






Stable Diffusion是一种基于扩散模型的文本到图像生成AI系统,由Stability AI公司开发。它可以根据文本描述生成高质量的图像。
下面是Stable Diffusion的详细介绍以及组件:
-
输入文本描述:用户输入一段文本描述,描述想要生成的图像内容。
-
编码器:文本描述首先会通过一个编码器模块,将文本转换为一个语义特征向量。
-
扩散模型:这个语义特征向量会输入到一个预训练的扩散模型中。扩散模型会通过多个去噪步骤,从一个随机噪声图像逐步生成出最终的图像。
-
解码器:最后,生成的图像会通过一个解码器模块,输出为最终的图像结果。


图像产生分两个阶段:
1.图像信息创建

2.图像解码器

通过这种方式,我们可以看到构成稳定扩散的三个主要组成部分(每个组成部分都有自己的神经网络):
-
ClipText用于文本编码。
输入:文本。
输出:77 个 token 嵌入向量,每个向量有 768 个维度。 -
UNet + Scheduler逐步处理/传播信息(潜在)空间中的信息。输入:文本嵌入和由噪声组成的
起始多维数组(结构化数字列表,也称为张量
)。 输出:处理后的信息数组 -
自动编码器解码器使用处理后的信息数组绘制最终图像。
输入:处理后的信息数组(维度:(4,64,64))
输出:生成的图像(维度:(3, 512, 512),即(红/绿/蓝,宽度,高度))

扩散是粉色“图像信息创建器”组件内部发生的过程。有了代表输入文本的标记嵌入和随机起始图像信息数组(这些也称为潜在信息),该过程会生成一个信息数组,图像解码器会使用该数组绘制最终图像。

这个过程是逐步进行的。每一步都会增加更多相关信息。为了直观地了解这个过程,我们可以检查随机潜在数组,并看到它转化为视觉噪声。在这种情况下,视觉检查是将其传递给图像解码器。

扩散分为多个步骤进行,每个步骤对输入潜在数组进行操作,并生成另一个潜在数组,该数组更类似于输入文本以及模型从训练模型的所有图像中获取的所有视觉信息。

我们可以将这些潜在信息集合形象化,看看每一步都添加了哪些信息。

扩散如何起作用
使用扩散模型生成图像的核心思想依赖于我们拥有强大的计算机视觉模型。给定足够大的数据集,这些模型可以学习复杂的操作。扩散模型通过以下方式构建问题来解决图像生成问题:
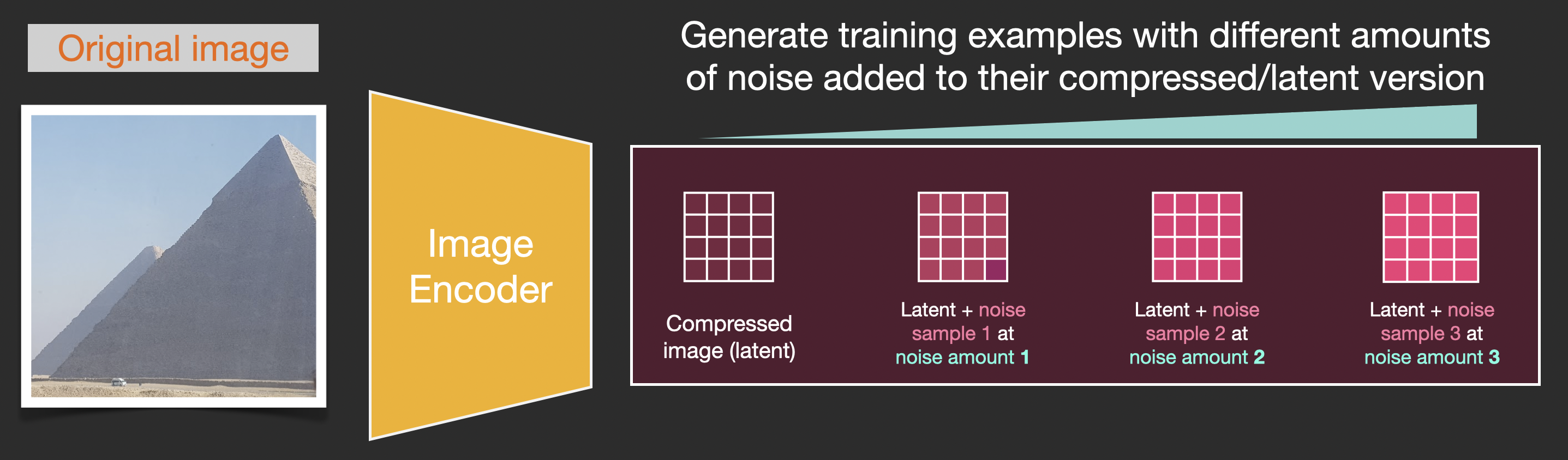
假设我们有一张图像,我们生成一些噪音,并将其添加到图像中。

