






时间序列存在于我们日常生活中的多个社会领域,例如金融、医疗保健和能源管理。其中一些领域需要大量数据,以便从分析或预测目标变量的行为中获得洞察力。跨多个用户的平台传输和处理高数据速率和容量需要存储和计算机电源可用性。压缩技术是避免系统不堪重负的有效方法。在下文中,将讨论时间序列压缩算法以及它们在不同领域的实际应用中的作用。
什么是时间序列?
时间序列被定义为在连续时间获得的量值的序列,通常具有相等的间隔。从我们使用健身应用程序监控我们的锻炼到我们跟踪我们在城市中一直到我们家门口的披萨交付时,我们都会体验到时间戳数据的使用。当需要了解变量随时间的演变时,时间序列与问题相关,例如了解变量的时间分布或预测其值。
时间序列最常以表格格式的带时间戳的数字数据的形式出现。音频数据本身已经表示为时间序列,因为它是根据频率定义的。然而,虽然时间序列本身就是一种数据类型,但它们也可以与其他数据类型组合以生成更复杂的实体,这些实体包含嵌入的时间方面,例如:
- 随着时间的推移一系列图像定义了一个视频。
- 来自地理空间数据的坐标对的时间序列定义了跟踪路径。
时间序列数据需要特定的技术,以便不仅从数据的不同模式中获得洞察力,而且随着时间的推移从这些模式中获得洞察力。在数据科学管道中,这些技术用于预处理、分析和建模步骤。最常见的时间序列技术如下图 1 所示:
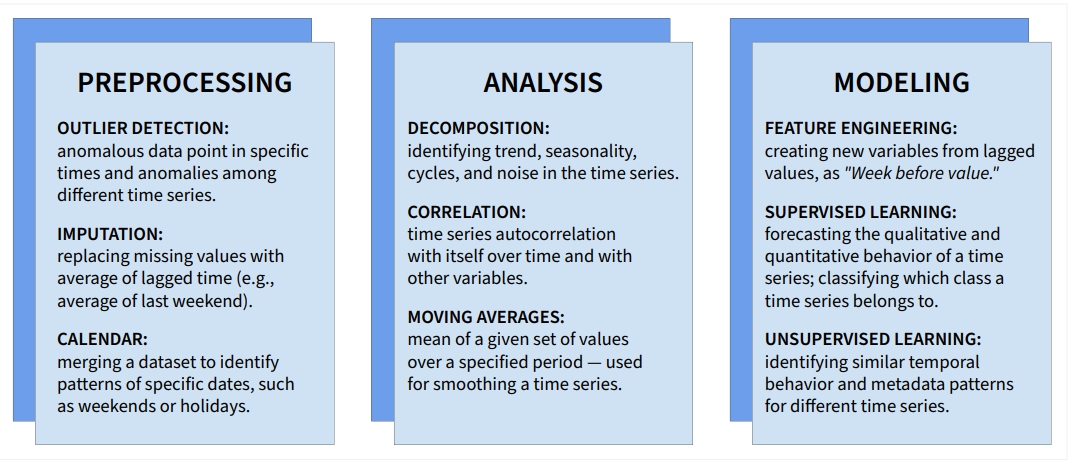
图 1:时间序列方法
数据压缩
数据压缩是转换数据以减少表示它所需的位数的过程。这个过程是通过编码改变数据或重新排列其位结构来完成的。压缩是一种有价值的技术,用于资源对数据的存储、处理和传输至关重要的场景。这种情况的两个极端是:
- 有限资源方案,可用存储和处理受成本限制。
- 大数据场景,高频数据涌入需要高效的数据管理
数据压缩过程涉及将数据编码为更小的格式。为了执行相反的过程,需要一个解码器来解压缩数据,如图 2 所示:
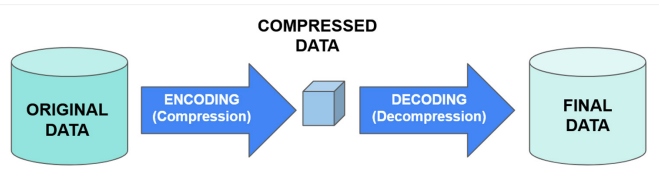
图 2:数据压缩方案
压缩以较小的格式和较少的位表示数据中存在的相同信息。由于它在可以编码的数据中搜索模式,因此它是一个计算量大的过程,可能需要时间和内存。最先进的压缩技术是:
- 无损压缩以在过程中不会丢失任何信息的方式识别和删除数据冗余。解码后的数据完全恢复到其原始状态。
- 常见用途:数据库、电子邮件、电子表格、文档和源代码
- 有损压缩 识别并永久删除冗余数据位,无法在解压缩后恢复原始数据。
- 常见用途:音频、图像、图形、视频和扫描文件
准确性和压缩之间的权衡,存在于试图保留数据同时仍解决存储限制的尝试中,是数据压缩中经常遇到的挑战。无损数据压缩只能在一定程度上收缩数据,以香农信息为阈值。对于高频数据,需要有损压缩才能有效减小大小。
表格1:
|
数据压缩的优点和缺点
| |
|---|---|
