clpE和dps;与胆汁盐水解酶相关的bsh;与耐酸性相关的gadC;与重金属清除能力相关的msrB;与持久性相关的clpC;与竞争能力相关的copA和met;与粘附能力相关的ispA;与生长能力相关的treC;以及与吸附能力相关的lsp)的词向量与益生菌之间的平均余弦相似度,显著高于这些基因与非益生菌的词向量之间的余弦相似度(如图2A所示)。
益生菌的另一项关键特性是其碳水化合物的代谢能力,包括将特定的碳水化合物转化为丙酸、乳酸或乙酸。我们对碳水化合物活性酶数据库(CAZy)中的六大类别家族的平均词向量进行了计算,这些家族包括辅助模块酶(AA)、碳水化合物结合模块(CBM)、碳水化合物酯酶(CE)、糖苷水解酶(GH)、糖苷转移酶(GT)和多糖裂解酶(PL)。接着,我们计算了这六大类别家族与益生菌以及非益生菌的余弦相似度。结果显示,每个CAZy家族与益生菌的平均余弦相似度显著高于与非益生菌的余弦相似度(如图2B所示)。
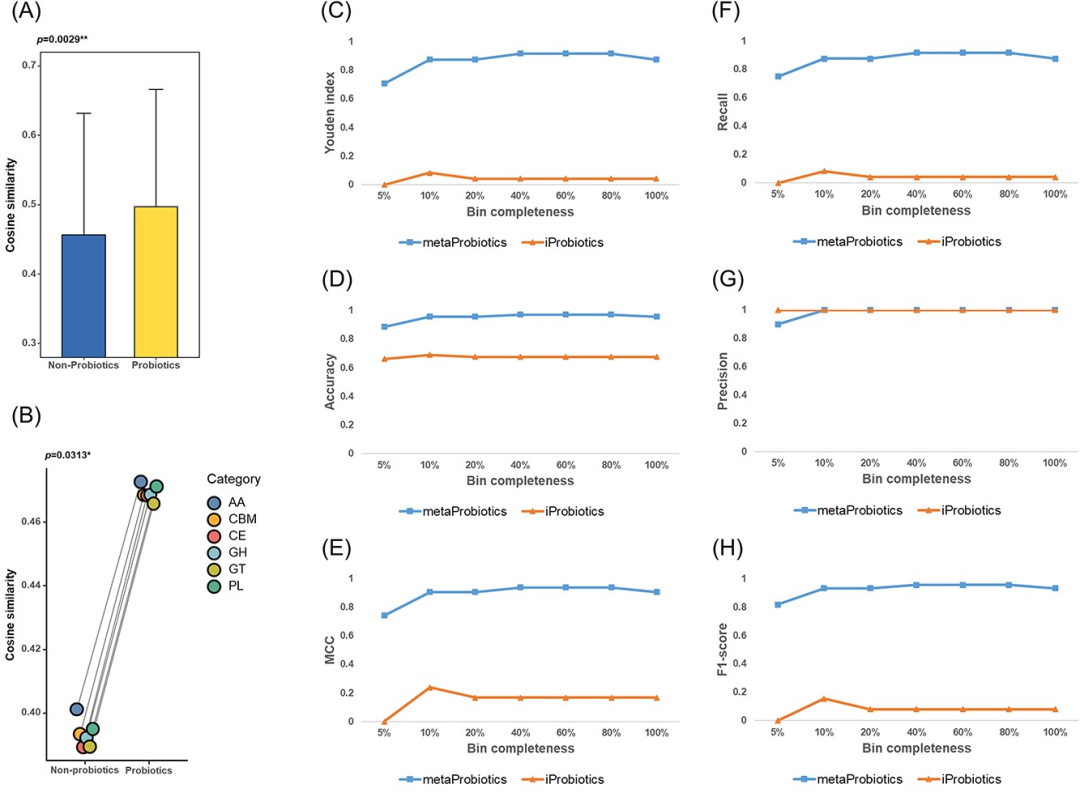
图2 基于余弦相似度来刻画词向量模型在表征益生菌属性中的能力(A-B),以及使用模拟的宏基因组分箱基准数据集来比较metaProbiotics和iProbiotics的性能(C-H)。
(A)我们计算了细菌基因组与和生存、定殖能力相关的基因(包括clpE、dps、bsh、gadC、msrB、clpC、copA、met、ispA、treC及lsp)之间的词向量平均余弦相似度。结果显示,与非益生菌相比,益生菌的余弦相似度显著更高(p=0.0029**,秩和检验)。
(B)我们计算了细菌基因组与碳水化合物活性酶数据库(CAZy)每个类别的基因之间词向量的平均余弦相似度。结果显示,与非益生菌相比,益生菌的余弦相似度显著更高(p=0.0313*,配对样本秩和检验)。
(C-H)使用不同完整性的测试集分箱来比较metaProbiotics和iProbiotics的性能,评价指标包括(C)Youden index、(D)accuracy、(E)MCC、(F)recall、(G)precision和(H)F1-score。
总的来说,无监督的词向量模型可以有效区分益生菌和非益生菌,并能着重表征出益生菌的相关属性。
对基于监督学习的随机森林模型的益生菌挖掘算法进行基准测试
Benchmarking the supervised random forest for probiotic mining
在监督训练阶段,我们利用词向量模型开发了一个用于挖掘益生菌的随机森林模型。我们首先将Sun数据集的基因组按照9:1的比例划分为训练集和测试集(参见表S1)。为了进行基准测试,我们从Sun数据集的完整基因组中随机提取DNA片段,构造模拟的宏基因组分箱。考虑到从宏基因组中重构出完整基因组的难度较大,我们构建了基因组完整性在5%到100%之间、序列长度均匀分布在2,000-20,000 bp之间的分箱。我们采用预训练的词向量模型编码这些分箱,在对训练集进行10倍交叉验证后,我们最终选择了随机森林模型作为分类器,因为它在准确率和曲线下面积(AUC)上的表现优于其他算法(参见图S2和图S3)。
在训练集分箱上完成了随机森林的监督训练过程后,我们使用基准测试集分箱来评估metaProbiotics和iProbiotics的性能。评估的指标包括Youden index、accuracy、Matthews correlation coefficient (MCC)、recall、precision和F1-score。在所有不同完整度的分箱中,metaProbiotics的表现一直优于iProbiotics(如图2C-H所示)。尽管metaProbiotics在5%完整性分箱中的性能略有下降,其在其他情况下性能都相对稳定。相比之下,iProbiotics在处理碎片化的宏基因组数据时表现不佳,特别是在Youden index和MCC这两个对预测偏差敏感的指标上。值得注意的是,iProbiotics经常将碎片化数据中的序列错误地分类为非益生菌,从而导致评估指标值的下降。以Lactobacillus属为例,我们评估了metaProbiotics对同一菌属不同菌种的益生菌预测能力,在对测试集中的Lactobacillus分箱进行的评估中,metaProbiotics的AUC达到了94.31%(如图S4),这充分证明了metaProbiotics在物种级别上具备优异的识别能力。