这现在可以被视为一个训练示例。我们可以使用相同的公式创建大量训练示例来训练图像生成模型的核心组件。

虽然此示例显示了一些噪声量值,从图像(噪声量 0,无噪声)到总噪声(噪声量 4,总噪声),但我们可以轻松控制向图像添加多少噪声,因此我们可以将其分散到数十个步骤中,为训练数据集中的所有图像为每个图像创建数十个训练示例。

利用此数据集,我们可以训练噪声预测器,最终得到一个出色的噪声预测器,该预测器在特定配置下运行时实际上会创建图像。如果您有过 ML 经验,那么训练步骤应该看起来很熟悉:
 现在让我们看看它如何生成图像。
现在让我们看看它如何生成图像。
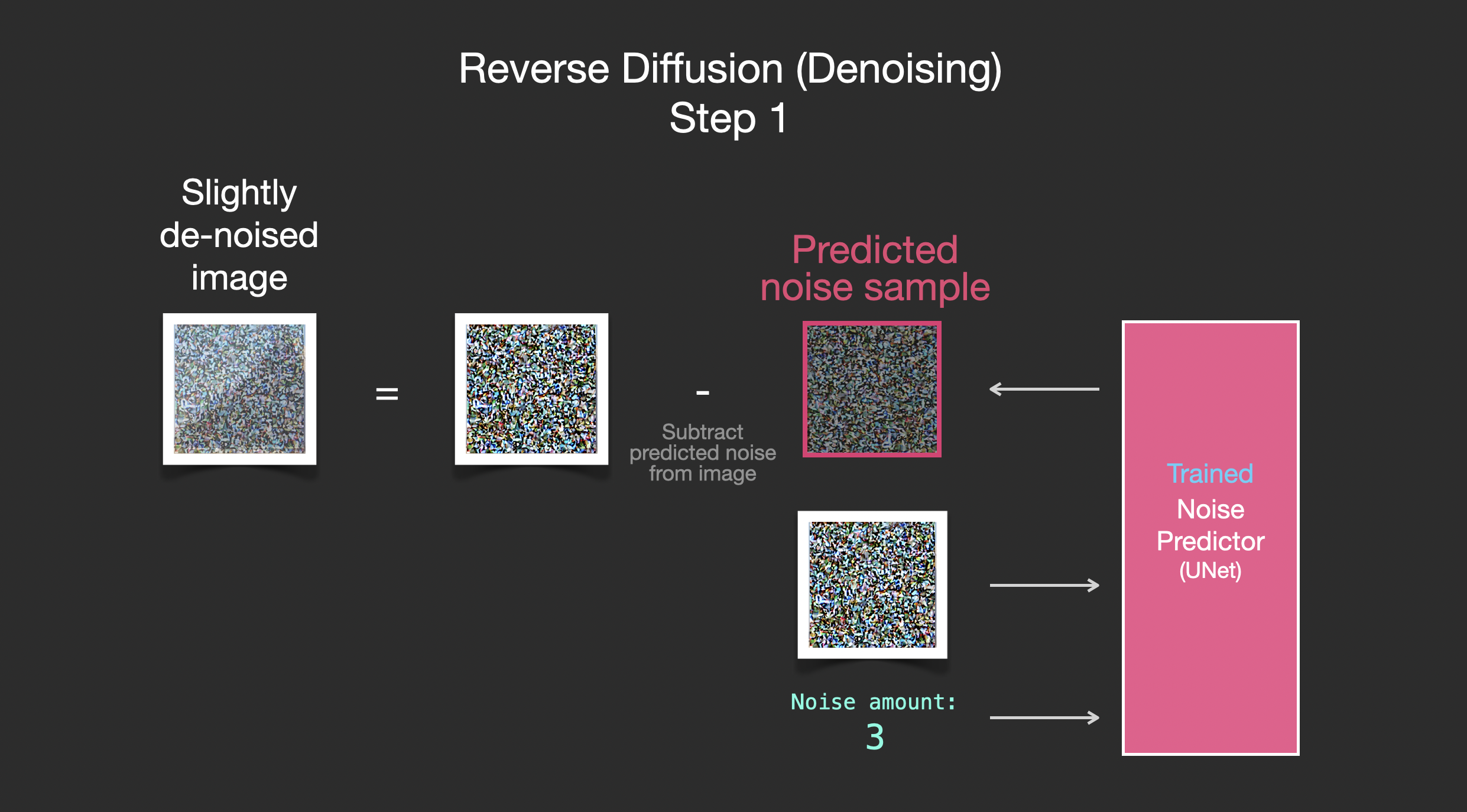
通过去除噪声来绘制图像
训练有素的噪声预测器可以拍摄一张噪声图像,以及去噪步骤的数量,并能够预测一片噪声。