| 压缩的优点 | 压缩的缺点 |
| 减少文件大小和存储使用成本 | 大数据量耗时 |
| 由于磁盘存储期间内存间隙的减少,提高了数据读取/写入速度 | 算法需要来自系统的密集处理,这对于大数据量变得昂贵 |
| 通过互联网更快地传输文件,需要更少的计算资源 | 解压缩数据的质量可能取决于压缩级别 |
| 算法可用于近似和/或预测数据,以及识别噪声 | 需要解码器程序才能解压缩文件 |
时间序列的压缩方法
大数据的兴起和智能设备的使用揭示了对强大压缩技术的需求,能够满足依赖时间序列数据的行业的处理需求。在高频(大约 10kHz)的情况下,即使是专门研究时间序列数据的数据库也可能会过载。压缩算法因其高价值回报而被广泛探索。压缩技术的质量是通过其压缩率(压缩文件和原始文件之间)、速度(以每比特的周期数来衡量)和恢复数据的准确性来衡量的。
时间序列压缩算法利用传感器产生的时间序列中的特定特征——例如,某些时间序列片段经常在相同或其他相关时间序列(冗余)中重复自身,或者通过近似恢复时间序列的可能性它通过函数或通过神经网络模型预测它们。下面列出了最先进的方法:
表 2:
时间序列压缩算法 | |||
|---|---|---|---|
| 算法 | 描述 | 常用方法 | 表现 |
| 基于字典 |
|
|
|
| 函数逼近 |
|
| 适用于平滑时间序列、低压缩比和高精度。 |
| 顺序算法 |
|
|
|
| 自动编码器 |
| 循环神经网络自动编码器 (RNNA) 方法考虑具有有损压缩和损失阈值参数的时间相关神经网络。 | 准确率和压缩率很大程度上取决于 RNN 在训练集中寻找模式的能力。 |
时间序列应用
为特定问题选择的压缩算法取决于应用程序的领域和相关数据。压缩的应用可以在许多领域找到,其中最流行的是通过压缩图像、视频和音频数据的多媒体。特别是,时间序列压缩用于关键行业。表 3 显示了不同部门的时间序列用例以及此类应用程序中压缩的重点。在所有用例中,表 1 中的优势也适用。
表3:
| 时间序列用例 | ||||
|---|---|---|---|---|
| 药物 | 维护 | 活力 | 经济学 | |
| 用例 | 将患者的多个生命信号监测集成到一个警告系统中,以保证全时援助。 | 监控工业设备,进一步自动报告设备状态,确保安全高效生产。 | 智能电表能耗的短期预测。 | 高频收集的数据实时报告股市统计的状态。 |
| 压缩附加值 | 更快的数据处理以执行计算,例如触发警告。 | 更轻松、更便宜地存储大量数据,使制造公司能够负担得起采用数据驱动的解决方案。 | 编码算法有助于从数据中收集见解,例如噪声和行为,从而做出更准确的预测。 | 通过大型网络更快地传输信息,允许用户实时做出决策。 |
















 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