我们进一步收集了NCBI数据库中的Lactobacillus属和Bifidobacterium属菌株的基因组草图,包括通常被视为益生菌的Lactobacillus paracasei(最近被重新划分为Lacticaseibacillus paracasei)和Bifidobacterium breve,同时也收集了通常不被视为益生菌的L. iners的基因组草图。我们发现,对于L. iners的基因组草图,metaProbiotics和iProbiotics都将其预测为非益生菌。对于通常被认为是益生菌的物种,metaProbiotics能大体上将这些基因组草图预测为益生菌,而iProbiotics仅识别出了少数高质量的Lc. paracasei基因组草图(平均重叠群长度大于20,000 bp,N50大于60,000 bp)为益生菌(见表S2、S3和S4)。这表明metaProbiotics对基因组完整性的要求相对较低,使其更适合在复杂的宏基因组数据中挖掘益生菌。我们通过文献搜索收集了六个最近分离和测序的Bifidobacterium菌株的基因组,这些菌株被报道具有益生菌功能(详见表S5获取accession)。我们发现metaProbiotics成功地将它们全部预测为益生菌,这进一步证明了metaProbiotics在识别未知益生菌菌株方面的潜力。
这些研究结果显示,metaProbiotics在分析碎片化且完整性较低的宏基因组数据上表现出色,适合用于挖掘益生菌,尤其是用于挖掘难以从宏基因组分离培养的新型益生菌。
使用真实肠道宏基因组数据验证metaProbiotics性能的应用案例
Application case for testing metaProbiotics with real gut metagenome
由于数据标签的缺失,真实的宏基因组数据常常难以用于评价专门为宏基因组数据分析设计的工具。为了更直观地展示metaProbiotics在实际场景中的性能,我们采用了接受益生菌干预的人群队列的肠道宏基因组作为验证数据,其中来自干预菌株的分箱被作为标签数据,用于对metaProbiotics的定量评估。
我们采用了两个样本队列的数据(详见表S6获取样本accession):一组样本接受了益生菌Lc. casei Zhang的干预(共30个样本,记为LcZ组,样本来源于纵向数据),另一组样本接受了B. longum AH1206的干预(干预亚组总共22个样本,记为BlA组)。这两组队列的测序数据都经过了序列拼接和分箱步骤。最终,我们在LcZ组中得到了209个分箱,在BlA组中得到了728个分箱,其中有大量的分箱完整性较低(图S5,S6)。通过计算与Culturable Genome Reference(CGR)数据库中基因组的平均核苷酸一致性(ANI),我们对metaProbiotics识别为益生菌的分箱进行物种注释。在这两组中,有大量的分箱无法归类到特定的属(如图3A所示),这表明metaProbiotics识别的大部分益生菌要么来自新物种,要么来源于不可单独培养的属。这凸显了metaProbiotics挖掘新型益生菌的巨大潜力。
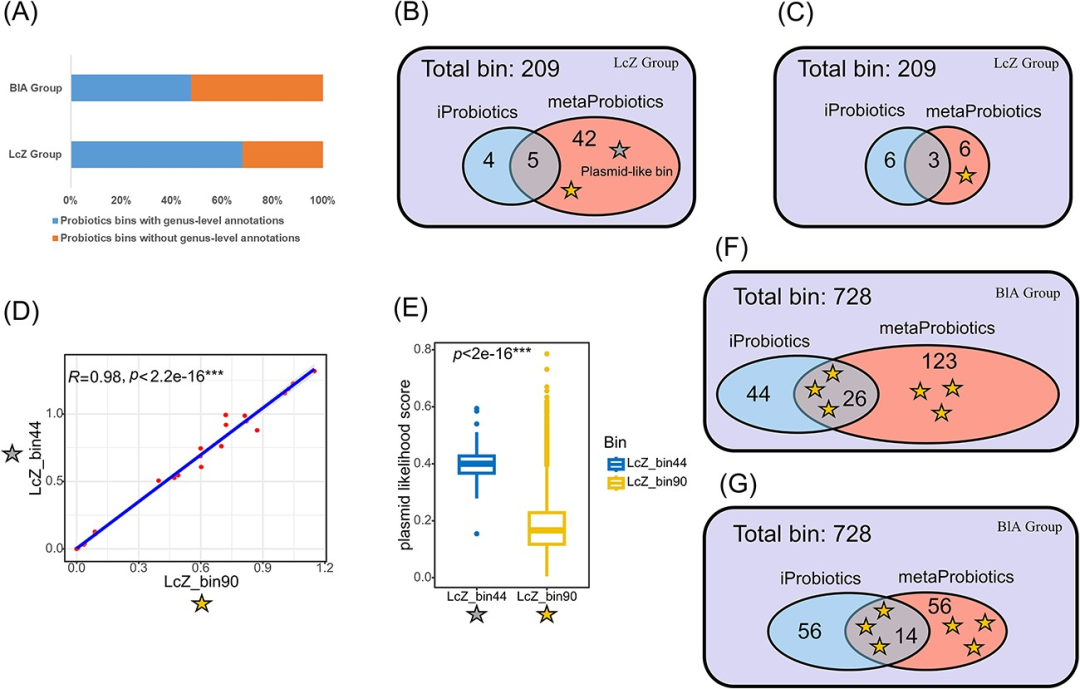
图3 从两个益生菌干预队列(LcZ组和BlA组)中挖掘健康人肠道样本中的益生菌。
(A)使用Culturable Genome Reference(CGR)数据库,统计metaProbiotics识别的益生菌分箱中可在属水平进行物种注释的比例。
(B)LcZ组中由metaProbiotics和iProbiotics工具识别的益生菌分箱的韦恩图。黄色星型点(LcZ_bin90)表示与干预菌株的ANI值高于98%的分箱,灰色星型点(LcZ_bin44)表示其丰度与干预菌株高度相关的质粒样分箱。
(C)LcZ组的韦恩图。我们调整了metaProbiotics的决策阈值,使其预测的益生菌分箱数量和iProbiotics一样多,以便进行更定量的比较。
(D)LcZ组中不同采样时间下LcZ_bin90与LcZ_bin44丰度之间的相关性。使用了Spearman相关性系数。
(E)PPR-Meta对LcZ_bin90和LcZ_bin44中每条contig计算的质粒可能性得分。
(F)与(B)相似,BlA组Venn图,黄色星型点表示与干预菌株ANI值高于98%的分箱。