采样噪声是可以预测的,因此如果我们从图像中减去它,我们会得到一幅更接近于模型训练图像的图像(不是精确的图像本身,而是分布-像素排列的世界,其中天空通常是蓝色的且高于地面,人有两只眼睛,猫看起来有某种样子 - 尖尖的耳朵,显然没有留下什么印象)。
如果训练数据集是美观的图像(例如, Stable Diffusion 就是在其上训练的LAION Aesthetics),那么生成的图像往往也美观。如果我们在徽标图像上训练它,我们最终会得到一个徽标生成模型。
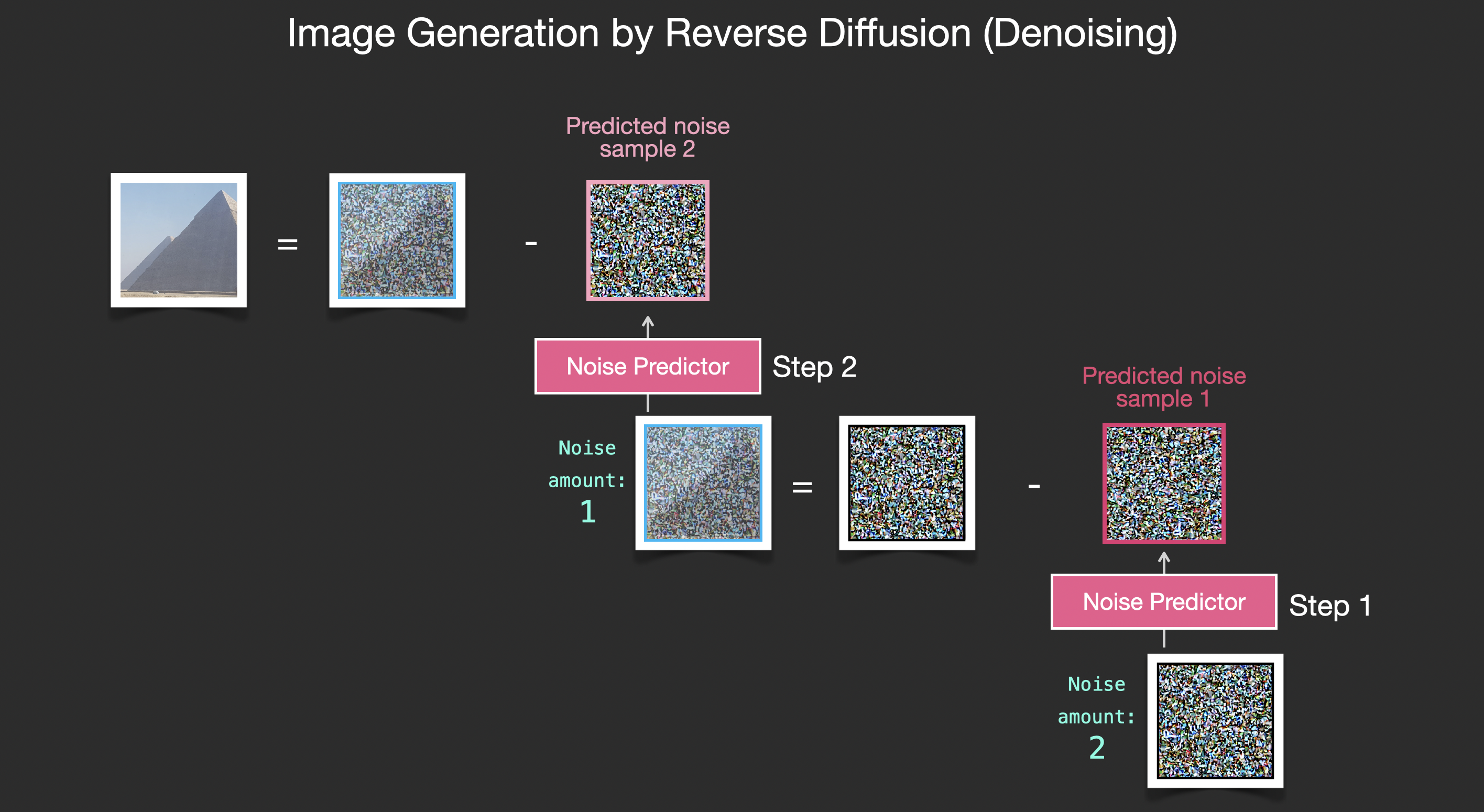
以上就是关于扩散模型生成图像的描述,大部分内容在去噪扩散概率模型中有描述。现在,你已经对扩散有了直观的了解,你不仅了解了稳定扩散的主要组成部分,还了解了 Dall-E 2 和 Google 的 Imagen。
请注意,我们迄今为止描述的扩散过程无需使用任何文本数据即可生成图像。因此,如果我们部署此模型,它将生成外观精美的图像,但我们无法控制它是金字塔、猫还是其他图像。在下一节中,我们将描述如何在过程中加入文本以控制模型生成的图像类型。
速度提升:在压缩(潜在)数据上进行扩散,而不是在像素图像上进行扩散
为了加快图像生成过程,稳定扩散论文不是对像素图像本身进行扩散过程,而是对图像的压缩版本进行扩散过程。论文称之为“离开潜在空间”。
这种压缩(以及随后的解压/绘制)是通过自动编码器完成的。自动编码器使用其编码器将图像压缩到潜在空间中,然后使用解码器仅使用压缩信息重建它。

现在,前向扩散过程在压缩的潜在变量上完成。噪声切片是应用于这些潜在变量的噪声,而不是应用于像素图像的噪声。因此,噪声预测器实际上经过训练以预测压缩表示(潜在空间)中的噪声。
前向过程(使用自动编码器的编码器)是我们生成数据以训练噪声预测器的方式。训练完成后,我们可以通过运行反向过程(使用自动编码器的解码器)来生成图像。

这两个流程就是 LDM/Stable Diffusion 论文图 3 中所示的:

该图还显示了“条件”组件,在本例中是描述模型应生成什么图像的文本提示。让我们深入研究文本组件。
文本编码器:Transformer 语言模型
Transformer 语言模型用作语言理解组件,它接受文本提示并生成 token 嵌入。发布的 Stable Diffusion 模型使用 ClipText(基于 GPT 的模型),而本文使用BERT。
Imagen 论文表明语言模型的选择非常重要。与较大的图像生成组件相比,更换较大的语言模型对生成的图像质量的影响更大。

早期的稳定扩散模型只是插入了 OpenAI 发布的预训练 ClipText 模型。未来的模型可能会切换到 CLIP 的新发布且更大的OpenCLIP变体(2022 年 11 月更新:确实,稳定扩散 V2 使用 OpenClip)。这个新批次包含大小高达 354M 个参数的文本模型,而 ClipText 中的参数为 63M。
CLIP 的训练方式
CLIP 是在图像及其说明的数据集上进行训练的。想象一下这样的数据集,只有 4 亿张图像及其说明:

图像及其标题的数据集。
实际上,CLIP 是基于从网络上抓取的图像及其“alt”标签进行训练的。
CLIP 是图像编码器和文本编码器的组合。其训练过程可以简化为拍摄图像及其标题。我们分别使用图像编码器和文本编码器对它们进行编码。