(G)与(C)相似,为调整metaProbiotics决策阈值后的BlA组的韦恩图。
我们进一步观察到,在LcZ和BlA两组中,metaProbiotics和iProbiotics预测出的益生菌的重合度较低。我们将ANI与Lc. casei Zhang和B. longum AH1206菌株超过98%的分箱视为来源于这两种菌株的分箱。值得一提的是,metaProbiotics准确地识别出了所有这些益生菌分箱。相比之下,iProbiotic难以识别这些分箱。从Venn图中可以看出,这些益生菌分箱主要由metaProbiotics预测得出(如图3B和3F所示)。由于metaProbiotics预测的益生菌分箱数量超过iProbiotics,我们调整了metaProbiotics的预测阈值使其预测的益生菌分箱数量和iProbiotics一样多,以评估metaProbiotics是否由于过于宽松的预测阈值才能识别到更多益生菌分箱。在这种情况下,metaProbiotics仍能识别所有与干预菌株高度相似的分箱(如图3C和3G所示),这表明metaProbiotics和iProbiotics之间预测数量的差异是由于iProbiotics的灵敏度较低,而不是metaProbiotics的假阳性率过高所导致的。我们进一步分析了BlA组中与干预益生菌株相关的六个分箱,评估了这些分箱的质量和两种工具的预测结果。我们发现iProbiotics对分箱内contig的长度和分箱的总体完整性特别敏感,其只将N50大于40,000 bp且完整性高于70%的分箱识别为益生菌(详见表S7)。另一方面,metaProbiotics展现出了强大的性能,它能够识别出所有这些益生菌的分箱,包括那些质量较低的分箱。
在LcZ组中,其中一个分箱(分箱ID:LcZ_bin44)的丰度与来源于Lc. casei Zhang菌株的分箱(分箱ID:LcZ_bin90)的丰度在不同采样时间下表现出严格的正相关性,且LcZ_bin44同样被metaProbiotics预测为益生菌(如图3B和3D所示)。尽管我们还不清楚它的具体分类,但它编码了一个来源于Lactobacillaceae的prtP基因,这是一种能分解乳蛋白的分泌型蛋白酶,这表明它与Lc. casei Zhang具有协同的益生功能。根据PPR-Meta的注释结果,LcZ_bin44中的contig表现出了显著更高的质粒可能性得分(如图3E所示),这暗示了LcZ_bin44可能来源于质粒,同时也显示出metaProbiotics在检测具有益生功能的可移动元件方面的能力。
为了评估工具的泛化能力,我们重点关注那些在益生菌训练集中未出现的、但多次被metaProbiotics识别为益生菌的属。这些属在任何一个队列中都有多个分箱,并且至少有一个分箱被metaProbiotics工具预测为益生菌。这些属包括Butyricicoccus、Parabacteroides、Phocaeicola、Agathobaculum、Alistipes、Collinsella和Ruminococcus,它们已被报道具有益生菌的功能,包括产生短链脂肪酸、免疫调节、代谢调以及通过多种分子机制保护肠道屏障等功能(见表S8)。
GO富集分析表明,metaProbiotics识别的益生菌分箱编码了一系列与益生机制相关的基因(如图4A所示)。值得注意的是,除了参与碳水化合物代谢的基因以及那些传统上被认为对益生菌至关重要的基因外,还有一些与金属铁响应相关的基因。这一发现与已报道的某些益生菌能够调节人体内有害金属积累和毒性的结果是一致的。此外,这些被识别的益生菌具有丰富的与合成具有益生作用物质相关的基因,包括已报道的能够防止诸如强直性脊柱炎和类风湿性关节炎等疾病的糖胺聚糖。
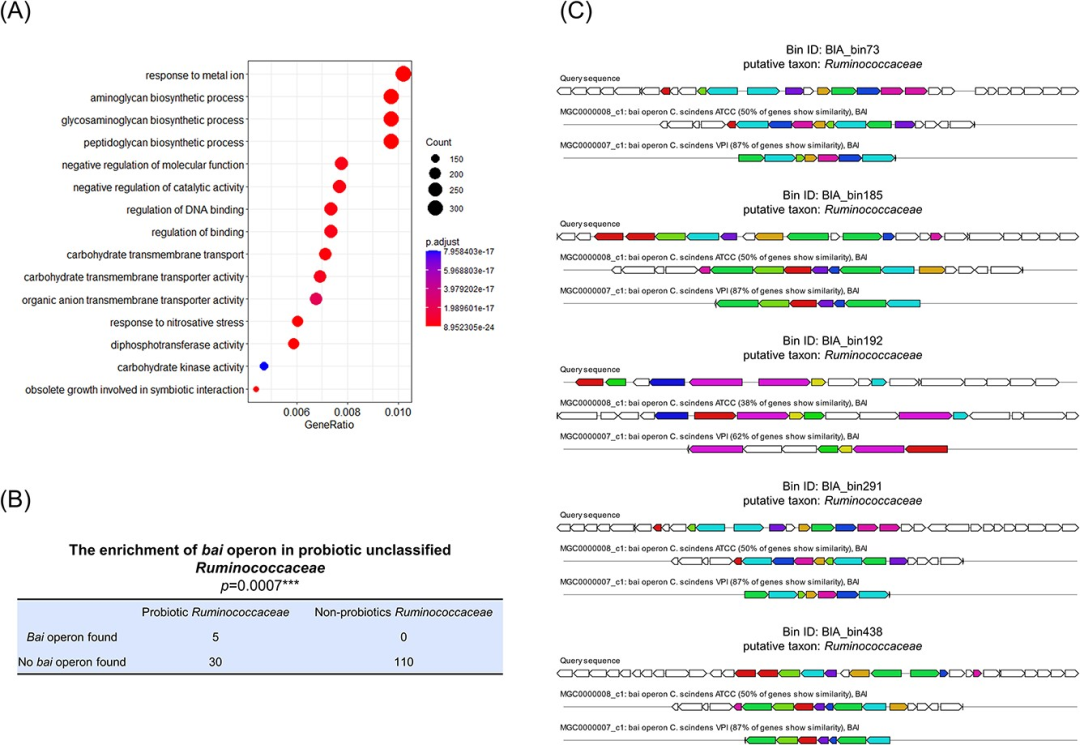
图4 metaProbiotics识别的益生菌分箱的基因功能分析。
(A)益生菌编码基因的GO富集分析。
(B)对unclassified Ruminococcaceae科中的益生菌进行了bai操纵子的富集(p=0.0007***,Fisher精确检验)。所有五个含有bai操纵子的unclassified Ruminococcaceae科的分箱都被metaProbiotics识别为益生菌,而在非益生菌的Ruminococcaceae科的分箱中并未发现bai操纵子。
(C)展示了相关Ruminococcaceae科分箱中的bai操纵子,包括含有bai操纵子的contig以及与参考bai操纵子的比对图。
在与unclassified Ruminococcaceae科相关的分箱中,我们发现所有五个含有bai操纵子的与Ruminococcaceae科相关的分箱均被metaProbiotics识别为益生菌,而在非益生菌的Ruminococcaceae科分箱中未发现bai操纵子(如图4B和4C所示)。我们之前的研究已经表明,Ruminococcaceae科的某些菌株可以通过微生物-胆汁酸轴来改善慢性失眠和心血管代谢疾病。因此我们推测,促进胆汁酸代谢可能是Ruminococcaceae科中某些菌株的重要益生功能,而与胆汁酸代谢相关的基因,如bai操纵子,可能是这些益生菌的标志基因。
我们进一步评估了metaProbiotics在不同来源的宏基因组分箱数据中识别益生菌的能力,以此来展示这个工具的普适性。我们使用了Huang等人的数据。在该研究中,研究者使用益生菌株Lactiplantibacillus plantarum HNU082分别对人和小鼠进行干预。我们下载了这些人类和小鼠的宏基因组数据,并用与处理LcZ和BlA组相同的方式来处理这些数据,得到了来自不同物种的宏基因组分箱,然后使用metaProbiotics和iProbiotics进行预测。结果显示,metaProbiotics始终能够将来自干预菌株的分箱识别为益生菌,其识别性能优于iProbiotics(如图S7所示)。这表明metaProbiotics识别益生菌的能力并不局限于特定类型的宏基因组数据,因此具有广泛的适用性。
健康和疾病个体中益生菌丰度谱的一致性和异质性
Consistency and heterogeneity in probiotic abundance profiles across healthy and diseased individuals
对metaProbiotics从上述应用案例中识别出的益生菌分箱,我们观察了它们在不同队列的个体肠道宏基因组中的丰度特征。每个队列由健康个体和患有特定疾病的个体的样本组成,包括2型糖尿病(T2D)、肝硬化(LC)和结直肠癌(CRC)。我们发现,在不同疾病类型的队列中,健康个体中益生菌总体归一化丰度(NAP)大于0的个体比例始终超过了疾病患者,表明这些益生菌对健康表型有更高的odd值(图5A:对某个队列中在所有个体中都存在的分箱进行统计;图S8:对所有分箱进行统计)。当将总NAP>0视为一个暴露因素时,这些益生菌分箱可以作为对抗多种疾病的保护因素(OR=0.5177,p=0.0005***,如图5A中的浅蓝色框所示),这强调了它们在不同疾病中的一致性作用。
然而,我们也观察到在不同类型的疾病队列中,这些益生菌在健康个体和疾病患者之间的丰度分布特征可能存在显著的异质性。如图5B所描述的方法,我们试图使用这些益生菌分箱的丰度特征为每种疾病类型训练一个基于随机森林的健康状态预测模型。然而,这些模型难以实现跨疾病类型的健康状态预测:当它们在一种疾病类型上进行训练并在另一种疾病类型上进行测试时,预测的AUC显著下降。这种下降在CRC和LC组中尤为明显,跨疾病预测的AUC下降到50%以下。这表明益生菌在对抗不同疾病时可能会表现出相当大的异质性。我们进一步探索了是否可以识别出在不同疾病类型的健康预测中均起到重要作用的核心益生菌子集,这可能有助于未来的跨疾病通用预测。我们使用基于随机森林的out-of-bag(OOB)特征重要性计算,提取出在不同疾病队列的健康状态预测模型中最重要的前20个分箱。然后,我们使用韦恩图观察这些分箱在不同预测模型中的一致性(如图S9所示)。结果显示,我们无法找到同时在所有三种疾病的健康状态预测中均起重要作用的分箱。此外,只有少数分箱在至少两种疾病的健康状态预测中起到了重要作用。这进一步表明,益生菌在不同疾病中的异质性非常明显,要识别出对所有类型疾病都有益的细菌物种仍然具有挑战性。
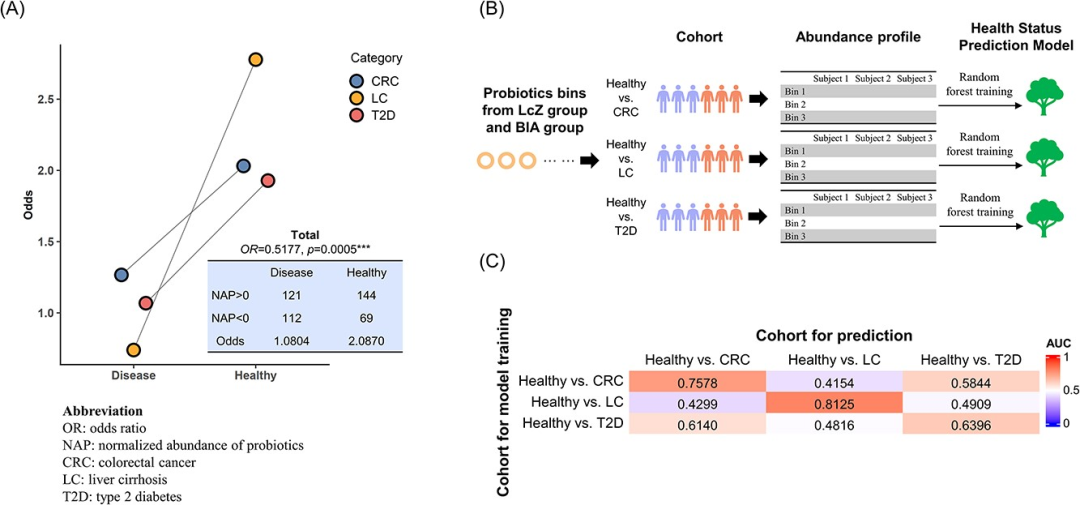
图5 识别出的益生菌分箱在不同状态(健康、CRC、LC和T2D)下的人群的丰度谱。
(A)不同队列中,健康个体与特定疾病个体之间的益生菌总归一化丰度(NAP)的比较。我们将益生菌的高丰度(NAP总和超过0)被视为暴露因素,基于此计算每种疾病类型队列的odd值。益生菌丰度与健康状态之间的关系展示在浅蓝色框中。该结果表明metaProbiotics识别的益生菌在不同疾病中起到保护作用(OR=0.5177,p=0.0005***,单侧Fisher精确检验)。