然后,我们使用余弦相似度比较生成的嵌入。当我们开始训练过程时,即使文本正确描述了图像,相似度也会很低。

我们更新这两个模型,以便下次嵌入它们时,得到的嵌入是相似的。

通过在整个数据集中重复此操作并使用较大的批量大小,我们最终使编码器能够生成狗的图像和句子“狗的图片”相似的嵌入。就像在word2vec中一样,训练过程还需要包含不匹配的图像和标题的负面示例,并且模型需要为它们分配较低的相似度分数。
将文本信息输入图像生成过程
为了使文本成为图像生成过程的一部分,我们必须调整噪声预测器以使用文本作为输入。
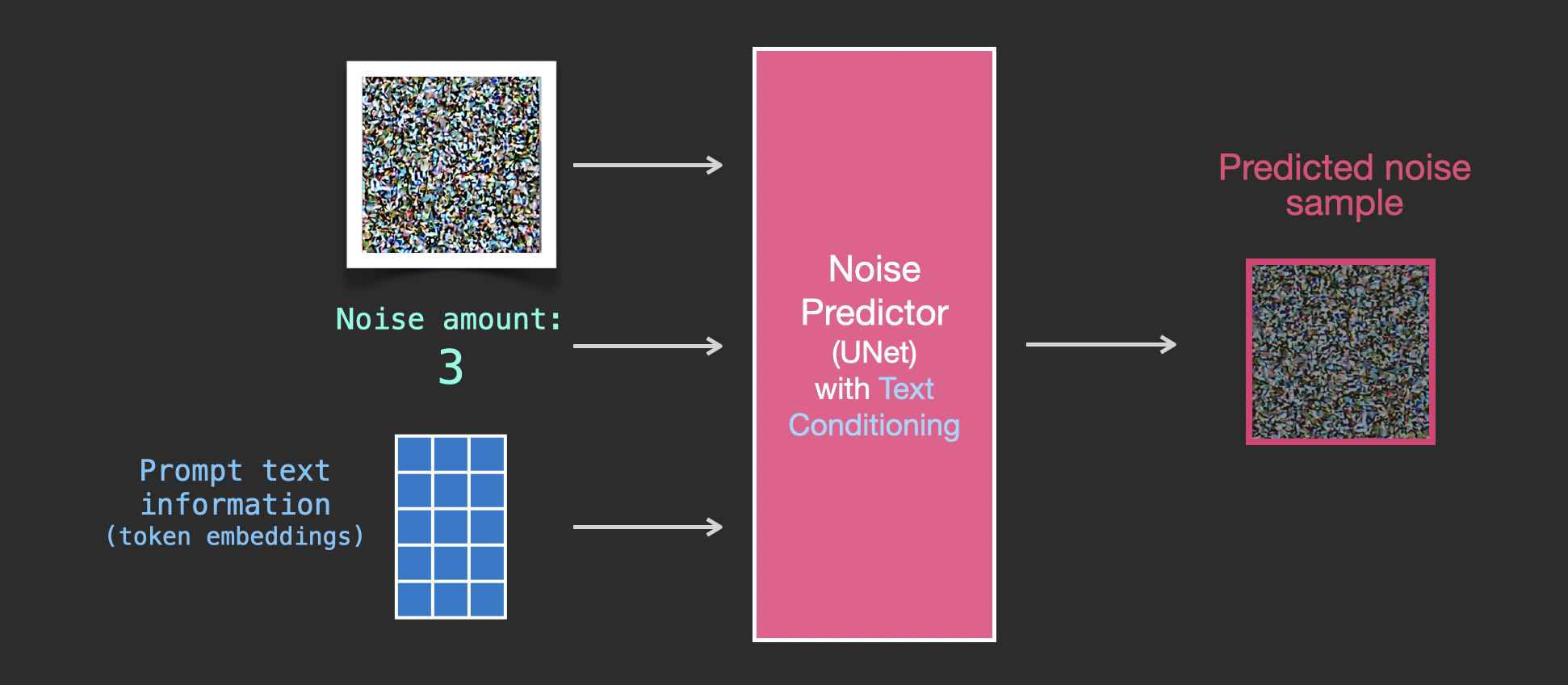
我们的数据集现在包含编码文本。由于我们在潜在空间中操作,因此输入图像和预测噪声都在潜在空间中。

为了更好地理解文本标记在 Unet 中的使用方式,让我们更深入地了解 Unet 内部。
Unet 噪声预测器的各层(无文本)
我们先来看一个不使用文本的扩散 Unet。它的输入和输出如下:

在里面我们看到:
- Unet 是一系列用于转换潜在数组的层
- 每一层都对前一层的输出进行操作
- 一些输出(通过残差连接)被输入到网络的后期处理中
- 时间步长被转换成时间步长嵌入向量,这就是在层中使用的

带有文本的 Unet 噪声预测器的各层
现在让我们看看如何改变这个系统来引起对文本的关注。

我们需要对系统进行的主要更改是添加对文本输入的支持(技术术语:文本调节)是在 ResNet 块之间添加一个注意层。

请注意,ResNet 块不会直接查看文本。但注意层会将这些文本表示合并到潜在层中。现在,下一个 ResNet 可以在其处理过程中利用合并的文本信息。















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