(B)在每个队列中,我们分别利用每个健康个体和每个特定疾病个体的益生菌分箱的丰度谱,训练了一个基于随机森林的健康状态预测模型,用于识别人的健康状态。
(C)我们用(B)中训练的每个模型,对每个疾病类型的队列中的每个个体的健康状态进行预测,并计算预测的AUC。当用于训练的队列与用于预测的队列相同时,采用留一法来评估AUC。我们发现当预测队列与训练队列不同时,AUC显著下降,尤其是在CRC与LC之间进行跨队列预测时。
我们进一步收集了包括肠易激综合症(IBS)和克罗恩病(CD)在内的两种其他疾病类型的队列(样本ID见表S10)。在进行了类似的分析之后,我们同样观察到了益生菌在不同疾病中表现出一致性和异质性的特点。具体而言,益生菌的整体丰度可以被认为是跨多种疾病的保护因素,但是使用这些益生菌丰度特征构建的健康状态预测模型在跨疾病预测中的效果并不理想(如图S10所示)。我们进一步分析了通过扩大健康预测模型训练集中的疾病类型能否增强其跨疾病预测的能力。我们合并了CRC、LC和T2D的队列数据(即将所有队列中的健康个体合并为一个类别,将患有任何一种疾病的个体合并为另一个类别)来训练健康状态预测模型。随后,将训练好的模型应用于预测IBS和CD队列中人群的健康状态。我们发现,在训练集中增加疾病种类并没有显著提高模型的跨疾病预测能力(如图S10B所示)。益生菌在不同疾病中的异质性依旧影响了通用预测模型的开发。
利用metaProbiotics创建的全球肠道益生菌集合揭示疾病间益生菌基因模块的异质性
Revealing the heterogeneity of probiotic gene modules across diseases using the global gut probiotic set created by metaProbiotics
为了全面阐述肠道益生菌菌群在各种疾病中的异质性,我们收集了HumGut数据库中超过来自5,700个全球健康肠道样本的30,691个宏基因组组装基因组(MAGs),并使用metaProbiotics从中识别出益生菌,最终得到了5,990个跨越不同门水平的益生菌(如图6A所示)。这一基因组集显著地扩大了当前益生菌数据库的物种覆盖范围。这些益生菌的信息可以在GitHub网站(https://github.com/zhenchengfang/metaProbiotics/releases/tag/Globle_gut_probiotics_set)的“probiotics_set.csv”文件中找到。
我们利用健康个体以及患有CRC、LC和T2D之一的疾病个体的肠道宏基因组数据,计算了metaProbiotics识别的5,990个益生菌的每个基因在不同表型中的丰度。接着,我们使用加权基因共表达网络分析(WGCNA)将这些益生菌基因划分为基因模块(如图6B所示)。在健康状态下,一部分基因模块显示出一定程度的富集(与表型正相关),同时我们并没有观察到显著缺失的模块(负相关),这说明在健康状态下,益生菌基因模块的组成相对完整。然而,在各种疾病状态中,尽管有基因模块的富集,但也明显存在基因模块的缺失。这意味着,部分益生菌基因模块的富集并不一定能够促进宿主的健康,而疾病的出现往往伴随着基因模块的缺失。
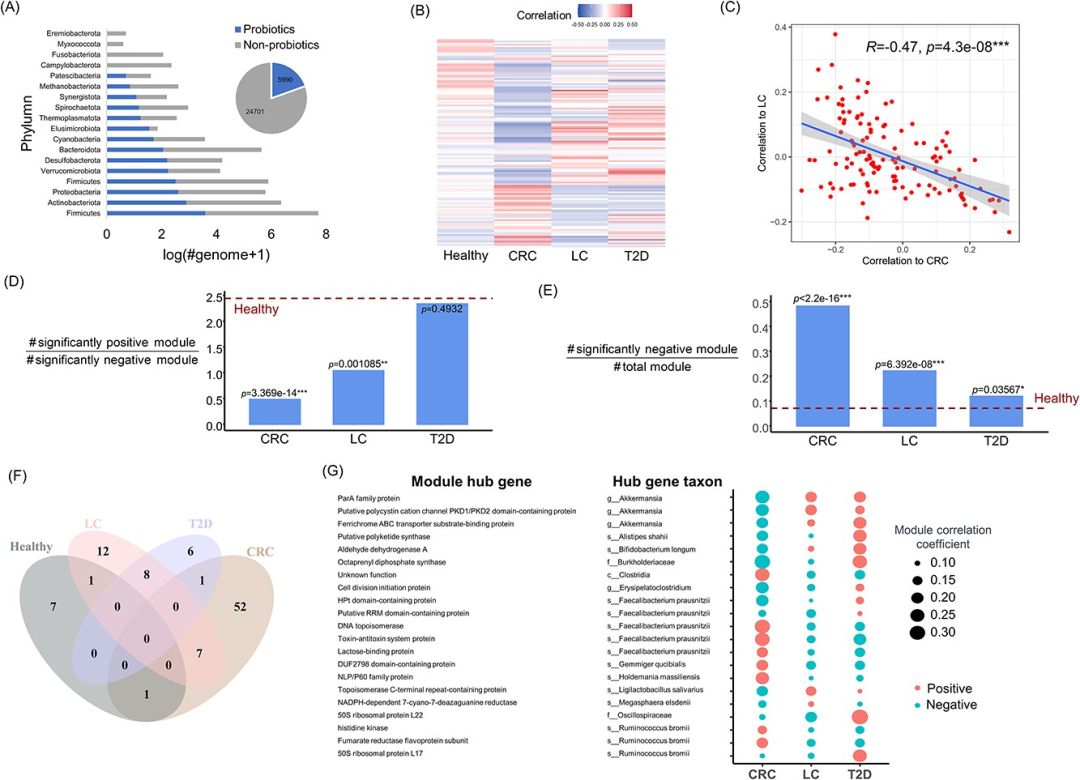
图6 利用metaProbiotics构建全面的肠道益生菌集合,并通过WGCNA揭示健康个体和不同疾病个体(包括CRC、LC和T2D)中这些益生菌的基因模块的丰度模式。
(A)从HumGut数据库的30,691个宏基因组组装基因组中,用metaProbiotics构建人类肠道益生菌数据集。饼图显示了从HumGut中识别出的益生菌基因组数量,条形图展示了识别出的益生菌在门水平的分布情况。
(B)计算(A)中的益生菌基因在包含健康个体和特定疾病(CRC、LC和T2D)的队列中的丰度,并使用WGCNA将这些基因划分为不同的基因模块。热图的每一行代表一个基因模块,模块的颜色表示其与相应表型的相关性。
(C)基于每个益生菌基因模块与CRC和LC疾病的相关性,展示模块与两种表型相关性的对比趋势。使用Spearman相关性指数。
(D)计算每种疾病显著正相关模块数量与显著负相关模块数量的比值,并将健康人群中的该比值作为参考值(图中红色虚线表示)。通过基于正相关模块数量占所有纳入统计的模块数量的比例的单侧二项检验得到p值。
(E)计算每种疾病显著负相关模块数量占总模块数量的比值,并将健康人群中的该比值作为参考值(图中红色虚线表示)。通过单侧二项检验得到p值。
(F)用韦恩图展示在不同疾病类型中显著负相关的模块。
(G)显示在三种疾病中具有显著相关性(p<0.05,包括正相关和负相关)的模块的hub基因信息。包括由hub基因编码的蛋白,hub基因所在物种的分类信息,以及展示不同疾病中相应基因模块的相关性大小的气泡图。
同时,我们观察到在不同疾病状态中,富集或缺失的模块类型存在显著差异。例如,与CRC正相关的模块在LC中表现出负相关,反之,与LC正相关的模块在CRC中也表现出负相关,这揭示了两者之间的明显对立关系(如图6C所示)。这也可以解释为什么在进行CRC与LC的跨队列健康状态预测时,图5C中观察到的AUC值低于0.5。此外,我们计算了每种表型下显著正相关模块数与负相关模块数(p<0.05)的比率。我们发现,这个比率在各种疾病状态下均低于健康状态,尽管这些差异在统计学上并不总是显著的(如图6D所示)。另外,我们评估了每个表型中显著负相关(p<0.05)的模块数占总模块数的比例。我们观察到,这一比例在疾病状态下显著高于健康状态(如图6E所示),并且不同表型下缺失的模块存在相当大的差别(如图6F所示)。这些观察结果显示,与仅增加特定功能基因的丰度相比,益生菌菌群内基因功能的完整性对于维持肠道稳态更为关键。由于同一益生菌基因模块在不同疾病中的表现存在异质性,因此,我们难以仅根据特定益生菌的富集或缺失来判断宿主的健康状态。
在此基础上,我们进一步选取在CRC、LC和T2D中均显著相关(包括正相关和负相关)的模块,并获取这些模块的hub基因(共21个),以及记录这些hub基因所在基因组的分类信息以及它们对应的模块在各种表型下的相关性(如图6G所示)。我们再次发现,益生菌对疾病的影响表现出异质性。我们没有发现任何一个hub基因所在的物种在所有分析的疾病中都具有益生效果。例如,益生菌Akkermansia对CRC有益(负相关),但对LC或T2D并无益处。此外,来自特定益生菌物种的不同基因可以被归为不同的基因模块,而同一模块在不同疾病中可能有不同的益生效果。例如,Faecalibacterium prausnitzii有五个基因被确定为五个模块的hub基因。其中两个hub基因(HPt domain–containing protein和putative RRM domain-containing protein)对CRC和LC有益,但对T2D并无益处,而其他三个则表现出相反的效果,对CRC没有保护效果,但对LC和T2D有益。同样,Ruminococcus bromii有三个基因被确定为三个模块的hub基因。其中两个模块对LC和T2D有益,但对CRC没有益处,而另一个模块对CRC和LC有益,但对T2D没有益处。
总的来说,我们利用metaProbiotics构建的全面肠道益生菌集合,通过分析CRC、LC和T2D队列的数据,阐明了益生菌基因功能完整性在维持宿主健康中的重要性,并强调了益生菌在不同疾病中的异质性特征。我们相信,这些发现为益生菌的临床应用提供了新的视角。特别地,并非所有益生菌的功能模块对每种疾病都产生保护作用。在进行益生菌干预时,我们应当首先考虑微生物功能的完整性,盲目地增加特定益生菌可能会产生意料之外的结果。
- 讨论 -
metaProbiotics的语言模型将八个相邻的碱基视为一个“词”来构建词向量。然而,在基因组中,基因或功能域(domain)往往是功能的基本单位。一些研究也将基因视为建模的“词”。metaProbiotics主要针对基于二代测序的宏基因组数据。这些数据中的contigs长度通常较短,而一个完整的代谢基因簇通常至少包含五个基因。如果使用基因作为“词”,那么从二代测序获得的contig不太可能包含一个完整的“句子”,这不允许充分展示语言模型的优势。因此,我们选择了碱基串而不是整个基因作为词的单位,以更好地捕捉DNA序列中不同模体(motif)的信息。如今,通过结合超高深度的二代测序和第三代测序,从宏基因组数据中重建一个完整的细菌基因组,而不是碎片化的草图基因组已成为可能。因此,在未来,我们将进一步结合不同测序技术的数据特性,从不同维度构建基因组语言模型,并提高算法对益生菌基因组的区分能力。
metaProbiotics无法直接使用原始测序读取来识别宏基因组中的益生菌。因此,通过序列组装和分箱重构益生菌基因组草图的能力,是metaProbiotics成功识别益生菌的先决条件。目前已经发布了许多组装和分箱工具,常见的组装工具包括MegaHit、IDBA-UD、metaSPAdes和MetaVelvet,常见的分箱工具包括MetaBAT2、MaxBin和CONCOCT。然而,研究表明,不同工具对具有不同微生物群落结构(如物种丰度和多样性)的样本表现出不同的偏好,导致使用不同工具对同一样本的数据的分析结果会有较大差异。这些差异可能会在metaProbiotics的预测中引入偏差。例如,在使用分箱工具时,我们尝试使用MetaBAT2和MaxBin对六个小鼠样本(登录号:PRJNA293015)的宏基因组数据进行分箱,分别得到了239个和448个分箱,差异显著。在没有微生物群落先验知识的情况下,很难判断哪个结果更准确。为了整合不同工具的优势,不少综合工作流程已被开发,如MetaWRAP和Metaphor。这些工具通常比单个工具的准确性更高,但以显著更长的运行时间为代价,使其不适合大规模数据处理。我们建议读者根据自己的需求灵活选择工具。例如,如果用户主要关注微生物群落中的优势物种而非物种多样性,可以使用metaSPAdes进行序列组装。该工具能够生成较长的contigs,但对物种多样性的敏感度较低,在处理物种多样性高且存在低丰度物种的样本时,可能会丢失信息。对于样本量较小的情况,可以使用像MetaWRAP这样的综合但耗时的工作流程,以提高metaProbiotics下游处理的准确性。关于常见序列组装和分箱工具的详细信息,读者可以参考Yang等人的综述。此外,如果研究者旨在获得高质量的宏基因组分箱数据,他们可以选择使用Hi-C测序数据。这种测序技术在测序前对同一细菌细胞内的DNA进行交联,并利用交联信息对DNA序列进行更加准确的分箱。然而,与标准宏基因组测序相比,Hi-C测序成本更高,研究者应根据自己的具体需求选择数据类型。
在某些情况下,分箱软件可能会将具有高序列相似性的不同菌株分组到同一个分箱中。例如,在表S7中,我们识别出一个分箱,其污染水平为281.82%。这个分箱很可能包含来自益生菌菌株和其他细菌菌株的序列。然而,当前metaProbiotics的设计不允许进一步区分分箱中来自益生菌和其他菌株的成分。一方面,如前所述,我们可以使用不同的分箱工具组合来进一步优化分箱质量,获得更纯净的益生菌序列。另一方面,本文的分析表明,在发挥益生菌效应时,益生菌基因组上的基因展现出相对独特的模块特征。在后续研究中,有必要进一步扩展我们工具的功能,包括增强对基因组内各种基因模块的建模和表征,以及为这些模块提供更全面的功能注释。这将使metaProbiotics能够回答“分箱中哪些基因模块负责哪种特定的益生菌功能?”的问题。这种方法不仅可以帮助研究人员从污染数据中提取核心功能模块进行深入的机理研究,还可以为益生菌在临床条件下的合理使用提供指导。
本工作的一个重要发现是,益生菌在不同疾病类型中的表现具有异质性。基于益生菌群落结构和宿主因素预测这种异质性,并建立一个健壮的健康状态预测模型以增强个性化益生菌干预,对未来的研究至关重要。事实上,某些细菌的益生属性可能受到多种因素的影响,如其他细菌的丰度、环境条件和宿主的饮食。尽管metaProbiotics能够使用语言模型从原始序列中准确捕获与益生菌功能相关的重要信息,但它并未考虑益生菌鉴别过程中的其他外部因素。这一限制可能会阻碍metaProbiotics在个性化疾病预防和治疗中的应用。近年来,已开发了许多生物信息学工具来预测微生物组-药物互作以及微生物组-饮食互作。这些工具在进一步分析益生菌在不同个体中的异质效应方面极为有用。用户可以根据自己的特定需求将它们用于识别出的益生菌的进一步分析,作为metaProbiotics的补充。由于这些工具考虑了更广泛的因素,它们可能需要更多样化的数据类型输入,如营养摄入矩阵。因此,在使用这些工具之前,建议从良好设计的实验来获取数据。在我们未来的工作中,我们计划利用大规模人群队列数据,收集全面的宿主信息,并利用这些多模态数据建立细菌株的数学模型。这些模型整合了包括基因组数据、环境因素和宿主细节信息在内的多样化信息,以开发更全面的鉴别算法。我们渴望最终通过大数据驱动的AI算法指导个性化医学,包括基于个人饮食习惯和生活方式信息的个性化益生菌干预,以及根据个人益生菌菌群特性来定制饮食和药物建议。
总之,通过利用人工智能语言模型,我们引入了一种从宏基因组分箱数据中识别益生菌的新型计算方法。这种方法促进了新益生菌的发现,并提供了一个新颖的视角,系统地阐明了益生菌群落在维持宿主健康中的特性和异质性表现。
参考文献
Wu S, Feng T, Tang W, et al. metaProbiotics: a tool for mining probiotic from metagenomic binning data based on a language model. Briefings in Bioinformatics 25.2 (2024): bbae085. https://doi.org/10.1093/bib/bbae085
- 第一作者简介 -

珠江医院检验医学部
吴姝芳
博士后
主要研究方向为微生物可移动元件的识别及细菌基因组功能注释。在GigaScience及Briefings in Bioinformatics期刊发表第一作者论文2篇。
- 团队及通讯作者简介 -
南方医科大学珠江医院检验医学部为国家临床重点专科、广东省高水平医院优势建设学科。拥有南方医科大学微生态医学中心、广东省医学检验临床研究中心(国家检验医学临床医学研究中心核心单位)、广东省病原微生物快检技术工程中心等多个前沿学科平台。具备先进的微生物组、代谢组、动物、分子、细胞、病理、生物信息、医学检验等科研条件。拥有国家教学名师、杰青、优青等领衔的专职科研团队近30人,科研场地2500平方,研究和转化经费充裕。以神经、代谢、母婴、感染、消化、肿瘤等多种疾病为对象,开展人体微生物组和检验新技术的基础及转化研究。

南方医科大学
珠江医院检验医学部
周宏伟
二级教授,国家杰青
国家百千万人才,南方医科大学珠江医院检验医学部主任、转化医学中心执行主任,广东省医学检验临床医学研究中心执行主任。主持国家重点研发计划、国自然重点、新冠专项、广州脑计划等课题。从事微生态医学及检验新技术研究。发现地域差异是疾病菌谱矛盾的关键原因(Nature Medicine 2018);揭示卒中、子痫、IBD、类风关等多种疾病中的菌群-宿主互作新机制(Cell Host & Microbe 2022,2023,Nature Microbiology 2022,Gut 2020, 2021, 2022);牵头成立中国临床微生态研究协作组(CALM),推动人体微生态大规模多中心研究。任Medicine in Microecology(Elsevier)主编。

珠江医院检验医学部
方臻成
博士后
2020年毕业于北京大学整合生命科学(生物学),主要从事基于人工智能的基因组注释算法研究,以第一和通讯作者在GigaScience、Bioinformatics、Briefings in Bioinformatics等杂志发表SCI文章7篇,主持国家自然科学基金青年、面上项目各1项,iMeta杂志青年编委。
宏基因组推荐
本公众号现全面开放投稿,希望文章作者讲出自己的科研故事,分享论文的精华与亮点。投稿请联系小编(微信号:yongxinliu 或 meta-genomics)
猜你喜欢
iMeta高引文章 fastp 复杂热图 ggtree 绘图imageGP 网络iNAP
iMeta网页工具 代谢组MetOrigin 美吉云乳酸化预测DeepKla
iMeta综述 肠菌菌群 植物菌群 口腔菌群 蛋白质结构预测
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature
一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流快速解决科研困难,我们建立了“宏基因组”讨论群,己有国内外6000+ 科研人员加入。请添加主编微信meta-genomics带你入群,务必备注“姓名-单位-研究方向-职称/年级”。高级职称请注明身份,另有海内外微生物PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。
点击阅读原文,跳转最新文章目录阅读


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









